Breathing Pattern Interpretation as an Alternative and Effective Voice Communication Solution

 ,
, 
Abstract
:1. Introduction
2. Materials and Method
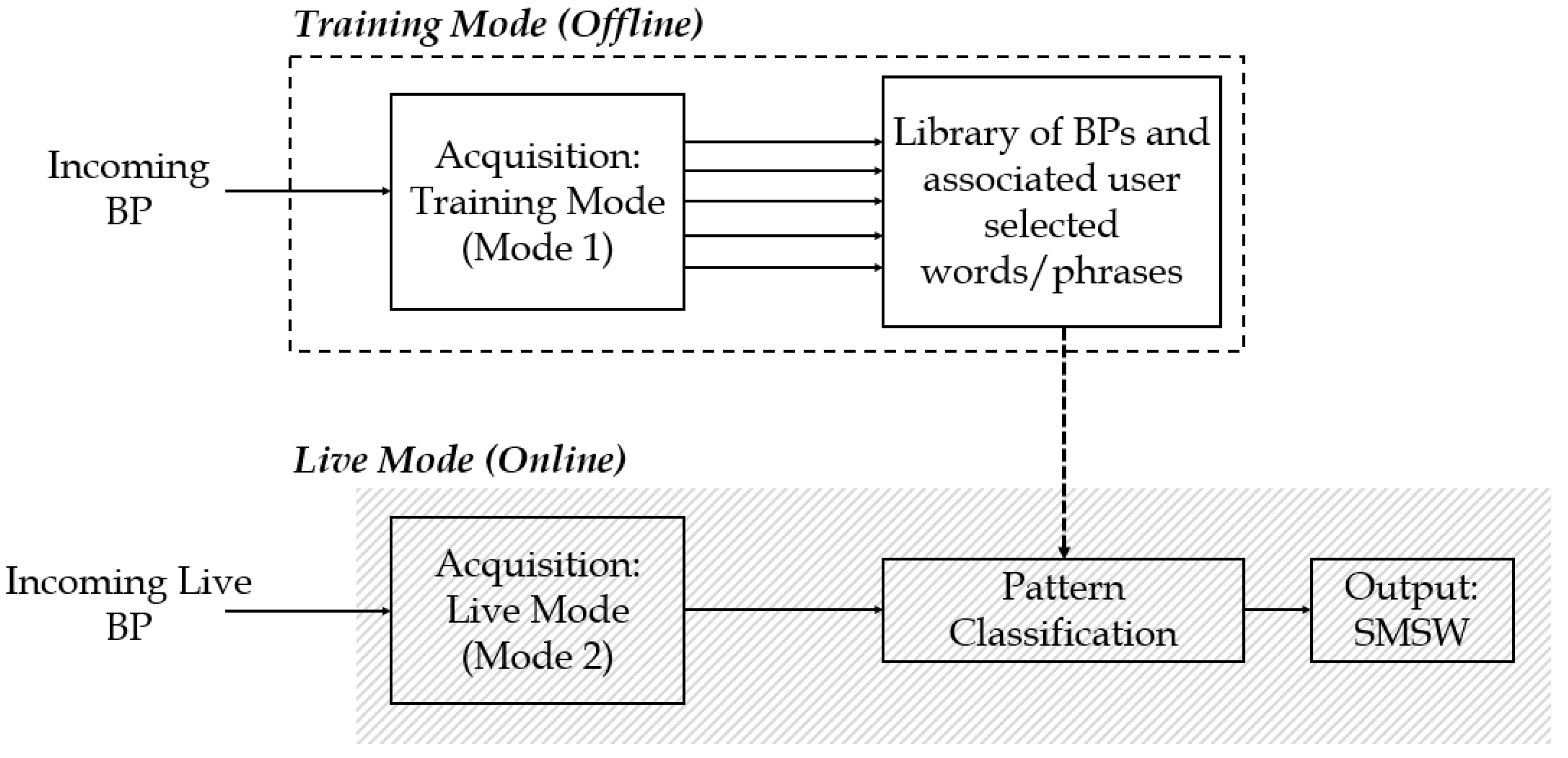
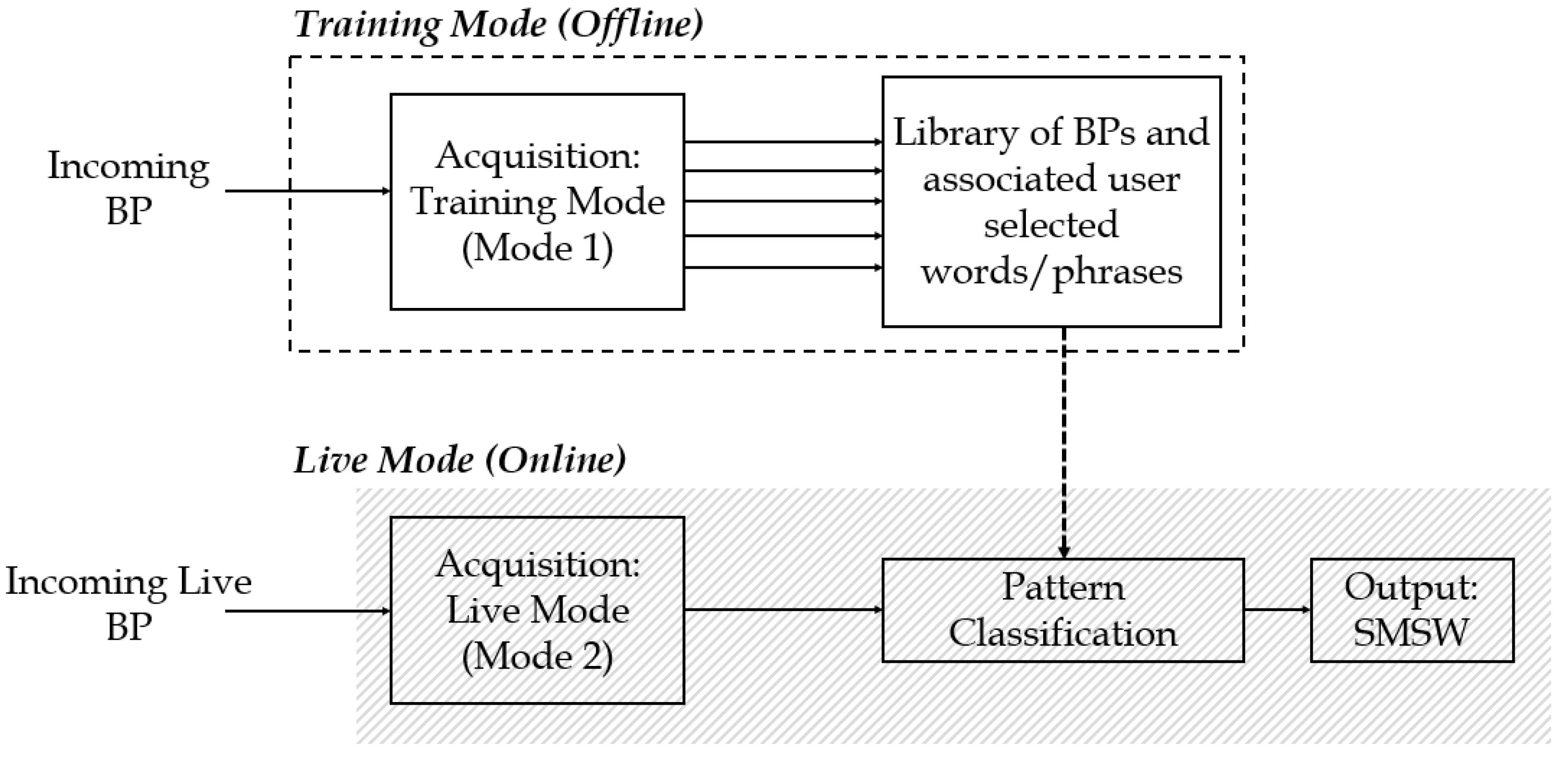
2.1. Overview of BPI Operational Modes
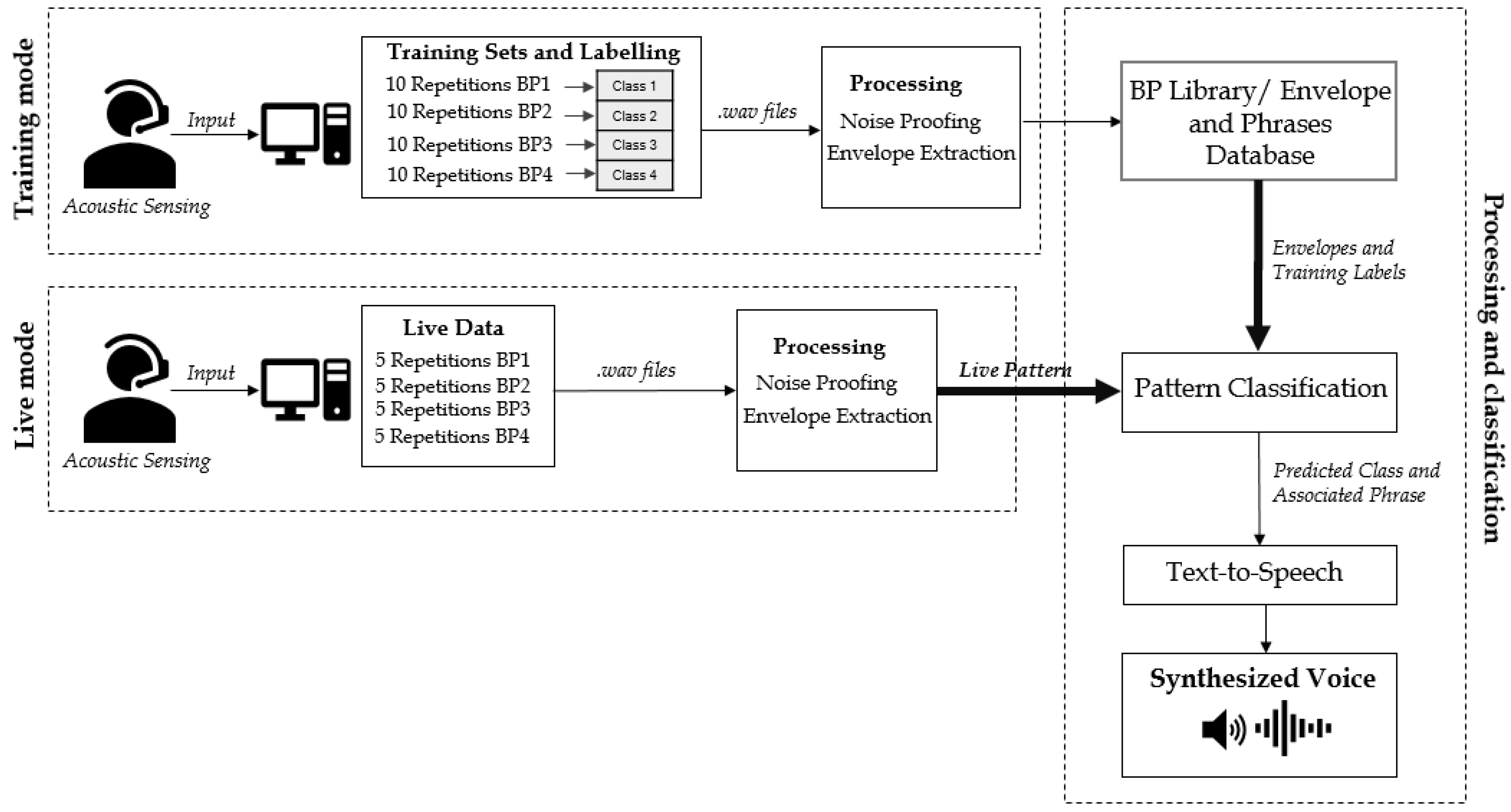
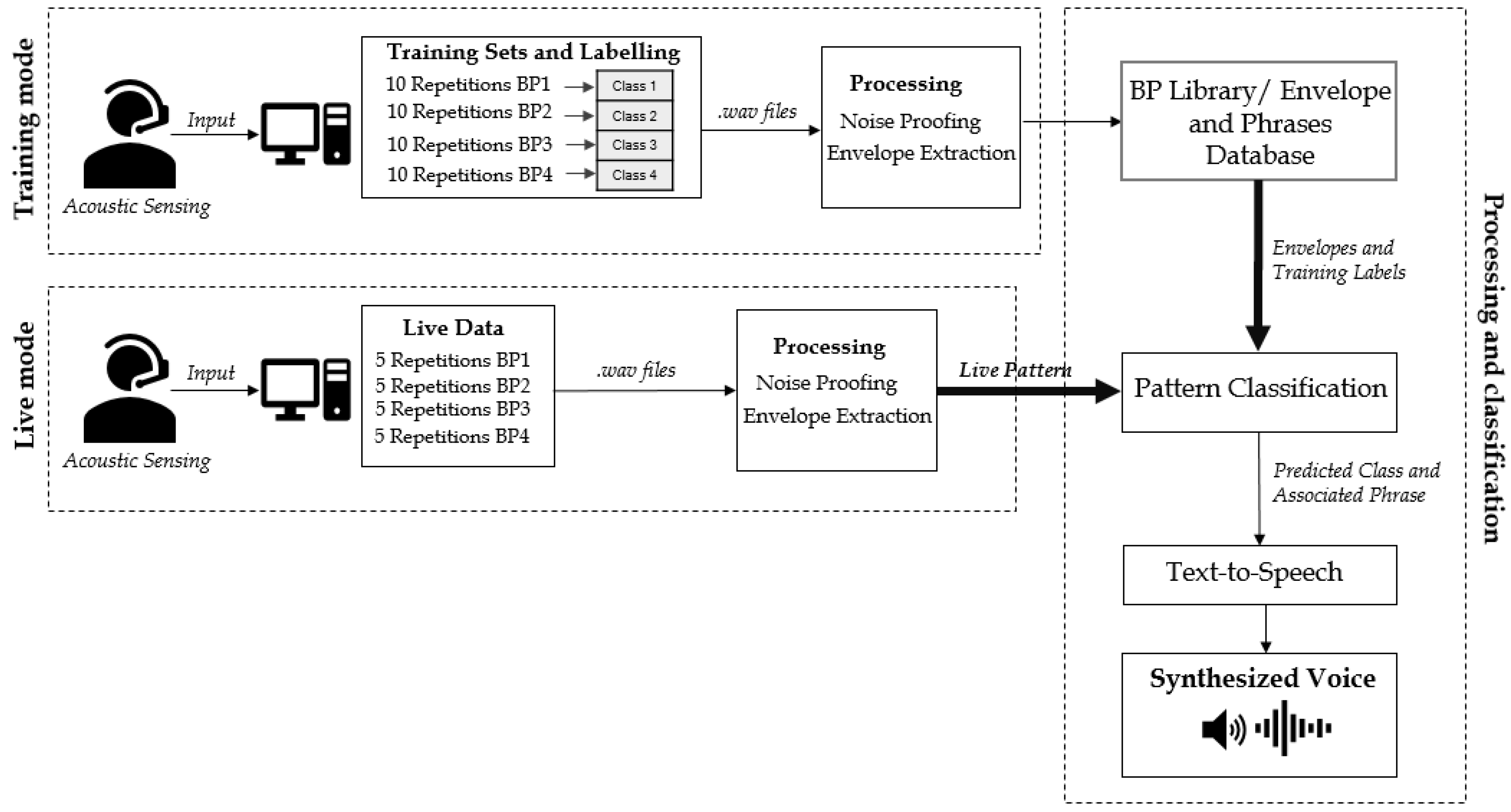
2.2. BPI System Architecture
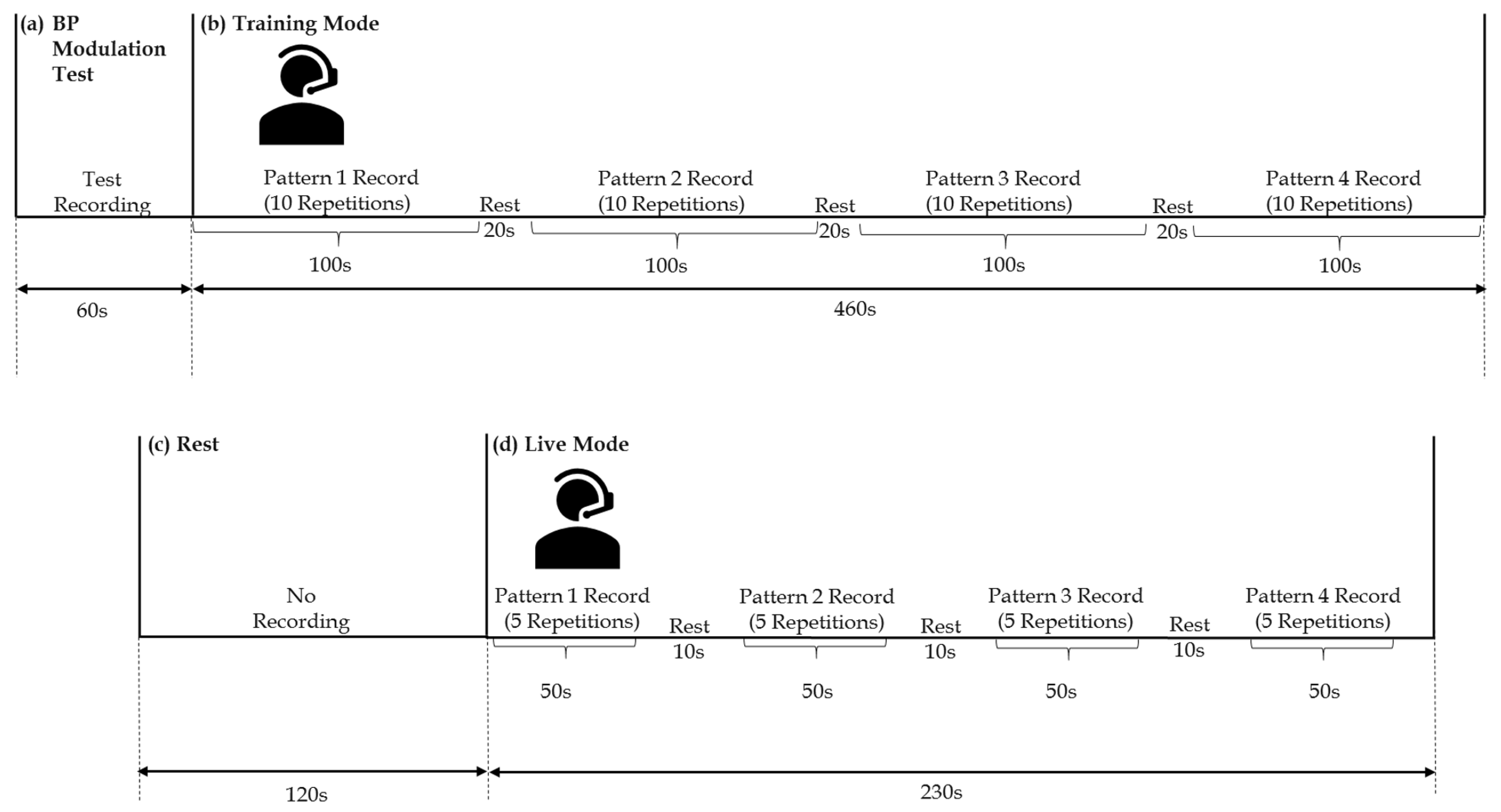
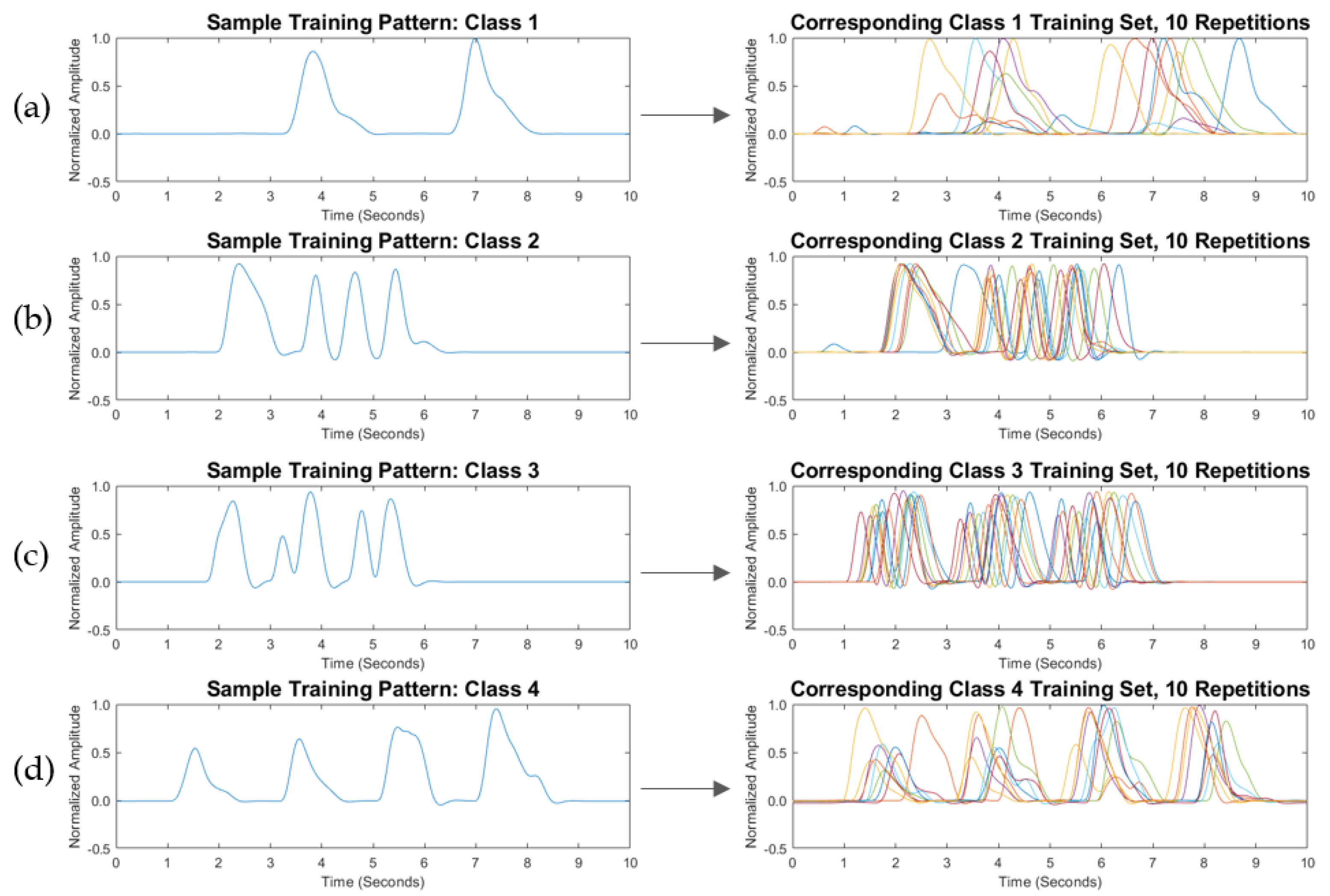
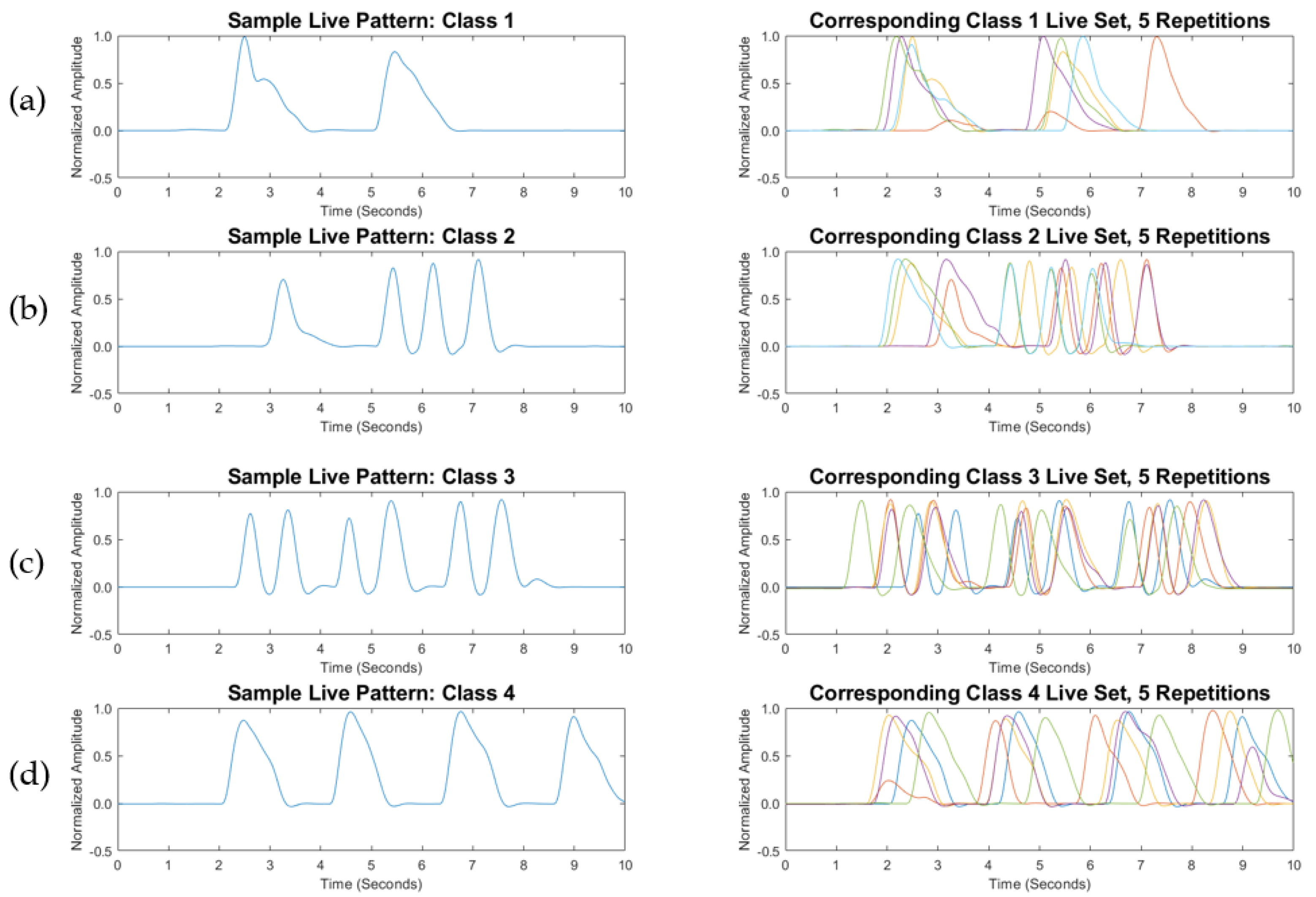
2.3. Experimental Protocol
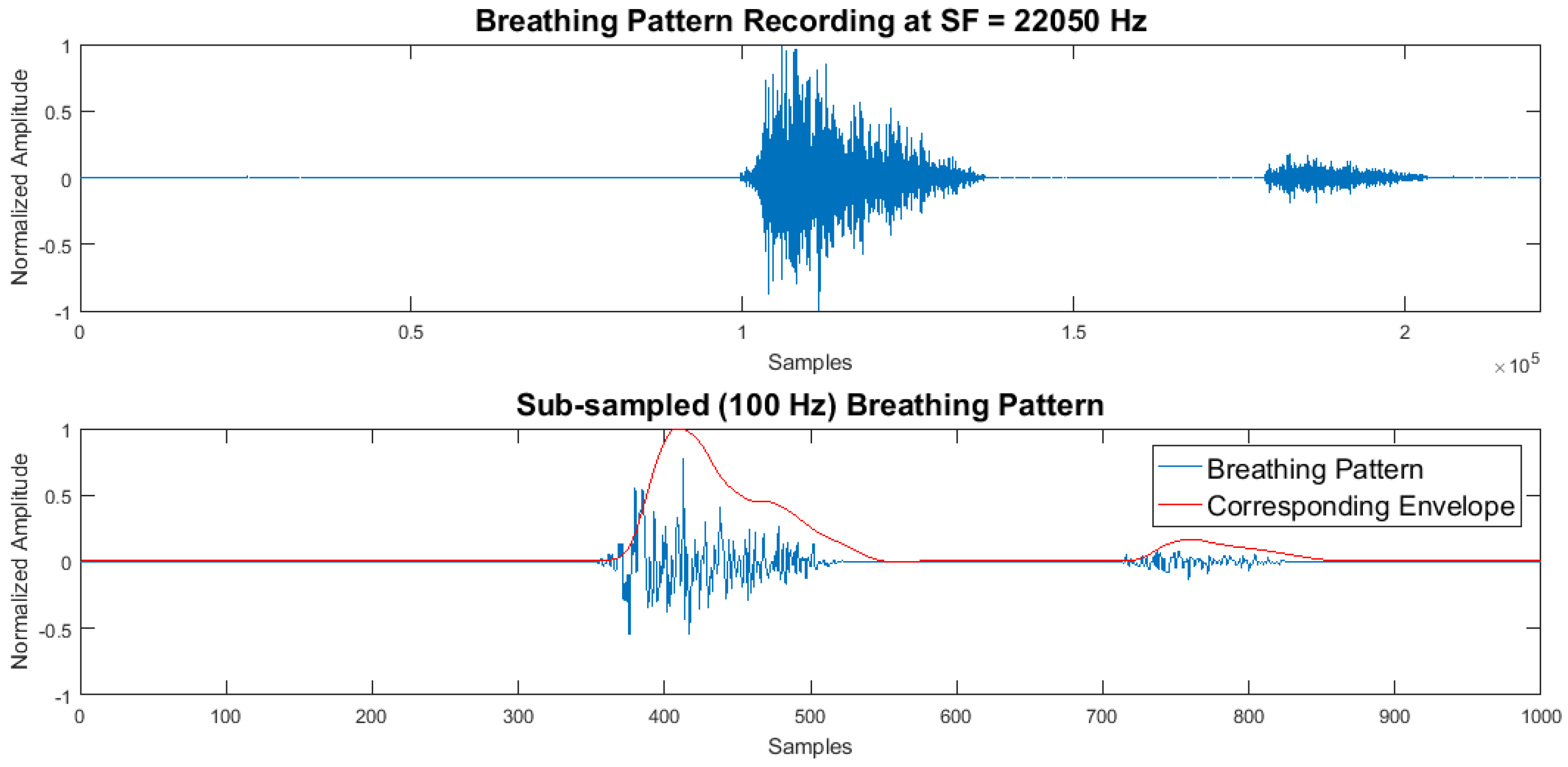
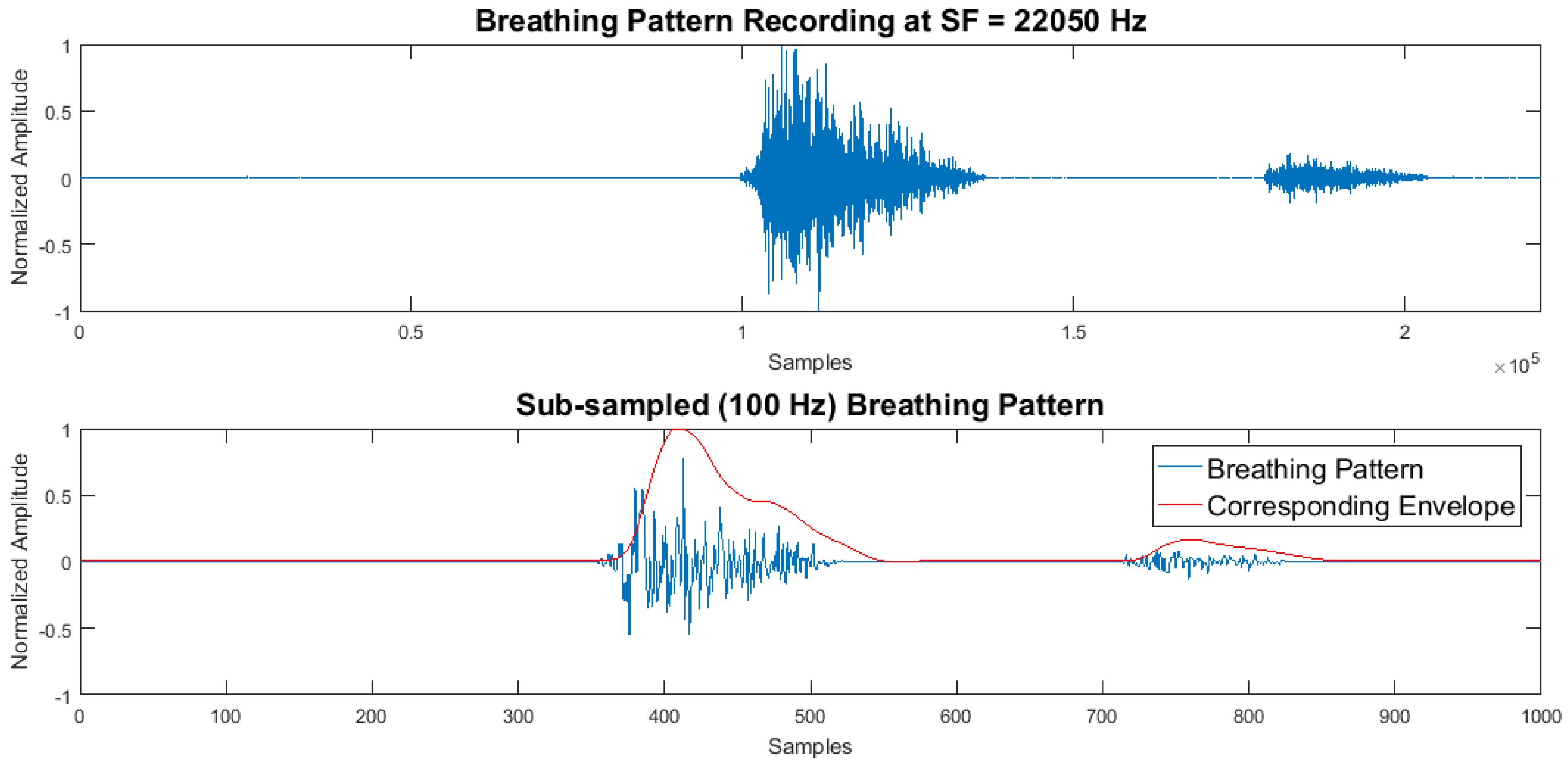
2.4. BP Processing
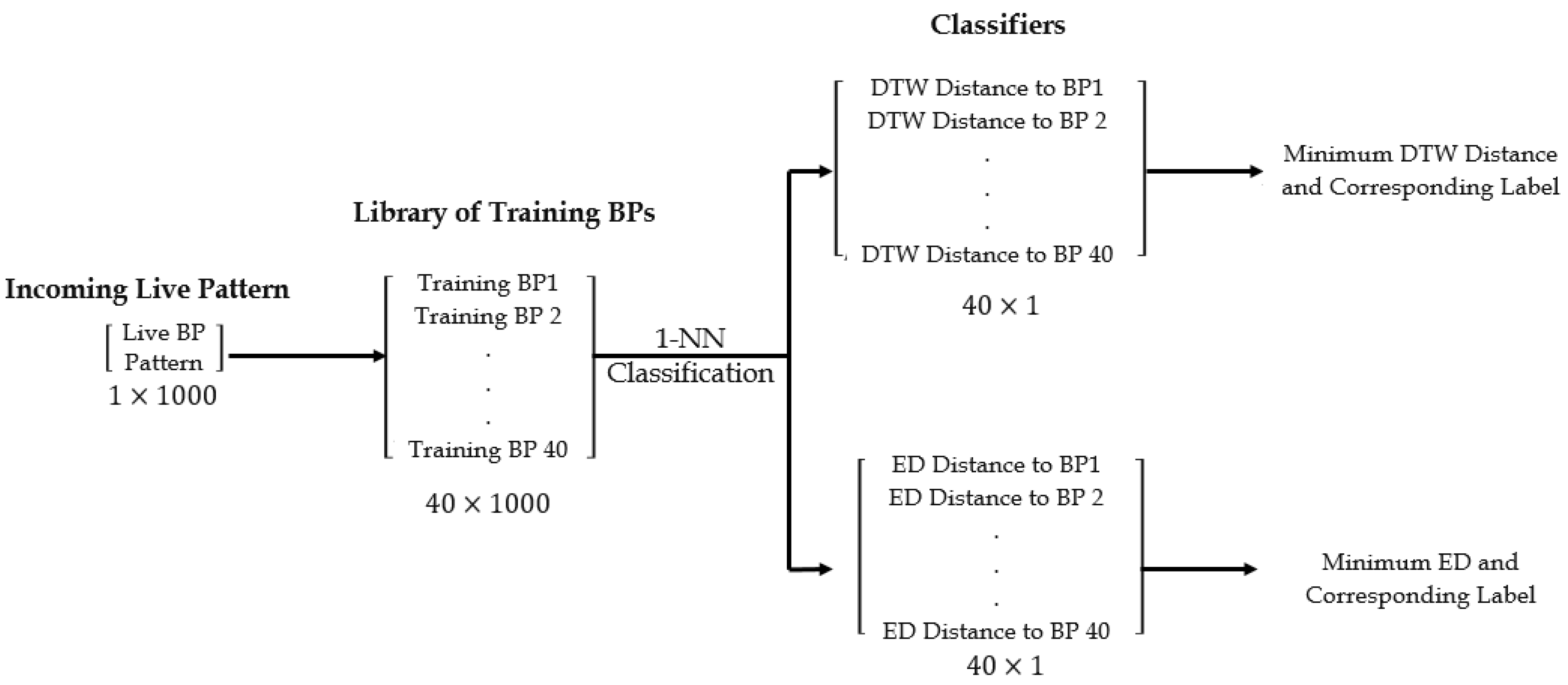
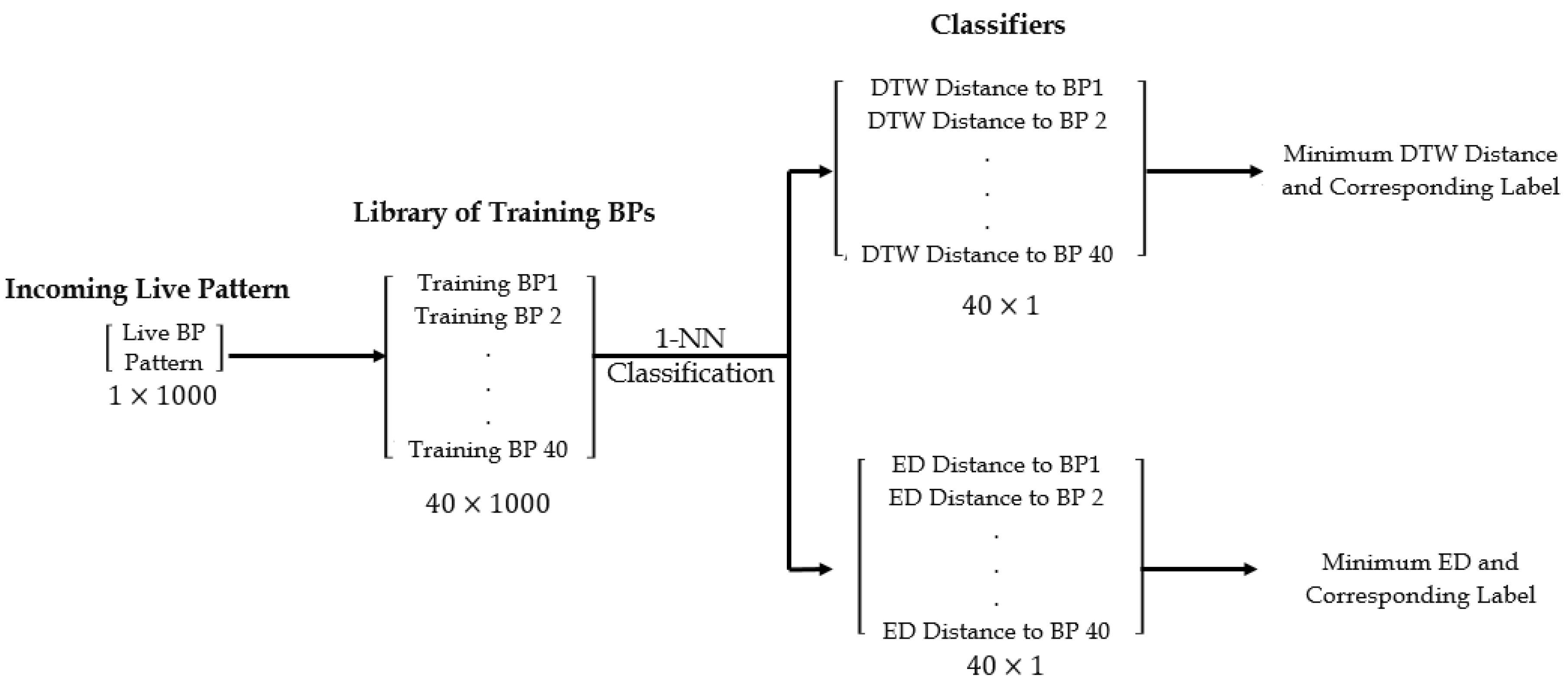
2.5. BP Classification and SMSW
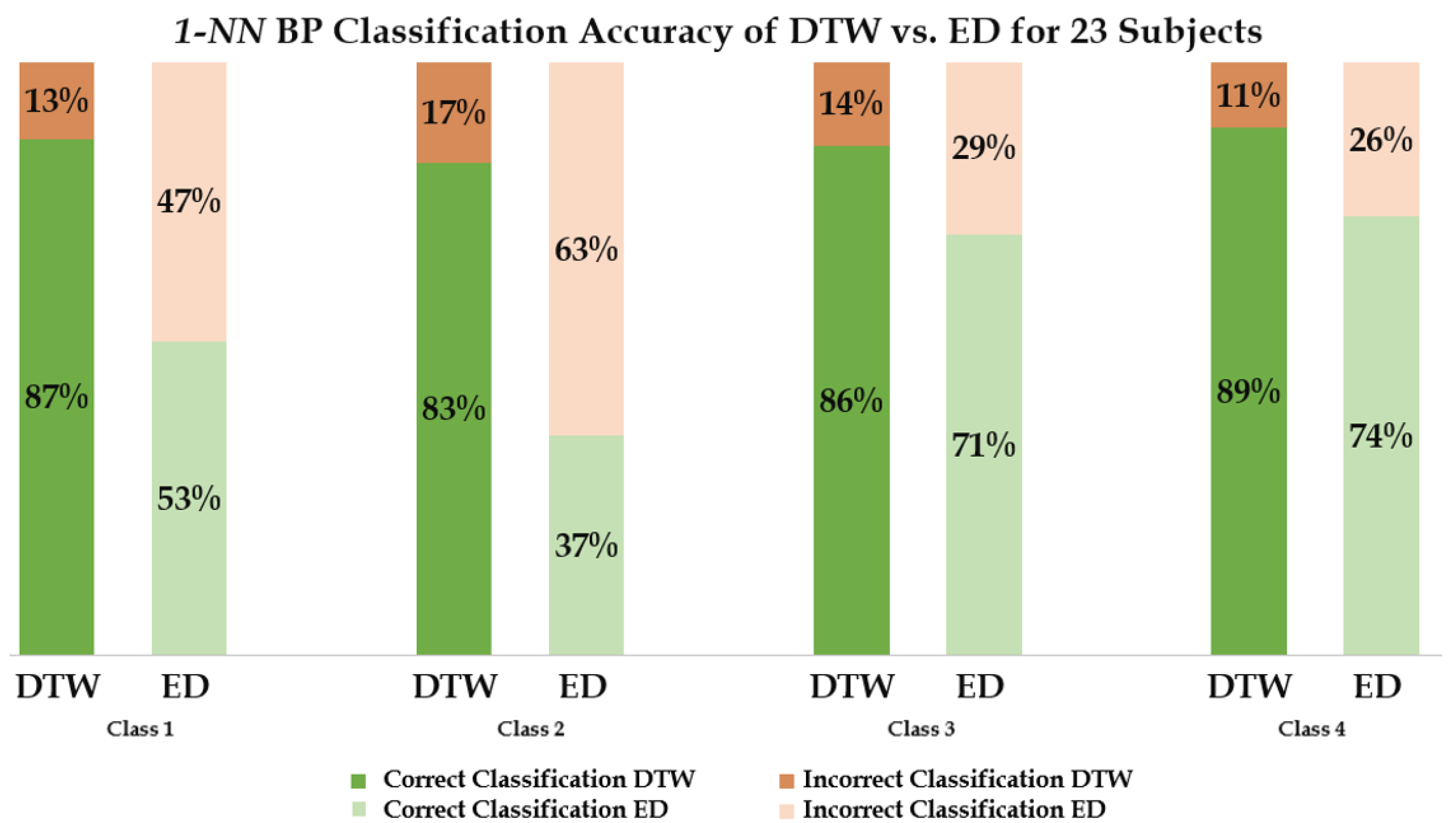
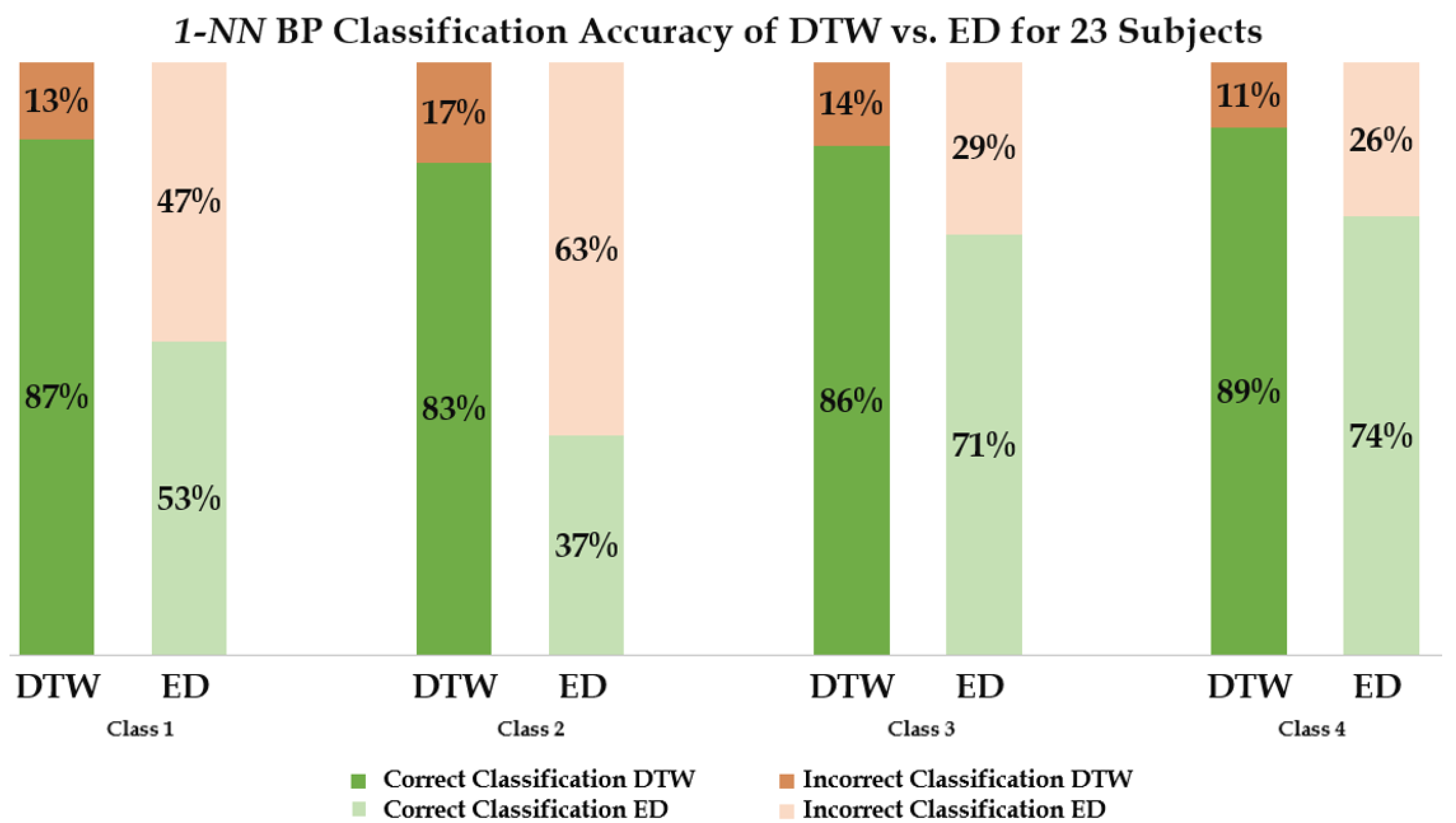
3. Results
4. Discussion
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Broyles, L.; Tate, J.; Happ, M. Use of Augmentative and Alternative Communication Strategies by Family Members in the Intensive Care Unit. Am. J. Crit. Care 2012, 21, e21–e32. [Google Scholar] [CrossRef] [PubMed]
- Simion, E. Augmentative and Alternative Communication – Support for People with Severe Speech Disorders. Procedia Soc. Behav. Sci. 2014, 128, 77–81. [Google Scholar] [CrossRef]
- Murray, J.; Goldbart, J. Augmentative and alternative communication: A review of current issues. J. Paediatr. Child. Health 2009, 19, 464–468. [Google Scholar] [CrossRef]
- Kerr, D.; Bouazza-Marouf, K.; Gaur, A.; Sutton, A.; Green, R. A breath controlled AAC system. In Proceedings of the CM2016 National AAC Conference, Orlando, FL, USA, 19–22 April 2016; pp. 11–13. [Google Scholar]
- Hodge, S. Why is the potential of augmentative and alternative communication not being realized? Exploring the experiences of people who use communication aids. Disabil. Soc. 2007, 22, 457–471. [Google Scholar] [CrossRef]
- Varady, P.; Benyo, Z.; Benyo, B. An open architecture patient monitoring system using standard technologies. IEEE Trans. Inf. Technol. Biomed. 2002, 6, 95–98. [Google Scholar] [CrossRef] [PubMed]
- Lindh, W.; Pooler, M.; Tamparo, C.; Dahl, B. Delmar’s Comprehensive Medical Assisting: Administrative and Clinical Competencies, 4th ed.; Delmar Cengage Learning: Clifton Park, NY, USA, 2009; p. 573. [Google Scholar]
- Yahya, O.; Faezipour, M. Automatic detection and classification of acoustic breathing cycles. In Proceedings of the 2014 Zone 1 Conference of the American Society for Engineering Education, Bridgeport, CT, USA, 3–5 April 2014. [Google Scholar]
- Massaroni, C.; Venanzi, C.; Silvatti, A.; Lo Presti, D.; Saccomandi, P.; Formica, D.; Giurazza, F.; Caponero, M.; Schena, E. Smart textile for respiratory monitoring and thoraco-abdominal motion pattern evaluation. J. Biophotonics 2018. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Ding, Q. Respiratory rate monitoring from the photoplethysmogram via sparse signal reconstruction. Physiol. Meas. 2016, 37, 1105–1119. [Google Scholar] [CrossRef] [PubMed]
- Itasaka, Y.; Miyazaki, S.; Tanaka, T.; Shibata, Y.; Ishikawa, K. Detection of Respiratory Events during Polysomnography—Nasal-Oral Pressure Sensor Versus Thermocouple Airflow Sensor—. Pract. Oto-Rhino-Laryngol. 2010, 129, 60–63. [Google Scholar] [CrossRef]
- Avalur, D. Human Breath Detection Using a Microphone. Master’s Thesis, University of Groningen, Groningen, The Netherlands, 2013. [Google Scholar]
- Plotkin, A.; Sela, L.; Weissbrod, A.; Kahana, R.; Haviv, L.; Yeshurun, Y.; Soroker, N.; Sobel, N. Sniffing enables communication and environmental control for the severely disabled. Proc. Natl. Acad. Sci. USA 2010, 107, 14413–14418. [Google Scholar] [CrossRef] [PubMed]
- Shorrock, T.; MacKay, D.; Ball, C. Efficient Communication by Breathing. In Deterministic and Statistical Methods in Machine Learning; Springer: Heidelberg/Berlin, Germany, 2005; pp. 88–97. [Google Scholar]
- Theodoridis, S.; Koutroumbas, K.; Pikrakis, A.; Cavouras, D. Introduction to Pattern Recognition, A Matlab Approach, 1st ed.; Academic Press: London, UK, 2010; pp. 21–25. [Google Scholar]
- Yin, X.; Hadjiloucas, S.; Zhang, Y. Pattern Classification of Medical Images: Computer Aided Diagnosis; Springer: Cham, Switzerland, 2017; p. 94. [Google Scholar]
- Chang, G.; Lai, Y. Performance evaluation and enhancement of lung sound recognition system in two real noisy environments. Comput. Methods Progr. Biomed. 2010, 97, 141–150. [Google Scholar] [CrossRef] [PubMed]
- Nam, Y.; Reyes, B.; Chon, K. Estimation of Respiratory Rates Using the Built-in Microphone of a Smartphone or Headset. IEEE J. Biomed. Health Inform. 2016, 20, 1493–1501. [Google Scholar] [CrossRef] [PubMed]
- Scalart, P.; Filho, J. Speech Enhancement Based on a Priori Signal to Noise Estimation. In Proceedings of the 1996 IEEE International Conference on Acoustics, Speech, and Signal Processing, Atlanta, GA, USA, 7–10 May 1996; pp. 629–632. [Google Scholar]
- Mathworks.com. Available online: https://uk.mathworks.com/matlabcentral/fileexchange/7673-wiener-filter (accessed on 2 February 2018).
- Ephraim, Y.; Malah, D. Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator. IEEE Trans. Acoust. Speech Signal Process. 1984, 32, 1109–1121. [Google Scholar] [CrossRef]
- Wei, L.; Xi, X.; Shelton, C.; Keogh, E.; Ratanamahatana, C. Fast Time Series Classification Using Numerosity Reduction. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 1033–1040. [Google Scholar]
- Yu, D.; Yu, X.; Hu, Q.; Liu, J.; Wu, A. Dynamic time warping constraint learning for large margin nearest neighbor classification. J. Inf. Sci. 2011, 181, 2787–2796. [Google Scholar] [CrossRef]
- Yadav, M.; Alam, A. Reduction of Computation Time in Pattern Matching for Speech Recognition. J. Comput. Appl. 2014, 90, 35–37. [Google Scholar] [CrossRef]
- Krishnan, R.; Sarkar, S. Conditional distance based matching for one-shot gesture recognition. Pattern Recognit. 2015, 48, 1302–1314. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Label | Transit Language |
|---|---|---|
| 1 | Breath_Pattern_1 | “Hello, good morning” |
| 2 | Breath_Pattern_2 | “Thank you” |
| 3 | Breath_Pattern_3 | “My name is …” |
| 4 | Breath_Pattern_4 | ”May I have a train ticket please?” |


© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Elsahar, Y.; Bouazza-Marouf, K.; Kerr, D.; Gaur, A.; Kaushik, V.; Hu, S. Breathing Pattern Interpretation as an Alternative and Effective Voice Communication Solution. Biosensors 2018, 8, 48. https://doi.org/10.3390/bios8020048
Elsahar Y, Bouazza-Marouf K, Kerr D, Gaur A, Kaushik V, Hu S. Breathing Pattern Interpretation as an Alternative and Effective Voice Communication Solution. Biosensors. 2018; 8(2):48. https://doi.org/10.3390/bios8020048
Chicago/Turabian StyleElsahar, Yasmin, Kaddour Bouazza-Marouf, David Kerr, Atul Gaur, Vipul Kaushik, and Sijung Hu. 2018. "Breathing Pattern Interpretation as an Alternative and Effective Voice Communication Solution" Biosensors 8, no. 2: 48. https://doi.org/10.3390/bios8020048
APA StyleElsahar, Y., Bouazza-Marouf, K., Kerr, D., Gaur, A., Kaushik, V., & Hu, S. (2018). Breathing Pattern Interpretation as an Alternative and Effective Voice Communication Solution. Biosensors, 8(2), 48. https://doi.org/10.3390/bios8020048