2. Background
Algorithms with pruning techniques store measured distances to take advantage of metric properties and/or of statistics from distance distribution over the data space. Most data structures use lower bounds of distances derived from the triangular inequality property as a pruning method to avoid unnecessary distance calculations. Another proposed technique is to store the minimum and the maximum values of measured distances within a group of elements and use them to discard entire regions during search algorithm execution [
9].
The OMNI concept [
10,
11] increases the pruning power of search operations using a few elements strategically positioned as pivots, named the foci set. OMNI methods store distances among the elements and the pivots, so the triangular inequality property is used to prune nodes and consequently reduce the number of visited sub-trees. Hashing, the “key to address” mapping, is the basis for D-Index [
12] and SH [
13].
Both ball and hash based methods have particular advantages that can be combined to achieve better metric structures. The way ball-based metric access methods (MAM) partitions the metric space leads to a partitioning of the data structure based on the similarity of indexed elements, so every resulting partition of the metric space groups similar elements. However, regions almost always overlap with search balls, forcing the search algorithm to visit many regions. Pivot partitioning methods have a powerful pruning power but are still affected by the selection of pivots and how the pivots are combined to prune regions. Hash-based methods partition the data into subsets that are addressed later to answer the queries, but the best methods still solve the problem of approximated similarity search.
If the application allows approximated results for similarity search, a trade-off between accuracy and time must be considered. Randomized search algorithms have been proposed to index high dimensional data in sub-linear time in terms of database size, as the locally sensitive hashing (LSH) methods [
14]. However, an important problem on LSH is to determine when a similarity function admit a LSH [
15].
In the literature, there are three distinct similarity join operators: the range join, the
k-nearest neighbor join and the
k-closest neighbor join [
16]. The range join operator relies on a given threshold
in order to retrieve all element pairs within the distance
. This is the join operator commonly found in the literature, and it is known as “similarity join” [
17], as we will refer to it in this paper. Applications of range join operator include, for example, string matching [
18,
19], near duplicate object detection [
20] and data cleaning [
21]. The other two similarity join operators are based on retrieving a given amount
k of pairs. The
k-nearest neighbor join retrieves, for each element from the first relation, the
k nearest elements from the second one. The
k-closest neighbor join retrieves the
k most similar element pairs among the two relations in general.
Those operators can be applied to data mining and data integration [
16], map-reduce [
22,
23] and high dimensional data querying [
24,
25]. In addition, researchers work on parallel approaches deal with partitioned data spaces with minimal redundancy in order to achieve faster algorithms [
26].
All presented works from the literature contributed to the similarity problem complexity, but the pruning ability is affected by the query radius or number of neighbors requested. Therefore, we propose a technique that combines the metric properties to strategically prune distances calculations producing faster similarity operations, as detailed in the next sections.
3. Metric Boundary Properties
Similarity search is the most frequent abstraction to compare complex data, based on the concept of proximity to represent similarity embodied in the mathematical concept of metric spaces [
27]. Evaluating (dis)similarity using a distance function is desirable when the data can be represented in metric spaces. Formally, a metric space is a pair
, where
is the data domain and
is the distance function, or metric, that holds the following axioms (properties) for any
:
Identity ();
Symmetry ( = );
Non-negativity (, ) and
Triangular inequality ().
The triangular inequality property of a metric is extensively used in most metric access methods to prune regions of metric space to perform similarity queries. Specifically, the lower bound property of a metric is commonly used to help prune regions on metric space that do not satisfy the search conditions.
In this section, we depict properties derived from the triangular inequality, and show how we can use them to avoid unnecessary distance calculations in similarity queries.
3.1. The Upper and Lower Bound Properties
Consider a metric space
and elements
. If the chosen distance function holds the metric properties, we can state the boundary limits of distances, based on the triangular inequality property, as follows:
Equation (
1) states the bounding limits of a distance
based on the triangular property. Thus, it can be used to estimate the range of values of a desired unknown distance. The lower bound property is the minimum estimated value for
, while the upper bound is the maximum one. We show that both bounding properties can help avoid unnecessary distances calculations.
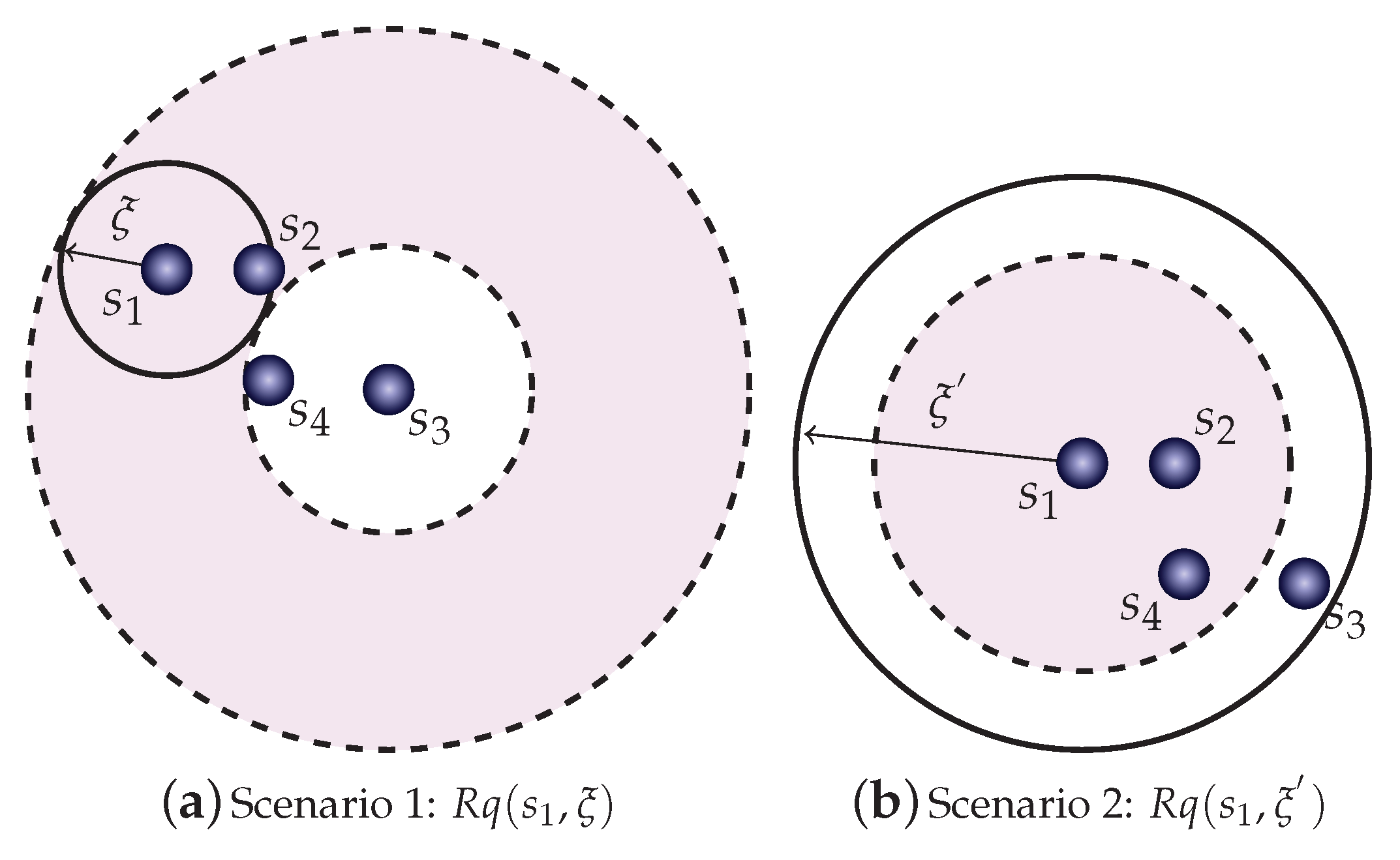
Figure 1 shows a bi-dimensional dataset where two range queries are posed, with different radius each,
and
, respectively, for example of the usage of both bounding properties.
Figure 1a shows a range query
centered at element
with radius
. Notice that using element
as a pivot, the calculation of the distance
can be discarded by using the lower bound property. Although multiple pivots can be used to increase the “prunability”, as well as the positioning of pivots at the corner of the space, we keep this example with one pivot to indicate how to use the properties. In the example, every element outside the shaded area can be pruned, while those inside are considered false positives and must be investigated by calculating the real distance from the query center. Following our example dataset, the condition to avoid calculating distances from a given element
to the query center
using the lower bound property on pivot
is then given by Equation (
2):
The lower bound pruning is effective when dealing with small query radius
, failing more often at higher values. This is because the proper formulation of the inequality uses
to estimate the lower bound, once as higher the value of
, higher the chance of the condition in Equation (
2) fails. This situation leads to the scenario two, shown in
Figure 1b, where a query with a larger radius
is set. In this case, it is useful to use the upper bound property to detect coverage between the query ball and elements to search for. Now, it can detect if the query ball covers element
, without the need to perform distance calculations to the query center
. Following our example data set, the condition to avoid calculating distances from a given element
to the query center
using the upper bound property on pivot
is given by the following. Elements detected inside the query ball can be directly added in the answer set without the verification of its distance from the query center. An element
is covered by the query ball
if
but, by the upper bound property on pivot
, we derive
so it is safe to include
if the following inequation holds:
Summarizing, we have now two support properties to aid similarity queries, one dedicated to prune elements from the query region (lower bound condition) and another dedicated to detect coverage of the query region (upper bound condition). Considering a query ball and a pivot , we can avoid calculation of , for all in the data set by using the following:
However, we must consider that we can choose multiple pivots, and also the efficiency of each condition can be optimized by the position of each pivot in the data set. A pivot selection technique for this purpose is presented in the next section.
3.2. Maximizing Efficiency by Pivots Selection
The previously discussed properties can be optimized by a proper choice of the pivots. In this section, we propose one solution to choose pivots in order to maximize the prunability of the double pruning properties. Although the double pruning can be applied for any pivot, we intended to show that it is desirable to select them accordingly to obtain a higher chance of pruning success of each property. Therefore, we propose to select two types of pivots, the inner and outer pivots, each type associated with a pruning condition. The outer pivots are chosen for the usage of the lower bound property, and the inner pivots for the upper bound property.
For choosing the outer pivots, there are already studies that lead to the choice of elements at the corner (border) of the dataset, i.e., elements farthest from most of elements in the dataset [
10]. This choice increases the efficiency of punning using the Equation (
6). However, for inner pivots chosen for the upper bound property usage, we have to choose pivots in a different manner.
In order to increase the chance of satisfying the Equation (
7), the left term can be minimized and the right term can be maximized, as an optimization problem. A directly but query dependent solution is by maximizing the right term, which is the radius value. Increasing radius on range joins will increase the chance of pruning using the upper bound property, which is a desirable effect on scalable joins. Another optimization possibility is to choose pivots nearest to the elements of the data set, minimizing in average the values of
and
, also minimizing the left term of Equation (
7).
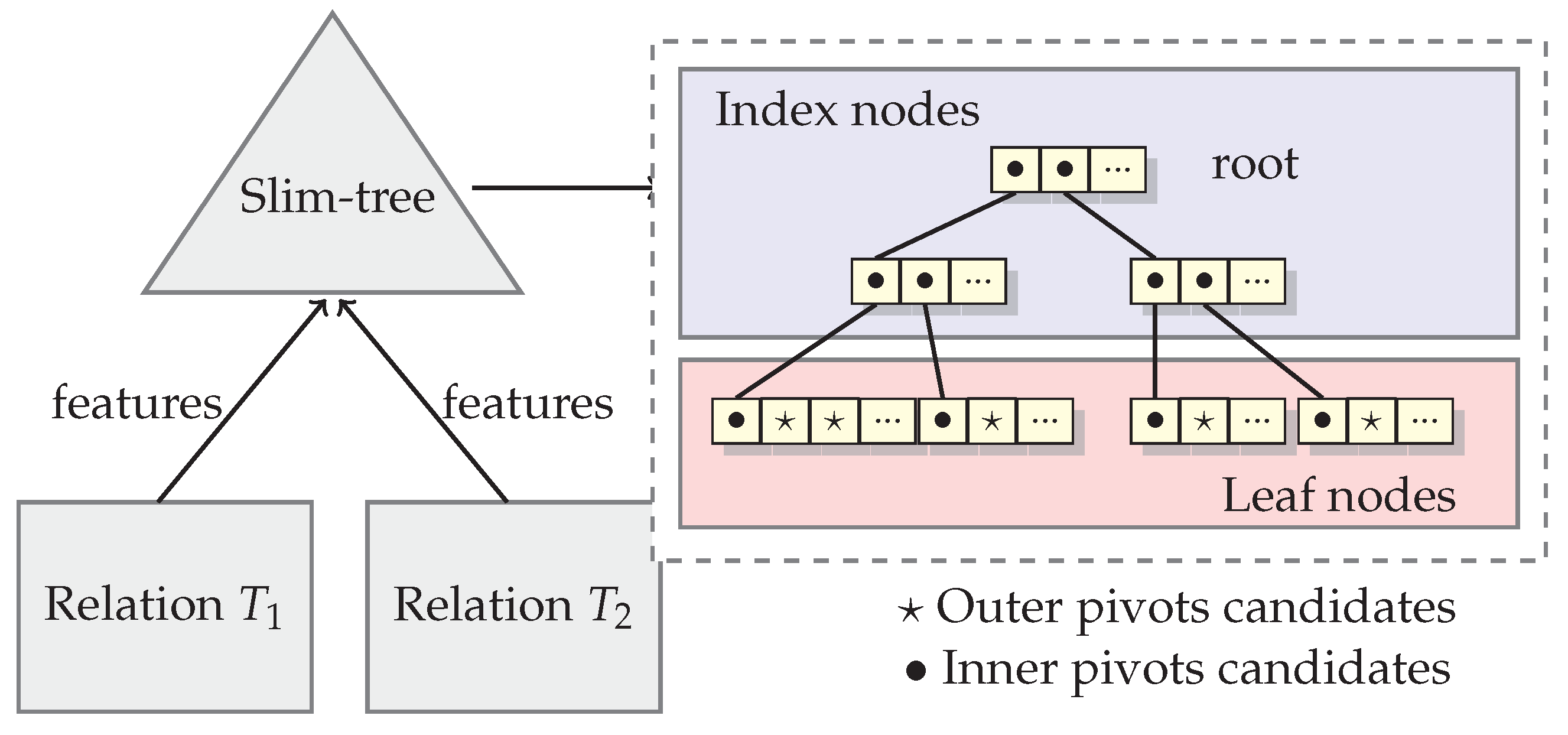
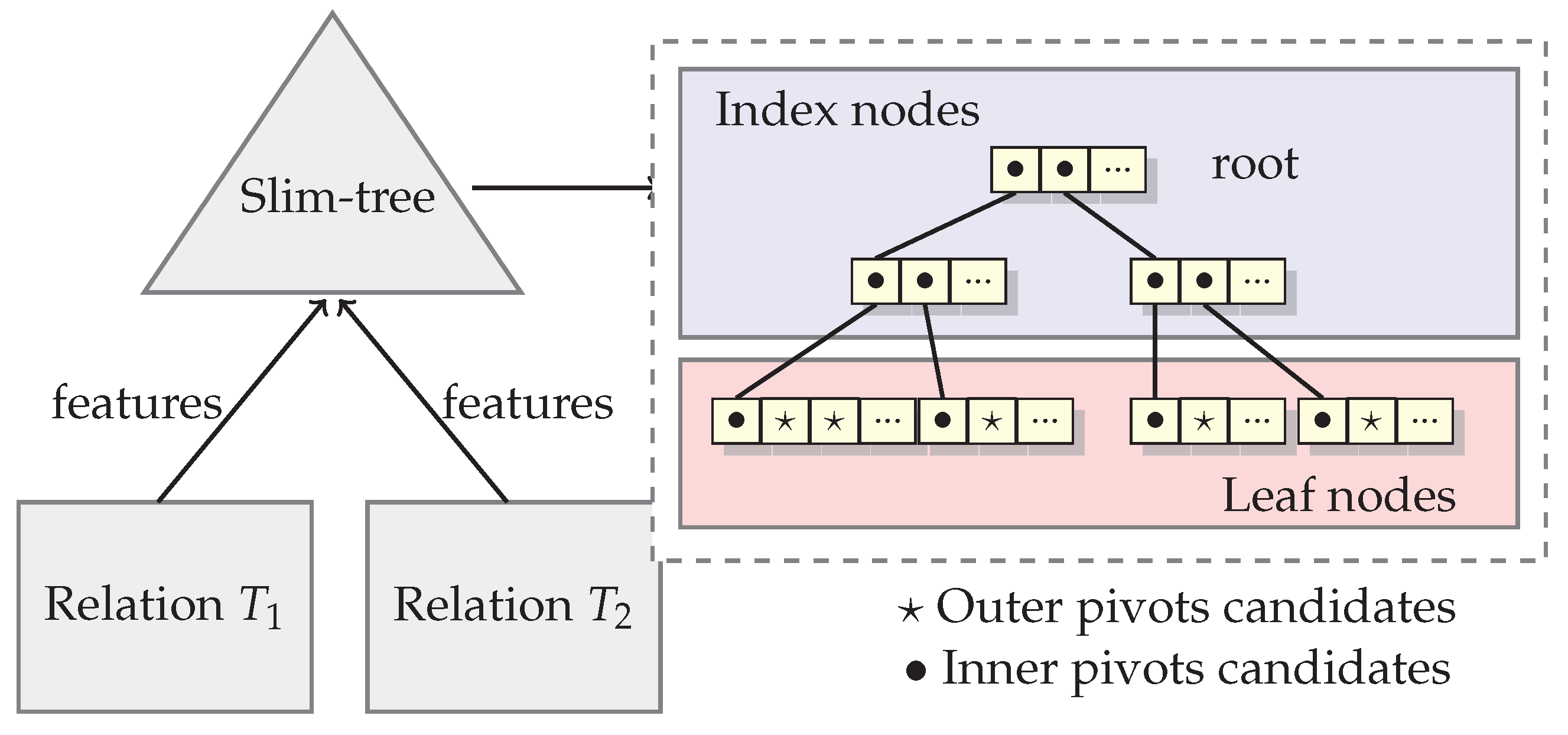
We propose one solution on how pivots can be selected attending the characteristics detailed above. Here, we choose pivots from a metric index created from both relations to be joined.
A Slim-tree is created from the relations to be joined, and this task can be performed offline before selecting pivots, once the Slim-tree is a disk-based metric tree. Since the elements stored on relations to be joined by similarity belong to the same metric space, the Slim-tree can index all elements of relations for the similarity join. The Slim-tree nodes group similar elements. Then, we take advantage of it to select proper pivots for each type of property.
Figure 2 shows an example of a tree-based index structure indexing features of elements from two relations to be joined, Relations
and
. The features must be from the same domain to be indexed in the same index. The index nodes of the structure will hold all node representatives hierarchically. They are good candidates to be elected as inner pivots because the representative elements have the smaller distance to their near elements, in average. On the other hand, the leaf nodes hold outer pivots candidates, excluding the elements from the first position of each leaf node (which are representatives on local node in Slim-tree).
For the number of pivots, we follow the same idea of OMNI concept findings [
10]. For the selection of outer pivots, we will follow the “Hull of Foci” (HF) algorithm on the OMNI concept. the HF algorithm randomly chooses an object
, find the farthest object
from
, and set it as the first pivot. Then, it finds the farthest object
from
, setting it as the second pivot. The HF algorithm selects other pivots using a minimal error measure. Considering elements
as the first chosen pivots, it searches for elements in order to minimize an error measure given by the following:
As the outer pivots candidates are stored in leaf nodes of the structure, excluding the first position of each leaf node, the list of outer pivots candidates is smaller and the algorithm will perform faster than the original OMNI strategy.
The task of selecting inner pivots is performed over the candidates list formed by index elements in the Slim-tree. In order to avoid selecting near pivots, the search must be performed in one tree level. For example, if the nodes in a same index level do not store the necessary number of candidates pivots, then the search will be performed entirely in the next level of the tree, until finding a suitable level.
The proposed technique can be applied to speed up any existing similarity search method. In this paper, we will illustrate an example of how our technique can be applied to resolve range joins, by applying it to the classical nested loop. Therefore, the next section shows the LUBJOIN algorithm, a simple nested loop join algorithm that uses our pruning technique. We will use it in experiments in order to analyze how the properties can be avoiding distance calculations.
4. Performing Similarity Joins
In the modern relational database management systems (RDBMSs), the information retrieval is performed by query operators, such as project, union, selection and join [
28]. In Database theory, the join binary operator can be defined as a combination of other operators [
17], as follows.
Definition 1 (Join operator)
. The join of two relations and is a binary relational operator algebraically defined as a composition of two fundamental operators: a Cartesian product followed by the selection that perform the join predicate c:
When we bring this concept for a similarity scenario, the selection operator of a range join will refer to a similarity range selection, as:
Definition 2 (Similarity range selection)
. The similarity range selection restricts the tuples of to those where the complex attribute is similar to considering a similarity threshold of ξ. It retrieves a subset such that .
Therefore, a range join will be defined according to the similarity range selection and the traditional join operator.
Definition 3 (Similarity range join)
. The similarity range join combines the tuples of and whose distance between the pair of complex attributes is less than or equal to the given threshold ξ. It retrieves a set of pairs such that .
According to the definition, at high values of join radius , the answer set will also converge to the Cartesian product itself, which needs no distance calculations at this point.
As detailed in the previous section, we use the upper bound property from the metric to detect covering at high values of
and the lower bound property to prune elements at low values of
. In addition, in order to maximize the efficiency of the bounding properties, the inner and outer pivots must be properly defined following the process discussed in
Section 3.2. Then, the pivots will be used for pruning and predicting.
The construction of the data structure for the new similarity join operator is performed in the following steps. Considering two relations and to be joined under a complex attribute, first the features are extracted into sets R and S within the same domain, respectively. The inner and outer pivots will be selected from an index composed of elements from both R and S. Then, the distances from pivots to elements of R and S are evaluated.
The algorithm of the proposed similarity join method is called LUBJOIN and it is described in Algorithm 1. The execution of the similarity join is performed in the following steps. For each element
, a range query with radius
will be executed over elements
. The evaluation of each distance will be conditioned to the bounding conditions defined in Equations (
6) and (
7).
| Algorithm 1: LUBJOIN Algorithm |
INPUT: Sets R and S, inner pivots , outer pivots , radius .
OUTPUT: Result pairs () at .- 1:
for each element do - 2:
for each element do - 3:
NeedDist = true - 4:
for each do - 5:
if then - 6:
NeedDist = false - 7:
break - 8:
if NeedDist == true then - 9:
for each do - 10:
if then - 11:
Add pair () in - 12:
NeedDist = false - 13:
break - 14:
if NeedDist == true then - 15:
Evaluate distance d() - 16:
if then - 17:
Add pair () in
|
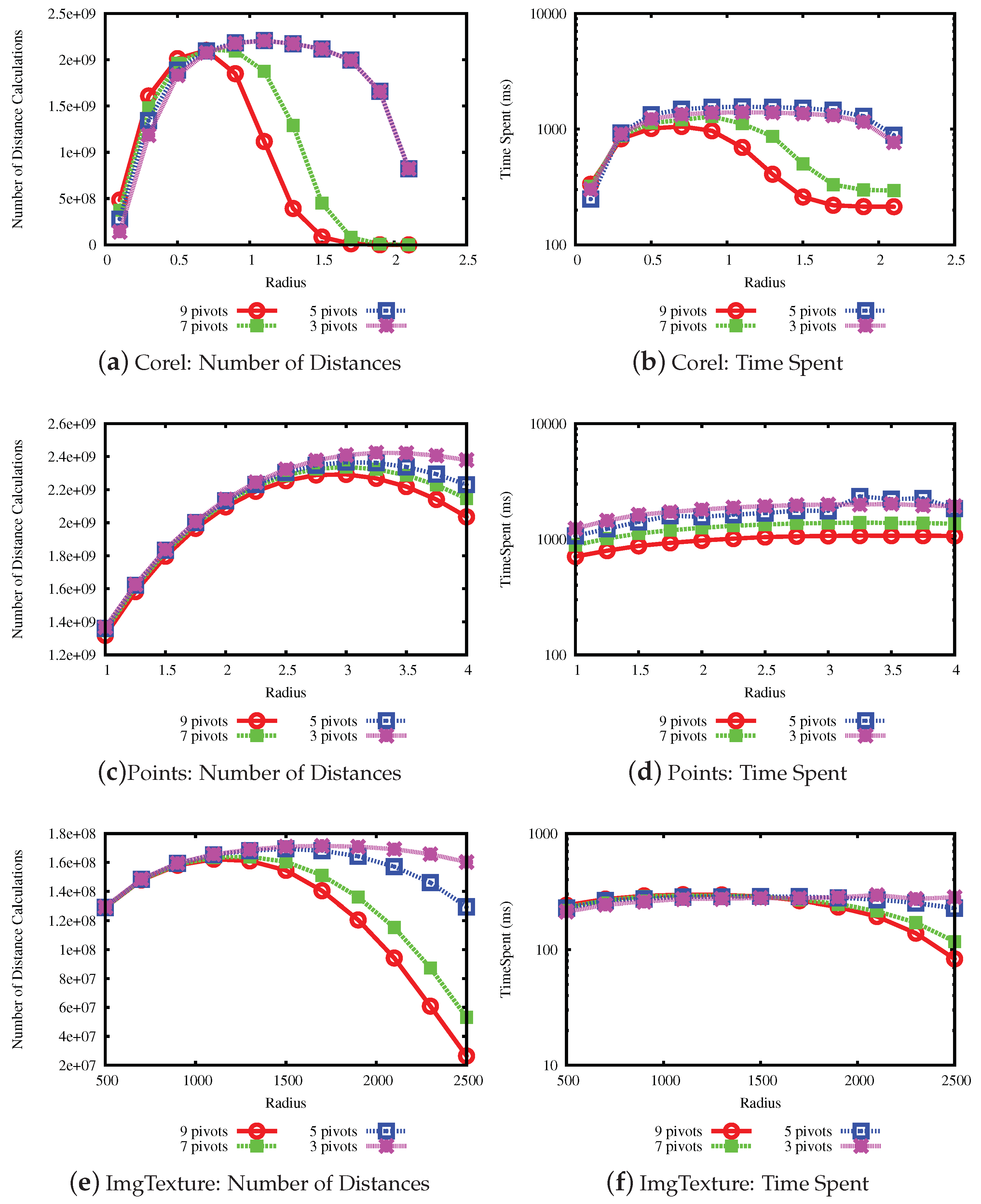
5. Experiments
This section presents the results from experiments to evaluate our technique by using the proposed LUBJOIN algorithm. We performed range joins with different values of radius of the selection operator. The experiments were divided in two parts. In the first one, it was measured the efficiency of the proposed bounding properties. In the second, the performance of the LUBJOIN was evaluated in terms of number of distances calculated and time spent.
The performed range joins used a full range of values for the radius (updated to each data set) of the selection operator, in order to analyze the stability of our proposed technique to every possible radius value. The values for the radius were set up based on the evaluation of the diameter of the data set.
The LUBJOIN was compared with the traditional nested loop as the baseline, and also with one indexed table, in this case the Slim-tree as the index. It was not considered to filter the join result by eliminating repeated pairs of elements. The tests were performed on a computer with Pentium Intel Core i7 2.67GHz processor with 8 GB of RAM memory.
We used five data sets for the experiments. The description of each data set is shown in
Table 2. The selected data sets allow exploring different types of data sets, varying the data set dimension, size, and type (geographic and images). The Corel data set consists of color histograms in a 32-dimensional space extracted from an image set. Using the
distance, the maximum distance was rounded up to 3.28. The ImgTexture data set consists of Haralick textures in a 140-dimensional space extracted from an image set from the web. Using the Euclidean distance, the maximum distance was rounded up to 3670. The Points data set consists of a million random points in a six-dimensional space. Using the
distance, the maximum distance was rounded up to 5.51. The USCities data set consists of Geographical coordinates (latitude and longitude) of USCities, villages, boroughs and towns. Using the spherical cosine distance, we considered to run at the maximum distance of 100 kilometers. the ImgMedical data set consists of color histograms formed by 256 grey levels from medical images. Using the
distance, the maximum distance was estimated at 8740 and using the Mahalanobis distance estimated at 5245.
There are two initial approaches when selecting pivots. The first is to process a training set, for which it is usually a consistent subset of the entire data set. This setup speeds up the pivot selecting process once the training set is smaller than the entire dataset. However, the second approach is to dynamically update the current pivots set as new data is added to the dataset. Thus, if the new data is posed outside of the convex hull formed by the current pivots, they are updated using the linear time complexity algorithm [
10,
11]. In this paper, we assume the dynamical approach.
The construction process consists on selecting the pivots according to the approach detailed in
Section 3.2. We used seven outer pivots and seven inner pivots selection in all experiments, which resulted in the best results compared to other tested quantities because the time spent increases if too many pivots are chosen. Although a high number of inner pivots may benefit the distance avoidance chance, the internal cost for this filtering stage can be higher than actually evaluating the distance. The cost of the construction relies on building the Slim-tree from the elements of both relations to be joined for pivots selection. We selected pivots from the candidates list produced by the index randomly. For simplicity, we considered the join relations as the same data set.
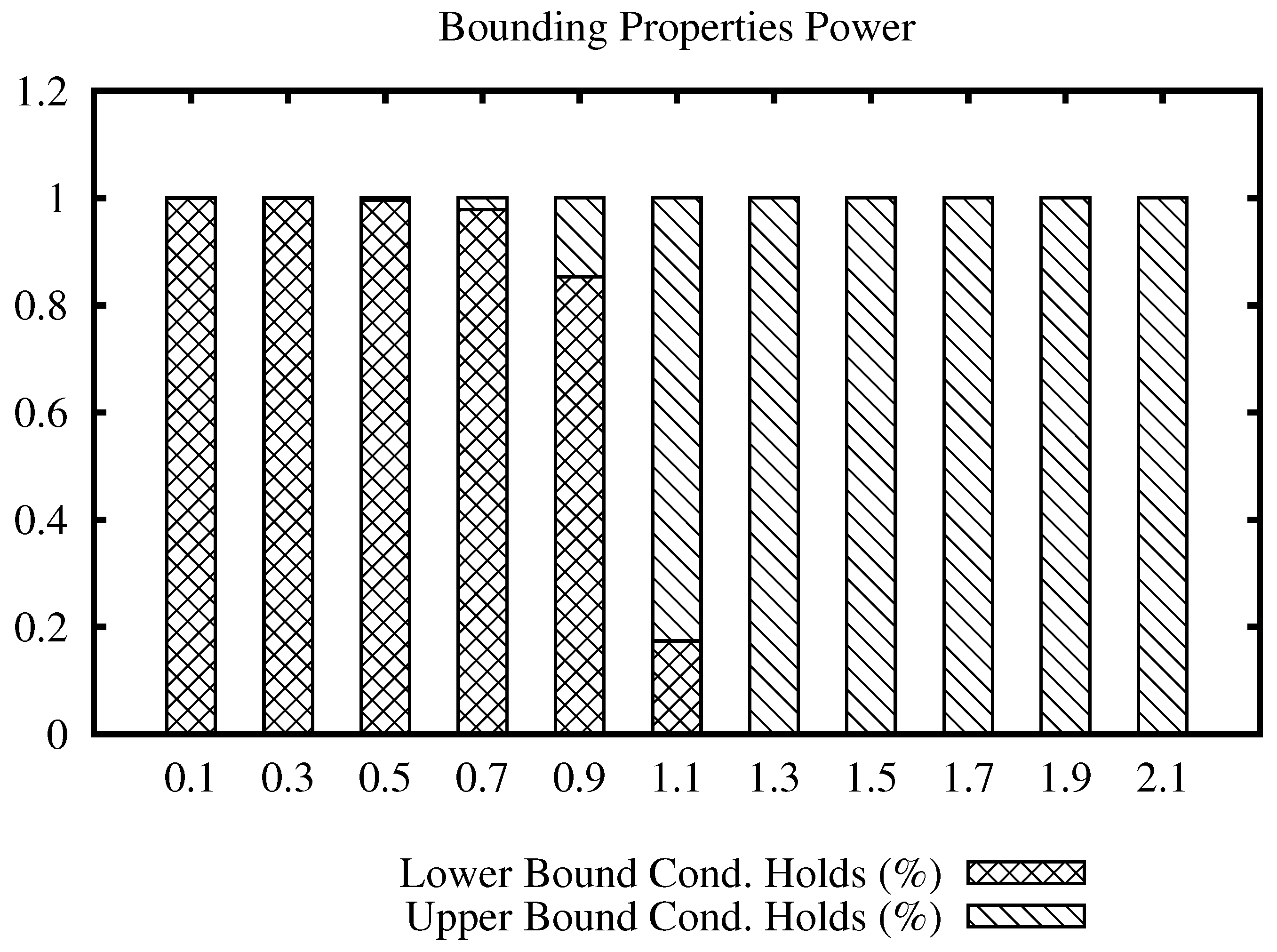
The first experiment evaluates the bounding properties filtering power. Similarity joins were performed varying the join radius from lower to higher values, but much smaller than the maximum distance in each data set. For the experiment, it was counted how many times each filter (lower or upper bound) successfully avoided the distance calculation. The results show which bounding property filters more elements according to the considered join radius, and bar plots show the proportion of each bounding property considering all successful prune operations.
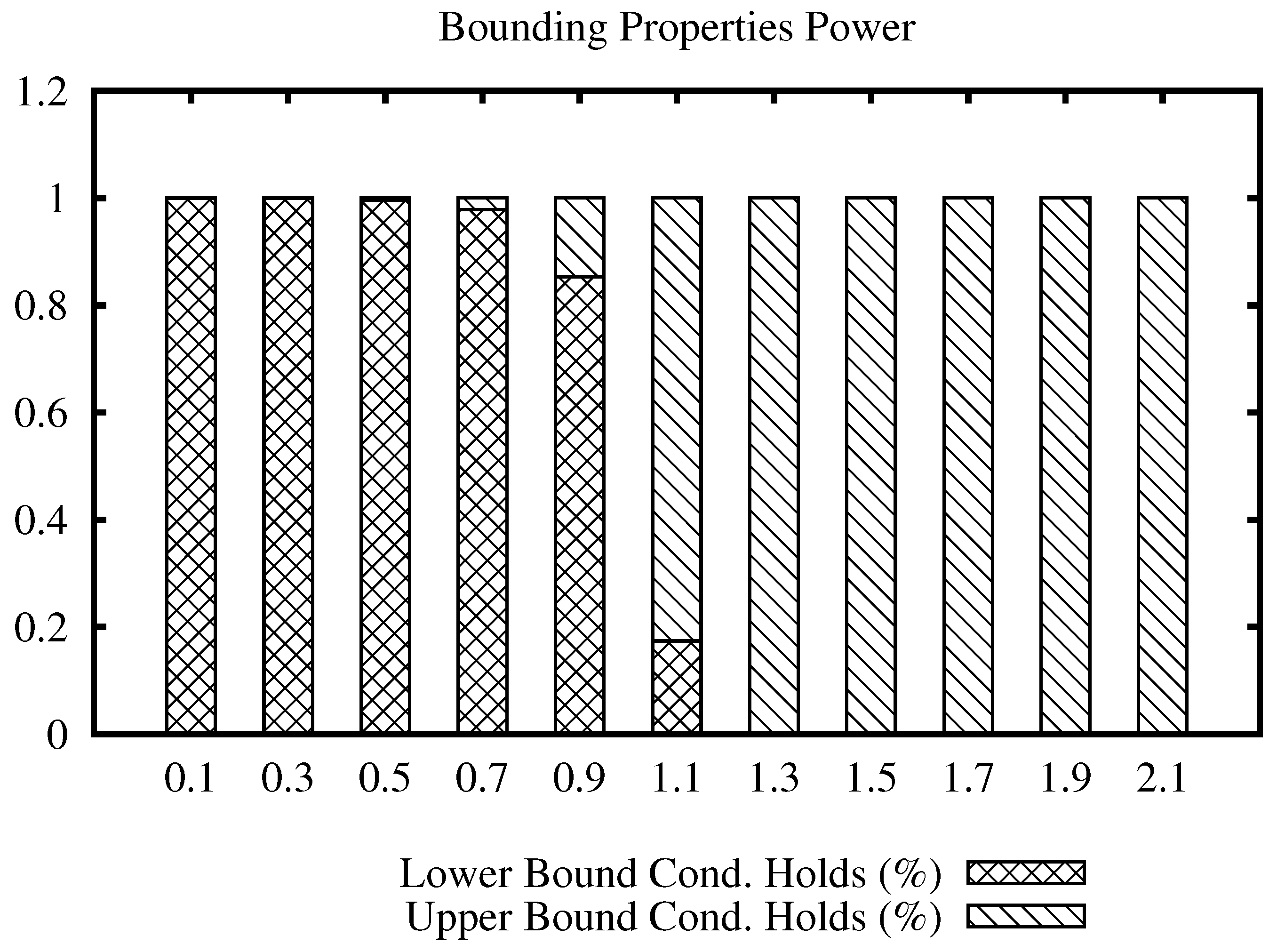
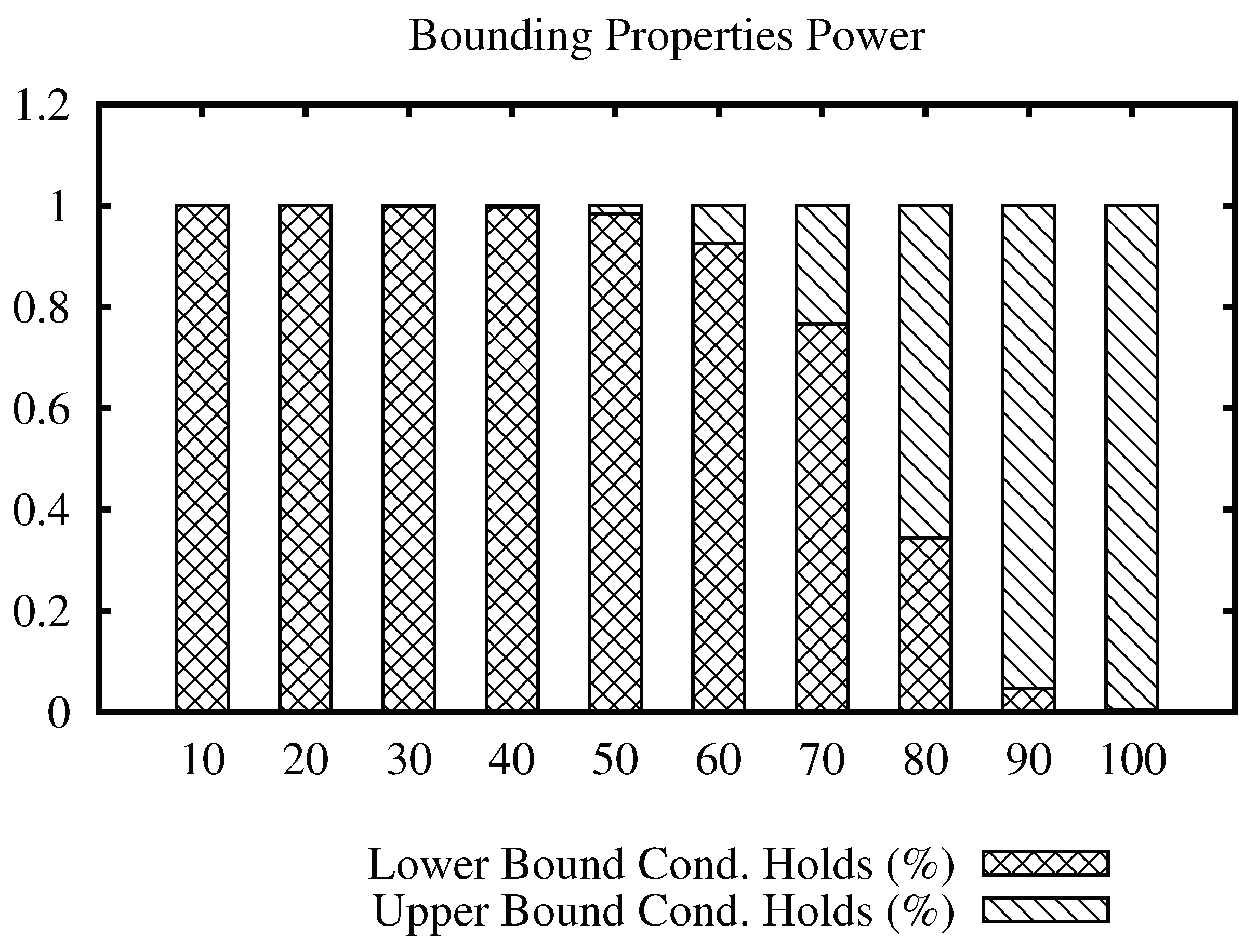
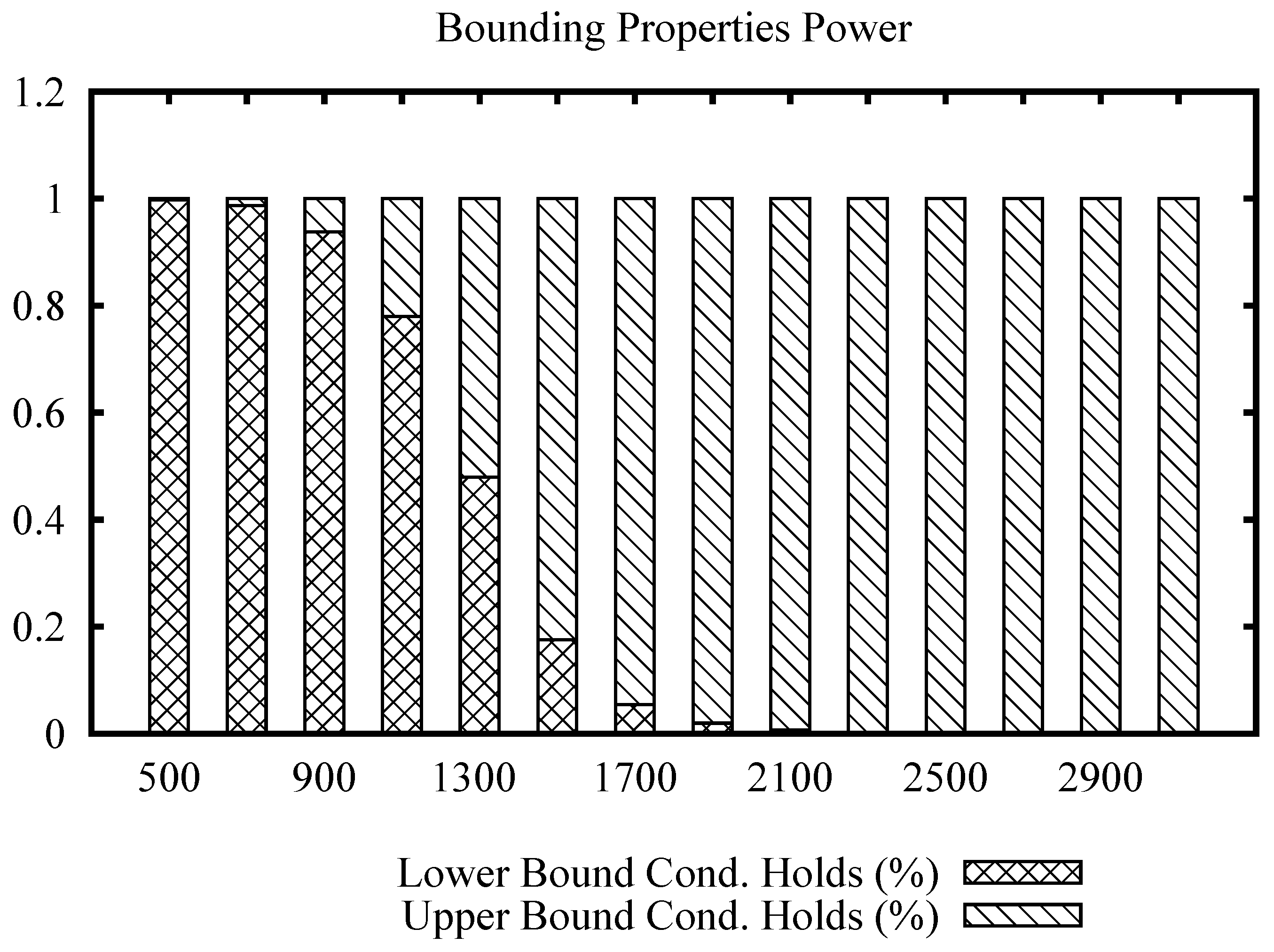
Figure 3 shows a bars plot indicating the percentage of filtering that each condition holds for the Corel data set, for a range of values of the join radius. The full bar indicates 100% of the number of times that a distance evaluation could be avoided. From the plot, we can note that the lower bound condition filters most of the time at low values, while the upper bound condition filters at high values of the radius. Considering that the maximum distance in this data set is 3.28, we can see that the upper bound condition started to filter massively from radius 1.1 and on, compared to the lower bound condition. This indicates that the upper bound condition filtering power remains at high values of the join radius, avoiding unnecessary distance calculations.
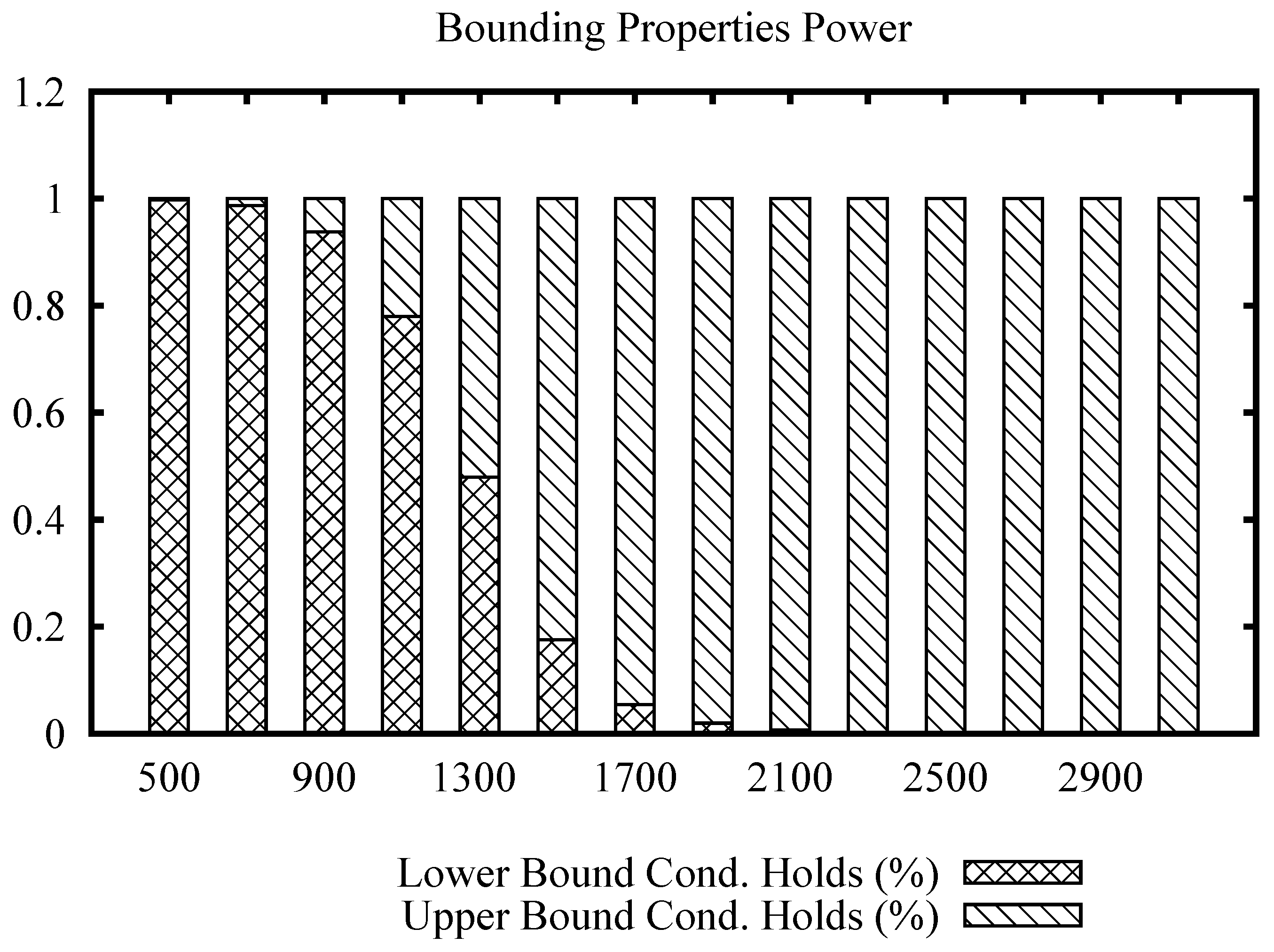
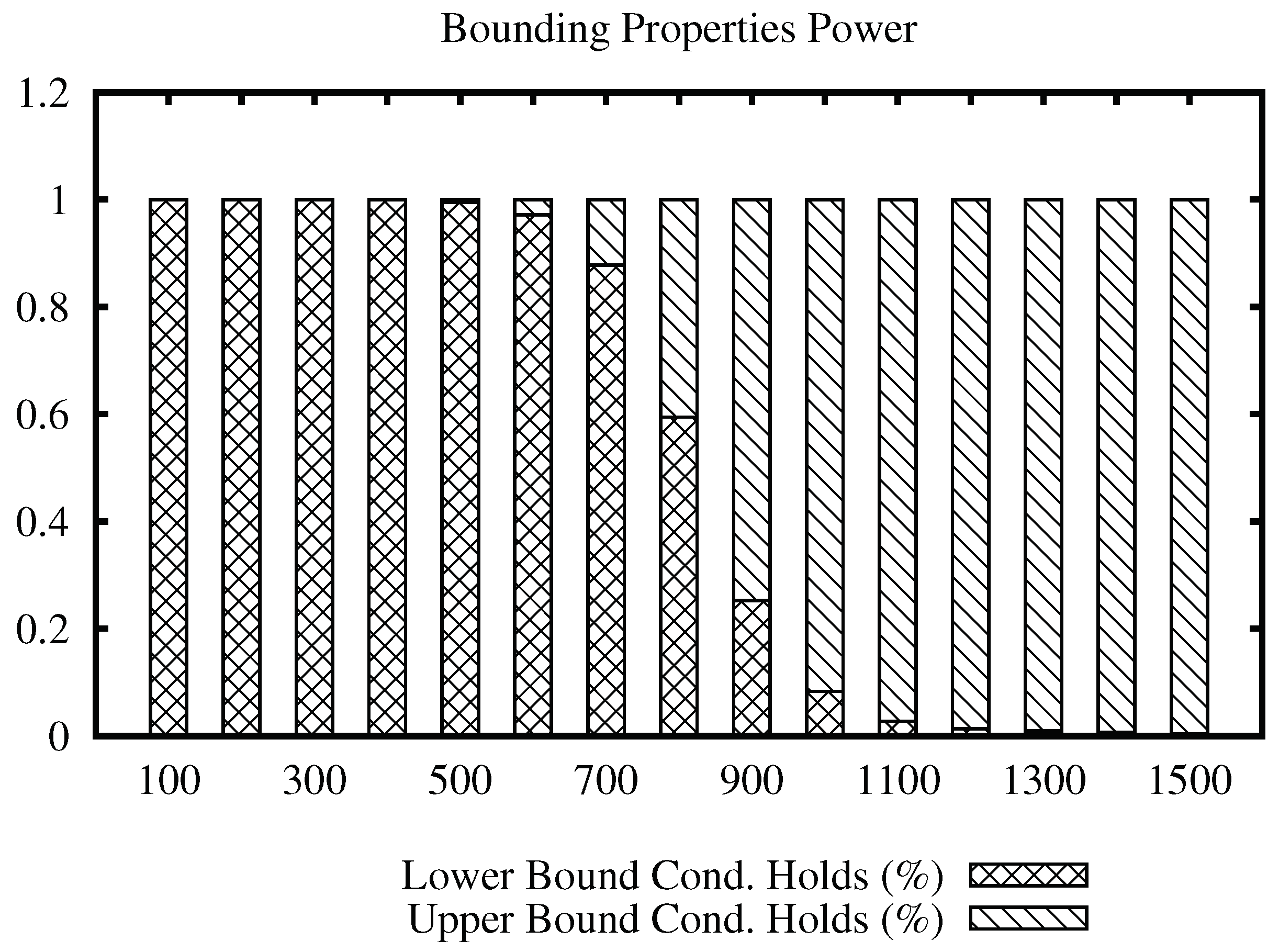
Figure 4 shows the bars plot for the Images data set, for a range of values of the join radius. In this data set, we can note that the upper bound condition achieves more efficiency sooner at radius 1300, becoming the only property to filter after radius 2100, while the maximum distance in the data set is 3670.
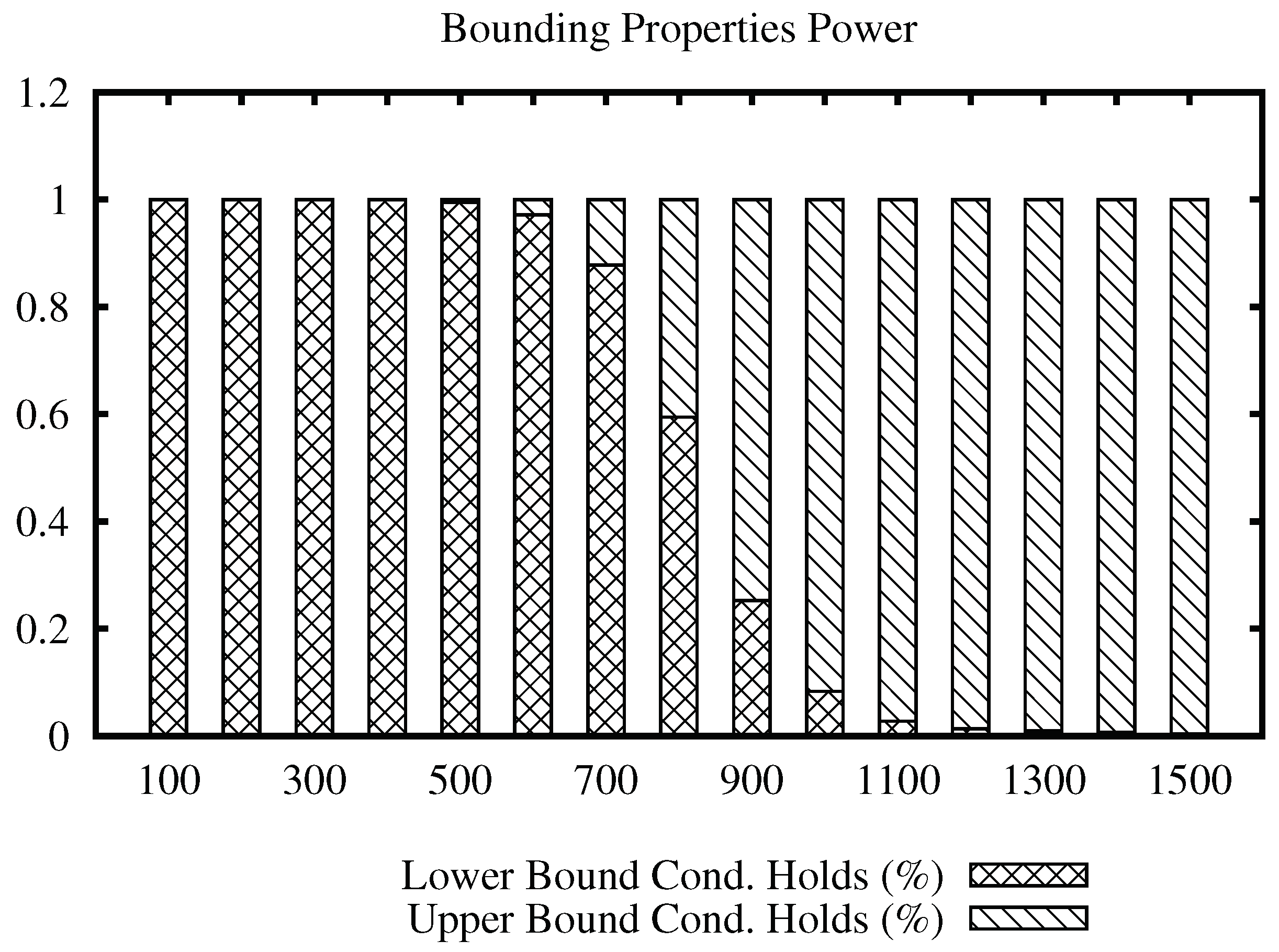
The bars plot for the Points data set is shown in
Figure 5. While the maximum distance is 5.51, we can note that the transition of filtering power from the lower to upper bound condition occurs at radius 3. Beyond that, the upper bound condition maintains filtering elements at higher values of the join radius.
The bars plot for the USCities data set is shown in
Figure 6. From the plot, we can note that the upper bound property is the main active filter from radius value 80 and on.
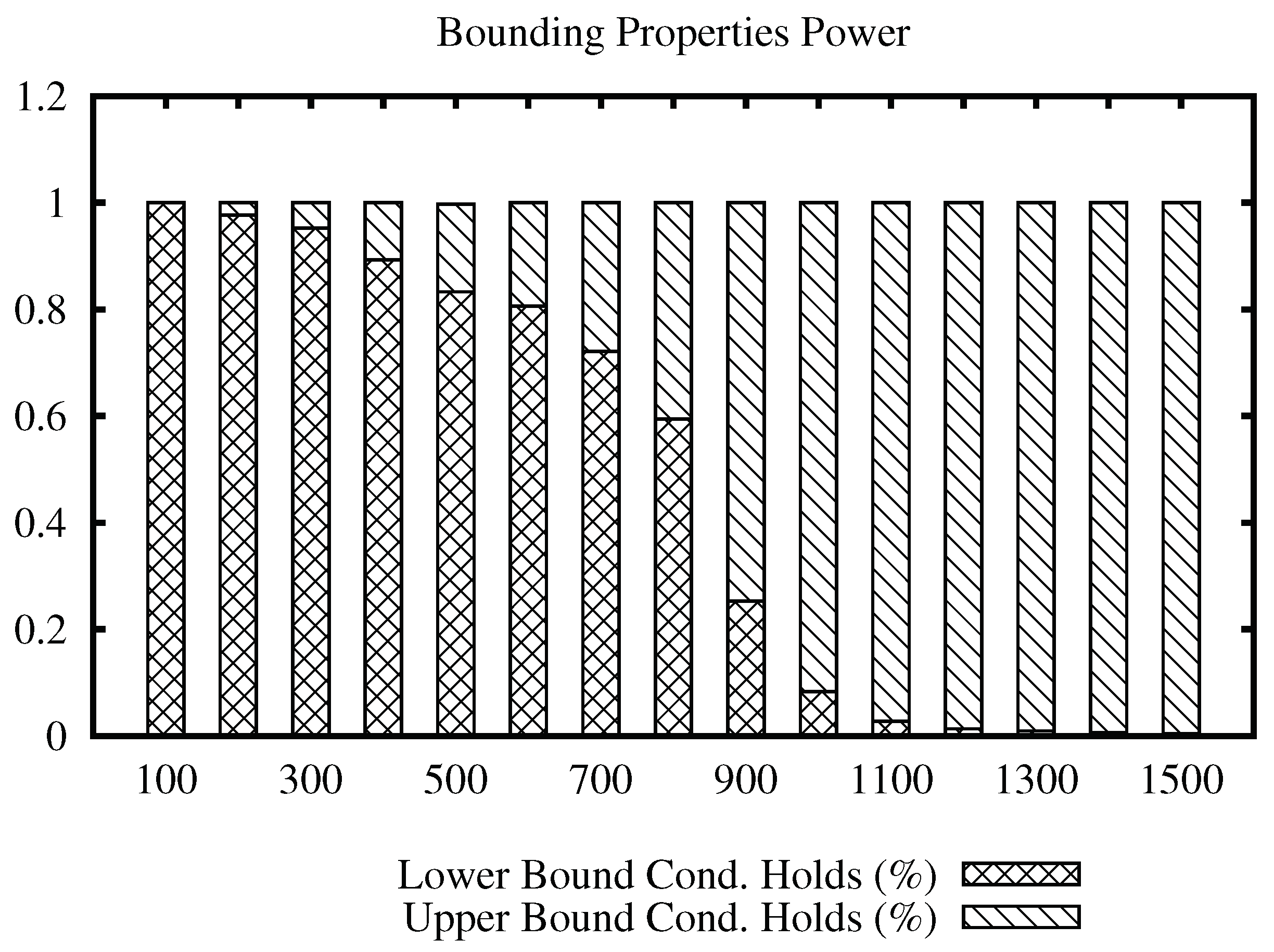
The bars plots for the ImgMedical data set are shown in
Figure 7 and
Figure 8. From the plot, we can see that the lower bound property filters mostly until radius 700 for the first and 400 for the second, and, from that value, the upper bound property filtering power increases.
The previous results measured the efficiency of both properties to filter pairs of elements during a similarity join. The next experiment analyzes how many pairs of elements each property actually filters (prune) and how the similarity join performance can be improved by using our technique.
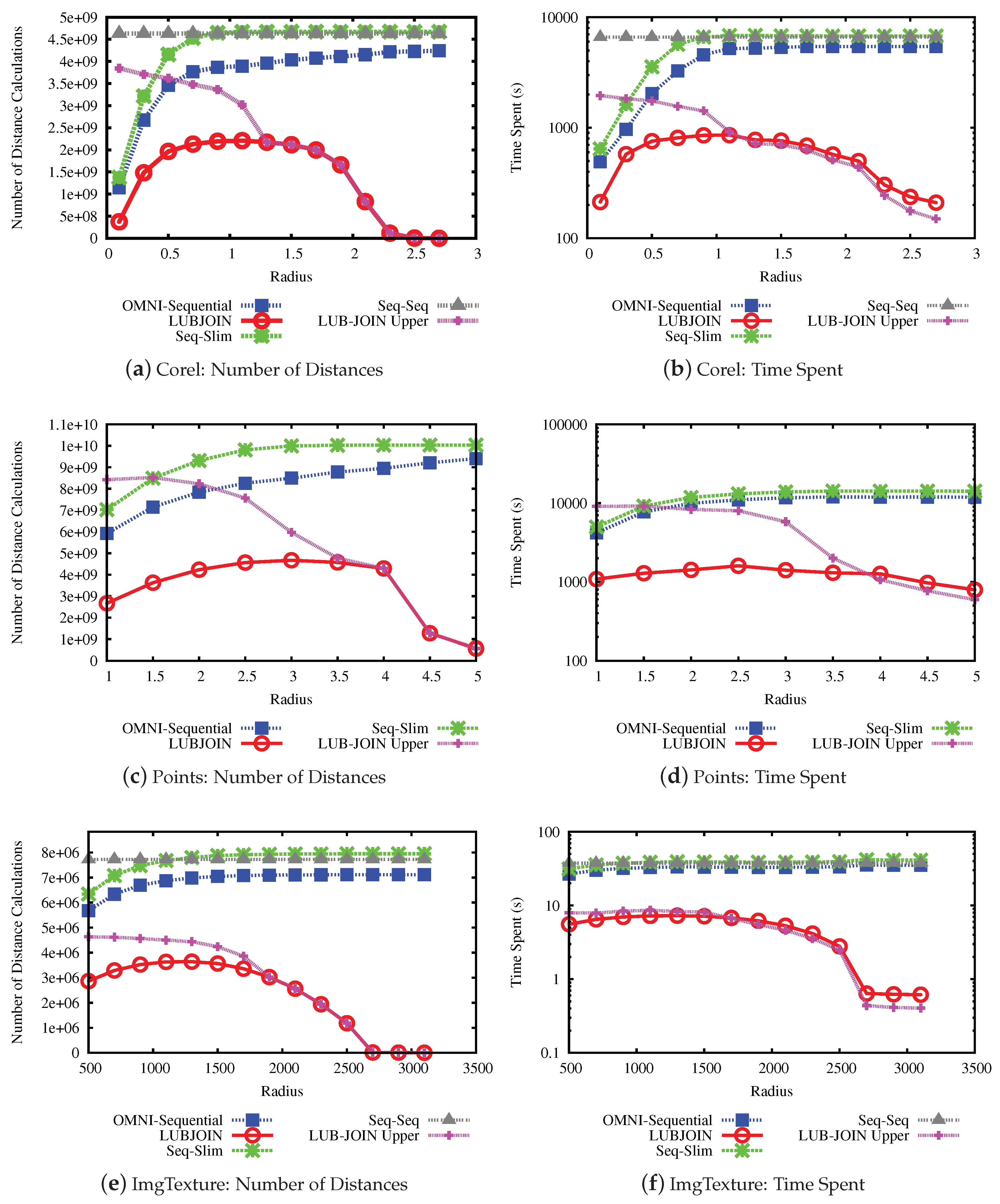
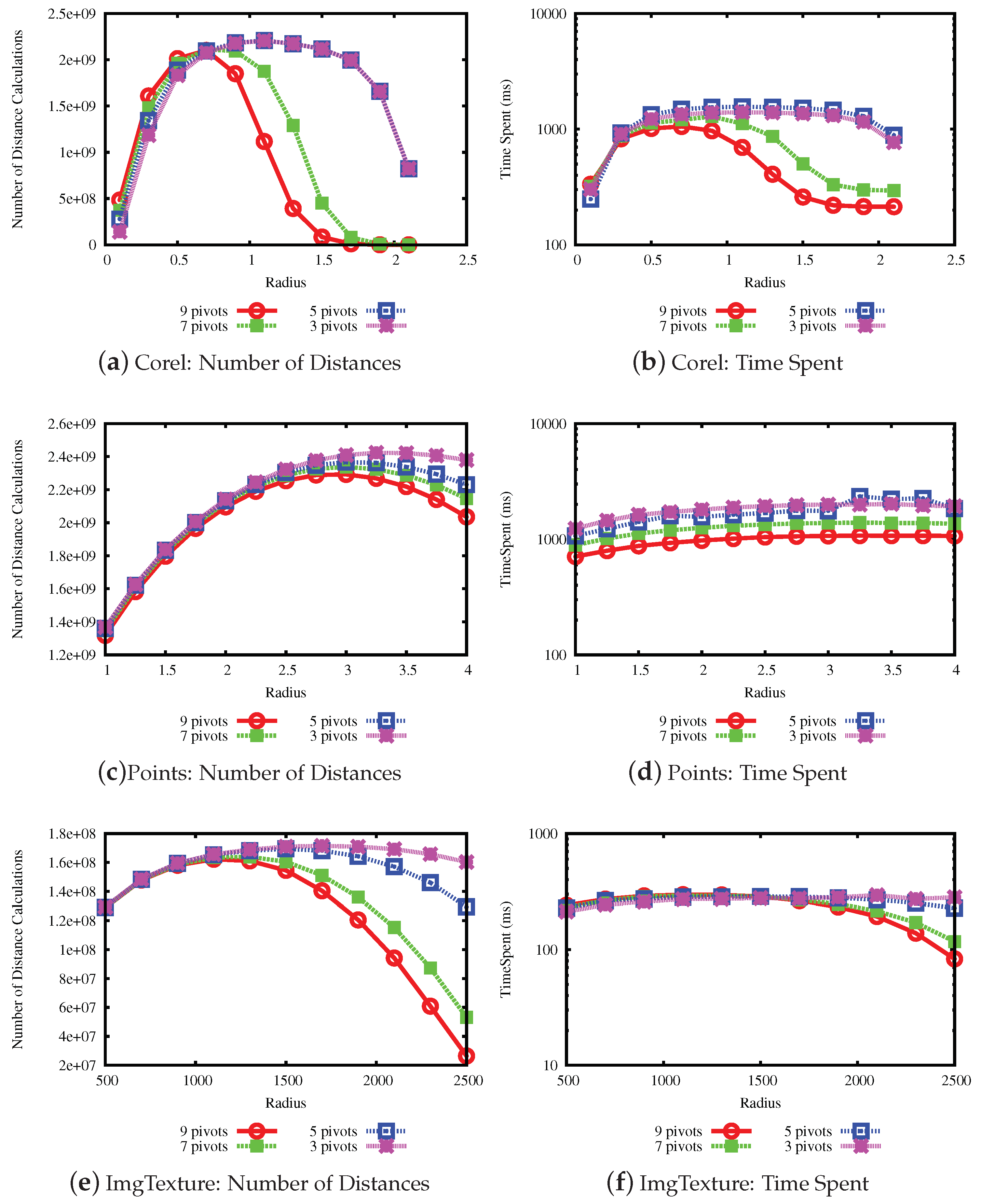
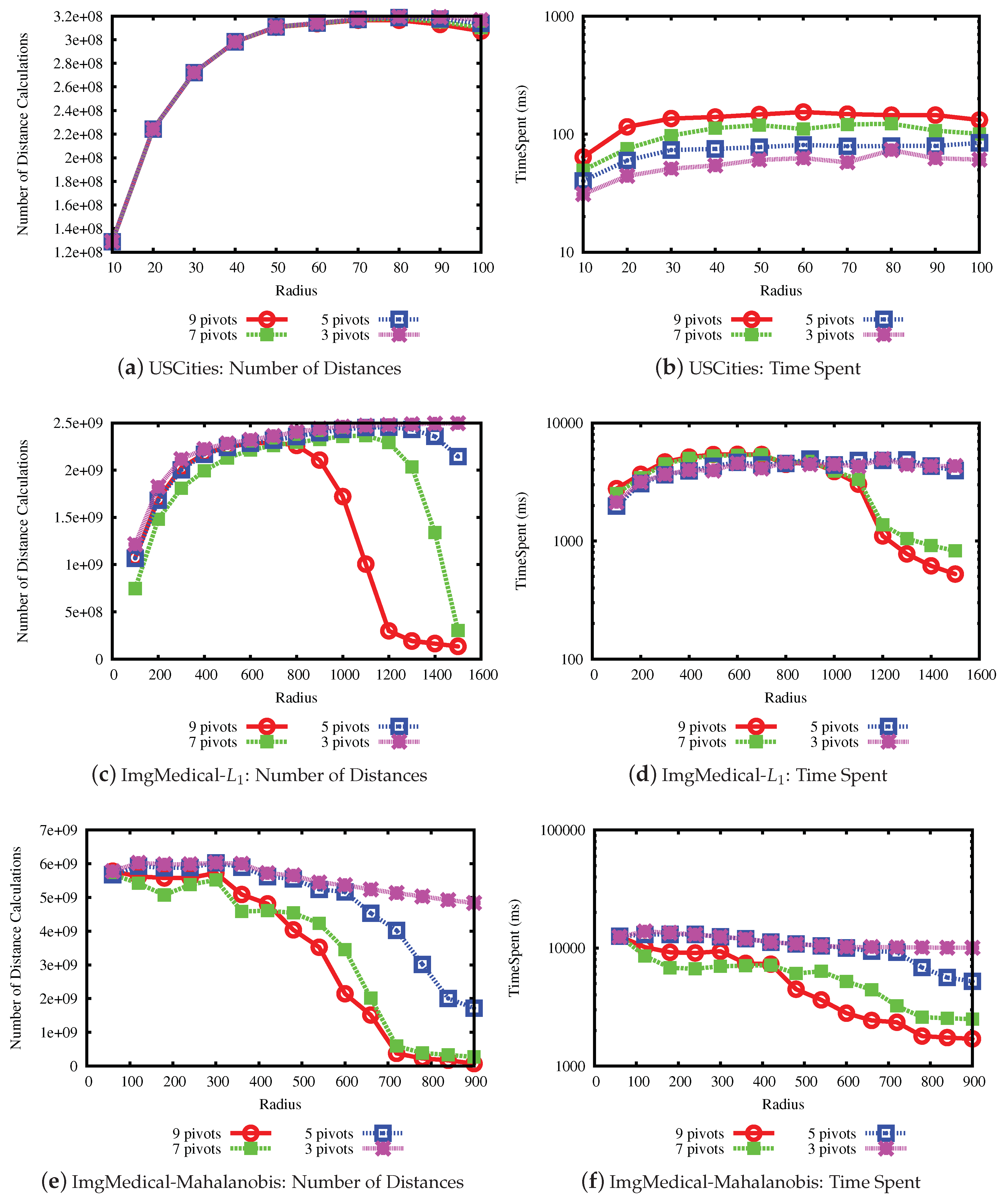
The next experiment measures the number of distance calculations and the time spent to perform similarity joins using the same data sets and values of radius. We evaluated the performance of the LUBJOIN against approaches such as the OMNI-sequential, Slim-tree (seq-Slim) and, for the small databases, we also calculated the statistics for the sequential scan (Seq-Seq). For comparison between properties of LUBJOIN, we also compared with a version where only the upper bound pruning is enabled. The selected range of values for the radius is different for each data set, according with the maximum estimated distance.
The results for the performance experiments on the data sets are shown in
Figure 9 and
Figure 10.
Figure 9a,c,e and
Figure 10a,c,e show the number of distance calculations needed to perform the similarity join, while
Figure 9b,d,f and
Figure 10b,d,f show the time measures.
Considering the results, the first notable result is that the LUBJOIN reduced the number of distance calculations and time spent as radius value increases. This is because of the upper bound condition that filters more distances as the radius increases, as seen in the previous experiments. Another notable result is that using indexes like hierarchical balls of Slim-tree are ineffective when dealing with high radius values, due to the tree nodes overlap of the same level, and some cases causing it to perform more distance calculations than traditional sequential scan.
The results from experiments indicated that the LUBJOIN reduced the time spent when performing joins. However, in cases where the dataset dimension is low, as in the USCities dataset (
Figure 10b), the computational cost of the distance is cheap and the quadratic traversing type of nested loops produced a major consumption of process time. Therefore, our technique can also benefit similarity operators that use non-cheap distance functions, which is the case of the Mahalanobis function on the ImgMedical dataset.
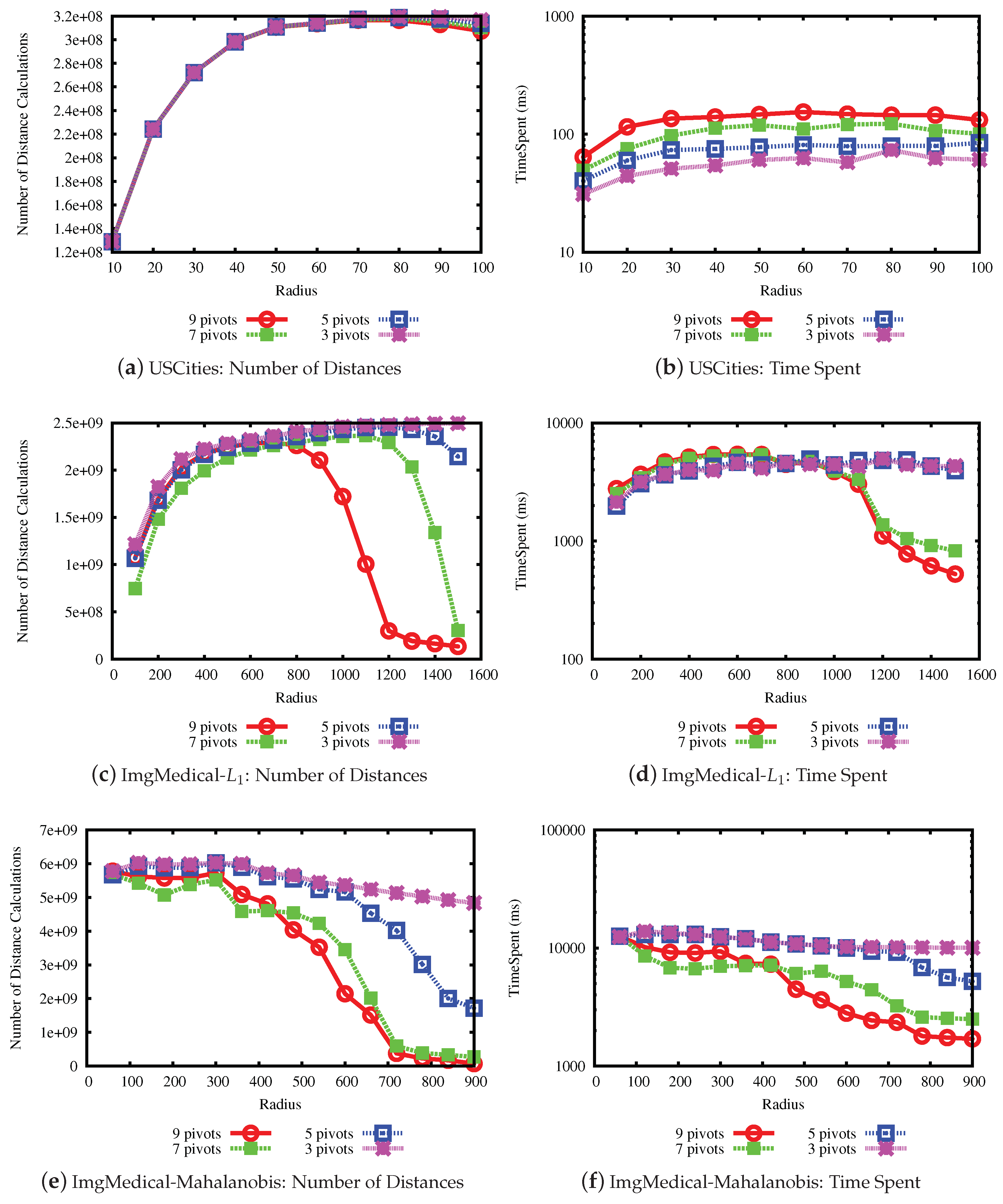
The last experiment measures the performance when varying the number of pivots in the LUBJOIN algorithm. A higher number of pivots may improve the performance when pruning with the upper bound property but not with the lower bound property, where the latter is related to the intrinsic dimension of the data set. The results are shown in
Figure 11 and
Figure 12. From the results, it can be seen that, in general, with a higher the number of pivots, the performance of pruning at high values of radius for the queries improve, but has little effect at lower values of radius.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}