1. Introduction
Voice is the most common and effective form of communication between persons. Since the early years of human kind, persons have exchanged thoughts, indications, and in general information using our voices. From the perspective of analysis and processing this information using technology, the voice is a sound signal, which will be disturbed by noises when it is propagated in living environments [
1].
The enhancement of these signals affected by noise has a long history among the researchers in signal processing and remains a challenging problem under a variety of dynamic scenarios and several types of noises and levels. The purpose of the various techniques developed to deal with the noise that contaminates the speech sounds is to remove the noise as much as possible, so users or systems can receive the original speech signal after removing the noise without sacrificing the intelligibility and clarity of the speech.
This process of enhancing is of great importance for many applications, such as mobile phone communications, VoIP, teleconferencing systems, hearing aids, and automatic speech recognition (ASR) systems. For example, several authors have reported a decrease in the performance of ASR in the presence of noise recently [
2,
3,
4], and there is concern about the performance of devices for hearing aids as well [
5,
6].
In order to overcome this relevant problem, a number of algorithms have been presented in the literature (reviews on this topic can be consulted in [
7,
8]). According to such reviews and previous references [
9,
10], those algorithms can be divided into two basic categories: Single-Channel Enhancing Techniques and Multi-Channel Enhancing Techniques.
From the first category, two main approaches have been presented:
- a
Spectral Subtraction Method, which uses estimations of statistics of the signal and the noise. It is suitable for real-time applications due to its simplicity. The first assumption is that the speech and the noise can be modeled using an addition of the single component:
where
is the clean speech signal and
the noise signal. In the frequency domain, this expression can be written as
The estimation of the enhanced speech
can be expressed as
The enhanced signal can be obtained in the time domain using the inverse Fourier transform in Equation (
3) with the phase information.
- b
Spectral Subtraction with Over-subtraction Model (SSOM):
The previous method applies a difference in the spectral domain based on a statistical average of the noise. If such a statistical average is not representative of the signal, for example, in musical background noise, in this case, a value floor of minimum spectrum values is established, which leads to minimizing the narrow spectral peaks by decreasing the spectral excursions.
- c
Non-Linear Spectral Subtraction: This method is based on a combination of the two previous algorithms, considering the subtraction based on the signal-to-noise ratio (SNR) of each frame. That makes the process nonlinear, applying less subtraction where the noise is less present, and vice versa.
The limitation of these spectral subtraction methods were addressed previously in [
11].
For the second class of algorithms, the systems take advantage of available multiple signal inputs in separate channels and perform significantly better for non-stationary noises. The main algorithms are:
- a
Adaptive Noise Cancellation: This method takes advantage of the principle of destructive interference between wave sounds, by using a reference signal to generate an anti-noise wave of equal amplitude, but opposite phase. Several strategies have been applied for defining this reference signal, for example using sensors located near the noise and interference sources.
- b
Multisensor Beamforming: This method is applicable when the sound is recorded using a geometric array of microphones. The sound signals are amplified or attenuated (in the time or frequency domain) depending on their direction of arrival. The phase information is particularly important, because most methods reject all the noisy components not aligned in phase.
Other authors, such as [
9], have presented complementary categories of speech enhancement algorithms, including statistical-model-based algorithms, where measurements of noisy segments of recordings are used to estimate the parameters of the clean speech from the segments where both signals are present. Another relevant category would be the subspace algorithms based on the principle of applying linear algebra theory: the speech signals can be mapped to a different subspace than the noise subspace.
With the recent developments in deep learning, based on complex models of artificial neural networks, the process of learning a mapping function between noise-corrupted speech to clean speech has been applied successfully. In this domain, artificial neural networks can be defined as a class of machine learning models initially intended to imitate some characteristics of the human brain by connecting units organized in layers, which propagate information through internal connections. Clean speech parameters can be predicted from noisy parameters by combining complex neural network architectures and deep learning procedures, as presented in [
12,
13,
14].
In most cases, the application of deep neural networks has surpassed the results of other algorithms previously presented in the literature and, thus, can be considered the state-of-the-art in speech denoising for several noisy conditions.
On the other hand, wavelet denoising, which considers a different approach than the mapping function, has also been presented in the literature for the task of removing noise in speech signals recently, even with noise collected from real environments [
15]. From these considerations, in this work, we study the combination of the wavelet and deep learning denoising approaches in a hybrid implementation, where both algorithms process the noisy signals to enhance their quality. The idea of combining algorithms in a cascade approach has been presented previously, but with a combination of deep learning and classical signal-processing-based algorithms. To our knowledge, this is the first extended study on the combination of Long Short-Term Memory neural networks and wavelet transforms.
The results of this experimental study can benefit current and future implementation of speech enhancement, in systems such as videoconferencing and audio restoration, where the improvement in the quality of the speech is imperative, and therefore the selection of the simple or hybrid approaches can be performed carefully. Furthermore, the hybrid methodology results can establish a baseline for future proposals on a new combination of enhancement algorithms.
1.1. Related Work
This section focuses on the hybrid approaches to speech denoising and previous experiences with wavelet transform presented in the literature. The application of deep neural networks as an isolated algorithm for this purpose has been reported in a number of publications and reviewed recently in [
16,
17].
The wavelet-denoising-based references usually specify the problem of the threshold in the wavelet functions and measuring the signal-to-noise ratio before and after the application of the functions. For example, in a recent report presented in [
1], four threshold selection methods were applied, using sym4 and db8 wavelets. Some authors provide experimental validation for different noisy signals and proved that the denoising method of the speech signal based on wavelet analysis is effective in enhancing noisy speech signals.
A two-stage wavelet approach was developed in [
18], first by estimating the speech presence probability and, then, removing the coefficients of the noise floor. Results in speech degraded with Pink and White noise from a signal-to-noise ratio of 0 to a signal-to-noise ratio of -8 surpassed several classical algorithms.
A hybrid of deep learning and the vector Wiener filter was presented recently in [
19], showing benefits from the combined application of algorithms. Other than the deep-learning-based hybrid approach, contemplating harmonic regeneration noise reduction and a comb filter was reported in [
20] and validated using also subjective measurements. Another two-stage estimation algorithm based on wavelets was proposed in [
21], as a previous stage to more traditional algorithms such as the Wiener filter and MMSE.
One implementation of the wavelet transform for enhancing noisy signals in ranges of the SNR from −10 to SNR 10, with a great variety of natural and artificial noises, was presented in [
22]. The success of the proposal was observed especially for lower SNR levels.
Hybrid approaches that combine wavelets and other techniques for speech enhancement are also part of the proposals presented in the literature. For example, a combination of wavelets and a modified version of principal component analysis (PCA) was presented in [
23]. The results showed relevant noise reduction for several kinds of artificial and natural noises and a lower signal distortion without introducing artifacts.
In terms of wavelets and deep learning hybrid approaches, some recent experiences were explored in [
24], by applying the wavelet transform for the decomposition of the signal and in a second stage, the radial basis function network (RFBN). The performance of the proposal was described as excellent by the authors, using objective measures such as the segmental signal-to-noise ratio (SegSNR) and PESQ.
In our work, we propose to take advantage of the application of wavelets as presented in [
1], with a hybrid approach similar to those of Ram and Mohanty [
24], but with the incorporation of initialized LSTM networks using transfer learning.
1.2. Problem Statement
The purpose of speech enhancement of a noisy signal is to estimate the uncorrupted speech signal from the degraded speech signal. Several speech denoising algorithms estimate the characteristics of the noise from silent segments in the speech utterances or by mapping the signal into new domains, such as with the wavelet transform.
In our case, we considered segments of noisy
and clean
speech to compare the enhancement using wavelets, deep learning, and both methods in cascade. As stated in [
25], the enhancing process using wavelets can be summarized as follows: Given
and
, the forward and inverse wavelet transform operators, and
, the denoising operator with threshold
, the process is performed using the three steps:
Transform using a wavelet: .
Obtain the denoised version using the threshold, in the wavelet domain: .
Transform the denoised version into the time domain: .
On the other hand, the enhancement using artificial neural networks is performed by learning a mapping function
f between the spectrum of
and
with the criteria
f is approximated using a Recurrent Neural Network, which outputs a version of the denoised signal after the training process.
In the hybrid approach, the first step of wavelet denoising provides
to the neural networks, which is trained with the criteria
with the purpose of obtaining
, a better approximation of
than
and
.
The rest of this paper is organized as follows:
Section 2 present in detail the Materials and Methods.
Section 3 presents the Results and Discussion, and finally, the Conclusions are presented in
Section 4.
2. Materials and Methods
In this section, the main techniques and procedures to establish the Experimental Setup to evaluate the proposed Hybrid approach are presented.
2.1. Wavelets
Wavelets are a class of functions that have been successfully applied in the discrimination of data from noise data, emulating a filter. The wavelet transform uses an infinite set of functions of different scales and at different locations to map a signal into a new domain, the wavelet domain [
26].
It has become an alternative to the Fourier transform and can be related to similar families of function transformations, but with a particular interest in the scale or resolution of the signals.
In the continuous-time domain, a wavelet transform of a function
is defined as [
25]:
where
and
are real numbers that represent dilating and translating coefficients. The function
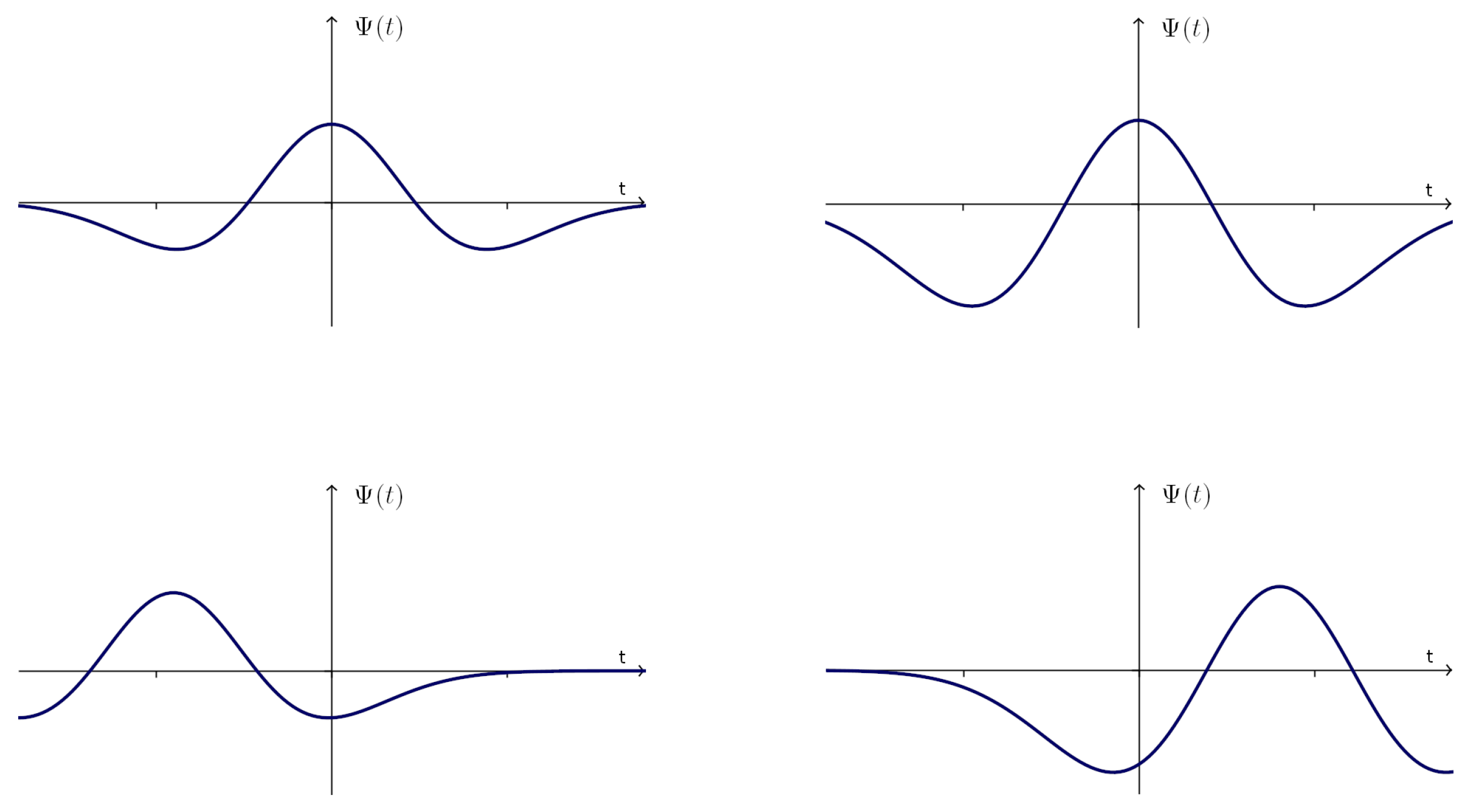
is called the mother wavelet and requires the property of having a zero net area. There is a variety of mother wavelet functions, for example: Haar, Symlet, and Ricker, among many others. Different values of
a and
b provide variants of scales and shifts of the mother wavelet, as shown in
Figure 1.
The fundamental idea behind wavelets is to analyze the functions according to the scale [
27], representing them as a combination of time-shifted and scaled representations of the mother wavelet. For the selection of the best mother wavelet for a particular application, an experimental approach needs to be implemented [
28]. For example, in the case of electroencephalogram (EEG) signals, more than forty mother functions were tested in [
29], to determine the Symlet wavelet of order nine as the best option for that problem.
The wavelet transform provides coefficients related to the similarity of the signal with the mother function. A detailed mathematical description of wavelets can be found in [
30,
31,
32].
The application of wavelets for denoising signals using thresholding emerged in the 1990s from the works [
33,
34]. The threshold can be of two types: soft thresholding and hard thresholding, and the idea is to reduce the magnitude or completely remove the coefficients in the wavelet domain.
The process of denoising using this approach can be described using the following steps [
35]:
Apply the wavelet transform to the noisy signal, to obtain the wavelet coefficients.
Apply the thresholding function and procedure to obtain new wavelet coefficients.
Reconstruct the signal by inverse transforming the coefficients after the threshold.
According to [
36], wavelet denoising gives good results in enhancing noisy speech for the case of White Gaussian noise. Wavelet denoising is considered a non-parametric method. The choice of the mother wavelet function determines the final waveform shape and has an important role in the quality of the denoising process.
2.1.1. Thresholding
The threshold process affects the magnitude or the amount of coefficients in the wavelet domain. The two most popular approaches are hard thresholding and the soft thresholding. In the first type, hard thresholding, the coefficients whose absolute values are lower than
, are set to zero. The soft thresholding performs a similar operation, but also shrinks the nonzero coefficients. This operation can be mathematically described as sign
if
and is 0 if
[
25]. The two types of thresholding are illustrated in
Figure 2.
To implement the thresholds, several estimation methods are available in the literature. Four of the well-known standard threshold estimation methods are [
37,
38]:
Minimax criterion: In statistics, the estimators face the problem of estimating a deterministic parameter from observations. The minimax method minimizes the cost of the estimator in the worst case. For the case of threshold selection, the principle is applied by assimilating the de-noised signal to the estimator of the unknown regression function. This way, the threshold can be expressed as:
where
and
is the wavelet coefficient vector of length
N.
Sqtwolog criterion: The threshold is calculated using the equation
where
is the median absolute deviation (MAD) and
is the length of the noisy signal at the
scale.
Rigrsure: The soft threshold can be expressed as
where
is the
squared wavelet coefficient chosen from a vector consisting of the squared values of the wavelet coefficients and
is the standard deviation.
Hersure: The threshold combines Sqtwolog and Rigrsure, given the property that the Rigrsure threshold does not perform well at a low SNR. In such a case, the Sqtwolog method gives better threshold estimation. If the estimation from Sqtwolog is
and from Rigrsure is
, then Hersure uses:
where, given the length of the wavelet coefficient
N and
s, the sum of squared wavelet coefficients, the values of
A and
B are calculated as
2.1.2. No Thresholding Alternative
Research on the implementation of wavelet denoising without using a threshold can be found in [
39,
40]. This approach considers using a functional analysis method based on the entropy of the signal, and this algorithm takes advantage of a constructive structural property of the wavelet tree with respect to a defined seminorm; it consists of searching for minima for the low-frequency domain and other minima for the high-frequency domain.
2.2. Deep Learning
Deep learning is a subset of machine learning techniques that allows computers to process information in terms of a hierarchy of concepts [
41]. Typically, deep learning is based on artificial neural networks, which are known for their capacity as universal function approximations with good properties of self-learning, adaptivity, and advancement in input to an output mapping [
42]. With this capacity, computers can learn complex operations and functions by building them out of simpler ones.
Previous to the development of deep learning techniques and algorithms, other approaches were almost unable to process natural data in their raw form. For this reason, the application of pattern-recognition or machine-learning systems required domain expertise to understand the problems, obtain the best descriptors, and apply the techniques using feature vectors that encompass the descriptors [
43].
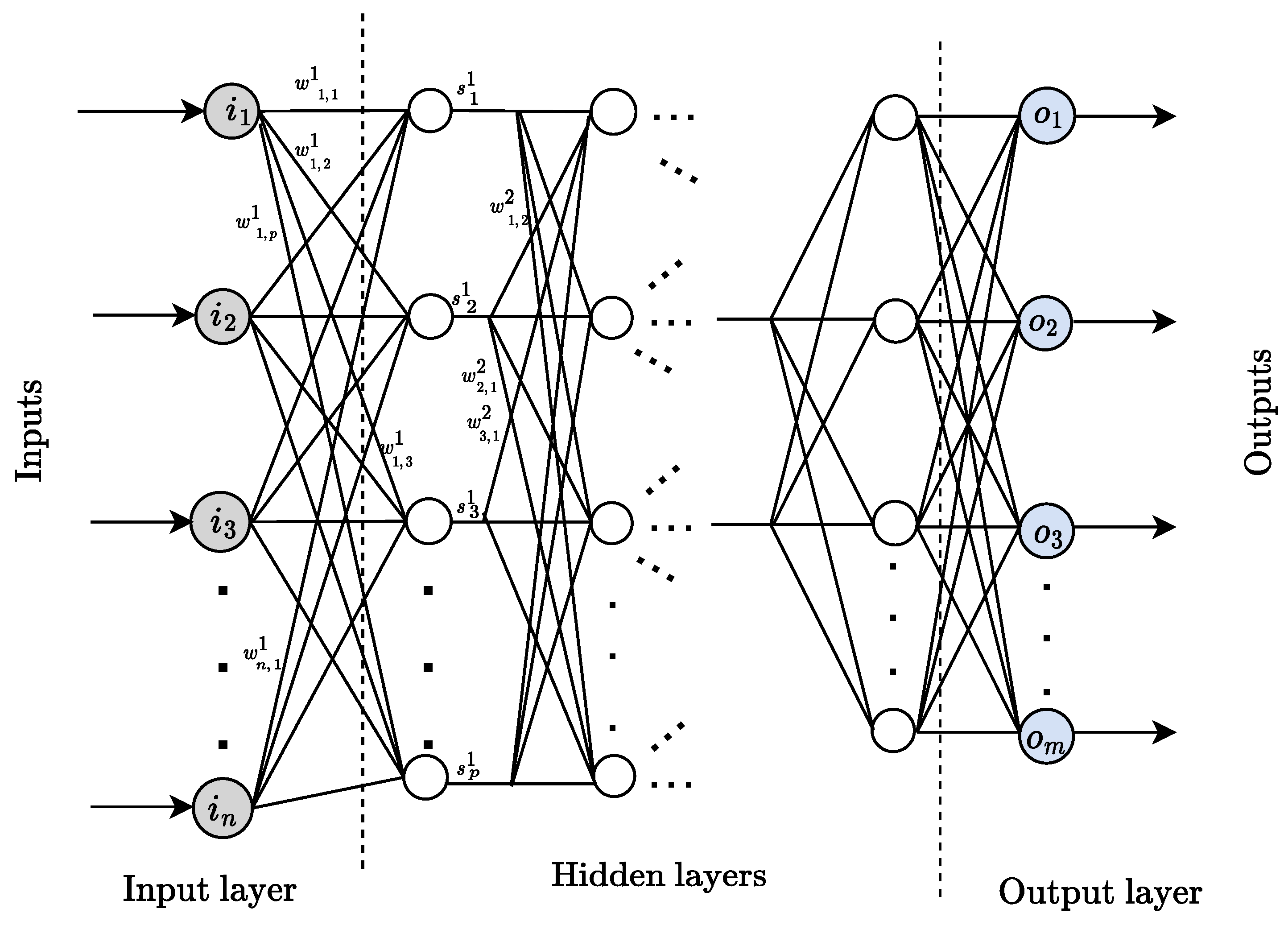
The most common form of deep learning is by composing layers of neural network units. The first level receives the data (in some cases, raw data), and subsequent layers perform other transformations. After several layers of this process, significantly complex functions can be learned. The feedforward deep neural network, or multi-layer perceptron (MLP) with more than three hidden layers, is a typical example of a deep learning algorithm. The architecture of a MLP organized with multiple units, inputs, outputs, and weights can be represented graphically [
44], as shown in
Figure 3.
Each layer performs a function from the inputs (or the outputs of the previous layer) to the outputs, using activation functions defined in each unit and the value of the weight of the connections. For example, a network with three layers defines functions
,
,
, and this way, the whole network performs a function from inputs
x to the outputs defined as
[
41].
The purpose of the training process of a deep neural network is to approximate some mapping function
, where
x are inputs and
the networks’ parameters, such as the value of the connections between units and the hyperparameters of learning (e.g., the learning rate and the bias). One of the most relevant aspects of deep learning is that the parameter
is learned from data using a general-purpose learning procedure [
43]. This way, deep learning has shown its capability to solve problems that have resisted previous attempts in the artificial intelligence community.
The success of deep learning in speech recognition and image classification in 2012 is often cited as the leading result of the renaissance of deep learning, using architectures and approaches such as deep feedforward neural networks, convolutional neural networks (CNNs), and Long Short-Term Memory (LSTM) [
45].
One of the most important architectures of deep neural networks applied to signal processing is autoencoders. Autoencoders are designed to reconstruct or denoise input signals. For this reason, the output presents the same dimensionality as the inputs. Thus, autoencoders consist of encoding layers and decoding layers. The first stage removes redundant information in the input, while decoding layers reverse the process [
17]. With the proper training, pairs of noisy/clean parameters can be presented to the autoencoder, and the approximation function gives denoising properties to the network.
A massive amount of data are often required, given the huge amount of parameters and hyperparameters of autoencoders and the deep networks in general. Furthermore, the recent advances in machine parallelism, such as cloud computing and GPUs, are of great importance to perform the training procedures in a short time [
45].
From this experience, we selected the recent implementation of the stacked dual-signal transformation LSTM network (DTLN). This implementation combines a short-time Fourier transform (STFT) and a pre-trained stacked network. This combination enables the DTLN approach to extract information from magnitude spectra and incorporate phase information, providing state-of-the-art performance.
The DTLN has 128 units in each of its LSTM layers. The networks’ inputs correspond to information extracted from a frame size of 32 ms and a shift of 8 ms, using an FFT of size 512. An internal convolutional layer with 256 filters to create the learned feature representation is also included. During training, 25% of dropout is implemented between the LSTM layers. The optimization algorithm applied to update the network weights was Adam, first presented in [
46], using a learning rate of
. This implementation is capable of real-time processing, showing state-of-the-art performance. Its architecture combines LSTM, dropout, and convolutional layers, resulting in a total of 986753 trainable parameters. Further details of the implementation can be found in [
47].
2.3. Proposed System
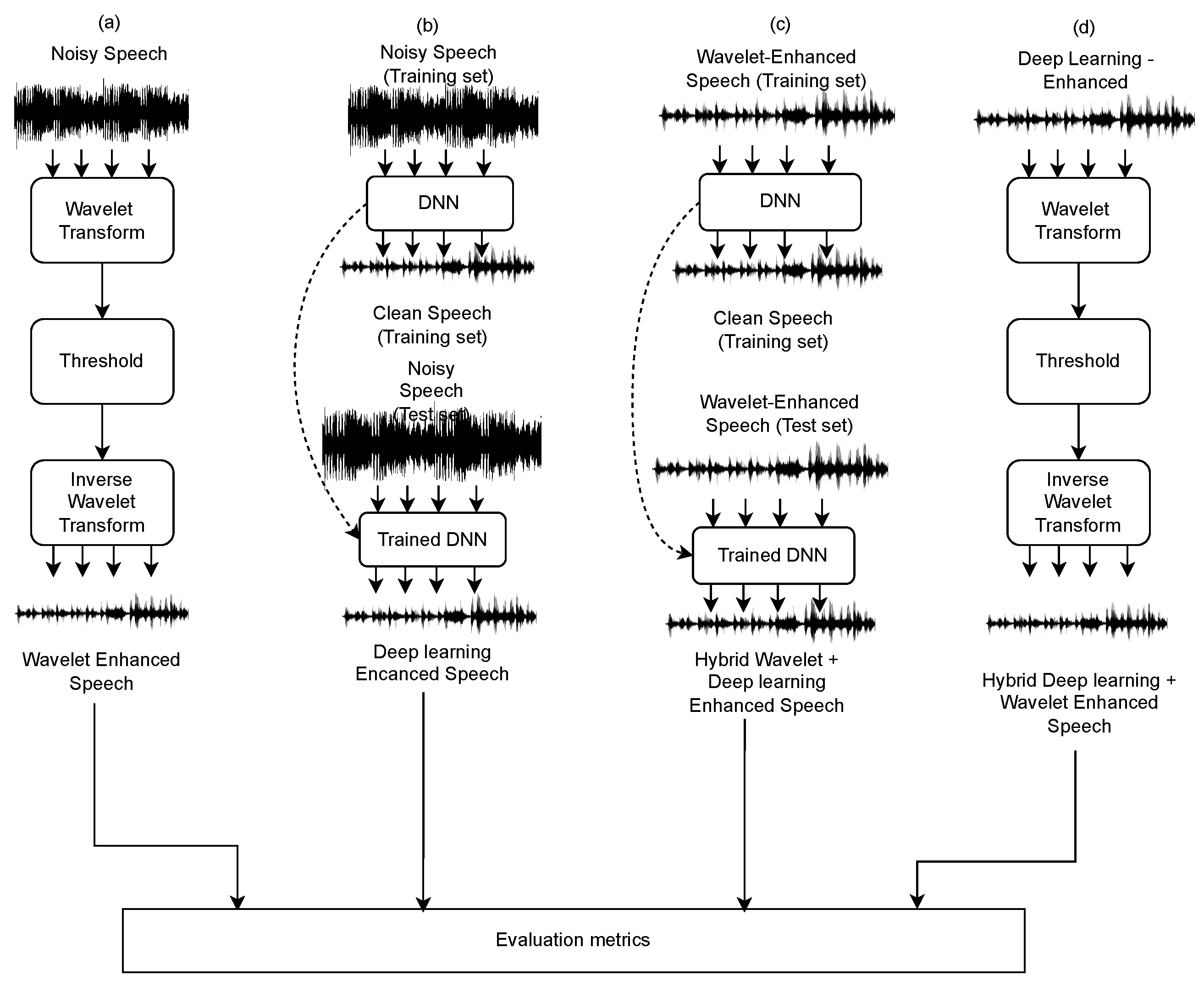
In order to test our proposal, the first step is to generate a dataset of noisy speech with both natural and artificial noise at several signal-to-noise ratio levels. This procedure establishes parallel data of clean and noisy speech and allows the comparison of speech quality before and after the application of the denoising procedures.
Our focus is on the combination of wavelet-based and deep-learning-based speech denoising, with the purpose of comparing the performance of both separately and analyzing the suitability of both in a two-stage approach. In the case of wavelet-based denoising, the following four steps were applied in an extensive experimentation, according to the description presented in
Section 2.1:
Select a suitable mother wavelet.
Transform each speech signal using the mother wavelet.
Select the appropriate threshold to remove the noise.
Apply the inverse wavelet transform to obtain the denoised signal.
There is a variety of criteria that can be used to choose the mother wavelet, such as the ones presented in [
27,
48]. In our case, an experimental approach was implemented, following a process of trial and error with commonly used wavelet families for speech denoising such as Daubechies, Symlet, and biorthogonal.Different wavelets from each family (using common ranges) were tested using objective measures, and the wavelets with the best results in each case were tested again; finally, the wavelet with the best results among the wavelet families was selected. This process was made using the Wavelet-Denoiser System (
https://github.com/actonDev/wavelet-denoiser, accessed on 28 April 2022) to determine the best combination of mother wavelets and parameters for each case.
For the application of the deep-learning-based denoising, the procedure can be summarized in the following steps:
Select one architecture of the network: In our experiments, we used the stacked dual-signal transformation LSTM network architecture presented in [
47]. The architecture was based on two LSTM layers followed by a fully connected (FC) layer.
Train the deep neural network with pairs of noisy and clean speech at the inputs and at the outputs. For the case of the hybrid approach, the outputs of the wavelet denoising were used as the inputs of the neural network, which were re-trained completely using pairs of wavelet-based denoising and clear speech.
Establish a stop criterion for the training procedure.
As in the case of wavelets, objective measures can be applied to validate the benefits of the deep neural networks in each noise type and level. With the purpose of performing a proper comparison, the same amount of epochs for training the deep neural networks was used for both (noisy, clean) and (wavelet-denoised, clean) procedures. Additionally, for the sake of completeness in the experiments, we also considered a two-stage approach with the application of wavelet denoising to the results of the deep-learning-based denoising procedure. This experimental approach can be summarized in four possibilities to implement and compare, as illustrated in
Figure 4.
2.4. Experimental Setup
In this section, a detailed description of the data and the evaluation process is presented.
2.4.1. Dataset
In order to test our hybrid proposal based on wavelets and deep learning, we chose the CMU ARCTIC databases, constructed at the Language Technologies Institute at Carnegie Mellon University. The recordings and their transcriptions are freely available in [
49]. The dataset consists of more than 1100 recorded sentences, selected from Project Gutenberg’s copyright-free texts. The recordings were sampled at 16KHz in WAV format.
Four native English speakers recorded each sentence, and their corresponding files were labeled as bdl (male), slt (female), clb (female), and rms (male). For our experiments, we chose the slt voice and defined the training, validation, and test sets according to the common criteria of the data available: 70%, 20%, and 10%, respectively. The randomly selected utterances that conform the test set for the deep neural networks were shared in the evaluation of the four cases described in
Section 2.3.
2.4.2. Noise
To compare the capacity of the four cases contemplated in our proposal, the database was degraded with additive noise of three types: two artificially generated noises (White, Pink) and one natural noise (Babble). To cover a wide range of conditions, five levels of signal-to-noise (SNR) ratios were considered for each case. This gives the following dataset:
The whole set of voices to compare can be listed as:
Clean, as the dataset described in the previous section.
The same dataset degraded with additive White noise added at five SNR levels: SNR −10, SNR −5, SNR 0, SNR 5, and SNR 10.
The clean dataset degraded with additive Pink noise added at five SNR levels: SNR −10, SNR −5, SNR 0, SNR 5, and SNR 10.
The clean dataset degraded with additive Babble noise added at five SNR levels: SNR −10, SNR −5, SNR 0, SNR 5, and SNR 10.
2.4.3. Evaluation
The evaluation metrics defined for our experiments were based on measures commonly applied in noise reduction and speech enhancement, namely, perceptual evaluation of speech quality (PESQ), and frequency domain segmental signal-to-noise ratio (SegSNR).
The first measure is based on a psychoacoustic model to predict the subjective quality of speech, according to ITU-T recommendation P.862.ITU. Results are given in interval
, where 4.5 corresponds to a perfect signal reconstruction [
50,
51].
The second measure is frame-based, calculated by averaging the SNR estimates at each frame, using the equation:
where
is Fourier transform coefficient of frame
i and
is the coefficient for the processed speech.
N is the number of frames and
L the number of frequency bins. The values of this measure are given in the interval
dB.
Additionally, we present waveforms and spectrogram visual inspection to illustrate the result of the different approaches.
3. Results and Discussion
In this study, five SNR levels, three types of noise, and two objective measurements were explored to evaluate the performance of the four different algorithms described in
Section 2.3. A sample visualization of the different waveforms involved in the study is shown in
Figure 5.
The objective measures of PESQ and SegSNR are reported as the mean of fifty measures calculated on the test set. To select the mother wavelet and the threshold, extensive experimentation was conducted. For every case reported in the results, more than twenty possibilities were tested. The most successful mother wavelets were db1 and db2.
For the deep learning and hybrid approaches involving neural networks, the stop criterion was defined as the number of epochs. The same number of epochs used for the training of the networks from the noisy to clean signal were replicated in the hybrid proposals, for the sake of comparison.
The results for the PESQ measure and the Babble noise degradation and filtering are presented in
Table 1. A first relevant result can be observed on the small benefit that was measured for the case of the wavelet enhancement. A better performance than those of the wavelets was obtained with the deep learning enhancement for every SNR level of Babble noise. In terms of the hybrid combination of wavelets and deep learning, the deep neural networks as a second stage achieved an improvement in three of the five cases of PESQ. Furthermore, an increase on SegSNR was measured in two of the five cases with the same hybrid combination, as presented in
Table 2.
For all the cases of the SegSNR measure with Babble noise, it was observed that the wavelet transform did not represent significant improvements of the results. This can explain why none of the hybrid approaches performed better than deep learning alone, with the exception of two cases.
The benefits of the hybrid approaches were consistently better for the case of Pink noise. The results for PESQ and the different levels of this type of noise are presented in
Table 3. For this measure, the hybrid approach of wavelets + deep learning gave better results in four of the five noise levels. This results are important because the application of wavelets did not improve any of the cases in terms of the SNR, but, as shown in
Table 4, an increase in SegSNR was consistent.
Such results can be interpreted in terms of improvements incorporated into the signals with the application of wavelets, which did not improve the perceptual quality of the speech sounds, but the mapping of the noisy signals into a different version is beneficial for the enhancement using deep learning.
The best results of the hybrid approach of wavelets + deep learning were obtained for the case of White noise.
Table 5 shows the results of the PESQ measure. For all the noise SNR levels, such a hybrid approach gave the best results, even when the first stage of wavelet enhancement did not improve the quality of the signal. However, in a similar way to the previous case,
Table 6 shows how the wavelets improved the SegSNR in all the cases of White noise degradation.
The improvements on the SegSNR measure with the hybrid approach were consistent also at all SNR levels of White noise. For this case, it is also significant that the hybrid combination of deep learning and wavelets as a second stage also surpassed the results of deep learning.
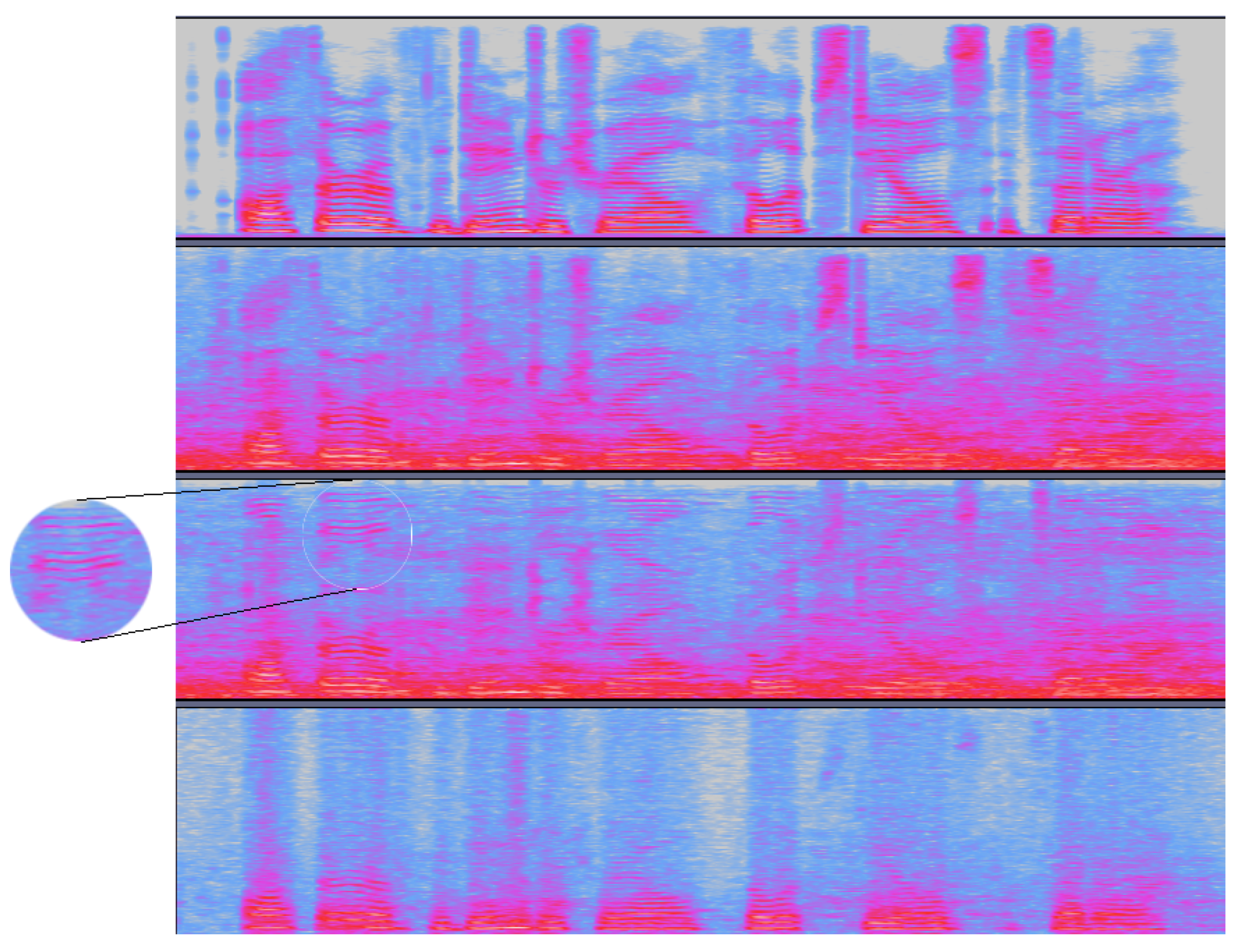
For all types of noise, the application of wavelets as the second stage of enhancement did not represent any relevant benefit in terms of PESQ, in comparison to the deep learning approach. From a visual inspection of the spectrograms in
Figure 6, it seems that the application of wavelets introduced some patterns at the higher frequencies and blurred some relevant information at those bands as well.
This kind of result may explain also why wavelets did not improve significantly the PESQ of the noisy utterances, but helped to improve the SegSNR (in particular in the case of White noise). Especially for the case of White noise, the wavelets as an intermediate representation of the signals seemed to represent advantages for the application of the deep learning enhancement.
The results of this work may represent similar benefits to recent proposals of combining wavelets and deep learning, for example, in [
52], where deep learning performed the mapping in the wavelet domain. In our case, deep learning was applied as a second stage of enhancement (and as a first stage prior to wavelets). In that work, relevant benefits in terms of improving the SNR were found.
Other hybrid or cascade approaches have been tested recently in similar domains, for example, speech emotion recognition [
53]. The results of this study may represent an opportunity to develop more hybrid approaches, where the benefit of each stage can be analyzed separately, in a similar way to image enhancement, where different algorithms to enhance aspects such as noise, blur, and compression have been applied separately, using a cascade approach.
4. Conclusions
In this paper, we analyzed the hybrid combination of wavelets and deep learning for the enhancement of speech signals. For this purpose, we conducted an extensive experimentation for the selection of parameters of the wavelet transform and the training of more than forty deep neural networks to measure whether or not the combination of both deep learning and wavelets (as both the first or second stages) benefits the enhancement of speech signals degraded with several kinds of noise. To establish a proper comparison, some restrictions were introduced in the experimentation, such as the limitation of epochs during training to match the hybrid and deep learning cases.
The results showed benefits of the hybrid application of first wavelet enhancement and deep learning as a second stage, especially for the case of White noise. Those benefits were measured in comparison to the noisy signal and the enhancement with wavelets and deep learning alone. For other types of noise, in particular Babble, the hybrid approach presented mixed results, with benefits on some of the SNR levels analyzed. This type of noise, which is more complex and irregular than the synthetic White and Pink noises, was the most challenging scenario of those contemplated in this work. The application of deep learning as a unique stage presents better results for that case. For the case of Pink noise, the hybrid approach enhancement shows better results than the separate algorithms for the higher levels of noise. When the SNR was as low as 5 or 10, deep learning performed better.
The wavelet denoising succeed in enhancing the signals in terms of SegSNR (except for Babble noise, where the benefits were almost null), but some artifacts observed in the spectrograms may explain why its benefits were not measurable in terms of PESQ. Regardless, the output obtained with the wavelet enhancement represents a better input to the deep neural networks than the noisy signals. The benefits of applying a combination of deep learning and other algorithms are present in the scientific literature, and future works may define the particular benefits of the separate algorithms in order to establish optimized hybrid applications for particular noise types and levels.
Several research opportunities can follow the results of this study. For example, an analysis of delays in real-time applications using the hybrid proposal could be addressed in order to establish the feasibility of implementation in a particular hardware and integrated software. Furthermore new scenarios, such as far-field speech enhancement for application in video conferencing or multi-speaker enhancement, can be analyzed in terms of hybrid approaches in order to select the best simple or hybrid algorithms.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}