1. Introduction
Electricity and energy production are increasing rapidly to meet the world’s energy needs. In order to minimize negative consequences, such as global warming, caused by fossil fuels, renewable energy sources are being turned to when alternative energy sources to fossil fuels are sought [
1]. Wind power generation is a promising field in terms of its potential and implementation, especially in the long term. Wind energy is supported for reasons such as being a renewable energy source. The total installed wind energy capacity in gigawatts was 1017.20 gigawatts (GW) as of 2023 [
2].
A wind turbine is a machine that converts kinetic energy from the wind into electricity [
3]. Wind turbine rotors consist of turbine blades. Turbine blades are critical in the process of converting wind kinetic energy into electrical energy. Depending on the aerodynamic performance of the turbine, a large part of the energy efficiency depends on these blades [
4].
As mentioned above, the limited reserves of fossil fuels and the increasing environmental risks posed by their carbon emissions have led to a shift toward other energy sources. Renewable energy sources are a sustainable and clean option for meeting energy needs. The scenario in World Wildlife (WWF), The Energy Report [
5], states that by 2050, 95 percent of the energy needed on Earth could be provided from renewable sources.
Wind energy has advantages, such as not emitting toxic gases, the energy spent during the establishment phase of wind turbines can be produced in a short time, and less dependence on foreign energy. The disadvantages are that it is dependent on wind availability and generates significant noise [
6].
The widespread use of wind energy applications has influenced the design of wind turbine blades to capture more wind and generate more energy, and blades are increasingly produced from longer and more flexible structures. This causes wind turbine blades to be exposed to more loads [
7]. The loads acting on wind turbine blades can be classified as aerodynamic, gravitational, centrifugal, gyroscopic, and operational [
8]. Aerodynamic load is the type of load produced by the lift and drag of the wing airfoil section, which depends on wind speed, wing speed, surface quality, angle of attack, and yaw [
9]. Gravitational loads include the mass of the components [
10].
Wind force and inertia forces caused by the rotation of the rotor create a significant load on the wind turbine blades. These forces cause bending and normal stresses in the tower and blades. If the safe limits of the material used are exceeded, structural fractures may occur [
7]. Wind turbine blades are subjected to cyclic loading conditions throughout their operational lifetime, making fatigue a crucial consideration in their design. Fatigue often leads to large-scale damage [
11].
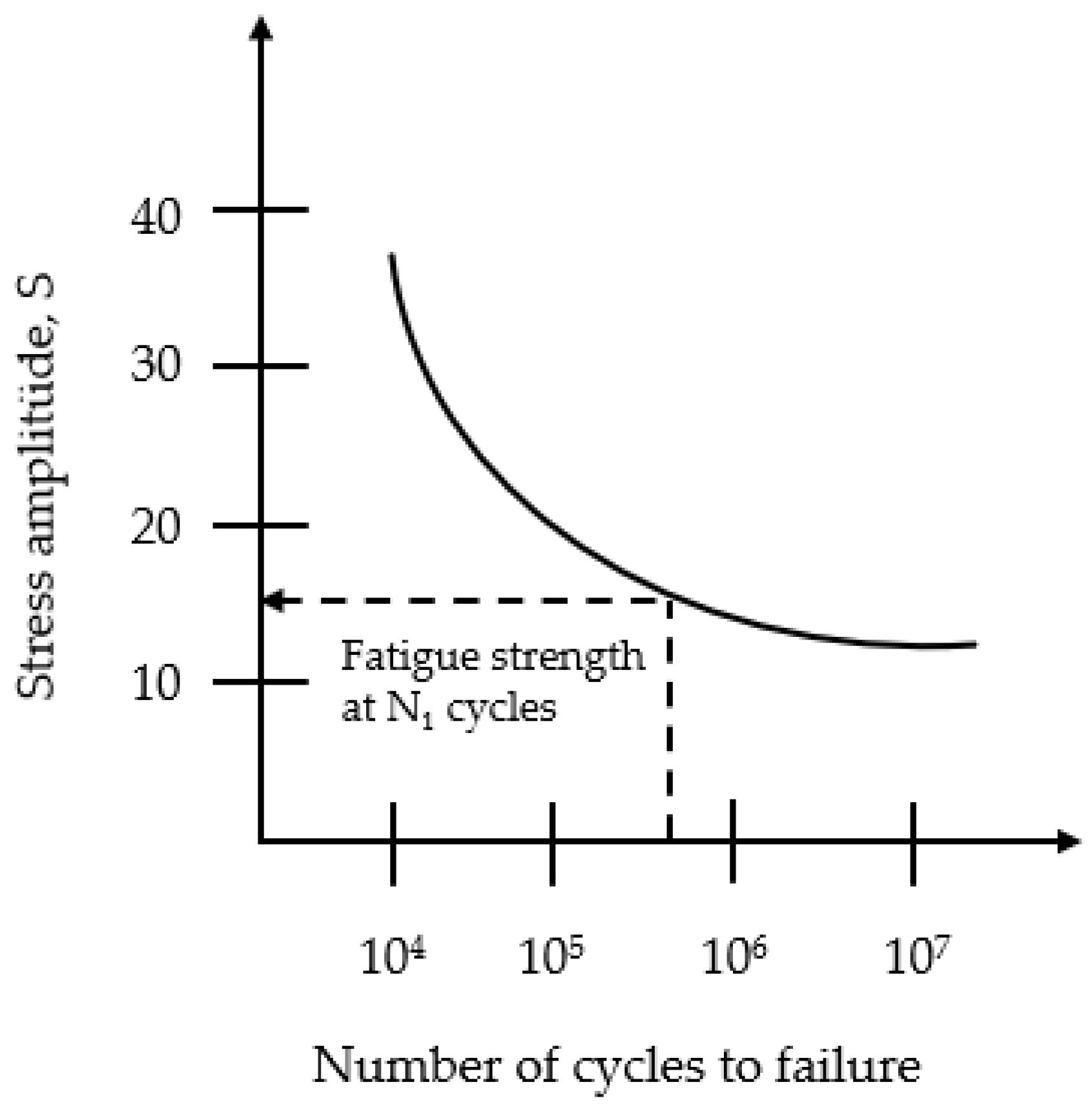
The wind turbine blades are one of the most prone to damage due to the forces they are subjected to. The main cause of damage to the blades is fatigue in these parts. This type of damage usually occurs at the points where the blades are connected to the root region of the propellers. When subjected to high fatigue loads, these damages occur in shorter periods of time [
12]. Fatigue is mechanical damage to a material or part under dynamic loading [
13] and is a phenomenon that affects the wind turbine lifetime. In this study, the number of cycles, which indicates the fatigue life of a specimen, is predicted using the stacking sequence, fiber volume fraction, stress amplitude, loading frequency, laminate thickness, and the number of cycles of a fatigue test carried out on a laminated composite specimen.
The costly and time-consuming nature of experimental tests, the ability to observe the relationships between variables using various statistical methods in data-driven methods, and the ability to develop a general model for different configurations by continuously feeding new data show the practical advantages of using data-driven methods. Fatigue behavior in composite turbine blades can be highly nonlinear and dependent on numerous parameters, such as the stacking sequence. Traditional analytical closed-form models often become cumbersome or less accurate with increasing complexity. On the other hand, data-driven models can capture higher-dimensional, nonlinear interactions more effectively, reducing prediction error and computational cost. This study presents the use of tree-based models and explainable artificial intelligence (XAI) to predict the fatigue life of wind turbine blades. Previous works in the literature usually use artificial neural network (ANN) and support vector regression (SVR) models, but the novelty here is provided by using tree-based models and XAI. In addition, the uniqueness of this study is that there is no other study that examines the fatigue life of composite material (especially the dataset we analyzed) with machine learning methods. Moreover, the proposed method can be easily applied to the real world.
Machine learning is an artificial intelligence (AI) method that is widely used in almost every field today. There are many ML studies on wind turbines and fatigue behavior. Dervilis et al. [
14] used the automatic associated neural network (AANN) and radial basis function (RBF) for fault detection of wind turbine blades under continuous fatigue loading. He et al. [
15] used support vector regression (SVR) to accurately predict the fatigue loads and power of wind turbines under yaw control. The results obtained demonstrated both the accuracy and robustness of the model. Miao et al. [
16] proposed a machine learning model based on the Gaussian process (GP) to predict the fatigue load of a wind farm. The results obtained showed that the GP improved prediction accuracy. Yuan et al. [
17] developed a machine-learning-based approach to model the fatigue loading of floating wind turbines. The results showed that the random forest (RF) model provided a prediction accuracy of up to 99.97%, with a minimum prediction error not exceeding 3.9%. Luna et al. [
18] trained and tested artificial neural network (ANN) architectures to predict the fatigue of a wind turbine tower using data based on tower top oscillation speed and previous fatigue state. The results obtained are promising. Bai et al. [
19] used a residual neural network (ResNet) to predict the fatigue damage of a wind turbine tower at different wind speeds. The results showed that the efficiency of the proposed probabilistic fatigue analysis method can be improved. Santos et al. [
20] trained loss function physics-guided learning of neural networks for fatigue prediction of offshore wind turbines. The study demonstrated the potential of the method. Wu et al. [
21] used an improved SVR model with gate recurrent unit (GRU) and grid search methodology to predict the fatigue load in the nacelle of wind turbines. The results showed that the proposed model framework can effectively predict the fatigue loads in the nacelle. Ziane et al. [
22] used ANN based on back propagation (BP), particle swarm optimization (PSO), and cuckoo search (CS) to predict the fatigue life of wind turbine blades under variable hygrothermal conditions. They used mean square error (MSE) to evaluate the results. CS-ANN achieved the best result.
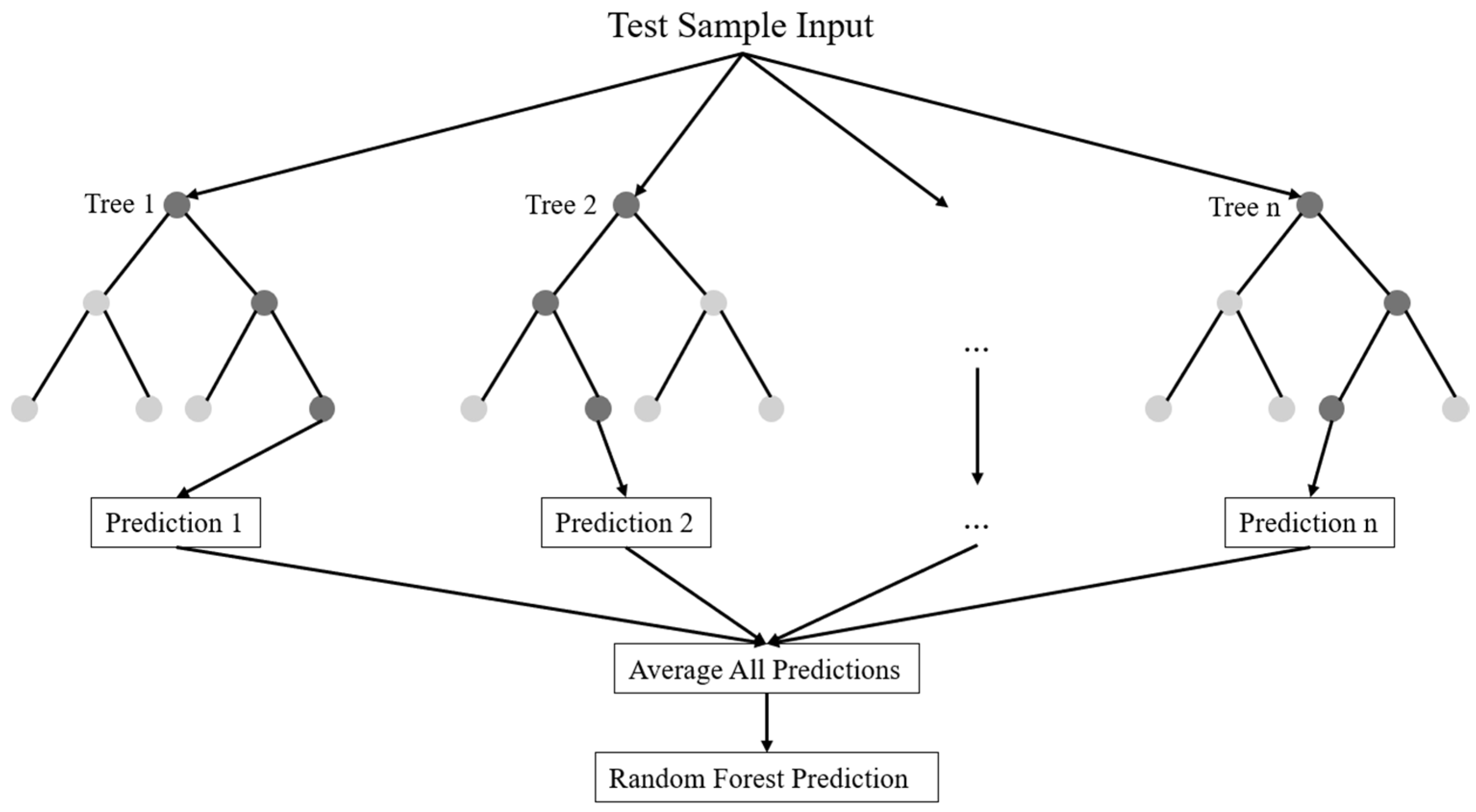
Damage to the wind turbine due to fatigue will cause economic damage and adversely affect energy production [
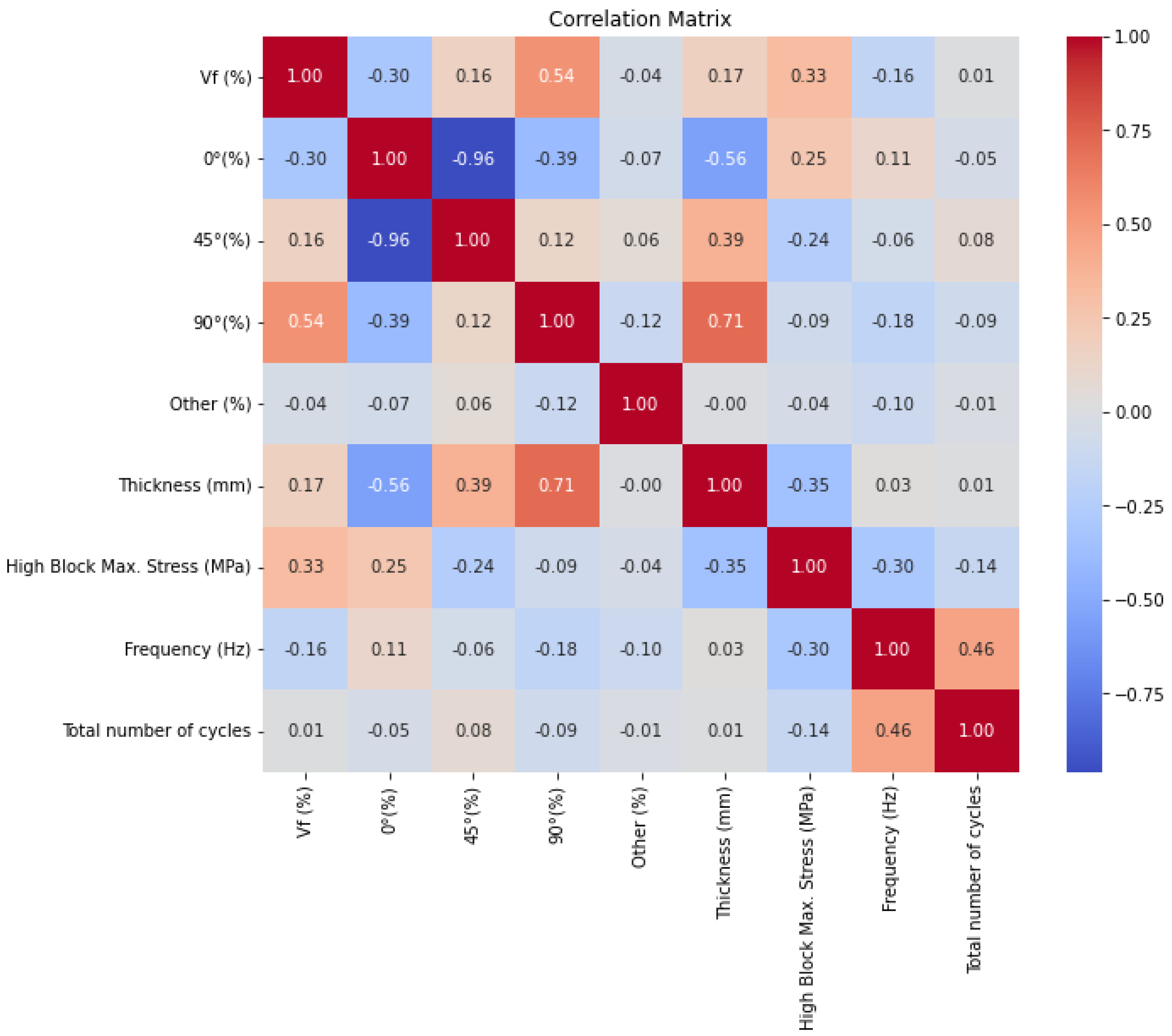
23]. Therefore, accurate prediction of the fatigue life of wind turbine blades is of engineering importance. A review of the literature revealed that most of the studies did not use explainable ML models. In this study, random forest (RF), extreme gradient boosting (XGBoost), categorical boosting (CatBoost), light gradient boosting machine (LightGBM), and extra trees regressor (ExtraTrees) models are used to predict the fatigue life of the specimens. In order to establish the cause-and-effect relationship in the ML model, it is important to know which variables the model is based on. This is where explainable models come into the picture and give the most critical factors affecting the fatigue life of a turbine blade. For this reason, the SHapley Additive exPlanations (SHAP) approach was also used in this study to understand which variables the model is based on. Coefficient of determination (R
2), mean squared error (MSE), and root mean squared error (RMSE) were chosen as performance metrics in this study.
3. Results and Discussion
In this study, the number of cycles, which indicates the fatigue life of a specimen, was estimated by using random forest (RF), extreme gradient boosting (XGBoost), categorical boosting (CatBoost), light gradient boosting machine (LightGBM), and ExtraTrees regressor algorithms from ML methods. Coefficient of correlation (R2), mean squared error (MSE), and root mean squared error (RMSE) values for the dataset were calculated to measure the accuracy of the predictions. SHAP analysis was then performed. The results obtained from the machine learning algorithms applied to the dataset were as follows: ML models analyzed on the fatigue dataset were optimized with principal component analysis (PCA).
Coefficient of correlation (R
2), mean squared error (MSE), and root mean squared error (RMSE) were used to evaluate the performance of the models. These metrics were used as benchmarks for the predictions performed on the training and test sets.
Table 2 gives the metrics of the training and test sets using random forest. In the training set, the model showed an R
2 of 0.9670, RMSE of 0.8543, and MSE of 0.7299. However, in the test set, the R
2 decreased to 0.9052, and the error values increased (MSE = 1.3683 and RMSE = 1.8724). This indicates that the model performed well on the test set and was not overfitting but did not generalize as well as on the training set. Since hyperparameter optimization was performed using GridSearchCV, it can be said that this was due to the nature of the data. The best hyperparameters for random forest were {‘max_depth’: 10, ‘min_samples_leaf’: 1, ‘min_samples_split’: 2, ‘n_estimators’: 200}.
Table 3 gives the metrics of the training and test sets using XGBoost. In the training set, the model showed an R
2 of 0.9548, RMSE of 1.00005, and MSE of 1.00011. However, in the test set, the R
2 decreased to 0.8958, and the error values increased (MSE = 1.4346 and RMSE = 2.0582). This indicates that the model performed well on the test set and was not overfitting but did not generalize as well as on the training set. Since hyperparameter optimization was performed using GridSearchCV, it can be said that this was due to the nature of the data. The best hyperparameters for XGBoost were {‘colsample_bytree’: 1.0, ‘learning_rate’: 0.1, ‘max_depth’: 3, ‘n_estimators’: 200, ‘subsample’: 0.8}.
Table 4 gives the metrics of the training and test sets using CatBoost. In the training set, the model showed an R
2 of 0.9468, RMSE of 1.0850, and MSE of 1.1772. However, in the test set, the R
2 decreased to 0.9027, and the error values increased (MSE = 1.3862 and RMSE = 1.9215). This indicates that the model performed well on the test set and was not overfitting but did not generalize as well as on the training set. Since hyperparameter optimization was performed using GridSearchCV, it can be said that this was due to the nature of the data. The best hyperparameters for CatBoost were {‘bagging_temperature’: 0.0, ‘depth’: 8, ‘iterations’: 50, ‘l2_leaf_reg’: 1, ‘learning_rate’: 0.2}.
Table 5 gives the metrics of the training and test sets using LightGBM. In the training set, the model showed an R
2 of 0.9658, RMSE of 0.8701, and MSE of 0.7571. However, in the test set, the R
2 decreased to 0.9054, and the error values increased (MSE = 1.3668 and RMSE = 1.8682). This indicates that the model performed well on the test set and was not overfitting but did not generalize as well as on the training set. Since hyperparameter optimization was performed using GridSearchCV, it can be said that this was due to the nature of the data. The best hyperparameters for LightGBM were {‘learning_rate’: 0.1, ‘max_depth’: 4, ‘n_estimators’: 200, ‘num_leaves’: 31, ‘reg_alpha’: 0.1, ‘reg_lambda’: 1.0}.
Table 6 gives the metrics of the training and test sets using ExtraTrees regressor. In the training set, the model showed an R
2 of 0.9154, RMSE of 1.3683, and MSE of 1.8724. However, in the test set, the R
2 decreased to 0.8958, and the error values increased (MSE = 1.4344 and RMSE = 2.0576). This indicates that the model performed well on the test set and was not overfitting but did not generalize as well as on the training set. Since hyperparameter optimization was performed using GridSearchCV, the very small difference between the test and training metrics suggests that the model was not overfitting but that some caution should be exercised against some uncertainty in the test data. This was due to the nature of the dataset. The best hyperparameters for ExtraTrees regressor were {‘max_depth’: 8, ‘min_samples_leaf’: 1, ‘min_samples_split’: 2, ‘n_estimators’: 200}.
GridSearchCV was used to avoid the risk of overfitting, and the biggest difference between training and test performance (about 0.06) in
Table 2,
Table 3, and
Table 5 was acceptable.
In the analyses performed with the dataset, prediction was made with five different algorithms, and the performances of all models are given in
Table 7. Using three different metrics, the results were satisfactory. The most successful algorithm was the category boosting LightGBM, with an R
2 of 0.9054, RMSE of 1.3668, and MSE of 1.8682. Unlike other methods, LightGBM may have shown the highest performance because it splits the tree in the direction of the leaf to obtain the best fit, uses histogram-based optimization, and is more efficient and lightweight. The other two best algorithms were random forest and CatBoost.
These results in
Table 7 show that decision-tree-based models showed a strong predictive ability on the dataset.
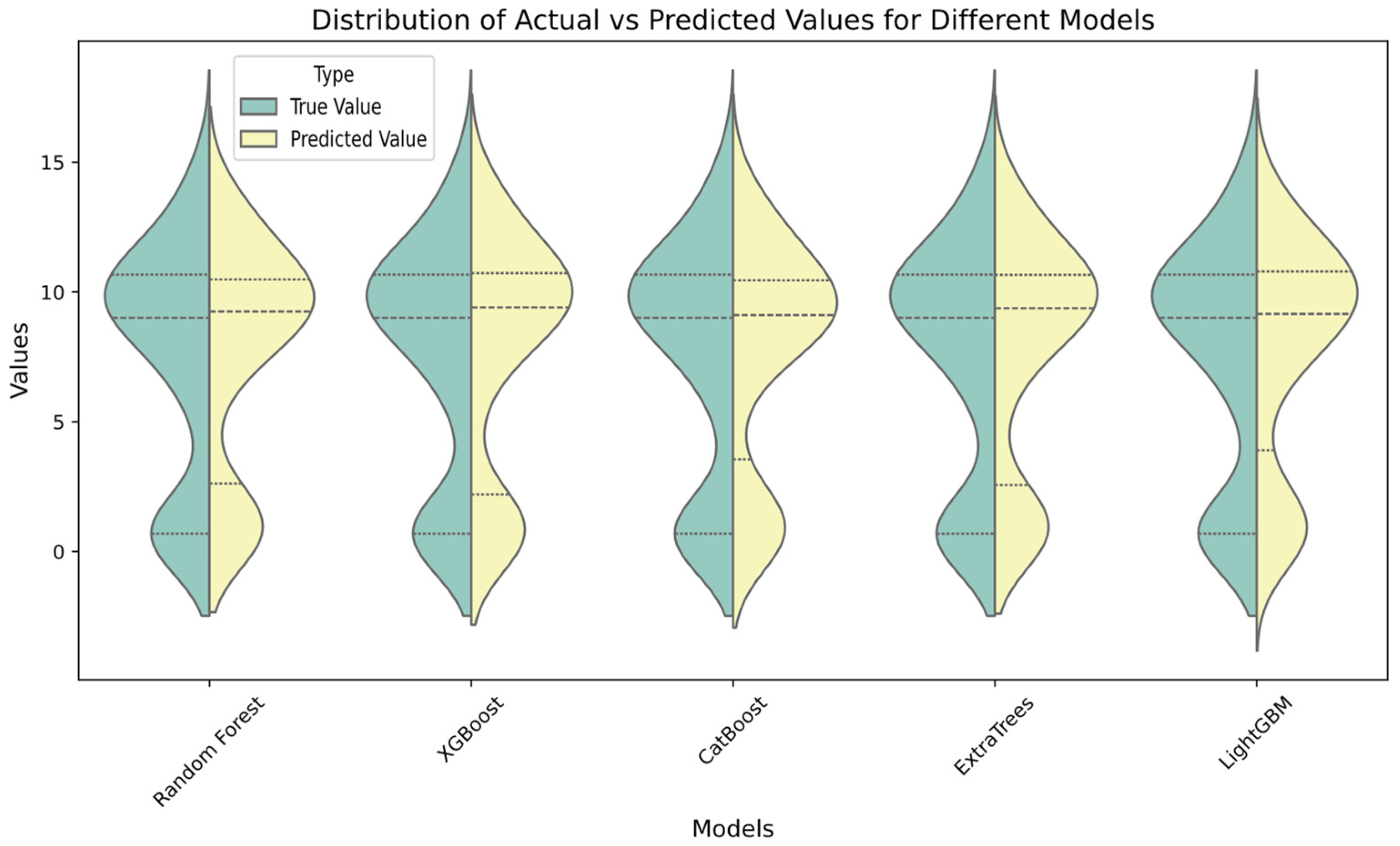
Figure 14 gives the violin plots for error distributions (true–predicted) for the models used in this study. In
Figure 14, the violin plot is used to visualize the prediction performance of different ML models used in this study. The X-axis shows the ML models used in the study, and the Y-axis shows the distribution of actual and predicted values. Green is the distribution of true values and yellow is the distribution of model-predicted values.
In
Figure 14, the line in the middle of each ML model shows the average of the actual or predicted values. Using the violin plot, the distribution and probability density of the data can be evaluated by looking at the visuals. It is seen that the predicted and observation values were close to each other in the ML models.
Figure 15 shows the scatter plots of the ML models used in the study. Using these plots, the relationship between the actual values and the values predicted by the models can be understood. In the graphs, which can be viewed as data point distributions, it is seen that these distributions were more homogeneous in random forest and LightGBM than in the other models in
Figure 15. However, the point distribution was good in the other models as well. Even though the data were randomly distributed, it was at an acceptable level.
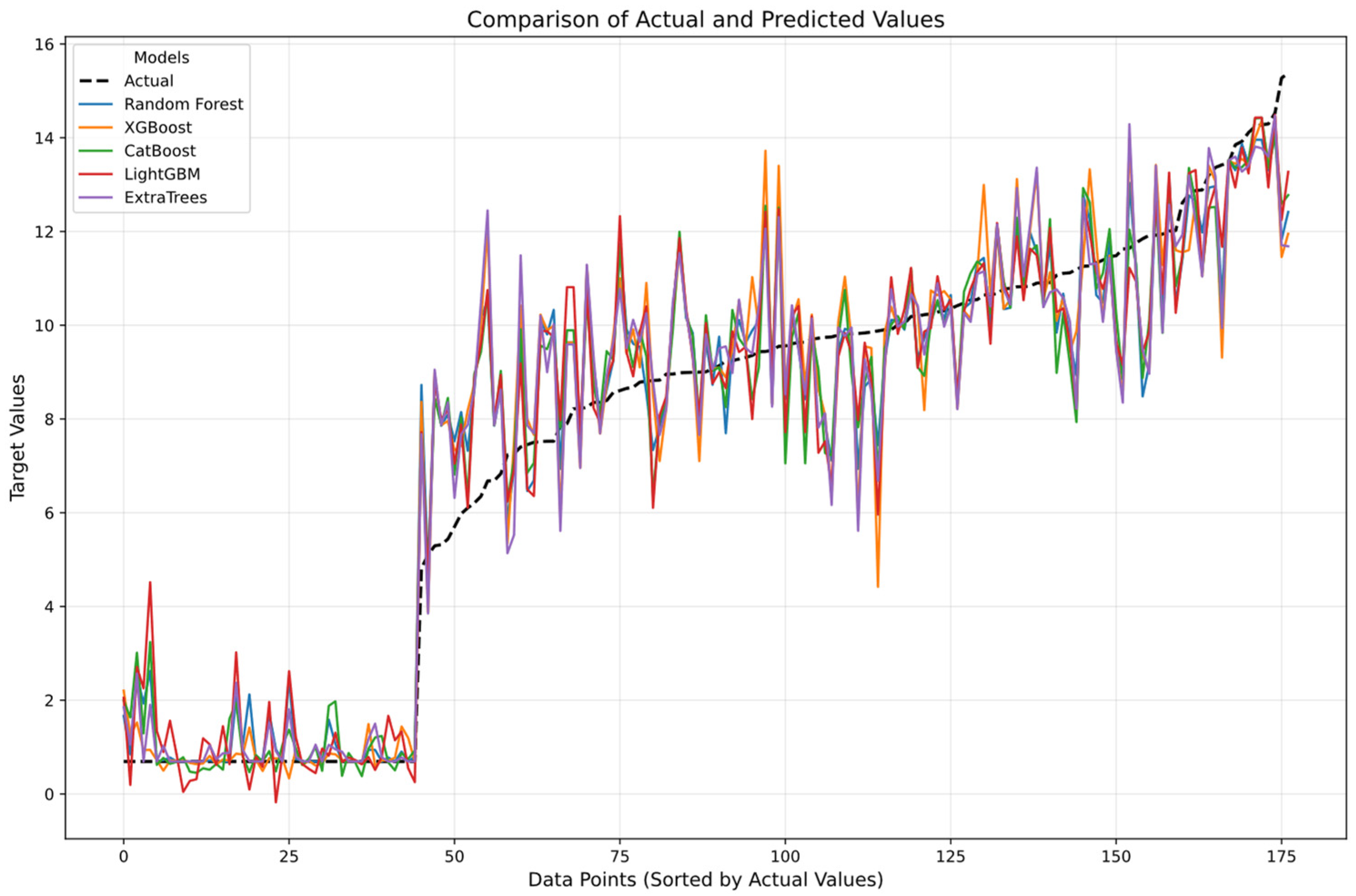
Figure 16 shows the line plot of the ML models used in the study. A comparison of actual and predicted values can be done using this plot. Random forest and LightGBM were closer to the actual values than the other models, as shown in
Figure 16. The jump in the curve (at the 45th point) was due to the differences in the fatigue resistance of different specimens. Also, the values in
Figure 16 are the transformed values as a result of PCA.
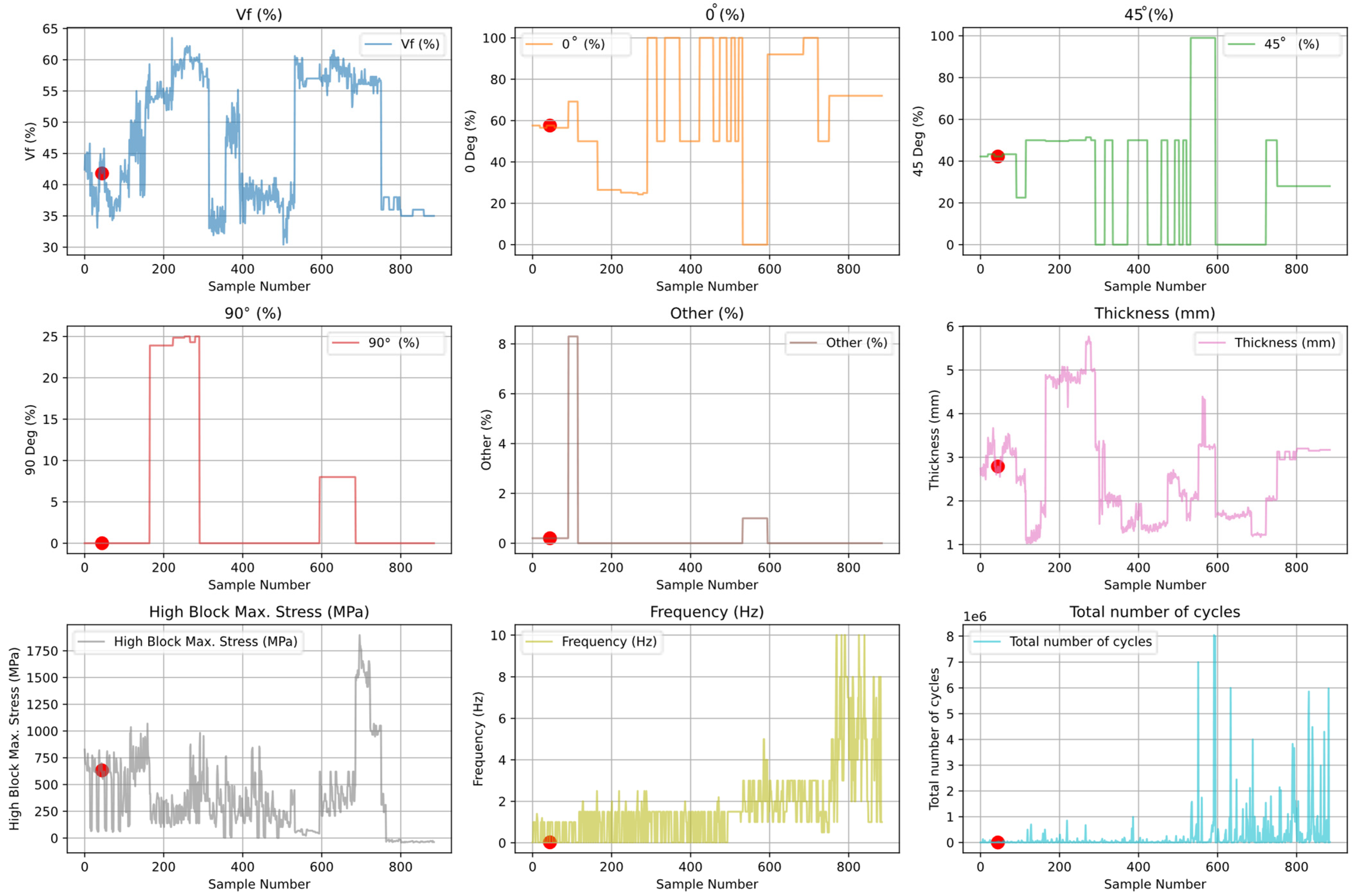
Each variable in the real dataset is shown as a line plot in
Figure 17, with data point 45 highlighted in red for clarity. Using the actual values, there was no jump at data point 45.
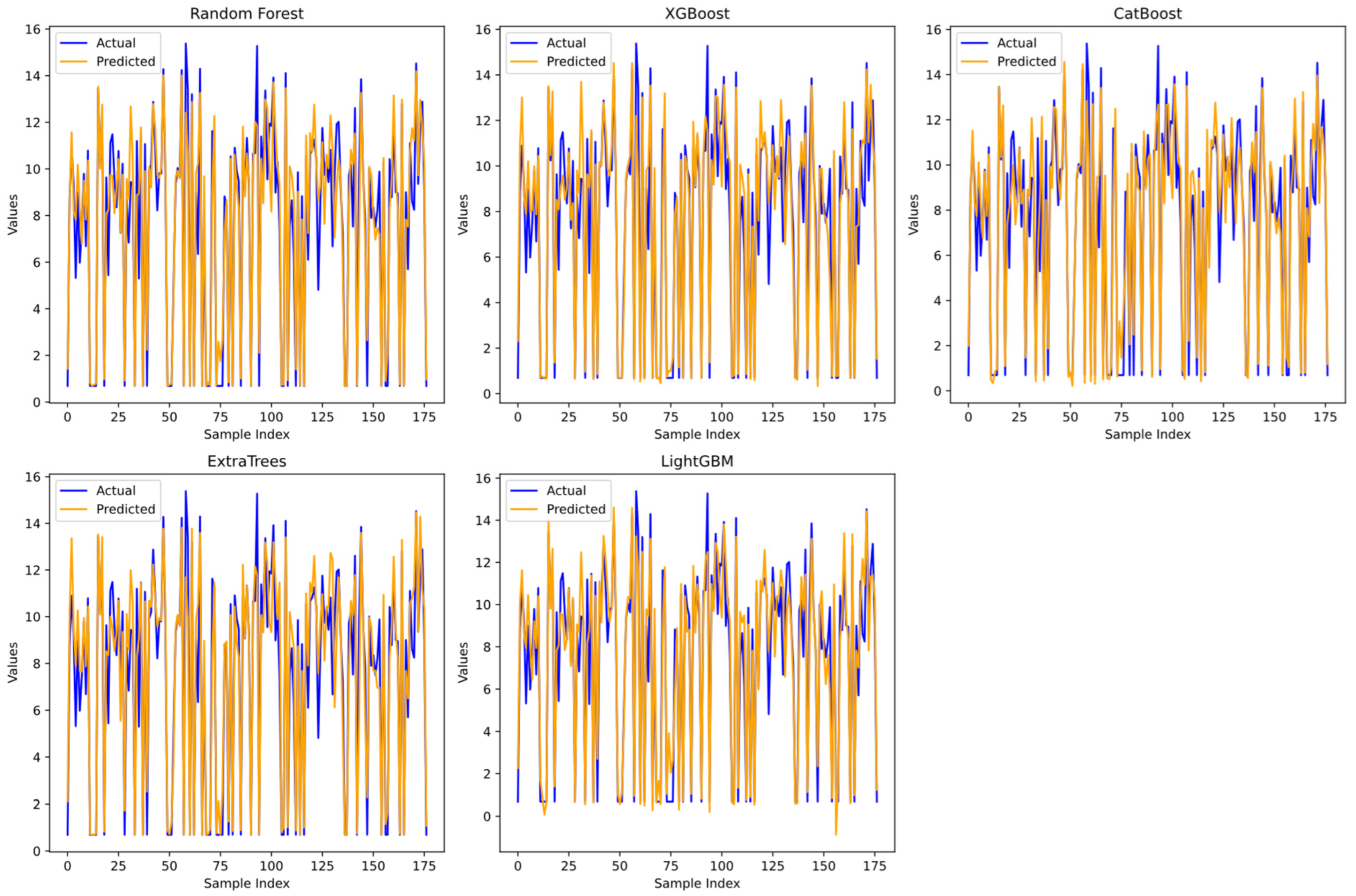
In addition, individual line plots for all ML models are shown in
Figure 18.
Figure 18 shows a comparison of the values predicted by ML models and the actual values. The blue line represents the actual values, and the orange line represents the predicted values. Although there were significant deviations in some examples, in general, the orange line (predicted) and the blue line (actual) were quite close to each other at most points, indicating that the models were able to make predictions close to the actual values.
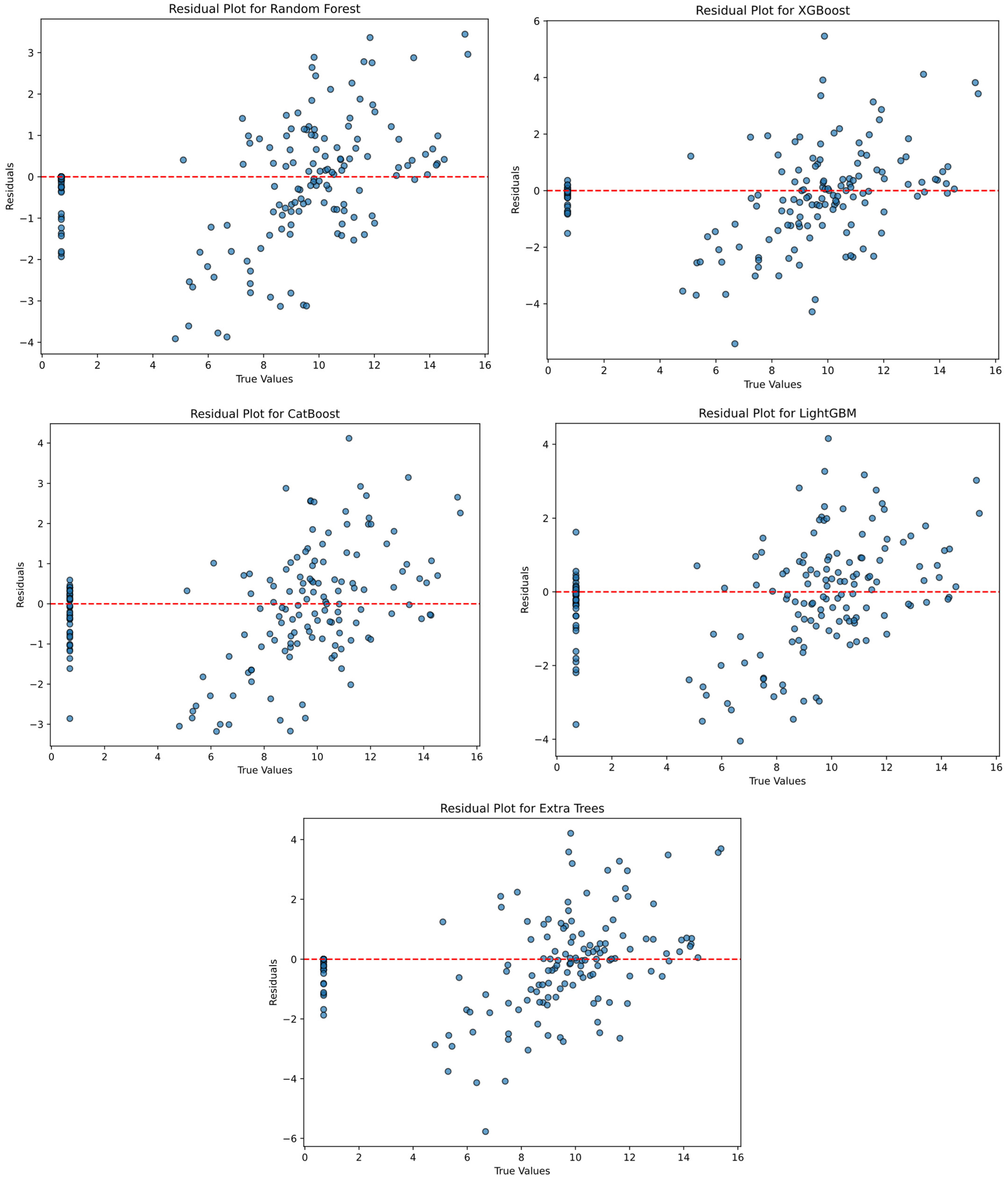
Figure 19 presents residual plots for random forest, XGBoost, CatBoost, LightGBM, and ExtraTrees. The X-axis represents the true values, and the Y-axis represents the residuals. The red dashed line represents the baseline where residual values should be evenly distributed around zero. Although the residual values were generally distributed around the red dashed line, as expected, in certain ranges, deviations were observed.
As seen in
Figure 19, the random distribution of points in the residual plots indicated that the models predicted the data well. Since the residuals were randomly distributed around zero, the models showed good performance.
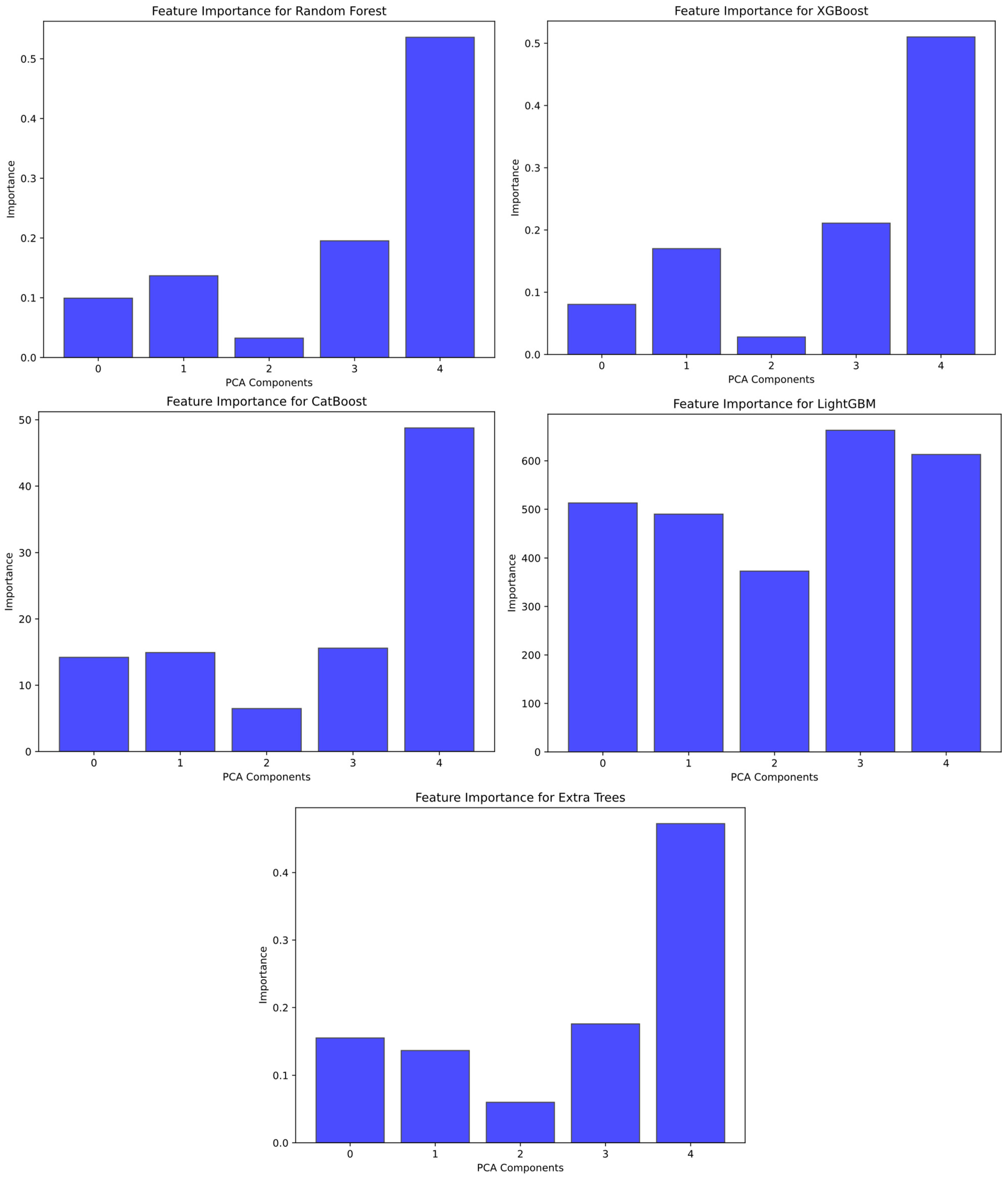
Figure 20 presents feature importance plots for random forest, XGBoost, CatBoost, LightGBM, and ExtraTrees.
Figure 20 shows the PCA components (1, 2, …, n) on the X-axis and the feature contribution of the model on the Y-axis. In general, the fifth component had the highest score, so the greatest variability of the data may be captured in the fifth component.
Feature importance is a measure of which features have more influence in a model. For example, according to the feature importance and PCA results obtained from the LighgtGBM model, features 3 and 4 had the highest scores and contributed significantly to the model’s predictions. This indicates that the model took these two features into account more when making accurate predictions. This suggests that the model can work with a lower dimensional representation and simplify the data without losing significant information. A 100% variance rate was achieved in component 8.
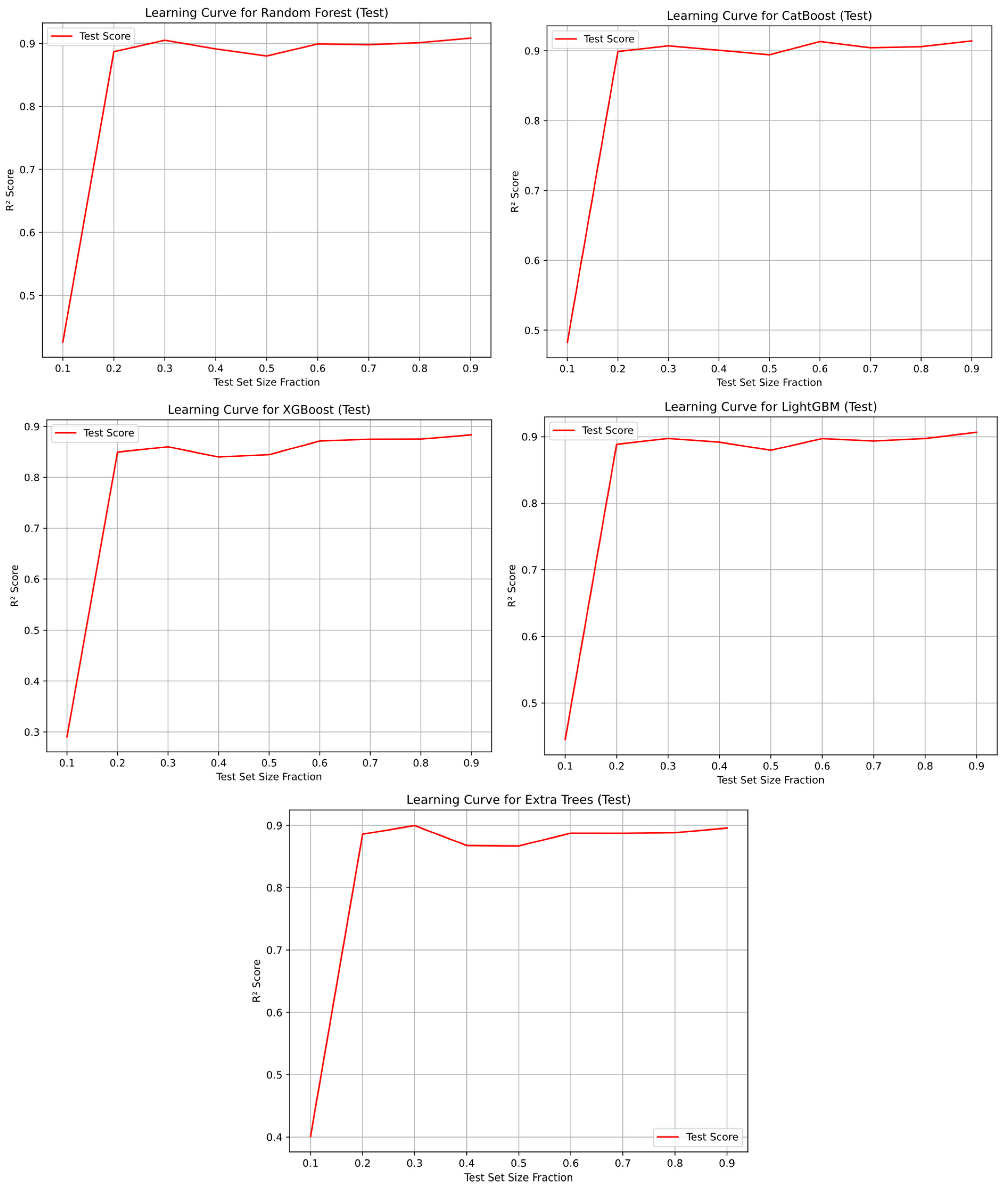
The learning curve is a graph that visualizes the change in performance of a model during the training process. This curve provides information about the model’s learning process on training data and how much it generalizes on test data.
Figure 21 shows learning curves for random forest, XGBoost, CatBoost, LightGBM, and ExtraTrees.
As seen in
Figure 21, there was an increase in the test R
2 value in the learning curve graphs.
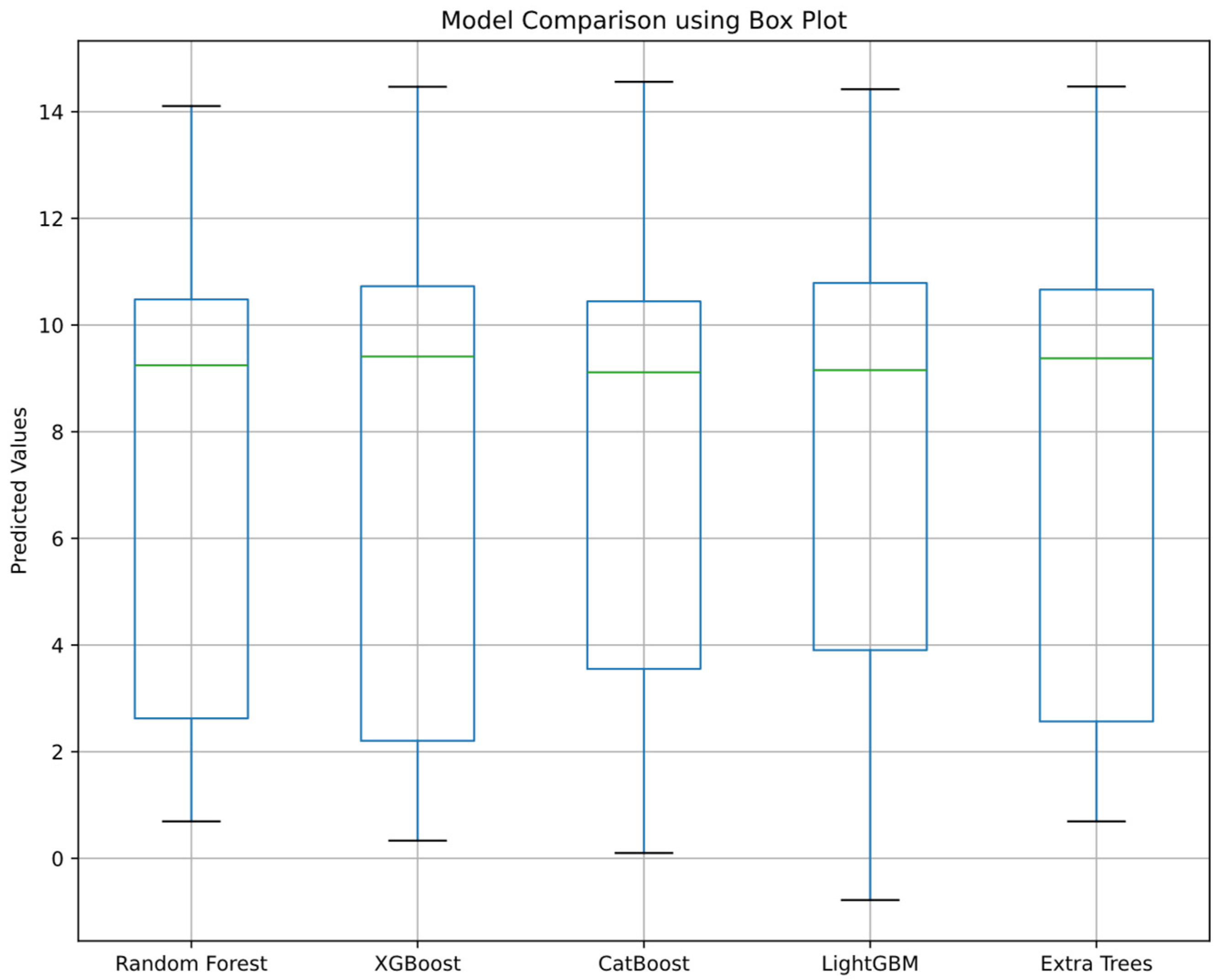
Figure 22 compares the prediction performance of random forest, XGBoost, CatBoost, LightGBM, and ExtraTrees using a box plot. On the X-axis are the machine learning models, and on the Y-axis are the predicted values. The box plots show the prediction distribution and central tendency of each model.
According to the box plot results in
Figure 22, it is clear from the box widths that LightGBM, random forest, and CatBoost performed better than the other models. Using the LightGBM algorithm, which was the most successful of all the algorithms, a SHAP bar plot was drawn, and it was observed which variable had the most impact on the predictions. In the LightGBM model, the SHAP method was used to visually explain how inputs affected the number of cycles, which indicates the fatigue life of a specimen.
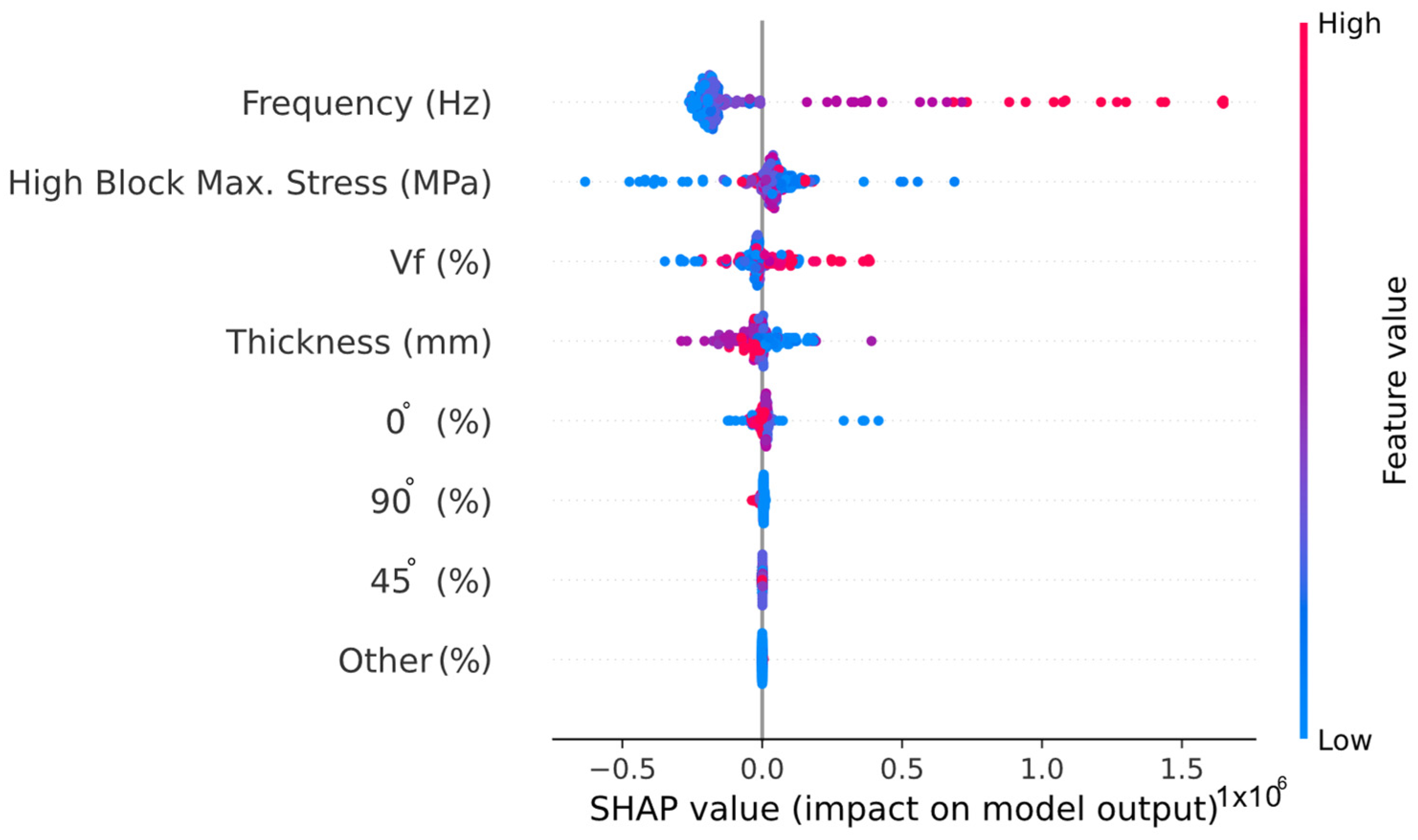
Figure 23 shows the importance rankings of the variables obtained as a result of SHAP analysis using the LightGBM algorithm.
As can be seen from
Figure 23, the variable that affected the number of cycles, which indicates the fatigue life of a specimen, the most was frequency. High block max. stress, Vf, and thickness came after frequency. Therefore, it can be said that these four inputs had the biggest impact on output.
Figure 24 shows the SHAP decision plot using LightGBM. This plot shows which inputs were most influential in the decision process.
As shown in
Figure 24, it can be said that frequency, Vf, thickness, and high block max. stress inputs had the biggest impact on output.
In this study, tree-based ML methods were preferred due to their shorter training time and lower computational resource requirements. In contrast, deep learning (DL) models were not used due to their long training time and high hardware requirements. Furthermore, since explainability is an important factor in this study, tree-based ML methods, which are more interpretable, were chosen instead of DL models.
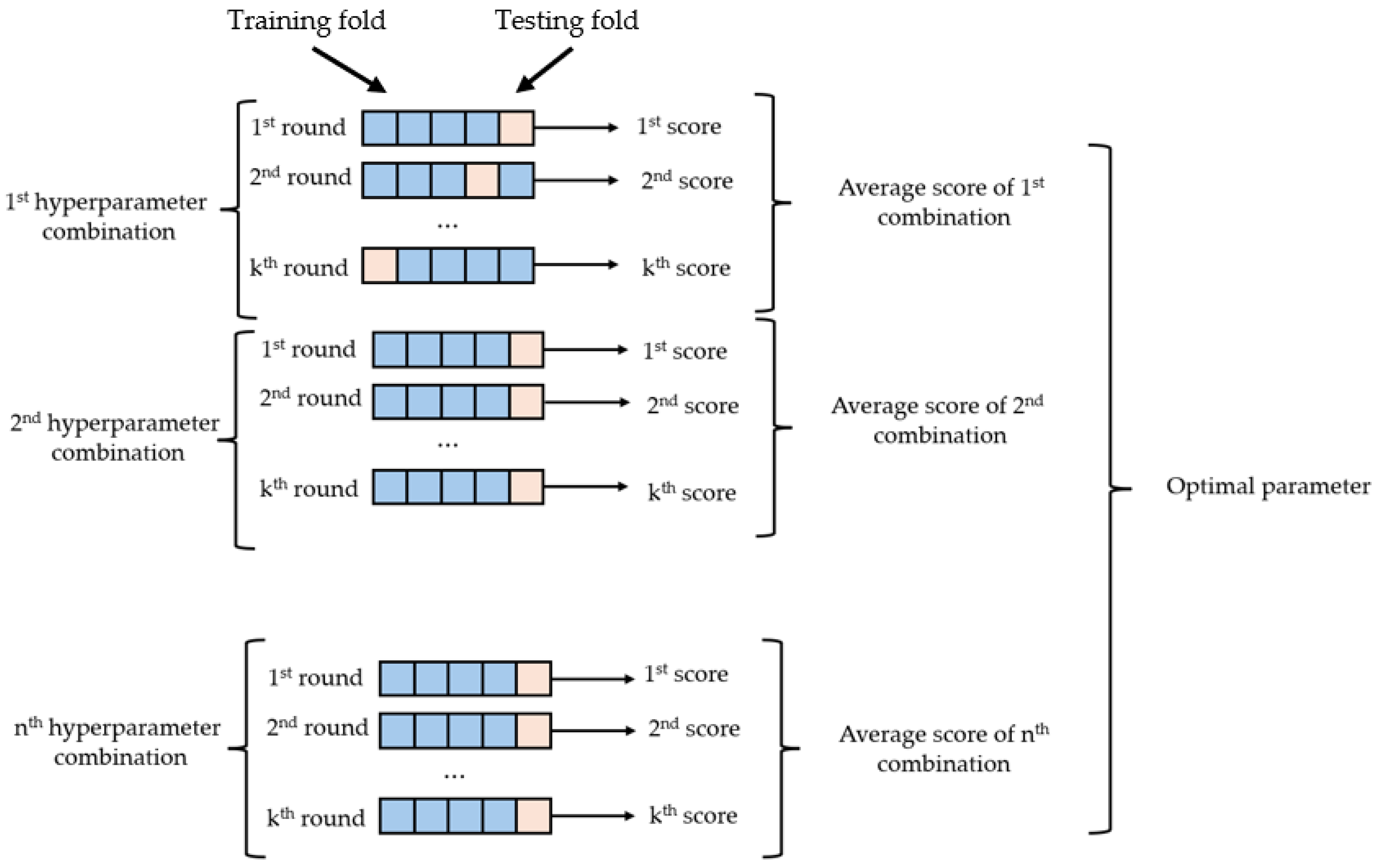
Hyperparameter optimization was performed using the GridSearchCV optimization method in this study. Thus, it offered a rigorous search process for the best performance of the model. GridSearchCV evaluates the model on different subsets of data to determine the most appropriate hyperparameter values and tries all possible combinations to identify the best hyperparameters. However, increasing the number of parameters increases the computation time. For this reason, the range of parameters for hyperparameter optimization was limited in the analysis code to optimize the performance of the model. Thus, the aim was both to improve the performance of the model and to keep the computational time of the optimization process at a reasonable level.
In the existing studies in the literature, it has been observed that the use of ANN is widespread for the fatigue life of wind turbine blades. For example, Ziane et al. [
22] used the back propagation neural network (BPNN), particle swarm optimization-based artificial neural network (PSO-ANN), and cuckoo search (CS)-based NN to predict the wind turbine blade fatigue life under varying hygrothermal conditions and achieved up to 94% accuracy. In this study, a dataset with inputs, such as different fiber ratios and orientation angles, was used to predict the fatigue life of wind turbine blades, and training set R
2 values of up to 96% and test set R
2 values of up to 90% were achieved using ML models.
In order to reduce the risk of overfitting the model, cross-validation was performed on the dataset to analyze how the model performed on different data subsets. Furthermore, SHAP plots were plotted using LightGBM to examine the effect of each parameter on fatigue life prediction. These graphs showed that frequency was the most effective parameter in fatigue life prediction.
The current study proposed a data-driven approach to predict the fatigue life of laminated composite wind turbine blades with varying stacking sequence configurations. The analyzed dataset also included fiber orientations outside the commonly used ±45°, 90°, and 0° orientations. Since there are no closed-form predictive equations available for predicting the fatigue life of composite materials with randomly oriented fibers, the best approach would be to use data-driven techniques. The accuracy and reliability of these techniques can be verified using statistical metrics of accuracy. A limitation of the current study was the size of the dataset and the value ranges of the input features, which can be enhanced in future studies as more data become available.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}