1. Introduction
Multivalency is an important phenomenon of binding processes characterized by an interaction of two or more molecules through several binding sites that enhance overall binding affinity [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13]. Ligands and receptors form a complex according to:
. While the binding mechanisms of one ligand to one receptor through one binding site have been studied widely, theoretical models for multivalent ligands and receptors are still lacking. In order to conduct numerical modeling and compare them to actual experimental results, ITC and kinITC data previously presented by Igde et al. [
14] were used. So far, the average
value of all titration steps has been used to obtain the binding rate
in the reaction equation above. Averaging
values implies that these values do not change systematically with regard to the titration steps. Instead, we propose a concentration-dependent binding rate approach and show that the binding rate follows a certain scheme over the titration steps. Isothermal titration calorimetry is a common tool to measure the thermodynamic parameters of mono- and multi-valent bindings in biochemistry. The experimental setup of ITC is the following: The apparatus consists of two adiabatic cells of a thermally-conducting material connected by a feedback circuit to measure their temperature difference upon binding. The titration cell contains a fixed number of receptors. The other cell is filled with a buffer solution only. According to the multiple injection method (MIM), a certain solution volume with a known concentration of ligands is injected into the cell at regular time intervals [
15]. The binding of ligands and receptors is in most cases an exothermic reaction (Ligand–receptor interaction may under some circumstances be endothermic, as well. In this case, the reference cell is cooled down to maintain equal temperatures. The isotherm has the same shape as in the exothermic case, but with negative signs.), i.e., heat is generated in the titration cell. The apparatus measures the heat that is necessary for the reference cell to have the same temperature as the titration cell. After binding and unbinding take place, the system is in equilibrium, and the titration cell has a constant temperature. Then, the next titration step takes place. Usually, the heights of the single heat peaks decrease with each injection. The shape of this time-dependent thermogram gives insights into thermodynamic parameters. With the kinITC method, it is possible to obtain kinetic parameters in addition to the thermodynamic information from the ITC experiment [
15]. Based on the paper of Vander Meulen et al. [
16], the heat power measured by ITC can be linked to the production rate of the complex taking into account the conservation equations of ligand and receptor concentrations. The change of the complex concentration over time is:
with
the difference between the equilibrium concentration of the complex and its current concentration
.
cannot be determined analytically, but together with
in a least squares approximation. The heat evolution function is:
The equilibrium constants are determined by the van’t Hoff equation:
with
R the gas constant and
T the temperature. The enthalpy change
is known from the ITC experiment. The association constant
is derived from a fitting procedure. The binding constants
k are temperature dependent and are determined with the Arrhenius equation:
with
A some pre-exponential factor depending on the type of chemical reaction,
the activation energy,
the Boltzmann constant, and
T the temperature.
is obtained by the relationship:
Since these binding rates depend on the temperature, usually several ITC experiments are run at different temperatures and an average is used.
Mathematically speaking, multivalent bindings of ligands and receptors to a complex comprise a high-dimensional system, which can be projected onto a subspace of lower dimension. Therefore, a rate matrix consisting of all the possible intermediate binding states is set up. Using the robust Perron cluster analysis (PCCA+), this high-dimensional system is projected on a two-dimensional system: bound and unbound. Because this projection is mathematically feasible, a fitting of the unknown binding and unbinding parameters
and
is possible, only by knowing the system’s valency and the receptor concentration per titration step. In contrast to standard kinITC methods, our projected overall
and
values are concentration dependent. The benefit of our method is the insight into multivalency: ITC experiments can be conducted for monovalent and multivalent systems. The fact that the states can be clustered to unbound and bound and that the inverse problem of fitting the single
and
parameters to the experimental data can be solved very well are an indication that our multivalent binding assumption is correct. This paper shows experimental data obtained from Igde et al. [
14], who previously applied ITC and kinITC to multivalent mannose: functionalized oligo(amidoamines) with different valencies and sequences of mannose ligands. The focus of the present paper is the mathematical aspect: the application of the invariant subspace projection to the given kinITC data.
Regarding ITC, there exists extensive literature. Both theoretical, as well as applied aspects have been studied in depth. An early theoretical paper was, e.g., Freire et al. from 1990 [
17]. For experimental details and applications, see for example Pierce et al. [
18]. For bridging the gap between computational and experimental analysis, Leavitt and Freire must be mentioned [
19]. kinITC is a relatively new technique. The pioneers here were Burnouf [
15] and Dumas [
20]. The matrix approach we used to translate our multivalent binding setting into discrete states was previously done by Aberg et al. [
21]. The mathematical literature concerning clustering is vast. A concise summary of the clustering of reversible Markov processes was given by the paper of Deuflhard and Weber [
22]. The present paper is mainly based on the PCCA+ algorithm from Röblitz and Weber [
23]. For both reversible and irreversible processes, the reader may consult [
24] for the advanced G-PCCA algorithm. To the authors’ knowledge, there is no publication on the application of clustering kinITC data.
The paper is organized as follows: In
Section 2, the biomolecular basics and their notations are introduced. The equations for bivalent bindings as stated in Kugel and Goodrich [
25] and their practical limitations are shown. In
Section 3, the ITC experiment and the kinetic data retrieval are outlined.
Section 4 is dedicated to the mathematical modeling. It is shown how the rate matrix is set up, once for a bivalent example and in general for the n-valent case, and how to derive the projected
rate matrix using the PCCA+ clustering algorithm.
Section 5 gives numerical results by applying the projection to the experimental kinITC data from
Section 3. Further, potential pitfalls and error sources of the method are discussed. The last
Section 6 summarizes the paper and gives an outlook on future research.
2. Biomolecular Preliminaries and Notations
Two biomolecules form a complex with the binding rate constant
in units M
−1 s
−1. The dissociation takes place according to the unbinding rate
in units s
−1. Rate constants are numeric representations of the time needed for molecules to associate or dissociate. The dissociation constant
and the association constant
are the ratios of
and
, i.e.,
and
[
25]. Note that in this paper, we assume a one-to-one stoichiometry between the protein and ligand after the bindings. Although aggregation may occur in some settings, i.e., for molecules with many binding sites, we consider in theory one multivalent ligand interacting with one multivalent receptor only.
In the same way as a one-step binding process, a two-step binding process can be described by inserting one intermediate step. Based also on Kugel and Goodrich [
25], the bivalent ligand–receptor encounter is:
with
the association rate for the first binding
,
the dissociation rate constant for the first binding
,
the association rate for the second binding
, and
the dissociation rate constant for the second binding
where
t denotes the time unit. The superscript * in [LR*] denotes the number of interaction sites in the complex. The second binding is an intramolecular transformation, a conformational change. It is a structural rearrangement of the complex formed by the first binding step. Therefore,
comes in units [t
−1] instead of [M
−1t
−1]. The rate equation for the change in bivalent complexes is:
and the rate equation for the first binding is:
The amount of receptors will be fixed throughout the experiment at
, and only the number of ligands changes. At time
t, the concentration of free receptor
depends on the number of monovalent and bivalent complexes and is given by:
The dissociation constant of the first binding is:
Substituting
from Equation (
3) into (
4) and rearranging for
gives:
Equation (
1) is an ODE of the form
and has the standard solution
. Substituting (
5) into (
1) and rearranging give:
Thus, the solution of Equation (
1) would be:
Note that and are time dependent, as they depend on time-sensitive parameters. The ligand concentration changes with each titration step. In the ideal case, we knew all the three quantities , and at all time steps. However, we only know that they depend on each other, and thus, we cannot solve this ODE straightforwardly. A kinITC approach is necessary.
3. From ITC to kinITC
As briefly explained in the Introduction, the ITC apparatus consists of two cells connected by a temperature feedback circuit. Each ligand injection causes a change in the solution composition in the sample cell, and during the relaxation to a new equilibrium, the heat of reaction is recorded as a peak in the power trace. Integration of this peak provides the total heat generated or consumed upon changing the solution composition [
26].
Numerically, ITC determines the change in Gibbs free energy
G using the Gibbs–Helmholtz equation:
, with
R being the gas constant,
T the temperature,
K the binding affinity,
H the binding enthalpy, and
S the entropy. The heat
Q itself is not measured from the thermogram, but the heat power
P, which is:
. Integrating
P over time yields the total heat generated or consumed upon changing the solution composition [
26]. Plotting the integrated heat against the ligand/receptor molar ratio gives
, and the stoichiometry can be inferred [
27].
Burnouf and his coworkers developed the ITC method further to kinITC. The ITC experiment and the measurement stayed the same, and just the output data were processed further using chemical kinetics knowledge. The essential link between the heat power and the rate of production of the complex [LR] is [
16]:
with
the volume of the titration cell. Knowing the ligand and receptor concentrations per time step leads to:
with respect to the conservation equations
and
.
The innovation is that more complex reactions, i.e., more than one binding step, can be addressed [
15,
20]. In their paper, Burnouf et al. [
15] gained both thermodynamic and kinetic information for the specific binding and folding processes. While the classical processing of raw ITC data (peak integration) yielded thermodynamic information (
and
), the analysis of the shape of each injection peak can give kinetic information (
and
) [
28,
29]. Especially the equilibration time curve, i.e., the end of each injection [
20], plays a key role. To find this exact effective end of each injection curve, an automatic baseline determination, integration of the power curves is necessary. Burnouf et al. [
15], as well as Dumas et al. [
20] explained how to derive
and
using the equilibration time.
ITC Data Generation for the Study
All ITC measurements and subsequent kinITC data in this paper were taken from Igde et al. [
14]. As model structures mimicking the multivalent nature of oligosaccharides, they used glycooligomers based on oligo(amidoamines) with pendant mannose side chains. These glycomimetics are built up by a stepwise assembly of functional building blocks on solid support, thereby allowing for the control of the monomer sequence. In their recent study, Igde et al. synthesized a library of mannose-functionalized oligo(amidoamines) varying the valency of the ligands from mono- to deca-valent, introducing different linkers between the mannose and the oligomer backbone, and varying the position of mannose ligands along the backbone.
Table 1 shows the ligands we used for comparing the experimental data to the mathematical model.
Binding of the glycooligomers to model lectin Concanavalin A (Con A) was studied by ITC performing normal titration where the glycooligomers were titrated into the sample cell containing the protein [
14]. ITC data were then evaluated for thermodynamic information on the ligand–receptor complex formation, and kinetic rate constants were extracted from the heat flow signals of the ITC isotherms following the work by Dumas et al. [
15], Vander Meulen and Butcher [
16], and Egawa et al. [
28]. Datasets of di-, tri-, and penta-valent ligands binding to tetrameric Con A were selected from the series of measurements [
14] to be compared with the model derived in this study (
Table 1; see the
Supplementary Information (SI) for additional information on thermodynamic and kinetic evaluation).
The ITC experimental data came in spreadsheets containing the following information per titration step:
Dissociation constant: in mM
Receptor concentration at injection time: in mM
Ligand concentration at injection time: in mM
Complex concentration at injection time: in mM
Receptor concentration at equilibrium: in mM
Ligand concentration at equilibrium: in mM
Complex concentration at equilibrium: in mM
Wiseman parameter at the beginning of each titration:
For the overall experiment, the following data entries were collected:
In a MATLAB script, a weighted average
, in this paper referred to as overall
, was determined for each titration step based on the reaction rate equation in the paper of Vander Meulen and Butcher [
16]. In order to fit
, an initial guess was made and subsequently fitted by a Gauss–Newton iteration such that it fulfilled equation:
with
and the subscript
eq denoting the equilibrium. The kinetic data were fitted with the ZIB algorithm
, the numerical solution of Nonlinear (NL) least Squares (S) problems with nonlinear Constraints (CON), especially designed for numerically-sensitive problems [
31].
4. The Mathematical Model
In general, the ligand–receptor interaction is modeled as a Markov process. Markov processes are memoryless stochastic processes. Let
be a stochastic process,
a measurable space for a given set
E, and
the probability space. A stochastic process
on a state space
E is a Markov process if the probability function
p fulfills the following condition [
32]:
If E consists of a finite number, say n, of states, we can construct a transition probability matrix . The entries denote the probability to jump from state i to state j within one time step t. The row sum of P is always one. The transition probability matrix P and the transition rate matrix K are linked through the matrix exponential .
, also called the intensity matrix, rate matrix, or infinitesimal generator, has the following properties [
33]:
- -
the off-diagonal entries are positive:
- -
each column sum is zero:
- -
each diagonal element is the sum of the column entries: .
A binding process can be interpreted as a kinetic projection from an infinitesimal generator
K onto a clustered rate matrix
such that the resulting process can be approximated by a Markov chain. Then, the binding process can be described in terms of transition probabilities between the bound and unbound state. This procedure is no longer valid when considering multivalent binding processes, since here, a clear distinction between the bound or unbound state is no longer possible. In detail, spatial effects spoil the Markovianity. Röblitz and Weber [
23] therefore introduced “soft conformations” respecting the spatial situation. In contrast to crisp clustering methods, where a molecule is in either one state or the other, with soft membership vectors, also called almost characteristic vectors, a molecule can partly belong to one state and partly to another one. For example, a bivalent receptor and a bivalent ligand connected through one binding site are partly bound and partly unbound.
For the mathematical model, a transition rate matrix
K was set up first. This technique was established by, e.g., Berberan-Santos and Martinho [
34]. In our model, an
n-valent binding process consists of
n receptors and
n ligands, with conformational states that can be unbound, singly bound, bivalently bound, etc., up to
n-valently bound. Further, it is assumed that ligands and receptors have a certain rigidity. That means that not every ligand arm can reach every receptor binding site, depending on the already existing bindings. There is no “cross binding” of ligand arms possible.
The number of possible states is:
The proof is a simple induction. Because
, we can further simplify this equation to
. This gives an intuition that the number of states increases exponentially when the valency goes up. The examples discussed in
Section 5 have 2, 3, and 5 binding sites. The number of states is hence
,
, and
.
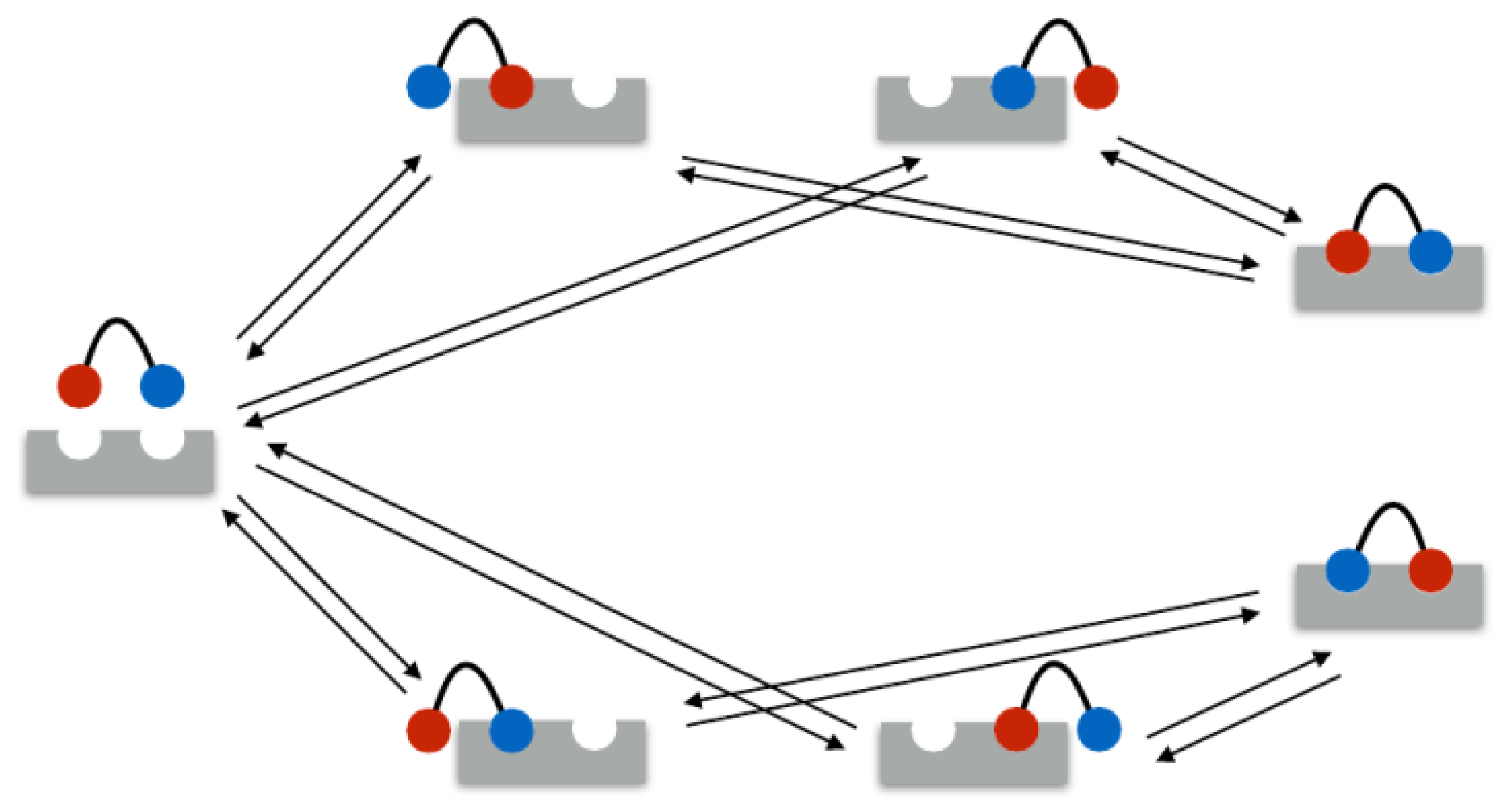
In the following example, the rate matrix is set up for a bivalent system. As mentioned above, in the bivalent case, there are seven different binding states: 1 unbound state, 4 monovalent binding states, and 2 bivalent binding states. These seven states are illustrated in
Figure 1. Therefore, the rate matrix is of size
. Assume the ligands
1 and
2 and the receptors
A and
B.
In the example, the seven states were ordered as listed in
Table 2.
Our model considers every possible combination of each ligand interacting with each receptor. In general, the states can also be summarized into
states, i.e., one unbound state, one singly-bound state, one doubly-bound state, ..., and one fully-bound state. Then, the rate matrix is of size
. This is particularly useful for bigger valency numbers
n, i.e., decavalent bindings and above. However, in the following, the procedure is explained in detail for all possible states in the bivalent case. The matrix entries depend on the order of the states, the receptor concentration
, as well as on the two
and two
rates, where
represent the binding rate for the first (monovalent) binding and
the second (bivalent) binding.
represents the first unbinding, i.e., from the bivalent to monovalent state, and
represents the second unbinding rate (from the monovalent to unbound state). The diagonal elements are the sum of the remaining column entries such that the column sum of
K is always zero.
Note that the positions of the entries in the submatrix on the upper right diagonal (in the red box):
depend on the order of the states. Likewise, this submatrix transpose with the
-values instead of
is inserted below the diagonal (see the submatrix in the blue dotted box). The matrix size increases exponentially. The rate matrix for the
n-valent binding is only sketched schematically.
Legend:
| * | diagonal matrix with the negative column sum such that the column sum is zero |
| koff | row vector of length with entry |
| column vector of length with entry |
| sparse matrix of size with entries to , respectively. |
| The positions of these entries depend on the theoretical order of conformational states. |
| sparse matrix of size with entries to , respectively. |
| | The positions of the entries are the transpose of the respective submatrices. |
Let
be the number of molecules in the respective conformation
. Then, the corresponding ODE system for
n-valent bindings to be solved is:
PCCA+
Our Markov process is space and time continuous and therefore needs to be discretized for numerical results. A possible discretization method is the Galerkin discretization. The key idea is to project this Markov process onto fewer macro states, i.e., in the bivalent case, we project the
matrix
K on a
matrix in order to cluster these seven states into only two distinct states: bound and unbound. To do so, the robust Perron cluster analysis (PCCA+) algorithm of Röblitz and Weber [
23] was used. Therefore, the eigenvalues of
K are computed first according to:
with
X the matrix of all the eigenvectors and a diagonal matrix of eigenvalues
. In this case, only two eigenvalues are of interest because all the states will be clustered into two states only. The eigenvector corresponding to the biggest eigenvalue is called the Perron eigenvalue. For rate matrices, the biggest eigenvalue is always
. This leading eigenvalue and its corresponding leading eigenvector were selected. The second eigenvector has to satisfy the criterion that the first entry and the respective last one have the maximum distance, to make sure that the two states “unbound” and “bound” are as distinct as possible. For regular matrices
K, the clustering algorithm gives a membership matrix
by:
with
A being a matrix of linear factors computed by an optimization process within the clustering algorithm.
is a
matrix stating the degree of membership of each of the seven states to the unbound and bound states, respectively. Its row sum is always one. Finally,
K is Galerkin discretized weighted by the stationary distribution
into
(clustered
K) using
.
Since we project on a two-dimensional subspace, our
matrix is of size
and has the following entries:
By dividing the lower left matrix entry by the respective receptor concentration of the titration step, we determine the overall binding rate . This projection is only possible because we project on an invariant subspace. No crucial information is lost by the clustering.
The following Algorithm 1 shows how the PCCA+ clustering is used to determine the optimal and values.
| Algorithm 1: Find the optimal overall curve after clustering |
| Require: 14 k_on-ITC and cR values from ITC |
| P ← permutation matrix of possible k_on and k_off values |
| for all rows of P do |
| set up rate matrix K; |
| for all titration steps t do |
| perform PCCA+ to obtain ; |
| k_on ; |
| end for |
| C ← correlation coefficient of k_on-ITC and k_on; |
| index ; |
| end for |
| return P(index), k_on(index); |
For details of the PCCA+ algorithm and specific MATLAB code with examples, please consult [
35] (specifically the file optimizeMetastab.m in folder “Figure 6”) and the respective paper.
5. Results and Discussion
To test the model fit, the overall binding rate was calculated and compared to the observed binding rate from the experiments. Therefore, the input variables for the mathematical model had to be fitted by a sensitivity analysis. The goal was to achieve the same qualitative behavior of the curve over time, that is over the titration steps and our computed curve. That means that the slope including anomalies like kinks should be equal. The goodness of fit was assessed via the correlation coefficient for the lower left entry , divided by the receptor concentration of the respective titration step and the from ITC experiments for each time step. The algorithm was tested for the bivalent Man(1,5)-5, trivalent Man(1,3,5)-5, and pentavalent Man(1,3,5,7,9)S-9 binding processes.
The valency of receptor and ligand was not always the same in the experiments. For setting up the rate matrix, one overall valency of the interaction process was needed. Because we assumed a one-to-one stoichiometry, we used the minimum number of binding sites of the receptor and ligand, i.e., . As we will see next, the subsequent projection and clustering of the rate matrix mimicked the experimental rate behavior very well. By allowing the theoretical and rates to move on a logarithmic scale, i.e., from –, some further conclusions of the valency of the overall binding can be drawn. If the single rates were searched for in a limited range due to computation time limits, it is not possible to learn about the different affinities of the binding steps. We were interested in the relation of say the first binding and the second. For instance, a first binding is quite rare, but if it is made, a second binding is 100-times more likely.
The subsequent discussion of the results should be considered as a preliminary explanation of the systematic change of the
and
rates of the kinITC experiments. Actually, kinITC is a suitable tool for describing:
settings, but for higher valent bindings, a mathematical projection becomes necessary. For the following comparison, the first 14 titration steps of each experiment were considered (see the
Supplementary Information (SI) for experimental data).
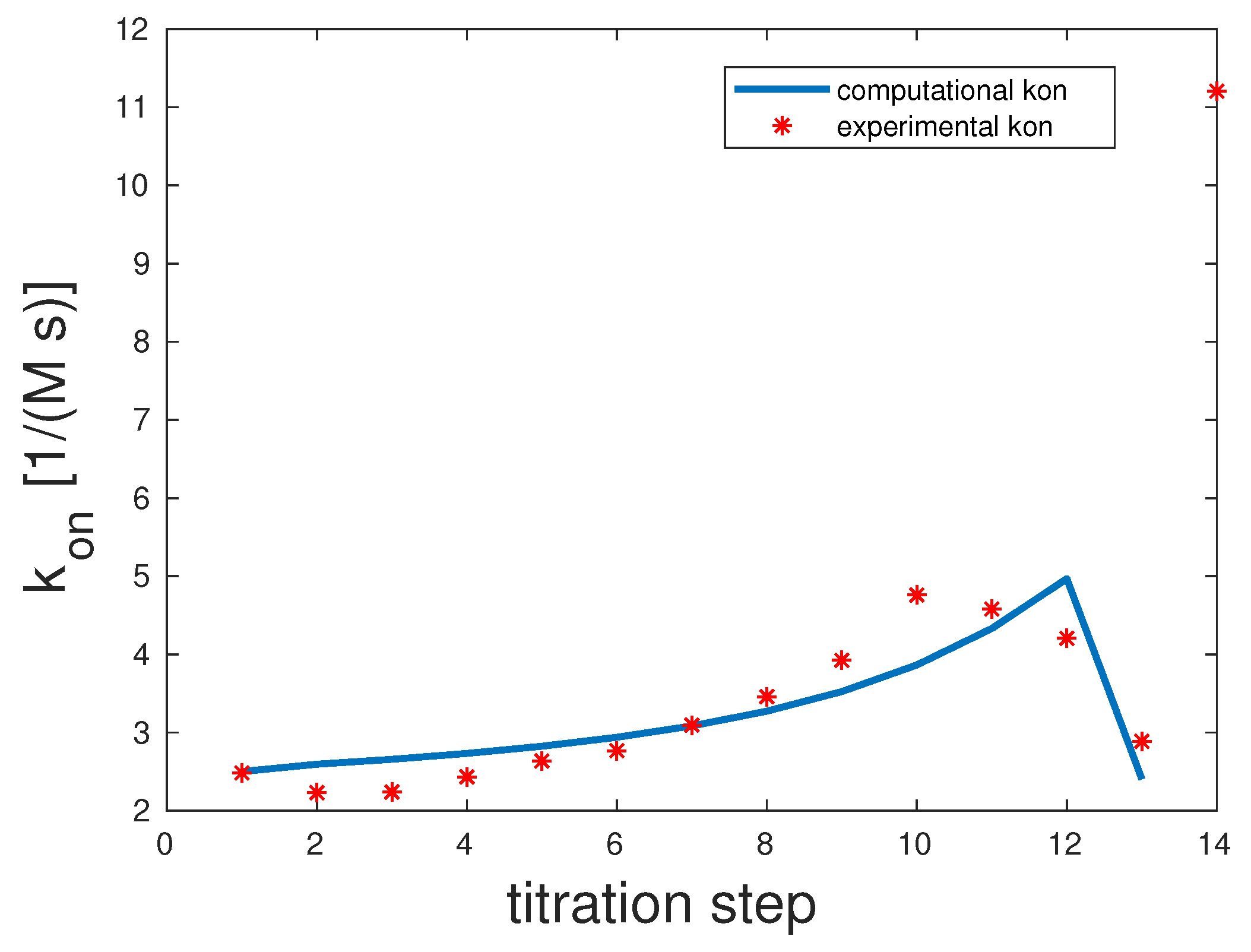
5.1. Bivalent Model Fitting
Man(1,5)-5
The experimental and computed
rates are depicted in
Figure 2. The correlation coefficient was 0.98. The experimental
showed a clear upward slope. To interpret these binding and unbinding rates from a mathematical model point of view, this constellation seemed to be a monovalent binding process, as only the first binding rate
was high, while the second one
was very low. Both unbinding rates were very low,
and
. We can assume that unbinding was very unlikely. All in all, there seemed to be one binding taking place, which was the equilibrium.
5.2. Trivalent Model Fitting
Man(1,3,5)-5
As shown in
Figure 3, only 13 out of 14 titration steps were considered for the fitting procedure. The 14
th overall
value was clearly an outlier, probably due to measurement inconsistencies. For completeness, it is depicted in the graph. The correlation coefficient was 0.87. The binding rates were the following:
. All three unbinding rates were
. One possible interpretation is that all the fully-bound state was what Whitesides called the kinetic origin of high stability [
36].
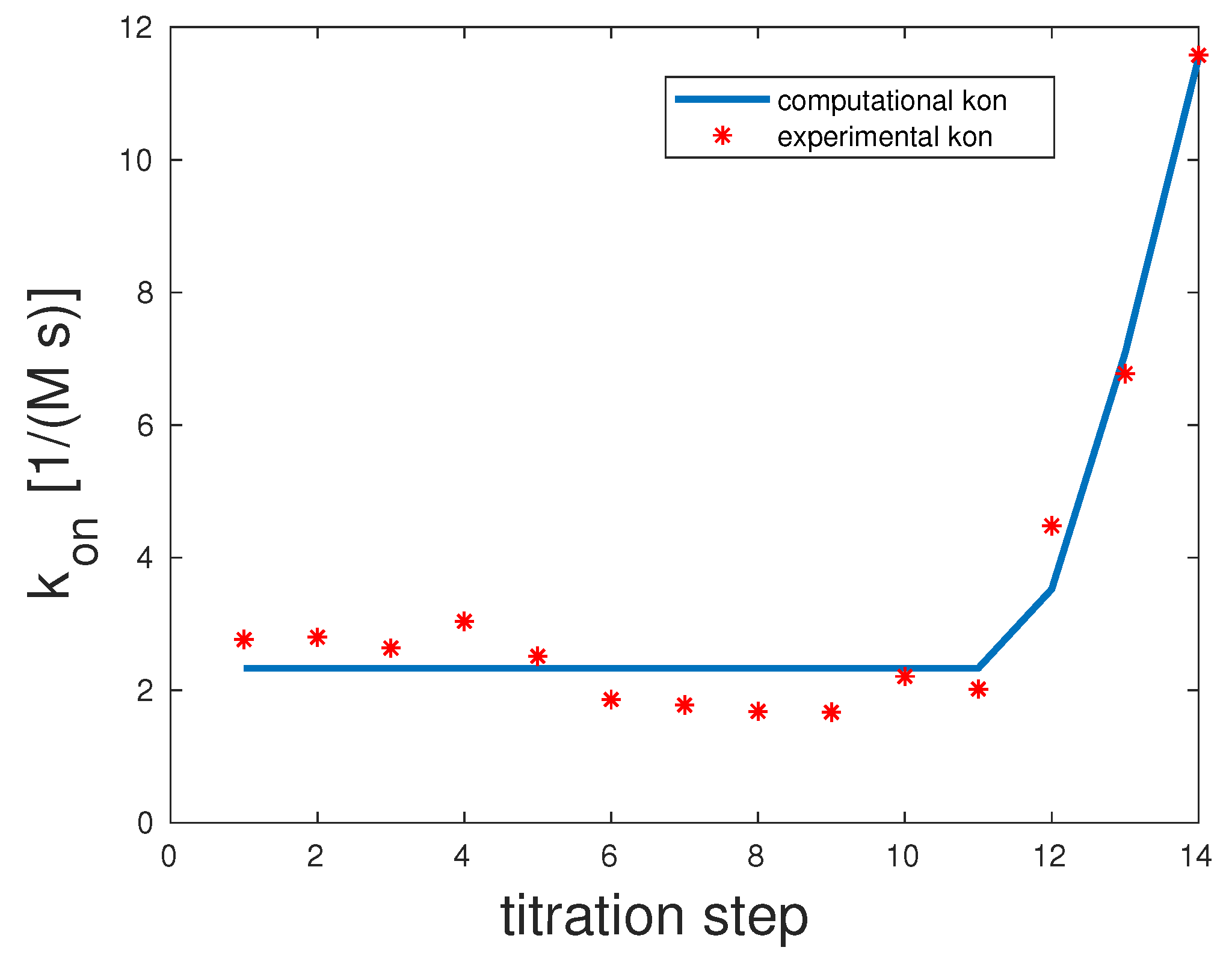
5.3. Pentavalent Model Fitting
Man(1,3,5,7,9)S-9
In the pentavalent example, there were only four specific
and
rates and not five. This was due to the fact that Con A was tetrameric, and within the model when assuming a one-to-one stoichiometry, there can only be a maximum of min
single bonds. Experimental and computed
rates are illustrated in
Figure 4.
The correlation coefficient for this example was 0.98. The scenario representing the best fit for this model showed that the first and second binding seemed to be highly unlikely with , but once they took place, the third binding happened almost surely with 10,000. The last binding was again unlikely with . 10,000 and . That means that overall unbinding was very low if there was more than one binding. If there was only one bond between the mannose and Con A, dissociation was very likely.
5.4. Limitations of the Model and Discussion
The deviation of the modeled rates to the experimental ones was due to several reasons. Our mathematical model was a simplification of complex binding processes and therefore had theoretical limitations. First, our mathematical models assumed a one-to-one stoichiometry. So far, intermolecular complex formation has been neglected. Especially for ligands with many binding sites, this intermolecular crosslinking does occur. This phenomenon was not considered in our mathematical model and can partly explain the deviations from our computed rates to the experimental rates . Secondly, so far, no rebinding has been considered. Every binding was treated as a first time ligand–receptor interaction no matter if this very couple was bound before. The heat absorption due to unbinding was not yet taken into account, but very likely had an effect on the ITC signal. As discussed in the outlook, we are working on a rebinding quantification for a better interpretation of the kinITC results.
Third, we solved an inverse problem by fitting four (two rates and two rates in the bivalent case), six (three rates and three rates in the trivalent case), or eight (four rates and four rates in the pentavalent case) specific binding and unbinding rates knowing 14 different titration data. We do not claim that our solution found was the only possible interpretation of the laboratory data with regard to our model. There may be other combinations that will yield a comparably good fit. For instance, in the trivalent example, 15,625 different combinations ( because five different values for each of the three and ) of the and rates were considered. Out of these, 25 had the maximum correlation coefficient. The results shown in this paper are one example out of these 25 fits. Despite not delivering unique results, this method helped in excluding inappropriate models.
The ITC method can be fragile, and single outliers occur due to experimental limitations. The thermodynamic parameters of the ITC data can have errors stemming from the ligand and receptor concentrations, unfavorable fitting procedures, and baseline drift. Other error sources were a combination of random noise, unclear instrument response time, uncertainty in
, and the instrumental rate constant
[
16]. For an uncertainty quantification in the experimental data used in the practical part, see Igde et al. [
14]. Numerically, the
parameters from our computation do not correspond to the kinITC experimental data yet. However, it is possible to model such a complicated process showing the same qualitative behavior with each titration step. Shifting our computed
rates down to the experimental
baseline level allowed for slope comparison. This is due to the fact that the
and
parameters were assumed to be on an exponential scale. This scaling could be refined further or even made adaptive to tackle this problem.
6. Conclusions and Outlook
This paper demonstrated that the overall binding rate of a ligand–receptor interaction implies a systematic dependency of the rates with regard to the titration steps. Taking the average value over all titration steps did not fully account for the whole process. It is possible to compute the overall binding rate of multivalent bindings, only by knowing the valency number and the ligand concentration per titration step. Our subspace projection approach could be successfully applied to kinITC data. The key finding of this study is that we can learn about the system’s association rate by projecting a high-dimensional process on a two-dimensional space, namely bound and unbound. Doing so, we obtained a binding rate per time step, i.e., one for each titration step. This rate showed the same qualitative behavior as the overall rate obtained from the kinITC experiments. This finding will be useful for the prediction of the binding behavior when no experimental data, but only the ligand and receptor concentration, are available.
Our method still has some limitations. In the present model, we assumed one-to-one bindings between ligands and receptors. However, other stoichiometries such as intermolecular aggregations were possible and could occur in the experiments. If this was not possible, an error estimate for overall rates would be necessary, as they were the result of a slightly different stoichiometric model.
Another aspect that was not considered in this paper is the so-called rebinding effect where the probability of a monovalent binding event of multivalent ligands is increased by the high local concentration of ligands with no regard to potential multivalent receptor binding. So far, there has been no distinction made between rebinding and new binding. Mathematically, there already existed a quantification of the lower bound of rebinding in the system [
32,
37]. Such an estimation could also be applied numerically for ITC data as presented in this paper.








{kind=link}
{kind=link}
{kind=link}
{kind=link}


