3.1. Data and Sample
We obtained publicly available assessment data for the Problem Solving and Inquiry tasks (PSI tasks), which were administered as part of the Trends in International Mathematics and Science Study (TIMSS) 2019. The PSI tasks were time-constrained, computer-based tests designed to evaluate students’ higher-order thinking skills, particularly reasoning and applying skills in mathematics and science (
Mullis et al. 2021). These tasks featured visually attractive, interactive scenarios with narratives or themes simulating real-world problems. As such, the PSI tasks represent an innovative item format that differs significantly from traditional assessment items. Student responses to the PSI tasks varied in format. In some cases, responses consisted of a single number, while in others, they included extended strings containing information about drawn lines or the dragging and dropping of objects. Additionally, the student response table contained typed responses, which were later transferred to the scoring system for human evaluation. This system also included screenshot images of responses generated using the line-drawing tool (
Martin et al. 2020). Detailed information about the PSI tasks and their scoring procedures can be found on the TIMSS 2019 website:
https://timss2019.org/psi/introduction/index.html (accessed on 15 April 2024).
This study focused on booklet ID 15 of the grade-four PSI mathematics assessment. In the assessment, 17 screens contained a total of 29 items distributed across 3 distinct scenarios (i.e., PSI tasks), while other screens introduced the items or provided clues. There were instances where a single screen presented multiple items. Therefore, screen response times were selected as a unit of analysis in this study because they represent the most granular and available variable linked to individual item response times. Screens that introduced the items or provided clues were excluded from the analyses because they were not involved in the problem-solving process.
The original sample consisted of 13,829 fourth-grade students from 30 countries, including 6724 girls and 6755 boys. Referencing the achievement benchmark adopted in TIMSS 2019 (
Mullis et al. 2020), the students’ test performance was distributed as follows: 1453 students (10.51%) did not reach low achievement (i.e., very low), 2522 students (18.24%) reached low achievement, 4301 students (31.10%) reached intermediate achievement, 4088 students (29.56%) reached high achievement, and 1465 students (10.59%) reached advanced achievement. Students’ mathematics test performance was derived from a single continuous score based on their response accuracy on the PSI tasks, calculated using the scaling method described in the TIMSS 2019 Technical Report (
Martin et al. 2020). The classification of students’ test performance did not aim for a precise interpretation of students’ achievement levels but rather to facilitate analyses to contribute to our understanding of how the relationship between response time and test performance may vary across different achievement levels.
3.2. Data Analysis
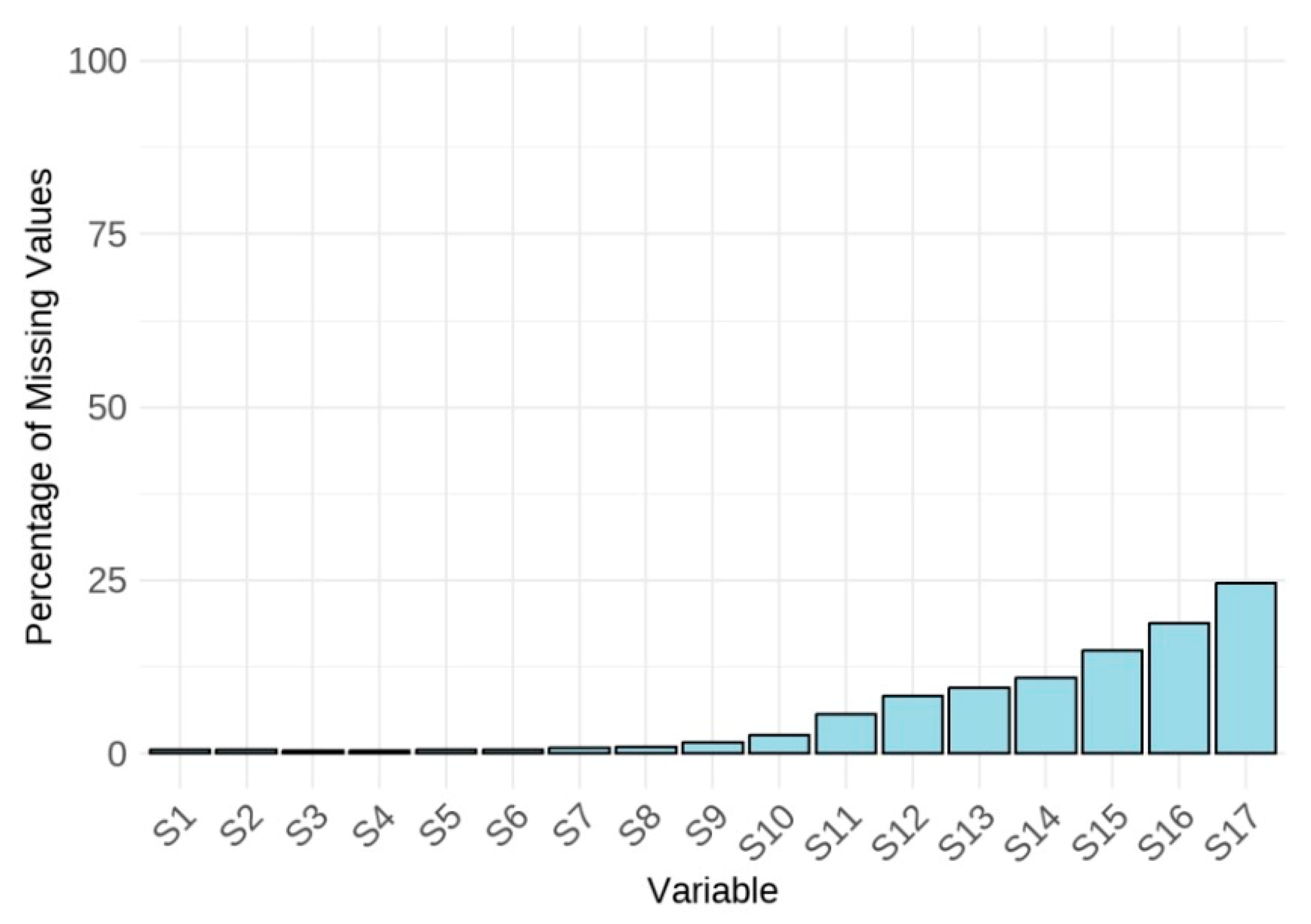
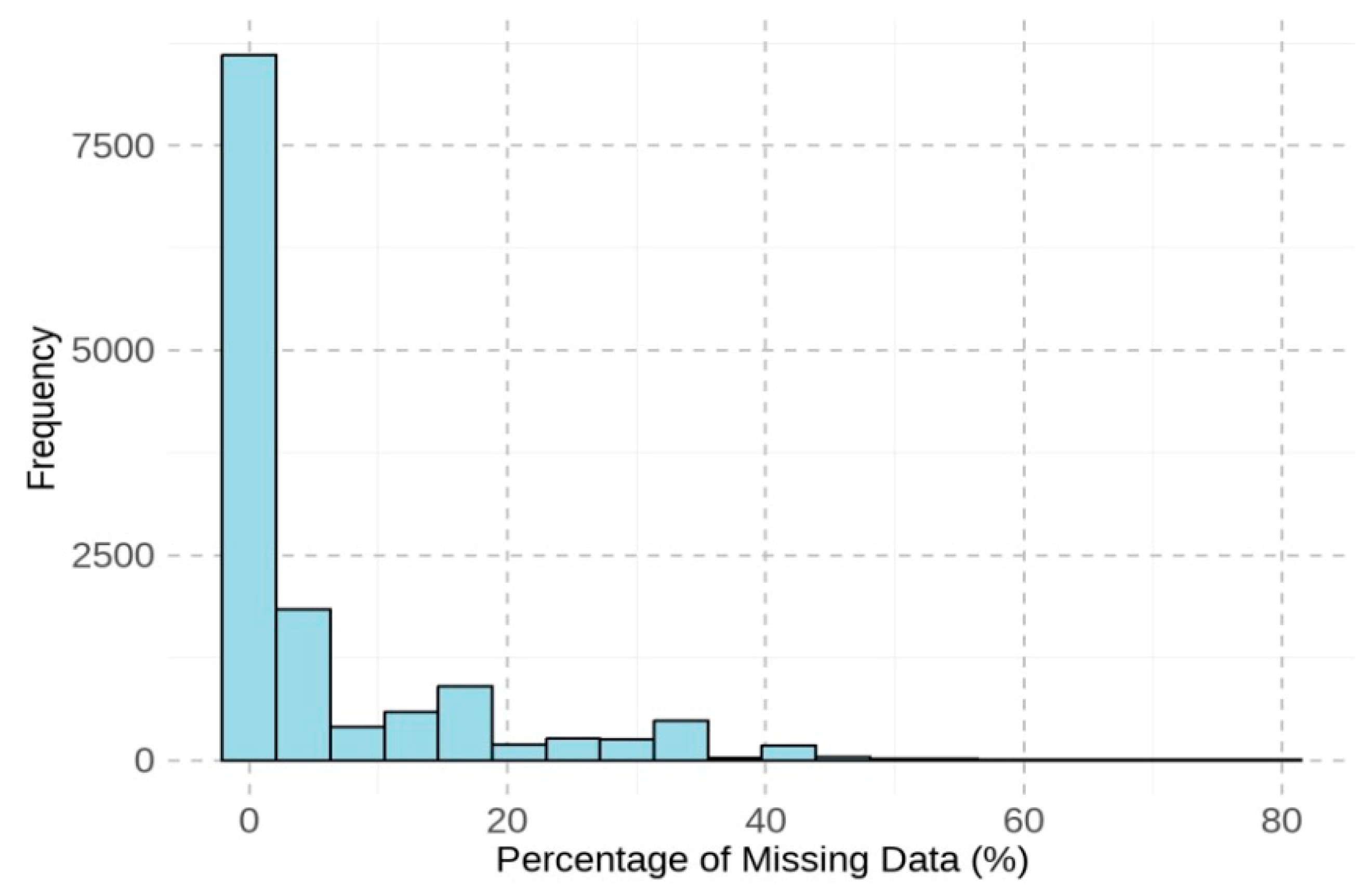
Descriptive statistics, including missing data analysis, were calculated first. Then, missing data were listwise deleted to facilitate the criterion-related profile analysis, which requires a complete matrix of observations across all screens. Listwise deletion was chosen over data imputation because the latter could introduce artificial patterns or assumptions about students’ test-taking behaviors or cognitive styles, potentially distorting the within-person variability central to our analysis. We report the percentage of missing data per screen and per student in the Results section to assess potential bias.
To facilitate comparisons of response times across screens, which contain items that inherently require different amounts of time to complete, we employed the z-score transformation. This involved subtracting the mean response time of all students on that screen from each student’s raw response time, then dividing the result by the standard deviation of students’ response time on that screen. The resulting z-scores represent standardized response times, with a mean of 0 and a standard deviation of 1. The standardized scores enable us to assess whether a student consistently maintained the same relative position, spending a similar amount of time on different items throughout the test compared to other students. In other words, each student would exhibit a consistent pattern of standardized scores across screens. The standardized response time data served as the unit of analysis for profile analyses.
To address RQ1, a one-sample profile analysis with Hotelling’s
T2 was used to examine whether students’ average standardized response times across screens were statistically equivalent. Since response times were standardized, the analysis focused on relative timing patterns—that is, whether students, on average, responded faster or slower on certain screens relative to other screens. The null hypothesis of the analysis assumes that on average, students would spend equal standardized time across all screens, with no screen standing out as faster or slower relative to others. Following
Bulut and Desjardins (
2020), this hypothesis could be conceptualized as that the ratios of the observed means over their hypothesized means are all equal to 1, against the alternative hypothesis that at least one of the ratios is not equal to 1. In this context, the observed means represent the average standardized response time on each screen, while the hypothesized means represent the expected standardized response time under the assumption of no relative differences—that is, a value of zero for each screen, due to standardization. Mathematically, they could be expressed as
where
μ is the observed means of the standardized response time for screens,
μ = [
μ1,
μ2,
…,
μp], whereas
μ0 is the vector of hypothesized means for the 1st–
pth screen,
μ0 = [
,
, …,
]. In addition to testing whether the ratios are all equal to 1, profile analysis can also be used to directly test whether all ratios are equal. Thus, another pair of hypotheses could be proposed:
While repeated measures analysis of variance (ANOVA) could be an alternative analysis to test mean differences across screens in our study, it treats response time as a single construct measured repeatedly. In contrast, one-sample profile analysis conceptualizes screen-level response times as a multivariate pattern, without assuming that response times on different screens reflect the same underlying construct or process (
Bulut and Desjardins 2020). This distinction is important for our study, as response time is not a stable trait but an outcome of student–task interactions with items that may vary across screens. Therefore, one-sample profile analysis offers a more flexible and conceptually appropriate framework for testing whether the pattern of response times is equivalent across screens.
To address RQs 2 and 3, this study employed criterion-related profile analysis, a regression-based statistical method developed by
Davison and Davenport (
2002), to quantify the predictive value of response time profiles. This method identifies profiles (i.e., combinations of subscores) correlated with a criterion variable. According to Davison and Davenport, when subscores are predictive, a specific criterion-related profile pattern emerges, such that it is associated with high scores on the criterion variable and minimizes prediction error. This criterion-related pattern can be described in terms of the linear regression coefficients and used to reveal the relationship between individual subscores and the criterion variable. Davison and Davenport have demonstrated that criterion-related profile analysis has the advantage of quantifying the predictive value of subscores beyond the total score. In this study, standardized screen response times were employed as the predictor subscores, and the criterion variable was students’ overall test performance. The following paragraphs outline Davison and Davenport’s procedures for identifying the criterion-related pattern and quantifying the predictive value of subscores.
In the first step, a multiple regression analysis is established to predict the criterion variable based on a composite of subscores. In general, multiple regression can be written as
where
represents the predicted criterion score for person
p,
denotes the regression coefficient for predictor subscore
v,
represents person
p’s subscore for predictor
v, and
a is the intercept constant. To determine the criterion-related pattern, the regression coefficients are subtracted by the mean regression coefficients identified in the multiple regression equation. Let the criterion-related pattern be
b*, the criterion-related pattern vector can be mathematically expressed as
, where
.
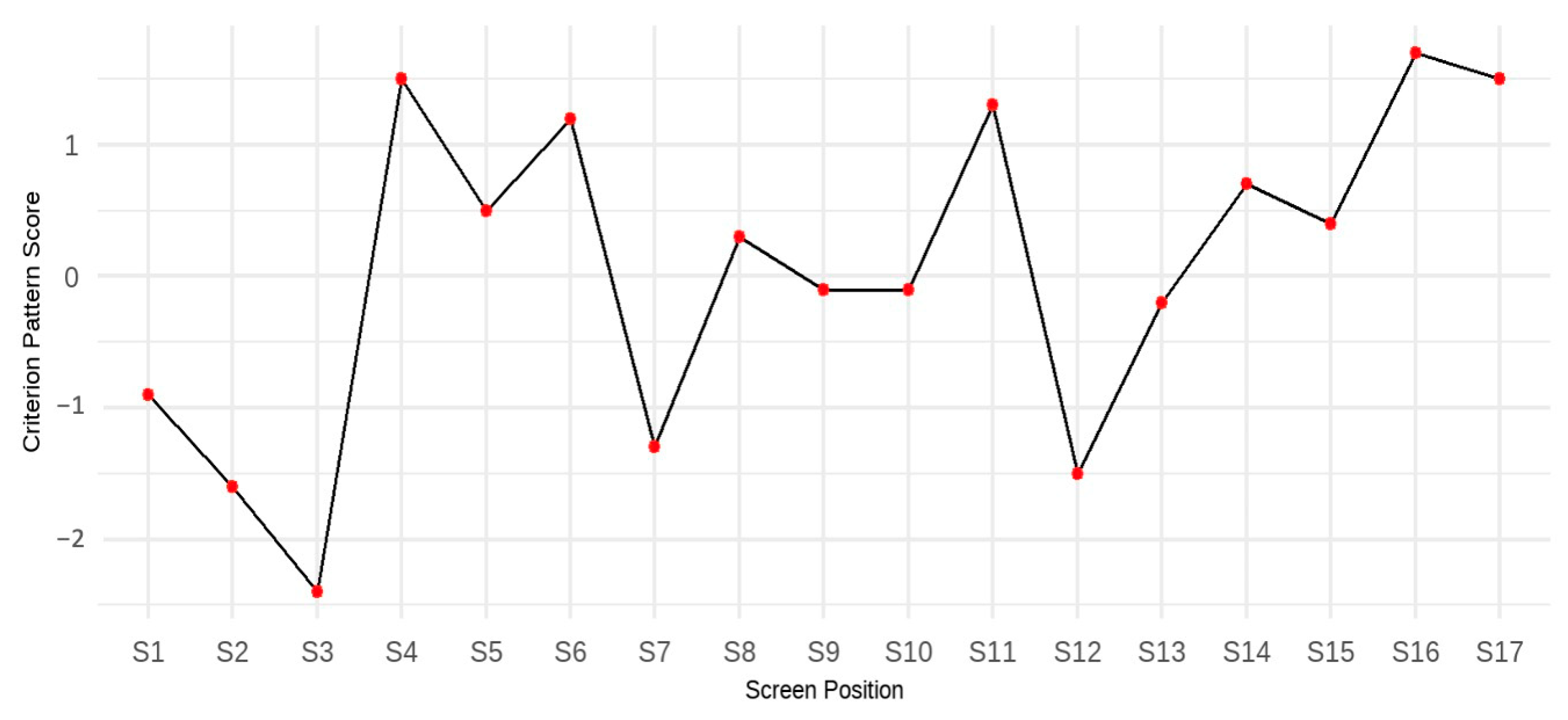
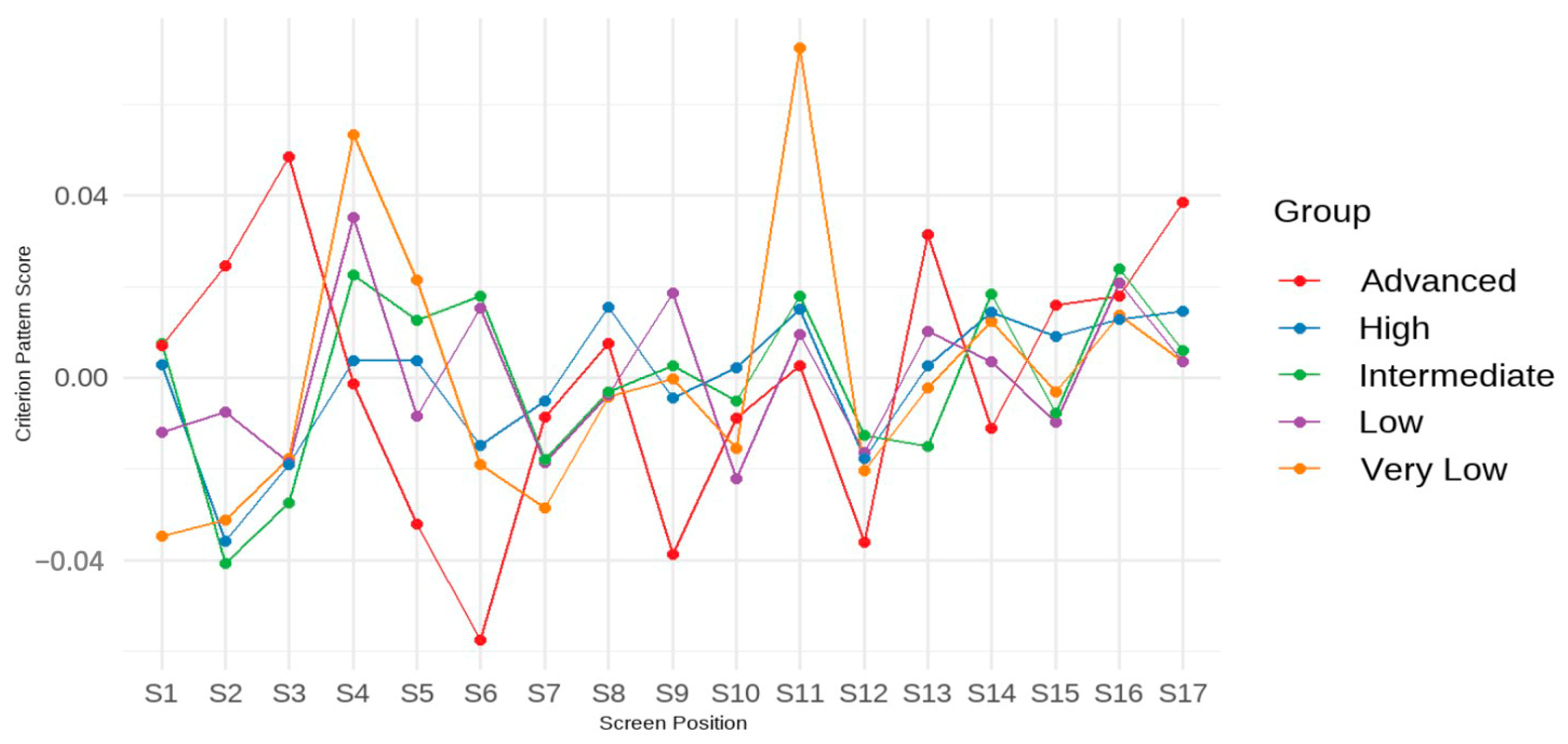
The
b* coefficients (also called the criterion-related pattern) must be interpreted in a configural manner; that is, each coefficient reflects a relative strength or weakness within the overall pattern (
Davison et al. 2023). A screen with a positive
b* indicates that, compared to other screens, spending more time on that screen contributes more to higher test performance. Conversely, a negative
b* value suggests that spending less time on that screen leads to higher performance. Importantly, these coefficients are not interpreted in isolation; rather, they form a response time profile that is predictive of performance when a student’s timing pattern closely matches the criterion-related profile. In such cases, students whose response time profiles align more closely with the pattern tend to achieve higher test scores.
This interpretation differs from that of the original regression coefficients (b), which quantify the unique predictive contribution of each screen’s response time to test performance, controlling for time spent on other screens. In other words, while b values reflect between-student differences in how time on a specific screen predicts outcomes, b* values describe a contrast pattern that captures the within-student configuration of time allocation associated with high performance.
In addition to identifying the criterion-related pattern, the multiple regression analysis decomposes each person’s profile of predictor subscores into two components: a profile level effect and a profile pattern effect. The level effect is defined as the mean of the subscores for person
p, while the pattern effect is defined as a vector consisting of the deviations between a person’s subscore and their mean score
. Therefore, the level effect can be expressed as
, where
V is the total number of subscores, and the pattern effect can be denoted as
. According to
Davison and Davenport (
2002), the pattern effect can be re-expressed as
.
The second step of criterion-related profile analysis involves estimating the variation of the criterion variable accounted for by the level and pattern effects. This is accomplished through another regression equation, which can be written as
where
is the mean of the predictor subscores for person
p (i.e., level effect),
is the pattern effect,
b1 is the regression coefficient of the level effect, and
b2 is the regression coefficient of the pattern effect. Then, the regression equation allows us to examine whether pattern effects incrementally explain the variation in the criterion variable over level effects. This is analyzed through a series of hierarchical regressions, where the criterion variable is predicted by (1) the level effect alone, (2) the pattern effect alone, (3) the increment of the pattern effect above and beyond the level effect, and (4) the increment of the level effect above and beyond the pattern effect.
F statistics and changes in
R2 are used to evaluate improvements in model performance.
The third and last step of criterion-related profile analysis is to conduct cross-validation, which involves replicating the profile pattern and level effects in another sample. The purpose is to test the generalizability of the results. Following the procedure suggested by
Davison and Davenport (
2002), the full dataset is randomly split into two subsets of equal size. The criterion-related pattern (
b*) obtained by analyzing one subset is then used to predict the criterion for the other subset, and vice versa. This cross-validation procedure aims to estimate the potential drop in explained variance (
R2) when regression-derived criterion-related patterns are applied to a new sample drawn from the same population. It is important to note that this procedure differs from common cross-validation techniques used in machine learning (e.g., k-fold or holdout validation). In the context of profile analysis, the primary goal is not to optimize model parameters but rather to evaluate the replicability and stability of the predictor–criterion relationships across samples.
For all analyses described above, we chose not to apply a log transformation to the response time data, despite the presence of skewness in many screen-level response times. This decision was made primarily to preserve the interpretability of the response time profiles. Additionally, the one-sample profile analysis with Hotelling’s
T2 test is essentially a multivariate extension of ANOVA, which is moderately robust to violations of multivariate normality, particularly in large samples (
Sheng 2008;
Wu 2009). This robustness reduces the likelihood of Type I error and supports the validity of our findings despite the skewed distributions. Furthermore, the criterion-related profile analysis, which relies on multiple regression techniques, assumes Gaussian errors but is also considered relatively robust to violations of multivariate normality (
Knief and Forstmeier 2021). To assess the impact of using the original response time data (which were standardized but non-log-transformed), we conducted a sensitivity analysis using log-transformed response times. The results were highly consistent with those obtained from the original z-standardized data. Therefore, while we acknowledge the skewness in the response time distributions, we retained the original z-standardized values (based on non-log-transformed response times) for the main analysis and results presented in this manuscript.
This study employed the profileR package (
Desjardins and Bulut 2020) in R (
R Core Team 2023) to address the proposed RQs. Specifically, the paos function was used to test the two null hypotheses of one-sample profile analysis with Hotelling’s
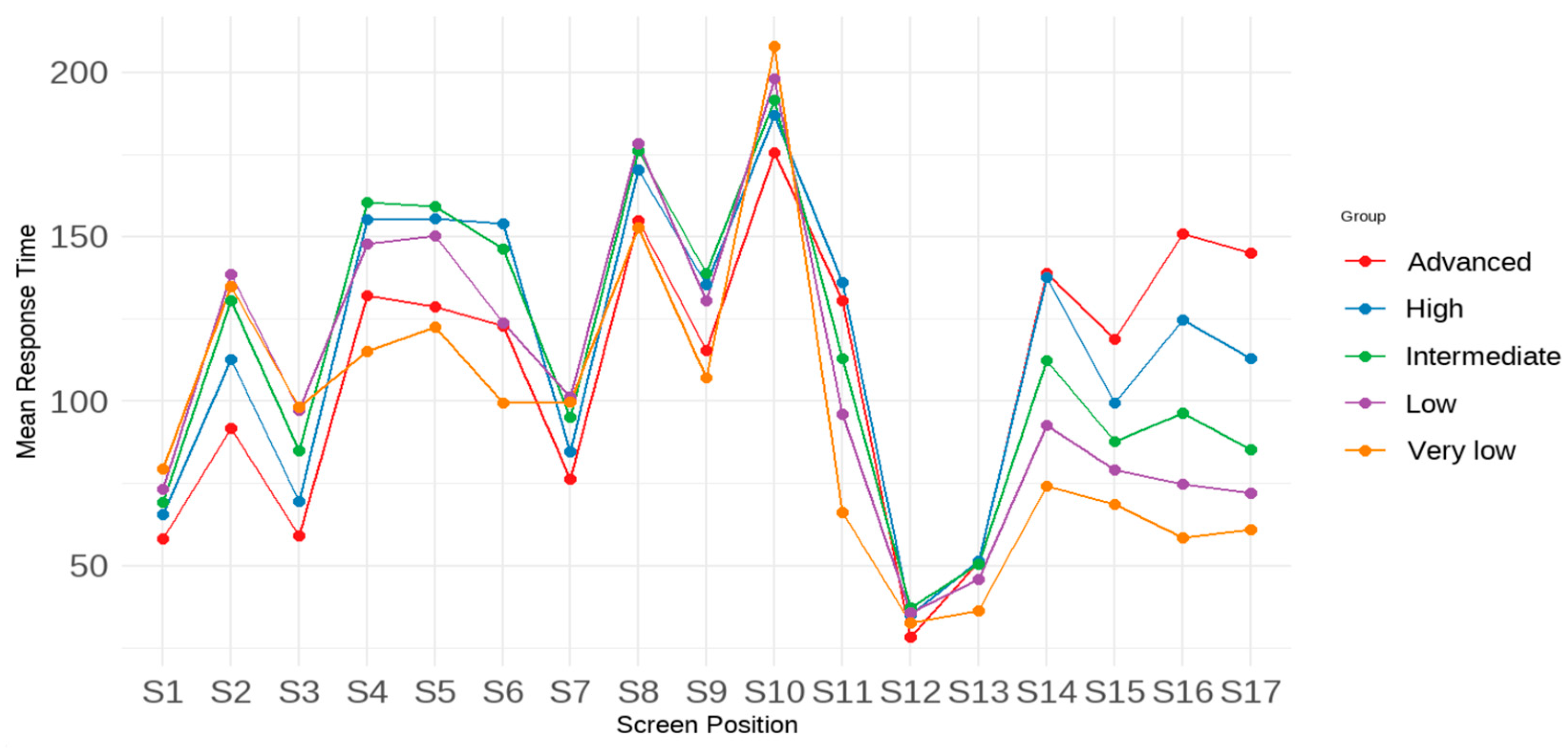
T2 (RQ1). Additionally, the cpa function with the default parameters (i.e., scalar constant = 100; Gaussian family with the “identity” model link function) was used to perform the criterion-related profile analysis for both the full sample (RQ2) and by each achievement group (RQ3). The function provided results for the estimated variation in test scores, which were explained by the level and pattern effects of response time.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}