Precipitation Data Assimilation System Based on a Neural Network and Case-Based Reasoning System

Abstract
:1. Introduction
2. Preliminaries
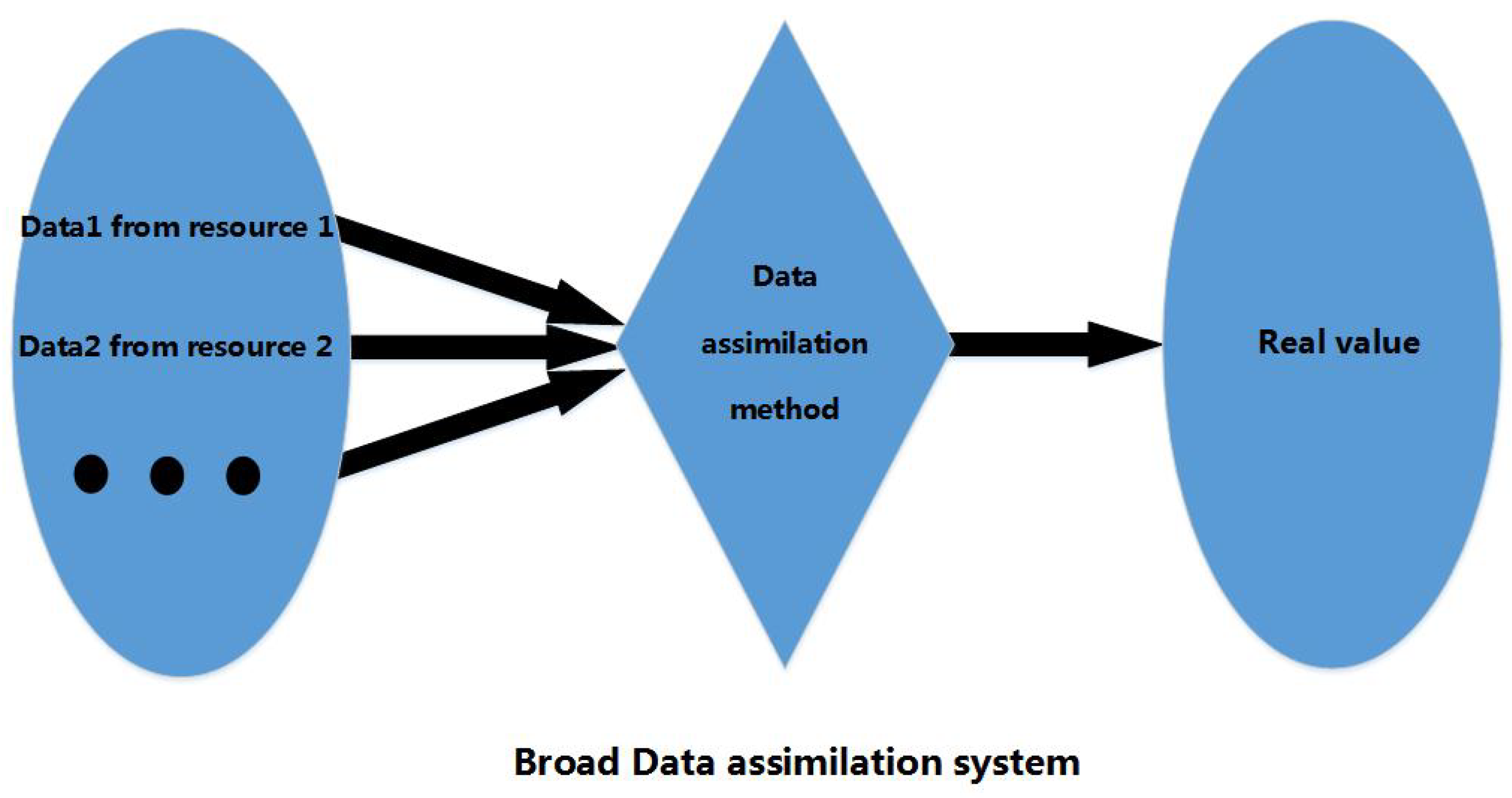
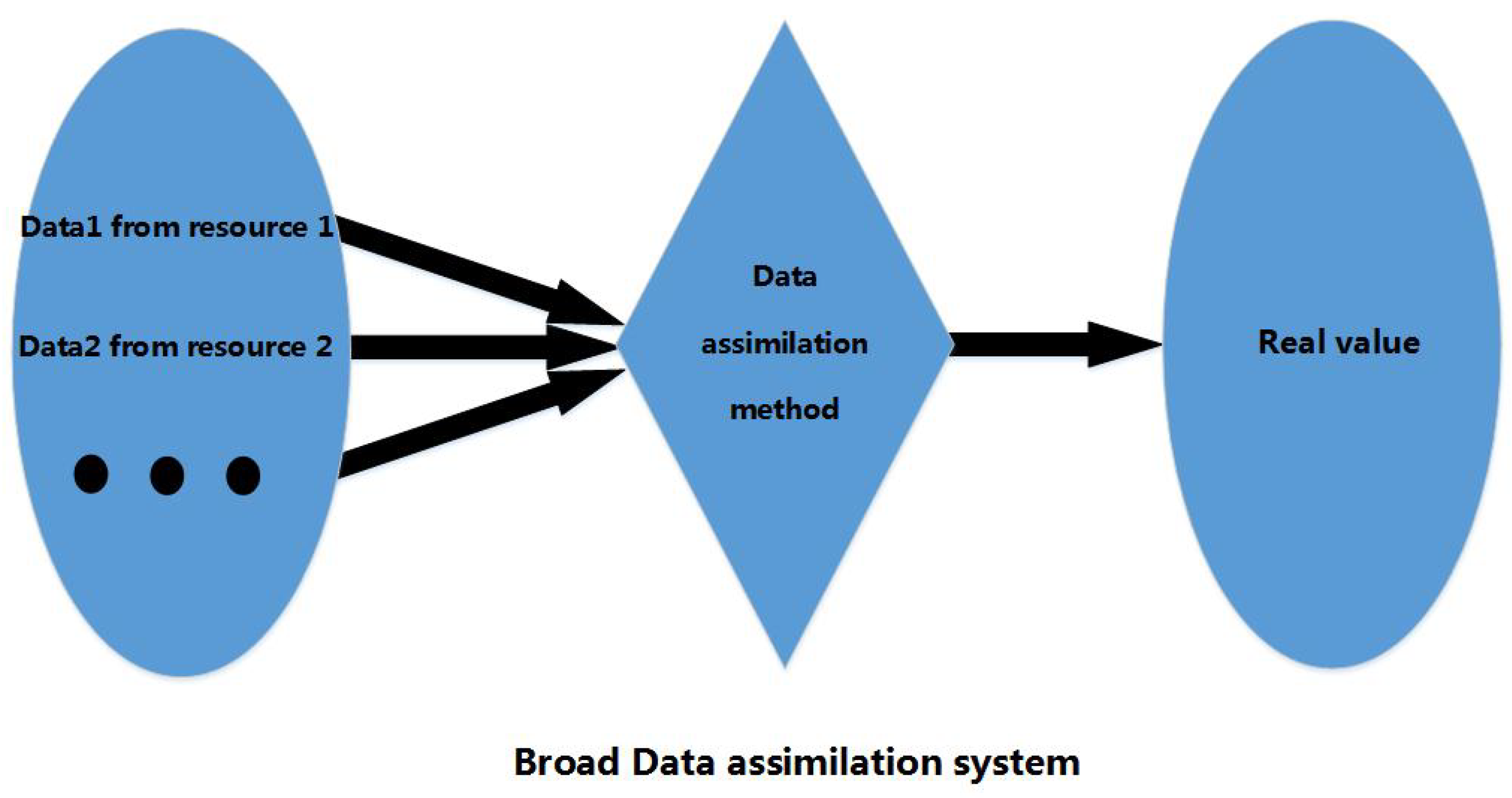
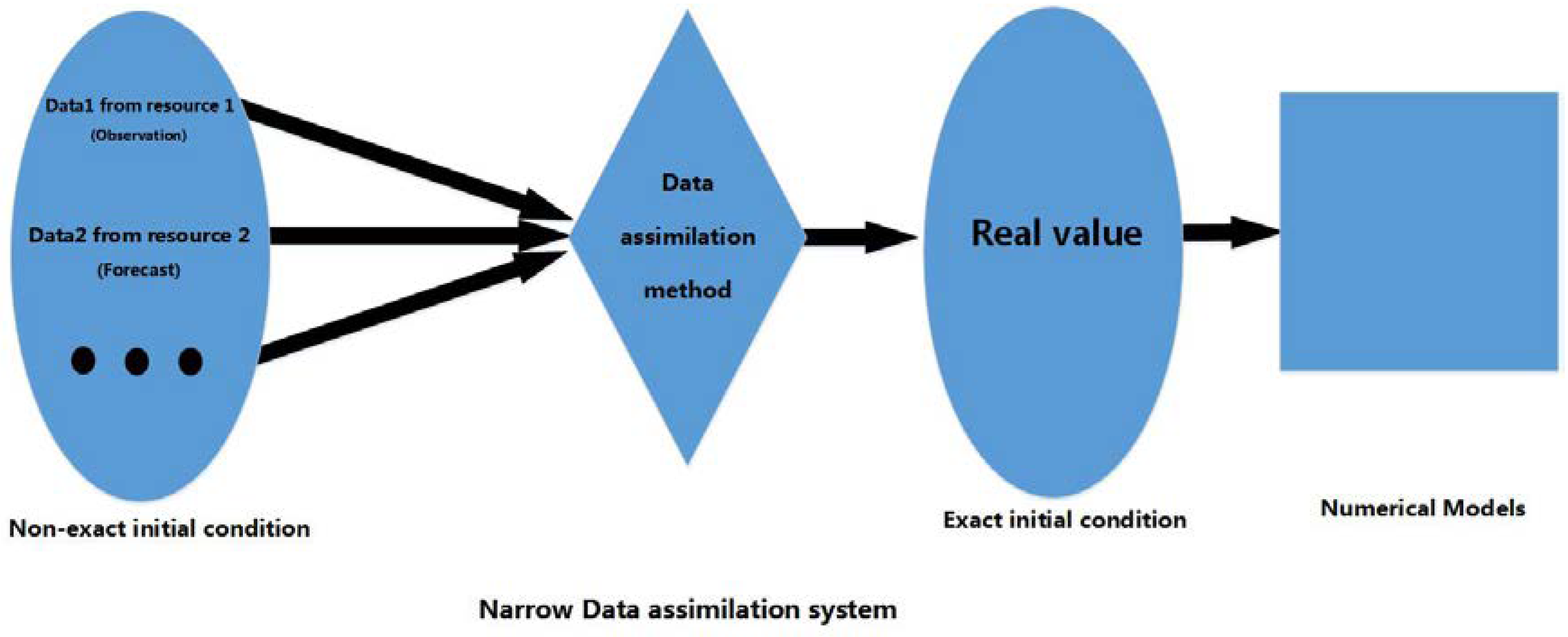
2.1. Data Assimilation
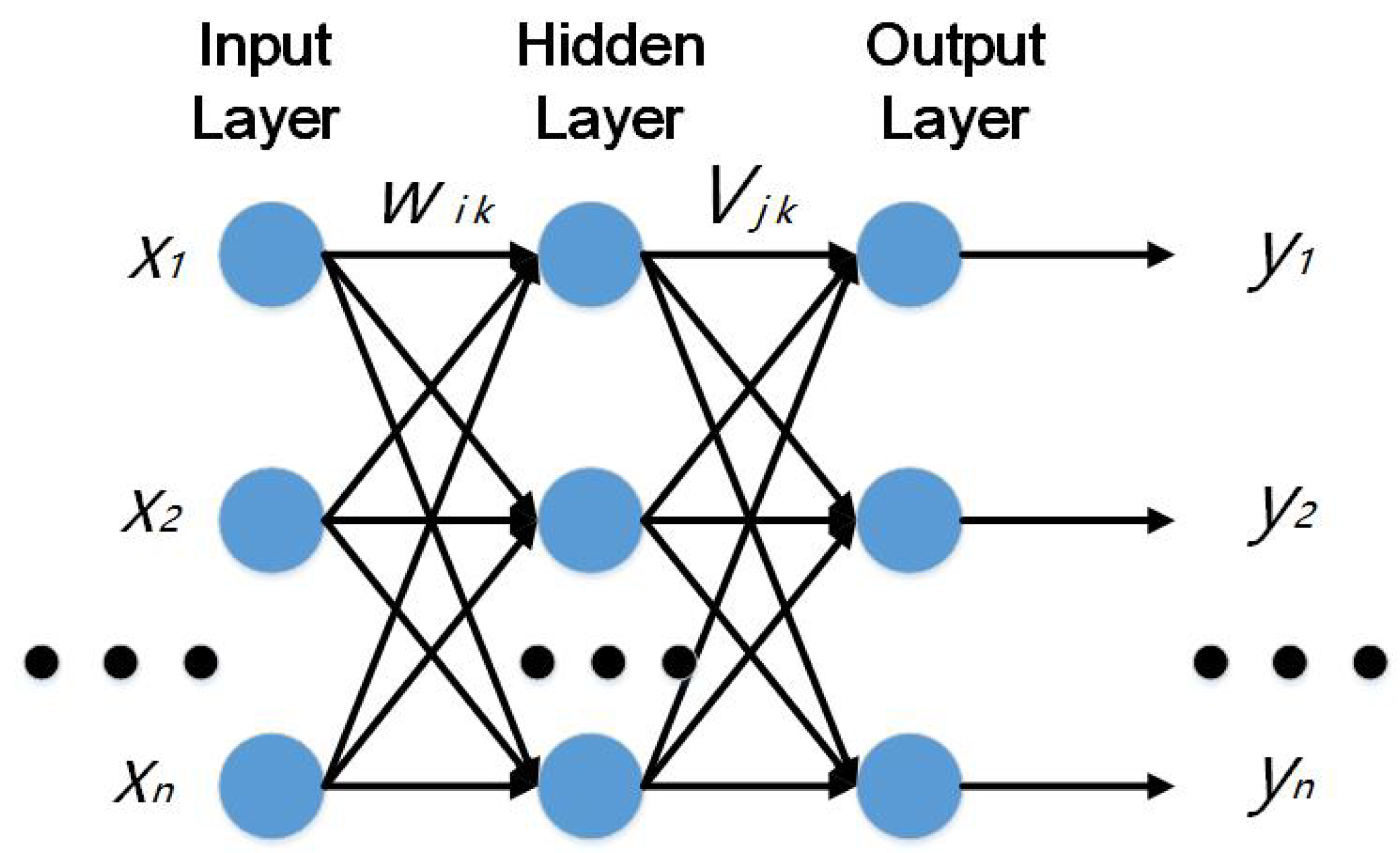
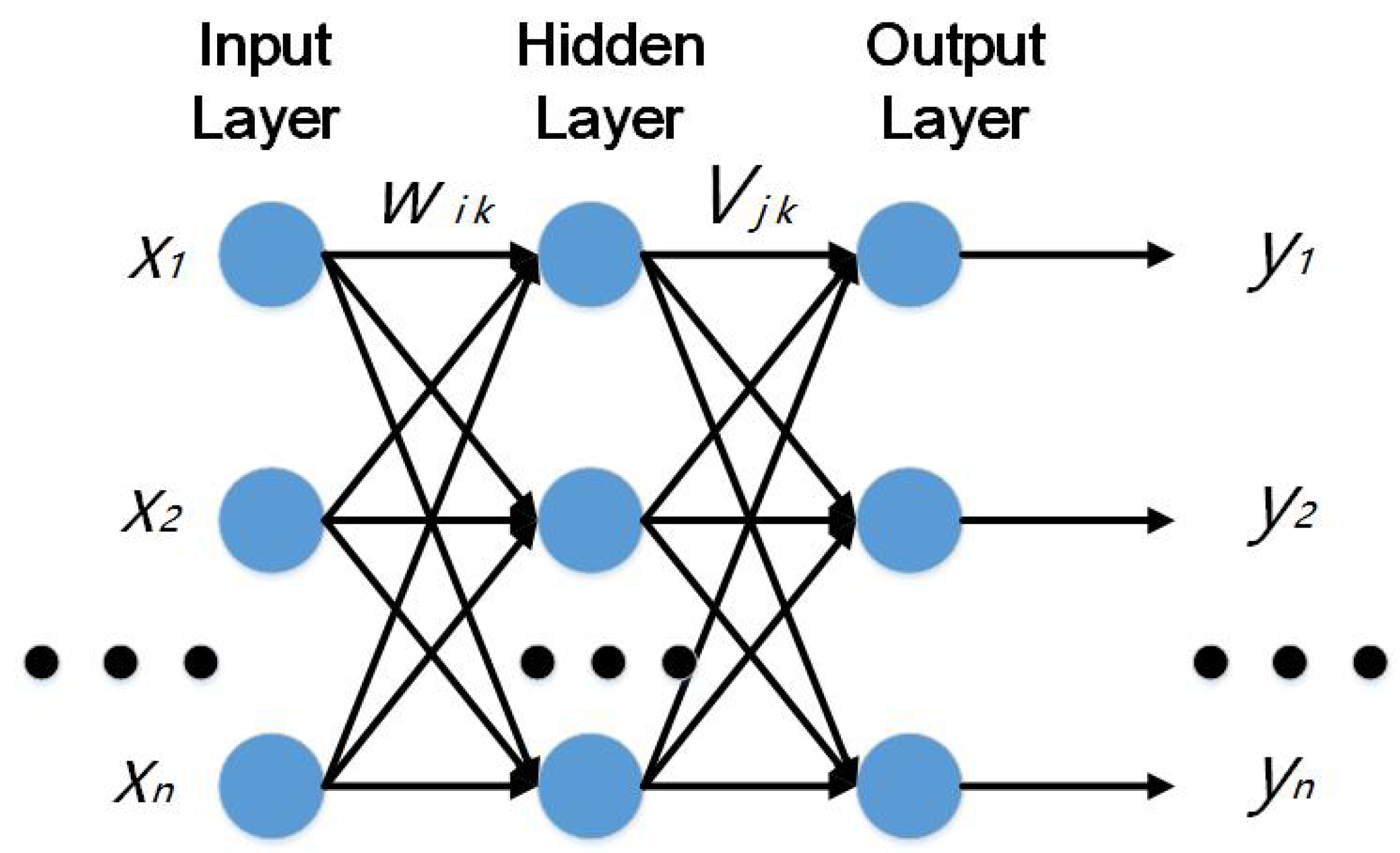
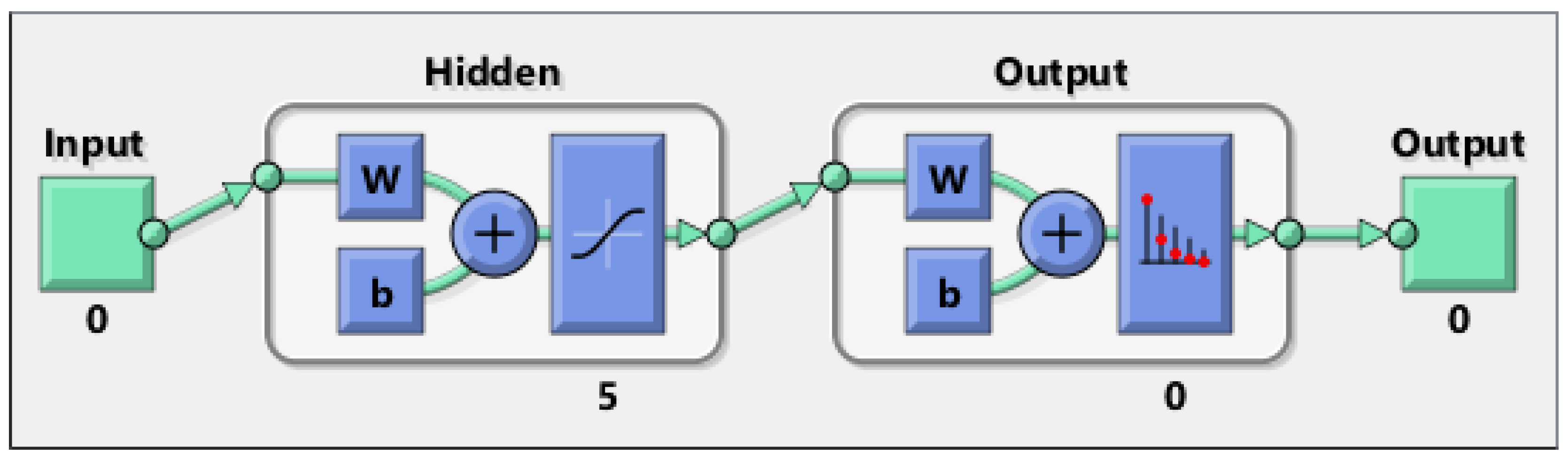
2.2. BP (Back Propagation) Neural Network
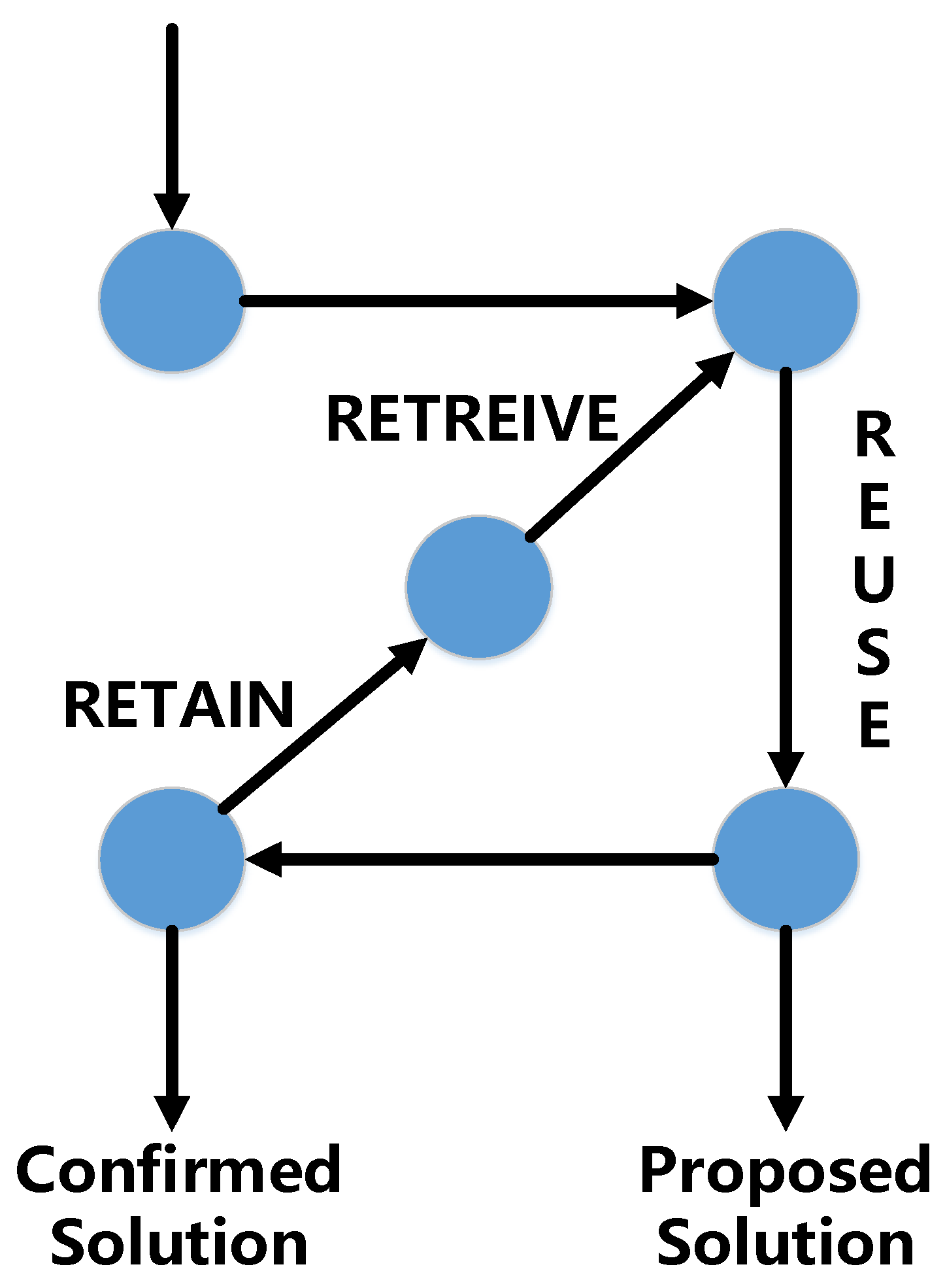
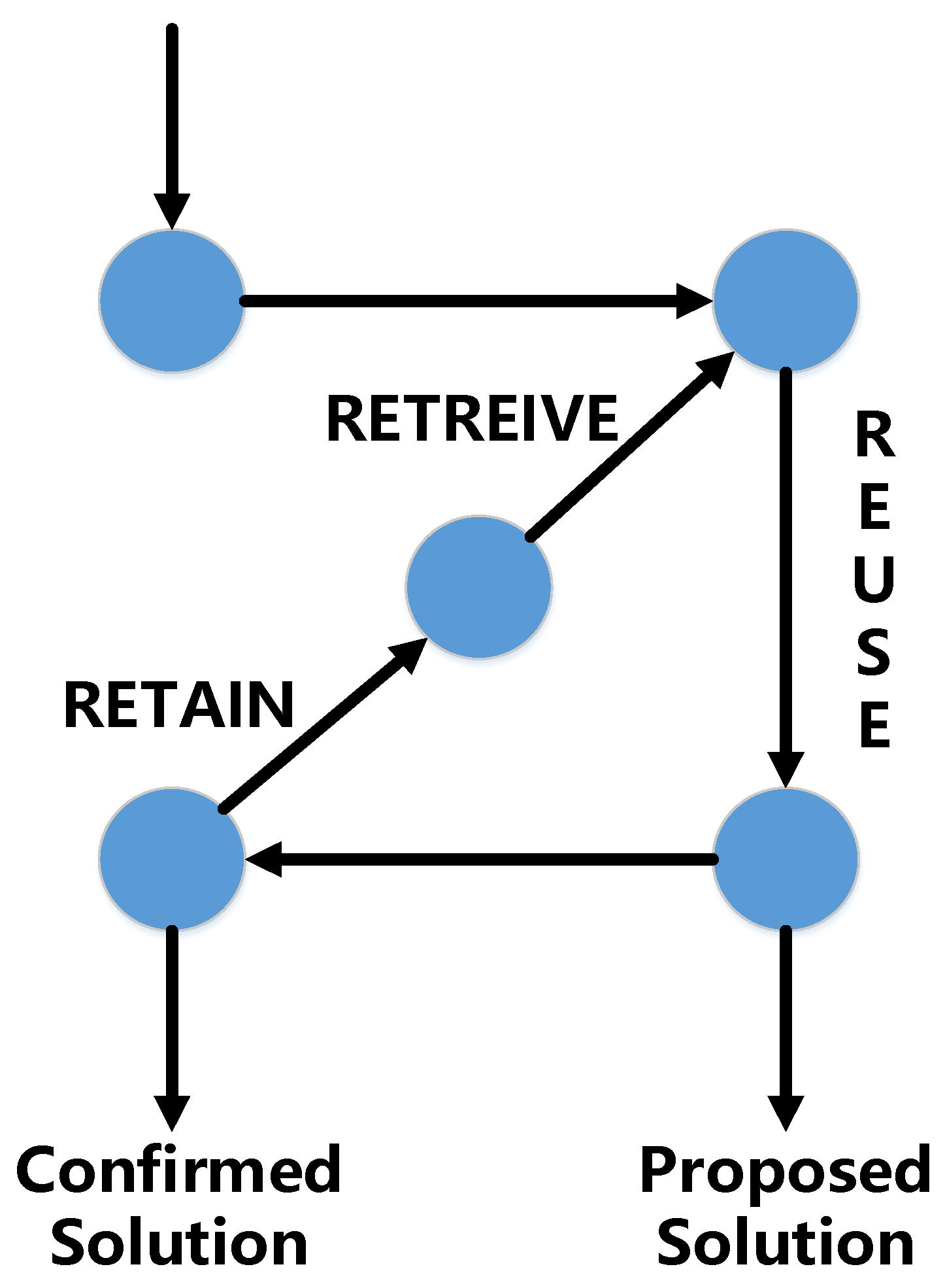
2.3. Case-Based Reasoning System
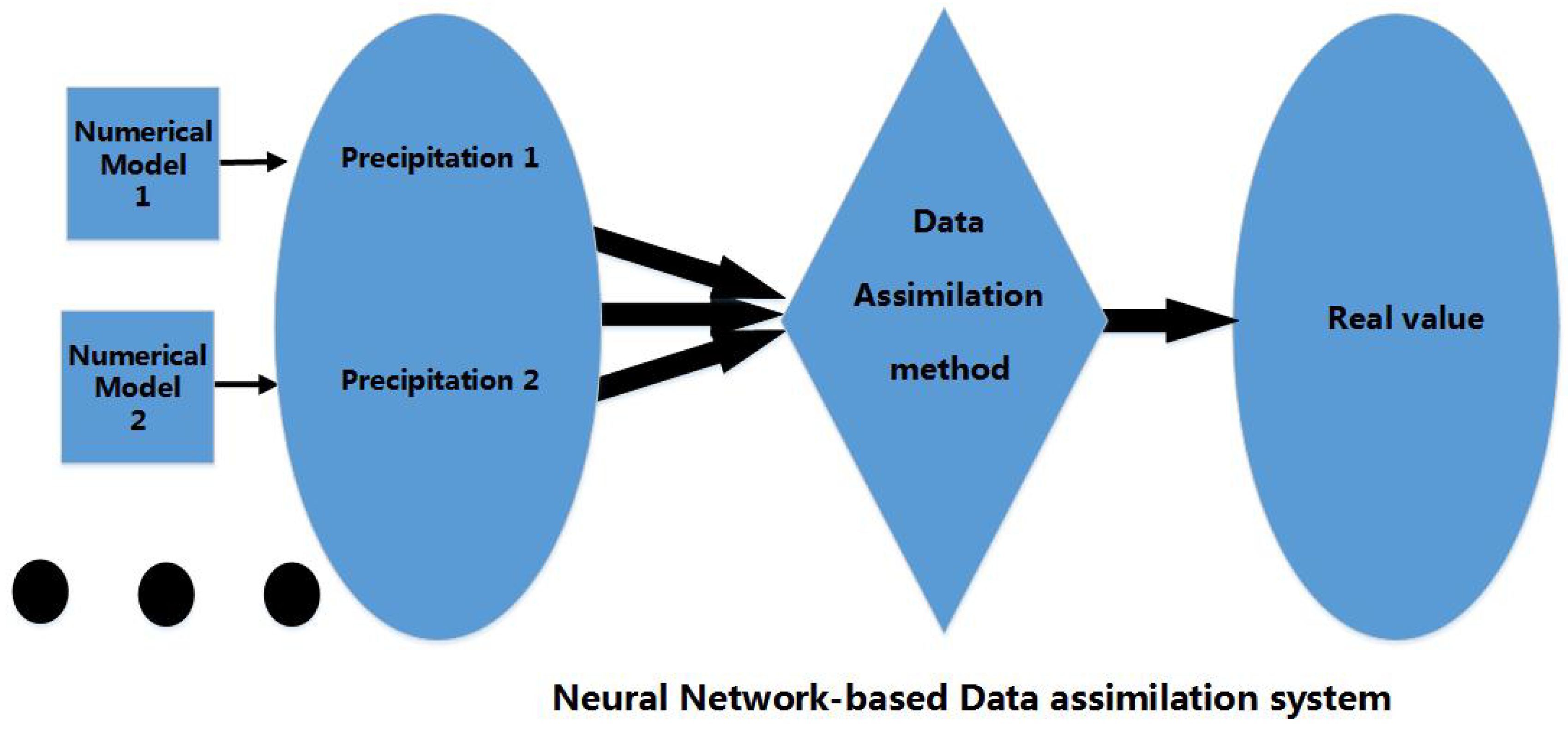
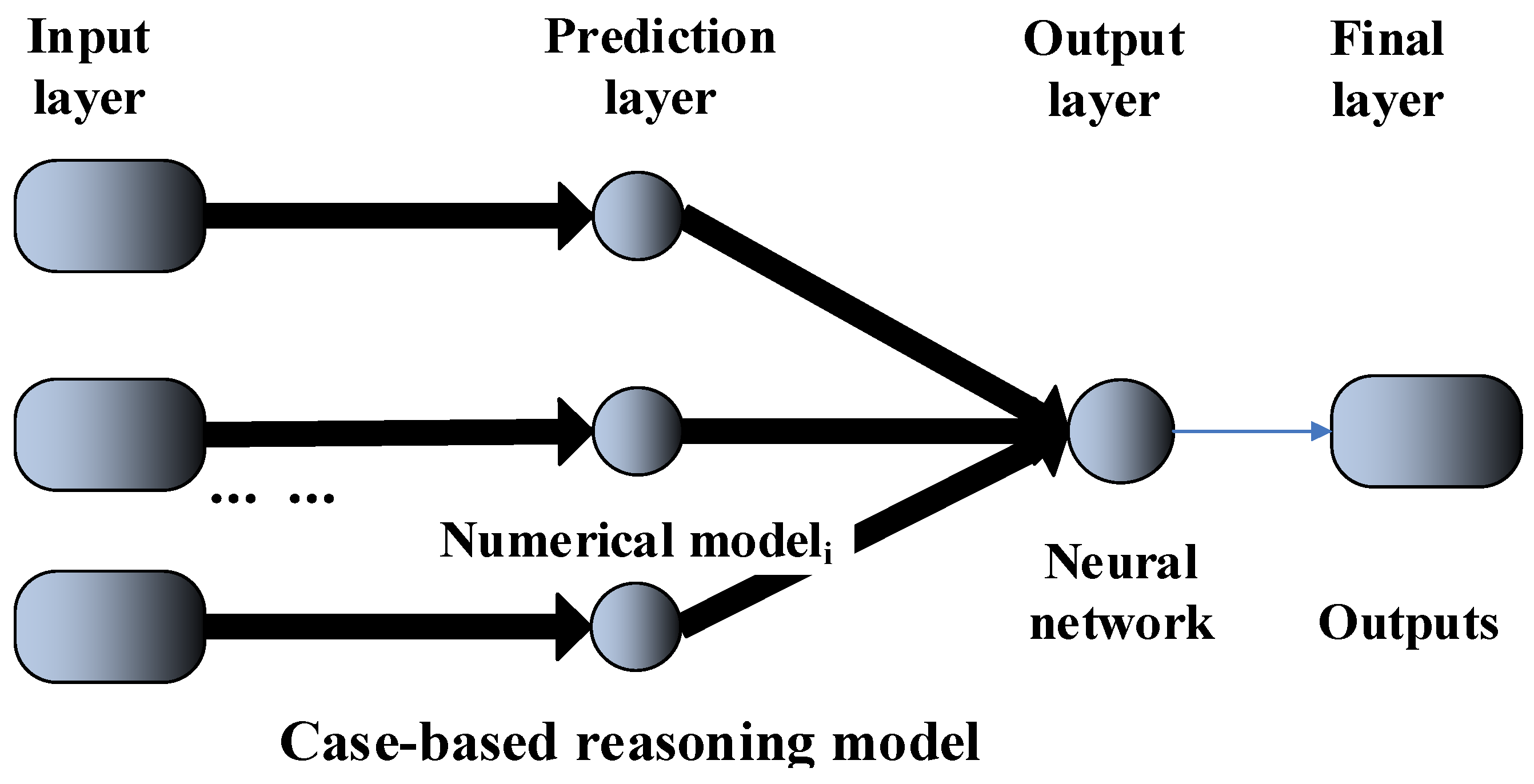
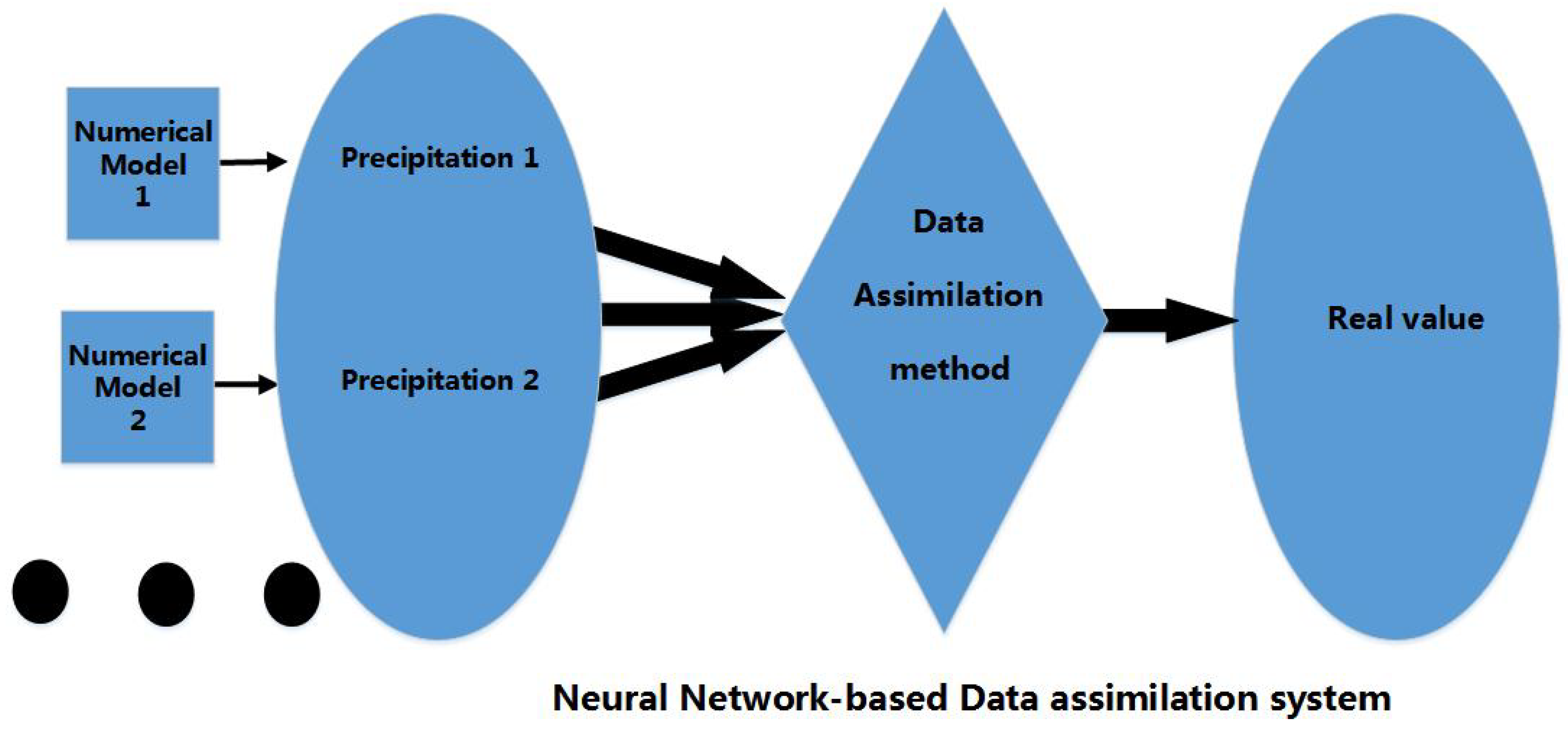
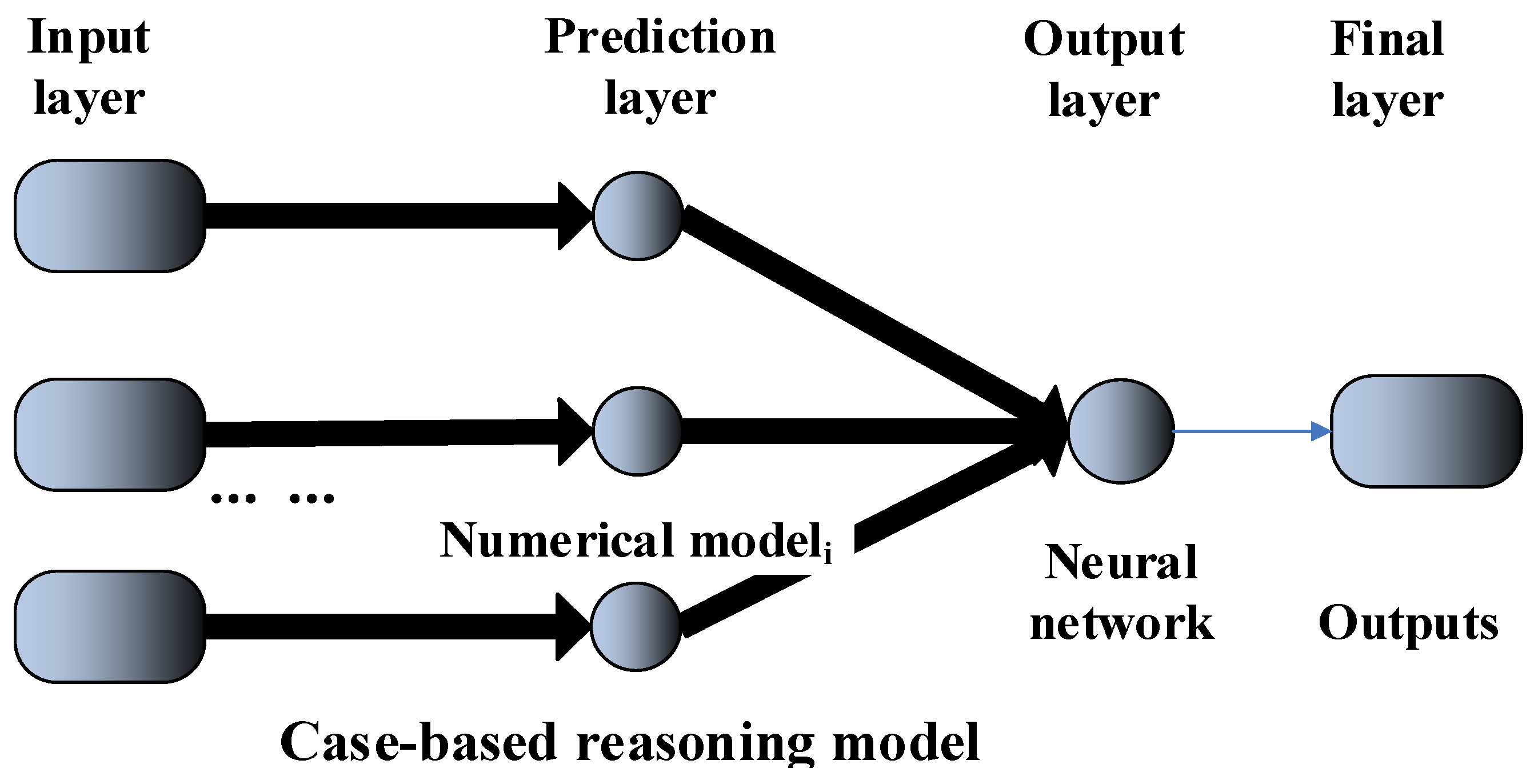
3. Description of the Proposed System
- Machine learning is a data learning algorithm that does not rely on rule design. It can get much information which cannot be described in detail, and the statistical model expresses the relationship between variables in mathematical form.
- The statistical model is based on a series of assumptions but the “nature” does not give any assumptions before it happens. The less the hypothesis of a prediction model, the higher the prediction efficiency can be achieved. Because machine learning does not rely on assumptions about real data, the prediction effect is very good. Statistical models are mathematical reinforcement, dependent on parameter estimation, so need the model builder to know or understand the relationship between variables in advance. For example, the statistical model obtains a simple boundary line in the classification problem, but for complex problems, a statistical model seems to have no way to compare with machine learning algorithms since the machine learning method obtains the information that any boundary cannot be described in detail.
- Machine learning can learn hundreds of or millions of observational samples, prediction and learning synchronization. Some algorithms, such as random forest and gradient boosting, are very fast when dealing with big data. Machine learning deals with data more broadly and deeply. However, statistical models are generally applied to small amounts of data and narrow data attributes. Most commonly this leads to the numerical modeling system alternately performing a numerical forecast and a data analysis. This is known as analysis/forecast cycling. The forecast from the earlier analysis to the current one is often called the background.
4. Experiments
4.1. Data Formatting
4.2. Ranking Key Features
5. Discussion
6. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Carton, J.A.; Giese, B.S. A Reanalysis of Ocean Climate Using Simple Ocean Data Assimilation (SODA). Mon. Weather Rev. 2008, 136, 2999–3017. [Google Scholar] [CrossRef]
- Williams, M.; Schwarz, P.A.; Law, B.E. An improved analysis of forest carbon dynamics using data assimilation. Glob. Chang. Biol. 2010, 11, 89–105. [Google Scholar]
- Fossum, K.; Mannseth, T. Parameter sampling capabilities of sequential and simultaneous data assimilation: II. Statistical analysis of numerical results. Inverse Probl. 2014, 30, 114003. [Google Scholar] [CrossRef]
- Dee, D.P.; Uppala, S.M.; Simmons, A.J. The ERA-Interim reanalysis: Configuration and performance of the data assimilation system. Q. J. R. Meteorol. Soc. 2011, 137, 553–597. [Google Scholar] [CrossRef]
- Makarynskyy, O.; Makarynska, D.; Rusu, E. Filling gaps in wave records with artificial neural networks. In Maritime Transportation and Exploitation of Ocean and Coastal Resources; Taylor & Francis Group: London, UK, 2005; Volume 2, pp. 1085–1091. [Google Scholar]
- Butunoiu, D.; Rusu, E. Wave modeling with data assimilation to support the navigation in the Black Sea close to the Romanian Ports. In Proceedings of the Second International Conference on Traffic and Transport Engineering (ICTTE), Belgrade, Serbia, 27–28 November 2014. [Google Scholar]
- Butunoiu, D.; Rusu, E. A data assimilation scheme to improve the Wave Predictions in the Black Sea. In Proceedings of the OCEANS 2015, Genoa, Italy, 18–21 May 2015; pp. 1–6. [Google Scholar]
- Rusu, E.; Raileanu, A. A multi-parameter data-assimilation approach for wave prediction in coastal areas. J. Oper. Oceanogr. 2016, 9, 13–25. [Google Scholar] [CrossRef]
- Leith, C.E. Numerical weather prediction. Rev. Geophys. 1975, 13, 681–684. [Google Scholar] [CrossRef]
- Buizza, R.; Tribbia, J.; Molteni, F. Computation of optimal unstable structures for a numerical weather prediction model. Tellus 2010, 45, 388–407. [Google Scholar]
- Rusu, L.; Soares, C.G. Impact of assimilating altimeter data on wave predictions in the western Iberian coast. Ocean Model. 2015, 96, 126–135. [Google Scholar] [CrossRef]
- Lorenz, E.N. Energy and Numerical Weather Prediction. Tellus 2010, 12, 364–373. [Google Scholar]
- Rodwell, M.J.; Palmer, T.N. Using numerical weather prediction to assess climate models. Q. J. R. Meteorol. Soc. 2010, 133, 129–146. [Google Scholar] [CrossRef]
- Kug, J.S.; Lee, J.Y.; Kang, I.S. Systematic Error Correction of Dynamical Seasonal Prediction of Sea Surface Temperature Using a Stepwise Pattern Project Method. Mon. Weather Rev. 2010, 136, 3501–3512. [Google Scholar] [CrossRef]
- Ghil, M.; Malanotte-Rizzoli, P. Data Assimilation in Meteorology and Oceanography. Adv. Geophys. 1991, 33, 141–266. [Google Scholar]
- Tombette, M.; Mallet, V.; Sportisse, B. PM10 data assimilation over Europe with the optimal interpolation method. Atmos. Chem. Phys. 2009, 9, 57–70. [Google Scholar] [CrossRef]
- Lee, E.H.; Jong, C. PM10 data assimilation over south Korea to Asian dust forecasting model with the optimal interpolation method. Asia-Pac. J. Atmos. Sci. 2013, 49, 73–85. [Google Scholar] [CrossRef]
- Piccolo, C.; Cullen, M. Adaptive mesh method in the Met Office variational data assimilation system. Q. J. R. Meteorol. Soc. 2011, 137, 631–640. [Google Scholar] [CrossRef]
- Krysta, M.; Blayo, E.; Cosme, E. A Consistent Hybrid Variational-Smoothing Data Assimilation Method: Application to a Simple Shallow-Water Model of the Turbulent Midlatitude Ocean. Mon. Weather Rev. 2011, 139, 3333–3347. [Google Scholar] [CrossRef]
- Wu, C.C.; Lien, G.Y.; Chen, J.H. Assimilation of Tropical Cyclone Track and Structure Based on the Ensemble Kalman Filter (EnKF). J. Atmos. Sci. 2010, 67, 3806–3822. [Google Scholar] [CrossRef]
- Wu, C.C.; Huang, Y.H.; Lien, G.Y. Concentric Eyewall Formation in Typhoon Sinlaku (2008). Part I: Assimilation of T-PARC Data Based on the Ensemble Kalman Filter (EnKF). Mon. Weather Rev. 2012, 140, 506–527. [Google Scholar] [CrossRef]
- Almeida, S.; Rusu, L.; Guedes Soares, C. Application of the Ensemble Kalman Filter to a high-resolution wave forecasting model for wave height forecast in coastal areas. In Maritime Technology and Engineering; Taylor & Francis Group: London, UK, 2015; pp. 1349–1354. [Google Scholar]
- Torn, R.D. Performance of a Mesoscale Ensemble Kalman Filter (EnKF) during the NOAA. High-Resolution Hurricane Test. Mon. Weather Rev. 2010, 138, 4375–4392. [Google Scholar] [CrossRef]
- Skachko, S.; Errera, Q.; Ménard, R. Comparison of the ensemble Kalman filter and 4D-Var assimilation methods using a stratospheric tracer transport model. Geosci. Model Dev. 2014, 7, 1451–1465. [Google Scholar] [CrossRef]
- Tong, J.; Hu, B.X.; Huang, H. Application of a data assimilation method via an ensemble Kalman filter to reactive urea hydrolysis transport modeling. Stoch. Environ. Res. Risk Assess. 2013, 28, 729–741. [Google Scholar] [CrossRef]
- Härter, F.P.; de Campos Velho, H.F.; Rempel, E.L. Neural networks in auroral data assimilation. J. Atmos. Sol.-Terr. Phys. 2008, 70, 1243–1250. [Google Scholar] [CrossRef]
- Cintra, R.S.; Haroldo, F.C.V. Data Assimilation by Artificial Neural Networks for an Atmospheric General Circulation Model. In Advanced Applications for Artificial Neural Networks; InTech: London, UK, 2018. [Google Scholar]
- Pereira, H.F.; Haroldo, F.C.V. Multilayer perceptron neural network in a data assimilation scenario. Eng. Appl. Comput. Fluid Mech. 2010, 4, 237–245. [Google Scholar] [CrossRef]
- Santhosh, B.S.; Shereef, I.K. An efficient weather forecasting system using artificial neural network. Int. J. Environ. Sci. Dev. 2010, 1, 321–326. [Google Scholar]
- Rosangela, C.; Haroldo, C.V.; Steven, C. Tracking the model: Data assimilation by artificial neural network. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 403–410. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
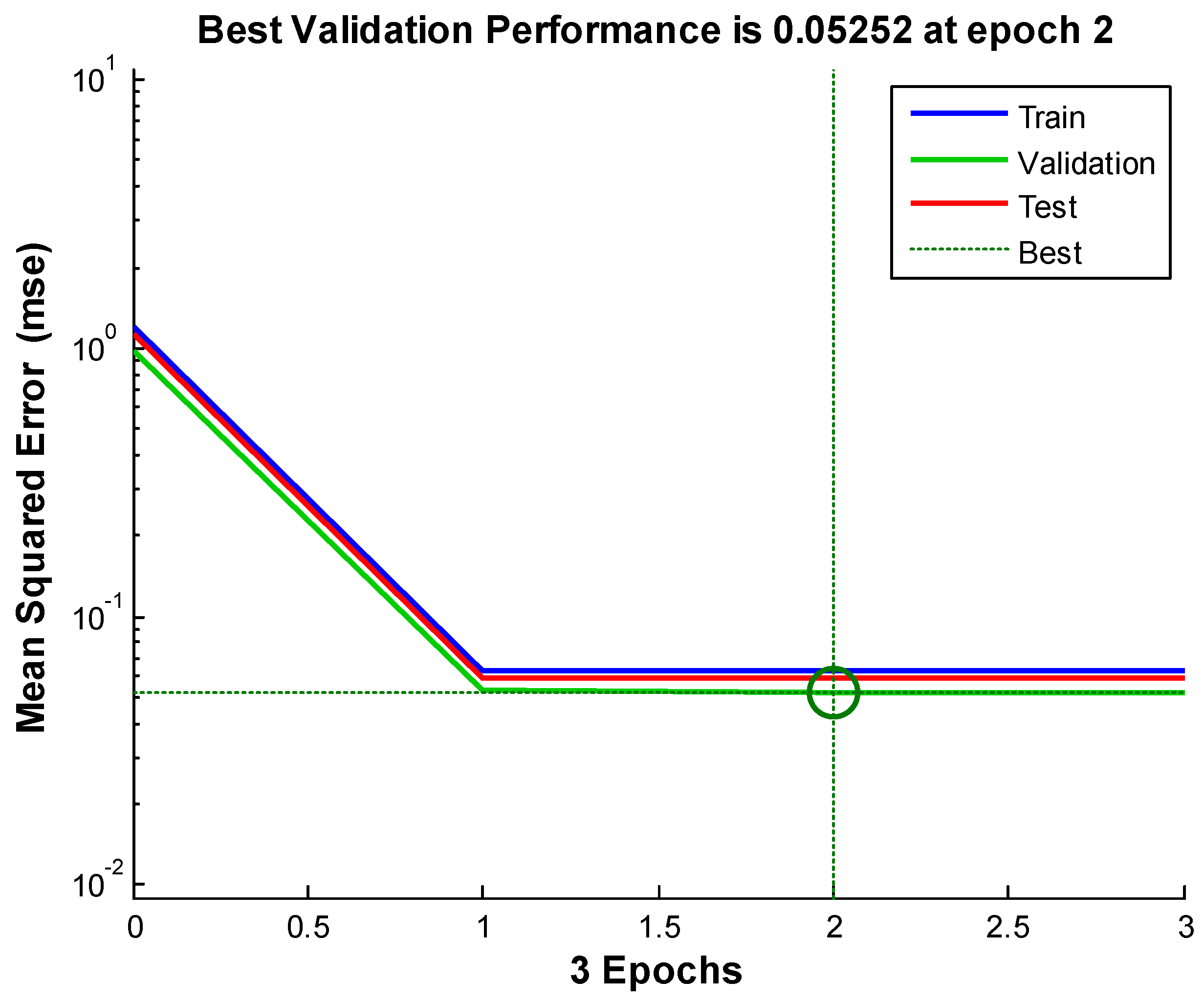{kind=link}
| X1 | X2 | X4 | X5 | Xi | Xn | Y | |
|---|---|---|---|---|---|---|---|
| e1 | e1(X1) | e1(X2) | e1(X4) | e1(X5) | e1(Xi) | e1(Xn) | e1(Y) |
| e2 | e2(X1) | e2(X2) | e2(X4) | e2(X5) | e2(Xi) | e2(Xn) | e2(Y) |
| Station Number | Ensemble Forecasting (MSE) | Case-Based Reasoning System (MSE) | Final Data Assimilation System (MSE) |
|---|---|---|---|
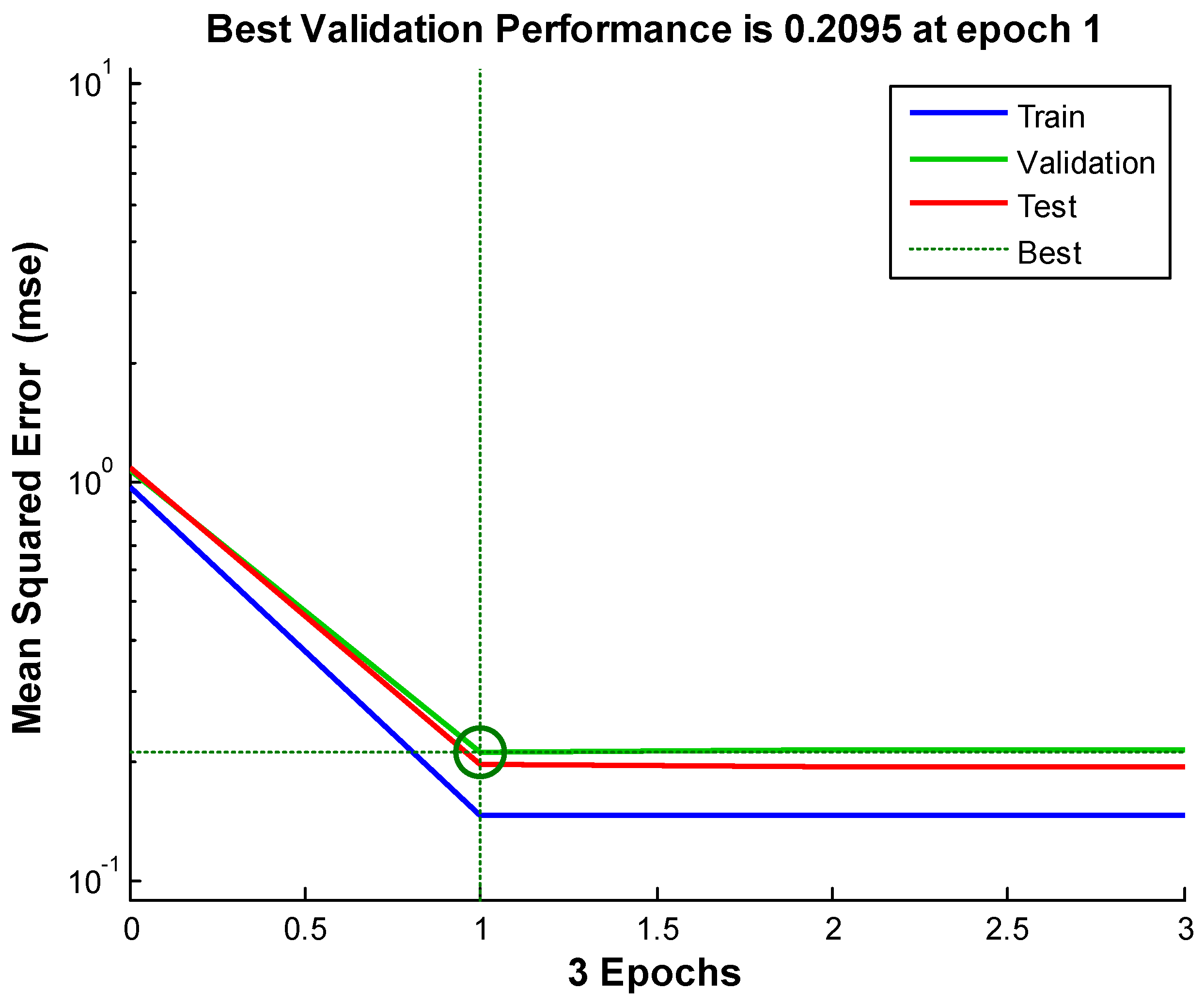
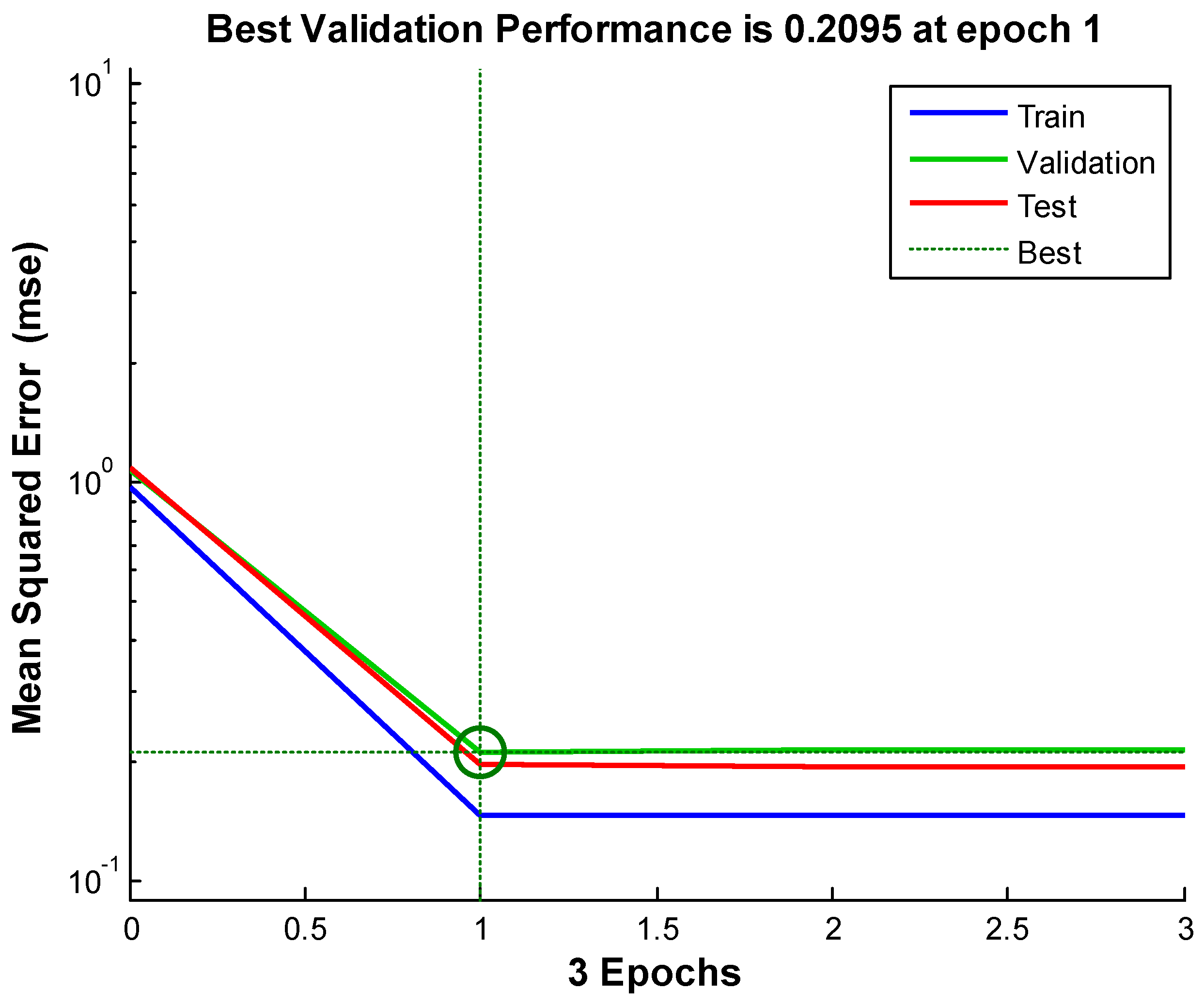
| 1 | 0.4111 | 0.5370 | 0.2095 |
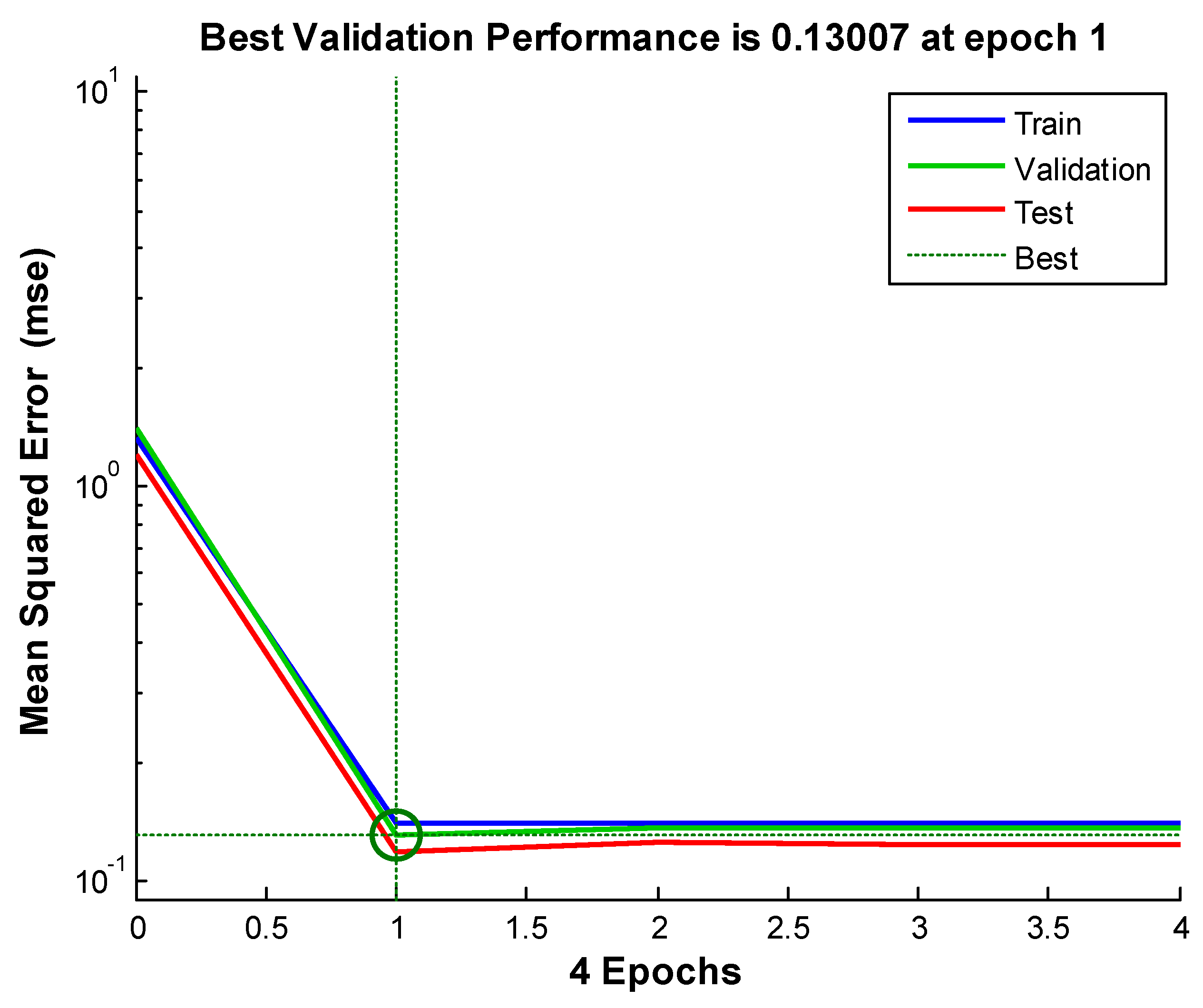
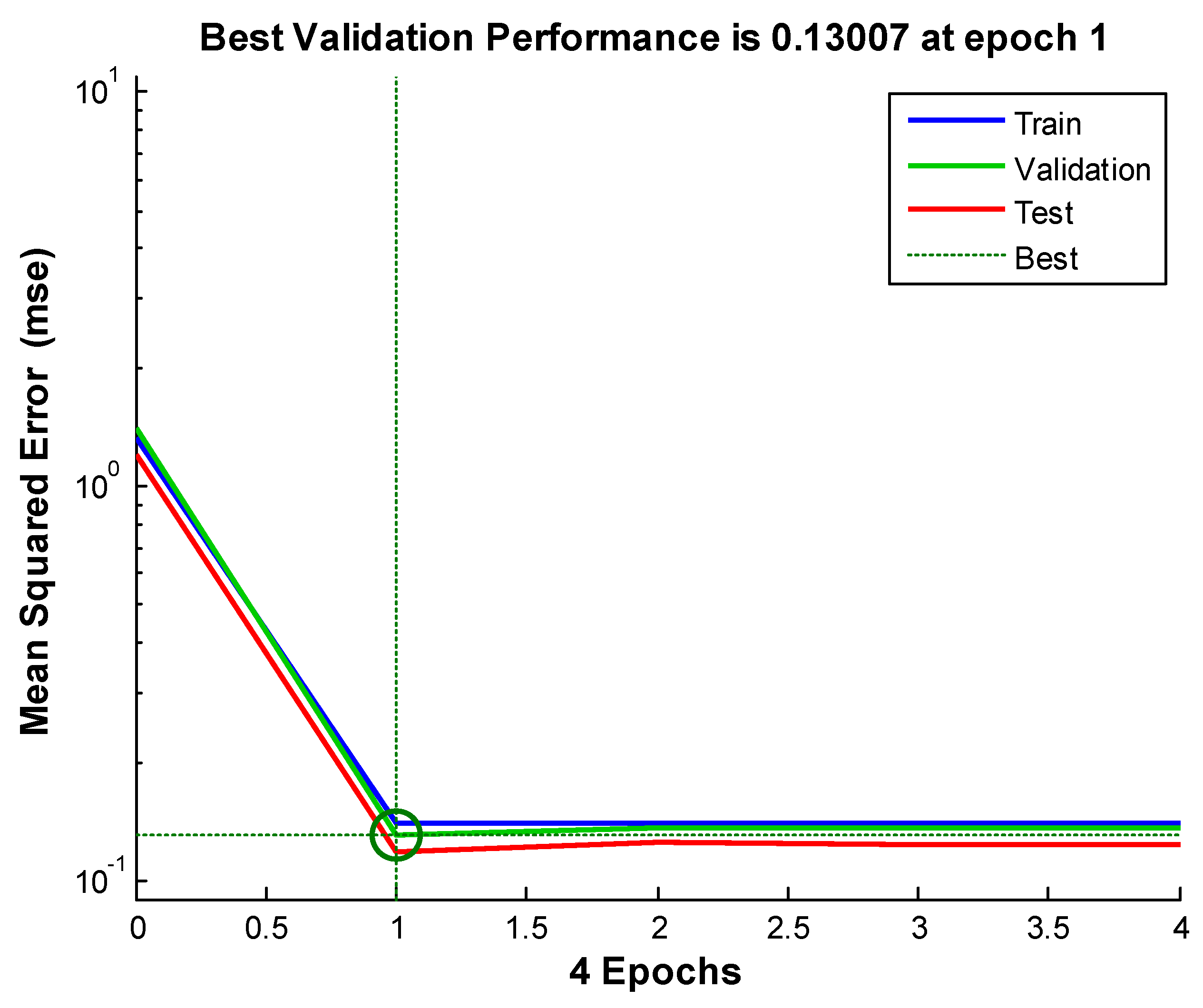
| 2 | 0.3963 | 0.2441 | 0.13007 |
| 3 | 0.2889 | 0.0741 | 0.05252 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, J.; Hu, W.; Zhang, X. Precipitation Data Assimilation System Based on a Neural Network and Case-Based Reasoning System. Information 2018, 9, 106. https://doi.org/10.3390/info9050106
Lu J, Hu W, Zhang X. Precipitation Data Assimilation System Based on a Neural Network and Case-Based Reasoning System. Information. 2018; 9(5):106. https://doi.org/10.3390/info9050106
Chicago/Turabian StyleLu, Jing, Wei Hu, and Xiakun Zhang. 2018. "Precipitation Data Assimilation System Based on a Neural Network and Case-Based Reasoning System" Information 9, no. 5: 106. https://doi.org/10.3390/info9050106
APA StyleLu, J., Hu, W., & Zhang, X. (2018). Precipitation Data Assimilation System Based on a Neural Network and Case-Based Reasoning System. Information, 9(5), 106. https://doi.org/10.3390/info9050106