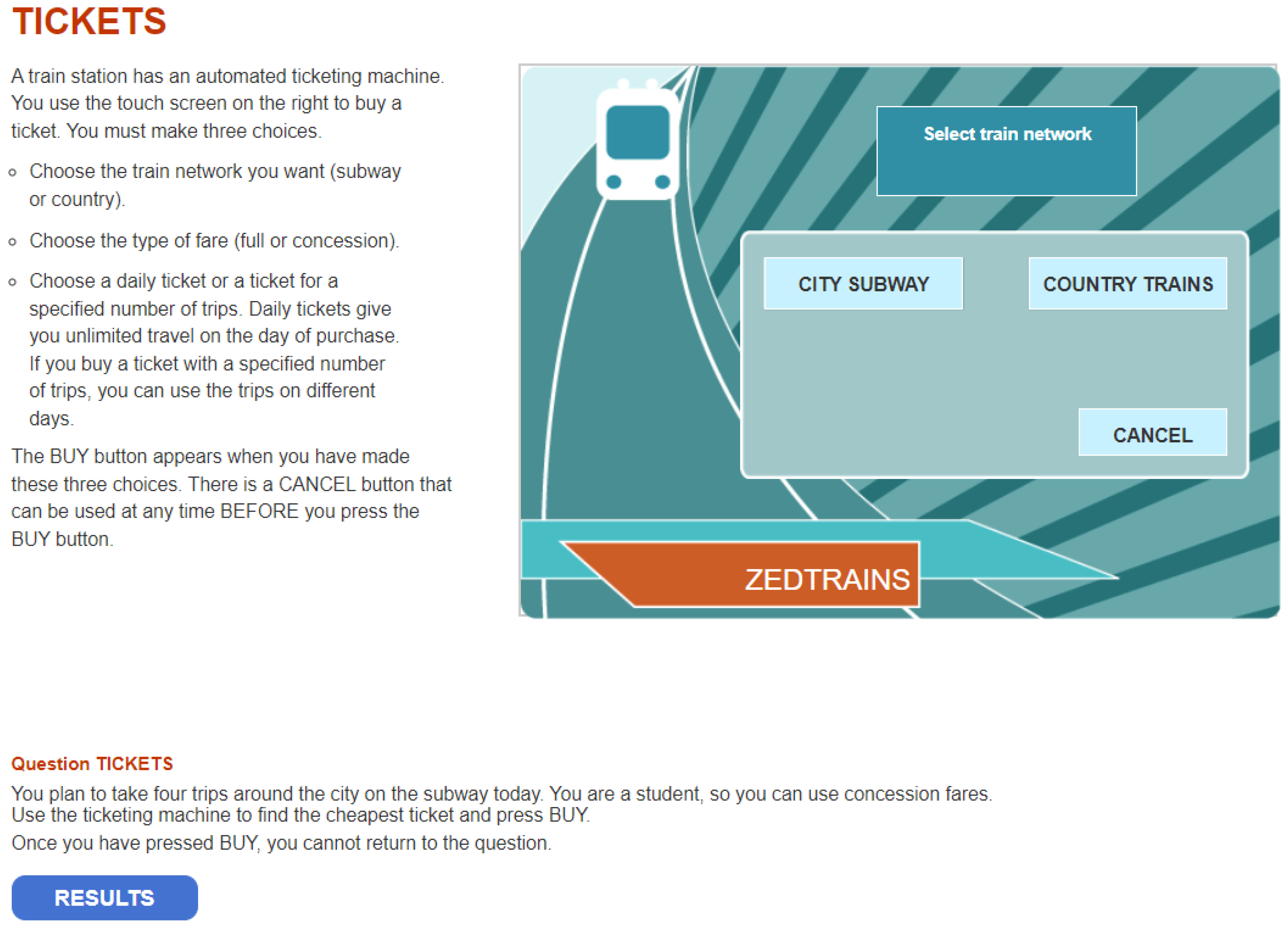
1. Introduction
Complex problem-solving (CPS) is a crucial skill in real-life settings that requires an individual to complete dynamic tasks by exploring and integrating information (
Buchner 1995) and by using the obtained information to solve the task (
Simon and Newell 1971). To assess CPS skills, researchers have suggested using interactive tasks in simulated problem-solving scenarios (
Funke 2001). Some large-scale assessments, such as the Programme for the International Assessment of Adult Competencies (PIAAC;
OECD 2013) and the Programme for International Student Assessment (PISA;
OECD 2014), have utilized computer-based interactive tasks that mimic real-life problem-solving scenarios (
Goldhammer et al. 2013). Computer-based assessments offer the opportunity to collect and log a new source of behavioral data related to the process of problem-solving. Typically, this data includes the time-stamped sequence of actions recorded by the computer system as the individual pursues to solve the task (
Bergner and von Davier 2019;
OECD 2013). The new type of data is commonly referred to as process data or log file data (
Greiff et al. 2016;
Tang et al. 2021). Compared with the traditional correct/incorrect response data on final outcome, process data can provide rich additional information that sheds light into the test takers’ problem-solving process, informing both assessment design and education (
He et al. 2021,
2019;
He and von Davier 2015,
2016).
Despite the richness of information, process data come often in a non-standard format, which can introduce complications to their analysis. Over the past decade, there has been a high demand for more innovative tools to handle this type of data (
von Davier et al. 2022). Feature extraction plays an important role in analyzing the process data, and there are two commonly used approaches. The first approach is theory-based feature extraction, which involves obtaining behavioral indicators based on established substantive theories (
Harding et al. 2017;
Yuan et al. 2019). These methods often define task-specific features and require input and validation from domain experts. The second approach is data-driven feature extraction, which involves extracting features directly from the data without relying on substantive theories (
He et al. 2022;
Qiao and Jiao 2018;
Tang et al. 2020,
2021;
Ulitzsch et al. 2022). This approach utilizes statistical and machine learning techniques to identify patterns and relevant features in the process data. This presents a data-driven way for the identification of potentially meaningful sequential patterns that provide insights into strategies and cognitive processes. In addition to feature extraction from action sequences, methods for incorporating additional timing information have also been proposed, providing a more comprehensive investigation of examinees’ interactions (
Tang et al. 2021;
Ulitzsch et al. 2021).
Process features extracted from log files are often high-dimensional and sometimes lack direct interpretations. To uncover substantively meaningful latent structures that reflect individual differences in problem-solving, a popular approach from unsupervised machine learning is clustering algorithms. Clustering is commonly applied to the exploratory analysis of process data, aiming to identify groups that exhibit distinct interactions with the tasks (
He et al. 2019;
Qiao and Jiao 2018;
Ren et al. 2019;
Ulitzsch et al. 2021). For instance, the widely used k-means method has been applied to analyze process data in PISA and PIAAC assessments, respectively, based on actions, the length of action sequences, and time spent on the item (
He et al. 2019;
Qiao and Jiao 2018). Furthermore, researchers have also adopted more sophisticated or robust clustering methods. For example, the partitioning around medoids (PAMs) algorithm (
Reynolds et al. 2006) was employed to explore the important role of multiple goals in the “Ticket” task in the PISA 2012 CPS test (
Ren et al. 2019), and the
k-medoids algorithm (
Kaufman 1990) was proposed for analyzing item CR551Q11 in the reading Rapa Nui unit in the PISA 2018 test (
He et al. 2022). These more advanced clustering approaches aim to improve the accuracy and effectiveness of extracting meaningful patterns and insights from the process data.
Clustering techniques like hierarchical clustering and k-means clustering algorithms (
Sokal and Michener 1958) are often rigid as they typically aim to find similarities considering all features of the subjects (
Aluru 2005). The method of clustering data matrices applied in one direction is commonly referred to as one-mode clustering (
Shojima 2022). However, when the number of features increases, the performance of these clustering methods may be poor: Intuitively, in the process data, certain behavioral patterns are commonly observed among a group of examinees under specific features. When the dimension of process features is high, different subsets of features may carry information on different kinds of individual differences in problem-solving patterns. In addition, there could be subsets of features that contain irrelevant information for clustering of examinees. Clustering based on individual differences in the full feature space would potentially mask these nuanced differences on specific dimensions. For instance, for the “Ticket” task in the PISA 2012 CPS test, through k-medoids clustering on the response time features,
Park et al. (
2023) found the significant role of time-based features in characterizing students’ learning styles. However, the time-related features did not demonstrate an advantage as expected in the one-mode clustering method, k-means method when clustering the time-based features and action sequences simultaneously (
Qiao and Jiao 2018). In these cases, variable selection on the process features used for clustering could potentially improve the interpretability and within-cluster homogeneity in identified subgroups (
Park et al. 2023). To overcome the limitations of one-mode clustering, biclustering algorithms have been introduced and widely studied over the last two decades (
Cheng and Church 2000;
Gan et al. 2008;
Gupta and Aggarwal 2010;
Ihmels et al. 2002;
Prelić et al. 2006;
Tanay et al. 2002;
Zhang et al. 2010). Biclustering algorithms cluster the rows and columns of a data matrix simultaneously, allowing for more flexible and meaningful groupings of the data (
Madeira and Oliveira 2004). Therefore, the biclustering algorithm is also referred to as two-mode clustering, signifying the approach of clustering data matrices in two directions (
Shojima 2022). By considering both row and column clustering, biclustering methods can capture more specific and context-dependent patterns in the data, making them particularly useful for certain types of datasets and analysis tasks.
The aim of this study is to assess the performance of biclustering algorithms in analyzing process data and to understand the local homogeneity in the biclusters considering the importance of time-based features and action sequences simultaneously. In this paper, we conduct a comparative analysis of the capabilities of various biclustering algorithms in analyzing the process data. Specifically, we selected four popular and commonly used biclustering algorithms, including the binary inclusion-maximal biclustering algorithm (BIMAX;
Prelić et al. 2006), factor analysis for bicluster acquisition (FABIA;
Girolami 2001;
Hochreiter et al. 2010;
Palmer et al. 2005) with Laplace prior, spectral biclustering (
Murali and Kasif 2002), and
Cheng and Church’s (
2000) biclustering algorithm (referred to as BCCC). We applied these biclustering algorithms along with the one-mode k-means algorithm to the “Ticket” task in the PISA 2012 CPS test. Through various evaluations, we identified the best-fitting clustering algorithm. The clustering results obtained from the best-fitting method were used to interpret timing and behavioral sequence patterns. Through comparison with the scores and results from one-mode clustering algorithms, we examine the utility of biclustering algorithms in analyzing the log file data. With these objectives, three specific research questions are as follows:
- RQ1.
What are the representative biclusters from simultaneously clustering based on the
time-based features and action sequence features? Which important features have been utilized across different biclusters?
- RQ2.
Is there any association between the resulting biclusters and students’ CPS performance?
- RQ3.
What are the similarities and differences in biclusters and clusters, using the selected
biclustering and clustering algorithms?
The remainder of this paper is organized as follows. In
Section 2, we introduce the “Ticket” task from the PISA 2012 CPS assessment under study, followed by a description of the participants and data sets utilized in this study. Additionally, in this section, we describe the biclustering algorithms and the evaluation metrics used for comparison. In
Section 4, we discuss the testing configurations and present the results of the comparative analysis. Furthermore, we provide detailed interpretations of the biclustering patterns observed considering the timing data and action sequences. Finally, we conclude with a discussion that includes the implications and future directions.
3. Data Analysis
Here, we outline the procedures taken in the current study to apply biclustering to the analysis of CPS log data. The procedures can be broken into 6 steps:
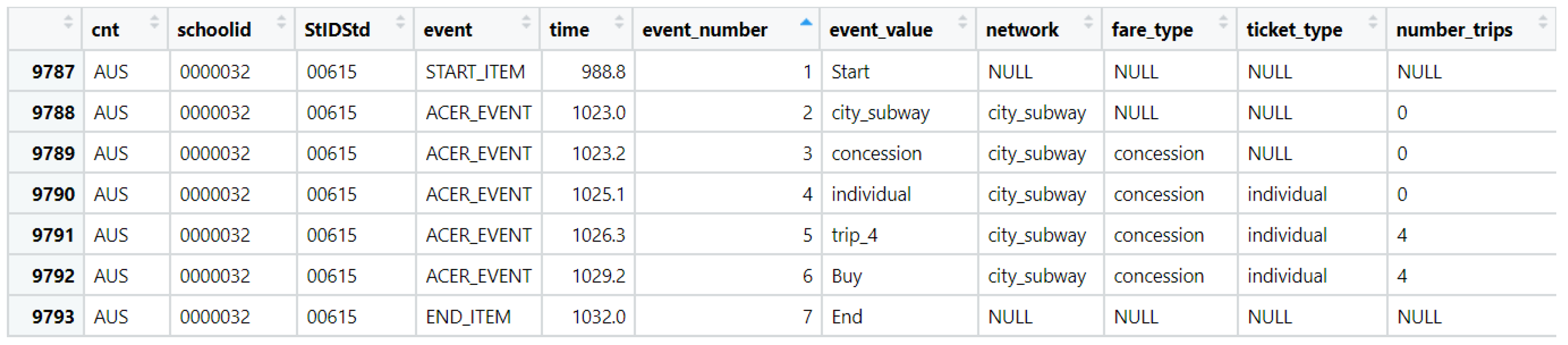
3.1. Procedure 1: Specification of Features
Before implementing biclustering, the first step is to specify the data matrix of features in the CPS data. In this article, we employed the features defined in
Qiao and Jiao (
2018) shown in Table 1 in
Qiao and Jiao (
2018) and
Figure 2. These 36 features, consisting of 32 action-based features and 4 time-based features, were derived in a theory-driven manner, where actions and subsequences in the log data with potential relationship with the measured construct of CPS were preserved. Such theory-driven feature engineering aids the interpretability of in subsequent clustering.
3.2. Procedure 2: Pre-Processing of Input
In our analysis, we chose not to standardize the features used in both clustering and biclustering to preserve the original scale of the data. As depicted in
Figure 2, the values of time-based features are notably larger than those of the action sequences. Standardization, in this case, would bring the action sequence and time-based features onto the same scale. However, preserving the original scale of the data, which captured presence/absence/frequency of actions and time spent, is crucial for meaningful interpretation within the context of complex problem-solving assessment.
It’s worth noting that some biclustering algorithms perform feature preprocessing within the algorithm. For instance, the BIMAX algorithm dichotomizes the input data matrix and subsequently seeks submatrices, followed by a post-processing step to restore the original data matrix. The Spectral and FABIA methods employ standardization based on a standard normal distribution. Conversely, the BCCC method does not apply any feature transformation during preprocessing.
3.3. Procedure 3: Configuration Testing and Selection of Biclustering Methods
In this procedure, the parameter settings for the BIMAX, FABIA, Spectral and BCCC algorithms were optimally set to the default values based on the aforementioned internal measures. For the BIMAX and FABIA algorithms, the number of possible biclusters varied from 2 to 30, as presented in
Table A1 and
Table A2. The aforementioned evaluation metrics including VAR, MSR, and VE, were employed to select the optimal number of clusters for BIMAX and FABIA algorithms. Further, evaluation metrics were employed to compare BIMAX, FABIA, Spectral and BCCC algorithms as well as k-means clustering.
3.4. Procedure 4: Interpret the Homogeneous Biclusters and Contribution of Features
First, under biclustering, subsets of features were utilized in different biclusters resembling sparsity. Therefore, the overall contribution of a feature was evaluated based on the number of times the feature was included across all the biclusters. Furthermore, to explain each bicluster, we examined the features included in the bicluster, as well as the magnitude on these features for examinees within the bicluster. A homogeneous bicluster contains examinees who are similarly high (or low) on the included features. In the analysis of the PISA CPS data, we picked several representative biclusters that exhibited high homogeneity on the selected features, to illustrate how the identified biclusters could be interpreted.
3.5. Procedure 5: Track the Association between the Biclusters and Scores
Based on the selected optimal biclustering solution, the distribution of scores was analyzed within each bicluster. Further, through the level of scores, biclusters were classified into four different types, including clusters that corresponded to scores of 0, 1, 2, or a mix of different scores.
3.6. Procedure 6: Comparison between the Biclustering and One-Mode Clustering
Finally, to understand the similarity and differences in grouping of examinees based on biclustering versus k-means clustering, we cross-tabulated the examinees’ memberships in biclusters with their memberships in the clusters identified based on k-means clustering.
4. Results
This section discusses the findings from applying biclustering to the PISA CPS data. BIMAX, FABIA, Spectral, and BCCC were applied using two R packages:
biclust (
Kaiser et al. 2015), and
fabia (
Hochreiter and Hochreiter 2013). Additionally, we compared these biclustering algorithms with clustering based on k-means. The k-means clustering was carried out using the
“k-means” function in the R package
stats (
R Core Team 2022).
4.1. Biclusters Identified from PISA CPS Ticket Item
4.1.1. Testing Configurations
To facilitate the comparison among these algorithms, we commenced by selecting the optimal number of clusters for each algorithm. As
Table A1 and
Table A2 showed, the criteria VAR, MSR, and VE consistently indicated the optimal solutions for the BIMAX and FABIA algorithms. Specifically, the twelve-bicluster solution for BIMAX and the ten-bicluster solution for FABIA demonstrated the lowest values across all three criteria. These findings strongly suggest that participants should be clustered into twelve and ten clusters, respectively, when utilizing the BIMAX and FABIA algorithms. For the Spectral algorithm, we determined the number of eigenvalues considered to find biclusters based on our internal measures and ultimately chose 2 as the optimal number. On the other hand, for the BCCC algorithm, we set the target number of biclusters to be found as 100.
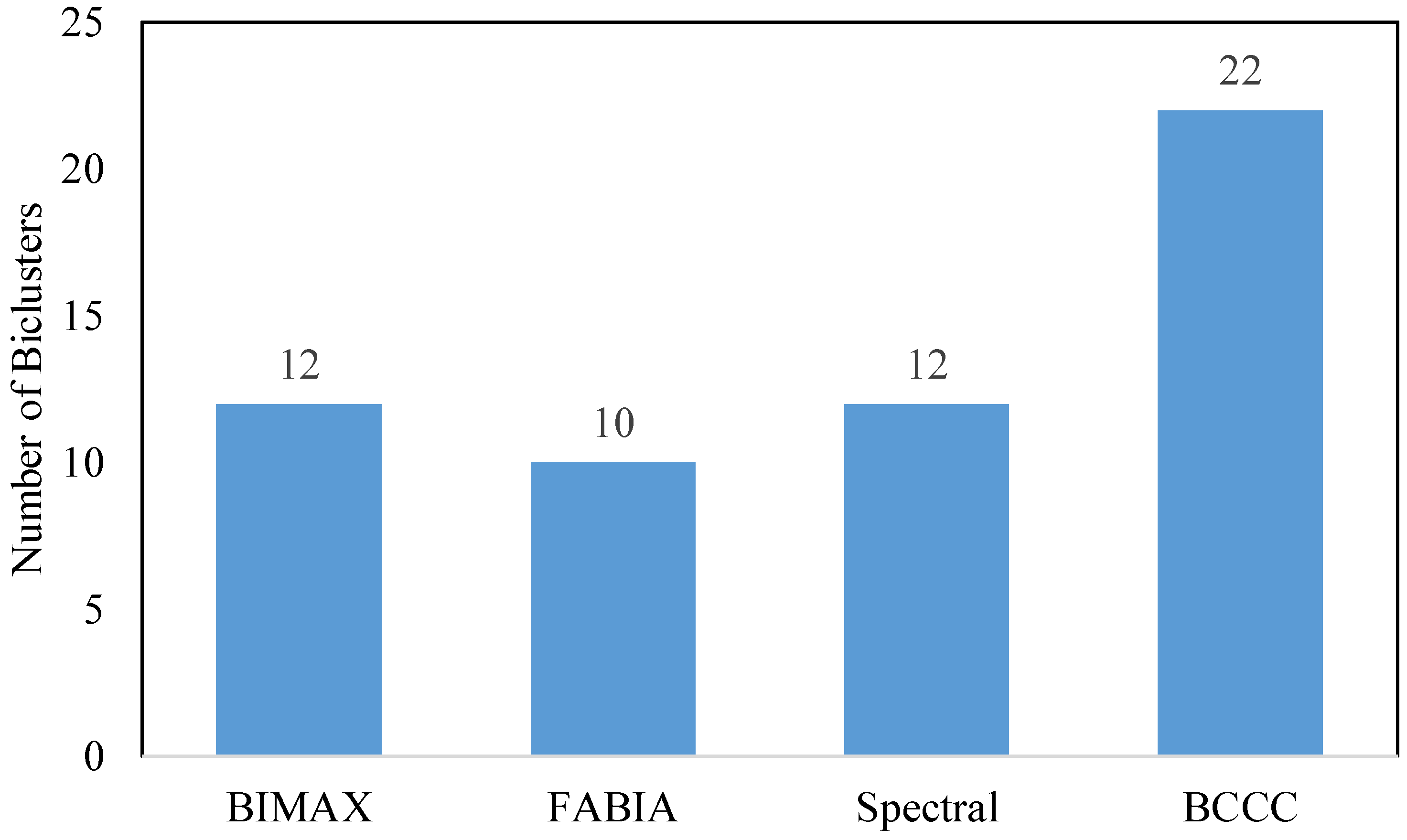
Figure 4 visually illustrates the results of our analysis, indicating that the Spectral algorithm identified 12 clusters, while the BCCC algorithm detected a total of 22 clusters.
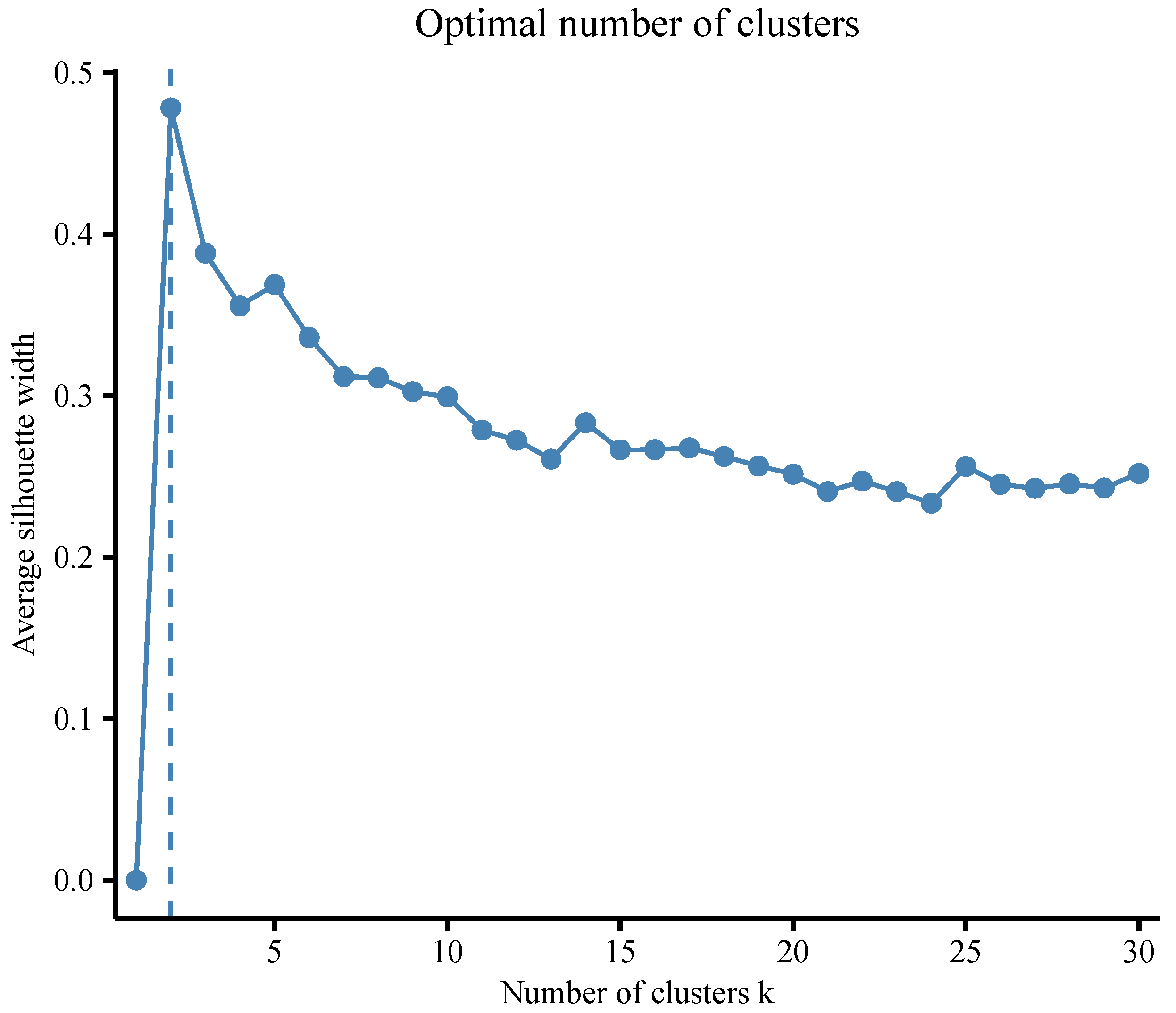
For the k-means method, we considered a maximum of 30 clusters to be found. We employed two different criteria to determine the optimal number of clusters. The first criterion was the average silhouette width, which is a commonly used measure. We employed the NbClust method to determine the optimal number of clusters for the data set using the
“fviz_nbclust” function in the R package
factoextra (
Kassambara and Mundt 2017). We calculated the average silhouette width for cluster numbers ranging from 1 to 30 and depicted the relationship in
Figure 5. Notably, the two-cluster solution exhibited the highest silhouette width, indicating that two clusters would be the optimal choice. The second criterion utilized was the evaluation of VAR, MSR, and VE.
Table A3 presents the mean values of VAR for different cluster numbers, which aligned with the results depicted in
Figure 5, suggesting that the optimal number of clusters was also two according to VAR. However, when considering the criteria MSR and VE, different solutions emerged. MSR identified a total of 20 clusters as the optimal configuration, while VE suggested a higher number of clusters, specifically 29.
Based on the optimal clusters selected from the analysis, the comparison results across different biclustering and clustering methods are presented in
Table 1. Regarding VAR, the BIMAX method was identified as the best-performing method. However, when considering the criteria of MSR and VE, the BCCC method consistently outperformed the other clustering methods. This suggests that the BIMAX method’s ability to discover high-quality biclusters may be limited since it yielded the highest values for the more appropriate measures MSR and VE. Additionally, both the Spectral and FABIA methods encountered similar challenges when considering the MSR and VE criteria. Their factorization-based approach primarily focuses on detecting specific types of bicluster structures, which restricts their ability to find diverse biclusters. Therefore, the BCCC method was suggested as the optimal clustering method in this study.
Furthermore,
Table 1 demonstrates that all the biclustering methods exhibited smaller values of VAR within clusters compared to the k-means method. This observation suggests that biclustering techniques tend to generate more homogeneous structures compared to one-mode clustering approaches.
4.1.2. Contribution of Features
The primary aim of biclustering is to cluster both rows and columns of a data matrix simultaneously to discover homogeneous submatrices. With this approach, these techniques can potentially identify overlapping submatrices (
Padilha and Campello 2017). Consistent with results of
Padilha and Campello (
2017), among the four selected methods, varying degrees of overlap were observed in the features. However, the BCCC and FABIA biclustering methods did not reveal any overlap among examinees, while the other two methods identified a significant amount of overlap.
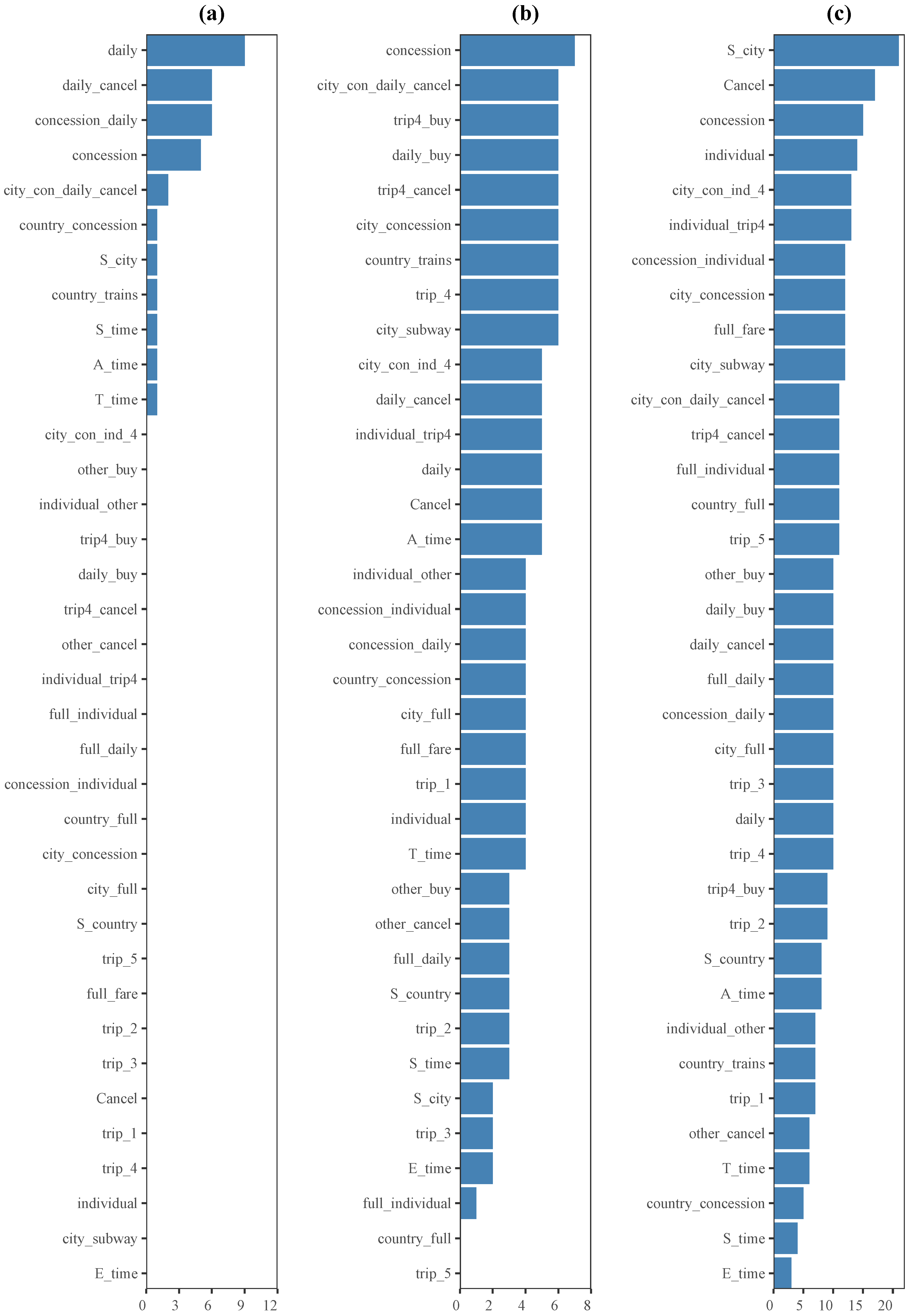
Figure 6 shows the frequency of features across clusters for different biclustering methods. As for the Spectral method, each of the 36 features was used four times, hence the results are not presented in
Figure 6. The BIMAX method utilized only 11 out of 36 features to identify biclusters, while the FABIA and BCCC methods employed 34 and 36 features, respectively. Furthermore, in the case of the k-means method, all 36 features were utilized to find each cluster. This indicates that the k-means method considered the entirety of the available features without any feature selection or exclusion. Consequently, each feature contributed to the clustering process, and no specific feature was deemed less important or excluded from consideration.
From
Figure 6, it could be concluded that the feature
city_con_daily_cancel played a significant role in the biclustering algorithms, which was consistent with the findings in
Qiao and Jiao (
2018). Moreover, in line with the phantom items defined by experts in
Zhan and Qiao (
2022), certain action sequences such as
concession,
Cancel, and
city_concession were also identified as important features for identifying coherent biclusters. Overall, these results suggest that biclustering algorithms strive to strike a balance between interpretability and data mining outcomes.
Note that these biclustering algorithms could select not only frequently used features for students but also those features that students would not typically utilize. For instance, in the case of the BCCC algorithm depicted in
Figure 6, the feature
full_fare was identified as one of the top nine frequently occurring features. However, this item specifically asked students to purchase a concession ticket, making it a distractor. Out of the total of 3760 students, 3192 students did not use this option at all, and only 11 students attempted to use
full_fare button more than five times. This finding aligns with the nature of biclustering algorithms, which tend to prioritize the identification of coherent biclusters. The same observation applies to the
country_concession feature in the BIMAX algorithm and the
country_trains feature in the FABIA algorithm, respectively.
Furthermore, it is worth highlighting that the time-related features, including
T_time,
A_time,
S_time, and
E_time, were consistently selected as important features for achieving coherence among the biclusters in
Figure 6. This suggests that there exists a similarity in terms of time-based patterns within certain coherent clusters. The significance of time-related features in classification is to be expected, since time intuitively plays a crucial role in problem-solving and learning dynamics. This finding is also consistent with the observations in
Wu and Molnár (
2022), where the presence of rapid learners in complex problem-solving scenarios was identified. Therefore, the inclusion of time-related features further enhances the understanding of students’ behaviors and performance in the context of the analysis.
4.2. Explanation of Representative Biclusters
Based on the results presented in
Section 4.1, the BCCC method was selected as the optimal biclustering algorithm. Consequently, in the following subsections, we specifically focus on conducting an in-depth analysis based on the clustering results obtained from the BCCC method.
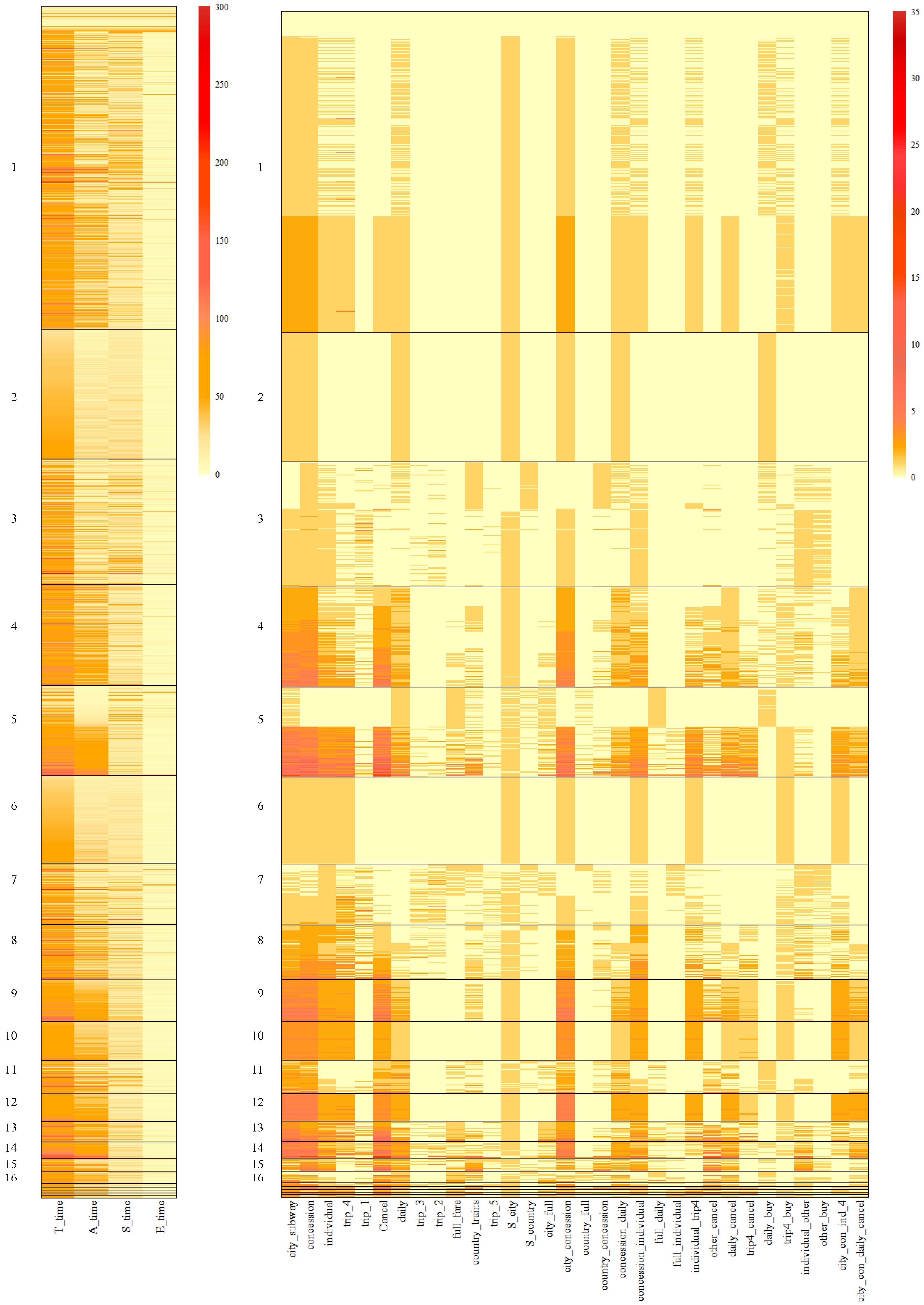
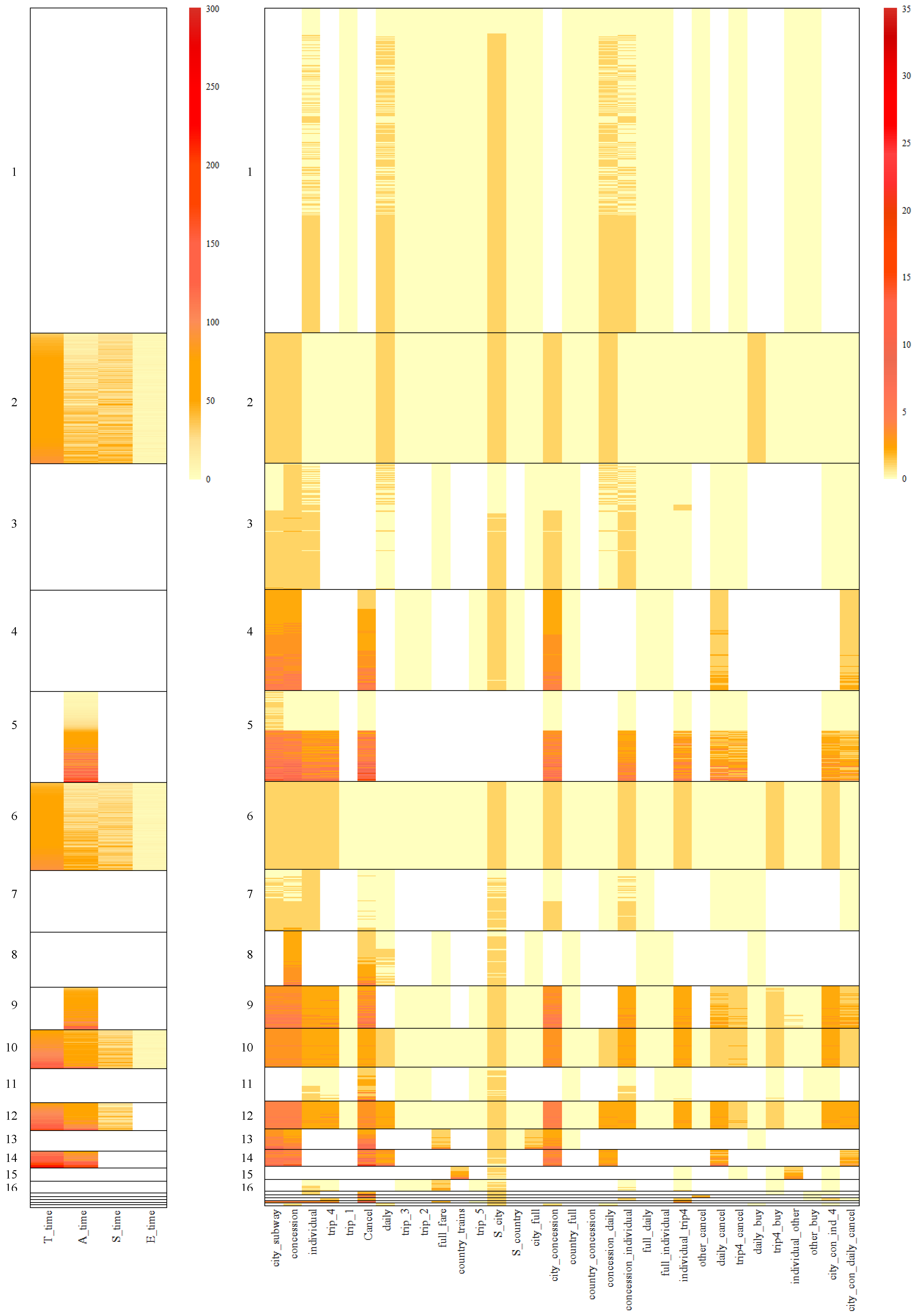
Figure 7 and
Figure 8 depict the specific performances of features for different clusters based on the results of the BCCC method. Additionally,
Table A4 and
Table A5 in the appendix offer the feature averages for each bicluster based on the outcomes of the BCCC method. Specifically,
Figure 7 provides a summary of all the features, while
Figure 8 presents the summary of the selected features within a specific cluster in the BCCC method.
First, comparing
Figure 7 and
Figure 8, we can observe that the features that were excluded in each bicluster typically exhibited larger within-cluster heterogeneity. For example, for time-based features, only
A_time was preserved in Cluster 9, and other time-based features presented a high variability, as indicated by bars of various colors in
Figure 7. In comparison, all the time-based features were preserved in Cluster 10, where individuals within the cluster were highly similar on these features. Similar trends were observed for Clusters 9 and 10 on action-based features. For example,
daily and
country_trains were excluded in Cluster 9.
When a feature was included in a bicluster, the average within-cluster magnitude on the feature could either be high or low. For example, in Clusters 9 and 10, features city_subway and concession exhibited homogeneity with high average values, while features trip_1 and country_full exhibited homogeneity with low values, suggesting that individuals within these biclusters seldom performed these two subsequences.
Comparing Clusters 9 and 10, it can be observed that on the included features, the magnitudes across these two clusters were relatively similar. In particular, examinees in both biclusters showed homogeneity on performing subsequences necessary for full credit, i.e., Start–city–subway–concession–individual–trip4, Start–city–subway–concession–daily, and Cancel. The difference between the two biclusters primarily lied in the included feature set. For Cluster 10, all action and time features were included, while Cluster 9 excluded three time features as well as action features that pertained to subsequences less relevant to the correct response (e.g., ones involving clicking daily and country). Individuals in Cluster 9 demonstrated greater heterogeneity on these less relevant actions, despite that they performed the necessary steps for completing the task after all.
4.3. Relationship between Biclusters and Performances
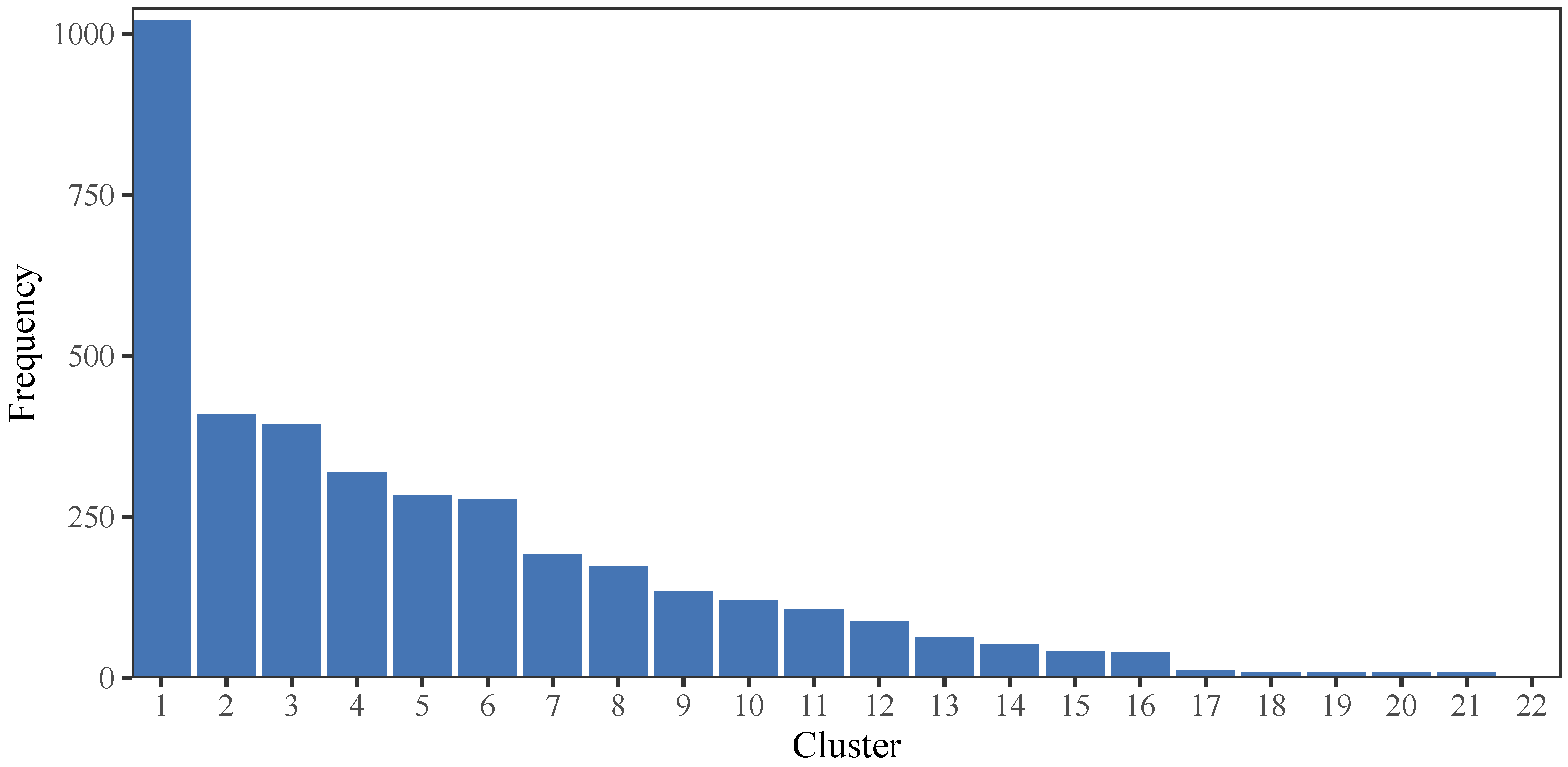
Figure 9 presents the number of examinees in each cluster under the BCCC method. Firstly, we ranked the clusters based on the number of examinees in each cluster in decreasing order. As depicted in
Figure 9, Cluster 1 contains the highest number of examinees, with a total of 1021 individuals, whereas Cluster 22 consists of only 2 examinees, which is the lowest among all clusters.
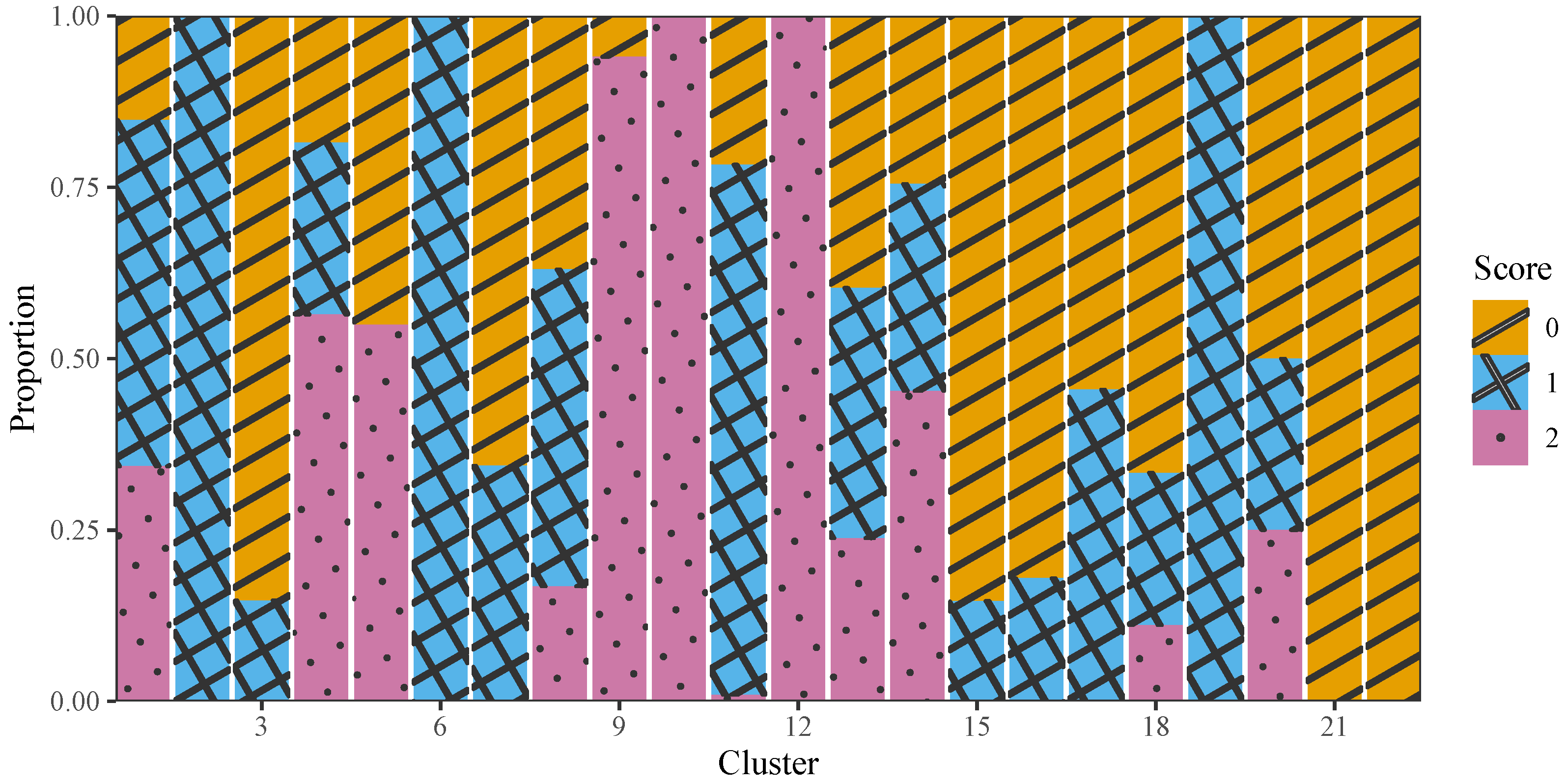
Figure 10 depicts a visual representation of the distribution for scores across various levels within each cluster, based on the BCCC method. Specifically, one observes distinct patterns in the score distribution across clusters. In particular, all the examinees in Clusters 10 and 12 answered the question correctly and achieved the full score of 2. Additionally, almost all examinees in Cluster 9 obtained the full score of 2. On the other hand, Clusters 2, 6, and 19 contained examinees who received partial credit with a score of 1, suggesting these examinees were able to purchase the correct type of ticket, without implementing the price comparison. In contrast, all the examinees in Clusters 21 and 22 and a high proportion of examinees in Cluster 3 displayed the lowest scores 0, which may indicate failure to execute the task based on the explicit requirements.
The remaining clusters (such as Clusters 1, 4, 5, and 20) exhibited a mixture of scores among the students as
Figure 10 shows. This suggests some degree of homogeneity in the actions or timing patterns among the students within these clusters, despite receiving different scores. This observation can be attributed to the biclustering algorithm, which primarily focuses on students’ problem-solving strategies from a behavioral perspective. This PISA ticket item was designed to assess exploring and understanding, requiring students to adopt a targeted exploration strategy and to synthesize the information about prices of different alternatives (
OECD 2014). Thus, students with different levels of proficiency on exploring and understanding may produce diverse results, even if they employ similar actions (
Wu and Molnár 2022).
4.3.1. Biclusters with Full Score
Clusters with a higher proportion of perfect scores, a full score of 2, demonstrated mostly homogeneous structures in their action sequences. As
Figure 8 showed, in Clusters 9, 10, and 12, the essential actions in
Start–city–subway–concession–individual–trip4,
Start–city–subway–concession–daily, and
Cancel were frequently utilized, while the irrelevant buttons were seldom chosen. From a behavioral perspective, this indicates that these students did compare the prices of individual tickets for four trips and a daily ticket, then finally made a correct decision to buy the cheaper one. Furthermore, examinees in Cluster 9 made more attempts to use the
Cancel button compared to the other two clusters. Examinees in Cluster 12 used feature
city_concession more frequently compared to the other two clusters.
4.3.2. Biclusters with Partial Score
Furthermore, clusters with a higher proportion of partial scores also exhibited homogeneous strategies. For instance, examinees in Cluster 2 utilized the key action sequence Start–city–subway–concession–daily, while rarely used other buttons. This indicates that these students purchased a daily ticket with minimum additional explorations, including comparing it to the prices of individual tickets. Similarly, examinees in Clusters 6 and 19 frequently employed the key action sequence Start–city–subway–concession–individual–trip4, while rarely using other buttons. This implies that these students bought individual tickets for four trips but did not compare them to the prices of a daily ticket. However, examinees in Cluster 19 used the Cancel button more frequently, whereas examinees in Cluster 6 rarely used it.
4.3.3. Biclusters with a Score of 0
Examinees in Cluster 3 exhibited relatively homogeneous structures in the action sequence, Start–city–subway–concession, but then became divided on the subsequent choices of daily or individual. They additionally lacked consecutive actions, where key subsequences including city_con_ind_4 and city_con_daily_cancel were rarely chosen. As a result, the majority of examinees in Cluster 3 obtained a score of 0. Furthermore, examinees in Cluster 22 demonstrated homogeneous structures by repeatedly attempting the features full_fare, trip_5, and full_individual for a long time, which also resulted in all of them obtaining a score of 0. In summary, examinees who scored 0 displayed more diversified strategies in the problem-solving process compared to individuals who answered correctly.
4.3.4. Biclusters with a Mixture of Scores
Interestingly, we have also observed some similarities in clusters that include a mixture of scores. For instance, in Cluster 4, examinees made multiple attempts on the action sequence city_con_daily_cancel, particularly focusing on the features city_subway, city_concession, and Cancel. Remarkably, many of these students still managed to provide correct responses despite their numerous attempts. Similar findings can be observed in Cluster 5, where students made multiple attempts to compare the action sequences Start–city–subway–concession–individual–trip4 and Start–city–subway–concession–daily for a longer action time.
4.4. Comparison of the Biclustering and Clustering Solutions
4.4.1. Homogeneity in Time-Based Features
Compared to one-mode k-means clustering, in addition to its effectiveness in clustering examinees, biclustering did indeed highlight the significant role of time-related features, as expected. Specifically, it is evident that time-based features, including features
T_time,
A_time,
S_time,
E_time, did play a crucial role in the BCCC method, as colors have segregated into distinct layers among different clusters, particularly concerning the total time of action. The results presented in
Figure 8 offer a clearer visualization of this.
Despite the fact that examinees in Cluster 9, 10 and 12, achieved perfect scores, their usage of time varied. Examinees in Cluster 10 showed homogeneity in terms of total time, action time, and relatively low start and end times. However, examinees in Cluster 12 exhibited similarity in time features except for the end time, while examinees in Cluster 9 displayed similarity only in the action time. This suggests the presence of homogeneity in time-based features within different clusters.
Additionally, there were differences in the time utilization between Cluster 6 and 19, with examinees in Cluster 19 taking longer total and action times to solve the problem compared to those in Cluster 6. To some extent, this suggests that examinees in Cluster 6 made decisions more decisively than those in Cluster 19.
4.4.2. Degree of Similarity of Biclustering and Clustering
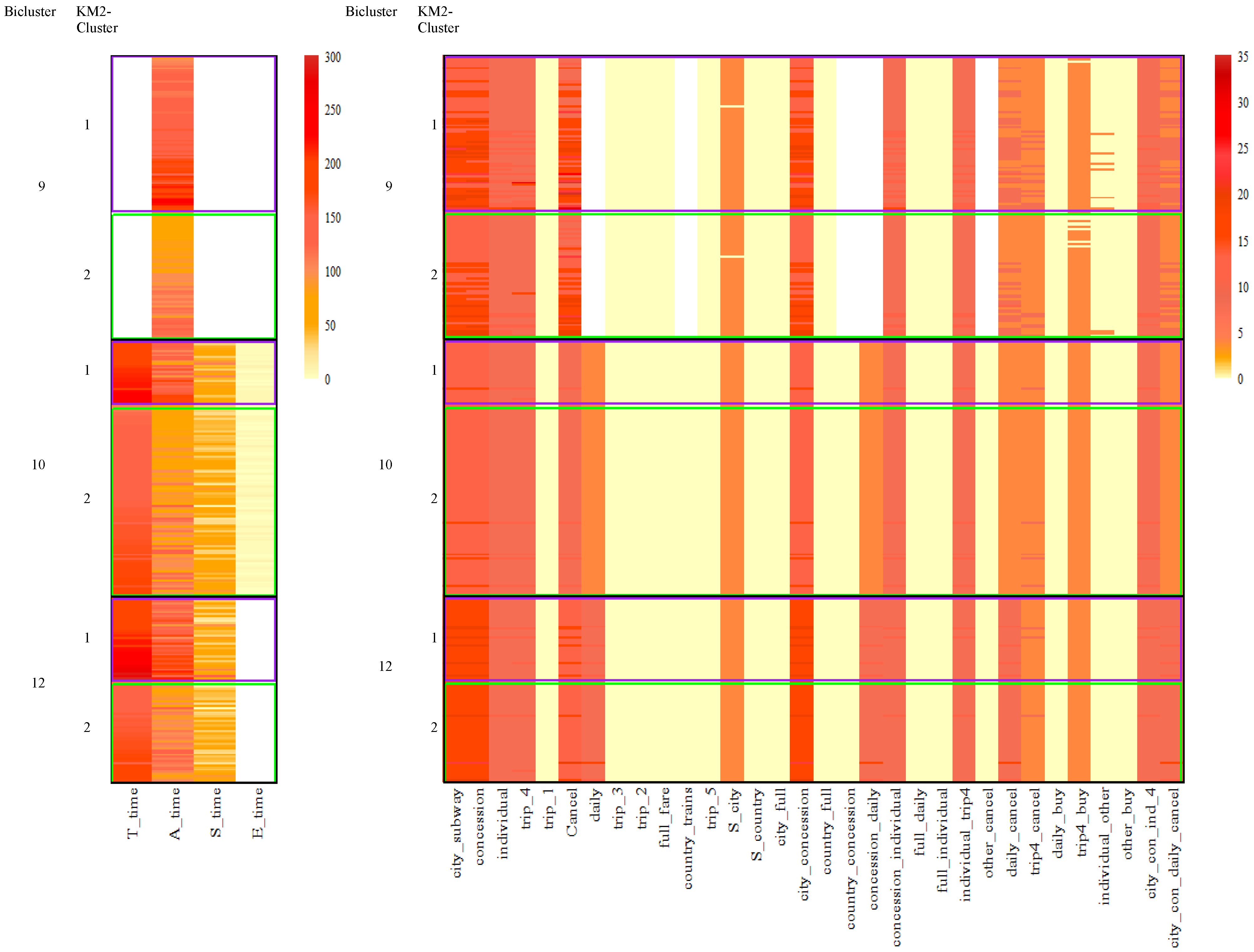
In
Table 2, cross-tabulations are presented between student memberships derived from biclusters and categories generated by the k-means method given two clusters. For instance, among the 134 students in Bicluster 9, 74 were assigned to the first k-means cluster, while 60 were assigned to the second k-means cluster. Therefore,
Table 2 presents the relationship between two groups of biclusters and k-means solution under two clusters. For clusters with a higher proportion of perfect scores, Clusters 9, 10 and 12 were nearly equally represented in both categories KM2-Cluster1 and KM2-Cluster2. However, for clusters with a higher proportion of partial scores, all the students in Clusters 2 and 6 presented in the second category KM2-Cluster2 and Cluster 19 were mostly present in the second category KM2-Cluster2.
Figure 11 provided the feature heatmap of biclusters 9, 10 and 12, crossed with the results from
k-means given two clusters. Cluster 10 showed homogeneity considering all the features as k-means method did. However, within Cluster 10, the sequence patterns of KM2-Cluster1 and KM2-Cluster2 were very similar, although slight differences were found on selecting timing features. The same trend showed up in Clusters 9 and 12. Further, the biclustering algorithm differentiated the three clusters considering the subset of features. Cluster 9 removed several features from action sequences for biclustering, and Cluster 12 excluded a time feature.
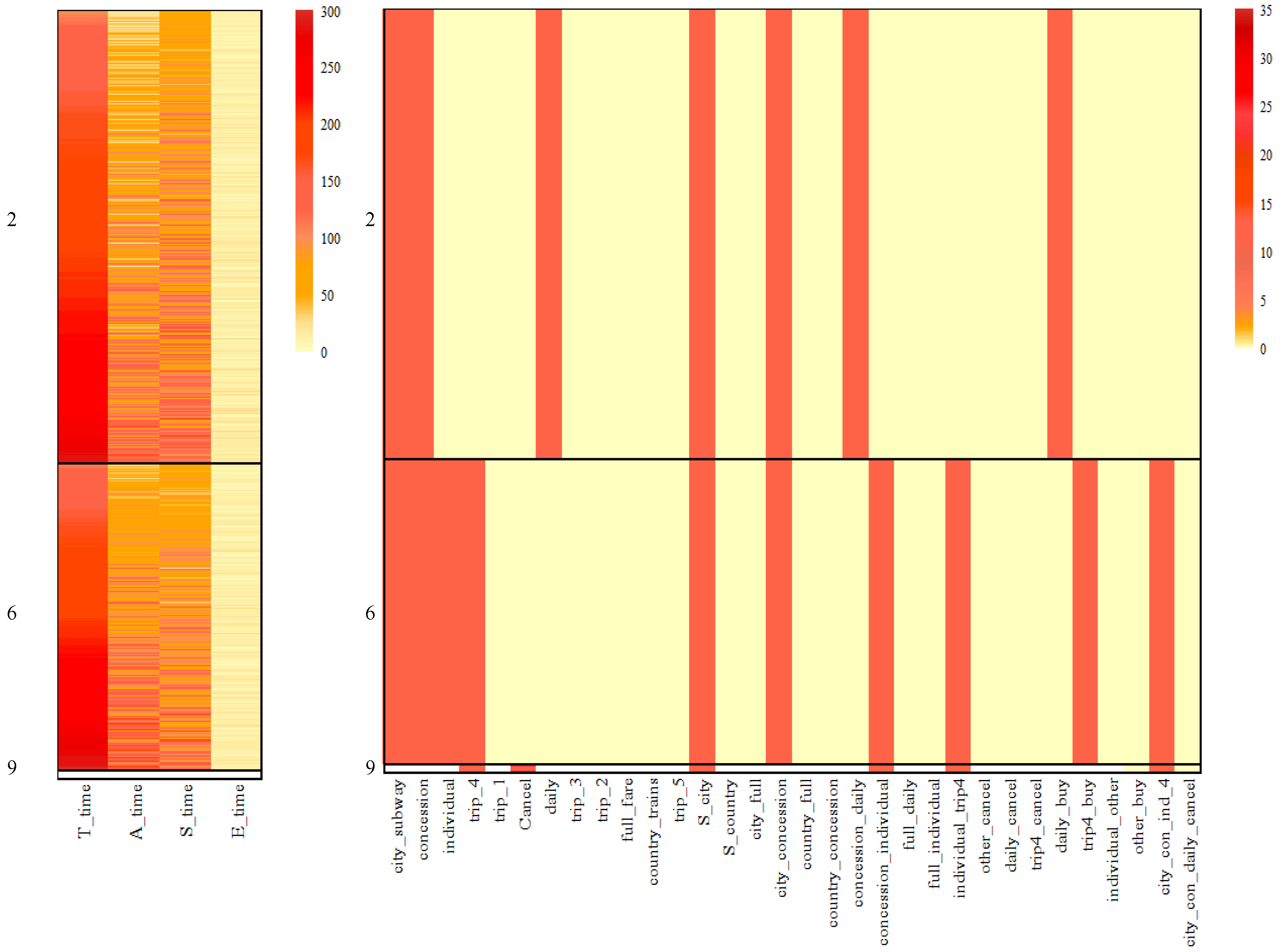
Based on results in
Table 2, there were very few data points in Clusters 2, 6 and 19 belong to KM2-Cluster1. Thus,
Figure 12 only provides the heatmap of Cluster 2, 6 and 19 which can nearly denote the comparison with k-means given two clusters. For Clusters 2 and 6, all the features have been employed in classification. There are clear differences between the two biclusters, especially in action features. However, KM2-Cluster2 classified them into one category.
5. Discussion
This study investigated the utilization of biclustering algorithms in the context of process data. Four different well-established biclustering algorithms were considered, along with the one-mode clustering algorithm based on k-means. To evaluate their capabilities of identifying the homogeneous groups, we analyzed a dataset consisting of 3760 students who participated in the “Ticket” task of the PISA 2012 CPS test. Then we applied the four biclustering algorithms using a set of well-defined features. To comprehensively evaluate the four biclustering and compare with the one-mode k-means clustering method, we consider three different evaluation metrics: variance, mean squared residue, and virtual error metrics. The results indicated that all the biclustering methods clearly outperformed the one-mode clustering approach when using the variance metric. This suggests that biclustering techniques tend to produce more homogeneous structures. Furthermore, the BCCC biclustering algorithm consistently outperformed the other methods when considering the mean squared residue and virtual error metrics. From the perspective of evaluation metrics, we find that biclustering algorithms are useful in achieving homogeneity on subsets of features.
Further, focusing on the individual performances of the four biclustering algorithms, the BCCC method exhibited high homogeneity levels in generating some small biclusters. To comprehensively understand respondents’ problem-solving competence and leverage the rich information contained in the process data, we examined the achievement data and process data simultaneously under the BCCC method. Specifically, for examinees who obtained a full score, their action sequence patterns revealed a high level of homogeneity in the biclustering results. For examinees who obtained partial credit, their action sequence patterns depicted a moderate level of homogeneity. However, for examinees who had incorrect responses, the biclusters demonstrated diverse action sequence patterns, such as frequent attempts on the wrong buttons or being stuck at certain steps. Moreover, we have also observed that students may produce diverse results even though they employed similar exploration strategies (
Wu and Molnár 2022). That is because the BCCC biclustering algorithm identified some homogenous structures across different scores, suggesting that similar problem-solving strategies were employed by students despite variations in their overall performance.
In conclusion, the biclustering technique is a powerful tool for discovering local patterns in process data analysis. By using features extracted from the process data established in prior literature, we demonstrated how to utilize biclustering algorithms to recognize and interpret homogeneous biclusters in the PISA 2012 CPS test. Our study highlights the promising potential of biclustering algorithms in analyzing process data to identify prototypical problem-solving patterns.
5.1. Biclustering and Clustering Methods
The key distinction of the biclustering algorithms from one-mode clustering is that they utilize only a subset of features instead of all features for clustering each observation, striking a balance between interpretability and capturing the individual differences across all features in the observed data. Our findings indicated that certain features played a crucial role.
First, through extraction of relevant features from the selected biclustering approaches, the study gave a broader understanding of contributions of features. On one hand, features like
city_con_daily_cancel were consistently included in multiple biclusters, aligning with previous findings from data mining techniques (
Qiao and Jiao 2018). On the other hand, certain action sequences such as
concession,
Cancel, and
city_concession were frequently employed, in agreement with results obtained from phantom items defined by experts (
Zhan and Qiao 2022). Additionally, the biclustering algorithms successfully identified homogeneous patterns in some less frequently used features.
In addition, as expected, the biclustering algorithms succeeded to capture the individual differences on time-based features, which outperformed the one-mode k-means method (
Qiao and Jiao 2018). Specifically, the time-related features in classification were found to be more relevant in certain clusters rather than being coherent across all biclusters.
For classification of examinees, the biclusters refined the categorization of the clusters under the k-means method. On one hand, the study identified cross-similarities between biclusters and clusters. On the other hand, the study differentiated biclusters from the categorization by k-means.
5.2. Implications
Our study has several implications for measurement. First, the information stored in the log files largely depends on the design of the user interface. Our results revealed that contribution differed across features with high homogeneity and some buttons did not differentiate examinees. Such evaluation will provide a deeper insight into the design of simulation tasks. For example, how challenging or difficult these irrelevant buttons should be set. Second, previous researches found the crucial role of time-based features. However, time-based features were not successfully identified in k-means clustering. The current study provided a more comprehensive view of the time-based feature and action sequences. Homogeneity could only be found in certain groups of students implying a universal skill among all examinees. Such information might support modeling and explanation of response time in evaluating students’ proficiency.
5.3. Considerations in Interpreting Biclusters
In one-mode clustering, like hierarchical clustering and k-means clustering algorithms, all features are considered when evaluating the dissimilarity of observations (e.g., examinees) within a cluster. Therefore, in the selection of the number of clusters, using within-cluster variability (e.g., sum of squares) as the selection criteria tends to favor solutions with a large number of clusters. However, in biclustering, the number of features included in each (bi)cluster of examinees is different—depending on the subset of examinees in a given bicluster. The biclustering algorithms also identify subsets of features that act in unison for that subset of examinees. As a consequence, breaking examinees into a larger number of smaller biclusters, which may increase the number of nuisance features included in each bicluster, will not necessarily lead to a decrease in within-bicluster variability across the included features. As the feature set changes in biclustering, we note that the meaning of within-cluster variability in biclustering inherently differs from that of one-mode clustering, which readers might be more familiar with. At the same time, the concept of between-cluster variability, which evaluates how dissimilar are observations from different clusters, is no longer straightforward in the biclustering case, because the biclusters can overlap in examinees, and the selected features differ across different biclusters. In interpreting biclustering solutions that are selected based on within-bicluster variability measures, rather than focusing on the partitioning of the examinees as in one-mode clustering, researchers should treat it as an algorithm that provides information on (potentially overlapping) subsets of examinees, who share similarities on certain features. The biclustering solutions selected based on measures such as MSR and VE are intended to identify subsets that are homogeneous, therefore facilitating the interpretation of each bicluster by making it more “pure” on the included dimensions. At the same time, we note that there are limitations to evaluation indices based on within-bicluster variability, as it does not consider solution parsimony: For instance, in the empirical example, the optimal solution based on VE and MSR contains 22 biclusters, which might be far more than needed for capturing cognitively meaningful individual differences on the ticket item. We leave it to future research to develop evaluation indices or methods for selecting the optimal number of biclusters that build in parsimony. In the meantime, rather than interpreting all identified biclusters which can be very taxing, substantive researchers interpreting the biclustering solutions may prioritize the interpretation of biclusters that either (1) contain a sufficient number of examinees of interest or (2) are linked to key variables of interest, e.g., task outcome, proficiency, or demographic background.
It is also worth mentioning how biclustering connects to other types of clustering-related methods. The first is
soft clustering. Methods such as
k-means and hierarchical clustering are
hard clustering algorithms, in that each examinee gets deterministically assigned to one class. Soft clustering, for instance via a probabilistic mixture model (e.g.,
McLachlan et al. 2019), still assumes that each examinee comes from a single class but characterizes class membership as the probability that an examinee stems from each class, rather than a single class label. In this sense, biclustering could also be seen as a hard two-mode clustering algorithm, in that for each bicluster, binary decisions are made for whether each examinee and feature is included. Another related type of probabilistic model is
mixed-membership models (e.g.,
Airoldi et al. 2014), which, similar to biclustering, relaxes the assumption that each examinee originates from a single class. When repeated measures are available for an examinee (e.g., multiple items or features), these models assume that the observations for the same examinee can stem from different latent classes, with the class probabilities characterized by an examinee-specific class proportion vector. Well-known examples include the grade of membership model (
Woodbury et al. 1978) and latent Dirichlet allocation (
Blei et al. 2003). Different from biclustering, most mixed-membership models do not simultaneously group features into latent classes. However, recent extensions, such as the dimension-grouped mixed-membership model (
Gu et al. 2023), additionally allow the grouping of feature dimensions, where the features from the same group act in unison in the latent class they originate from for a given examinee. Future research may consider the application of these models to the analysis of log data and compare it to biclustering.
5.4. Limitations and Future Directions
The current study has limitations and can be extended in several ways. Firstly, time-based features in process data are not limited to total time, action time, and end time. Some researchers have discovered there are other important time-based features in the process data. For example,
Park et al. (
2023) established item-level response time data, while
Fu et al. (
2023) discovered the elapsed time of completing a state transition. Future studies can further consider incorporating more precise time-based features in the biclustering algorithms to effectively identify homogeneous structures. Additionally, in this paper, we only employed four commonly used biclustering algorithms, but many other interesting biclustering algorithms have been developed. In the future, we could explore and compare more biclustering algorithms to gain deeper insights into their performances. Third, the validation of biclustering algorithms is also one of the most important issues that need to be addressed.
It is also worth emphasizing the limited scope of substantive conclusions that can be drawn from the current exploratory study. The current study aims to introduce an exploratory process data analysis approach based on biclustering, for uncovering types of problem-solving patterns. Although the exploratory findings could serve as a data-driven guide to uncover meaning individual differences in problem-solving processes and proficiency, interpretations on the cognitive processes or strategies underlying observed patterns are speculative. For instance, some buttons that were frequently used within certain clusters, e.g., clicking cancel, could be attributed to a multitude of reasons, ranging from familiarizing oneself with the task’s structure via exploring various routes, to an interrupted problem-solving process featured by frequent restarts. Therefore, the exploratory findings and speculations based on observed sequential/time patterns should not be construed as establishing theoretical models for cognitive processes, which require follow-up confirmatory analyses and formal scientific inferences.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}