
Evaluation of Pseudo-Random Number Generation on GPU Cards


Abstract
:1. Introduction
2. Methodology
2.1. GPU Architecture
2.2. PRNG Parameters
2.3. Experimental Setting
3. Results
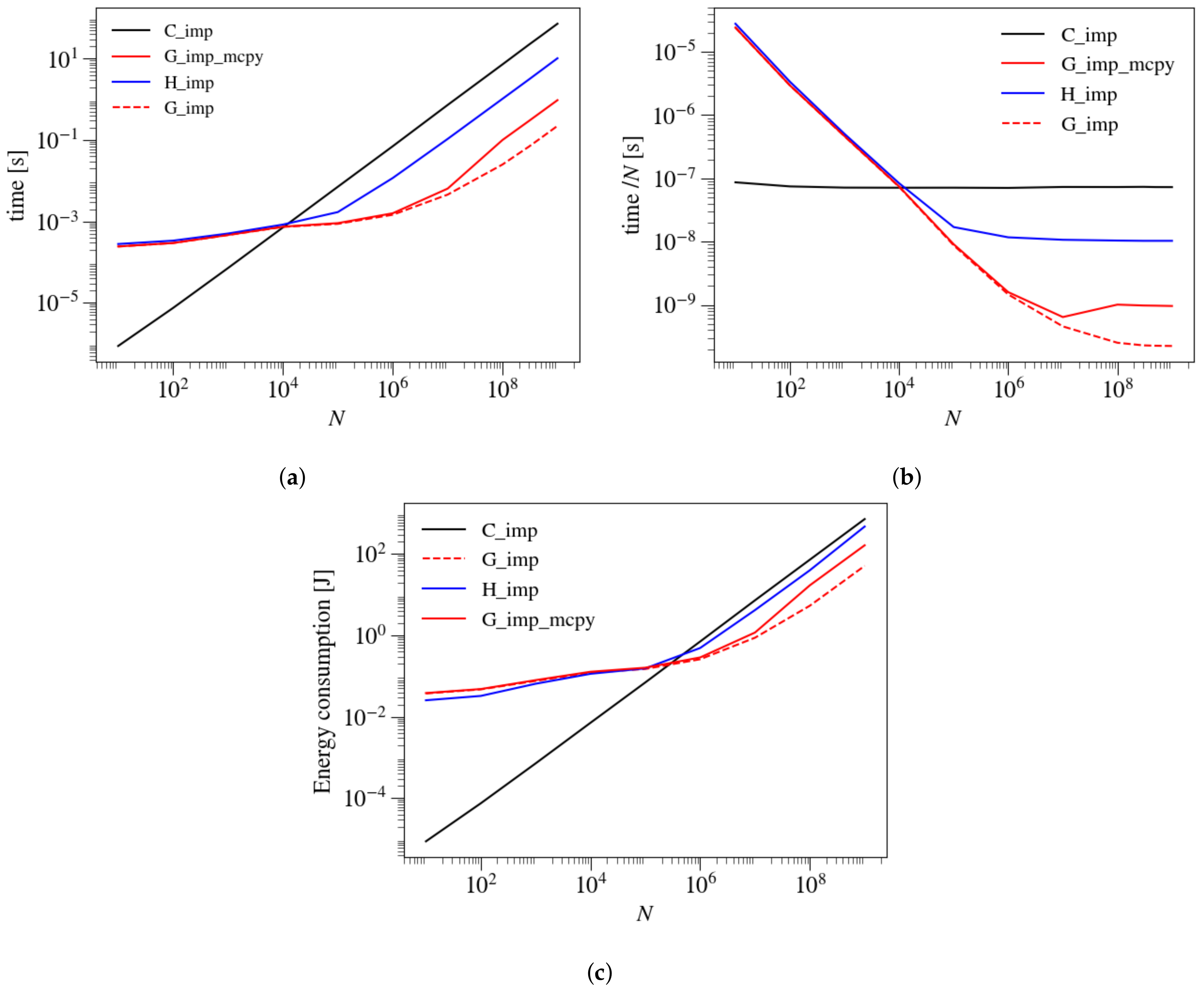
3.1. Comparison of GPU and CPU Implementations
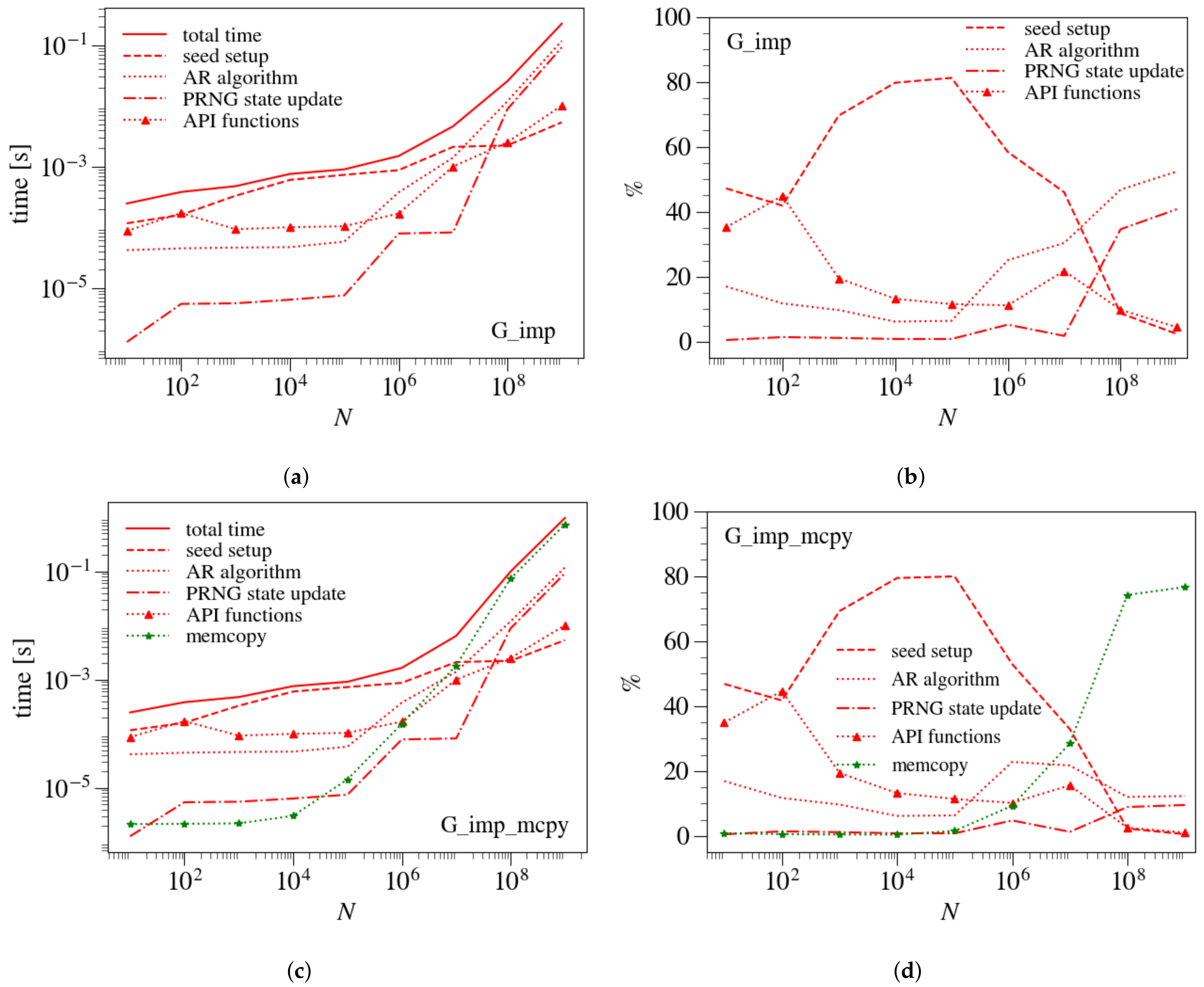
3.2. Operation-Wise Load Analysis
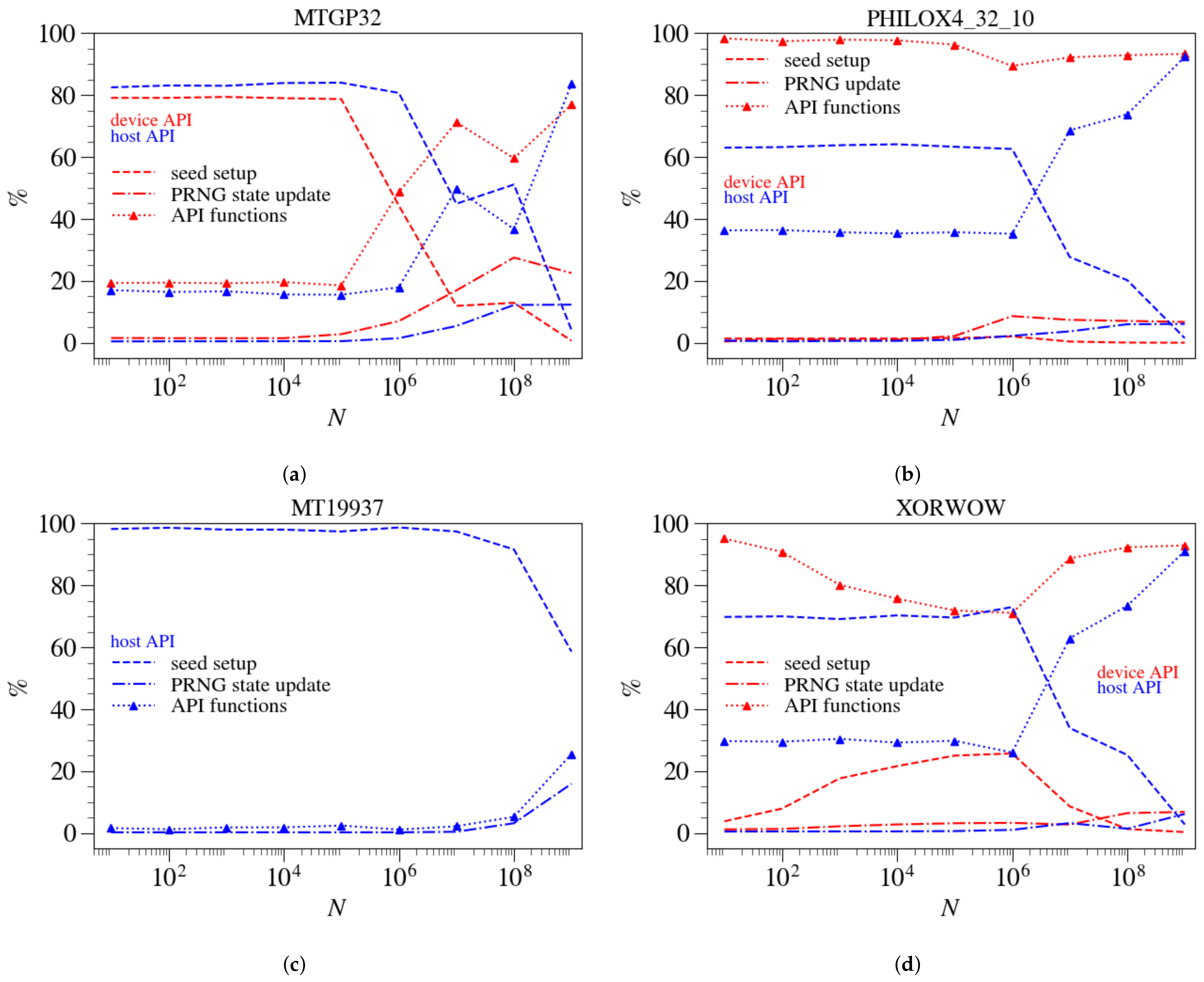
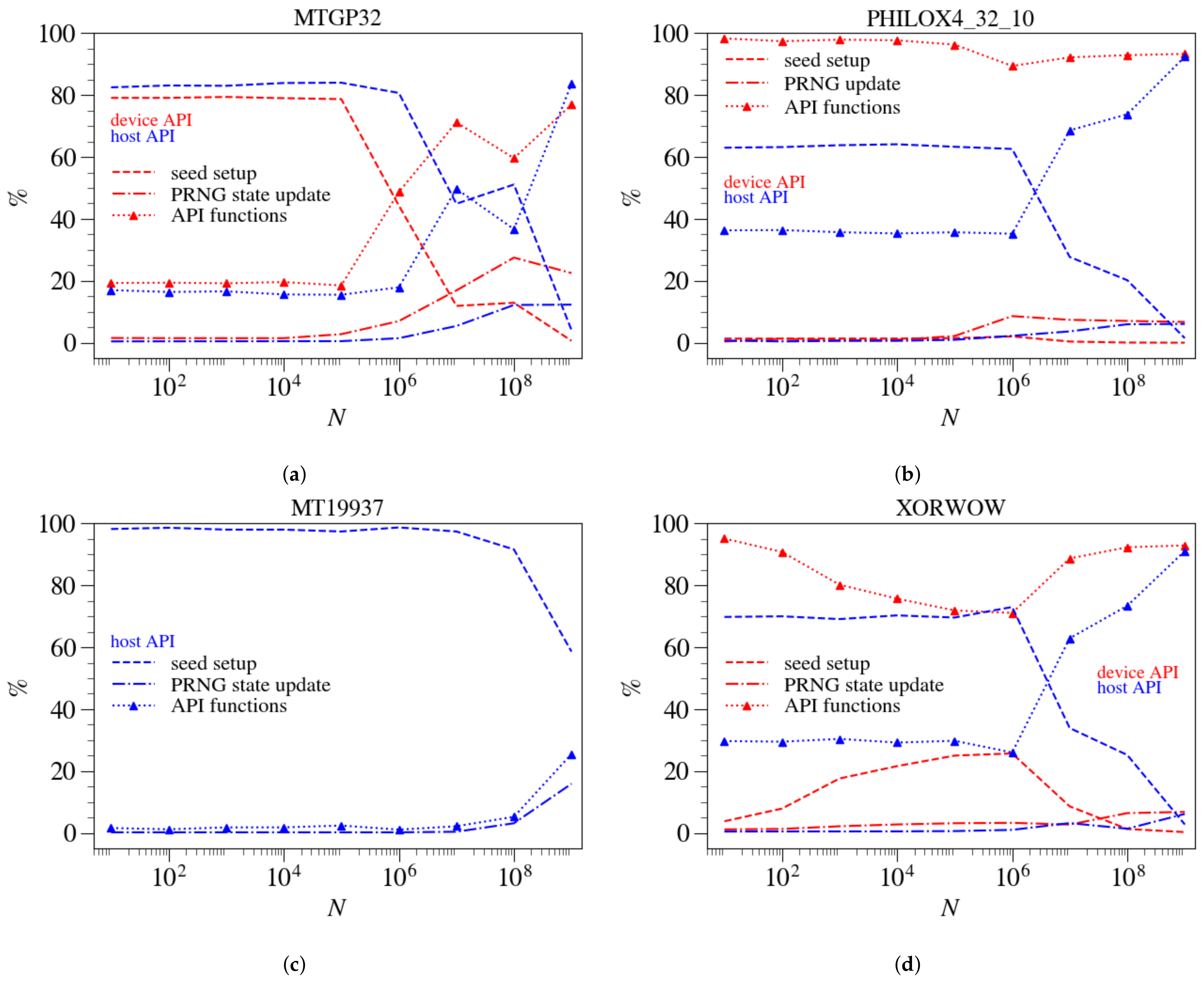
3.3. Device API and Host API Implementations
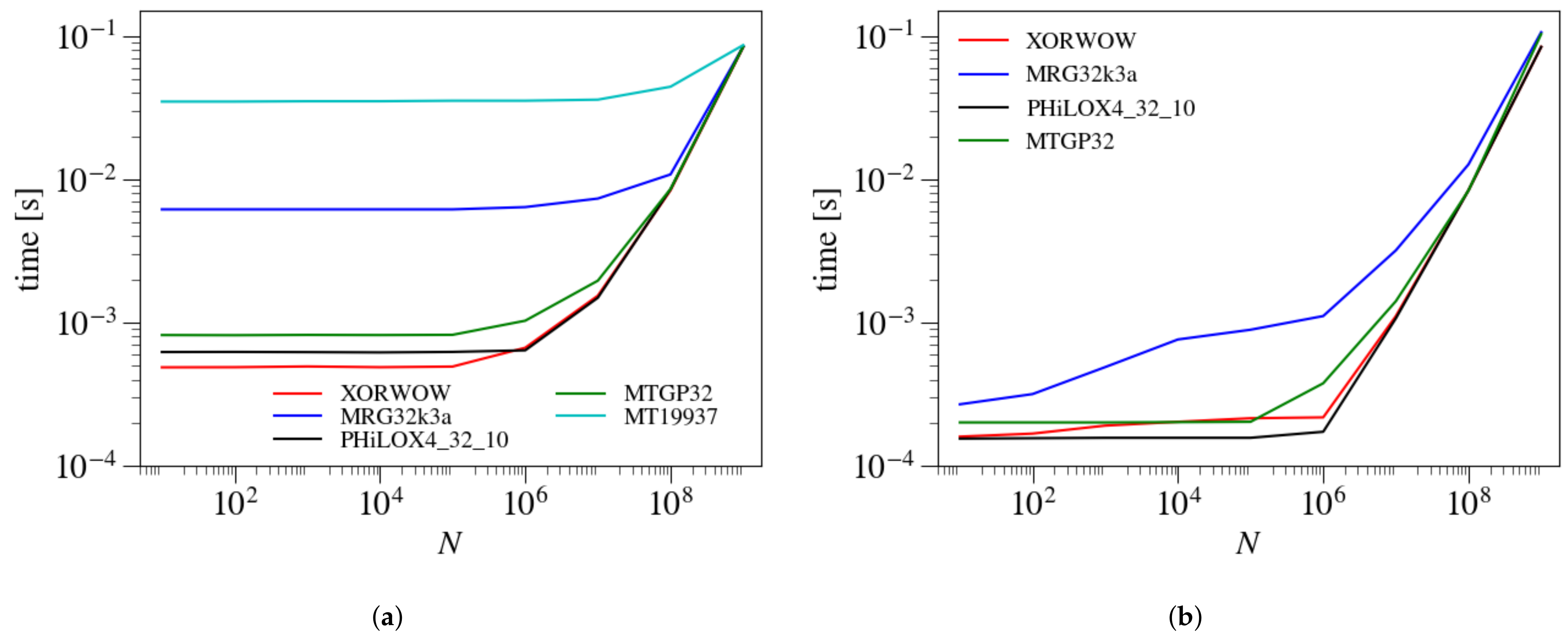
3.4. Comparison of Different PRNGs
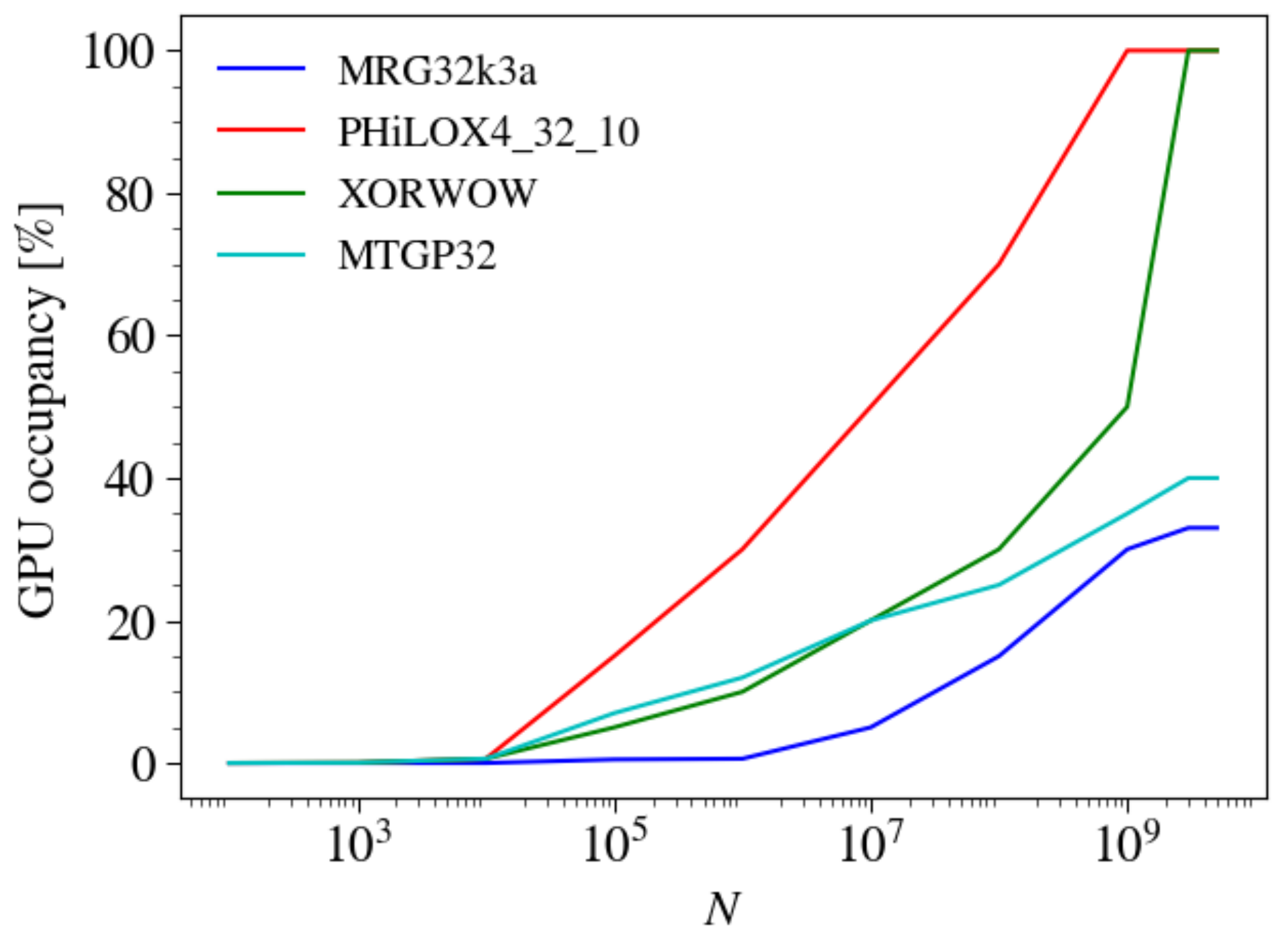
3.5. Comparison of Different GPU Cards
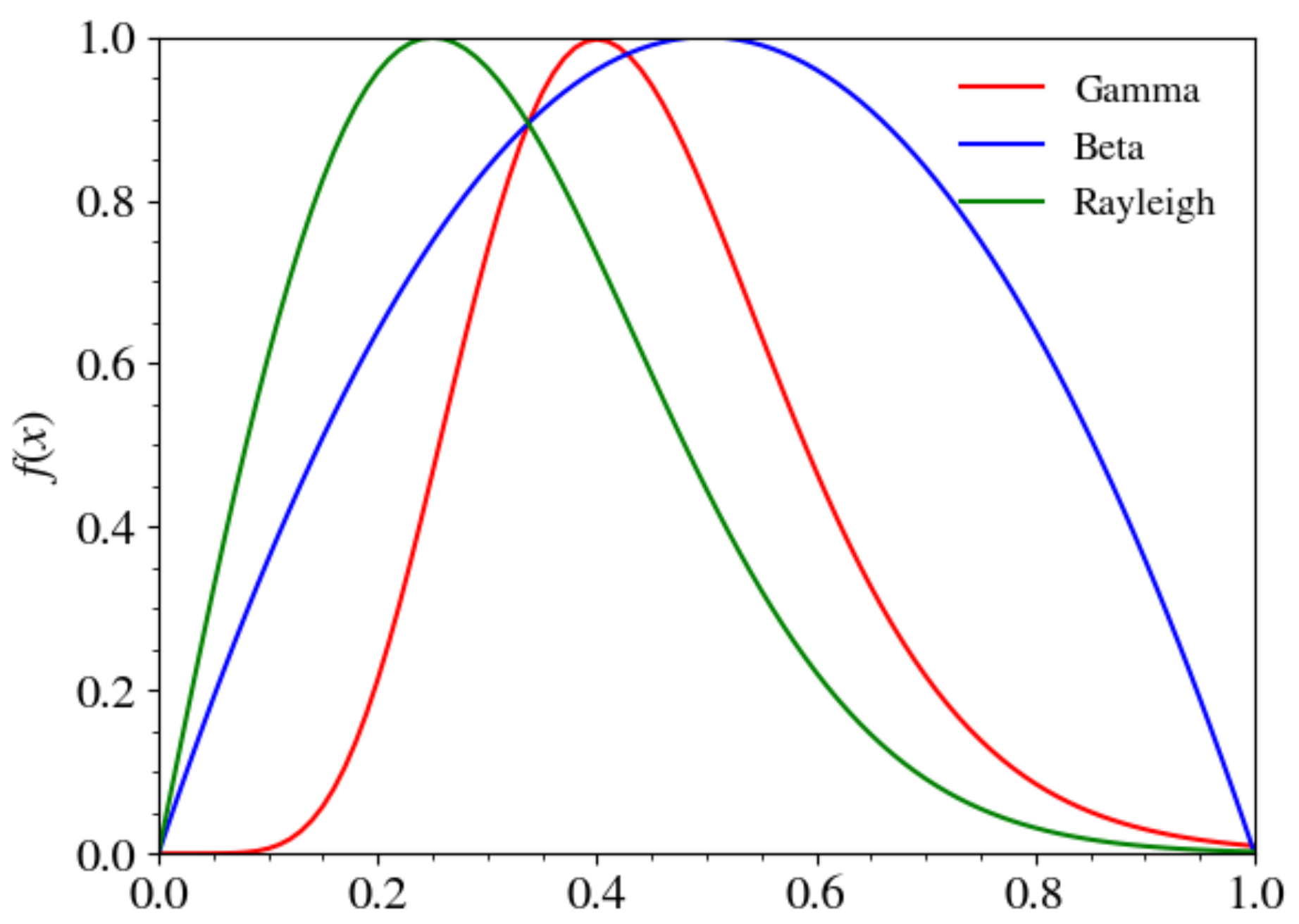
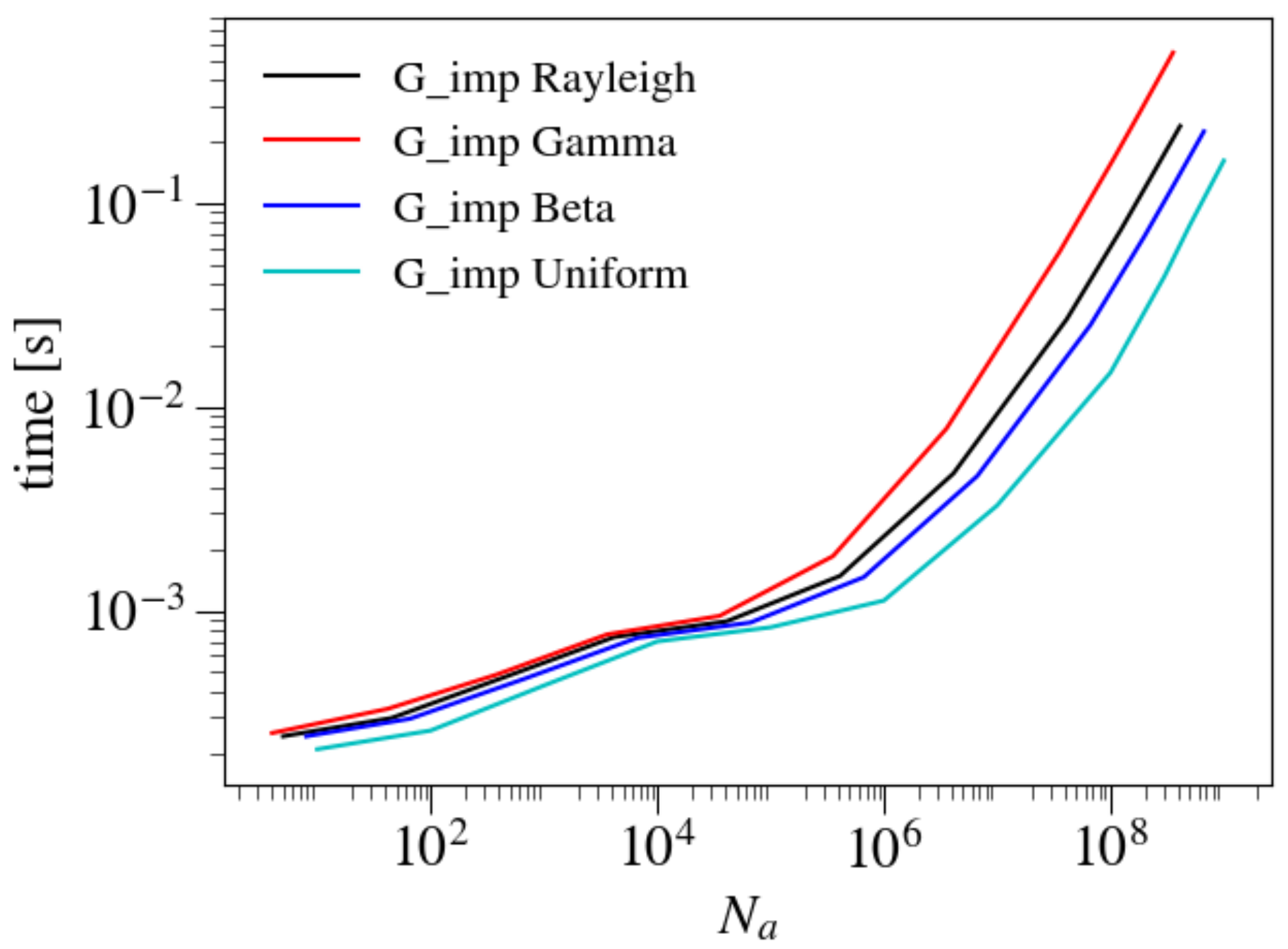
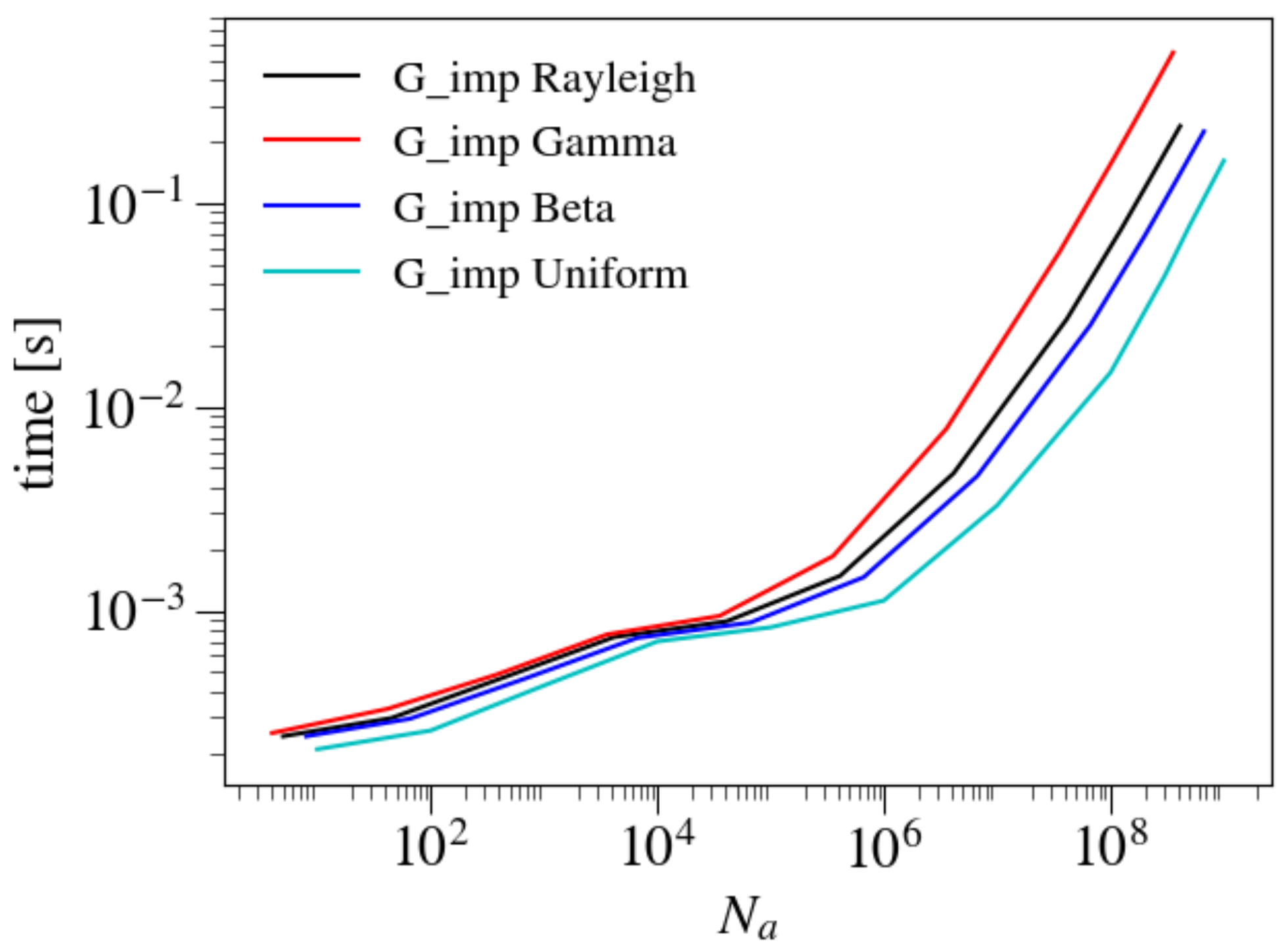
3.6. Dependence on Distributions
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Xanthis, C.; Venetis, I.; Chalkias, A.; Aletras, A. MRISIMUL: A GPU-based parallel approach to MRI simulations. IEEE Trans. Med. Imaging 2014, 33, 607–617. [Google Scholar] [CrossRef] [PubMed]
- Yudanov, D.; Shaaban, M.; Melton, R.; Reznik, L. GPU-based simulation of spiking neural networks with real-time performance & high accuracy. In Proceedings of the International Joint Conference on Neural Networks, Barcelona, Spain, 18–23 July 2010; pp. 1–8. [Google Scholar] [CrossRef]
- Dolan, R.; DeSouza, G. GPU-based simulation of cellular neural networks for image processing. In Proceedings of the International Joint Conference on Neural Networks, Atlanta, GA, USA, 14–19 June 2009; pp. 730–735. [Google Scholar] [CrossRef] [Green Version]
- Heimlich, A.; Mol, A.; Pereira, C. GPU-based Monte Carlo simulation in neutron transport and finite differences heat equation evaluation. Prog. Nucl. Energy 2011, 53, 229–239. [Google Scholar] [CrossRef]
- Liang, Y.; Xing, X.; Li, Y. A GPU-based large-scale Monte Carlo simulation method for systems with long-range interactions. J. Comput. Phys. 2017, 338, 252–268. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Spurzem, R.; Aarseth, S.; Giersz, M.; Askar, A.; Berczik, P.; Naab, T.; Schadow, R.; Kouwenhoven, M. The DRAGON simulations: Globular cluster evolution with a million stars. Mon. Not. R. Astron. Soc. 2016, 458, 1450–1465. [Google Scholar] [CrossRef] [Green Version]
- Press, W.H.; Teukolsky, S.A.; Vetterling, W.T.; Flannery, B.P. Numerical Recipes 3rd Edition: The Art of Scientific Computing, 3rd ed.; Cambridge University Press: Cambridge, MA, USA, 2007. [Google Scholar]
- Hastings, W. Monte carlo sampling methods using Markov chains and their applications. Biometrika 1970, 57, 97–109. [Google Scholar] [CrossRef]
- Kroese, D.; Brereton, T.; Taimre, T.; Botev, Z. Why the Monte Carlo method is so important today. Wiley Interdiscip. Rev. Comput. Stat. 2014, 6, 386–392. [Google Scholar] [CrossRef]
- Abdikamalov, E.; Burrows, A.; Ott, C.; Löffler, F.; O’Connor, E.; Dolence, J.; Schnetter, E. A new monte carlo method for time-dependent neutrino radiation transport. Astrophys. J. 2012, 755, 111. [Google Scholar] [CrossRef] [Green Version]
- Richers, S.; Kasen, D.; O’Connor, E.; Fernández, R.; Ott, C. Monte Carlo Neutrino Transport Through Remnant Disks from Neutron Star Mergers. Astrophys. J. 2015, 813, 38. [Google Scholar] [CrossRef] [Green Version]
- Murchikova, E.; Abdikamalov, E.; Urbatsch, T. Analytic closures for M1 neutrino transport. Mon. Not. R. Astron. Soc. 2017, 469, 1725–1737. [Google Scholar] [CrossRef] [Green Version]
- Foucart, F.; Duez, M.; Hebert, F.; Kidder, L.; Pfeiffer, H.; Scheel, M. Monte-Carlo Neutrino Transport in Neutron Star Merger Simulations. Astrophys. J. Lett. 2020, 902, L27. [Google Scholar] [CrossRef]
- Richers, S. Rank-3 moment closures in general relativistic neutrino transport. Phys. Rev. D 2020, 102, 083017. [Google Scholar] [CrossRef]
- Fatica, M.; Phillips, E. Pricing American options with least squares Monte Carlo on GPUs. In Proceedings of the WHPCF 2013: 6th Workshop on High Performance Computational Finance—Held in Conjunction with SC 2013: The International Conference for High Performance Computing, Networking, Storage and Analysis, Denver, CO, USA, 17–22 November 2013; pp. 1–6. [Google Scholar] [CrossRef]
- Karl, A.T.; Eubank, R.; Milovanovic, J.; Reiser, M.; Young, D. Using RngStreams for parallel random number generation in C++ and R. Comput. Stat. 2014, 29, 1301–1320. [Google Scholar] [CrossRef] [Green Version]
- Entacher, K.; Uhl, A.; Wegenkittl, S. Parallel random number generation: Long-range correlations among multiple processors. In International Conference of the Austrian Center for Parallel Computation; Springer: Berlin/Heidelberg, Germany, 1999; pp. 107–116. [Google Scholar]
- Entacher, K. On the CRAY-system random number generator. Simulation 1999, 72, 163–169. [Google Scholar] [CrossRef]
- Coddington, P.D. Random number generators for parallel computers. Northeast. Parallel Archit. Cent. 1997, 2. Available online: https://surface.syr.edu/cgi/viewcontent.cgi?article=1012&context=npac (accessed on 3 November 2021).
- De Matteis, A.; Pagnutti, S. Parallelization of random number generators and long-range correlations. Numer. Math. 1988, 53, 595–608. [Google Scholar] [CrossRef]
- l’Ecuyer, P. Random number generation with multiple streams for sequential and parallel computing. In Proceedings of the 2015 Winter Simulation Conference (WSC), Huntington Beach, CA, USA, 6–9 December 2015; pp. 31–44. [Google Scholar]
- Manssen, M.; Weigel, M.; Hartmann, A.K. Random number generators for massively parallel simulations on GPU. Eur. Phys. J. Spec. Top. 2012, 210, 53–71. [Google Scholar] [CrossRef] [Green Version]
- Kirk, D.; Wen-Mei, W.H. Programming Massively Parallel Processors: A Hands-On Approach; Morgan Kaufmann: Burlington, MA, USA, 2016. [Google Scholar]
- L’Ecuyer, P.; Oreshkin, B.; Simard, R. Random Numbers for Parallel Computers: Requirements and Methods. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.434.9223&rep=rep1&type=pdf (accessed on 3 November 2021).
- Wadden, J.; Brunelle, N.; Wang, K.; El-Hadedy, M.; Robins, G.; Stan, M.; Skadron, K. Generating efficient and high-quality pseudo-random behavior on Automata Processors. In Proceedings of the 2016 IEEE 34th International Conference on Computer Design (ICCD), Scottsdale, AZ, USA, 2–5 October 2016; pp. 622–629. [Google Scholar]
- Ciglarič, T.; Češnovar, R.; Štrumbelj, E. An OpenCL library for parallel random number generators. J. Supercomput. 2019, 75, 3866–3881. [Google Scholar] [CrossRef]
- Demchik, V. Pseudorandom numbers generation for Monte Carlo simulations on GPUs: OpenCL approach. In Numerical Computations with GPUs; Springer: Berlin/Heidelberg, Germany, 2014; pp. 245–271. [Google Scholar]
- Kim, Y.; Hwang, G. Efficient Parallel CUDA Random Number Generator on NVIDIA GPUs. J. KIISE 2015, 42, 1467–1473. [Google Scholar] [CrossRef]
- Mohanty, S.; Mohanty, A.; Carminati, F. Efficient pseudo-random number generation for monte-carlo simulations using graphic processors. J. Phys. 2012, 368, 012024. [Google Scholar] [CrossRef] [Green Version]
- Barash, L.Y.; Shchur, L.N. PRAND: GPU accelerated parallel random number generation library: Using most reliable algorithms and applying parallelism of modern GPUs and CPUs. Comput. Phys. Commun. 2014, 185, 1343–1353. [Google Scholar] [CrossRef] [Green Version]
- Bradley, T.; du Toit, J.; Tong, R.; Giles, M.; Woodhams, P. Parallelization techniques for random number generators. In GPU Computing Gems Emerald Edition; Elsevier: Amsterdam, The Netherlands, 2011; pp. 231–246. [Google Scholar]
- Sussman, M.; Crutchfield, W.; Papakipos, M. Pseudorandom number generation on the GPU. In Proceedings of the SIGGRAPH/Eurographics Workshop on Graphics Hardware, Vienna, Austria, 3–4 September 2006; pp. 87–94. [Google Scholar] [CrossRef]
- Abeywardana, N. Efficient Random Number Generation for Fermi Class GPUs. Available online: https://www.proquest.com/openview/e4cd0bc00b2dd0572824fe304b5851e4/1?pq-origsite=gscholar&cbl=18750 (accessed on 3 November 2021).
- Howes, L.; Thomas, D. Efficient random number generation and application using CUDA. GPU Gems 2007, 3, 805–830. [Google Scholar]
- Preis, T.; Virnau, P.; Paul, W.; Schneider, J. GPU accelerated Monte Carlo simulation of the 2D and 3D Ising model. J. Comput. Phys. 2009, 228, 4468–4477. [Google Scholar] [CrossRef]
- Thomas, D.B.; Howes, L.; Luk, W. A comparison of CPUs, GPUs, FPGAs, and massively parallel processor arrays for random number generation. In Proceedings of the ACM/SIGDA International Symposium on Field Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2009; pp. 63–72. [Google Scholar]
- Anker, M. Pseudo Random Number Generators on Graphics Processing Units, with Applications in Finance. Mémoire de maîtrise à l’Université d’Edinburgh. 2013. Available online: https://static.epcc.ed.ac.uk/dissertations/hpc-msc/2012-2013/Pseudo (accessed on 3 November 2021).
- Jia, X.; Gu, X.; Sempau, J.; Choi, D.; Majumdar, A.; Jiang, S. Development of a GPU-based Monte Carlo dose calculation code for coupled electron-photon transport. Phys. Med. Biol. 2010, 55, 3077–3086. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alerstam, E.; Svensson, T.; Andersson-Engels, S. Parallel computing with graphics processing units for high-speed Monte Carlo simulation of photon migration. J. Biomed. Opt. 2008, 13, 060504. [Google Scholar] [CrossRef] [Green Version]
- Bert, J.; Perez-Ponce, H.; Bitar, Z.; Jan, S.; Boursier, Y.; Vintache, D.; Bonissent, A.; Morel, C.; Brasse, D.; Visvikis, D. Geant4-based Monte Carlo simulations on GPU for medical applications. Phys. Med. Biol. 2013, 58, 5593–5611. [Google Scholar] [CrossRef] [PubMed]
- Okada, S.; Murakami, K.; Incerti, S.; Amako, K.; Sasaki, T. MPEXS-DNA, a new GPU-based Monte Carlo simulator for track structures and radiation chemistry at subcellular scale. Med. Phys. 2019, 46, 1483–1500. [Google Scholar] [CrossRef] [Green Version]
- Spiechowicz, J.; Kostur, M.; Machura, L. GPU accelerated Monte Carlo simulation of Brownian motors dynamics with CUDA. Comput. Phys. Commun. 2015, 191, 140–149. [Google Scholar] [CrossRef] [Green Version]
- Ayubian, S.; Alawneh, S.; Thijssen, J. GPU-based monte-carlo simulation for a sea ice load application. In Proceedings of the Summer Computer Simulation Conference, Montreal, QC, Canada, 24–27 July 2016; pp. 1–8. [Google Scholar]
- Langdon, W.B. PRNG Random Numbers on GPU; Technical Report; University of Essex: Colchester, UK, 2007. [Google Scholar]
- Passerat-Palmbach, J.; Mazel, C.; Hill, D.R. Pseudo-random number generation on GP-GPU. In Proceedings of the 2011 IEEE Workshop on Principles of Advanced and Distributed Simulation, Nice, France, 14–17 June 2011; pp. 1–8. [Google Scholar]
- Fog, A. Pseudo-random number generators for vector processors and multicore processors. J. Mod. Appl. Stat. Methods 2015, 14, 23. [Google Scholar] [CrossRef] [Green Version]
- Beliakov, G.; Johnstone, M.; Creighton, D.; Wilkin, T. An efficient implementation of Bailey and Borwein’s algorithm for parallel random number generation on graphics processing units. Computing 2013, 95, 309–326. [Google Scholar] [CrossRef]
- Gong, C.; Liu, J.; Chi, L.; Hu, Q.; Deng, L.; Gong, Z. Accelerating Pseudo-Random Number Generator for MCNP on GPU. AIP Conf. Proc. 2010, 1281, 1335–1337. [Google Scholar]
- Gao, S.; Peterson, G.D. GASPRNG: GPU accelerated scalable parallel random number generator library. Comput. Phys. Commun. 2013, 184, 1241–1249. [Google Scholar] [CrossRef] [Green Version]
- Monfared, S.K.; Hajihassani, O.; Kiarostami, M.S.; Zanjani, S.M.; Rahmati, D.; Gorgin, S. BSRNG: A High Throughput Parallel BitSliced Approach for Random Number Generators. In Proceedings of the 49th International Conference on Parallel Processing-ICPP, Workshops, Edmonton, AB, Canada, 17–20 August 2020; pp. 1–10. [Google Scholar]
- Pang, W.M.; Wong, T.T.; Heng, P.A. Generating massive high-quality random numbers using GPU. In Proceedings of the 2008 IEEE Congress on Evolutionary Computation (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–6 June 2008; pp. 841–847. [Google Scholar]
- Yang, B.; Hu, Q.; Liu, J.; Gong, C. GPU optimized Pseudo Random Number Generator for MCNP. In Proceedings of the IEEE Conference Anthology, Shanghai, China, 1–8 January 2013; pp. 1–6. [Google Scholar]
- Nandapalan, N.; Brent, R.P.; Murray, L.M.; Rendell, A.P. High-performance pseudo-random number generation on graphics processing units. In International Conference on Parallel Processing and Applied Mathematics; Springer: Berlin/Heidelberg, Germany, 2011; pp. 609–618. [Google Scholar]
- Kargaran, H.; Minuchehr, A.; Zolfaghari, A. The development of GPU-based parallel PRNG for Monte Carlo applications in CUDA Fortran. AIP Adv. 2016, 6, 045101. [Google Scholar] [CrossRef] [Green Version]
- Riesinger, C.; Neckel, T.; Rupp, F.; Hinojosa, A.P.; Bungartz, H.J. Gpu optimization of pseudo random number generators for random ordinary differential equations. Procedia Comput. Sci. 2014, 29, 172–183. [Google Scholar] [CrossRef] [Green Version]
- Jun, S.; Canal, P.; Apostolakis, J.; Gheata, A.; Moneta, L. Vectorization of random number generation and reproducibility of concurrent particle transport simulation. J. Phys. 2020, 1525, 012054. [Google Scholar] [CrossRef]
- Amadio, G.; Canal, P.; Piparo, D.; Wenzel, S. Speeding up software with VecCore. J. Phys. Conf. Ser. 2018, 1085, 032034. [Google Scholar] [CrossRef]
- Gregg, C.; Hazelwood, K. Where is the data? Why you cannot debate CPU vs. GPU performance without the answer. In Proceedings of the (IEEE ISPASS) IEEE International Symposium on Performance Analysis of Systems and Software, Austin, TX, USA, 10–12 April 2011; pp. 134–144. [Google Scholar]
- Hoffman, D.; Karst, O.J. The theory of the Rayleigh distribution and some of its applications. J. Ship Res. 1975, 19, 172–191. [Google Scholar] [CrossRef]
- Theodoridis, S. Chapter 2—Probability and Stochastic Processes. In Machine Learning, 2nd ed.; Theodoridis, S., Ed.; Academic Press: Cambridge, MA, USA, 2020; pp. 19–65. [Google Scholar] [CrossRef]
- Papoulis, A. Probability, Random Variables and Stochastic Processes. IEEE Trans. Acoust. Speech Signal Process. 1985, 33, 1637. [Google Scholar] [CrossRef]
- Fatica, M.; Ruetsch, G. CUDA Fortran for Scientists and Engineers: Best Practices for Efficient CUDA Fortran Programming; Elsevier Inc.: Amsterdam, The Netherlands, 2013; pp. 1–323. [Google Scholar] [CrossRef]
- Nvidia, C. CUDA C Programming Guide, Version 11.2; NVIDIA Corp.: 2020. Available online: https://docs.nvidia.com/cuda/pdf/CUDA_C_Programming_Guide.pdf (accessed on 3 November 2021).
- Nvidia, C. CUDA C Best Practices Guide; NVIDIA Corp.: 2020. Available online: https://www.clear.rice.edu/comp422/resources/cuda/pdf/CUDA_C_Best_Practices_Guide.pdf (accessed on 3 November 2021).
- Nvidia, C. Toolkit 11.0 CURAND Guide. 2020. Available online: https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html (accessed on 3 November 2021).
- Marsaglia, G. Xorshift RNGs. J. Stat. Softw. 2003, 8, 1–6. [Google Scholar] [CrossRef]
- Saito, M.; Matsumoto, M. Variants of Mersenne twister suitable for graphic processors. ACM Trans. Math. Softw. 2013, 39, 1–20. [Google Scholar] [CrossRef] [Green Version]
- L’ecuyer, P. Good parameters and implementations for combined multiple recursive random number generators. Oper. Res. 1999, 47, 159–164. [Google Scholar] [CrossRef] [Green Version]
- Salmon, J.K.; Moraes, M.A.; Dror, R.O.; Shaw, D.E. Parallel random numbers: As easy as 1, 2, 3. In Proceedings of the 2011 International Conference for High Performance Computing, Networking, Storage and Analysis, Seattle, WA, USA, 12–18 November 2011; pp. 1–12. [Google Scholar]
- Matsumoto, M.; Nishimura, T. Mersenne twister: A 623-dimensionally equidistributed uniform pseudo-random number generator. ACM Trans. Model. Comput. Simul. (TOMACS) 1998, 8, 3–30. [Google Scholar] [CrossRef] [Green Version]
- Fog, A. Instruction Tables: Lists of Instruction Latencies, Throughputs and Micro-Operation Breakdowns for Intel, AMD and VIA CPUs; Technical Report; Copenhagen University College of Engineering: Ballerup, Denmark, 2021. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| XORWOW | MTGP32 | MRG32K3A | PHILOX4_32_10 | MT19937 | |
|---|---|---|---|---|---|
| Algorithm | Linear feedback shift registers [66] | Twisted generalized feedback shift register generator [67] | Combined Multiple Recursive [68] | Counter-Based Random Number Generation [69] | Twisted generalized feedback shift register generator [70] |
| Period | |||||
| Sub-sequence length | − | ||||
| State size | 48 bytes | 4120 bytes | 48 bytes | 64 bytes | 2500 bytes |
| Parallelization method | Sequence splitting | Parameterization | Sequence splitting | Sequence splitting, parameterization | Sequence splitting |
| GTX1080 | GTX1080Ti | RTX3080 | RTX3090 | |
|---|---|---|---|---|
| SMs | 20 | 28 | 68 | 82 |
| CUDA cores | 2560 | 3584 | 4352 | |
| Max clock rate | GHz | GHz | GHz | GHz |
| Global memory | 8 GB | 11 GB | 10 GB | 24 GB |
| Theoretical performance | TFLOPS (FP32) | TFLOPS (FP32) | TFLOPS (FP32) | TFLOPS (FP32) |
| Bandwidth | GB/s | GB/s | GB/s | GB/s |
| Parameter | Value |
|---|---|
| Implementation | G_imp |
| API | device API |
| GPU | RTX 3090 |
| PRNG | MRG32k3a |
| Distribution | Beta distribution |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Askar, T.; Shukirgaliyev, B.; Lukac, M.; Abdikamalov, E. Evaluation of Pseudo-Random Number Generation on GPU Cards. Computation 2021, 9, 142. https://doi.org/10.3390/computation9120142
Askar T, Shukirgaliyev B, Lukac M, Abdikamalov E. Evaluation of Pseudo-Random Number Generation on GPU Cards. Computation. 2021; 9(12):142. https://doi.org/10.3390/computation9120142
Chicago/Turabian StyleAskar, Tair, Bekdaulet Shukirgaliyev, Martin Lukac, and Ernazar Abdikamalov. 2021. "Evaluation of Pseudo-Random Number Generation on GPU Cards" Computation 9, no. 12: 142. https://doi.org/10.3390/computation9120142
APA StyleAskar, T., Shukirgaliyev, B., Lukac, M., & Abdikamalov, E. (2021). Evaluation of Pseudo-Random Number Generation on GPU Cards. Computation, 9(12), 142. https://doi.org/10.3390/computation9120142