Performance and Energy Footprint Assessment of FPGAs and GPUs on HPC Systems Using Astrophysics Application

 , , , , , , , , and
, , , , , , , , and
Abstract
1. Introduction and Motivation
- (I-II) two Linux x86 HPC clusters that represent the state-of-the-art of HPC architectures (Intel-based and equipped with NVIDIA GPUs);
- (III) a Multiprocessor SoC micro-cluster that represents a low purchase-cost and low-power approach to HPC;
- (IV) an Exascale prototype that represents a possible future for supercomputers. This prototype was developed by the ExaNeSt European project (ExaNeSt: https://exanest.eu/) [10,11,12] and customized by the EuroExa project.
2. Computing Platforms
2.1. Intel Cluster
2.2. GPU Cluster
2.3. ARM-Micro-Cluster
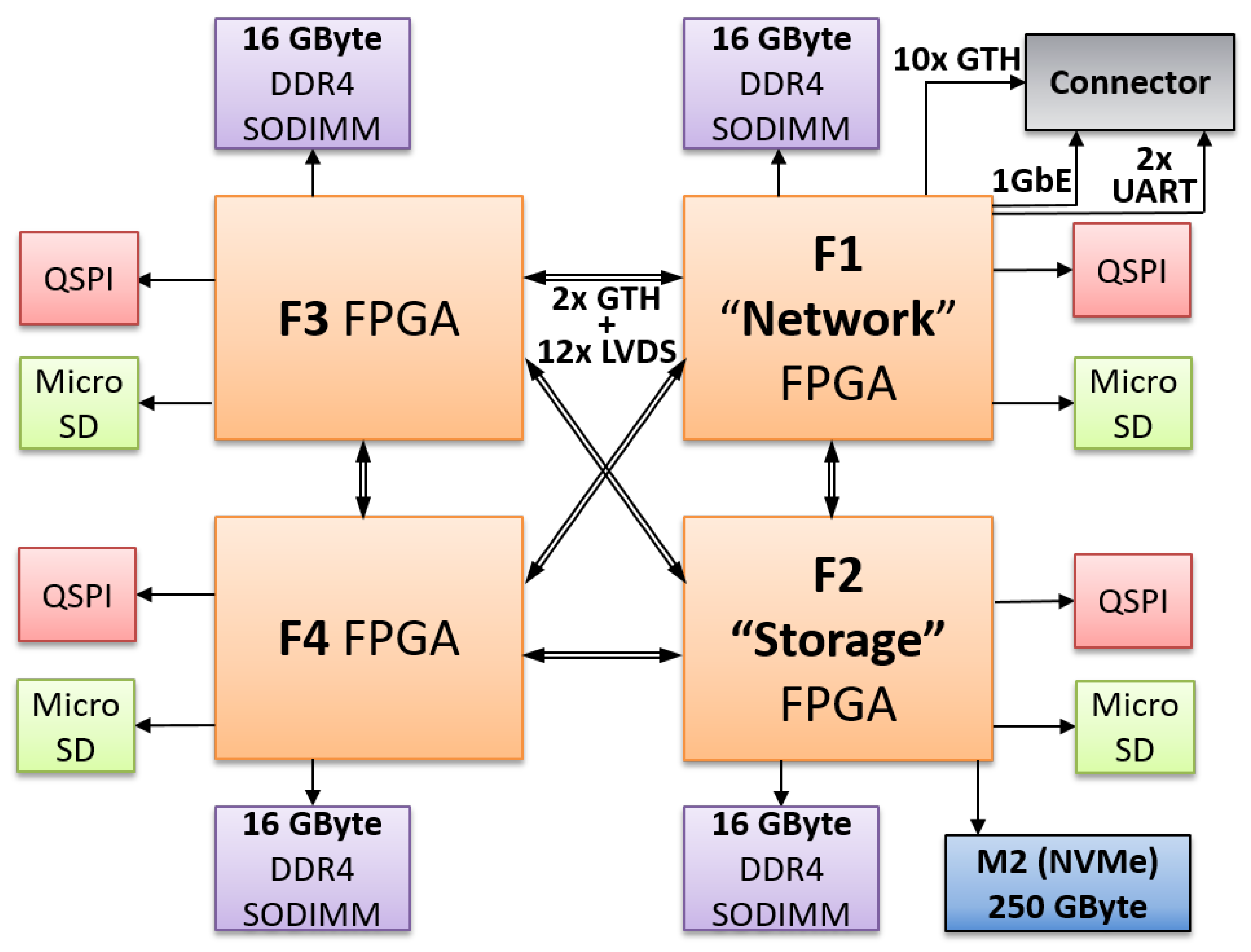
2.4. ExaNest HPC Testbed Prototype
3. Methodology and Considerations
4. Power Consumption Measurements
5. Astrophysical Code
- (i)
- Standard C code: cache-aware designed for CPUs and parallelized with hybrid MPI+OpenMP programming;
- (ii)
- OpenCL code: conceived to target accelerators like GPGPUs or embedded GPUs. All the stages of the Hermite integrator are performed on the OpenCL-compliant device(s). The kernel implementation exploits local memory (OpenCL terminology) of device(s), which is generally accepted as the best method to reduce global memory latency in discrete GPUs. However, on ARM embedded GPUs, the global and local OpenCL address spaces are mapped to main host memory (as reported by the ARM developer guide (http://infocenter.arm.com/help/topic/com.arm.doc.100614_0312_00_en/arm_mali_midgard_opencl_developer_guide_100614_0312_00_en.pdf)). Therefore, a specific ARM-GPU-optimized version of all kernels of Hy-Nbody, in which local memory is not used, has been implemented and used in the results shown in the paper. The impact of such an optimization is shown in [21].Regarding the host parallelization schema, a one-to-one correspondence between MPI processes and computational nodes is established and each MPI process manages all the OpenCL-compliant devices available per node (the number of such devices is user defined). Inside each share-memory computational node the parallelization is achieved by means of OpenMP. Such an implementation requires that particle data be communicated between the host and the device at each time-step, which gives rise to synchronization points between host and device(s). Accelerations and time-step computed by the device(s) are retrieved by the host on every computational node, reduced and then sent back again to the device(s);
- (iii)
- Standard C targeting HLS tool: Xilinx Vivado High-Level Synthesis tool (https://www.xilinx.com/products/design-tools/vivado/integration/esl-design.html) was used to develop a highly optimized hardware accelerator for QFDB’s FPGAs. The kernel was designed to be parameterizable, to experiment with different area vs performance implementations and to provide the capability of deploying it to any Xilinx FPGA with any amount of reconfigurable resources.Vivado HLS provides a directive-oriented style of programming where the tool transforms the high-level code (C, C++, SystemC, OpenCL) to a Hardware Description Language (HDL) according to the directives provided by the programmer. Some of the optimizations performed in this kernel are described below:
- calculation in chunks: Given the finite resources of the FPGA and the need to accelerate the Hermite algorithm in large arrays that exceed the amount of internal memory inside the FPGA (Block RAM), we followed a tiled approach where the kernel loops over the corresponding tiles of the original arrays and the core Hermite algorithm is performed in chunks of data stored internally. Block RAM is a low latency memory cell that can be configured in various widths and depths to store data inside the FPGA fabric, but their capacity is limited (32.1 MB in our device). Thus, at the start of each computation the kernel fetches the data for the corresponding tile from main memory and stores it into Block RAM. During computation, the partial results are also kept internally and as soon as the kernel finishes working with a tile, it writes the results back to the main memory and fetches the data for the next tile. Hence, the kernel has immediate access to the data it needs and communicates with the higher-latency DRAM only at the beginning and end of processing each tile, resulting in higher computational efficiency.
- burst memory mode: As defined in the AXI4 protocol (which is used by the kernel to communicate with the DRAM) a “beat” is an individual transfer of a single data word, while a “burst” is a transaction in which multiple sequential data are transferred based upon a single address request. Since the data to be processed are stored sequentially in large arrays inside the DRAM, the kernel was implemented to request and fetch the data in bursts, and the burst size selected was the maximum burst size allowed by the AXI4, which is 4 kB. This results in higher hardware complexity and resource use inside the FPGA fabric, but provides higher memory bandwidth and more efficient communication with the device’s memory controller.
- loop pipeline, loop unroll, array partitioning: Core Hermite algorithm has been pipelined achieving an initiation interval of 1 clock cycle. To achieve this, we increased the amount of the kernel’s AXI4 read/write interfaces that communicate with the DRAM to fetch data from multiple arrays simultaneously. Also, by applying the loop unrolling directive we allowed the algorithm to be performed on more particles per cycle, with the corresponding increase of the FPGA resources needed due to the demand of more computational units. To achieve pipelining, the arrays stored internally were partitioned in multiple Block RAMs, since each BRAM has 2 ports for reading/writing and the kernel needs to access the data of many particles per cycle. These modifications minimized the idle time, considering the kernel is able to perform calculations on many particles in each individual cycle and remains idle only at the beginning and at the end of the processing of each tile when it communicates with the DRAM.
In our previous work [22] we demonstrated a kernel showing a single QFDB’s FPGA full potential. Due to its extra connectivity capabilities, the ”Network” FPGA results in a higher reconfigurable resource congestion to operate. Thus, the above kernel’s high demand of resources made it unfeasible to deploy it to the ”Network” FPGA, so in order to demonstrate the application running in many FPGAs and split the computation load evenly inside the QFDB we chose a different size for this work’s kernel. This kernel has 75% throughput of the previous one and operates on a slightly higher frequency (320 MHz compared to 300 MHz).
Floating Point Arithmetic Considerations
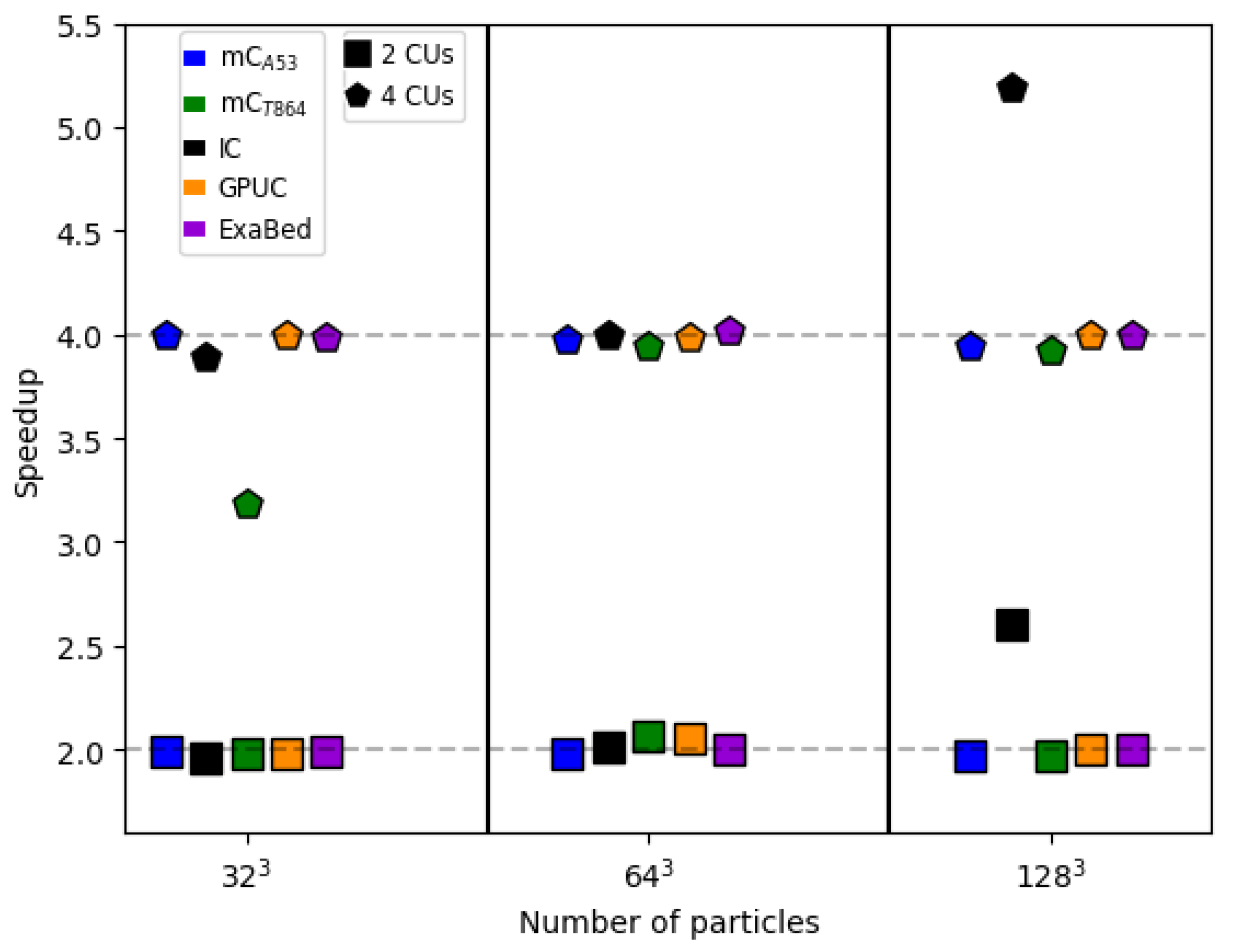
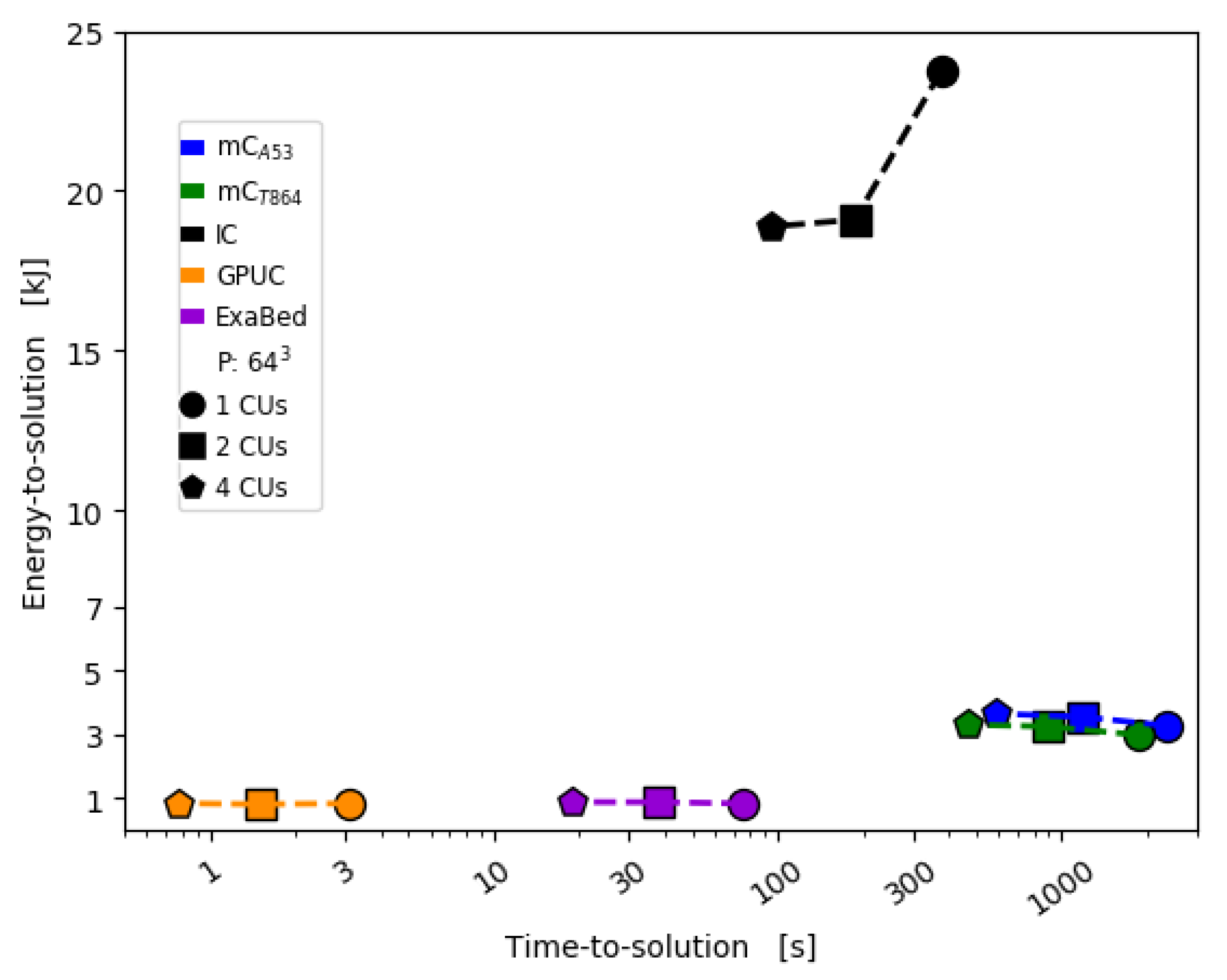
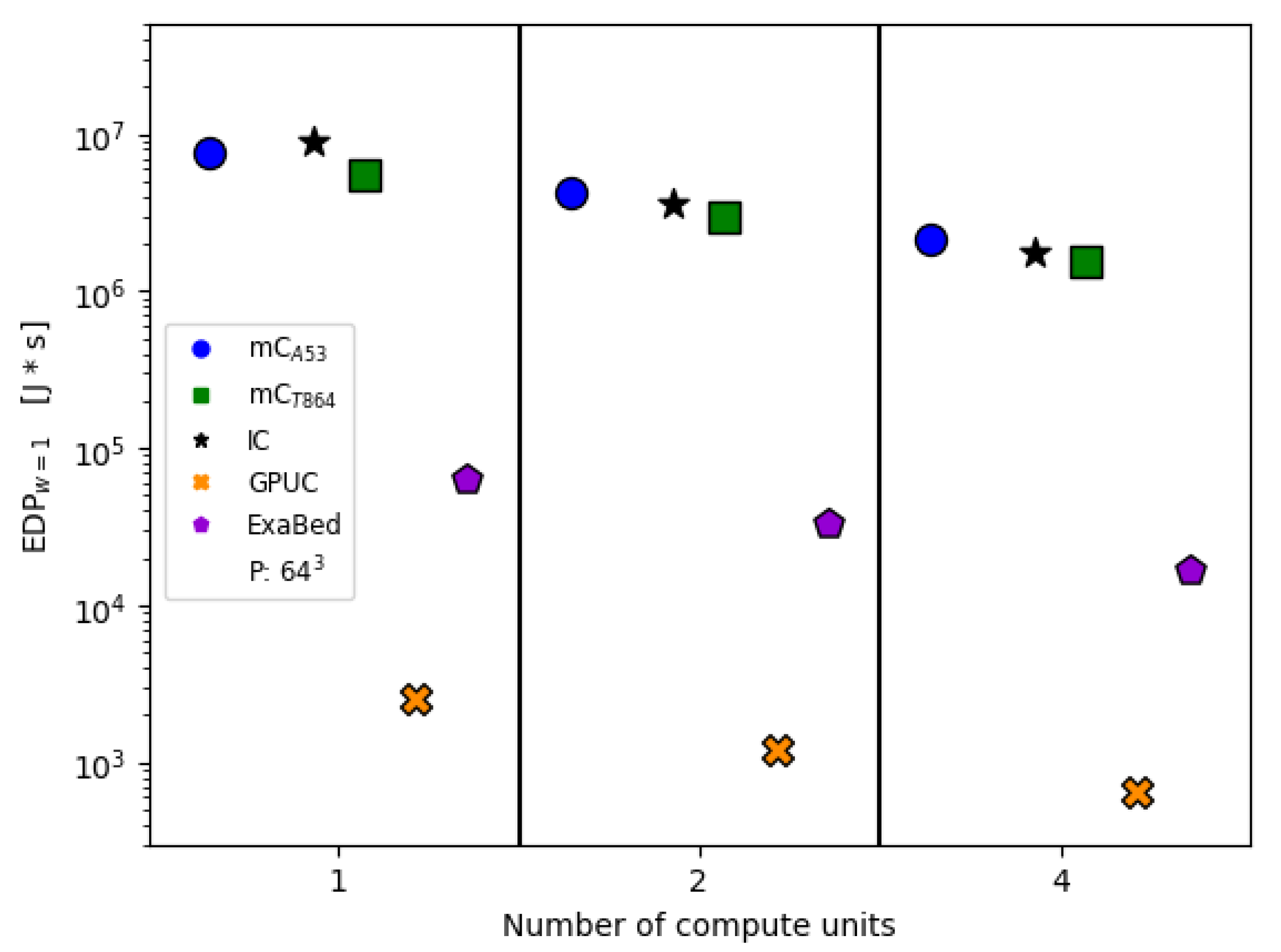
6. Computational Performance and Energy Consumption
7. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| AA | Astronomy and Astrophysics |
| CPU | Central Processing Unit |
| CU | Compute Unit |
| CUDA | Compute Unified Device Architecture |
| EDP | Energy Delay Product |
| ExaBed | EaxNeSt HPC testbed |
| ExaNeSt | European Exascale System Interconnect and Storage |
| FLOPS | FLoating point Operations Per Second |
| FPGA | Field Programmable Gate Array |
| GPU | Graphic Processing Unit |
| GPUC | GPU cluster |
| HDL | Hardware Description Language |
| HLS | High-Level Synthesis |
| HPC | High-Performance Computing |
| IC | Intel Cluster |
| ICS-FORTH | Institute of Computer Science-FORTH |
| INAF | Istituto Nazionale di Astrofisica |
| INFN | Istituto Nazionale di Fisica Nucleare |
| mC | ARM-Micro-Cluster |
| MPI | Message Passing Interface |
| MPSoC | Multi-Processing System-on-Chip |
| OpenCL | Open Computing Language |
| OpenMP | Open Multi-Processing |
| QFDB | Quad-FPGA Daughterboard |
References
- Dutot, P.; Georgiou, Y.; Glesser, D.; Lefevre, L.; Poquet, M.; Rais, I. Towards Energy Budget Control in HPC. In Proceedings of the 2017 17th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGRID), Madrid, Spain, 14–17 May 2017; pp. 381–390. [Google Scholar]
- Cesini, D.; Corni, E.; Falabella, A.; Ferraro, A.; Morganti, L.; Calore, E.; Schifano, S.F.; Michelotto, M.; Alfieri, R.; De Pietri, R.; et al. Power-Efficient Computing: Experiences from the COSA Project. Sci. Program. 2017, 2017, 7206595. [Google Scholar] [CrossRef]
- Ammendola, R.; Biagioni, A.; Capuani, F.; Cretaro, P.; Bonis, G.D.; Cicero, F.L.; Lonardo, A.; Martinelli, M.; Paolucci, P.S.; Pastorelli, E.; et al. The Brain on Low Power Architectures—Efficient Simulation of Cortical Slow Waves and Asynchronous States. arXiv 2018, arXiv:1804.03441. [Google Scholar]
- Simula, F.; Pastorelli, E.; Paolucci, P.S.; Martinelli, M.; Lonardo, A.; Biagioni, A.; Capone, C.; Capuani, F.; Cretaro, P.; De Bonis, G.; et al. Real-Time Cortical Simulations: Energy and Interconnect Scaling on Distributed Systems. In Proceedings of the 2019 27th Euromicro International Conference on Parallel, Distributed and Network-Based Processing (PDP), Pavia, Italy, 13–15 February 2019; pp. 283–290. [Google Scholar]
- Calore, E.; Schifano, S.F.; Tripiccione, R. Energy-Performance Tradeoffs for HPC Applications on Low Power Processors. In Euro-Par 2015: Parallel Processing Workshops; Hunold, S., Costan, A., Giménez, D., Iosup, A., Ricci, L., Gómez Requena, M.E., Scarano, V., Varbanescu, A.L., Scott, S.L., Lankes, S., et al., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 737–748. [Google Scholar]
- Nikolskiy, V.P.; Stegailov, V.V.; Vecher, V.S. Efficiency of the Tegra K1 and X1 systems-on-chip for classical molecular dynamics. In Proceedings of the 2016 International Conference on High Performance Computing Simulation (HPCS), Innsbruck, Austria, 18–22 July 2016; pp. 682–689. [Google Scholar]
- Morganti, L.; Cesini, D.; Ferraro, A. Evaluating Systems on Chip through HPC Bioinformatic and Astrophysic Applications. In Proceedings of the 2016 24th Euromicro International Conference on Parallel, Distributed, and Network-Based Processing (PDP), Crete, Greece, 17–19 February 2016; pp. 541–544. [Google Scholar]
- Taffoni, G.; Bertocco, S.; Coretti, I.; Goz, D.; Ragagnin, A.; Tornatore, L. Low Power High Performance Computing on Arm System-on-Chip in Astrophysics. In Proceedings of the Future Technologies Conference (FTC) 2019; Arai, K., Bhatia, R., Kapoor, S., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 427–446. [Google Scholar]
- Taffoni, G.; Murante, G.; Tornatore, L.; Goz, D.; Borgani, S.; Katevenis, M.; Chrysos, N.; Marazakis, M. Shall numerical astrophysics step into the era of Exascale computing? arXiv 2019, arXiv:1904.11720. [Google Scholar]
- Katevenis, M.; Chrysos, N.; Marazakis, M.; Mavroidis, I.; Chaix, F.; Kallimanis, N.; Navaridas, J.; Goodacre, J.; Vicini, P.; Biagioni, A.; et al. The ExaNeSt Project: Interconnects, Storage, and Packaging for Exascale Systems. In Proceedings of the 19th Euromicro Conference on Digital System Design, DSD, Limassol, Cyprus, 31 August–2 September 2016; pp. 60–67. [Google Scholar]
- Ammendola, R.; Biagioni, A.; Cretaro, P.; Frezza, O.; Cicero, F.L.; Lonardo, A.; Martinelli, M.; Paolucci, P.S.; Pastorelli, E.; Simula, F.; et al. The Next Generation of Exascale-Class Systems: The ExaNeSt Project. In Proceedings of the 2017 Euromicro Conference on Digital System Design (DSD), Vienna, Austria, 30 August–1 September 2017; pp. 510–515. [Google Scholar]
- Katevenis, M.; Ammendola, R.; Biagioni, A.; Cretaro, P.; Frezza, O.; Cicero, F.L.; Lonardo, A.; Martinelli, M.; Paolucci, P.S.; Pastorelli, E.; et al. Next generation of Exascale-class systems: ExaNeSt project and the status of its interconnect and storage development. Microprocess. Microsyst. 2018, 61, 58–71. [Google Scholar] [CrossRef]
- Spera, M.; Capuzzo-Dolcetta, R. Rapid mass segregation in small stellar clusters. Astrophys. Space Sci. 2017, 362. [Google Scholar] [CrossRef]
- Spera, M.; Mapelli, M.; Bressan, A. The Mass Spectrum of Compact Remnants From the Parsec Stellar Evolution Tracks. Mon. Not. R. Astron. Soc. 2015, 451, 4086–4103. [Google Scholar] [CrossRef]
- Bertocco, S.; Goz, D.; Tornatore, L.; Ragagnin, A.; Maggio, G.; Gasparo, F.; Vuerli, C.; Taffoni, G.; Molinaro, M. INAF Trieste Astronomical Observatory Information Technology Framework. arXiv 2019, arXiv:1912.05340. [Google Scholar]
- Taffoni, G.; Becciani, U.; Garilli, B.; Maggio, G.; Pasian, F.; Umana, G.; Smareglia, R.; Vitello, F. CHIPP: INAF pilot project for HTC, HPC and HPDA. arXiv 2020, arXiv:2002.01283. [Google Scholar]
- Bertocco, S.; Goz, D.; Tornatore, L.; Taffoni, G. INCAS: INtensive Clustered ARM SoC—Cluster Deployment. INAF-OATs Technical Report; INAF-ICT 2018. Available online: https://www.ict.inaf.it/index.php/31-doi/96-2018-4 (accessed on 17 April 2020).
- Pascual, J.A.; Navaridas, J.; Miguel-Alonso, J. Effects of Topology-Aware Allocation Policies on Scheduling Performance. In Job Scheduling Strategies for Parallel Processing; Frachtenberg, E., Schwiegelshohn, U., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 138–156. [Google Scholar]
- Chaix, F.; Ioannou, A.; Kossifidis, N.; Dimou, N.; Ieronymakis, G.; Marazakis, M.; Papaefstathiou, V.; Flouris, V.; Ligerakis, M.; Ailamakis, G.; et al. Implementation and Impact of an Ultra-Compact Multi-FPGA Board for Large System Prototyping. In Proceedings of the 2019 IEEE/ACM International Workshop on Heterogeneous High-performance Reconfigurable Computing (H2RC), Denver, CO, USA, 17 November 2019; pp. 34–41. [Google Scholar]
- Cameron, K.W.; Ge, R.; Feng, X. High-performance, power-aware distributed computing for scientific applications. Computer 2005, 38, 40–47. [Google Scholar] [CrossRef]
- Goz, D.; Bertocco, S.; Tornatore, L.; Taffoni, G. Direct N-body Code on Low-Power Embedded ARM GPUs. In Intelligent Computing; Arai, K., Bhatia, R., Kapoor, S., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 179–193. [Google Scholar]
- Goz, D.; Ieronymakis, G.; Papaefstathiou, V.; Dimou, N.; Bertocco, S.; Ragagnin, A.; Tornatore, L.; Taffoni, G.; Coretti, I. Direct N-body application on low-power and energy-efficient parallel architectures. arXiv 2019, arXiv:1910.14496. [Google Scholar]
- Capuzzo-Dolcetta, R.; Spera, M.; Punzo, D. A Fully Parallel, High Precision, N-Body Code Running on Hybrid Computing Platforms. J. Comput. Phys. 2013, 236, 580–593. [Google Scholar] [CrossRef]
- Capuzzo-Dolcetta, R.; Spera, M. A performance comparison of different graphics processing units running direct N-body simulations. Comput. Phys. Commun. 2013, 184, 2528–2539. [Google Scholar] [CrossRef]
- Spera, M. Using Graphics Processing Units to solve the classical N-body problem in physics and astrophysics. arXiv 2014, arXiv:1411.5234. [Google Scholar]
- Nitadori, K.; Makino, J. Sixth- and eighth-order Hermite integrator for N-body simulations. New Astron. 2008, 13, 498–507. [Google Scholar] [CrossRef]
- Thall, A. Extended-Precision Floating-Point Numbers for GPU Computation; Association for Computing Machinery: Boston, MA, USA, 2006; p. 52. [Google Scholar]
- Pérez, F.; Granger, B. IPython: A System for Interactive Scientific Computing. Comput. Sci. Eng. 2007, 9, 21–29. [Google Scholar] [CrossRef]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. Scipy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nat. Methods 2020. [Google Scholar] [CrossRef] [PubMed]
- Van der Walt, S.; Colbert, S.; Varoquaux, G. The NumPy Array: A Structure for Efficient Numerical Computation. Comput. Sci. Eng. 2011, 13, 22–30. [Google Scholar] [CrossRef]
- Hunter, J. Matplotlib: A 2D Graphics Environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Node | CPU | GPU | FPGA |
|---|---|---|---|
| mC | 4×(ARM A53) + 2×(ARM A72) | ARM Mali-T864 | None |
| IC | 40×(Xeon Haswell E5-4627v3) | None | None |
| ExaBed | 16×(ARM A53) + 8×(ARM R5) | 4×(ARM Mali-400) | 4×(Zynq-US+) |
| GPUC | 32×(Xeon Gold 6130) | 8×(Tesla-V100-SXM2) | None |
| CUs | ||||
|---|---|---|---|---|
| Platform | ||||
| CU-Type | IC | mC | ExaBed | GPUC |
| CPU | 10 | 1 | None | None |
| GPU | None | 1 | None | 8 |
| FPGA | None | None | 4 | None |
| Platforms | ||||
|---|---|---|---|---|
| IC | mC | ExaBed | GPUC | |
| 160 | 3.15 | 42.5 | 440 | |
| 223 | 4.55 | N/A | N/A | |
| N/A | 4.75 | N/A | 710 | |
| N/A | N/A | 53.5 | N/A | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Goz, D.; Ieronymakis, G.; Papaefstathiou, V.; Dimou, N.; Bertocco, S.; Simula, F.; Ragagnin, A.; Tornatore, L.; Coretti, I.; Taffoni, G. Performance and Energy Footprint Assessment of FPGAs and GPUs on HPC Systems Using Astrophysics Application. Computation 2020, 8, 34. https://doi.org/10.3390/computation8020034
Goz D, Ieronymakis G, Papaefstathiou V, Dimou N, Bertocco S, Simula F, Ragagnin A, Tornatore L, Coretti I, Taffoni G. Performance and Energy Footprint Assessment of FPGAs and GPUs on HPC Systems Using Astrophysics Application. Computation. 2020; 8(2):34. https://doi.org/10.3390/computation8020034
Chicago/Turabian StyleGoz, David, Georgios Ieronymakis, Vassilis Papaefstathiou, Nikolaos Dimou, Sara Bertocco, Francesco Simula, Antonio Ragagnin, Luca Tornatore, Igor Coretti, and Giuliano Taffoni. 2020. "Performance and Energy Footprint Assessment of FPGAs and GPUs on HPC Systems Using Astrophysics Application" Computation 8, no. 2: 34. https://doi.org/10.3390/computation8020034
APA StyleGoz, D., Ieronymakis, G., Papaefstathiou, V., Dimou, N., Bertocco, S., Simula, F., Ragagnin, A., Tornatore, L., Coretti, I., & Taffoni, G. (2020). Performance and Energy Footprint Assessment of FPGAs and GPUs on HPC Systems Using Astrophysics Application. Computation, 8(2), 34. https://doi.org/10.3390/computation8020034