How Much g Is in the Distractor? Re-Thinking Item-Analysis of Multiple-Choice Items

 , , and
, , and
Abstract
1. Introduction
1.1. Distractor Analysis as Part of Traditional Analysis of Multiple-Choice Items
1.1.1. Distractor Choice Frequency
1.1.2. The Point-Biserial Correlation
1.1.3. Trace Line Plots and χ2 Statistics
1.1.4. Rising Selection Ratios
1.2. Effect Sizes for the Detection of Discriminatory Distractors
1.2.1. Cohen’s ω Based on Ability Groups and Distractor Choice
1.2.2. Canonical Correlation Based on Ability and Distractor Choice
1.3. Aim of the Current Study
2. Simulation Study
2.1. Method
2.1.1. Data Generating Model
2.1.2. Facets of the Simulation Design
- Sample size (three levels): N = 100; N = 200; and N = 500.
- Number of items (three levels): I = 10; I = 20; and I = 50.
- Number of distractors (two levels): D = 3; and D = 7.
- 2-PL difficulty (three levels): Moderate [βi ~ U(−0.15, 0.15)]; difficult [βi ~ U(−1.15, −0.85)]; and very difficult [βi ~ U(−2.25, −1.85)].
- 2-PL discrimination (three levels): Low [αi ~ U(0.25, 0.55)]; moderate[αi ~ U(0.85, 1.15)]; and high [αi ~ U(1.60, 1.90)].
- NRM discrimination parameters (four levels) are depicted in Table 2.
- 7.
- Effect size threshold (three levels): Small: Effect size > 0.10; moderate: Effect size > 0.30; and large: Effect size > 0.50.
- 8.
- Type of effect size (three levels): Cohen’s ω based on two ability groups; Cohen’s ω based on five ability groups; and the canonical correlation coefficient.
2.1.3. Dependent Variables
2.1.4. Simulation Setup
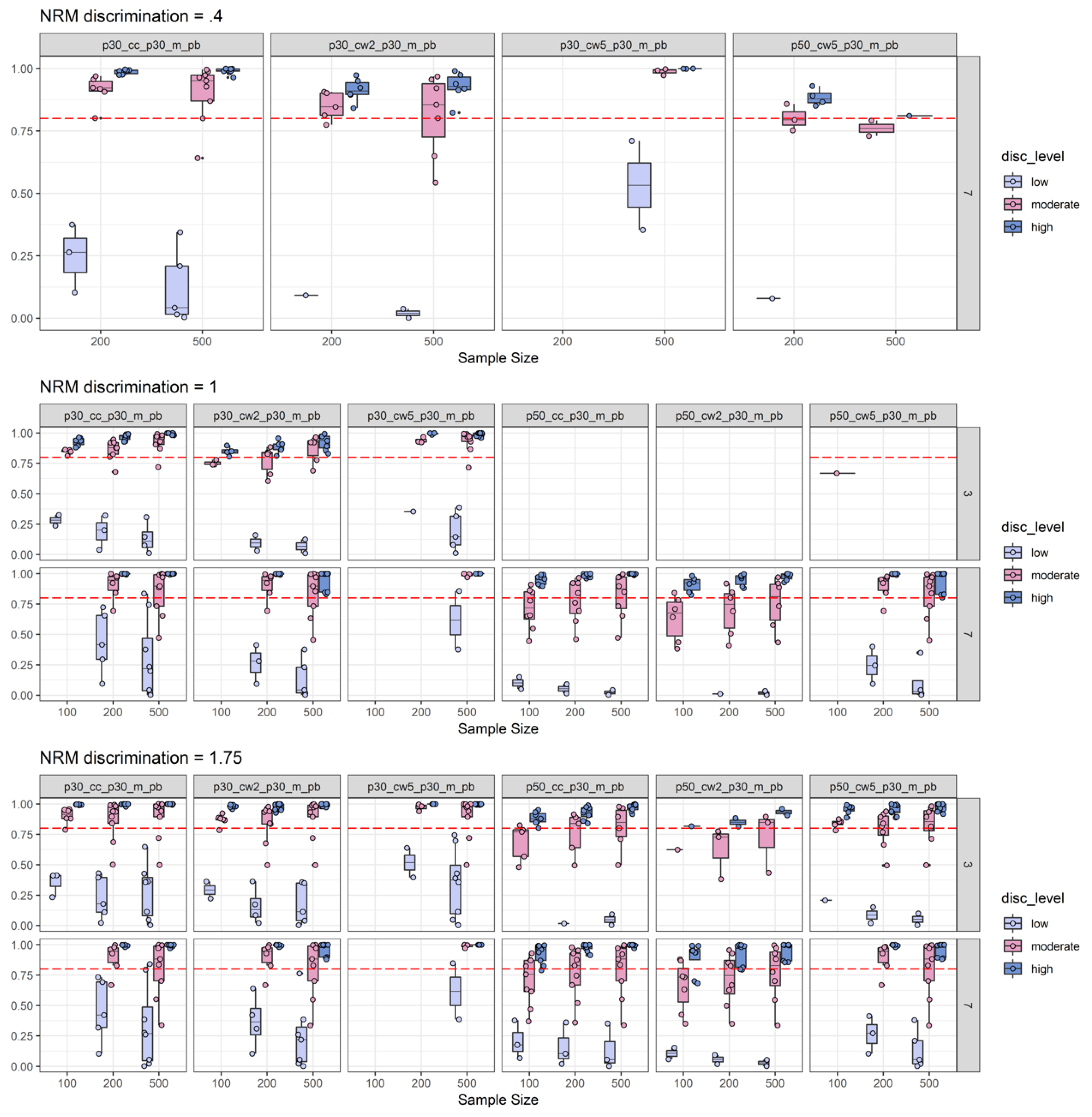
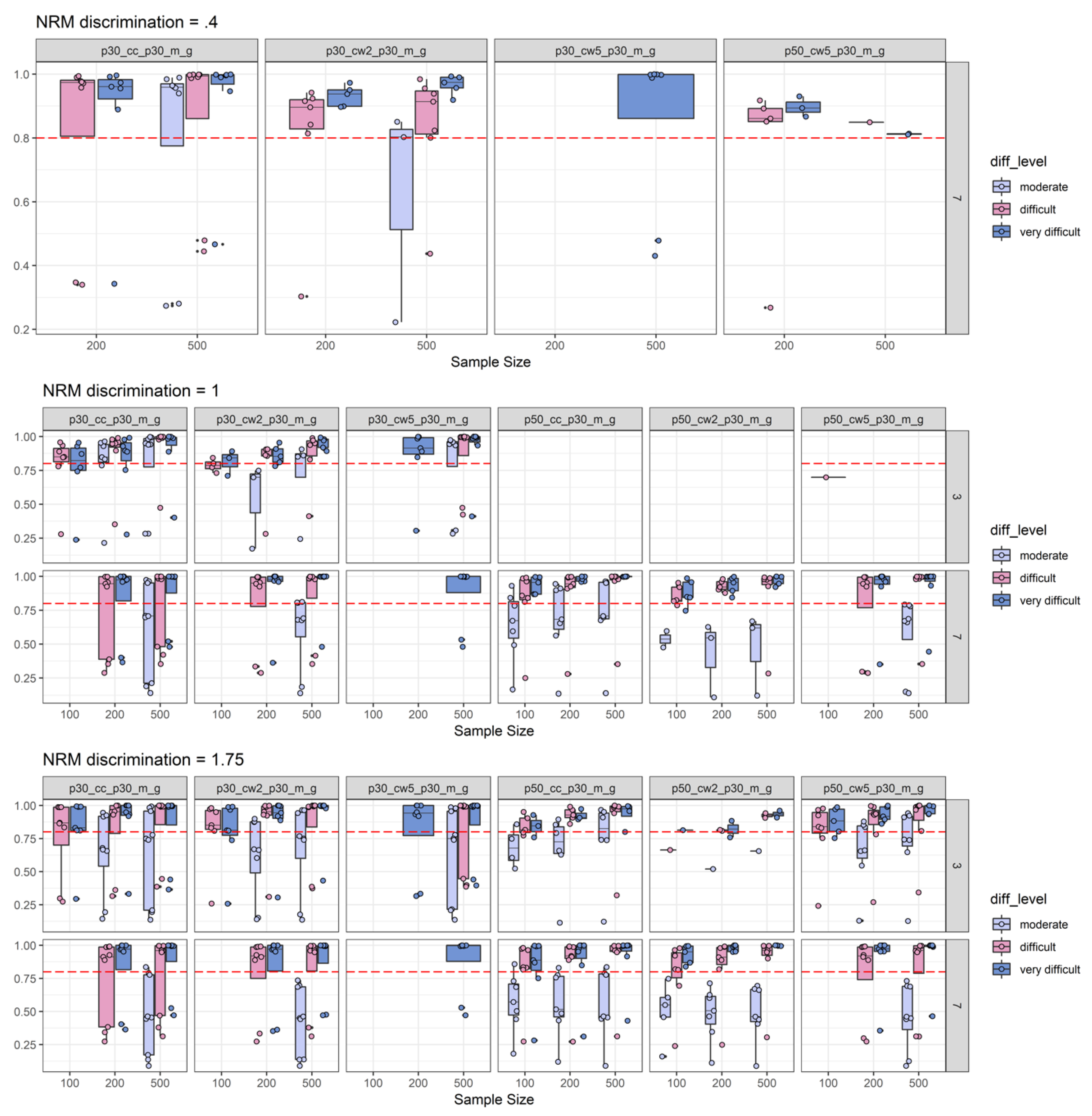
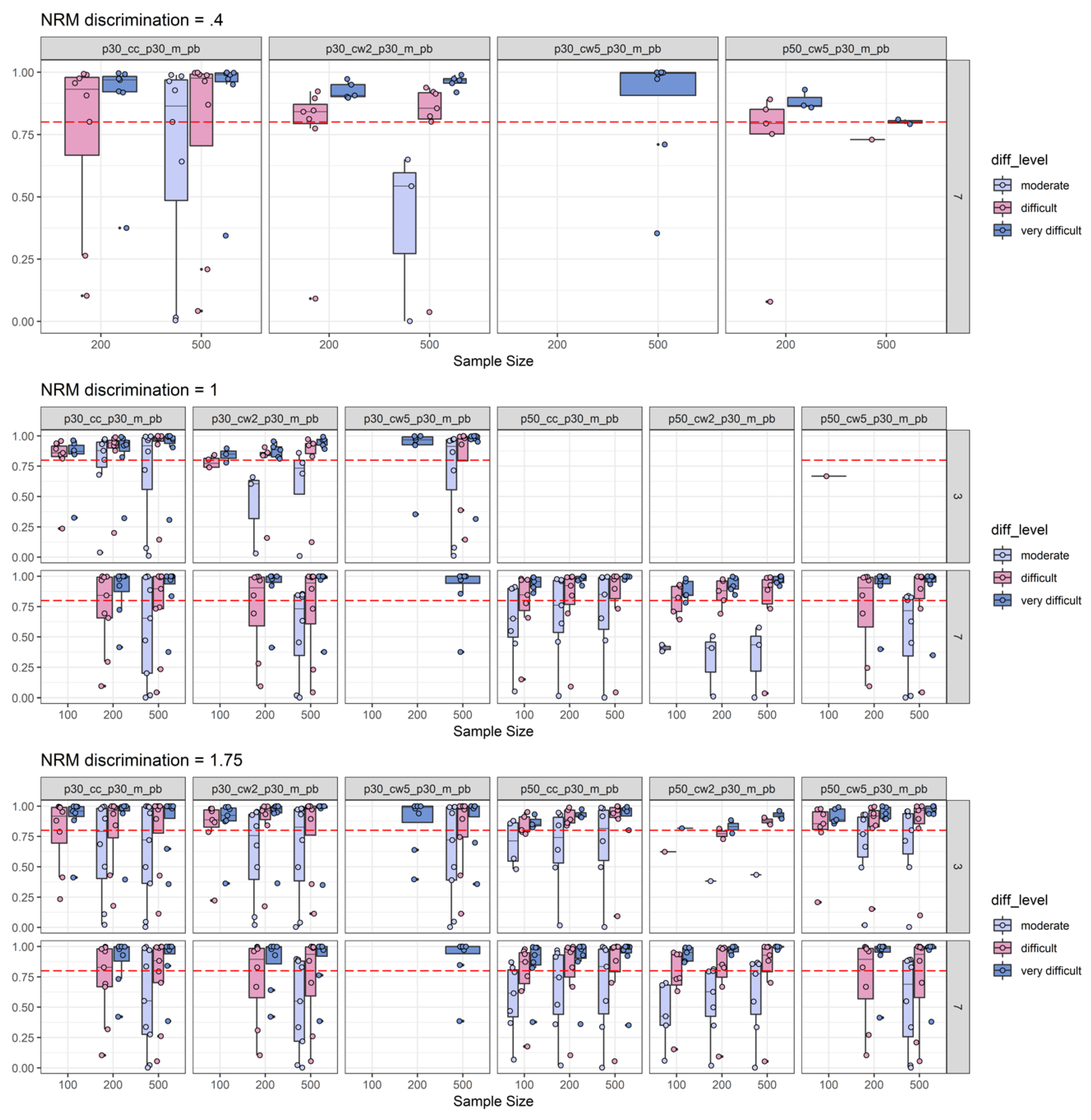
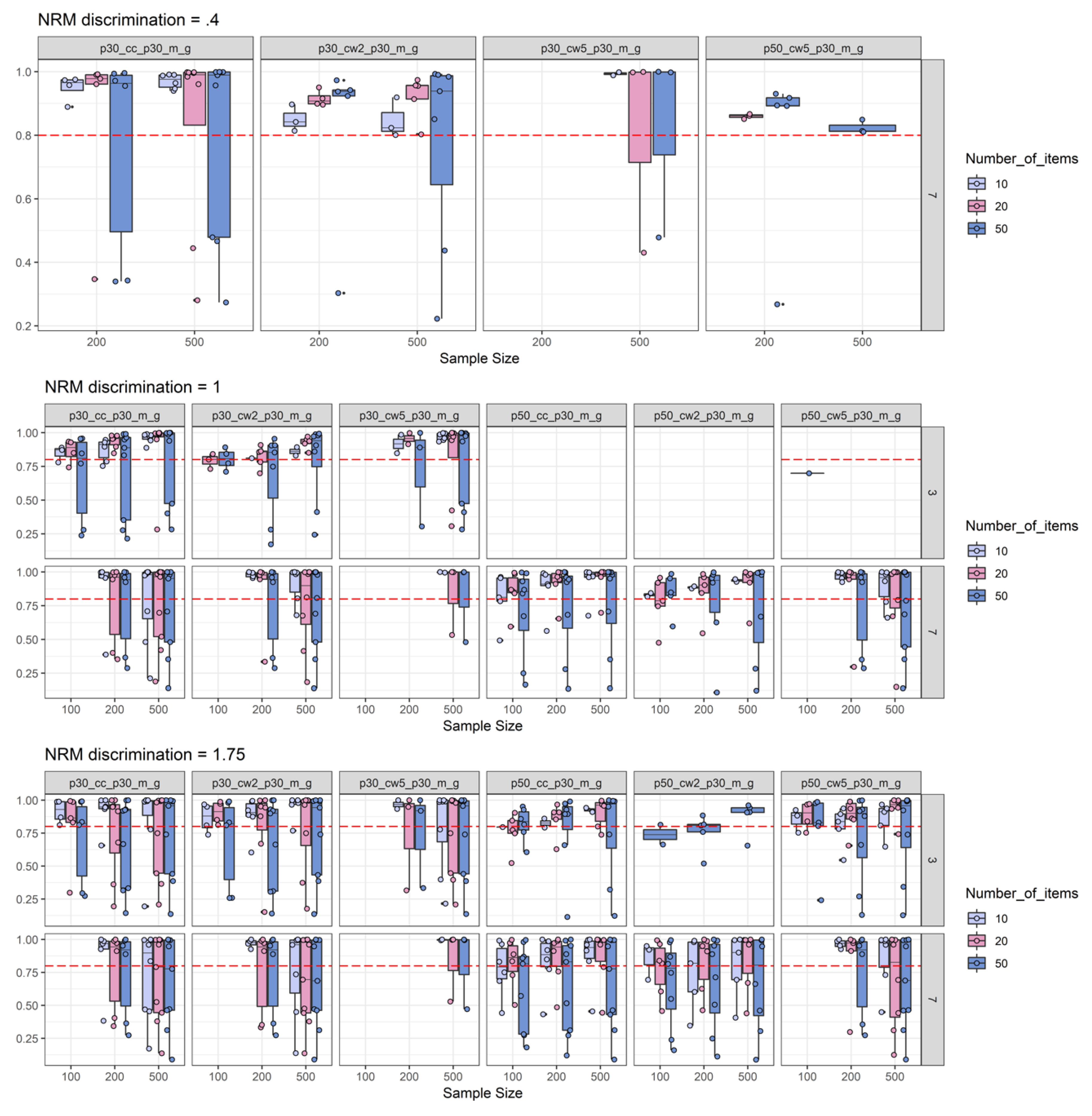
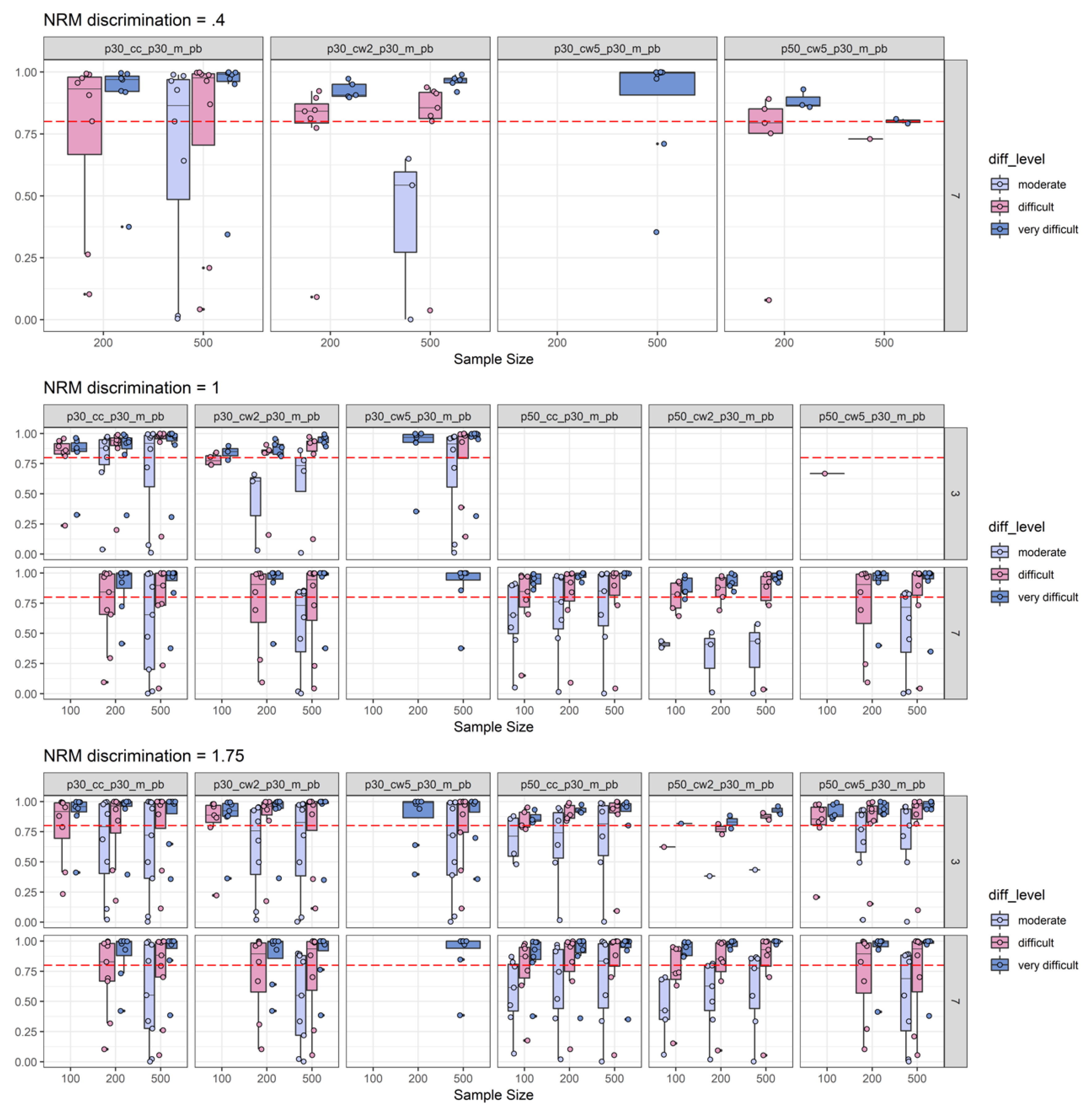
2.2. Simulation Results
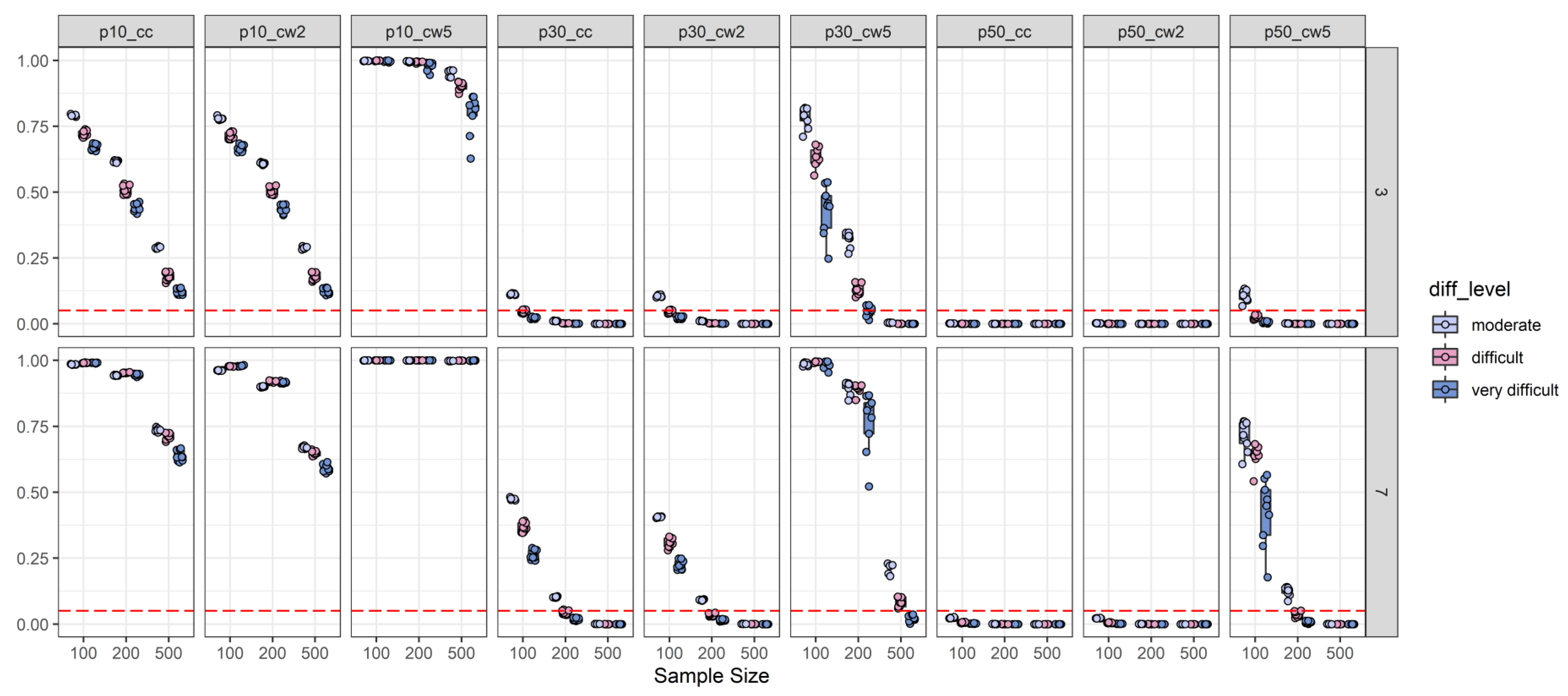
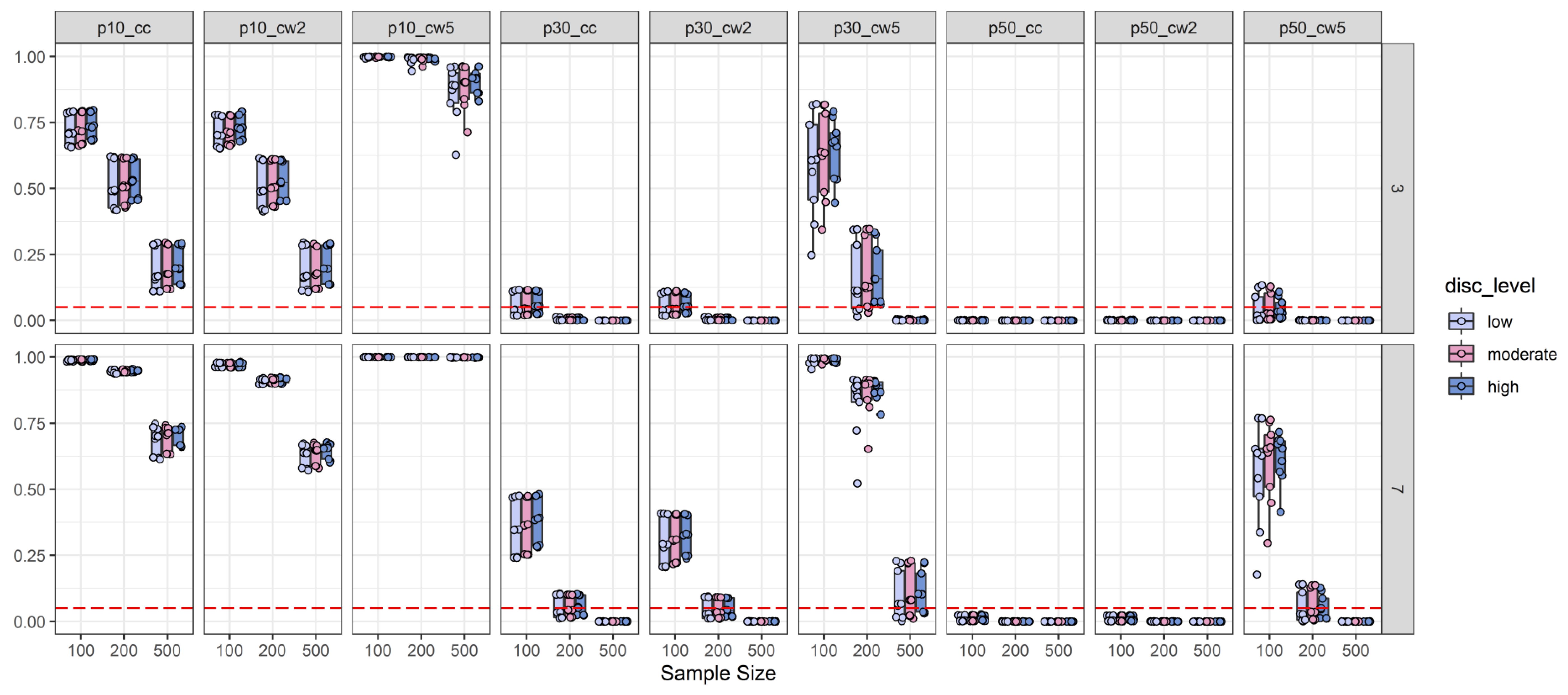
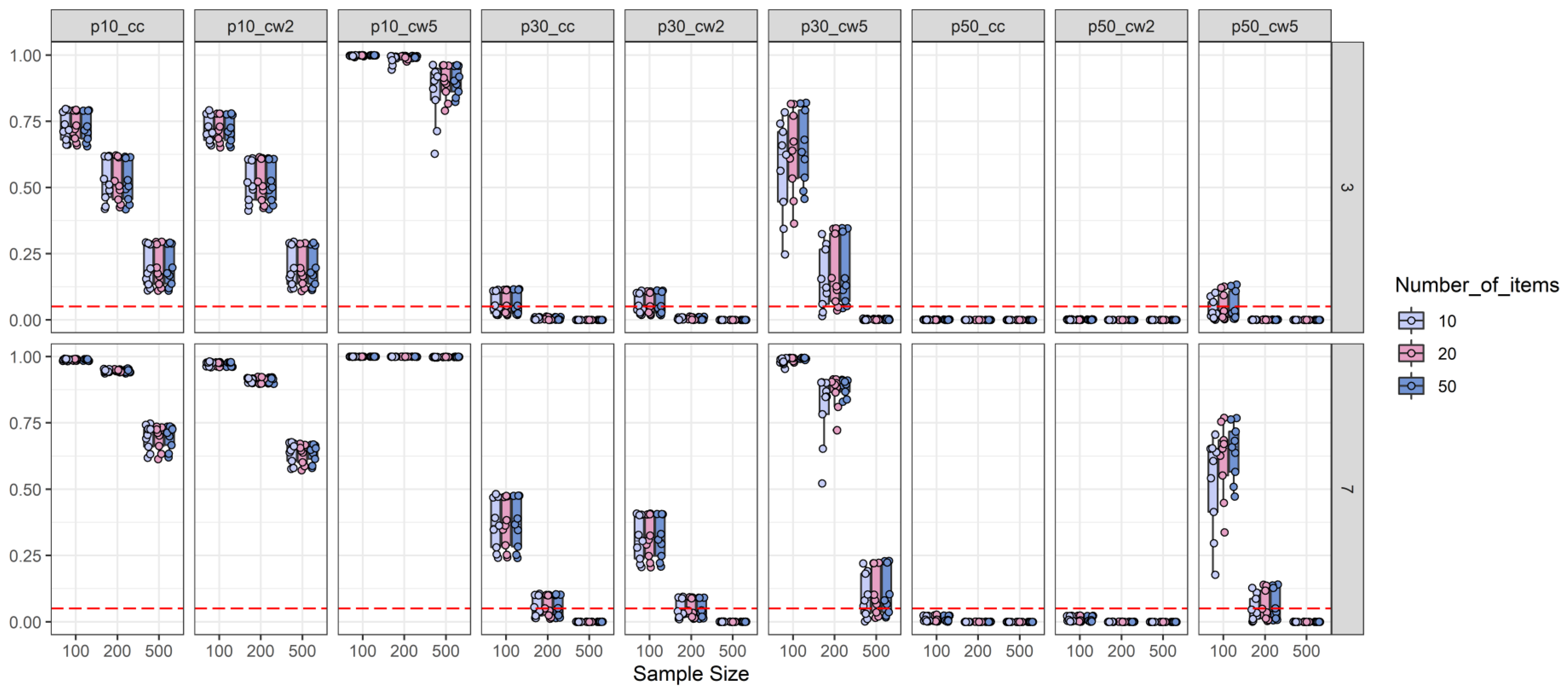
2.2.1. Type-I-Error Results
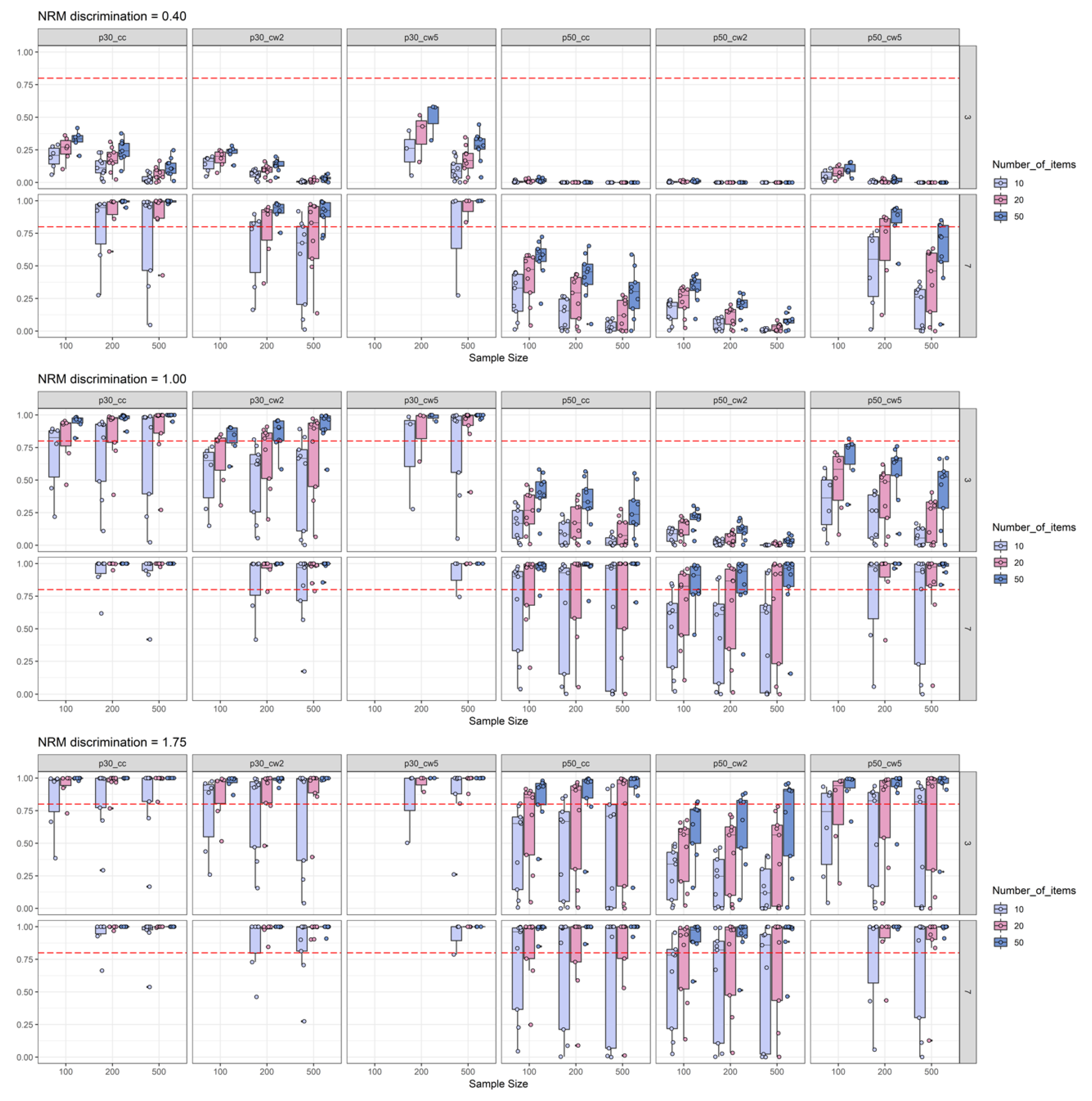
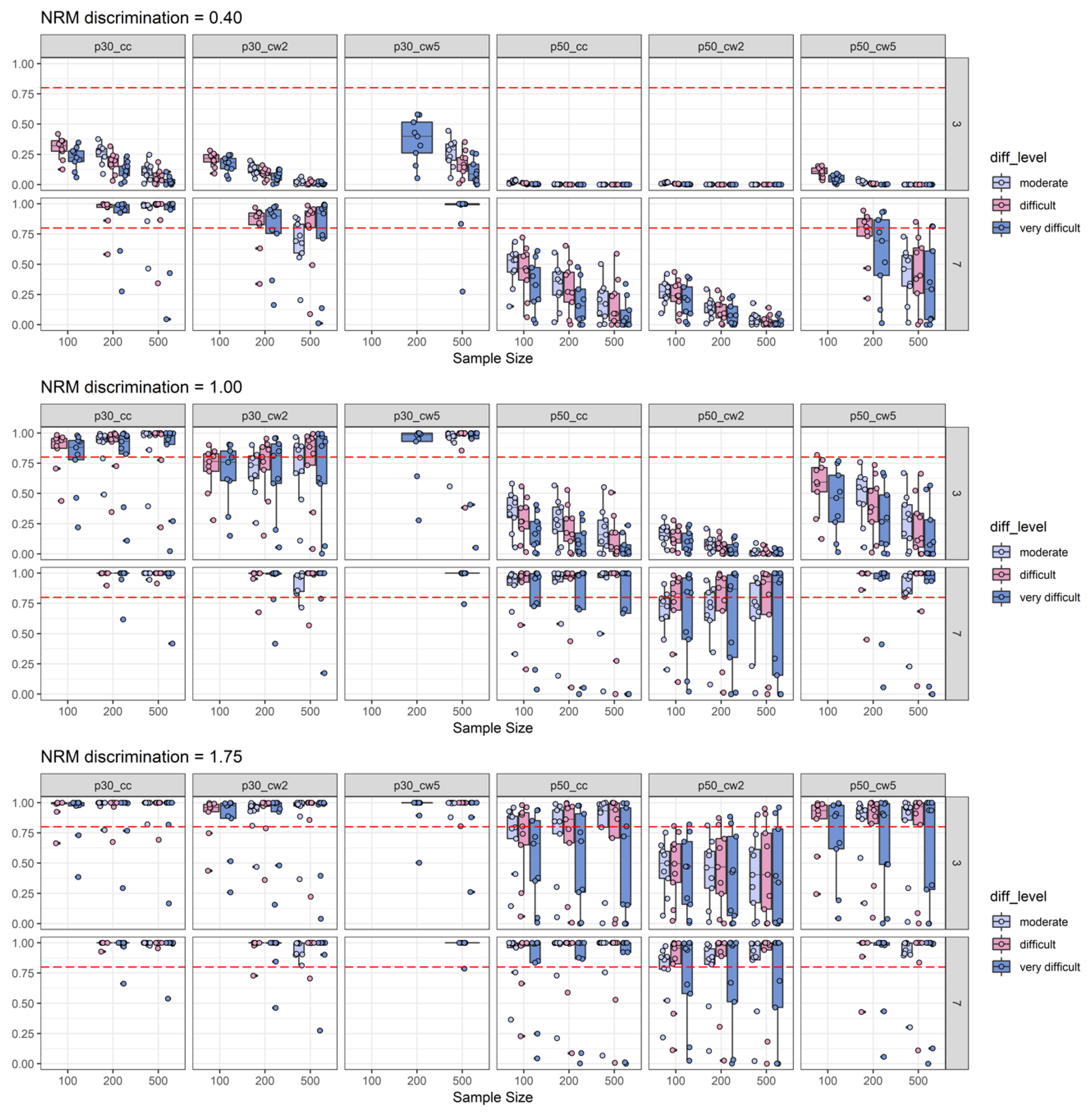
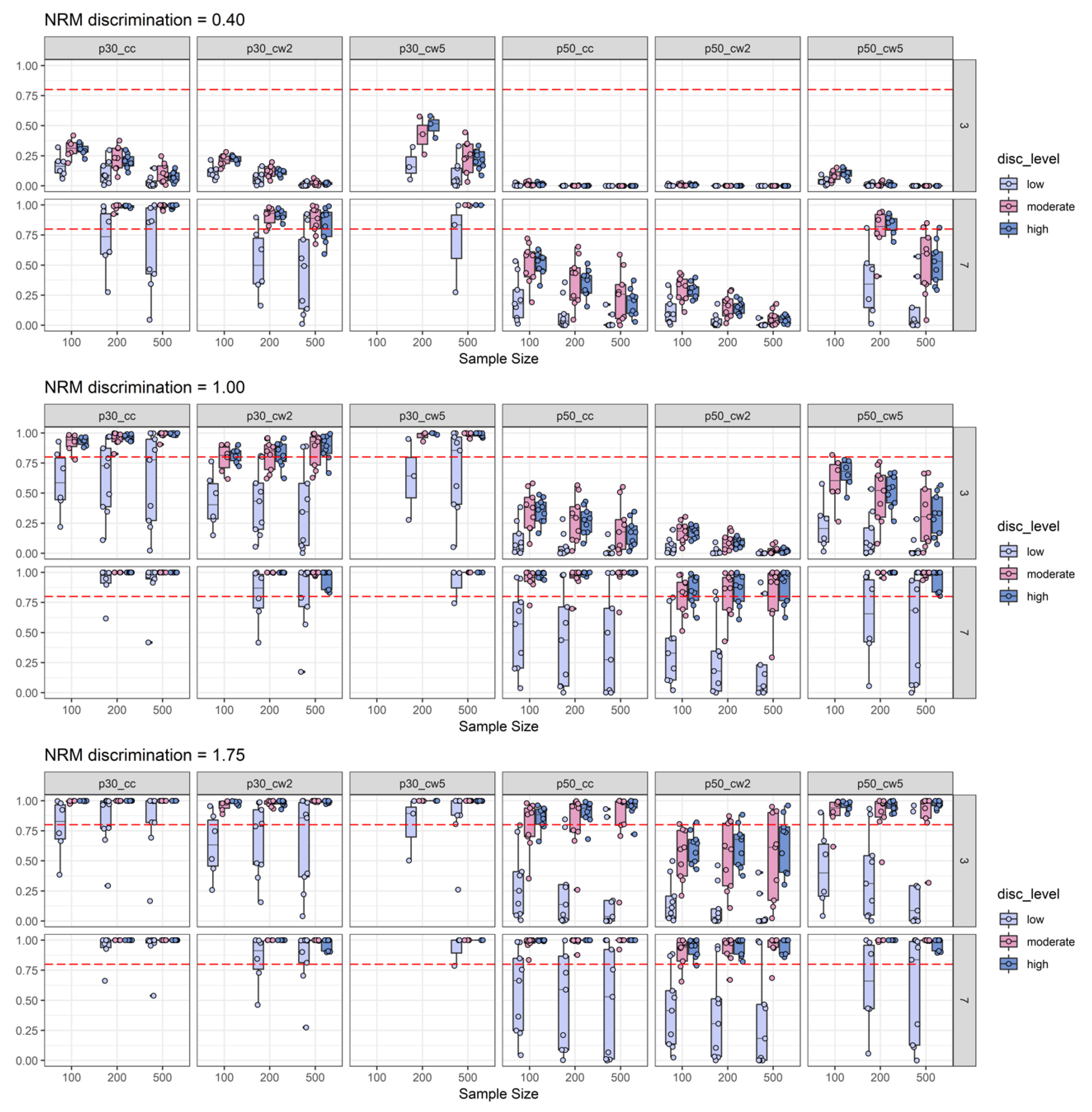
2.2.2. Power Results
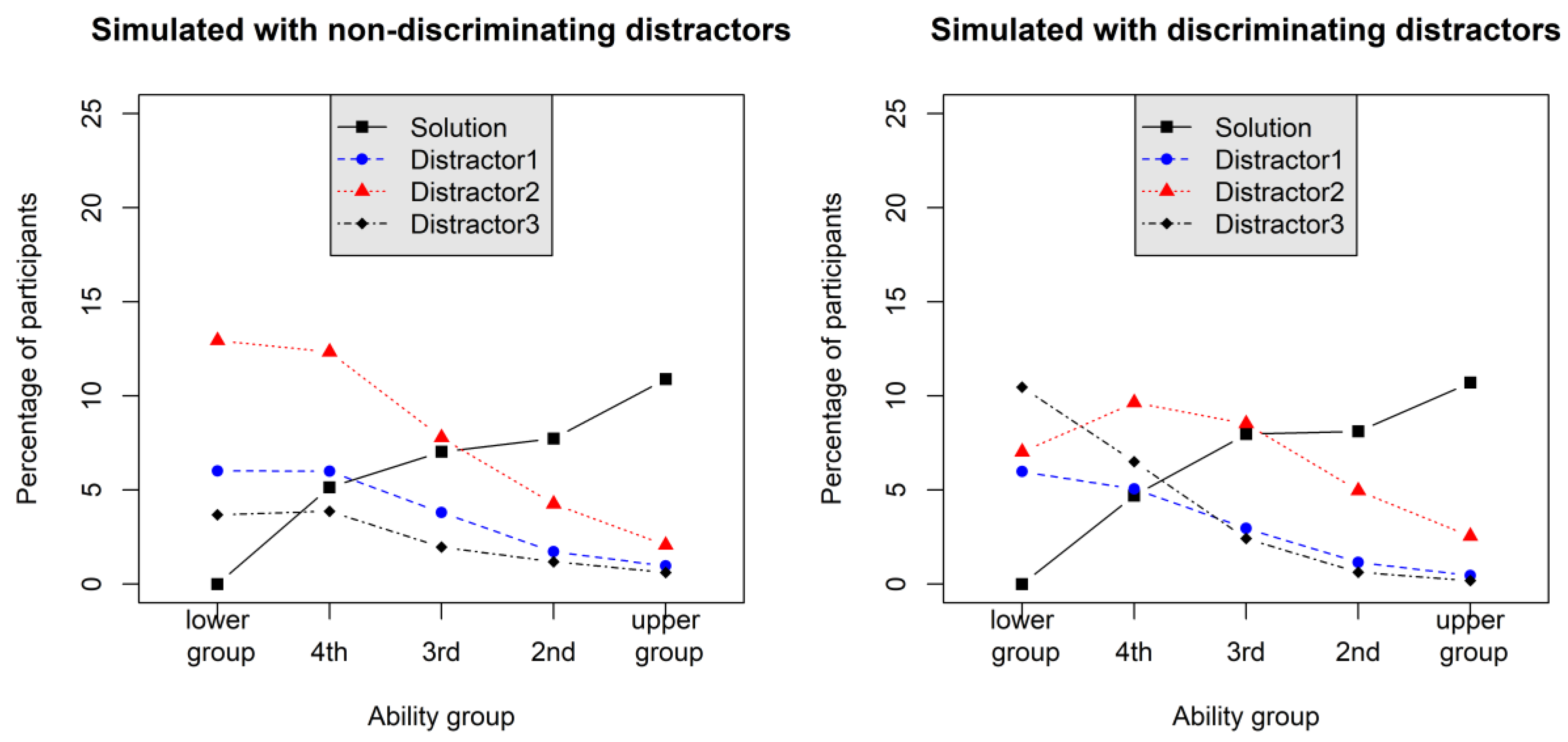
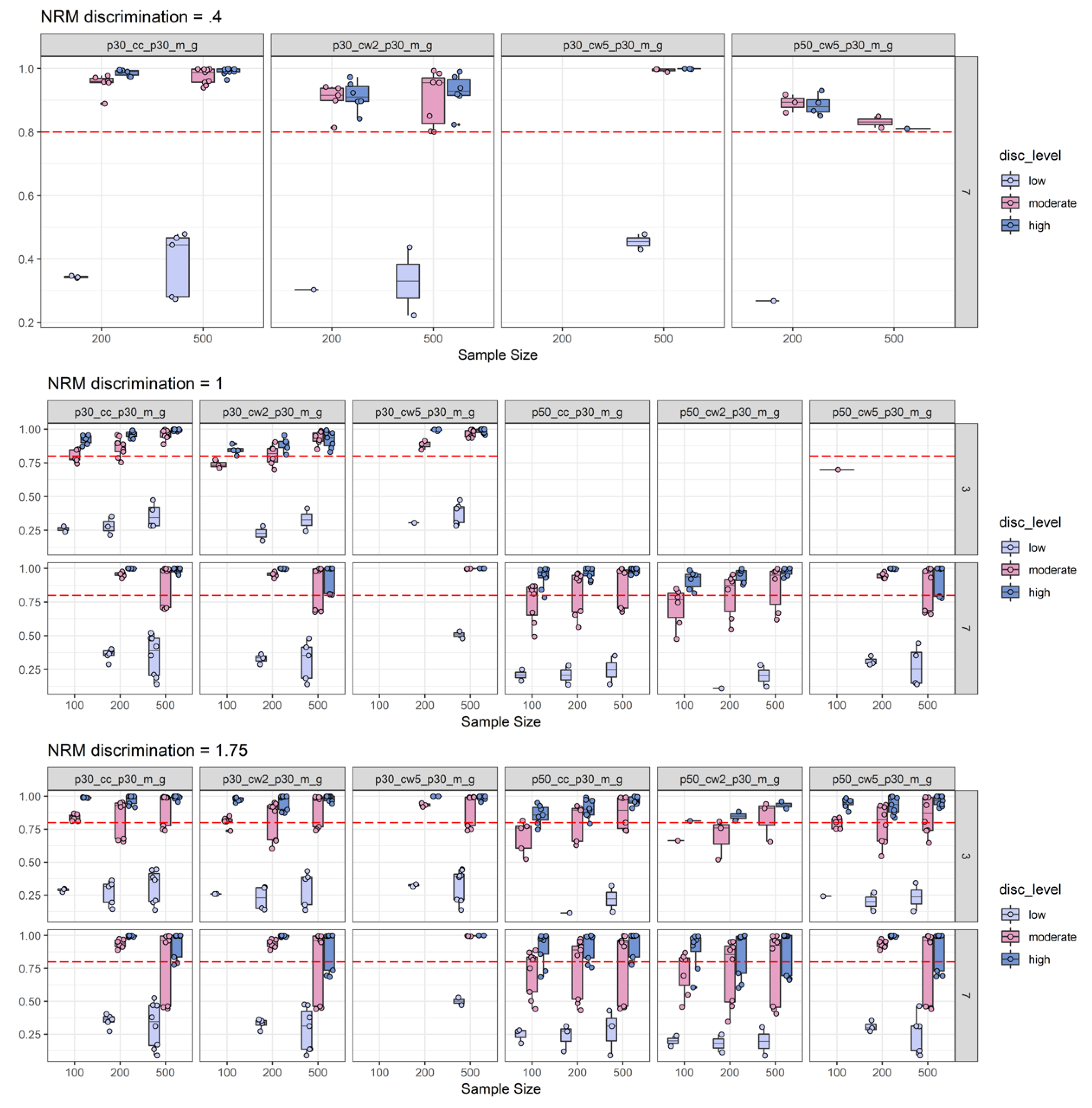
2.2.3. Empirical Substance Examination
2.2.4. Discussion of Simulation Study Findings
3. Empirical Illustration
3.1. Method
3.1.1. Dataset
3.1.2. Analytical Strategy
3.2. Results and Discussion
4. Overall Discussion
Limitations
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A


Appendix B






Appendix C
### load data # ### downloaded from # https://data.mendeley.com/datasets/h3yhs5gy3w/1 dataset <- read.csv(“dataset.csv”, stringsAsFactors=FALSE) ### install required packages (if needed) ### remove # to make this code run #install.packages(c(“psych”,”mirt”)) ### get results function ### includes also the effect size measures that were ### studied in the simulation and also more useful ### descriptive statistics get_results <- function(data,keys=“sim”){ ### keys for scoring if(length(keys)==1){keys <- rep(0,ncol(data))}else{ keys <- keys } ### quantiles for two ability groups p2 <- .5 ### quantiles for five ability groups p5 <- c(.2,.4,.6,.8) ### load psych library require(psych) ### score all items scored <- score.multiple.choice(key=keys,data=data,score=F) ### ability groups abil2.c <- rep(0,nrow(scored)) for(i in 1:length(p2)){ if(i < length(p2)){ abil2.c[rowSums(scored)>quantile(rowSums(scored),p=p2[i]) & rowSums(scored)<=quantile(rowSums(scored),p=p2[i+1])] <- i }else{abil2.c[rowSums(scored)>quantile(rowSums(scored),p=p2[i])] <- i } } ### ability groups abil5.c <- rep(0,nrow(scored)) for(i in 1:length(p5)){ if(i < length(p5)){ abil5.c[rowSums(scored)>quantile(rowSums(scored),p=p5[i]) & rowSums(scored)<=quantile(rowSums(scored),p=p5[i+1])] <- i }else{abil5.c[rowSums(scored)>quantile(rowSums(scored),p=p5[i])] <- i } } ### list distractors with relative frequency < .05 rf05 <- list() for(j in 1:ncol(data)){ rf05[[j]] <- table(data[,j][data[,j]!=keys[j]])/length(data[,j])<.05 } ### general Cohen’s w, 2 ability groups chi_g2 <- list() cw_g2 <- list() tab_c2_l <- list() zero_columns2 <- list() for(k in 1:ncol(data)){ tab_c2 <- matrix(table(data[,k][data[,k]!=keys[k]],abil2.c[data[,k]!=keys[k]])[!rf05[[k]],],ncol=length(unique(abil2.c[data[,k]!=keys[k]]))) zero_columns2[[k]] <- colSums(tab_c2)==0 tab_c2 <- tab_c2[,colSums(tab_c2)>0] tab_c2_l[[k]]<-tab_c2 if(sum(!rf05[[k]])>=2){chi_g2[[k]] <- chisq.test(tab_c2)}else{ chi_g2[[k]] <- NA } ### Cohen’s w - general if(sum(!rf05[[k]])>=2){cw_g2[[k]] <- sqrt(sum(((chi_g2[[k]]$observed/sum(tab_c2)-chi_g2[[k]]$expected/sum(tab_c2))^2)/(chi_g2[[k]]$expected/sum(tab_c2))))}else{ cw_g2[[k]] <- NA } } ### general Cohen’s w, 5 ability groups chi_g5 <- list() cw_g5 <- list() tab_c5_l <- list() zero_columns5 <- list() for(k in 1:ncol(data)){ tab_c5 <- matrix(table(data[,k][data[,k]!=keys[k]],abil5.c[data[,k]!=keys[k]])[!rf05[[k]],],ncol=length(unique(abil5.c[data[,k]!=keys[k]]))) zero_columns5[[k]] <- colSums(tab_c5)==0 tab_c5 <- tab_c5[,colSums(tab_c5)>0] tab_c5_l[[k]]<-tab_c5 if(sum(!rf05[[k]])>=2){chi_g5[[k]] <- chisq.test(tab_c5)}else{ chi_g5[[k]] <- NA } ### Cohen’s w - general if(sum(!rf05[[k]])>=2){cw_g5[[k]] <- sqrt(sum(((chi_g5[[k]]$observed/sum(tab_c5)-chi_g5[[k]]$expected/sum(tab_c5))^2)/(chi_g5[[k]]$expected/sum(tab_c5))))}else{ cw_g5[[k]] <- NA } } ### canonical correlation can_cor <- list() ncol_mmat <- list() for(k in 1:ncol(data)){ ncol_mmat[[k]] <- if(sum(!rf05[[k]])>=2){ncol(model.matrix(rowSums(scored[scored[,k]==0,-1])~-1+factor(data[,k][scored[,k]==0]))[,!rf05[[k]]])}else{ NA } can_cor[[k]] <- if(sum(!rf05[[k]])>=2){cancor(rowSums(scored[scored[,k]==0,-k]),model.matrix(rowSums(scored[scored[,k]==0,-1])~-1+factor(data[,k][scored[,k]==0]))[,!rf05[[k]]])$cor}else{ NA } } ### point-biserial coefficient PB_DC pb_dc <- list() ### Goodman-Kruskal gamma gkg <- list() gkg_tab <- list() ### start loop for(v in 1:ncol(data)){ pb_dc_d <- list() gkg_d <- list() gkg_tab_d <- list() ### function to calculate ### Goodman-Kruskal gamma ### taken from here: ### https://stat.ethz.ch/pipermail/r-help/2003-March/030835.html goodman <- function(x,y){ Rx <- outer(x,x,function(u,v) sign(u-v)) Ry <- outer(y,y,function(u,v) sign(u-v)) S1 <- Rx*Ry return(sum(S1)/sum(abs(S1)))} ### start loop non_key <- unique(data[,v])[!unique(data[,v])%in%keys[v]] for(w in non_key){ MDC <- mean(rowSums(scored)[data[,v]%in%c(keys[v],w)]) SDC <- sd(rowSums(scored)[data[,v]%in%c(keys[v],w)]) MD <- mean(rowSums(scored)[data[,v]%in%w]) PD <- mean(data[,v]%in%w) PC <- mean(data[,v]%in%keys[v]) ### r-PB_D ### r-PB_DC pb_dc_d[[w]] <- (MD-MDC)/SDC*sqrt(PD/PC) ### Goodman-Kruskal gamma score_other_items <- factor(rowSums(scored[,-v])) tab_gkg_d <- table(data[data[,v]%in%c(keys[v],w),v],score_other_items[data[,v]%in%c(keys[v],w)]) ### exclude ability levels with zero frequency tab_gkg_d <- tab_gkg_d[,colSums(tab_gkg_d)>0] gkg_d[[w]] <- goodman(as.numeric(colnames(tab_gkg_d)), tab_gkg_d[as.numeric(rownames(tab_gkg_d))%in%keys[v],]/colSums(tab_gkg_d)) gkg_tab_d[[w]] <- tab_gkg_d } pb_dc[[v]] <- pb_dc_d gkg[[v]] <- gkg_d gkg_tab[[v]] <- gkg_tab_d } ### return results res <- list(rf05 = rf05, tab_c2_l = tab_c2_l, zero_columns2 = zero_columns2, tab_c5_l = tab_c5_l, zero_columns5 = zero_columns5, cw_g2 = cw_g2, cw_g5 = cw_g5, can_cor = can_cor, pb_dc = pb_dc, gkg = gkg, gkg_tab = gkg_tab, ncol_mmat = ncol_mmat) return(res) } ### frequencies of distractor usage ### including correct response apply(dataset,2,table) ### load psych library library(psych) ### score all items scored <- score.multiple.choice(key=c(7,6,8,2,1,5,1,6,3,2,4,5),data=dataset,score=F) ### does choosing a certain other distractor ### imply better overall scores? # ### run suggested distractor analysis ms_res<-get_results(dataset,keys = c(7,6,8,2,1,5,1,6,3,2,4,5)) ### show Results for Table 4 # ### show for which items the distractor choice frequencies were ### below 5%: ms_res$rf05 ### Items 1 to 5 have too many distractors with response frequencies ### below 5%. # ### get 2PL parameters from mirt library(mirt) est_test2pl <- mirt(scored, 1, itemtype=“2PL”) ### show results coef(est_test2pl) # a1 = 2PL-discrimination # d = 2PL-difficulty # ### canonical correlation findings ms_res$can_cor[6:12] ### check boundary conditions # ### average pb_dc lapply(ms_res$pb_dc,function(x)mean(unlist(x),na.rm=T))[6:12] ### average gamma lapply(ms_res$gkg,function(x)mean(unlist(x),na.rm=T))[6:12]
References
- Arendasy, Martin, and Markus Sommer. 2013. Reducing response elimination strategies enhances the construct validity of figural matrices. Intelligence 41: 234–43. [Google Scholar] [CrossRef]
- Arendasy, Martin, Markus Sommer, Georg Gittler, and Andreas Hergovich. 2006. Automatic generation of quantitative reasoning items: A pilot study. Journal of Individual Differences 27: 2–14. [Google Scholar] [CrossRef]
- Attali, Yigal, and Tamar Fraenkel. 2000. The point-biserial as a discrimination index for distractors in multiple-choice items: Deficiencies in usage and an alternative. Journal of Educational Measurement 37: 77–86. [Google Scholar] [CrossRef]
- Barton, Mark A., and Frederic M. Lord. 1981. An upper asymptote for the three-parameter logistic item-response model. ETS Research Report Series 1: i-8. [Google Scholar] [CrossRef]
- Bethell-Fox, Charles E., David F. Lohman, and Richard E. Snow. 1984. Adaptive reasoning: Componential and eye movement analysis of geometric analogy performance. Intelligence 8: 205–38. [Google Scholar] [CrossRef]
- Blum, Diego, and Heinz Holling. 2018. Automatic generation of figural analogies with the IMak package. Frontiers in Psychology 9: 1286. [Google Scholar] [CrossRef]
- Blum, Diego, Heinz Holling, Maria S. Galibert, and Boris Forthmann. 2016. Task difficulty prediction of figural analogies. Intelligence 56: 72–81. [Google Scholar] [CrossRef]
- Bock, R. Darrell. 1972. Estimating item parameters and latent ability when responses are scored in two or more nominal categories. Psychometrika 37: 29–51. [Google Scholar] [CrossRef]
- Chalmers, R. Philip. 2012. mirt: A multidimensional item response theory package for the R environment. Journal of Statistical Software 48: 1–29. [Google Scholar] [CrossRef]
- Cohen, J. 1992. A power primer. Psychological Bulletin 112: 155–59. [Google Scholar] [CrossRef]
- Crocker, Linda S., and James Algina. 1986. Introduction to Classical and Modern Test Theory. Forth Worth: Harcourt Brace Jovanovich. [Google Scholar]
- Cureton, Edward. 1966. Corrected item-test correlations. Psychometrika 31: 93–96. [Google Scholar] [CrossRef]
- Davis, Frederick B., and Gordon Fifer. 1959. The effect on test reliability and validity of scoring aptitude and achievement tests with weights for every choice. Educational and Psychological Measurement 19: 159–70. [Google Scholar] [CrossRef]
- DeMars, Christine E. 2003. Sample size and recovery of nominal response model item parameters. Applied Psychological Measurement 27: 275–88. [Google Scholar] [CrossRef]
- Garcia-Perez, Miguel A. 2014. Multiple-choice tests: Polytomous IRT models misestimate item information. Spanish Journal of Psychology 17: e88. [Google Scholar] [CrossRef] [PubMed]
- Gierl, Mark J., Okan Bulut, Qi Guo, and Xinxin Zhang. 2017. Developing, analyzing, and using distractors for multiple-choice tests in education: A comprehensive review. Review of Educational Research 87: 1082–116. [Google Scholar] [CrossRef]
- Gonthier, Corentin, and Jean-Luc Roulin. 2019. Intraindividual strategy shifts in Raven’s matrices, and their dependence on working memory capacity and need for cognition. Journal of Experimental Psychology: General 149: 564–79. [Google Scholar] [CrossRef] [PubMed]
- Gonthier, Corentin, and Noémylle Thomassin. 2015. Strategy use fully mediates the relationship between working memory capacity and performance on Raven’s matrices. Journal of Experimental Psychology: General 144: 916–24. [Google Scholar] [CrossRef] [PubMed]
- Goodman, Leo A., and William H. Kruskal. 1979. Measures of Association for Cross Classifications. New York: Springer. [Google Scholar]
- Guttman, Louis, and Izchak M. Schlesinger. 1967. Systematic construction of distractors for ability and achievement test items. Educational and Psychological Measurement 27: 569–80. [Google Scholar] [CrossRef]
- Haladyna, Thomas M. 2004. Developing and Validating Multiple-Choice Test Items. New York: Routledge. [Google Scholar]
- Haladyna, Thomas M., and Steven M. Downing. 1993. How many options is enough for a multiple-choice test item? Educational and Psychological Measurement 53: 999–1010. [Google Scholar] [CrossRef]
- Harville, David A. 2008. Matrix Algebra from a Statistician’s Perspective. New York: Springer. [Google Scholar]
- Hayes, Taylor R., Alexander A. Petrov, and Per B. Sederberg. 2011. A novel method for analyzing sequential eye movements reveals strategic influence on Raven’s Advanced Progressive Matrices. Journal of Vision 11: 1–11. [Google Scholar] [CrossRef]
- Henrysson, Sten. 1962. The relation between factor loadings and biserial correlations in item analysis. Psychometrika 27: 419–29. [Google Scholar] [CrossRef]
- Henrysson, Sten. 1971. Gathering, analyzing, and using data on test items. In Educational Measurement, 2nd ed.; Edited by Robert L. Thorndike. Beverly Hills: American Council on Education. [Google Scholar]
- Hornke, Lutz F., and Michael W. Habon. 1986. Rule-based item bank construction and evaluation within the linear logistic framework. Applied Psychological Measurement 10: 369–80. [Google Scholar] [CrossRef]
- Jacobs, Paul I., and Mary Vandeventer. 1970. Information in wrong responses. Psychological Reports 26: 311–15. [Google Scholar] [CrossRef]
- Jarosz, Andrew F., and Jennifer Wiley. 2012. Why does working memory capacity predict RAPM performance? A possible role of distraction. Intelligence 40: 427–38. [Google Scholar] [CrossRef]
- Johanson, George A., and Gordon P. Brooks. 2010. Initial scale development: Sample size for pilot studies. Educational Psychological Measurement 70: 394–400. [Google Scholar] [CrossRef]
- Klecka, William R. 1980. Discriminant Analysis. Beverly Hills: SAGE Publications. ISBN 0-8039-1491-1. [Google Scholar]
- Kline, Paul. 2000. The Handbook of Psychological Testing. London: Routledge. [Google Scholar]
- Kunda, Maithilee, Isabelle Soulieres, Agata Rozga, and Ashok K. Goel. 2016. Error patterns on the Raven’s Standard Progressive Matrices test. Intelligence 59: 181–98. [Google Scholar] [CrossRef]
- Levine, Michael V., and Fritz Drasgow. 1983. The relation between incorrect option choice and estimated ability. Educational Psychological Measurement 43: 675–85. [Google Scholar] [CrossRef]
- Lord, Frederic M. 1980. Applications of Item Response Theory to Practical Testing Problems. Hillsdale: Lawrence-Erlbaum Associates. [Google Scholar]
- Love, Thomas E. 1997. Distractor selection ratios. Psychometrika 62: 51–62. [Google Scholar] [CrossRef]
- Matzen, Laura E., Zachary O. Benz, Kevin R. Dixon, Jamie Posey, James K. Kroger, and Ann E. Speed. 2010. Recreating Raven’s: Software for systematically generating large numbers of Raven-like matrix problems with normed properties. Behavor Research Methods 42: 525–41. [Google Scholar] [CrossRef]
- Mitchum, Ainsley L., and Colleen M. Kelley. 2010. Solve the problem first: Constructive solution strategies can influence the accuracy of retrospective confidence judgments. Journal of Experimental Psychology: Learning, Memory, Cognition 36: 699–710. [Google Scholar] [CrossRef]
- Muraki, Eiji. 1992. A generalized partial credit model: Application of an EM algorithm. ETS Research Report Series 1: i-30. [Google Scholar] [CrossRef]
- Myszkowski, Nils, and Martin Storme. 2018. A snapshot of g? Binary and polytomous item-response theory investigations of the last series of the Standard Progressive Matrices (SPM-LS). Intelligence 68: 109–16. [Google Scholar] [CrossRef]
- Nunnally, Jum C., and Ira H. Bernstein. 1994. Psychometric Theory. New York: McGraw-Hill. [Google Scholar]
- R Core Team. 2019. R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing. [Google Scholar]
- Revelle, William. 2018. Psych: Procedures for Personality and Psychological Research. Evanston: Northwestern University. [Google Scholar]
- Revuelta, Javier. 2005. An item response model for nominal data based on the rising selection ratios criterion. Psychometrika 70: 305–24. [Google Scholar] [CrossRef]
- Schiano, Diane J., Lynn A. Cooper, Robert Glaser, and Hou C. Zhang. 1989. Highs are to lows as experts are to novices: Individual differences in the representation and solution of standardized figural analogies. Human Performance 2: 225–48. [Google Scholar] [CrossRef]
- Sigel, Irving E. 1963. How intelligence tests limit understanding of intelligence. Merrill-Palmer Quarterly of Behavior and Development 9: 39–56. [Google Scholar]
- Snow, Richard E. 1980. Aptitude processes. In Aptitude, Learning, and Instruction: Cognitive Process Analyses of Aptitude. Edited by Richard E. Snow, Pat-Anthony Federico and William E. Montague. Hillsdale: Erlbaum, vol. 1, pp. 27–63. ISBN 978-089-859-043-2. [Google Scholar]
- Storme, Martin, Nils Myszkowski, Simon Baron, and David Bernard. 2019. Same test, better scores: Boosting the reliability of short online intelligence recruitment tests with nested logit item response theory models. Journal of Intelligence 7: 17. [Google Scholar] [CrossRef]
- Suh, Youngsuk, and Daniel M. Bolt. 2010. Nested logit models for multiple-choice item response data. Psychometrika 75: 454–73. [Google Scholar] [CrossRef]
- Thissen, David. 1976. Information in wrong responses to the Raven Progressive Matrices. Journal of Educational Measurement 13: 201–14. [Google Scholar] [CrossRef]
- Thissen, David, Lynne Steinberg, and Anne R. Fitzpatrick. 1989. Multiple-choice models: The distractors are also part of the item. Journal of Educational Measurement 26: 161–76. [Google Scholar] [CrossRef]
- Thompson, Bruce. 1984. Canonical Correlation Analysis. Newbury Park: SAGE Publications. ISBN 0-8039-2392-9. [Google Scholar]
- Vejleskov, Hans. 1968. An analysis of Raven matrix responses in fifth grade children. Scandinavian Journal Psychology 9: 177–86. [Google Scholar] [CrossRef]
- Vigneau, François, André F. Caissie, and Douglas A. Bors. 2006. Eye-movement analysis demonstrates strategic influences on intelligence. Intelligence 34: 261–72. [Google Scholar] [CrossRef]
- Vodegel Matzen, Linda B. L., Maurits W. van der Molen, and Ad C. M. Dudink. 1994. Error analysis of Raven test performance. Personality and Individual Differences 16: 433–45. [Google Scholar] [CrossRef]
- Von der Embse, Nathaniel P., Andrea D. Mata, Natasha Segool, and Emma-Catherine Scott. 2014. Latent profile analyses of test anxiety: A pilot study. Journal of Psychoeducational Assessessment 32: 165–72. [Google Scholar] [CrossRef]
- Wainer, Howard. 1989. The future of item analysis. Journal of Educational Measurement 26: 191–208. [Google Scholar] [CrossRef]
- Yen, Wendy M., and Anne R. Fitzpatrick. 2006. Item Response Theory. In Educational Measurement. Edited by Robert L. Brennan. Westport: Praeger Publishers. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Distractor | Relative Choice Frequency < 0.05 | PBD | PBDC | ωD | γ |
|---|---|---|---|---|---|
| Item 1/Item 2 | Item 1/Item 2 | Item 1/Item 2 | Item 1/Item 2 | Item 1/Item 2 | |
| Distractor 1 | 0/0 | −0.18/−0.21 | −0.54/−0.58 | 0.57/0.68 | 1/1 |
| Distractor 2 | 0/0 | −0.29/−0.08 | −0.56/−0.47 | 0.55/0.39 | 1/1 |
| Distractor 3 | 0/0 | −0.13/−0.36 | −0.50/−0.68 | 0.58/0.97 | 1/1 |
| Distractor | Level 1—Zero | Level 2—Moderate | Level 3—High | Level 4—Very High |
|---|---|---|---|---|
| 3 distractors/7 distractors | 3 distractors/7 distractors | 3 distractors/7 distractors | 3 distractors/7 distractors | |
| λi1 | 0.00/0.00 | −0.40/−1.20 | −1.00/−3.00 | −1.75/−5.25 |
| λi2 | 0.00/0.00 | 0.00/−0.80 | 0.00/−2.00 | 0.00/−3.50 |
| λi3 | 0.00/0.00 | 0.40/−0.40 | 1.00/−1.00 | 1.75/−1.75 |
| λi4 | -/0.00 | -/0.00 | -/0.00 | -/0.00 |
| λi5 | -/0.00 | -/0.40 | -/1.00 | -/1.75 |
| λi6 | -/0.00 | -/0.80 | -/2.00 | -/3.50 |
| λi7 | -/0.00 | -/1.20 | -/3.00 | -/5.25 |
| NRM discrimination (step size) | 0.00 | 0.40 | 1.00 | 1.75 |
| Threshold = 0.30 | Threshold = 0.50 | |||||
|---|---|---|---|---|---|---|
| RCC | ω2 | ω5 | RCC | ω2 | ω5 | |
| Adequate type-I-error rate | ||||||
| All | 69 | 70 | 25 | 100 | 100 | 72 |
| Adequate power | ||||||
| NRM Discrimination = 0.40 | ||||||
| All | 23 | 17 | 5 | 0 | 0 | 7 |
| M(γ) > 0.30 | 17 | 3 | 4 | - | - | 6 |
| M(PBDC) < −0.30 | 16 | 3 | 4 | - | - | 3 |
| NRM Discrimination = 1.00 | ||||||
| All | 61 | 45 | 23 | 35 | 24 | 23 |
| M(γ) > 0.30 | 39 | 31 | 16 | 25 | 17 | 14 |
| M(PBDC) < −0.30 | 41 | 30 | 16 | 24 | 15 | 15 |
| NRM Discrimination = 1.75 | ||||||
| All | 65 | 62 | 26 | 65 | 41 | 54 |
| M(γ) > 0.30 | 38 | 38 | 14 | 41 | 25 | 36 |
| M(PBDC) < −0.30 | 40 | 41 | 15 | 44 | 24 | 40 |
| Item | Number of Distractors with Relative Choice Frequency < 0.05 | 2PL-Difficulty | 2PL-Discrimination | RCC | M(PBDC) 2 | M(γ) 3 |
|---|---|---|---|---|---|---|
| Item 1 | 6 | 1.32 | 0.85 | NA 1 | NA 1 | NA 1 |
| Item 2 | 7 | 3.56 | 2.01 | NA 1 | NA 1 | NA 1 |
| Item 3 | 6 | 2.07 | 1.69 | NA 1 | NA 1 | NA 1 |
| Item 4 | 6 | 4.11 | 4.10 | NA 1 | NA 1 | NA 1 |
| Item 5 | 7 | 5.51 | 4.97 | NA 1 | NA 1 | NA 1 |
| Item 6 | 5 | 2.13 | 2.38 | 0.46 | −0.38 | 0.48 |
| Item 7 | 4 | 1.23 | 1.55 | 0.28 | −0.36 | 0.40 |
| Item 8 | 1 | 0.50 | 1.61 | 0.34 | −0.47 | 0.65 |
| Item 9 | 3 | 0.40 | 1.27 | 0.34 | −0.39 | 0.37 |
| Item 10 | 1 | −0.70 | 2.20 | 0.36 | −0.61 | 0.77 |
| Item 11 | 1 | −0.82 | 1.51 | 0.21 | −0.48 | 0.21 |
| Item 12 | 1 | −0.91 | 1.14 | 0.31 | −0.43 | 0.23 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Forthmann, B.; Förster, N.; Schütze, B.; Hebbecker, K.; Flessner, J.; Peters, M.T.; Souvignier, E. How Much g Is in the Distractor? Re-Thinking Item-Analysis of Multiple-Choice Items. J. Intell. 2020, 8, 11. https://doi.org/10.3390/jintelligence8010011
Forthmann B, Förster N, Schütze B, Hebbecker K, Flessner J, Peters MT, Souvignier E. How Much g Is in the Distractor? Re-Thinking Item-Analysis of Multiple-Choice Items. Journal of Intelligence. 2020; 8(1):11. https://doi.org/10.3390/jintelligence8010011
Chicago/Turabian StyleForthmann, Boris, Natalie Förster, Birgit Schütze, Karin Hebbecker, Janis Flessner, Martin T. Peters, and Elmar Souvignier. 2020. "How Much g Is in the Distractor? Re-Thinking Item-Analysis of Multiple-Choice Items" Journal of Intelligence 8, no. 1: 11. https://doi.org/10.3390/jintelligence8010011
APA StyleForthmann, B., Förster, N., Schütze, B., Hebbecker, K., Flessner, J., Peters, M. T., & Souvignier, E. (2020). How Much g Is in the Distractor? Re-Thinking Item-Analysis of Multiple-Choice Items. Journal of Intelligence, 8(1), 11. https://doi.org/10.3390/jintelligence8010011