Knowledge Acquisition from Critical Annotations


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. The Role of Critical Annotations in Literary Research
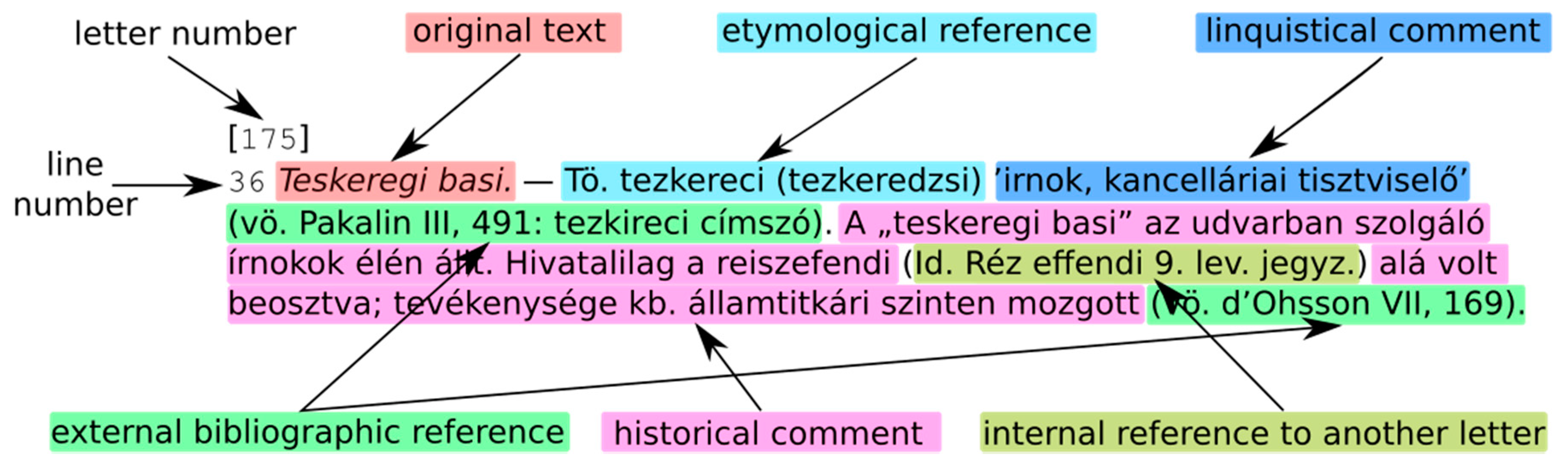
2.1. Structural and Content Analysis of Critical Annotations
“[1.]0 Constantinapolyban—Előfordul még Constantinápoly, Constancinapoly, Constancinápoly, Constáncinápoly [...]”
- historical (events, persons, their background information, etc.);
- social (relations and affairs);
- geographic;
- explanatory;
- grammatical, etymological, and filologica;
- literary history;
- cultural history.
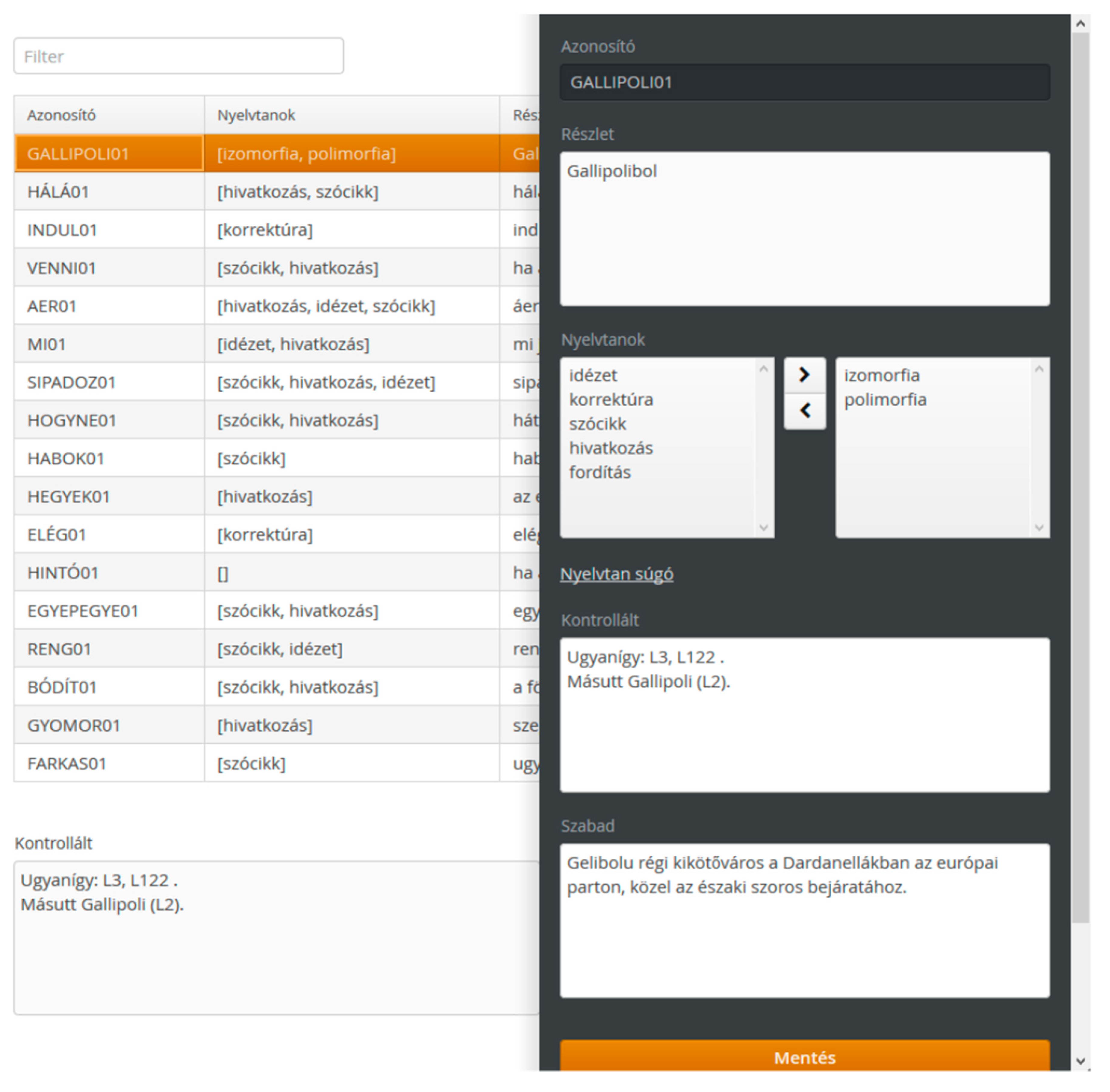
2.2. Storing Annotations in a Computer-Processable Form
3. Extracting Knowledge from Already Existing Critical Annotations
4. Authoring Critical Annotations Using Controlled Natural Languages
4.1. Controlled Natural Languages
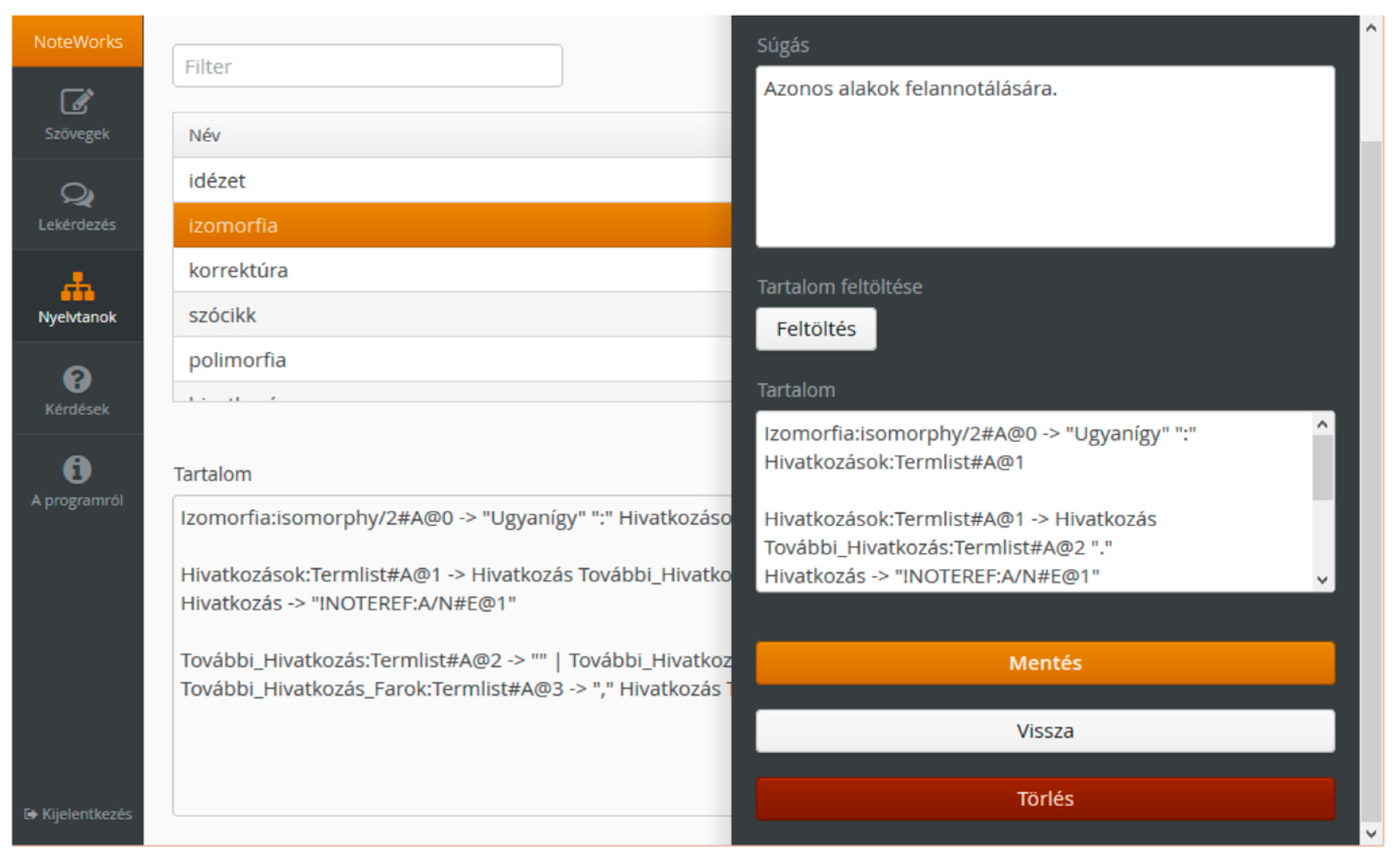
4.2. Writing Annotations in Controlled Natural Languages
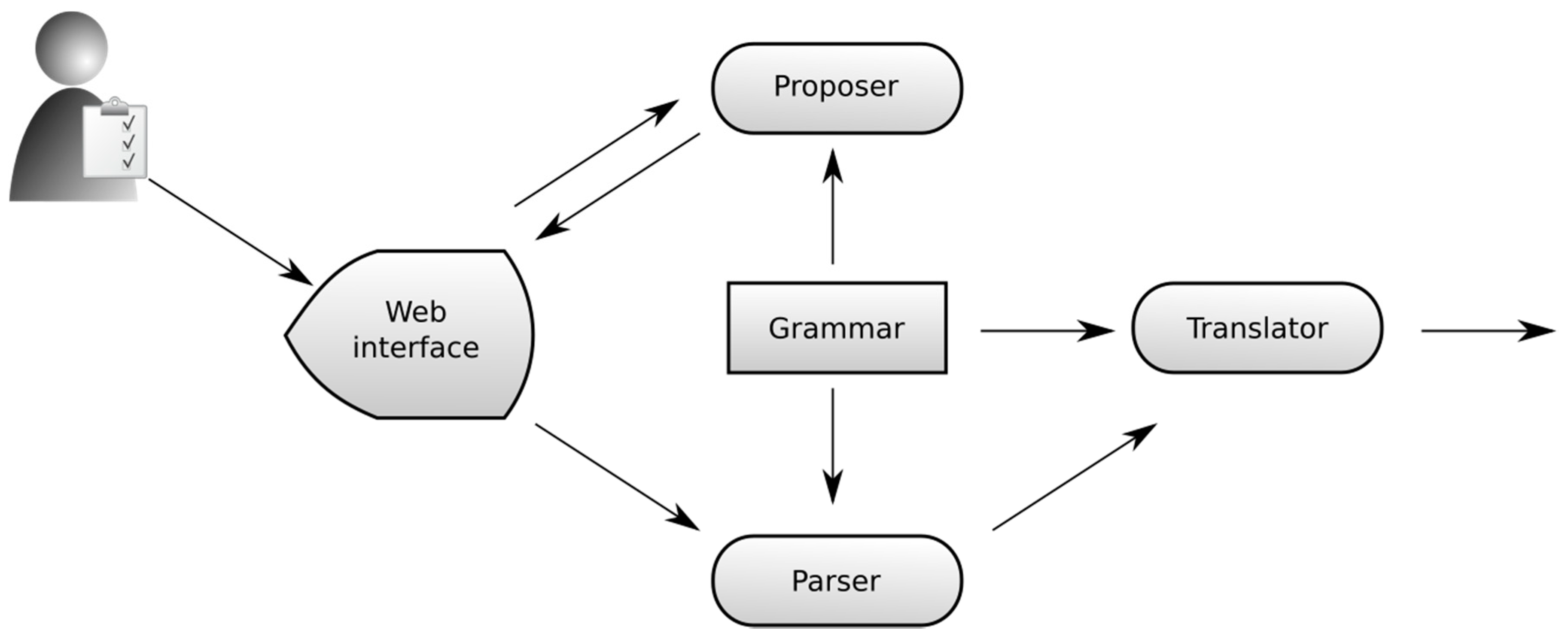
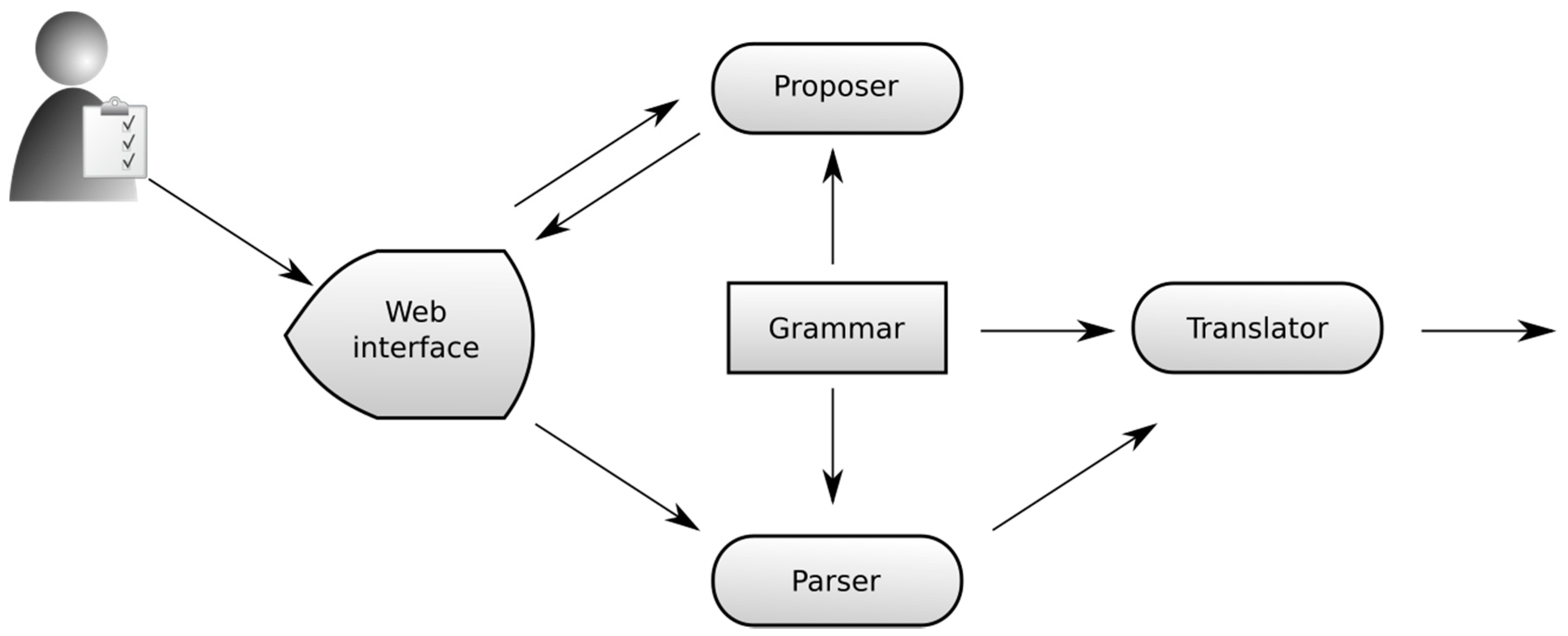
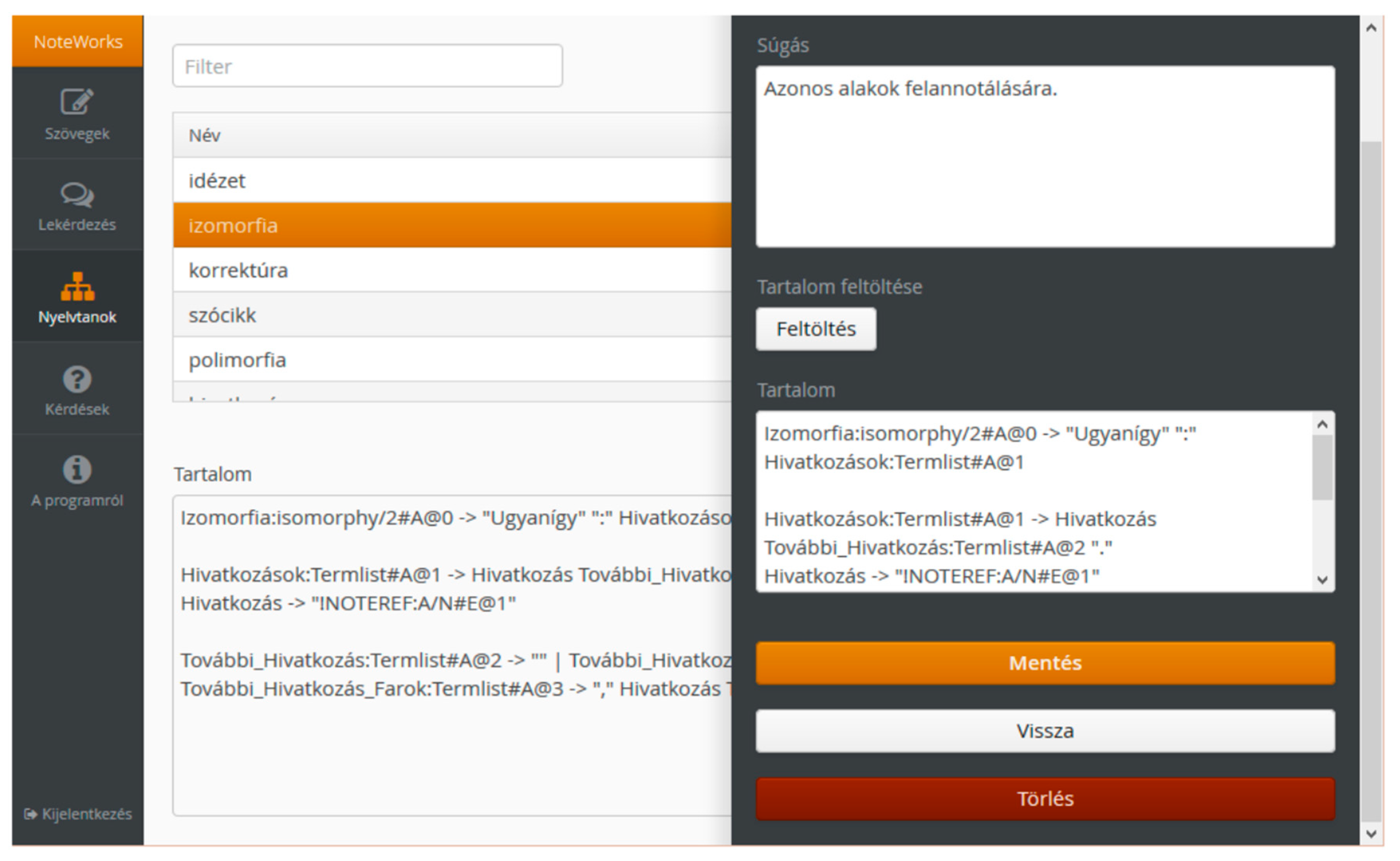
4.3. Selecting the Grammar Representation and Language Parser
4.4. Constructing the Controlled Natural Language
4.5. Knowledge Acquisition from Controlled Natural Language Annotations
5. Prototype Implementations
6. Discussion
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mészáros, T. Agent-supported knowledge acquisition for digital humanities research. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics, Budapest, Hungary, 9–12 October 2016. [Google Scholar]
- Kiss, M. The Digital Mikes-Dictionary. In Literaturtransfer und Interkultralität im Exil; Peter Lang Verlag: Bern, Switzerland, 2012; pp. 288–297. [Google Scholar]
- Mészáros, T.; Kiss, M. The DHmine dictionary work-flow: Creating a knowledge-based author’s dictionary. Euralex: Ljubjana, Slovenia, Unpublished work. 2018. [Google Scholar]
- Bartalesi, V.; Meghini, C.; Andriani, P.; Tavoni, M. Towards a semantic network of Dante’s works and their contextual knowledge. Digit. Scholarsh. Hum. 2016, 30, 28–35. [Google Scholar] [CrossRef]
- Nugues, P. From Digitization to Knowledge: Resources and Methods for Semantic Processing of Digital Works/Texts. Available online: http://dh2016.adho.org/abstracts/96 (accessed on 17 July 2018).
- Lana, M.; Alice, B.; Fabio, C.; Timothy, T. Ontologies and the Cultural Heritage. The Case of GO! Available online: http://ceur-ws.org/Vol-1595/paper1.pdf (accessed on 17 July 2018).
- Safaryan, A.; Kaufmann, S.; Andrews, T. Critical Edition as Graph: The Chronicle of Matthew of Edessa Online. In Digital Humanities, 2016: Conference Abstracts; Jagiellonian University: Kraków, Poland; Pedagogical University of Kraków: Kraków, Poland, 2016; pp. 879–880. [Google Scholar]
- Cheema, M.; Jänicke, S.; Scheuermann, G. Enhancing Close Reading. In Proceedings of the Digital Humanities Conference, Krakow, Poland, 11–16 July 2016; pp. 758–761. [Google Scholar]
- Hopp, L. Mikes Kelemen Összes Művei; Hopp, L., Ed.; Akadémiai Kiadó: Budapest, Hungary, 1966–1988. [Google Scholar]
- Text Encoding Initiative. Available online: http://www.tei-c.org/ (accessed on 30 June 2018).
- DBpedia. Available online: http://www.dbpedia.org/ (accessed on 30 June 2018).
- Kittredge, R.I. Sublanguages and controlled languages. In The Oxford Handbook of Computational Linguistics; Mitkov, R., Ed.; Oxford University Press: New York, NY, USA, 2005. [Google Scholar]
- Kuhn, T. A Survey and Classification of Controlled Natural Languages. Comput. Linguist. 2013, 40, 121–170. [Google Scholar] [CrossRef]
- Kamprath, C.; Adolphson, E.; Mitamura, T.; Nyberg, E. Controlled language for multilingual document production: Experience with Caterpillar technical English. In Proceedings of the Second International Workshop on Controlled Language Applications, Pittsburgh, PA, USA, 21–22 May 1998. [Google Scholar]
- Androutsopoulos, I. Natural Language Interfaces to Databases—An Introduction. J. Nat. Lang. Eng. 1995, 1, 29–81. [Google Scholar]
- Kuhn, T. Controlled English for Knowledge Representation. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.470.9617&rep=rep1&type=pdf (accessed on 17 July 2018).
- Mitamura, T. Controlled language for multilingual machine translation. Mach. Transl. Summit 1999, VII, 46–52. [Google Scholar]
- Funk, A.; Tablan, V.; Bontcheva, K.; Cunningham, H.; Davis, B.; Handschuh, S. Clone: Controlled language for ontology editing. In Proceedings of the International the Semantic Web and, Asian Conference on Asian Semantic Web Conference, Busan, Korea, 11–15 November 2007; pp. 142–155. [Google Scholar]
- Bernstein, A.; Kaufmann, E. GINO–A guided input natural language ontology editor. In International Semantic Web Conference; Springer: Berlin, Heidelberg, 2006; pp. 144–157. [Google Scholar]
- Davis, B.; Dantuluri, P.; Dragan, L.; Handschuh, S.; Cunningham, H. On designing controlled natural languages for semantic annotation. In Proceedings of the International Workshop on Controlled Natural Language, Marettimo Island, Italy, 8–10 June 2009; pp. 187–205. [Google Scholar]
- Mészáros, T.; Dobrowiecki, T. Controlled natural languages for interface agents. In Proceedings of the 8th International Conference on Autonomous Agents and Multiagent Systems, Budapest, Hungary, 10–15 May 2009; pp. 1173–1174. [Google Scholar]
- Dobi, J.S. Kontrollált Természetes Nyelvű Szövegannotáló-Rendszer. Bachelor’s Thesis, Budapest University of Technology and Economics, Budapest, Hungary, 2015. [Google Scholar]


© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mészáros, T.; Kiss, M. Knowledge Acquisition from Critical Annotations. Information 2018, 9, 179. https://doi.org/10.3390/info9070179
Mészáros T, Kiss M. Knowledge Acquisition from Critical Annotations. Information. 2018; 9(7):179. https://doi.org/10.3390/info9070179
Chicago/Turabian StyleMészáros, Tamás, and Margit Kiss. 2018. "Knowledge Acquisition from Critical Annotations" Information 9, no. 7: 179. https://doi.org/10.3390/info9070179
APA StyleMészáros, T., & Kiss, M. (2018). Knowledge Acquisition from Critical Annotations. Information, 9(7), 179. https://doi.org/10.3390/info9070179