
Unveiling AI-Generated Financial Text: A Computational Approach Using Natural Language Processing and Generative Artificial Intelligence

 ,
,  ,
,  ,
, 
Abstract
1. Introduction
2. Background
2.1. Machine Learning
2.1.1. Supervised Learning
2.1.2. Unsupervised Learning
2.2. Twitter
2.3. ChatGPT-3.5
2.4. QuillBot
- We meticulously compiled a substantial dataset of finance-related tweets sourced from Twitter, forming the cornerstone of our research.
- Utilizing this financial tweet dataset, we harnessed advanced language models, including ChatGPT and QuillBot, to craft pertinent content, augmenting the depth and breadth of our collection for in-depth studying.
- Our exploration commences with a strategic approach to address the complexities of this scenario as a multiclass categorization problem, thus enabling us to achieve high-precision classification of economic content.
- To validate the efficacy of our methodology, we conducted a thorough evaluation of a spectrum of cutting-edge machine learning models, systematically gauging their applicability to this specific task.
- We used a comprehensive feature extraction methodology that combines TF–IDF with Word2Vec, enhancing the effectiveness of our model.
- By combining a Random Forest model with Word2Vec, we achieved impressive outcomes in accuracy, precision, recall, and F1 measure.
- We investigated the significance of window size parameters in the Word2Vec approach, highlighting the effectiveness of a window size of one.
3. Materials and Methods
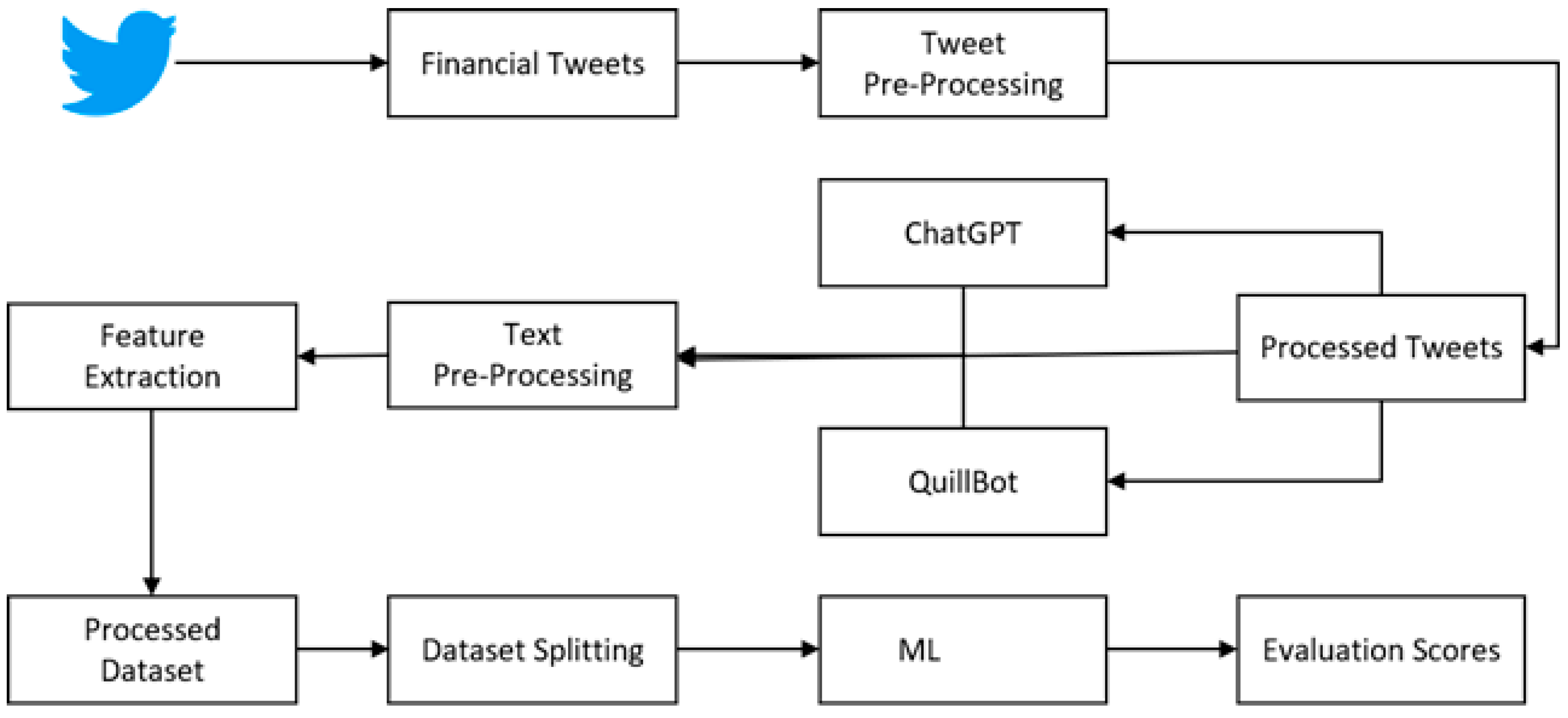
3.1. Dataset
Tweet Preprocessing
- Irregular term removal: A significant ratio of users consists of elements such as URL links, hashtags, numerals, emojis, and emoticons in their tweet statements. In the context of our study, these elements encompass no materiality and may cover up the factual judgment of the tweet’s sentiment. Hence, it is critical to implement a term reduction process to wipe out these odd elements and improve the accuracy of tweets.
- Accept only English tweets: In this study, our introductory focus revolves around English-language text. It is worth pointing out that both ChatGPT and QuillBot are too firmly embedded in the English language, further reinforcing our conclusion to eliminate tweets not documented in complete English from our dataset. This strategy ensures that our study remains consistent with the grammatical context of these language models.
3.2. Text Preprocessing
- Stop word removal: This involves the removal of common words that lack significant meaning or contribute minimally to the overall understanding of the text. Stop words such as “the”, “is”, and “and”, are examples of these. The elimination of these words can enhance the efficiency and accuracy of text identification tasks [22].
3.3. Feature Extraction
3.3.1. Term Frequency–Inverse Document Frequency (TF–IDF)
3.3.2. Word2Vec
3.4. Classification Algorithms
3.4.1. Logistic Regression
3.4.2. KNN
3.4.3. SVM
3.4.4. Random Forest
3.4.5. Decision Tree
4. Results and Discussion
4.1. Evaluation Matrics
- Accuracy: Assesses the global accuracy of the model’s predictions by determining the ratio of correctly classified samples to the total number of samples. However, accuracy alone may prove inadequate for evaluation, particularly when handling imbalanced datasets or situations where different types of errors carry differing consequences.
- Precision: Quantifies the model’s capacity to accurately detect positive samples among the predicted positives. It computes the ratio of true positives to the sum of true positives and false positives. Precision primarily evaluates the trustworthiness of positive predictions.
- Recall: Often referred to as sensitivity or the true positive rate, recall assesses the model’s capability to correctly identify positive samples among all the genuine positives. It computes the ratio of true positives to the sum of true positives and false negatives. Recall primarily assesses the comprehensiveness of positive predictions.
- F1 score: The harmonic mean of precision and recall. It provides a single metric that balances both precision and recall, making it useful for when there is an uneven class distribution or an equal emphasis on both types of errors. The F1 score ranges from 0 to 1, with 1 denoting the best performance.
4.2. Experimental Setup
4.3. Experimental Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Muneer, A.; Alwadain, A.; Ragab, M.G.; Alqushaibi, A. Cyberbullying Detection on Social Media Using Stacking Ensemble Learning and Enhanced BERT. Information 2023, 14, 467. [Google Scholar] [CrossRef]
- Hadi, M.U.; Al Tashi, Q.; Qureshi, R.; Shah, A.; Muneer, A.; Irfan, M.; Zafar, A.; Shaikh, M.B.; Akhtar, N.; Wu, J.; et al. Large Language Models: A Comprehensive Survey of its Applications, Challenges, Limitations, and Future Prospects. Authorea Prepr. 2023. [Google Scholar] [CrossRef]
- Tyagi, N.; Bhushan, B. Demystifying the Role of Natural Language Processing (NLP) in Smart City Applications: Background, Motivation, Recent Advances, and Future Research Directions. Wirel. Pers. Commun. 2023, 130, 857–908. [Google Scholar] [CrossRef]
- Khurana, D.; Koli, A.; Khatter, K.; Singh, S. Natural language processing: State of the art, current trends and challenges. Multimed. Tools Appl. 2023, 82, 3713–3744. [Google Scholar] [CrossRef]
- Pavlik, J.V. Collaborating with ChatGPT: Considering the Implications of Generative Artificial Intelligence for Journalism and Media Education. J. Mass Commun. Educ. 2023, 78, 84–93. [Google Scholar] [CrossRef]
- Yew, A.N.J.; Schraagen, M.; Otte, W.M.; van Diessen, E. Transforming epilepsy research: A systematic review on natural language processing applications. Epilepsia 2022, 64, 292–305. [Google Scholar] [CrossRef]
- Muneer, A.; Fati, S.M. A Comparative Analysis of Machine Learning Techniques for Cyberbullying Detection on Twitter. Futur. Internet 2020, 12, 187. [Google Scholar] [CrossRef]
- Fati, S.M.; Muneer, A.; Alwadain, A.; Balogun, A.O. Cyberbullying Detection on Twitter Using Deep Learning-Based Attention Mechanisms and Continuous Bag of Words Feature Extraction. Mathematics 2023, 11, 3567. [Google Scholar] [CrossRef]
- Gligorić, K.; Anderson, A.; West, R. Adoption of Twitter’s New Length Limit: Is 280 the New 140? arXiv 2020, arXiv:2009.07661. [Google Scholar]
- How Many Users Does Twitter Have? Available online: https://www.bankmycell.com/blog/how-many-users-does-twitter-have (accessed on 4 September 2023).
- Fitria, T.N. QuillBot as an online tool: Students’ alternative in paraphrasing and rewriting of English writing. Englisia J. 2021, 9, 183–196. [Google Scholar] [CrossRef]
- Nurmayanti, N.; Suryadi, S. The Effectiveness of Using Quillbot In Improving Writing for Students of English Education Study Program. J. Teknol. Pendidik. 2023, 8, 32–40. [Google Scholar] [CrossRef]
- Alawida, M.; Mejri, S.; Mehmood, A.; Chikhaoui, B.; Abiodun, O.I. A Comprehensive Study of ChatGPT: Advancements, Limitations, and Ethical Considerations in Natural Language Processing and Cybersecurity. Information 2023, 14, 462. [Google Scholar] [CrossRef]
- Liao, W.; Liu, Z.; Dai, H.; Xu, S.; Wu, Z.; Zhang, Y.; Liu, T. Differentiate ChatGPT-Generated and Human-Written Medical Texts. arXiv 2023, arXiv:2304.11567. [Google Scholar]
- Perkins, M. Academic integrity considerations of AI Large Language Models in the post-pandemic era: ChatGPT and beyond. J. Univ. Teach. Learn. Pract. 2023, 20, 7. [Google Scholar] [CrossRef]
- Zellers, R.; Holtzman, A.; Rashkin, H.; Bisk, Y.; Farhadi, A.; Roesner, F.; Choi, Y. Defending Against Neural Fake News. Adv. Neural Inf. Process. Syst. 2019, 32. Available online: https://arxiv.org/abs/1905.12616v3 (accessed on 5 September 2023).
- Alamleh, H.; AlQahtani, A.A.S.; ElSaid, A. Distinguishing Human-Written and ChatGPT-Generated Text Using Machine Learning. In Proceedings of the 2023 Systems and Information Engineering Design Symposium (SIEDS), Charlottesville, VA, USA, 27–28 April 2023. [Google Scholar]
- Das, M.; Kamalanathan, S.; Alphonse, P. A Comparative Study on TF-IDF Feature Weighting Method and Its Analysis Using Unstructured Dataset. arXiv 2023, arXiv:2308.04037. [Google Scholar]
- Jang, B.; Kim, I.; Kim, J.W. Word2vec convolutional neural networks for classification of news articles and tweets. PLoS ONE 2019, 14, e0220976. [Google Scholar] [CrossRef]
- Haddi, E.; Liu, X.; Shi, Y. The Role of Text Pre-processing in Sentiment Analysis. Procedia Comput. Sci. 2013, 17, 26–32. [Google Scholar] [CrossRef]
- Tweet-Preprocessor · PyPI. Available online: https://pypi.org/project/tweet-preprocessor/ (accessed on 20 March 2022).
- Makrehchi, M.; Kamel, M.S. Extracting domain-specific stopwords for text classifiers. Intell. Data Anal. 2017, 21, 39–62. [Google Scholar] [CrossRef]
- Kanerva, J.; Ginter, F.; Salakoski, T. Universal Lemmatizer: A sequence-to-sequence model for lemmatizing Universal Dependencies treebanks. Nat. Lang. Eng. 2020, 27, 545–574. [Google Scholar] [CrossRef]
- Zhou, H. Research of Text Classification Based on TF-IDF and CNN-LSTM. J. Physics 2022, 2171, 012021. [Google Scholar] [CrossRef]
- Cox, D.R. The Regression Analysis of Binary Sequences. J. R. Stat. Soc. Ser. B 1958, 20, 215–232. [Google Scholar] [CrossRef]
- Fix, E.; Hodges, J.L., Jr. Discriminatory analysis. Nonparametric discrimination: Consistency properties. Int. Stat. Rev./Rev. Int. Stat. 1989, 57, 238–247. [Google Scholar] [CrossRef]
- Altman, N.S. An Introduction to Kernel and Nearest-Neighbor Nonparametric Regression. Am. Stat. 1992, 46, 175–185. [Google Scholar] [CrossRef]
- Han, T. Research on Chinese Patent Text Classification Based on SVM. In Proceedings of the 2nd International Conference on Mathematical Statistics and Economic Analysis, MSEA 2023, Nanjing, China, 26–28 May 2023. [Google Scholar]
- Altin, F.G.; Budak, I.; Özcan, F. Predicting the amount of medical waste using kernel-based SVM and deep learning methods for a private hospital in Turkey. Sustain. Chem. Pharm. 2023, 33, 101060. [Google Scholar] [CrossRef]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995. [Google Scholar]
- Colab.Google. Available online: https://colab.google/ (accessed on 9 September 2023).
- Zeini, H.A.; Al-Jeznawi, D.; Imran, H.; Bernardo, L.F.A.; Al-Khafaji, Z.; Ostrowski, K.A. Random Forest Algorithm for the Strength Prediction of Geopolymer Stabilized Clayey Soil. Sustainability 2023, 15, 1408. [Google Scholar] [CrossRef]
- Valero-Carreras, D.; Alcaraz, J.; Landete, M. Comparing two SVM models through different metrics based on the confusion matrix. Comput. Oper. Res. 2023, 152, 106131. [Google Scholar] [CrossRef]
- Aoumeur, N.E.; Li, Z.; Alshari, E.M.M. Improving the Polarity of Text through word2vec Embedding for Primary Classical Arabic Sentiment Analysis. Neural Process. Lett. 2023, 55, 2249–2264. [Google Scholar] [CrossRef]
- Kale, A.S.; Pandya, V.; Di Troia, F.; Stamp, M. Malware classification with Word2Vec, HMM2Vec, BERT, and ELMo. J. Comput. Virol. Hacking Tech. 2023, 19, 1–16. [Google Scholar] [CrossRef]
- Wei, L.; Wang, L.; Liu, F.; Qian, Z. Clustering Analysis of Wind Turbine Alarm Sequences Based on Domain Knowledge-Fused Word2vec. Appl. Sci. 2023, 13, 10114. [Google Scholar] [CrossRef]
- Zhu, J.-J.; Ren, Z.J. The evolution of research in resources, conservation & recycling revealed by Word2vec-enhanced data mining. Resour. Conserv. Recycl. 2023, 190, 106876. [Google Scholar] [CrossRef]
- Sharma, A.; Kumar, S. Ontology-based semantic retrieval of documents using Word2vec model. Data Knowl. Eng. 2023, 144, 102110. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Financial Terms | |||
|---|---|---|---|
| Accounts payable | Debt | Liquidity | Variable cost |
| Accounts receivable | Debt consolidation | Loan | Venture capital |
| Accounts receivable finance | Debt finance | Loan to value ratio (LVR) | Working capital |
| Accrual accounting | Debtor | Margin | Average cost |
| Amortisation | Debtors finance | Margin call | Bank draft |
| Assets | Default | Mark down | Bank rate |
| Audit | Depreciation | Mark up | Bond |
| Bad debts | Disbursements | Maturity date | Borrowing |
| Balance sheet | Discount | Net assets | Capital Good |
| Balloon payment | Double-entry bookkeeping | Net income | Capital inflow |
| Bank reconciliation | Drawings | Net profit | Capital infusion |
| Bankrupt | Drip pricing | Net worth | Capital loss |
| Bankruptcy | Employee share schemes | Overdraft facility | Capital market |
| Benchmark | Encumbered | Overdrawn account | Capital movement |
| Benchmarking | Equity | Overheads | Capital stock |
| Bill of sale | Equity finance | Owner’s equity | Constant dollars |
| Bookkeeping | Excise duty | Personal property | Consumer price index |
| Bootstrapping | Facility | Personal Property Security Register (PPSR) | Conversion price |
| Bottom line | Factoring | Petty cash | Currency |
| Break-even point | Transactions | Plant and equipment | income tax |
| Budget | Financial year | Principal | Cost of capital |
| Capital | Financial statement | Profit | Allowance |
| Capital cost | Fixed asset | Profit and loss statement | Price |
| Capital gain | Fixed cost | Profit margin | Deposit |
| Capital growth | Fixed interest rate | Projection | Money |
| Cash | Float | R&D | Dollar |
| Cash accounting | Forecast | Receipts | Income |
| Cash book | Fringe benefits | Record keeping | Economy |
| Cash flow | Fully drawn advance | Refinance | Exchange Rate |
| Cash incoming | Goodwill | Rent to buy | Import |
| Cash outgoing | Gross income | Repossess | Export |
| Chart of accounts | Gross profit | Retention of title | Foreign Aid |
| Chattel mortgage | Guarantor | Return on investment (ROI) | Funds |
| Collateral | Hire-purchase | Return on investment (ROI) formula example | Payment |
| Commercial bill | Initial public offering (IPO) | Revenue | Wealth |
| Contingent liability | Insolvent | Single-entry bookkeeping | World Bank |
| Cost of goods sold | Intangible assets | Scam | Recession |
| Credit | Interest rate | Security | Mortgage |
| Creditor | Inventory | Shareholder’s equity | Overdraft |
| Credit limit | Investment | SMSF | Shares |
| Credit rating | Invoice | Stock | Stocks |
| Credit history | Invoice finance | Stocktaking | Rally |
| Crowdfunding | Liability | Superannuation | Bull market |
| Current asset | Line of credit | Tax invoice | Bear market |
| Current liability | Liquidate | Turnover | Ruppee |
| Debit | Liquidation | Variable interest rate | |
| Billion | Million | Trillion | |
| Original Tweet | ChatGPT Text | QuillBot Text |
|---|---|---|
| “trillion even issue trillion roughly budget year period anyone bit knowledge government able figure along medium curb perhaps also worth talk medium capability.” | “A trillion is a matter that cannot be dismissed lightly. With approximately a trillion allocated within the annual budget, anyone possessing even a modicum of knowledge about government finance should be capable of discerning the significance. The idea of a medium-term approach to rein in such expenditures warrants consideration, and it might be worth discussing our medium-term capabilities as well.” | “infinity even problem trillion around budget year period anyone with some understanding of how the government would calculate a medium curb, possibly also worth discussing a medium capacity.” |
| “one trillion rupees one thousand billion entire cost billion only exaggeration ma humble suggestion in future ppp dispensation suggest consider ministry finance.” | “A sum of one trillion rupees... equating to one thousand billion, the entire cost is in the billions, not merely an exaggeration. In my humble suggestion, for future PPP dispensations, I propose that the Ministry of Finance takes into account this consideration.” | “One trillion rupees, or $1000 billion in total cost, is merely an exaggeration. My modest recommendation is that in future PPP administrations, ministry finance be taken into consideration.” |
| “the exchange rate lock.” | “The stability of the exchange rate remains unchanged.” | “a lock on the exchange rate.” |
| ML Models | Accuracy | Weighted Precision | Weighted Recall | Weighted F1 |
|---|---|---|---|---|
| Random Forest | 0.39 | 0.40 | 0.39 | 0.39 |
| LR | 0.37 | 0.39 | 0.37 | 0.37 |
| KNN | 0.24 | 0.11 | 0.24 | 0.15 |
| Decision tree | 0.33 | 0.35 | 0.33 | 0.33 |
| SVM | 0.23 | 0.25 | 0.23 | 0.23 |
| Confusion Matrix (TF-IDF) | |
|---|---|
 (RF) |  (LR) |
 (KNN) |  (Decision Tree) |
 (SVM) | |
| ML Models | Accuracy | Weighted Precision | Weighted Recall | Weighted F1 |
|---|---|---|---|---|
| Random Forest | 0.71 | 0.70 | 0.71 | 0.70 |
| LR | 0.58 | 0.56 | 0.58 | 0.56 |
| KNN | 0.61 | 0.63 | 0.61 | 0.61 |
| Decision tree | 0.56 | 0.57 | 0.56 | 0.56 |
| SVM | 0.59 | 0.64 | 0.59 | 0.61 |
| Confusion Matrix (Word2Vec) | |
|---|---|
 (RF) |  (LR) |
 (KNN) |  (Decision Tree) |
 (SVM) | |
| ML Models | Accuracy | Weighted Precision | Weighted Recall | Weighted F1 |
|---|---|---|---|---|
| Random Forest | 0.67 | 0.67 | 0.67 | 0.67 |
| LR | 0.65 | 0.63 | 0.65 | 0.63 |
| KNN | 0.32 | 0.38 | 0.32 | 0.33 |
| Decision tree | 0.53 | 0.54 | 0.53 | 0.53 |
| SVM | 0.63 | 0.61 | 0.63 | 0.61 |
| Confusion Matrix (TF–IDF + Word2Vec) | |
|---|---|
 (RF) |  (LR) |
 (KNN) |  (Decision Tree) |
 (SVM) | |
| Precision | Recall | F1 | Support | |
|---|---|---|---|---|
| Gpt | 0.80 | 0.80 | 0.80 | 41 |
| Quil | 0.71 | 0.59 | 0.65 | 51 |
| Real | 0.72 | 0.83 | 0.77 | 58 |
| Macro avg | 0.75 | 0.74 | 0.74 | 150 |
| Weighted avg | 0.74 | 0.74 | 0.74 | 150 |
| Overall Accuracy = 0.74 | ||||
| Precision | Recall | F1 | Support | |
|---|---|---|---|---|
| Gpt | 0.69 | 0.74 | 0.71 | 99 |
| Quil | 0.64 | 0.47 | 0.54 | 102 |
| Real | 0.86 | 0.96 | 0.90 | 99 |
| Macro avg | 0.71 | 0.72 | 0.71 | 300 |
| Weighted avg | 0.71 | 0.72 | 0.71 | 300 |
| Overall Accuracy = 0.72 | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arshed, M.A.; Gherghina, Ș.C.; Dewi, C.; Iqbal, A.; Mumtaz, S. Unveiling AI-Generated Financial Text: A Computational Approach Using Natural Language Processing and Generative Artificial Intelligence. Computation 2024, 12, 101. https://doi.org/10.3390/computation12050101
Arshed MA, Gherghina ȘC, Dewi C, Iqbal A, Mumtaz S. Unveiling AI-Generated Financial Text: A Computational Approach Using Natural Language Processing and Generative Artificial Intelligence. Computation. 2024; 12(5):101. https://doi.org/10.3390/computation12050101
Chicago/Turabian StyleArshed, Muhammad Asad, Ștefan Cristian Gherghina, Christine Dewi, Asma Iqbal, and Shahzad Mumtaz. 2024. "Unveiling AI-Generated Financial Text: A Computational Approach Using Natural Language Processing and Generative Artificial Intelligence" Computation 12, no. 5: 101. https://doi.org/10.3390/computation12050101
APA StyleArshed, M. A., Gherghina, Ș. C., Dewi, C., Iqbal, A., & Mumtaz, S. (2024). Unveiling AI-Generated Financial Text: A Computational Approach Using Natural Language Processing and Generative Artificial Intelligence. Computation, 12(5), 101. https://doi.org/10.3390/computation12050101