
Stochastic Fusion Techniques for State Estimation


Abstract
1. Introduction
2. Fusion Algorithms
2.1. Particle Filtering
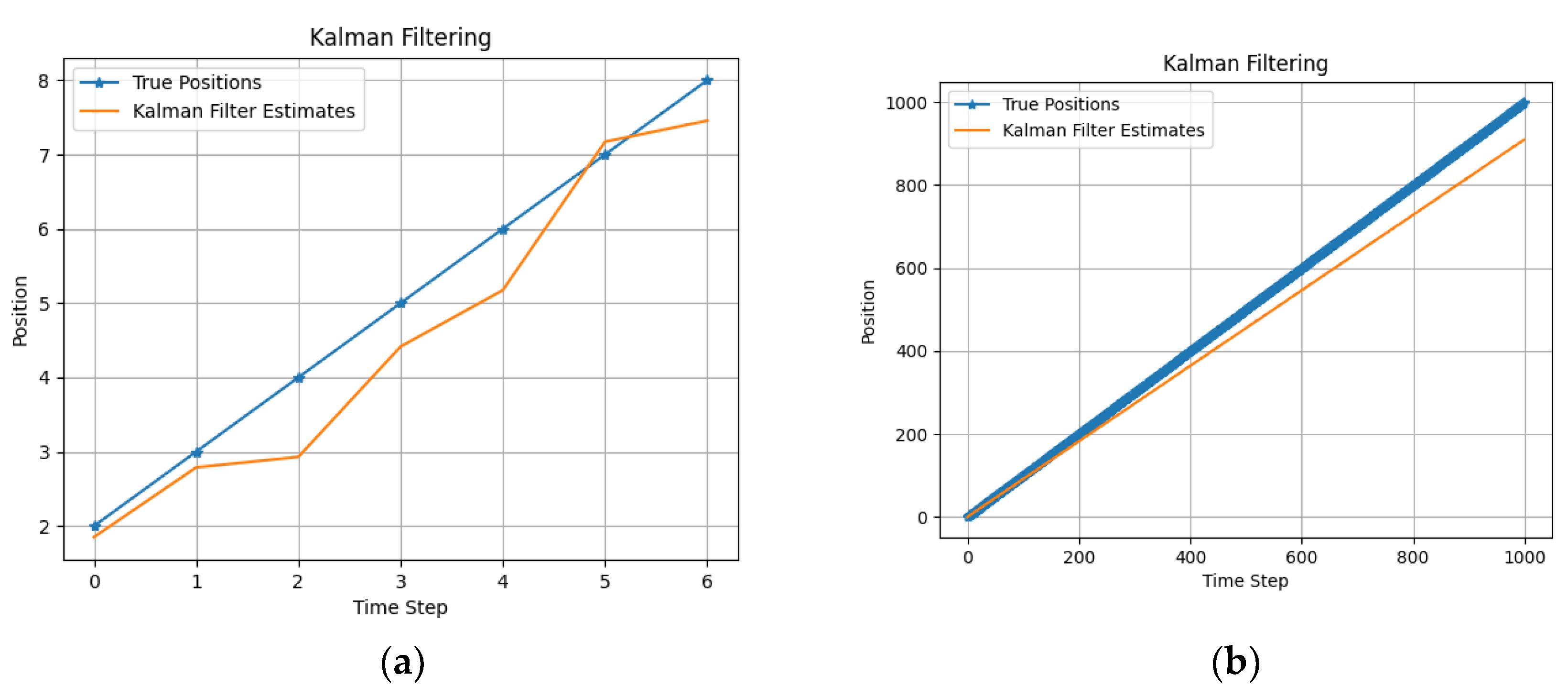
2.2. Kalman Filtering
2.2.1. Extended Kalman Filtering
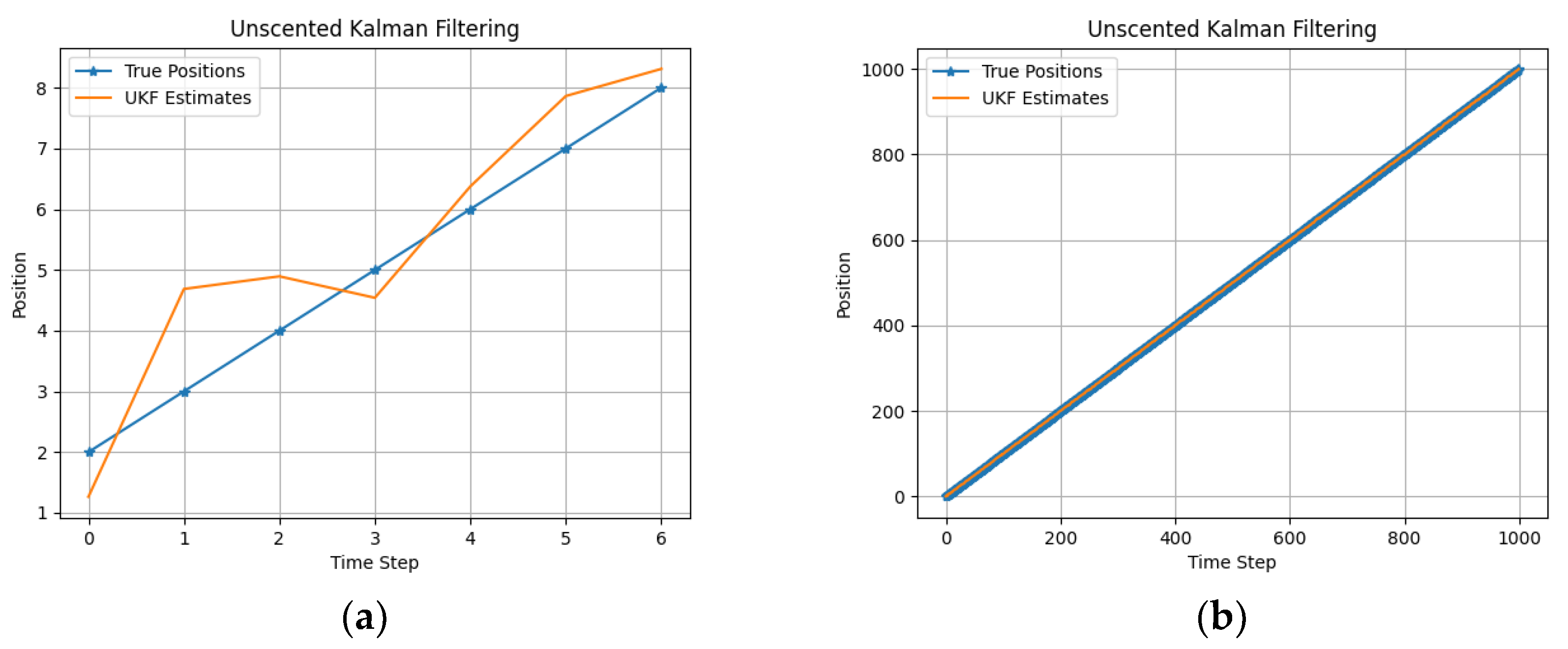
2.2.2. Unscented Kalman Filtering
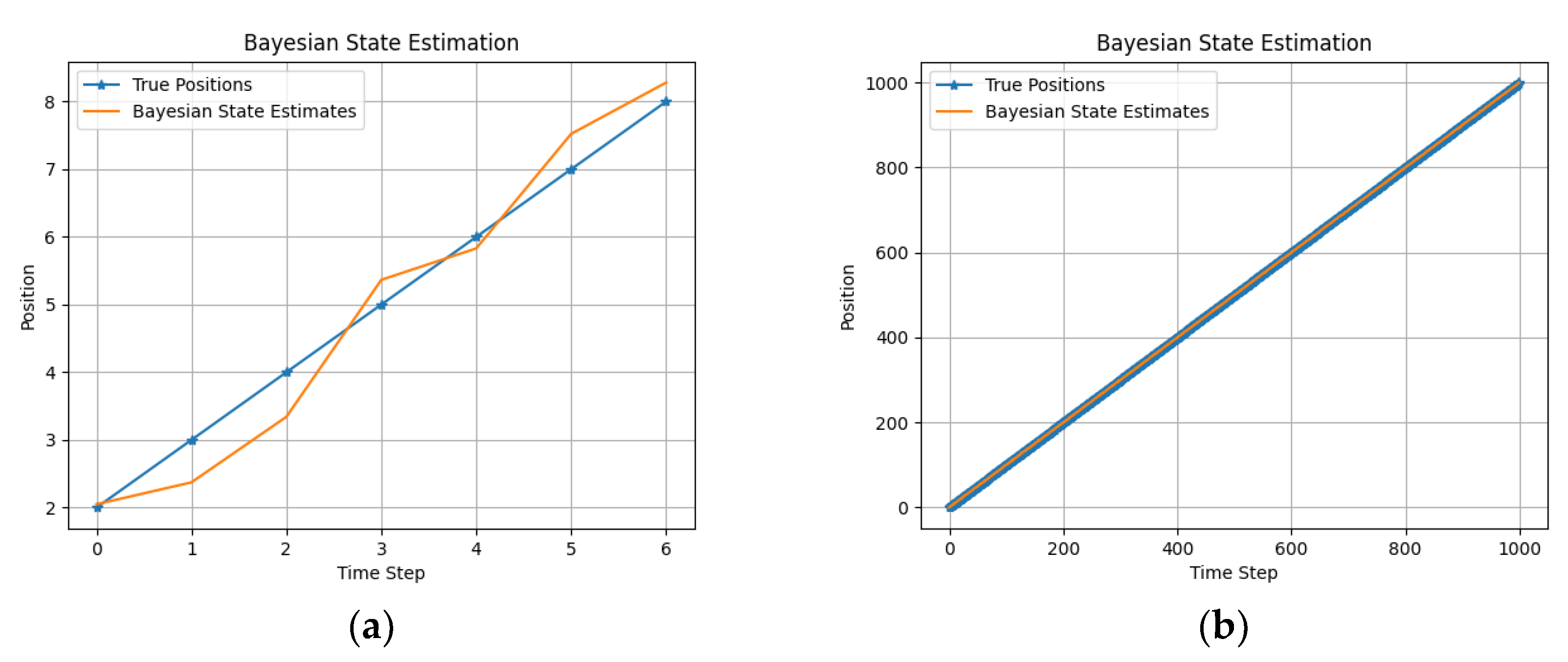
2.3. Bayesian Probability
Bayesian Network
3. Datasets
4. State Estimation
5. Experiments and Evaluation
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Nomenclature
| Symbols | Description |
| PF | Particle filtering |
| K | Time step |
| Xk | Estimated state at k time step |
| Zk | Measurements at k time step |
| Particle’s weight at k time step | |
| KF, EKF, UKF | Kalman filtering, extended Kalman filtering, unscented Kalman filtering |
| A, B | Representors of system dynamic |
| U(K) | The control input |
| W(K), V(K) | Random noise |
| H, I | Measurement matrix, identical matrix |
| f | Nonlinear state transition |
| h | Nonlinear measurement model |
| K | Kalman gain |
| P | Covariance matrix |
| BP, BN | Bayesian probability, Bayesian network |
| CPT | Conditional probabilistic table |
| Posterior probability of X given E | |
| P(x) | Prior probability of X |
| Marginal probability of all evidence |
References
- Ahmed, A.H.; Sadri, F. Datafusion: Taking source confidences into account. In Proceedings of the 8th International Conference on Information Systems and Technologies, Istanbul, Turkey, 16–18 March 2018. [Google Scholar] [CrossRef]
- Pochampally, R.; Das Sarma, A.; Dong, X.L.; Meliou, A.; Srivastava, D. Fusing data with correlations. In Proceedings of the SIGMOD ’14: Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data, Snowbird, UT, USA, 22–27 June 2014. [Google Scholar] [CrossRef]
- Dong, X.L.; Gabrilovich, E.; Heitz, G.; Horn, W.; Murphy, K.; Sun, S.; Zhang, W. From data fusion to knowledge fusion. Proc. Vldb Endow. 2014, 7, 881–892. [Google Scholar] [CrossRef]
- Hall, D.; Llinas, J. An introduction to multisensor data fusion. Proc. IEEE 1997, 85, 6–23. [Google Scholar] [CrossRef]
- Yeong, D.J.; Velasco-Hernandez, G.; Barry, J.; Walsh, J. Sensor and sensor fusion technology in autonomous vehicles: A review. Sensors 2021, 21, 2140. [Google Scholar] [CrossRef]
- Canalle, G.K.; Salgado, A.C.; Loscio, B.F. A survey on data fusion: What for? in what form? what is next? J. Intell. Inf. Syst. 2020, 57, 25–50. [Google Scholar] [CrossRef]
- Doumbia, M.; Cheng, X. State Estimation and localization based on sensor fusion for autonomous robots in indoor environment. Computers 2020, 9, 84. [Google Scholar] [CrossRef]
- Wills, A.G.; Schön, T.B. Sequential Monte Carlo: A unified review. Annu. Rev. Control. Robot. Auton. Syst. 2023, 6, 159–182. [Google Scholar] [CrossRef]
- Djuric, P.; Kotecha, J.; Zhang, J.; Huang, Y.; Ghirmai, T.; Bugallo, M.; Miguez, J. Particle filtering. IEEE Signal Process. Mag. 2003, 20, 19–38. [Google Scholar] [CrossRef]
- Sekehravani, E.A.; Babulak, E.; Masoodi, M. Flying object tracking and classification of military versus nonmilitary aircraft. Bull. Electr. Eng. Inform. 2020, 9, 1394–1403. [Google Scholar] [CrossRef]
- Kitagawa, G. Monte Carlo Filtering and smoothing for nonlinear NON-Gaussian state space model. In Proceedings of the ISCIE International Symposium on Stochastic Systems Theory and Its Applications, Online, 28 May 1998; Volume 1998, pp. 1–6. [Google Scholar] [CrossRef]
- Urrea, C.; Agramonte, R. Kalman Filter: Historical Overview and Review of Its Use in Robotics 60 Years after Its Creation. J. Sensors 2021, 2021, 9674015. [Google Scholar] [CrossRef]
- Goh, S.T.; Zekavat, S.A.; Abdelkhalik, O. An introduction to Kalman filtering implementation for localization and tracking applications. In Handbook of Position Location; Wiley: Hoboken, NJ, USA, 2018; pp. 143–195. [Google Scholar]
- Chadha, H.S. Extended Kalman Filter: Why do we need an Extended Version? Medium. 16 December 2019. Available online: https://towardsdatascience.com/extended-kalman-filter-43e52b16757d (accessed on 7 April 2018).
- Lagraoui, M.; Nejmi, A.; Rayhane, H.; Taouni, A. Estimation of lithium-ion battery state-of-charge using an extended kalman filter. Bull. Electr. Eng. Inform. 2021, 10, 1759–1768. [Google Scholar] [CrossRef]
- Kamarposhti, M.A.; Solyman, A.A.A. The estimate of amplitude and phase of harmonics in power system using the extended kalman filter. Bull. Electr. Eng. Inform. 2021, 10, 1785–1792. [Google Scholar] [CrossRef]
- Kirad, A.; Groini, S.; Soufi, Y. Improved sensorless backstepping controller using extended Kalman filter of a permanent magnet synchronous machine. Bull. Electr. Eng. Inform. 2022, 11, 658–671. [Google Scholar] [CrossRef]
- Julier, S.; Uhlmann, J. New extension of the Kalman filter to nonlinear systems. In Signal Processing, Sensor Fusion, and Target Recognition VI; SPIE: Weinheim, Germany, 1997. [Google Scholar] [CrossRef]
- György, K.; Kelemen, A.; Dávid, L. Unscented kalman filters and particle filter methods for nonlinear state estimation. Procedia Technol. 2014, 12, 65–74. [Google Scholar] [CrossRef]
- Wan, E.A.; Van Der Merwe, R. The unscented Kalman filter for nonlinear estimation. In Proceedings of the IEEE 2000 Adaptive Systems for Signal Processing, Communications, and Control Symposium (Cat. No.00EX373), Lake Louise, AB, Canada, 4 October 2000; pp. 153–158. [Google Scholar]
- van de Schoot, R.; Depaoli, S.; King, R.; Kramer, B.; Märtens, K.; Tadesse, M.G.; Vannucci, M.; Gelman, A.; Veen, D.; Willemsen, J.; et al. Bayesian statistics and modelling. Nat. Rev. Methods Prim. 2021, 1, 1–26. [Google Scholar] [CrossRef]
- Imoto, S.; Matsuo, H.; Miyano, S. Gene Networks: Estimation, Modeling, and Simulation; Elsevier: Amsterdam, The Netherlands, 2014; pp. 89–112. [Google Scholar] [CrossRef]
- Bielza, C.; Larraã±Aga, P. Bayesian networks in neuroscience: A survey. Front. Comput. Neurosci. 2014, 8, 131. [Google Scholar] [CrossRef]
- Ibeni, W.N.L.W.H.; Salikon, M.Z.M.; Mustapha, A.; Daud, S.A.; Salleh, M.N.M. Comparative analysis on bayesian classification for breast cancer problem. Bull. Electr. Eng. Inform. 2019, 8. [Google Scholar] [CrossRef]
- Chollet, F. Deep Learning with Python, 2nd ed.; Simon and Schuster: New York, NY, USA, 2021. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Toy Dataset with Seven Positions | Dataset with 1000 Positions | ||
|---|---|---|---|---|
| MAE | RMSE | MAE | RMSE | |
| PF | 0.138224009 | 0.174072531 | 1.011800165 | 1.011808264 |
| KF | 2.354036380 | 2.883750821 | 6.437892525 | 7.8795381774 |
| EKF | 0.504055178 | 0.546664779 | 0.582870877 | 0.726412512 |
| UKF | 0.3654765721 | 0.414921186 | 0.2751082709 | 0.3431953125 |
| BP | 0.381908303 | 0.438160207 | 0.396795988 | 0.4981912005 |
| Algorithm | Estimated States Using Toy Dataset [2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0] |
|---|---|
| PF | [2.023, 3.023, 4.2201, 5.328, 6.186, 7.114, 8.064] |
| KF | [1.496, 3.098, 3.058, 3.428, 5.806, 6.023,7.273] |
| EKF | [1.463, 3.366, 4.168, 5.330, 6.588, 7.729, 8.808] |
| UKF | [2.014, 3.075, 4.164, 5.586, 6.399, 7.214, 8.344] |
| BP | [2.611, 3.406, 4.001, 5.168, 6.751, 6.016, 7.462] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahmed, A.H.; Tomán, H. Stochastic Fusion Techniques for State Estimation. Computation 2024, 12, 209. https://doi.org/10.3390/computation12100209
Ahmed AH, Tomán H. Stochastic Fusion Techniques for State Estimation. Computation. 2024; 12(10):209. https://doi.org/10.3390/computation12100209
Chicago/Turabian StyleAhmed, Alaa H., and Henrietta Tomán. 2024. "Stochastic Fusion Techniques for State Estimation" Computation 12, no. 10: 209. https://doi.org/10.3390/computation12100209
APA StyleAhmed, A. H., & Tomán, H. (2024). Stochastic Fusion Techniques for State Estimation. Computation, 12(10), 209. https://doi.org/10.3390/computation12100209