2. The Toolkit’s Design
In this section, the overall design of the Tawa toolkit shown diagrammatically in
Figure 1 is described. The aim of the toolkit is to simplify the conceptualisation and implementation for a broad range of text mining and NLP applications involving textual transformations. The toolkit presently consists of eight main applications (
align,
classify,
codelength,
decode,
encode,
markup,
segment and
train). These applications are built using three libraries—
TXT for text-based operations,
TLM for language modelling operations, and
TTM for transformation operations.
Underlying the design of these libraries and applications is a novel compression-based architecture called the “Noiseless Channel Model” to distinguish it from the standard “Noisy Channel Model”. The key insight is that each application performs a search to find the best encoding of the target message rather than performing a decoding of the observed message. The noisy channel model is a common architecture for many NLP applications, such as OCR, spelling correction, parts-of-speech (POS) tagging and machine translation [
5]. In this architecture, applications are formulated as a communication process with the source text conceptualised as being sent down a communication channel by the sender, with the receiver trying to recover the original message in the presence of noise by correcting the observed text that is received. This process of text correction involves the search for the most probable corrected target text which is often referred to as decoding (see
Figure 2a). Note that the correct source text is unknown—the search process for the target text makes a best guess as to what it might be.
The noisy channel model leads to robust and effective performance for many NLP tasks despite it being perhaps a rather arbitrary and abstract characterisation for NLP. As an alternative, we wish to adopt language models based on well performing text compression techniques such as PPM which have already been found to be highly effective in many NLP applications [
4,
6,
7,
8,
9,
10,
11]. Therefore, we have also investigated in previous research [
4] an alternative design perspective with an emphasis based on encoding rather than decoding. This has culminated in the architectural design shown in
Figure 2b. This design adheres to two main principles—the communication process must be both
lossless and
reversible. A lossless encoding by definition is reversible with no loss of information, with no noise being added to the message being transmitted. Note that any transformation that occurs prior to the encoding in our approach also needs to be reversible. This is so that there is no loss in information during the communication in order to ensure the message is transmitted correctly and as efficiently as possible and this can be verified during decoding.
The Tawa toolkit based on this architecture has now gone through several design cycles culminating in the latest version of the toolkit described in this paper. In this updated toolkit, an NLP process is not thought of as being one of noisy communication, therefore requiring a decoding process to recover the original message. Instead, the approach taken by the toolkit is to characterise an NLP process as a noiseless or noise-free communication. In this setting, the sender will search for the best encoding of the target message and this is then transmitted losslessly down the communication channel. In this case, the decoding process is of secondary importance, mainly to verify the encoding process—the emphasis instead is placed on how efficiently the target message can be encoded. Also encoded is additional information on how to transform the source message into the target message. In this case, the search process—that of finding the best transformation, plus the information required to transform between them—occurs prior to the encoding phase rather than during the decoding phase. (See
Figure 2b).
Following the workflow in the figure, the sender first starts from a known source text and transforms it in some way (as shown by the dark gray box labelled ‘Transform’) into the target text. This is the text that is the desired output for some application (such as compression, text mining, spelling correction, machine translation and so on). In order to illustrate the variety of possible transformations which includes but goes beyond those traditionally covered by the noisy channel model, some example transformations are listed below. (The first two examples below are transformations possible using a related tag insertion approach [
12] that was similar to what was implemented in an earlier version of the toolkit. However, the subsequent examples above go beyond the tag insertion approach and are used to illustrate what is possible in the updated toolkit):
inserting markup tags into the text (called tag insertion), such as to indicate where different languages are in the text for language segmentation [
7,
13];
inserting extra characters, such as spaces for word segmentation [
9];
changing the alphabet, such as replacing common character bigraphs or word bigrams with new symbols to aid compression [
6,
14];
transforming the text into a grammar, such as for grammar-based compression [
15];
encoding extra information such as POS tags for POS tagging and tag-based compression [
6,
16];
switching between models used to encode each symbol in the text [
7,
17].
The transformations are done in such a way that they are reversible (as shown by the line labelled ‘Reverse transform’ in the figure). If tags or spaces are added, for example, then these can simply be removed to recover the original source text without any loss of information. If the alphabet is altered, then there is a one-to-one mapping between the old and new alphabets so that the original source text is easily recoverable. This property of reversibility ensures that information is communicated losslessly.
The target text is then encoded to produce the compressed target text (as depicted by the dark gray box labelled ‘Encode’). A search process shown in the figure by the rightmost arrow is used to find the most compressed text by repeatedly trying out different variations of the transformation (for example, by inserting or not inserting spaces after each character if performing word segmentation). This search can be thought of as the transformation & encoding phase whose purpose is to generate a suitable target text. This search may also require extra transformations in order to ensure that the encoding is fully reversible (for example, reversible word segmentation requires replacing any existing spaces with another unique character so that the original text can be unambiguously recovered).
The remaining parts of the workflow shown in the figure is the verification & decoding phase. This step is not necessarily needed depending on the application since just producing the target text will usually be sufficient in order to complete the task(s) required. However, as argued below, verification is of fundamental importance in ensuring the output is correct. This is done by sending the compressed target text down a noise-free communication channel, and then checking that the decoded target text matches the original target text.
Mahoui et al. [
4] pointed out that the noiseless channel model could be viewed simply as “the noisy channel model in another guise”. This is because the search processes (e.g., the Viterbi algorithm [
18]) produce a similar result with the best target text being found in both cases. However, as Mahoui et al. have argued, there are important differences. Firstly, when designing text compression systems, it is well-known that the encoding and decoding processes are not necessarily equivalent (for example, often either the encoding or decoding process can take noticeably longer as further effort is required to maintain probability tables in the form required for coding).
Secondly, the perspective has changed from correcting ‘noise’ (which is just one approach to NLP) to one of efficiently encoding the source text plus further information to transform the message into the target text (which can be considered an equally plausible alternative approach to NLP).
Thirdly, as stated, the decoding process for the noiseless channel model provides a means for physically
verifying the correctness of the communication. That is, we can directly apply standard techniques used for lossless text compression by checking that we can directly encode and decode the target message to and from a file on disk. (That is, there is a physical measurable object that exists in the real world). The noiseless channel model makes it clear that all information must be transmitted. Many current approaches using the noisy channel model base the decoding on implicit information and make the assumption that this information has little or no effect on the accuracy of the transformation. This may be correct, or erroneous, but this first needs to be verified, which is one of the main arguments for supporting the alternative approach in
Figure 2b. All necessary information must be encoded explicitly otherwise it would not be possible to get the decoder to work. As a consequence, the encoding codelengths (how much it takes in bits to physically encode the information) becomes a useful and verifiable means for measuring the effectiveness of the language models being used.
And fourthly, the changed perspective opens up further possibilities for improved language models based on models found effective for lossless text compression, such as: alternative encoding methods, not necessarily probabilistic, e.g., the Burrows Wheeler Transform [
19] and Lempel-Ziv methods [
20,
21]; methods for preprocessing the text prior to encoding [
22,
23]; and hybrid methods for combining or switching between models [
17,
24].
It is also clear from
Figure 2 that the source text for the noiseless channel model is known when it is encoded which contrasts with the noisy channel model where the original source text is unknown. This is a fundamental difference that must be considered when designing applications based on these two architectures. In the noiseless case, the designer has access to all the information from the source text (since it is known) during the search which may be significantly more efficient as a result. For example, one method found effective at improving compression of natural language text is to replace common bigraphs with new single unique symbols prior to compression [
15,
23]. This is a very straightforward task for an encoder working from a known source to find the most common bigraphs. However, bigraph replacement at the decoding stage is not possible in the same way since the original source text is not known.
4. Sample Applications Provided by the Toolkit
This section gives sample pseudo-code for the following nine applications:
a method that encodes symbols using the PPM compression scheme (Algorithm 1);
a context-based encoding method (Algorithm 2);
a context-based decoding method (Algorithm 3);
a context-based method for computing compression codelength without coding (Algorithm 4);
a context-based method for building (“training”) models (Algorithm 5);
a compression-based method for text classification (Algorithm 6);
a compression-based method for verifying sentence alignment in a parallel corpus (Algorithm 7);
a compression-based method for performing word segmentation on a text file (Algorithm 8);
a compression-based method for performing language segmentation on a text file (Algorithm 9).
These examples are used to illustrate the use of methods from the toolkit’s libraries. Also, a further purpose of the examples is to illustrate the brevity of the solutions especially the algorithms for word segmentation and language segmentation considering the complexity of each of these applications which is hidden to the most extent from the developer.
In addition, these algorithms adopt the key insight of separation of encoding into
modelling and
coding processes as proposed by Rissanen and Langdon [
25] which was an important and seminal contribution for the field. There are a number of papers that have improved on this simple design in often subtle ways that at first glance seem trivial (see, for example, [
6,
27]). These subtle variations are also very important contributions to the field. We argue that the algorithms included in this paper also provide similar subtle variations that can be considered contributions in the same vein.
4.9. Applications Implemented by the Toolkit
The algorithms detailed above have all been implemented using the Tawa toolkit’s libraries in the C programming language.
Table 3 summarises these applications that come bundled with the toolkit. The table lists for each application its name (in bold font), a short description (in bold and italic fonts), the algorithms detailed above they are based on and selected arguments. The
encode,
decode and
train applications for PPM compression, decompression and model building, for example, use similar arguments which specify amongst other things the argument size, order of the model, and whether the model performs full exclusions and update exclusions. The
train application has additional arguments for specifying the title of the model, and whether the model should be written out as a static model. The
markup and
segment applications use arguments for specifying whether Viterbi search should be adopted, and the stack depth if the stack algorithm should be used instead.
These application arguments provide a wide range of possible settings that have proven to be very effective in many NLP experiments as summarised in
Section 5. Many further possible uses still exist for these applications which have the advantage that they can be used “off-the-shelf” without the need to perform any further development using the toolkit’s libraries.
Some examples of shell commands and output using these applications are shown in
Table 4. The purpose of including these here is to demonstrate typical use and also some of the possibilities offered by the commands. Line 1 provides an example of typical use for the
encode application. In this case the raw text from the million-word Brown corpus of American English [
39] in the file
Brown.txt is being encoded (compressed) to the file
Brown.encoded using the order 5 PPMD algorithm (which is the default) with an alphabet of 256. Some summary data is output when the program completes such as the number of input bytes, the number of output bytes and the compression ratio of 2.152 bpc (bits per character). Line 2 provides the command that can be used to decode (decompress) the encoded file, and the
diff command on Line 3 confirms that the decoded file is the same as the original file since no differences are produced as output.
Line 4 provides an example of how the
train command can be used to build a model. In this case, the Brown corpus is being used to train a static order 5 PPMD model which is written out to the file
Brown.model when the command completes. Line 5 loads the model directly into memory (without the need for processing the original training text which is much slower), and then uses it to encode another text, the raw text from the million-word LOB corpus of British English [
40] in the file
LOB.txt with a compression ratio of 2.191 bpc for the encoded output file
LOB.encoded. Line 6 encodes the LOB corpus directly without loading a model, therefore will use a dynamic model that adapts to the text being encoded (i.e., at the beginning, the model is empty but is updated as the text is processed sequentially). The compression ratio of 2.131 for this adaptive approach is slightly better than the static approach used in Line 5 despite the dynamic model being empty at the start. This is a typical result for PPM models and reflects the effectiveness of these models at adapting quickly to the specific nature of the text. Also, the earlier language in the source document (British English in this case from the LOB corpus) is often a better predictor of subsequent text in the same document rather than using some other source to prime the encoding model in advance (American English from the Brown corpus).
Line 7 provides an example of the use of the codelength tool. This application computes the compression codelength without the need for performing any physical coding which is much slower since it requires performing I/O operations. In the example, a list of models trained on Bibles in various languages (English, French, German, Italian, Latin, Mori and Spanish) is specified in the text file (models.txt). These models are loaded and then the compression cross-entropies for each of these models is calculated for the source text (the Brown corpus). The output clearly shows that the English Bible model is a better predictor of American English with a compression ratio of 3.514 bpc compared to the compression ratios produced by models for the other languages (all above 5.4 bpc).
The command on Line 8 uses the segment tool to perform word segmentation using the Viterbi algorithm on a sample text (woods_unsegm.txt) which contains the text for Robert Frost’s poem Stopping by Woods on a Snowy Evening with spaces removed. The Brown corpus model is used as the training model. The output text file produced by the tool is then compared to the correct text using the diff command on Line 9. The output produced shows that the word segmentation tool has made just one mistake: “down yflake” instead of “downy flake”.
The language segmentation tool is being used on Line 10. In this case, the same Bible models specified in the file
models.txt that were used on Line 7 are used again to define the possible languages for the segmentation, with the Viterbi search being used to find the most compressible sequence for all possible segmentations of languages at the character level. The output produced on the sample text (an extract from the M
ori-English Niupepa collection from the NZ Digital Library [
41] from the mid-19th to early-20th centuries) shows that only two languages were detected (M
ori and English) and the other languages did not appear in the final segmented text that was output. The output shown contains only one error (“
Kainga” should be tagged as M
ori text).
4.10. Implementation Details, Memory Usage and Execution Speeds
This section discusses some implementation details for the toolkit applications, as well as their typical memory usage and execution speeds.
Table 5 provides execution speeds and memory usage for the commands in
Table 4 (ignoring commands 3 and 9 which do not use any of the toolkit’s applications). The execution speed is calculated from the average of 10 runs of the command on a MacBook Pro (15-Inch Retina display running OSX El Capitan Version 10.11.6 with 2.5 GHz Intel Core i7 processor and 16 GB 1600 MHz DDR3 memory). The memory usage is provided in megabytes and represents the maximum resident set size as reported by the
/usr/bin/time -l command.
From the average execution speeds in
Table 4, commands 1 and 2 show that for the Brown corpus, unprimed encoding is slightly faster than decoding (7.3 s as opposed to 8.0 s). This is a typical result for PPM compression and is due to way the arithmetic coding ranges are decoded by the toolkit. (This result backs up the statement in
Section 2 concerning that “the encoding or decoding process are not necessarily equivalent”). In the PPM case, the encoding process is usually quicker but this depends on the implementation. The average speed for command 4 shows that building a model from the Brown corpus takes a similar amount of time to the encoding. This is because the text processing is similar, and the difference is because the
train command needs to perform I/O to write out the model at the end whereas the encoding program needs to write out the arithmetic encoding stream as each symbol in the text is processed one-by-one. The result for command 5 shows that using a static (pre-primed) model for encoding purposes is significantly quicker than using a purely adaptive dynamic model (5.0 s versus 7.2 s for command 6). Command 7 loads seven static models and uses each of them to process the Brown corpus text and therefore this takes considerably longer than the other commands as the Brown corpus is processed multiple times using the approach adopted in Algorithm 6. The results for Commands 9 and 10 shows that word segmentation is very fast (just 0.18 s), and language segmentation is also relatively fast (1.6 s). The slower time for the latter is because the branching factor of the tree being searched is seven (for the seven Bible models in different languages) as opposed to just two for the word segmentation problem.
Referring to the memory usage figures in
Table 4, commands 1, 2, 3 and 6 all use similar amounts of memory as they need to build in memory a dynamic PPM model for either the Brown corpus or the LOB corpus. Commands 5 and 9 in contrast load a static model of the Brown corpus, so hence use significantly less memory (roughly 14 Mb as opposed to 21 or 22 Mb). Command 7 needs to load the seven static Bible models so therefore uses the most memory of any of the commands; similarly, command 10 also needs to use the same seven models but uses less memory (34 Mb as opposed to 56 Mb) as the text being processed is much smaller.
Table 6 lists the sizes (in bytes) of some sample texts including the Brown and LOB corpora, the English and Latin bibles, and the Wall Street Journal (WSJ) texts from the Tipster corpus available from the Linguistic Data Consortium. The sizes (in bytes) of the static or dynamic PPMD models for different orders when trained on the texts using the toolkit’s
train tool are listed in the table (in columns 4 and 6). These models store the trie data structure that records all the contexts in the training text and their predictions (i.e., using the frequencies of symbols that follow the context) up to the maximum order of the model. So an order 6 model, for example, will contain information about all contexts of lengths 6 down to 0 plus their predictions. The symbol frequencies stored in the trie are used by the toolkit’s libraries for estimating probabilities and for arithmetic coding purposes. In order to reduce the size of the dynamic model as it is being updated, each dynamic model also maintains pointers back into a copy of the input text when a context becomes unique and this is stored in conjunction with the model’s trie data structure.
Also included in the table are two further texts added for illustration purposes to highlight aspects of the static and dynamic model mechanisms provided by the toolkit. The first, indicated by ‘’ in the table, is for when a dynamic model was first created from the Brown corpus and written out, then the same Brown corpus text was added again after the model was reloaded by the train tool, and then eventually the model was written out to a different model file (either as a static or dynamic model). The second, indicated by ‘’ in the table, is for the case when the Brown corpus was used three times to train the final model.
The table also provides average execution times to build the models across 10 runs (on the same MacBook Pro used for the experiments reported in
Table 4) in columns 5 and 7 for static and dynamic models respectively. In general, the time for building a static model takes roughly 1 MB per second and is on average slightly quicker than for building a dynamic model. However, the time required to build models will depend on the complexity of the model and the length of the text with the models trained on repeated Brown corpus text, for example, being more complex and therefore slower to build, and the order 5 model for the much longer Tipster WSJ text having a much faster build rate of 1.85 MB per second.
For the model sizes, the results show that the sizes of the model grow substantially with order, but the rate of growth in model size reduces with higher orders. For example, for the Brown and LOB corpus, the size of the order 6 models is just under twice the size of the order 5 models. This compares with order 4 models being roughly three times the size of the order 3 models. Experiments with PPM models show that model size eventually plateaus even with higher orders [
6] (pp. 138–139). A comparison between the static model sizes and the dynamic model sizes shows that the former is consistently between 0.56 and 0.6 of the latter. This is due to the method used to prune the dynamic model’s trie stored in the model when it is written out to a file on disk in static form. The size of the static models compared to the size of the Brown and LOB source texts ranges from approximately four times for the order 6 models, twice for the order 5 models and down to once and 0.3 times for the order 4 and 3 models respectively. With much larger training size, however, the ratio of the model size to text size reduces significantly. For example, for the Tipster WSJ text, the size of the static order 5 model is pruned down to just 0.4 of the size of the text.
Further pruning is also possible when a dynamic model is written out in dynamic form as opposed to static form. When the model is written out as a dynamic model, the copy of the input text that is stored in the model can be substantially pruned by removing those parts which no longer have any possibility of being required for future updates of the trie (since the model has a fixed maximum order and the maximum depth of the trie has already been reached for some contexts). The trie pointers have to be changed to point at the new positions in the pruned input text copy. This pruning can lead to substantial reductions in the size of the models being stored. The percentages of the input text that need to be kept are shown in the last column of
Table 6. For example, when the order 6 models of the Brown and LOB corpora are written out in dynamic form, the input text copy stored in the model can be pruned to just over 16% of the training text size. This reduces even more to roughly 8% for order 5 models, 3% for order 4 models and just under 1% for order 3 models which represents a substantial reduction for these models whose training texts are close to 6 Mb in size. When the training text is much longer, as for Tipster WSJ, then a much greater percentage of the input text can be pruned out (over 98% with just 1.48% remaining). For the cases where the Brown corpus text is used to update a dynamic model twice or three times, then the entire input text copy can be pruned away (i.e., 0% remains) since all leaf nodes in the trie are at maximum depth according to the maximum order of the model with all contexts now being repeated.
4.11. Search Algorithms
The Tawa toolkit implements several search algorithms for the method that is used to search for the best transformation
TTM_perform_transform method). Various search algorithms can be used to prune the search space produced when the transformations specified by one or more calls to the
TTM_add_transform method. Both the Viterbi dynamic programming algorithm [
18] and the stack decoding algorithm [
26] have been implemented in the toolkit and are available for the developer to trade off accuracy, memory and execution speed. The Viterbi algorithm guarantees that the segmentation with the best compression will be found by using a trellis-based search—all possible segmentation search paths are extended at the same time and the poorer performing alternatives that lead to the use of the same conditioning context are discarded.
One of the drawbacks of the Viterbi algorithm is that it is an exhaustive search rather than a selective one, unlike sequential decoding algorithms commonly used in convolutional coding which rely on search heuristics to prune the search space [
42]. Teahan et al.’s [
9] Chinese word segmentation method used a variation of the sequential decoding algorithm called the stack algorithm—an ordered list of the best paths in a segmentation tree is maintained, and only the best path in terms of some metric is extended while the worst paths are deleted. The metric they used was the compression codelength of the segmentation sequence in terms of the order 5 PPMD model. This variation has also been implemented in the toolkit.
In the stack algorithm’s ordered list, paths vary in length (essentially, it is like a best first search whereas the Viterbi search is more like a breadth first search). For deleting the worst paths, the traditional method is that the list is set to some maximum length, and all the worst paths longer than this length are deleted. For Teahan et al.’s [
8] PPM word segmenter and in the toolkit, another variation was used instead. All the paths in the ordered list except the first one were deleted if the length of the path plus
m was still less than the length of the first’s path, where
m is the maximum order of the PPM model. The reasoning behind this pruning heuristic is that it is extremely unlikely (at least for natural language sequences) that the bad path could ever perform better than the current best path as it still needs to encode a future
m characters despite being already worse in codelength. One further pruning method was also found to significantly improve execution speed. As for the Viterbi algorithm, poorer performing search paths that lead to the same conditioning context are discarded. However, unlike the Viterbi algorithm, search paths vary in length, so only poorer performing search paths with both the same length and conditioning context are discarded. These heuristics have been implemented in the toolkit.
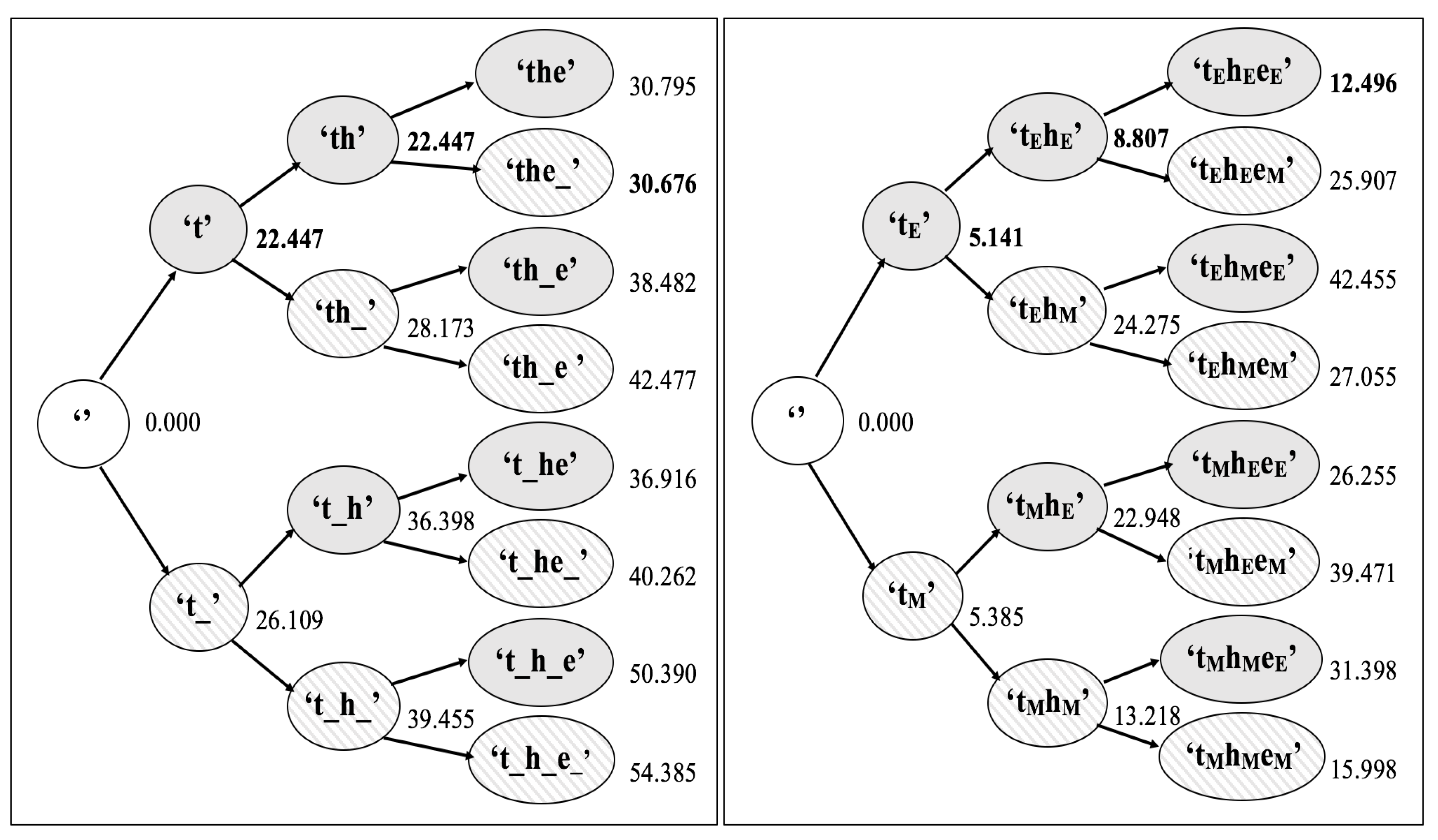
In order to illustrate some important aspects of the search process,
Figure 3 provides examples of initial search trees for the
segment and
markup tools for the small sample text ‘
the’. The search tree for this text for the word segmentation problem (using the tool
segment) is shown in the left box of the figure. The transformed sequences delimited by quotes ‘’ are shown in each node of the tree with an underscore being used (to make it more visible) to indicate where a space has been inserted into the sequence. The root node is for the start of the search where no symbol has been inserted yet. The branching factor of the tree is two as there are two possible transformations—the symbol being processed in the source text is kept unchanged (as represented by the gray nodes); and a space is added after the symbol being processed (as represented by the hashed nodes). So, for example, there are two nodes at level 1 of the tree. Here the first symbol to be processed is the letter ‘
t’. Two possible search paths are generated—one for the letter unchanged (‘
t’) and one with a space added to it (‘
t_’). At the next level, two further nodes are added for each node at level 1, so there are four nodes at level 2, and consequently 8 nodes at the next level and so on.
The search tree for the language segmentation problem (using the tool markup) is shown in the right box. The tree in this example also has a branching of two as only two transformations are being used here for the languages being segmented—English and Mori. Hence the search process is analogous to the word segmentation problem—instead of a space being added or not, the transformation simply decides to encode the symbol being processed using the English model for the gray nodes or using the Mori model for the hashed nodes. The subscripts shown in the transformed sequences within each node indicate which model was used to code each symbol—the subscript ‘E’ if the English model was used and the subscript ‘M’ if the Mori model was used instead. If a symbol switches coding from one model to the other, then the sentinel symbol is encoded which will incur a significant cost as it will have to back off to the null context as a result.
Shown to the right of each node in both trees is the compression codelength for the transformed sequence as calculated by the toolkit (based on a static order 5 PPMD model trained on the Brown corpus for the left box, and static order 5 PPMD models trained on the English and Mori bibles for the right box). The smallest codelength for each level of the tree is shown in bold font. Note that these trees show the complete search tree as if a breadth-first search was being applied. In reality, many of the nodes in the full trees would be pruned away depending on the search algorithm being applied based on these compression codelength values. (For example, for the Viterbi algorithm, all nodes at the same level of the tree with the same conditioning context for the maximum order of the model would be pruned away except for the one with the lowest codelength).
Table 7 lists some experimental results for the two search algorithms implemented by the toolkit—the Viterbi algorithm and the stack algorithm. In this case, the
segment tool was used to segment the first 10,000 words of the unsegmented LOB corpus using a static order 5 PPMD model trained on the Brown corpus with the
train tool. Shown in the table are the following: a description of the algorithm used (including the size of the stack if the stack algorithm was used); the Levenshtein editdistance (
e) between the correct LOB source text and the output produced by the tool (where the cost of a deletion and an insertion was counted as 1, and of a substitution as 2); the editdistance accuracy as a percentage calculated as
where
N was the size of the source text; the average time in seconds to complete the segmentation task for 10 runs on the MacBook Pro; and the number of nodes that were generated in the search tree as a measure of the memory used. The results show that the Viterbi algorithm produces the least number of errors, and the number of errors reduces with a larger stack size for the stack algorithm as expected. However, the time and memory results show that a smaller stack size runs more quickly (twice as fast when the stack size is only 5) and uses less memory but at a cost in reduced accuracy. Therefore, if speed and/or memory is a concern (when processing many texts or texts that are much larger in size), then accuracy can be traded for improved speed and memory by choosing the stack algorithm. These results mirror those published for the Chinese word segmentation problem using an earlier version of the toolkit [
7] and confirm that the latest version produces similar behaviour.
6. Related Work
Many different toolkits, suites, architectures, frameworks, libraries, APIs and/or development environments have been produced over the years for NLP purposes and more specifically for statistical NLP. The use of these terms to describe the functionality and nature of the various NLP systems and approaches have often been inconsistent in the literature. For example, Cunningham [
43] stated for the GATE system—a general ‘architecture’ for text engineering—that it “
is generally referred to as an ‘architecture’, when, if we were a little more pedantic, it would be called a framework, architecture and development environment”. The meaning of the term ‘framework’ in software engineering has also evolved over the years—its more specific meaning in recent years requires that a framework has the key characteristic of ‘inversion of control’ where a framework must handle the flow of control of the application. This characteristic is not appropriate for the design used for the Tawa toolkit’s libraries which do not handle the flow of control in many of its applications (except for when
objects are used). The meaning of the term ‘architecture’ is clearer in the literature—it involves the abstract design concepts and structures behind an application. For these reasons for the work described in this paper, the well accepted terms toolkit, libraries and architecture have been used to describe the system, and its design and implementation.
Table 9 lists a selection of systems that have been developed for NLP. The table lists the name of the system, a reference, the type of system described using terms used by the developers of the system and the language(s) in which the system has been developed. The table illustrates that there have been many systems developed to date in a number of different programming languages with Java predominating. The preferred type of system is a toolkit and/or an external library being available. These systems in general provide a suite of tools for various applications, such as tokenisation, classification, POS tagging, named entity recognition and parsing being the ones provided the most.
A number of further freely available systems that have been developed by the NLP research community are based on a range of underlying architectures including those listed in
Table 9. For example, DKPro and ClearTK are two examples that use the UIMA framework architecture for analysing unstructured information. Alternatively, some of the systems are primarily designed around a core external library or libraries that can be called from an application. Often these systems are not described as having an underlying architecture (for example, FreeLing, NLTK and OpenNLP in the table). The two main approaches all of these systems use for text processing involve a rule-based approach (either manually designed or automatically generated) and statistical. These systems also predominantly process natural language text in a word-based manner.
What distinguishes the Tawa toolkit from most of these systems is threefold: firstly, the toolkit is character-based; secondly, the design of the applications is based around an integrated compression-based architecture; and thirdly, none of the toolkits in the table (apart from Tawa itself), provide explicit support for compression-based applications. Tawa is also written with carefully memory-managed C code for each object type and is designed to be memory efficient and fast.
Like the Tawa system, the LingPipe system also uses character language models but uses the noisy channel model approach for various applications. Using a character or symbol-based approach means that methods used for solving the tasks required for applications can be quite different to the traditional word-based approach. For example, the Tawa toolkit for classification avoids the need for explicit word-based feature extraction and simply processes all the characters in the text being classified.
The application of compression-based models to NLP has had a long history and one of the main purposes of the Tawa toolkit is to make these models more easily available for developers to use. In many cases, the applications implemented using these models have produced state-of-the-art results. For example, PPM character based language models have been applied successfully to many applications in NLP [
6] such as language identification and cryptography [
51] including various applications for automatically correcting words in texts such as OCR and word segmentation [
8,
9] (also see
Table 8 for a further selection of results).
Text mining and named entity extraction in Tawa can also be performed using character-based language models using an approach similar to that used by Mahoui et al. [
4] to identify gene function. Bratko [
52] have also used data compression models for text mining, specifically for spam filtering. Witten et al. [
10,
11] have shown how text compression can be used as a key technology for text mining. Here, character-based language modelling techniques based on PPM to detect sub-languages of text instead of explicit programming are used to extract meaningful low-level information about the location of semantic tokens such as names, email addresses, locations, URLs and dates. In this approach, the training data for the model of the target text contains text that is already marked up in some manner. A correction process is then performed to recover the most probable target text (with special markup symbols inserted) from the unmarked-up source text. Yeates et al. [
12] show how many text mining applications can be recast as ‘tag insertion’ problems such as word segmentation and identifying acronyms in text [
53] where tags are re-inserted back into a sequence to reveal the meta-data implicit in it. Teahan & Harper [
17] describe a competitive text compression scheme which also adopts this tag insertion model. The scheme works by switching between different PPM models, both static and dynamic (i.e., that adapt to the text as it is being encoded). Tags are inserted to indicate where the encoder has switched between models. Tag insertion problems, however, are just part of a much broader class of applications encompassed by the noiseless channel model and therefore possible using the Tawa toolkit. The toolkit diverges substantially from the tag insertion model of Yeates et al. [
12] (by allowing regular expressions and functions in the specification of both the matching source sequence and corrected target sequence) and arguably also the noisy channel model approach (for example, by making it easier to combine models using hybrid encoding methods or by using preprocessing techniques to modify alphabets).














{kind=link}
{kind=link}
{kind=link}