Enhancing Sensitivity of Point-of-Care Thyroid Diagnosis via Computational Analysis of Lateral Flow Assay Images Using Novel Textural Features and Hybrid-AI Models





Abstract
1. Introduction
1.1. Recent Advances in LFA Technology
1.2. Applications of LFAs in POC Diagnostics
1.3. Challenges and Sensitivity Enhancement in LFA Diagnostics
2. Textural-Analysis-Based Sensitivity Enhancement
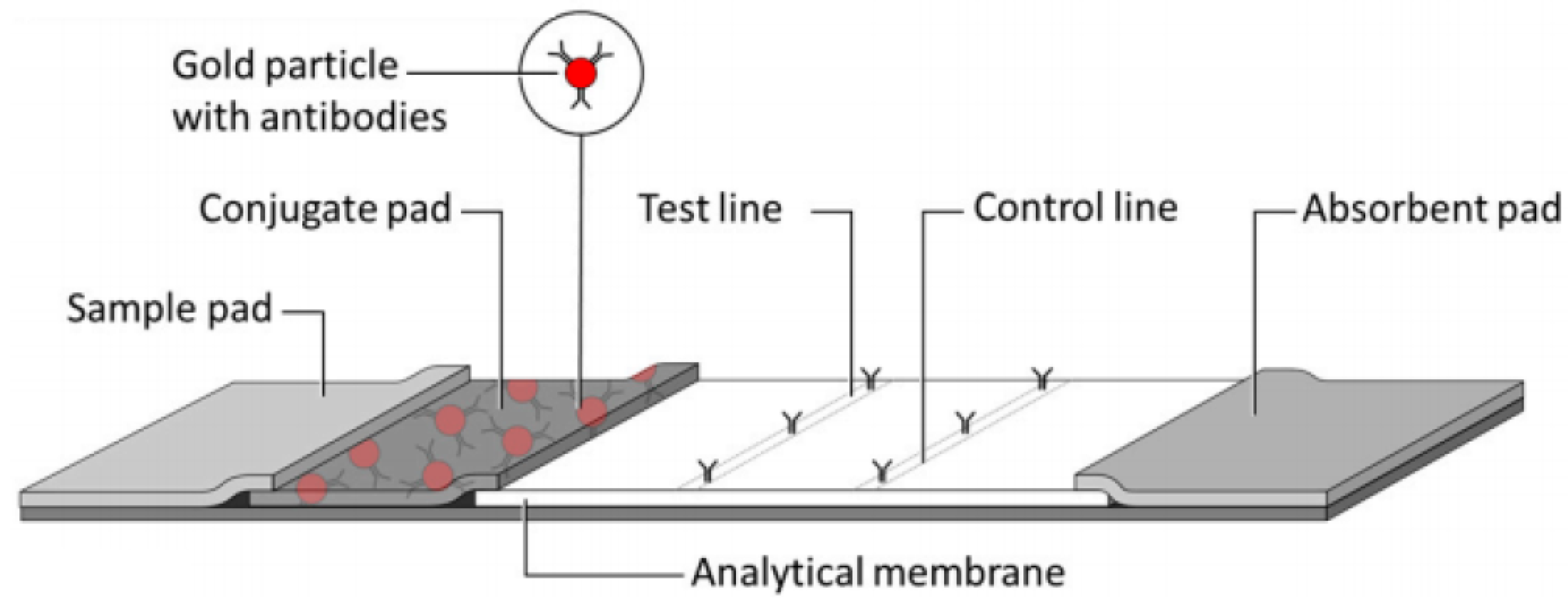
Dataset and LFA Preparation
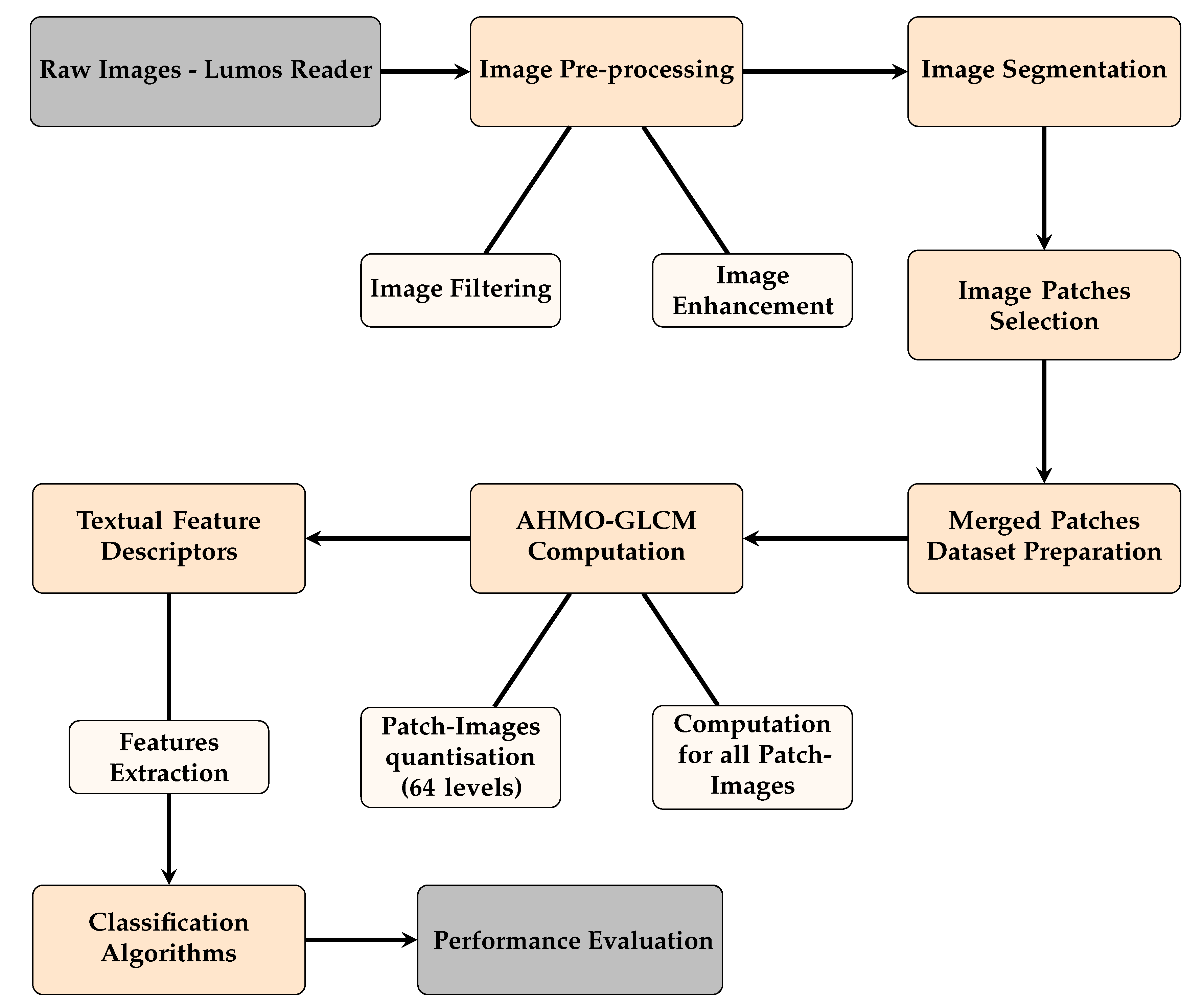
3. Methods
3.1. LFA Image Data Acquisition
3.2. Image Pre-Processing
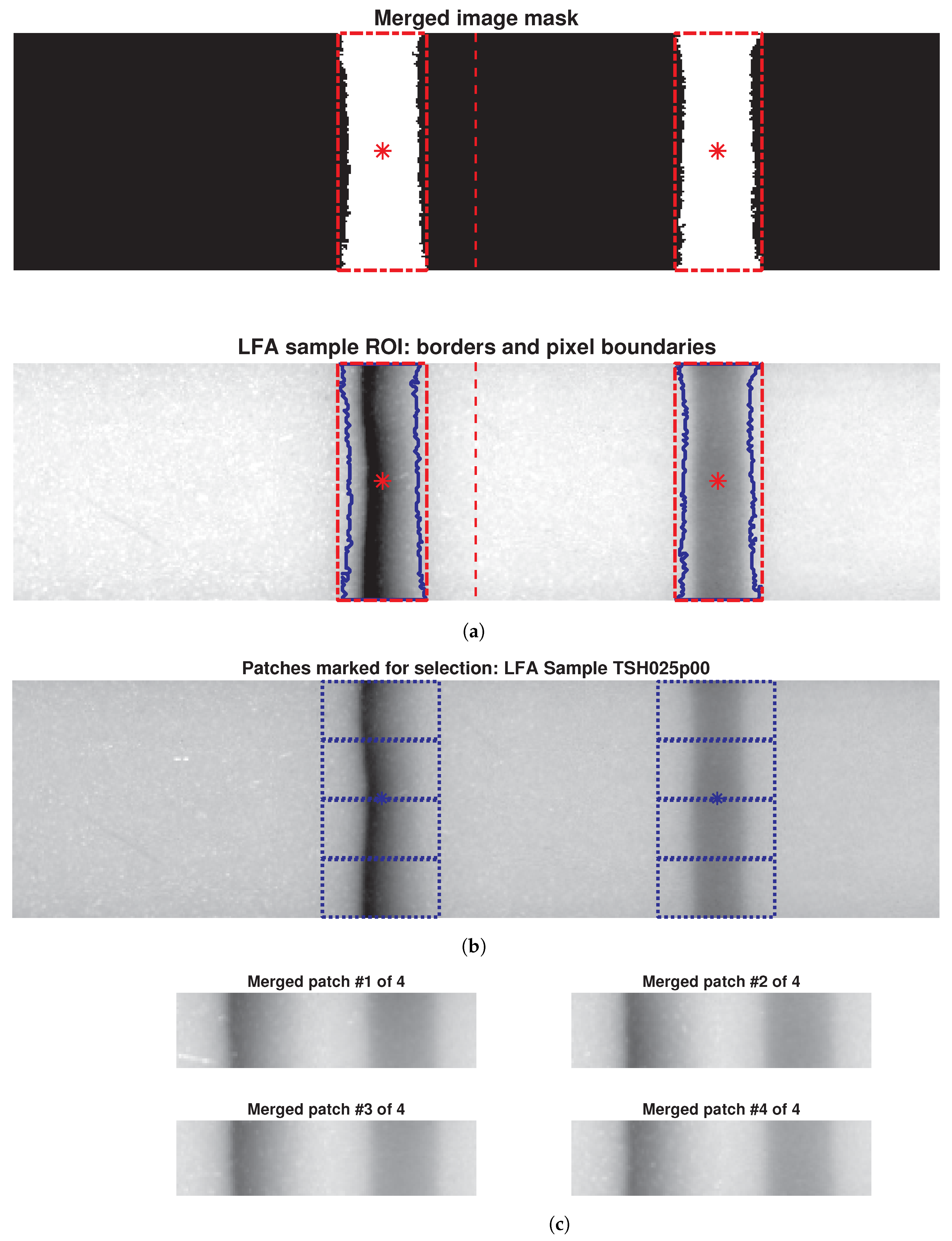
3.3. Image Segmentation and ROI Detection
3.4. Patch Selection and Dataset Expansion
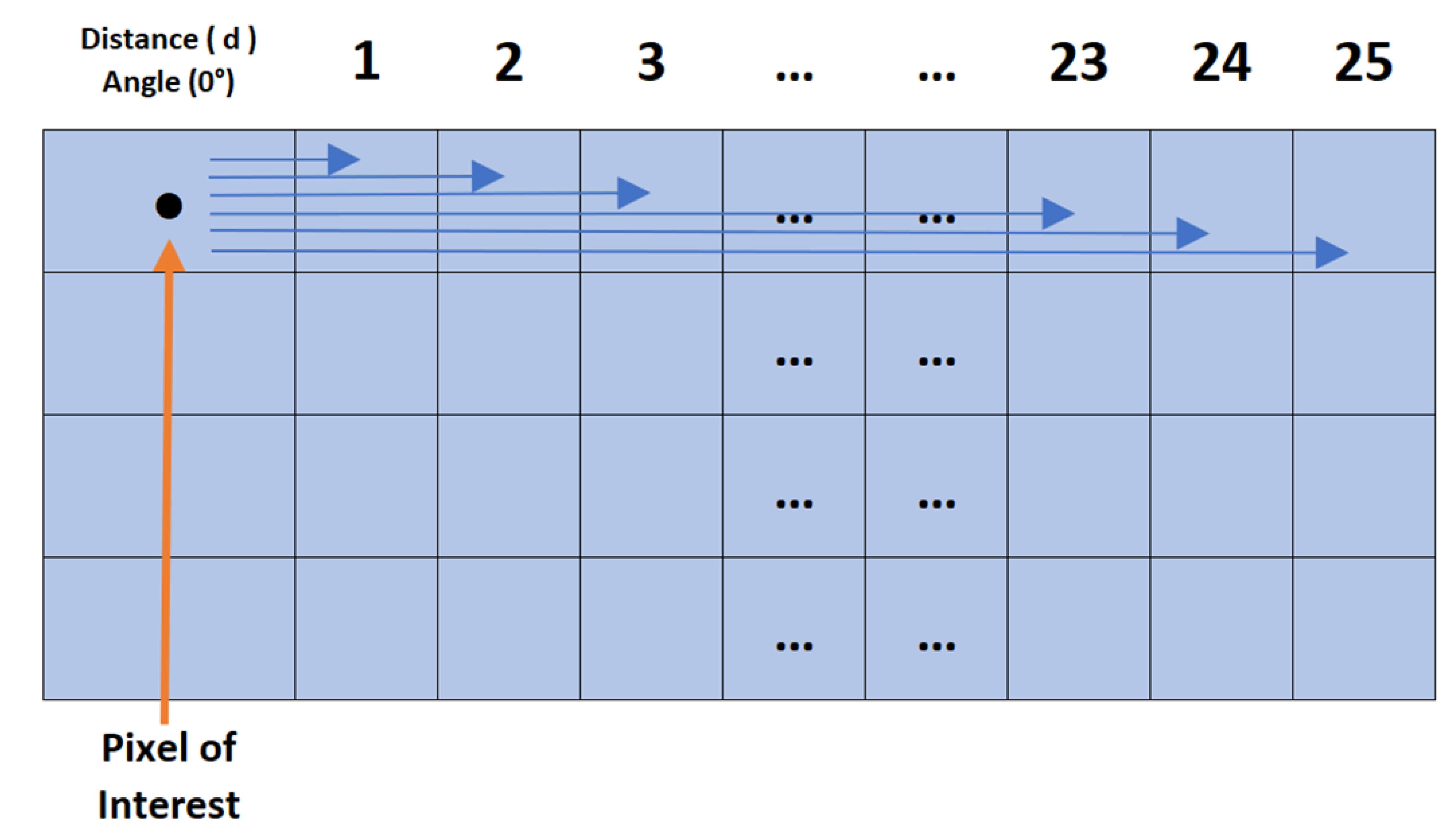
3.5. Averaged Horizontal Multi-Offset GLCM
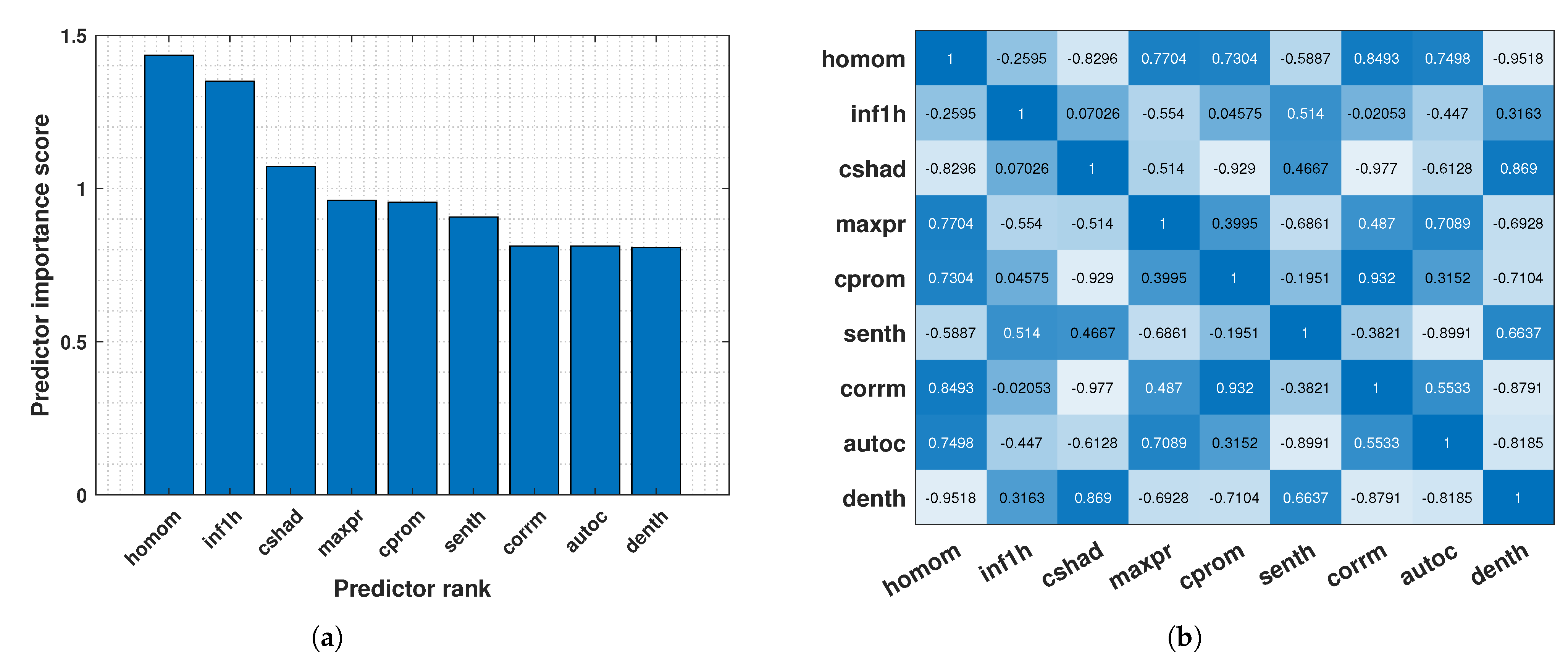
3.6. Texture Feature Extraction and Selection
3.7. CNN for Tabular Data
3.8. CNN Training and Feature Exploration
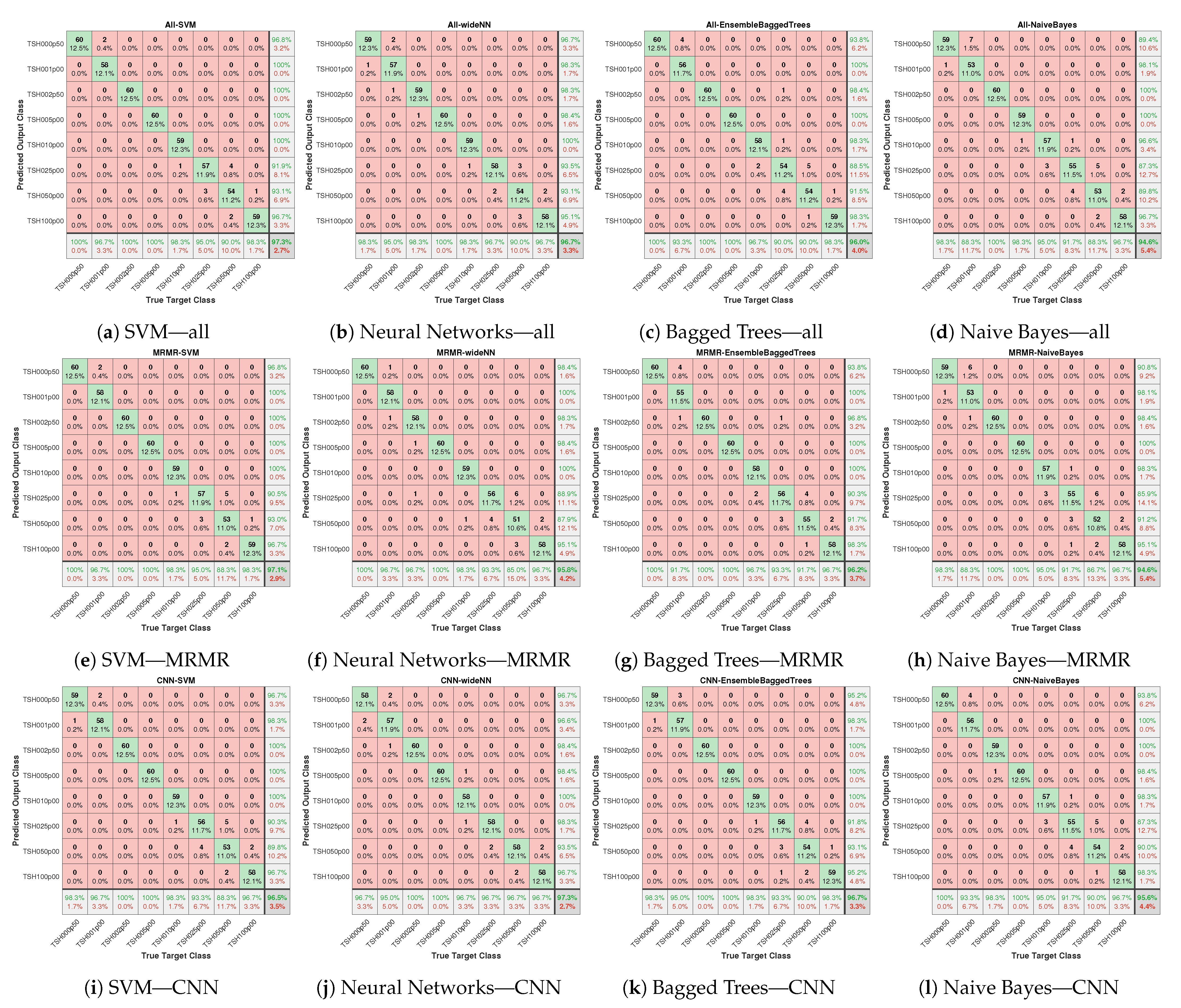
3.9. Performance Evaluation
4. Results and Discussion
5. Comparative Analysis of Imaging Techniques in Diagnostic Testing
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Roth, G.A.; Mensah, G.A.; Johnson, C.O.; Addolorato, G.; Ammirati, E.; Baddour, L.M.; Barengo, N.C.; Beaton, A.Z.; Benjamin, E.J.; Benziger, C.P.; et al. Global burden of cardiovascular diseases and risk factors, 1990–2019: Update from the GBD 2019 study. J. Am. Coll. Cardiol. 2020, 76, 2982–3021. [Google Scholar] [CrossRef] [PubMed]
- Klein, I.; Danzi, S. Thyroid disease and the heart. Circulation 2007, 116, 1725–1735. [Google Scholar] [CrossRef]
- Rodondi, N.; den Elzen, W.P.; Bauer, D.C.; Cappola, A.R.; Razvi, S.; Walsh, J.P.; Åsvold, B.O.; Iervasi, G.; Imaizumi, M.; Collet, T.H.; et al. Subclinical Hypothyroidism and the Risk of Coronary Heart Disease and Mortality. JAMA 2010, 304, 1365–1374. [Google Scholar] [CrossRef] [PubMed]
- Scanlan, T.S.; Suchland, K.L.; Hart, M.E.; Chiellini, G.; Huang, Y.; Kruzich, P.J.; Frascarelli, S.; Crossley, D.A.; Bunzow, J.R.; Ronca-Testoni, S.; et al. 3-Iodothyronamine is an endogenous and rapid-acting derivative of thyroid hormone. Nat. Med. 2004, 10, 638–642. [Google Scholar] [CrossRef]
- Kaur, M.A.; Gupta, S.; Kaur, V.; Chopra, B.; Singh, K. Comparison of measurement of serum TSH by two 3rd generation techniques. Int. J. Bioassays 2014, 3, 3040–3043. [Google Scholar]
- Thyroid-Stimulating Hormone (TSH) Levels. 2023. Available online: https://my.clevelandclinic.org/health/articles/23524-thyroid-stimulating-hormone-tsh-levels (accessed on 6 July 2023).
- Vargas-Uricoechea, H.; Bonelo-Perdomo, A.; Sierra-Torres, C.H. Effects of thyroid hormones on the heart. ClíNica Investig. Arterioscler. 2014, 26, 296–309. [Google Scholar] [CrossRef] [PubMed]
- Vadiveloo, T.; Donnan, P.T.; Cochrane, L.; Leese, G.P. The Thyroid Epidemiology, Audit, and Research Study (TEARS): Morbidity in patients with endogenous subclinical hyperthyroidism. J. Clin. Endocrinol. Metab. 2011, 96, 1344–1351. [Google Scholar] [CrossRef]
- Bianco, A. Metabolic effects of thyroid hormones–beyond traditional prospects. Thyroid 2008, 18, 99–101. [Google Scholar] [CrossRef]
- Leung, A.M. Subclinical hyperthyroidism is associated with increased risks of hip fractures, fractures at any site, nonspine fractures, and clinical spine fractures in the largest meta-analysis to date. Clin. Thyroidol. 2015, 27, 174–176. [Google Scholar] [CrossRef]
- Gencer, B.; Collet, T.H.; Virgini, V.; Bauer, D.C.; Gussekloo, J.; Cappola, A.R.; Nanchen, D.; den Elzen, W.P.; Balmer, P.; Luben, R.N.; et al. Subclinical thyroid dysfunction and the risk of heart failure events: An individual participant data analysis from 6 prospective cohorts. Circulation 2012, 126, 1040–1049. [Google Scholar] [CrossRef] [PubMed]
- British Thyroid Foundation. Thyroid Function Tests. 2021. Available online: https://www.btf-thyroid.org/thyroid-function-tests (accessed on 20 January 2023).
- St John, A.; Price, C.P. Existing and Emerging Technologies for Point-of-Care Testing. Clin. Biochem. Rev. 2014, 35, 155–167. [Google Scholar]
- Urdea, M.; Penny, L.A.; Olmsted, S.S.; Giovanni, M.Y.; Kaspar, P.; Shepherd, A.; Wilson, P.; Dahl, C.A.; Buchsbaum, S.; Moeller, G.; et al. Requirements for high impact diagnostics in the developing world. Nature 2006, 444, 73–79. [Google Scholar] [CrossRef]
- Habiyambere, V.; Nguimfack, B.D.; Vojnov, L.; Ford, N.; Stover, J.; Hasek, L.; Maggiore, P.; Low-Beer, D.; González, M.P.; Edgil, D.; et al. Forecasting the global demand for HIV monitoring and diagnostic tests: A 2016–2021 analysis. PLoS ONE 2018, 13, e0201341. [Google Scholar] [CrossRef]
- Yager, P.; Domingo, G.J.; Gerdes, J. Point-of-Care Diagnostics for Global Health. Annu. Rev. Biomed. Eng. 2008, 10, 107–144. [Google Scholar] [CrossRef] [PubMed]
- Hsieh, H.V.; Dantzler, J.L.; Weigl, B.H. Analytical Tools to Improve Optimization Procedures for Lateral Flow Assays. Diagnostics 2017, 7, 29. [Google Scholar] [CrossRef]
- Choi, J.R.; Yong, K.W.; Choi, J.Y.; Cowie, A.C. Emerging point-of-care technologies for food safety analysis. Sensors 2019, 19, 817. [Google Scholar] [CrossRef]
- Taranova, N.A.; Berlina, A.N.; Zherdev, A.V.; Dzantiev, B.B. ‘Traffic light’ immunochromatographic test based on multicolor quantum dots for the simultaneous detection of several antibiotics in milk. Biosens. Bioelectron. 2015, 63, 255–261. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Liang, R.; Guo, X.; Liang, J.; Deng, Q.; Li, M.; An, T.; Liu, T.; Wu, Y. Simultaneous quantitation of cytokeratin-19 fragment and carcinoembryonic antigen in human serum via quantum dot-doped nanoparticles. Biosens. Bioelectron. 2017, 91, 60–65. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Choi, N.; Cheng, Z.; Ko, J.; Chen, L.; Choo, J. Simultaneous Detection of Dual Nucleic Acids Using a SERS-Based Lateral Flow Assay Biosensor. Anal. Chem. 2017, 89, 1163–1169. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Jiang, Y.Z.; Tang, M.; Wu, L.L.; Xie, H.; Zhang, Z.L.; Pang, D.W. Colorimetric-Fluorescent-Magnetic Nanosphere-Based Multimodal Assay Platform for Salmonella Detection. Anal. Chem. 2019, 91, 1178–1184. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Wang, K.; Cao, B.; Shen, L.; Ke, X.; Cui, D.; Zhong, C.; Li, W. Multifunctional Nano-Sunflowers with Color-Magnetic-Raman Properties for Multimodal Lateral Flow Immunoassay. Anal. Chem. 2021, 93, 3626–3634. [Google Scholar] [CrossRef]
- Tanaka, R.; Yuhi, T.; Nagatani, N.; Endo, T.; Kerman, K.; Takamura, Y.; Tamiya, E. A novel enhancement assay for immunochromatographic test strips using gold nanoparticles. Anal. Bioanal. Chem. 2006, 385, 1414–1420. [Google Scholar] [CrossRef] [PubMed]
- Singer, J.M.; Plotz, C.M. The latex fixation test: I. Application to the serologic diagnosis of rheumatoid arthritis. Am. J. Med. 1956, 21, 888–892. [Google Scholar] [CrossRef]
- Atchison, C.; Pristerà, P.; Cooper, E.; Papageorgiou, V.; Redd, R.; Piggin, M.; Flower, B.; Fontana, G.; Satkunarajah, S.; Ashrafian, H.; et al. Usability and acceptability of home-based self-testing for severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) antibodies for population surveillance. Clin. Infect. Dis. 2021, 72, e384–e393. [Google Scholar] [CrossRef] [PubMed]
- Boxer, J.; Weddell, S.; Broomhead, D.; Hogg, C.; Johnson, S. Home pregnancy tests in the hands of the intended user. J. Immunoass. Immunochem. 2019, 40, 642–652. [Google Scholar] [CrossRef] [PubMed]
- Valanis, B.G.; Perlman, C.S. Home pregnancy testing kits: Prevalence of use, false-negative rates, and compliance with instructions. Am. J. Public Health 1982, 72, 1034–1036. [Google Scholar] [CrossRef] [PubMed]
- Rodriguez, N.M.; Linnes, J.C.; Fan, A.; Ellenson, C.K.; Pollock, N.R.; Klapperich, C.M. Paper-based RNA extraction, in situ isothermal amplification, and lateral flow detection for low-cost, rapid diagnosis of influenza A (H1N1) from clinical specimens. Anal. Chem. 2015, 87, 7872–7879. [Google Scholar] [CrossRef] [PubMed]
- Sheng, E.; Lu, Y.; Xiao, Y.; Li, Z.; Wang, H.; Dai, Z. Simultaneous and ultrasensitive detection of three pesticides using a surface-enhanced Raman scattering-based lateral flow assay test strip. Biosens. Bioelectron. 2021, 181, 113149. [Google Scholar] [CrossRef]
- Raeisossadati, M.J.; Danesh, N.M.; Borna, F.; Gholamzad, M.; Ramezani, M.; Abnous, K.; Taghdisi, S.M. Lateral flow based immunobiosensors for detection of food contaminants. Biosens. Bioelectron. 2016, 86, 235–246. [Google Scholar] [CrossRef]
- Drain, P.K.; Hyle, E.P.; Noubary, F.; Freedberg, K.A.; Wilson, D.; Bishai, W.R.; Rodriguez, W.; Bassett, I.V. Diagnostic point-of-care tests in resource-limited settings. Lancet Infect. Dis. 2014, 14, 239–249. [Google Scholar] [CrossRef] [PubMed]
- NHS-UK. Colour Vision Deficiency (Colour Blindness). 2021. Available online: https://www.nhs.uk/conditions/colour-vision-deficiency/ (accessed on 19 January 2022).
- Hu, J.; Wang, L.; Li, F.; Han, Y.L.; Lin, M.; Lu, T.J.; Xu, F. Oligonucleotide-linked gold nanoparticle aggregates for enhanced sensitivity in lateral flow assays. Lab Chip 2013, 13, 4352–4357. [Google Scholar] [CrossRef] [PubMed]
- Choi, J.R.; Hu, J.; Feng, S.; Wan Abas, W.A.; Pingguan-Murphy, B.; Xu, F. Sensitive biomolecule detection in lateral flow assay with a portable temperature-humidity control device. Biosens. Bioelectron. 2016, 79, 98–107. [Google Scholar] [CrossRef] [PubMed]
- Rivas, L.; Medina-Sánchez, M.; de la Escosura-Muñiz, A.; Merkoçi, A. Improving sensitivity of gold nanoparticle-based lateral flow assays by using wax-printed pillars as delay barriers of microfluidics. Lab Chip 2014, 14, 4406–4414. [Google Scholar] [CrossRef] [PubMed]
- Sumonphan, E.; Auephanwiriyakul, S.; Theera-Umpon, N. Interpretation of nevirapine concentration from immunochromatographic strip test using support vector regression. In Proceedings of the 2008 IEEE International Conference on Mechatronics and Automation, Takamatsu, Japan, 5–8 August 2008; pp. 633–637. [Google Scholar]
- Huang, L.; Zhang, Y.; Xie, C.; Qu, J.; Huang, H.; Wang, X. Research of reflectance photometer based on optical absorption. Optik 2010, 121, 1725–1728. [Google Scholar] [CrossRef]
- Lei, H.; Wang, K.; Ji, X.; Cui, D. Contactless measurement of magnetic nanoparticles on lateral flow strips using tunneling magnetoresistance (TMR) sensors in differential configuration. Sensors 2016, 16, 2130. [Google Scholar] [CrossRef]
- Zangheri, M.; Cevenini, L.; Anfossi, L.; Baggiani, C.; Simoni, P.; Di Nardo, F.; Roda, A. A simple and compact smartphone accessory for quantitative chemiluminescence-based lateral flow immunoassay for salivary cortisol detection. Biosens. Bioelectron. 2015, 64, 63–68. [Google Scholar] [CrossRef]
- Mudanyali, O.; Dimitrov, S.; Sikora, U.; Padmanabhan, S.; Navruz, I.; Ozcan, A. Integrated rapid-diagnostic-test reader platform on a cellphone. Lab Chip 2012, 12, 2678–2686. [Google Scholar] [CrossRef]
- Pilavaki, E.; Valente, V.; Demosthenous, A. CMOS image sensor for lateral flow immunoassay readers. IEEE Trans. Circuits Syst. II Express Briefs 2018, 65, 1405–1409. [Google Scholar] [CrossRef]
- Mak, W.C.; Beni, V.; Turner, A.P. Lateral-flow technology: From visual to instrumental. TrAC Trends Anal. Chem. 2016, 79, 297–305. [Google Scholar] [CrossRef]
- Fairooz, T.; McNamee, S.E.; Finlay, D.; Ng, K.Y.; McLaughlin, J. A novel patches-selection method for the classification of point-of-care biosensing lateral flow assays with cardiac biomarkers. Biosens. Bioelectron. 2023, 223, 115016. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I. Textural Features for Image Classification. IEEE Trans. Syst. Man Cybern. 1973, SMC-3, 610–621. [Google Scholar] [CrossRef]
- Jing, M.; Mc Laughlin, D.; Steele, D.; Mc Namee, S.; Mac Namee, B.; Cullen, P.; Finlay, D.; McLaughlin, J. Detection and categorisation of multilevel high-sensitivity cardiovascular biomarkers from lateral flow immunoassay images via recurrent neural networks. Bioimaging 2020, 2020, 177–183. [Google Scholar]
- Lumos Diagnostics. 2023. Available online: https://lumosdiagnostics.com/products (accessed on 19 December 2023).
- Senthilkumaran, N.; Vaithegi, S. Image segmentation by using thresholding techniques for medical images. Comput. Sci. Eng. Int. J. 2016, 6, 1–13. [Google Scholar]
- Huang, Q.; Gao, W.; Cai, W. Thresholding technique with adaptive window selection for uneven lighting image. Pattern Recognit. Lett. 2005, 26, 801–808. [Google Scholar] [CrossRef]
- Uppuluri, A. GLCM Features4 (MATLAB Central Exchange). 2023. Available online: https://www.mathworks.com/matlabcentral/fileexchange/22354-glcm_features4-m-vectorized-version-of-glcm_features1-m-with-code-changes (accessed on 14 March 2023).
- Ding, C.; Peng, H. Minimum redundancy feature selection from microarray gene expression data. J. Bioinform. Comput. Biol. 2005, 3, 185–205. [Google Scholar] [CrossRef]
- Gholamy, A.; Kreinovich, V.; Kosheleva, O. Why 70/30 or 80/20 Relation Between Training and Testing Sets: A Pedagogical Explanation. Technical Report: UTEP-CS-18-09. 2018. Available online: https://scholarworks.utep.edu/cs_techrep/1209/ (accessed on 9 October 2024).
- Mutlu, A.Y.; Kiliç, V.; Özdemir, G.K.; Bayram, A.; Horzum, N.; Solmaz, M.E. Smartphone-based colorimetric detection: Via machine learning. Analyst 2017, 142, 2434–2441. [Google Scholar] [CrossRef]
- Jing, M.; McLaughlin, D.; McNamee, S.E.; Raj, S.; Namee, B.M.; Steele, D.; Finlay, D.; McLaughlin, J. A Novel Method for Quantitative Analysis of C-Reactive Protein Lateral Flow Immunoassays Images via CMOS Sensor and Recurrent Neural Networks. IEEE J. Transl. Eng. Health Med. 2021, 9, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Solmaz, M.E.; Mutlu, A.Y.; Alankus, G.; Kılıç, V.; Bayram, A.; Horzum, N. Quantifying colorimetric tests using a smartphone app based on machine learning classifiers. Sens. Actuators B. Chem. 2018, 255, 1967–1973. [Google Scholar] [CrossRef]
- Rahmat, R.F.; Royananda; Muchtar, M.A.; Taqiuddin, R.; Adnan, S.; Anugrahwaty, R.; Budiarto, R. Automated color classification of urine dipstick image in urine examination. J. Phys. Conf. Ser. 2018, 978, 012008. [Google Scholar] [CrossRef]



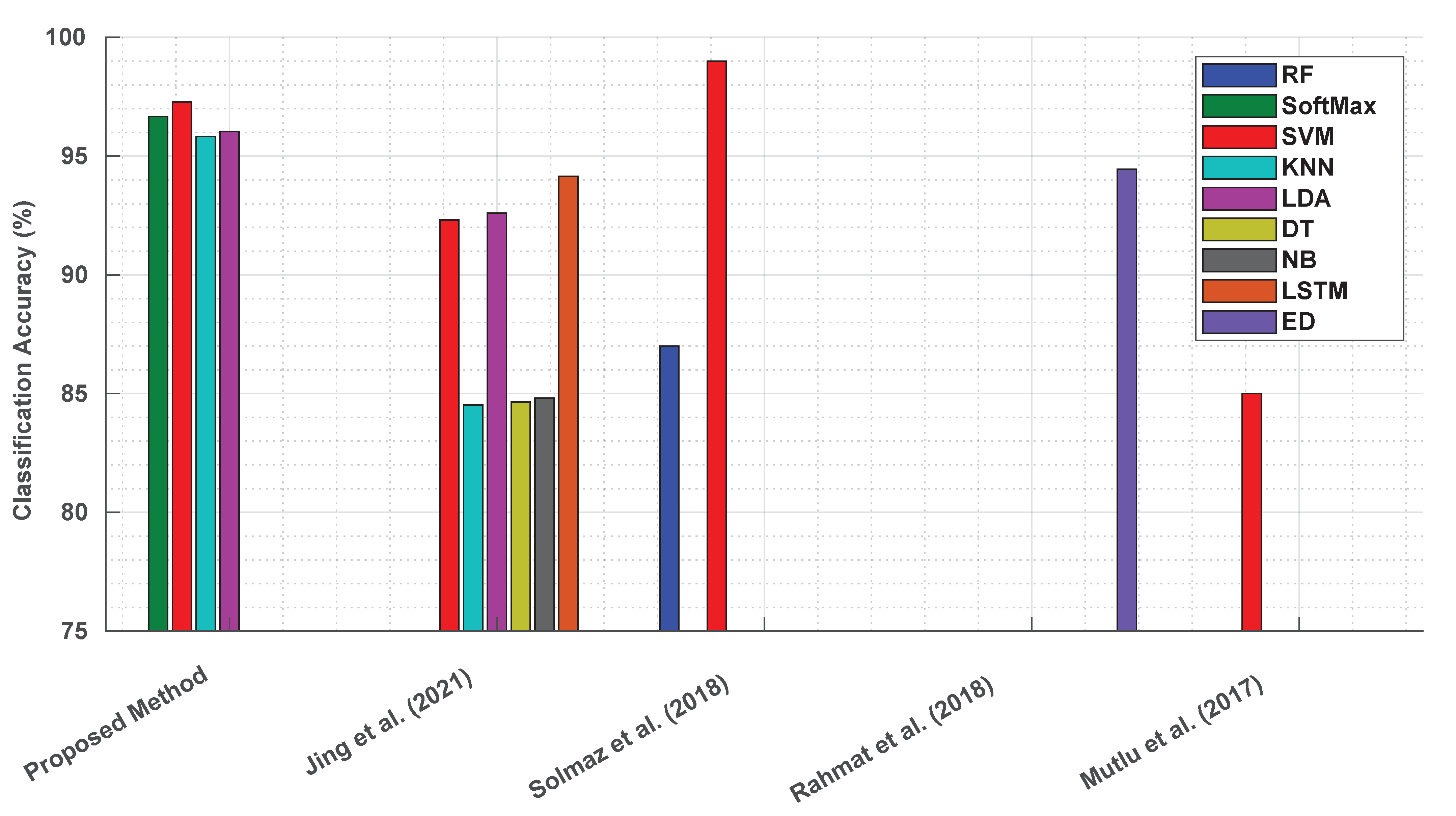

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
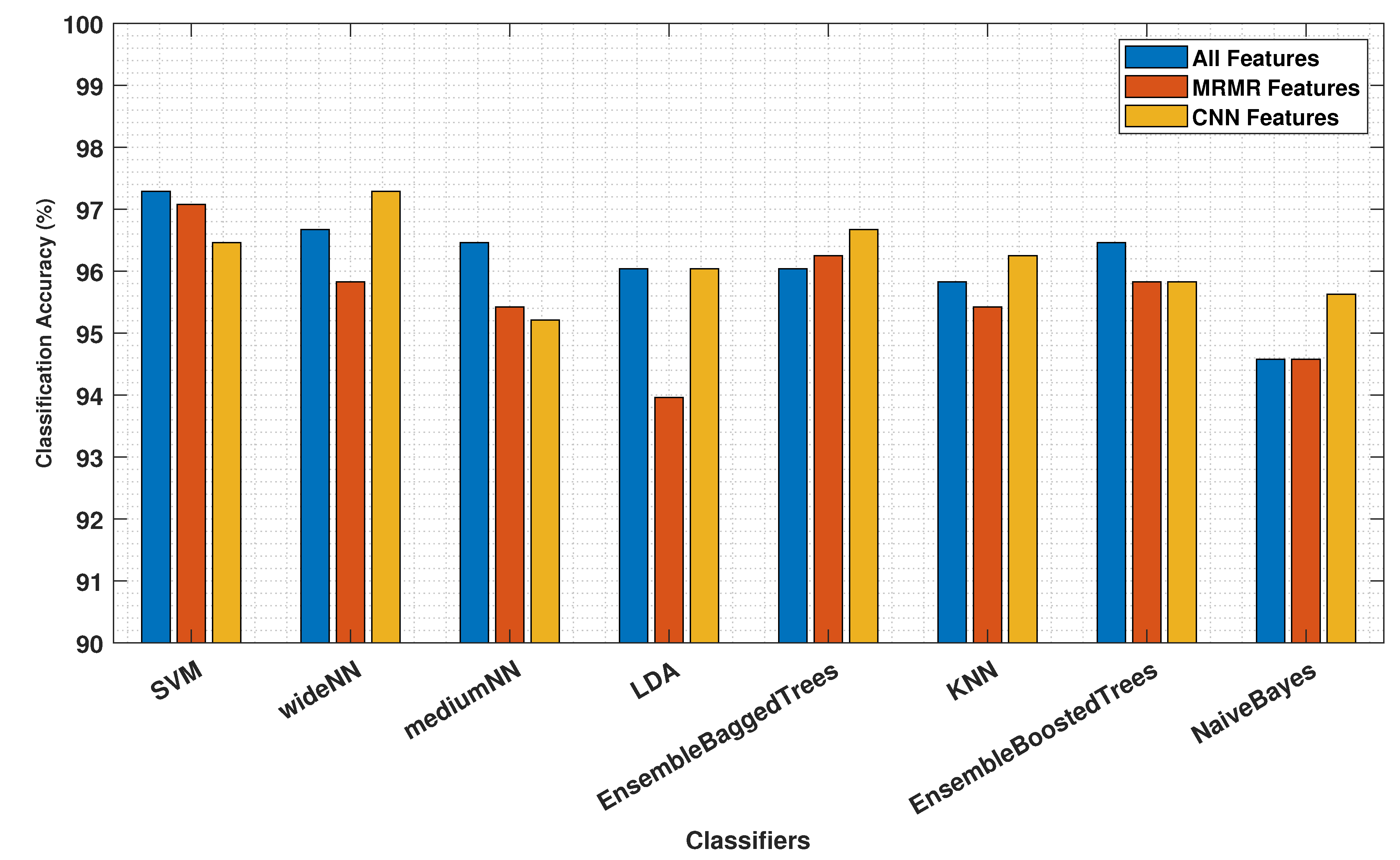
| Classifiers | Accuracy (%) | Sensitivity (%) | Specificity (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| (Feature Sets) | (All) | (MRMR) | (CNN) | (All) | (MRMR) | (CNN) | (All) | (MRMR) | (CNN) |
| SVM | 97.29 | 97.08 | 96.46 | 97.29 | 97.08 | 96.46 | 99.61 | 99.58 | 99.49 |
| Wide-NN | 96.67 | 95.83 | 97.29 | 96.67 | 95.83 | 97.29 | 99.52 | 99.40 | 99.61 |
| Medium-NN | 96.46 | 95.42 | 95.21 | 96.46 | 95.42 | 95.21 | 99.49 | 99.35 | 99.32 |
| LDA | 96.04 | 93.96 | 96.04 | 96.04 | 93.96 | 96.04 | 99.43 | 99.14 | 99.43 |
| Ensemble Bagged Trees | 96.04 | 96.25 | 96.67 | 96.04 | 96.25 | 96.67 | 99.43 | 99.46 | 99.52 |
| K-NN | 95.83 | 95.42 | 96.25 | 95.83 | 95.42 | 96.25 | 99.40 | 99.35 | 99.46 |
| Ensemble Boosted Trees | 96.46 | 95.83 | 95.83 | 96.46 | 95.83 | 95.83 | 99.49 | 99.40 | 99.40 |
| Naive Bayes | 94.58 | 94.58 | 95.63 | 94.58 | 94.58 | 95.63 | 99.23 | 99.23 | 99.38 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fairooz, T.; McNamee, S.E.; Finlay, D.; Ng, K.Y.; McLaughlin, J. Enhancing Sensitivity of Point-of-Care Thyroid Diagnosis via Computational Analysis of Lateral Flow Assay Images Using Novel Textural Features and Hybrid-AI Models. Biosensors 2024, 14, 611. https://doi.org/10.3390/bios14120611
Fairooz T, McNamee SE, Finlay D, Ng KY, McLaughlin J. Enhancing Sensitivity of Point-of-Care Thyroid Diagnosis via Computational Analysis of Lateral Flow Assay Images Using Novel Textural Features and Hybrid-AI Models. Biosensors. 2024; 14(12):611. https://doi.org/10.3390/bios14120611
Chicago/Turabian StyleFairooz, Towfeeq, Sara E. McNamee, Dewar Finlay, Kok Yew Ng, and James McLaughlin. 2024. "Enhancing Sensitivity of Point-of-Care Thyroid Diagnosis via Computational Analysis of Lateral Flow Assay Images Using Novel Textural Features and Hybrid-AI Models" Biosensors 14, no. 12: 611. https://doi.org/10.3390/bios14120611
APA StyleFairooz, T., McNamee, S. E., Finlay, D., Ng, K. Y., & McLaughlin, J. (2024). Enhancing Sensitivity of Point-of-Care Thyroid Diagnosis via Computational Analysis of Lateral Flow Assay Images Using Novel Textural Features and Hybrid-AI Models. Biosensors, 14(12), 611. https://doi.org/10.3390/bios14120611