

Reviewing and Discussing Graph Reduction in Edge Computing Context

Abstract
:1. Introduction
1.1. Literature Review
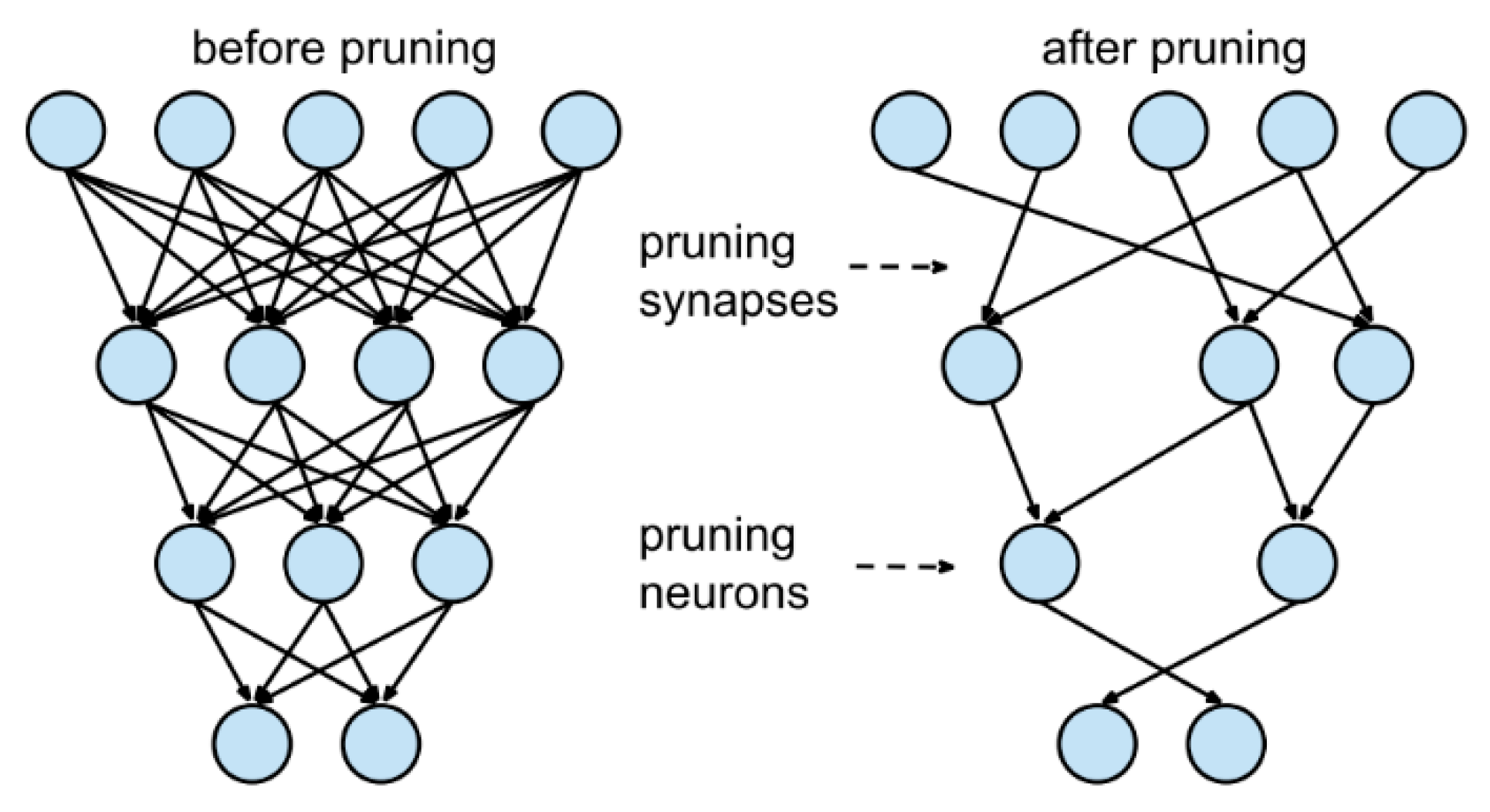
Pruning
- Element pruned;
- Structured/Unstructured;
- Static/Dynamic,
1.2. Static Pruning
1.3. Dynamic Pruning
1.4. Quantization
2. Materials and Methods
2.1. Heuristic Partial Search
- Compare the score of the 1st weight and (n/2 + 1)th weight.
- If the 1st weight is less relevant compare it with the (n/4 + 1)th weight. Otherwise, compare the (n/2 + 1)th weight with the (3n/4 + 1)th weight.
- Find, in a predefined number of iterations, the weight that has the best score for each row and remove it from the original network.
- Complete the process until the desired reduction in the network is achieved for each row, until the predefined number of eliminations is achieved. Successively repeat the process for the remaining rows until the entire layer has been pruned.
| Algorithm 1. Pseudo-code of the Heuristic Partial Search (HPS). |
| For a in nrows: For b in neliminations: top_score = 0 step = ncolumns//2 For c in niterations: update pos1 and pos2 weights_copy[pos1] = 0 set model weights evaluate the model => score1 weights_copy2[pos2] = 0 set model weights evaluate the model => score2 if score2 < score1: if top_score < score1: top_score = score1 best_pos = pos1 else: if top_score < score2: top_score = score2 best_pos = pos2 original_weights[best_pos] = 0 evaluate the pruned model End |
2.2. Experimental Settings
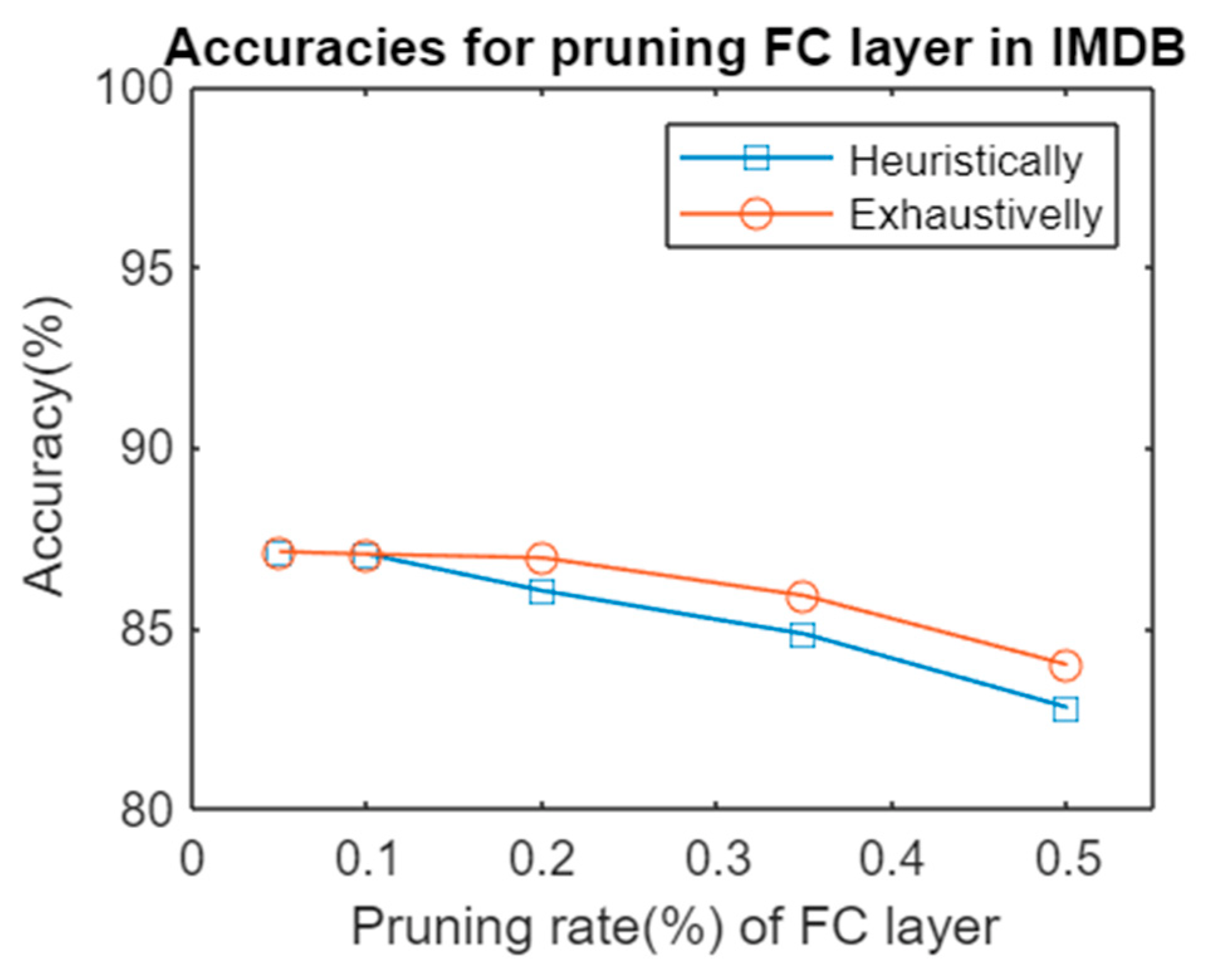
3. Results
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- LeCun, Y.; Denker, J.S.; Solla, S.A. Optimal Brain Damage. Adv. Neural Inf. Process. Syst. (NIPS) 1990, 598–605. [Google Scholar] [CrossRef]
- Hassibi, B.; Stork, D.G.; Wolff, G.J. Optimal Brain Surgeon and General Network Pruning. In Proceedings of the IEEE International Conference on Neural Networks, San Francisco, CA, USA, 28 March–1 April 1993; IEEE Xplore: Piscataway, NJ, USA, 1993. [Google Scholar]
- Molchanov, P.; Tyree, S.; Karras, T.; Aila, T.; Kautz, J. Pruning Convolutional Neural Networks for Resource efficient Transfer Learning. In Proceedings of the International Conference on Learning Representations (ICLR) 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Yu, C.; Wang, J.; Chen, Y.; Qin, X. Transfer channel pruning for compressing Deep domain adaptation models. Int. J. Mach. Learn. Cybern. 2019, 10, 3129–3144. [Google Scholar] [CrossRef]
- Muthukrishnan, R.; Rohini, R. LASSO: A feature selection technique in predictive modeling for machine learning. In Proceedings of the 2016 IEEE International Conference on Advances in Computer Applications (ICACA), Coimbatore, India, 24 October 2016; pp. 18–20. [Google Scholar] [CrossRef]
- Yuan, M.; Lin, Y. Model selection and estimation in regression with grouped variables. J. R. Stat. Soc. Ser. B 2006, 68, 49–67. [Google Scholar] [CrossRef]
- Yeom, S.K.; Seegerer, P.; Lapuschkin, S.; Binder, A.; Wiedemann, S.; Müller, K.-R.; Samek, W. Pruning by explaining: A novel criterion for Deep neural network pruning. Pattern Recognit. 2021, 115, 107899. [Google Scholar] [CrossRef]
- Ayinde, B.O.; Inanc, T.; Zurada, J.M. Redundant feature pruning for acelerated inference in deep neural neutworks. Neural Netw. 2019, 118, 148–158. [Google Scholar] [CrossRef] [PubMed]
- Swaminathan, S.; Garg, D.; Kannan, R.; Andres, F. Sparse low rank factorization for deep neural network compression. Neurocomputing 2020, 398, 185–196. [Google Scholar] [CrossRef]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning Filters for Efficient ConvNets. In Proceedings of the International Conference on Learning Representations (ICLR) 2017, Toulon, France, 24–26 April 2017. [Google Scholar] [CrossRef]
- Luo, J.H.H.; Wu, J.; Lin, W. ThiNet: A Filter Level Pruning Method for Deep Neural Network Compression. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5068–5076. [Google Scholar] [CrossRef]
- Hu, H.; Peng, R.; Tai, Y.-W.; Tang, C.-K. Network Trimming: A Data-Driven Neuron Pruning Approach towards Efficient Deep Architectures. arXiv 2016, arXiv:1607.03250. [Google Scholar]
- Bengio, Y. Estimating or Propagating Gradients Through Stochastic Neurons. arXiv 2013, arXiv:1305.2982. [Google Scholar]
- Davis, A.; Arel, I. Low-Rank Approximations for Conditional Feedforward Computation in Deep Neural Networks. In Proceedings of the International Conference on Learning Representations 2013, Scottsdale, AZ, USA, 2–4 May 2013. [Google Scholar]
- Leroux, S.; Bohez, S.; De Coninck, E.; Verbelen, T.; Vankeirsbilck, B.; Simoens, P.; Dhoedt, B. The cascading neural network: Building the Internet of Smart Things. Knowl. Inf. Syst. 2017, 52, 791–814. [Google Scholar] [CrossRef]
- Bolukbasi, T.; Wang, J.; Dekel, O.; Saligrama, V. Adaptive Neural Networks for Efficient Inference. In Proceedings of the Thirty-fourth International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Odena, A.; Lawson, D.; Olah, C. Changing Model Behavior at Test-Time Using Reinforcement Learning. In Proceedings of the International Conference on Learning Representations Workshops (ICLRW), International Conference on Learning Representations ICLR, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Wu, Z.; Nagarajan, T.; Kumar, A.; Rennie, S.; Davis, L.S.; Grauman, K.; Feris, R. BlockDrop: Dynamic Inference Paths in Residual Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8817–8826. [Google Scholar] [CrossRef]
- Lin, J.; Rao, Y.; Lu, J.; Zhou, J. Runtime Neural Pruning. Advances in Neural Information Processing Systems (NIPS). In Proceedings of the Neural Information Processing Systems 2017—NIPS, Long Beach, CA, USA, 4–9 December 2017; pp. 2178–2188. [Google Scholar]
- Guo, Y.; Yao, A.; Chen, Y. Dynamic Network Surgery for Efficient DNNs. In Proceedings of the 30th Conference on Neural Information Processing Systems (NIPS), Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Gao, X.; Zhao, Y.; Dudziak, Ł.; Mullins, R.; Xu, C.-Z. Dynamic Channel Pruning: Feature Boosting and Suppression. arXiv 2019, arXiv:1810.05331. [Google Scholar]
- Zhang, C.; Hu, T.; Guan, Y.; Ye, Z. Accelerating Convolutional Neural Networks with Dynamic Channel Pruning. In Proceedings of the 2019 Data Compression Conference (DCC), Snowbird, UT, USA, 26–29 March 2019; p. 563. [Google Scholar] [CrossRef]
- Tang, Y.; Wang, Y.; Xu, Y.; Deng, Y.; Xu, C.; Tao, D.; Xu, C. Manifold Regularized Dynamic Network Pruning. arXiv 2021, arXiv:2103.05861. [Google Scholar]
- Chen, W.; Qiu, H.; Zhuang, J.; Zhang, C.; Hu, Y.; Lu, Q.; Wang, T.; Shi, Y.; Huang, M.; Xu, X. Quantization of Deep Neural Networks for Accurate Edge Computing. ACM J. Emerg. Technol. Comput. Syst. 2021, 17, 1–11. [Google Scholar] [CrossRef]
- Pattanayak, S.; Nag, S.; Mittal, S. CURATING: A multi-objective based pruning technique for CNNs. J. Syst. Archit. 2021, 116, 102031. [Google Scholar] [CrossRef]
- Liu, J.; Sun, J.; Xu, Z.; Sun, G. Latency-aware automatic CNN channel pruning with GPU runtime analysis. BenchCouncil Trans. Benchmarks Stand. Eval. 2021, 1, 100009. [Google Scholar] [CrossRef]
- Khoram, S.; Li, J. Adaptive Quantization of Neural Networks. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Xu, W.; Fang, W.; Ding, Y.; Zou, M.; Xiong, N. Accelerating Federated Learning for IoT in Big Data Analytics With Pruning, Quantization and Selective Updating. IEEE Access 2021, 9, 38457–38466. [Google Scholar] [CrossRef]
- Courbariaux, M.; Hubara, I.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or −1. arXiv 2016, arXiv:1602.02830. [Google Scholar]
- Rastegari, M.; Ordonez, V.; Redmon, J.; Farhadi, A. XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks. In European Conference on Computer Vision; Springer: Amsterdam, The Netherlands, 2016; pp. 525–542. [Google Scholar]
- Li, F.; Zhang, B.; Liu, B. Ternary Weight Networks. arXiv 2016, arXiv:1605.04711. [Google Scholar]
- Leng, C.; Dou, Z.; Li, H.; Zhu, S.; Jin, R. Extremely Low Bit Neural Network: Squeeze the Last Bit Out with ADMM. In Proceedings of the AAAI Conference on Artificial Intelligence; AAAI Press: Palo Alto, CA, USA, 2018. [Google Scholar]
- Lin, Z.; Courbariaux, M.; Memisevic, R.; Bengio, Y. Neural Networks with Few Multiplications. arXiv 2016, arXiv:1510.03009. [Google Scholar]
- Zhou, A.; Yao, A.; Guo, Y.; Xu, L.; Chen, Y. Incremental Network Quantization: Towards Lossless CNNs with Low-Precision Weights. arXiv 2017, arXiv:1702.03044. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
| Layer Name | Layer Type | Feature Map | Output size | Kernel Size | Stride | Activation |
|---|---|---|---|---|---|---|
| Input | Image | 1 | 32 × 32 × 1 | - | - | - |
| Conv1 | 1xconv | 6 | 28 × 28 × 6 | 5 × 5 | 1 | tanh |
| Pool1 | Avg pooling | 6 | 14 × 14 × 6 | 2 × 2 | 2 | tanh |
| Conv2 | 1xconv | 16 | 10 × 10 × 16 | 5 × 5 | 1 | tanh |
| Pool2 | Avg pooling | 16 | 5 × 5 × 16 | 2 × 2 | 2 | tanh |
| Flatten | Flatten | - | 400 | - | - | tanh |
| FC3 | Dense | - | 120 | - | - | relu |
| FC4 | Dense | - | 84 | - | - | relu |
| FC5 | Dense | - | # classes | - | - | softmax |
| Layer Name | Layer Type | Feature Map | Output Size | Kernel Size | Stride | Activation |
|---|---|---|---|---|---|---|
| Input | Image | 1 | 10,000 × 1 | - | - | - |
| FC1 | Dense | - | 100 × 1 | - | - | relu |
| Dropout1 | Dropout | |||||
| FC2 | Dense | 100 × 1 | - | - | relu | |
| Dropout1 | Dropout | - | - | - | - | - |
| FC3 | Dense | # classes | - | - | sigmoid |
| Method | Pr = 0.06 | Pr = 0.125 | Pr = 0.25 | Pr = 0.37 | Pr = 0.5 |
|---|---|---|---|---|---|
| Exh. | 2.91 | 5.02 | 9.97 | 15.56 | 22.57 |
| HPS | 1.18 | 1.33 | 1.74 | 2.19 | 2.77 |
| Method | Pr = 0.05 | Pr = 0.1 | Pr = 0.2 | Pr = 0.35 | Pr = 0.5 |
|---|---|---|---|---|---|
| Exh. | 14.84 | 29.28 | 55.93 | 97.74 | 142.19 |
| HPS | 5.12 | 10.12 | 19.43 | 34.4 | 50.25 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Garmendia-Orbegozo, A.; Núñez-Gonzalez, J.D.; Antón, M.Á. Reviewing and Discussing Graph Reduction in Edge Computing Context. Computation 2022, 10, 161. https://doi.org/10.3390/computation10090161
Garmendia-Orbegozo A, Núñez-Gonzalez JD, Antón MÁ. Reviewing and Discussing Graph Reduction in Edge Computing Context. Computation. 2022; 10(9):161. https://doi.org/10.3390/computation10090161
Chicago/Turabian StyleGarmendia-Orbegozo, Asier, José David Núñez-Gonzalez, and Miguel Ángel Antón. 2022. "Reviewing and Discussing Graph Reduction in Edge Computing Context" Computation 10, no. 9: 161. https://doi.org/10.3390/computation10090161
APA StyleGarmendia-Orbegozo, A., Núñez-Gonzalez, J. D., & Antón, M. Á. (2022). Reviewing and Discussing Graph Reduction in Edge Computing Context. Computation, 10(9), 161. https://doi.org/10.3390/computation10090161