1. Introduction
The Internet of Things (IoT) is a contemporary paradigm that comprises a wide range of heterogeneous inter-connected devices capable of transmitting and receiving messages in various formats through different protocols to achieve diverse goals, as noted by Bai Lan et al. [
1]. Presently, the IoT ecosystem encompasses over 20 billion devices, each with a unique identifier that can seamlessly interact via existing Internet infrastructure, as noted in [
2]. These devices have diverse areas of application, ranging from inside the human body to deep within the oceans and underground. The IoT refers to a network of physical devices, vehicles, buildings, and other items that are embedded with sensors, software, and other technologies to enable them to collect and exchange data. The main focus of the IoT is on enabling communication between these devices to enable automation and control.
CPS (cyber-physical systems) are similar to the IoT; however, CPS specifically refer to a system of physical, computational, and communication components that are tightly integrated to monitor and control physical processes. CPS typically involve a closed-loop feedback control system that involves sensors, actuators, and computational elements to continuously monitor and adjust physical processes in real-time.
CPS integrate physical components with software components, as noted by Buffoni et al. [
3]. According to references [
4,
5], CPS are able to operate on different spatial and temporal scales.
Control systems coupled to physical systems are a common example of CPS, with applications in various domains such as smart grids, autonomous automobile systems, medical monitoring, industrial control systems, robotics systems, and automatic pilot avionics. CPS are becoming data-rich, enabling new and higher degrees of automation and autonomy.
New, smart CPS drive innovation and competition in a range of application domains, including agriculture, aeronautics, building design, civil infrastructure, energy, environmental quality, healthcare, personalized medicine, manufacturing, and transportation.
Despite some similarities, the primary distinction between the IoT and CPS is their focus. CPS are mainly focused on controlling physical processes, while the IoT is primarily focused on communication and data exchange between physical devices. CPS are typically used in industrial and manufacturing settings, where they facilitate real-time control of physical processes. On the other hand, the IoT has a broader range of applications, including home automation, healthcare, transportation, and other domains, where it enables seamless communication and integration of smart devices.
With the ever-increasing number of IoT and CPS devices, the need for more functional and high-quality software has become even more pressing. According to industry estimates, the global IoT market reached
$100 billion in 2017, and this figure is projected to soar to
$1.6 trillion by 2025, as noted in [
6]. In 2022, enterprise spending on the IoT experienced a significant increase of 21.5%, reaching a total of
$201 billion. Back in 2019, IoT analytics had initially projected a spending growth of 24% for the year 2023. However, their growth outlook for 2023 has been revised to 18.5% according to [
7], as shown in
Figure 1.
A model-based approach to CPS development is based on describing both the physical and software parts through models, allowing the whole system to be simulated before it is deployed.
There are several programming languages used in IoT and CPS development, including C/C++, Python, Java, JavaScript, and others. Among these, C/C++ is considered to be the most popular language for IoT development, with a popularity rate of 56.9%, according to recent research [
8]. As of June 2023, GitHub has reported a total of over 53,285 IoT public repositories, with approximately 28,536 of them being C/C++ repositories, accounting for approximately 53.6% of the total number of IoT public repositories. Additionally, GitHub has reported over 22,776 CPS public repositories, out of which around 8892 are C/C++ repositories, making up approximately 39% of the total number of CPS public repositories. This is due to the fact that IoT devices typically have limited computing resources, and C/C++ is capable of working directly with the RAM while requiring minimal processing power.
CPS languages provide a unified approach to describing both the physical components and control software, making it possible to integrate modeling and simulation. Open standards such as FMI (Functional Mock-up Interface) and SSP (System Structure and Parameterization) facilitate this integration by defining a model format that utilizes the C language for behavior and XML for the interface. These standards, as specified in [
9,
10], enable the representation of pre-compiled models that can be exchanged between tools and combined for co-simulation.
According to the specifications outlined in [
11], Modelica has been employed for the automatic generation of deployable embedded control software in C code from models. This utilization enhances the utility of Modelica as a comprehensive solution for the modeling, simulation, and deployment of CPS components.
The selection of a programming language for IoT and CPS development is highly dependent on the specific requirements of the project as well as the developer’s proficiency. According to [
12], utilizing C++ in embedded systems can be an effective solution, even considering the limited computing resources of microcontrollers used in small embedded applications compared to standard PCs. The clock frequency of microcontrollers may be much lower, and the amount of available RAM memory may be significantly less than that of a PC. Additionally, the smallest devices may not even have an operating system. To achieve the best performance, it is essential to choose a programming language that can be cross-compiled on a PC and then transferred as machine code to the device, avoiding any language that requires compilation or interpretation on the device itself, as this can lead to significant resource wastage.
For these reasons, C or C++ is often the preferred language for embedded systems, with critical device drivers requiring assembly language. If you follow the proper guidelines, using C++ can consume only slightly more resources than C, so it can be chosen based on the desired program structure. Overall, choosing the appropriate language for embedded systems can make a significant impact on performance and resource utilization.
The increasing number of IoT and CPS devices has resulted in a growing need for software that is both highly functional and of the utmost quality. As these devices become more ubiquitous and seamlessly integrated into our daily lives, the demand for dependable and efficient software becomes more critical than ever before. As a result, developers are constantly striving to enhance their software development methodologies and technologies to meet the ever-evolving demands of the IoT and CPS landscape.
However, given the increasing importance of the IoT and CPS as emerging technologies, it is expected that there will be more literature available on the topic of IoT and CPS software verification and quality assurance.
The typical software development life cycle (SDLC) involves several steps, including requirement analysis, design, implementation, testing and verification, and deployment and maintenance. While testing can increase our confidence in the program’s correctness, it cannot prove it definitively. To establish correctness, we require a precise mathematical specification of the program’s intended behavior and mathematical proof that the implementation meets the specification.
IoT verification encompasses a range of testing methodologies. These include conformance testing, as highlighted by Xie et al. [
13], randomness testing, as discussed by Parisot et al. [
14], statistical verification, as explored by Bae et al. [
15], formal verification, as studied by Silva et al. [
16], and the method known as model-based testing, as outlined by Ahmad [
17]. In the specific context of the IoT, the model-checking technique, as emphasized by Clarke et al. [
18], has notable representatives closely associated with it.
However, such software verification is difficult and time-consuming and is not usually considered cost-effective. In addition, modern verification methods would not replace testing in SDLC because most programs are not correct initially and need debugging before verification. The primary principle of verification involves adding specifications and invariants to the program and checking the verification conditions by proving generated lemmas based on the requirement specifications, as noted by Back [
19].
However, most existing verification tools cannot detect software errors arising from incorrect usage of dimensions or units, which are commonly referred to as dimensionality errors or unit errors. These errors occur when software code or algorithms manipulate data with incompatible dimensions or units, resulting in incorrect calculations, unexpected behavior, or system failures. Such errors can have significant consequences across various domains, including engineering, finance, and scientific research:
Inconsistent unit conversions
Mixing incompatible units
Incorrect scaling or normalization
Mathematical operations on incompatible dimensions
Inaccurate assumptions about input units
By being aware of these potential pitfalls and implementing proper checks, validation, and unit-aware programming techniques, developers can mitigate dimensionality or unit errors, ensuring accurate and reliable software functioning.
The failure of the Mars Climate Orbiter during its mission to study Mars’ climate serves as a stark reminder of the consequences of navigational errors [
20,
21]. The spacecraft was intended to enter orbit around Mars in September 1999 but tragically entered the planet’s atmosphere too low and disintegrated. This catastrophic error occurred due to a mismatch in the use of metric and imperial units, leading to incorrect calculations. Lockheed Martin, the contractor responsible for the spacecraft’s navigation, used imperial units while NASA’s software expected metric units. The failure resulted in a loss of
$193.1 million and valuable scientific data. Lessons learned from this incident have since led to improved communication and unit conversion protocols in future space missions.
NASA’s conversion concerns are particularly relevant to the constellation project, which places significant emphasis on manned spaceflight [
22]. Launched in 2005, the project ambitiously aims to facilitate future moon landings. However, an obstacle arises as the project’s specifications and blueprints are exclusively in British imperial units. The conversion of this extensive body of work into metric units poses a considerable estimated expenditure of approximately
$370 million.
In 2003, Tokyo Disneyland’s Space Mountain roller coaster experienced a disruptive event when it came to a halt due to a broken axle that failed to meet design requirements [
23]. The axle’s excessive gap, which exceeded 1 mm instead of the required 0.2 mm, led to fractures caused by vibrations and stress. Fortunately, no injuries occurred despite the derailment. The accident resulted from discrepancies in unit systems. In 1995, the coaster’s axle specifications switched to metric units, but in August 2002, an order mistakenly reverted to British imperial units, leading to 44.14 mm axles instead of the required 45 mm ones.
In 1983, an Air Canada Boeing 767 experienced fuel depletion during a Montreal to Edmonton flight [
24]. Low fuel pressure warnings at 41,000 feet led to engine failures. However, the skilled captain and first officer managed to land the plane safely at an unused air force base nearby, with only a few minor passenger injuries. The incident was caused by a malfunctioning fuel indication system and an incorrect density ratio of 1.77 pounds per liter instead of the correct 0.80 kg per liter. These factors led maintenance workers to manually calculate and pump less than half the required amount of fuel, contributing to the incident.
Adding to the list of errors, in the early 1990s during the creation of the “Mir” space orbital station, another incident occurred due to incorrect usage of units of measurement. When experts from the Moscow Design Bureau sent data in kilogram-force to Khartron in Kharkiv, Ukraine (where one of the authors of this article worked), it was mistakenly interpreted as newtons. Consequently, the control system of the module, weighing approximately 20 tons, had to be reprogrammed during the flight, leading to a two-week delay in its journey to the station.
To mitigate dimensionality or unit errors, it is crucial to follow best practices, which include the following:
Clearly specifying and documenting the expected units and dimensions of input and output data.
Implementing reliable and consistent unit conversion routines.
Leveraging libraries or frameworks with built-in support for units and dimensions.
Conducting comprehensive testing, including dedicated unit tests, to validate the accuracy of calculations and conversions.
Validating assumptions about input units and implementing suitable checks.
Providing informative error messages or warnings when dimensionality or unit errors are detected.
By being mindful of dimensions and units during software development, developers can reduce the occurrence of errors and ensure the accuracy and reliability of their software.
There are several libraries and frameworks available that offer built-in support for handling units and dimensions in software development. In the following are some popular options:
As noted by Matthias Christian Schabel et al. [
25], Boost.Units provides a comprehensive framework for handling physical quantities in C++ programming. It allows you to work with quantities with different units, perform arithmetic operations, and ensure dimensional consistency at compile-time. Boost.Units offers compile-time dimensional analysis, type-safe unit conversions, and supports custom unit systems. It is particularly useful in scientific and engineering applications, where precise handling of units and dimensions is crucial for accurate calculations.
As noted by Edzer Pebesma [
26], UDUNITS is a flexible and extensive library primarily used in scientific and meteorological applications. It offers a comprehensive database of physical units, allowing for unit conversions, arithmetic operations, and parsing of unit expressions. UDUNITS supports a wide range of units and provides bindings for various programming languages, including Python and Java. It is a reliable solution for managing units and dimensions, especially in domains that require extensive support for physical quantities.
According to [
27], Units.NET is a powerful and user-friendly library for managing physical quantities in C# applications. It provides a comprehensive set of units, supporting unit conversions, arithmetic operations, and dimensional analysis. With Units.NET, developers can work with units and dimensions in a strongly typed manner, ensuring type safety and accurate calculations. It simplifies the handling of units and dimensions in C# projects, making it convenient to work with physical quantities.
Common disadvantages of the described libraries are that they cannot utilize orientational information for checking software code.
In addition, the utilization of a specialized software language called F# enables efficient manipulation of physical units and dimensions [
28]. While F# is widely recognized for its applications in general-purpose programming and data analysis, it also proves to be highly effective in the context of the IoT (Internet of Things) and CPS (cyber-physical systems) domains.
However, in the case of reusing IoT and CPS software programs that employ different physical units and orientations of physical values, which are typically implemented in languages like C++, it becomes essential to undergo additional formal verification. This verification process should incorporate orientational and dimensional information to ensure successful integration and reduce the development time of new software projects.
This article focuses on exploring a formal verification method that utilizes dimensional and orientational homogeneities and natural software invariants. Specifically, it considers the dimensions and orientations of physical quantities as defined by the International System of Units (SI), as described in references [
29,
30]. Additionally, it incorporates transformations of physical quantity orientations proposed by Siano [
31,
32] and extended by Santos et al. [
33]. By leveraging these invariants, this method can effectively verify the correctness of software and detect errors that may arise due to inconsistent or incorrect use of units and dimensions, as well as incorrect usage of software operations, variables, and procedures, among other things.
The SI defines a set of base units, such as meters for length, kilograms for mass, and seconds for time, along with derived units, which are combinations of base units, such as meters per second for velocity or kilograms per cubic meter for density.
When it comes to software code, developers often need to work with and manipulate physical quantities in their programs. To ensure the correctness of such code, formal software verification methods can be applied. These methods use mathematical techniques to formally prove the properties of the software, such as its correctness, safety, or absence of certain errors.
The concept of homogeneity, derived from the SI system, plays a significant role in formal software verification. Siano proposed extending dimension homogeneity via orientation [
31,
32]. Now, the main concept of homogeneity states that any physical equation involving physical quantities must be both dimensionally and orientationally consistent. In other words, the units on both sides of an equation must match.
It is important to note that formal software verification involves more than just ensuring the homogeneity of physical quantities. It encompasses a broader range of techniques and methods to rigorously analyze and prove properties about software systems. However, leveraging the concept of homogeneity from the SI system can be a valuable tool in the pursuit of formal software verification, especially when dealing with physical quantities. The approach of leveraging the homogeneity of physical quantities and applying formal software verification techniques can make a significant contribution to ensuring functional and high-quality software for the IoT and CPS.
The advantages of the proposed method for software correctness and safety are that by utilizing formal software verification techniques, such as enforcing both dimensional and orientational homogeneity, developers can detect errors early in the development process and ensure that the software behaves as intended. This, in turn, reduces the potential for system failures or safety incidents.
IoT and CPS systems are typically subject to updates, maintenance, and evolution throughout their lifecycle. Enforcing both dimensional and orientational homogeneity and applying formal verification methods can enhance software maintainability and evolvability. By establishing clear and consistent units and enforcing them in the code, developers can more easily understand and modify the software, reducing the risk of introducing errors during updates or modifications. This promotes efficient maintenance and facilitates the evolution of the software as new requirements or functionalities are introduced.
Formal software verification methods, including the use of homogeneity, contribute to a rigorous quality assurance process. By systematically applying verification techniques, developers can identify and eliminate potential software defects, thereby improving the overall quality and reliability of IoT and CPS systems. This, in turn, enhances user satisfaction, reduces the risk of failures, and increases confidence in the deployed software. The thorough verification process helps ensure that the software meets the specified requirements and operates correctly in various scenarios, thereby ultimately enhancing the overall quality assurance efforts.
By combining the principles of homogeneity from the SI system with formal software verification methods, developers can create more robust, reliable, and functional software for the IoT and CPS. This approach helps mitigate risks, ensures safety, enhances interoperability, facilitates maintenance, and improves the overall quality of the software deployed in these systems.
2. The Formal Software Verification Method
Proposed is the utilization of natural software invariants, which are the physical dimensions and spatial orientation of software variables that correspond to real physical quantities. By incorporating these invariants into the program specification, it becomes possible to convert all program expressions into a series of lemmas that must be proven. This enables the verification of the homogeneity and concision of the program.
2.1. Using Dimensional Homogeneity in Formal Software Verification
According to Martínez-Rojas et al. [
34], dimensional analysis is a widely used methodology in physics and engineering. It is employed to discover or verify relationships among physical quantities by considering their physical dimensions. In the SI a physical quantity’s dimension is the combination of the seven basic physical dimensions: length (meter, m), time (second, s), amount of substance (mole, mol), electric current (ampere, A), temperature (kelvin, K), luminous intensity (candela, cd), and mass (kilogram, kg). Derived units are products of powers of the base units, and when the numerical factor of this product is one, they are called coherent derived units. The base and coherent derived units of the SI form a coherent set designated as the set of coherent SI units. The word “coherent” in this context means that equations between the numerical values of quantities take the same form as the equations between the quantities themselves, ensuring consistency and accuracy in calculations involving physical quantities.
Some of the coherent derived units in the SI are given specific names and, together with the seven base units, form the core of the set of SI units. All other SI units are combinations of these units. For instance, plane angle is measured in radians (rad), which is equivalent to the ratio of two lengths; solid angle is measured in steradians (sr), which is equivalent to the ratio of two areas. The frequency is measured in hertz (Hz), which is equivalent to one cycle per second. The force is measured in newtons (N), which is equivalent to kg m/s2. The pressure and stress are measured in pascals (Pa), which is equivalent to kg/m s2 or N/m2. The energy and work are measured in joules (J), which is equivalent to kg m2/s2 or N m.
The fundamental principle of dimensional analysis is based on the fact that a physical law must be independent of the units used to measure the physical variables. According to the principle of dimensional homogeneity, any meaningful equation must have the same dimensions on both sides. This is the fundamental approach to performing dimensional analysis in physics and engineering.
Existing software analysis tools only check the syntactic and semantic correctness of the code, but not its physical correctness. However, we can consider the program code of systems as a set of expressions consisting of operations and variables (constants). By using DA, we can verify the physical consistency of the program code and detect errors that may arise due to inconsistent or incorrect use of units and dimensions.
To check the correctness of expressions, we can use the dimensionality of program values. Preservation of the homogeneity of the expressions may indicate the physical usefulness of the expressions. Violation of homogeneity indicates the incorrect use of a program variable or program operation. Dimensional analysis provides an opportunity to check not only simple expressions but also calls to procedures and functions. The use of the physical dimension allows the verification of the software.
Dimensional analysis is a powerful tool that can be used to ensure the physical correctness of software code. By checking the dimensionality of program values, we can ensure the preservation of the homogeneity of expressions, which may indicate the physical usefulness of the code. In cases where homogeneity is violated, it may indicate an incorrect use of program variables or operations. Dimensional analysis can be applied not only to simple expressions but also to calls to procedures and functions, providing a comprehensive approach to verifying the physical consistency of the software.
We can view software as a model, and dimensional analysis can serve as a validation tool to ensure that this model adheres to the physical laws and principles governing the system it represents. By incorporating physical dimensions into the validation process, we can effectively identify and rectify errors that may arise from inconsistent or incorrect usage of units and dimensions. This approach ultimately contributes to the development of more reliable and accurate software.
In the software system, we can define it as a collection of interacting sub-systems. Each sub-system consists of interacting software units, and each unit comprises a set of operators. Operators, in turn, are ordered sets of statements or expressions. By structuring the software system in this hierarchical manner, we can effectively check the interactions and operations within the system.
To prove the homogeneity of software systems, we need to demonstrate the homogeneity of each subsystem. Similarly, to prove the homogeneity of subsystems, we need to establish the homogeneity of each software unit. Finally, to ensure the homogeneity of software units, we need to demonstrate the homogeneity of each software statement or expression. This stepwise approach allows us to systematically verify the homogeneity of the software and ensure its adherence to the specified physical dimensions.
Let us introduce a set of “multiplicative” operations {*, /, etc.} that generate new physical dimensions, while “additive” operations {+, −, =, <, ≤, >, ≥, !=, etc.} act as checkpoints to ensure dimensional homogeneity. If the source code contains variables that preserve specific physical dimensions, we can utilize this property, known as dimensional homogeneity, as a software invariant. Each additive operation serves as a source for generating lemmas. Following the principle of dimensional homogeneity, we can develop a set of lemmas to support the verification process.
By employing dimensional analysis, we can verify the physical dimensions of variables to identify errors resulting from inconsistent or incorrect usage of units and dimensions, as well as improper utilization of software operations, variables, and procedures. However, it is worth noting that certain variables may possess the same dimensions, such as moments of inertia and angular velocities. In order to detect software defects arising from the erroneous handling of such variables, careful examination of expressions involving angles, angular speed, and related quantities is required. It is important to remember that, according to the SI, angles are considered dimensionless values.
2.2. Using Orientational Homogeneity in Formal Software Verification
To address this issue, we can utilize features for transformations of angles and oriented values. In [
31,
32], Siano proposed an orientational analysis as an extension of dimensional analysis. This approach involves considering not only the physical dimensions but also the orientations of the quantities to enhance the analysis.
The use of orientational analysis can aid in expanding the base unit set while also ensuring dimensional and orientational consistency. Additionally, the orientational analysis technique can be applied for the formal verification of software code, allowing for a thorough evaluation of its accuracy and reliability.
Siano’s proposed notation system for representing vector directions involved the use of orientational symbols
,
,
[
31,
32]. Furthermore, a symbol without orientation represented by
was introduced to represent vectors that do not possess a specific orientation.
For example, a velocity in the x-direction can be represented by , while a length in the x-direction can be represented by . Here, the symbol denotes that the quantity on the left-hand side has the same orientation as the quantity on the right-hand side. In non-relativistic scenarios, mass is considered to be a quantity without orientation.
In order for equations involving physical variables to be valid, they must exhibit orientational homogeneity, meaning that the same orientation must be utilized on both sides of the equation. Furthermore, it is crucial that the orientations of physical variables are assigned in a consistent manner. For instance, the representation of acceleration in the x-direction as , , and is only valid if both sides have the same orientation.
But what about the orientation of time? From the expression we can define the time as follows: .
The physical quantity of time is considered to be without orientation, meaning it does not possess a specific orientation in space.
In order to maintain orientational homogeneity, it is necessary to introduce a characteristic length scale , since time is a quantity without orientation. Therefore, can be expressed as and , ensuring that the orientation of remains consistent. That is why .
It is essential to assign orientations to physical variables in a consistent manner. For instance, pressure is defined as force per unit area. If the force is acting in the
z-direction, then the area must be normal to it etc.:
In order for pressure to be considered a quantity without orientation, the area S must have the same orientation as the force F. If the force F is in a particular direction, then the area S must be normal to that direction, meaning that both variables have the same orientation. Therefore, pressure can only be a quantity without orientation if this consistent orientation is maintained.
We define this as follows:
If
,
,
a volume of space,
V, is a quantity without orientation:
Let us take a look at uniformly accelerated motion in the x-direction: , where is the total distance, is the initial distance, is the velocity, and is the acceleration.
According to orientational homogeneity
The orientation of derived physical variables, such as kinetic energy, can be determined by properly assigning orientation to primitive variables and applying the corresponding multiplication rules:
We considered the orientation of an angle in the x-y plane. Because and we deduced that and an angular velocity of .
Let us take the following series:
If has any orientation, then sine () would also have that orientation, while the cosine () would be a quantity without orientation. This is because the sine function involves the odd powers of , while the cosine function involves the even powers of .
Siano demonstrated that orientational symbols have an algebra defined by the multiplication table for the orientation symbols [
31,
32], which is as follows:
Based on the above, the product of two orientated physical quantities has an orientation as follows:
If a source code contains variables that represent physical quantities with orientations, we can use the property of orientational homogeneity as a software invariant. By applying orientational homogeneity, we can transform the source code into a set of lemmas. Multiplicative operations, such as multiplication and division, introduce new physical orientations. On the other hand, additive operations such as addition, subtraction, and relational operators (e.g., =, <, ≤, >, ≥, !=) serve as checkpoints for verifying orientational homogeneity.
2.3. Examples of Software Formal Verifications
Example 1. Consider the expression , where is a force with physical units of (kg m s−2), is the mass in (kg), and is the acceleration in (m s−2). This expression allows us to derive the orientation and dimension of the product . If is without orientation (denoted by ) and is in the x-direction (denoted by ), then has the x-orientation. If has units of (kg) and has units of (m s−2), then the dimensions of the result are (kg m s−2). The assignment operation “=“, which is also known as the equality operator, acts as a checkpoint for our software invariants. It ensures that the physical orientation of is equal to the physical orientation of and that the physical dimensions of are equal to the physical dimensions of the result.
Example 2. Consider the expression , where represents the total distance, is the initial distance, is the velocity, is the acceleration, and is the time. This expression generates two new physical dimensions and orientations. The second “+” operation checks the dimensions and orientations of and . The first “+” operation checks the homogeneity of and the result of the previous operation. Finally, the assignment operator “=“ checks the homogeneity of and the result of the previous operation. By checking the homogeneity of these variables and operations, we can ensure that the physical dimensions and orientations are consistent throughout the expression.
Example 3. When calling procedures and functions, it is not always possible to check the physical dimensions and orientation of the arguments. However, for function signatures such as Type1 and some Function2 (Type2 x…), where Type1 and Type2 have information about the physical dimensions and orientations of their arguments, it is possible to check the physical dimensions and orientations of the arguments. Each argument of a function generates a special lemma that can be used to prove dimensional and orientational homogeneities. Only after proving all the lemmas can we prove the correctness of the function call. It is important to note that real arguments of exponential and logarithmic functions must be dimensionless and without orientation to preserve dimensional and orientational homogeneities. On the other hand, arguments of trigonometric functions such as sine(x), cosine(x), and tan(x) must be orientated to preserve orientational homogeneity, while also being dimensionless to preserve dimensional homogeneity. The proposed method allows for the checking of physical dimensions and orientations in software statements and units. Repeating this check helps to ensure the correctness of the software system.
Example 4. Let us examine Euler’s rotation equations, as described in [35], which find numerous applications in fields such as cyber-physical systems (CPS) and the Internet of Things (IoT). These equations are utilized in various contexts, including unmanned cars, helicopters, and other aerial vehicles. The general vector form of the equations is , where M represents the applied torques and is the inertia matrix. The vector represents the angular acceleration.
In orthogonal principal axes of inertia coordinates the equations become
where
,
,
are the components of the applied torques (kg m
2 s
−2);
,
, and
are the principal moments of inertia (kg m
2);
,
, and
are the components of the angular velocities (s
−1); and
,
, and
have dimension (s
−2). However,
,
,
, and
have different orientations
, where
.
We can verify the dimensional homogeneity of Equation (1), but it is not possible to identify all defects. This is because certain quantities have the same dimensions and cannot be distinguished solely based on their units. For example, the dimensions of the moments of inertia (, , ) are (kg m2) and angular velocities (, , ) are (s−1), and the dimensions of the angular acceleration components (, , ) are (s−2) since angles are dimensionless. Therefore, while dimensional analysis can help identify some potential issues with the equation, it may not be able to catch all possible defects. For example, we cannot detect a defect if the expression does not include the initial position .
In the context of Equation (1), the parameters (, , , etc.) may have different orientations or values, which can help in detecting defects.
Furthermore, checking both the dimensional and orientational homogeneities of an equation can improve our ability to detect defects and ensure their correctness. This approach can be useful in the formal verification of CPS and IoT software, as it can help identify potential issues before they lead to real-world problems.
Let us assess the probability of detecting a software defect using both dimensional analysis and orientational analysis.
2.4. Software Defect Detection Models
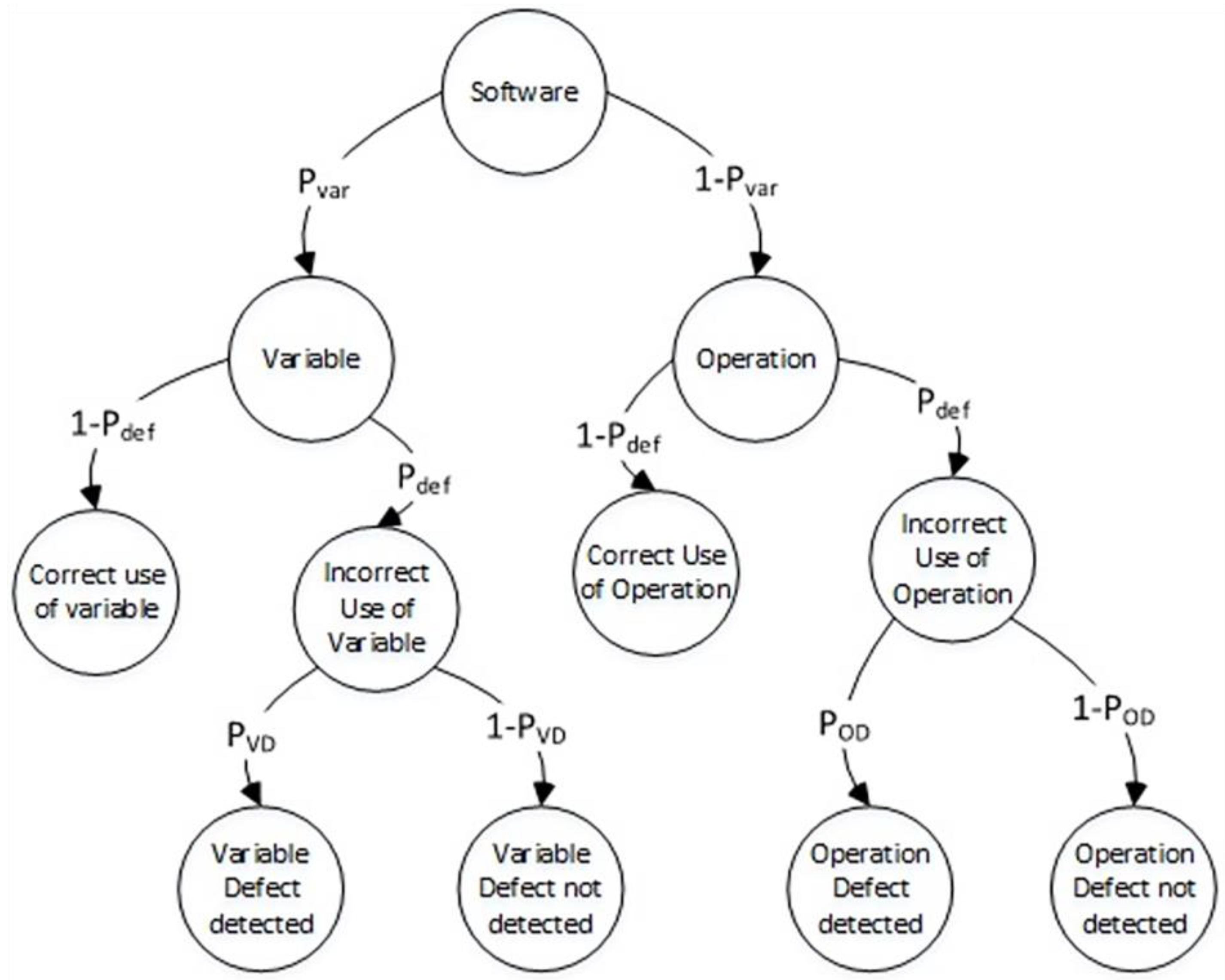
2.4.1. General Software Defect Detection Model
To simplify the analysis, we assume that the software statement can only have one defect with a probability of . The model starts with the initial event state of ‘Software’ and branches out into two possible outcomes at the next level: ‘Software has a defect’ and ‘Software does not have a defect’, with probabilities of and , respectively.
Decision trees, as described in [
36], are visual representations utilized in decision analysis and machine learning. They illustrate decisions or events along with assigned probabilities or outcomes. Decision trees offer a structured approach to analyzing intricate decision-making processes. They can be applied to predict software defect detection, facilitating the identification and prevention of software issues, as demonstrated in
Figure 2.
In the state ‘Software has a defect’, our focus shifts to detecting the defect. At the third level, the model branches out into two possible outcomes: ‘Defect detected’ and ‘Defect not detected’, with probabilities of and , respectively.
The revised sentence maintains clarity and correctness in grammar.
To define the conditional probability of software defect detection, we used the following formula:
Here represents a probability of a software defect in the code; represents a probability of a software defect detection.
We can also introduce a more complex general software defect detection model (see
Figure 3), which accounts for two types of defects: variable defects (uncorrected usage of a variable with incorrect dimension or orientation) and operation defects (incorrect usage of an operation). Despite the presence of multiple types of defects, the model still assumes that there is only one defect present in the software statement at any given time.
In this more complex model, the software statement can have two types of defects: variable defects and operation defects. A ‘Variable defect’ occurs when there is an incorrect usage of a variable in the code, such as using the wrong variable name. An ‘Operation defect’ occurs when there is an incorrect usage of an operation in the code, such as using the wrong operator symbol. Despite the presence of these two types of defects, the model still assumes that only one defect is present in the statement at any given time.
In this more complex model, the initial event state is ‘Software’. At the branching point, the model expands into two possible outcomes: ‘Variable’ and ‘Operation’, with probabilities of and , respectively.
The ‘Variable’ state has two potential outcomes at the next level: ‘Correct use of variable’ and ‘Incorrect use of variable’, with probabilities of and , respectively.
The ‘Incorrect use of variable’ state then branches out into two possible outcomes at the next level: ‘Variable defect detected’ and ‘Variable defect not detected’, with probabilities of and , respectively. Here, represents the probability of detecting a variable defect in the source code.
In addition to the ‘Variable’ state, the model also has an ‘Operation’ state, which has two possible outcomes at the next level: ‘Correct use of operation’ and ‘Incorrect use of operation’, with probabilities of and , respectively.
The ‘Incorrect use of operation’ state then branches out into two possible outcomes at the next level: ‘Operation defect detected’ and ‘Operation defect not detected’, with probabilities of and , respectively. Here, represents the probability of detecting an operation defect in the source code.
The conditional probability of a software defect can be defined as follows:
After substitution
in the source expression:
As per Expression (2), the conditional probability of software defect detection depends on the probability of the software variables used in the source code and the conditional probabilities of detecting defects (defects of operations and defects of variables). We can determine the value of by analyzing the software code statically, i.e., without executing the code. However, to determine the values of and , we would need to build additional software defect detection models.
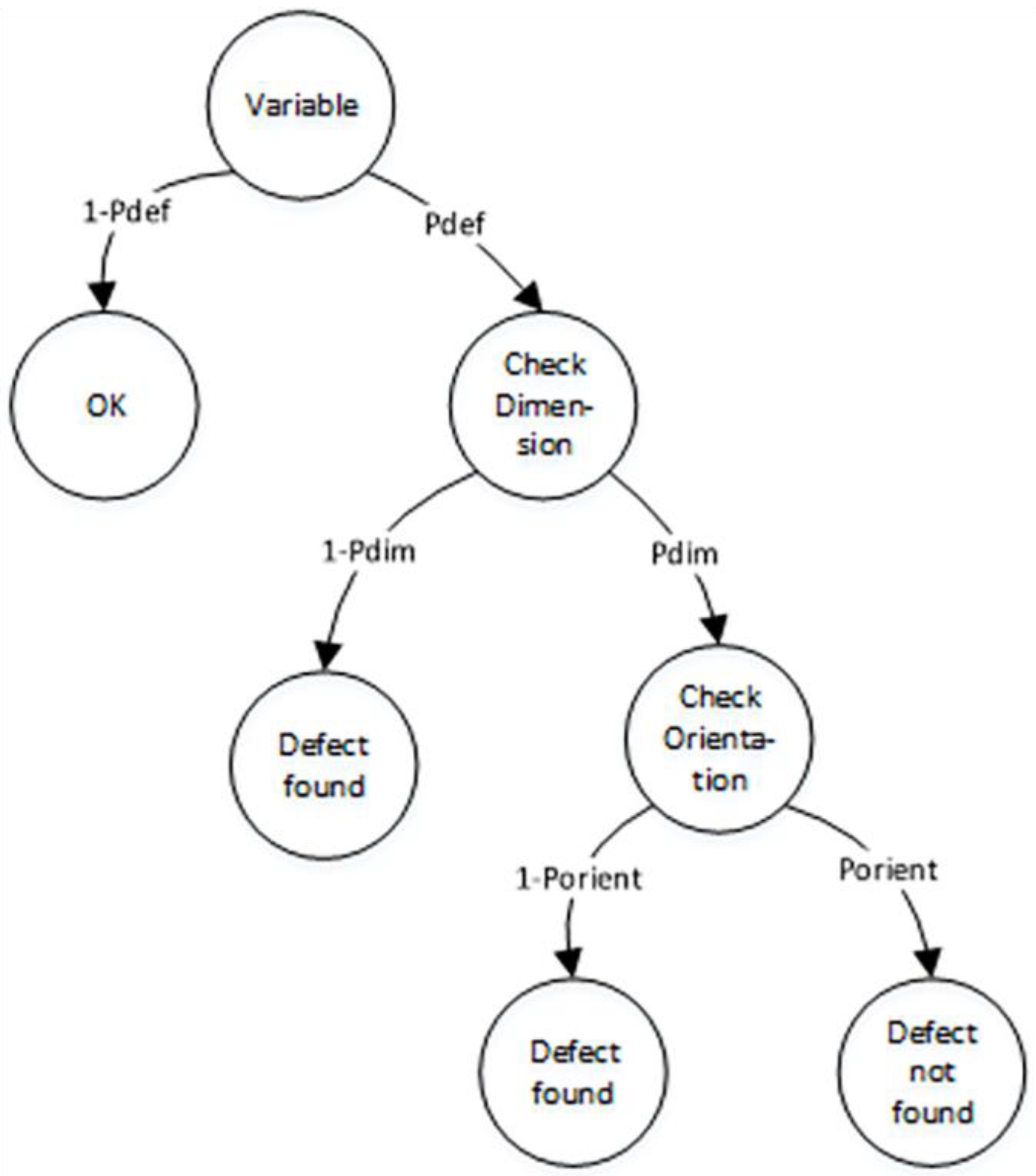
2.4.2. Simple Model for Detection of Incorrect Use of Variables Based on Dimensional Analysis
Next, we introduce the simple model for the detection of incorrect use of variables based on dimensional analysis, as depicted in
Figure 4.
This model has an initial state of ‘Variable’. The initial state has two transitions to states ‘OK’ and ‘Check Dimension’, with probabilities and , respectively. In the state ‘Check Dimension’, we can evaluate the required physical dimension of the variable using dimensional analysis, such as length, mass, time, thermodynamic temperature, etc.
If the actual physical dimension is equal to the required physical dimension, we cannot detect the software defect. However, if they differ, we can identify the software defect. In this case, the probabilities are and , where represents the probability of two random variables having the same physical dimension.
Let us define the conditional probability of defect detection of incorrect use of a program variable as follows:
Let us consider a set of distinct software variables and a set of diverse physical dimensions , where represents the cardinality of set and represents the cardinality of set .
To depict the relationship between these variables and dimensions, we can make use of an
-matrix (4):
The equation for the total quantity of usages of all software variables that have the same j dimension can be written as follows:
where
represents the total quantity usage of
i-variable which has a
j-physical dimension, and
is the cardinality set of software variables.
Equation (5) shows the total number of variable usages in the code:
To define the probability of choosing
i-variable and
j-variable with the same dimensions, we can use the total number of usages of variables with the
j-physical dimension and the total number of usages of all variables in the code:
According to (7), the probability of choosing two random variables that have the same physical dimension is given by the following equation:
Here represents the element of the matrix representing the quantity of usage for the i-variable with the j-physical dimension; represents the total number of variable usages in the code; represents the total number of different dimensions of variables in the code; and represents the total number of variables in the code.
For increasing the conditional probability detection of incorrect use of software variables we need to use other independent properties of variables. Using additional independent properties of variables can help increase the conditional probability detection of incorrect use of software variables. This is because using multiple properties helps to reduce the chance of false positives and increase the reliability of the detection model.
2.4.3. Simple Model for Detection of Incorrect Use of Variables Based on Orientational Analysis
In many cases, variables in CPS or the IoT have not only physical dimensions but also orientation information, which can be utilized to enhance the software quality of these systems. Therefore, we introduce a simple model for the detection of incorrect variable use based on orientational analysis (see
Figure 5).
According to
Figure 5, the initial state of the model is ‘Variable’. This state has two transitions to states ‘OK’ and ‘Check orientation’ with probabilities
and
, respectively. In the state ‘Check orientation’, we can evaluate the required physical orientation of the variable using orientation analysis, such as
,
,
, and
. If the physical orientation of the variable matches the required orientation, we cannot detect a software defect. However, if the physical orientation is different from the required orientation, we can detect a software defect. These cases have probabilities
and
, where
is the probability that two randomly selected variables have the same physical orientation.
Now we need to define .
This defect model is similar to the dimension defect model of variables. However, in this case, we have four different orientations and
different variables. We can describe the relationship between variables and their orientations using an
matrix:
where
is a direction of orientation and
k = 0,
x,
y,
z.Because, every software variable (as a host of a physical value) has only one orientation, every i-row of the matrix has only one non-zero number —the item of M matrix—the number of using of i-variable which has k-orientation.
We can use Expression (8) for defining the probability of choosing two random variables that have the same physical orientation; this is given by the following Equation (10)
Here represents the element of the matrix representing the quantity of usage for the i-variable with the j-physical orientation. represents the total number of variable usages in the code; represents the total number of variables in the code.
We can increase the conditional probability of software defect detection by concurrently using both dimensional and orientational analysis. By combining these two methods, we can improve the accuracy of defect detection and reduce the likelihood of undetected defects.
2.4.4. Complex Model for Detection of Incorrect Use of Variables Based on Dimensional and Orientational Analysis
The complex model of the detection of incorrect use of variables based on both dimensional and orientational analysis is described in
Figure 6.
According to
Figure 6, the initial state of the model is ‘Variable’. This state has two transitions to the states ‘OK’ and ‘Check Dimension’ with probabilities
and
, respectively. In the ‘Check Dimension’ state, we evaluate the required physical dimension of the variable using dimensional analysis, such as length, mass, time, thermodynamic temperature, etc.
If the actual physical dimension matches the required dimension, we cannot detect the software defect with a probability of . However, if they differ, we can identify the software defect with a probability of , where represents the probability that two randomly selected variables have the same physical dimension.
When we cannot detect the software defect, in the state ‘Check orientation’, we evaluate the required physical orientation of the variable using orientational analysis. If the physical orientation matches the required orientation, we cannot detect a software defect. However, if the physical orientation differs from the required orientation, we can detect a software defect. These cases have probabilities
and
, where
represents the probability that two randomly selected variables have the same physical orientation.
After the substitution of Expressions (8) and (10) in (11) we have
Here represents the element of the matrix, which represents the quantity of usage for the k-variable with the j-physical orientation, represents the element of the matrix representing the quantity of usage for the i-variable with the j-physical dimension, represents the total number of different dimensions of variables in the code, represents the total number of variables in the code, and represents the total number of variable usages in the code. Furthermore, there are four different orientations (, , , ) in the code.
According to Equation (12), denotes the conditional probability of detecting the incorrect use of software variables. The probability depends on the distribution of the software variables according to different dimensions and orientations.
To evaluate the correctness of the conditional probability of software defect detection, we need a model for detecting the incorrect use of operations. This model should take into account the types of operations that are commonly used in CPS and IoT software, as well as their potential incorrect use.
2.4.5. Model for Detection of Incorrect Use of Operations Based on Dimensional and Orientational Analysis
Let us consider three subsets of C++ operations: “additive” (A), “multiplicative” (M), and “other” (O) operations.
In addition, we are given three probabilities associated with the utilization of this operation in the source code, namely,
,
, and
. Let us define the sum of these probabilities as the full group probability:
Let us define
,
, and
as follows:
Here, represents the total number of “additive” operations in a file, represents the total number of “multiplicative” operations in a file, and represents the total number of “other” operations in the file.
In this case, we can build a decision tree for the detection of incorrect use of operations based on dimensional and orientational analysis. The model allows us to define the conditional probability of operation defect detection (see
Figure 7).
According to
Figure 7, the initial state of the model is ‘Operation’. This state has three transitions to the states ‘Additive Operation’, ‘Multiplicative Operation’, and ‘Other Operation’ with probabilities
,
, and
, respectively.
In the state ‘Additive Operation’, any ‘additive’ operation can be replaced by another operation. This event has the probability . We then transition to the ‘Using incorrect operation 1’ state with this probability. In the other case, with a probability of , we transition to the ‘Using correct operation 1’ state.
In the state ‘Using incorrect operation 1’, for a mutation where an additive operation mutates to another additive operation, we can transition to the ‘Additive Operation 2’ state with a probability of . In this case, we cannot detect a software defect, and the full probability for this scenario is .
For a mutation where an additive operation mutates to other operations, we can transition to the ‘Other Operation 2’ state with a probability of . In this case, we can detect a software defect, and the full probability for this scenario is .
For a mutation where an additive operation mutates to a multiplicative operation, we can transition to the ‘Multiplicative Operation 2’ state with a probability of . In this case, we can detect a software defect, and the full probability for this scenario is .
In the state ‘Multiplicative Operation’, any ‘multiplicative’ operation can be replaced by another operation. This event has the probability , and we transition to the ‘Using incorrect operation 2’ state. In the other case, with a probability of , we transition to the ‘Using correct operation 2’ state.
In the state ‘Using incorrect operation 2’, for a mutation where a multiplicative operation mutates to other additive operations, we can transition to the ‘Additive Operation 3’ state with a probability of . In this case, we can detect a software defect. The full probability for this scenario is .
For a mutation where a multiplicative operation mutates to ‘other’ operations, we can transition to the ‘Other Operation 3’ state with a probability of . In this case, we can detect a software defect. The full probability for this scenario is .
For a mutation where a multiplicative operation mutates to other multiplicative operations, we can transition to the ‘Multiplicative Operation 3’ state with a probability of . In this case, we can detect a software defect. The full probability for this scenario is .
In the state ‘Other Operation’, any ‘other’ operation can be replaced by another operation. This event has the probability , and we transition to the ‘Using incorrect operation 3’ state. In the other case, with a probability of , we transition to the ‘Using correct operation 3’ state.
In the state ‘Using incorrect operation 3’, for a mutation where an ‘other’ operation mutates to additive operations, we can transition to the ‘Additive Operation 4’ state with a probability of . In this case, we can detect a software defect. The full probability for this scenario is .
For a mutation where an ‘other’ operation mutates to other ‘other’ operations, we can transition to the ‘Other Operation 4’ state with a probability of . In this case, we cannot detect a software defect. The full probability for this scenario is .
For a mutation where an ‘other’ operation mutates to multiplicative operations, we can transition to the ‘Multiplicative Operation 4’ state with a probability of . In this case, we can detect a software defect. The full probability for this scenario is .
Additionally, we can conclude, that
,
,
. We can define the conditional probability of detecting incorrect use of software operations as follows:
Here, , , , , , , , , .
According to
,
. Because
and
, then
Here, represents the conditional probability of ‘additive’ operations in a file and represents the conditional probability of ‘other’ operations in a file.
According to Equation (16), denotes the conditional probability of detecting the incorrect use of software operations. The value of depends on the square of the probabilities of additional operations (such as +, −, =, <, etc.) and other operations (such as = {“||”, “&&”, “&”, “|”, “^”, “~”, “<<“, “>>“, “::”, “?” etc.) in a source file. In order to evaluate , it is necessary to define the values of and . This evaluation requires analyzing the real source code.
Using Equation (2), which defines the conditional probability of software defect detection as a function of (defined by the source code of the file) and the conditional probabilities of variable usage defect detection (, defined by Equation (12)) and operation usage defect detection (, defined by Equation (16)), allows us to evaluate the conditional probability of software defect detection.
3. Results
After analyzing the source code of Unmanned Aerial Vehicle Systems, which had a total volume of 2 GB and a total number of files of 20,000, saved on GitHub using our own statistical analyzer, we were able to determine the necessary statistical characteristics of the C++ source code.
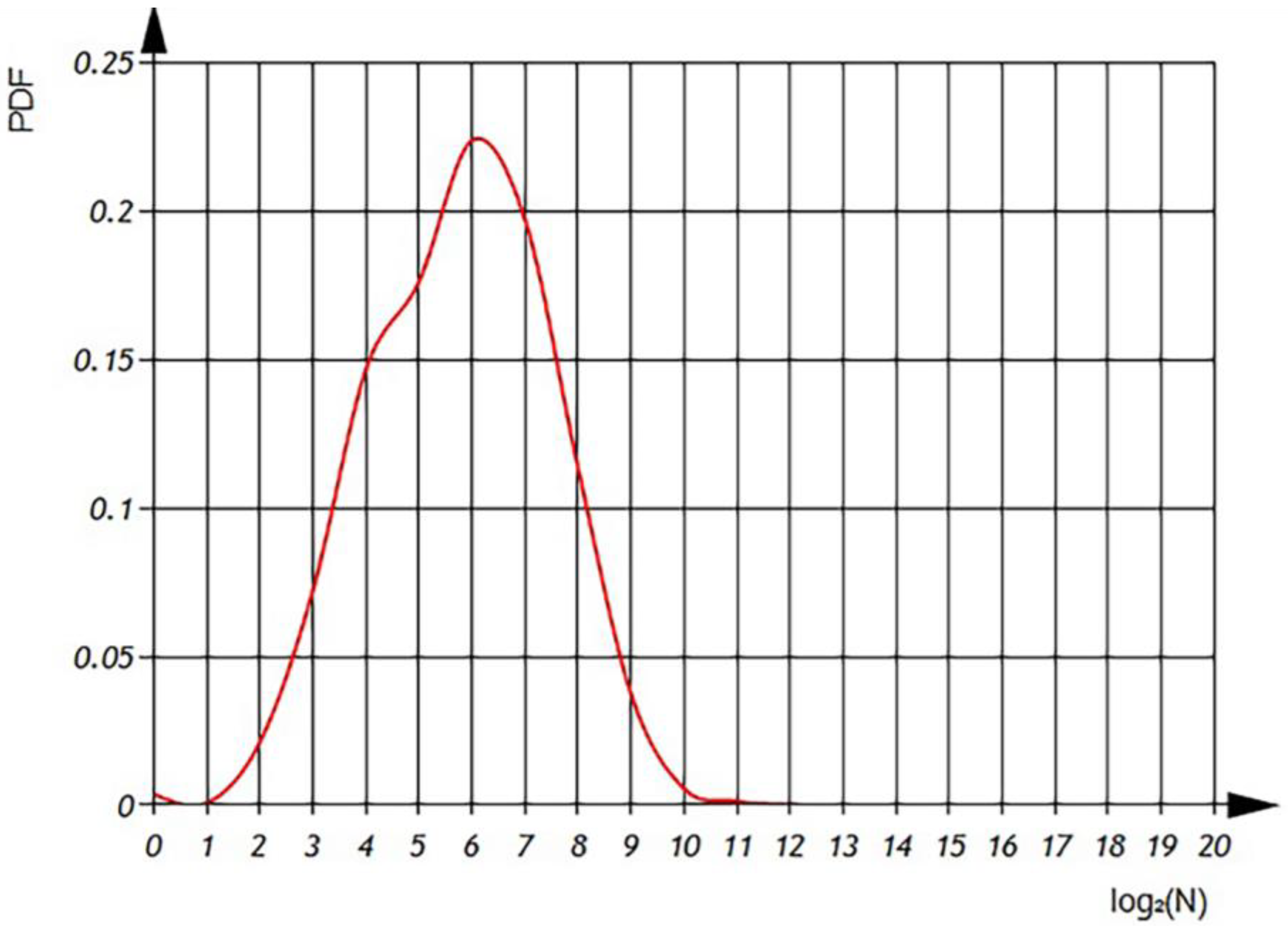
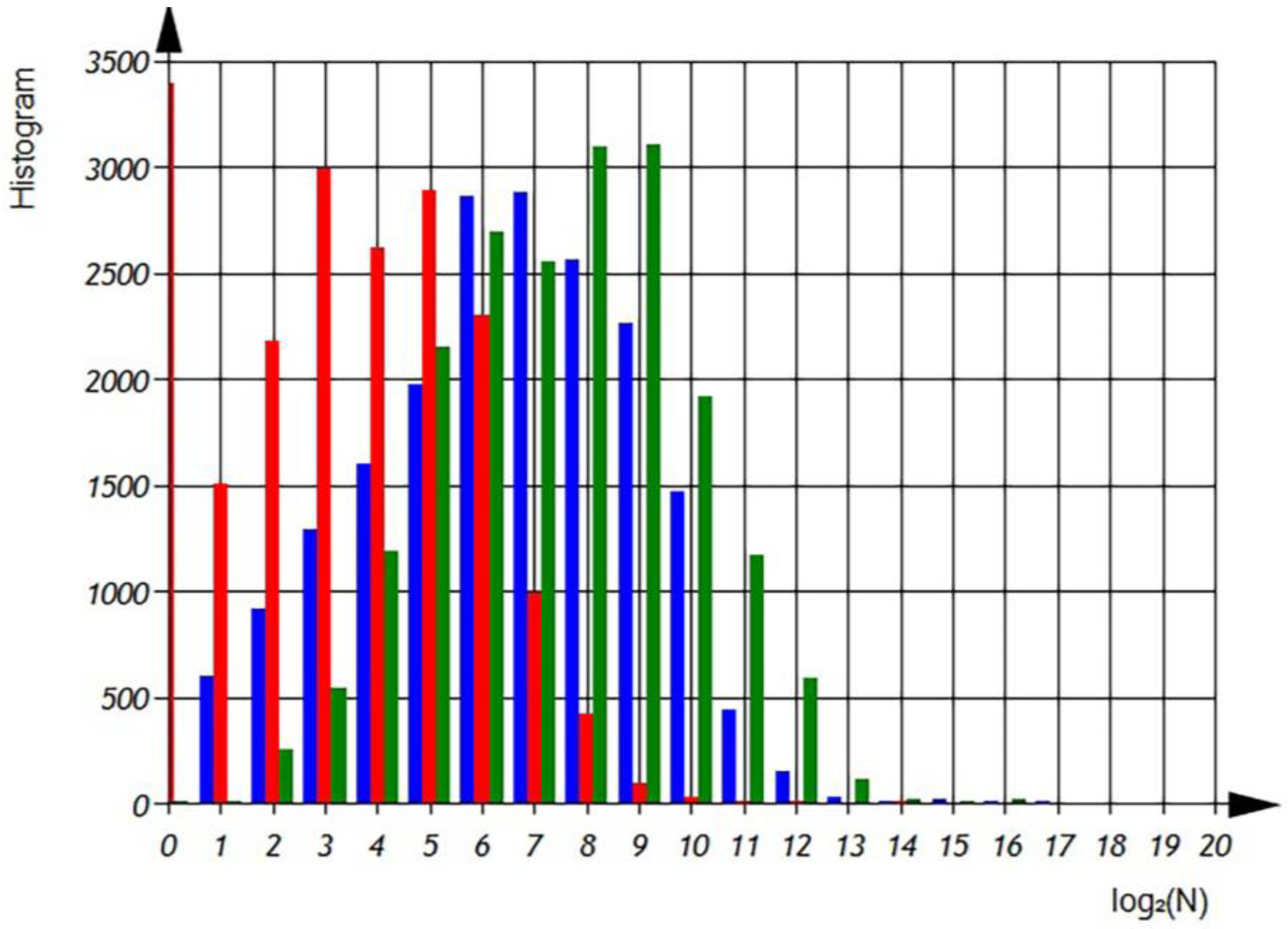
Distribution
—total number of different variables per file (
Figure 8 and
Figure 9).
According to
Figure 8 and
Figure 9 we can observe the distribution of different variables per file in semi-logarithmic coordinates. The histogram (
Figure 8) reveals that the average number of different variables is 2
6, with a maximum of 64 variables observed in 4500 files. However, there are files that contain only one variable, as well as files with 1024 variables. The sum of the histogram columns corresponds to the total number of files, which is 20,000.
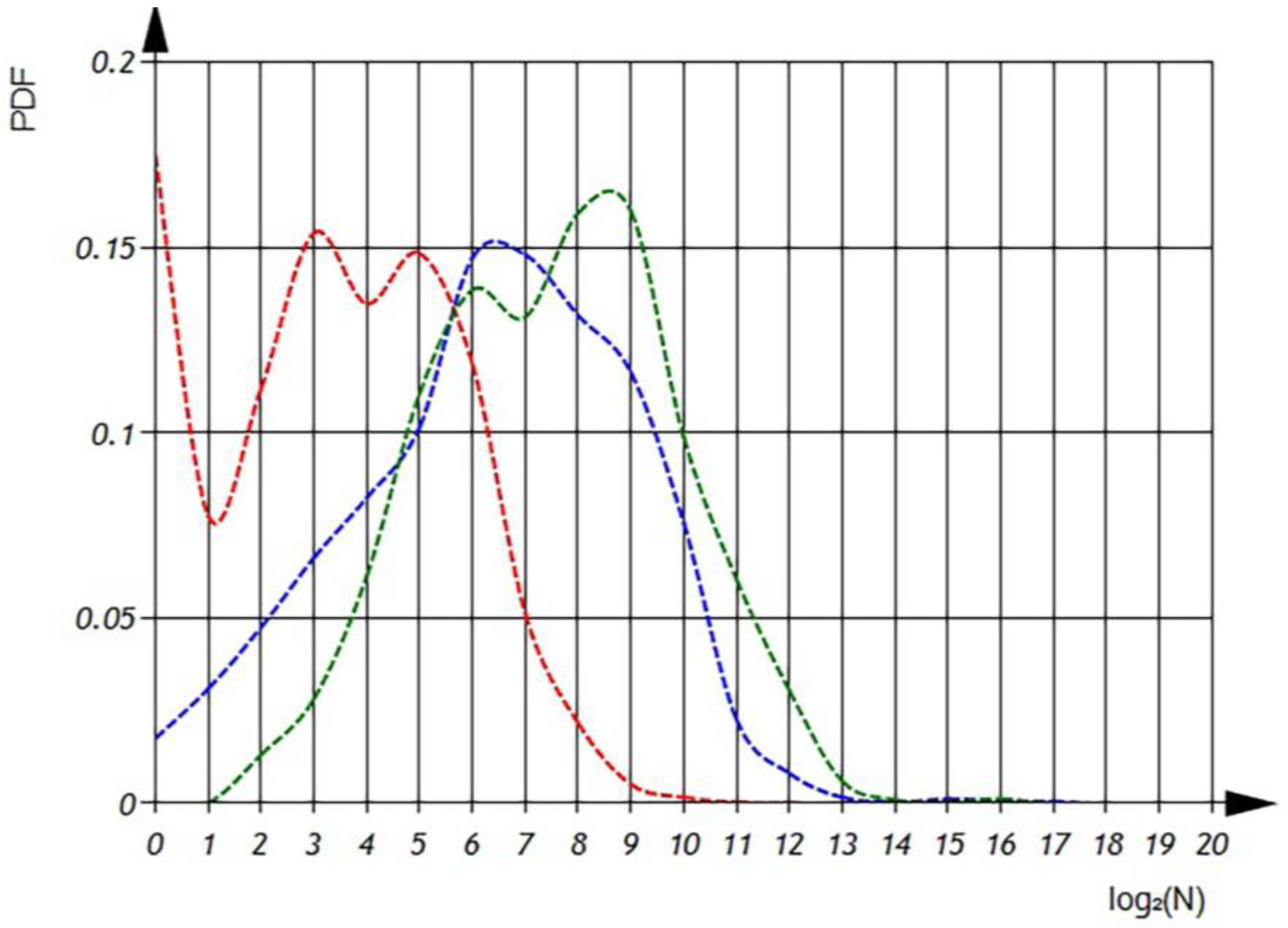
In
Figure 9, presented subsequently, we can examine the probability density function of variable distributions. It is important to note that the integral of the probability density function should always equal one, ensuring a proper probability distribution.
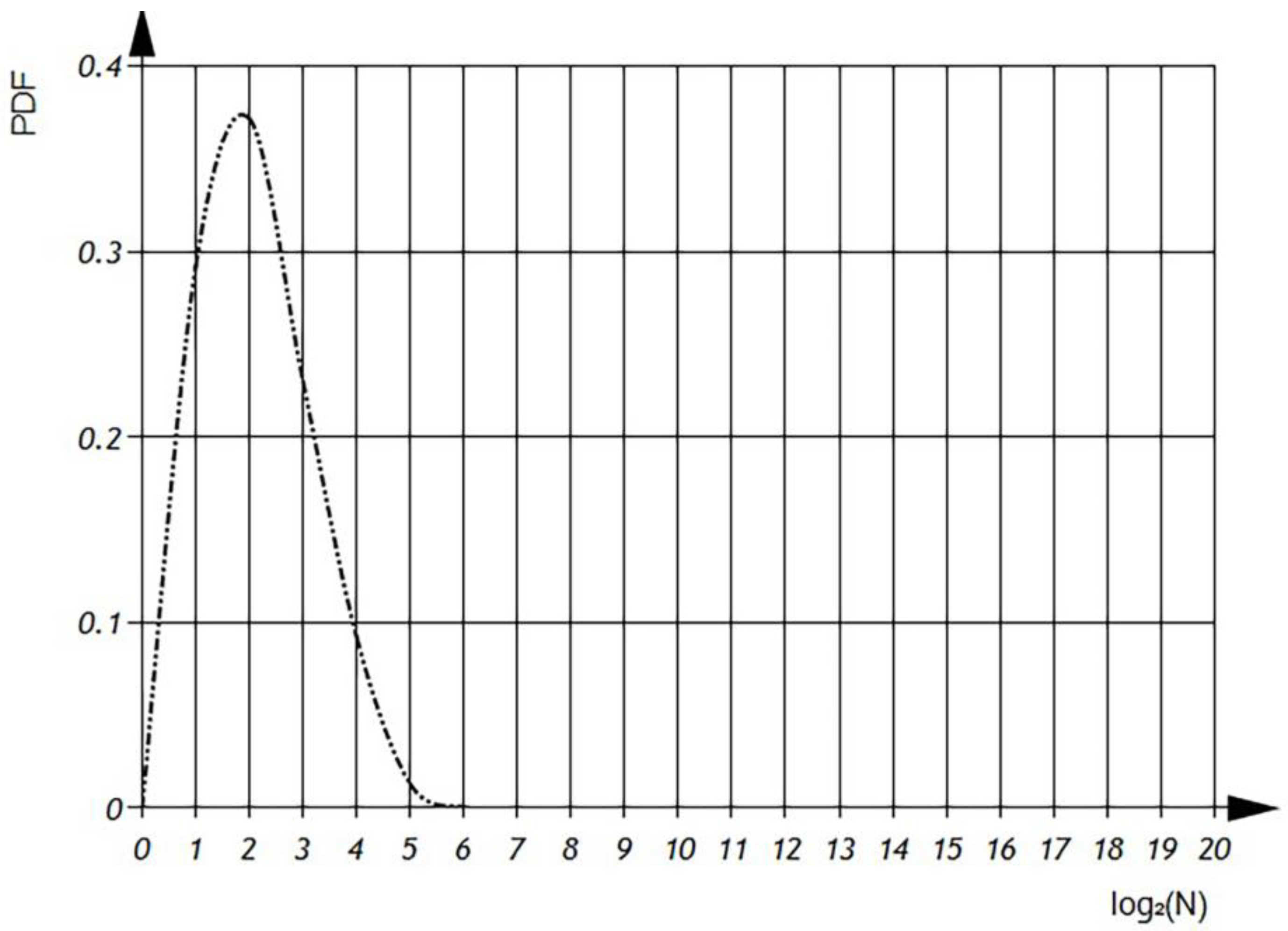
According to
Figure 10 and
Figure 11 we can observe the distribution of
, which represents the average number of variables uses per file, in semi-logarithmic coordinates. The histogram (
Figure 10) shows that the average number of variable usages is 5. The sum of the histogram columns corresponds to the total number of files, which is 20,000.
In the subsequently presented
Figure 11, we can analyze the probability density function of the distributions for the average usage of variables. According to the Probability Density Function, we can see that there are files with an average usage of 64 variables. It is crucial to note that the integral of the probability density function should always equal one, ensuring a proper probability distribution.
According to Equation (12) and the distributions described in
Figure 8 and
Figure 10, as well as the uniform distribution for both
and
, we can obtain the Probability Density Functions of conditional probability of detecting incorrect use of software variables
, shown in
Figure 12.
According to
Figure 12, when combining dimensional and orientational analysis, the conditional probability for detecting incorrect use of software variables is greater than 0.9.
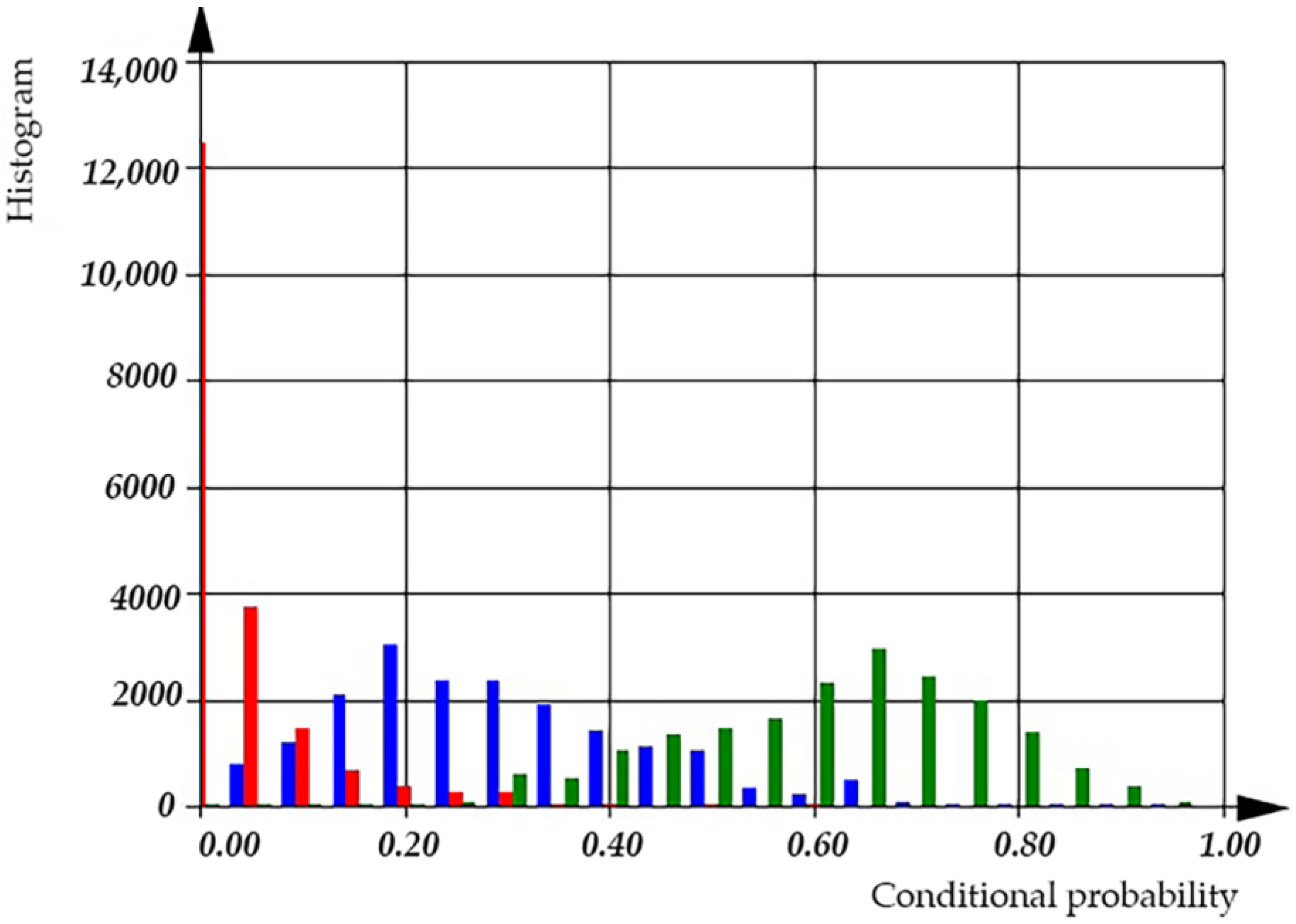
Additional statistical characters of C++ source code was evaluated:
—total numbers of additive operations per file;
—total numbers of ‘other’ operations per file;
—total numbers of multiplicative operations per file. Corresponded distributions shown on the
Figure 13 and
Figure 14.
In
Figure 14 we can observe the distributions of
,
, and
, which represent the average number of operations per file in semi-logarithmic coordinates. The histograms show that the average number of ‘additive’ operations is 128, observed in 2500 files. However, there are files that only contain 2 additive operations, as well as files with an average usage of 8192 additive operations. The sum of the histogram columns corresponds to the total number of files, which is 20,000. The histogram shows that the average number of ‘multiplicative’ operations is 16, observed in 2600 files. However, there are files that only contain 2 multiplicative operations, as well as files with an average usage of 512 multiplicative operations. The histogram shows that the average number of ‘other’ operations is 256, observed in 3000 files. However, there are files that only contain 4 ‘other’ operations, as well as files with an average usage of 4096 ‘other’ operations. The sum of the histogram columns corresponds to the total number of files, which is 20,000.
In the subsequently presented, we can examine the probability density function of the distributions for different operations per file. It is crucial to note that the integral of the probability density function should always equal one, ensuring a proper probability distribution.
By referring to Equation (15) and the distributions of
(total number of additive operations),
(total number of multiplicative operations), and
(total number of other operations) (as shown in
Figure 15), we can calculate the distributions of
,
, and
.
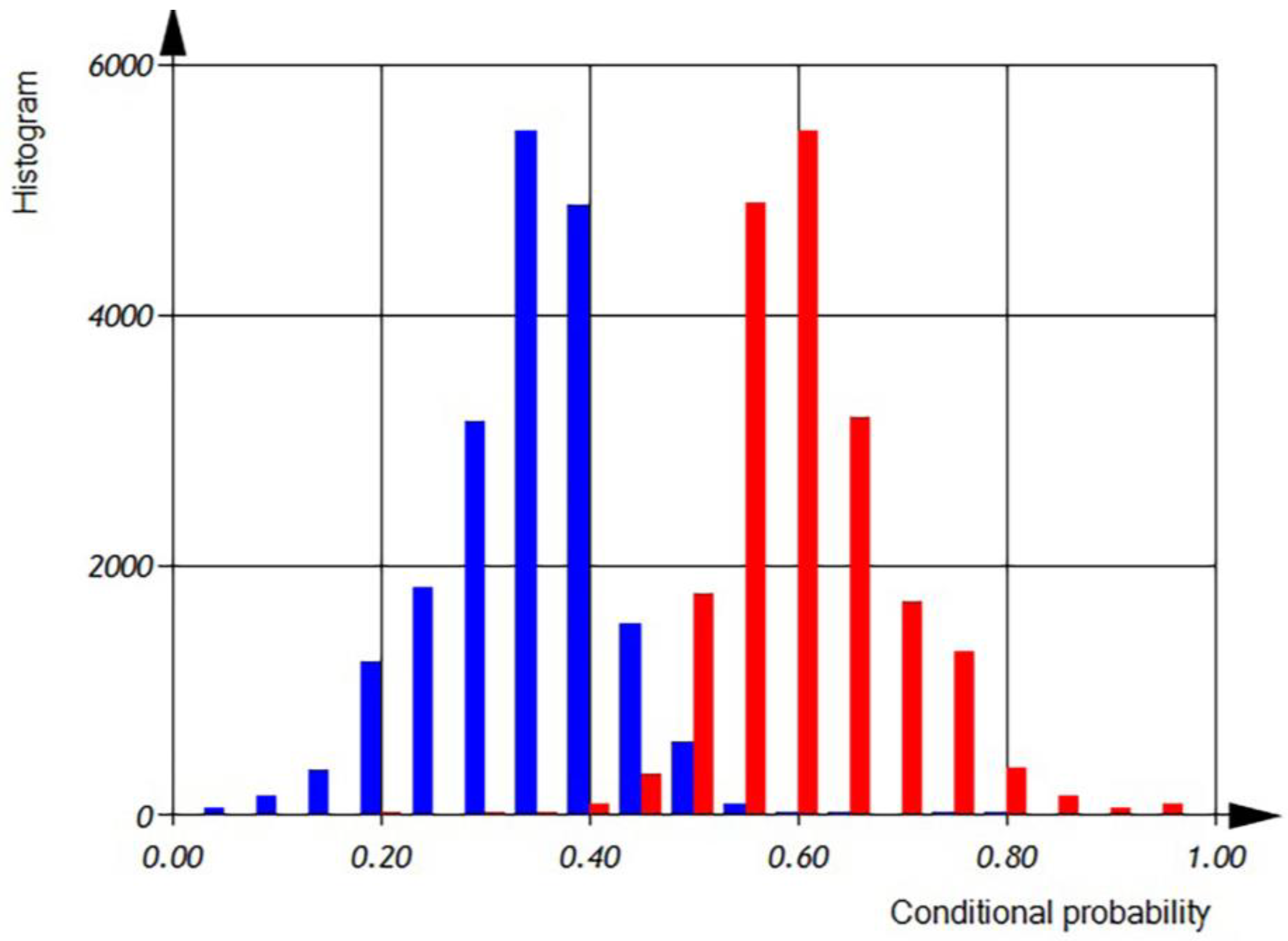
In
Figure 15 and
Figure 16, we can observe the distribution of conditional probabilities of operations per file in semi-logarithmic coordinates. The histogram shows that the average of conditional probabilities of operations per file. The value of conditional probability of ‘additive’ operations is
= 0.309 ± 0.161 [0.000… 0.75]. The value of conditional probability of ‘multiplicative’ operations is
= 0.056 ± 0.056 [0.000… 0.636]. The value of conditional probability of ‘other’ operations is
= 0.635 ± 0.155 [0.2… 0.992].
In the subsequently presented, we can examine the probability density functions of the conditional probability of different operations. It is crucial to note that the integral of the probability density function should always equal one, ensuring a proper probability distribution.
Based on the distributions of
,
, and
we can calculate the distribution of the conditional probability of operation defect detection
(as depicted in
Figure 17 The histogram reveals that the average conditional probability of operation defect detection per file is
= 0.45 ± 0.161 [0.000… 0.8].
According to
Figure 18, we can see that the mean value of the conditional probability of software operation defect detection is 0.5.
After analyzing real C++ code statistically, we built the distributions of
and
(as shown in
Figure 19 and
Figure 20).
The histogram shows that the average conditional probability of operations is = 0.65 ± 0.12 [0.4… 0.9]. Similarly, the histogram reveals that the average conditional probability of variables is = 0.35 ± 0.12 [0.000… 0.55].
Figure 20, displays two distributions of the conditional probability for software operations and software variables, with peaks at 0.35 and 0.65, satisfying the equation
.
Now, we can calculate the conditional probability of software defect detection based on the embedded source code and the proposed defect models (see Expression (2)). Let be the conditional probability, then we have , where is the conditional probability of variables in the source code, —is the conditional probability of the defects detection of variables using the defect in the source code, and is the conditional probability the defects detection of operation using defect in the source code.
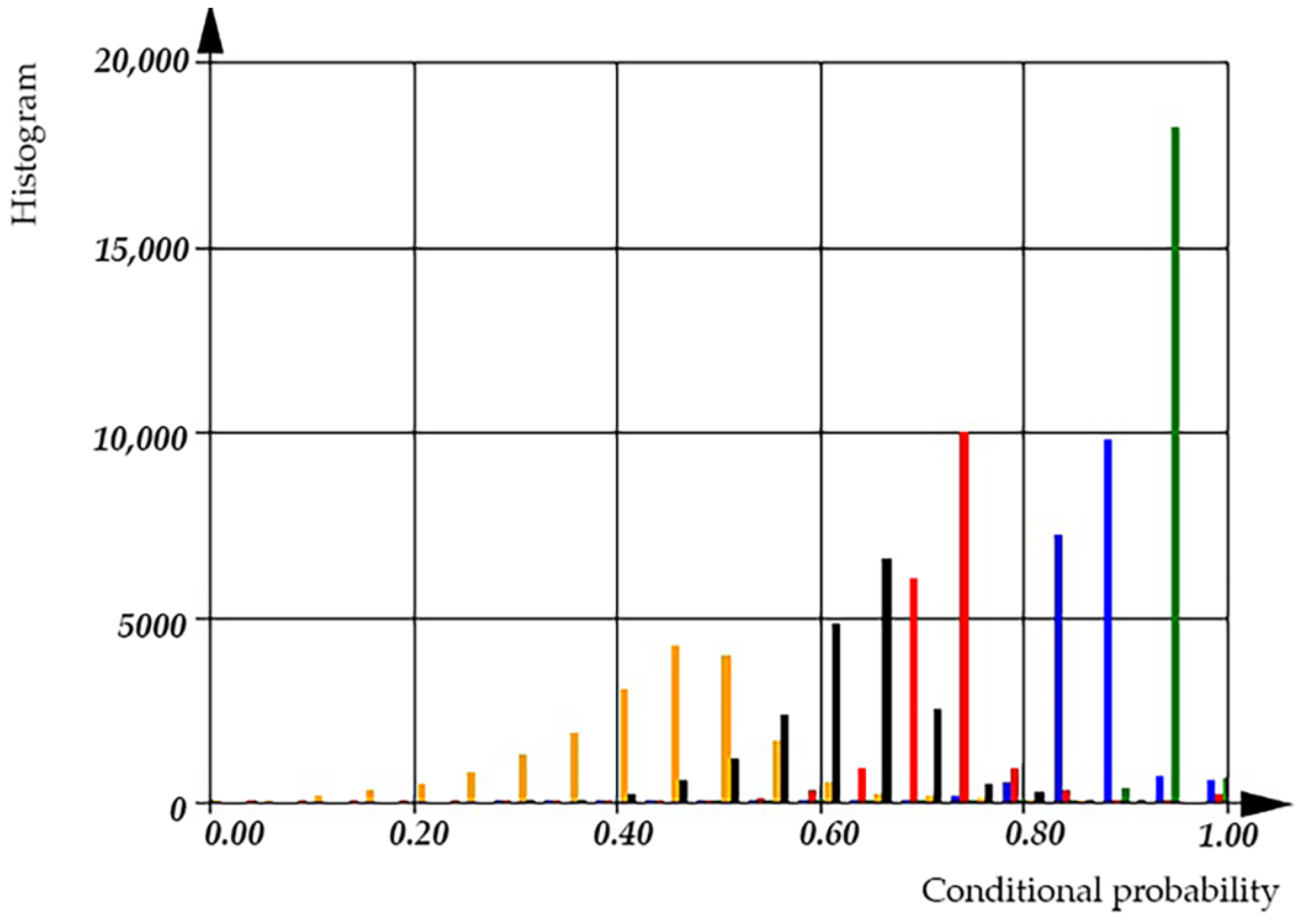
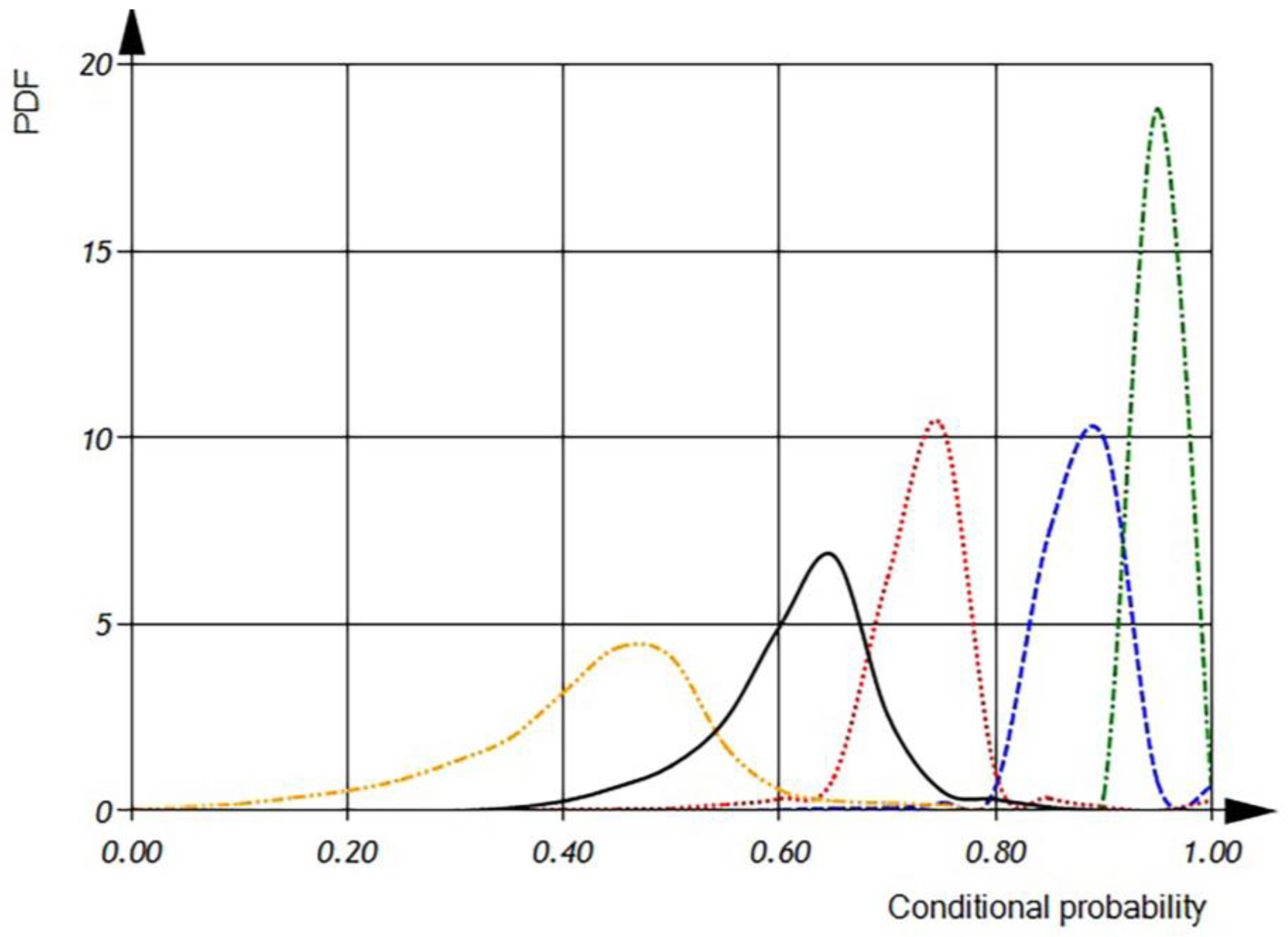
In the upcoming figures,
Figure 21 presents a histogram of the conditional probabilities of defect detection, while
Figure 22 shows probability density functions of software defect detection.
According to the histogram (see
Figure 21), the conditional probability for the detection of incorrect usage of variables is 0.95, while the conditional probability for the detection of incorrect usage of operations has a mean of 0.5. We can observe that the conditional probability of the incorrect usage of variables increases after incorporating both dimensional and orientational analysis. Using dimensional analysis alone yields a conditional probability of a defect detection of 0.9, while orientational analysis alone provides a conditional probability of a defect detection of 0.73. However, the overall conditional probability for the detection of the incorrect usage of operations or variables has a mean value of 0.60.
According to
Figure 22, the conditional probability for the detection of the incorrect usage of variables has a mean value of 0.95 and is distributed in the interval of 0.4 to 0.8, while the conditional probability for the detection of the incorrect usage of operations has a mean of 0.5 and is distributed in the interval of 0 to 0.65. It is evident that the conditional probability of the incorrect usage of variables increases after incorporating both dimensional and orientational analysis. The incorporation of both analysis methods narrows the interval of distribution. When using dimensional analysis alone, the conditional probability of a defect detection is 0.9 within the interval of 0.8 to 0.95, while orientational analysis alone provides a conditional probability of a defect detection of 0.73 within the interval of 0.6 to 0.83. However, the overall conditional probability for the detection of the incorrect usage of operations or variables has a mean value of 0.60 within the interval of 0.4 to 0.75.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





















