1. Introduction with Related Work and Novelties
Over the past few decades, the development of new regularization techniques has played an important role in addressing the ill-posedness of inverse problems. A few example applications include image reconstruction in X-ray tomography [
1,
2] and various partial differential equation constrained inversion problems, for instance, inverse scattering and parameter identification [
3,
4,
5,
6,
7]. Popular techniques, such as Tikhonov regularization and truncated singular value decomposition (truncated SVD), are ubiquitous in practical inverse problems [
8,
9,
10]. However, one particular challenge of Tikhonov-based regularization strategies is the need to specify a suitable choice of the regularization parameter. Suboptimal choices can lead to excessively smooth or unstable reconstructions. While methods such as Morozov’s discrepancy principle, the
L-curve criterion, and cross validation are popular for choosing a satisfactory regularization parameter, these are often computationally expensive and may require the computation of multiple inverse solutions. Even when the “right” regularization parameter is chosen, the smoothing effect leading to smeared reconstructions is unavoidable. On the other hand, spectral-decomposition-based methods, such as truncated SVD, aim to avoid regularizing data-informative features while applying infinite regularization on the rest. It is, however, not trivial to determine how many dominant modes should be retained. Furthermore, these SVD-typed approaches are typically suitable only for linear inverse problems.
Other regularization techniques have been proposed to combat the smoothing effect of Tikhonov regularization. Total variation (TV) regularization is designed with an anisotropic diffusion mechanism to ensure discontinuities and sharp interfaces in the inverse solution to be maximally preserved [
9,
10,
11]. One problem with TV regularization is that, due to the non-differentiability of the TV functional, it could produce a staircasing effect [
12]. To overcome this issue, smooth approximations and sophisticated optimization methods have been developed [
9,
13]. One of the reasons why Tikhonov and TV regularizations are popular is their convexity. This is a particularly appealing feature for inversion techniques using optimization. Though less popular, non-convex regularization strategies [
14,
15,
16] are viable alternatives. However, inverse solutions with non-convex regularizations also require advanced optimization methods, such as alternating direction method of multipliers (ADMM) [
17,
18,
19] or iteratively reweighted least squares (IRLS) [
20].
In our previous work [
21], inspired by the truncated SVD method, we put forward a new regularization approach, called data-informed (DI) regularization. DI was designed to overcome the ill-posed nature of inverse problems by placing regularization only where it is necessary in order to preserve the fidelity of the reconstructions. This is accomplished by a two-step process: first, find data-informed directions in the solution space, and then apply Tikhonov regularization only in the data-uninformed directions. We theoretically showed that DI is a valid regularization strategy. Numerically, we demonstrated that the reconstruction accuracy is robust for a wide range of regularization parameter values and DI outperforms both Tikhonov and truncated SVD (TSVD) for various inverse and imaging problems. Since DI, as well as TSVD, exploits the SVD of the forward operator, extension is necessary for nonlinear inverse problems. One straightforward extension for the Newton-based optimizer is to apply the DI approach at each Newton iteration by linearizing the forward operator around the current parameter estimate. However, this approach can require significant additional computation, especially in high dimensions.
Meanwhile, one recent tool for studying sensitivity is the active subspace (AS) method introduced in [
22]. The active subspace is designed to study the sensitivity of a given nonlinear function with respect to the input parameters. The key idea is to identify a set of the directions in the input space that, on average, contribute most to the variation of the function. The beauty of the approach is that it requires the computation of the active subspace only once for any nonlinear input–output map. An application where AS is particularly useful is dimension reduction [
23,
24,
25,
26,
27]. Due to the computational cost involved in dealing with high-dimensional parameter spaces in traditional Markov chain Monte Carlo simulations (MCMC), the active subspace method was used to accelerate MCMC [
28]. The work in [
29] combined the active subspace method and proper orthogonal decomposition with interpolation to obtain a better reconstruction of the modal coefficients when a small number of snapshots are used. More recently, the active subspace method was adopted to develop neural network based surrogate models [
30].
In this work, we equip the DI idea with the active space approach and we call this combination the data-informed active subspace (DIAS) regularization strategy. The DIAS method retains all of the DI advantages, including being robust with respect to the regularization parameter, and avoids polluting solution features informed by the data while estimating the data-informed subspace better than the original DI approach. Unlike DI or Tikhonov, DIAS takes into account the uncertain nature of the inverse problem via the active subspace using the prior distribution of the unknown parameter. More importantly, it is applicable not only for linear, but also seamlessly for nonlinear inverse problems. Indeed, the active subspace, thanks to its global nature, is computed once at the beginning regardless of the linear or nonlinear nature of the inverse problem under consideration. Furthermore, the DIAS approach can effectively reuse any Tikhonov regularization codes/libraries. In fact, DIAS regularization can be considered a special Tikhonov regularization once the DIAS regularization operator is constructed.
Table 1 summarizes the main advantageous features of DIAS approaches over the classical Tikhonov regularization method and the DI method [
21].
The paper is structured as follows.
Section 2 briefly reviews the standard (uncentered) active subspace method and discusses its centered variation. The relationship between uncentered and centered active subspaces is then rigorously investigated. Each of these active subspace approaches can be incorporated into the DI framework with either the original data misfit or an approximate one. For linear inverse problems,
Section 3 proposes two DIAS regularization methods with approximate data misfit: one using centered active subspaces (cDIAS-A) and the other using uncentered active subspaces (DIAS-A). An important result is that the truncated SVD approach is a special case of cDIAS-A. Similarly, two DIAS approaches with the original (full) data misfit—one using centered active subspaces (cDIAS-F) and the other using uncentered active subspaces (DIAS-F)—are presented for linear inverse problems in
Section 4. It is in this section that the practical aspect of the four DIAS variants is discussed. The full data misfit variants, DIAS-F and cDIAS-F, are non-intrusive, while the approximate misfit counterparts are intrusive. We also show that the DI approach in [
21] is a special case of cDIAS-F. Various numerical results for linear inverse problems are presented in
Section 5 to expose the pros and cons of each of the DIAS variants and to compare them with Tikhonov regularization.
Section 6 concludes the paper with future work.
2. Centered versus Uncentered Active Subspace Methods for Linear Inverse Problems
In this section, we first recall some results on the active subspaces (AS) method that are useful for our developments. A detailed derivation of the active subspace can be consulted in [
28]. The main issue that we investigate is the difference between the uncentered AS and the centered AS. To begin, let
be a differentiable function from
to
and its gradient vector be denoted as
. The key object in the AS method is the uncentered covariance matrix
defined by
where
is a probability density in
(we assume it to be a centered Gaussian
in this paper, where
is the covariance matrix), and
are matrices containing eigenpairs of
. The eigenvalue and eigenvector matrices can be partitioned as
where
is the diagonal matrix containing the
r largest eigenvalues of
, and
the corresponding eigenvectors. The
active subspace —the subspace on which
is most sensitive on average—is defined to be the span of the columns of
. This is in turn determined by the
r largest eigenvalues. Likewise, the
inactive subspace—the subspace on which
is almost invariant on average—is defined by the span of the columns of
. It is thus sensible to “ignore” the inactive subspace without compromising much of the accuracy in computing
(see [
28] for a rigorous proof). If
, significant computational gain can be achieved by focusing on only the active variables. One way to eliminate inactive variables is to integrate them out, as we now describe. Any
can be written as
where
are called the
active variables, and
the
inactive variables. The density function
can be therefore considered as the joint density between the active and inactive variables:
In the AS approach, one typically approximates
using the active variables by integrating out the inactive ones
where
is the conditional density of
given
. Note that if
, which is the case in this paper,
is trivial (see
Section 3.1). The integral evaluation is less straightforward, in fact, computationally prohibited, for nonlinear
, and it is typically approximated using Monte Carlo sampling.
From a statistical perspective, the uncentered covariance matrix of the form (
1) is not common, though it has been investigated. Comparisons between centered and uncentered covariance matrices have been carried out for general covariance matrices in the context of principal component analysis [
31,
32,
33,
34]. We now address the difference between uncentered and centered covariance matrices in the context of active subspaces. As we will show, more can be said in this context by exploiting the structure of the inverse problems. To that end, let us introduce the centered version of the AS covariance matrix
where the gradient mean is given by
For notational convenience, we will refer to the active subspace based on (
1) as the
uncentered active subspace, and the one based on (
3) as the
centered active subspace.
To understand the advantages/disadvantages of uncentered AS and centered AS, we restrict ourselves in the linear inversion setting. Consider the following additive noise observational model
with
,
, and the data
. The inverse problem is to determine
given
. Posing this problem as a least squares problem in a weighted Euclidean norm, we minimize the data misfit:
To overcome an ill-conditioning issue due to the ill-posed nature of the inverse problem, we can employ the classical Tikhonov regularization approach:
where
is a given weight matrix. In the context of Bayesian inverse problems,
is typically chosen as the covariance of the prior distribution of
. Following [
22], we determine the active subspaces based on the data misfit, i.e.,
whose gradient is
Since we choose
, it is easy to see that the uncentered covariance matrix
in (
1) can be written as [
22]
Similarly, the mean of the gradient with respect to
is
and thus the centered covariance matrix
in (
3) becomes
In order to gain insights into the difference between centered and uncentered active subspaces, for the rest of
Section 2, we assume
. Let the full SVD of the noise covariance whitened forward operator be
. Since
resides in the column space of
, there exists
such that
Lemma 1. Let and be eigenvalue matrices of and , respectively, such that and .
For , and for .
Define . For , , and .
Proof. The first assertion is obvious as
using the SVD of
. For the second assertion, we have
Since
is a similarity transformation of
, we seek the relationship between the spectra of
and
. Now, since
is a rank-one perturbation of the diagonal matrix
, using a standard interlacing eigenvalue perturbation result (see, for example, ([
35],
Section 5) and [
36]) concludes the proof. □
Lemma 1 shows that the eigenvalues of
are not smaller than those of
, but this does not reveal insights on how
could make a difference going from
to
. To wit, let us consider a special case of
, where
is the
k-th column of
and
is some number, then it is straightforward to see that
Now if
is sufficiently large such that
where
, then
. As a direct consequence, while
is not part of the centered active subspace, it is for the uncentered one. In other words, it is important to see that the uncentered AS approach takes both the forward operator
and the data into account when constructing the active subspace, while the centered AS approach is purely determined by the spectrum of the forward operator. When
, both approaches are similar. However, the uncentered AS is expected to outperform the centered counterpart when
since eigendirections, classified as inactive in the centered approach, are in fact active when taking the data into account; we verify this fact later in
Section 5. The proof of Lemma 1 also implies that, due to the symmetry of
, the eigenvectors of
are not only a reordering, but also a rotation of the eigenvectors of
in general since
is not necessarily diagonal.
Remark 1. Note that we can alternatively first perform the whitening to transform the inverse problem to the standard setting with and , and then compute the active subspaces. This simplifies the exposition. However, as shown in Appendix A, the active subspaces for the whitened problem change, and the corresponding DIAS solutions are less accurate. 5. Numerical Results
We now test the proposed DIAS approaches against the Tikhonov method on a variety of popular linear inverse problems. In particular, we consider one-dimensional (1D) deconvolution, various benchmark problems from [
38], and X-ray tomography. In all linear inverse problems, we assume
and
. Under this assumption, we have
. Furthermore, by Propositions 2 and 3, the cDIAS-A and cDIAS-F methods become the truncated SVD (TSVD) and the DI approaches, respectively. Thus, for clarity we use TSVD and DI in the places of cDIAS-A and cDIAS-F for all examples. Additionally, by
additive white noise we mean additive Gaussian noise with the standard deviation of
of the maximum value of synthetic data. In the 1D deconvolution problem, we numerically investigate the difference in the inverse solutions, using the uncentered AS approaches and the centered AS approaches. In particular, we highlight the reordering and rotation effect of the uncentered AS induced by the data
(see
Section 2 for a theoretical discussion).
5.1. 1D Deconvolution Problem
We consider the one-dimensional deconvolution problem (see, for example, [
9,
39])
where
is a Gaussian convolution kernel with
,
(
),
, and
e is 5% additive white noise. The exact solution, which we aim to reconstruct from the noisy data
, is given as
Figure 1a shows the projected components of the true solution
in the uncentered active eigenspace
and the centered active eigenspace
. In the uncentered eigenspace, the true solution lies almost entirely in the first eigenmode, while it predominantly lies in the second and sixth modes of the centered eigenspace. The relative error between projection
with
dimensional AS and the true solution
is shown in
Figure 1b. It can be seen that the uncentered AS provides more accurate projection, even with one active direction (
). The result also shows that the centered AS needs at least 10 active directions to start being comparable to the uncentered counterpart in terms of accuracy. These numerical observations verify the reordering and rotating results of Lemma 1.
The uncentered AS eigenvector reordering and rotating effects induced by the data
are presented in
Table 2, where we compute the cosine of the angle between the centered and uncentered active modes. As can be seen,
is slightly rotated from
. That is, compared to the centered AS method, the uncentered AS, under the influence of the data, reorders the eigenvectors of the forward operator so that
is in the first position and slightly rotates it to align better with the directions in which the data are informative. The most significant shortcoming of the DI method and others using the basis
is that they misclassify
as the most data-informed direction, while for the data under consideration,
is much more informative. Indeed, the relative error in
Figure 1b shows that the true parameter is almost orthogonal to
.
Figure 2 presents solutions for the 1D deconvolution problem with various combinations of active subspace dimension
r and regularization parameter
. For the one-dimensional active subspace
, the TSVD method is not able to reconstruct the solution since the first mode of
contributes very little to the true solution. On the contrary, DIAS-A yields a reasonable solution, as its first mode is the most data-informative one. For large dimensional active subspace, the DIAS-A and TSVD solutions are almost the same. These observations are consistent with the discussion following Lemma 1. Recall that the uncentered eigenvectors are a reordering and rotation of the centered ones. By considering a sufficiently large number of modes to be data informed, the subspaces spanned by
and
become more similar. This can also be clearly seen in
Table 2 along the diagonal. Notice that
except for the first two modes. This is because the first two eigenvectors are swapped and slightly rotated. Furthermore, inherited from the DI approach [
21], DIAS-A, and TSVD (in fact cDIAS-A) solutions are almost invariant with respect to the regularization parameter. This is not surprising since the DIAS approach, by design, regularizes only the data-uninformed modes. Its solution should remain unaffected if sufficient data-informed modes are taken into account.
Figure 2 also shows that the DIAS-F, DI, and Tikhonov solutions are indistinguishable for small regularization parameter regardless of whether
or
. This is due to two reasons: (1) the DIAS approaches and Tikhonov regularize inactive modes in the same way, and (2) Tikhonov regularization has little effect on the active modes when the regularization parameter is small, thus having little impact on the inverse solution. The situation changes for larger regularization parameters, especially for
. Both DIAS-F and DI, by leaving the active parameters untouched, are insensitive to the regularization while Tikhonov oversmooths the solution by heavily regularizing the active parameters.
Another important observation that
Figure 2 conveys is the difference among DIAS approaches with centered and uncentered active subspaces. For
, the uncentered approaches DIAS-A and DIAS-F outperform the centered counterparts TSVD and DI, especially for large regularization parameters. In other words, uncentered approaches are more robust to the regularization parameter. The reason is that uncentered methods do not penalize the data-informed direction
while the centered ones—without taking data into account—regularize
, the most data-informative direction in the basis
. As discussed in
Section 2, for sufficiently large active subspace dimension
, all the DIAS solutions are similar since all methods end up spanning the same subspace. However, at the optimal regularization parameter
, determined by the L-curve method [
38], the DIAS-F solution is visibly closer to the ground truth than TSVD and Tikhonov.
5.2. Benchmark Problems
In this section, we apply the DIAS regularization approach with centered AS and uncentered AS methods to six benchmark problems from
regularization tools [
38]. We briefly describe the Shaw benchmark [
40] here, and we refer the readers to [
38] for the descriptions of other benchmark problems. It is in fact a deconvolution problem in which the kernel is given as
where
, and the true solution is given by
where
. For all benchmark problems, the domain
is divided into 1000 subdomains. These problems provide good examples to study the robustness and accuracy properties of the DIAS approaches. Observational data for each problem are corrupted with 1% additive white noise.
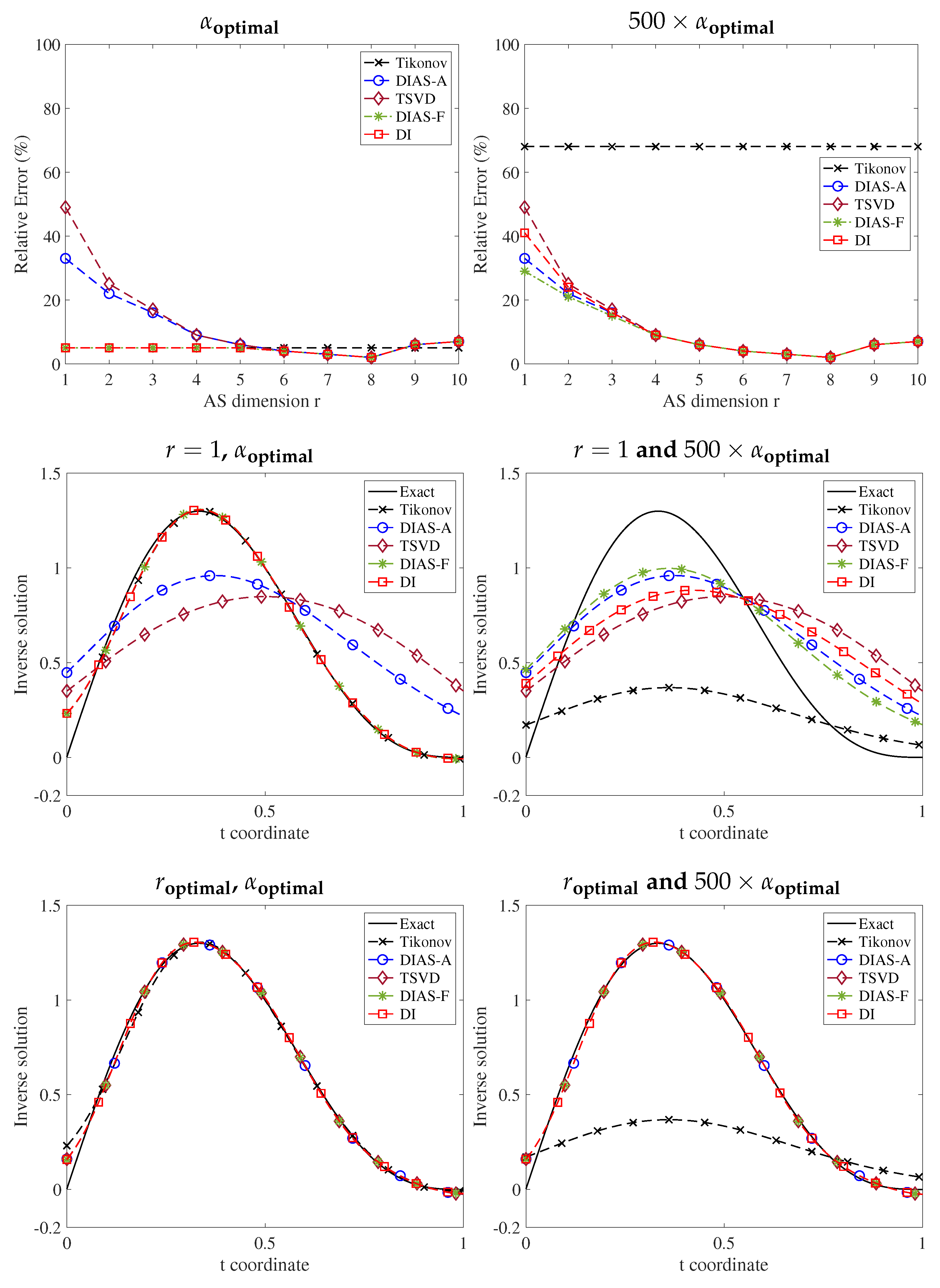
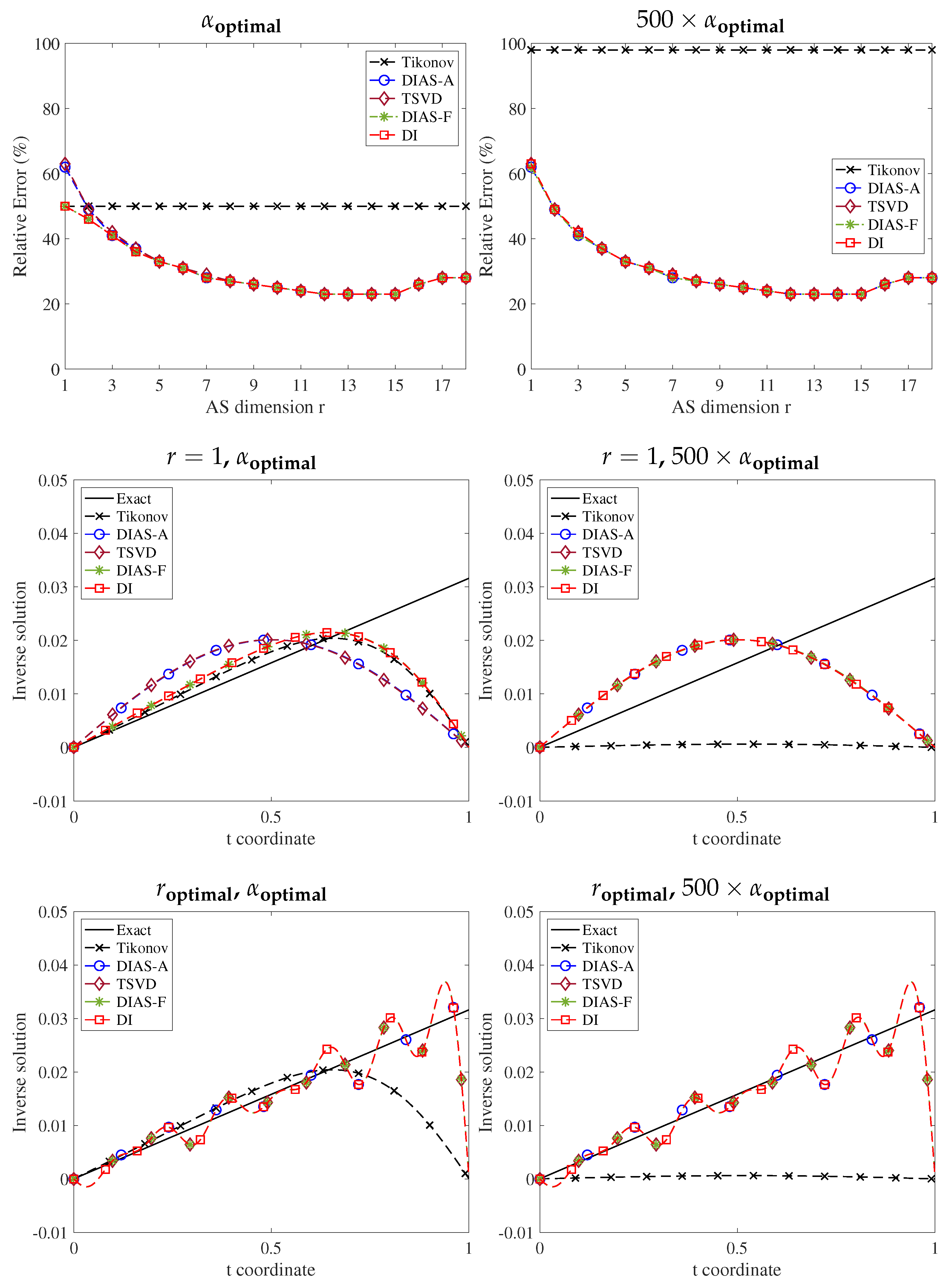
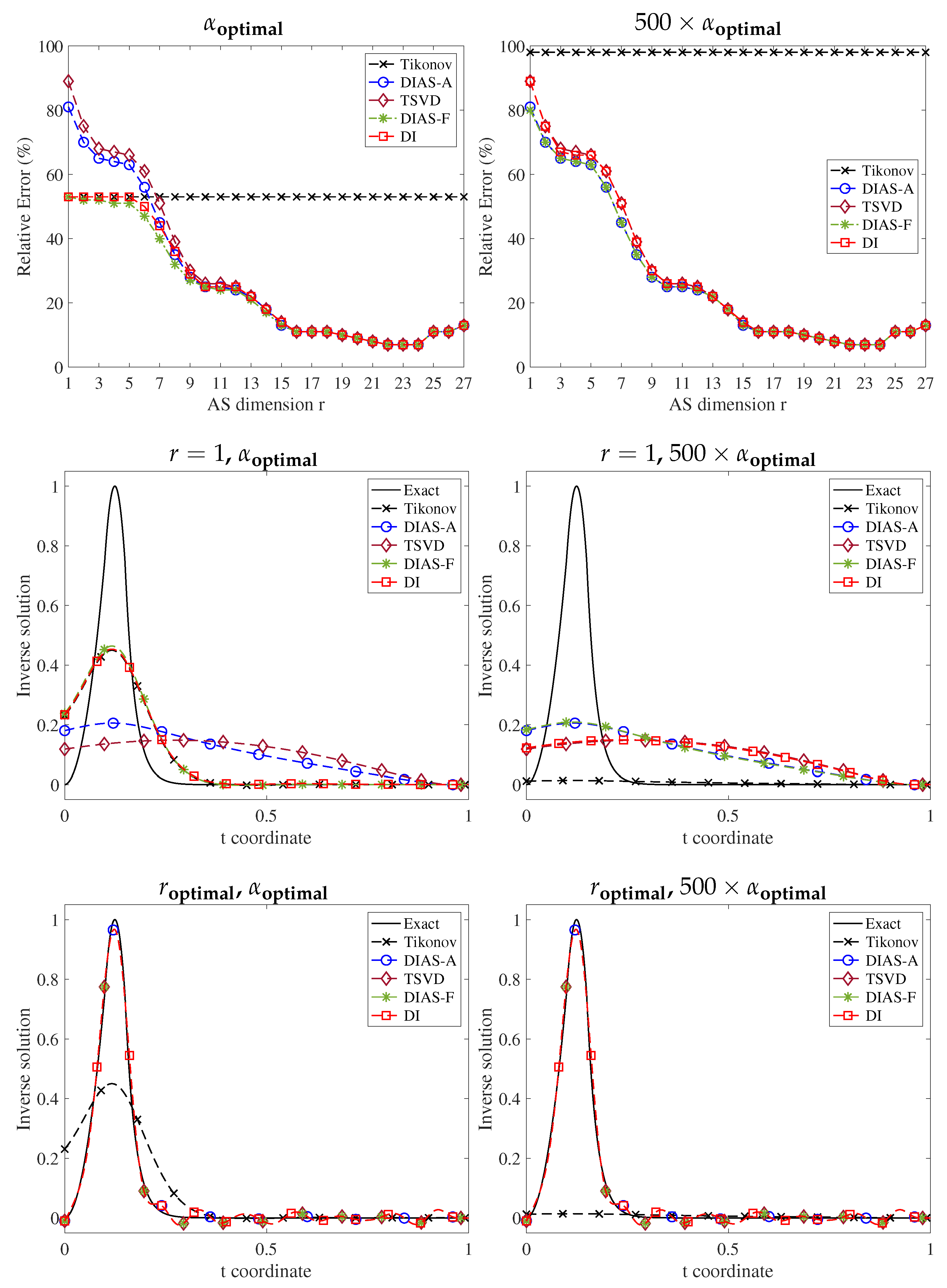
Figure 3 measures the relative error between the ground truth
and its projection
on both centered and uncentered active subspaces with various values of the active subspace dimension
r. For Shaw, heat, gravity, and Phillips problems, projecting the exact solution on the uncentered AS results in a lower error than on the centered AS. For the Deriv2 and Foxgood problems, the results are identical for both centered and uncentered AS. The reason is that the data for these two problems do not provide new information and thus the active subspaces are entirely determined by the forward operator
.
Figure 4,
Figure 5,
Figure 6,
Figure 7,
Figure 8 and
Figure 9 show the following: (1) top row—relative errors in the inverse solutions for different regularization methods for two values of regularization parameter (
and
); (2) middle row—inverse solutions with Tikhonov regularization and DIAS regularizations with one dimensional active subspace (
) for two values of regularization parameter; and (3) bottom row—inverse solutions with Tikhonov regularization and DIAS regularizations with optimal active subspace dimension for two values of the regularization parameter. Here, the optimal regularization parameters are chosen based on the L-curve method with Tikhonov regularization [
38], and the optimal AS dimension is found experimentally for each method. It turns out that the optimal AS dimension is the same for all methods.
Around the optimal AS dimension (top rows of all figures), regardless of what the regularization parameter is, all DIAS regularizations have similar accuracy and they are more accurate than Tikhonov, as expected. As can be seen in the middle rows, when the active subspace dimension is from to , less than the optimal dimension for the Shaw problem, the full data misfit methods outperform the approximated misfit counterparts. We provide the reason only for the Shaw problem, as it is the same for others. When taking , the approximate misfit approaches completely remove six other active modes, which are misclassified as inactive, in addition to removing the truly inactive modes. The inverse solutions thus lack the important contribution from these modes, leading to inaccurate reconstructions. Even when the active subspace is chosen to be too small, the full misfit methods only regularize the misclassified modes rather than eliminating them from the solution entirely.
The results also show that the DIAS regularizations with full data misfit are at least as good as Tikhonov regularization with and are more accurate with . Again, the reason is that for a reasonably small regularization parameter, the smoothing effect from Tikhonov regularization does not change the solution significantly. On the bottom rows where the AS dimensions are optimal, DIAS solutions are similar and outperform the Tikhonov counterparts for both values of regularization parameters.
From middle to bottom rows, the DIAS solutions with approximate data misfit change from worse to comparable to the DIAS solutions with original data misfit, and thus from worse to more accurate than Tikhonov solutions. This is not surprising: Equation (
2) shows that as the active subspace dimension increases, the error due to the data misfit approximation decreases. On the other hand, for the same reasons as in the deconvolution problem, the uncentered AS methods (DIAS-A and DIAS-F) are more accurate than the corresponding centered AS counterparts (TSVD and DI) for all problems with any active subspace dimension and with any regularization parameter.
Note that for these benchmarks, we take
as a large regularization parameter case to show that DIAS regularization is robust with respect to the choice of regularization parameter while Tikhonov is not. The DIAS solutions are much more accurate than the Tikhonov solutions, as the latter overregularizes all modes in this case. Additionally, we observe that the full data misfit approaches become similar to the approximate misfit ones as the regularization parameter increases. To see why, we recall from Equation (
7) that the only difference between approximate and full misfit approaches is the removal of the inactive variables in the former. When the regularization parameter approaches infinity, it annihilates the contribution of the inactive subspace in the inverse solution. In fact, they behave like TSVD in the limit and we know that TSVD is equivalent to applying infinite regularization on the truncated modes [
21]. Thus both approaches would yield identical solutions in the limit. For the case we consider here, the regularization is sufficiently large for us to already see this asymptotic behavior.
5.3. X-ray Tomography
X-ray tomographic reconstruction is another well-known linear inverse problem. A more detailed description of this problem can be found in [
9]. Synthetic data are generated with 1%, 3% and 5% white noise added to be realistic. Tikhonov solutions using the optimal regularization parameter
, obtained by the L-curve method [
9], are compared with DIAS approaches.
Figure 10 depicts the eigenvalues of
and
. While the first eigenvalue of the uncentered active subspace matrix is significantly larger than the first eigenvalue of the centered active subspace matrix, this only hints that
is more important than any of the vectors in
.
Figure 11 shows that there is indeed a striking difference between the first eigenvector of the two active subspaces. Visual inspection of the eigenvectors
and
makes it obvious that
contributes significantly to the solution, while the contribution of
to the solution is much less pronounced.
The Tikhonov solutions with different regularization parameters and the original image are shown in the
Figure 12 for the case of
noise. Clearly, underregularization results in noisy solutions and overregularization yields overly smoothed and blurry solutions.
Table 3 and
Figure 13 show the relative error and the reconstructed images for the underregularization case. The approximated misfit methods (DIAS-A and TSVD) remove the inactive variables so they are not prone to noise pollution amplified by inverting the small singular values corresponding to these data-uninformed modes. This has a regularization effect known as regularization by truncation. Since the full misfit approaches and Tikhonov capture all modes, their solutions are much more vulnerable to noise in the underregularization regime. For optimal regularization case in
Table 4 and
Figure 14, the full misfit methods DIAS-F and DI are more accurate than their approximate misfit counterparts for small active subspace dimensions, while all methods give similar results when the active subspace dimension is sufficiently large. For the overregularization case in
Table 5 and
Figure 15, the approximate and full misfit approaches provide comparable solutions, as they both behave like the TSVD method. Moreover, DIAS regularization solutions are robust to the regularization parameter as opposed to the Tikhonov solution. Another observation is that DIAS methods perform poorly when the active subspace dimension is taken to be too large (
12,000). This is not surprising since as
, all regularization is removed and the problem becomes ill-posed again.
To better understand the robustness of the DIAS approaches to various noise levels, we perform a sensitivity analysis, increasing the noise levels to 3% and 5%. One might expect that the DIAS method would be especially sensitive to noise since it is a data-driven approach. The following discussion shows, however, that the DIAS approaches maintain their advantages, even in the presence of significant noise. The results with higher noise levels are presented in
Table 6,
Table 7 and
Table 8 for 3%, and
Table 9,
Table 10 and
Table 11 for 5%. It can be observed that approximately the first 500 modes of the active subspace are not perturbed by noise (1%, 3% and 5%). For example, at
, the relative error of DIAS-A and TSVD are approximately 49% and 56%, respectively, for all noise levels. Meanwhile, when
, the corresponding figures for both approaches in the cases of 1%, 3% and 5% are (27.39%, 29.10%), (33.95%, 35.10%) and (43.49 % and 44.39%), respectively. This is consistent with the well-known fact that higher modes of the active subspace (corresponding to smaller eigenvalues) contain more noise. In other words, as the noise level increases, the 5000-th mode moves to the inactive side of the space because it becomes dominated by noise rather than useful information.
6. Conclusions
We have presented four different data-informed regularization approaches for linear inverse problems using active subspaces (DIAS): two with approximate data misfit, and two with full data misfit. We rigorously showed the connection between the centered and uncentered active subspaces and the consequences on the performance of the corresponding DIAS approaches. For linear inverse problems, we showed that the TSVD and the DI regularization methods are members of DIAS regularization. Regularizing only the inactive directions is fundamental to the success of the DIAS approaches. All four DIAS regularization methods are robust to a wide range of regularization parameter values and outperform Tikhonov regularization for many choices of regularization parameter. The uncentered DIAS approaches are more robust and more accurate than their centered counterparts (the TSVD and DI approaches). Among DIAS regularizations methods, DIAS-F (uncentered active subspace with the original data misfit) has the best compromise: it is a data-informed non-intrusive approach.
By data-informed, we mean that the method balances the information encoded in the forward operator and information gained from the particular realization of the data. By non-intrusive, we mean that the method provides the ability to reuse existing inverse codes with minor modification only on the regularization. Various numerical results have demonstrated that the DIAS-F approach is the most effective method presented. In particular, excellent results can be obtained from DIAS-F with only a one-dimensional data informed subspace.
For problems with significant noise in the data, DIAS regularization methods could result in noisy reconstructions unless a small number of active directions are taken, since the less data-informed directions, reflecting the noise in the data, still need some regularization to smooth out the noise. Ongoing work is to equip the DIAS regularization approach with a mechanism to combat high noise scenarios while ensuring the fidelity of inverse solutions. Another appealing feature of the DIAS framework is that it is applicable not only for linear, but also seamlessly for nonlinear inverse problems. Detailed numerical investigations and rigorous analysis of the DIAS approach for nonlinear inverse problems are part of ongoing work.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}