1. Introduction
Human ability to express reasoning through natural language has given rise to an overwhelming amount of data. To tackle such huge amounts of information of heterogeneous quality, new tools are needed that assist humans in processing and interpreting written discourse. Being able to grasp the reasoning behind a given text is a path towards understanding its content.
Writing persuasive texts implies the use of appropriate argumentation skills. Backing up conclusions with appropriate premises may lead to convincing arguments. Cogent arguments typically denote rational reasoning [
1]; however, valid arguments are better assessed through their consensual interpretation or objectivity [
2]. The less assumptions are needed to interpret the argument, the more likely we are in the presence of an entailment relation, i.e., an inference employing logical and objective reasoning.
In natural language processing (NLP),
recognizing textual entailment (RTE) [
3] is precisely devoted to identifying entailment relations between text fragments. Approaches to RTE have been applied before to address the problem of mining arguments from text [
4]. Given two text fragments, typically denoted as “Text” (
T) and “Hypothesis” (
H), RTE is the task of determining whether the meaning of the hypothesis (e.g., “Joe Smith contributes to academia”) is entailed (can be inferred) from the text (e.g., “Joe Smith offers a generous gift to the university”) [
5]. In other words, a sentence
T entails another sentence
H if after reading and knowing that
T is true, a human would infer that
H must also be true.
We may think of textual entailment and paraphrasing in terms of logical entailment (⊧) [
6]. If the logical meaning representations of
T and
H are
and
respectively, then
corresponds to a textual entailment pair if and only if
, where
B is a knowledge base containing postulates that correspond to knowledge that is typically assumed to be shared by humans (i.e., common sense reasoning and world knowledge). Similarly, if the logical meaning representations of text fragments
and
are
and
, respectively, then
is a paraphrase of
if and only if
and
.
Building a computational approach to detect textual entailment is challenged by the richness and ambiguity of natural language. Writers often make use of a rich vocabulary and different referring expressions to obtain a more fluent reading experience. In addition, writers tend to appeal to common-sense knowledge and inferring capabilities they assume the target reading audience to have. These assumptions turn out to pose very difficult challenges to computational systems aiming to automatically interpret natural language text. It turns out that the NLP community typically adopts a relaxed definition of textual entailment [
6], so that
T entails
H if a human knowing that
T is true would be expected to infer that
H must also be true in a given context. A similar relaxed definition can be formulated for paraphrases.
RTE has been recently proposed as a general task that captures major semantic inference needs in several NLP applications [
6,
7], including: question answering [
8], information extraction [
9], document summarization [
10], machine translation [
11] and argumentation mining [
4,
12,
13]. Since 2005, several challenges have been organized with the aim of providing concrete datasets that could be used by the research community to evaluate and compare different approaches. However, RTE from Portuguese text remains little explored. Recently, at the “International Conference on the Computational Processing of Portuguese” 2016 (
PROPOR 2016), the “Evaluation of Semantic Similarity and Textual Inference” challenge (ASSIN, “Avaliação de Similaridade Semântica e Inferência Textual”) has been proposed [
14]. This challenge introduces a Portuguese annotated corpus, useful for semantic similarity and textual inference tasks. This resource allows for the development of NLP systems using machine learning (ML) techniques to address this challenging RTE task.
In this paper, we aim to explore different approaches to address the task of recognizing textual entailment and paraphrases from text written in the Portuguese language, using supervised ML algorithms.
This paper is structured as follows:
Section 2 presents related work on recognizing textual entailment and paraphrases, focusing on approaches based on text written in the Portuguese language.
Section 3 introduces the existing corpora developed to provide annotated resource to train ML techniques for the task of RTE and paraphrases from text. We also describe the ASSIN corpus, the first corpus annotated with relations of entailment from Portuguese text, that was used in our experiments to validate the approach presented in this work.
Section 4 describes the methods that were used to address the task of recognizing textual entailment and paraphrases using supervised machine learning algorithms.
Section 5 presents the results obtained by the system described in this paper. Finally,
Section 6 concludes and points to directions of future work.
2. Related Work
Computational methods for textual entailment and paraphrasing differ mainly on the initial assumptions and specific goals they were designed to address. In [
6], the authors divided these systems in two main dimensions: (a) whether they focus on
paraphrasing or
textual entailment between text fragment pairs; and (b) whether they perform
recognition,
generation or
extraction of paraphrases or textual entailment pairs. Since, in this paper, we focus on the recognition of paraphrase and textual entailment relations between pairs of sentences, the remainder of this section will focus on related work for this specific task. The main input given to a paraphrase or textual entailment recognizer is a pair of sentences, possibly in a particular context. The desired output is a (probabilistic) judgment, indicating whether or not the text fragments are paraphrases or a textual entailment pair.
State-of-the-art systems for RTE and paraphrase in natural language text typically follow a supervised machine learning approach. These systems rely on NLP pipelines (including tokenization, named entity recognition, syntactic tree parsing and dependency parsing, among other preprocessing tasks), extensive manual creation of features, several external resources (e.g., WordNet [
15]) and specialized sub-components to address specific auxiliary sub-tasks [
6,
7,
16], such as negation detection [
6,
17], semantic similarity [
18], logical inference techniques [
19,
20], and coreference resolution [
3,
20,
21]. More recently, state-of-the-art approaches for RTE rely on complex deep learning architectures employing sophisticated sentence encoding techniques and more straightforward NLP techniques (i.e., commonly requiring only tokenization and projection of the words into a distributional representation space). This paradigm shift follows a recent trend in the scientific community—focusing on how to employ ML techniques to directly extract structured and relevant knowledge from natural language resources. Deep learning techniques do not require extensive NLP pipelines in the preprocessing step.
For English text, several challenges have been proposed by the community, namely: eight RTE Challenges [
22] organized between 2005 and 2013; SemEval 2014 Task 1 entitled “Evaluation of compositional distributional semantic models on full sentences through semantic relatedness and textual entailment” [
23], where the SICK dataset [
24] has been presented; and, more recently, the Second Workshop on Evaluating Vector Space Representations for NLP (RepEval 2017) [
25], featuring a shared task competition meant to evaluate natural language understanding models based on sentence encoders on the task of RTE, where the MultiGenre SNLI Corpus [
26] has been presented. These challenges had a central role on the creation of the vast set of resources that are currently available to employ machine learning techniques for the task of RTE, and were responsible for stimulating the research community to work on these research lines. To the best of our knowledge, the first available resources and proposed computational systems to address the task of RTE and paraphrases for Portuguese were proposed in the ASSIN challenge [
14] at
PROPOR 2016. The ASSIN challenge follows similar guidelines and introduces the first corpus containing entailment and semantic similarity annotations between pairs of sentences in two Portuguese variants, European and Brazilian, suitable for the exploration of supervised machine learning techniques to address these tasks. To the best of our knowledge, the best ML approaches for RTE and paraphrases in Portuguese texts are presented in the ASSIN challenge.
In the following sections, we describe the current state-of-the-art on computational approaches that employ machine learning techniques to address the task of RTE and paraphrases from text. In
Section 2.1, we present ML approaches that rely on heavily engineered NLP pipelines and extensive manual creation of features. These were the first approaches presented to addressed this task using ML techniques and remained state-of-the-art in terms of performance until 2015. In
Section 2.2, we present ML approaches that rely on neural networks algorithms and sentence encoding techniques. These approaches constitute the current state-of-the-art in terms of accuracy.
2.1. Feature-Engineered Machine Learning Models
Conventional RTE systems employ (semi-)supervised ML techniques that rely on the manual creation of features that are given as input to the ML algorithms. These features map the input (i.e., natural language sentences T and H) to a numerical space that is used to represent the input in a structured format that can be used by ML algorithms. For the task of RTE, these features must capture the content of T and H and, more importantly, interconnections between T and H. Throughout the years, different features have been proposed by exploring several external resources. Typically, systems employ features at different levels of abstraction, namely lexical (e.g., words overlap, bag-of-words models, and substring matching), syntactic (e.g., part-of-speech tags, adverbs, punctuation marks, and syntactic trees), structural (e.g., sentence length), and semantic (e.g., exploring relations of synonyms and hypernyms from a WordNet, and similarity metrics from models of distributional representation of words). For instance, Bowman et al. [
27] propose a classifier trained and evaluated on the SNLI [
27] and SICK [
24] corpora that implements six features at the lexical, syntactic and structural level, namely: BLEU [
28] score of the hypothesis with respect to the premise, the length difference between the hypothesis and the premise, overlap between words in the premise and hypothesis (over all words and over just nouns, verbs, adjectives, and adverbs), an indicator for every unigram and bigram in the hypothesis, cross-unigrams, and cross-bigrams. The authors report an accuracy of
on SNLI and
on SICK training set, and an accuracy of
on SNLI and
on SICK test set.
One of the most widely used platforms to explore feature-based approaches is the Excitement Open Platform [
29]. This platform follows a generic and modular architecture that allows developers to combine linguistic pipelines, entailment algorithms and linguistic resources within and across languages. The platform includes state-of-the-art algorithms, many knowledge resources, and facilities experimenting and testing different approaches. Moreover, the platform has various multilingual components for languages such as English, German and Italian.
In the remainder of this section, we will introduce some of the approaches that have been proposed by the community to address the task of RTE in Portuguese texts, using feature-based ML models. All of the proposed systems use the ASSIN Corpus to train and test ML algorithms.
In [
30], Hartmann followed the supervised ML paradigm with an approach based on the cosine similarity of the vectorial representation of each sentence. These sentence representations were obtained from the sum of the vectors representing each word in a sentence using two word weighting schemes, namely:
TF-IDF [
31] and
word2vec [
32]. Then, for each sentence pair, the cosine similarity between the vectorial representation (i.e., sum of the word vectors using the weighting schemes previously described) of the text sentence T and the hypothesis sentence H is used as features (one feature using TF-IDF and another using word2vec to represent each sentence) and given as input to train a linear classifier.
Fialho et al. [
33] extracted several metrics for each pair of sentences, namely edit distance, words overlap,
BLEU [
28] and
ROUGE [
34], among others. They reported several experiments considering different preprocessing steps in the NLP pipeline, namely: original sentences (baseline), removing stop-words, lower-case words and clusters of words. A feature set containing more than 90 features to represent each pair of sentences was used as input for a
SVM classifier. Fialho et al. also reported experiments merging the original ASSIN corpus with annotated data from the SICK corpus translated from English to Portuguese, using a Python wrapper over the Microsoft Bing translation service. They added 9191 examples from the
SICK corpus to the 6000 examples from the ASSIN training set in one of their experiments. The results reported on the augmented version of the training data were worse than the results reported on the original training data. The authors associated these results to translation errors that were probably made during the process. In addition, they trained their model in one of the Portuguese variants of the ASSIN corpus and evaluated the performance of the model in the other Portuguese variant. Reported results following this experimental setup were worse when compared with the model trained and tested in the same variant, but were better than the results obtained in the augmented version of the original dataset (with the
SICK data). They obtained the best results for RTE in the ASSIN challenge:
of accuracy and
of macro F1-score.
In [
35], Alves et al. explored two different approaches for RTE and paraphrases: a heuristic-based approach (“Reciclagem” system) and a supervised ML approach (“ASAPP” system). Both approaches made use of the same component for analyzing lexical semantic relations, which is based on the analysis of semantic networks (e.g., wordnet for Portuguese). The “Reciclagem” system is based on lexical and semantic knowledge that calculates the similarity and relations of two sentences without any kind of supervised ML methods. This system was used as a baseline for the “ASAPP” system and to evaluate the quality of different lexical and semantic resources for Portuguese. The “ASAPP” system follows the supervised ML approach and adds to “Reciclagem” features based on the syntactic and structural information extracted from the pair of sentences, such as number of tokens, overlapping words, synonyms, hyperonyms, meronyms, antonyms and number of words with negative connotation, type of named entities, among others. In their experiments, the authors explored different strategies to divide the training data, combining results from different classifiers and several feature selection techniques. They reported accuracy of
and macro F1-score of
in the European Portuguese test data.
2.2. Neural Network Models Based on Sentence Encoding
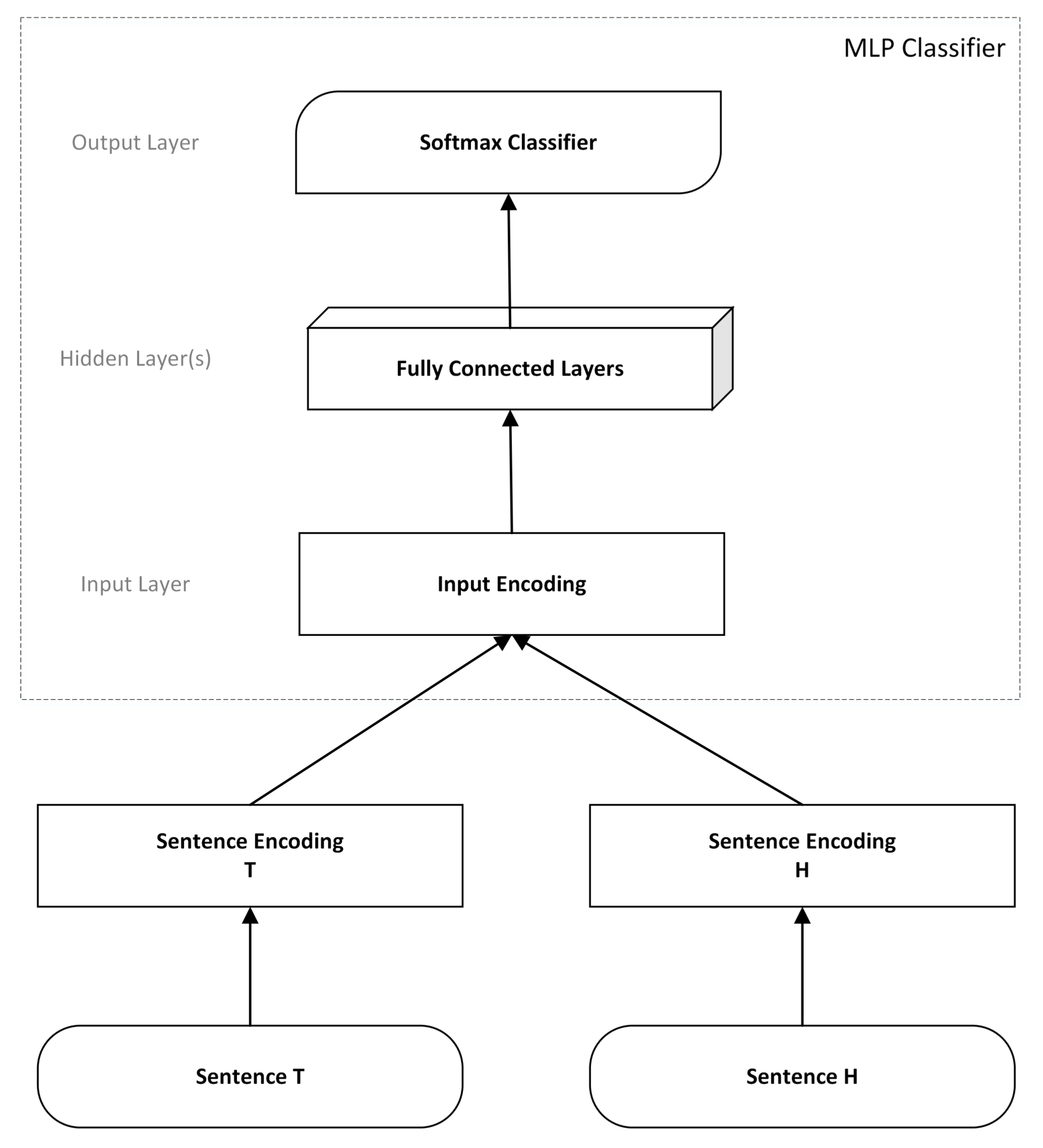
Current state-of-the-art results on RTE were obtained by exploring neural networks with several layers of neurons (know as
deep learning architectures) and with complex encoding of the sentences
T and
H. In general, these approaches follow the architecture depicted in
Figure 1. In a RTE setting, the system receives as input a pair of sentences. The bottom layers are responsible for encoding the sentences written in natural language into a representation capturing information from both sentences (sentence encoding). First, we have to map natural language sentences into a representation that is suitable for being processed by a computational system. The conventional approach is to split each natural language sentence in tokens (tokenization), mapping the original sentence to a set of tokens. Then, each token is mapped to a word embedding space, a representation that is used henceforth. Next, the set of tokens must be mapped to a fixed-length vector that captures all the relevant information presented in the sentence and that is suitable for being used by the following layers in the neural network (sentence encoding step). Different ways of performing sentence encoding have been proposed by the community, but typically this step is performed in one of two ways: (a) sentence encoding-based models that encode
T and
H separately and then merge the encodings in a fixed-length vector; or (b) join methods that share the encoding for each sentence in a single representation (e.g., cross-features, attention mechanisms, sequence representations).
From the sentence encoding step, a fixed-length vector is obtained that captures the information for T and H and, possibly, the relation between the sentences. The resulting vector is fed into a multilayer neural network that culminates in a softmax layer (output layer) to output the final predictions made by the neural network. The softmax layer outputs a vector of non-negative real numbers that sum to one, making the output layer a discrete probability distribution over the possible output classes (e.g., None, Entailment and Paraphrase in the ASSIN Corpus). Different architectures have been proposed for the multilayer neural network that maps the sentence encoding step to the softmax layer.
Following the sentence-encoding setting identified as (a) above, Bowman et al. [
27] proposed three different architectures, namely Sum of Words, RNN and LSTM [
36], each of them mapping the sentences to a 100d vector and concatenating each vector to obtain a 200d vector in the end. For a sentence
S containing a sequence of
n words
, this approach computes a representation of
S as
, where
represents the embedding vector of word
. In the Sum of Words architecture (baseline approach), the 100d vector representation of a sentence is obtained by summing the embeddings of the tokens in the sentence. In the sequence embeddings models (RNN and LSTM), the authors fed each 100d vector representation sequentially in a recurrent neural net (RNN and LSTM) and use the final 100d representation of the hidden state as the final sentence representation. For a sequence of
n words
the network computes a set of
n hidden representations
with
. A sentence is represented by the last hidden vector
. The neural network classifier is a stack of three 200d tanh layers that feeds a final softmax layer. The learning procedure for the neural network classifier and sentence encoding is performed jointly. Results reported on the SNLI corpus show that the LSTM sentence encoding setting performs better in both training set (
) and test set (
), followed by the Sum of Words setting (
on the training set and
on the test set) and, finally, by the RNN setting (
on the training set and
on the test set). All the reported results are presented in terms of overall accuracy for a three-class classification task. Comparing these results with a feature-based approach, they obtained similar results when training on the full corpus. However, from the increase of accuracy experienced by the LSTM as new examples were added to the corpus in comparison with the feature-based approach, the authors claim that this can be an indicator that the LSTM model may take more advantage of larger datasets and, therefore, they expect the LSTM model to achieve better performance when the number of annotations in the dataset increases.
Following the sentence encoding identified as (b) above, Rocktäschel et al. [
16] employed an attentive neural network that is capable of reasoning over entailments of pairs of words and spans of text by processing the hypothesis conditioned on the premise. In contrast with the approach presented by Bowman et al. [
27] who encoded each sentence independently into a semantic space, in this work, the authors processed the two sentences as follows. First, a LSTM is employed to encode sentence
T by processing each word in a sequential setting
. Then, a second LSTM with different parameters reads a delimiter and the hypothesis
H, but its memory state is initialized with the last cell state of the previous LSTM. In other words, the second LSTM is conditioned on the representation of the first LSTM that was obtained after processing text sentence
T (conditional encoding). For classification, a softmax layer is employed over a non-linear projection of the output vector obtained from the last hidden state of the second LSTM into the target space of the three classes available in the SNLI corpus. The learning procedure of the sentence encoding and neural network classifier is performed jointly using a cross-entropy loss method. Finally, the authors propose to augment the LSTM with attention mechanisms. The idea is to allow the model to attend over past output vectors with the aim of focusing the model to pay more attention to some parts of the output vector that are more relevant. More precisely, a LSTM with attention for RTE does not need to capture the whole semantics of the sentence
T in its cell state and final hidden state. Instead, the attention mechanism informs the second LSTM about which hidden states, obtained while reading sentence
T, it should attend to determine the RTE class. From the analysis of the results obtained by employing these models in the SNLI corpus, the authors concluded that: (a) conditional encoding gives an improvement of
percentage points in accuracy over Bowman et al. [
27] LSTM and outperforms a simple lexicalized classifier by
percentage points; and (b) incorporating attention mechanisms improved the accuracy of the LSTM with conditional encoding by
percentage points.
In sum, the current best performing state-of-the-art systems for the task of recognizing textual entailment and contradictions from text written in English (
https://nlp.stanford.edu/projects/snli/) employ neural network algorithms based on deep learning architectures, following a setting similar to the one depicted in
Figure 1.
4. Methods
We here describe the approach we follow to address the task of entailment and paraphrase recognition from natural language Portuguese text. We formulated the problem following two different settings: first, as a multi-class classification problem, in which we aimed to classify each
with one of the labels
Entailment (if
),
Paraphrase (if
and
, i.e., if
T is paraphrase of
H), or
None (if
T and
H are not related with one of the previous labels); and, second, as a binary classification problem, aimed ti distinguish each
with one of the labels
Entailment or
None (details regarding the experimental setup and obtained results following these formulations is described in
Section 5). In both formulations, we employed supervised ML techniques to construct a computational system capable of RTE and paraphrases from text, using the ASSIN corpus to train and test the quality of the predictions made by the system (using the training and test partitions of the ASSIN corpus, respectively).
Designing a system able to automatically recognize textual entailment and paraphrases given a pair of sentences written in natural language requires the implementation of different techniques to process natural language text written in the Portuguese language. Additionally, methods to represent natural language pairs of sentences into a set of features suitable to employ ML algorithms is also a required step in this pipeline.
Firstly, to transform each sentence into the corresponding set of tokens and to obtain for each token the corresponding lemma and part-of-speech information (including syntactic function, person, number and tense, among others), we used the
CitiusTagger [
43] NLP tool. This tool includes a named entity recognizer trained in natural language text written in Portuguese.
Several experiments were made using different NLP techniques to process the sentences received as input: removing stop-words, removing auxiliary words (i.e., words relevant for the discourse structure but not domain specific, such as prepositions, determiners, conjunctions, interjections, numbers and some adverbial groups) and lemmatization. From this possible pre-processing setup, we expect that: (a) Transforming each token into the corresponding lemma is a promising approach, particularly in Portuguese, a language where word inflection is extremely rich. Additionally, it will make explicit that some of the words are repeated in both sentences even if small variations of these words are used in each sentence (e.g., different verb tenses). (b) Removal of stop-words and auxiliary words will have a positive impact in the obtained results by focusing the attention on words that may indicate relations of entailment (e.g., hypernyms).
After this pre-processing step, each sentence contained in the pair under analysis is represented in a structured format (set of tokens) and annotated with some additional information regarding the content of the text (e.g., part-of-speech tags).
Secondly, to apply ML algorithms, we need to represent each learning instance, each pair, by a set of numerical features. A good set of features should represent the training instances in such a way that would make it possible for the machine learning algorithms to find patterns in the data which can be used to classify instances according to the desired target labels. Since in this problem we received a pair of sentences as input and we aimed to automatically classify the relation between them as output, the feature set should be designed taking special attention to the properties that characterize such relation.
To represent each pair
, we employed a set of features (listed in
Table 4) at the lexical, syntactic and semantic level. The first four lexical features aimed to capture the overlap of information expressed in
T in relation to
H and vice versa. Feature
T_Bigger_H tries to capture the intuition that in a relation of
Entailment, sentence
H is usually smaller than sentence
T. Regarding syntactic features, changes in verb tense are typically not expected to occur in
Paraphrase relations, while rewriting the same sentence using alternation between passive and active voice is the most common case of paraphrase relations. Semantic features were employed for tokens in one of the sentences that do not occur in the other, after removing auxiliary words and named entities, to focus attention on words that are possible indicators of relations of entailment. The first three features captured semantic relations between each pair of tokens using knowledge extracted from a Portuguese wordnet. The last two features explored the word embeddings model and aimed to capture different ways of measuring semantic relations between
H and
T, after projecting each sentence in the embedding space.
Knowledge about the words of a language and their semantic relations with other words can be exploited with large-scale lexical databases. With the aim of enabling the system to better deal with the diversity and ambiguity of natural language text, we explore external semantic resources. Similar to WordNet [
15] for the English language, CONTO.PT [
44] is a wordnet for Portuguese, which groups words into sets of cognitive synonyms (synsets), each expressing a distinct concept. In addition, synsets are interlinked by means of conceptual and semantic relations (e.g., “hyperonym” and “part-of”). Synsets included in CONTO.PT were automatically extracted from several linguistic resources, namely based on the redundancy of the relations existing on other Portuguese wordnets. Since CONTO.PT can be seen as an updated agglomeration of existing resources for Portuguese, we decided to use CONTO.PT in our experiments. Additionally, all relations represented in CONTO.PT (both relations between words and synsets, and relations between synsets) include degrees of membership. Two tokens (obtained after tokenization and lemmatization) are considered synonyms if they occur in the same synset. Token
is considered hyperonym of
if there exists a hyperonym relation (“hyperonym_of”) between the synset of
and the synset of
. Similarly,
is considered meronym of
if there exists a meronym relation (“part_of” or “member_of”) between the synset of
and the synset of
. Given that in CONTO.PT each synset contains words combined with the corresponding syntactic function (e.g., noun and adjective), we retrieve the corresponding synsets taking into account the part-of-speech tags that were associated to each word in the pre-processing stage; this allows us to perform a simplified disambiguation of CONTO.PT senses.
Finally, we exploit a distributed representation of words (word embeddings) to compute the last two features listed in
Table 4. These distributions map a word in a dictionary to a feature vector in a high-dimensional space, without human intervention, by observing the usage of the word on large (non-annotated) corpora. This real-valued vector representation tries to arrange words with similar meanings close to each other based on the occurrences of these words in large-scale corpora. Then, from these representations, interesting features can be explored, such as semantic and syntactic similarities. In our experiments, we used a pre-trained model provided by the
Polyglot (
http://polyglot.readthedocs.io/en/latest/index.html) tool [
45], in which a neural network architecture was trained with Portuguese Wikipedia articles.
To obtain a score indicating the similarity between two text fragments T and H, we compute the cosine similarity between the vectors that represent each of the text fragments in the high-dimensional space. Each text fragment is projected into the embedding space as , where represents the embedding vector of the word and n corresponds to the number of words contained in the text fragment (T or H). Then, we compute the final value of the cosine similarity , where , followed by the following rescaling and normalization: . The entailment versor () corresponds to the normalized direction vector obtained by subtracting the projection of H () from the projection of T () in the embedding space.
For each classification task, we have run several experiments exploring some well known state-of-the-art algorithms, namely:
Support Vector Machine (SVM) using linear and polynomial kernels,
Maximum Entropy model (MaxEnt),
Adaptive Boosting (AdaBoost) using
Decision Trees as weak classifiers,
Random Forests using
Decision Trees as weak classifiers, and
Multilayer Perceptron (Neural Net) with one hidden layer. All the ML algorithms previously mentioned were employed using the
scikit-learn library [
46] for the
Python programming language. Since the best overall results for the baseline scenario (see
Section 5.1) were obtained using
MaxEnt, all results reported in
Section 5 were obtained using this classifier.
6. Conclusions
In this paper, we present several approaches to address the NLP task of recognizing textual entailment and paraphrases from text written in the Portuguese language. We started by the natural formulation of this task as a multi-class classification problem. The overall results obtained following this setting are promising (with an accuracy of
in the test set). Comparing our results with those of the participants in the
ASSIN Challenge [
14], our approach obtains an overall accuracy close to the results obtained by the best performing system (
of accuracy obtained by Fialho et al. [
33]) and outperforms all the proposed systems in the corresponding macro F1-score metric (the best performing system [
33] reported
of macro F1-score). Additionally, we observe that the performance of our approach improved with semantic-based features, albeit not significantly. Notwithstanding, a detailed analysis points that this is one of the most promising directions for future work.
A closer assessment of our results shows that the number of annotated sentence pairs may not be sufficient to build a system that generalizes well for unseen data since the implemented classifiers tend to prefer labels that contain more training instances simply because they are more representative of the training data in statistical terms. As discussed in this paper, we believe that training with more quality data, balanced in relation to the different classes, and covering more entailment phenomena (e.g., by reasoning with quantifiers) is essential to obtain systems to address the task of RTE and paraphrases that generalizes better to unseen data.
Some subtasks could be added to help capturing relations of entailment and paraphrase, namely: reasoning over numerical and temporal expressions, dealing with missing values in the semantic resources employed, detecting negated expressions, named entity disambiguation, and semantic role labeling. By addressing these subtasks in future work, we believe that our results could be significantly improved.
To overcome the lack of annotated data and to improve the coverage of textual entailment phenomena captured in the ASSIN corpus, we aim to explore natural language generation techniques to synthesize new learning instances in a semi-automatic process, where annotators would validate the sentence pairs generated automatically. For instance, based on a given text sentence T (extracted from some textual resource), we aim to study techniques to generate artificial hypothesis sentences based on the knowledge extracted from semantic resources (e.g., wordnet relations and knowledge graphs). This approach to automatically generate learning instances follows similar guidelines as the ones defined in the construction of the SICK and SNLI corpora but, instead of asking to human annotators to manually provide the hypothesis sentences, we aim to interact with human annotators only in the validation step. These approaches have the advantage of generating balanced datasets and at the same time a large quantity of data. Providing a synthesized dataset containing considerable annotations of entailment relations is, in our perspective, one of the most promising directions of future work to train systems capable of better recognizing textual entailments in the Portuguese language.
Increasing the training set with the Brazilian Portuguese partition of the ASSIN corpus had an unexpected impact in the overall performance of the system. We associate this result to syntactic and semantic differences between European and Brazilian Portuguese and because some of the external resources that were employed (i.e., fuzzy wordnet, part-of-speech tagger, and word embeddings model) are based on the European Portuguese language. Consequently, some lexical, syntactic and semantic Brazilian Portuguese linguistic phenomena may be missing or misleading in this approach.
Furthermore, formulating the problem as a binary classification task seems to be adequate for recognizing textual entailment, but attempts to adapt the binary classification for recognizing textual entailments and paraphrases in a multi-class classification setting led to poor generalization.
In future work, we would like to enhance the semantic-based features employed in our system, including: metrics to evaluate semantic similarity between fragments of text using the fuzzy wordnet described in this paper, sentence-level representations (e.g., using a dependency parser) and more sophisticated computations using distributed representation models. Furthermore, we aim to study transfer learning techniques using deep neural network models (current state-of-the-art models for RTE from English text). The idea is to explore large-scale corpora annotated with relations of entailment from text written in English that is currently available. First, a deep neural network model will be trained on these large-scale annotated resources for recognizing textual entailment from text written in English. Next, we adapt the trained model by providing pre-trained word embeddings for Portuguese and by performing some retraining on the ASSIN corpus to obtain a ML model that is capable of using the knowledge gathered when training in the English corpora to make predictions for unseen data in the Portuguese language. Then, we aim to compare the performance of the obtained model with the feature-engineered ML models presented in this paper.
References




{kind=link}