1. Introduction
Text chunking, or text segmentation, divides a given long text into segments of several sentences. Semantic text chunking, which is a type of text chunking, divides texts into semantically coherent chunks of several sentences depending on the meanings of the text. Many researchers have explored the text segmentation task at different levels, ranging from low-level, characters, words, and tags to higher-level, dealing with phrases or sentences, and to a higher level, dealing with text, blocks, topics, and subtopics. This paper focuses on high-level text chunking, which segments text into segments of many sentences and blocks, as shown in
Figure 1.
Since the text chunking task was first introduced in 1994 [
1], several text chunking categories have been defined and evaluated. Text chunking is an essential preprocessing step in different downstream tasks in natural language processing (NLP), such as text summarization, information retrieval, and machine translation.
Also, since semantic text chunking emerged, several approaches and methods have been explored and evaluated for segmenting texts into semantically coherent chunks. They are broadly divided into unsupervised and supervised methods, and they utilize several approaches such as RNN (Recurrent Neural Network), LSTM (Long Short Term Memory), and, recently, transformers [
2] which have gotten State-of-the-Art results in many downstream NLP tasks. After that, deep learning has been utilized primarily in the semantic text chunking task. However, the research area of semantic text chunking in deep learning is still novel and relatively undiscovered [
3]. Pre-trained language models (PLM) are also exploited to improve the semantic text chunking. BERT (Bidirectional Encoder Representations from Transformers) is one of the most essential PLMs used mainly with NLP tasks.
Semantic Textual Similarity (STS) refers to determining the degree of similarity between two textual inputs based on their meanings. STS serves as a foundational signal for semantic text chunking, as chunking relies on identifying coherent groupings of sentences or text spans that exhibit high semantic relatedness; thus, accurate measurement of similarity between text units directly supports the detection of meaningful chunk boundaries.
Despite advances made in semantic text chunking for English through deep learning models such as BERT [
4] and RoBERTa [
5], several significant limitations and gaps remain, such as limited dataset variety. Current chunking models are mostly trained and evaluated on structured and domain-specific datasets like WikiSection [
6]. As a result, models often fail to generalize across different text types such as news articles, fiction, and technical manuals. In addition, most existing segmentation methods are unsupervised and use similarity thresholds between embeddings to determine the segmentation boundaries, but none have used fine-tuning PLM to calculate these similarities. Motivated by results obtained in the literature using unsupervised semantic text chunking methods and by State-of-the-Art results obtained using PLM in different NLP downstream tasks, the research question of the paper is whether integrating unsupervised semantic text chunking and the power of PLM, especially BERT, will provide an effective semantic text chunking method.
The dominating languages in previous research are English and Chinese [
7] and some research into text chunking in Arabic has been conducted at a low level, such as [
8] who divided texts into separate sentences. While semantic text chunking has achieved notable success in English through the use of pre-trained transformer models, e.g., BERT, RoBERTa, there remains a significant gap in extending these advances to Arabic, a morphologically rich and syntactically complex language. Most Arabic NLP models, like AraBERT, are fine-tuned for tasks such as classification, named entity recognition, or question answering, but not explicitly optimized for semantic text chunking task. Semantic text chunking in Arabic faces specific challenges not as prominent in English; Arabic’s complex morphology can affect sentence boundary detection and semantic coherence. To the best of our knowledge, there is an absence of annotated datasets constructed specifically for semantic text chunking in Arabic.
In this paper, to fill the gap, we combined unsupervised methods for semantic text chunking and the power of transfer learning from PLM to provide a practical and flexible semantic text chunking method for English and Arabic. We utilized transfer learning, especially fine-tuning pre-trained BERT on the semantic textual similarity task, to propose a semantic text chunking method. The main contributions of our paper are:
Novel semantic chunking method: Utilizing fine-tuned pre-trained BERT embeddings from the Semantic Textual Similarity (STS) task, presenting the first method of its kind for semantic text chunking.
AraWiki50k dataset: Constructing AraWiki50k, the first large-scale Arabic dataset explicitly annotated for semantic text chunking, accompanied by AraWiki50 as a smaller dataset for detailed evaluation. This addresses a critical gap in Arabic NLP resources.
Enhanced robustness through data augmentation: Applying paraphrasing-based and Synonym replacement-based data augmentation techniques to the STSb dataset (both English and Arabic versions), significantly enhancing robustness and generalizability.
Comprehensive experimental analysis: Conducting extensive experiments to analyze each component of our method, evaluating various hyperparameters, and comparing different embedding models, demonstrating clear improvements in chunking accuracy over baseline methods.
The rest of the paper is organized as follows.
Section 2 provides background information about text chunking and semantic textual similarity.
Section 3 introduces a review of related work about semantic text chunking.
Section 4 describes our methodology.
Section 5 shows our experimental setup, including datasets used, evaluation metrics, and baselines.
Section 6 produces results and
Section 7 is about discussion. A conclusion and future research are introduced in
Section 8.
2. Background
2.1. Text Chunking
Text chunking, also known as text segmentation, divides a text into semantically coherent and meaningful chunks. These chunks or segments vary in size and scope, ranging from individual words, phrases, or sentences to paragraphs and larger blocks of text. The process is driven by the need to identify coherent chunks within a text that reflect topic changes [
1,
7,
9]. Text chunking can be processed at multiple levels. Chunking at the sentence and phrase level involves isolating smaller linguistic units, such as words or tokens, which are functional for tasks like syntactic parsing or fine-grained sentiment analysis. However, at the text and paragraph level, chunking aims to segment larger bodies of text into chunks that maintain topical and semantic integrity [
3,
10,
11]. This research concentrates on the latter approach, aiming to chunk texts into semantically coherent segments.
Text chunking is one of the fundamental NLP problems [
12]. It plays a central role in enhancing the efficiency and quality of different NLP tasks. By breaking down texts into coherent segments, text chunking reduces noise, increases focus, and provides cleaner inputs for downstream tasks. For example, segmentation supports applications such as document summarization, sentiment analysis, question answering, emotion extraction, opinion mining, topic identification, language detection, dialog modeling, information retrieval, passage extraction, discourse analysis, machine reading, context understanding, document noise removal, natural language understanding, movie subtitling, language identification, cross-lingual plagiarism identification, clustering, story segmentation, topic partitioning, and image retrieval by their captions [
3,
7,
10,
12,
13]. In each of these cases, well-defined segments serve as reliable units of analysis, making it easier for algorithms to identify patterns, relationships, and topical shifts [
10]. Moreover, these smaller, coherent segments enable accurate embedding representations, further enhancing results’ precision and relevance in information retrieval and content generation tasks. Text chunking is considered a key preprocessing step for achieving a high-precision performance in different NLP tasks [
8], i.e., it is a critical component in developing effective, high-performing NLP pipelines. Although the text chunking or segmentation dates back to 1994 [
1], it has received considerable attention in recent years, and researchers still address different levels and aspects of this problem [
13].
2.1.1. Text Chunking Categories
Researchers have provided many categories and types of text chunking based on their underlying principles and objectives. These types can be categorized in several ways, each of which is based on specific knowledge and methods, as shown in the following
Figure 2.
Categorization by chunking unit: Text chunking can be classified based on the chunking unit used. The main types include character-based chunking, where text is segmented at the character level, often useful for languages without clear word boundaries or for processing OCR (optical character recognition) data, and also helpful for tasks that require deep text analysis. Token-based chunking divides text into meaningful tokens, typically words or phrases, making it suitable for different NLP tasks. For machine translation and summarization applications, sentence-based chunking that splits text into sentences is the appropriate method. Moreover, segment-based chunking chunks text into segments that consist of several statements based on the meanings of statements, but not necessarily a paragraph. In addition, paragraph-based chunking, which chunks texts at a paragraph level, is beneficial for document processing, discourse analysis, and maintaining text structure.
Categorization based on structure or meaning: Categorizes text chunking into structural text chunking, e.g., character-based, token-based, sentence and paragraph-based, and meaning-based chunking, known as semantic-based chunking which chunks texts based on their meaning, where correlated sentences and segments are grouped in one chunk. It is crucial for tasks that require an understanding of the context [
14].
Categorization by prior knowledge of chunk count: Another way to categorize text chunking is based on whether the number of chunks is known in advance or not; here, text chunking is either fixed chunk count chunking where the number of chunks is predetermined before chunking, or dynamic chunk count chunking, where the number of chunks is not known beforehand and is determined dynamically based on text patterns and context.
Categorization by topic awareness: Text chunking can be classified based on whether topics are determined before chunking into topic-based and topic-agnostic chunking. Topic-based chunking first identifies the main topics within a text and then chunks it accordingly, often used in topic modeling and summarization. Meanwhile, topic-agnostic chunking chunks of text without prior knowledge of the topics makes it more flexible but potentially less structured.
Categorization based on the methodology used in text chunking: Various methodologies have been developed for text chunking based on their underlying principles and objectives. The primary categories of text chunking methodology include rule-based chunking, statistical chunking, machine learning-based chunking, and deep learning-based chunking: (1) Rule-based chunking relies on predefined linguistic rules and patterns to identify and extract text chunks. These rules are often formulated using regular expressions, part-of-speech (POS) tagging, and syntactic constraints. Rule-based approaches are interpretable and practical for well-structured languages with defined grammatical rules but may lack flexibility when dealing with complex linguistic variations. (2) Statistical chunking employs probabilistic models to determine text chunks based on the likelihood of word sequences. Techniques that have been used in this category include Hidden Markov Models (HMMs), Conditional Random Fields (CRFs), and Probabilistic Context-Free Grammars (PCFGs). These methods leverage annotated corpora to learn patterns and probabilities, making them more adaptive than purely rule-based approaches. (3) Machine learning-based chunking involves training supervised models using labeled data to identify chunk boundaries automatically. Traditional models e.g., Decision Trees and Support Vector Machines (SVMs) have been utilized to classify and extract phrase structures. These approaches improve generalization and adaptability but require substantial labeled data for effective performance. (4) Deep learning-based chunking has significantly advanced text chunking by leveraging neural networks to learn hierarchical representations of text. The chunking task has reached State-of-the-Art results using methods such as LSTM, Bidirectional LSTMs (Bi-LSTMs), Transformer models, and BERT-based architectures. These models capture long-range dependencies and contextual relationships within text, improving accuracy and robustness.
2.1.2. Text Chunking Methods
Over the years, various methodologies have been proposed for text chunking, which can be broadly categorized into unsupervised, supervised, and hybrid approaches [
1,
15]:
Unsupervised methods: Unsupervised text chunking methods rely on intrinsic properties of the text, such as lexical cohesion, statistical modeling, topic modeling, or semantic similarity between sentences to identify segment boundaries without requiring labeled training data [
10]. These methods are often heuristic and require substantial computational resources and memory [
7,
12]. Despite their limitations, they have historically been the preferred approach due to the absence of large annotated datasets in the text chunking problem. Several techniques have been used in unsupervised methods for text chunking, as in the following [
12,
16]: (1) Lexical cohesion: measures word similarity across sentences to determine segment boundaries [
17]. (2) Statistical modeling uses probabilistic techniques to identify shifts in topic distribution [
18]. (3) Clustering approaches: C99 [
19] and GraphSeg [
20] cluster similar sentences into segments based on cosine similarity and graph representations. (4) Topic modeling: Latent Dirichlet Allocation (LDA) [
21] assigns topic distributions to sentences and detects segment shifts based on topic divergence. (5) Bayesian models capture statistical regularities in a text to determine boundaries. Although some unsupervised models achieve reasonable results, they generally suffer from high computational cost, poor generalization, and sensitivity to domain variations.
Supervised methods: Supervised methods for text chunking require many labeled data to train models capable of predicting segment boundaries [
12]. These approaches traditionally employed decision trees and probabilistic models but have evolved to include deep learning-based techniques, demonstrating significant improvements in chunking accuracy. However, the research in text chunking in the deep learning realm until 2021 is considered novel and relatively undiscovered [
3]. Several techniques have been used in supervised methods: (1) Decision trees and probabilistic models: early approaches utilized handcrafted features and probabilistic frameworks to determine chunk boundaries. (2) Recurrent neural networks (RNNs): Hierarchical RNNs, such as those proposed by Koshorek et al. [
9], learn sentence-level dependencies for segmentation. (3) BiLSTM models: ref. [
6] used bidirectional LSTMs to encode sentence information and predict segment shifts. (4) Transformer-based models: recent advancements have seen the adoption of transformer architectures, such as BERT and RoBERTa, for text chunking. These models employ pre-trained contextual embeddings and fine-tune them to predict segment boundaries [
10]. (5) Multi-task learning approaches: some models introduce auxiliary objectives, such as topic classification, to improve segmentation performance [
16]. While supervised methods outperform unsupervised techniques in accuracy, they require substantial labeled data, which is often scarce and computationally expensive.
Hybrid Approaches: Hybrid methods leverage the strengths of both supervised and unsupervised techniques by combining pre-trained transformer embeddings with heuristic or clustering-based segmentation approaches such as: (1) Pre-trained Transformer-based models: approaches such as BERT and XLNet utilize transfer learning, where general language knowledge is fine-tuned for chunking tasks. (2) Self-supervised learning: models like SECToR [
6] incorporate self-supervised objectives to enhance text coherence understanding. (3) Graph-based hybrid methods: graph-based text representations are integrated with supervised learning techniques to improve segmentation coherence.
Text chunking methodologies have evolved from heuristic-driven unsupervised methods to highly sophisticated deep learning-based supervised approaches. While unsupervised methods are computationally intensive and lack adaptability, supervised techniques offer high accuracy at the cost of large labeled datasets and computational resources. The hybrid models using transformer-based architectures show a promising direction by combining the advantages of both paradigms. The research continues to evolve by moving toward the development of more efficient models that balance performance, generalizability, and computational feasibility.
2.1.3. Semantic Chunking
Semantic chunking is a type of text chunking that divides a document into meaningful, semantically coherent chunks rather than relying on fixed-length or syntactic rules. Traditional chunking approaches differ from semantic chunking because they divide the text into a fixed token or character counts or sentence lengths, whereas semantic chunking maintains contextual and conceptual coherence between chunks, which makes it suitable for NLP applications.
Text processing, comprehension, and retrieval become more efficient through semantic chunking because it keeps segments focused on one topic. The method proves helpful for tasks that need context preservation, including (1) Information retrieval: semantic chunking enables better search and ranking because it retrieves text sections that are contextually relevant. (2) Text summarization: semantic chunking produces more coherent summaries by maintaining semantic continuity. (3) Machine translation: semantic chunking ensures that segmented units preserve the meaning for more accurate translations. (4) Retrieval-Augmented Generation (RAG): semantic chunking enhances generative models by providing semantically meaningful input.
Semantic chunking has several advantages over other chunking categories; it preserves contextual integrity, unlike fixed-length segmentation, which may break meaningful sentences or ideas. Semantic chunking keeps logically related content together. Moreover, semantic chunking is adaptive to text variability, i.e., it dynamically adjusts chunk boundaries based on meaning, making it more robust across different text genres and domains. Also, semantic chunking improves downstream NLP performance since many NLP models perform better when input text retains semantic coherence, leading to more accurate embeddings and improved task-specific performance. In addition, semantic chunking reduces redundancy in text processing where traditional fixed-length chunking may introduce incomplete or redundant text segments. Also, semantic chunking provides a better representation of discourse structure, i.e., it aligns with human reading patterns, enhancing readability and usability for document analysis and AI-driven applications.
2.2. Semantic Textual Similarity (STS)
Semantic Textual Similarity (STS) refers to the process of determining the degree of similarity between two textual inputs based on their meanings rather than just surface-level word matches, which makes it very significant and widely used in the field of NLP [
22]. Unlike traditional text similarity measures that rely on syntactic comparisons (such as edit distance or exact word matching), STS evaluates the deeper semantic relationships between words, phrases, and sentences. It is beneficial in NLP for tasks that require a nuanced understanding of language.
STS identification in short texts was proposed in 2006. After that, the focus was shifted to large documents or individual words. Since 2012, semantic similarity has been limited to find out the similarity between two texts and generating a similarity score from 0 to 5 (0 means unrelated and 5 means complete semantic equivalence) [
23]. The introduction of BERT [
4] and SBERT [
24] further revolutionized STS research, making it a key area in various applications such as search engines, automated grading systems, and chatbots. With advancements in large language models (LLMs) nowadays, STS remains an active and evolving field in NLP research.
STS has numerous advantages in computational linguistics and artificial intelligence, including (1) improved information retrieval, where search engines are enhanced by ranking results based on meaning rather than just keyword matching. (2) better text summarization where STS helps generate summaries that retain the original text’s core meaning. (3) enhanced chatbots and virtual assistants by understanding user queries in context and providing better responses. (4) plagiarism detection by identifying reworded and semantically similar content. (5) sentiment analysis and opinion mining, where STS helps group similar sentiments in user reviews, social media posts, or surveys. STS is widely used in various domains, such as machine translation, question-answering systems, paraphrase identification, text classification, topic retrieval, programmed question and response systems, and textual summary research [
25]. Moreover, STS contributes to many semantic web applications, such as community extraction, ontology generation, and entity disambiguation [
23].
Several methodologies have been used to measure STS, ranging from traditional linguistic techniques to deep learning models such as [
23]: (1) Lexical-based methods such as Jaccard similarity, which measures the overlap of words between two texts and cosine similarity that uses vector representations of words to compute the similarity between two text documents. (2) Statistical/Corpus-based similarity, where statistical similarity is learned from data, i.e., corpus, which is a collection of written or spoken text. (3) Machine Learning and Deep Learning approaches: some ML methods were used for STS, such as support vector machine (SVM). Also, due to the successful use of neural networks in major NLP tasks, researchers were investigating using neural network models for text semantic representation. Typically, the CNN (Convolutional Neural Network) and the RNN models performed well in learning the sentence representations and the relationship between elements in the input sentence. Researchers utilized the CNN model to solve the textual semantic similarity task. A semantic similarity score between two sentences was calculated by comparing their semantic vectors.
Nowadays, many methods are aimed at gaining a better understanding of the text’s context in order to express its semantics better. It was discovered that the Siamese network architecture can be utilized to evaluate the semantic similarity of images or texts since it can encode sentence pairs using equal weights and parameters and produce similar semantic sentence representations using the same parameters. Researchers combined convolution and recurrent neural networks to measure the semantic similarity of sentences. The Siamese network model was a neural network framework, not a specific neural network model. Therefore, the LSTM, CNN, or gated recurrent unit (GRU) model can be applied to its implementation [
22]. The Siamese network is mainly composed of two branches. The two branches have the same structure and share weights and parameters. Because of the characteristics of sharing parameters and weights, the Siamese network model decreases the number of parameters during the training process, reducing the model’s complexity.
3. Related Work
The existing text segmentation approaches are mainly categorized into unsupervised and supervised methods. Unsupervised text segmentation methods depends on statistical, lexical, and semantic features for analysis without the need for labeled data. The adaptability of these approaches to new domains is high, but their accuracy tends to be lower than supervised models. The supervised methods use machine learning algorithms which learn optimal segmentation patterns through the use of annotated datasets. The supervised methods achieve better accuracy results but need substantial labeled data for training and experience difficulties when trying to generalize. The following subsections provide a discussion of the existing research about unsupervised and supervised text chunking.
3.1. Unsupervised Text Chunking
Initially, two contributions set a new standard in the text chunking field [
11] which are TextTiling [
17], an unsupervised algorithm that identifies segment boundaries by calculating the similarity between blocks of words using cosine similarity, and clustering segmentation algorithm introduced by [
19] where they demonstrated the efficacy of unsupervised methods by analyzing sentence similarities, and calculating the maximum-probability segmentation of a given text. Then, the TopicTiling algorithm was issued that employs Latent Dirichlet Allocation to detect topic changes within documents [
26]. Moreover, other earliest methods developed for text chunking are graph-based segmentation, such as in [
20,
27], and Bayesian-based methods introduced in [
28,
29].
After that, research on the text chunking field continued to exploit unsupervised methods since no large labeled dataset existed until 2018 [
9]. These studies used heuristics to identify whether two sentences belong to the same topic. Such approaches either exploit the fact that topically related words tend to appear in semantically coherent segments or focus on text representation in terms of latent topic vectors using topic modeling methods, such as Latent Dirichlet Allocation [
1]. Ref. [
30] proposed a Bidirectional RNN with LSTM cells for topic segmentation in Automatic Speech Recognition (ASR) transcripts. Their model is trained in an unsupervised way without topic labels, using news articles concatenated to create artificial topic boundaries. Moreover, ref. [
31] provided an unsupervised approach for topic segmentation of meeting transcripts using BERT embeddings. It enhances TextTiling by replacing word frequency-based similarity with a BERT-based semantic similarity score, leading to a 15.5% reduction in error rate over existing methods. They provided a modified version of the TextTiling “gold-standard unsupervised method for topic segmentation”. While TextTiling detects topic changes with a similarity score based on word frequencies, it detects topic changes based on a similarity score using BERT embeddings.
In addition, ref. [
7] proposed a semantic chunking approach using BERT-based next-sentence prediction. It calculates local incoherence scores by comparing intra-cluster and inter-cluster coherence to detect semantic boundaries. Ref. [
11] introduced Coherence, an unsupervised text segmentation method that extracts keywords using KeyBERT and stores them in a Keyword Map. They utilized related words and their contextual meanings within sentences for text chunking. Their method compares contextual keyword embeddings instead of complete sentence embeddings, improving cohesion-based segmentation. The comparison between the mentioned unsupervised chunking methods is shown in
Table 1.
3.2. Supervised Text Chunking
Ref. [
12] proposed a supervised text segmentation model that uses an attention-based CNN-BiLSTM architecture. It extracts sentence representations using CNNs, applies BiLSTMs with attention to model contextual dependencies, and uses a softmax classifier to determine segment boundaries. Like any supervised method, it needs labeled segment boundaries, limiting its applicability in domains where labeled segmentation data is scarce. In 2018, ref. [
9] formulated text segmentation as a supervised learning problem, where a label for every sentence in the document denotes whether it ends a segment using a hierarchical BiLSTM model. It learns segment boundaries by representing sentences using word-level BiLSTM embeddings and predicting binary segmentation labels using a sentence-level BiLSTM classifier. Their model requires a large labeled dataset; therefore, they created Wiki727k, which is automatically labeled from Wikipedia articles and may contain noisy or inaccurate segment boundaries. It is limited to non-Wikipedia texts, i.e., the model performs well on Wikipedia, but its effectiveness on other domains (e.g., spoken dialogue, legal documents) is unclear.
Moreover, ref. [
6] introduced a deep neural network model, SECTOR, a supervised topic segmentation and classification model using Bidirectional LSTM with topic embeddings trained on Wikipedia headings. It integrates Bloom filter encoding and softmax classification to improve segmentation accuracy and topic prediction for structured documents. To support this task, the authors introduced WikiSection, a large-scale dataset containing 242k labeled English and German sections covering two domains: diseases and cities. In 2020, ref. [
10] proposed CATS (Coherence-Aware Text Segmentation), a supervised Transformer-based text segmentation model incorporating simple and explicit coherence modeling. It employs two hierarchically connected Transformer networks to capture token-level and sentence-level information and predict segmentation boundaries while simultaneously learning to differentiate coherent vs. incoherent sentence sequences. CATS’ main learning objective is a binary sentence-level segmentation prediction.
Also, in 2020, ref. [
15] provided Segment Pooling LSTM (S-LSTM) that jointly predicts segment boundaries and labels segments using a Bidirectional LSTM (BiLSTM) with pooling and alignment techniques. The model improves segmentation accuracy by aligning predicted and ground truth segments, allowing it to recover from segmentation errors. Ref. [
13] presented their supervised topic segmentation model in 2020 through the addition of a coherence-related auxiliary task and restricted self-attention to a hierarchical attention-based BiLSTM. The model achieves better results through these modifications which enable it to concentrate on local information and maintain coherence between consecutive sentences. Later, ref. [
1] proposed a supervised segmentation model that formulates structural text segmentation as a topical change detection task using pre-trained transformer networks such as RoBERTa and Sentence-RoBERTa. The model performs a series of binary classifications to determine if consecutive paragraphs belong to the same topic, allowing for efficient fine-tuning of task-specific legal data.
Moreover, ref. [
32] introduced a supervised text segmentation model, HITS (Hierarchical Transformer-Based Model), that utilizes pre-trained RoBERTa as the lower transformer and a sentence-level upper transformer. It enhances domain transferability by incorporating adapter-based fine-tuning, which prevents overfitting to the training domain while retaining the general-purpose linguistic knowledge learned by RoBERTa. The model achieves State-of-the-Art results on Wikipedia-based segmentation and improves transfer performance to educational texts using the newly introduced K12SEG dataset. Ref. [
16] proposed a supervised text chunking model, Transformer
2, which uses a two-level architecture combining pre-trained transformer-based sentence encoders with an upper-level transformer segmentation model. At the bottom level, it integrates sentence embeddings derived from single-sentence tasks (e.g., masked language modeling) and pairwise-sentence tasks (e.g., next sentence prediction). At the same time, the upper-level model is trained with a multi-task loss to predict segmentation boundaries and topic labels simultaneously.
In addition, in 2021, ref. [
3] introduced a supervised model for sentence-level text segmentation that leverages Distilbert as a sentence encoder. The model combines a dense layer, a Bi-LSTM, and an attention mechanism to capture contextual dependencies and predict segment boundaries. To address the class imbalance problem typical in segmentation tasks, the authors propose a data augmentation technique that segments text into smaller, balanced training samples. This architecture achieves State-of-the-Art performance across three domains: clinical, fiction, and Wikipedia texts. In 2024, ref. [
33] provided a supervised model that segments documents by predicting paragraph-level topic boundaries. It introduces a core segmentation task (Paragraph Topic Prediction) alongside two auxiliary tasks: the Paragraph Similarity Model, which models semantic similarity using graph-based contrastive learning, and the Paragraph Structure Model, which models sequential order using shuffled paragraph arrangements. The model uses pre-trained BERT as an encoder and is evaluated on multiple datasets, including a newly created communication-specific dataset. It outperforms prior models by leveraging paragraph granularity instead of sentence-level segmentation, improving semantic coherence and reducing computational cost. Finally, ref. [
34] proposed a supervised model that enhances BERT-based paragraph segmentation by integrating segmentation distance into the model input and loss function. The segmentation distance, defined as the word count between the paragraph start and the potential breakpoint, is modeled using Kernel Density Estimation to derive a probability distribution. The model incorporates this statistical information through a cumulative distribution function to guide the segmentation decision and penalize long-distance splits, improving segmentation coherence. The comparison between the mentioned supervised text chunking methods is shown in
Table 2.
As shown in the mentioned text chunking methods, unsupervised text chunking methods did not evaluate their methods in different and diverse datasets, except Coherence [
11], which we use as a baseline to compare it with our chunking method, that needs more computations to prepare KeyBERT keywords extraction. Also, unsupervised text chunking methods did not achieve efficient results yet in terms of PK and WindowDiff metrics.
On the other hand, supervised text chunking methods are heavily based on utilizing large labeled datasets. The majority of the mentioned supervised methods exploit Wikipedia-based labeled data, which contradicts the concept of diversity of the data and reduces the generality of the text chunking methods. Also, some of the mentioned supervised text chunking methods did not utilize the standard evaluation metrics; PK and WindowDiff to assess their chunking methods.
Text chunking methods that are evaluated or trained on an Arabic dataset are absent from the supervised or unsupervised text chunking methods. Therefore, researchers should fill a significant gap related to the Arabic language in the text chunking task.
4. Methodology
We want to provide a semantic text method that fills the gap in utilizing diverse evaluation text datasets in unsupervised semantic text chunking methods. We also try to employ PLMs to improve the efficiency of unsupervised semantic text chunking methods in terms of evaluation metrics. Moreover, we want to bridge the gap in Arabic semantic text chunking at a higher lever, which has not been explored yet.
We enhance semantic text segmentation by proposing a method that segments texts at the sentence level. This method employs dynamic chunk count chunking and topic-agnostic chunking, i.e., it divides texts into non-fixed-count chunks without first determining the topics of the text. A text chunking problem is often defined as a sequence labeling task where a document is treated as a sequence of statements, with each statement assigned a binary label. A label of 1 indicates the beginning of a new chunk, while a label of 0 denotes that the statement remains within the current chunk.
We defined a semantic text chunking problem as follows: given a document D = {S1, S2, S3, …, Sn}, i.e., a document consists of n consecutive sentences Si, and we divide the document into semantically coherent segments, each of which consists of several consecutive sentences. The chunking task results in a sequence of labels for each sentence, i.e., {L1, L2, L3, …, Ln} where Li = 1 if a sentence is the beginning of a chunk and 0 otherwise. Therefore, the document D after segmenting will consist of a number of chunks; D = {C1, C2, C3, …, Cm} where Ck = {Si, Si+1, Si+2, …, Sj}.
The main idea that our chunking method depends on is to fine-tune a pre-trained BERT model on the semantic textual similarity (STS) task. Then, the fine-tuned model will be utilized in a hybrid chunking method that combines unsupervised techniques and PLM powers. The proposed hybrid chunking method is carried out through two main phases:
Fine-tune pre-trained BERT model on STS task.
Hybrid semantic text chunking which further consists of two steps: (1) unsupervised semantic text chunking, (2) utilize the fine-tuned BERT model to improve semantic text chunking.
The overall structure of the proposed hybrid semantic text chunking is shown in
Figure 3. The detailed description of the two phases is provided in subsequent subsections.
4.1. Fine-Tune Pre-Trained BERT on STS
The fine-tuning of pre-trained BERT on the STS task falls under inductive transfer learning (TL), where the source domain is BERT’s pre-training and the target domain is the STS task, which is similar but not identical. Moreover, the source tasks, which are masked language modeling and next-sentence prediction, are different from the target task, which is semantic similarity regression. Inductive TL is used when labeled data in the target domain is available, and performance needs to be improved by leveraging knowledge from a related but different source task. The source domain data for pre-training BERT includes large corpora like Wikipedia and BooksCorpus [
35]. Pre-training tasks involve Masked Language Modeling (MLM) and Next Sentence Prediction (NSP). In the target domain, the STS dataset is used to fine-tune BERT, predicting semantic similarity scores between sentence pairs as a regression task. The fine-tuning process went through the following steps:
Dataset selection and pre-processing: To utilize the power of pre-trained BERT for semantic text chunking, we fine-tuned it on the Semantic Textual Similarity Benchmark (STSb) [
36], one of the most varied and referenced datasets for the STS task, for English and Arabic experiments. STSb dataset contains sentence pairs extracted from image captions, user forums, and news headlines in more than 10 languages. It contains 8k+ pairs, each containing two sentences and a corresponding similarity score (1–5) assigned to each text pair as the result of a human annotation process. We consider a pair of sentences similar if their similarity score is greater than or equal to 2.5 and dissimilar otherwise. In this case, there are 3422 similar pairs and 2327 dissimilar pairs in both English and Arabic versions of STSb, as shown in
Figure 4a.
Moreover, we applied the augmentation process to the STSb dataset for both English and Arabic versions with several methods to improve the robustness and generalization of the STSb dataset. These methods enhance training data diversity by generating semantically similar and dissimilar sentence pairs and introducing controlled variations. These augmentation methods include:
- –
Paraphrasing-based augmentation: To introduce natural linguistic variations while preserving sentence meaning, we used a pre-trained paraphrasing model based on T5 for both English and Arabic languages [
37]. In a given pair of sentences, one is paraphrased, and the other is kept as it is while retaining the original similarity score. This method ensures that models learn robust representations that generalize beyond syntactic variations.
- –
Synonym replacement augmentation: We applied a WordNet-based synonym replacement method for the English language to introduce lexical diversity further. Random words in a sentence were replaced with synonyms from the WordNet lexicon. By maintaining the original similarity scores, this method helps models develop a stronger understanding of lexical semantics. Also, we applied the same concept to the Arabic language with pre-trained FastText [
38] word embeddings.
- –
Negative sampling using random pairing: To improve the model’s ability to distinguish semantically unrelated sentence pairs, a negative sampling strategy was implemented: a sentence was randomly paired with a different sentence and then shuffled from the dataset. These mismatched sentence pairs were assigned a low similarity score (0.1). This augmentation method forces the model to learn better discrimination between truly related and unrelated text pairs.
After augmentation, the newly generated sentence pairs were merged with the original datasets. For English and Arabic versions, we obtained an augmented STSb dataset with 34K+ sentence pairs: 17k+ similar sentence pairs and 17K+ dissimilar pairs, as shown in
Figure 4b. By incorporating these augmentation methods, the datasets become more robust, ensuring better generalization of semantic similarity models when fine-tuned on augmented STS data.
Before training, entries of the STSb dataset are prepared by the following: (1) tokenization, where each sentence pair is tokenized using the BERT tokenizer, a crucial preprocessing component designed to convert raw text into token sequences compatible with BERT models. We utilized two standard versions of the BERT tokenizer, BERT-base-uncased and BERT-large-uncased, both of which process input in lowercase and remove case sensitivity to align with their respective model training data. The BERT-base-uncased tokenizer corresponds to a 12-layer BERT model with 110 million parameters. This provides a balance between performance and computational efficiency. In contrast, the BERT-large-uncased tokenizer relates to a 24-layer BERT model with 340 million parameters. It achieves better performance, but requires more computational resources. Both versions add special tokens such as [CLS] and [SEP], [CLS] at the beginning, and [SEP] between two sentences, generate input IDs and attention masks, and ensure consistent input formatting required for downstream tasks. (2) embedding representation, where we employ sentence-level embeddings by applying mean pooling over the token embeddings produced by BERT. (3) normalization of the similarity score, where the scores are scaled to the range 0–1 to align with the cosine similarity approach.
Model architecture: Siamese network architecture is effective for evaluating semantic similarity. BERT excels at capturing word contexts bidirectionally and achieves State-of-the-Art results in NLP tasks. Thus, we used a Siamese network architecture with a shared-weight BERT model for sentence embeddings. Therefore, we fine-tuned the Siamese BERT on STS. The core components of the architecture include, as shown in
Figure 5, (1) BERT encoder: two (Siamese) pre-trained BERT model, we evaluated on different pre-trained BERT [
4] variants; BERT-base which has 12 layers and the other is a 24 layers Bert-large, and AraBERT for Arabic language experiment [
39] with also two different versions; AraBERT-base and AraBERT-large, with a maximum sequence length in BERT and AraBERT of 128, or 256. (2) pooling layer: computes mean pooling of token embeddings to generate sentence embeddings. (3) cosine similarity computation: the similarity between sentence embeddings is computed via cosine similarity, producing a similarity score. This architecture ensures semantically similar sentence pairs have closer vector representations, making it effective for chunking tasks that rely on the semantics of the text.
In contrast to the used architecture, ref. [
40] proposed a Siamese network model to obtain textual semantic similarity. Their Siamese structure network is based on a Bi-LSTM model for extracting semantic features. Ref. [
22] constructed a Siamese network model to compute textual semantic similarity. Their Siamese exploits a BERT model and an attention mechanism to obtain more advanced semantic features.
Training strategy: In training, the loss function is a cosine similarity loss based on mean squared error (MSE) that is used to minimize the difference between actual and predicted similarity scores. Also, as inspired by experiments of others with semantic text chunking and our experiments, we used AdamW [
41] as an optimizer with a learning rate of 1 ×
or 2 ×
to ensure stable convergence. Moreover, we used a linear learning rate scheduler to prevent drastic learning rate changes. We used a batch size of 16 and an epoch of 5 for the training setup, and the hardware used to train is a GPU for efficient computation.
Evaluation metrics: To assess the effectiveness of the fine-tuned Siamese BERT on STS, we employed multiple evaluation metrics that quantify its ability to measure semantic similarity accurately. The metrics used in our evaluation include accuracy, precision, recall, F1-score, and Spearman correlation:
- –
Accuracy, which is a fundamental metric that quantifies the percentage of correctly classified out of all the instances
where: TP (True Positives) is the model correctly classifies similar sentence pairs as similar, TN (True Negatives) is the model correctly classifies dissimilar sentence pairs as dissimilar, FP (False Positives) is the model incorrectly classifies dissimilar sentence pairs as similar, and FN (False Negatives) is the model incorrectly classifies similar sentence pairs as dissimilar. Accuracy provides a general performance measure but may not be sufficient when class imbalances exist.
- –
Precision, which assesses the model’s ability to identify actual positive instances among all correctly predicted positives:
A higher precision value indicates that fewer dissimilar pairs are mistakenly classified as similar, which is crucial in tasks requiring high confidence in similarity detection, e.g., information retrieval, or question-answering systems.
- –
Recall, which quantifies the ability of the model to identify all actual positive instances correctly:
A High recall ensures that most similar sentence pairs are correctly captured, even if some incorrect positive classifications occur. This is particularly important for applications such as document clustering, where missing relevant groupings is more detrimental than including some irrelevant ones.
- –
F1-Score is the harmonic of precision and recall, providing a balanced evaluation:
It is beneficial when there is an imbalance between similar and dissimilar sentence pairs, as it ensures that neither precision nor recall is disproportionately emphasized.
- –
The Spearman rank correlation coefficient
, which is generally used to evaluate semantic textual similarity (STS), measures the alignment between model-predicted similarity scores and human-annotated ground truth. Spearman correlation assesses the monotonic relationship between two ranked variables, making it well-suited for STS tasks where human ratings are typically ordinal. By computing the rank-order correlation between predicted and reference similarity scores, Spearman
provides a robust, non-parametric measure of how well a model preserves the relative semantic similarity of sentence pairs. This allows for a more meaningful assessment of model performance, mainly when absolute values differ, but relative rankings remain consistent. We used Spearman’s rank correlation coefficient
to compare the used method of predicting semantic textual similarity with others mentioned in [
42].
During evaluation, the cosine similarity scores produced by the model are binarized to determine whether two sentences are similar or dissimilar. Based on prior STS literature, we chose 0.5 as the threshold to binarize similarity scores, where similarity scores ≥ 3 on a 1–5 scale indicate similar pairs (3 equals 0.6 after normalization). We obtained robust estimates of the model’s generalization performance by computing these metrics in five cross-validation folds.
Experimental results: The base and large versions of BERT fine-tuned on the augmented version of STSb have got better results in terms of our chosen evaluation metrics: accuracy, precision, recall, and F1 than the base and large versions of BERT fine-tuned on STSb without augmentation.
Table 3 shows the results of fine-tuning the base and large versions of BERT on the English STSb; base and augmented versions. The base and large BERT versions with 128 and 256 input lengths, fine-tuned on an augmented version of STSb, are enhanced by more than 10 points in terms of accuracy and F1. Moreover, we noticed that the results of the chosen evaluation metrics of the BERT base version with a 128-input length are better than the base version with an input length of 256. Also, the BERT large version had better results with an input length of 256 than 128.
For Arabic experiments, we fine-tuned BERT with its two versions, BERT base and BERT large versions, on Arabic STSb. Also, we fine-tuned AraBERT with two versions, the base version and the large version, on Arabic STSb; base and augmented versions.
Table 4 shows the results of fine-tuning different BERT versions on Arabic STSb. BERT base version fine-tuned on augmented Arabic STSb achieved better results than the same version fine-tuned on basic Arabic STSb, i.e., it improved by approximately 10 points in Accuracy and 6 points in F1. Generally, the BERT base version achieves better results than the BERT large version in Arabic STSb. Also, fine-tuning the AraBERT base and large models achieved better results in terms of evaluation metrics than fine-tuning BERT, and fine-tuning with an augmented version of Arabic STSb achieved better results than with basic STSb. Therefore, the best results are achieved when fine-tuning AraBERT with the augmented Arabic STSb dataset.
Moreover, we compared our method with some methods that have been used for semantic textual similarity mentioned in [
42] in terms of Spearman correlation, as shown in
Table 5. As shown, the Siamese BERT method for fine-tuning BERT on STS in English, as the best result among our experiments, outperformed the previous works mentioned in [
42] by approximately 13 points in terms of Spearman correlation. For the Arabic language, it also outperformed the mentioned methods by approximately 6 points.
4.2. Hybrid Chunker
After finalizing the first phase of the proposed semantic text chunking method, as shown in
Figure 3, we move to the second phase, hybrid chunking. The proposed hybrid chunking method mainly combines the power of unsupervised semantic chunking and transfer learning from PLMs. It primarily consists of two steps: (1) unsupervised semantic text chunking and (2) utilizing a fine-tuned BERT model on STS to improve unsupervised semantic chunking, as follows:
Unsupervised semantic text chunking: An unsupervised semantic chunking model is utilized to segment text into semantically coherent chunks inspired by the semantic chunking mentioned by Greg Kamradt [
43]. It is based on cosine similarity between sentence embeddings to define semantically coherent chunks. The chunking method divides textual input into sentences, and then each sentence in the input text is assigned a corresponding embedding, which enables semantic similarity calculations across consecutive sentences. We utilized and evaluated five different recently issued embeddings that have obtained efficent results and have been reported as contextual embeddings models in order to achieve best results: (1) OpenAI Embeddings [
44], (2) Sentence-BERT Embeddings [
45] which is a transformer-based approach that provides high-quality sentence embeddings, (3) Universal AnglE Embeddings [
46] that is developed by WhereIsAI and designed to produce high-quality sentence embeddings, (4) voyage-3 [
47] which is a State-of-the-Art embedding model released by Voyage AI, (5) Cohere Embeddings [
48] and (6) GATE-AraBert-v1, [
49] a general Arabic text embedding trained using sentence Transformers, specially for Arabic experiments.
To determine where to split the text, the chunking method computes the cosine similarity between adjacent sentence embeddings. Given two consecutive sentence embeddings, the cosine similarity is calculated as:
where
and
are the embeddings of two consecutive sentences. The cosine distance is then computed as the distance where
This distance metric measures how different two consecutive sentences are in terms of semantic meaning. If two sentences have a high cosine similarity (close to 1), their cosine distance will be low (close to 0), indicating that they belong to the same conceptual unit. On the contrary, if two sentences have a low cosine similarity (close to 0), their cosine distance will be high (close to 1), suggesting a significant semantic shift. Higher cosine distances indicate greater semantic gaps between adjacent sentences, making them potential points where the text can be split into separate chunks.
Then, the semantic chunking method follows a data-driven, unsupervised approach to identify natural segment boundaries. A data-driven thresholding approach is used to determine the optimal segmentation points. Instead of setting a fixed threshold, a percentile-based method is applied that dynamically selects boundaries based on the distribution of cosine distances within the text. After experimenting different values ranging from 85 to 98 and according to the resulting evaluation metrics, we chose the 92nd percentile of cosine distances functions as the threshold. The approach prevents excessive fragmentation by selecting only the most significant semantic shifts for splitting purposes. The data-driven thresholding method works across various texts to enable flexible segmentation instead of using a predetermined fixed value for cut-off. Leveraging the adaptive thresholding technique introduces meaningful breaks, leading to well-structured and semantically coherent text chunks. Once the threshold is established, the chunking process identifies chunk boundaries, which are sentences where cosine distance exceeds the threshold. Then, the text is divided into chunks based on these boundaries, ensuring each segment maintains semantic continuity.
Finally, we added a post-processing step, which aims to avoid existing of small chunks, i.e., chunks with just one sentence. Therefore, single-sentence chunks are merged with the previous chunk to prevent fragmentation. Therefore, this unsupervised semantic chunking model segments textual input based on natural semantic boundaries, making it suitable for various information retrieval and text processing applications.
Utilize fine-tuned pre-trained BERT model on STS task: The assumption here is that some sentences may have been chosen as a cut-off point in the previous step, but they are still in a similar context, i.e., the whole chunk is about the similar topic, but the chosen sentences to cut off seemed to be about different topics. Therefore, in this step, the fine-tuned BERT model is used to predict the similarity score between each successive semantic chunk produced in the first step to further improve the performance of unsupervised semantic text chunking. The similarity label is computed as 1 in the case of similar chunks where the similarity score between these adjacent chunks is more than the specific threshold and 0 in the case of non-similar chunks where the similarity score between these adjacent chunks is less than the specific threshold. The threshold is chosen as 0.5, interpreted as sentences with a similarity score above 2.5 are considered similar. Then, according to the similarity labels already computed, if the similarity label is one between two successive chunks, they will be merged as one chunk. If the similarity label is 0, the chunks will not be merged. Finally, according to the merged chunks, the sentences in the texts are labeled with 1 and 0; 1 if a sentence begins a chunk and zero if it is inside a chunk. Therefore, the result of chunking is an original text segmented into chunks, and a series of labels, ones, and zeros, indicates whether each sentence is the beginning of a chunk or inside it. An example of chunking a text using the hybrid chunking through its two steps is shown in
Appendix A.
5. Experimental Setup
We conducted several experiments to ensure the robustness of the proposed hybrid text chunking method. This section gives a detailed description of these experiments, including the datasets used, evaluation metrics, experimental design, and baselines that our method compares with.
5.1. Datasets
Although text chunking as a task dates back to 1994, most existing text segmentation datasets are small and have limited scope in English [
1]. Until 2018, all existing datasets for text chunking were small in size and mainly used to evaluate text chunking algorithms’ performance [
9]. Later, some datasets with different sizes and details were published. However, datasets still focus on the English language. Little is published in other languages, such as German in the Wikisection dataset created by [
6], the Italian dataset created by [
7], Chinese datasets evaluated by [
13,
33] and French such as dataset evaluated in [
30]. To the best of our knowledge, no Arabic dataset has been created, mainly for semantic text chunking at the same level we are working on.
In our English experiments, to deal with diversity in datasets we chose the following five diverse English datasets, each offers distinct textual structures and challenges, for evaluating our semantic text chunking method: Wiki50 [
9], Choi [
19], Manifesto [
20], Clinical [
27] and Fiction [
50].
To evaluate our semantic text chunking method for Arabic, we created an Arabic dataset AraWiki50, and AraWiki50k, inspired by [
9]. They created Wiki727k and Wiki50 as two datasets for text chunking in English; Wiki727k has approximately 700k files from Wikipedia that are divided into chunks automatically as Wikipedia files divided into sections. Wiki727k is used mainly to train supervised text chunking methods, while Wiki50 is used as an evaluation dataset to evaluate and compare different text chunking methods.
Table 6 shows the statistics of the above datasets in terms of the number of documents, number of chunks, number of sentences, and average chunk lengths.
Wiki50: Consists of 50 Wikipedia articles on different topics, ensuring a variety in the textual structure. The articles have been manually annotated with coherent topic boundaries, making them ideal for assessing the effectiveness of text chunking methods. Human annotators manually segment article into semantically coherent sections.
Choi: Is a widely used benchmark corpus for evaluating text chunking methods. It is a synthetic dataset constructed by concatenating randomly selected passages from the Brown corpus, thus it is an important resource for evaluating text chunking methods. It has 920 documents, each of which is 10 concatenated paragraphs from the Brown corpus [
51]. The documents in the dataset are categorized based on segment length variability: 400 documents with segment lengths varying between 3 and 11 sentences, and 100 documents for each of the following segment-length categories: 3–5 sentences per segment, 6–8 sentences per segment and 9–11 sentences per segment. Each document simulates the structural flow of real-world text, making it a controlled and challenging dataset for segmentation models.
Manifesto: Is a real-world corpus designed to evaluate text chunking models by testing their effectiveness on political discourse. Unlike synthetic datasets like Choi, the Manifesto dataset consists of expert-annotated political texts, ensuring coherent and meaningful segmentation. The dataset comprises political documents that domain experts have carefully segmented into seven distinct topics: economy and welfare, foreign affairs, political system, social issues, security and defense, cultural and national identity and public infrastructure. It is curated by [
20], providing a high-quality benchmark for evaluating coherence-driven text chunking models. Its structured nature allows researchers to validate segmentation algorithms on real-world political documents, analyze the semantic coherence of chunking methods across different domains, and compare unsupervised and supervised segmentation approaches using human-defined topic boundaries. Compared to Choi’s synthetic dataset, the Manifesto dataset offers: (1) more realistic topic transitions, as the texts originate from political documents rather than artificially concatenated segments. (2) expert-defined boundaries, and (3) ensuring segmentation reflects real-world topic shifts rather than abrupt textual breaks.
Clinical: Is a medical text segmentation benchmark consisting of 227 chapters extracted from a medical textbook. Each chapter is expertly segmented into sections, with 1136 section boundaries explicitly defined by the author. The dataset stands out from synthetic datasets because it contains genuine text structures that occur naturally, which makes it helpful in testing semantic text chunking models in medical contexts. This dataset is highly relevant for biomedical NLP research, as it enables developing and evaluating text segmentation models that can accurately detect natural topic transitions in clinical and medical literature. The structured segmentation allows a quantitative assessment of how well a model preserves semantic coherence within specialized content.
Fiction: Project Gutenberg [
52] provides 85 fiction books which form the basis of this dataset. The segmentation boundaries in this dataset are defined by chapter breaks which makes it an important benchmark for testing text segmentation models in narrative-based texts. Unlike technical or structured documents, Fiction presents unique segmentation challenges, as chapter breaks may not always correspond to Abrupt changes in the text but instead serve narrative or stylistic purposes. This dataset introduces additional diversity in text segmentation research, requiring models to account for storytelling structures and narrative flow. Evaluating text chunking methods on the Fiction dataset allows for assessing their performance in longer-form narratives, which is helpful for applications such as automated summarization, content structuring, and discourse analysis.
AraWiki50k and AraWiki50: Inspired by Wiki727k constructed by [
9], we created AraWiki50k as a core resource to support researchers in the Arabic language, specifically for advancing supervised learning in semantic text chunking, i.e., it will open the door for researchers in Arabic language to train and explore supervised semantic text chunking methods. And AraWiki50 is a light version of AraWiki50k that will be used to evaluate and compare different text chunking methods for Arabic. AraWiki50k is considered as a first Arabic dataset specifically constructed for semantic text chunking at a level of segmenting texts into semantically coherent chunks. It contains 50 k+ files, constructed similarly to the one used in creating the Wiki727k dataset.
The assumption behind constructing the dataset is that Wikipedia articles sections are normally divided into separate topics, i.e., each section is about a specific idea and its statements are semantically coherent. Therefore, to construct our dataset, we started with a collection of Arabic Wikipedia articles in a dataset in Kaggle [
53]. It is a dataset intended for NLP, each Wikipedia article is in a separate text file. We processed files by separating sections automatically with special tokens. Then, we removed small files to avoid small and unnecessary chunks. Also, we preprocessed the resulting files by normalizing writing of some Arabic letters, normalising some letters shape, removing diacritics, and removing non-Arabic characters.
AraWiki50 is, light version of AraWiki50k, fifty files are chosen randomly to use as an evaluation dataset across different semantic text chunking methods. Then, they were manually checked to ensure that they contained no empty chunk or one statement chunk.
5.2. Evaluation Metrics
To assess the effectiveness of text chunking models, we employed two probabilistic evaluation metrics that have been reliable in evaluating text segmentation methods for the past two decades [
3]. They measure how a model identifies segment boundaries. The evaluation metrics are Pk and WindowDiff (WD), which use a sliding window approach to compare predicted segmentations with ground truth annotations.
Pk metric: Introduced by [
54], evaluates the probability that two randomly chosen sentences, k sentences apart, are incorrectly classified as belonging to the same segment. It quantifies segmentation accuracy by comparing predicted boundaries with reference segmentations using a fixed sliding window of size k, typically set to half the average segment length in the gold standard. Mathematically, Pk is:
where
is an indicator function that equals one if the reference and predicted segments differ and zero otherwise. Lower Pk values indicate better segmentation performance, reflecting greater agreement between the predicted and actual segment boundaries. While Pk has been a standard metric in text segmentation for over two decades, it has limitations. One key issue is its leniency toward false positives, meaning it does not penalize excessive boundary predictions as firmly as necessary.
WindowDiff (WD) metric: To address the limitations of Pk, ref. [
55] introduced the WD metric. It operates similarly to Pk but penalizes false optimistic predictions more rigorously. Instead of simply checking whether two points in a document belong to the same segment, WD counts the number of segment boundaries within a fixed sliding window and compares it to the gold standard, i.e., WD moves a sliding window through the text and counts the number of times the hypothesized and actual segment boundaries are different within the window. Mathematically, WD is
where
represent the number of segment boundaries in the reference and hypothesis within a window of size k. A key advantage of WD over Pk is its penalization of over-segmentation—a common issue in text chunking models. WD scores are usually higher by comparison due to Pk’s leniency towards false positives [
3]. Higher WD scores indicate poorer performance, making it a stricter measure of segmentation quality.
Both metrics operate within a range of [0, 1], where lower values signify better segmentation quality. Pk is widely accepted but has limitations in handling false positives, making it less effective for models that over-segment text. WD stands out as a more powerful metric because it can penalize over-predicted boundaries, which makes it more appropriate for evaluating segmentation algorithms that may introduce too many splits. The window size k in both metrics is usually set to half the average segment length to ensure fairness in boundary evaluations.
5.3. Experimental Design
For our experiments, we treated the input texts of different chosen evaluation datasets as a sequence of sentences with a length of 32 or 64 statements. For English and Arabic experiments, we designed two different types of experiments: the first type of experiments was designed to evaluate an unsupervised semantic text chunking method, the first step in the proposed hybrid chunking method, across different embedding models. The second type of experiments assess the importance and effect of utilizing the fine-tuned BERT on STS in improving the unsupervised semantic text chunking, which is the second step of the proposed hybrid chunking. Moreover, we performed experiments that compare the performance of the proposed hybrid chunking with the chosen baselines.
For Arabic experiments, to determine the best performance provided for Arabic dataset, we adopted the zero-shot cross-lingual transfer learning, cross-lingual transfer learning and supervised learning. In zero-shot cross-lingual learning, we fine-tuned the pre-trained BERT model on STSb (English version) and then evaluated the proposed chunking method on the AraWiki50 dataset. In the cross-lingual transfer learning, we fine-tuned the pre-trained BERT model on STSb (Arabic version) and then evaluated the proposed chunking method on the AraWiki50 dataset. Finally, for supervised learning, we fine-tuned the pre-trained AraBERT model on STSb (Arabic version), then evaluated the proposed chunking method on the AraWiki50 dataset
5.4. Baselines
We compare the performance of our proposed hybrid chunking method against competitive baselines; first of all, the basic baseline chunking method that we compared our chunking method against is fixed-length baseline chunking. The fixed length baseline chunking defines a simple yet effective method for splitting a long text into chunks approximately the same length. We designed this chunking strategy to respect sentence boundaries, avoiding the common pitfall of fragmentation in the middle of a sentence, which could disrupt semantic coherence. In addition, we compared our results with the results obtained from Coherence [
11] as one of the newest published unsupervised chunking methods.
6. Results
As stated earlier in the experimental design, we did several types of experiments. We show results of these experiments in the following subsections.
6.1. Unsupervised Semantic Text Chunking Results
The first type of experiments aims to evaluate unsupervised semantic text chunking across different embedding models in the English and Arabic. Also, this experiment includes evaluating the fixed-length baseline chunking across different embedding models. For English, the results obtained for unsupervised semantic text chunking and fixed-length baseline chunking across different embedding models and using two different input sequence lengths, 32 and 64, are shown in
Table 7, and represented in
Figure 6 and
Figure 7. While for Arabic, the results obtained for unsupervised semantic text chunking and fixed-length baseline chunking across different embedding models and using two different input sequence lengths, 32 and 64, are shown in
Table 8 and represented in
Figure 8.
6.2. Utilizing the Fine-Tuned BERT on STS
As stated earlier, the second type of experiments assess the importance and effect of utilizing the fine-tuned BERT on STS in improving the unsupervised semantic text chunking, which is the second step of the proposed hybrid chunking. Since, as shown in the first type of experiments, the best results of unsupervised semantic text chunking are obtained with OpenAI embeddings, we evaluated the proposed hybrid chunking using OpenAI embeddings. The results obtained for the proposed hybrid chunking in English datasets are shown in
Table 9 and represented in
Figure 9 and
Figure 10.
In addition, as our assumption of the second step in the proposed hybrid chunking states that some sentences may have been predicted as a cut-off point in the previous step, but they are still in a similar context, we show that this assumption is valid by showing the confusion matrix of the unsupervised semantic text chunking (the first step in the proposed hybrid chunking) and confusion matrix of the hybrid chunking as whole.
Figure 11 and
Figure 12 show the confusion matrices for all five chosen English datasets and the AraWiki50 Arabic dataset. As seen in all datasets, the number of sentences that have accurate label 0 and predicted as 1 in unsupervised semantic text chunking (the first step in the hybrid chunking), which means sentences that are not cut-points but predicted as cut-points, is decreased in the hybrid chunking, by merging chunks which are similar. Although there is a decrease in the number of sentences that have been predicted correctly as cut-points (1 label) in the unsupervised semantic text chunking, it is still less than those predicted mistakenly by 1 s, but they are actually 0 s.
6.3. Arabic Experiments
Regarding Arabic experiments and the proposed hybrid chunking method, the results obtained from the earlier stated experiments, zero-shot cross-lingual, cross-lingual transfer learning, and supervised learning are shown in
Table 10 and represented in
Figure 13 6.4. Baseline Results
Finally, we show a comparison between fixed-length baseline chunking, the proposed hybrid chunking and chosen already stated baseline in terms of PK and WindowDiff for Manifesto, Clinical and Fiction datasets, where results are taken as claimed from their original paper, as shown in
Table 11.
6.5. Ablation Study
To assess the effectiveness of our proposed hybrid chunking method, we conducted an ablation study isolating each core component of the proposed method. We evaluate each of the two main steps of the proposed hybrid chunking and compare them with the proposed hybrid method. The first step is unsupervised semantic text chunking, which has already been evaluated as the first type of our experiments. To assess the second step, which is utilizing the fine-tuned BERT on STS in semantic text chunking, we apply the fine-tuned BERT directly to semantically chunk text. The fine-tuned BERT is used on the sentence level to determine the cut points between sentences by predicting the similarity scores between successive sentences.
Figure 14 shows results comparing the unsupervised semantic text chunking, the fine-tuning BERT text chunking and the proposed hybrid chunking that combines two previous steps across all five English datasets and on the AraWiki50 dataset in both 32 and 64 sequence lengths for both PK and WindowDiff. The proposed hybrid chunking method outperforms both, achieving the best scores across all datasets and all evaluation metrics. This demonstrates that the hybrid method effectively combines unsupervised semantic text chunking and the fine-tuned BERT on STS.
7. Discussion
As shown in
Section 6, the unsupervised semantic chunking generally outperforms all datasets’ fixed-length baseline chunking. However, For English datasets, the best results among Wiki50, Choi, Manifesto and Clinical datasets are taken using OpenAI embeddings with an input sequence length of 64, except for the Choi dataset, where the best results are taken with an input sequence length of 32. For the Fiction dataset, the best results are taken with voyage-3 embeddings with an input length of 64. Also, voyage-3 embeddings provide comparable results with those provided using OpenAI embeddings for Wiki50, Manifesto, and Clinical datasets. The worst results among the datasets and embeddings are taken using SBERT and Cohere embeddings. In addition, the Clinical and Fiction datasets have worse results in general than those obtained by Wiki50, Choi and Manifesto datasets. This refers to the nature of the text in those two datasets, which, as stated earlier, the Fiction dataset consists of fiction books and the Clinical dataset consists of medical chapters of text. In this case, the pre-trained BERT models used in the chunking method should be fine-tuned to the same nature texts as fiction books and medical chapters. Alternatively, since Fiction and Clinical datasets are chapters from the books, it may be suitable to chunk them using paragraph-level chunking methods rather than sentence-level chunking methods, Also, as stated in the datasets’ statistics, the average chunk lengths in both Clinical and Fiction datasets are large compared with other datasets.
In addition for Arabic in the first type of experiments, the best results were obtained using OpenAI embeddings for Pk and WindowDiff, with an input length 32. Compared with the results we obtained from English Wiki50 and OpenAI embeddings, we achieved competitive results from AraWiki50 and OpenAI embeddings with a difference of approximately 1 point in Pk and 2 points in WindowDiff.
Regarding the results obtained from the second type of experiments, aiming to assess the effect of utilizing the fine-tuned BERT in improving unsupervised semantic chunking as a second step in the proposed hybrid chunking, the results are improved on all datasets except Manifesto. The Wiki50 dataset shows a 2.3 improvement in Pk with an input length of 32 and approximately 1 point improvement with a 64 input length. In the same dataset for WindowDiff, there is an improvement of approximately 3 points with an input length of 32 and an improvement of approximately 2 points with an 64 input length. For the Choi dataset, there is approximately an improvement of 0.5 in both Pk and WindowDiff in both 32 and 64 lengths. The clinical dataset improved better than in Wiki50 and Choi, i.e., it improved by approximately 21 points with an input length of 32 in Pk and approximately 16 points with an input length of 64. Moreover, for the same dataset and WindowDiff, we improved approximately 33 points with an input length of 32 and approximately 26 points with an input length of 64. Finally, the Fiction dataset improved by approximately 12 points in PK with an input length of 32 and by approximately 9 points with an input length of 64. Moreover, for WindowDiff, there is an improvement of approximately 16 points with an input length of 32 and 12 points with an input length of 64. We attributed the significant enhancements in PK and WindowDiff on the Fiction and Clinical datasets to the nature of texts in these datasets, which are books. When the hybrid chunking merges chunks, it achieves the level of sections in books; therefore, it produces semantically coherent chunks. Therefore, the hybrid chunking method generally improves over unsupervised semantic text chunking, emphasizing the importance of utilizing the fine-tuned pre-trained BERT model in semantic text chunking.
Regarding Arabic, we evaluated the proposed hybrid chunking method using different versions of BERT, according to different experiments mentioned: zero-shot cross-lingual by fine-tuning BERT on English STSb, then evaluate on AraWiki50, cross-lingual transfer learning by fine-tuning BERT on Arabic STSb, then evaluate on AraWiki50, and supervised learning by fine-tuning AraBERT on Arabic STSb, then evaluate on AraWiki50. The best result was obtained using supervised learning by fine-tuning AraBERT base version on Augmented Arabic STSb.
The last experiments aim to compare the proposed hybrid chunking method with chosen baselines; the hybrid chunking method achieved better results than fixed-length baseline chunking with an improvement of approximately 7 points in terms of Pk and WindowDiff in the Wiki50 dataset. Also, it improved 27 points in PK and 38 points in WindowDiff for the Clinical dataset. The Fiction dataset achieved 20 points improvements in PK and 39 points in WindowDiff. Moreover, the hybrid chunking method achieved competitive results with Coherence, which is a recently proposed unsupervised semantic text chunking method, but without extra computation, which they used to compute keywords map in their method.
Although our proposed hybrid chunking method demonstrates promising performance on diverse English datasets and Wikipedia-based Arabic dataset, its effectiveness on other text types remains untested. Our experiments for Arabic were limited primarily to Wikipedia articles, and thus, our findings might not directly translate to domains such as informal social media content, specialized technical documentation, or conversational texts. Additionally, while fine-tuning BERT significantly improves accuracy, the computational resources required for training large transformer models might pose practical challenges.
8. Conclusions
This paper presents a hybrid chunking method to segment texts into coherent chunks semantically. The proposed chunking method combines the effectiveness of the unsupervised semantic chunking method based on the differences in the cosine similarities between successive sentences and the powerful transfer learning of PLM, specifically fine-tuning different versions of pre-trained BERT and AraBERT on semantic textual similarity tasks. We utilize Siamese BERT architecture to fine-tune BERT on STS, and it achieves State-of-the-Art results in terms of the Spearman correlation metric in both English and Arabic. We evaluate the proposed hybrid chunking method on existing English datasets and create a new Arabic evaluation dataset. Through several experiments, we show that our proposed chunking method provides competitive results compared to a recently published unsupervised semantic chunking method. Also, we show the importance and effect of utilizing the fine-tuned pre-trained BERT on STS in improving the results of the unsupervised semantic text chunking in terms of evaluation metrics, PK and WindowDiff. Future work should explore extending our semantic chunking approach to diverse genres and formats, including conversational and informal Arabic texts, noisy and informal domains such as social media, and customer reviews to verify generalizability. Developing methods to reduce computational costs, through model compression or distillation techniques, could further improve practical usability. Also, future work should utilize the primary version of the created AraWiki50k dataset after enhancements to explore supervised learning approaches for Arabic and evaluate a State-of-the-Art supervised chunking method on AraWiki50. Finally, integrating our chunking method within downstream NLP applications such as automated summarization, information retrieval, or conversational agents could offer additional insights into its utility and effectiveness.







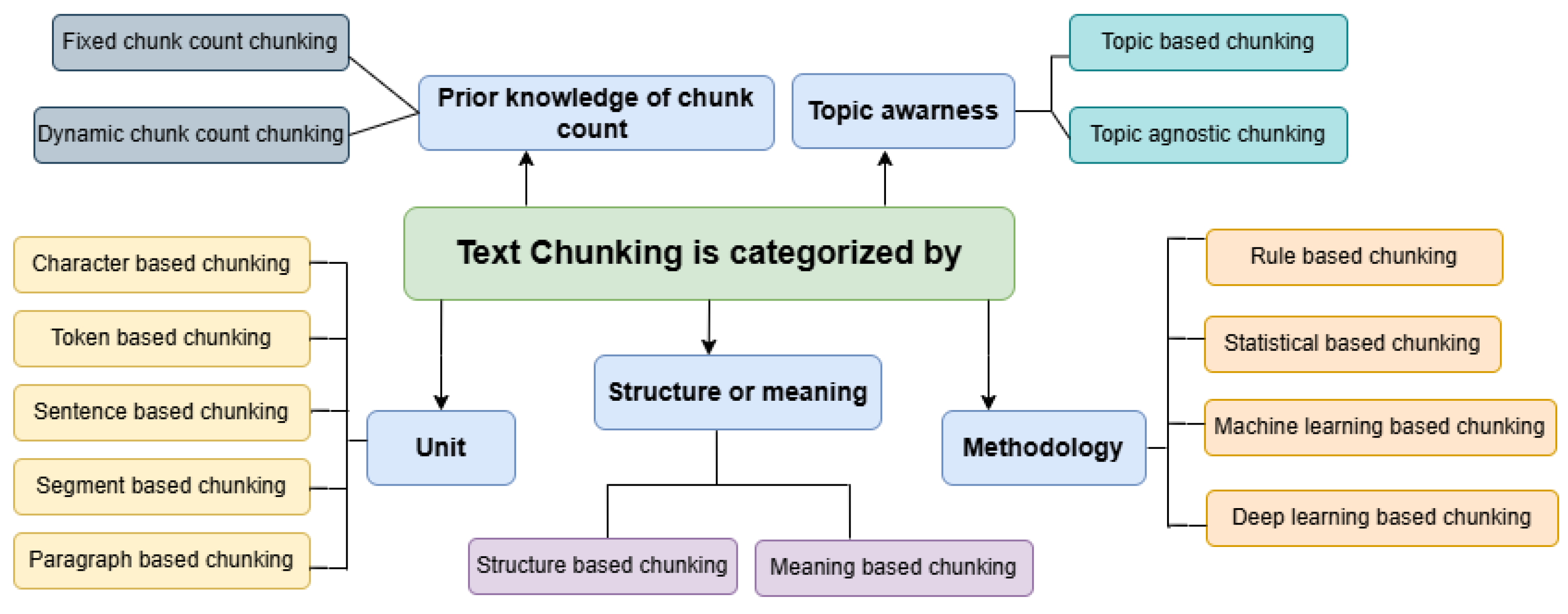
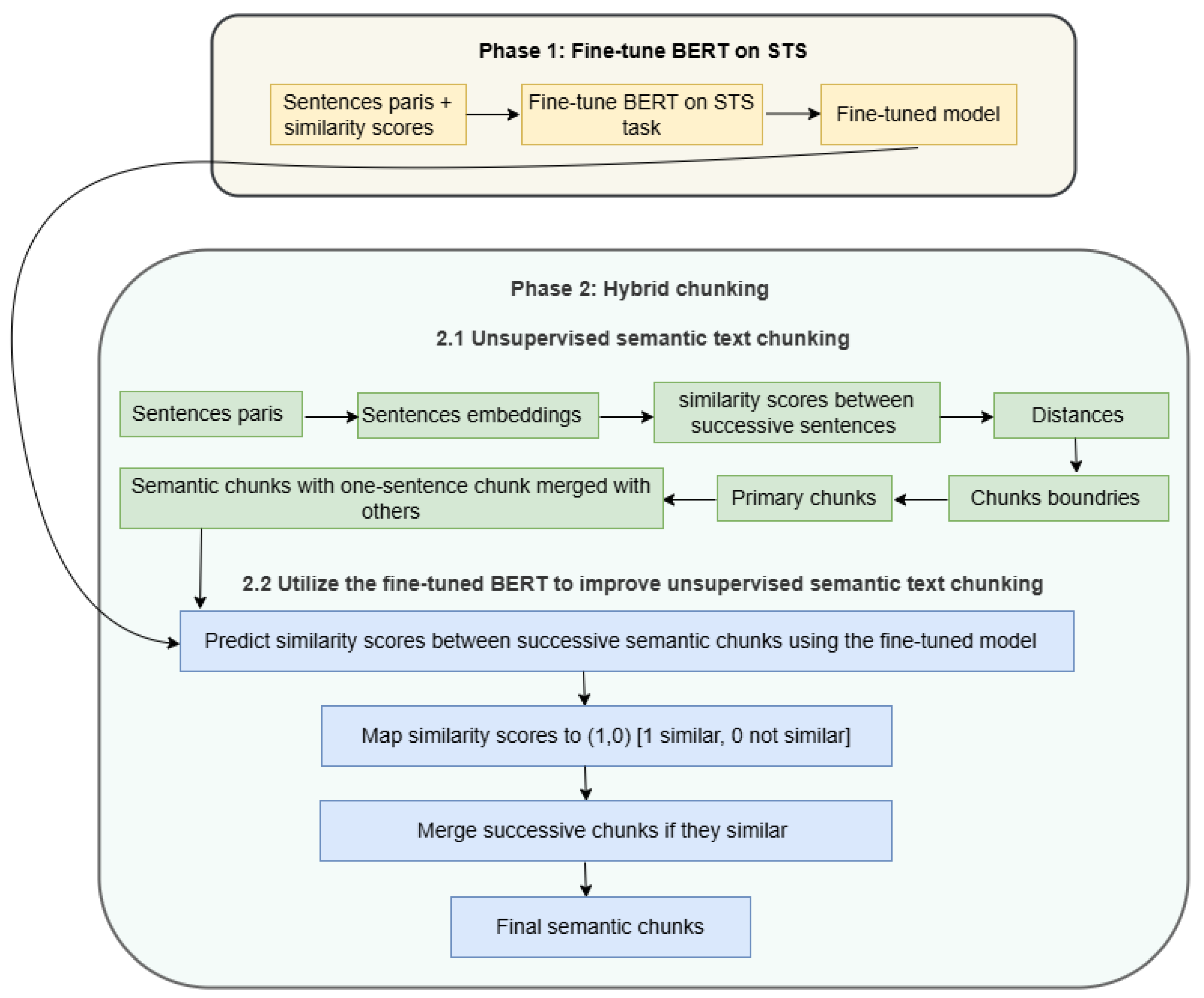
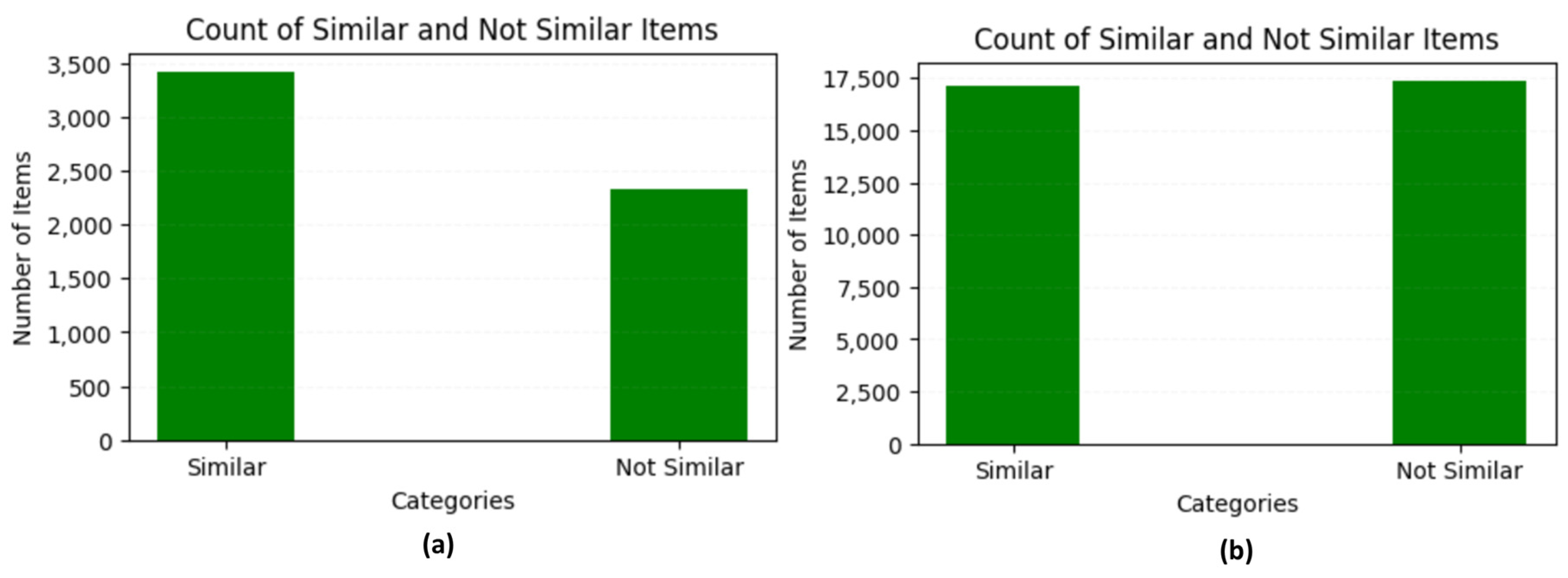
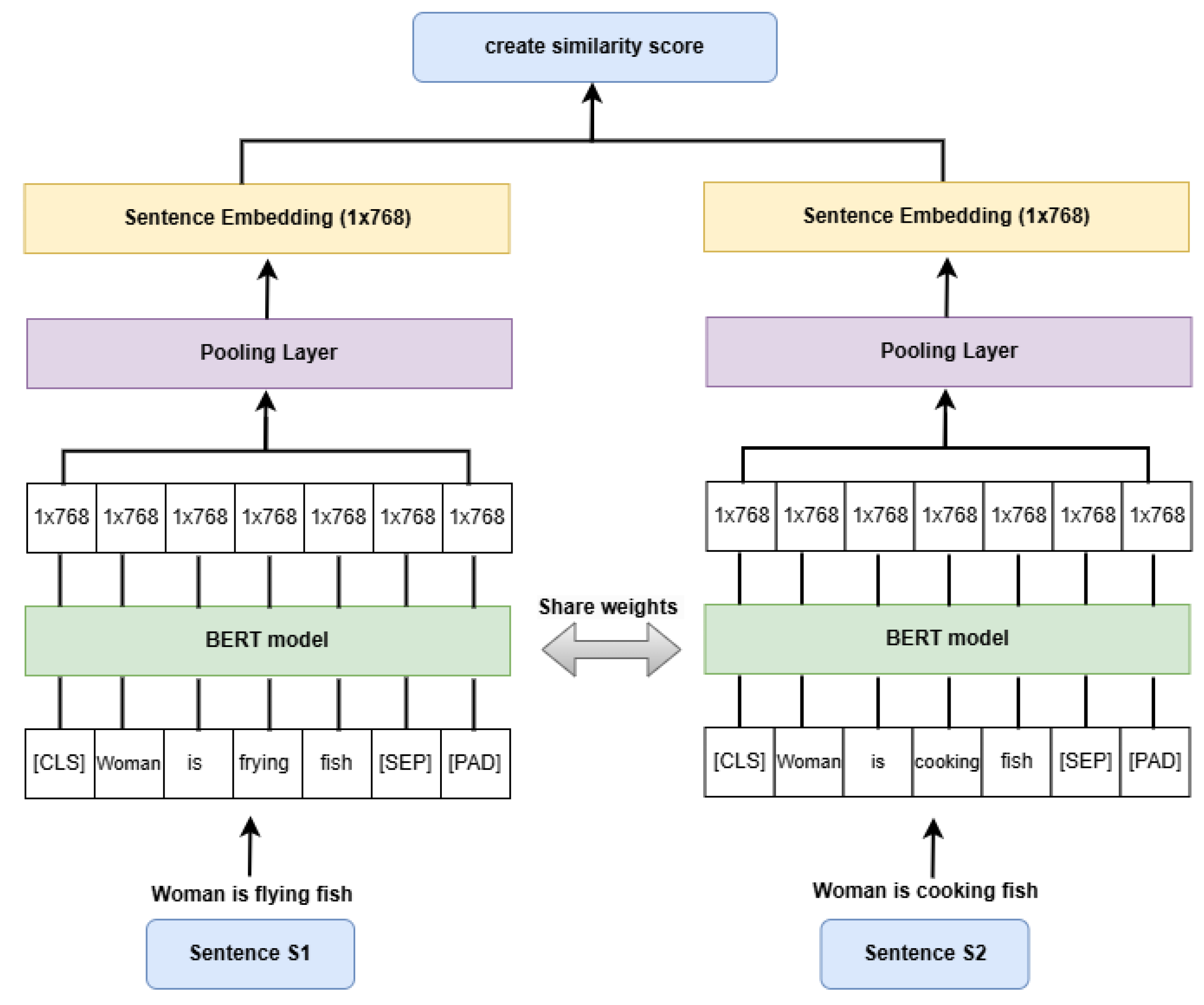
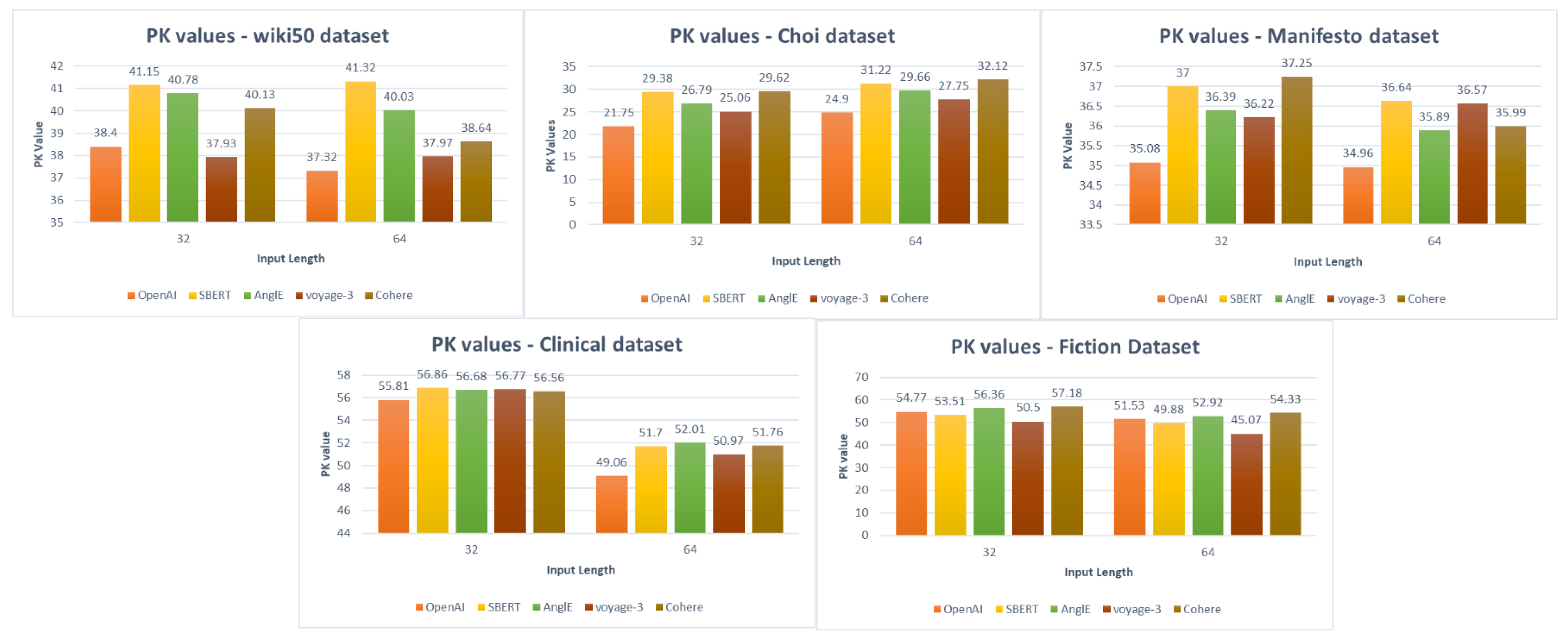
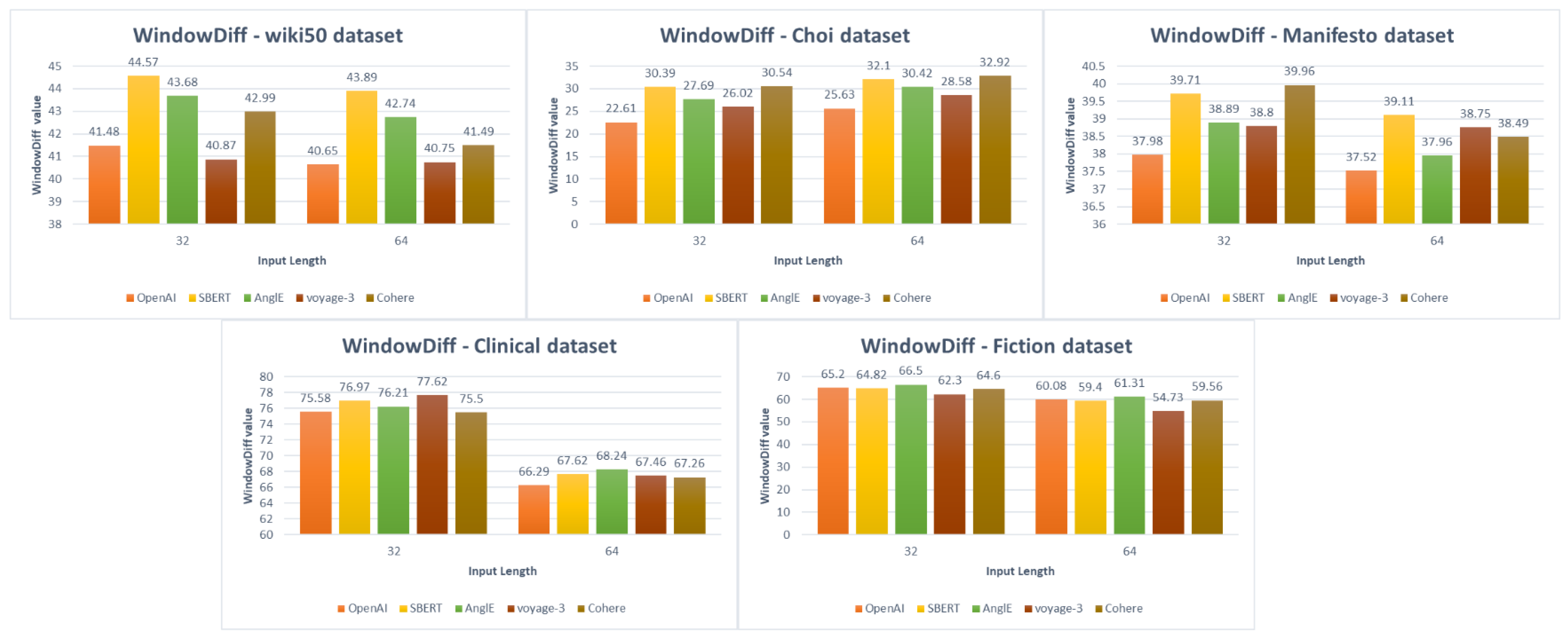
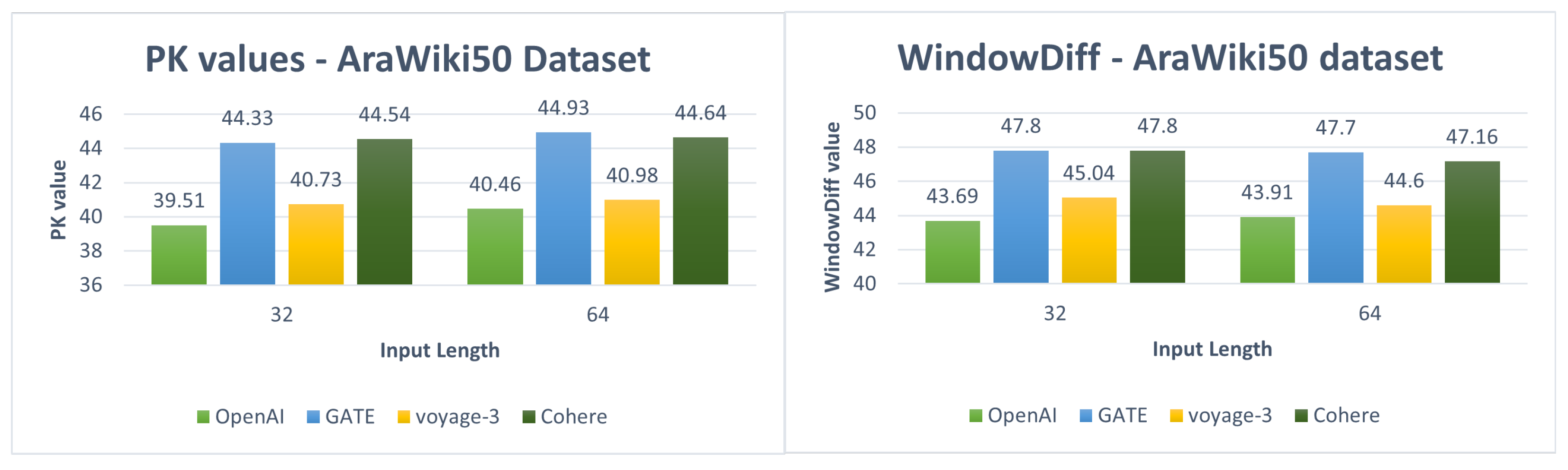
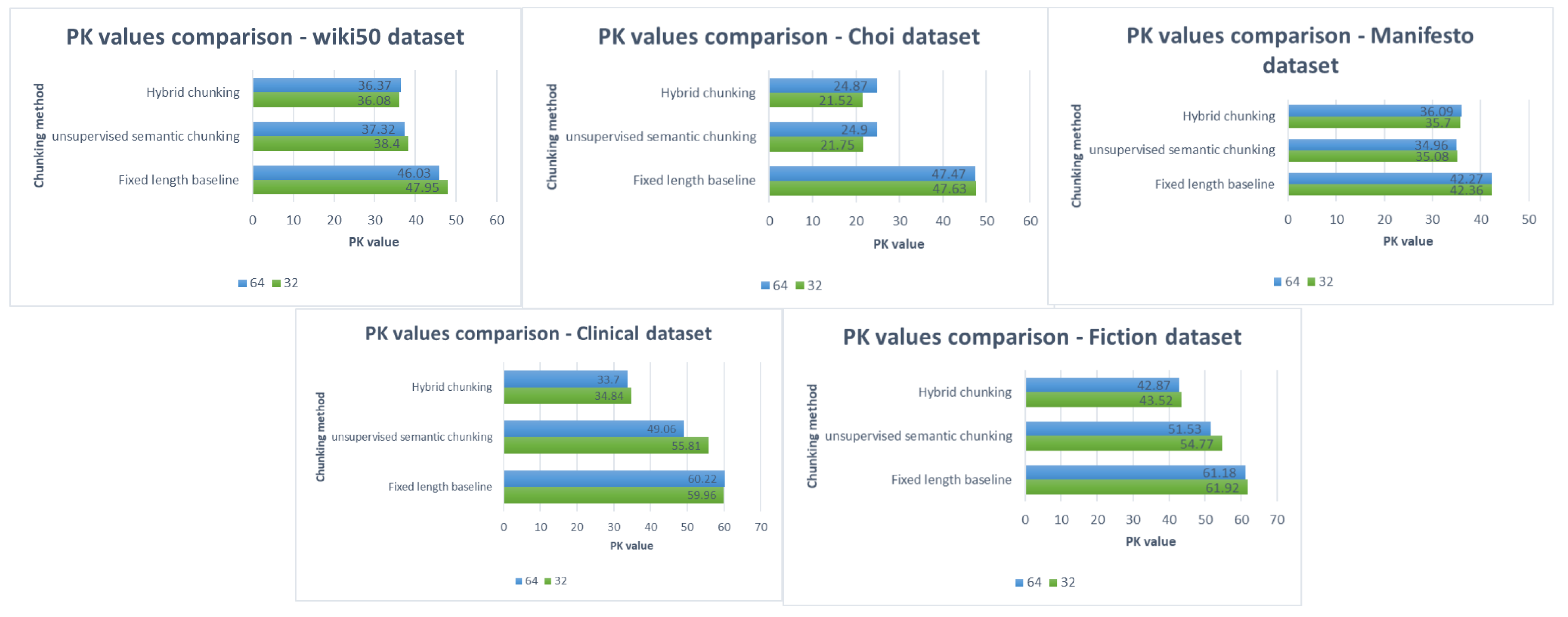
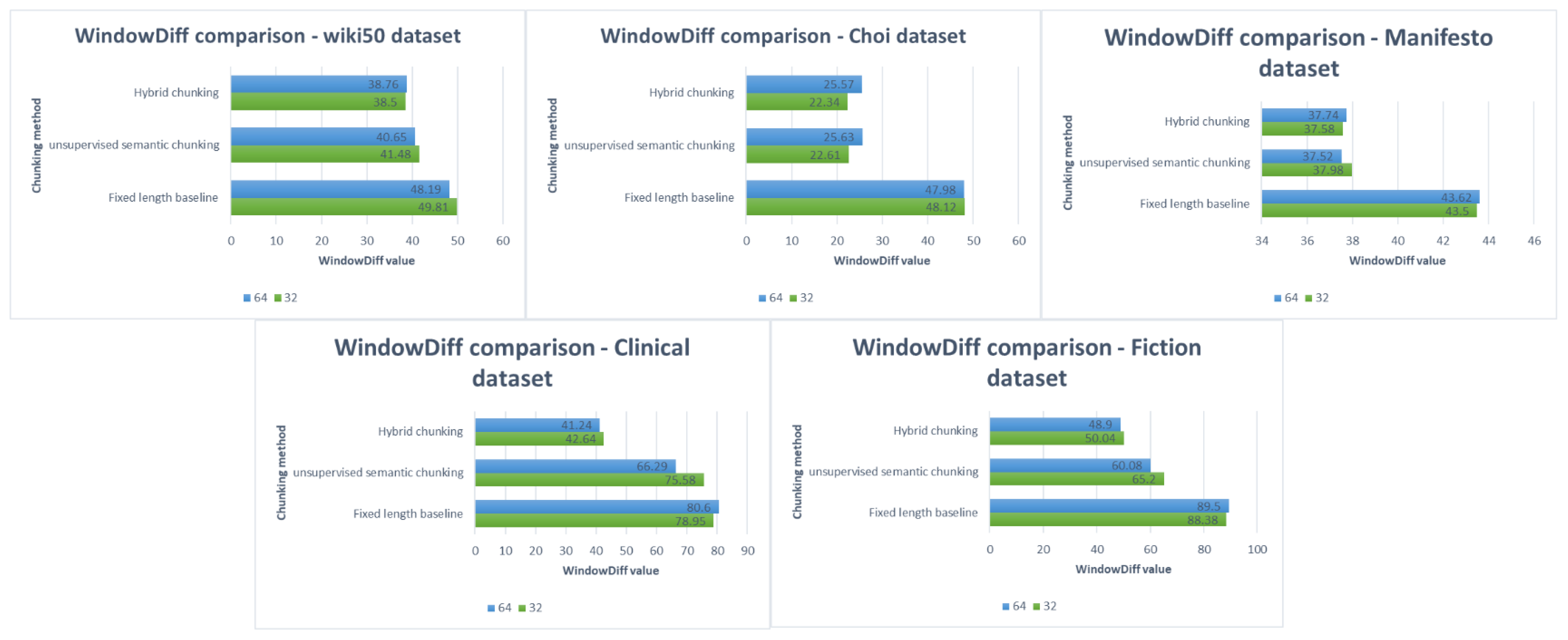
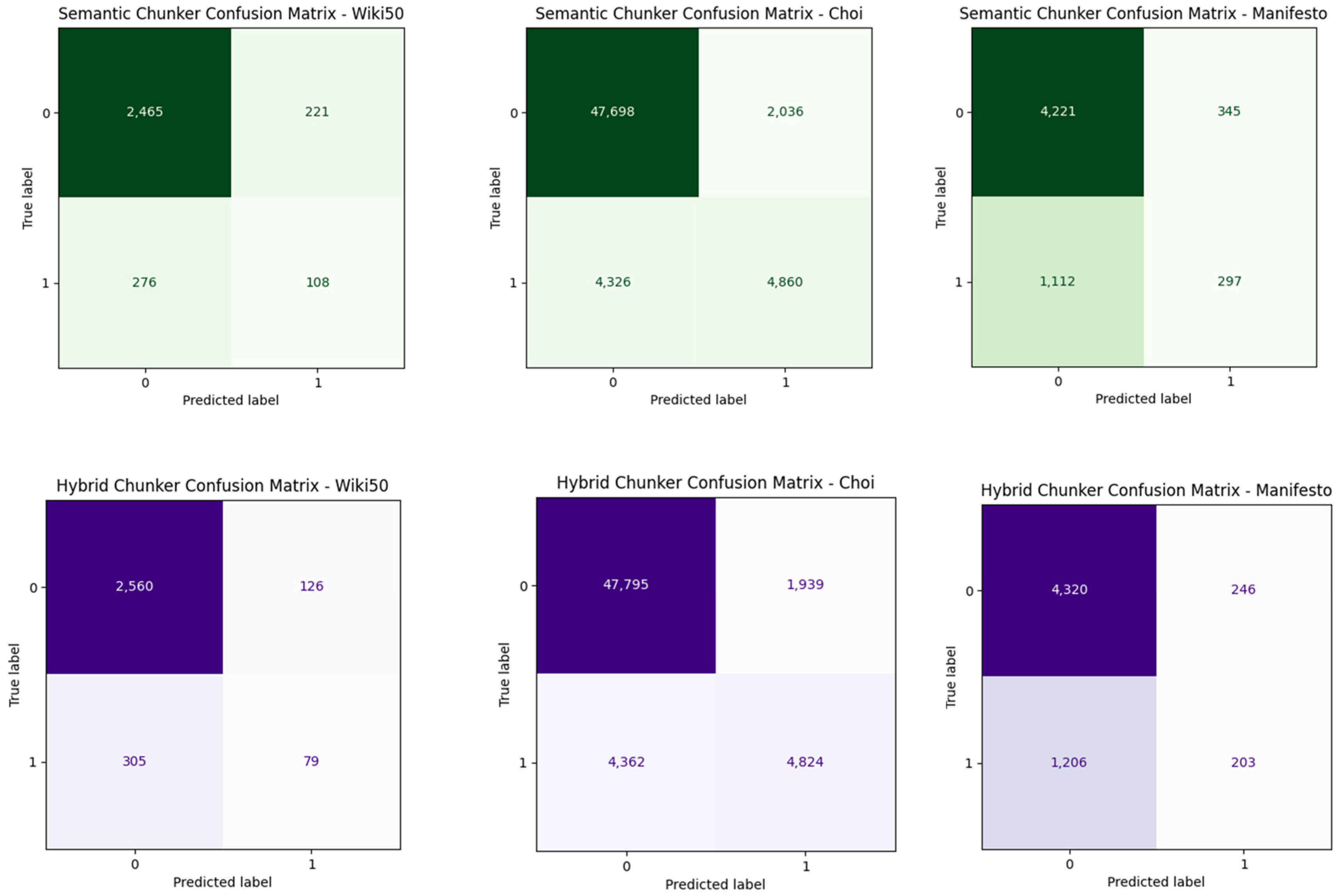
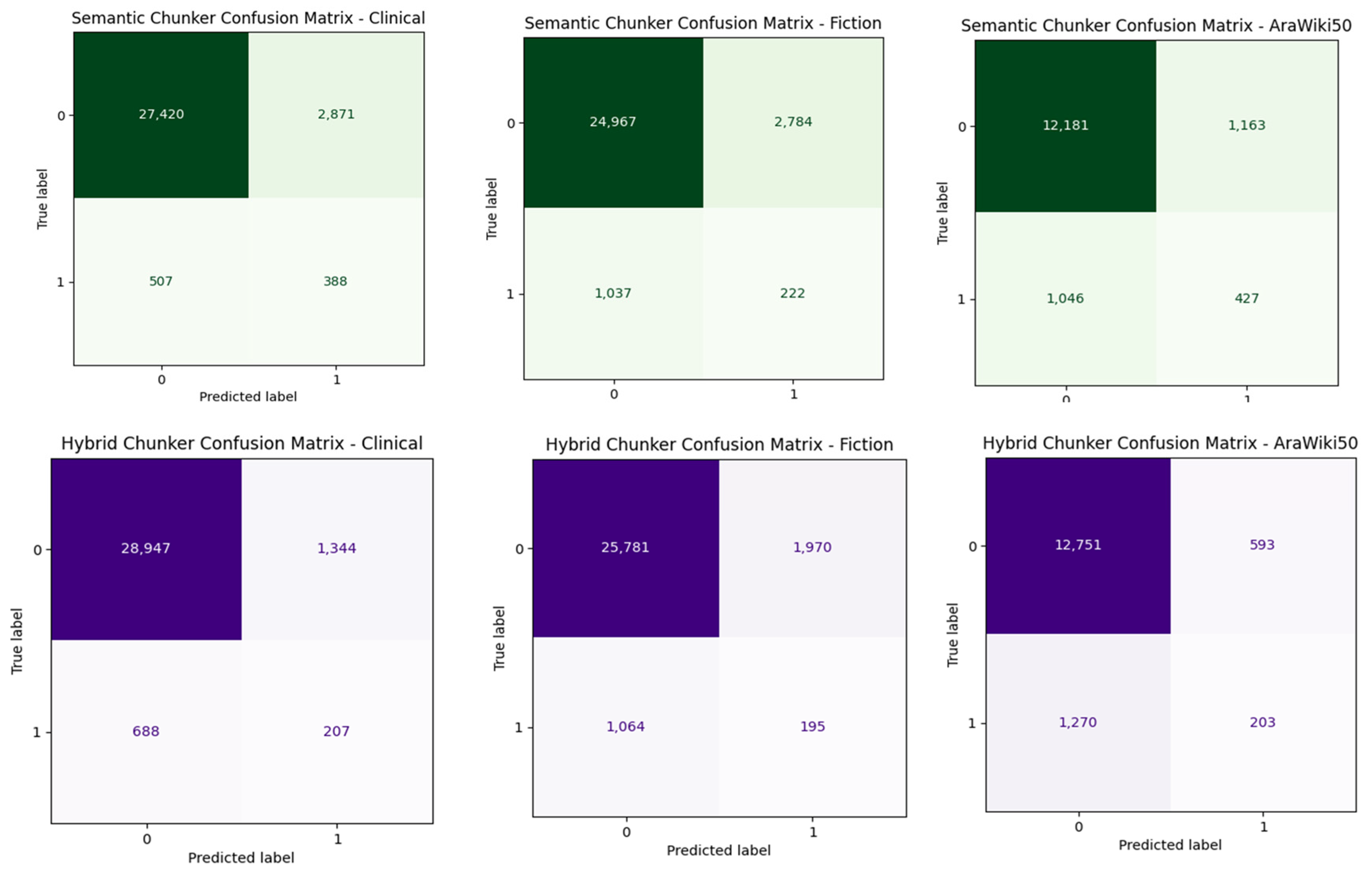
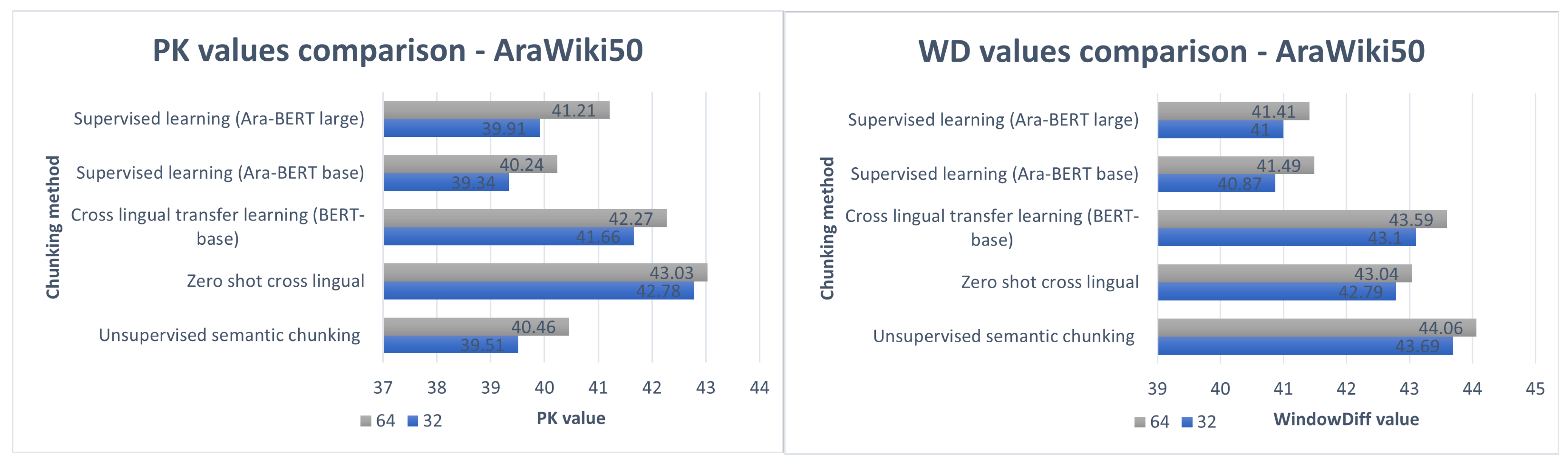
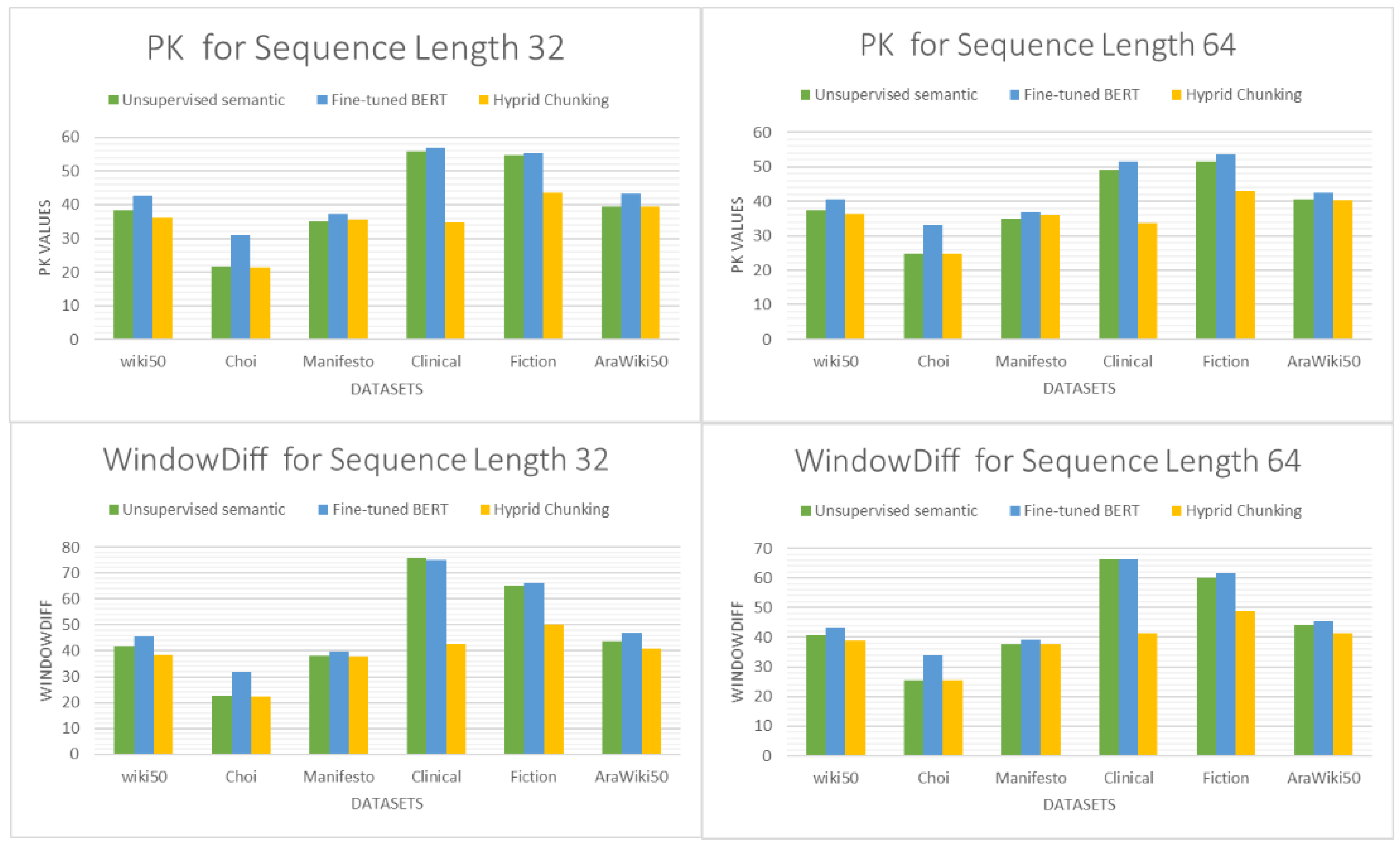

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}