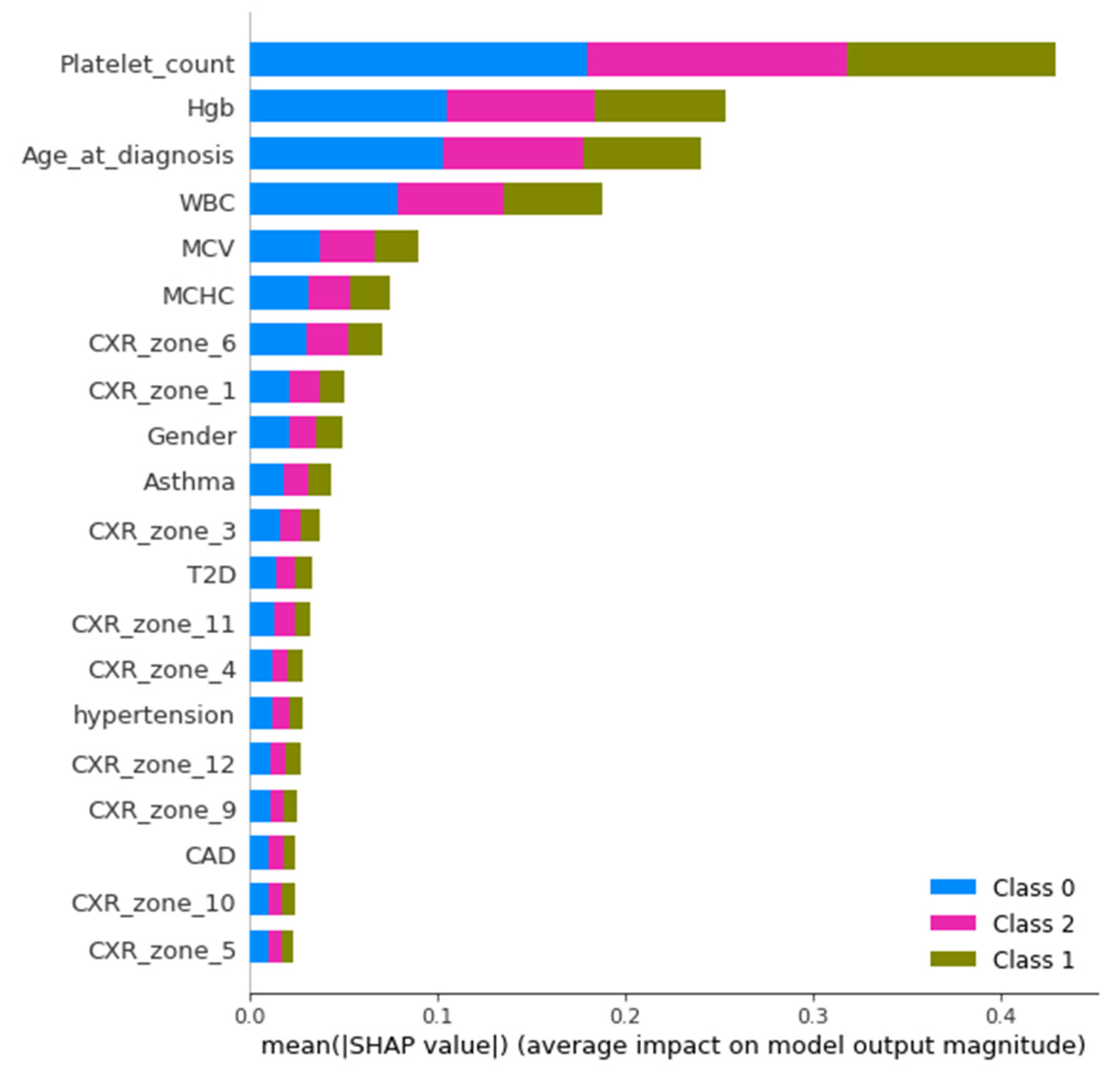
The study was performed using Python ver. 3.9.7. The libraries used during the implementation were Tensor Flow Keras ver. 2.5.2, Dalex ver. 1.4.1, Matplotlib ver. 3.4.3, Sklearn ver. 0.24.2, Pandas ver. 1.3.4 and NumPy ver. 1.19.5. Several sets of experiments were conducted to determine the significance of different categories of attributes in the early prediction of mortality and identification of at-risk patients who require ventilator support. The study mainly consisted of two objectives: to predict the patients who will need ventilatory support and to predict the mortality of the patients. Therefore, we carried out experiments with three cases defined in
Table 1. The first case predicted mortality, while cases 2 and 3 predicted ventilator support for COVID-19-hospitalized patients. For each case, three sets of experiments were performed using the full-feature set, with selected features using the EAI feature importance method for all three cases. Meanwhile, the third experiment for case 1 was performed using only the comorbidity feature and for cases 2 and 3 only CXR features were used. These features were used to further investigate the findings made by Aljouie et al. [
17]. They found that mortality in COVID-19 patients could be predicted using the comorbidity feature, while CXR functions could be used to predict ventilatory support.
3.1. Exploratory Dataset Analysis
The study was conducted using retrospective data from COVID-19-hospitalized patients in the Kingdom of Saudi Arabia (KSA). The dataset was introduced and used in the study by Aljouie et al. [
17]. The dataset consists of 5739 patient demographics, clinical and laboratory investigations, and CXR findings. Moreover, the dataset includes two target attributes, namely patient outcome (deceased or alive) and ventilatory support. The inclusion criteria for the patient sample included in the current study correspond to those of Aljouie et al. to find the mortality and ventilatory support dataset.
Table 1 shows the number of samples per category for case 1 (target class vital status (deceased, alive)), case 2 (ventilatory support status (mechanical ventilator (MV), noninvasive ventilation (NIV) and no ventilator support (NVS)) and case 3 (ventilation support status (ventilation support (VS) and no ventilation support (NVS)). Five values were missing in the ventilator support status attribute, so they were removed in cases 2 and 3.
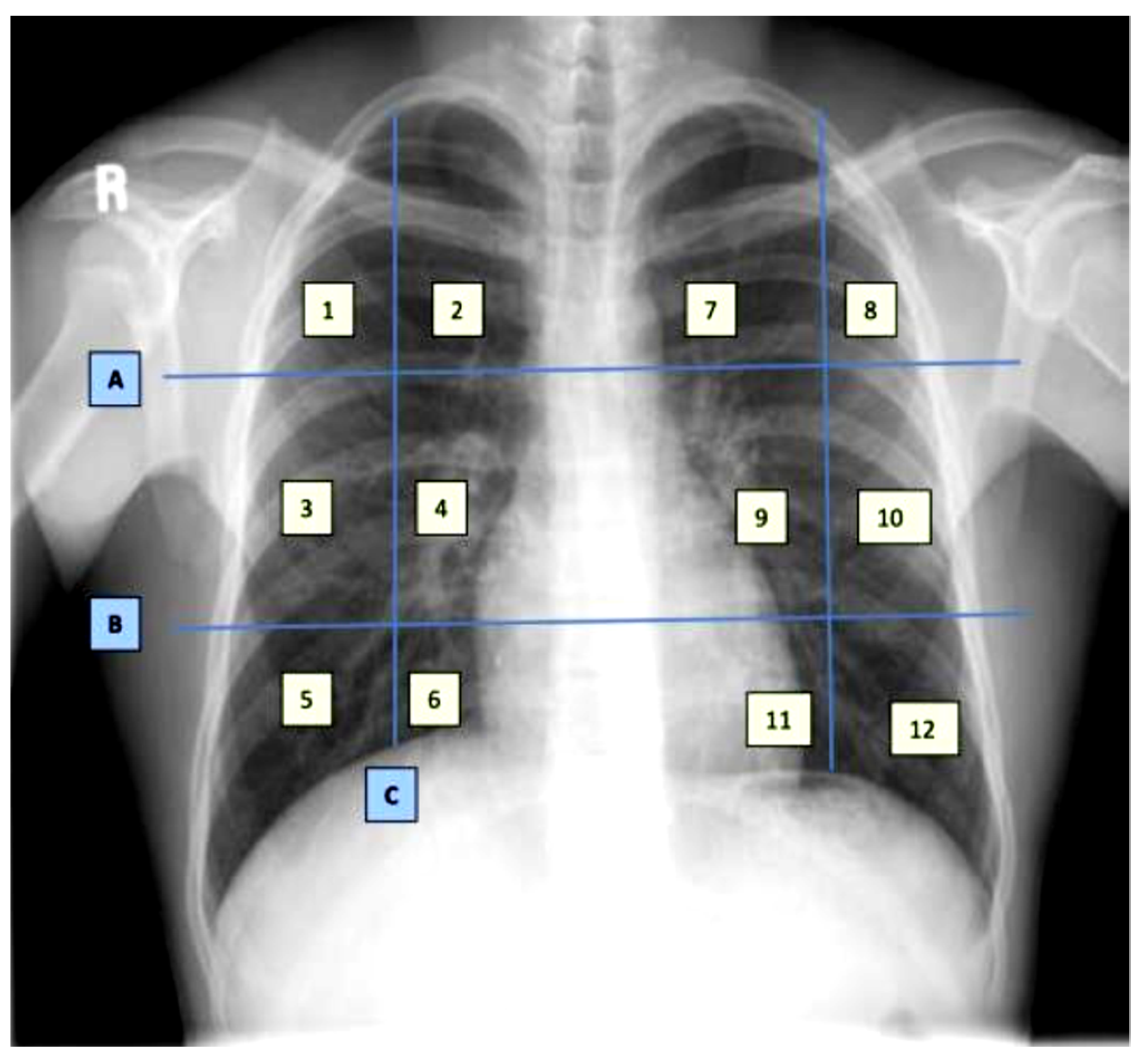
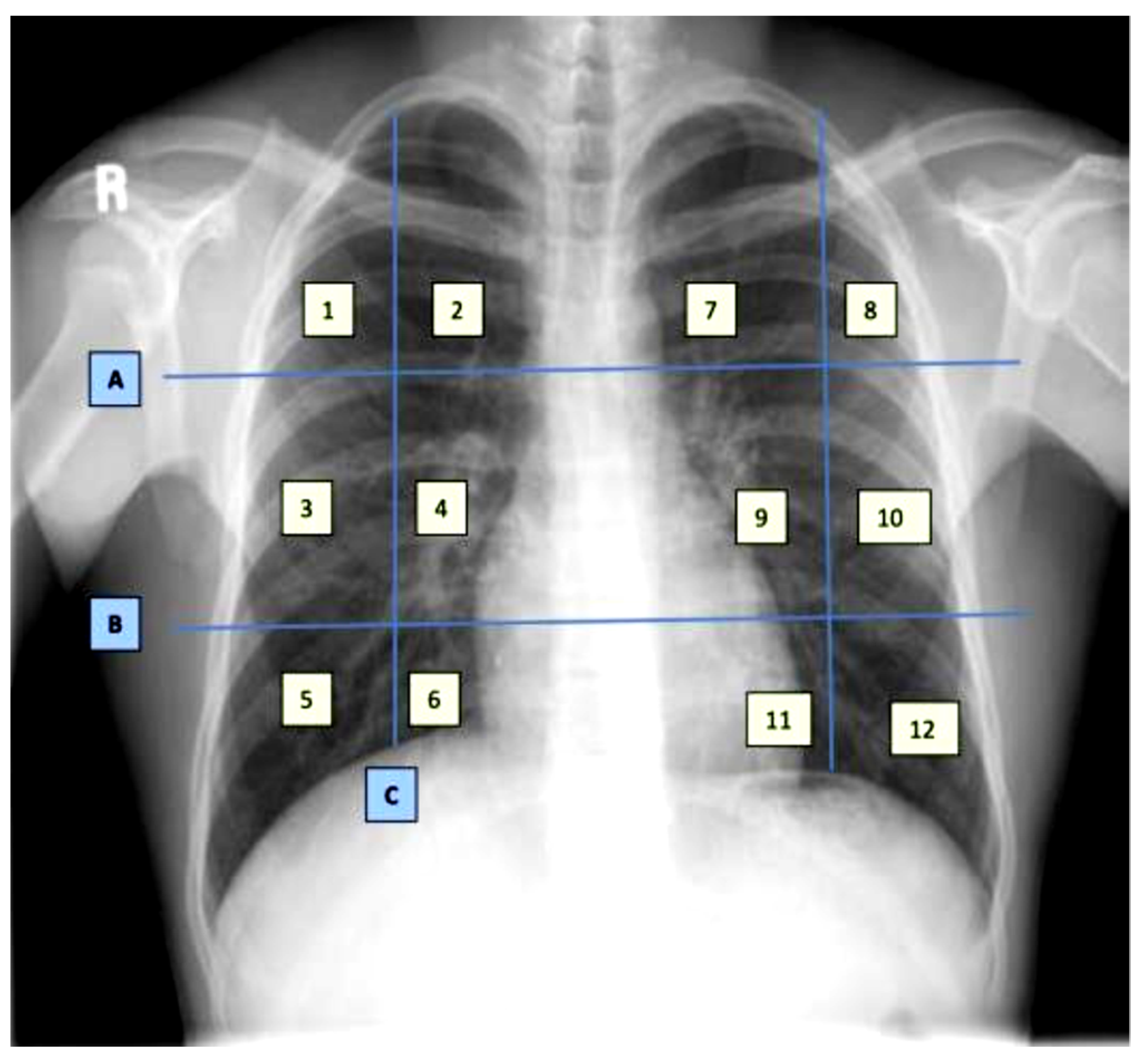
The dataset contains demographic features (gender, age), laboratory results from complete blood count CBC (hematocrit, hemoglobin, mean corpuscular hemoglobin concentration (MCHC), mean corpuscular hemoglobin (MCH), mean corpuscular volume (MCV), mean platelet volume (MPV), red blood cells (RBC), Platelet count, red cell distribution width (RDW), white blood cells (WBC), and radiological findings and comorbidity (cancer, coronary artery disease (CAD), hypertension (HTN), asthma, chronic obstructive pulmonary disease (COPD), type II diabetes mellitus (T2D), liver cirrhosis (LC), chronic hepatitis B (CHB), chronic hepatitis C (HCV) and chronic kidney disease (CKD)). Age and all CBC attributes are numeric, while the remaining attributes are categorical. The CXRs are annotated in twelve zones, as shown in
Figure 1. Initially the CXR is divided in two upper (A) and lower zone (B) and also the junction (C). Then these zones are further divided into twelve zones which indicate the points where the radiologist assign severity levels. The zone attributes consist of three possible values (0–2) indicating the severity of ground glass opacity (GGO). Zero indicates the absence of GGO. Ultimately, the dataset contains 35 predictors and 2 class attributes.
Furthermore, for the exploratory analysis of the dataset, the age attribute was discretized by applying equal-width binning. The minimum patient age in the dataset was 19 and the maximum age was 107. A bin length of 10 was used, with the first bin range being [19–29), [29–39) and so on. The number of bins was 9.
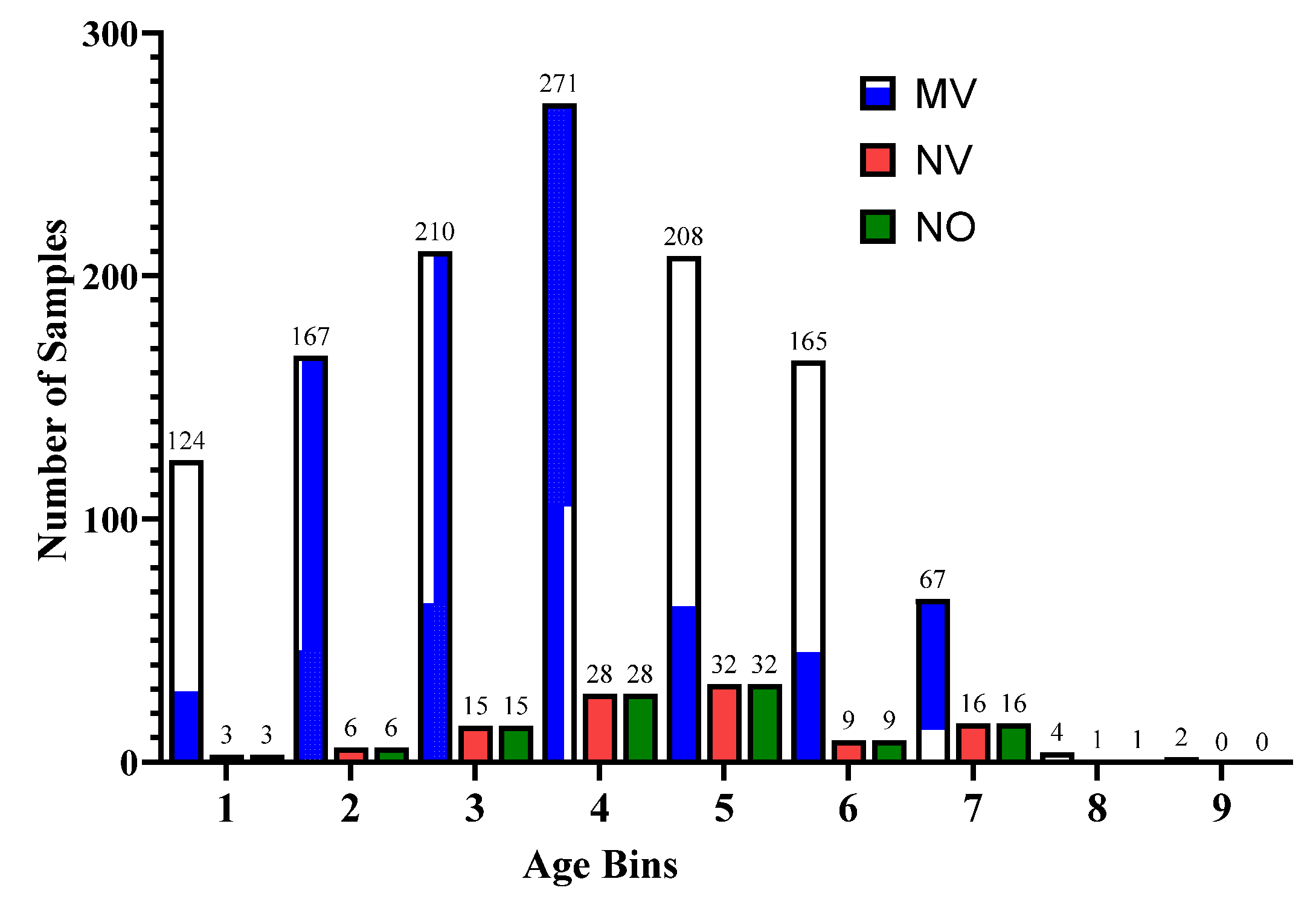
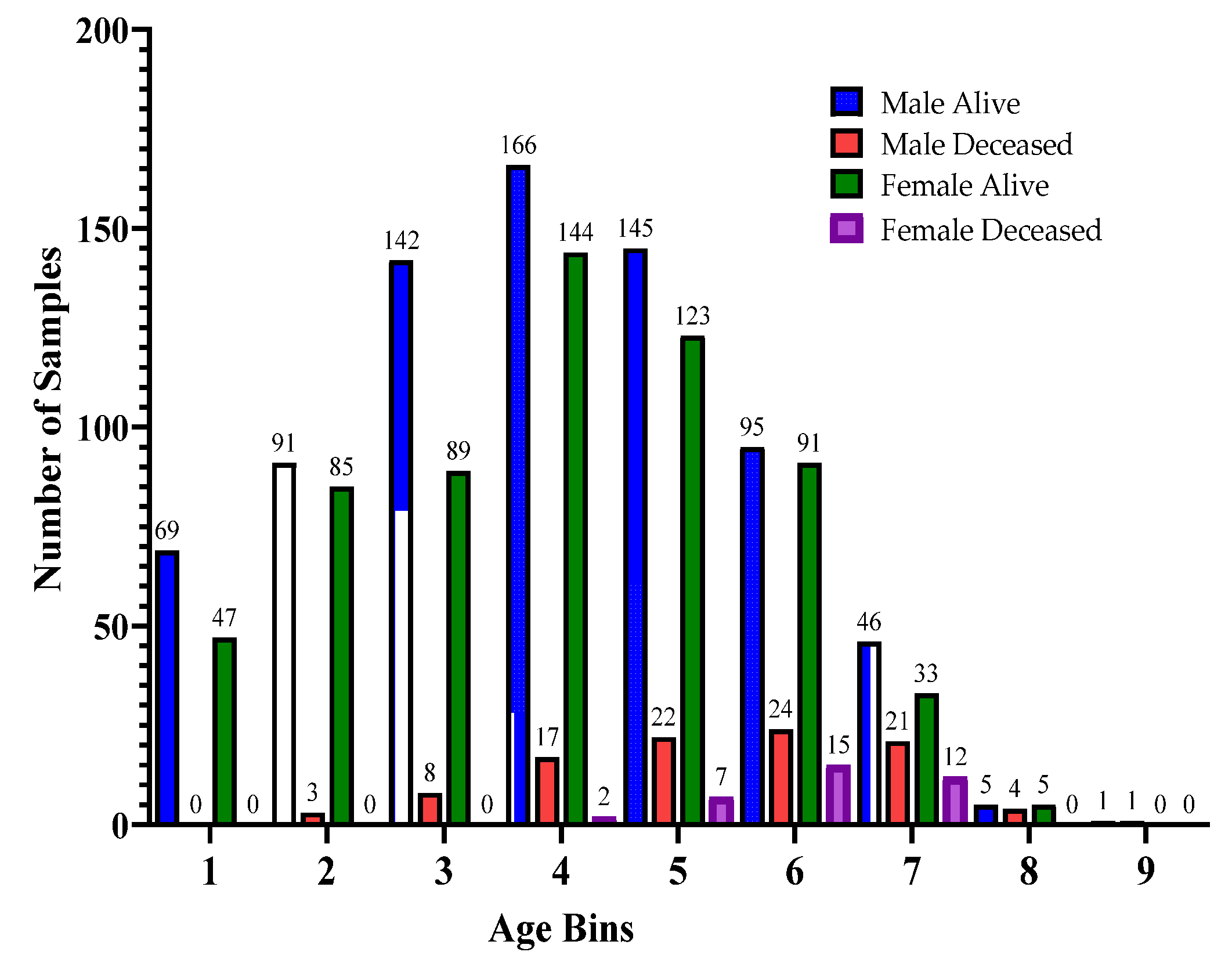
Figure 2 and
Figure 3 represent the age distribution of the patients according to their ventilation status and vital status. As seen in
Figure 2, the huge number of patients that need MV support were in the range of 50–59. However, for most of the age ranges, the number of patients for the other two categories, i.e., noninvasive ventilator (NV) and no ventilator (NO) was similar. Correspondingly, for the mortality prediction, the maximum number of survived patients was in the range of [49–59). However, the number of deceased patients was high, in the range of [69–79), as shown in
Figure 3. The mean age of the patients in the dataset was 54.83. Similarly,
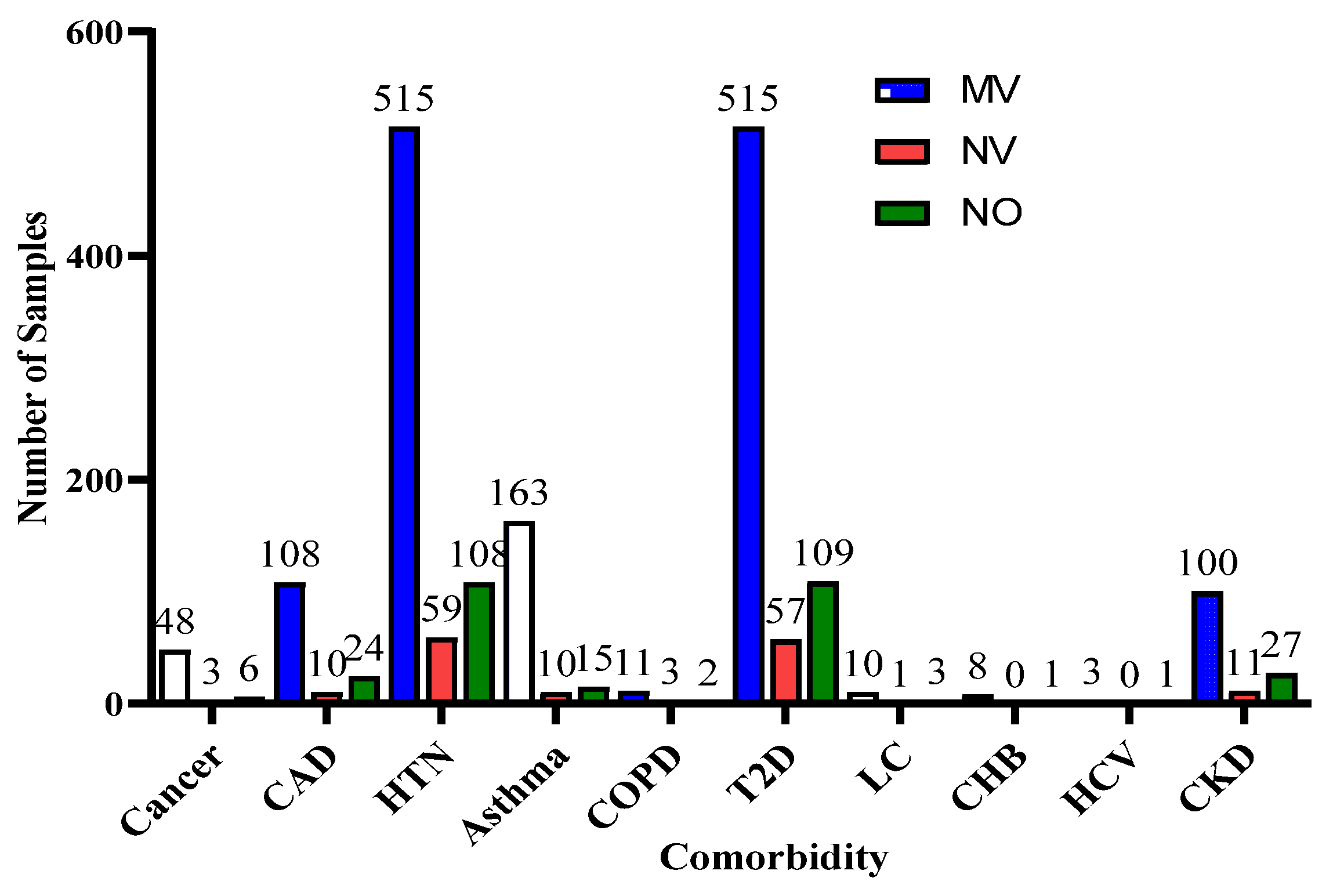
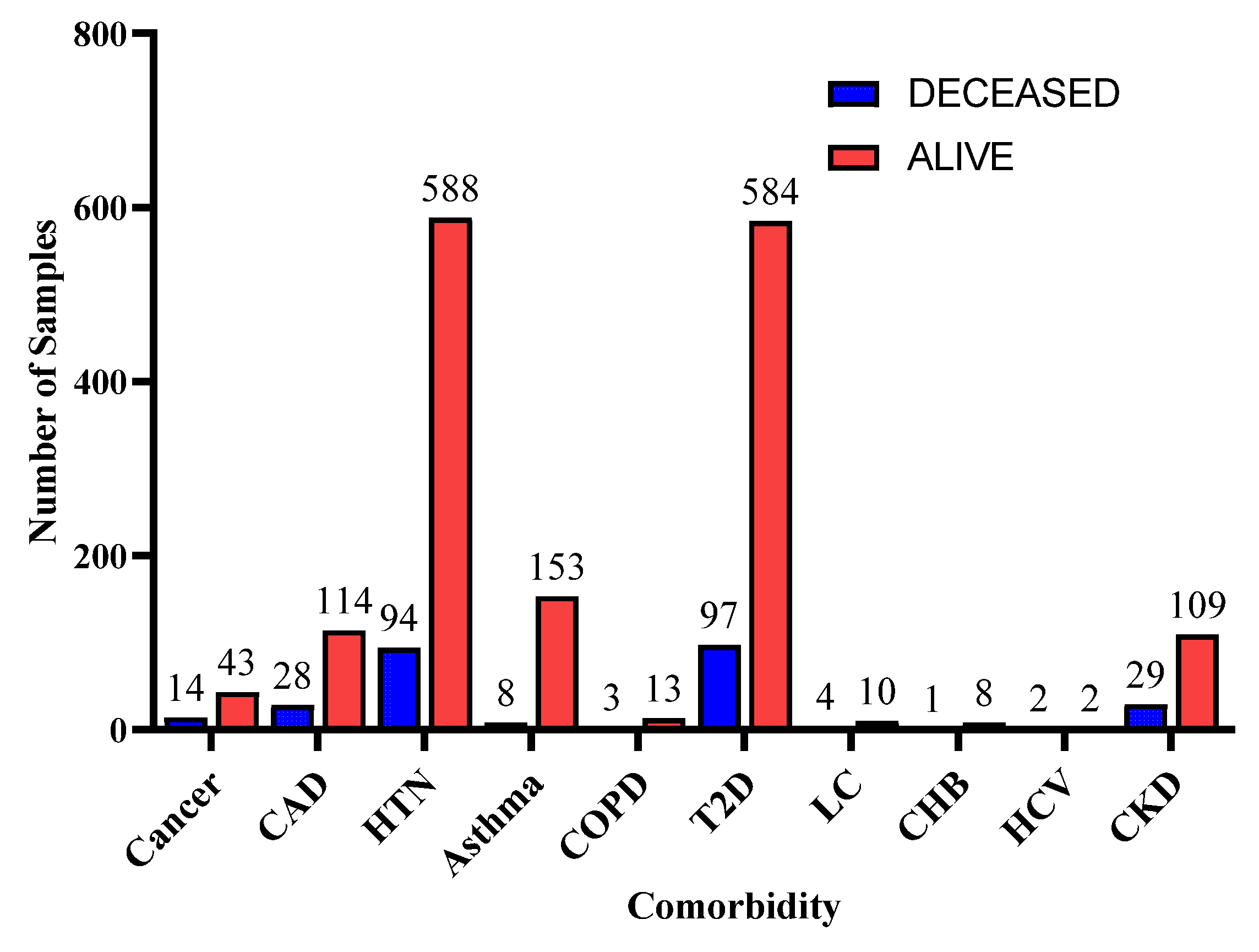
Figure 4 indicates the distribution of comorbidity in patients according to their ventilator support status, while
Figure 5 indicates the distribution of comorbidity according to the patient’s outcome, i.e., deceased or alive. The dataset contains the sample of the hospitalized COVID-19 patients, and it can be seen from
Figure 4 and
Figure 5 that the most common chronic diseases are hypertension and Type II diabetes. The dataset contains a huge number of male samples as compared to female samples. Furthermore,
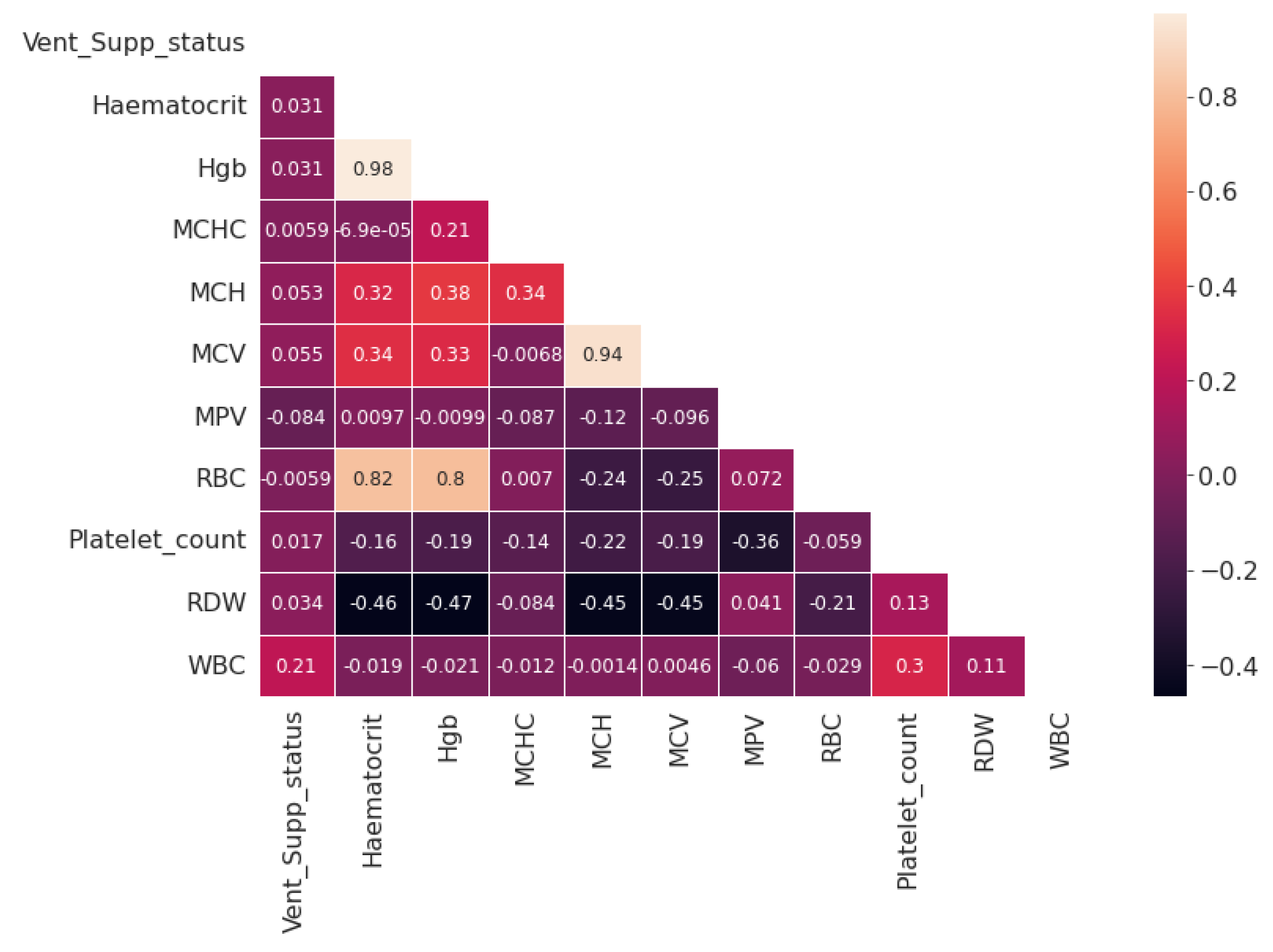
Figure 6 represents the correlation of CBC attributes.
3.2. Deep Learning Model
In the last decades, DL models have been extensively used and investigated for various prediction tasks. Instead of using handcrafted features and then applying the traditional ML technique, DL models are better able to understand and learn complex patterns from the data. These models are feedforward and contain three main layers, i.e., the input layer, hidden layers, and the output layer. The input layer is used to obtain data from the source and provide it to the model for further processing, the hidden layers are mainly used to collect the complex pattern from the data, and the output layer is used to classify the data. The backpropagation technique is used to update the weights of the model using a gradient descent algorithm.
Gradient descent is a first-order derivative function used for optimization in DL. The function measures the effect of parameter values on model performance. The gradient descent equation is shown below:
where
y represents the current outcome,
x represents the true values, and
f(
x) represents the predicted outcomes. The negative sign indicates the reduction in GD, and
represents the gradient factor, also known as the learning rate. The GD function aims to reduce the cost function, i.e.,
f(
w, y) and achieve the local minima. It is an iterative function and is represented as
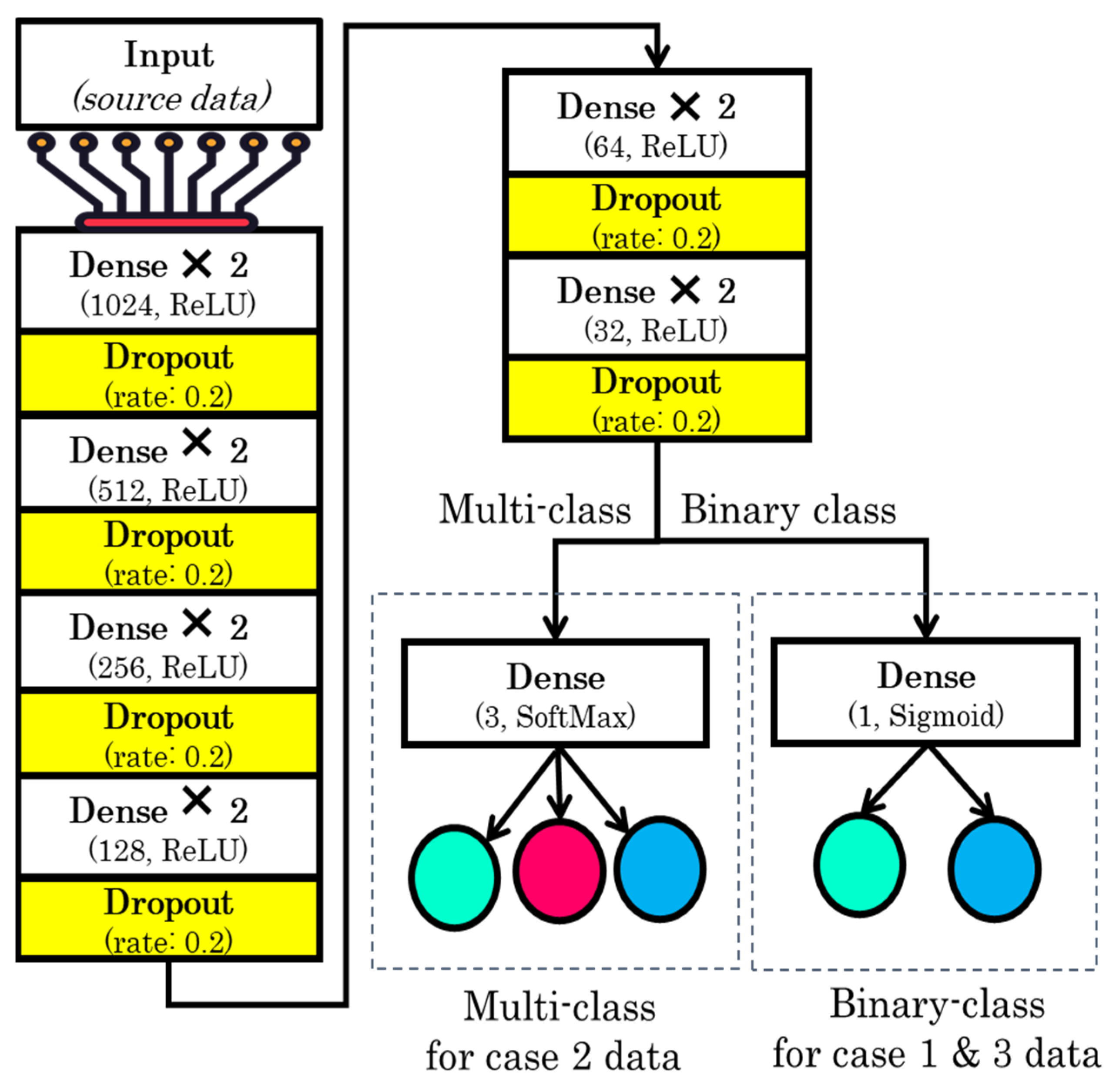
Based on the aim of the study, we performed three set of experiments. In the proposed study, three deep learning models were developed with slight variations in the input and output layers, based on the number of features for the input and the number of class labels. We used three sets of data as input to the models (full features, selected features, and comorbidity features). The full-feature set size was 34, the input layer was defined with 34 neurons, and the selected-feature set size was 9, so the input layer was designed with 9 neurons, and the comorbidity-feature set size was 10, so the input layer contained 10 neurons. In addition to this output class, we have 2 output requirements, binary and multiclass i.e., 3 classes. Therefore, the structure of the output layer was modified accordingly: for binary classification, we used 1 neuron in the output layer, while for 3 classes, we used 3 neurons in the output layer.
The structure of the model includes 13 layers. The 12 layers were hidden layers with 1024, 1024, 512, 512, 256, 256, 128, 128, 64, 64, 32, and 32 neurons. Rectified linear unit (ReLU) was used as the activation function for the hidden layers, while dropout layers with a rate of 20% were added after two consecutive hidden layers in order to avoid model overfitting. Sigmoid and softmax activation functions were used at the output layer to perform binary and multiclass classification, respectively.
The equation for the ReLU is
ReLU activation function is used to deal with negative values. If the input is negative, the output is zero, and thus the neuron does not participate in model processing for that particular epoch. This makes the neural network sparser and more efficient. Meanwhile, the sigmoid equation is mentioned below:
The sigmoid function provides the model with a value that is between 0 and 1. This is useful because we can use the resulting value as a probability for a particular class.
where
is the input vector for the softmax function,
is elements of the input vectors,
is the standard exponential function applied to each element, and K represents the number of classes. The softmax function turns a vector of K into values between 0 and 1. These values are considered as probabilities.
The DL model was optimized using the Adam optimizer [
26]. Model configurations include the Adam optimization algorithm with a learning rate of 0.001. Moreover, the loss was calculated using binary and categorical cross entropy, and the accuracy metric was used to evaluate the model’s accuracy. To train the model, we used 200 epochs with a batch size of 128. The structure of the model is shown in
Figure 7.
3.4. Evaluation Measures
The performance of the proposed model was compared using balanced accuracy, sensitivity, specificity, Youden index, and area under the curve (AUC). There are several evaluation measures that can be used for investigating the performance of the classification algorithms. Among these measures, some of the measures are highly influenced by class distribution, such as accuracy, precision, and recall [
28]. Therefore, the unbalanced class problem uses measures such as balanced accuracy, AUC, and Youden index. Correspondingly, balanced accuracy and AUC are also used in the baseline study.
Sensitivity (SN) represents the true positive rate of the model and is calculated using the following equation:
Specificity represents the true negative rate and is calculated using the equation below:
As can be seen from Equations (6) and (7), the above measures are not affected by class distribution.
Similarly, balanced accuracy is the mean of the sensitivity and the specificity:
Likewise, the Youden index (YI) is one of the measures used specifically to determine the effectiveness of the diagnostic test. It evaluates the discriminative power of the diagnostic test. It is computed using the equation below:
The YI values range from 0–1. A smaller value indicates poor diagnostic capability, while a value closer to 1 indicates the significance of the test.
Furthermore, the model discriminative power is further validated using AUC. As is the case with the Youden index, the value of AUC also ranges from 0–1, with a value closer to zero indicating poor performance and a value closer to 1 indicating significant performance of the model.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}