A Web Page Clustering Method Based on Formal Concept Analysis

Abstract
:1. Introduction
- Propose a bi-directional maximum matching word segmentation method based on a Chinese word segmentation method and propose a word weighting scheme based on term frequency.
- Propose a ListFCA algorithm based on the study of different types of concept lattice construction algorithms. The ListFCA uses a more efficient method to traverse the header list based on cross data link when constructing concept lattices, which makes it easier to generate the Hasse graph corresponding to the concept lattice.
2. Related Work
2.1. The Background of FCA
2.2. Related Algorithms for Constructing Concept Lattice
2.2.1. The Batch Algorithm
2.2.2. The Incremental Algorithm
2.2.3. The Parallel Algorithm
3. The ListFCA Algorithm
3.1. Web Data Cleaning
3.1.1. Disturbance Cleaning
3.1.2. Tag Weighting
- If the number of the result words in forward or the reverse maximum matching is different, then take the fewer words as the correct result;
- If the number of the result words is the same, there is no ambiguity, then return to any one as a result.
3.2. Web Formal Context Construction
3.3. The Construction Process of the Cross Data Link
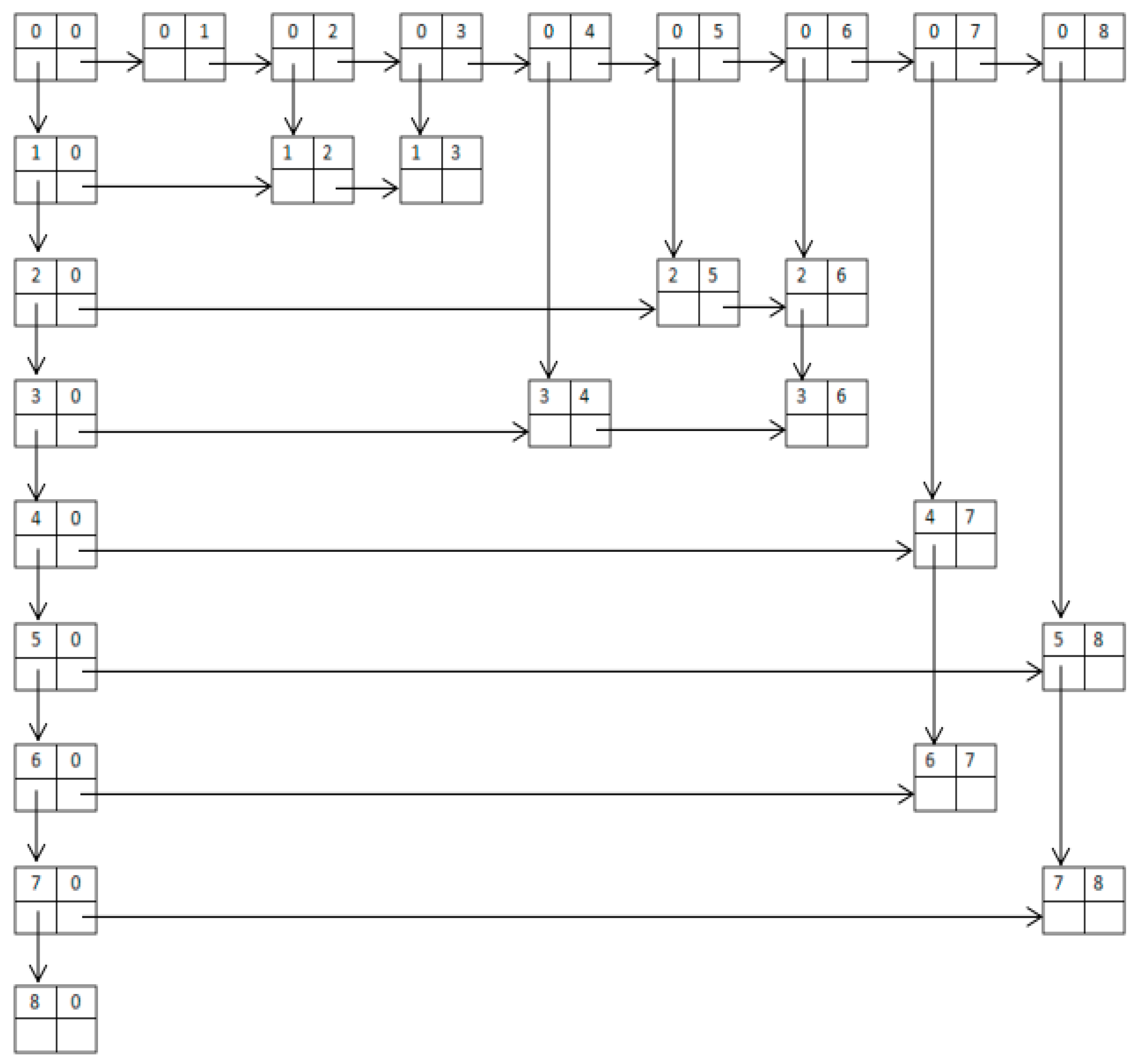
- Step 1. The concept preprocessing: We iterate through the concepts, and sort them in ascending order based on their number of intensions. If the number of intensions is the same, we sort the concepts by lexicographic order.
- Step 2. Creating the link header: We create a new node based on the definition of the node structure and empty the row field and col field of the node.
- Step 3. Creating the row headers and the column headers: All the col field in row header nodes and all the row fields in column header nodes are emptied. For each row, the row field of ith header node stores the ith concept and for each column, the col field of ith header node stores the ith concept. The down field of the i − 1th row header node points to the ith row header node, and the last down field is empty. The right field of i − 1th column header node points to the ith line node, and the last right field is empty.
- Step 4. Constructing nodes based on subconcept-superconcept relations: If the superconcept is numbered as x and the subconcept is numbered as y, we can insert a new node in the xth row and the yth list. Then the superconcept is stored in the row field of the new node, and the subconcept is stored in the col field. The down field of the new node points to the next node in this column and the right field points to the next node in this row. If it does not have a next node, we empty its down field or right field.
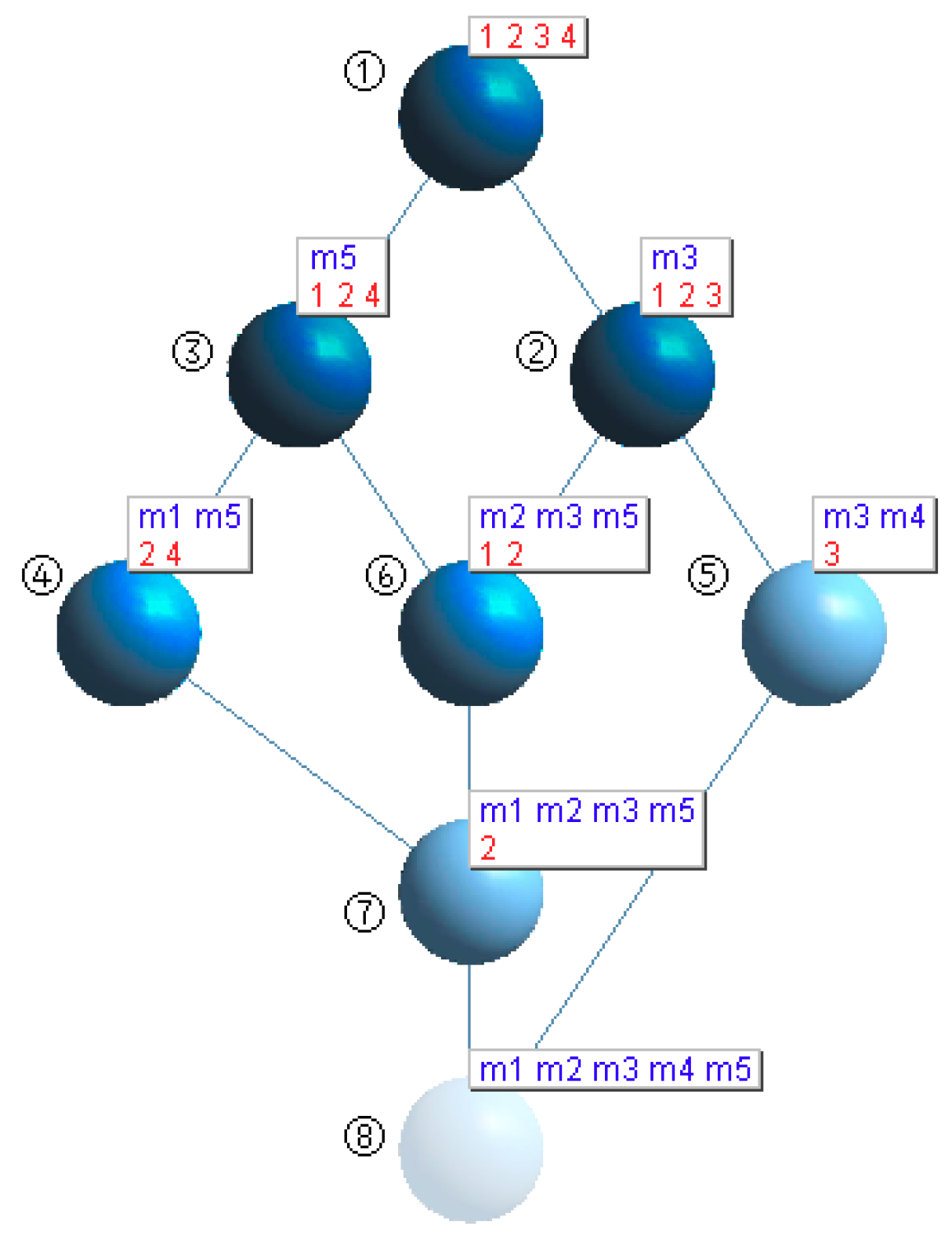
- Step 1. Ordering the eight concepts in Figure 1 based on the number of intentions as ① to ⑧.
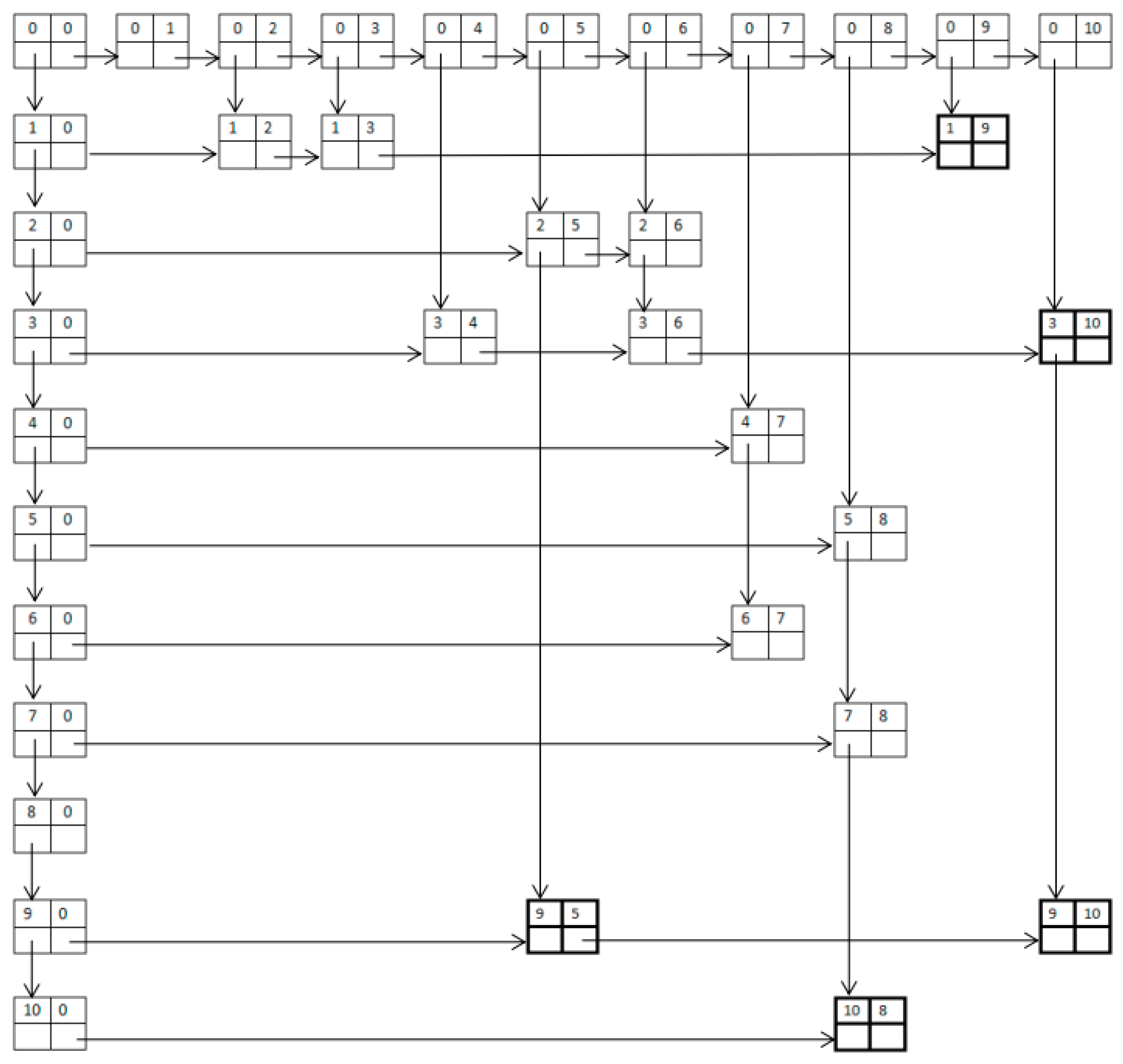
- Step 2. Creating the total header and setting the row field and the col field to “0”.
- Step 3. Creating the row headers and list heads; all col field of the row headers are set to “0”, the row field stores concepts from ① to ⑧, the down field points to the next node, and the last one is empty. All the row fields of the column headers are set to “0”, the col field stores concepts from ① to ⑧, the right field points to the next node, and the last one is also empty.
- Step 4. Inserting the concepts in Figure 1. Concepts ② and ③ are direct subconcepts of the concept ①. A node is inserted at the first row and the second column. Concept ① is stored in the row field and concept ② is stored in the col field in this node. Then a node is inserted in the first row and the third column. Concept ① is stored in the row field and concept ③ is stored in the col field in this node. The right field and the down field point to the next node. This process is repeated for all the other nodes.
3.4. Construction Algorithm of the Concept Lattice Based on a Cross Data Link
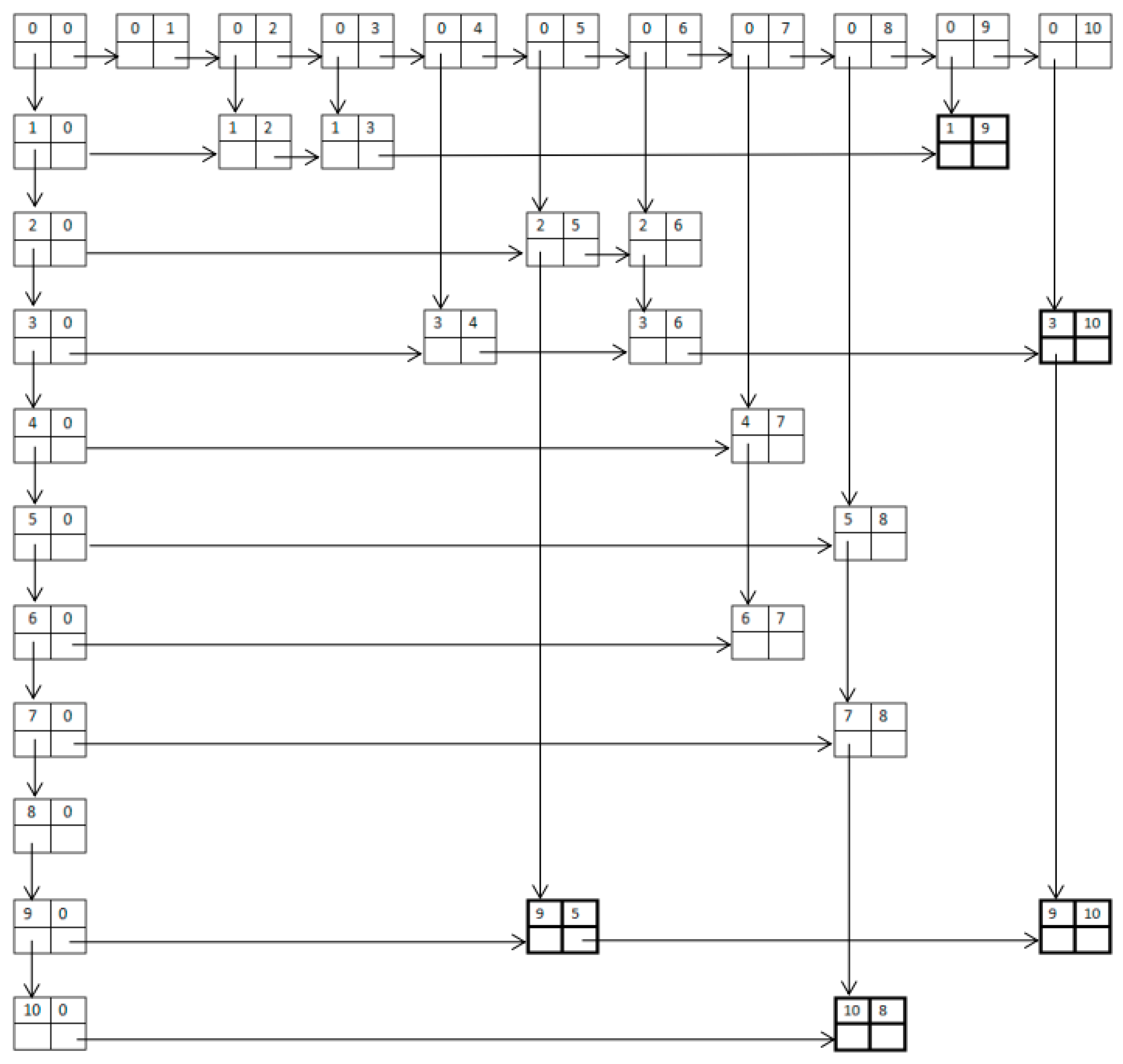
- For a concept, if B ⊆ {p}′, the concept is an updating concept, and the extension of this concept will be updated.
- For a concept, ifand, the concept is an invariant concept, and no operation is required.
- For a concept, ifand the intension of any concept innot equal toand for any superconceptof concept, B2 ∩ {p}′ ≠ H is established, the concept is a generation concept, and the new concept will be created.
- Step 1. Insert a new header node at the end of the row header and the column header. The row field of the new row header node and the col field of the new column header node are set to be the new concept.
- Step 2. Insert the new node at this column and the new line. The col field of the new node is consistent with the col field of this column, and the new concept is stored in the row field in the new node.
- Step 3. We need to determine the relationship between the direct superconcept set A in the col field in the new node and the direct superconcept set B in the new concept. The results are divided into two cases: one is where set A has an intersection set C with set B. In this situation, we delete the nodes in this column where the row field concept belongs to set C. Another situation is where set A and set B have no intersection, in which case no operation is required.
- Step 4. We simply insert new nodes based on set B; the number of new nodes is equal to the size of set B. The row field in the new nodes stores each concept in set B, and the col field in the new nodes stores the new concepts.
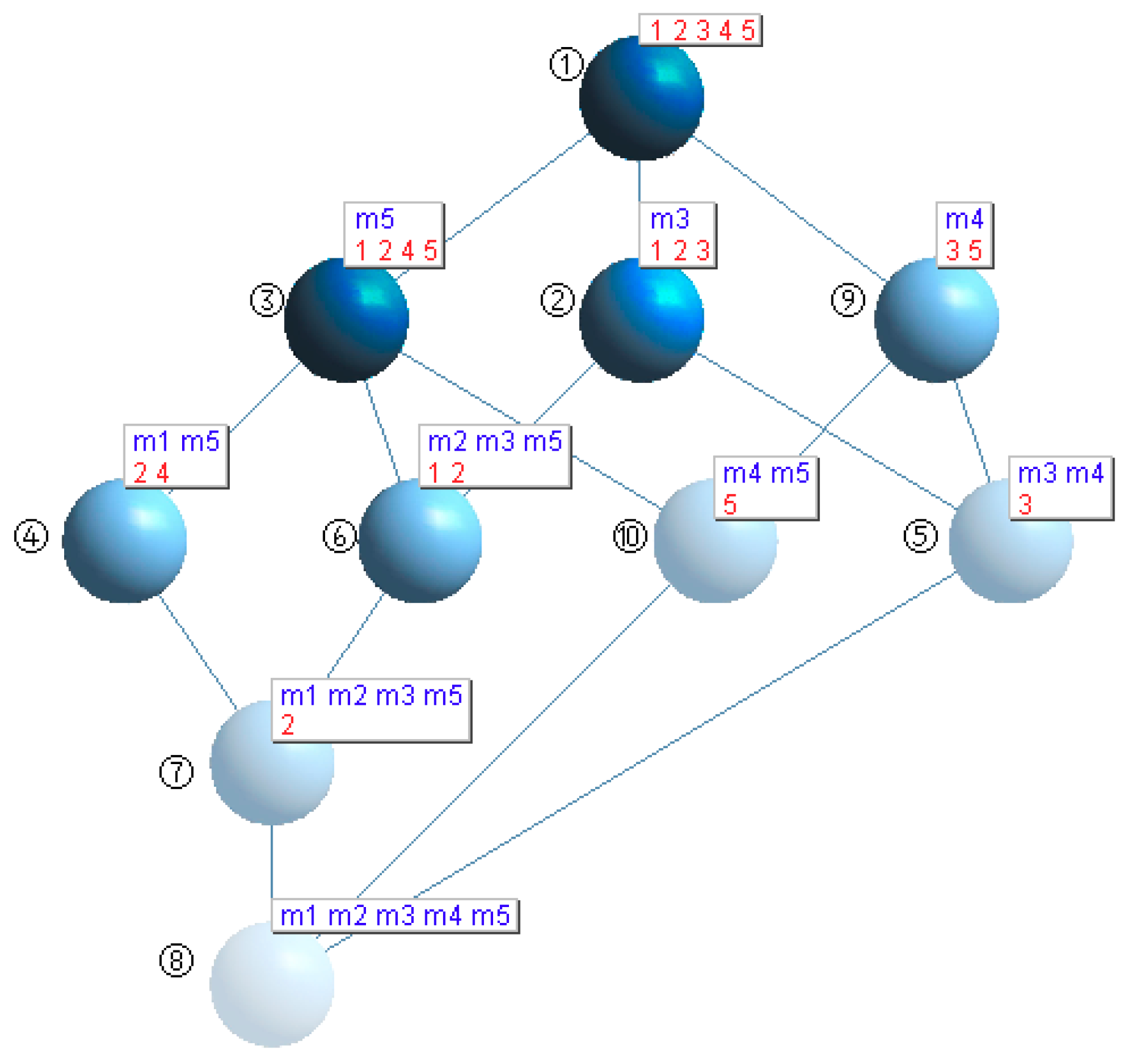
- Concepts ②, ④, ⑥, ⑦ are invariant concepts. No operation is required.
- Concepts ①, ③ are updating concepts. We add the new object “5” to the extension of these concepts.
- Concepts ⑤, ⑧ are generation concepts. We create the new concepts ⑨ and ⑩ and, taking concept ⑨ as an example, the following operations are performed:
- Step 1. Insert a new header node at the end of row header and column header.
- Step 2. Insert a new node at the 5th column and the 9th row. Concept ⑤ is stored in the col field of the new node and concept ⑨ is stored in the row field of the new node.
- Step 3. The relationship between the direct superconcept of concept ⑤ and concept ⑨ have no intersection.
- Step 4. Insert a new node at the 9th column and the 1st row, because the direct superconcept of concept ⑨ is concept ①. Concept ⑨ is sotred in the col field of the new node and concept ⑤ is stored in the row field of the new node.
4. Experiments
4.1. The Evaluation of the Clustering Effect
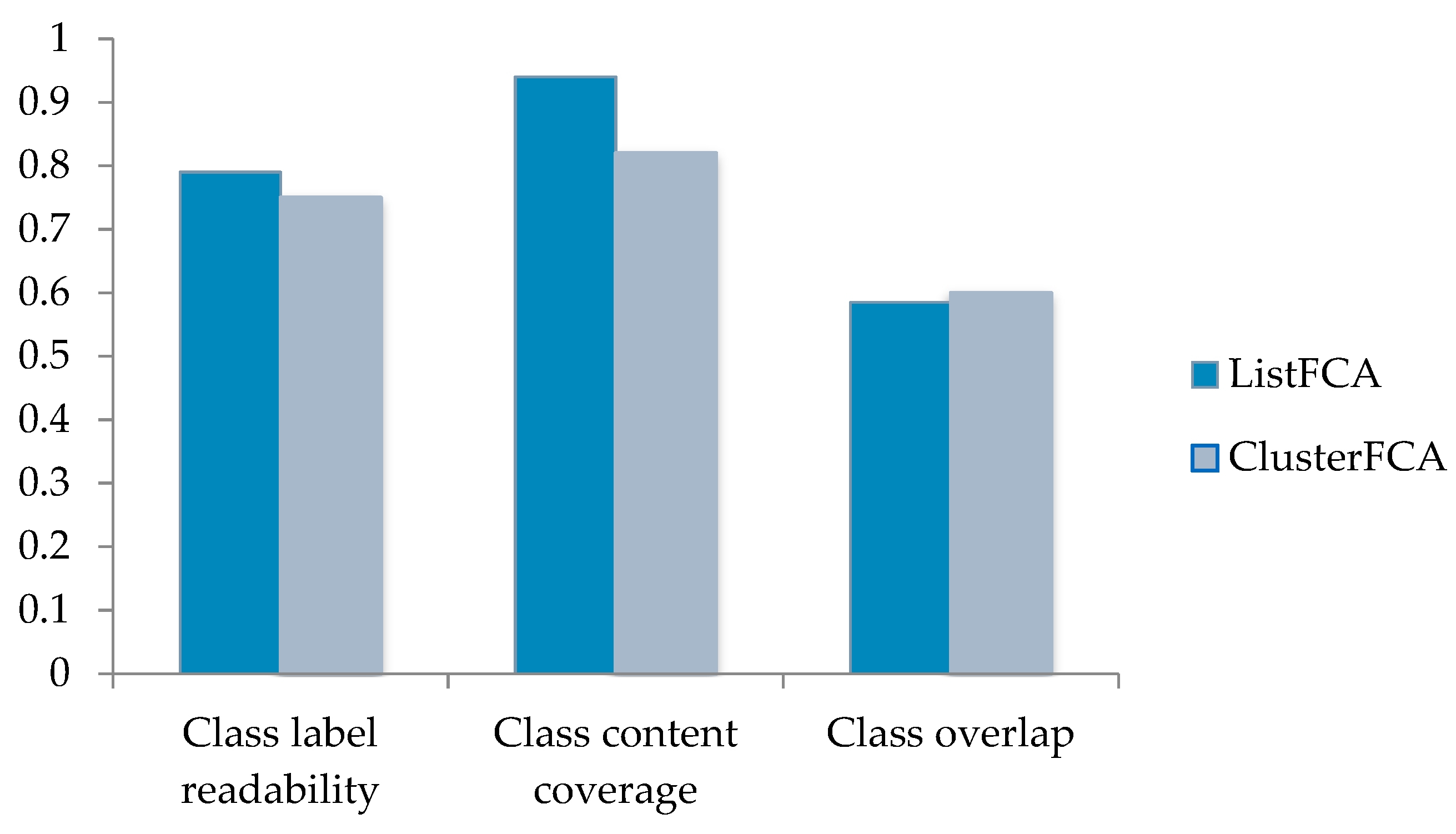
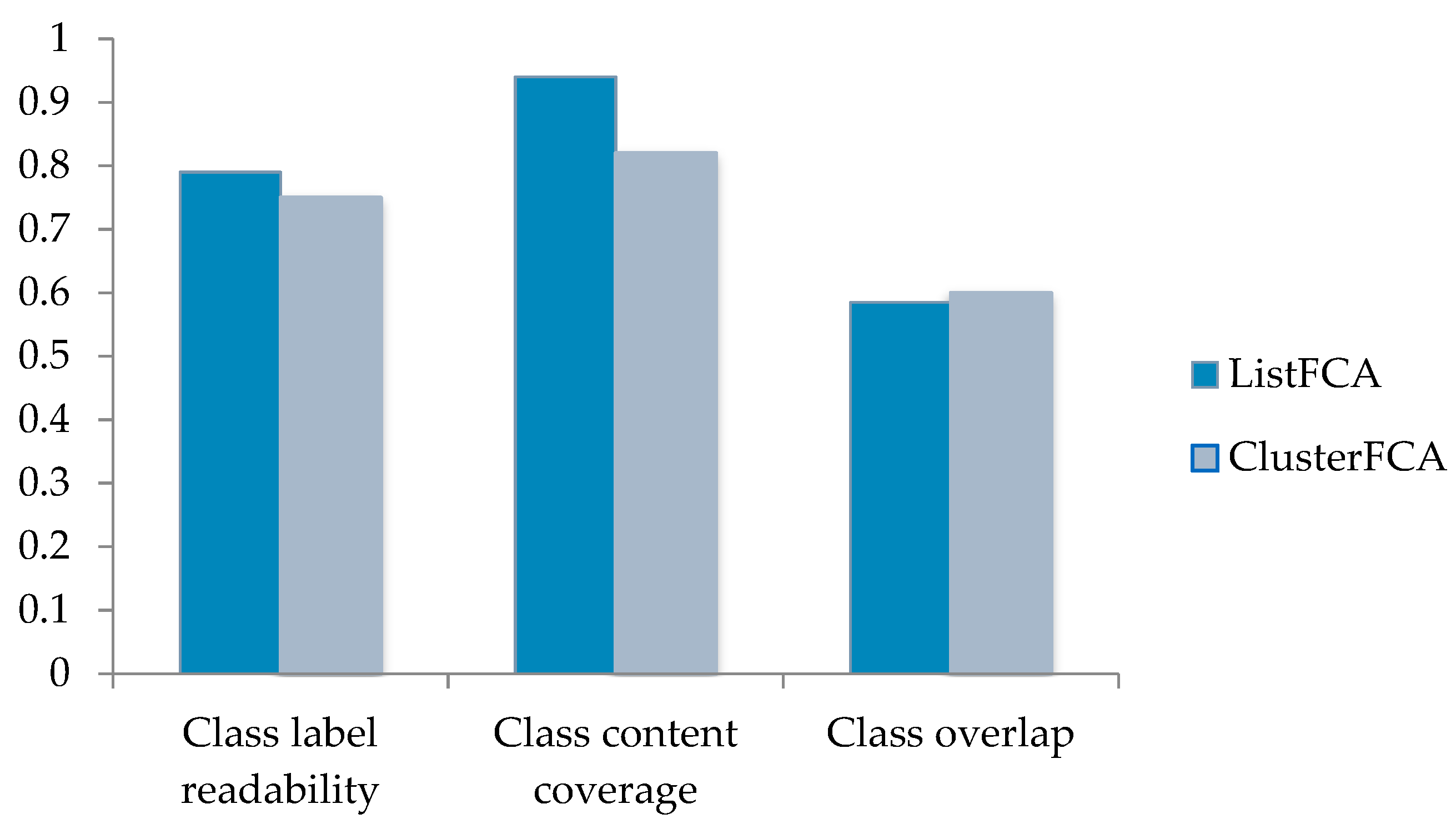
4.1.1. Cluster Label Readability
4.1.2. Cluster Content Coverage
4.1.3. Cluster Overlap
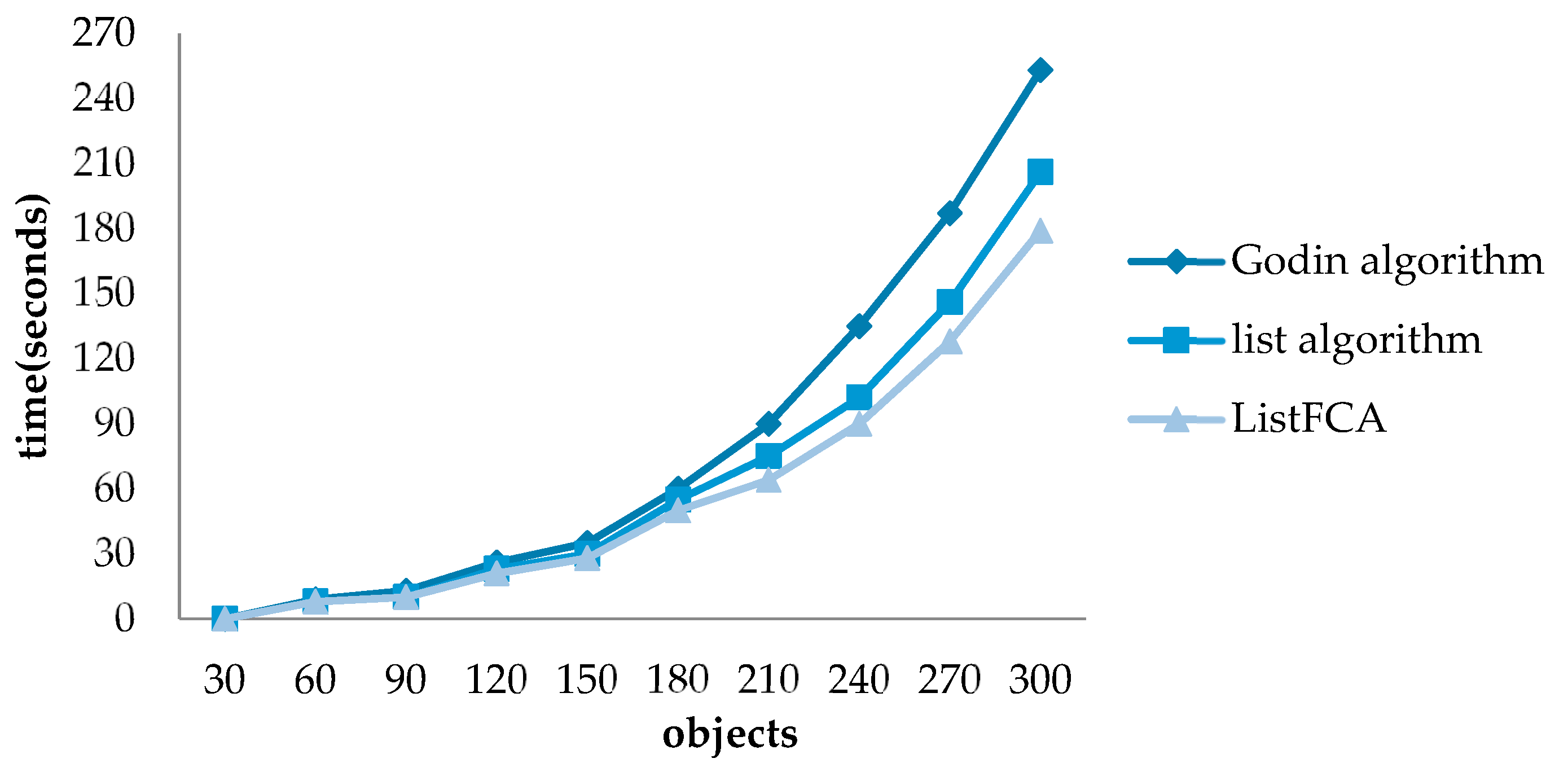
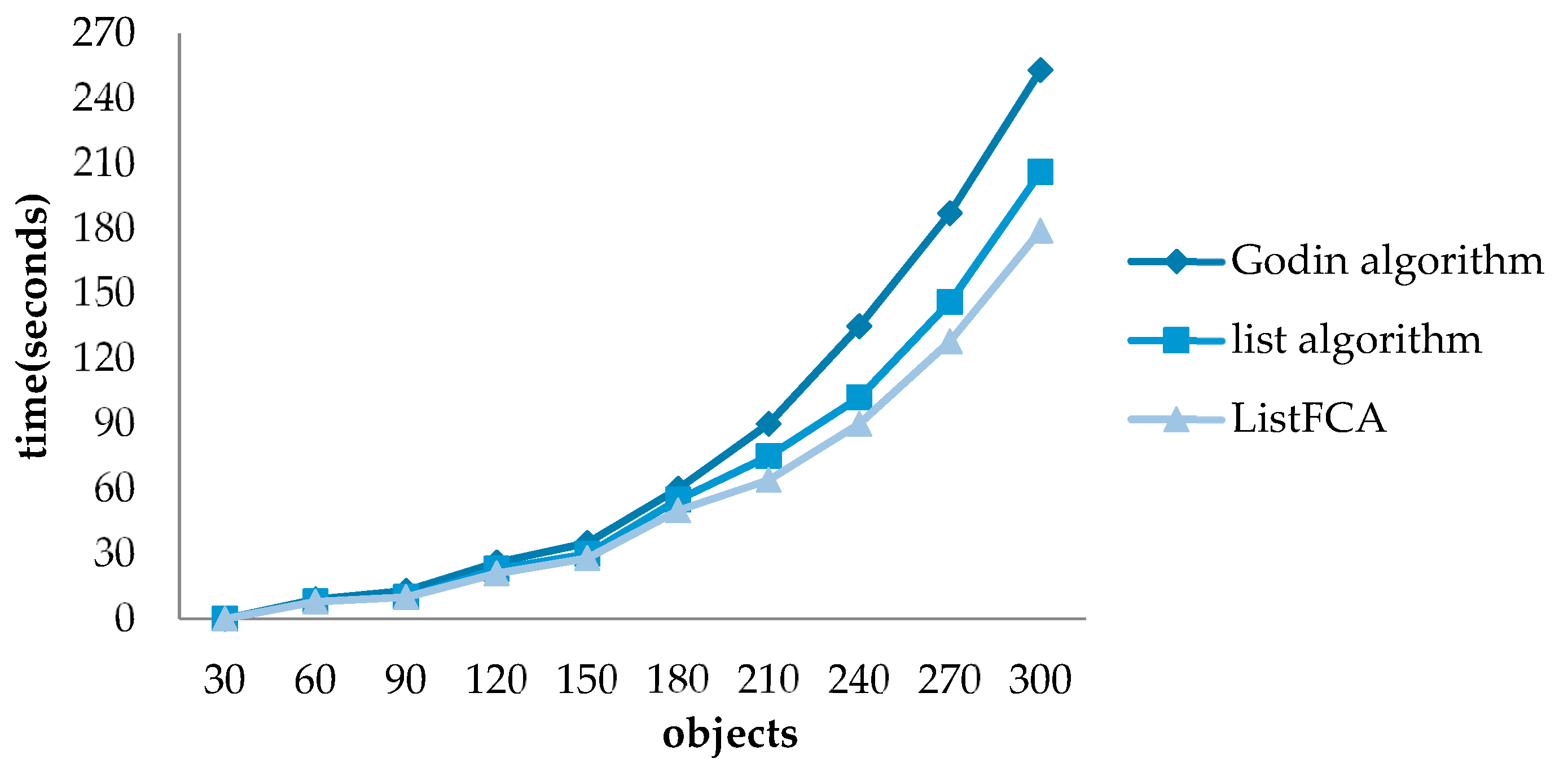
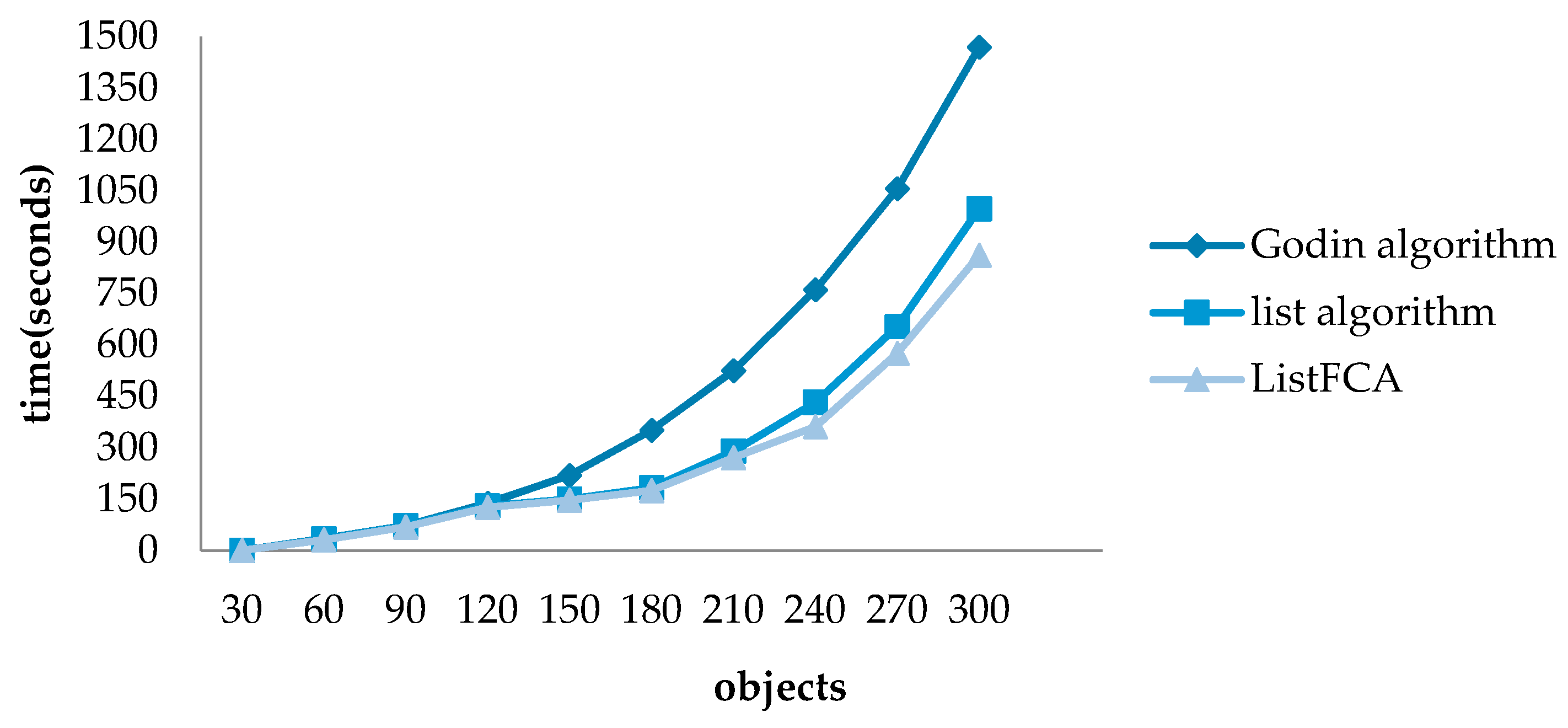
4.2. Efficiency Verification
4.3. Experiment and Analysis
5. Conclusions and Future
- Although the structure of Web pages is different from ordinary text, some research results of text classification and text clustering can also be used in Web page clustering. We should consider applying existing research results in other fields to Web clustering.
- The concept lattice is the core content of formal concept analysis, and there is still much room for improvement in the study of its construction algorithm. We can optimize the concept lattice construction algorithm based on a cross linked list in order to reduce the traversing times while maintaining the concept lattice with an increase or decrease in the number of objects.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- He, X.; Ding, C.H.; Zha, H.; Simon, H.D. Automatic topic identification using webpage clustering. In Proceedings of the 2001 IEEE International Conference on Data Mining, San Jose, CA, USA, 29 November–2 December 2001; pp. 46–54. [Google Scholar]
- Dau, F.; Ducrou, J.; Eklund, P. Concept similarity and related categories in searchsleuth. In Proceedings of the 16th International Conference on Conceptual Structures, Toulouse, France, 7–11 July 2008; pp. 255–268. [Google Scholar]
- Zamir, O.; Etzioni, O. Web document clustering: A feasibility demonstration. In Proceedings of the 21st Annual ACM/SIGIR International Conference on Research and Development in Information Retrieval, Melbourne, Australia, 24–28 August 1998; pp. 46–54. [Google Scholar]
- Mecca, G.; Raunich, S.; Pappalardo, A. A new algorithm for clustering search results. Data Knowl. Eng. 2007, 32, 504–522. [Google Scholar] [CrossRef]
- Sun, X. Construction data mining information management system based on FCA and ontology. In Advances in Electronic Engineering, Communication and Management; Springer: Berlin/Heidelberg, Germany, 2012; pp. 19–24. [Google Scholar]
- Hitzler, P. What’s happening in semantic web: And what FCA could have to do with it. In Proceedings of the International Conference on Formal Concept Analysis, Nicosia, Cyprus, 2–6 May 2011; pp. 18–23. [Google Scholar]
- Shen, X.; Xu, Y.; Yu, J.; Zhang, K. Intelligent search engine based on formal concept analysis. In Proceedings of the 2007 IEEE International Conference on Granular Computing (GRC 2007), San Jose, CA, USA, 2–4 November 2007; p. 669. [Google Scholar]
- Freeman, L.C.; White, D.R. Using Galois lattices to represent network data. Sociol. Methodol. 1993, 23, 127–146. [Google Scholar] [CrossRef]
- Wille, R. Restructuring lattice theory: An approach based on hierarchies of concepts. In Ordered Sets; Springer: Dordrecht, The Netherlands, 1999; pp. 445–470. [Google Scholar]
- Ganter, B.; Wille, R. Formal Concept Analysis: Mathematical Foundations; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Valtchev, P.; Missaoui, R.; Godin, R. Formal concept analysis for knowledge discovery and data mining: The new challenges. In Proceedings of the Second International Conference on Formal Concept Analysis, Sydney, Australia, 23–26 February 2004; pp. 352–371. [Google Scholar]
- Poelmans, J.; Ignatov, D.I.; Viaene, S.; Dedene, G.; Kuznetsov, S.O. Text mining scientific papers: A survey on FCA-based information retrieval research. In Proceedings of the 12th Industrial Conference on Data Mining, Berlin, Germany, 13–20 July 2012; pp. 273–287. [Google Scholar]
- Kuznetsov, S.O.; Obiedkov, S.A. Comparing performance of algorithms for generating concept lattices. J. Exp. Theor. Artif. Intell. 2002, 14, 189–216. [Google Scholar] [CrossRef] [Green Version]
- Kovács, L. Efficiency analysis of concept lattice construction algorithms. Procedia Manuf. 2018, 22, 11–18. [Google Scholar] [CrossRef]
- Godin, R.; Missaoui, R.; Alaoui, H. Incremental concept formation algorithms based on Galois (concept) lattices. Comput. Intell. 1995, 11, 246–267. [Google Scholar] [CrossRef]
- Chen, Q.Y. Improvement on Bordat algorithm for constructing concept lattice. Comput. Eng. Appl. 2010, 46, 33–35. (In Chinese) [Google Scholar]
- Yang, S.T. A webpage classification algorithm concerning webpage design characteristics. Int. J. Electron. Bus. Manag. 2012, 10, 73. [Google Scholar]
- Wang, Y.Z.; Chen, X.; Dai, Y.F. Web information extraction based on webpage clustering. J. Chin. Comput. Syst. 2018, 39, 111–115. (In Chinese) [Google Scholar]
- Tan, K.W.; Han, H.; Elmasri, R. Web data cleansing and preparation for ontology extraction using WordNet. In Proceedings of the International Conference on Web Information Systems Engineering, Hongkong, China, 19–21 June 2000; pp. 11–18. [Google Scholar]
- Bu, Z.; Zhang, C.; Xia, Z.; Wang, J. An FAR-SW based approach for webpage information extraction. Inf. Syst. Front. 2014, 16, 771–785. [Google Scholar] [CrossRef]
- Cai, D.; Yu, S.; Wen, J.R.; Ma, W.Y. Extracting content structure for web pages based on visual representation. In Proceedings of the 5th Asia-Pacific Web Conference and Application, Xian, China, 23–25 April 2003; pp. 406–417. [Google Scholar]
- Kwon, O.W.; Lee, J.H. Web page classification based on k-nearest neighbor approach. In Proceedings of the 5th international workshop on Information Retrieval with Asian Languages, Hong Kong, China, 30 September–1 October 2000; pp. 9–15. [Google Scholar]
- Huang, C.N.; Gao, J.; Li, M.; Chang, A. Chinese Word Segmentation. U.S. Patent 10/662,602, 31 March 2005. [Google Scholar]
- Cohen, W.W.; Singer, Y. Context-sensitive learning methods for text categorization. ACM Trans. Inf. Syst. (TOIS) 1999, 17, 141–173. [Google Scholar] [CrossRef] [Green Version]
- Kuznetsov, S.O.; Obiedkov, S.A. Algorithms for the construction of concept lattices and their diagram graphs. In Proceedings of the European Conference on Principles of Data Mining and Knowledge Discovery, Barcelona, Span, 20–24 September 2010; pp. 289–300. [Google Scholar]
- Zou, L.; Zhang, Z.; Long, J.; Zhang, H. A fast incremental algorithm for deleting objects from a concept lattice. Knowl. Based Syst. 2015, 89, 411–419. [Google Scholar] [CrossRef]
- Croitoru, M.; Ferré, S.; Lukose, D. Conceptual Structures: From Information to Intelligence. Lect. Note Comput. Sci. 2010, 9, 26–30. [Google Scholar]
- Frakes, W.B.; Baeza-Yates, R. Information Retrieval: Data Structures and Algorithms; Prentice Hall: Englewood Cliffs, NJ, USA, 1992. [Google Scholar]
- Zamir, O.E. Clustering Web Documents: A Phrase-Method for Grouping Search Engine Results. Ph.D. Thesis, University of Washington, Seattle, WA, USA, 1999. [Google Scholar]
- Wang, J. Research of Web Search Result Clustering Based on Formal Concept Analysis. Ph.D. Thesis, Xihua University, Chengdu, China, 2008. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tag |
|---|
| <ALT> |
| <BR> |
| <IMG> |
| <TABLE> |
| <STYLE> |
| <APPLET> |
| <FORM> |
| <META> |
| <SCRIPT> |
| <LINK> |
| Tag | Weight | Tag | Weight |
|---|---|---|---|
| <TITLE> | 5 | <H2> | 3 |
| <EM> | 4 | <H3> | 2 |
| <STRONG> | 4 | <H4> | 2 |
| <B> | 3 | <DT> | 3 |
| <BIG> | 3 | <A> | 3 |
| <H1> | 4 | <UL><OL> | 3 |
| m1 | m2 | m3 | m4 | m5 | |
|---|---|---|---|---|---|
| 1 | |||||
| 2 | |||||
| 3 | |||||
| 4 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Zhao, J.; Yan, X. A Web Page Clustering Method Based on Formal Concept Analysis. Information 2018, 9, 228. https://doi.org/10.3390/info9090228
Zhang Z, Zhao J, Yan X. A Web Page Clustering Method Based on Formal Concept Analysis. Information. 2018; 9(9):228. https://doi.org/10.3390/info9090228
Chicago/Turabian StyleZhang, Zuping, Jing Zhao, and Xiping Yan. 2018. "A Web Page Clustering Method Based on Formal Concept Analysis" Information 9, no. 9: 228. https://doi.org/10.3390/info9090228
APA StyleZhang, Z., Zhao, J., & Yan, X. (2018). A Web Page Clustering Method Based on Formal Concept Analysis. Information, 9(9), 228. https://doi.org/10.3390/info9090228