
Stock Price Prediction in the Financial Market Using Machine Learning Models



Abstract
1. Introduction
- Providing a basic understanding of how the stock market works and how ML is being used to predict it.
- Evaluating which features are best suited to be used as inputs to stock market prediction models.
- Developing and applying various ML models for stock price prediction.
- Evaluating and comparing the performance of different models using a variety of metrics to identify which techniques and combination of techniques provide the best results in stock price prediction.
Literature Review
2. Materials and Methods
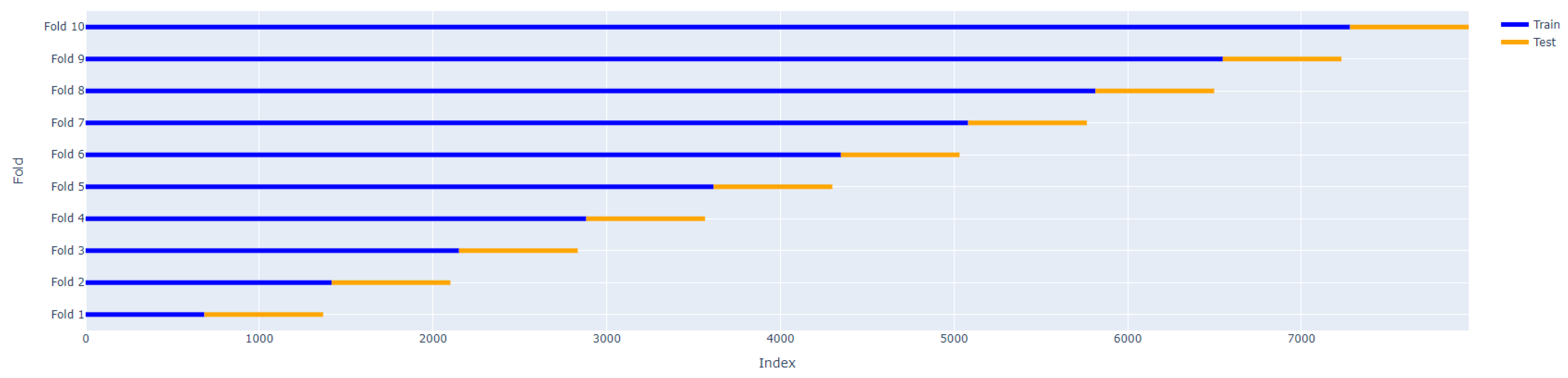
2.1. Dataset
2.2. Features
2.3. Performance Measures
2.4. Data Processing
2.4.1. Data Acquisition
2.4.2. Calculation of Technical Indicators
2.4.3. Normalization and Data Preparation
3. Prediction Models
3.1. LSTM Model
3.2. GRU Model
3.3. LSTM + GRU Model
3.4. CNN Model
3.5. RNN Model
3.6. XGBoost Model
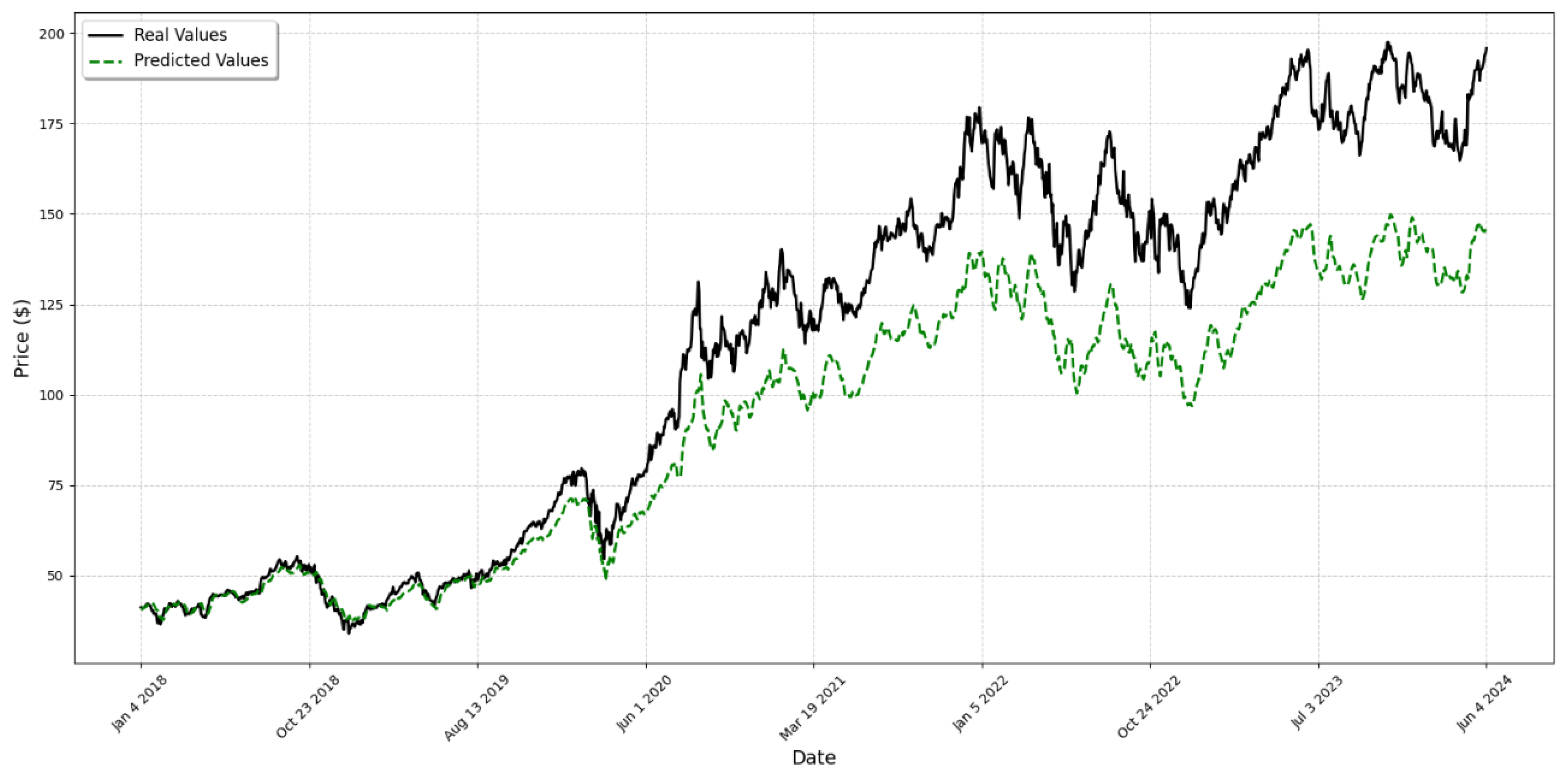
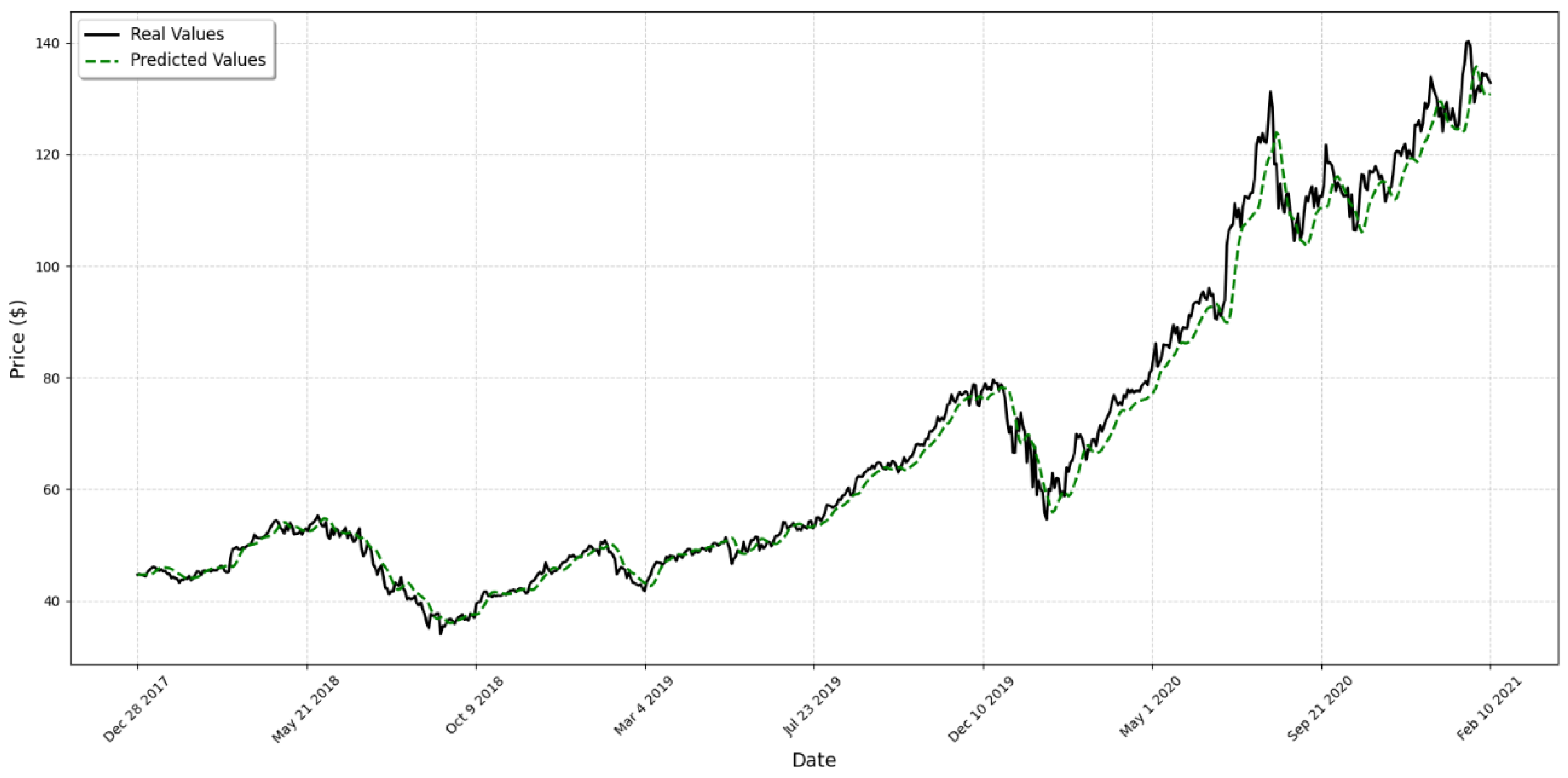
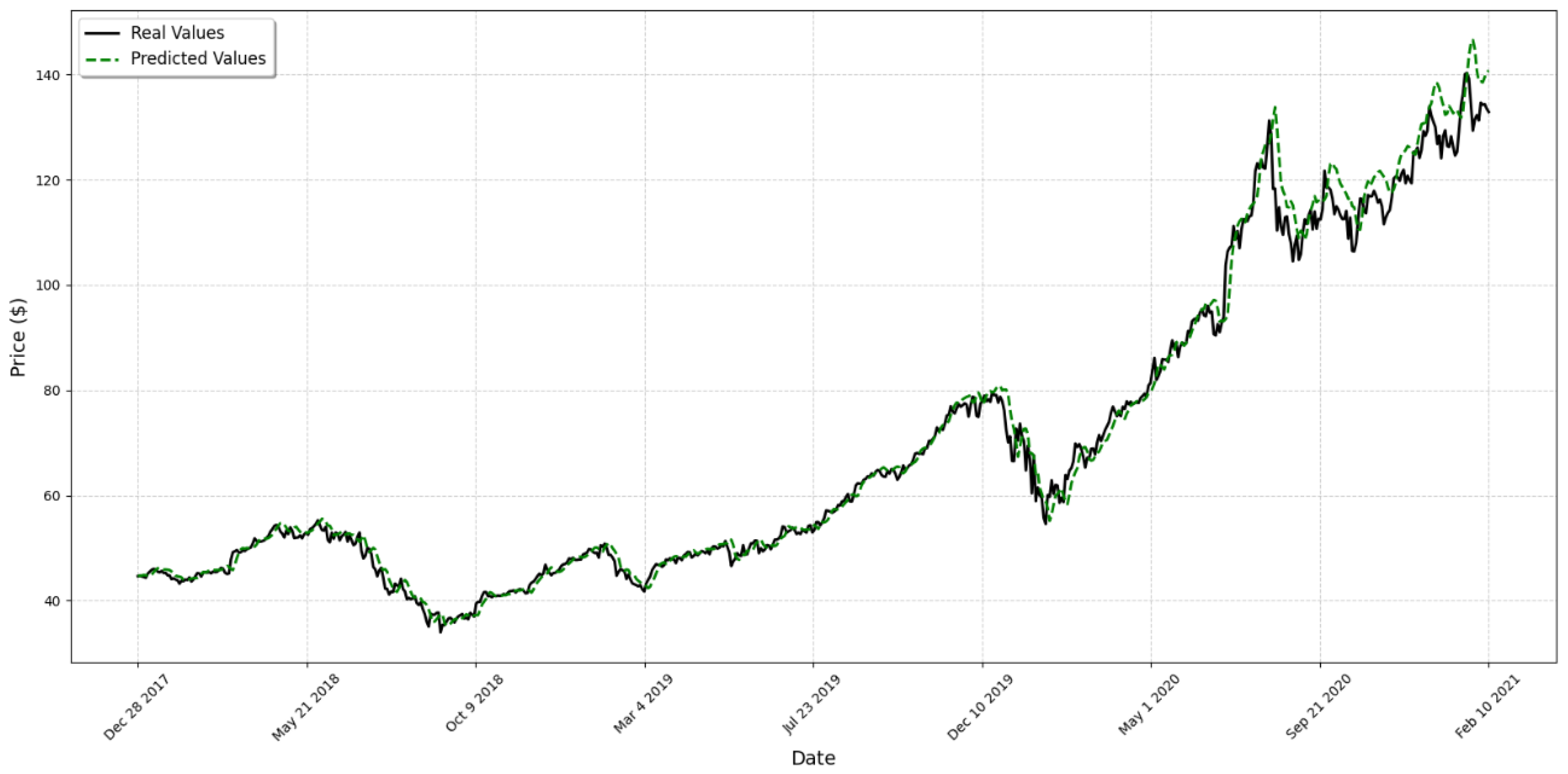
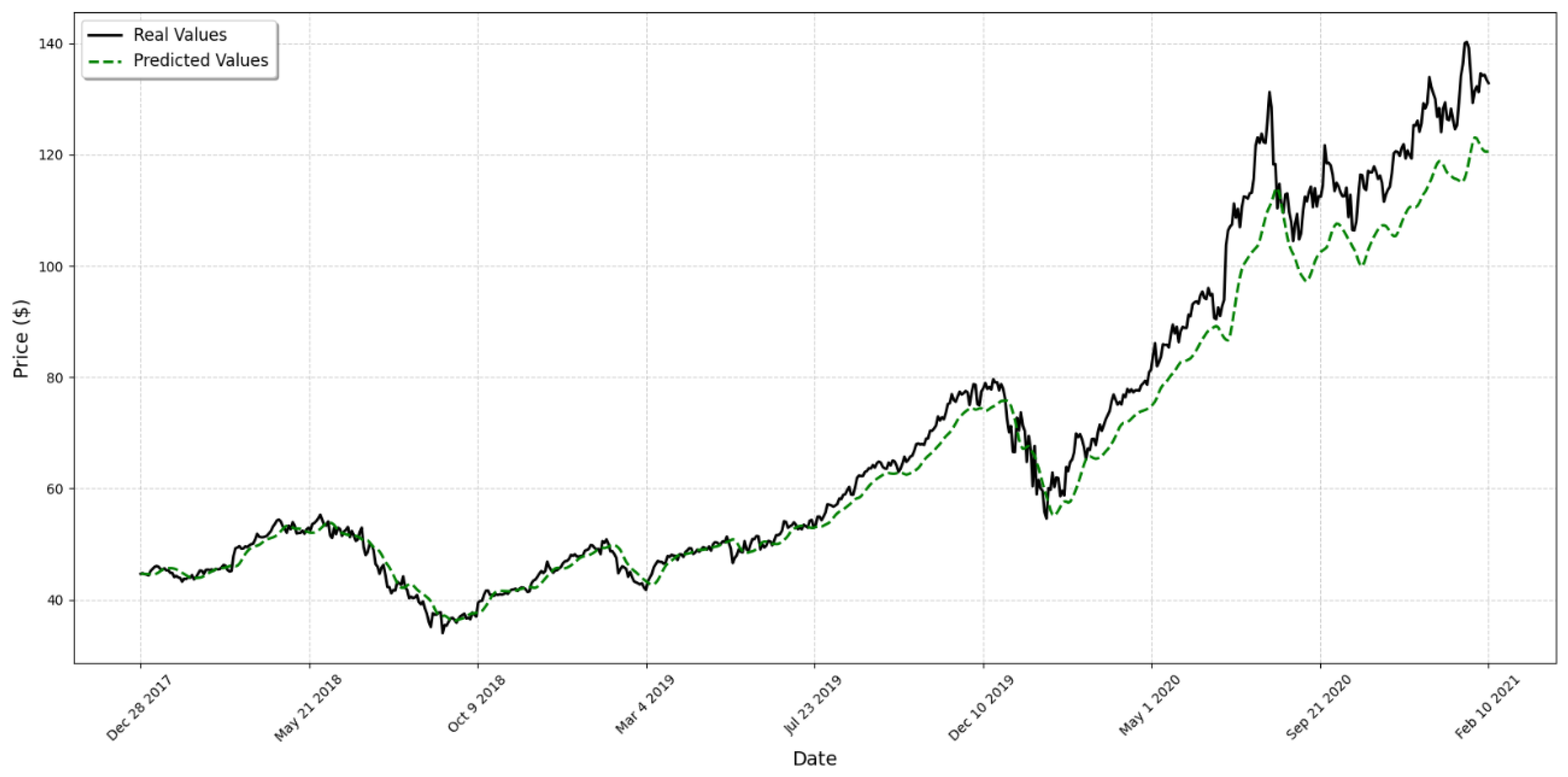
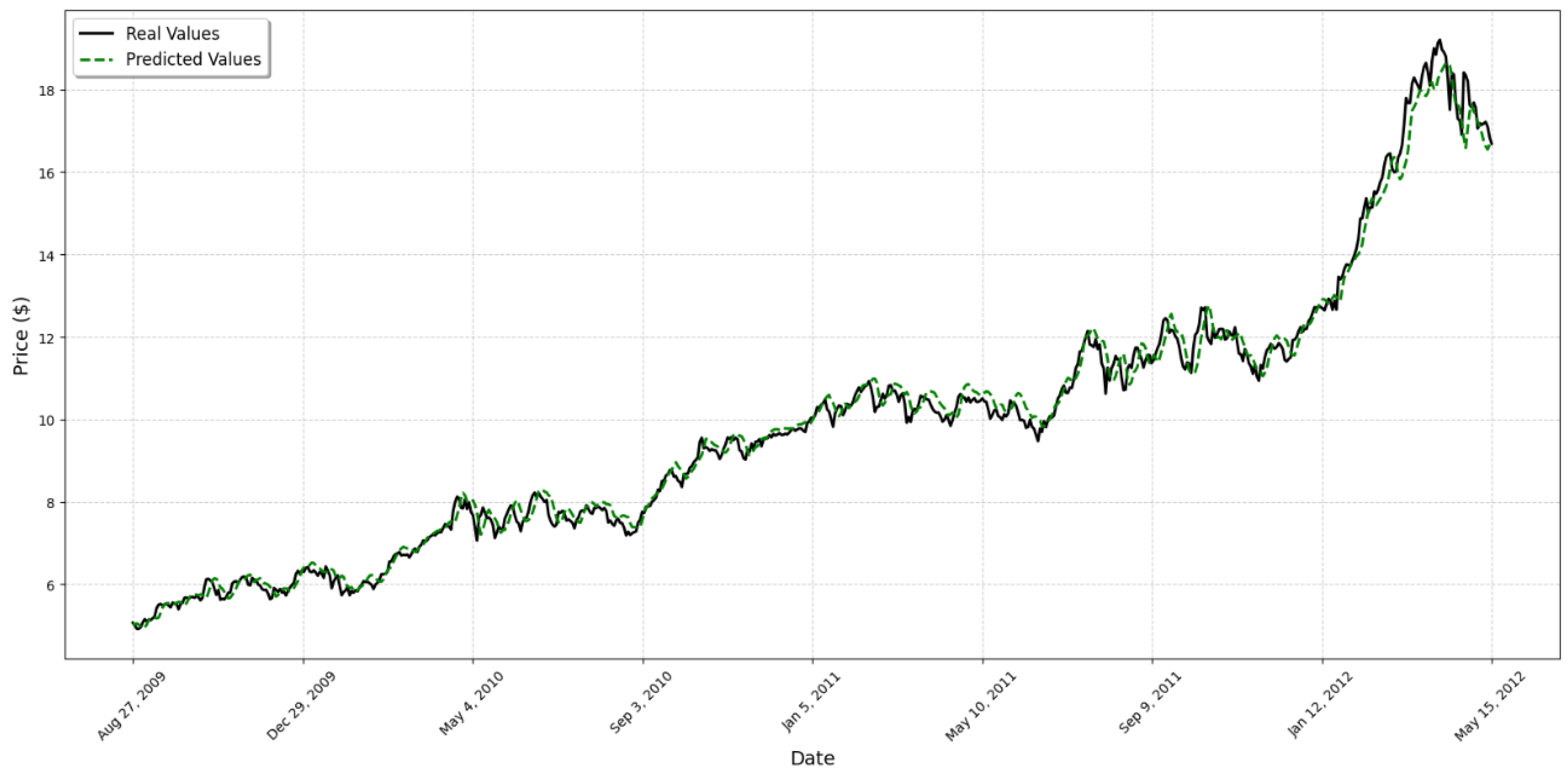
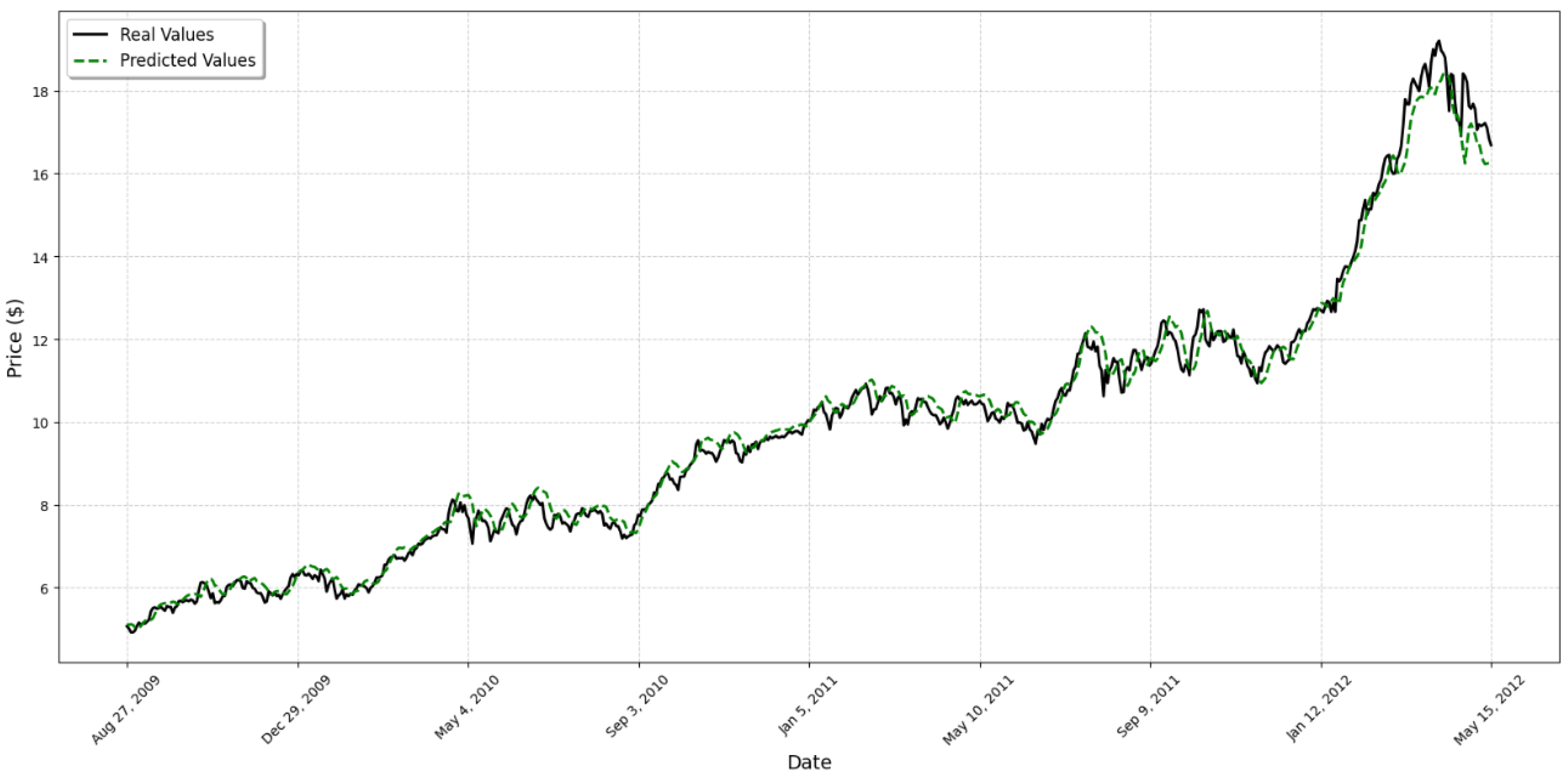
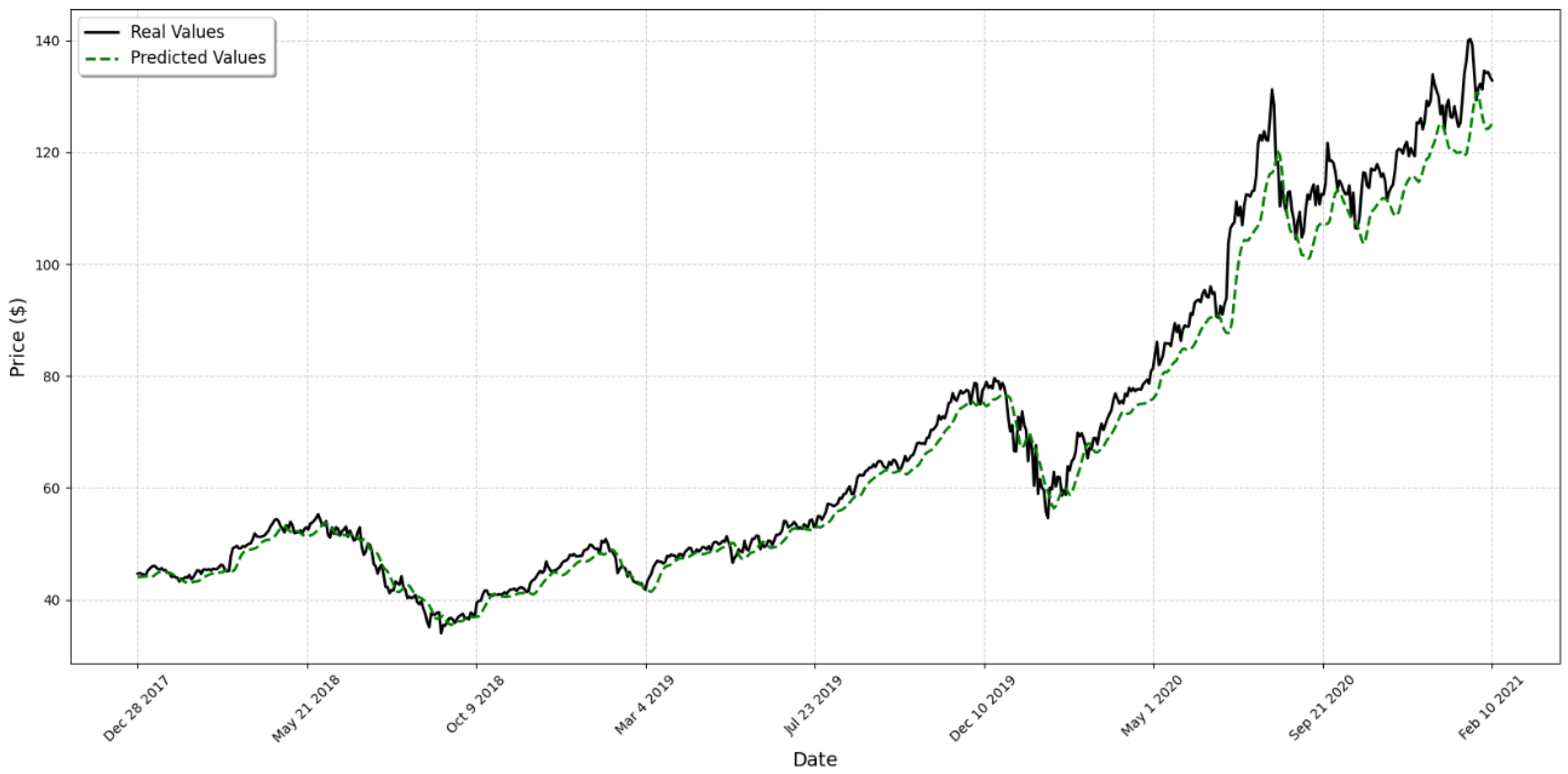
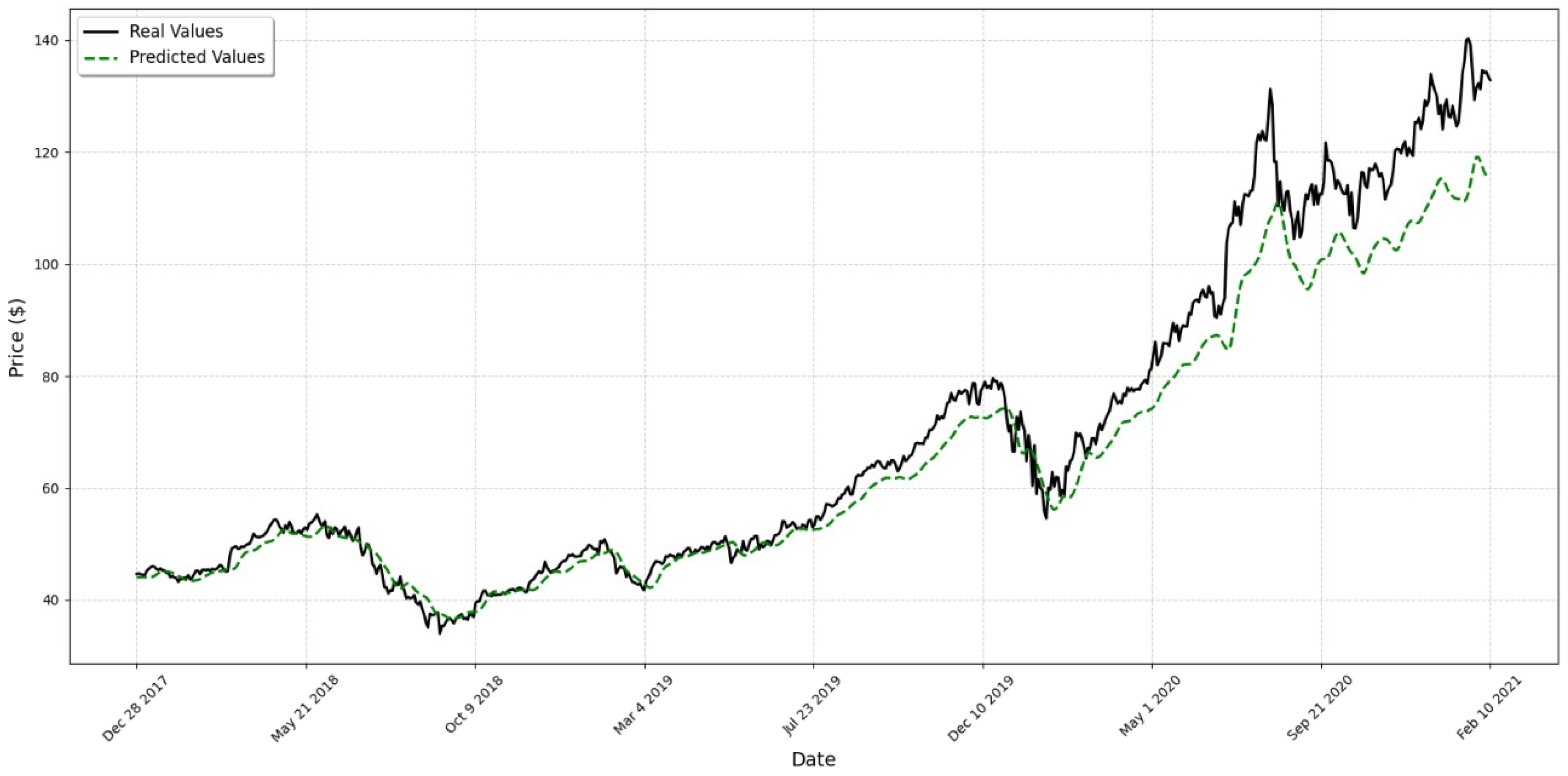
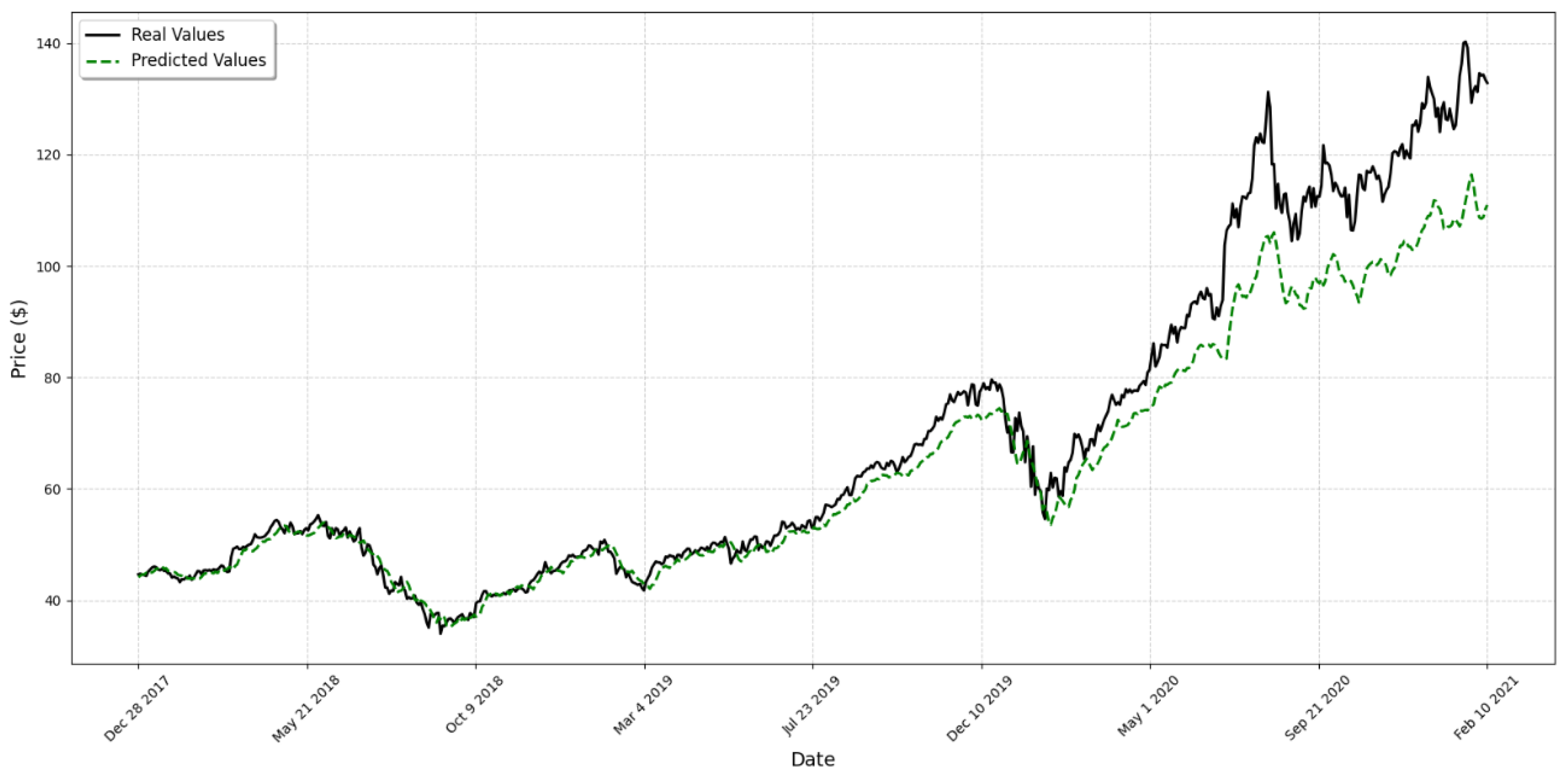
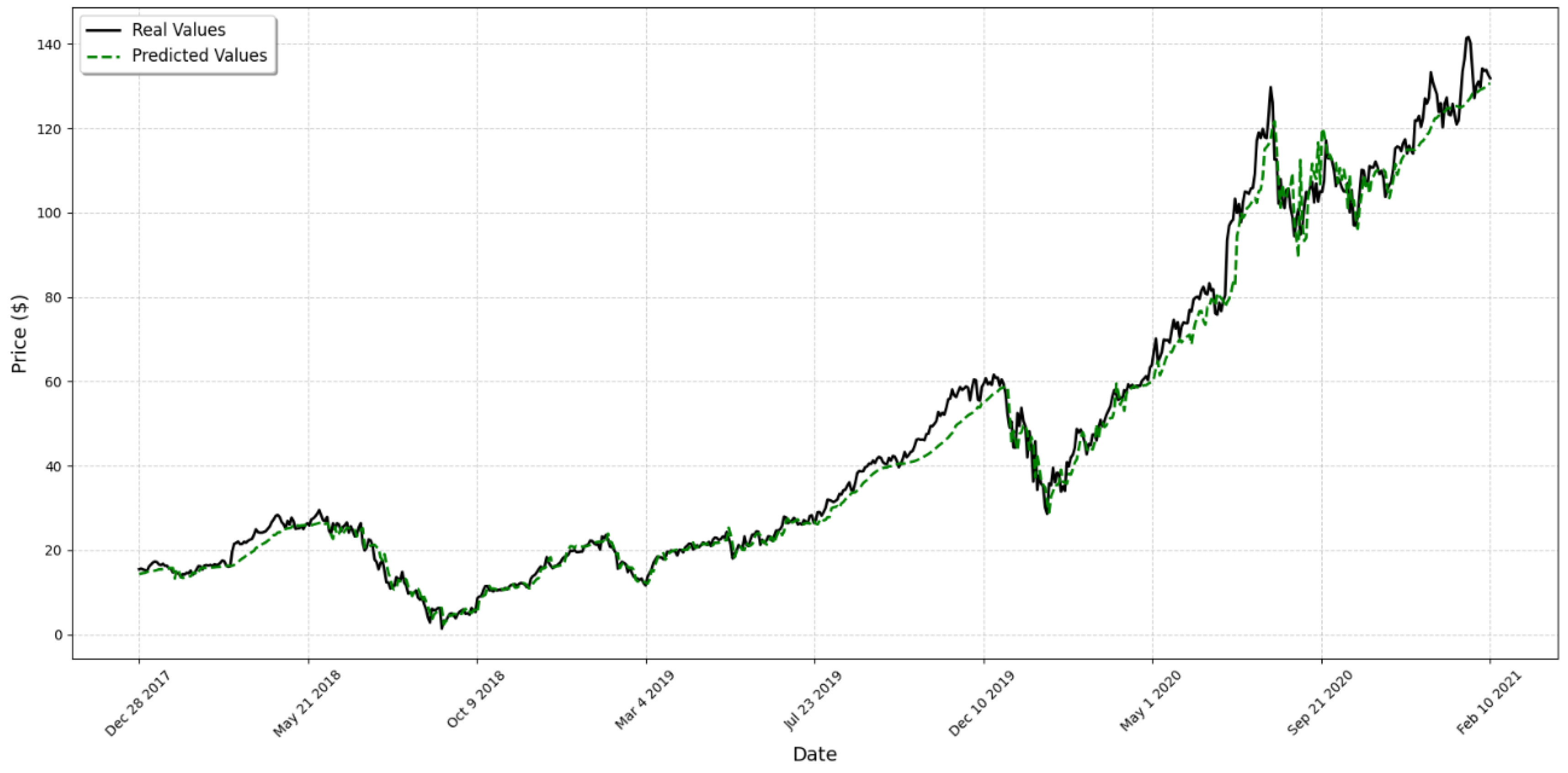
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jesse, A. Algorithmic Trading: Leveraging AI and ML in Finance. RapidInnovation. Available online: https://www.rapidinnovation.io/post/algorithmic-trading-leveraging-ai-and-ml-in-finance (accessed on 28 September 2024).
- Shah, D.; Isah, H.; Zulkernine, F. Stock Market Analysis: A Review and Taxonomy of Prediction Techniques. Int. J. Financ. Stud. 2019, 7, 26. [Google Scholar] [CrossRef]
- Li, Z.; Yu, H.; Xu, J.; Liu, J.; Mo, Y. Stock Market Analysis and Prediction Using LSTM: A Case Study on Technology Stocks. Innov. Appl. Eng. Technol. 2023, 2, 1–6. [Google Scholar] [CrossRef]
- Sonkavde, G.; Dharrao, D.S.; Bongale, A.M.; Deokate, S.T.; Doreswamy, D.; Bhat, S.K. Forecasting Stock Market Prices Using Machine Learning and Deep Learning Models: A Systematic Review, Performance Analysis, and Discussion of Implications. Int. J. Financ. Stud. 2023, 11, 94. [Google Scholar] [CrossRef]
- Hoque, K.E.; Aljamaan, H. Impact of Hyperparameter Tuning on Machine Learning Models in Stock Price Forecasting. IEEE Access 2021, 9, 163815–163824. [Google Scholar] [CrossRef]
- Gülmez, B. Stock Price Prediction with Optimized Deep LSTM Network Using Artificial Rabbits Optimization Algorithm. Expert Syst. Appl. 2023, 227, 120346. [Google Scholar] [CrossRef]
- Nabipour, M.; Nayyeri, P.; Jabani, H.; Mosavi, A.; Salwana, E.; Shamshirband, S. Deep Learning for Stock Market Prediction. Entropy 2020, 22, 840. [Google Scholar] [CrossRef] [PubMed]
- Naufal, G.R.; Wibowo, A. Time Series Forecasting Based on Deep Learning CNN-LSTM-GRU Model on Stock Prices. Int. J. Eng. Trends Technol. 2023, 71, 126–133. [Google Scholar] [CrossRef]
- Zhang, J.; Ye, L.; Lai, Y. Stock Price Prediction Using CNN-BiLSTM-Attention Model. Mathematics 2023, 11, 1985. [Google Scholar] [CrossRef]
- Mehtab, S.; Sen, J. Stock Price Prediction Using CNN and LSTM-Based Deep Learning Models. In Proceedings of the 2020 International Conference on Decision Aid Sciences and Application (DASA), Chiangrai, Thailand, 5–6 November 2020; pp. 447–452. [Google Scholar] [CrossRef]
- Yahoo Finance. Available online: https://finance.yahoo.com/ (accessed on 28 September 2024).
- Pandas. Available online: https://pandas.pydata.org/ (accessed on 28 September 2024).
- Scikit-Learn. Available online: https://scikit-learn.org (accessed on 5 October 2024).
- Hoseinzade, E.; Haratizadeh, S. CNNpred: CNN-based stock market prediction using a diverse set of variables. Expert Syst. Appl. 2019, 129, 273–285. [Google Scholar] [CrossRef]
- Federal Reserve Economic Data (FRED). Available online: https://fred.stlouisfed.org/ (accessed on 28 September 2024).
- Kavya, D. Optimizing Performance: SelectKBest for Efficient Feature Selection in Machine Learning. Medium. 2023. Available online: https://medium.com/@Kavya2099/optimizing-performance-selectkbest-for-efficient-feature-selection-in-machine-learning-3b635905ed48 (accessed on 30 September 2024).
- Cort, J. Willmott and Kenji Matsuura. Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance. Clim. Res. 2005, 30, 79–82. [Google Scholar] [CrossRef]
- Ken, S. Mean Squared Error. Encyclopedia Britannica, 2024. Available online: https://www.britannica.com/science/mean-squared-error (accessed on 30 September 2024).
- Deepchecks. Root Mean Squared Error (RMSE). Available online: https://www.deepchecks.com/glossary/root-mean-square-error/ (accessed on 30 September 2024).
- Scott, N. Coefficient of Determination: How to Calculate It and Interpret the Result. Investopedia. 2024. Available online: https://www.investopedia.com/terms/c/coefficient-of-determination.asp (accessed on 30 September 2024).
- Keras. Available online: https://keras.io (accessed on 4 October 2024).
- Hu, Z.; Zhao, Y.; Khushi, M. A Survey of Forex and Stock Price Prediction Using Deep Learning. Appl. Syst. Innov. 2021, 4, 9. [Google Scholar] [CrossRef]
- Mancuso, P.; Piccialli, V.; Sudoso, A.M. A machine learning approach for forecasting hierarchical time series. Expert Syst. Appl. 2021, 182, 115102. [Google Scholar] [CrossRef]
- XGBoost Documentation. Available online: https://xgboost.readthedocs.io/en/latest/python/ (accessed on 5 October 2024).
- Prashant, B. A Guide on XGBoost Hyperparameters Tuning. Kaggle. 2020. Available online: https://www.kaggle.com/code/prashant111/a-guide-on-xgboost-hyperparameters-tuning/ (accessed on 5 October 2024).
- GeeksforGeeks. GeeksforGeeks: A Computer Science Portal for Geeks. Available online: https://www.geeksforgeeks.org/ (accessed on 23 October 2024).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Date | Open | High | Low | Close | Adj Close 1 | Volume |
|---|---|---|---|---|---|---|
| 1980-12-12 | 0.128348 | 0.128906 | 0.128348 | 0.128348 | 0.098943 | 469,033,600 |
| 1980-12-15 | 0.122210 | 0.122210 | 0.121652 | 0.121652 | 0.093781 | 175,884,800 |
| 1980-12-16 | 0.113281 | 0.113281 | 0.112723 | 0.112723 | 0.086898 | 105,728,000 |
| 1980-12-17 | 0.115513 | 0.116071 | 0.115513 | 0.115513 | 0.089049 | 86,441,600 |
| 1980-12-18 | 0.118862 | 0.119420 | 0.118862 | 0.118862 | 0.091630 | 73,449,600 |
| # | Variable | Description | Type | Source |
|---|---|---|---|---|
| 1 | Open | Open Price | Price | Yahoo Finance |
| 2 | High | Highest Price | Price | Yahoo Finance |
| 3 | Low | Lowest Price | Price | Yahoo Finance |
| 4 | Close | Closing Price | Price | Yahoo Finance |
| 5 | Adj Close | Adjusted Closing Price | Price | Yahoo Finance |
| 6 | Volume | Volume of transactions | Volume | Yahoo Finance |
| 7 | MOM2 | 2-day momentum | Technical Indicator | Calculated |
| 8 | MOM3 | 3-day momentum | Technical Indicator | Calculated |
| 9 | MOM4 | 4-day momentum | Technical Indicator | Calculated |
| 10 | MACD | Moving Average Convergence/Divergence | TA-Lib | |
| 11 | RSI | Relative Strength Index | Technical Indicator | TA-Lib |
| 12 | ROC5 | 5-day Rate of Change | Technical Indicator | TA-Lib |
| 13 | ROC10 | 10-day Rate of Change | Technical Indicator | TA-Lib |
| 14 | ROC15 | 15-day Rate of Change | Technical Indicator | TA-Lib |
| 15 | ROC20 | 20-day Rate of Change | Technical Indicator | TA-Lib |
| 16 | SMA5 | 5-day Simple Moving Average | Technical Indicator | TA-Lib |
| 17 | SMA25 | 25-day Simple Moving Average | Technical Indicator | TA-Lib |
| 18 | SMA50 | 50-day Simple Moving Average | Technical Indicator | TA-Lib |
| 19 | SMA100 | 100-day Simple Moving Average | Technical Indicator | TA-Lib |
| 20 | SMA200 | 200-day Simple Moving Average | Technical Indicator | TA-Lib |
| 21 | EMA10 | 10-day Exponential Moving Average | Technical Indicator | TA-Lib |
| 22 | EMA12 | 12-day Exponential Moving Average | Technical Indicator | TA-Lib |
| 23 | EMA20 | 20-day Exponential Moving Average | Technical Indicator | TA-Lib |
| 24 | EMA26 | 26-day Exponential Moving Average | Technical Indicator | TA-Lib |
| 25 | EMA50 | 50-day Exponential Moving Average | Technical Indicator | TA-Lib |
| 26 | EMA100 | 100-day Exponential Moving Average | Technical Indicator | TA-Lib |
| 27 | EMA200 | 200-day Exponential Moving Average | Technical Indicator | TA-Lib |
| 28 | DTB4WK | 4-Week Treasury Bill | Interest Rate | FRED |
| 29 | DTB3 | 3-Month Treasury Bill | Interest Rate | FRED |
| 30 | DTB6 | 6-Month Treasury Bill | Interest Rate | FRED |
| 31 | DGS5 | 5-Year Treasury Constant Maturity Rate | Interest Rate | FRED |
| 32 | DGS10 | 10-Year Treasury Constant Maturity Rate | Interest Rate | FRED |
| 33 | DAAA | Moody’s Seasoned Aaa Corporate Bond Yield | Interest Rate | FRED |
| 34 | DBAA | Moody’s Seasoned Baa Corporate Bond Yield | Interest Rate | FRED |
| 35 | TE1 | DGS10-DTB4WK | Interest Rate Spread | Calculated |
| 36 | TE2 | DGS10-DTB3 | Interest Rate Spread | Calculated |
| 37 | TE3 | DGS10-DTB6 | Interest Rate Spread | Calculated |
| 38 | TE5 | DTB3-DTB4WK | Interest Rate Spread | Calculated |
| 39 | TE6 | DTB6-DTB4WK | Interest Rate Spread | Calculated |
| 40 | DE1 | DBAA-BAAA | Credit Spread | Calculated |
| 41 | DE2 | DBAA-DGS10 | Technical Indicator | Calculated |
| 42 | DE4 | DBAA-DTB6 | Technical Indicator | Calculated |
| 43 | DE5 | DBAA-DTB3 | Technical Indicator | Calculated |
| 44 | DE6 | DBAA-DTB4WK | Technical Indicator | Calculated |
| 45 | DCOILWTICO | Crude Oil Prices: West Texas Intermediate (WTI) | Commodity | FRED |
| 46 | IXIC | NASDAQ Composite Index | Index | Yahoo Finance |
| 47 | GSPC | S&P 500 Index | Index | Yahoo Finance |
| 48 | DJI | Dow Jones Industrial Index | Index | Yahoo Finance |
| 49 | NYA | NYSE Composite Index | Index | Yahoo Finance |
| Nº | Feature | Correlation | Nº | Feature | Correlation |
|---|---|---|---|---|---|
| 1 | Adj Close | 0.999757 | 26 | DCOILWTICO | 0.163709 |
| 2 | Low | 0.999527 | 27 | TE6 | 0.140110 |
| 3 | High | 0.999503 | 28 | MOM5 | 0.089892 |
| 4 | Open | 0.999411 | 29 | MOM4 | 0.080078 |
| 5 | SMA5 | 0.999335 | 30 | MOM3 | 0.067845 |
| 6 | EMA10 | 0.999167 | 31 | MOM2 | 0.052424 |
| 7 | EMA12 | 0.999064 | 32 | RSI | 0.007301 |
| 8 | EMA20 | 0.998661 | 33 | ROC5 | −0.014739 |
| 9 | EMA26 | 0.998375 | 34 | ROC10 | −0.017959 |
| 10 | SMA25 | 0.997924 | 35 | ROC15 | −0.021291 |
| 11 | EMA50 | 0.997375 | 36 | ROC20 | −0.023569 |
| 12 | SMA50 | 0.996326 | 37 | DGS5 | −0.116094 |
| 13 | EMA100 | 0.995705 | 38 | DE1 | −0.169746 |
| 14 | SMA100 | 0.994129 | 39 | DE2 | −0.325379 |
| 15 | EMA200 | 0.992936 | 40 | DGS10 | −0.327576 |
| 16 | SMA200 | 0.990444 | 41 | Volume | −0.472102 |
| 17 | IXIC | 0.963824 | 42 | DBAA | −0.495441 |
| 18 | GSPC | 0.955474 | 43 | DAAA | −0.502339 |
| 19 | DJI | 0.931631 | 44 | DE6 | −0.524144 |
| 20 | NYA | 0.876839 | 45 | TE1 | −0.533726 |
| 21 | MACD | 0.266051 | 46 | DE5 | −0.538855 |
| 22 | TE5 | 0.228270 | 47 | DE4 | −0.543380 |
| 23 | DTB3 | 0.185540 | 48 | TE2 | −0.556787 |
| 24 | DTB6 | 0.184989 | 49 | TE3 | −0.563363 |
| 25 | DTB4WK | 0.166905 |
| Nº | Feature | Score | Nº | Feature | Score |
|---|---|---|---|---|---|
| 1 | Adj Close | 11,500,000 | 26 | DE6 | 2120 |
| 2 | Low | 5,900,000 | 27 | DAAA | 1890 |
| 3 | High | 5,630,000 | 28 | DBAA | 1820 |
| 4 | Open | 4,740,000 | 29 | Volume | 1600 |
| 5 | SMA5 | 4,200,000 | 30 | DGS10 | 672 |
| 6 | EMA10 | 3,350,000 | 31 | DE2 | 662 |
| 7 | EMA12 | 2,980,000 | 32 | MACD | 6.72 |
| 8 | EMA20 | 2,080,000 | 33 | TE5 | 307 |
| 9 | EMA26 | 1,720,000 | 34 | DTB3 | 199 |
| 10 | SMA25 | 1,340,000 | 35 | DTB6 | 198 |
| 11 | EMA50 | 1,060,000 | 36 | DE1 | 166 |
| 12 | SMA50 | 756,000 | 37 | DTB4WK | 160 |
| 13 | EMA100 | 647,000 | 38 | DCOILWTICO | 154 |
| 14 | SMA100 | 472,000 | 39 | TE6 | 112 |
| 15 | EMA200 | 392,000 | 40 | DGS5 | 76.4 |
| 16 | SMA200 | 288,000 | 41 | MOM5 | 45.6 |
| 17 | IXIC | 73,100 | 42 | MOM4 | 36.1 |
| 18 | GSPC | 58,600 | 43 | MOM3 | 25.9 |
| 19 | DJI | 36,800 | 44 | MOM2 | 15.4 |
| 20 | NYA | 18,600 | 45 | ROC20 | 3.11 |
| 21 | TE3 | 2600 | 46 | ROC15 | 2.54 |
| 22 | TE2 | 2510 | 47 | ROC10 | 1.80 |
| 23 | DE4 | 2340 | 48 | ROC5 | 1.22 |
| 24 | DE5 | 2290 | 49 | RSI | 0.298 |
| 25 | TE1 | 2230 |
| Input Window | MAE | MSE | RMSE | MAPE | R2 |
|---|---|---|---|---|---|
| 25 | 6.26876 | 77.20209 | 8.65152 | 4.65% | 0.97240 |
| 50 | 7.31752 | 101.58542 | 9.99415 | 5.32% | 0.96358 |
| 75 | 7.01544 | 95.13397 | 9.61283 | 5.11% | 0.96580 |
| 100 | 6.05663 | 70.33266 | 8.32452 | 4.52% | 0.97458 |
| 125 | 6.15711 | 73.20857 | 8.46008 | 4.58% | 0.97361 |
| 150 | 7.01215 | 93.64945 | 9.54157 | 5.13% | 0.96606 |
| Input Window | MAE | MSE | RMSE | MAPE | R2 |
|---|---|---|---|---|---|
| 25 | 5.32076 | 59.54124 | 7.58995 | 4.21% | 0.97871 |
| 50 | 4.80348 | 47.84422 | 6.80072 | 3.88% | 0.98285 |
| 75 | 5.10483 | 55.17844 | 7.25437 | 4.07% | 0.98017 |
| 100 | 4.47343 | 40.44012 | 6.30300 | 3.67% | 0.98542 |
| 125 | 5.04923 | 57.31991 | 7.17754 | 4.03% | 0.97928 |
| 150 | 5.15170 | 55.66220 | 7.23008 | 4.10% | 0.97982 |
| Model | MAE | MSE | RMSE | MAPE | |
|---|---|---|---|---|---|
| 2 LSTM | 4.47343 | 40.44012 | 6.30300 | 3.67% | 0.98542 |
| 3 LSTM | 6.39245 | 93.64143 | 8.81530 | 5.02% | 0.96624 |
| 4 LSTM | 13.27586 | 326.50295 | 17.63884 | 9.49% | 0.88230 |
| 5 LSTM | 12.78660 | 296.52519 | 16.96558 | 9.26% | 0.89311 |
| Layer Type | Units | Dropout Rate | Activation | Input Shape | Output Shape |
|---|---|---|---|---|---|
| Input | - | - | - | - | (None, 100, 20) |
| LSTM | 256 | - | - | (None, 100, 20) | (None, 100, 256) |
| Dropout | - | 0.1 | - | (None, 100, 256) | (None, 100, 256) |
| LSTM | 256 | - | - | (None, 100, 256) | (None, 256) |
| Dropout | - | 0.1 | - | (None, 256) | (None, 256) |
| Dense | 1 | - | Linear | (None, 256) | (None, 1) |
| Model | MAE | MSE | RMSE | MAPE | |
|---|---|---|---|---|---|
| 2 GRU | 6.05663 | 70.33266 | 8.32452 | 4.52% | 0.97458 |
| 3 GRU | 6.68641 | 86.15809 | 9.19105 | 4.98% | 0.96894 |
| 4 GRU | 7.18087 | 101.49023 | 9.90276 | 5.33% | 0.96341 |
| Layer Type | Units | Dropout Rate | Activation | Input Shape | Output Shape |
|---|---|---|---|---|---|
| Input | - | - | - | - | (None, 100, 20) |
| GRU | 192 | - | - | (None, 100, 20) | (None, 100, 192) |
| Dropout | - | 0.1 | - | (None, 100, 192) | (None, 100, 192) |
| GRU | 256 | - | - | (None, 100, 192) | (None, 256) |
| Dropout | - | 0.1 | - | (None, 256) | (None, 256) |
| Dense | 1 | - | Linear | (None, 256) | (None, 1) |
| Model | MAE | MSE | RMSE | MAPE | |
|---|---|---|---|---|---|
| 2 LSTM + 1 GRU | 4.66154 | 44.05334 | 6.50991 | 3.84% | 0.98412 |
| 2 LSTM + 2 GRU | 5.67349 | 67.02369 | 7.84312 | 4.56% | 0.97584 |
| 2 GRU + 1 LSTM | 6.61557 | 90.00225 | 9.30896 | 4.96% | 0.96756 |
| Layer Type | Units | Dropout Rate | Activation | Input Shape | Output Shape |
|---|---|---|---|---|---|
| Input | - | - | - | - | (None, 100, 20) |
| LSTM | 160 | - | - | (None, 100, 20) | (None, 100, 160) |
| Dropout | - | 0.1 | - | (None, 100, 160) | (None, 100, 160) |
| GRU | 192 | - | - | (None, 100, 160) | (None, 100, 192) |
| Dropout | - | 0.1 | - | (None, 100, 192) | (None, 100, 192) |
| LSTM | 256 | - | - | (None, 100, 192) | (None, 256) |
| Dropout | - | 0.1 | - | (None, 256) | (None, 256) |
| Dense | 1 | - | Linear | (None, 256) | (None, 1) |
| Model | MAE | MSE | RMSE | MAPE | |
|---|---|---|---|---|---|
| 2 CNN | 20.76584 | 724.55197 | 26.22878 | 14.65% | 0.73881 |
| 3 CNN | 20.06864 | 638.61763 | 25.10520 | 14.28% | 0.76979 |
| 4 CNN | 19.67139 | 625.07460 | 24.67110 | 13.97% | 0.77467 |
| 2 CNN + 1 GRU | 15.11428 | 363.29719 | 18.89790 | 10.87% | 0.86904 |
| 2 CNN + 2 GRU | 15.53270 | 388.34495 | 19.55753 | 11.08% | 0.86001 |
| 2 CNN + 1 LSTM | 16.25192 | 427.81101 | 20.43434 | 11.58% | 0.84578 |
| 2 CNN + 2 LSTM | 12.39301 | 268.00793 | 15.79895 | 8.95% | 0.90339 |
| 3 CNN + 1 GRU | 12.40942 | 255.89493 | 15.63696 | 8.97% | 0.90775 |
| 3 CNN + 2 GRU | 15.67831 | 396.61022 | 19.67131 | 11.21% | 0.85703 |
| 3 CNN + 1 LSTM | 16.20975 | 418.35857 | 20.35480 | 11.55% | 0.84919 |
| 3 CNN + 2 LSTM | 14.10113 | 332.74085 | 17.91368 | 10.06% | 0.88005 |
| 3 CNN + 3 LSTM | 18.60184 | 589.70890 | 24.19487 | 12.84% | 0.78742 |
| 2 LSTM + 2 CNN | 21.08852 | 709.25973 | 26.36363 | 15.25% | 0.74432 |
| 2 LSTM + 3 CNN | 16.82985 | 444.44235 | 20.96579 | 12.32% | 0.83978 |
| 1 LSTM + 2 CNN | 19.62809 | 613.01076 | 24.52411 | 14.26% | 0.77902 |
| 1 LSTM + 3 CNN | 17.40287 | 471.46663 | 21.60685 | 12.79% | 0.83004 |
| 2 GRU + 2 CNN | 21.17739 | 714.77203 | 26.39351 | 15.30% | 0.74233 |
| 2 GRU + 3 CNN | 16.98616 | 453.64580 | 21.13578 | 12.38% | 0.83647 |
| 1 GRU + 2 CNN | 19.42900 | 597.05003 | 24.13958 | 14.13% | 0.78477 |
| 1 GRU + 3 CNN | 16.49147 | 425.36262 | 20.47938 | 12.04% | 0.84666 |
| Layer Type | Units | Filters | Kernel Size | Padding | Pool Size | Dropout Rate | Activation | Input Shape | Output Shape |
|---|---|---|---|---|---|---|---|---|---|
| Input | - | - | - | - | - | - | - | - | (None, 100, 20) |
| Conv1D | - | 256 | 3 | same | - | - | relu | (None, 100, 20) | (None, 100, 256) |
| MaxPooling1D | - | - | - | - | 2 | - | - | (None, 100, 256) | (None, 50, 256) |
| Conv1D | - | 128 | 3 | same | - | - | relu | (None, 50, 256) | (None, 50, 128) |
| MaxPooling1D | - | - | - | - | 2 | - | - | (None, 50, 128) | (None, 25, 128) |
| Conv1D | - | 224 | 3 | same | - | - | relu | (None, 25, 128) | (None, 25, 224) |
| MaxPooling1D | - | - | - | - | 2 | - | - | (None, 25, 224) | (None, 12, 224) |
| GRU | 256 | - | - | - | - | - | - | (None, 12, 224) | (None, 256) |
| Dropout | - | - | - | - | - | 0.1 | - | (None, 256) | (None, 256) |
| Dense | 1 | - | - | - | - | - | linear | (None, 256) | (None, 1) |
| Layer Type | Units | Filters | Kernel Size | Padding | Pool Size | Dropout Rate | Activation | Input Shape | Output Shape |
|---|---|---|---|---|---|---|---|---|---|
| Input | - | - | - | - | - | - | - | - | (None, 100, 20) |
| Conv1D | - | 256 | 3 | same | - | - | relu | (None, 100, 20) | (None, 100, 256) |
| MaxPooling1D | - | - | - | - | 2 | - | - | (None, 100, 256) | (None, 50, 256) |
| Conv1D | - | 128 | 3 | same | - | - | relu | (None, 50, 256) | (None, 50, 128) |
| MaxPooling1D | - | - | - | - | 2 | - | - | (None, 50, 128) | (None, 25, 128) |
| LSTM | 256 | - | - | - | - | - | - | (None, 25, 128) | (None, 25, 256) |
| Dropout | - | - | - | - | - | 0.1 | - | (None, 25, 256) | (None, 25, 256) |
| LSTM | 224 | - | - | - | - | - | - | (None, 25, 256) | (None, 224) |
| Dropout | - | - | - | - | - | 0,1 | - | (None, 224) | (None, 224) |
| Dense | 1 | - | - | - | - | - | linear | (None, 224) | (None, 1) |
| Model | MAE | MSE | RMSE | MAPE | |
|---|---|---|---|---|---|
| 2 RNN | 13.42476 | 312.82043 | 17.50414 | 9.40% | 0.88723 |
| 3 RNN | 11.00183 | 203.15732 | 14.07731 | 8.00% | 0.92676 |
| 4 RNN | 54.26821 | 5309.99157 | 67.45029 | 38.61% | −0.91418 |
| 2 RNN + 1 GRU | 16.08922 | 487.06017 | 21.59222 | 11.02% | 0.82442 |
| 2 RNN + 1 LSTM | 35.61142 | 2324.05876 | 46.58004 | 24.14% | 0.16221 |
| 3 RNN + 1 GRU | 52.63348 | 4653.71260 | 67.37217 | 36.14% | −0.67760 |
| 3 RNN + 2 GRU | 58.07854 | 5481.42100 | 73.94511 | 39.95% | −0.97597 |
| 3 RNN + 1 LSTM | 51.58560 | 4527.09365 | 65.51352 | 36.24% | −0.63195 |
| 3 RNN + 2 LSTM | 49.62855 | 4271.30501 | 63.29981 | 34.38% | −0.53974 |
| 1 GRU + 2 RNN | 34.71628 | 3311.86846 | 43.18345 | 24.90% | −0.19388 |
| 2 GRU + 2 RNN | 6.86930 | 85.52800 | 9.10183 | 5.18% | 0.96917 |
| 1 LSTM + 2 RNN | 5.20305 | 59.16789 | 7.28287 | 4.05% | 0.97867 |
| 2 LSTM + 2 RNN | 15.04343 | 360.47080 | 18.85734 | 10.79% | 0.87006 |
| Layer Type | Units | Dropout Rate | Activation | Input Shape | Output Shape |
|---|---|---|---|---|---|
| Input | - | - | - | - | (None, 100, 20) |
| SimpleRNN | 64 | - | - | (None, 100, 20) | (None, 100, 64) |
| Dropout | - | 0.1 | - | (None, 100, 64) | (None, 100, 64) |
| SimpleRNN | 64 | - | - | (None, 100, 64) | (None, 100, 64) |
| Dropout | - | 0.1 | - | (None, 100, 64) | (None, 100, 64) |
| SimpleRNN | 160 | - | - | (None, 100, 64) | (None, 160) |
| Dropout | - | 0.1 | - | (None, 160) | (None, 160) |
| Dense | 1 | - | linear | (None, 160) | (None, 1) |
| Layer Type | Units | Dropout Rate | Activation | Input Shape | Output Shape |
|---|---|---|---|---|---|
| Input | - | - | - | - | (None, 100, 20) |
| GRU | 256 | - | - | (None, 100, 20) | (None, 100, 256) |
| Dropout | - | 0.1 | - | (None, 100, 256) | (None, 100, 256) |
| GRU | 224 | - | - | (None, 100, 256) | (None, 100, 224) |
| Dropout | - | 0.1 | - | (None, 100, 224) | (None, 100, 224) |
| SimpleRNN | 128 | - | - | (None, 100, 224) | (None, 100, 128) |
| Dropout | - | 0.1 | - | (None, 100, 128) | (None, 100, 128) |
| SimpleRNN | 128 | - | - | (None, 100, 128) | (None, 128) |
| Dropout | - | 0.1 | - | (None, 128) | (None, 128) |
| Dense | 1 | - | linear | (None, 128) | (None, 1) |
| Layer Type | Units | Dropout Rate | Activation | Input Shape | Output Shape |
|---|---|---|---|---|---|
| Input | - | - | - | - | (None, 100, 20) |
| LSTM | 256 | - | - | (None, 100, 20) | (None, 100, 256) |
| Dropout | - | 0.1 | - | (None, 100, 256) | (None, 100, 256) |
| SimpleRNN | 128 | - | - | (None, 100, 256) | (None, 100, 128) |
| Dropout | - | 0.1 | - | (None, 100, 128) | (None, 100, 128) |
| SimpleRNN | 128 | - | - | (None, 100, 128) | (None, 128) |
| Dropout | - | 0.1 | - | (None, 128) | (None, 128) |
| Dense | 1 | - | linear | (None, 128) | (None, 1) |
| Parameter | Value |
|---|---|
| n_estimators | 2000 |
| colsample_bytree | 1 |
| learning_rate | 0.2 |
| max_depth | 3 |
| gamma | 0 |
| Fold | MAE | MSE | RMSE | MAPE | |
|---|---|---|---|---|---|
| Fold 1 | 11.91214 | 173.74637 | 13.18129 | 28.19% | 0.72660 |
| Fold 2 | 5.48417 | 64.95642 | 8.05955 | 11.48% | 0.93242 |
| Fold 3 | 7.12520 | 90.16903 | 9.49574 | 18.75% | 0.89422 |
| Fold 4 | 7.82829 | 118.52146 | 10.88676 | 17.69% | 0.85099 |
| Fold 5 | 5.50201 | 49.62010 | 7.04415 | 16.50% | 0.93648 |
| Fold 6 | 4.23446 | 29.60616 | 5.44115 | 12.99% | 0.94402 |
| Fold 7 | 4.62862 | 34.22093 | 5.84987 | 16.33% | 0.94550 |
| Fold 8 | 2.90414 | 13.93436 | 3.73288 | 13.31% | 0.98302 |
| Fold 9 | 2.37138 | 12.61277 | 3.55145 | 9.07% | 0.98228 |
| Fold 10 | 7.26365 | 82.00893 | 9.05588 | 18.41% | 0.86375 |
| Fold | MAE | MSE | RMSE | MAPE | |
|---|---|---|---|---|---|
| Fold 1 | 9.38743 | 112.10150 | 10.58780 | 24.17% | 0.81665 |
| Fold 2 | 3.80284 | 30.20025 | 5.49548 | 9.05% | 0.96462 |
| Fold 3 | 6.53096 | 80.15704 | 8.95305 | 17.95% | 0.90176 |
| Fold 4 | 4.52784 | 40.58004 | 6.37025 | 11.26% | 0.94898 |
| Fold 5 | 3.46230 | 21.34289 | 4.61984 | 11.55% | 0.97268 |
| Fold 6 | 2.92680 | 15.30314 | 3.91192 | 9.35% | 0.97106 |
| Fold 7 | 3.27320 | 18.19441 | 4.26549 | 12.26% | 0.97102 |
| Fold 8 | 2.85786 | 12.80357 | 3.57821 | 11.79% | 0.98474 |
| Fold 9 | 1.74535 | 7.79488 | 2.79193 | 7.20% | 0.98905 |
| Fold 10 | 4.22626 | 28.97903 | 5.38322 | 14.54% | 0.95185 |
| Fold | MAE | MSE | RMSE | MAPE | |
|---|---|---|---|---|---|
| Fold 1 | 15.61992 | 304.28257 | 17.44370 | 32.22% | 0.42145 |
| Fold 2 | 6.58491 | 90.83563 | 9.53077 | 12.86% | 0.91279 |
| Fold 3 | 9.75717 | 146.71980 | 12.11279 | 23.25% | 0.83451 |
| Fold 4 | 8.35856 | 135.42022 | 11.63702 | 18.56% | 0.82974 |
| Fold 5 | 6.63776 | 71.98634 | 8.48448 | 17.41% | 0.90786 |
| Fold 6 | 4.11538 | 30.06600 | 5.48325 | 12.28% | 0.94315 |
| Fold 7 | 5.46603 | 48.51339 | 6.96516 | 18.34% | 0.92274 |
| Fold 8 | 3.64409 | 20.73590 | 4.55367 | 14.48% | 0.97792 |
| Fold 9 | 3.40643 | 26.82287 | 5.17908 | 10.67% | 0.96232 |
| Fold 10 | 13.67531 | 288.78473 | 16.99367 | 27.59% | 0.52021 |
| Fold | MAE | MSE | RMSE | MAPE | |
|---|---|---|---|---|---|
| Fold 1 | 15.84411 | 394.05949 | 19.85093 | 115.52% | 0.44548 |
| Fold 2 | 5.13977 | 39.20318 | 6.26124 | 16.41% | 0.95428 |
| Fold 3 | 6.78728 | 80.04204 | 8.94662 | 20.03% | 0.89396 |
| Fold 4 | 7.10962 | 86.71263 | 9.31196 | 17.15% | 0.89098 |
| Fold 5 | 8.52569 | 106.01388 | 10.29630 | 20.45% | 0.89054 |
| Fold 6 | 1.78212 | 66.78008 | 2.60386 | 6.62% | 0.98718 |
| Fold 7 | 3.08410 | 15.72239 | 3.96515 | 12.45% | 0.97496 |
| Fold 8 | 3.51261 | 18.40017 | 4.28954 | 12.85% | 0.97906 |
| Fold 9 | 6.00269 | 79.04072 | 8.89048 | 14.95% | 0.88897 |
| Fold 10 | 7.17542 | 74.19858 | 8.61386 | 18.17% | 0.87673 |
| Fold | MAE | MSE | RMSE | MAPE | |
|---|---|---|---|---|---|
| Fold 1 | 9.13247 | 112.04292 | 10.58503 | 31.55% | 0.84233 |
| Fold 2 | 5.02402 | 42.28999 | 6.50308 | 14.17% | 0.95217 |
| Fold 3 | 9.32432 | 141.95356 | 11.91443 | 23.72% | 0.82479 |
| Fold 4 | 7.49673 | 101.83279 | 10.09122 | 17.12% | 0.87197 |
| Fold 5 | 13.93033 | 298.15672 | 17.26722 | 32.21% | 0.61835 |
| Fold 6 | 2.48617 | 12.01712 | 3.46657 | 8.58% | 0.97728 |
| Fold 7 | 5.35937 | 49.82275 | 7.05852 | 17.21% | 0.92065 |
| Fold 8 | 3.30675 | 17.96454 | 4.23846 | 13.03% | 0.97811 |
| Fold 9 | 4.73759 | 51.08354 | 7.14728 | 13.07% | 0.92824 |
| Fold 10 | 13.72379 | 268.47856 | 16.38532 | 28.15% | 0.55395 |
| Fold | MAE | MSE | RMSE | MAPE | |
|---|---|---|---|---|---|
| Fold 1 | 20.43294 | 520.61169 | 22.81692 | 36.14% | −0.25661 |
| Fold 2 | 5.03719 | 54.84815 | 7.40595 | 10.53% | 0.94288 |
| Fold 3 | 12.52122 | 236.24971 | 15.37042 | 26.12% | 0.74038 |
| Fold 4 | 4.65742 | 41.43034 | 6.43664 | 12.35% | 0.94791 |
| Fold 5 | 5.17978 | 43.72179 | 6.61225 | 15.30% | 0.94403 |
| Fold 6 | 2.89011 | 15.50343 | 3.93744 | 9.56% | 0.97068 |
| Fold 7 | 3.10744 | 16.44907 | 4.05575 | 13.83% | 0.97380 |
| Fold 8 | 3.02516 | 15.28663 | 3.90981 | 12.22% | 0.98314 |
| Fold 9 | 1.95716 | 9.06983 | 3.01162 | 8.35% | 0.98726 |
| Fold 10 | 4.46924 | 32.06349 | 5.66246 | 16.79% | 0.94673 |
| Fold | MAE | MSE | RMSE | MAPE | |
|---|---|---|---|---|---|
| Fold 1 | 21.60152 | 584.82707 | 24.18320 | 37.04% | −0.43740 |
| Fold 2 | 12.30615 | 311.19502 | 17.64072 | 18.32% | 0.79094 |
| Fold 3 | 9.75456 | 147.50570 | 12.14519 | 40.51% | 0.79226 |
| Fold 4 | 8.82793 | 153.85131 | 12.40368 | 19.76% | 0.80657 |
| Fold 5 | 9.42369 | 143.48814 | 11.97865 | 20.42% | 0.88240 |
| Fold 6 | 5.96017 | 65.14044 | 8.07096 | 15.85% | 0.87682 |
| Fold 7 | 6.84051 | 71.70855 | 8.46809 | 18.72% | 0.91875 |
| Fold 8 | 4.25580 | 27.70397 | 5.26346 | 14.54% | 0.97135 |
| Fold 9 | 3.99332 | 35.35340 | 5.94587 | 11.98% | 0.95034 |
| Fold 10 | 8.53610 | 106.69535 | 10.32934 | 20.17% | 0.82274 |
| Fold | MAE | MSE | RMSE | MAPE | |
|---|---|---|---|---|---|
| Fold 1 | 18.79646 | 450.99004 | 21.23653 | 36.52% | −0.13532 |
| Fold 2 | 7.83663 | 146.67303 | 12.11086 | 12.44% | 0.88968 |
| Fold 3 | 10.08343 | 169.39137 | 13.01504 | 23.21% | 0.80053 |
| Fold 4 | 7.55458 | 117.31707 | 10.83130 | 17.20% | 0.85250 |
| Fold 5 | 5.35813 | 50.49704 | 7.10613 | 15.70% | 0.93536 |
| Fold 6 | 6.21144 | 78.75409 | 8.87435 | 15.83% | 0.85108 |
| Fold 7 | 6.44382 | 71.14777 | 8.43491 | 16.84% | 0.92295 |
| Fold 8 | 6.78867 | 77.44861 | 8.80049 | 15.54% | 0.93456 |
| Fold 9 | 4.94555 | 57.88303 | 7.60809 | 13.15% | 0.91869 |
| Fold 10 | 7.40324 | 80.10582 | 8.95019 | 18.35% | 0.86691 |
| Fold | MAE | MSE | RMSE | MAPE | |
|---|---|---|---|---|---|
| Fold 1 | 3.69458 | 23.64308 | 4.86242 | 9.75% | 0.96143 |
| Fold 2 | 6.79941 | 112.42946 | 10.60328 | 32.67% | 0.84349 |
| Fold 3 | 5.93764 | 56.58240 | 7.52213 | 23.35% | 0.91745 |
| Fold 4 | 5.70026 | 69.96937 | 8.36477 | 13.82% | 0.94610 |
| Fold 5 | 5.62707 | 53.09575 | 7.28668 | 16.83% | 0.94447 |
| Fold 6 | 2.55833 | 11.56099 | 3.40014 | 8.48% | 0.98544 |
| Fold 7 | 2.27182 | 9.39108 | 3.06449 | 7.90% | 0.98974 |
| Fold 8 | 2.16358 | 8.24167 | 2.87083 | 9.37% | 0.99018 |
| Fold 9 | 1.96006 | 8.20051 | 2.86365 | 6.53% | 0.99105 |
| Fold 10 | 3.69458 | 23.64308 | 4.86242 | 9.75% | 0.96143 |
| Model | MAE | MSE | RMSE | MAPE | |
|---|---|---|---|---|---|
| LSTM | 5.92541 | 66.93970 | 7.62987 | 16.27% | 0.90593 |
| GRU | 4.27408 | 36.74568 | 5.59572 | 12.91% | 0.94724 |
| LSTM + GRU | 7.72656 | 116.41675 | 9.83836 | 18.77% | 0.82327 |
| CNN + GRU | 6.49634 | 90.01732 | 8.30299 | 25.46% | 0.87821 |
| CNN + LSTM | 7.45215 | 109.56400 | 9.46571 | 19.88% | 0.84678 |
| GRU + RNN | 6.32777 | 98.52341 | 7.92193 | 16.12% | 0.81802 |
| LSTM + RNN | 9.14998 | 164.74689 | 11.64290 | 21.73% | 0.73748 |
| RNN | 8.14220 | 130.02079 | 10.69679 | 18.48% | 0.78369 |
| XGBoost | 4.04073 | 37.67574 | 5.57008 | 13.85% | 0.95308 |
| Model | MAE | MSE | RMSE | MAPE | |
|---|---|---|---|---|---|
| LSTM | 2.63375 | 48.33650 | 2.95376 | 4.99% | 0.07316 |
| GRU | 2.08338 | 31.83310 | 2.33101 | 4.70% | 0.04938 |
| LSTM + GRU | 3.97725 | 99.07641 | 4.42984 | 6.65% | 0.18335 |
| CNN + GRU | 3.70506 | 106.46030 | 4.59103 | 30.27% | 0.15004 |
| CNN + LSTM | 3.83563 | 95.58068 | 4.46817 | 8.00% | 0.14019 |
| GRU + RNN | 5.46571 | 154.36099 | 5.95051 | 8.19% | 0.36459 |
| LSTM + RNN | 4.81639 | 160.07914 | 5.40272 | 8.93% | 0.39642 |
| RNN | 3.80369 | 113.08736 | 3.94962 | 6.64% | 0.30914 |
| XGBoost | 1.72911 | 32.91994 | 2.57875 | 7.90% | 0.04330 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Teixeira, D.M.; Barbosa, R.S. Stock Price Prediction in the Financial Market Using Machine Learning Models. Computation 2025, 13, 3. https://doi.org/10.3390/computation13010003
Teixeira DM, Barbosa RS. Stock Price Prediction in the Financial Market Using Machine Learning Models. Computation. 2025; 13(1):3. https://doi.org/10.3390/computation13010003
Chicago/Turabian StyleTeixeira, Diogo M., and Ramiro S. Barbosa. 2025. "Stock Price Prediction in the Financial Market Using Machine Learning Models" Computation 13, no. 1: 3. https://doi.org/10.3390/computation13010003
APA StyleTeixeira, D. M., & Barbosa, R. S. (2025). Stock Price Prediction in the Financial Market Using Machine Learning Models. Computation, 13(1), 3. https://doi.org/10.3390/computation13010003