1. Introduction
Parkinson’s disease (PD) is a progressive neurological condition. Its motor disabilities are caused by a degeneration of the dopamine-releasing nerve cells in the substantia nigra. Other neuronal systems are also affected, and this contributes to the various nonmotor features of the disorder [
1]. One challenge in the search for disease-modifying treatments is the difficulty in identifying PD at an early stage, before its motor signs are clearly developed. Later, fluctuating responses to symptomatic treatment make it hard to monitor the progression of PD [
2,
3]. Early detection and monitoring of progression using objective measures can play an important role in maintaining quality of life in PD by facilitating symptomatic medical interventions [
4,
5]. There are a limited number of motor features that have been identified as appearing in the early stages of PD, often before clinical diagnosis [
3,
6,
7]. As such, measurements of changes in gait [
8,
9], handwriting [
10,
11] and speech [
12,
13] have been proposed for the early, computer-assisted diagnosis of the disease.
Dysarthria [
14] is commonly observed in PD patients [
12,
13], and is often one of the first symptoms. It results from a combination of impairments to upper airway, laryngeal and respiratory muscle control. The non-invasive nature of speech analysis makes it an attractive tool to aid in the prediction or early detection of PD. Using automated speech analysis to diagnose and monitor PD has several advantages, primary among them the ability to make unbiased and objective measurements. Importantly, speech analysis also allows the progression of the disease to be monitored remotely [
15,
16], reducing the number and expense of clinical visits. Acoustic analysis of the voice of PD patients also has therapeutic applications. Voice analysis can be used when training patients to improve their voice. The Lee Silverman voice treatment (LSVT) is one such system that combines voice analysis and feedback to patients [
17].
Studies have reported the use of acoustic analysis to identify vocal pathologies in PD [
18,
19,
20]. The voice of PD patients is associated with low volume, monotonicity, high pitch, tremulousness, breathiness, hoarseness and, sometimes, the inability to spontaneously maintain loudness [
21]. Perturbation measures are the most commonly used acoustic features; these determine the intercycle differences in frequency and amplitude of the speech signal [
22,
23]. However, it has been shown that perturbation measures, especially jitter and shimmer, can be inconsistent when applied to aperiodic signals [
24,
25] and may give invalid results when differentiating pathological from normal voices [
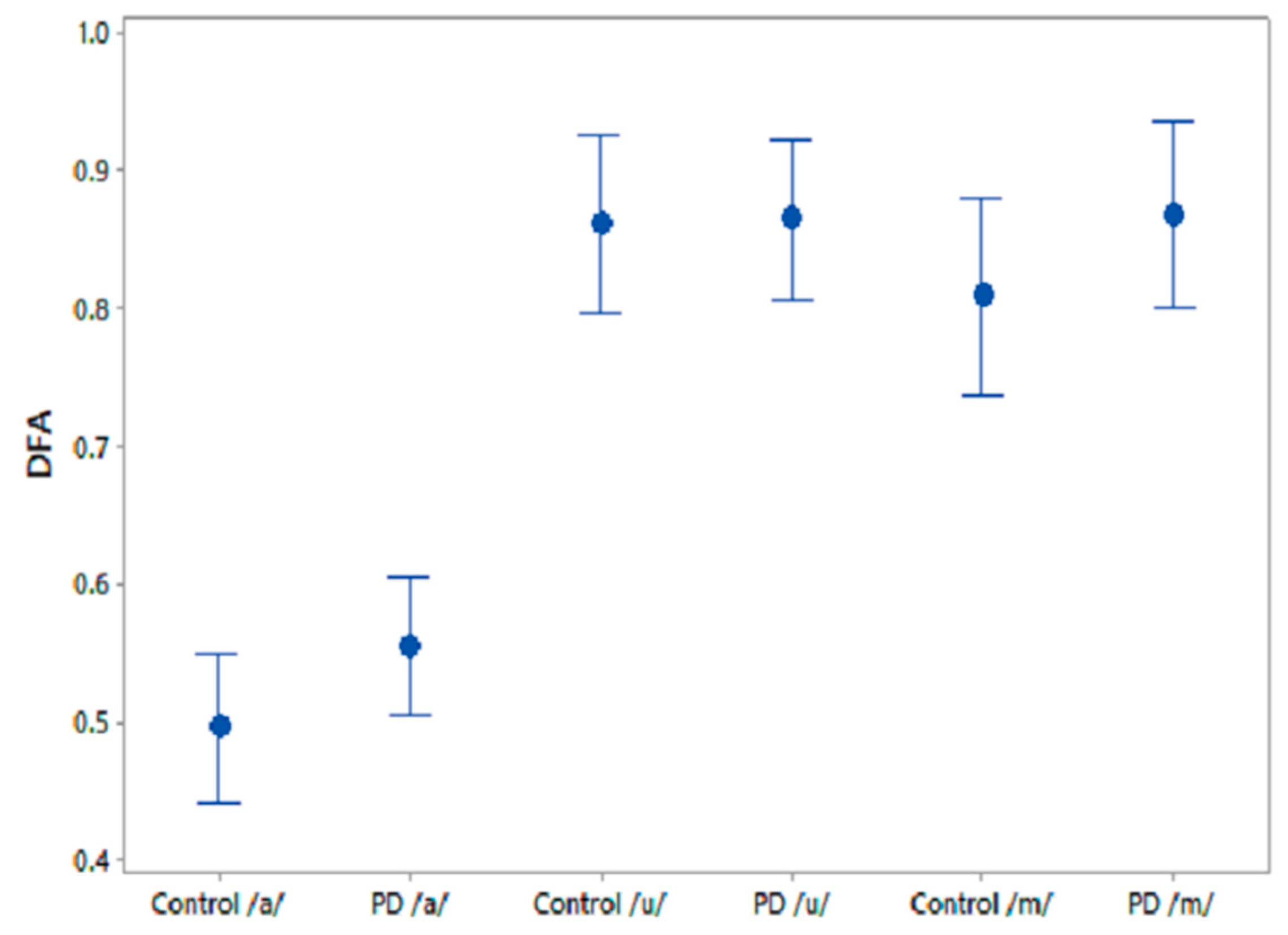
26]. Recent advances in speech analysis for the diagnosis of PD have shown that nonlinear features such as detrended fluctuation analysis (DFA), correlation dimension (D2), Lyapunov exponent (L1) and recurrence pitch period entropy (RPDE) are more suitable for distinguishing between the voices of controls (CO) and PD patients [
27,
28,
29]. These features may discern PD from CO subjects based on the presence of aperiodicity in the vocal fold vibration during sustained phonation, which correlates with a perceptually rough or hoarse voice [
30,
31]. However, with nonpathologically large differences in the voices of people in any population, detecting the differences between PD and CO subjects at early stages of PD can be difficult.
Speech contains complex information that is embedded in the acoustic features [
32]. This information includes, but is not restricted to, markers of sex, age, health, psychological state, voice production mechanism and linguistic mechanisms [
32]. Healthy people can modify their voices to generate different sounds that require fine control and coordination of the articulatory and respiratory muscles. However, PD patients have reduced neuromotor control, which affects the voice mechanism and thus the sounds produced. Machine analysis of speech could augment standard clinical assessments [
33] in the early detection of PD, but there are significant inter- and intra-individual variations [
32], which makes this challenging. Thus, there is a need to find features for identifying differences between healthy and pathological voices that can be adapted for a given population.
It is well recognised from the literature that aging and disease change the complexity of biological systems [
34,
35,
36,
37]. Based on the above and on evidence from other nonspeech PD studies [
38,
39], we hypothesize (Hypothesis 1) that the voice of PD patients will have reduced complexity when compared with CO, indicative of reduced vocal dynamics (richness). We also hypothesize (Hypothesis 2) that, because of the reduced complexity in the voice of PD patients, the information shared between them will be greater than the information shared between voices of CO. The shared information can be in terms of the temporal and spatial information in the voice recordings, which reflect periodicity, fine structures and fundamental frequency. We use two complexity measures—fractal dimension (FD) and normalised mutual information (NMI)—to test these hypotheses.
Fractals can be described as infinitely complex self-similar patterns across different scales and are created by a simple process continually reiterated in a feedback loop [
35]. Fractal dimension (FD) is generally employed to measure the complexity of such fractal objects. While measured in the temporal domain, FD provides an estimation of the overall complexity in the signal and has been used in biomedical applications to quantify complexity in biosignals [
40,
41].
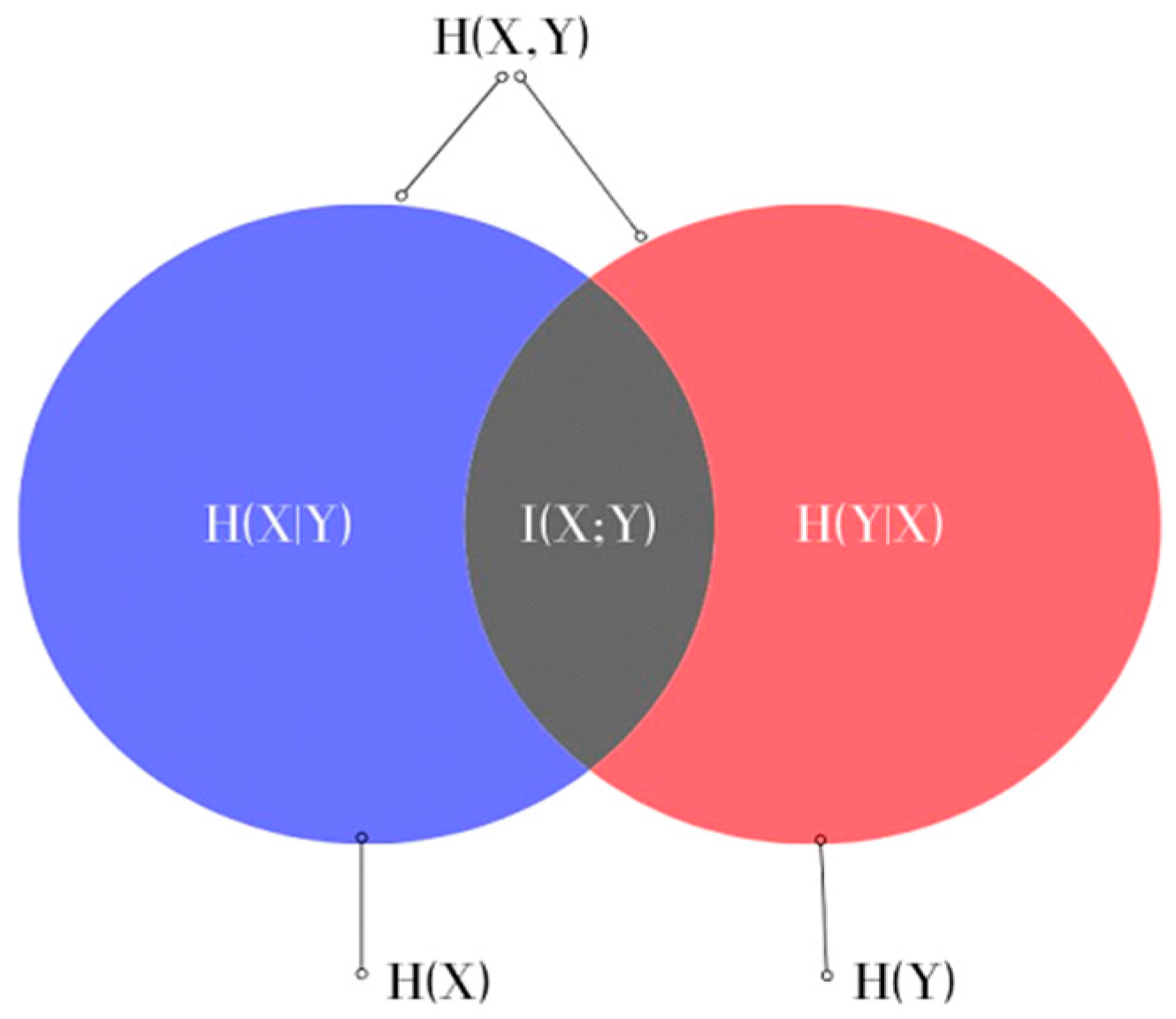
Mutual information (MI) is a measure of the dependence between the two time series and includes both linear and nonlinear relationships [
34]. It is estimated based on the independent entropies and joint entropy of the time series; MI has a lower bound of zero and the upper bound of MI is determined by the independent entropies [
42,
43]. Difficulties arise when comparing data, but they can be minimised by normalising the MI, termed Normalised Mutual Information (NMI). One application of MI is feature selection, which has been the focus of many recent dysphonic speech studies [
35,
36,
37]. In these, phonetic recordings were analysed to obtain all potential features, from which the most suitable ones were selected. There are several advantages to computing NMI directly from the raw phonetic sound recordings that address some of the limitations of existing acoustic features. While a lot of speech features require accurate detection of the fundamental frequency or pitch of the speech signal [
44], by applying the calculation directly to the time series, NMI provides quantification of the dependency between signals.
In this study, Hypothesis 1 was verified using FD, and Hypothesis 2 with NMI. This paper is organized as follows:
Section 2 provides a brief introduction to FD, NMI, the experimental protocol and the data analysis methods. Results are presented in
Section 3, with a discussion provided in
Section 4. Finally,
Section 5 concludes the paper.
4. Discussion
Human speech transmits information-rich signals [
32] that are determined by habitual voice production combined with contextual factors relating to communication. In PD, depletion of dopamine in the basal ganglia causes the complex motor deficit of bradykinesia—reduced speed, reduced amplitude, loss of rhythm and loss of ability to sustain repetitive movement. Habitual actions such as speech and gait, which are associated with higher degrees of automaticity, are particularly affected [
72,
73]. It has been shown that over 80% of PD patients suffer from dysarthria [
74,
75]. This has been attributed to reduced respiratory power and to defects in the control of articulatory musculature [
76]. Their voice becomes breathier, more monotonous and softer. The degradation of the voice production mechanism in PD patients leads to the generation of aperiodic and irregular voice characteristics, which has been identified with the help of acoustic analysis [
56,
74,
75]. However, it is often difficult to observe these changes in the early stages of the disease with features extracted from phonation tasks [
77,
78].
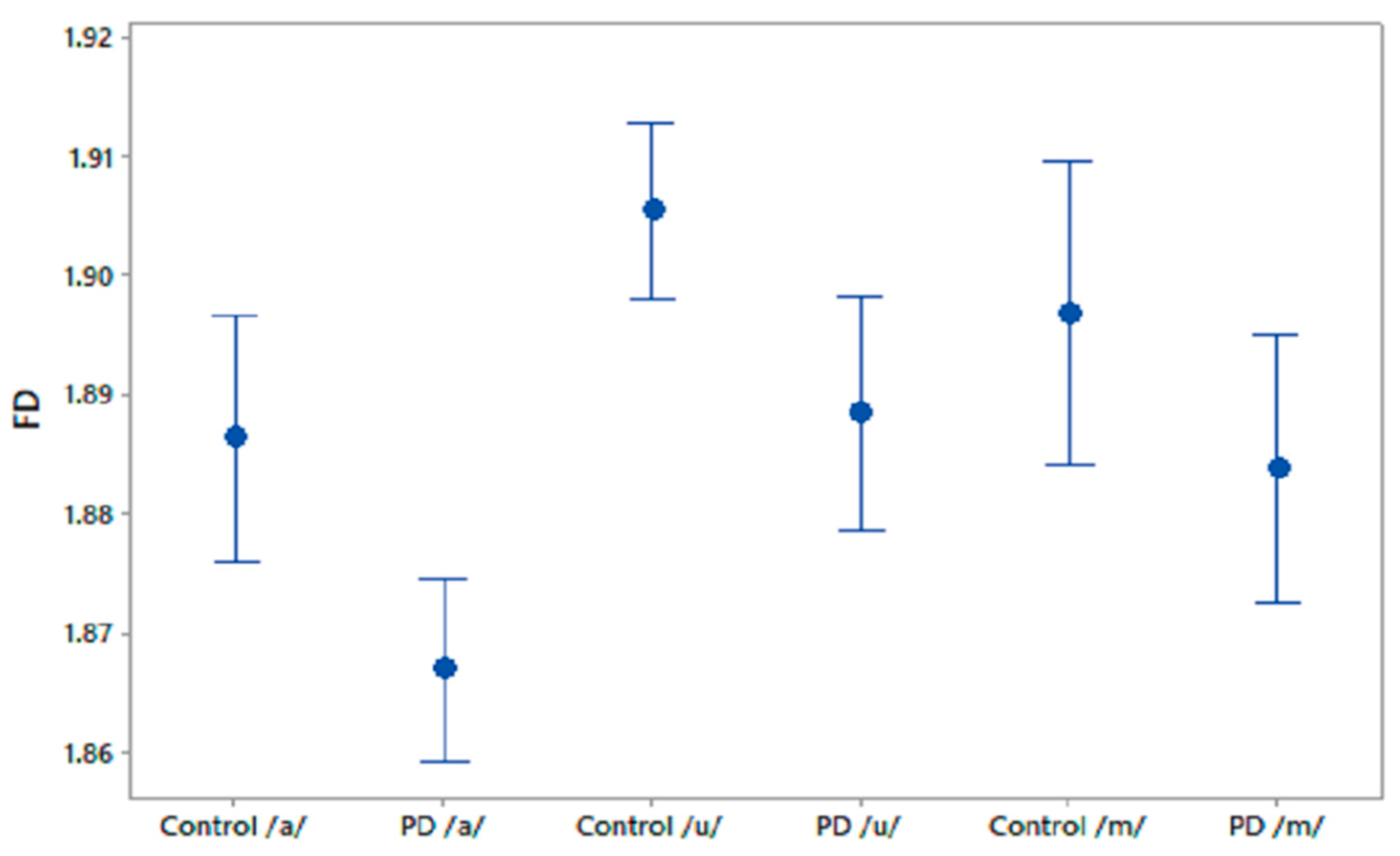
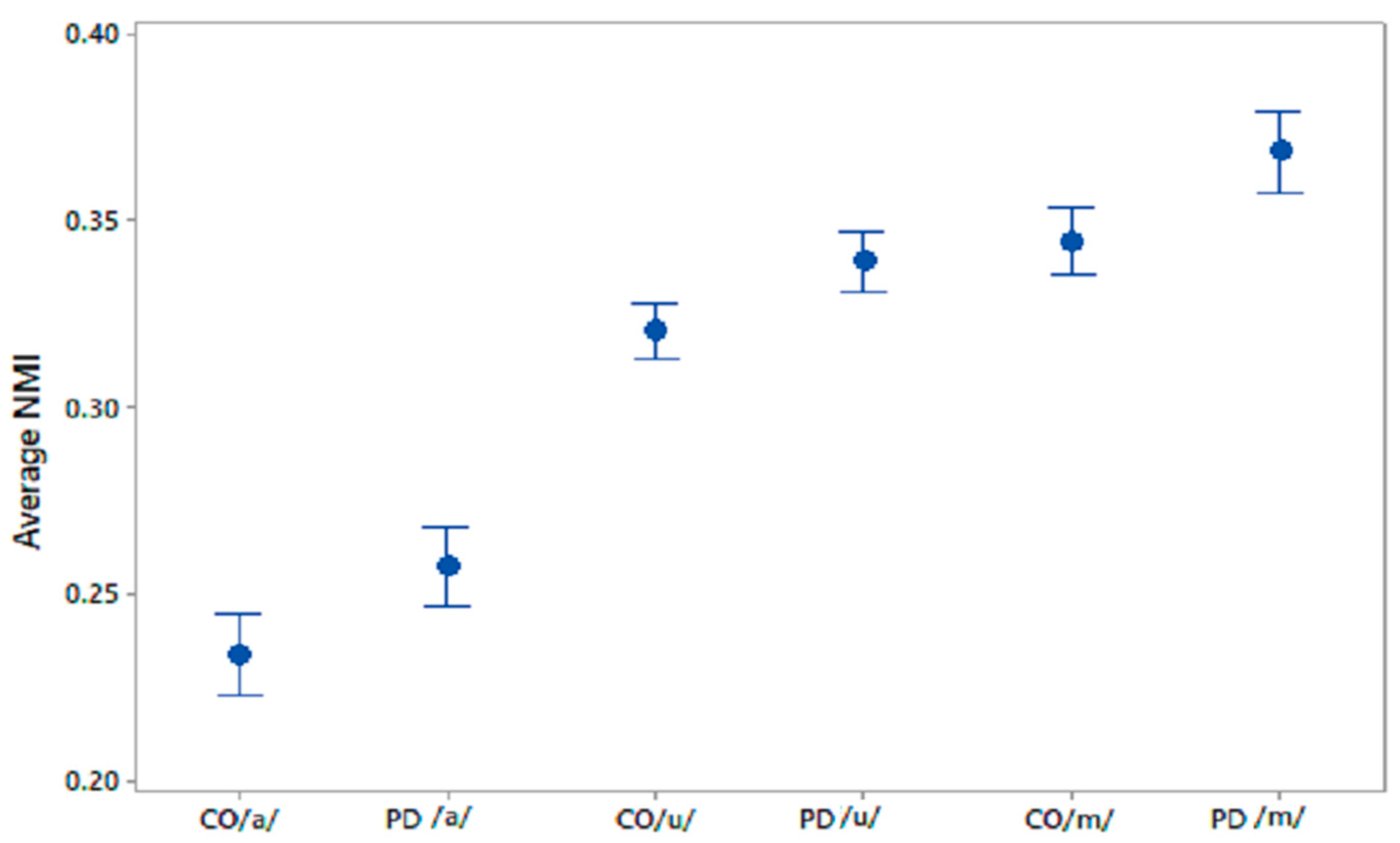
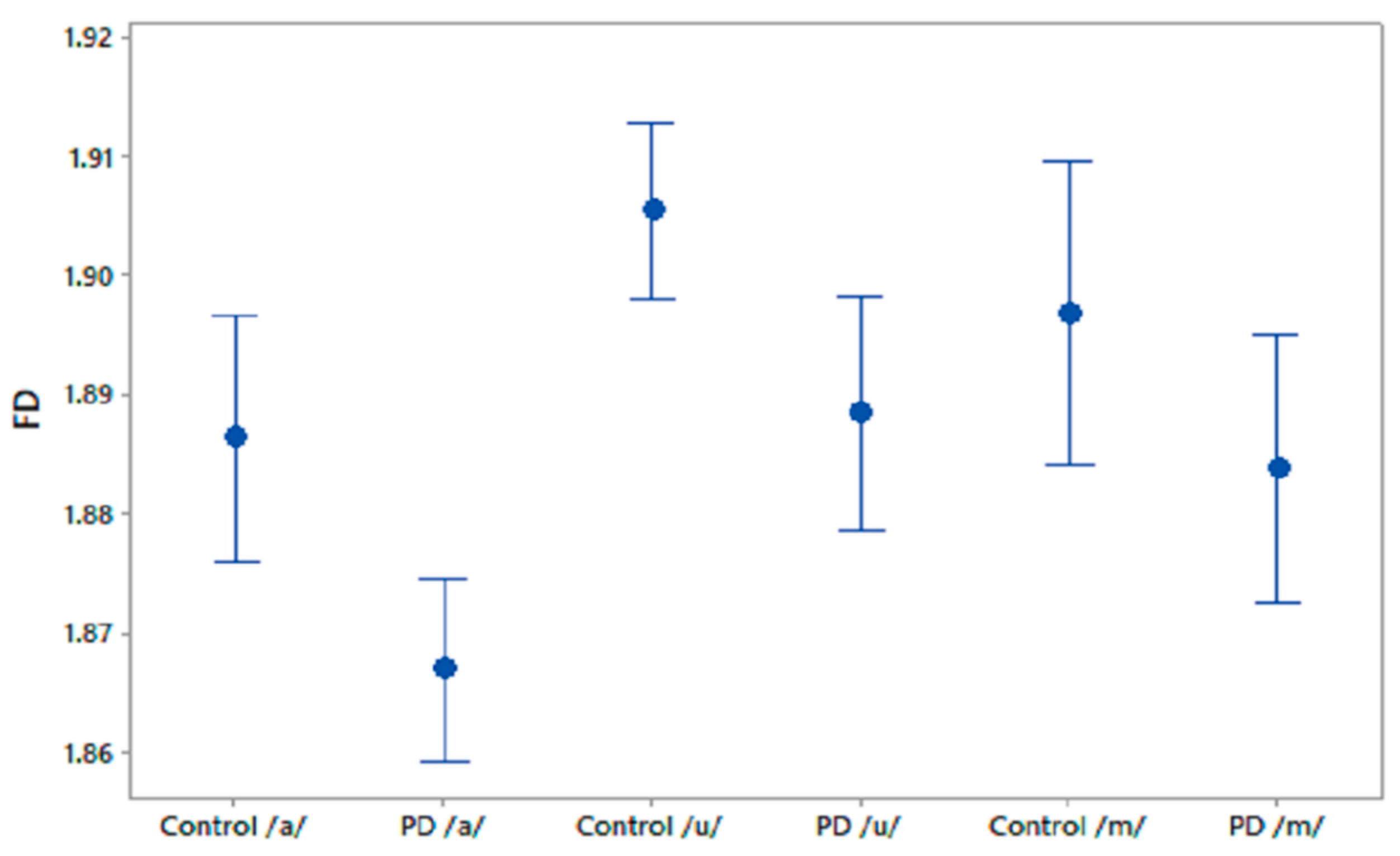
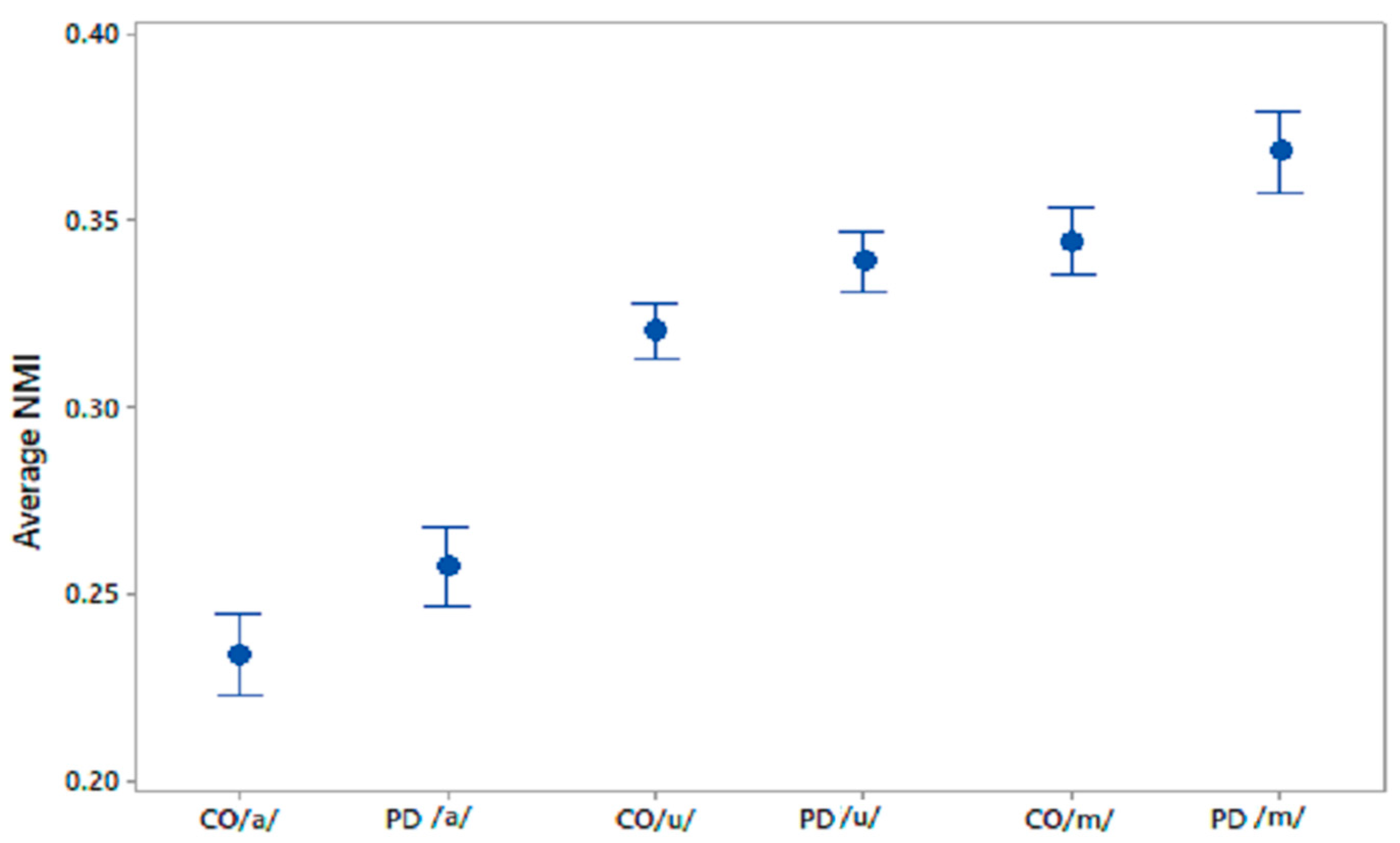
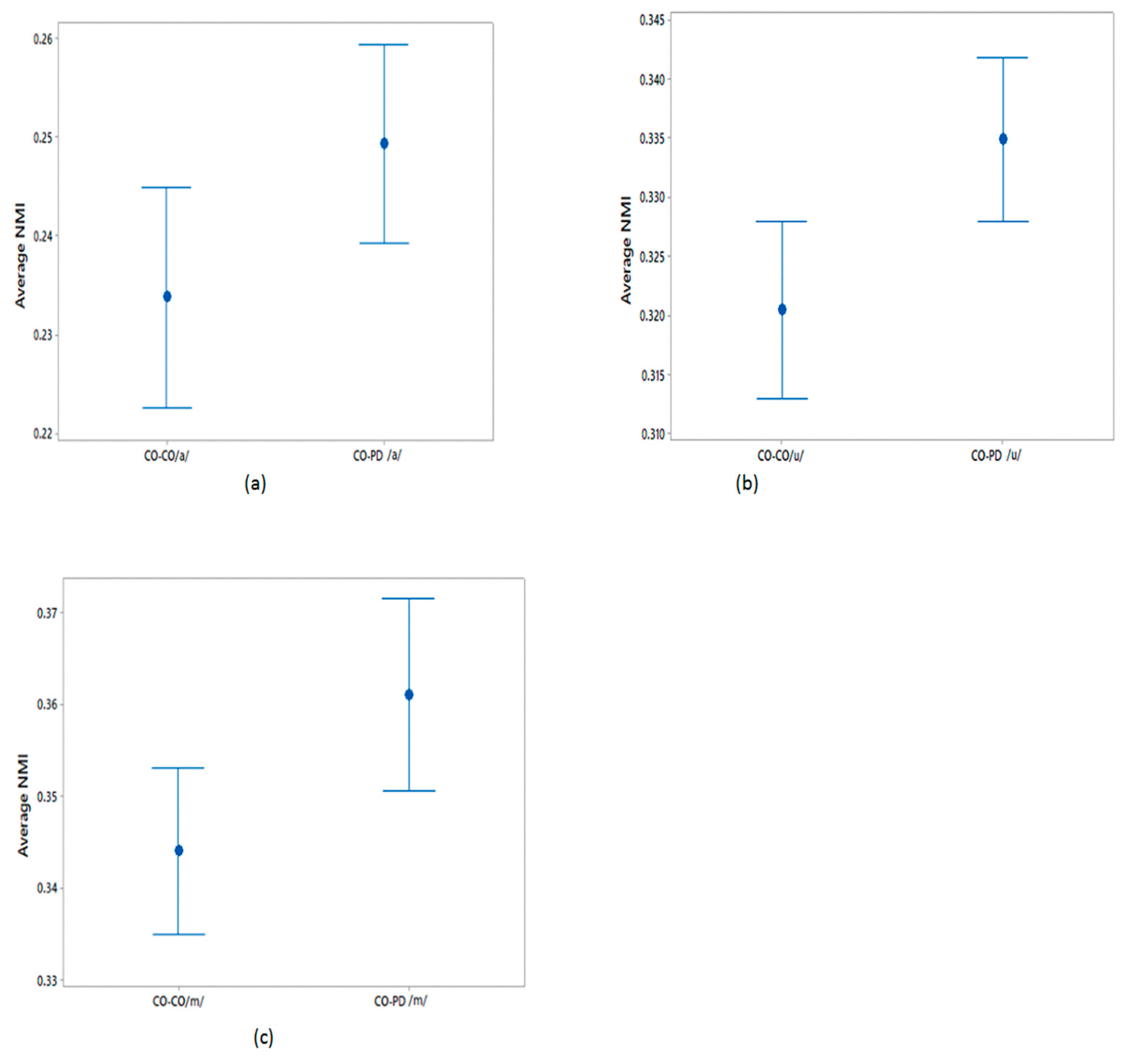
This study has investigated the complexity in voices of PD patients using FD. We found a reduced complexity in phonetic sound recordings compared with CO subjects. Furthermore, from the computation of NMI we observed a significantly higher NMI within the PD group compared with the CO group. It was also found that CO–PD had higher NMI compared with CO–CO. The increase in the average NMI associated with PD can be explained by a reduced richness of voice. One explanation is that PD patients have less ability to modify their speech articulators. In comparison, there is a richness of content in healthy voices due to the ability of the person to continuously manipulate the spectrum of their speech, and to respond to auditory feedback. Thus, healthy people have a larger range of vocal parameters, which results in more variation between the signals. Hence, the lower observed proportion of shared information within the CO group. Effects of PD on the vocal apparatus [
79] lead to a restricted voice production mechanism, with less richness than in healthy individuals [
27]. PD voices can be considered to contain limited temporal and spectral information with respect to CO voices. This limitation in turn leads to the PD voices having higher similarity with other voices compared with CO–CO. Thus, the NMI of all voices, when paired with PD patients, would be increased. Lower NMI would indicate CO, while higher NMI would indicate PD. The threshold may be dependent on the local population.
The use of FD and NMI has shown higher AUC and more true positives. Another major advantage of using this method is the simplicity of the analysis. A number of speech features reported in other studies for the screening of PD [
48,
50,
80] use measures of linear and nonlinear acoustic features that require the accurate detection of a fundamental frequency and reconstruction of the voice signal. FD and NMI do not require any such assessment and are more suited to automatic analysis. Another potential advantage, though not explored here, is that these measurements could, through training in a given population, overcome the confounding effects of accents and culture.
The novelty of this study is that it has found a reduction in FD in the voice of PD patients, showing the reduction in the richness of their speech and an increase in mutual information. It has also been shown that FD and NMI can differentiate PD speech from age-matched controls, even before clinically detectable speech impairment. This method could therefore be applied to early diagnosis as well as the clinical monitoring of PD patients. This study has also observed that /m/ is the best phoneme for differentiating between the two groups, followed by /u/, while /a/ shows the least sensitivity (
Table 7). Another strength of our study is that it was able to show the PD vs. CO difference, without gender separation, thereby reducing the complexity of the potential applications of the method.
A study limitation is the relatively small number of participants. While this number is comparable to other similar studies, the sample is insufficient to evaluate differences caused by gender and ethnicity. Thus, while this method may be suitable for identifying people with early-stage dysarthria, it is not specific to the underlying disease. Another limitation of this work is that it has only been trialled for a single suburban cohort near Melbourne, Australia. To realise the full potential of this method, it is important to train and test this for different regions of the world, and for different group sizes.

 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}