1. Introduction
Sentiment analysis is a line of research within natural language processing (NLP) that analyzes texts to determine the way users express themselves. This expression constitutes the associated sentiment—for example, positive, negative, or neutral. Positive texts contain optimistic content and typically use polite or politically correct language. Negative texts express ideas steeped in pessimism, or they contain critiques or messages with vulgar language regarding a circumstance, object, person, or group of people. Neutral texts lack a clearly defined orientation toward positive or negative and are sometimes explicitly neutral because they express general ideas without emotion.
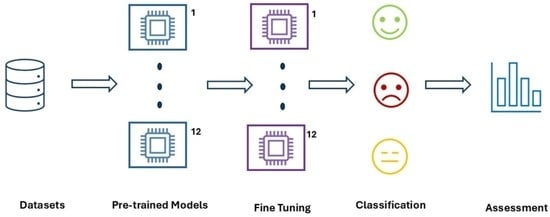
Social media platforms are a significant source of data for sentiment analysis research due to the richness of user comments and interactions. In politics, the social media network X, formerly Twitter, stands out due to its large and active user base. This guarantees an abundance of posts of all types and orientations toward all political parties, public policies, governors, candidates, proposals, and outcome evaluations. Sentiment analysis provides us with a clear overview of preferences or opinions across all these categories of political activities. This approach uses NLP to achieve a reasonably accurate understanding of expressions on X, typically classifying them into three categories: positive, negative, and neutral. Various methods exist for this purpose, including lexicon-based methods, machine learning models (non-pre-trained), and pre-trained models with fine-tuning for sentiment analysis. Pre-trained models offer key characteristics for achieving high accuracy in interpreting social media texts. Some are originally trained to understand one or several languages—that is, they know how to read and write in them—but they know nothing about sentiment analysis. What is done in this case is to train a new model based on these pre-trained models and add the component of interest to perform sentiment analysis, in our case, on political topics. There are models pre-trained specifically for sentiment analysis, but even in these cases, it is necessary to retrain them to perform fine-tuning for the specific required task. This research utilizes models pre-trained in Spanish and multilingual models as a foundation for training new models for sentiment analysis of political posts in Mexico from the social media network X. Pre-trained models built with transformer neural networks are used, the fine-tuning process for political sentiment recognition is carried out, and the accuracy of each one is determined. The name X or Twitter will be used interchangeably to refer to this social media network, as in some instances it is named Twitter—for example, in related works published before the name change to X. Similarly, the words “tweet” or “post” will be used to refer to user publications.
1.1. Transformer Neural Networks
Transformer neural networks emerged in 2017 as an approach to improve text processing while maintaining coherence in long conversational threads [
1]. They incorporate a self-attention mechanism that processes entire sentences simultaneously rather than sequentially. They implement encoders whose objective is to create an abstract mathematical representation of the input texts. This involves analyzing grammar, context, and the relationships between words. They also include decoders, whose task is to take the encoder’s understanding and construct a response word by word. In the case of a translator, for example, the encoder takes the input sentence and understands the message, and the decoder produces the output message in another language. This transformer technology has enabled the development of large language models (LLMs), including ChatGPT, Claude, Gemini, Grok, LLaMA, and DeepSeek, among others. For natural language processing tasks, transformer networks demonstrate high performance across multiple applications. The concept of a pre-trained model is closely related to transformer technology, as these models have the capability to be retrained by adding data in order to specialize them for a specific task. This characteristic allows the capabilities of the original model to be leveraged in applications for diverse purposes related to language processing.
1.2. Problem Statement
Opinions on social media platforms, particularly X, are ubiquitous; this medium represents a preferred venue for users in Mexico to debate political topics, among others. For this reason, it is essential to utilize deep learning models capable of comprehending the Spanish language and discerning textual semantics for political classification tasks. Currently, a significant number of pre-trained models are available, including multilingual models that incorporate Spanish, as well as those trained on general natural language processing tasks focusing exclusively on this language. Furthermore, pre-trained models are available that have already undergone a fine-tuning process for specific tasks, such as political discourse analysis or hate speech detection, to name a few. There is a need to investigate the classification accuracy of models with diverse original training characteristics, as well as subsequent specializations, when employed specifically for sentiment analysis training within the political domain. To evaluate the accuracy of a series of Spanish-language or multilingual pre-trained models, it is necessary to retrain them using consistent parameters to equip them with the ability to identify sentiment in political texts from the social media network X. The performance of the twelve models must be assessed using precision, recall, and F1-score metrics to obtain comparable benchmarks. Once training and testing accuracy scores are obtained, they will be analyzed to determine the optimal models and their characteristics regarding prior fine-tuning and the number of parameters within the transformer-based neural network architecture.
1.3. Research Question
What is the accuracy of deep learning models for sentiment analysis of political topics published on the social media network X—whether pre-trained in Spanish or multilingual—utilizing either base training for language recognition exclusively or specialized finetuning for sentiment analysis, hate speech detection, toxic language detection, or political theme classification?
1.4. Contributions
The contribution of this work lies in the retraining of pre-trained models for accuracy comparison, with different characteristics in their original or base training which involve an initial fine-tuning stage in sentiment analysis, hate speech detection, toxic language detection, political topic classification, and toxicity classification. Fine-tuning was applied to specialize the models in sentiment analysis of Spanish-language texts on political topics. Some of the pre-trained models were originally trained exclusively in Spanish, while others were trained in multiple languages, including Spanish. To determine the accuracy of each model, the training parameters were configured with identical values. The selected pre-trained models vary, in addition to their base specialization, in the number of parameters in the neural network, although all of them contain more than 100 million parameters. To examine accuracy in detail, three metrics are used: precision, recall, and F1-score. Comparing these models using different characteristics in order to specialize them in sentiment analysis of texts related to political topics in Spanish allows us to determine which model characteristics are best suited for this type of specialization. Additionally, we explore whether models trained exclusively in the target language—Spanish, in this case—perform better or equally well compared to multilingual models. This contribution can be divided into the following parts:
Training models with identical parameters based on other pre-trained transformer networks in Spanish and multilingual settings to specialize them in three-class sentiment analysis of political posts from Mexico on the social media network X.
Measuring the accuracy of transformer-based models retrained for sentiment analysis of political content in Mexico, in Spanish, with identical training and testing parameters. The metrics used are precision, recall, and F1-score.
Analyzing the accuracy of pre-trained models with distinct characteristics, but with identical fine-tuning parameters and the same training and testing dataset, to determine the best-performing models and their characteristics in terms of prior specialization and number of transformer neural network parameters.
Our objective is to compare the accuracy of deep learning pre-trained models with differing characteristics through fine-tuning for the recognition of sentiments associated with Spanish-language texts on political topics, using identical training and testing parameters.
In the remainder of this article,
Section 2 discusses related work;
Section 3 describes the methodology used in this research;
Section 4 presents the results obtained for the twelve trained models using the precision, recall, and F1-score metrics;
Section 5 contains a discussion; and finally,
Section 6 presents our conclusions.
2. Related Work
Sentiment analysis of social media, a subfield of natural language processing, has multiple applications. Its primary objective is to understand the sentiment reflected in texts published by a large number of people. Its applications include measuring sentiment on social media regarding aspects such as health, finance, products or services, individuals, public policies, and political candidates, among others. Within the variants of sentiment analysis are works that refer to aspect or topic detection, which focus on measuring the sentiment of social media users but with an additional task: classifying opinions or posts according to specific topics identified in the analysis. Another modality involves the number of variables involved; for example, the scenario with the fewest variables is two, which can be “positive” and “negative.” Studies using three categories incorporate the “neutral” class for those texts where it is not possible to clearly identify whether the sentiment is positive or negative. There are also sentiment analyses with a greater number of specific categories tailored to measurement needs or characteristics.
On the other hand, there are the technical aspects of sentiment analysis, which have seen significant variants emerge over time in an attempt to improve its accuracy. It is important to clarify that sentiment analysis is a classification problem in which the texts being analyzed correspond to the inputs in this process, and the classification result is the output. Several machine learning algorithms perform sentiment classification without using transformer networks, including naive Bayes, decision trees, random forests, logistic regression, linear regression, and support vector machines (SVMs). Other solutions are based on deep learning with pre-trained models. Pre-trained models possess language handling capabilities, which is an advantage for NLP tasks because it is no longer necessary to train the model to learn all the intricacies of one or more languages. Fine-tuning is the training of a model based on another pre-trained model but adding the function or specialization for the task of interest, for example, sentiment analysis.
Recurrent neural networks (RNNs) were once an efficient solution for NLP problems; however, more advanced alternatives now exist. Recurrent neural networks create a form of memory to process sentence sequences in a repetitive manner. Another technique for NLP applied to text classification is word embedding, which consists of mapping words from a vocabulary into high-dimensional vector spaces. In these vector spaces, semantically related words remain together or close to one another. Ref. [
2] uses recurrent neural networks (RNNs) for sentiment analysis of comments on politics on the social media network YouTube. The authors used an automatic annotator for three categories: positive, negative, and other. They utilized word embedding with Python, fastText, and word2vec, employing a model based on Keras and TensorFlow backend. Their results showed an accuracy above 0.70, superior to SVM and logistic regression algorithms, across three metrics: precision, recall, and F1-score.
2.1. Stance Detection
Stance detection (SD) is a classification problem similar to sentiment analysis but with some important differences. It focuses on identifying a subject’s orientation toward an object, product, or policy. In the political domain, SD aims to determine public opinion expressed on social media networks regarding candidates, political parties, or public policies. SD can identify the orientation toward one of these objects, but it does not take sentiments into account; that is, stances in favor may be expressed using positive language, others using strong or what may be considered negative language. The same occurs for an opposing stance, which may be expressed with either positive or negative sentiments. SD is also applied to political posts on social media networks, for example, in debates with multilingual solutions based on machine learning [
3]. Stance detection can be combined with sentiment analysis, thereby enabling the identification of the orientation of a text or post along with the associated sentiment, which represents additional information.
2.2. Sentiment in Politics
One method for conducting sentiment analysis in politics combines convolutional neural networks (CNNs) and bidirectional long short-term memory (BiLSTM). Broadly, this approach involves the CNN’s convolutional layer receiving the word embeddings; subsequently, a pooling layer reduces the dimensionality of the features extracted from the previous network layer, and the result is passed to the next dense layer. The network’s output is computed using an activation function corresponding to the categories defined for the sentiment analysis. Meanwhile, the bidirectional LSTM network combines the previous and subsequent layers and contains memory cells that maintain long-term dependencies. This approach, which merges these two technologies, reports high-accuracy results for the learning model [
4].
With the emergence of AI technologies, there has been an increased interest in analyzing political opinions or stances on social media from various perspectives. This includes programs that publish automated content—also known as bots—due to their significant influence in intervening during electoral campaigns [
5]. In the political sphere, interest has also arisen in classifying political materials such as videos through large language models based on the videos’ title and description text [
6]. The scientific literature also proposes the prediction of populist voting through random forests [
7]. According to this author, populist voting possesses specific characteristics that can be distinguished through opinions and sentiments.
Social media posts are utilized, among other things, to measure sentiment regarding public policy, specifically on X (formerly Twitter). In [
8], a study is presented applying five machine learning models to analyze political sentiments on Twitter: multinomial naive Bayes (MNB), complement naive Bayes (CNB), convolutional neural networks, stochastic gradient descent (SGD), and linear support vector classifier (LSVC). The authors employ an “ensemble technique” to determine the optimal model accuracy; that is, they utilize all models to determine the classification of the Twitter posts.
Another proposal for political sentiment analysis on the social media network Twitter utilizes a combination of BERT (bidirectional encoder representations from transformers) and CNN for a dataset of tweets concerning the 2022 Philippine national elections—the former for text analysis and the latter for emojis [
9].
The implementation of sentiment analysis (SA) in politics represents an active and rich line of research due to the variants demanded by this application area. Below are additional examples in social media networks beyond those previously discussed: social policy on Twitter [
10], politics and disinformation in the 2026 Austrian elections [
11], detection of emerging political topics on Twitter [
12], energy transition in Germany from 2017 to 2022 using Twitter posts [
13], public health debates on social media [
14], sentiment and political risk at the firm level using machine learning [
15], sentiments regarding nuclear energy in the United States [
16], transformer-based models for sentiment analysis of tweets related to U.S. elections [
17], and political bias in SA using large language models [
18]. An extensive study of sentiment analysis and emotion detection in text is provided by the systematic review in [
19], which covers research reports in articles, conferences, and theses published between 2013 and 2023, illustrating the evolution of this research line.
In the scientific literature, we also find works involving sentiment analysis that consider specific contexts. In [
20], a deep learning model based on BERT is developed and specialized for the context of the 2024 Indonesian presidential elections. This study includes a comparison of the BERT model with other machine learning methods such as naive Bayes, support vector machines, and random forests. Other applications include analyzing customer satisfaction in commercial airlines through Twitter posts using machine learning algorithms such as SVM, ANN, and CNN [
21].
Furthermore, pre-trained models are yielding successful results in sentiment-related text classification, as is the case with Llama 3.2. This pre-trained model was implemented with transformer architecture and features 3 billion parameters. Llama 3.2 was used to classify Twitter posts containing political propaganda information in Mexico [
22].
In [
23], a study on political sentiment was conducted using a dataset of tweets from parliamentarians in Spain, the United Kingdom, and Greece. The authors sought to improve political sentiment measurement and identify whether the dissemination of tweets is conditioned by the sentiment expressed in the post. They utilized six deep learning models for comparison among themselves and with non-transformer algorithms such as SVM and LSTM.
Social media networks generate significant information for multiple applications, such as sentiment analysis, political stance identification, the creation of user profiles for targeted political advertising [
24], measuring opinions and topic modeling regarding food security on Twitter [
25], measuring voting intention on social media via machine learning [
26], and measuring sentiment on Twitter regarding road works through machine learning and deep learning [
27], among many others.
Sentiment analysis is also applied in health topics such as those related to COVID-19, which caused a pandemic that impacted the mood of people worldwide. This topic remains active due to its social impact and ongoing infections despite the lower level of danger compared to the peak of the pandemic. Some works measuring public sentiment on COVID-19 aspects include: sentiment analysis of COVID-19 vaccines across seven categories using a combination of deep learning algorithms or models [
28]; sentiment analysis with a hybrid model using bidirectional encoder representations from transformers and long short-term memory (LSTM) networks [
29]; and classification of COVID-19-related tweets through a hybrid model composed of convolutional neural networks (CNNs) and fuzzy C4.5 [
30].
Recent studies on applications of natural language processing, specifically in sentiment analysis, provide insight into advancements in this research line, as the focus can be on classifying any topic to achieve high precision through proposed innovations—whether in model training, utilized algorithms, labeling, or the combination of deep learning models and algorithms. In this regard, ref. [
31] reports a hybrid model for sentiment analysis in tweets consisting of a transformer-based pre-trained model and a BiLSTM network. Additionally, ref. [
32] presented a hybrid model for multilingual SA combining CNN, LSTM, and the grey wolf optimization algorithm. This proposal aims to improve accuracy by accounting for language differences during the classification process.
Hybrids in sentiment analysis combine two or more models to improve prediction or classification accuracy. For example, BiLSTM and BiGRU (bidirectional gated recurrent unit) neural networks are used to extract information from the corpus for the fine-tuning process, while BERT base and BERT mini pre-trained models are used for sentiment classification—using the three classic categories: positive, negative, and neutral—on three datasets obtained from Twitter: one featuring airline comments and two regarding Apple products [
33].
The work in [
34] presents a systematic analysis of sentiment in social media using ensemble-based techniques. It addresses machine learning solutions with techniques distinct from pre-trained models to specialize them in sentiment classification tasks. However, although pre-trained models are more recent, this provides an overview of the predominant techniques for sentiment analysis before the massive adoption of large language models.
On social media, individuals share their own political views, often based on ambiguous, unverifiable, or false information. In the political arena, so-called “negative campaigns” are sometimes employed, focusing on highlighting opponents’ weaknesses in order to discredit them. While this practice can be controversial, it is considered acceptable in some countries. In this context, fact-checking has become a critical issue across social media content, and there are notable efforts aimed at combating misinformation [
35,
36].
3. Materials and Methods
3.1. Data Collection
Spanish-language posts from X related to Mexican political topics were collected using Python 3.12 and the Tweepy library. Keywords were selected based on the Mexican political context, including names of 2024 presidential candidates, political parties, campaign proposals, public policies, and terms identifying political movements.
The number of tweets collected was 20,000, and after preprocessing, which includes balancing the number of tweets per category, 10,244 were selected for training and testing. Balancing consists of selecting tweets such that they contain a similar number across the categories considered, in this case, positive, negative, and neutral. The balancing process was carried out after the labeling, which is explained later.
3.2. Preprocessing
Data preprocessing primarily consisted of cleaning the texts to remove elements such as emojis, email addresses, HTTP links, special characters, and hashtags. This was done using Python programming, where the dataset was stored in DataFrames, and all preprocessing operations were performed on these. Hashtags were removed to prevent bias toward specific political topics or threads, ensuring topic variety in the training texts. The names of the authors of the posts or replies were not considered. The data was balanced by taking into account positive, negative, and neutral tweets to form a corpus that was balanced in these three categories. A dataset was considered with a roughly balanced number of instances per category: a total of 3500, 3154, and 3590 for the negative, positive, and neutral classes, respectively.
Duplicate tweets were removed using Python code. First, the entire dataset—including both training and test records—was loaded into a Pandas dataframe. Next, the function duplicated().sum() was applied to determine the total number of exact duplicates as follows: total_duplicated = df[‘tweet’].duplicated().sum(), which identified 582 records with duplicated tweet content. The dataframe was then processed using the drop_duplicates() function to remove duplicates as shown: df_no_duplicates = df.drop_duplicates(subset = [‘tweet’], keep = ‘first’). The data was collected between December 2023 and February 2024.
3.3. Labeling
The training dataset was labeled automatically using the pysentimiento model. This model is trained for sentiment analysis in the Spanish language, based on BERT, and is not specialized in political topics. The data labeled by the pysentimiento model were reviewed by the researchers, and pertinent adjustments were made to the tweets. Three categories were considered: positive, negative, and neutral. The labeling was conducted on a dataset of 20,000 tweets; subsequently, the dataset was balanced so that the categories had a similar number of instances.
The pysentimiento model uses a softmax function in its final layer, producing three outputs corresponding to the negative, positive, and neutral classes. Each output represents the probability assigned by the model to each category, and, as probabilities, their sum equals 1. For classification purposes in our study, labels 0, 1, and 2 were assigned to these categories by selecting the highest of the three values. In the dataframe containing the 10,244 tweets, three columns—negative, positive, and neutral—store the scores produced by pysentimiento.
Pysentimiento is capable of classifying text according to sentiment in Spanish, which provides the foundation required to automatically label our dataset. The subsequent step involved enabling the system to recognize sentiment specifically in politically oriented texts, leveraging the knowledge acquired during training.
After automatic labeling by the pysentimiento model, the dataset was manually reviewed by three annotators. The annotation criteria were defined as follows: tweets were labeled as positive if they expressed political ideas or statements using optimistic language; negative labels were assigned to tweets containing aggressive or depressive language; and neutral labels were used for those that did not exhibit a clear tendency toward either positive or negative sentiment. Meetings were held among the annotators to analyze examples and reach consensus on these criteria. Approximately 2% of the dataset was modified during this manual review process.
3.4. Model Selection
We selected pre-trained transformer-based models with distinct characteristics, all of which incorporate Spanish, since this study uses a Spanish dataset for retraining. The selected models were originally trained for various tasks such as Spanish language recognition in their base versions; subsequently, other models were built upon them and specialized through fine-tuning for tasks such as sentiment analysis in politics, news, hate speech, and toxicity classification. In the present work, these selected models were specialized to determine which resulting model achieves the highest accuracy in analyzing sentiment in posts from the social media network X addressing political topics. In other words, the models were retrained using the political text dataset, considering that while all recognize the Spanish language, their prior training characteristics vary. The models selected for this study were obtained from the Hugging Face platform [
37].
3.5. Training
Twelve pre-trained models were utilized, all based on transformer neural networks. The training dataset consists of 10,244 political tweets labeled into three classes. All models recognize the Spanish language; through fine-tuning, they were equipped with the capability to interpret or classify tweets according to sentiment analysis criteria related to political topics.
We conducted development on a GPU using Google Colaboratory 2026. Training employed Python with the PyTorch 2.10 and transformers libraries, with consistent parameter configuration across all models. Consistent parameters were used for the fine-tuning of all pre-trained models; the intention was to measure the accuracy of these models using the same parameters and dataset.
The training was configured with a maximum sequence length of 200 tokens (character reading extension from the beginning), a batch size of 16 (number of phrases that are read in parallel), random seed 42, and 3 classes (number of possible classifications in the response). The dataset was split into 70% for training and 30% for testing. Models were trained over 3 epochs, with a dropout rate of 0.30% and the AdamW optimizer using a learning rate of 2 × 10−5 across all models. The loss function employed was cross-entropy.
Precision, recall, and F1-score metrics were used to measure model performance. During training, correctly identified texts are called true positives. In cases where the model identifies texts as positive when they are actually false, these are termed false positives. The same applies to negative values: if the model identifies texts as negative when they truly are, these are true negatives; conversely, if it incorrectly identifies negative values, they are designated as false negatives.
A linear scheduler was used via the get_linear_schedule_with_warmup() function from the Hugging Face transformers library to control the optimizer’s learning rate throughout training. The parameters used for all models were optimizer, num_warmup_steps = 0, and num_training_steps = total_steps. The first corresponds to AdamW, and the second indicates the warm-up phase—set to 0 in this case—meaning that training starts immediately with the learning rate defined in the optimizer and then decreases linearly to 0 over the number of steps specified by num_training_steps = total_steps.
For our models, a batch size of 16 was used, resulting in approximately steps per epoch, rounded up to 641. The total number of training steps is calculated as: , where represents the total number of steps.
The learning rate is adjusted according to the scaling factor:
where
is the current step.
Thus, the learning rate at step is .
For example, at the beginning of training (step 1), the scaling factor is:
resulting in a learning rate of
.
At key points during training, the learning rate evolves as follows:
End of the first epoch: .
Midpoint of training: .
Final step: .
As observed, the learning rate decreases progressively as training advances. This schedule ensures that the learning rate reaches 0 only at the final step. This is critical, since if the learning rate were to reach 0 too early—e.g., halfway through training (step 961)—the model would stop learning from that point onward.
Special tokens for transformer models, such as [PAD] and [CLS], were used. A max_length of 200 was defined; therefore, shorter tweets were padded using the [PAD] token, while longer texts were truncated. The truncation strategy applied was right-side truncation, meaning that only the first 200 tokens of tweets exceeding this length were retained. The tokenizer was configured with the parameters padding = max_length, add_special_tokens = True, truncation = True, and return_attention_mask = True.
Stratified sampling was not applied. Instead, the dataset was balanced to include 3500, 3154, and 3590 instances for the negative, positive, and neutral categories, respectively. The dataset was then shuffled to ensure random distribution, allowing each training batch (of size batch_size) to contain a diverse mix of sentiment labels.
3.6. Pre-Trained Models
Twelve models were employed to determine which pre-training characteristics most improve accuracy after fine-tuning with the specific dataset of political topic posts from X. Pre-trained models with diverse characteristics were selected: multilingual models that include Spanish, models trained exclusively in Spanish, models specialized in general sentiment analysis, models specialized in political discourse, and others trained for hate speech detection.
Table 1 specifies the details of each model.
Below, we present the main characteristics of the selected models for fine-tuning in sentiment analysis as reported by their creators.
The model dccuchile/bert-base-spanish-wwm-uncased is based on BERT and trained in Spanish. It has the following accuracy scores: natural language inference, 80.15; part-of-speech tagging, 97.10; document classification, 89.5; paraphrase detection, 98.44; and in named entity recognition, it achieves an F1-score of 82.67.
On the other hand, the model microsoft/Multilingual-MiniLM-L12-H384 is multilingual and based on the BERT transformer network. It contains 12 layers, 384 hidden units (neurons), 21 million parameters, and 96 million embedding parameters.
MMG/xlm-roberta-base-sa-spanish is derived from RoBERTa-base and specializes in sentiment analysis in Spanish. It classifies into three categories: positive, negative, and neutral. The Transformer network contains a total of 768 nodes, 12 hidden layers, and 12 attention heads. UMUTeam/beto-cased-political-agendas is a pre-trained model built upon another model named BETO. The dataset used for fine-tuning includes government and public administration, social policy, foreign policy, trade and industrial policy, and defense policy. It achieved an F1-score accuracy of 68.9. It was trained for 3 epochs, with a batch size of 16, 768 hidden layers in the neural network, 12 attention heads and a dropout of 0.1, and it contains 100 million parameters. The test accuracy during training is reported as 69.22 in F1-score.
Another model selected for this study is Newtral/xlm-r-finetuned-toxic-political-tweets-es. It is multilingual and based on xlm-roberta-base. Fine-tuning was performed using a dataset of tweets from members of Spain’s Congress. Tweets were labeled according to toxicity level into two classes: toxic and highly toxic. Training employed a batch size of 32, a learning rate of 2 × 10−5, 5 epochs, the AdamW optimizer, and binary cross-entropy loss.
A Spanish-language model included in this study is Venkatakrishnan-Ramesh/Hate_speech_spanish_vk, which was trained for hate speech detection. The reported metrics include accuracy, micro F1, micro precision, and micro recall of 0.501. The neural network contains 768 nodes and 12 hidden layers, uses a dropout of 0.1, and includes 12 attention heads.
The multilingual pre-trained model oxygeneDev/sentiment-multilingual includes Spanish and 22 additional languages. It is a refined version of the model distil-bert/distilbert-base-multilingual-cased [
51], enhanced with general sentiment analysis capabilities. Fine-tuning was performed with data from multiple real and synthetic sources. It was trained for 3 epochs, and the accuracy obtained on the test set was 0.93.
Another selected model is gplsi/Toxicity_model, which is an adjusted version of RoBERTa-base-bne [
52] for classifying toxic text in Spanish-language news article comments. It recognizes three categories: non-toxic, slightly toxic, and toxic. The dataset used to train this model is SocialTOX, which contains real texts from debates on news topics in Spanish. Training was conducted for 7 epochs, with a learning rate of 1.51 × 10
−6, Adam_epsilon optimizer, batch size of 16, and a maximum sequence length of 512.
Meanwhile, the pre-trained model marianna13/bert-multilingual-sentiment is specialized in sentiment analysis. It is multilingual and based on bert-base-multilingual-cased, with 768 nodes per transformer layer, 12 layers, 12 attention heads, 5-class classification, and a dropout of 0.1 during training. The dataset used for training was SEntiment ANalysis in Twitter (SENAT). No training or test accuracy metrics are reported, but based on the BERT architecture, its F1-score, precision, and recall should be acceptable.
bertin-project/bertin-gpt-j-6B is an optimized Spanish version of the GPT-J 6B model, trained with Mesh Transformer JAX, a framework for training large models with Google’s JAX library. It contains 6 billion parameters, was trained on 65 billion tokens over one million steps, used cross-entropy loss, and was trained on a TPU v3-8 virtual machine over approximately 6 months. The model has 28 layers with a model dimension of 4096 and a feed-forward dimension of 16,384. The first dimension is divided into 16 heads with a head size of 256. This model was trained on a subset of mc4, known as mc4-es-sampled, containing only Spanish data.
MoritzLaurer/multilingual-MiniLMv2-L6-mnli-xnli was created by Microsoft and is based on 472 XLM-RoBERTa-large. The XNLI training set contains 2490 English texts translated into 14 languages, resulting in a total of 37,350 texts [
53].
lxyuan/distilbert-base-multilingual-cased-sentiments-student is a distilled model for zero-shot sequence classification for the multilingual sentiment dataset. Teacher model: Moritz-Laurer/mDeBERTa-v3-base-mnli-xnli. Teacher hypothesis template: “The sentiment of this text is {}.” Student model: distilbert-base-multilingual-cased. Fine-tuning is performed using labeled data from tweets on political topics in Spanish. This fine-tuning is applied on top of the pre-training layer that uses an unlabeled dataset constructed through the larger base model. The experiment for this model consists specifically of retraining it with a labeled dataset.
4. Results
The results from training the 12 models used for sentiment analysis in politics are presented below. It should be recalled that these models have distinct characteristics in their original training and subsequent fine-tuning to specialize them for the specific task, as previously discussed.
Table 2 shows a summary of each model’s accuracy for training and testing with fine-tuning for political sentiment classification, including the precision, recall, and F1-score metrics for each of the three categories—negative, positive, and neutral—labeled with the values 0, 1, and 2, respectively. Fine-tuning was performed on these models using the same dataset and parameter configuration. The dataset consists of tweets with political themes in Spanish within the Mexican context on the social media network X.
The results for the precision, recall, and F1-score metrics indicate that the best-performing model is UMUTeam/beto-cased-political-agendas, which is originally trained in Spanish and specifically designed to recognize political text. Its performance ranges between 0.97 and 0.99 on the training set and between 0.78 and 0.88 on the test set.
Other models achieved results slightly below UMUTeam/beto-cased-political-agendas, suggesting that their overall performance is very similar. In particular, the models Newtral/xlm-r-finetuned-toxic-political-tweets-es and dccuchile/bert-base-spanish-wwm-uncased showed a difference of approximately 0.01 lower in recall and precision compared to the top-performing model.
Other models that achieved high accuracy scores include Venkatakrishnan-Ramesh/Hate_speech_spanish_vk and marianna13/bert-multilingual-sentiment, with training performance ranging from 0.97 to 0.98 and 0.93 to 0.95 across the three metrics, respectively. On the test set, these models obtained scores of 0.77–0.88 and 0.77–0.87, respectively. Based on these results, the five models discussed in the previous paragraphs exhibit very similar performance in classifying political text in Spanish. The differences observed in the evaluation metrics across both training and test sets are within acceptable ranges, indicating a good balance without evidence of overfitting.
Regarding the models originally trained in Spanish, dccuchile/bert-base-spanish-wwm-uncased is included; this model was trained for language recognition and does not have any additional training. Fine-tuning for political sentiment was performed, and the model presented high values for categories 0, 1, and 2. Other models such as the gplsi/Toxicity_model, whose base training was exclusively for the Spanish language, showed low accuracy despite the original language and the role of toxicity as a potentially important attribute in political discourse on social media. On the other hand, bertin-project/bertin-gpt-j-6B yielded lower scores across the three metrics—precision, recall, and F1-score—mainly in categories 0, 1, and 2.
The complete results of the pre-trained models, in terms of the precision, recall, and F1-score metrics used in this study, are presented in
Table 2.
All models were trained for three epochs and with identical configurations in order to measure accuracy under equal conditions. The models with the highest accuracy, UMUTeam/beto-cased-political-agendas and Newtral/xlm-r-finetuned-toxic-political-tweets-es, have additional training beyond the original, that is, fine-tuning that enables them to perform other functions, specifically in political contexts. This is particularly interesting because it shows that providing models beforehand with certain capabilities related to the intended purpose of fine-tuning—in our case, the classification of texts on political topics—favors the final performance of the model. These pre-trained models have at least 100 million parameters, which is a significant number for the results to be considered reliable.
Figure 1 and
Figure 2 illustrate the accuracy and loss behavior for the two top-performing models; each graph displays four curves representing the training and testing accuracy and loss. The blue and orange lines depict the training accuracy and loss, respectively. The green and red lines represent the testing accuracy and loss, respectively. Similar plots for all models are provided in
Appendix A.
The following tables present the accuracy metrics for the training and testing phases of the highest-scoring models.
Table 3 and
Table 4 display the training and testing scores for the UMUTeam/beto-cased-political-agendas model, which demonstrates robust results in precision, recall, and F1-score. Furthermore, data balancing was performed for categories 0, 1, and 2.
The results for category 0 in training and testing, according to
Table 5 and
Table 6, are 0.98 and 0.82. This demonstrates that for this class, the results are reliable. Category 2 obtained good training results—0.97 for precision, recall, and F1-score, respectively. In testing, acceptable results were also obtained across the three metrics, with scores of 0.78.
Figure 2 and
Table 5 and
Table 6 include the training and testing measurements for the model Newtral/xlm-r-finetuned-toxic-political-tweets-es for precision, recall, and F1-score. As in the previous case with the model UMUTeam/beto-cased-political-agendas, these scores show high values with an acceptable difference between training and testing, which allows us to conclude that the results are reliable.
To determine the best model, we focused on the F1-score and recall metrics in the test set, as the former provides a better balance of precision—that is, how many of the texts classified as positive or negative truly are. Recall, for its part, provides information on which of the actual positive or negative texts were detected. To illustrate the number of correct and incorrect predictions, the confusion matrices of the two best-performing models are included. In
Figure 3 and
Figure 4, corresponding to the training and test sets, respectively, the main diagonal shows the correctly classified instances for UMUTeam/beto-cased-political-agendas, along with the misclassifications—for example, positive instances labeled as neutral or negative—across both training and evaluation scenarios.
The values along the main diagonal in both confusion matrices, shown in
Figure 3 and
Figure 4, are balanced, indicating that the model performs well in classifying all three categories.
The confusion matrices for the second-best model, Newtral/xlm-r-finetuned-toxic-political-tweets-es, are shown in
Figure 5 and
Figure 6 for the training and test sets, respectively. The largest values appear along the main diagonal of each matrix, while smaller values outside the diagonal represent the model’s misclassifications. For example, during training, the model correctly identified 2380 negative texts, while 19 negative texts were classified as neutral and 46 as positive.
In the test set, the second row of the confusion matrix shows that the model correctly classified 823 tweets as neutral, while 19 and 102 neutral tweets were misclassified as negative and positive, respectively. These numbers are acceptable and demonstrate a balanced performance across the three categories. For instance, in the training confusion matrix, the main diagonal values—representing correct predictions—are 2380, 2176, and 2440 for the negative, neutral, and positive categories, respectively.
In the test set confusion matrix, the correct predictions are 846, 823, and 843, further indicating that the model maintains balanced classification across all three categories.
On the other hand, dccuchile/bert-base-spanish-wwm-uncased and Venkatakrishnan-Ramesh/Hate_speech_spanish_vk achieved results very close to those of the top-performing models. These two models were pre-trained in Spanish and rank third and fourth, respectively, in terms of the highest scores. The case of dccuchile/bert-base-spanish-wwm-uncased is notable because it had no prior fine-tuning before the training conducted in this study; that is, it was trained solely to understand Spanish. Its training scores averaged 0.98 across macro precision, macro recall, and macro F1, while on the test set, it achieved 0.82 for the same metrics.
Table 7 and
Table 8 present the results for all models on the training and test sets, reporting macro precision, macro recall, and macro F1 metrics. Additionally, the tables include averages for the categories with the greatest weight. Values to the left of the “|” symbol correspond to the macro scores, while those to the right represent the averages of the most heavily weighted categories.
The Venkatakrishnan-Ramesh/Hate_speech_spanish_vk model, on the other hand, was also trained exclusively in Spanish, but it additionally underwent fine-tuning for hate speech classification. This model achieved training scores of 0.97 across all three macro metrics and 0.81 on the test set when considering the weighted average of the most prominent categories.
Another model with outstanding performance is marianna13/bert-multilingual-sentiment. Its scores are slightly lower than the top four models but are still considered acceptable, meaning the model accurately identifies negative, positive, and neutral sentiment in Spanish political tweets. Its macro precision, macro recall, and macro F1-scores are 0.95 for training and 0.80 for testing.
The differences in precision, recall, and F1-score metrics between the training and test sets for the top four models across the three categories indicate that these models are well balanced, supporting the conclusion that there is no overfitting.
There were also models with moderate performance, such as oxygene-Dev/sentiment-multilingual, which achieved average scores of 0.77 and 0.70 across the three metrics for training and testing, respectively. These results indicate that the model makes slightly more errors than the top-performing models. Another moderate performer was gpl-si/Toxicity_model, which scored 0.70 on macro precision, macro recall, and macro F1. Even lower performance on the same metrics was observed for MMG/xlm-roberta-base-sa-spanish, with a value of 0.61.
Finally, four models exhibited low scores: microsoft/Multilingual-MiniLM-L12-H384, bertin-project/bertin-gpt-j-6B, MoritzLau-rer/multilingual-MiniLMv2-L6-mnli-xnli, and lxyuan/distilbert-base-multilingual-cased-sentiments-student. These models recorded macro precision, macro recall, and macro F1-scores of 0.44, 0.57, 0.56, and 0.70, respectively, on the test set.
Table 7 and
Table 8 present the macro values for all models.
Appendix A provides graphical representations of the model’s performance values during training and testing for this and all other models.
5. Discussion
The best results were obtained with UMUTeam/beto-cased-political-agendas, a model pre-trained exclusively in Spanish and further specialized in political agendas through fine-tuning. The second-best model is Newtral/xlm-r-finetuned-toxic-political-tweets-es, which is multilingual and was previously fine-tuned for detecting toxic language in political texts. These two models achieved the highest scores across the three evaluation metrics— precision, recall, and F1-score—and the macro averages provide an overall view of performance across the negative, positive, and neutral categories.
Table 3,
Table 4,
Table 5 and
Table 6 present the results for these metrics, showing that all three categories are balanced, with no significant differences between training and test set performance. Both models share a distinctive feature relevant to this study: pre-training on political topics and hate speech detection, which appears to have enhanced their ability to classify tweets within the context of political discussions in Mexico.
The models dccuchile/bert-base-spanish-wwm-uncased, Venkatakrishnan-Ramesh/Hate_speech_spanish_vk, and marianna13/bert-multilingual-sentiment also demonstrated high performance, with scores very close to the top model. The first two were pre-trained in Spanish, while the other is multilingual, achieving results similarly close to the top performer in terms of accuracy.
Additionally, three multilingual models showed moderate performance: MMG/xlm-roberta-base-sa-spanish, oxygene-Dev/sentiment-multilingual, and gpl-si/Toxicity_model. Two of these had prior training in Spanish, while the third is multilingual. These results indicate that high accuracy in classifying political texts does not depend on whether a model is originally trained exclusively in Spanish or is multilingual, as both approaches achieved strong performance. The common factor among the best-performing models is pre-training in hate or toxic language detection and political subject matter.
Another important case for our research is the pre-trained model bertin-project/bertin-gpt-j-6B, which was trained with a Spanish subset of mc4. This dataset is a massive version of the Internet processed by Google and contains terabytes of text in multiple languages. mc4-es-sampled is a subset of Spanish texts. The original GPT-J was trained with the dataset known as Pile, which contains aggressive and lascivious language. In addition, it has 6 billion parameters, which may give the impression that it would provide high accuracy values during training and testing after fine-tuning. It classifies texts using a mechanism known as “perplexity,” which consists of determining how surprised or perplexed a model is when analyzing a text. If this level is low, it means that the text is very simple or repetitive; if it is very high, then the text is incomprehensible or Internet noise; and finally, if the level is intermediate, then it corresponds to text correctly written by humans. However, the results in the metrics used during training and testing to endow it with the capability to classify sentiments in posts on political topics were lower than those of other models that do not use the “perplexity” method. The model takes texts and classifies them into low, medium, or high perplexity and groups those in the medium range; that is, it operates using Gaussian sampling based on perplexity. This model did not perform well in classifying Spanish political texts into the three sentiment categories.
An interesting experiment conducted in this study involved the bertin-project/bertin-gpt-j-6B model to assess how well a GPT-type architecture adapts to classification tasks. This model is based on transformer networks and follows a decoder-only architecture, specializing in next-word prediction; that is, it is primarily designed for text generation, where it performs very well. However, combining this GPT model with fine-tuning approaches typically used for encoder-only methods, such as BERT—which was the approach applied to all pre-trained models in this study—did not yield good results. This is because BERTIN’s original objective differs from that of classification tasks. Bidirectional models like BERT are highly effective for classification, labeling, and feature extraction, whereas BERTIN is better suited for conversational tasks, writing, and summarization.
From a technical standpoint, the classification head involves adding a final layer to the BERTIN architecture with three output units corresponding to the classification task. However, BERTIN’s original final layer is designed to output probabilities over a vocabulary of approximately 50,000 words, as its primary objective is text generation. Thus, forcing it into a three-output configuration introduces a mismatch in design. Unlike BERT, BERTIN does not include a mechanism for extracting sentence-level representations for classification, such as the [CLS] token used in BERT to summarize the input sequence for downstream tasks. In summary, BERTIN excels at word prediction—a fundamentally different task from classification—which explains its lower performance in this context.
On the other hand, three models achieved the highest accuracy scores: UMUTeam/beto-cased-political-agendas, Newtral/xlm-r-finetuned-toxic-political-tweets-es, and Venkatakrishnan-Ramesh/Hate_speech_spanish_vk. The first two were pre-trained on political content, while the second and third were additionally specialized in toxic language detection.
The evidence that fine-tuning was effective for these models lies in their high scores across all evaluation metrics. We argue that the characteristics of their prior training strengthened the models developed in this study due to alignment with political topics, as well as the presence of toxic language commonly used in political content on the social media platform X in Mexico.
As further support for this claim, when comparing the macro precision, macro recall, and macro F1 results of these models against others, such as MMG/xlm-roberta-base-sa-spanish, oxygeneDev/sentiment-multilingual, and lxyuan/distilbert-base-multilingual-cased-sentiments-student, the differences are notable. Although these three models were pre-trained for sentiment analysis, unlike the previously mentioned models, they were not fine-tuned for toxic language or political topics. This comparison for the test set is presented in
Table 9.
Some models that were originally pre-trained exclusively in the Spanish language obtained good scores in precision, recall, and F1-score. This result is important because one might assume that models pre-trained in Spanish would be better suited for fine-tuning to classify sentiments in Spanish; however, this is not true in all cases. The specialization of models during pre-training for a text classification task related to the task of interest is an important factor in improving model accuracy, even when the base model is multilingual.
The results indicate that balancing the dataset used for training and testing was effective in achieving equilibrium in the three-class classification. Accuracy results across the three categories for the top-performing models show low loss and consistent values between training and test sets.
6. Conclusions
The two top-performing base models, based on precision, recall, and F1-score, were UMUTeam/beto-cased-political-agendas and Newtral/xlm-r-finetuned-toxic-political-tweets-es. These models were trained in Spanish, with both achieving nearly identical scores across all three categories using the applied metrics. Both models underwent prior training to recognize texts related to political topics. Additionally, Newtral/xlm-r-finetuned-toxic-political-tweets-es specializes in toxic language, which aligns with the nature of political posts on the social media platform X in Mexico. Based on the results obtained, we can conclude that pre-trained models in Spanish have a slight advantage over multilingual models for sentiment classification in Spanish.
The distilled models bertin-project/bertin-gpt-j-6B and MoritzLaurer/multilingual-MiniLMv2-L6-mnli-xnli yielded poor results during testing. The latter was originally trained for multilingual natural language processing; therefore, it was not exclusively specialized in Spanish nor does it recognize hate speech or toxic language. Two models that demonstrated strong metric results for the political post classification task on X are Venkatakrishnan-Ramesh/Hate_speech_spanish_vk and dccuchile/bert-base-spanish-wwm-uncased. The first model stands out in accuracy across the measurements utilized in this study despite being originally trained for hate speech classification. A distinguishing feature of political debate in Mexico on the social media network X is the presence of aggressive language and negative or toxic comments; consequently, this model was favored for classifying tweets with these characteristics. The knowledge transfer from “hate speech” to “political negative sentiment” was highly effective. These models are pre-trained for Spanish NLP, which, combined with pre-training on political content or, in this case, hate speech, can lead to strong accuracy results. The results of BERT-based models, such as RoBERTa, possess millions of parameters—for instance, 125 million in the base version—allowing them not only to learn rules and patterns but also to memorize specific instances from the training data. Furthermore, short texts in posts on X that are repetitive, or those that refer to the same subject with minimal variations in content, can be considered instances that become memorized. For this reason, it is important to remove duplicate tweets from the training dataset. The balanced scores across the three classification categories indicate that the top-performing models are robust in identifying the sentiment associated with each tweet.
The models gplsi/Toxicity_model and UMUTeam/beto-cased-political-agendas were originally trained with very low learning rates (1.51 × 10−6), which undoubtedly aids in fine convergence but may cause the model to become trapped in the training dataset’s local optimum and memorize noise or specific details. Although the learning rate was similar during both pre-training and fine-tuning for these models, UMUTeam/beto-cased-political-agendas achieved the best results, while gpl-si/Toxicity_model showed moderate performance.
Twelve models with varying characteristics were trained using a similar configuration for training and testing parameters. The comparison of precision results identified the optimal models and their associated details; for example, the highest performance was observed in both types of models: those originally trained exclusively in Spanish and the multilingual models. The fine-tuning of the original model is also significant, as the best results were obtained from models specialized in sentiment analysis and hate speech detection.
Through the training of the twelve models and the application of precision, recall, and F1-score metrics, the research question was addressed, and the research objective was fulfilled. The model comparison conducted in this study revealed that for a specific language—Spanish in this case—either Spanish-pre-trained or multilingual models can be employed. Layers can be added to the original model’s network; that is, it can be retrained for a specific function. In this study, the majority of the models utilized had already undergone additional fine-tuning beyond their base training. These models were adjusted once more and trained again for the recognition of sentiments expressed in political texts.
The best-performing models, mentioned above, showed good results for categories 0, 1, and 2 and some demonstrated superior precision for sentiment classification in political topics. Transformer technology, since its implementation in large language models, has shown immense strength in language processing and in multiple derivative applications. It is a technology that consistently delivers high-precision results for sentiment analysis.


 ,
, 






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}