1. Introduction
Misophonia, derived from the Greek roots miso-(meaning “hatred”) and -phonia (meaning “sound”), is a condition characterized by intense negative emotional reactions—such as irritation, anger, or disgust—when individuals encounter specific “trigger” sounds [
1]. Common triggers often include human-generated sounds such as chewing, slurping, sniffing, and throat clearing [
2], as well as repetitive noises from objects like pen clicking or keyboard typing [
3]. Beyond emotional discomfort, these reactions are often accompanied by increased autonomic arousal, leading to significant distress [
4]. To manage this discomfort, individuals with misophonia may avoid situations where triggers are present or endure them with great difficulty [
2]. Over time, this avoidance and distress can cause profound functional impairments, disrupting daily life and social interactions. Despite growing awareness of this condition, the underlying neurophysiological mechanisms, specific to the realm of auditory processing, and their broader perceptual consequences remain poorly understood, underscoring the need for further research.
Neurophysiological studies have begun to elucidate the underlying mechanisms of misophonia, shedding light on both cortical and functional anomalies associated with this condition. Research using fMRI has consistently highlighted hyperactivity in the anterior insular cortex (AIC; a key region in the salience network) in response to misophonic trigger sounds (e.g., [
5]). This hyperactivity is accompanied by increased functional connectivity between the AIC and regions involved in emotional processing and regulation (e.g., ventromedial prefrontal cortex, posterior cingulate cortex), suggesting an exaggerated salience assigned to specific sounds in individuals with misophonia [
5]. Furthermore, the anterior cingulate cortex (ACC; involved with top-down executive control) and superior temporal cortex have also shown hyperactivity, indicating a broader network dysfunction in response to misophonic stimuli [
6].
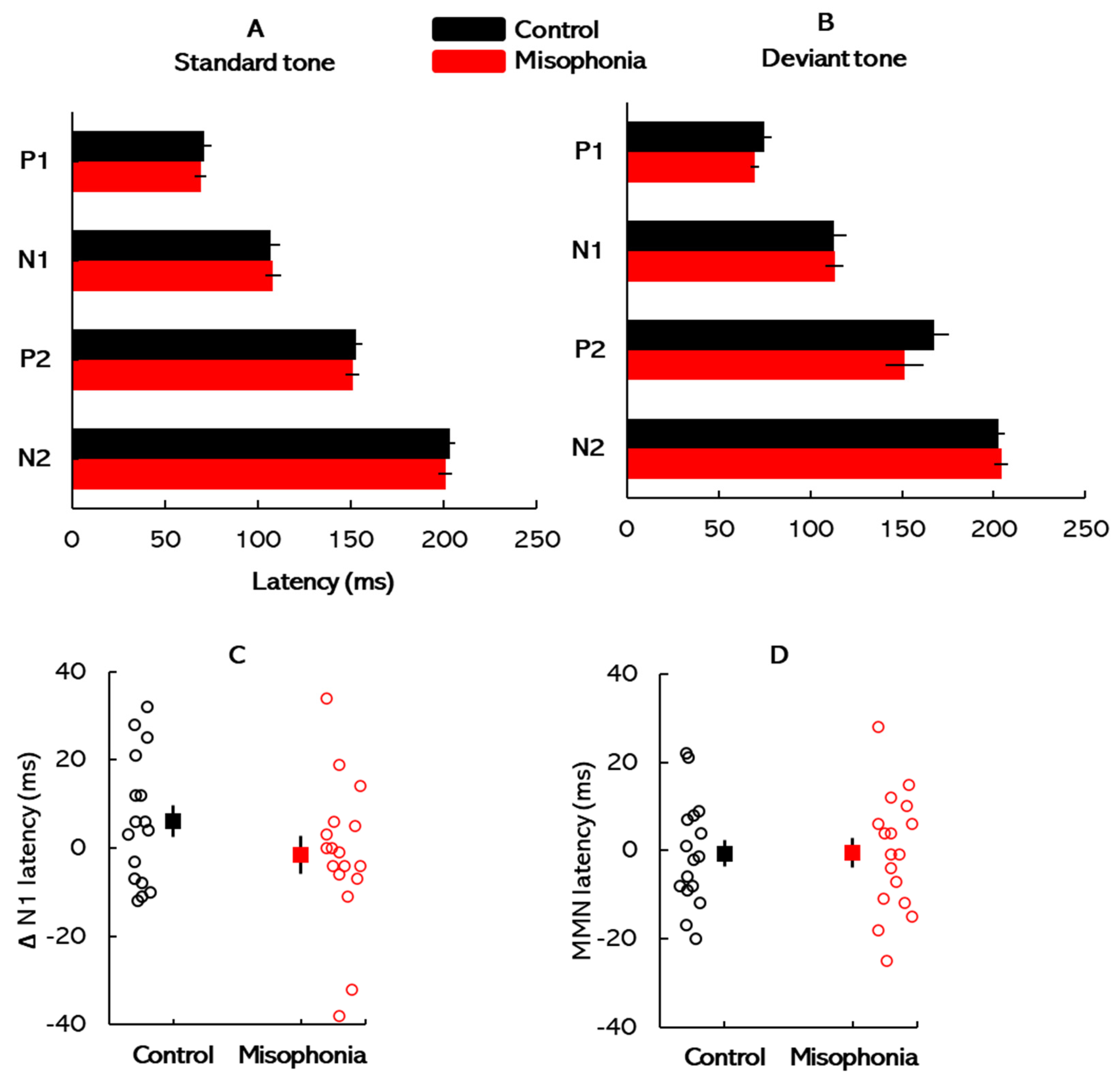
On the electrophysiological front, Aryal and Prabhu [
7] recently observed significant differences in the latency of P1 and N1 peaks of Auditory Late Latency Responses (ALLRs) between individuals with misophonia and controls. These latency differences suggest that individuals with misophonia may experience delayed or altered cortical processing of auditory stimuli. Similarly, Schröder et al. [
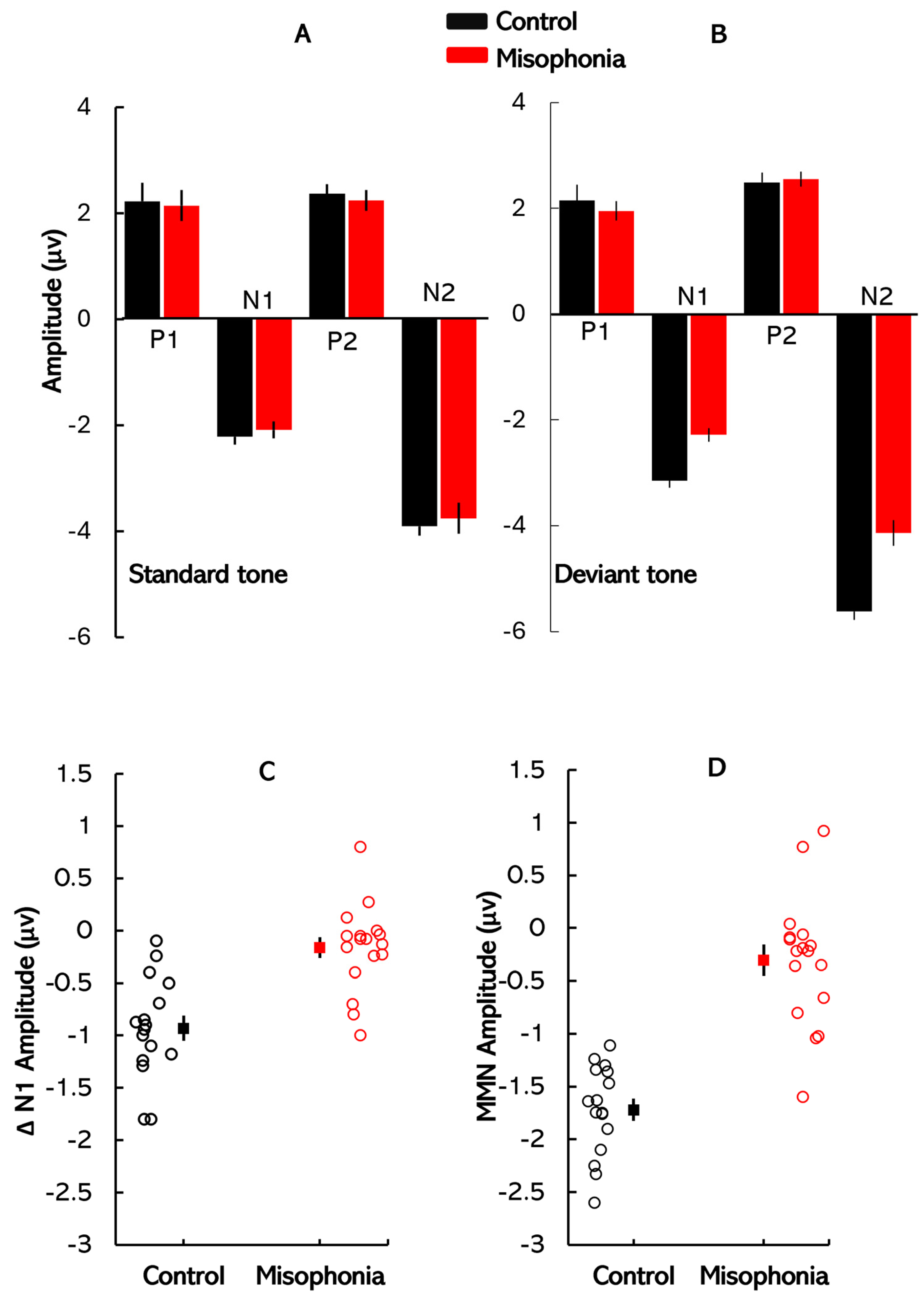
8] investigated auditory processing in misophonia patients using auditory event-related potentials (ERPs) during an oddball task. They found that misophonia patients exhibited a smaller mean amplitude of the N1 peak in response to oddball tones compared to controls, with no significant differences in the P1 and P2 components. Importantly, no differences were observed in ERP components in response to standard tones, indicating that the deficits in misophonia are specific to change detection mechanisms in the auditory cortex, rather than reflecting broader auditory processing impairments.
Given this evidence, the mismatch negativity (MMN) paradigm provides a strong rationale for investigating auditory processing deficits in misophonia, as it is a well-established tool for assessing automatic change detection mechanisms in a repetitive auditory context [
9]. Individuals with misophonia exhibit intense emotional responses to specific auditory triggers, and MMN, which operates without conscious attention, could reveal how these individuals’ brains respond to “deviant” sounds that deviate from the expected norm, providing insights into heightened sensitivity or aversive reactions to certain stimuli [
10]. MMN is also closely tied to sensory memory processes, requiring the formation of short-term memory traces to compare incoming auditory stimuli against the established auditory context [
11]. In misophonia, a diminished MMN may indicate a disrupted sensory memory system that fails to appropriately filter and encode auditory stimuli. Such deficits could cause certain sounds to be perceived as disproportionately salient, exacerbating emotional distress. In this study, MMN was utilized to investigate how these auditory processing deficits contribute to misophonia. Further, our analysis that focuses on the N1 peaks elicited by the standard and deviant stimuli, latency, and amplitude difference between the N1 peaks of the standard and deviant waveforms provides insights into early neural responses to acoustic changes. This metric helps compare findings with Schröder et al. [
8], who reported that individuals with misophonia exhibit a selective reduction in N1 response to deviant stimuli, thereby diminishing the N1 amplitude difference between standard and deviant waveforms.
While the neurophysiological basis of misophonia has been increasingly studied, with some research highlighting altered cortical activity in affected individuals, the perceptual consequences of these neural changes remain largely unexplored. In particular, how individuals with misophonia process speech under adverse listening conditions—such as noisy or acoustically challenging environments—has received limited attention. Since individuals with misophonia do not typically exhibit peripheral auditory processing deficits, any difficulties in speech perception are likely to stem from central processes, particularly those involved in auditory scene analysis [
12,
13]. The spatial release from masking (SRM) paradigm is well suited to investigate these central mechanisms, as it examines how individuals segregate target speech from background noise based on spatial cues [
14,
15,
16,
17,
18]. By comparing SRM performance in individuals with and without misophonia, this study aims to illuminate the perceptual challenges that characterize this population.
Cognitive operations, especially attention, are fundamental to the perception and processing of sensory stimuli, enabling individuals to focus on relevant information while suppressing distractions. In misophonia, the attentional process is often disrupted due to abnormally increased sensitivity to specific trigger sounds [
19,
20]. This increased vigilance towards aversive sounds can impede the ability to allocate attention to other important stimuli, resulting in difficulties in task performance and broader cognitive functioning. The attentional deficits observed in individuals with misophonia—such as an exaggerated focus on trigger sounds—suggest that cognitive resources are disproportionately allocated to these stimuli, thereby reducing the capacity to engage with other aspects of the environment [
21]. To further investigate these attentional mechanisms in misophonia, we employed the flanker task, a controlled method for assessing selective attention. This task presents distracting stimuli (flankers) alongside a central target stimulus, requiring participants to focus on the target while inhibiting attention to the flankers [
22,
23]. We hypothesized that individuals with misophonia would exhibit greater difficulty disengaging attention from the flankers. This would suggest that their attention deficits are not confined to auditory stimuli alone but may extend to broader, domain-general cognitive processes.
In summary, this study aimed to investigate the neurophysiological, perceptual, and cognitive mechanisms underlying misophonia. Three tasks were utilized: ERP measurements to assess automatic change detection in auditory processing, the SRM paradigm to examine speech segregation in the presence of background noise, and the flanker task to evaluate selective attention and cognitive control. These tasks collectively offer a detailed understanding of the neural and perceptual impairments associated with misophonia.
2. Method
2.1. Participants
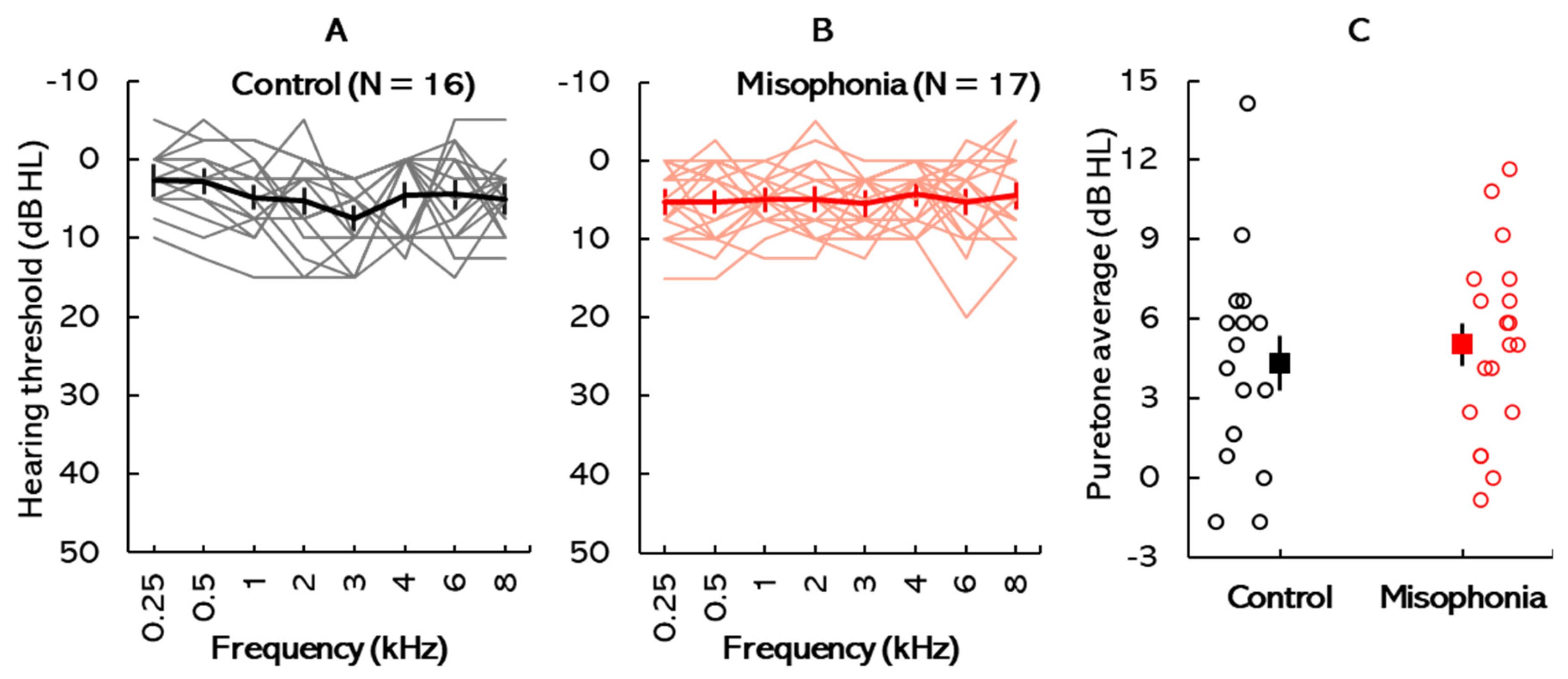
An a priori power analysis (effect size,
d = 0.25,
α = 0.05) indicated that a total sample size of 24 participants (12 per group) would be required to achieve a statistical power of 0.8. To ensure a sufficiently powered study, 35 participants (2 males, 33 females; age range: 18–30 years,
M = 24 years,
SD = 3 years) were recruited via word of mouth and social media. However, due to abnormally high electrode impedances during data collection, reliable ERP responses could not be recorded for two participants, leading to their exclusion from the analysis. This resulted in a final sample of 33 participants, with 16 assigned to the control group (1 male, 15 females;
M = 24.37 years,
SD = 1.76 years) and 17 to the misophonia group (1 male, 16 females;
M = 23.94 years,
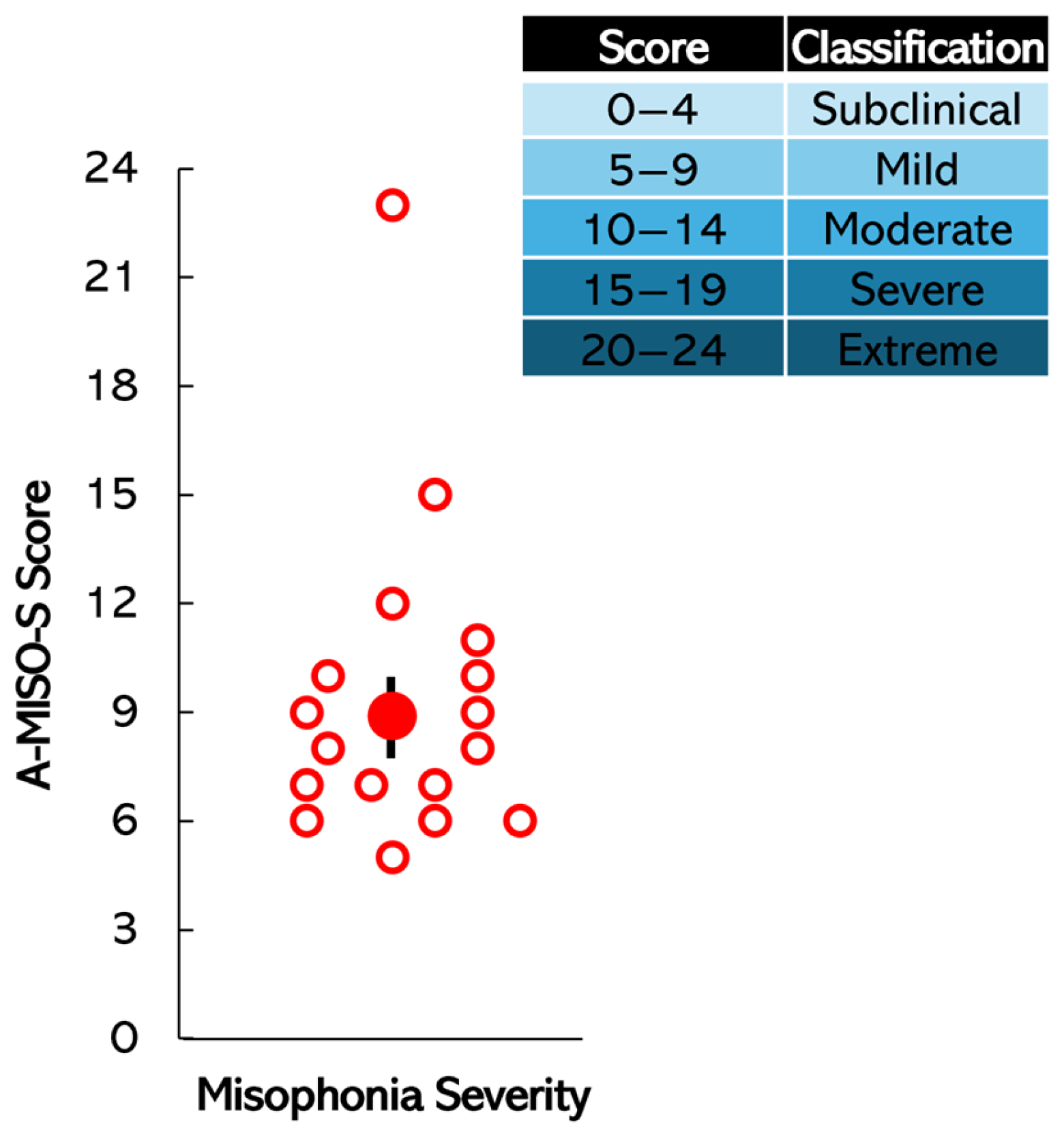
SD = 2.94 years). Each participant was screened for misophonia using the Amsterdam Misophonia Scale (A-MISO-S; Schröder et al. [
3]). The A-MISO-S, based on the Yale–Brown Obsessive–Compulsive Scale (Y-BOCS), includes six items assessing overall symptoms, distress, interference, effort to resist, control over symptoms, and avoidance [
3]. Participants were placed in either the experimental (misophonic) group or control group based on their A-MISO-S score (0–4 subclinical, 5–9 mild, 10–14 moderate, 15–19 severe, 20–24 extreme). Scores of 5 and above indicated misophonia. Participants were blinded to the outcome of the A-MISO-S screening and were not informed of their group allocation to ensure unbiased participation in the study. Participants also described scenarios where they encountered triggers, such as in classrooms and at home, and their reactions (e.g., “anger (extreme)”, “extremely uncomfortable”, “anxiety/panic attack”, “flee the environment”, “irritated”, “distress”, “disgust”), aligning with diagnostic criteria [
24,
25,
26,
27,
28]. In total, 16 participants were included in the control group (1 male, 15 females, aged 24,
M = 24,
SD = 2), and 19 in the misophonic group (1 male, 18 females, aged 24,
M = 24,
SD = 3), with an average A-MISO-S score of 9. Within the misophonic group, 11 participants scored in the mild range, 4 in the moderate range, 1 in the severe range, and 1 in the extreme range.
Participants were screened for hearing deficits through otoscopic inspection, tympanometry, and standard pure-tone audiometry. Written informed consent was obtained from all participants in accordance with the Towson University Institutional Review Board (IRB #1717, approved on 21 April 2022), Towson, MD, USA. Participants were compensated at a rate of USD 15 per hour for their time. Payment was issued in the form of gift cards upon completion of the study session.
2.2. ERP: Stimuli, Acquisition Parameters, and Response Analyses
ERP recordings were conducted using a pair of stimuli following an oddball paradigm (i.e., standard and deviant stimuli). The stimulus pair consisted of a 600 Hz tone presented binaurally. Each stimulus had a total duration of 200 ms, including a 30 ms rise time, a 140 ms steady-state plateau, and a 30 ms fall time. The standard stimulus was an unaltered 600 Hz tone delivered to both ears. The deviant stimulus featured the same 600 Hz tone but with a 15° phase shift (equivalent to 0.2618 radians) applied to the right channel. This phase difference corresponds to a small temporal delay relative to the left channel over the 600 Hz tone’s period (~1.67 ms). All stimuli were generated using MATLAB version 2024 (MathWorks, Inc., Natick, MA, USA).
The MMN response waveforms were obtained using a Duet two-channel SmartEP system (Intelligent Hearing Systems, Miami, FL, USA). Stimuli were presented at 70 dBnHL in an ‘oddball’ paradigm, with the standard stimulus occurring 80% of the time and the deviant stimulus 20% of the time. The stimuli were presented in rarefaction polarity, with a repetition rate of 1.1/s. Responses were averaged over 200 sweeps of deviant stimuli and 800 sweeps of standard stimuli, within a time frame of −50 to 500 ms relative to stimulus offset. A bandpass filter with a frequency range of 0.1 to 30 Hz was applied, and the signal was amplified up to 50,000 times. Stimuli were presented binaurally to each participant.
Participants were seated comfortably to minimize muscular artifacts and engaged in watching a subtitled movie without sound to ensure a passive listening state. Each participant was informed about the preparation and placement process of the electrode montage (2-channel, vertical montage). Before electrode placement, the skin was cleansed using an exfoliating gel, and an electrolytic paste was applied for electrode attachment. The electrodes were securely affixed using micropore tape in the designated regions according to the standard 10–20 electrode placement system: ground electrode (Fp), positive electrode (Fz), and reference electrodes on the mastoids (M1 for the left channel, M2 for the right channel). Foam insert earphones were placed in each participant’s ears for a binaural setup. Participants were instructed to remain quiet and focus solely on the movie content, disregarding any acoustic stimuli delivered through the earphones. Impedance levels were confirmed before each run (3–5 runs), maintaining less than 5 kΩ for absolute impedance and below 2 kΩ for inter-electrode impedance.
All ERP waveforms elicited by the standard and deviant stimuli were visually inspected, and the peak latencies and amplitudes were manually identified and marked for subsequent analysis. This manual marking ensured accuracy and consistency in capturing the electrophysiological responses across participants. The normative latency ranges for each ERP peak were referenced based on established guidelines to standardize interpretations. For the standard stimuli, the P1, N1, and P2 peaks were observed at approximate latencies of 50 ms, 100 ms, and 200 ms, respectively. These values align with expected auditory cortical responses to simple auditory stimuli under normal conditions [
28]. For the deviant stimuli, the same peaks typically appeared within similar latency ranges, although slight shifts in latency and amplitude were occasionally observed, likely reflecting stimulus-specific neural processing.
To isolate components related to auditory deviance detection, difference waveforms were calculated by subtracting the ERP elicited by standard stimuli from that elicited by deviant stimuli for each trial. Subsequent analyses focused on two primary negative peaks: ΔN1 and MMN. ΔN1 was defined as the difference in latency and amplitude between the N1 peaks of the standard and deviant waveforms, typically occurring within the 80–120 ms latency range. In contrast, MMN was identified as a distinct negative deflection in the difference waveform, occurring within the 150–250 ms latency range. MMN amplitude was calculated as the difference between the N2 peak elicited by deviant stimuli and the corresponding segment of the standard waveform [
9]. This measure reflects neural processes involved in the automatic detection of auditory irregularities. In addition to amplitude measures, we analyzed the latencies of individual ERP components and difference waveforms. The latency analyses provided complementary insights into the temporal dynamics of neural responses [
29], offering a detailed perspective on the temporal dynamics of auditory processing and potential deficits associated with misophonia.
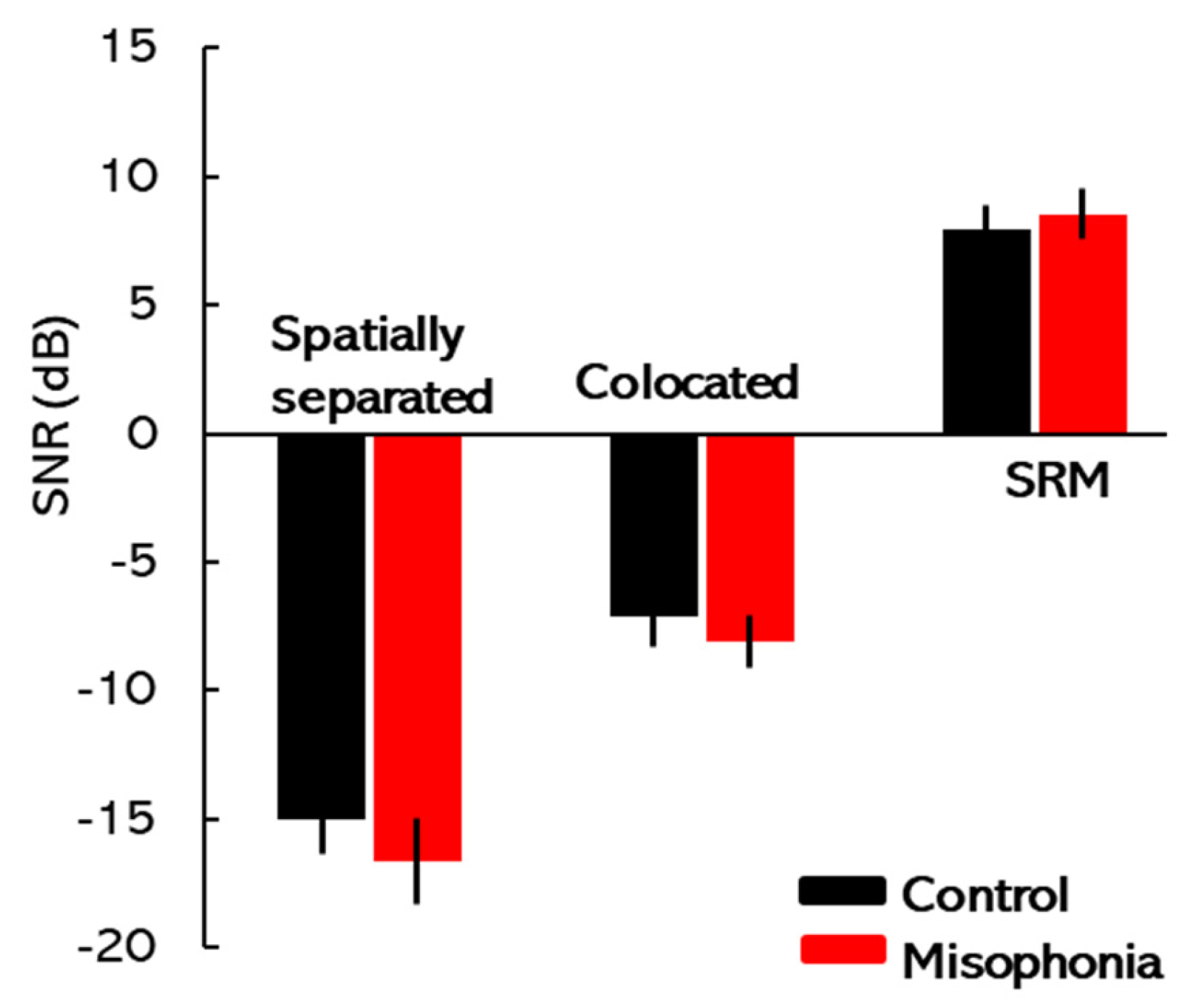
2.3. SRM Paradigm
The speech corpus recorded at Boston University’s Hearing Research Center [
15] was used to assess SRM. This corpus contained sentences composed of five monosyllabic words that are syntactically correct but semantically unpredictable. Prior research has shown that access to semantic cues may obscure the observation of any potential relationship between misophonia and speech perception. The target (and the masker) sentences in this corpus had the structure <name> <verb> <number> <adjective> <object> (e.g., Jane found five red toys), with each word being randomly selected from 8 possible options. The target always contained the <name> call-sign “Jane” with other keywords being randomly selected from other available choices. The target was always presented in the center (0° azimuth), while the maskers were either colocated with the target at 0° azimuth or spatialized at ±15° (spatially separated). The spatial locations of the target and background speakers were simulated by applying non-individualized head-related transfer functions (HRTFs) to the test stimuli, downloaded from an MIT website (sound.media.mit.edu). The target/masker voices (female voice: f0 = 175–200 Hz) varied across trials but remained the same within each given trial. The stimuli were generated in MATLAB version 2024 (MathWorks, Inc., Natick, MA, USA) on a PC and played using a Lynx Hilo sound card (Lynx Studio Technology, Costa Mesa, CA, USA). The stimuli were presented via Sennheiser HDA 650 (Sennheiser, Old Lyme, CT, USA) headphones. The masking stimuli were fixed at 70 dB SPL, while the target signal level was adaptively adjusted using a one-up, one-down tracking procedure to determine the Target-to-Masker Ratio (TMR) threshold corresponding to 50% correct performance. SRM was quantified by subtracting the TMR threshold of the spatially separated condition from that of the colocated condition, representing the improvement in speech perception due to spatial separation. The methodology for stimulus presentation and response analysis for SRM has been detailed in recent studies conducted by our laboratory [
30,
31,
32,
33]. Participants were tasked with identifying target sentences beginning with the call-sign “Jane”, always delivered from the center. Each trial featured a randomized pairing of target and masker voices, consistent within a given trial. Practice runs for both conditions were conducted to familiarize participants with the task. The experiment used a fixed set of conditions, and the target–masker configurations were randomized to minimize predictability effects.
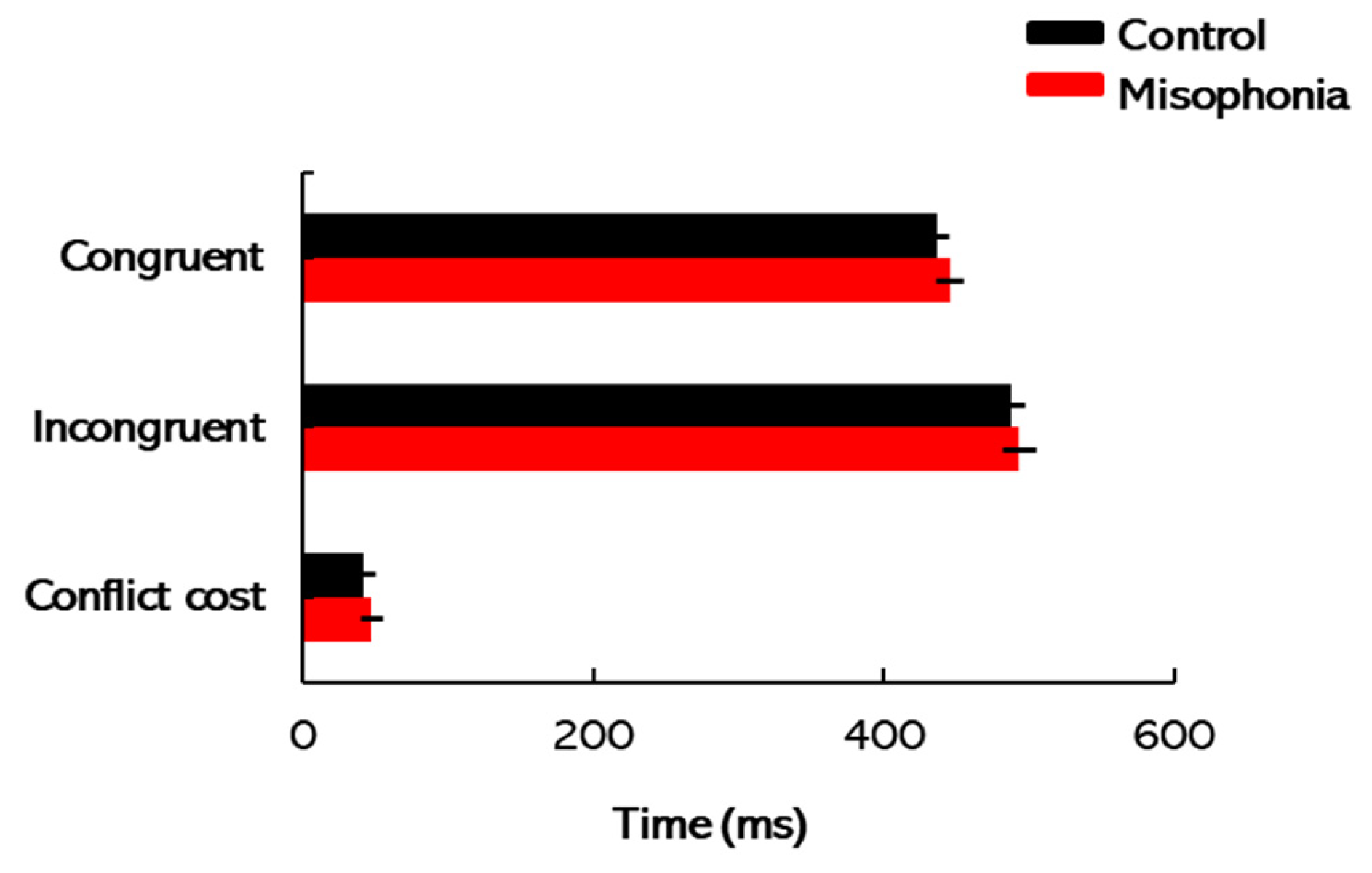
2.4. Flanker Task
The flanker test was conducted using the Psychology Experiment Building Language (PEBL version 2.0.4) platform (The PEBL Project, Fairfax, VA, USA) [
34]. In this task, participants were presented with a central stimulus and tasked with identifying its left–right orientation while actively disregarding surrounding stimuli, referred to as ‘flankers’ [
35]. The primary objective was to determine whether the centrally located arrow pointed to the left or right, while ignoring the orientation of the surrounding arrows [
36]. The surrounding arrows were either congruous, where the target stimulus and distracting stimuli were associated with the same response (e.g., all arrows pointing in the same direction), or incongruous, where the target stimulus and distracting stimuli were associated with different responses (e.g., the central arrow pointing left while flankers point right) [
37]. The key manipulation in this task was the congruency of the target stimulus and its flankers.
Each participant underwent 160 trials, with accuracy and response times recorded. These measurements served as indicators of cognitive attention, in line with the methodology detailed by Zelazo et al. [
38]. The task setup is straightforward, with stimuli shown for an unlimited time until the participant responds to advance to the next trial. The stimuli were typically composed of a target image in the center flanked by one or more distractor stimuli on either side. Completion times for the flanker task were scored separately for congruent, incongruent, and conflict cost conditions. To account for potential confounding factors such as motor skills, visual acuity, and processing speed, a differential measure termed conflict cost was employed. Conflict cost was calculated by subtracting the total completion times for congruent trials from those for incongruent trials, providing a more targeted assessment of attentional control [
35]. Higher conflict costs would indicate greater difficulty in filtering out irrelevant distractors and focusing on the target stimulus, suggesting weaker attentional control. Conversely, lower conflict costs demonstrate an enhanced ability to manage interference and maintain focus. By analyzing conflict cost, this study aimed to gain insight into the attentional processes that may be disrupted in individuals with misophonia.
2.5. Testing Procedure
The participants’ testing journey began with audiometric assessments to establish baseline hearing thresholds. Following this, the A-MISO-S scale was used to assess the severity of misophonia symptoms, providing context for individual differences in misophonia severity. Next, participants completed the ERP task to examine neural responses to auditory deviance, focusing on MMN and ΔN1 components. This task assessed the brain’s automatic response to standard and deviant auditory stimuli, providing insights into auditory processing and potential neural impairments associated with misophonia. The SRM paradigm followed, where participants’ ability to segregate speech from background noise was tested. By measuring SRM, this task evaluated how well participants could perceive speech in noisy environments, highlighting potential challenges faced by individuals with misophonia in real-world listening situations. Finally, participants engaged in the flanker task, which assessed cognitive control and attentional processes. The conflict cost measure was used to examine participants’ ability to filter distractions and focus on the target stimulus, offering insights into the attentional challenges that may be present in individuals with misophonia.
5. Limitations
While this study offers valuable insights into the potential impact of misophonia on auditory function, it is important to acknowledge several limitations that could affect the interpretation of the findings. Firstly, the relatively small sample size of 33 participants (17 misophonics, 16 control subjects) raises concerns about the generalizability of the results. A larger and more diverse sample could enhance the statistical power of the study, allowing for more robust conclusions and better detection of subtle differences between groups. Secondly, the study exclusively focused on college students, which may not accurately represent the broader population affected by misophonia. Misophonia can affect individuals of all ages and backgrounds, and limiting the study to this demographic may restrict the applicability of the findings to other age groups or populations. Furthermore, the study did not account for potential comorbid conditions that could influence physiological measurements. Misophonia often coexists with other psychiatric or neurological disorders, such as anxiety or obsessive–compulsive disorder, which could confound the results. Future research should consider controlling these comorbidities to better isolate the effects of misophonia on auditory function. Similarly, another limitation of this study is that we neither asked participants nor explicitly screened for the presence of tinnitus or hyperacusis. As these conditions could influence auditory cortical potentials and confound the findings in the misophonia group, this should be considered when interpreting the results. Future studies should account for these factors to more accurately isolate the neural and perceptual effects of misophonia.
Another key limitation of the present study is that cognitive status was assessed solely with the flanker task, which, while informative, does not provide a comprehensive evaluation of overall cognitive function. Therefore, conclusions about participants’ general cognitive status cannot be made based on this test alone. Similarly, ERP analysis focused only on cortical responses to standard and deviant tones, specifically the P1-N1-P2-N2 components. This limits the scope of the findings, as it does not include the brainstem or other auditory and cognitive potentials that may provide a fuller picture of misophonia-related neural processes. Future research should include a wider range of neurophysiological measures for a more complete understanding of the neural mechanisms involved in misophonia.
Lastly, the use of the A-MISO-S questionnaire as the primary measure of misophonia severity relies on self-reporting, which introduces the possibility of response bias or inaccurate reporting. Individuals may under-report or over-report their symptoms, leading to potential inaccuracies in the assessment of misophonia severity. Supplementing self-report measures with objective measures of misophonia, such as physiological assessments or behavioral observations, could provide a more comprehensive understanding of the condition. Future research with larger and more diverse samples, consideration of comorbid conditions, and incorporation of objective measures of misophonia could further advance our understanding of this complex disorder.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}