When ChatGPT Writes Your Research Proposal: Scientific Creativity in the Age of Generative AI


Abstract
1. Introduction
1.1. Scientific Creativity
1.2. The Present Study
2. Materials and Methods
“A recent survey showed that university students in Rhineland-Palatinate who are introverts tend to order pizza with peppers and mushrooms, while university students that rate themselves as extroverts tend to order pizza with eggplant and corn. At the same time, these introverted students also stated that they like rock music, while the extroverts stated that they like to listen to chill out music. Imagine you are an experienced scientist working at the Department of Psychology at the University of Kaiserslautern-Landau. Your colleague argues that this must have something to do with their diet, because eggplant contains a high amount of magnesium which makes the extrovert students more relaxed and thus more interested in relaxing music. You are skeptical because you think that the preference for music has more to do with a personality trait rather than a person’s diet. But how could you test this? Please outline a short research proposal to convince a jury of the German Research Foundation to fund your research.”
2.1. Assignment 1—Generating a Hypothesis
2.2. Assignment 2—Outlining the Procedure
2.3. Assignment 3—Listing Necessary Equipment
2.4. Assignment 4—Reasoning of Rationale
2.5. Rating
2.6. Evaluation
3. Results
3.1. Assignment 1—Generating a Hypothesis
Qualitative Assessment
3.2. Assignment 2—Outlining the Procedure
Qualitative Assessment
3.3. Assignment 3—Listing Necessary Equipment
Qualitative Assessment
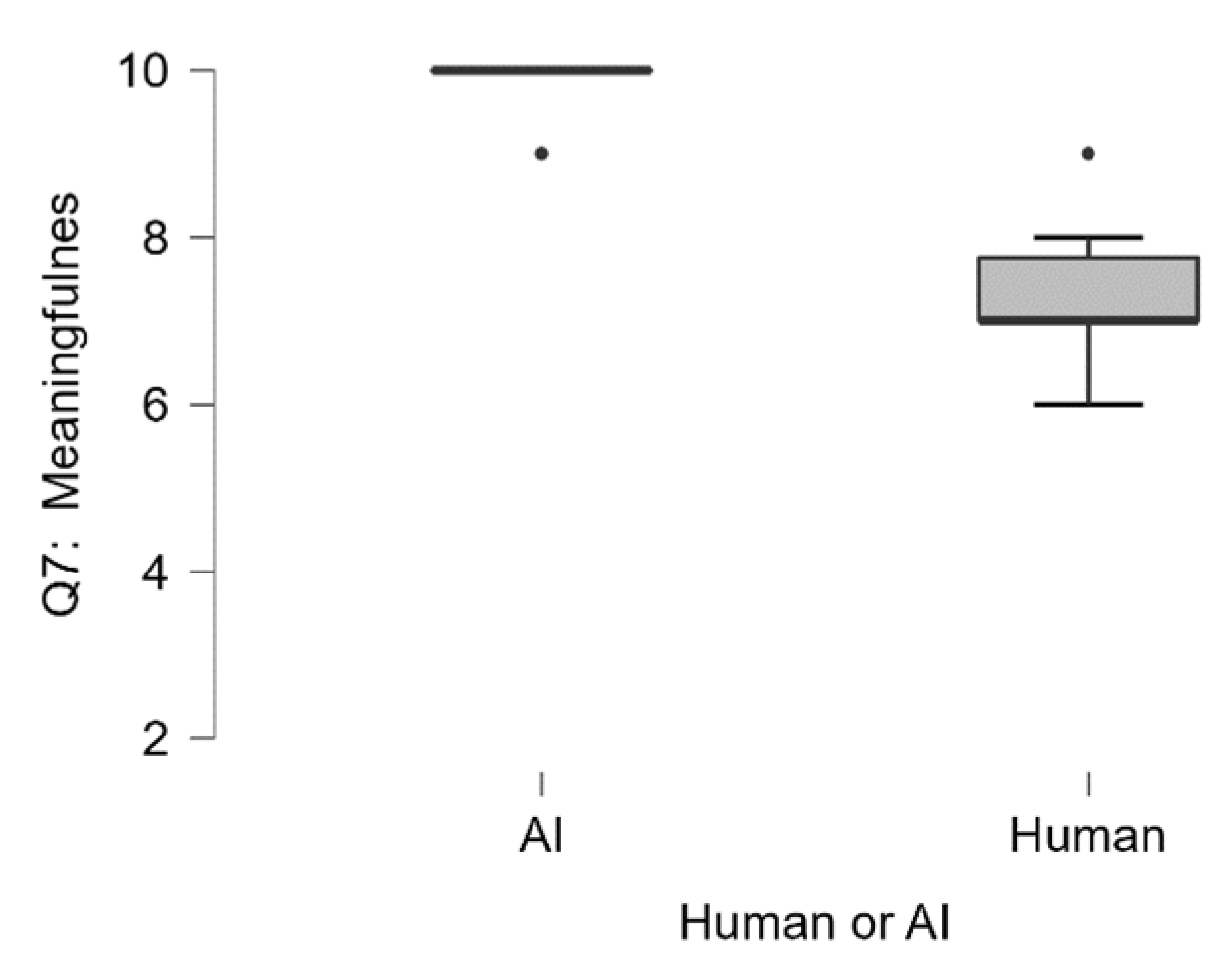
3.4. Assignment 4—Reasoning of Rationale
Qualitative Assessment
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| GPT | Generative Pre-trained Transformer |
| LLM | Large Language Model |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
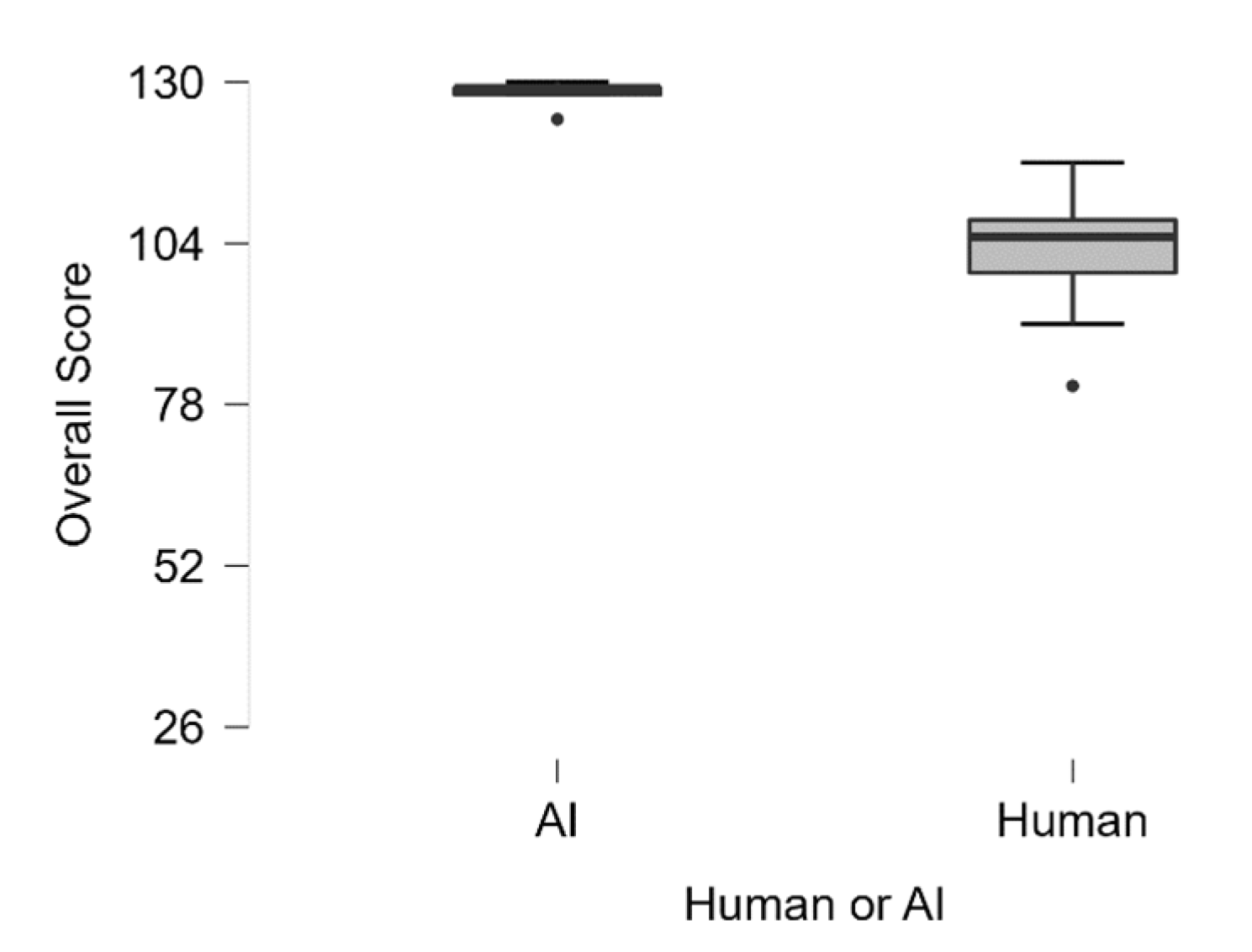
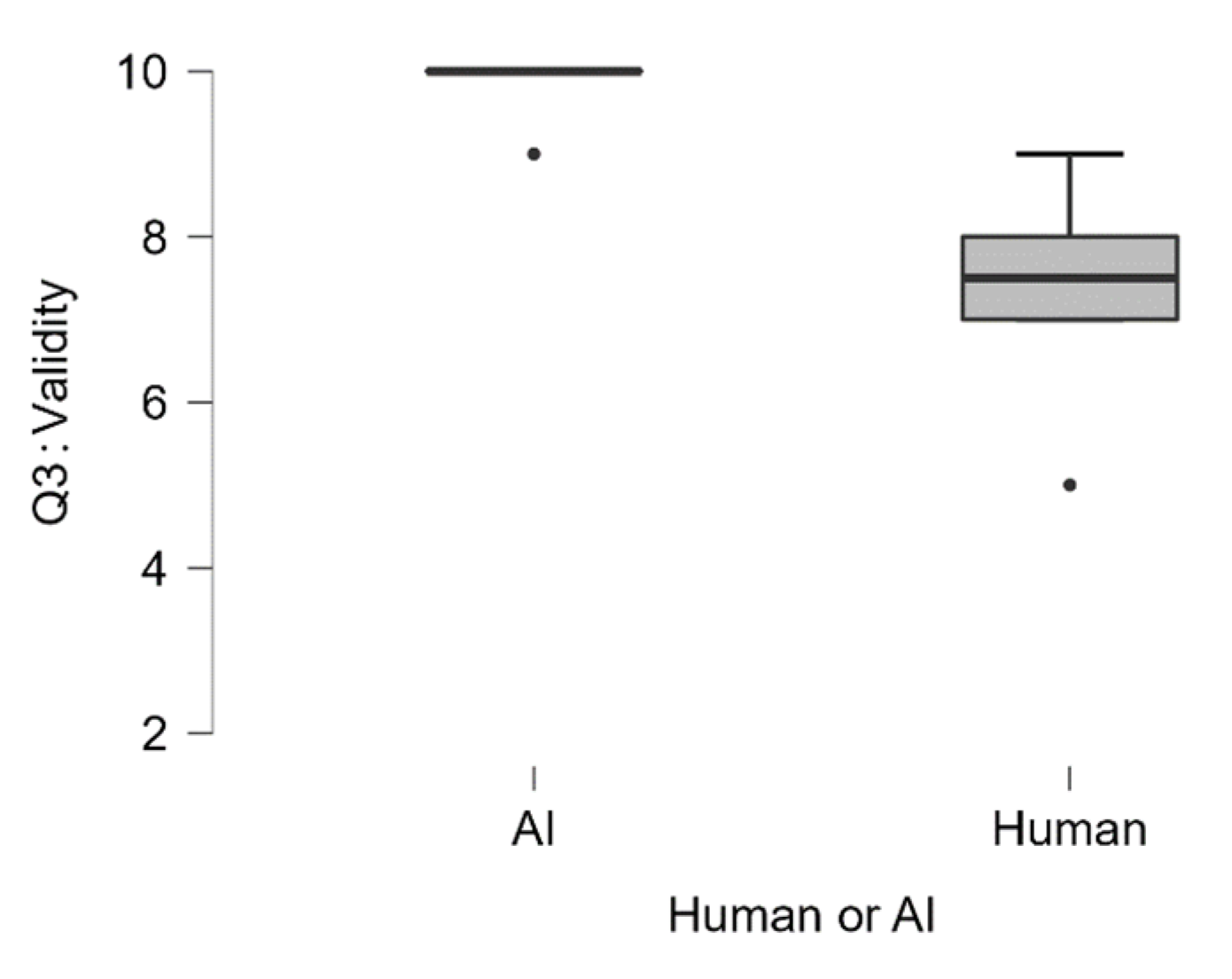
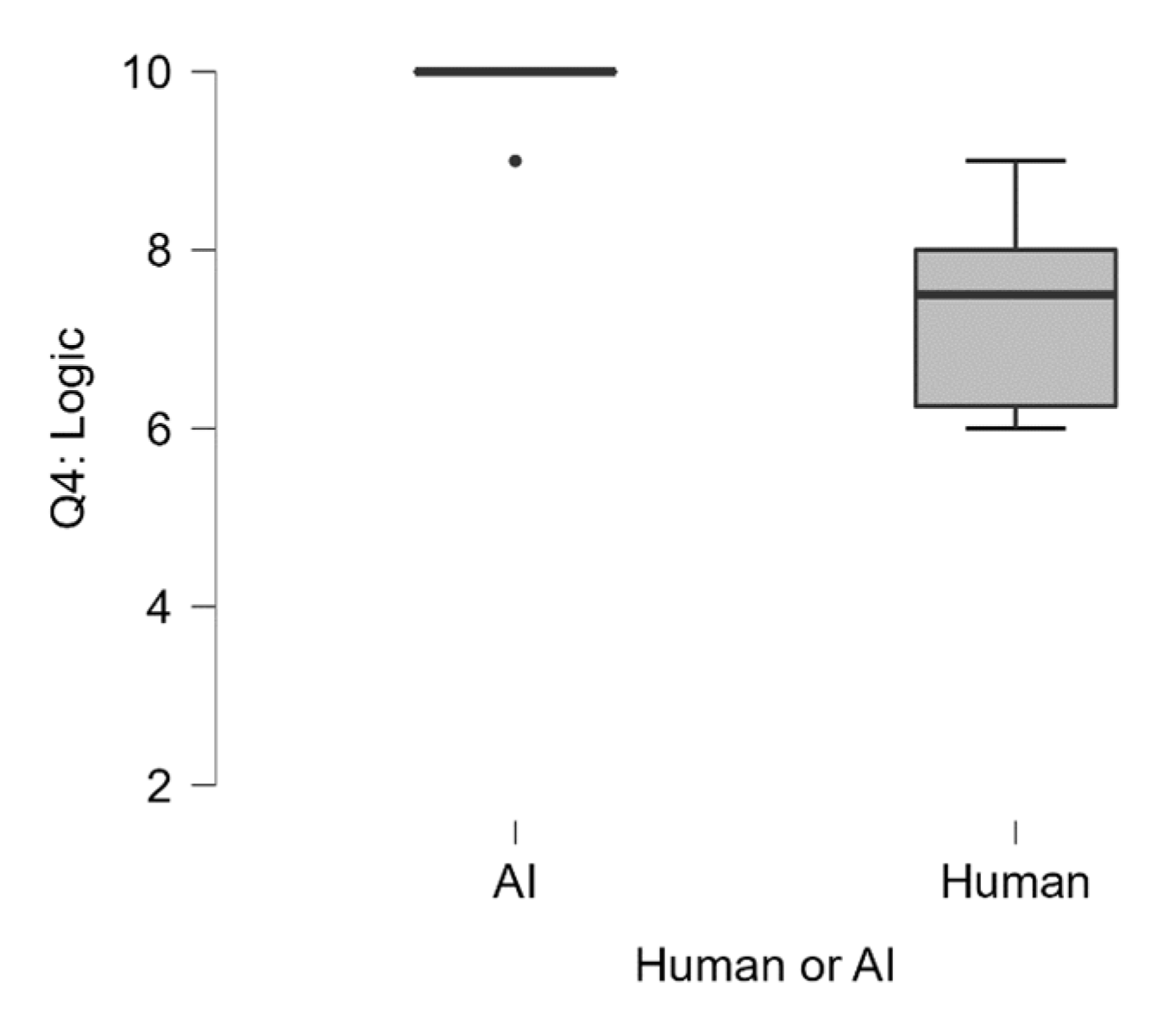
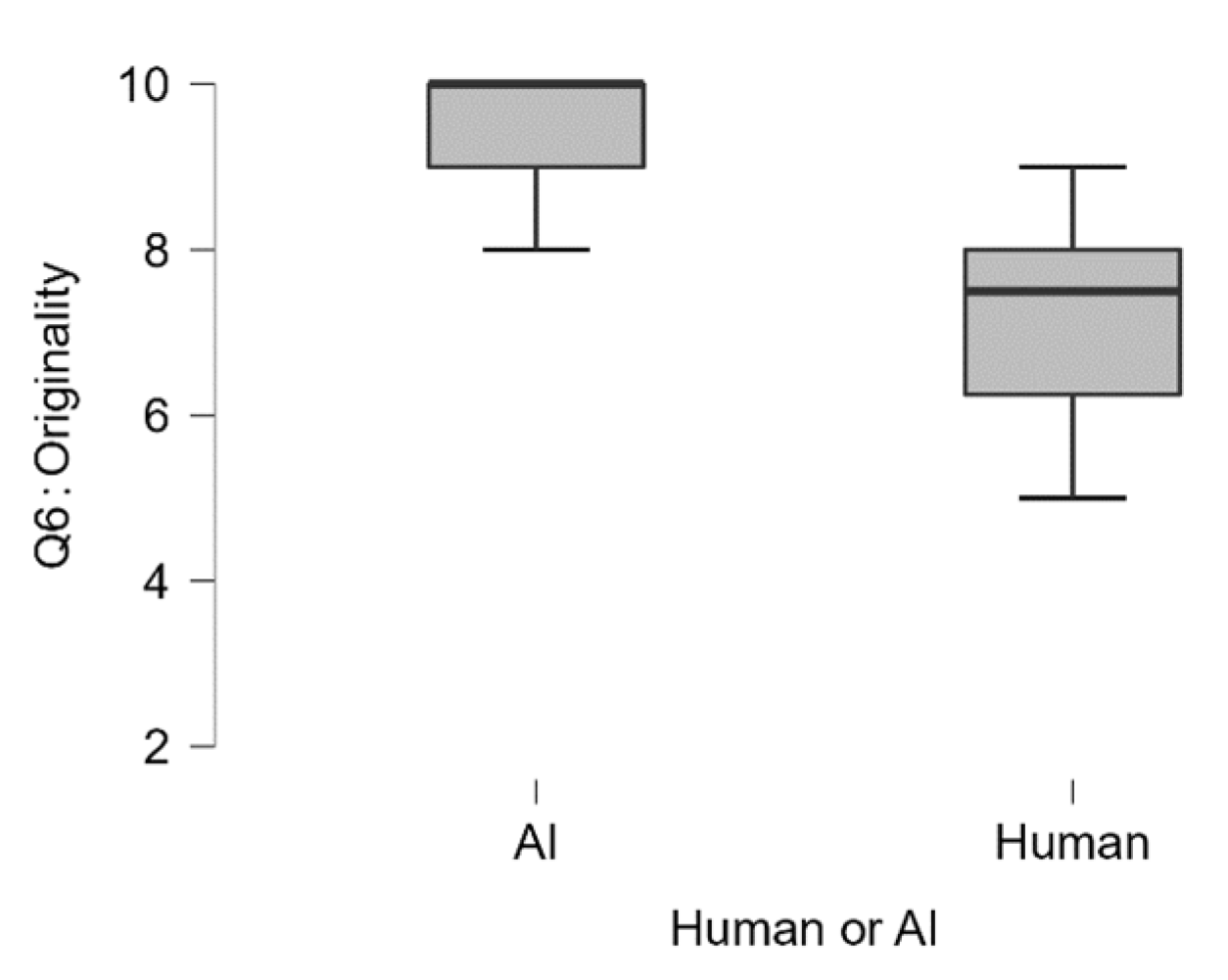
| Overall Score | Q1 Adequat | Q2 Falsification | Q3 Validity | Q4 Logic | Q5 Adequat | Q6 Originality | Q7 Meaningfulness | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AI | Human | AI | Human | AI | Human | AI | Human | AI | Human | AI | Human | AI | Human | AI | Human | |
| Median | 129.00 | 105.00 | 10.00 | 9.00 | 10.00 | 10.00 | 10.00 | 7.50 | 10.00 | 7.50 | 10.00 | 8.50 | 10.00 | 7.50 | 10.00 | 7.00 |
| Mean | 128.00 | 102.10 | 9.80 | 8.40 | 9.60 | 8.30 | 9.80 | 7.40 | 9.80 | 7.40 | 9.80 | 8.30 | 9.40 | 7.10 | 9.80 | 7.20 |
| Std. Deviation | 2.35 | 10.09 | 0.45 | 2.17 | 0.55 | 2.91 | 0.45 | 1.07 | 0.45 | 1.17 | 0.45 | 1.57 | 0.89 | 1.37 | 0.45 | 0.92 |
| Range | 6.00 | 36.00 | 1.00 | 6.00 | 1.00 | 8.00 | 1.00 | 4.00 | 1.00 | 3.00 | 1.00 | 4.00 | 2.00 | 4.00 | 1.00 | 3.00 |
| Minimum | 124.00 | 81.00 | 9.00 | 4.00 | 9.00 | 2.00 | 9.00 | 5.00 | 9.00 | 6.00 | 9.00 | 6.00 | 8.00 | 5.00 | 9.00 | 6.00 |
| Maximum | 130.00 | 117.00 | 10.00 | 10.00 | 10.00 | 10.00 | 10.00 | 9.00 | 10.00 | 9.00 | 10.00 | 10.00 | 10.00 | 9.00 | 10.00 | 9.00 |
Appendix B
References
- Barbot, Baptiste, Maud Besançon, and Todd Lubart. 2016. The generality-specificity of creativity: Exploring the structure of creative potential with EPoC. Learning and Individual Differences 52: 178–87. [Google Scholar] [CrossRef]
- Beaty, Roger, Simone Luchini Robert A. Cortes, Boris Forthmann John D. Patterson, Baptiste Barbot Brendan S. Baker, Mariale Hardiman, and Adam Green. 2024. The scientific creative thinking test (SCTT): Reliability, validity, and automated scoring. PsyArxiv Preprints. [Google Scholar] [CrossRef]
- Cicchetti, Domenic V. 1994. Guidelines, criteria, and rules of thumb for evaluating normed and standardized assessment instruments in psychology. Psychological Assessment 6: 284. [Google Scholar] [CrossRef]
- Davis, Joshua, Brigitte N. Durieux Liesbet Van Bulck, and Charlotta Lindvall. 2024. The temperature feature of ChatGPT: Modifying creativity for clinical research. JMIR Human Factors 11: e53559. [Google Scholar] [CrossRef]
- Eymann, Vera, Thomas Lachmann, and Daniela Czernochowski. 2024a. Scientific creativity in cognitive scientists. Pre-registered on 2024/12/19—12:24 AM on As predicted, #205248. (in preparation). Available online: https://aspredicted.org/gqv9-dy2m.pdf (accessed on 27 February 2025).
- Eymann, Vera, Thomas Lachmann, Ann-Kathrin Beck, Saskia Jaarsveld, and Daniela Czernochowski. 2024b. Reconsidering divergent and convergent thinking in creativity—A neurophysiological index for the convergence-divergence continuum. Creativity Research Journal, 1–8. [Google Scholar] [CrossRef]
- Farina, Mirko, Witold Pedrycz, and Andrea Lavazza. 2024. Towards a mixed human–machine creativity. Journal of Cultural Cognitive Science 8: 151–65. [Google Scholar] [CrossRef]
- Formosa, Paul, Sarah Bankins, Rita Matulionyte, and Omid Ghasemi. 2024. Can ChatGPT be an author? Generative AI creative writing assistance and perceptions of authorship, creatorship, responsibility, and disclosure. AI & SOCIETY, 1–13. [Google Scholar]
- Garcia, Manuel B. 2024. The paradox of artificial creativity: Challenges and opportunities of generative AI artistry. Creativity Research Journal, 1–14. [Google Scholar] [CrossRef]
- Ghafarollahi, Alireza, and Markus J. Buehler. 2024. Sciagents: Automating scientific discovery through multi-agent intelligent graph reasoning. arXiv arXiv:2409.05556. [Google Scholar]
- Girotra, Karan, Lennart Meincke, Christian Terwiesch, and Karl T. Ulrich. 2023. Ideas are dimes a dozen: Large language models for idea generation in innovation. SSRN Electron. J. [Google Scholar] [CrossRef]
- Guzik, Erik E., Christian Byrge, and Christian Gilde. 2023. The originality of machines: AI takes the Torrance Test. Journal of Creativity 33: 100065. [Google Scholar] [CrossRef]
- Huang, Jingshan, and Ming Tan. 2023. The role of ChatGPT in scientific communication: Writing better scientific review articles. American Journal of Cancer Research 13: 1148. [Google Scholar] [PubMed]
- Jaarsveld, Saskia, and Thomas Lachmann. 2017. Intelligence and creativity in problem solving: The importance of test features in cognition research. Frontiers in Psychology 8: 134. [Google Scholar] [CrossRef]
- Kaufman, James C., and Jonathan A. Plucker. 2011. Intelligence and Creativity. Cambridge: Cambridge University Press. [Google Scholar]
- Kitano, Hiroaki. 2021. Nobel Turing Challenge: Creating the engine for scientific discovery. NPJ Systems Bbiology and Applications 7: 29. [Google Scholar] [CrossRef]
- Kramer, Stefan, Mattia Cerrato, Sašo Džeroski, and Ross King. 2023. Automated scientific discovery: From equation discovery to autonomous discovery systems. arXiv arXiv:2305.02251. [Google Scholar]
- Langley, Pat. 1987. Scientific Discovery: Computational Explorations of the Creative Processes. Cambridge: MIT Press. [Google Scholar]
- Lenat, Douglas B., and John Seely Brown. 1984. Why AM and EURISKO appear to work. Artificial Intelligence 23: 269–94. [Google Scholar] [CrossRef]
- Licuanan, Brian F., Lesley R. Dailey, and Michael D. Mumford. 2007. Idea evaluation: Error in evaluating highly original ideas. The Journal of Creative Behavior 41: 1–27. [Google Scholar] [CrossRef]
- Lissitz, Robert W., and Joseph L. Willhoft. 1985. A methodological study of the Torrance Tests of Creativity. Journal of Educational Measurement 22: 1–11. [Google Scholar] [CrossRef]
- Liu, Jiaxi. 2024. ChatGPT: Perspectives from human–computer interaction and psychology. Frontiers in Artificial Intelligence 7: 1418869. [Google Scholar] [CrossRef]
- Lockhart, Ezra N. 2024. Creativity in the age of AI: The human condition and the limits of machine generation. Journal of Cultural Cognitive Science 9: 83–8. [Google Scholar] [CrossRef]
- Lubart, Todd. 1994. Creativity. In Thinking and Problem Solving. Cambridge: Academic Press, pp. 289–32. [Google Scholar]
- Lubart, Todd, Anatoliy V. Kharkhurin, Giovanni Emanuele Corazza, Maud Besançon, Sergey R. Yagolkovskiy, and Ugur Sak. 2022. Creative potential in science: Conceptual and measurement issues. Frontiers in Psychology 13: 750224. [Google Scholar] [CrossRef] [PubMed]
- Opara, Emmanuel. 2025. AI Is Not Intelligent. [Google Scholar] [CrossRef]
- OpenAI. 2023. Gpt-4 technical report. arXiv arXiv:2303.08774. [Google Scholar]
- Orwig, William, Emma R. Edenbaum, Joshua D. Greene, and Daniela L. Schacter. 2024. The language of creativity: Evidence from humans and large language models. The Journal of Creative Behavior 58: 128–36. [Google Scholar] [CrossRef]
- Raj, Hans, and Deepa Rani Saxena. 2016. Scientific creativity: A review of researches. European Academic Research 4: 1122–38. [Google Scholar]
- Runco, Mark A. 2023. Updating the standard definition of creativity to account for the artificial creativity of AI. Creativity Research Journal 37: 1–5. [Google Scholar] [CrossRef]
- Runco, Mark A., and Garrett J. Jaeger. 2012. The standard definition of creativity. Creativity Research Journal 24: 92–6. [Google Scholar] [CrossRef]
- Runco, Mark A., and Selcuk Acar. 2012. Divergent thinking as an indicator of creative potential. Creativity Research Journal 24: 66–75. [Google Scholar] [CrossRef]
- Sánchez-Dorado, Julia. 2023. Creativity, pursuit and epistemic tradition. Studies in History and Philosophy of Science 100: 81–9. [Google Scholar] [CrossRef]
- Si, Chenglei, Diyi Yang, and Tatsunori Hashimoto. 2024. Can llms generate novel research ideas? A large-scale human study with 100+ nlp researchers. arXiv arXiv:2409.04109. [Google Scholar]
- Sternberg, Robert J. 2024. Do not worry that generative AI may compromise human creativity or intelligence in the future: It already has. Journal of Intelligence 12: 69. [Google Scholar] [CrossRef] [PubMed]
- Sternberg, Robert J., and Karin Sternberg. 2017. Measuring scientific reasoning for graduate admissions in psychology and related disciplines. Journal of Intelligence 5: 29. [Google Scholar]
- Sternberg, Robert J., and Linda A. O’Hara. 2000. Intelligence and creativity. In Handbook of Intelligence. Edited by R. J. Sternberg. Cambridge: Cambridge University Press, pp. 611–30. [Google Scholar]
- Vinchon, Florent, Valentin Gironnay, and Todd Lubart. 2024. GenAI Creativity in Narrative Tasks: Exploring New Forms of Creativity. Journal of Intelligence 12: 125. [Google Scholar] [CrossRef] [PubMed]
- Wang, Qingyun, Lifu Huang, Zhiying Jiang, Kevin Knight, Heng Ji, Mohit Bansal, and Yi Luan. 2019. PaperRobot: Incremental draft generation of scientific ideas. arXiv arXiv:1905.07870. [Google Scholar]
| Variable | Q1 Adequate | Q2 Falsification | Q3 Validity | Q4 Logic | Q5 Adequate | Q6 Originality | Q7 Meaningfulness |
|---|---|---|---|---|---|---|---|
| ICC | 0.606 | 0.876 | 0.684 | 0.453 | 0.56 | 0.7 | 0.621 |
| Range R1 | 2.0 | 4.0 | 4.0 | 3.0 | 3.0 | 4.0 | 3.0 |
| Range R2 | 4.0 | 4.0 | 1.0 | 2.0 | 1.0 | 2.0 | 1.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Eymann, V.; Lachmann, T.; Czernochowski, D. When ChatGPT Writes Your Research Proposal: Scientific Creativity in the Age of Generative AI. J. Intell. 2025, 13, 55. https://doi.org/10.3390/jintelligence13050055
Eymann V, Lachmann T, Czernochowski D. When ChatGPT Writes Your Research Proposal: Scientific Creativity in the Age of Generative AI. Journal of Intelligence. 2025; 13(5):55. https://doi.org/10.3390/jintelligence13050055
Chicago/Turabian StyleEymann, Vera, Thomas Lachmann, and Daniela Czernochowski. 2025. "When ChatGPT Writes Your Research Proposal: Scientific Creativity in the Age of Generative AI" Journal of Intelligence 13, no. 5: 55. https://doi.org/10.3390/jintelligence13050055
APA StyleEymann, V., Lachmann, T., & Czernochowski, D. (2025). When ChatGPT Writes Your Research Proposal: Scientific Creativity in the Age of Generative AI. Journal of Intelligence, 13(5), 55. https://doi.org/10.3390/jintelligence13050055