Following a similar framework of building bivariate models for ordinal panel data via [
1], we constructed a class of bivariate integer-valued time series models using copula theory. Applying either the bivariate Gaussian copula or the bivariate t-copula functions, we jointly modeled two copula-based Markov time series models (see [
2,
3]). Such a method allows for flexible dependence structures between the two time series and within each one, which allow for both positive or negative correlations, which is theoretically not presented with most existing methods.
The count time series data have multiple applications, many of which have been covered in the literature; see [
4] for a comprehensive review. Sometimes, in finance, climate, public health, and crime data analysis, time series counts come as bivariate vectors that observe not only serial dependence within each time series, but also interdependence or cross-dependence between the two series. To accurately study such data, one needs to account for the two types of dependence that emerge from the observed data by applying multivariate time series models. The literature covering normally distributed multivariate time series is plentiful. However, with count time series data and due to the complexity of the computational burden of analyzing such data, the literature on bivariate or multivariate count time series is limited, and so is the zero-inflated cases of time series.
Following the concepts of the integer-valued autoregressive moving average (INARMA) model, Reference [
5] introduced the bivariate integer-valued moving average (BINMA) model, which allows for both positive and negative correlation between counts. Further, they presented an extension to the multivariate version starting from the BINMA model. Reference [
6] proposed a bivariate zero-inflated Poisson model to analyze occupational injuries. Reference [
7] introduced a multivariate autoregressive conditional double Poisson model, which can accommodate overdispersion, serial dependence, and cross-correlation. They used a multivariate normal copula to capture the cross-correlation between time series, and parameter estimation was conducted using a two-stage estimation procedure. The work of [
8] presented a bivariate integer-valued autoregressive process (BINAR(1)) in which the cross-correlation was modeled using a copula to accommodate both positive and negative correlation. They presented the use of a Frank and Gaussian copula to model dependence, and marginal time series were modeled using Poisson and negative binomial INAR(1) models. Reference [
9] applied state space models for multivariate count time series and used the to analyze marketing datasets. Reference [
10] proposed a new bivariate Poisson INGARCH model, which allows for positive or negative cross-correlation between time series. Reference [
11] proposed a class of flexible bivariate Poisson INGARCH(1,1) models whose dependence was established by a special multiplicative factor. The parameter estimation was conducted using maximization by parts the algorithm and its modified version to reduce the computation time. Reference [
12] proposed a model for longitudinal data where the univariate margins were selected from the class of zero-inflated distributions, and the dependence structure was modeled using a D-vine copula. Reference [
13] presented a comprehensive review on a copula and its applications in different fields. They presented the use of a copula in time series under both univariate and multivariate setups. Reference [
14] also wrote a comprehensive review, but on multivariate time series for count time series.
The rest of the paper is organized as follows. In
Section 2, we first provide a brief background on the Poisson and ZIP regression model and the copula theory. Then,
Section 3 presents the proposed class of copula-based bivariate models to analyze two dependent time series, each being modeled via copula-based Markov chains and then jointly handled using either the bivariate Gaussian or t-copula functions. In
Section 5, we give some simulation results.
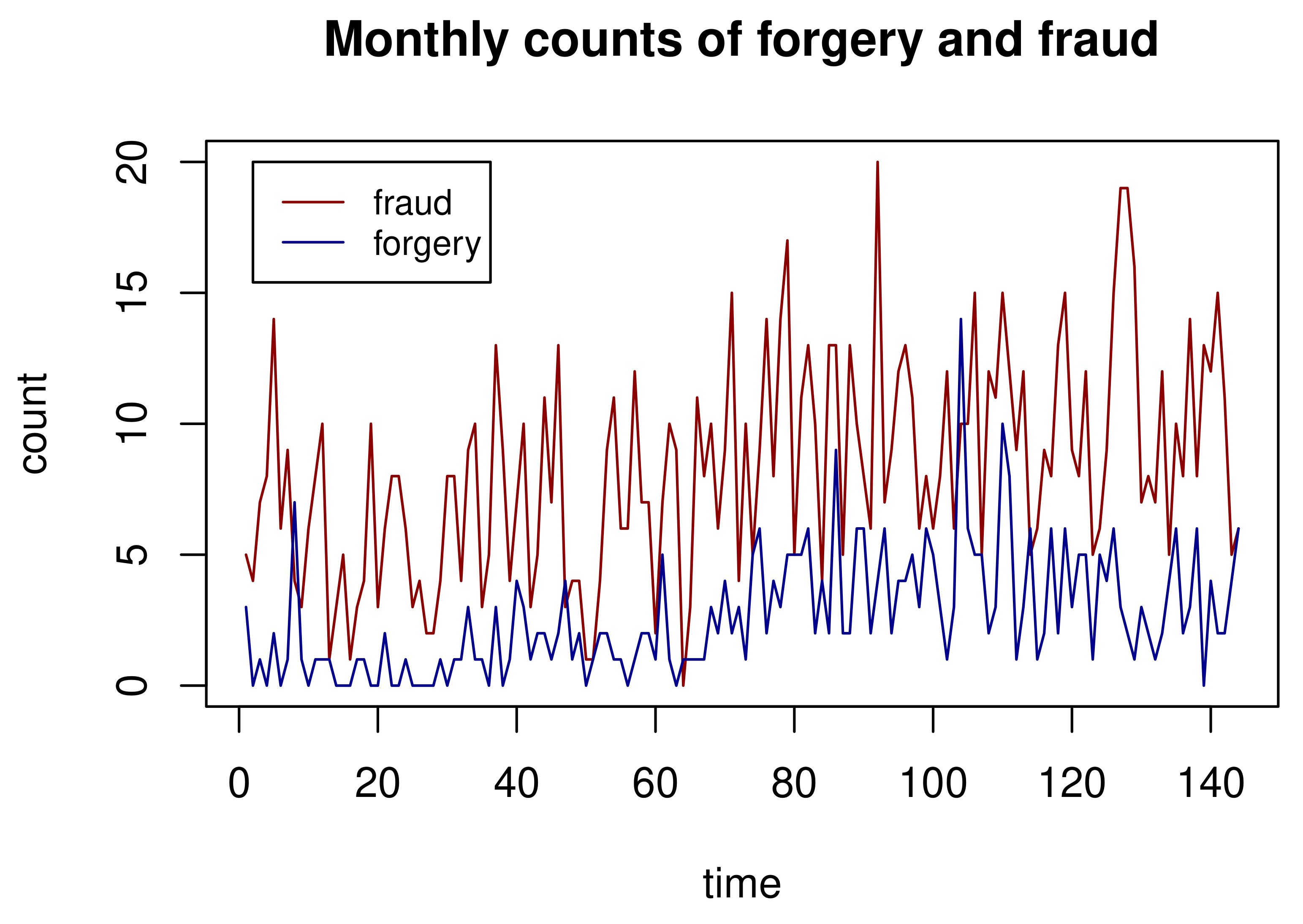
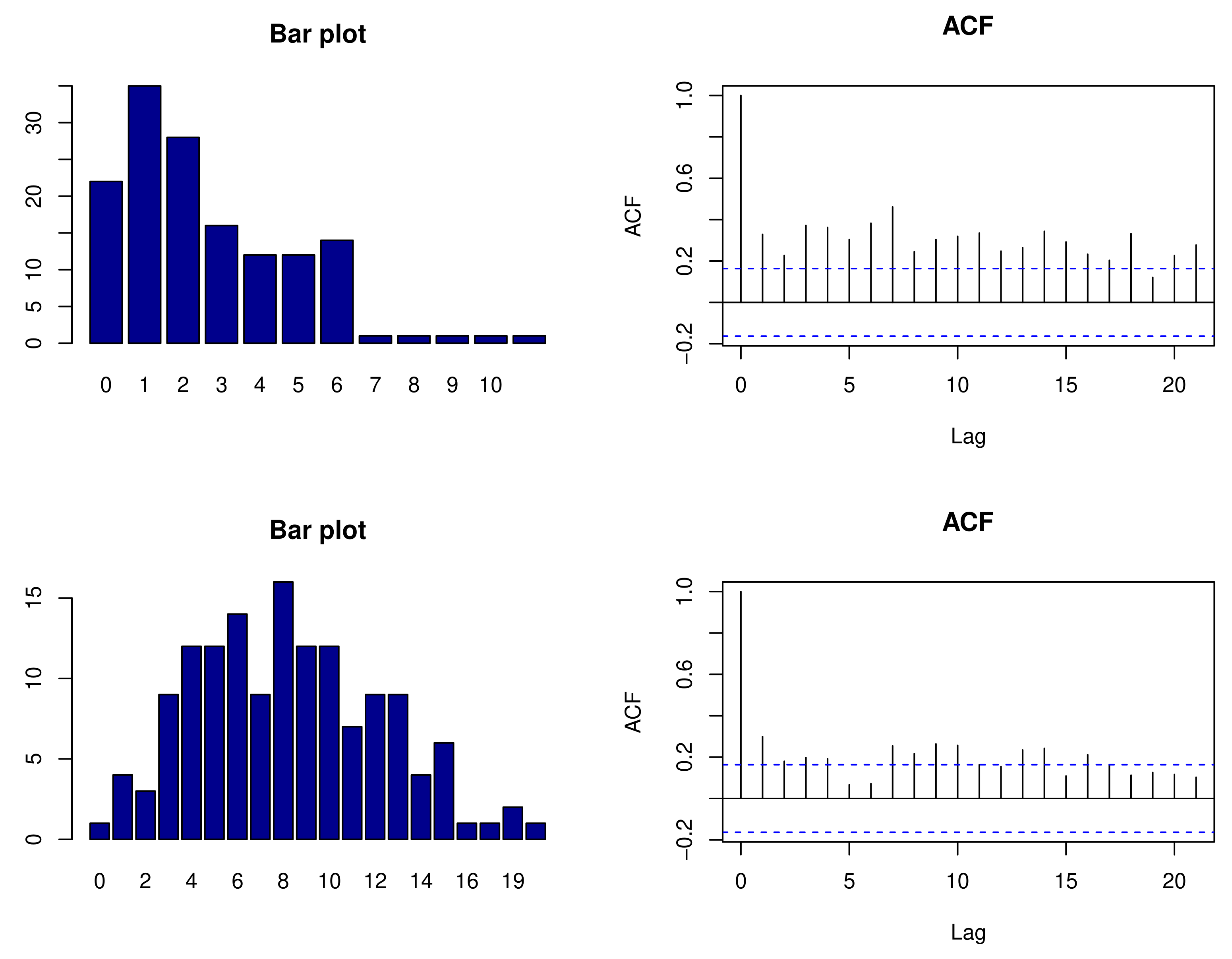
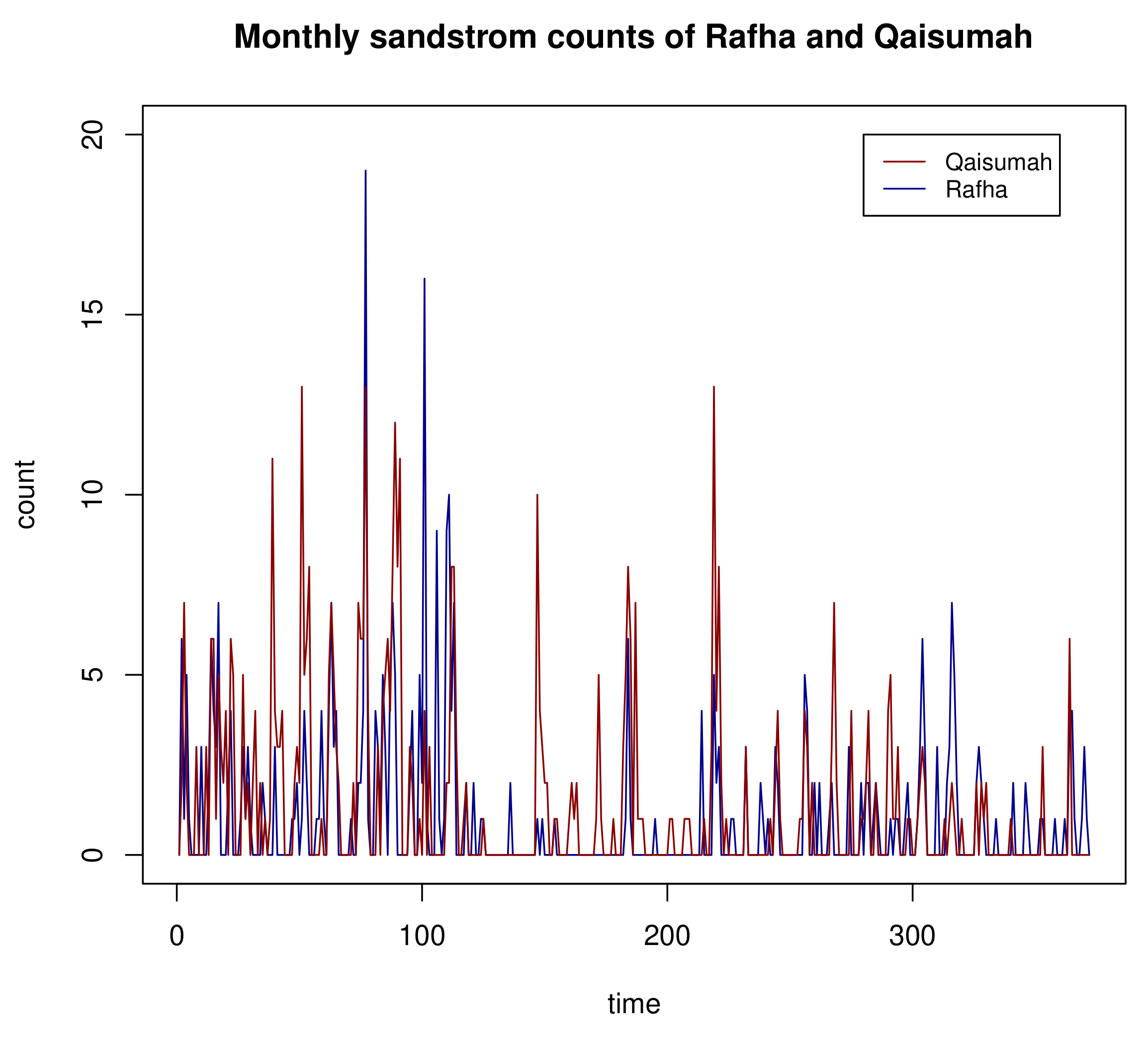
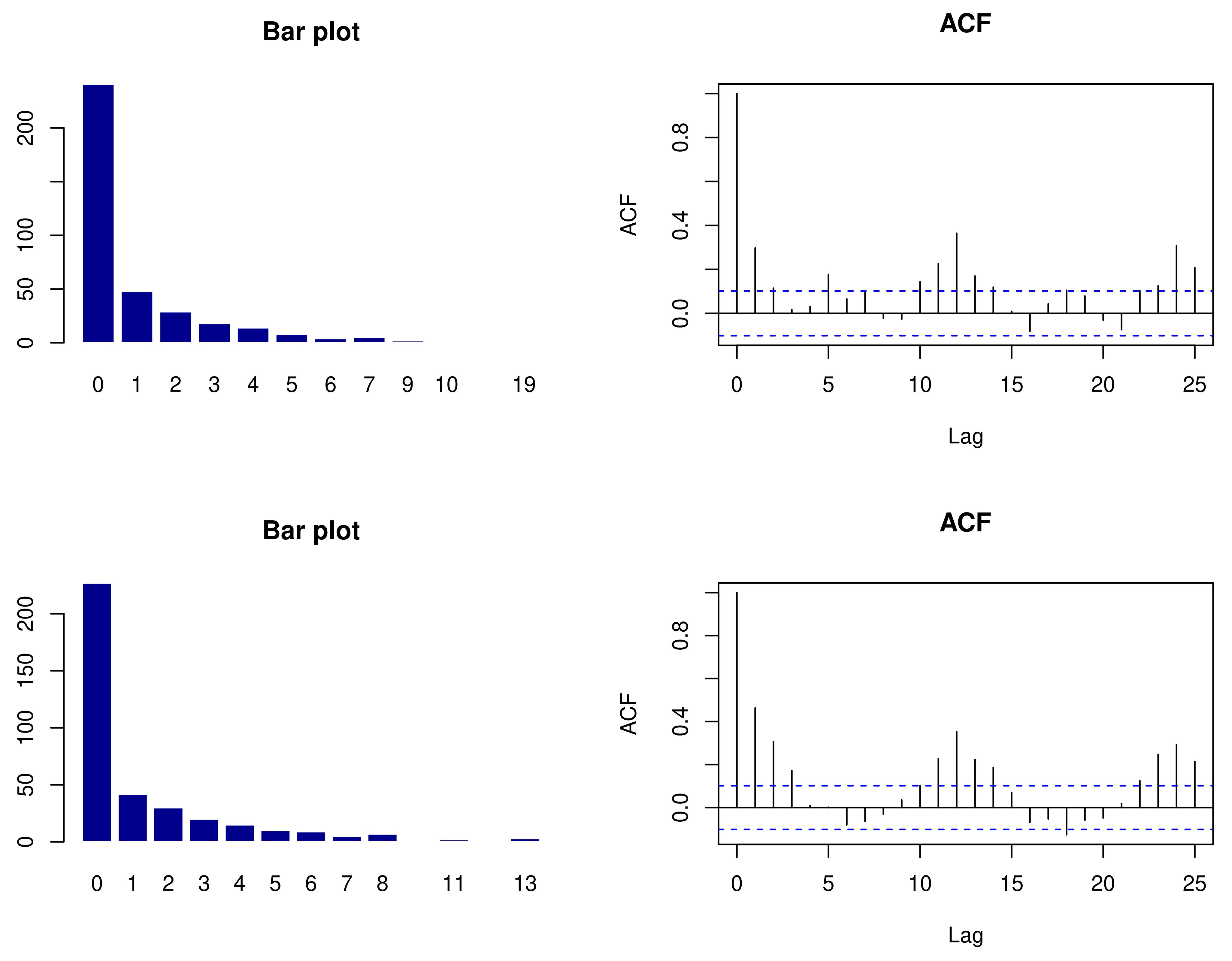
Section 6 provides two real data examples. The conclusion is given in
Section 7.





{kind=link}
{kind=link}
{kind=link}
{kind=link}