1. Introduction
Most phenomena in engineering are described by sequential data. In the context of data-driven simulation and control [
1], time series classification and forecasting play therefore a fundamental role. A huge variety of applications, such as financial mathematics, language and speech recognition, weather forecasting, physical and chemical unsteady systems, are extensively discussed in the literature [
2,
3,
4,
5].
In the last decade, data-driven approximations of the Koopman operator have successfully been applied to build reduced-models of complex dynamical systems, allowing their identification and control [
6,
7,
8,
9]. Several approaches are based on combining algorithms derived from the dynamic mode decomposition–DMD–with deep learning–DL–techniques, as discussed in [
10,
11] and references therein.
Many algorithms have been applied in artificial intelligence–AI–for the estimation of output time series from input time series. Among them, convolution and recurrent neural networks–CNNs, RNNs– [
12,
13,
14], time delay neural networks–TDNNs– [
15,
16,
17], nonlinear autoregressive neural networks–NARNETs– [
18,
19] and nonlinear autoregressive neural networks with exogenous inputs–NARXNETs– [
20,
21,
22,
23,
24].
In this work, several surrogates based on standard and transposed convolution neural networks–CNNs– [
25,
26,
27] are applied to a thermohydraulic problem in the context of heat exchangers involving change of phase [
28,
29,
30]. The problem will be described in detail later. It basically consists in fixing the input heat power
injected into a two-phase flow and monitoring some quantities
at the outlet of a pipeline in which the gas-liquid mixture is confined and flows.
Mathematically speaking, let us consider an input and output time series, respectively and , tracking time instants. The problem is the estimation of the non-linear transfer function h such that . Learning the function h allows the real-time integration of a newly defined input to know the impact on some outputs of interest.
A first approach is based on exploiting a parametrization of the input function
, through a few values
. In this case, the modeling framework is non-incremental, since the whole output time series is computed from the inputs
, that is:
The estimation of
h will be done through the use of artificial neural networks. However, since the output consists of
evaluations, while the input of
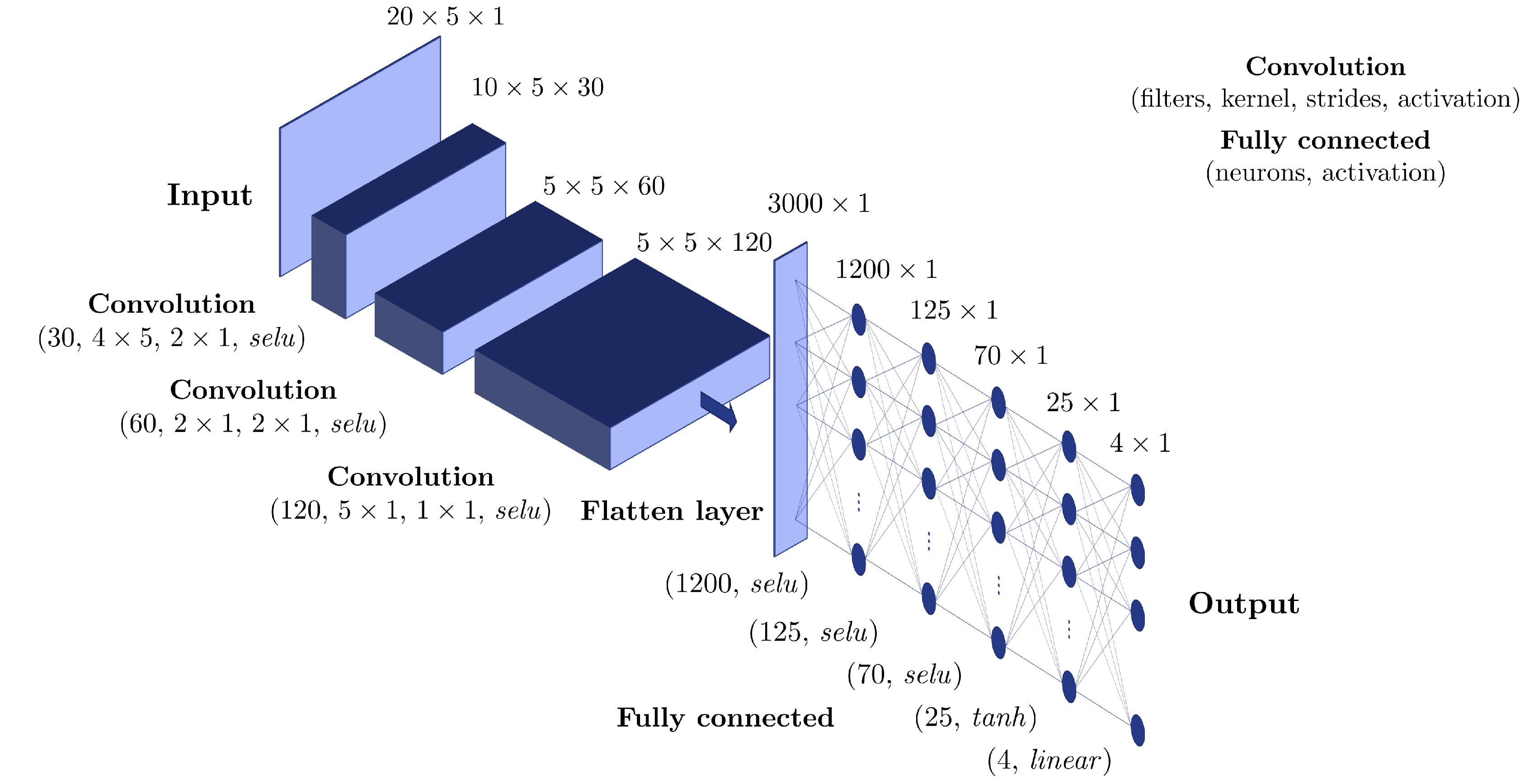
parameters, a transposed convolution (also known as fractionally-strided convolution) is employed to reach the right dimension at the output layer. As a matter of fact, transposed convolutions increase (up sample) the spatial dimensions of intermediate feature maps, reversing down sample operations obtained by classical convolutions [
25].
A second approach consists of considering an incremental modelling framework, in which the model (also known as integrator) computes the next value of the output sequence from a given number of previous inputs and outputs. Such approach has some similarities with the NARXNETs [
18]. Denoting with
, for
, we can write:
where the parameter
is a delay term, known as the process dead time. We can also note
,
being the known
y outputs used to predict future values of
y. A neural-network architecture based on a convolution approach can then be defined. Two non-incremental models (for different values of the delay coefficient
k) will be compared, in terms of speed and accuracy.
The paper aims to build a data-driven model that is capable of reproducing the data with high fidelity, while possibly performing the integrator task over a large time frame. First of all, the model of the addressed problem and the simulation data structure are described in
Section 2.
Section 3 presents three different surrogates:
Finally,
Section 4 addresses the conclusion summarizing the results and highlighting the main differences among the learned models.
2. Problem Statement
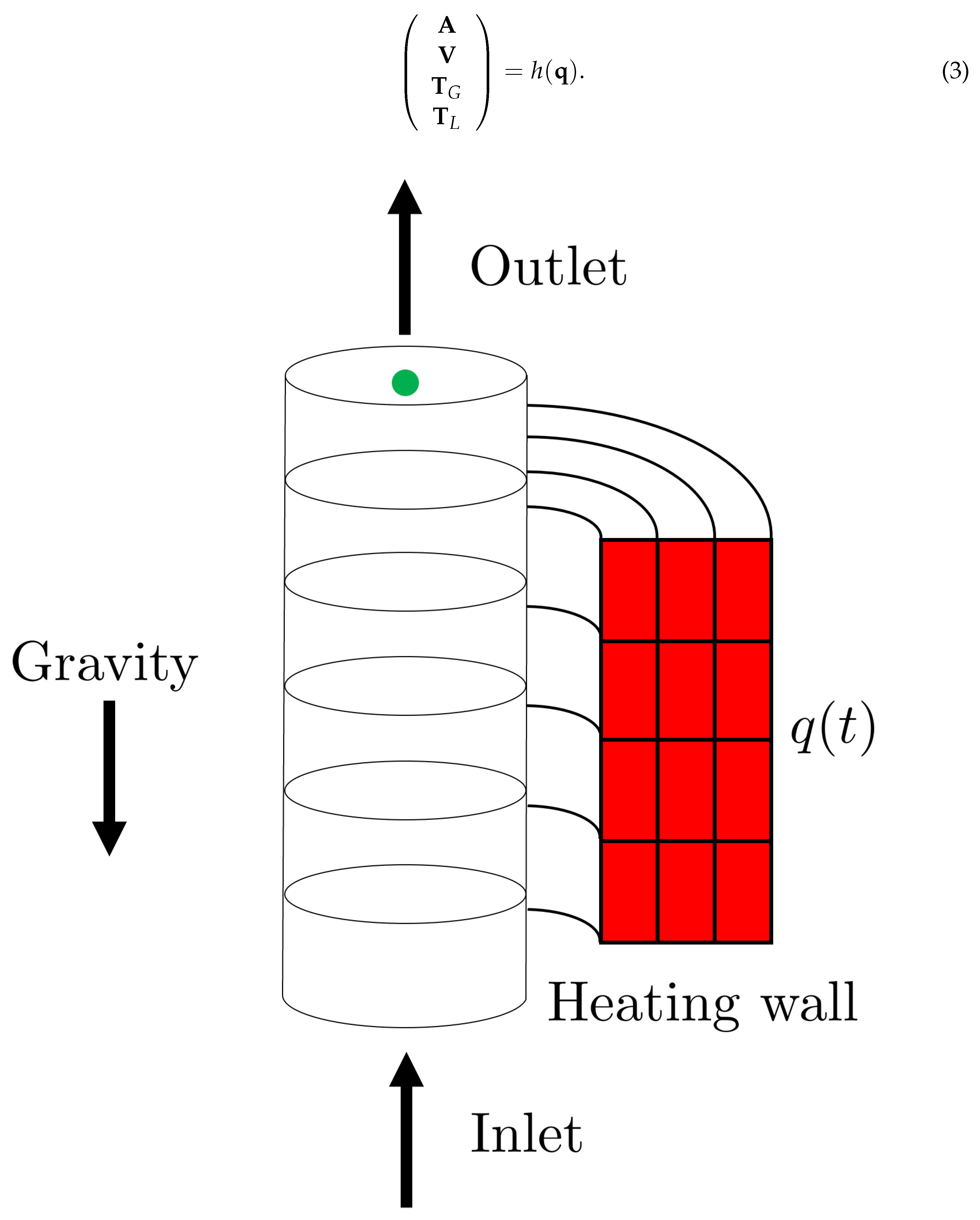
High-fidelity numerical simulations of a thermohydraulic problem are performed using the software
CATHARE for nuclear safety analysis [
31,
32,
33]. The simulation consists into a two-phase (steam-water) flow moving upward against gravity into a channel heated by hot walls, as sketched in
Figure 1. The model input is the time-varying thermal power
injected into the fluid through the walls, while the outputs are the time histories of several fluid properties at the channel outlet. The simulation covers the interval
s, with a time step
s.
Using the bold notation for vectors (sequences of 1000 elements corresponding to the time discretization), the quantities of interest are the steam fraction in the flowing system
, the liquid velocity
, the steam temperature
and the liquid temperature
. This work aims to produce a surrogate model
h for inferring the outputs as a function of the input variable
:
The surrogate model is built in a non-intrusive manner, defining a Design of Experiments–DoE–on the power density and combining the outputs of the corresponding offline simulations.
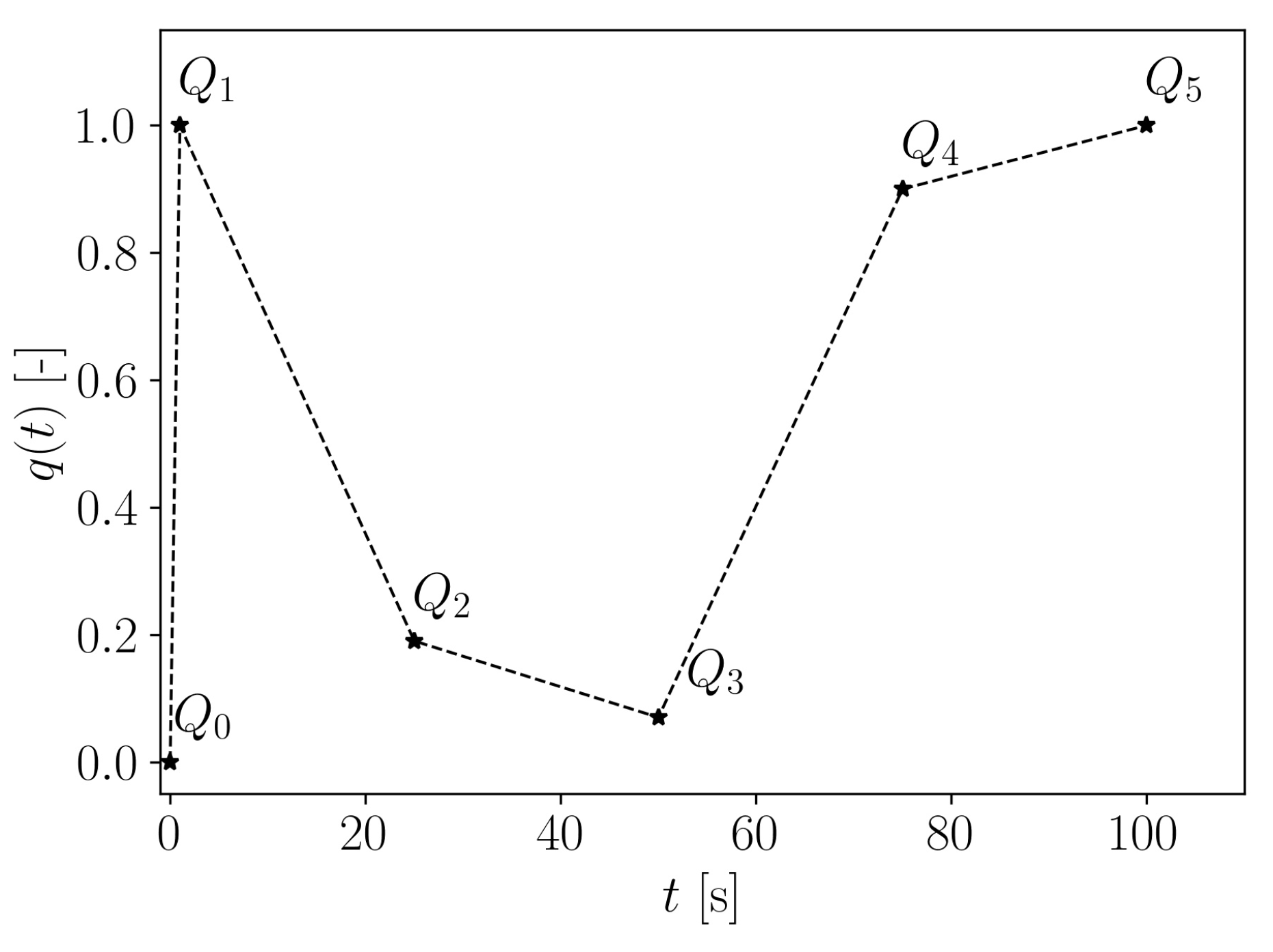
A user-defined power control law allows to assign the value of the provided power density at specific time instants. Therefore, the input function is defined through a few values , normalized by the maximum power density W/m3, and then linearly interpolating in-between. In particular, the time instants (in seconds) are considered for the power changes. The corresponding values , for , define a parametrization of the input function .
A DoE of 23 data points is established using different combinations of the values
, as listed in
Table 1. For the rest of this work, the last 4 datasets are considered in the testing set and therefore not fed into the training loop of the built surrogate model. Note that some of the values are fixed (
,
) thus the model input parameters are only
and
.
Figure 2 shows an example of the heat power density
defined from values
.
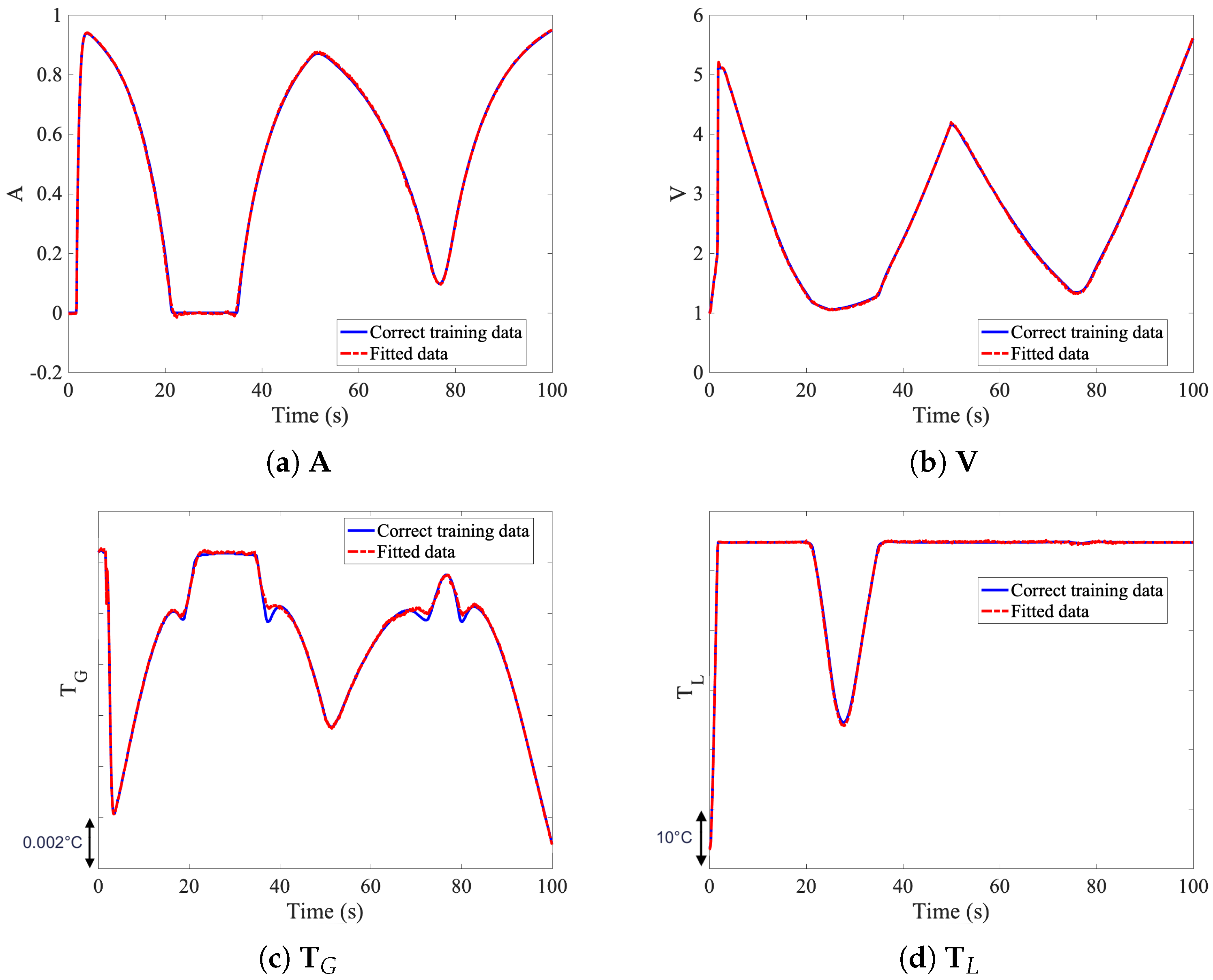
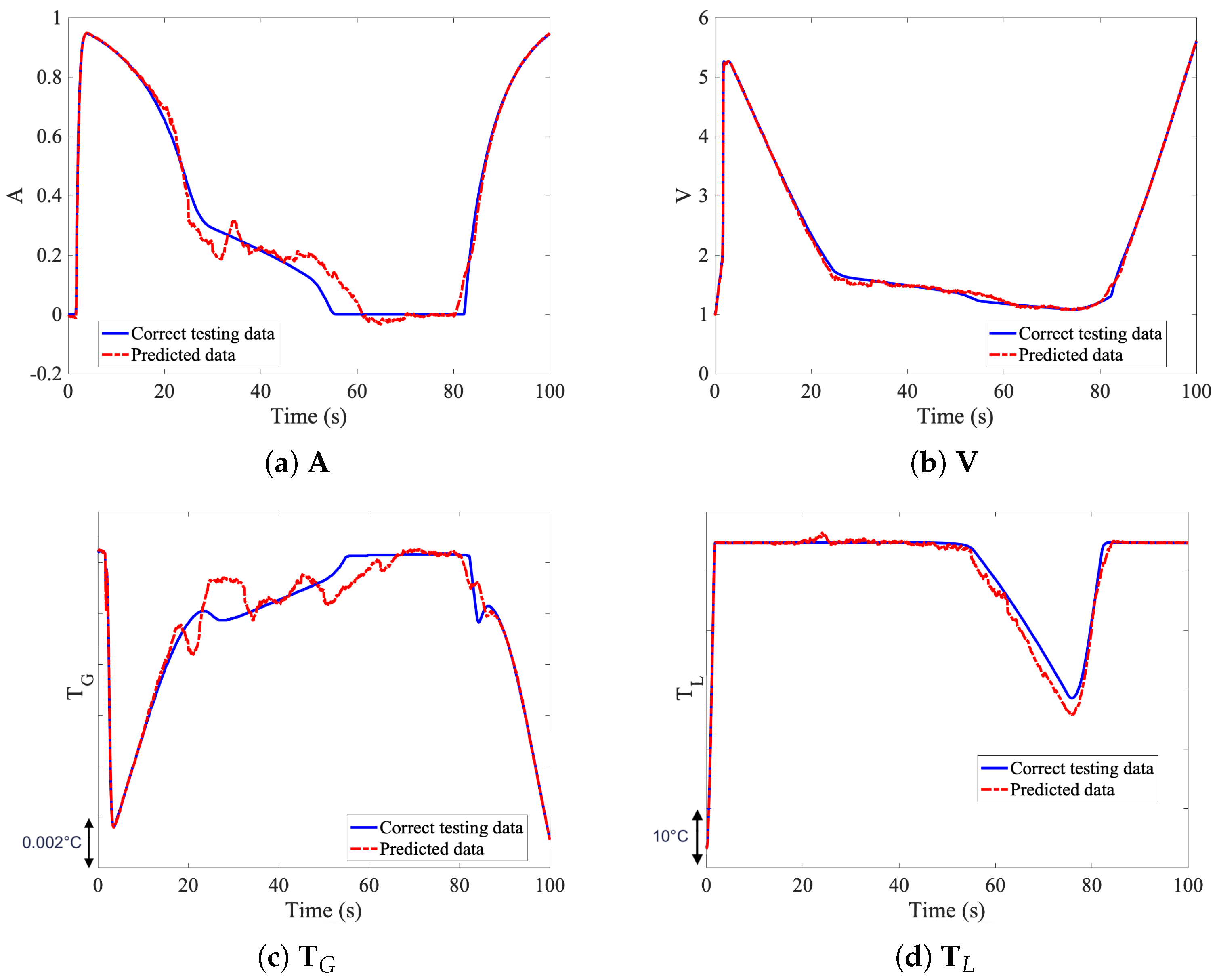
A sample set of results, of the available datasets number 1, 2, 3 and 4 of
Table 1, is shown in
Figure 3 for illustration purposes.
4. Conclusions
In this work several prediction models for output time series from input time series have been compared. Without loss of generality, a coupled problem in thermohydraulics has been considered, but the procedure generalizes to many other phenomena and fields. Moreover, instead of simulation-based data, experimental data can be used.
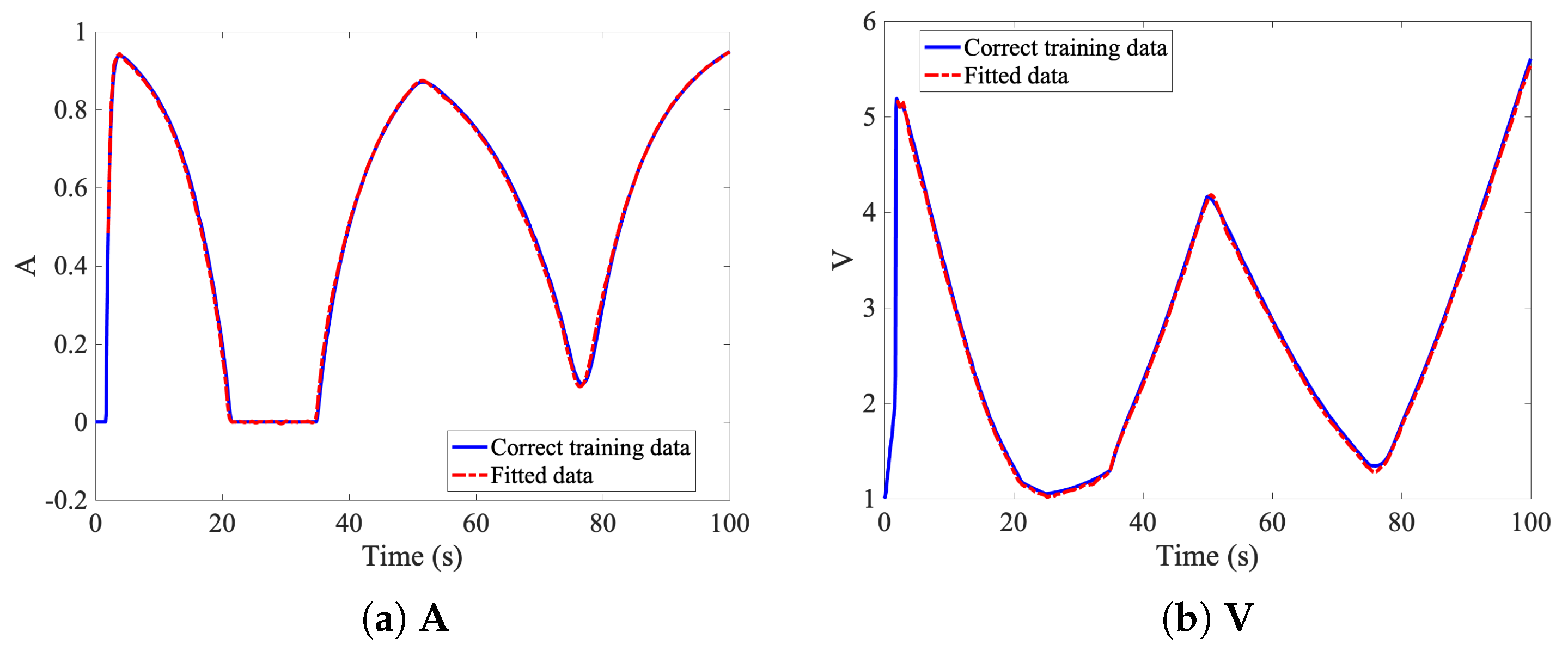
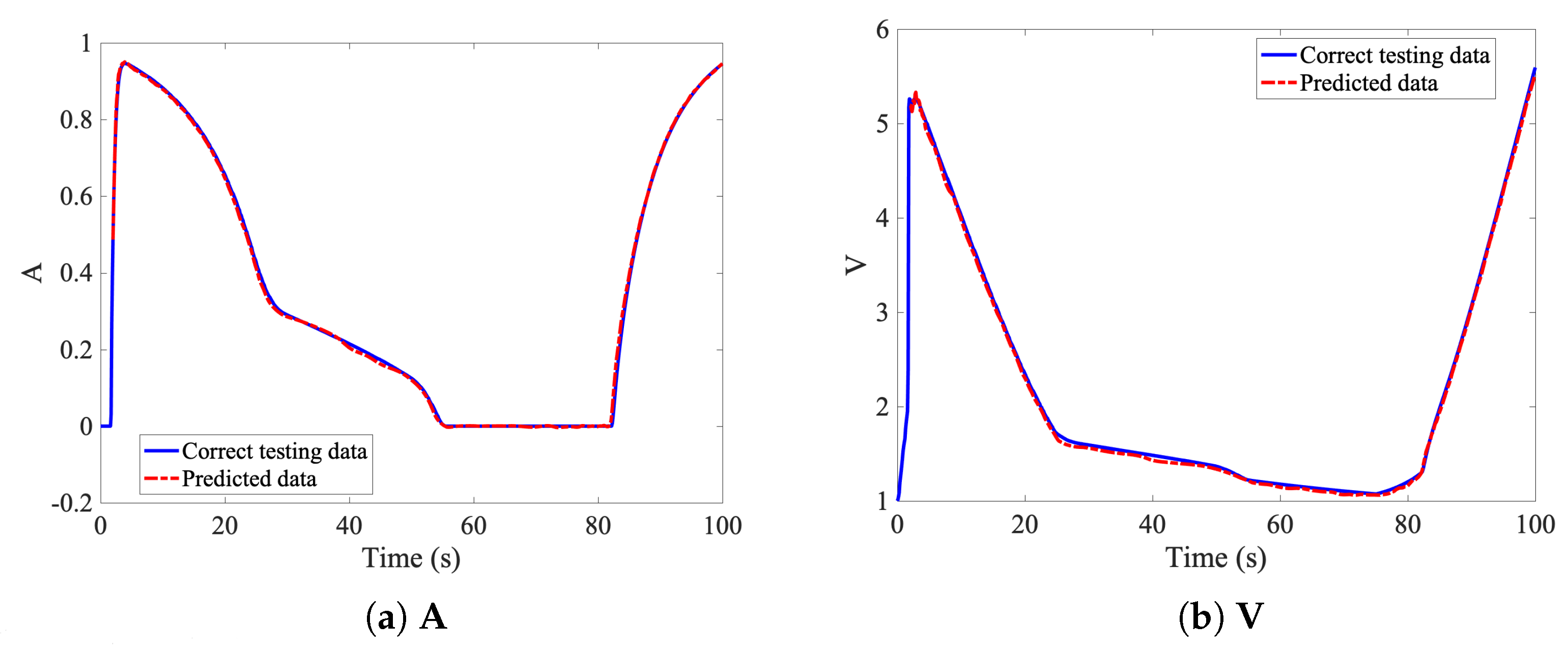
The models are based on different deep neural networks architectures. If a parametrization of the input function is available, a non-incremental approach involving transposed convolution neural networks allows the prediction of the whole sequence, as described and discussed in
Section 3.1. The non-incremental approach is based on convolution transpose layers, which takes a low amount of data as an input and increase the size of the output to reach a desired dimension. These layers appears as a suitable approach in this situation where only few inputs are required to built the whole sequence of time measurements.
The incremental models (dynamical system integrators) presented in
Section 3.2 are based on regressing the variable on its own lagged (i.e., past) values together with the ones of the input, through standard deep convolution neural networks. Therefore, the prediction occurs step-by-step. The difference between the two incremental models stands in the delay (or lag) factor
. A small value of
allows really fast predictions. However, the model can be unstable when its input is taken from the previous model outputs (this occurs, for instance, when
). In such case, the surrogate cannot be used as an integrator of the system. Results are thoroughly improved for
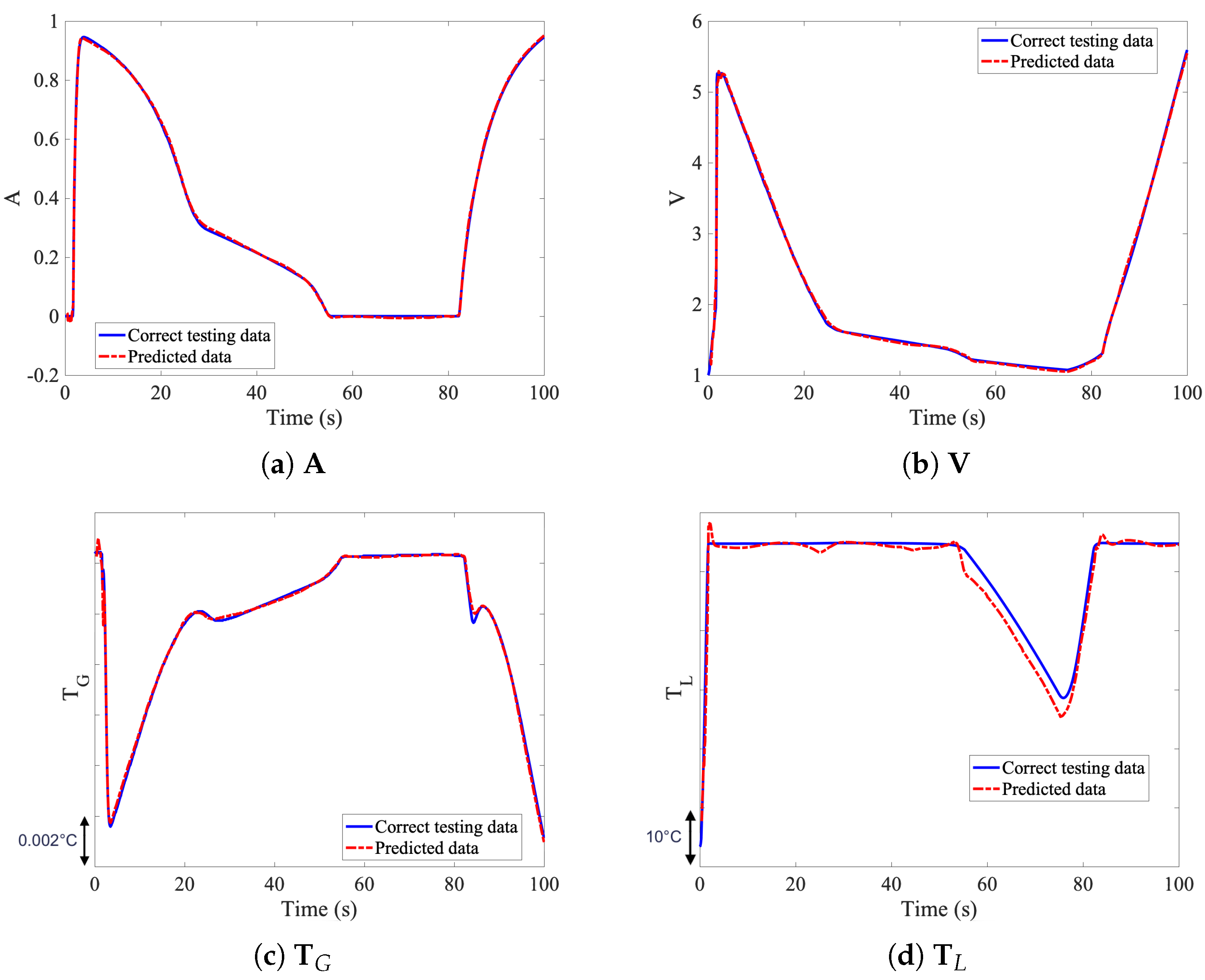
, where also a regularization term was introduced in the loss function. The incremental approach is based on convolution layers. In fact, these layers will take a large input and reduce the input size to extract relevant information. The filters are designed with a large dimension along the time axis, to allow easier extraction of the inputs’ time variation.
The non-incremental approach can be clearly faster to evaluate the output of the solution, however, the integrator clearly outperforms the non-incremental approach. Moreover, the integrator can be used on novel datasets, and potentially outside of the simulated time frame. The initialization requires only time-steps to be simulated, and the remaining dynamics is predicted in real time, allowing huge computational gains. However, the non-incremental approach can’t be used on a different time frame, out of the simulated region, as the output is hardly coded to predict only time steps.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}