
An Elaborate Preprocessing Phase (p3) in Composition and Optimization of Business Process Models




Abstract
1. Introduction
2. Related Work
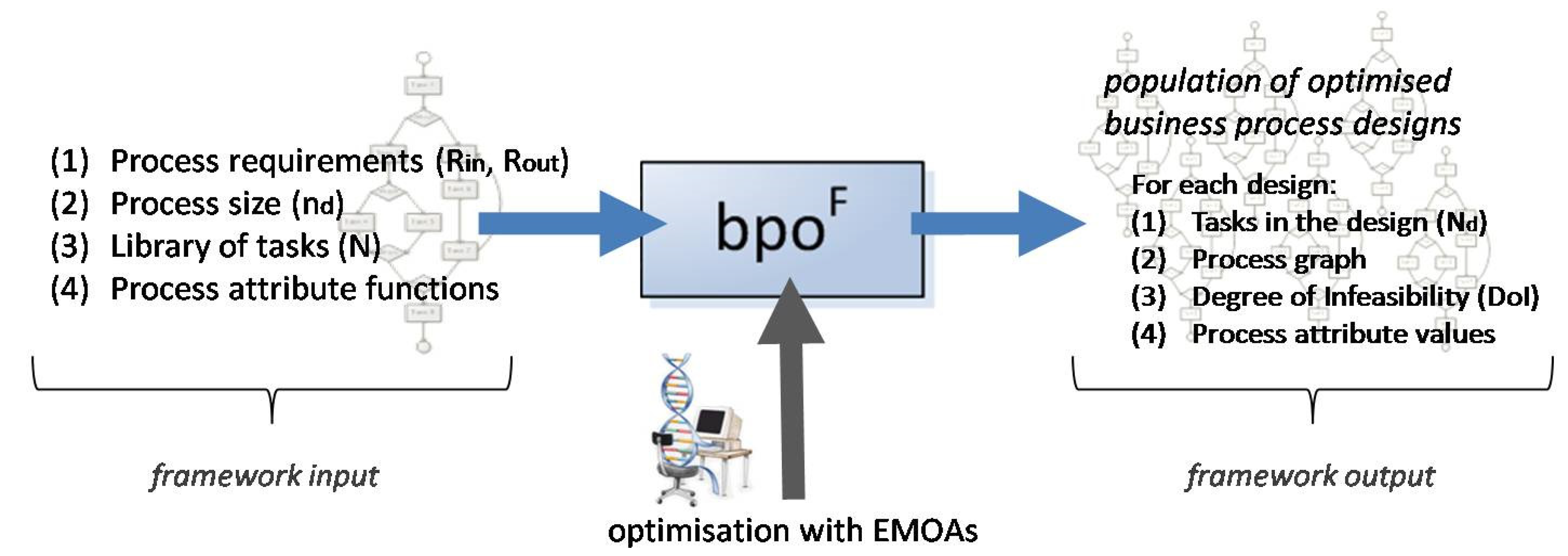
3. Task Composition and Optimization of Process Designs
- The process requirements for the design are the required process inputs (Rin) and process outputs (Rout). All of the generated designs consume the same inputs and produce the same outputs.
- The process size (nd). The process size denotes the number of participating tasks in the process designs.
- The library of tasks (N). This set contains all of the candidate tasks that can participate in a process design.
- The process attribute functions for each quantitative process attribute. These functions are the optimization objectives.
- The tasks in the design, stored in the Nd set.
- The process graph, which is the diagrammatic representation of the design.
- The degree of infeasibility, a penalty function for infeasible designs (equals to zero for feasible solutions).
- The process attribute values of each feasible optimized design.
- To identify and preserve feasible solutions;
- To converge these solutions towards optimal;
- To maintain diversity of the solutions across the Pareto front.
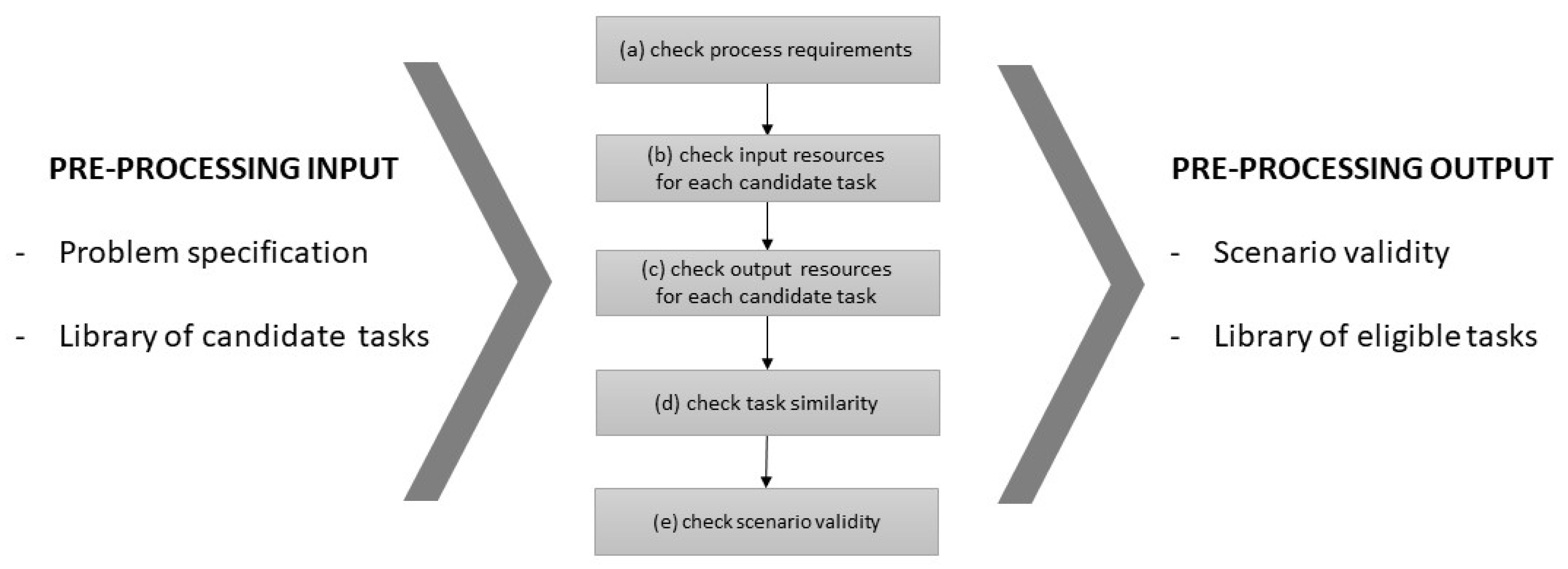
4. The p3 Preprocessing Phase
- Tasks that require input resources that are part of the process output (steps a, e);
- Tasks that produce output resources that are required in the process input (steps a, e);
- Tasks with input resources that are not required in the process input or in any other task output to connect to (step b);
- Tasks with output resources that do not exist in process output or in any other task input to connect to (step c);
- Tasks with identical input and output resources that are dominated in all their attribute values by an equivalent task (step d).
4.1. Check Process Requirements (Input and Output Resources)
| Algorithm 1 Check process requirements |
| Require: T = {t1, …, tn}, a set of n tasks, Rin, a set of process input resources from the available resources, Rin ⊆ R Rout, a set of process output resources from the available resources, Rout ⊆ R Ensure: T’ ⊆ T, a set that contains eligible tasks based on this step’s requirements 1://Iterate on T 2: For each ti task ∈ T 3: if Oi ⊄ Rin then insert ti in T’ 4: else if Rout ⊄ Ii then insert ti in T’ 5: return T’ |
4.2. Check Individual Task Input Resources
4.3. Check Individual Task Output Resources
| Algorithm 2 Check individual task input resources |
| Require: T = {t1, …, tn}, a set of n tasks, Rin, a set of process input resources from the available resources, Rin ⊆ R Ensure: T’ ⊆ T, a set that contains eligible tasks based on this step’s requirements 1: //Iterate on T 2: For each ti task ∈ T, iterate on its set of input resources Ii 3: if Ii ⊆ Rin then insert ti in T’ 4: else for each tj ≠ ti task ∈ T, 5: iterate on its set of output resources Oj 6: if Ii ⊆ Oj then insert ti, tj in T’ 7: return T’ |
| Algorithm 3 Check individual task output resources |
| Require: T = {t1, …, tn}, a set of n tasks, Rout, a set of process output resources from the available resources, Rout ⊆ R Ensure: T’ ⊆ T, a set that contains eligible tasks only 1: //Iterate on T 2: For each ti task ∈ T, iterate on its set of output resources Oi 3: if Oi ⊆ Rout then insert ti in T’ 4: else for each tj ≠ ti task ∈ T, 5: iterate on its set of input resources Ij 6: if Oi ⊆ Ij then insert ti, tj in T’ 7: return T’ |
4.4. Check Task Similarity
| Algorithm 4 Check task similarity |
| Require: T = {t1, …, tn}, a set of n tasks, PAnm, a two-dimensional matrix containing for each of the n tasks, their m attribute values Ensure: T’ ⊆ T, a set that contains eligible tasks only 1: j = 1 2: //Iterate on library of candidate tasks T 3: For each ti task ∈ T 4: if ti does not belong to an existing category Sj then 5: create category Sj 6: j = j + 1 7: add ti in Sj 8: //Iterate on k task categories 9: For j in (1, k) 10: For each ti task ∈ Sj 11: if PAi dominate or are equivalent to the attribute values of other tasks in Sj then 12: insert ti in T’ 13: return T’ |
4.5. Check Scenario Validity
| Algorithm 5 Check scenario validity |
| Require: T = {t1, …, tn}, a set of n tasks, Ι = {r1, …, rn}, a set of m input resources of the n tasks in the library, I ⊆ R O = {r1, …, rk}, a set of k output resources of the n tasks in the library, O ⊆ R Rin, a set of process input resources from the available resources, Rin ⊆ R Rout, a set of process output resources from the available resources, Rout ⊆ R Ensure: return True or False based on whether a scenario is feasible or not 1: Scenario_validity = True 2://Iterate on the process input resources Rin 3: For each ri resource ∈ Rin 4: if ri ∉ I then 5: Scenario_validity = False 6://Iterate on the process output resources Rout 7: For each ri resource ∈ Rout 8: if ri ∉ O then 9: Scenario_validity = False 10: return Scenario_validity |
5. Creating Experimental BP Scenarios
6. Experimental Results
6.1. Scenario Validity
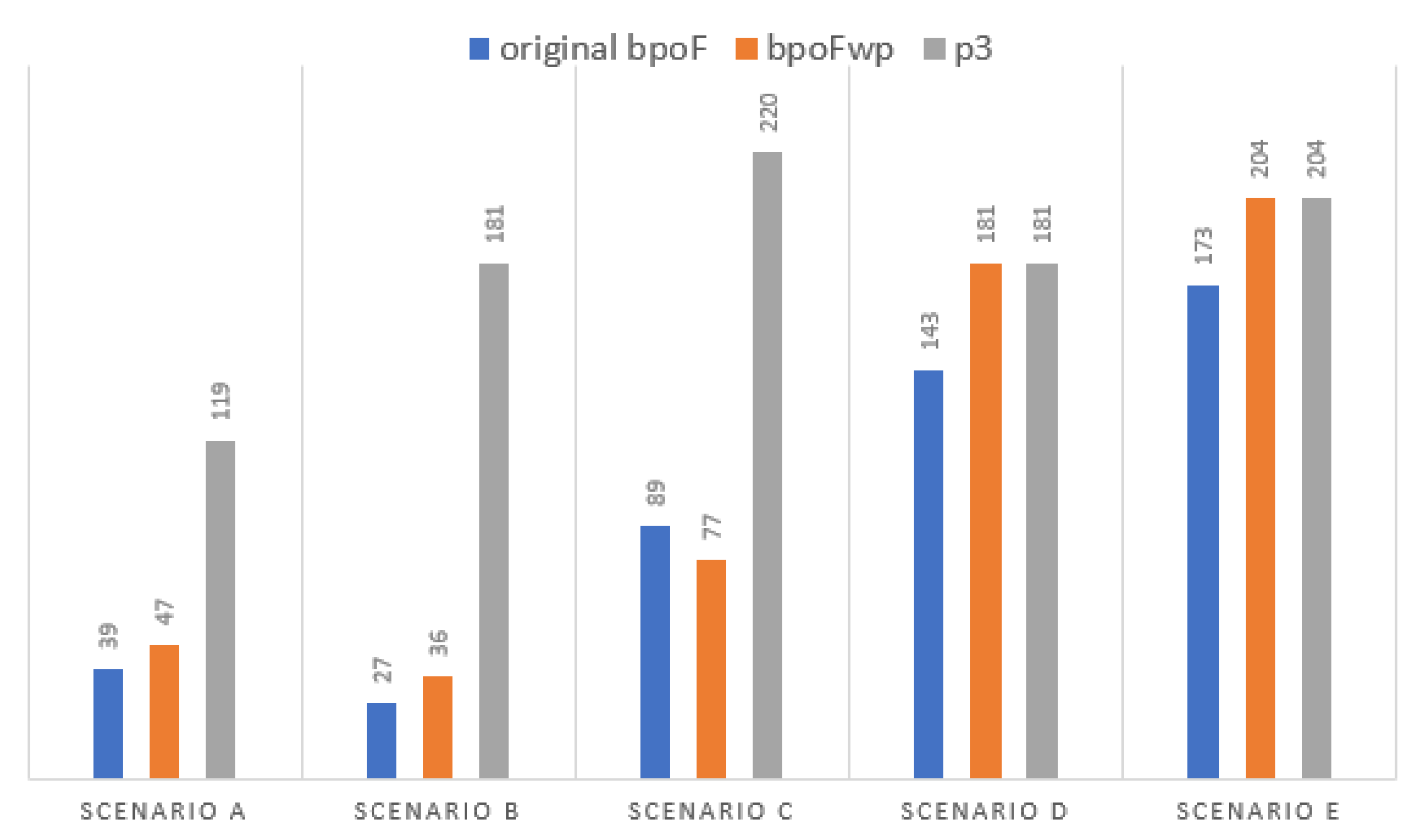
6.2. Task Elimination and Library Reduction
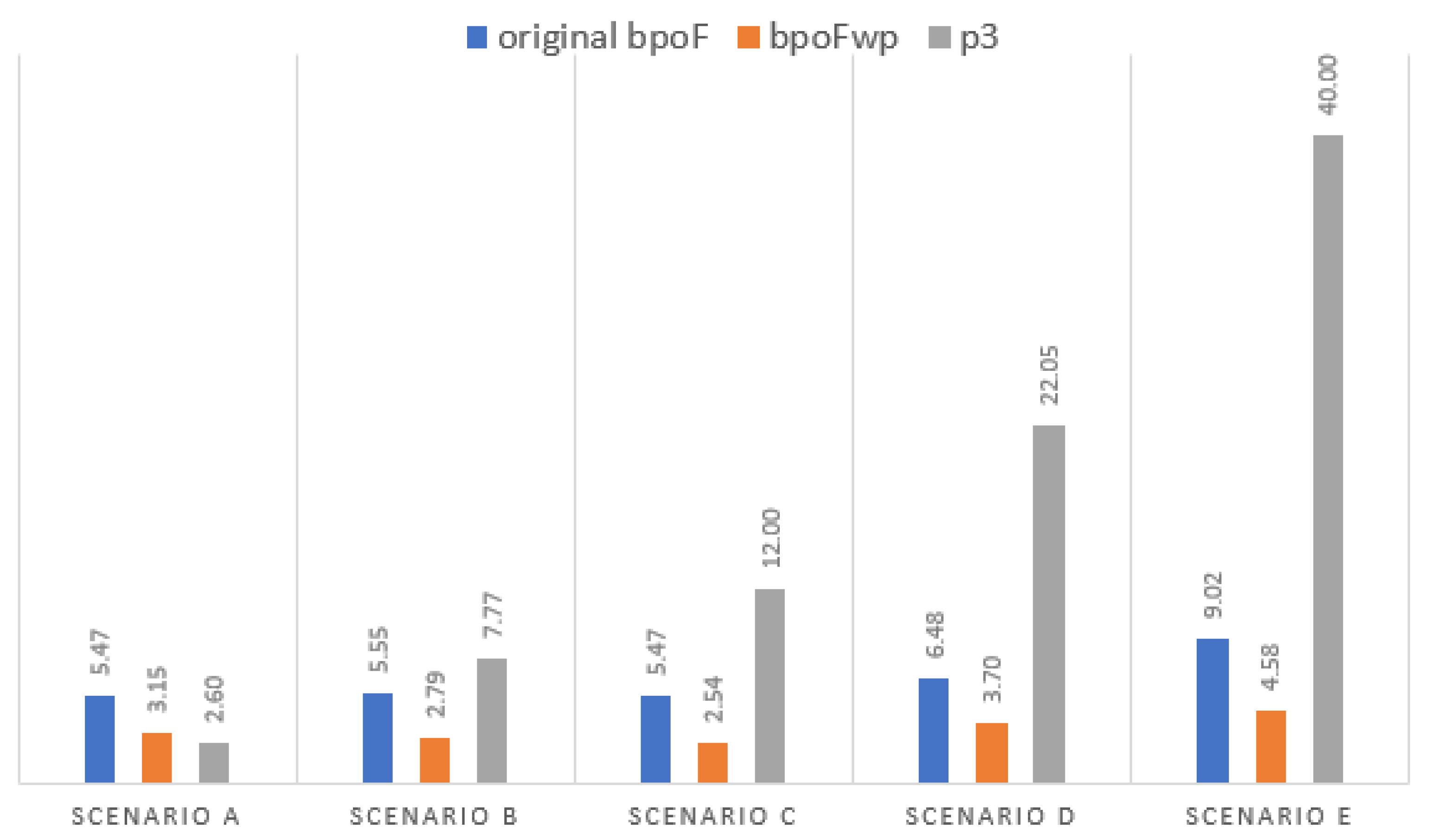
6.3. bpoF Performance
7. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tsakalidis, G.; Vergidis, K. Towards a Comprehensive Business Process Optimization Framework. In Proceedings of the IEEE 19th Conference on Business Informatics (CBI), Thessaloniki, Greece, 24–27 July 2017; Volume 1, pp. 129–134. [Google Scholar]
- Lemos, A.L.; Daniel, F.; Benatallah, B. Web Service Composition: A Survey of Techniques and Tools. ACM Comput. Surv. CSUR 2015, 48, 1–41. [Google Scholar] [CrossRef]
- Liu, X.; Hui, Y.; Sun, W.; Liang, H. Towards Service Composition Based on Mashup. In Proceedings of the 2007 IEEE Congress on Services (Services 2007), Salt Lake City, UT, USA, 9–13 July 2007; pp. 332–339. [Google Scholar]
- Hofacker, I.; Vetschera, R. Algorithmical Approaches to Business Process Design. Comput. Oper. Res. 2001, 28, 1253–1275. [Google Scholar] [CrossRef]
- Vergidis, K. Business Process Optimisation Using an Evolutionary Multi-Objective Framework. Ph.D. Thesis, Cranfield University, Silsoe, UK, 2008. [Google Scholar]
- Georgoulakos, K.; Vergidis, K.; Tsakalidis, G.; Samaras, N. Evolutionary Multi-Objective Optimization of Business Process Designs with Pre-Processing. In Proceedings of the IEEE Congress on Evolutionary Computation (CEC), San Sebastián, Spain, 5–8 June 2017; pp. 897–904. [Google Scholar]
- Houy, C.; Fettke, P.; Loos, P. Empirical Research in Business Process Management—Analysis of an Emerging Field of Research. Bus. Process Manag. J. 2010, 16, 619–661. [Google Scholar] [CrossRef]
- Xiang, J.; Archer, N.; Detlor, B. Business Process Redesign Project Success: The Role of Socio-Technical Theory. Bus. Process Manag. J. 2014, 20, 773–792. [Google Scholar] [CrossRef]
- Mendling, J.; Decker, G.; Hull, R.; Reijers, H.A.; Weber, I. How Do Machine Learning, Robotic Process Automation, and Blockchains Affect the Human Factor in Business Process Management? Commun. Assoc. Inf. Syst. 2018, 43, 19. [Google Scholar] [CrossRef]
- Kerpedzhiev, G.D.; König, U.M.; Röglinger, M.; Rosemann, M. An Exploration into Future Business Process Management Capabilities in View of Digitalization. Bus. Inf. Syst. Eng. 2020, 1–14. [Google Scholar] [CrossRef]
- Mendling, J.; Weber, I.; Aalst, W.V.D.; Brocke, J.V.; Cabanillas, C.; Daniel, F.; Debois, S.; Ciccio, C.D.; Dumas, M.; Dustdar, S. Blockchains for Business Process Management-Challenges and Opportunities. ACM Trans. Manag. Inf. Syst. TMIS 2018, 9, 1–16. [Google Scholar] [CrossRef]
- Szelągowski, M. Evolution of the BPM Lifecycle. In Proceedings of the Federated Conference on Computer Science and Information Systems, Poznań, Poland, 9–12 September 2018. [Google Scholar]
- vom Brocke, J.; Rosemann, M. Handbook on Business Process Management 1: Introduction, Methods, and Information Systems; Springer: Berlin/Heidelberg, Germany, 2014; ISBN 978-3-642-45099-0. [Google Scholar]
- Dumas, M.; La Rosa, M.; Mendling, J.; Reijers, H.A. Fundamentals of Business Process Management, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2013; ISBN 978-3-642-43473-0. [Google Scholar]
- Reijers, H.A.; Mansar, S.L. Best Practices in Business Process Redesign: An Overview and Qualitative Evaluation of Successful Redesign Heuristics. Omega 2005, 33, 283–306. [Google Scholar] [CrossRef]
- Dumas, M.; Rosa, M.L.; Mendling, J.; Reijers, H.A. Fundamentals of Business Process Management, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2018; ISBN 978-3-662-56509-4. [Google Scholar]
- Tsakalidis, G.; Vergidis, K.; Kougka, G.; Gounaris, A. Eligibility of BPMN Models for Business Process Redesign. Information 2019, 10, 225. [Google Scholar] [CrossRef]
- Zellner, G. A Structured Evaluation of Business Process Improvement Approaches. Bus. Process Manag. J. 2011, 17, 203–237. [Google Scholar] [CrossRef]
- Valiris, G.; Glykas, M. Business Analysis Metrics for Business Process Redesign. Bus. Process Manag. J. 2004, 10, 445–480. [Google Scholar] [CrossRef]
- Moon, C.; Seo, Y. Evolutionary Algorithm for Advanced Process Planning and Scheduling in a Multi-Plant. Comput. Ind. Eng. 2005, 48, 311–325. [Google Scholar] [CrossRef]
- Vergidis, K.; Turner, C.; Alechnovic, A.; Tiwari, A. An Automated Optimisation Framework for the Development of Re-Configurable Business Processes: A Web Services Approach. Int. J. Comput. Integr. Manuf. 2015, 28, 41–58. [Google Scholar] [CrossRef]
- Wang, K.; Salhi, A.; Fraga, E.S. Process Design Optimisation Using Embedded Hybrid Visualisation and Data Analysis Techniques within a Genetic Algorithm Optimisation Framework. Chem. Eng. Process. Process Intensif. 2004, 43, 657–669. [Google Scholar] [CrossRef]
- Tiwari, A.; Vergidis, K.; Majeed, B. Evolutionary Multi-Objective Optimization of Business Processes. In Proceedings of the 2006 IEEE International Conference on Evolutionary Computation, Vancouver, BC, Canada, 16–21 July 2006; pp. 3091–3097. [Google Scholar]
- Vergidis, K.; Tiwari, A.; Majeed, B. Business Process Improvement Using Multi-Objective Optimisation. BT Technol. J. 2006, 24, 229–235. [Google Scholar] [CrossRef]
- Ahmadikatouli, A.; Aboutalebi, M. New Evolutionary Approach to Business Process Model Optimization. In Proceedings of the International MultiConference of Engineers and Computer Scientists, Hong Kong, China, 14–16 March 2011; Volume 2. [Google Scholar]
- Wibig, M. Dynamic Programming and Genetic Algorithm for Business Processes Optimisation. Int. J. Intell. Syst. Appl. 2012, 5, 44. [Google Scholar] [CrossRef]
- Osuszek, L. Workflow Map Optimization by Using Multiobjective Algorithms. In Proceedings of the International Conference on Software Engineering Research and Practice (SERP), Las Vegas, NV, USA, 16–19 July 2012; The Steering Committee of The World Congress in Computer Science, Computer Engineering and Applied Computing (WorldComp). p. 1. [Google Scholar]
- Vergidis, K.; Tiwari, A.; Majeed, B. Composite Business Processes: An Evolutionary Multi-Objective Optimization Approach. In Proceedings of the 2007 IEEE Congress on Evolutionary Computation, Singapore, 25–28 September 2007; pp. 2672–2678. [Google Scholar]
- Altiparmak, F.; Gen, M.; Lin, L.; Paksoy, T. A Genetic Algorithm Approach for Multi-Objective Optimization of Supply Chain Networks. Comput. Ind. Eng. 2006, 51, 196–215. [Google Scholar] [CrossRef]
- Mehdiyev, N.; Emrich, A.; Stahmer, B.P.; Fettke, P.; Loos, P. IPRODICT-Intelligent Process Prediction Based on Big Data Analytics. In Proceedings of the BPM (Industry Track), Barcelona, Spain, 10–15 September 2017; pp. 13–24. [Google Scholar]
- Lavangnananda, K.; Wangsom, P. Multi-Objective Shipment Allocation Using Extreme Nondominated Sorting Genetic Algorithm-III (E-NSGA-III). In Proceedings of the 2019 18th IEEE International Conference On Machine Learning And Applications (ICMLA), Boca Raton, FL, USA, 16–19 December 2019; pp. 1500–1505. [Google Scholar]
- Mahammed, N.; Benslimane, S.M.; Ouldkradda, A.; Fahsi, M. Evolutionary Business Process Optimization Using a Multiple-Criteria Decision Analysis Method. In Proceedings of the 2018 International Conference on Computer, Information and Telecommunication Systems (CITS), Alsace, France, 11–13 July 2018; pp. 1–5. [Google Scholar]
- Mahammed, N.; Benslimane, S.M. Solving a Business Process Optimization Issue With a Genetic Algorithm Coupled With Multi-Criteria Decision Analysis Method. Int. J. Organ. Collect. Intell. IJOCI 2021, 11, 71–94. [Google Scholar] [CrossRef]
- Vergidis, K.; Tiwari, A. Business Process Design and Attribute Optimization within an Evolutionary Framework. In Proceedings of the 2008 IEEE Congress on Evolutionary Computation (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–6 June 2008; pp. 668–675. [Google Scholar]
- Vergidis, K.; Saxena, D.; Tiwari, A. An Evolutionary Multi-Objective Framework for Business Process Optimisation. Appl. Soft Comput. 2012, 12, 2638–2653. [Google Scholar] [CrossRef]
- Kaur, S.; Verma, A. An Efficient Approach to Genetic Algorithm for Task Scheduling in Cloud Computing Environment. Int. J. Inf. Technol. Comput. Sci. IJITCS 2012, 4, 74. [Google Scholar] [CrossRef]
- Tsakalidis, G.; Vergidis, K.; Delias, P.; Vlachopoulou, M. A Conceptual Business Process Entity with Lifecycle and Compliance Alignment. In Proceedings of the International Conference on Decision Support System Technology, Madeira, Portugal, 27–29 May 2019; pp. 70–82. [Google Scholar]
- Pruyt, E. Integrating Systems Modelling and Data Science: The Joint Future of Simulation and ‘Big Data’ Science. Int. J. Syst. Dyn. Appl. IJSDA 2016, 5, 1–16. [Google Scholar] [CrossRef]
- Eno, J.; Thompson, C.W. Generating Synthetic Data to Match Data Mining Patterns. IEEE Internet Comput. 2008, 12, 78–82. [Google Scholar] [CrossRef]
- Paganias, D.; Tsakalidis, G.; Vergidis, K. A Systematic Investigation of the Main Variables of the Business Process Optimisation Problem. In Proceedings of the University of Macedonia & Hellenic Operational Research Society (HELORS), Thessaloniki, Greece, 30 October 2020. [Google Scholar]
- Mahammed, N.; Benslimane, S.M. Toward Multi Criteria Optimization of Business Processes Design. In Model and Data Engineering; Bellatreche, L., Pastor, Ó., Almendros Jiménez, J.M., Aït-Ameur, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 98–107. [Google Scholar]
- Mahammed, N.; Benslimane, S.M.; Hamdani, N. Evolutionary Multi-Objective Optimization of Business Process Designs with MA-NSGAII. In Proceedings of the IFIP International Conference on Computational Intelligence and Its Applications, Oran, Algeria, 8–10 May 2018; pp. 341–351. [Google Scholar]
- Oracle. Java Programming Language; Java SE Documentation; Oracle: Redwood City, CA, USA, 2018. [Google Scholar]
- Yang, X.-S. A new metaheuristic bat-inspired algorithm. In Nature inspired Cooperative Strategies for Optimization (NICSO 2010); Springer: Berlin/Heidelberg, Germany, 2010; pp. 65–74. [Google Scholar]
- Yazdani, M.; Jolai, F. Lion Optimization Algorithm (LOA): A Nature-Inspired Metaheuristic Algorithm. J. Comput. Des. Eng. 2016, 3, 24–36. [Google Scholar] [CrossRef]
- Tang, R.; Fong, S.; Yang, X.-S.; Deb, S. Wolf Search Algorithm with Ephemeral Memory. In Proceedings of the Seventh International Conference on Digital Information Management (ICDIM 2012), Macau, China, 22–24 August 2012; pp. 165–172. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Description | Parameter | Description |
|---|---|---|---|
| n | No. of candidate tasks in the library | N = {t1, t2, …, tn} | Set of all candidate tasks |
| nd | No. of tasks in a process design (nd ≤ n) | Nd = {t1, t2, …, tnd} | Set of the nd tasks in a design |
| rall | No. of available resources | R = {r1, r2, …, rall} | Set of all available resources |
| rin | No. of process input resources (rin ≤ r) | Rin = {r1, r2, …, rout} | Set of the process input resources |
| rout | No. of process output resources (rout ≤ r) | Rout = {r1, r2, …, rin} | Set of the process output resources |
| pall | No. of task/process attributes (pall ≤ 2) * | PAd = {p1, …, pall} | Set of the process attribute values for a particular design |
| tin | No. of task input resources ** | I | Set of the tin resources for a task i |
| tout | No. of task output resources ** | O | Set of the tout resources for a task i |
| TAnp | Two-dimensional array with the task attribute values ** |
| Parameter | Scenarios A–E |
|---|---|
| nd | 15 |
| nmin | 11 |
| r | 30 |
| tin/tout | 2/2 |
| rin/rout | 2/2 |
| p | 2 |
| (min) Attribute1 | 100–200 |
| (max) Attribute2 | 300–400 |
| Parameter | Scenario A | Scenario B | Scenario C | Scenario D | Scenario E |
|---|---|---|---|---|---|
| n | 100 | 500 | 1000 | 2000 | 3000 |
| Library of Candidate Tasks (before p3) | Library of Eligible Tasks (after p3) | Eliminated Tasks (Absolute/%) | |
|---|---|---|---|
| Scenario A | 100 | 78 | 22/22% |
| Scenario B | 500 | 396 | 104/20.8% |
| Scenario C | 1000 | 746 | 254/25.4% |
| Scenario D | 2000 | 1553 | 447/22.35% |
| Scenario E | 3000 | 2437 | 563/18.77% |
| average library size reduction (%): | 21.86% | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsakalidis, G.; Georgoulakos, K.; Paganias, D.; Vergidis, K. An Elaborate Preprocessing Phase (p3) in Composition and Optimization of Business Process Models. Computation 2021, 9, 16. https://doi.org/10.3390/computation9020016
Tsakalidis G, Georgoulakos K, Paganias D, Vergidis K. An Elaborate Preprocessing Phase (p3) in Composition and Optimization of Business Process Models. Computation. 2021; 9(2):16. https://doi.org/10.3390/computation9020016
Chicago/Turabian StyleTsakalidis, George, Kostas Georgoulakos, Dimitris Paganias, and Kostas Vergidis. 2021. "An Elaborate Preprocessing Phase (p3) in Composition and Optimization of Business Process Models" Computation 9, no. 2: 16. https://doi.org/10.3390/computation9020016
APA StyleTsakalidis, G., Georgoulakos, K., Paganias, D., & Vergidis, K. (2021). An Elaborate Preprocessing Phase (p3) in Composition and Optimization of Business Process Models. Computation, 9(2), 16. https://doi.org/10.3390/computation9020016