1. Introduction
Semantic similarity is a key problem in natural language processing (NLP) and understanding (NLU). Specifically, word similarity aims at determining the likeness of meaning transmitted by two words, and is generally a necessary step towards computing the semantic similarity of larger units, such as phrases or sentences. This is why there are many automatic approaches for computing word similarity, as well as several benchmarks that enable the assessment and comparison of distinct approaches for this purpose.
As it happens for other NLP tasks, most related work targets English, because it is widely spoken, which also results in more benchmarks in this language. Yet, especially since word embeddings–vector representations of words learned with a neural network [
1]–became a trend in NLP, researchers have developed both benchmarks and approaches for computing semantic similarity in other languages, including Portuguese.
This work uses recently released word similarity tests in Portuguese and answers them with unsupervised approaches that either exploit the structure of existing lexical knowledge bases (LKBs) or distributional models of words, including word embeddings. The goal of the automatic procedures is to score the similarity of two words, which may then be assessed by comparison with the scores in the benchmark test, in this case, based on human judgements.
The main contribution of this work is the comparison of several unsupervised procedures employed for computing word similarity in Portuguese, which might support the choice of approaches to adopt in more complex tasks, such as semantic textual similarity (for Portuguese, see ASSIN [
2]) or other tasks involved in a NLU pipeline (useful for e.g., conversational agents), or in a semantically-enriched search engine. Indirectly, the resources underlying each approach end up also being compared. For instance, results provide cues on the most suitable LKBs for computing word similarity, also a strong hint on the quality and coverage of these resources. Overall, this work involved different procedures for computing word similarity and several resources, namely: two procedures applied to open Portuguese wordnets, including one fuzzy wordnet; two different procedures applied to available semantic networks for Portuguese, or to networks that result from their combination; one procedure based on the co-occurrence of words in articles of the Portuguese Wikipedia; and one final procedure that computes similarity from several different models of word embeddings currently available for Portuguese. The work is especially directed to those users that are interested in computing the similarity of Portuguese words but do not have the conditions for creating new broad-coverage semantic models from scratch. In fact, it can also be seen as a survey of resources–semantic models and benchmarks–currently available for this purpose.
The remainder of this paper starts with a brief overview on semantic similarity, variants, common approaches, and a focus on this topic for Portuguese. After that, the benchmarks used here are presented, followed by a description of the resources and approaches applied. Before concluding, the results obtained for each approach are reported and discussed, which includes a look at the state-of-the-art and the combination of different approaches towards better results. In general, the best results obtained are highly correlated with human judgements. Yet, depending on the nature of the dataset, both the best approach and underlying resource is different. An important conclusion is that the best results are obtained, first, with approaches that combine different resources of the same kind, then, by combining the former with models of a different kind.
2. Related Work
Semantic similarity measures the likeness of the meaning transmitted by two units, which can either be instances in an ontology or linguistic units, such as words or sentences. This involves comparing the features shared by each meaning, which sets their position in a taxonomy, and considers semantic relations such as synonymy, for identical meanings, or hypernymy, hyponymy and co-hyponymy, for meanings that share several features. Semantic relatedness goes beyond similarity and considers any other semantic relation that may connect meanings. For instance, the concepts of dog and cat are semantically similar, but they are not so similar to bone. On the other hand, dog is more related to bone than cat is, because dogs like and are often seen with bones.
Word similarity tests are collections of word pairs with a similarity score based on human judgements. To answer such tests, humans would either look for the words in a dictionary or search for their occurrence in large corpora, possibly with the help of a search engine. This has a parallelism with the common approaches for determining word similarity automatically and unsupervisedly: (i) corpus-based approaches, also known as distributional, resort to a large corpus and analyse the distribution of words; (ii) knowledge-based approaches exploit the contents of a dictionary or lexical knowledge base (i.e., a machine-friendly representation of dictionary knowledge). It should be noted that the distinction of similarity and relatedness is not very clear for everyone. Therefore, whether the test scores reflect similarity or relatedness is also not always completely clear. Nevertheless, approaches for one are often applied to the other.
Corpus-based approaches rely on the distributional hypothesis–words that occur in similar contexts tend to have similar meanings [
3]–and often represent words in a vector space model [
4]. Recent work uses neural networks to learn vectors from very large corpora, which are more accurate and computationally efficient at the same time. Sucessfull models of this kind include word2vec [
1], GloVE [
5], or fastText [
6].
The similarity of two words may also be computed from their probability of occurrence in a corpus. Pointwise Mutual Information (PMI) [
7] quantifies the discrepancy between the probability of two words,
a and
b, co-occurring (
), given their joint distribution and their individual distributions (
and
), and assuming their independence. PMI can be computed according to Equation (
1).
Knowledge-based approaches for computing word similarity exploit the contents of a dictionary [
8] or lexical knowledge-base (LKB), often WordNet [
9], a resource where synonyms are grouped together in synsets and semantic relations (e.g., hypernymy, part-of) are held between synsets. Typical measures consider words used in the definition or example sentences, as well as the semantic connections between words.
Distributional word representations consider how language is used, while LKBs are more theoretical and often based on the work of lexicographers. In the former, several types of relation are present, but not explicit, while in LKBs semantic relations are explicit, but limited to a small set of types. For instance, despite the presence of a few other relations, WordNet is mainly focused on synonymy and hypernymy. This is why it is better-suited to measure similarity, but is outperformed by corpus-based approaches when it comes to measuring relatedness. Some authors have thus adopted hybrid approaches, where distributional and knowledge-based approaches are combined [
10,
11].
Related work for Portuguese has tackled mostly paraphrasing [
12] or semantic textual similarity [
13], which consists of computing the similarity of larger units of text. A shared task was recently organised on the latter [
2]. In this case, supervised approaches typically perform better, by exploiting several features, including semantic features that might involve word similarity measures. In addition to semantic textual similarity, Portuguese word embeddings have also been recently used for part-of-speech tagging and to solve analogies [
14].
When it comes to word similarity, Granada et al. [
15] created a Portuguese test for this purpose, compared the judge agreement with other languages, and applied a distributional approach, based on Wikipedia, to answer it. Wilkens et al. [
16] compiled the B
SG test and used it to assess distributional similarity measures. However, B
SG is slightly different from the tests used in this work because, instead of a similarity score, a related word is to be selected from a group where it is shuffled with distractors.
6. Results
This section presents and discusses the results obtained for the four Portuguese word similarity tests. As usual in this kind of tests, performance is assessed with the Spearman correlation () between the automatically-computed similarities and the gold ones in the test.
The section starts with the results using LKBs and then using the distributional models. After that, the global results are discussed and compared with the state-of-start results for English, for which the original versions of the target tests have been extensively used as benchmarks. A brief error analysis is then presented and discussed. Finally, following the trend of the best performing approaches for English, our results are further improved for three of the four tests, when the scores of the best knowledge-based approaches are combined with the best distributional models.
6.1. Results for LKBs
The selected knowledge-based approaches were adopted to answer the four similarity tests automatically. Yet, before computing similarities, the coverage of each similarity test by each LKB was analysed.
Table 6 shows those numbers considering that, in order to cover a pair of words in a test, a LKB must include both words of this pair. The main conclusion is that different LKBs have a significantly different coverage of different tests. TeP is the only original LKB to cover all the pairs of a test (PT-65, the smallest one). Three of the combined LKBs (All-LKB, CARTÃO and CONTO.PT) also cover all the pairs of the latter test. Although no other test has all the pairs covered by a LKB, as expected, the highest coverages are those by the combined LKBs, always above 90% for PT-65, SimLex-999 and WordSim-353, with a single exception (Redun2 in WordSim-353). Again, as expected, coverage of the RareWords test is considerably lower, though always higher than 50% for the combined LKBs, while only three of the original LKBs have more than 50% coverage for this test (TeP, PAPEL and DA). It is also clear that OT is not only the smallest resource, but has also the lowest coverages for every test.
In all the following experiments, similarity was set to 0 for every pair not covered by a LKB. Of course this will have a relevant impact on the results, but we believe this is the fairest way of comparing the performance of the LKB on these tests. In addition, we recall that coverage is one of the most important features to consider when selecting a LKB to use.
After analysing coverage, the results obtained when computing word similarity with the LKBs are presented.
Table 7,
Table 8,
Table 9 and
Table 10 show a selection of those results, respectively for PT-65, Simlex-999, WordSim-353 and RareWords. For each test, we present the top 5 or 6 results, depending on their differences, and the best results for each other resource not in the top 5. Besides the identification of each LKB, the relation set and the algorithm used are revealed for each result, plus the mean Spearman correlation (
) and the standard deviation (
). The latter were computed as suggested by Batchkarov et al. [
42], who criticise how word similarity tests are used for assessing similarity models. What happens is that even the largest test, RareWords, is too small for taking conclusions about the performance of a broad-coverage resource, that aims at covering the whole language. Therefore, considering that human annotation of more word pairs is not possible, in order to better understand the variance of the applied methods, 500 random samples of the same test were created, which enabled the computation of the mean and standard deviation.
The numbers show that using as much knowledge as possible leads to the best results. The All-LKB, which we recall, contains all the relation instances in all the other LKBs, clearly got the best performance in PT-65, SimLex-999 and WordSim-353, with second best in the RareWords tests, where CONTO.PT achieved the best . We recall that, though with a significantly different structure, CONTO.PT is also a combination of all the other LKBs. A possible explanation for the latter result is that the words in RareWords are less frequent, probably left out in smaller resources, but covered in larger resources and, in the case of CONTO.PT, also grouped with similar words.
Besides CONTO.PT and All-LKB, the other combined LKBs, with contents from more than a single original LKB, are CARTÃO and Redun2, both in the first half of the rank for the majority of the tests. The main exception is Redun2 which, in WordSim-353, is below this margin, possibly because, when considering only instances in two or more LKBs, important knowledge for computing word relatedness is discarded.
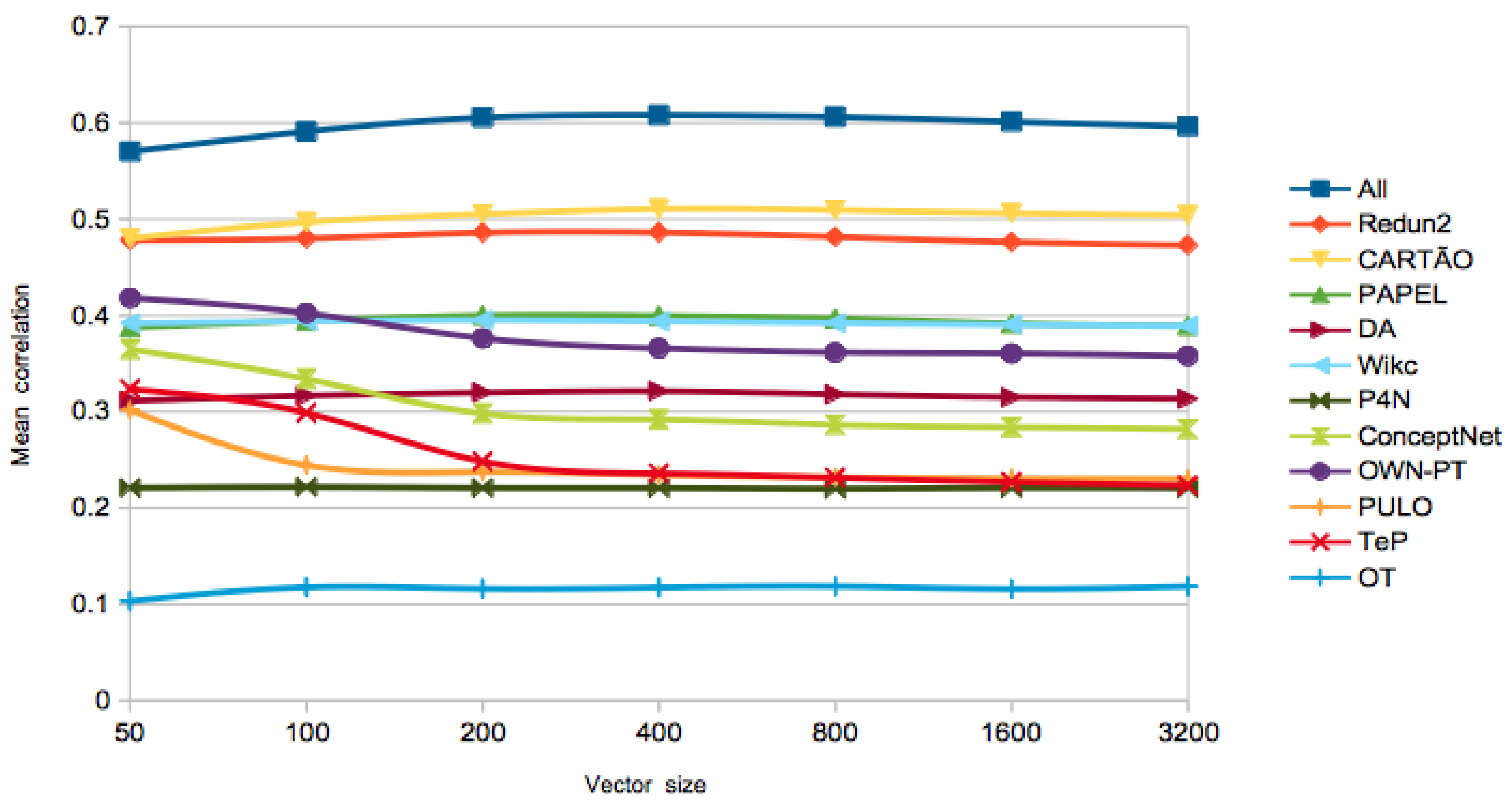
On the best algorithm to use, the PageRank vectors got the highest performance in the first three tests. The size of the vectors did not seem to play a huge role, as the differences are not significant for different sizes. In order to further analyse this issue,
Figure 1 and
Figure 2 show the evolution of the
for different LKBs, with different vector sizes and similarity computed with the cosine. At a first glance, the
of the word-based networks extracted from wordnets gets lower for larger vectors, while, for the other LKBs, performance is improved, at least until vectors of size 200 or 400, depending on the LKB. A possible explanation is that the synset deconstruction procedure used in the extraction of the former networks might result in undesired ambiguity, which makes those networks noisier. Since the PageRank vectors algorithm has a high time complexity, especially for large networks, we also show the best result with a simpler algorithm, Adj-Cos or Adj-Jac, which is within the range of one standard deviation in PT-65 and WordSim-353, less than two in SimLex-999, and achieved the best performance of the All-LKB in the RareWords test.
On the selected relation types, for most LKBs, using only synonymy and hypernymy relations resulted in best results in SimLex-999, which makes sense because these are also the most relevant relations for computing genuine similarity. For the other tests, the majority of the best results were achieved using all the relations, also relevant when computing relatedness. This trend is less clear in PT-65, where there might be some confusion between the concepts of similarity and relatedness.
Looking at individual LKBs, PAPEL, OWN-PT and ConceptNet performed generally well, when compared to the others. Although with modest performances in the first three tests, TeP was within two standard deviations to the best performance in the RareWords dataset. Again, although TeP only covers synonymy and antonymy, it covers a large number of words and, when the synsets are deconstructed, it becomes the second LKB with more relation instances, which might have played a positive role.
A remark should be given on the presented results, which are not only influenced by the contents and structure of the LKBs, but also by the applied algorithms. Therefore, although they provide useful hints, our results are only valid for the tested algorithms, and better results could possibly be obtained by alternative ways of exploiting the LKBs.
6.4. Comparison with State-of-the-Art
To the best of our knowledge, there are not published results for the Portuguese versions of SimLex-999, WordSim-353 nor RareWords, because they were only translated recently. On the other hand, our results for PT-65 clearly outperform experimental results by Granada et al. [
15], who used a LSA distributional model based on the Portuguese Wikipedia and achieved
, which is substantially lower than the 0.87 achieved with the All-LKB.
State-of-the-art results for the English versions of RG-65, SimLex-999 and WordSim-353 can be found in the ACL Wiki (
https://aclweb.org/aclwiki/Similarity_(State_of_the_art), checked in November 2017). Although with different distances, all our results (so far) are below the best results for English, which are all quite recent. For RG-65, the best performance (
) was achieved with a knowledge-based approach [
37] that exploits Wiktionary [
43], and is 4 points higher than our best. The best results for SimLex-999 (
), obtained by combining distributional knowledge with WordNet [
10], are not far from our results obtained with the All-LKB (
) and are even closer to those obtained with the Portuguese Numberbatch (
). The best results for WordSim-353 (
) were obtained with hybrid approaches, including Numberbatch (word2vec, GloVe and ConceptNet) [
11]. In this case, our best results were also obtained with Numberbatch, but with a significantly lower performance (
). Although not in the ACL Wiki, a
was recently reported for the English RareWords test, using the fastText embeddings [
6], which is again higher than the best results reported here (
for two of the NILC embeddings and
for CONTO.PT). As in our experiments, this is also the test with lower state-of-the-art results.
We believe that the main reason for the difference in the performances between Portuguese and English is that languages are different, which means that approaches in Portuguese had to resort to different resources than those of English. Moreover, this kind of research is very recent for Portuguese, while there has been much work on this topic for English. On top of this, there might be translation issues. While at the conceptual level, similarity scores should be the same, word meanings might “shift” after translation. However, analysing the quality of the translations and the scores of the tests, which were not created by us, is out of the scope of this paper. Some issues are, nevertheless, presented in the following section. Yet, from our superficial observation, and given the size of tests, we believe that they should have no more than a residual impact on the final results.
6.5. Error Analysis
In order to analyse where the best approaches were still failing and could possibly be improved, an error analysis was conducted. For this purpose, the word pairs of each test were ranked, based on their gold similarity scores, and compared to the ranking of the same pairs after the automatic computation of the similarity scores. The pairs with a higher difference between these rankings were analysed for a selection of approaches in the four similarity tests. The difference of the similarity scores was not considered because the scales used by each test and by different approaches is also different.
Table 13,
Table 14,
Table 15 and
Table 16 show the previous analysis, respectively for each similarity test. Several pairs are presented, together with their gold rank, their rank in the best approaches of each kind (knowledge-based and distributional) and the difference between the latter and the gold rank (
). The presented pairs are the top-5 with higher
for each test and approach. Some tables have less than five pairs per approach because some pairs are the same for different approaches.
PT-65 is the smallest test, where all or the majority of the word pairs are covered by the best approaches, so there is no clear reason for the problem with the presented pairs. The exception is meio-dia, not covered by Numberbatch, and thus put in a lower rank by this resource. About the other pairs in a lower rank, we can just say that they are not as strongly related in the exploited resources as they probably should.
In SimLex-999, several pairs include one multiword expression, with less probability of being covered by the exploited resources. In the English version of SimLex-999, these were not multiwords, but they became so after translation, because there was no suitable Portuguese singleword with exactly the same meaning, at least for those presented. A related issue results from a highly debatable option in the creation of the All-LKB, where prepositions and pronouns in the end of the multiwords were removed, for uniformisation purposes. This means that the All-LKB contains the multiword ter_direito (roughly, “have the right to”) and several others matching ter_direito_a_X, where X is a verb, but not ter_direito_a. The same LKB does contain reunir, but not reunir-se. For cama_de_bebé the problem is different. The All-LKB covers this term, but written in the Brazilian way (cama_de_bebê). Another writing issue occurs for the pair {visão, perceção}. Although the All-LKB covers both words, visão is not directly related to perceção, but to percepção, a synonym written according to the old Portuguese norm. This analysis also showed that word embeddings do not deal very well with antonyms (namely {levar,trazer}, {lembrar, esquecer}, {perder, ganhar}, {aceitar, rejeitar}).
In WordSim-353, in addition to the multiword expressions, the problematic pairs for the LKBs involve named entities (e.g., Maradona, OPEC, Freud), which are not expected to be covered by LKBs, as the latter typically cover language and not world knowledge. For the distributional models, the issues with the presented pairs is less clear. There are multiword expressions and others, such as: again meio-dia, not covered by Numberbatch; a word that, in English is often used in the plural (clothes → roupas), but has a singular in Portuguese (roupa), which is its only form in Numberbatch; or the name of two drinks that are translated to Portuguese (vodka → vodca, brandy → brande), even though the translation is rarely used.
Finally, in RareWords, two of the problematic pairs for CONTO.PT include words that are covered but not related (vil and cruel; constringir and adstringir), and the other three include an uncovered word. Two of the latter are words (repórteres and consensos) that, for some reason, appear in the plural, though, as well as the other LKBs, CONTO.PT stores words in their lemma form.




{kind=link}
{kind=link}