1. Introduction
With the rapid urbanization and high concentration of humans, utilizing underground space can be an efficient method to solve the problem in the area of urban transportation, water, energy, and other services [
1]. Shield tunneling is currently the primary method for underground tunnel construction, and disc cutters are essential components of the cutter head on a shield tunneling machine during rock breaking and excavation. Their overall condition directly affects the efficiency and quality of shield tunneling [
2,
3].
In the TBM tunneling process, the disc rolling cutters make contact with the rock and penetrate the rock continuously until the rock slabs. In this process, the cutters will inevitably be worn [
4,
5]. When a worn disc reaches its threshold and is not replaced in time, the surrounding cutters will be worn quickly. Furthermore, the failure of seals and bearings may occur which results in damage to the cutter head [
6]. If the TBM continues to excavate, some risks may occur including project delay, TBM stoppage, equipment damage, etc. [
7]. Excessively frequent shutdowns for maintenance can increase economic and time costs, while excessively long tool-changing distances can reduce the efficiency of shield tunneling [
8]. As pointed out by Wang et al. [
9] and Wan et al. [
10], nearly one-third of the project cost and construction time are occupied by the maintenance and replacement of disc cutters in TBMs. Therefore, accurately identifying and predicting the wear condition of disc cutters at different tunneling stages is of great significance for reducing the number of cutter changes, shortening the tunneling duration, and lowering construction risks and costs. Existing reports demonstrate that intelligent models have already been embedded in TBM control systems. For example, Wei et al. [
11] employed a GA-BP model to predict real-time excavation speed, while Lin et al. [
12] and Armaghani et al. [
13] developed systems based on GRU and PSO-ANN models, respectively, to forecast TBM cutter head torque and penetration rate in real time, thereby informing engineering decisions. Nevertheless, manual inspection and expert judgment remain the principal means of disc cutter management, and current approaches to predicting cutter wear can be broadly classified into empirical models and soft computing models.
Most empirical models use linear models and analytical and numerical methods to predict the disc cutters’ wear. Representative models include the Colorado School of Mines (CSM) model and the Norwegian University of Science and Technology (NTNU) model [
14,
15]. Many scholars have also analyzed the wear patterns of disc cutters in specific scenarios by establishing finite element models or constructing experimental setups. Collecting and analyzing wear data from various projects to extract key factors influencing wear is also a common research approach. Sun et al. [
8] use a disc cutter scaled to 1/10 of the actual cutter and a test device to study the relationship between cutter wear and abrasive stratum. Hassanpour et al. [
16] summarize that most empirical models for disc cutter life rely on a single factor, such as the Cerchar abrasivity index (CAI), uniaxial compressive strength (UCS), or the cutter life index (CLI). Yang et al. [
17] perform a statistical examination of the correlation between geological parameters and the life cycle of cutters. Zahiri et al. [
18] use multiple linear regression methods and find the relationship between UCS and wear life. Soft computing techniques use data-driven solutions in assisting engineer decisions, it they offer an effective method for investigating more intricate, nonlinear connections among disc cutter wear, geological conditions, and shield operational parameters. The above methods have achieved valuable results by considering shield tunneling parameters such as the disc cutter structure, cutter head thrust, penetration depth, and torque as factors influencing wear. However, due to the numerous assumptions required for boundary conditions in these algorithms, they often yield good results only in tunneling environments with uniform geological strata.
Machine learning (ML) technology provides an effective means for exploring more complex nonlinear relationships between disc cutter wear, geological conditions, and shield tunneling operation parameters [
19]. Elbaz et al. [
20] apply group method of data handling (GMDH)-type neural networks to model cutter wear. Afradi et al. [
21] use supporting vector regression (SVR) and neural networks to predict the TBM penetration rate and the number of consumed disc cutters. Mahmoodzadeh et al. [
22] use a 5-fold cross-validation method to evaluate the model and search model hyperparameters. Ding et al. [
23] developed a BPNN model using Guangzhou Metro monitoring data to derive an empirical formula model. Similarly, Akhlaghi et al. [
24], Shin et al. [
25], and Bai et al. [
26] used Gaussian process regression (GPR), extreme gradient boosting (XGBoost), particle swarm optimization (PSO), and the genetic algorithm (GA) to study the wear pattern of disc cutters. Compared with empirical models, the application of ML methods is more flexible, as they can combine multiple algorithms to reveal the impact of different factors on disc cutter wear. However, tunneling is a continuous excavation process, and the aforementioned models lack the utilization of time series information. Therefore, time series models are one of the most suitable neural networks for studying disc cutter wear, which can also be supported by the research by Shahrour et al. [
1], Zhou et al. [
27], and Xie et al. [
28]. It should be noted that “time series models” usually refer to methods such as ARIMA and SARIMAX in classical statistics; however, in the field of machine learning, recurrent neural networks (RNNs), like LSTM and GRU, are also broadly regarded as “time series models”. To avoid any ambiguity, in this paper, all subsequent “time series models” refer to “RNN-based time series models”.
Previous research has provided valuable insights, yet limitations persist. (1) The parameters used as model inputs are derived from theoretical studies and empirical formulas. However, current shield tunneling parameters are sourced from onsite monitoring systems, encompassing over 171 features such as grouting amount, foam system, advance jack oil pressure, synchronized grouting pressure, shield tail seal grease compartment pressure, etc. Apart from the explicit influencing factors, there may also be parameters that indirectly exert significant impacts on disc cutter wear. (2) The limitations of different models stem from their structural characteristics, making it unreasonable to apply the same preprocessing methods to heterogeneous data and models. For instance, in classical ML models, the common practice is to simply average shield operation parameters; this approach may ignore the effects of short-term extremes. By contrast, time series models use a sliding window input format that can alleviate this oversight. Therefore, further research is necessary to explore the optimal combination of input data obtained through various preprocessing techniques paired with different prediction models.
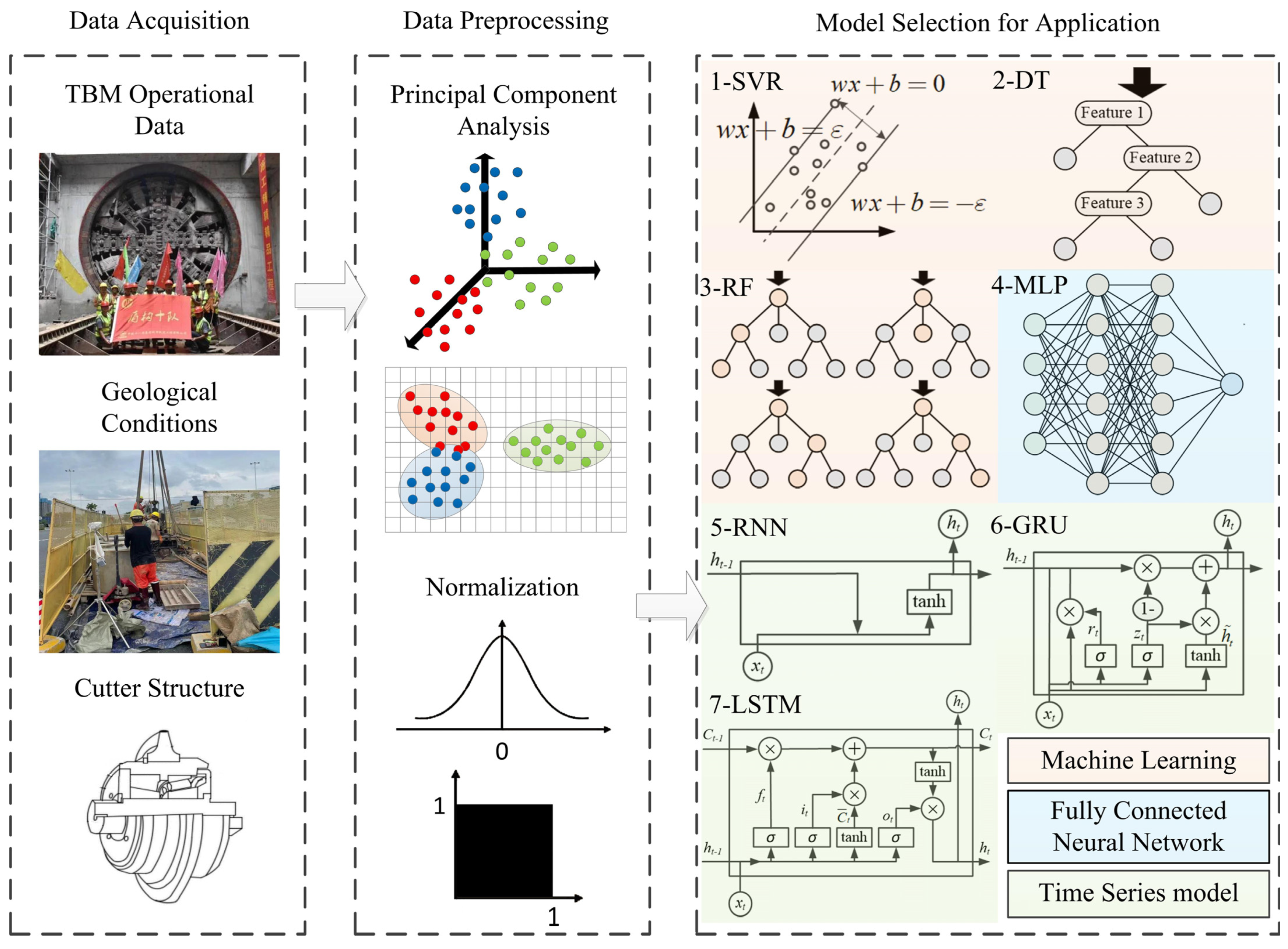
In this study, we explore the practical approach for predicting disc cutter wear by combining various normalization and dimensionality reduction methods with multiple machine learning and recurrent neural networks based on a practical case project in Guangzhou, China.
3. Data Preprocessing
Data preprocessing contains the following basic steps. (1) Drop out the feature columns containing more than 10% of missing data. (2) Use the linear interpolation method to fill the missing data. (3) Use PCA to reduce the dimension of features with the same meaning but collected in different sensors. (4) Use different scalers to transform the feature data. The scales include the Min Max Scaler, standardization, and Max Absolute (Max Abs) Scaler. (5) Integrate the features of TBM operational data (field data), geological features, and cutter information to generate the merged dataset. (6) Divide the dataset into a training dataset, validation dataset, and testing dataset.
3.1. Data Analysis
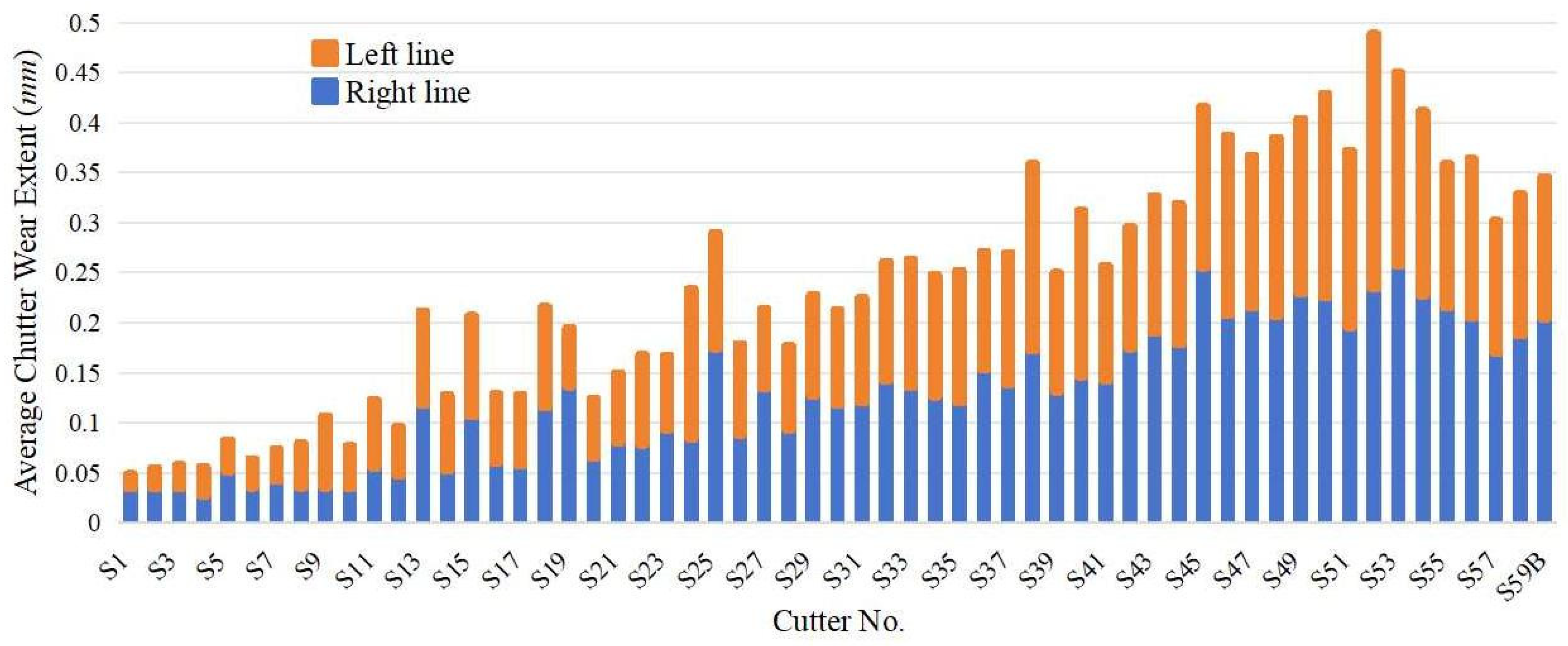
By organizing the information about cutter wear in both the right and left lines, we have compiled a total of 886 wear measurement records. Among these, there are only a few instances of abnormal cutter wear, specifically 26 records. Among the 26 abnormal wear records, nearly 20 involve the double-edged disc cutters installed around the center of the cutter head. Owing to their small gyration radius, these cutters undergo both sliding and rolling motions and are subjected to large axial forces, which leads to uneven wear of the cutter rings. Because wear measurement can only be taken manually when the TBM shuts down, it is impossible to determine the exact moment or precise position at which the abnormal wear occurs. To avoid the imbalance between normal and abnormal wear records from interfering with subsequent model training, we have excluded these data points from further analysis.
Figure 8 illustrates the average cutter wear extent in two lines. The average cutter wear extent is calculated as the average extent of the interval between cutter wear measurements. The cutters near the center of the cutter head are less likely to be worn than the others in the outer cutter head. The original wear extent is used as a predictive variable in the time series model, and the average wear extent is used in traditional machine learning and MLP models.
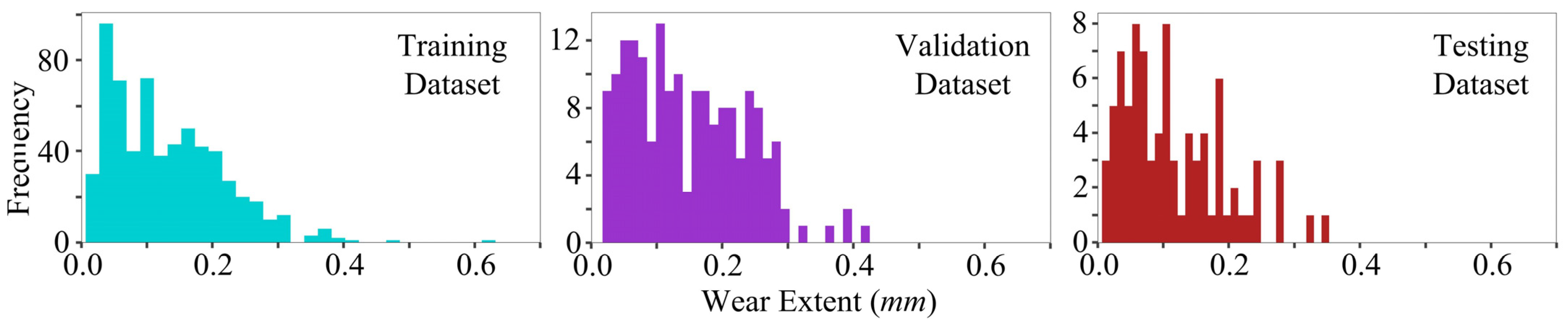
To avoid model overfitting and estimate the performance, we simulate the real scenario of the TBM excavation process; the last two measurements of the cutter wear extent results are extracted and treated as a testing dataset. The remaining data are randomly divided into training datasets and validation datasets. The ratio of the training dataset, validation dataset, and testing dataset is about 7:2:1.
Figure 9 displays the average cutter wear extent distributions for the training, validation, and testing datasets based on the aforementioned statistics. The wear in all three datasets is predominantly concentrated in the 0~0.3 mm range with consistent peaks, while a small number falls within 0.3~0.5 mm. Their distribution shapes and frequency scales closely match, indicating that the data split maintained distributional consistency and thus provided a solid foundation for fair model performance evaluation.
3.2. Operation Parameter Feature Reduction
There are 171 features in the parameters of the TBM excavation operation. Initially, features with missing data exceeding 10% of the entire dataset are removed, leaving 110 features. The operational parameters are collected once every minute by sensors distributed across various key components of the TBM, with sensors on each component categorized into groups. Due to the influence of complex working conditions, information collected by the sensors may inevitably have missing values. To address this issue, we employ the linear interpolation method to fill in the missing data. These remaining 110 features primarily originate from 18 sensor groups. To enhance the prediction model to better focus on core features, we further utilize PCA for dimensionality reduction in the current operational features.
As a Karhunen–Loeve transformation, PCA is also widely used in feature selection [
36]. It transforms
n vectors in a
d-dimensional space (
x1,
x2, …,
xn) into
n new vectors, which are in a new
d′-dimensional space (
x′
1,
x′
2, …,
x′
n) as follows:
where
ek is the eigenvectors corresponding to the
d′ largest eigenvalues
λk for the scatter matrix
S and
ak,i are the projections of the original vector
xi on the eigenvectors
ek. The calculation of the scatter matrix can be defined as follows:
Generally, the cumulative explained variance should be up to 80% after PCA. The PCA scaler first fits the data in the training dataset and validation dataset. The scaler later transforms the whole dataset to reduce dimensions. After transformation, feature group data are merged together as the new dataset. The PCA features dimension reduction result is shown in
Table 1.
3.3. Data Normalization
Previous research has shown that different data normalization methods have different effects on data analysis [
37]. However, few studies discuss different data normalization methods on TBM data. To fully use the information of the original dataset and avoid the effects of data normalization methods, three methods are used in this study, including the Min Max Scaler, standardization, and the Max Absolute Scaler.
- (1)
The Min Max Scaler method is calculated as follows:
where
i denotes each feature in vector
X.
- (2)
Similarly, the standardization method is calculated as follows:
- (3)
And the Max Absolute Scaler method is calculated as follows:
In addition, the direct PCA method is also applied in the feature dimension reduction directly instead of the above feature groups.
Table 2 lists the explained variance ratios for the selected components and the scree plots as shown in
Figure 10. Under the same normalization, the geological and cutter geometry features are merged into datasets.
4. Method Performance and Comparison
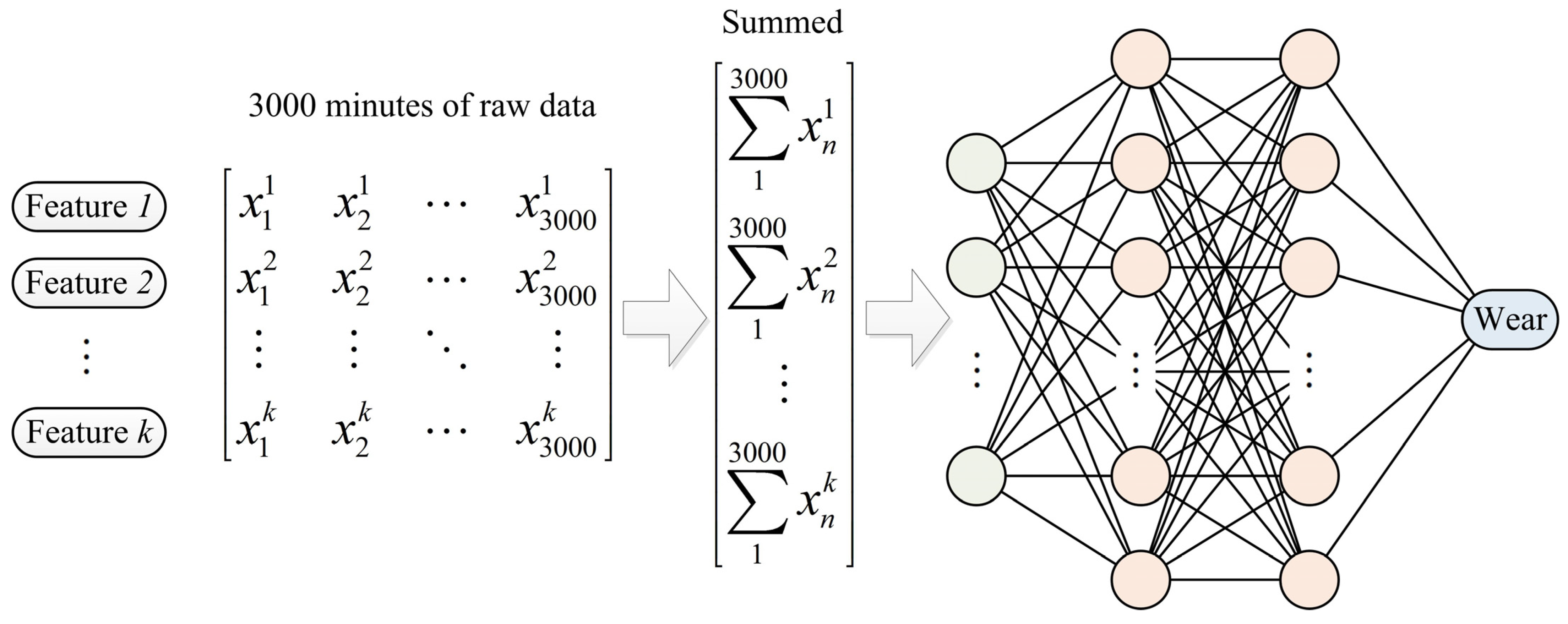
In this study, we utilize an SVR with an RBF kernel function and an RF algorithm where the maximum depth of the tree is explored between 10 and 21, and the minimum sample split parameter ranges from 2 to 5, to predict the extent of cutter wear. Additionally, traditional neural networks (MLP) and time series neural network models (RNN, LSTM, and GRU) are employed for learning and predicting the disc cutter wear. It is worth noting that while the predictive variable used in the time series model is the wear extent between measurement intervals, the predictive variable used in traditional machine learning algorithms (SVR, RF, and MLP) is the average cutter wear in the corresponding interval.
To verify the performance of the models, the coefficient of determination
R2 and the mean absolute percentage error (
MAPE) describe the error between the predicted and actual values.
where
weari represents the actual wear value,
is the predicted wear value of the model,
represents the average of the actual wear values, and
N is the number of samples in the training or test dataset.
R2 represents the proportion of the total variance in wear explained by the model; the closer
R2 is to 1, the better the wear predictions. The
MAPE measures the mean absolute percentage error of those predictions; the smaller the
MAPE, the more accurate the wear forecasts.
Traditional machine learning algorithms are performed on an ACER E5-572G-528R laptop with an i5-4210M CPU, 2.60 GHZ, and 8.00GB of RAM memory. Neural networks are run in the cloud server AutoDL with an E5-2680 v4@ CPU, 2.40 GHz, 20 GB of memory, and a 12 GB RTX 3060 GPU.
4.1. Traditional Machine Learning
In this section, we attempt to establish a predictive model by three traditional machine learning models (SVR, DT, and RF) and test their performance under different datasets and normalization methods. Among them, with SVR using RBF kernel’s best hyperparameters, the value of “C” tends to be large and “gamma” tends to be small; the optimal hyperparameters for DT and RF are “max_depth = 20, min_samples_split = 5”, and “max_depth = 10, min_samples_split = 5, n_estimators = 60”, respectively. Different models’ model metrics are listed in
Table 3.
As shown in
Table 3, (1) random forest ranks first among these methods. (2) Although the decision tree outperforms random forest on the training dataset, the performance of decision tree even is worse than the average model (i.e.,
R2 less than 0 on the testing dataset). Therefore, further exploration of the random forest model metric of different datasets under three kinds of normalization is listed in
Table 4.
As shown in
Table 4, the (1) PCA directly dataset outperforms the other two datasets across three normalization methods, and the performance of the PCA dataset is the worst. (2) For normalization methods, no obvious difference between test
R2 and test
MAPE is found within these three datasets.
4.2. Neural Networks
The MLP models train various kinds of datasets, and the validation datasets are used as the model’s early stopping criterion. Different hidden layer numbers and activation functions are the hyperparameters of these models.
Table 5 lists the running time of two hidden layer MLP models, whose test
R2 ranks first in all the hyperparameter settings. (1) Under Max Absolute or Min Max Scaler, MLP on the raw dataset fits the training dataset with a smaller number of hidden layers than the other dataset (i.e., PCA, PCA directly). (2) The PCA dataset requires fewer epochs and less time to fit the data.
The model metrics of MLP models, as shown in
Table 6, indicate several observations. (1) Under standardization, the models generally achieve better
R2 values compared to other normalization methods. However, not all the corresponding
MAPE values are the smallest. (2) Unlike the raw dataset, the other three kinds of datasets require more neurons in the hidden layer to effectively fit the dataset. (3) With standardization, both the raw dataset and PCA dataset exhibit the best performance among these models. However, as seen from the above table, the PCA dataset takes less time to train the model.
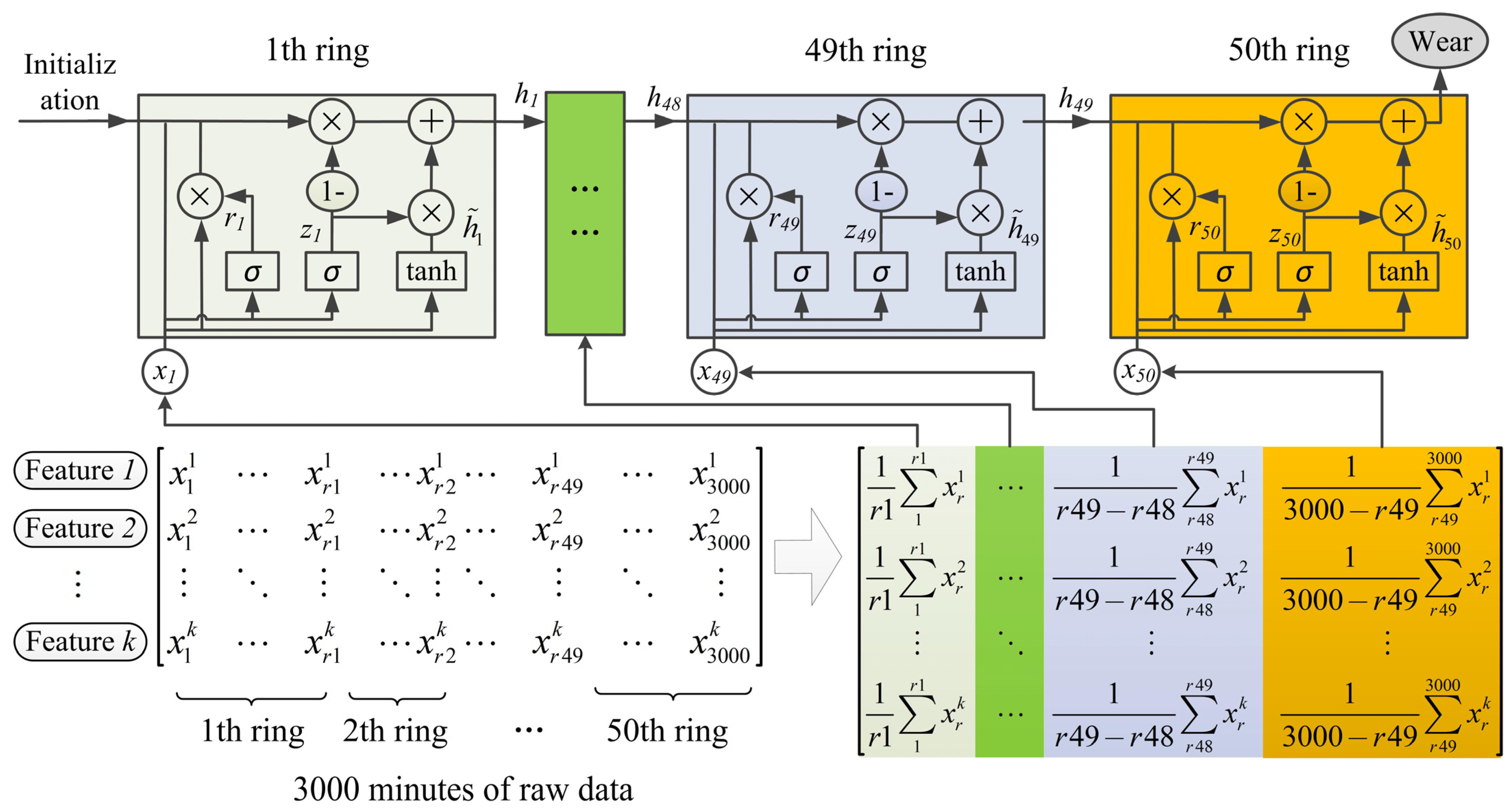
4.3. Time Series Model
We evaluate time series models with different structures and hyperparameters on various datasets under three types of normalization, as detailed in
Appendix A. For each experimental configuration, an early stopping mechanism was implemented: training will terminate if model performance fails to improve for 10 consecutive epochs.
Table 7 and
Table 8 list the running time of these models that achieved the best score on the testing dataset after model fitting and evaluation using the validation dataset. (1) As for the training time, standardization methods use less time than the other two normalization methods. (2) PCA directly takes less time than the other three datasets for model fitting. (3) The training time of the time series model is longer than that of the ANN model listed above.
Table 8 lists the model metrics of the time series models with the best score on the testing dataset after model fitting and evaluation using the validation dataset. (1) The
R2 value of the time series model is greater than the
R2 of the MLP model and traditional machine learning model. The test
MAPE of the time series model is better than that of MLP. These two results mean the predictive performance of the time series model is superior to the other two types of models. (2) The models using a standardization scaler perform worse than the other two methods in the time series model. This result is different from the MLP model. (3) The performance of the GRU model to fit and predict the cutter wear extent is usually better than the other two time series models. (4) The PCA dataset achieves the best performance under the Min Max Scaler with the GRU model. The
R2 of the model is 0.712, and the
MAPE is 0.471. The other three datasets cannot predict the cutter wear extent to achieve the
R2 metric value greater than 0.710. The second-best performance is achieved by the raw dataset under the Min Max Scaler.
4.4. Comparison and Discussion
Based on the comparison of various dataset dimensions, normalizations, and models, the result shows that the time series models proved to be an effective model to predict the cutter wear extent. Feature size cannot always correlate with the model training time. The feature size is raw > PCA > PCA directly. For the time series models, the PCA directly dataset takes the least time for model training, but the raw dataset does not take the longest time. Similar patterns also emerge in MLP models. Generally, raw datasets take the longest time to train when using machine learning models or MLP. This rule breaks in the time series model, which can be a result of information loss in feature dimension reduction. The reduced feature sometimes needs more epochs or hidden layer numbers for model training.
There are three kinds of dimension reduction strategies. Among these strategies, the PCA dataset has high interpretations of the feature, as this method keeps all the features. However, the PCA datasets seldom achieve better performance than the other two strategies. The PCA directly dataset has the poorest explainability of the feature since the components are calculated according to the covariance matrix.
The most proper normalization methods for models are different. MLP models predict the cutter wear extent well under standardization methods. However, the Max Absolute Scaler is more proper than standardization for time series models, even though the model trains the dataset under the standardization method more quickly.
The model with a large value of
R2 does not always result in a small value of the
MAPE. Take
Table 8 as an example. In the PCA dataset, the model obtains the highest
R2 under Min Max normalization but the smallest
MAPE under Max Absolute normalization. This phenomenon results from different scales of each cutter’s wear extent in the denominator of Equation (12). MLP and the time series neural network have proved to be more effective than the traditional machine learning models. In the hidden layer, different interactions of input features are calculated to predict the cutter wear extent. As Shahrour et al. [
1] discuss, the potential mechanism under these interactions still needs to be figured out.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}