
The Spatial Precision of Contextual Feedback Signals in Human V1

Abstract
Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Participants
2.2. Stimuli
2.3. Design and Procedure
2.4. Retinotopic Mapping of Early Visual Areas
2.5. MRI Data Acquisition
2.6. Data Analysis
2.7. Retinotopic Mapping
2.8. Cortical Surface Reconstruction and Region-of-Interest (ROI) Definition
2.9. Multivariate Pattern Classification Analysis
3. Results
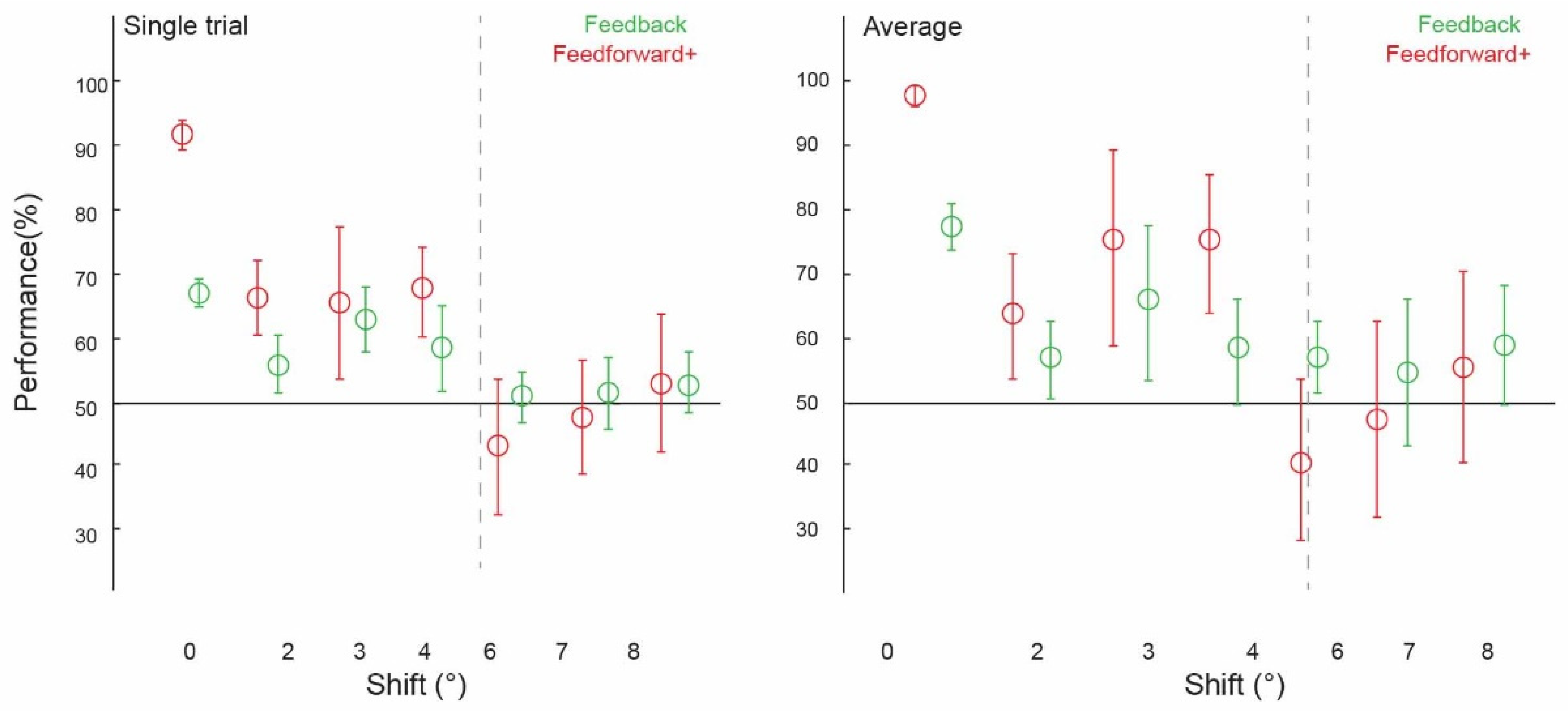
3.1. Contextual Feedback Processing and Comparison with Feedforward Classification
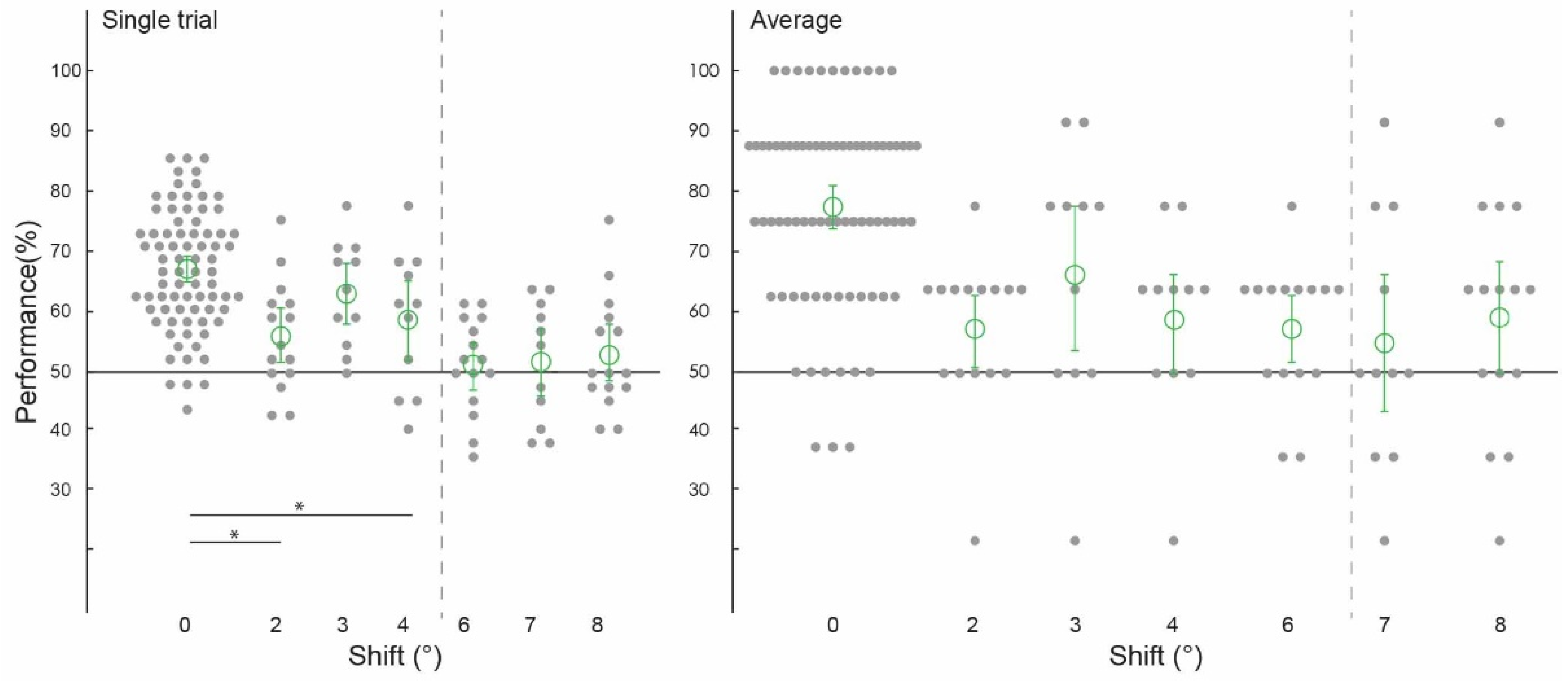
3.2. Spatial Precision of Cortical Feedback Processing
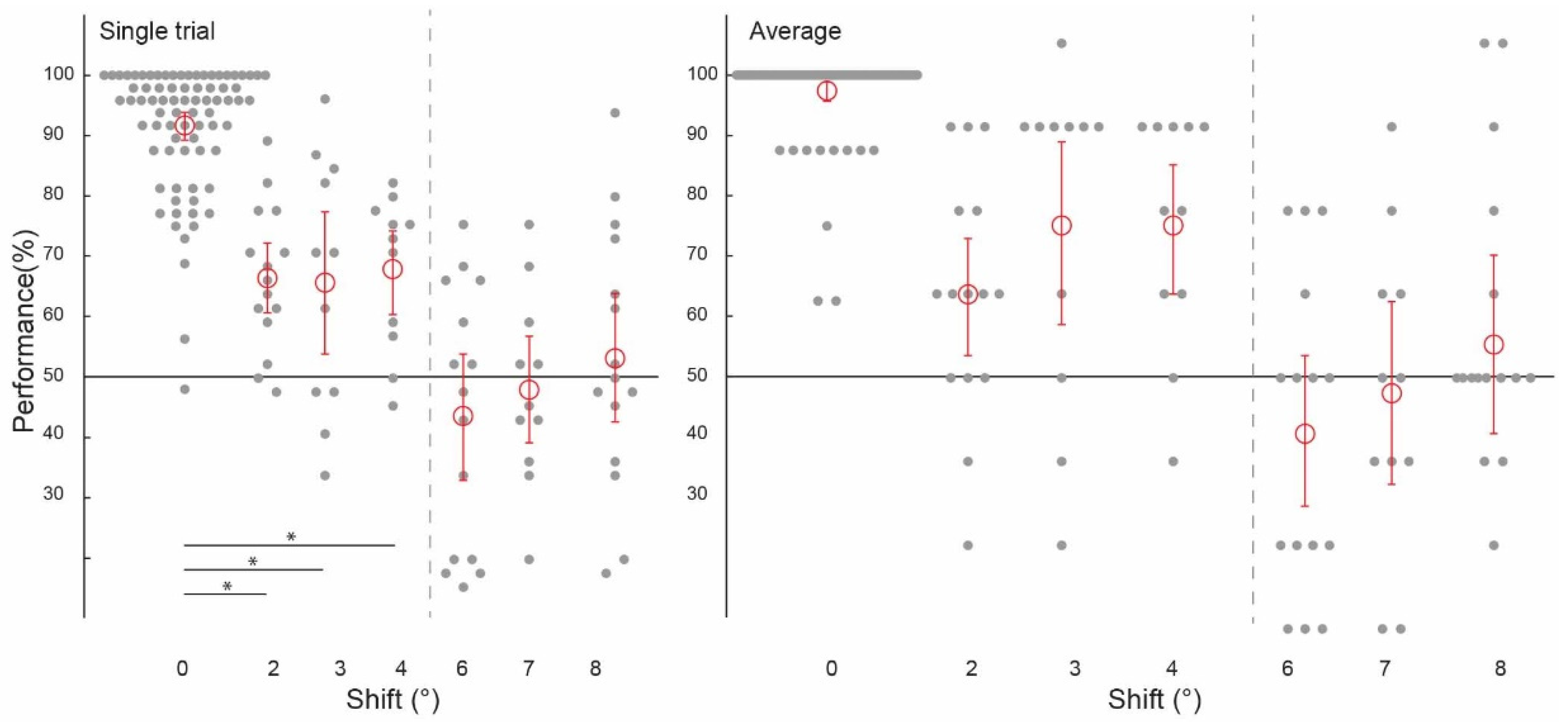
3.3. Spatial Precision of Feedforward + Processing
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Niell, C.M. Cell types, circuits, and receptive fields in the mouse visual cortex. Annu. Rev. Neurosci. 2015, 38, 413–431. [Google Scholar] [CrossRef] [PubMed]
- Gilbert, C.D. Laminar differences in receptive field properties of cells in cat primary visual cortex. J. Physiol. 1977, 268, 391–421. [Google Scholar] [CrossRef] [PubMed]
- Ringach, D.L. Spatial structure and symmetry of simple-cell receptive fields in macaque primary visual cortex. J. Neurophysiol. 2002, 88, 455–463. [Google Scholar] [CrossRef]
- Yoshor, D.; Bosking, W.H.; Ghose, G.M.; Maunsell, J.H. Receptive fields in human visual cortex mapped with surface electrodes. Cereb. Cortex 2007, 17, 2293–2302. [Google Scholar] [CrossRef] [PubMed]
- Dumoulin, S.O.; Wandell, B.A. Population receptive field estimates in human visual cortex. Neuroimage 2008, 39, 647–660. [Google Scholar] [CrossRef] [PubMed]
- Fracasso, A.; Petridou, N.; Dumoulin, S.O. Systematic variation of population receptive field properties across cortical depth in human visual cortex. Neuroimage 2016, 139, 427–438. [Google Scholar] [CrossRef] [PubMed]
- Keliris, G.A.; Li, Q.; Papanikolaou, A.; Logothetis, N.K.; Smirnakis, S.M. Estimating average single-neuron visual receptive field sizes by fMRI. Proc. Natl. Acad. Sci. USA 2019, 116, 6425–6434. [Google Scholar] [CrossRef]
- D’Souza, R.D.; Wang, Q.; Ji, W.; Meier, A.M.; Kennedy, H.; Knoblauch, K.; Burkhalter, A. Hierarchical and nonhierarchical features of the mouse visual cortical network. Nat. Commum. 2022, 13, 503. [Google Scholar] [CrossRef]
- Smith, F.W.; Muckli, L. Nonstimulated early visual areas carry information about surrounding context. Proc. Natl. Acad. Sci. USA 2010, 107, 20099–20103. [Google Scholar] [CrossRef]
- Muckli, L.; De Martino, F.; Vizioli, L.; Petro, L.S.; Smith, F.W.; Ugurbil, K.; Goebel, R.; Yacoub, E. Contextual feedback to superficial layers of V1. Curr. Biol. 2015, 25, 2690–2695. [Google Scholar] [CrossRef]
- Revina, Y.; Petro, L.S.; Muckli, L. Cortical feedback signals generalise across different spatial frequencies of feedforward inputs. Neuroimage 2018, 180, 280–290. [Google Scholar] [CrossRef] [PubMed]
- Morgan, A.T.; Petro, L.S.; Muckli, L. Scene representations conveyed by cortical feedback to early visual cortex can be described by line drawings. J. Neurosci. 2019, 39, 9410–9423. [Google Scholar] [CrossRef] [PubMed]
- Willenbockel, V.; Sadr, J.; Fiset, D.; Horne, G.; Gosselin, F.; Tanaka, J. Controlling low-level image properties: The SHINE toolbox. Behav. Res. Methods 2010, 42, 671–684. [Google Scholar] [CrossRef] [PubMed]
- Engström, M.; Ragnehed, M.; Lundberg, P. Projection screen or video goggles as stimulus modality in functional magnetic resonance imaging. Magn. Reson. Imaging 2005, 23, 695–699. [Google Scholar] [CrossRef]
- Sereno, M.I.; Dale, A.M.; Reppas, J.B.; Kwong, K.K.; Belliveau, J.W.; Brady, T.J.; Rosen, B.R.; Tootell, R.B.H. Borders of multiple visual areas in humans revealed by functional magnetic resonance imaging. Science 1995, 268, 889–893. [Google Scholar] [CrossRef]
- Petro, L.S.; Smith, F.W.; Schyns, P.G.; Muckli, L. Decoding face categories in diagnostic subregions of primary visual cortex. Eur. J. Neurosci. 2013, 37, 1130–1139. [Google Scholar] [CrossRef]
- Talairach, J.; Tournoux, P. Co-Planar Stereotaxic Atlas of the Human Brain; Thieme: Stuttgart, Germany, 1988. [Google Scholar]
- Kriegeskorte, N.; Goebel, R. An efficient algorithm for topologically correct segmentation of the cortical sheet in anatomical MR volumes. NeuroImage 2001, 14, 329–346. [Google Scholar] [CrossRef]
- Chang, C.C.; Lin, C.J. LIBSVM: A Library for Support Vector Machines. 2001. Available online: http://www.csie.ntu.edu.tw/ (accessed on 1 April 2023).
- Angelucci, A.; Levitt, J.B.; Lund, J.S. Anatomical origins of the classical receptive field and modulatory surround field of single neurons in macaque visual cortical area V1. Prog. Brain Res. 2002, 136, 373–388. [Google Scholar] [CrossRef]
- Angelucci, A.; Bullier, J. Reaching beyond the classical receptive field of V1 neurons: Horizontal or feedback axons? J. Physiol. Paris 2003, 97, 141–154. [Google Scholar] [CrossRef]
- Wandell, B.A.; Winawer, J. Computational neuroimaging and population receptive fields. Trends Cogn. Sci. 2015, 19, 349–357. [Google Scholar] [CrossRef]
- Markov, N.T.; Vezoli, J.; Chameau, P.; Falchier, A.; Quilodran, R.; Huissoud, C.; Lamy, C.; Misery, P.; Giroud, P.; Ullman, S.; et al. Anatomy of hierarchy: Feedforward and feedback pathways in macaque visual cortex. J. Comp. Neurol. 2014, 522, 225–259. [Google Scholar] [CrossRef] [PubMed]
- Self, M.W.; Jeurissen, D.; van Ham, A.F.; van Vugt, B.; Poort, J.; Roelfsema, P.R. The segmentation of proto-objects in the monkey primary visual cortex. Curr. Biol. 2019, 29, 1019–1029. [Google Scholar] [CrossRef] [PubMed]
- Shipp, S. Neural elements for predictive coding. Front. Psychol. 2016, 7, 1792. [Google Scholar] [CrossRef] [PubMed]
- Larkum, M. A cellular mechanism for cortical associations: An organizing principle for the cerebral cortex. Trends Neurosci. 2013, 36, 141–151. [Google Scholar] [CrossRef]
- Schuman, B.; Dellal, S.; Prönneke, A.; Machold, R.; Rudy, B. Neocortical layer 1: An elegant solution to top-down and bottom-up integration. Annu. Rev. Neurosci. 2021, 44, 221–252. [Google Scholar] [CrossRef]
- Semedo, J.D.; Jasper, A.I.; Zandvakili, A.; Krishna, A.; Aschner, A.; Machens, C.K.; Kohn, A.; Yu, B.M. Feedforward and feedback interactions between visual cortical areas use different population activity patterns. Nat. Commun. 2022, 13, 1099. [Google Scholar] [CrossRef]
- Papale, P.; Wang, F.; Morgan, A.T.; Chen, X.; Gilhuis, A.; Petro, L.S.; Muckli, L.; Roelfsema, P.R.; Self, M.W. Feedback brings scene information to the representation of occluded image regions in area V1 of monkeys and humans. bioRxiv 2022. bioRxiv: 11.21.517305. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Petro, L.S.; Smith, F.W.; Abbatecola, C.; Muckli, L. The Spatial Precision of Contextual Feedback Signals in Human V1. Biology 2023, 12, 1022. https://doi.org/10.3390/biology12071022
Petro LS, Smith FW, Abbatecola C, Muckli L. The Spatial Precision of Contextual Feedback Signals in Human V1. Biology. 2023; 12(7):1022. https://doi.org/10.3390/biology12071022
Chicago/Turabian StylePetro, Lucy S., Fraser W. Smith, Clement Abbatecola, and Lars Muckli. 2023. "The Spatial Precision of Contextual Feedback Signals in Human V1" Biology 12, no. 7: 1022. https://doi.org/10.3390/biology12071022
APA StylePetro, L. S., Smith, F. W., Abbatecola, C., & Muckli, L. (2023). The Spatial Precision of Contextual Feedback Signals in Human V1. Biology, 12(7), 1022. https://doi.org/10.3390/biology12071022