Improving Collaborative Filtering-Based Image Recommendation through Use of Eye Gaze Tracking


Abstract
:1. Introduction
2. Literature Review
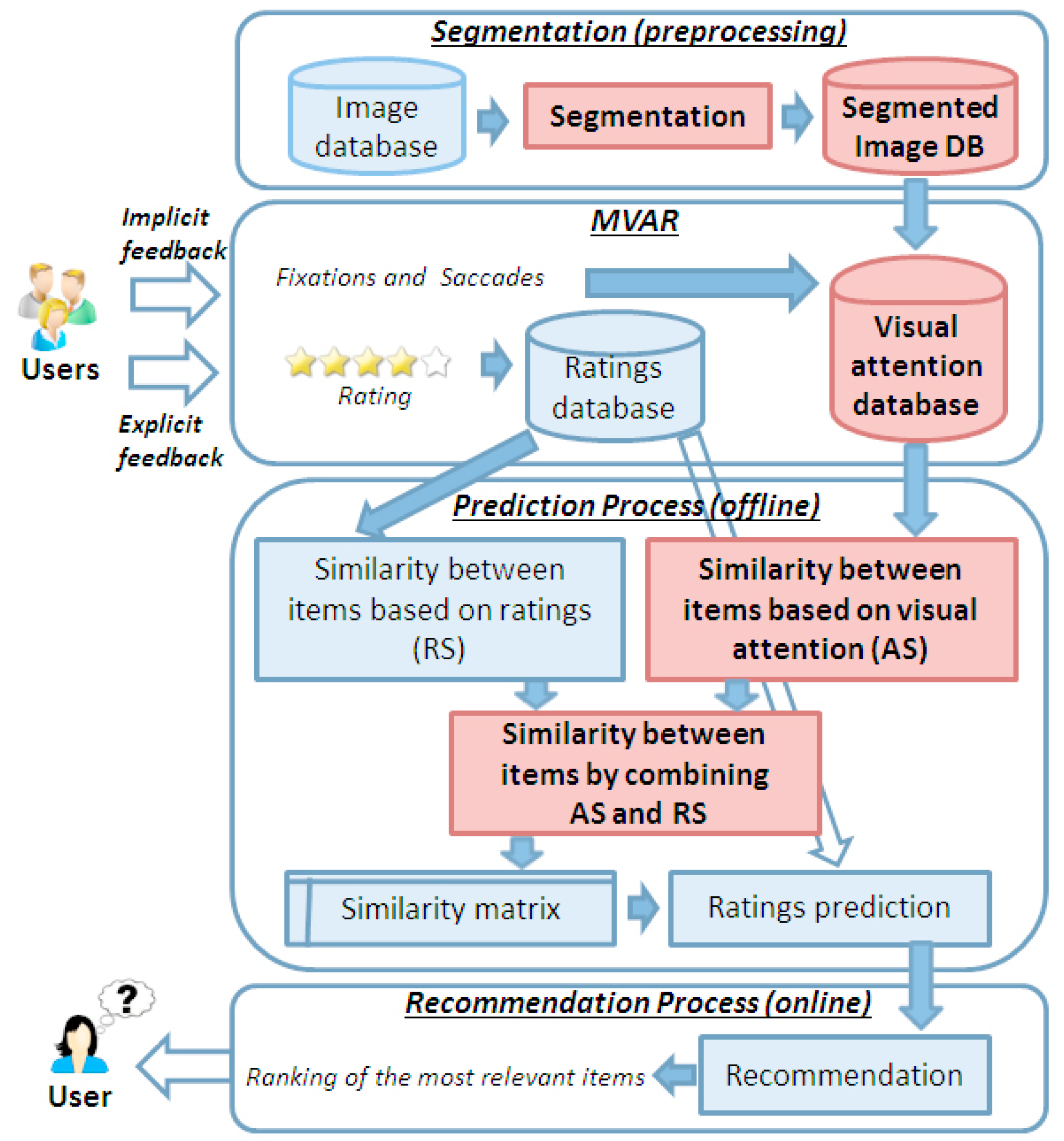
3. A Proposed Image Recommendation System
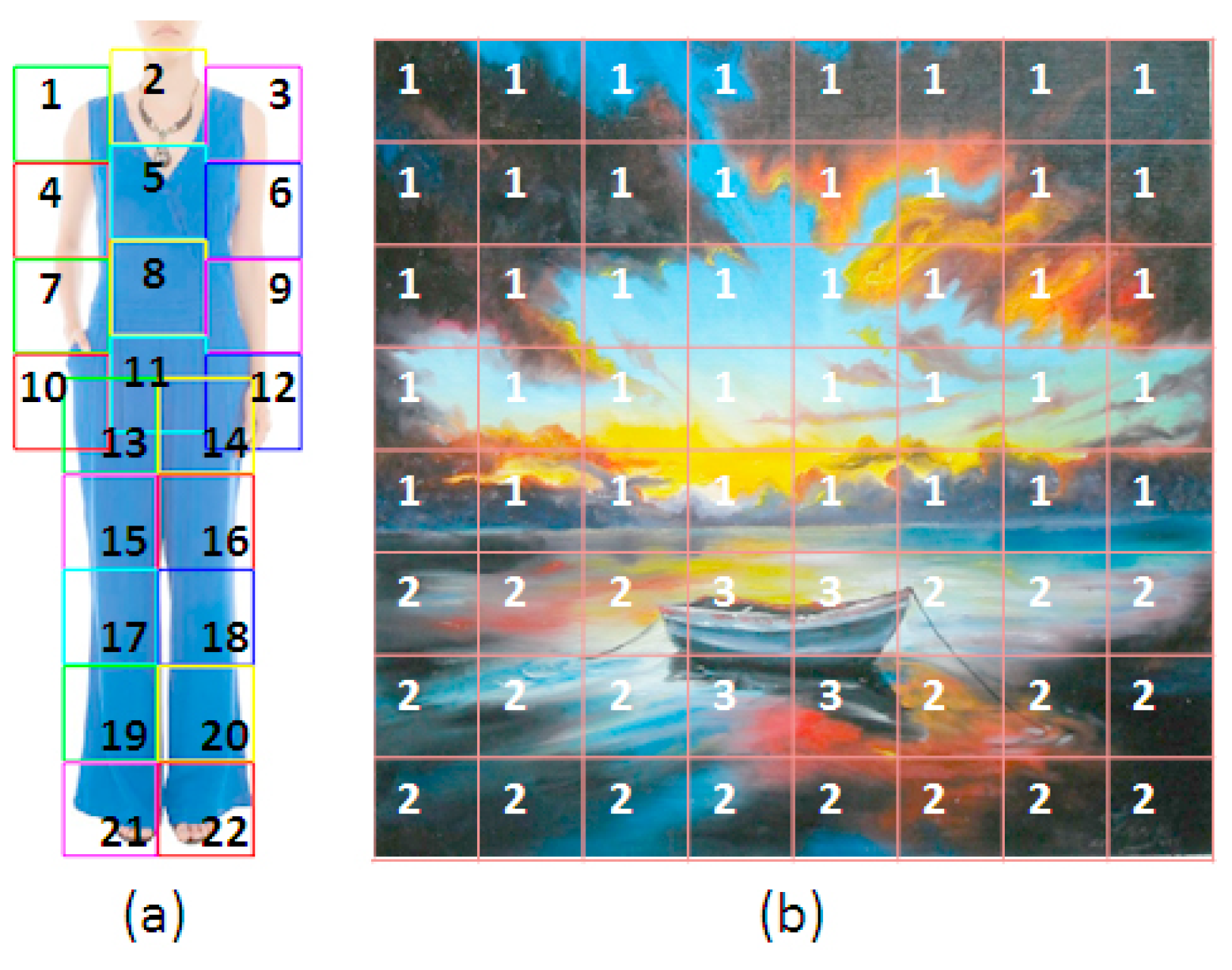
3.1. Segmentation Process
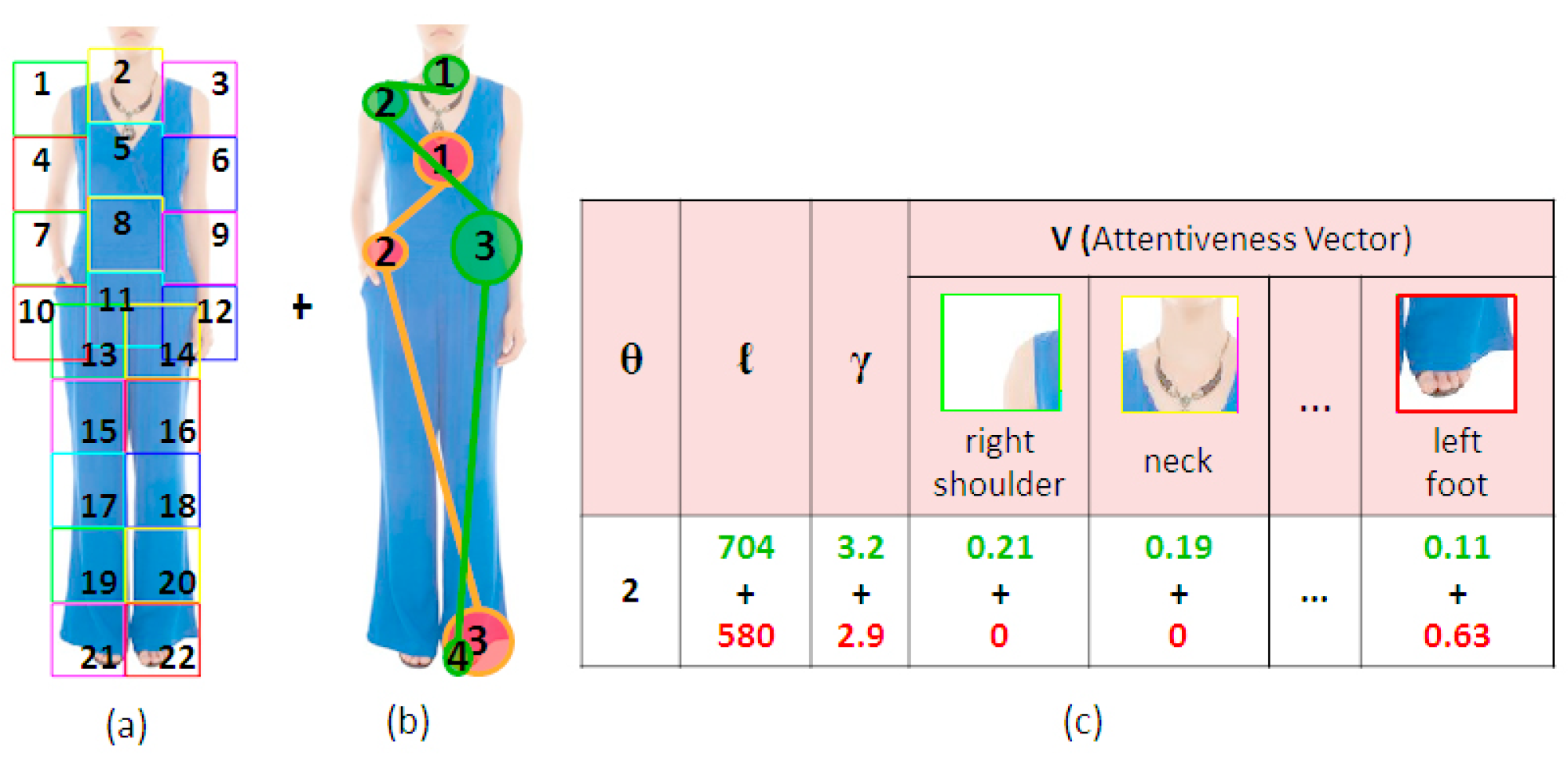
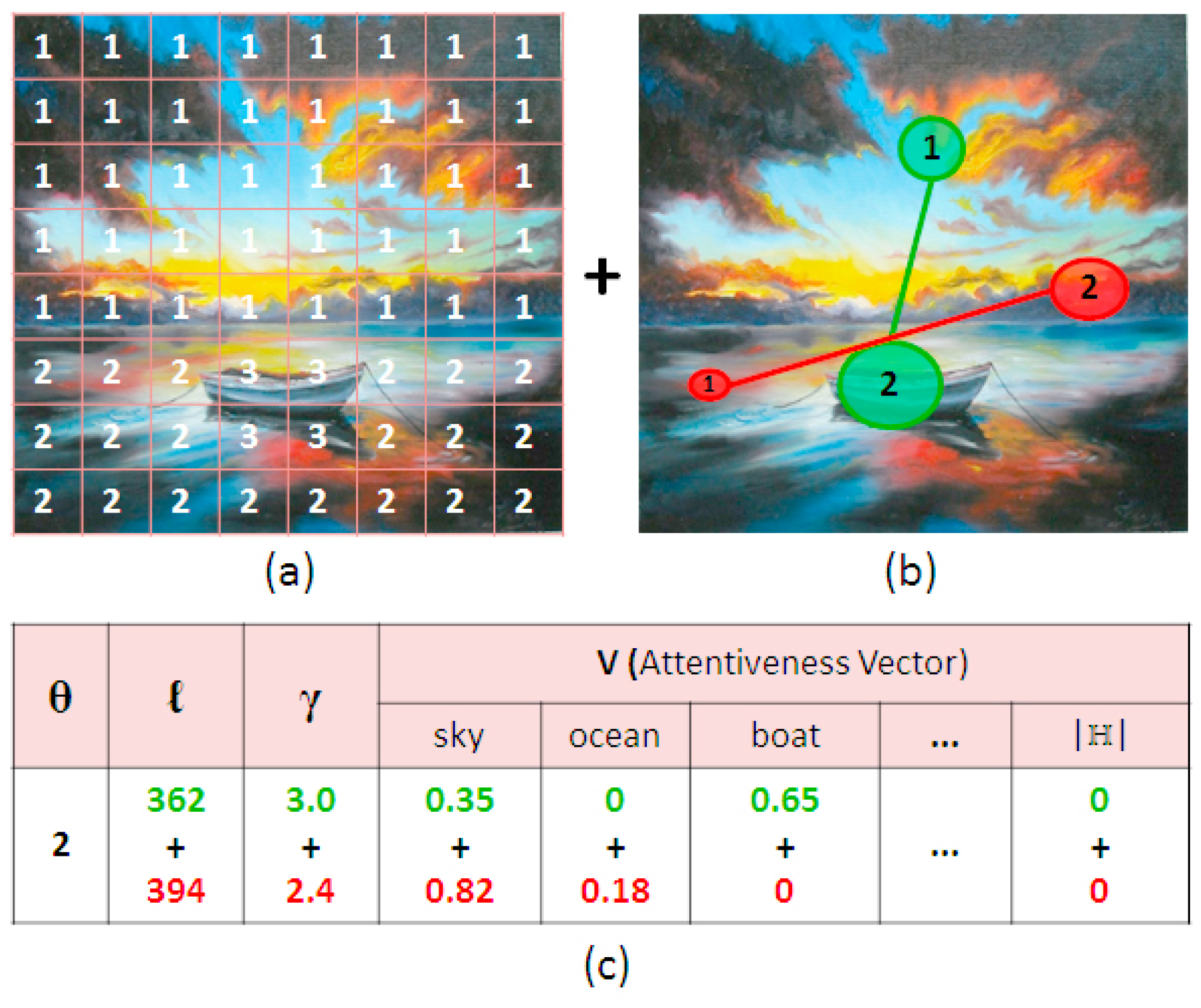
3.2. Management of Visual Attention and Ratings (MVAR)
3.3. Prediction Process
3.4. Recommendation Process
4. Methodology of the Experiments
4.1. Experimental Setting
4.1.1. Database
4.1.2. Evaluation Criteria
4.1.3. Assessing Statistical Significance
4.1.4. Comparison Algorithms
- UserKNN + Baseline (UKB): This method [11] predicts an unknown rating as a weighted average of the ratings of neighbouring users, while adjusting for user and item biases effects.
- SVD: This is the traditional matrix factorization model [11].
- SVD + Baseline (SB): This is the matrix factorization model with user and item biases. This model [27], also called Biased MF, is widely used as a baseline in recommender systems.
4.1.5. Parameter Setting
- (ii) We chose a linear aggregation function (Equation (11)) for calculating attentive similarity, using for the database UFU-CLOTHING and for database UFU-PAINTINGS (the size of the saccades is not relevant information for the painting domain);
- (iii) We adopted the shrinkage parameter from Equation (6);
- (iv) A linear aggregation function was also chosen, in accordance with Equation (12), for calculating the combined similarity , using . The similarity was adjusted with the Case Amplification parameter, which adopted the value of 4 for the methods UKB, IKB, and CFAS and the value of 2 for the methods based on latent factors IKB (SVD) and CFAS (SVD).
4.2. Experimental Results and Analysis
4.2.1. Rating Prediction
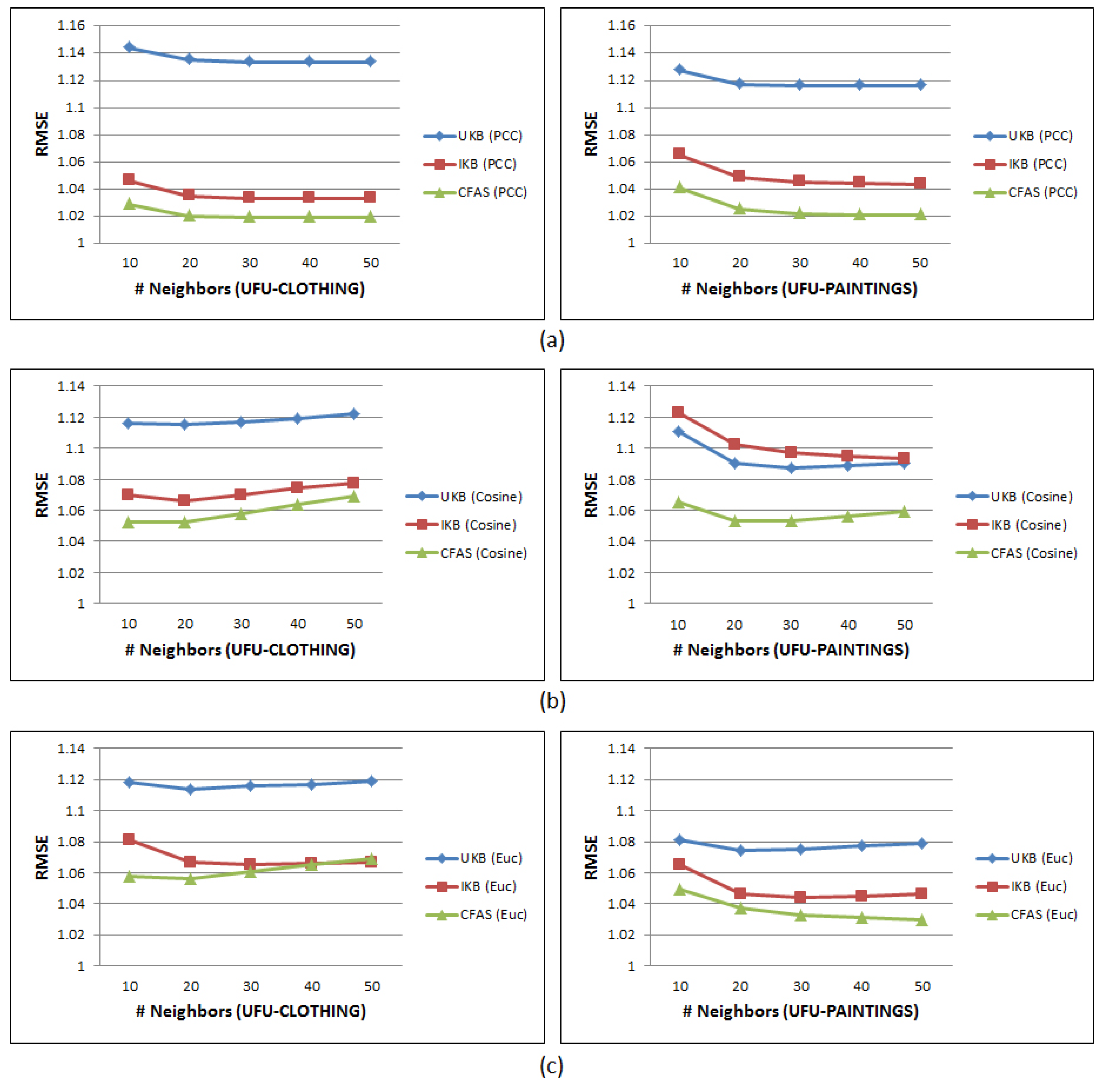
- Methods that use the neighbourhood parameter: The methods UKB, IKB, and CFAS use the neighbourhood parameter. The experiments are executed with a varying number of closest neighbours (k) of 10 to 50 and then the RMSE is computed for each method. These tests are conducted using three similarity measures based on ratings, Pearson Correlation Coefficient (PCC), cosine, and the inverted Euclidean distance (Euc). Figure 5 illustrates the obtained results in terms of RMSE in the database UFU-CLOTHING and UFU-PAINTINGS. It was noted that the similarity measure with the best results was the PCC and that the proposed method CFAS was superior in every case, with gains in relation to the UKB of 7.6% to 10%, and in relation to the IKB from 1.4% to 2.3%.
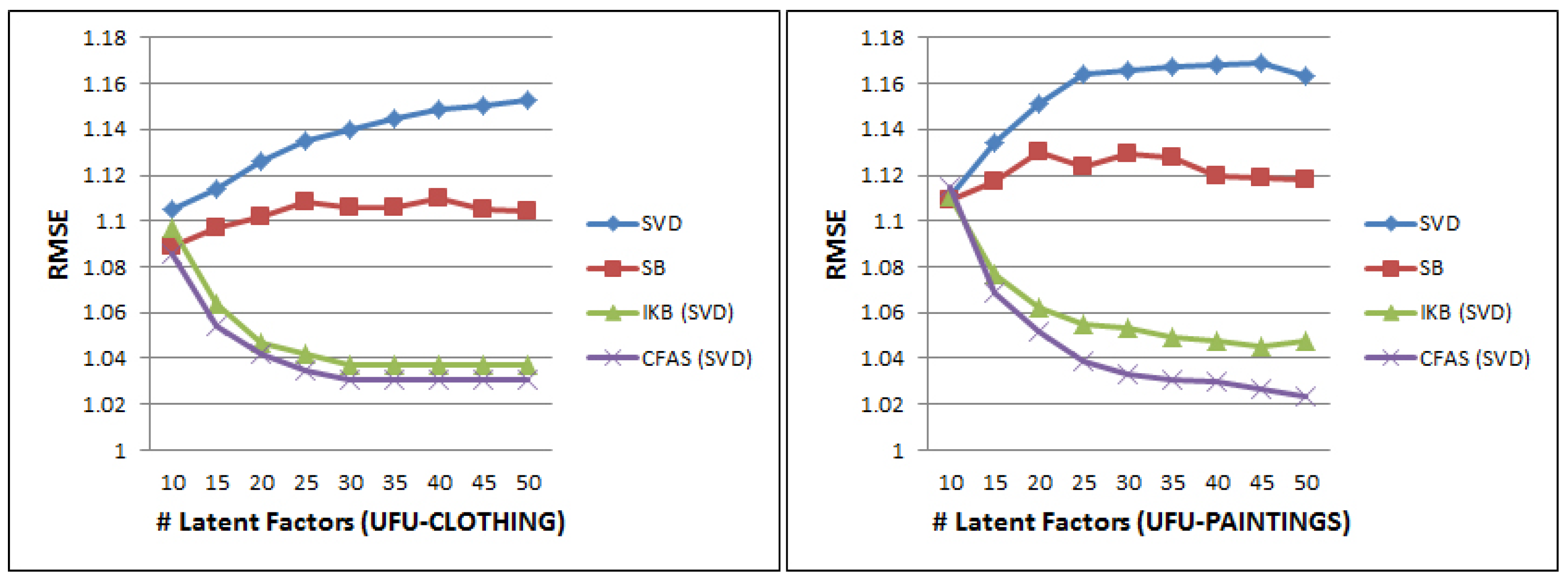
- Methods that use the parameter of latent factors: The CFAS method can combine the similarity between latent factors with attentive similarity, thus denoted CFAS (SVD). The experiments were performed varying the number of latent factors between 10 and 50 for the methods of SVD, SB, IKB (SVD), and CFAS (SVD). Figure 6 shows that the proposed method of CFAS (SVD) was superior in every case, in terms of the RMSE. The gain in relation to the SVD was of 6.7% to 7.9%, in relation to the SB was of 5.3% to 6.1%, and in relation to the IKB (SVD) it was of 1% to 2%.
4.2.2. Recommendation Process
5. Conclusions
Conflicts of Interest
References
- Goldberg, D.; Nichols, D.; Oki, B.M.; Terry, D. Using collaborative filtering to weave an information tapestry. Commun. ACM 1992, 35, 61–70. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, H. Study on recommender systems for business-to-business electronic commerce. Commun. IIMA 2015, 5, 8. [Google Scholar]
- Qin, S.; Menezes, R.; Silaghi, M. A recommender system for youtube based on its network of reviewers. In Proceedings of the 2010 IEEE Second International Conference on Social Computing, Minneapolis, MN, USA, 20–22 August 2010; pp. 323–328. [Google Scholar]
- Wang, M.; Kawamura, T.; Sei, Y.; Nakagawa, H.; Tahara, Y.; Ohsuga, A. Context-aware music recommendation with serendipity using semantic relations. In Semantic Technology; Springer: Berlin/ Heidelberg, Germany, 2014. [Google Scholar]
- Albanese, M.; d’Acierno, A.; Moscato, V.; Persia, F.; Picariello, A. A multimedia recommender system. ACM Trans. Int. Technol. 2013, 13, 3. [Google Scholar] [CrossRef]
- Adomavicius, G.; Tuzhilin, A. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. IEEE Trans. Knowl. Data Eng. 2005, 17, 734–749. [Google Scholar] [CrossRef]
- Lops, P.; De Gemmis, M.; Semeraro, G. Content-based recommender systems: State of the art and trends. In Recommender Systems Handbook; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Ge, Y.; Xiong, H.; Tuzhilin, A.; Liu, Q. Collaborative filtering with collective training. In Proceedings of the Fifth ACM Conference on Recommender Systems, Chicago, IL, USA, 23–27 October 2011; pp. 281–284. [Google Scholar]
- Burke, R. Hybrid web recommender systems. In The Adaptive Web; Springer: Berlin/Heidelberg, Germany, 2007; pp. 377–408. [Google Scholar]
- Koren, Y.; Bell, R. Advances in collaborative filtering. In Recommender Systems Handbook; Springer: Berlin/Heidelberg, Germany, 2015; pp. 77–118. [Google Scholar]
- Koren, Y. Factor in the neighbors: Scalable and accurate collaborative filtering. ACM Trans. Knowl. Discov. Data 2010, 4, 1. [Google Scholar] [CrossRef]
- Jahrer, M.; Töscher, A. Collaborative Filtering Ensemble. In Proceedings of the 2011 International Conference on KDD Cup, San Diego, CA, USA, 21–24 August 2011; pp. 61–74. [Google Scholar]
- Breese, J.S.; Heckerman, D.; Kadie, C. Empirical analysis of predictive algorithms for collaborative filtering. In Proceedings of the Fourteenth Conference on Uncertainty in Artificial Intelligence, Madison, WI, USA, 24–26 July 1998; pp. 43–52. [Google Scholar]
- Stanescu, A.; Nagar, S.; Caragea, D. A hybrid recommender system: User profiling from keywords and ratings. In Proceedings of the 2013 IEEE/WIC/ACM International Joint Conferences on Web Intelligence (WI) and Intelligent Agent Technologies (IAT), Atlanta, GA, USA, 17–20 November 2013; pp. 73–80. [Google Scholar]
- Mobasher, B.; Jin, X.; Zhou, Y. Semantically enhanced collaborative filtering on the web. In Web Mining: From Web to Semantic Web; Springer: Berlin/Heidelberg, Germany, 2004; pp. 57–76. [Google Scholar]
- Dong, R.; O’Mahony, M.P.; Schaal, M.; McCarthy, K.; Smyth, B. Combining similarity and sentiment in opinion mining for product recommendation. J. Intell. Inf. Syst. 2015, 49, 1–28. [Google Scholar] [CrossRef]
- Li, Q.; Kim, B.M. An approach for combining content-based and collaborative filters. In Proceedings of the Sixth International Workshop on Information Retrieval with Asian Languages, Sappro, Japan, 7 July 2003; pp. 17–24. [Google Scholar]
- Jung, J.; Matsuba, Y.; Mallipeddi, R.; Funaya, H.; Ikeda, K.; Lee, M. Evolutionary programming based recommendation system for online shopping. In Proceedings of the Signal and Information Processing Association Annual Summit and Conference (APSIPA), Kaohsiung, Taiwan, 29 October–1 November 2013; pp. 1–4. [Google Scholar]
- Xu, S.; Jiang, H.; Lau, F. Personalized online document, image and video recommendation via commodity eye-tracking. In Proceedings of the 2008 ACM Conference on Recommender System, Lausanne, Switzerland, 23–25 October 2008; pp. 83–90. [Google Scholar]
- Melo, E.V.; Nogueira, E.A.; Guliato, D. Content-based filtering enhanced by human visual attention applied to clothing recommendation. In Proceedings of the 2015 IEEE 27th International Conference on Tools with Artificial Intelligence (ICTAI), Vietri sul Mare, Italy, 9–11 November 2015; pp. 644–651. [Google Scholar]
- Felício, C.Z.; de Almeida, C.M.M.; Alves, G.; Pereira, F.S.F.; Paixão, K.V.R.; de Amo, S. Visual perception similarities to improve the quality of user cold start recommendations. In Proceedings of the 29th Canadian Conference on Artificial Intelligence, Victoria, BC, Canada, 31 May–3 June 2016; pp. 96–101. [Google Scholar]
- Liu, S.; Song, Z.; Liu, G.; Xu, C.; Lu, H.; Yan, S. Street-to-shop: Cross-scenario clothing retrieval via parts alignment and auxiliary set. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3330–3337. [Google Scholar]
- Fu, J.; Wang, J.; Li, Z.; Xu, M.; Lu, H. Efficient clothing retrieval with semantic-preserving visual phrases. In Computer Vision—ACCV 2012; Springer: Berlin/Heidelberg, Germany, 2013; pp. 420–431. [Google Scholar]
- Demšar, J. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Shani, G.; Gunawardana, A. Tutorial on application-oriented evaluation of recommendation systems. AI Commun. 2013, 26, 225–236. [Google Scholar]
- Gantner, Z.; Rendle, S.; Freudenthaler, C.; Schmidt-Thieme, L. MyMediaLite: A free recommender system library. In Proceedings of the Fifth ACM Conference on Recommender Systems, Chicago, IL, USA, 23–27 October 2011; pp. 305–308. [Google Scholar]
- Menon, A.K.; Elkan, C. A log-linear model with latent features for dyadic prediction. In Proceedings of the 2010 IEEE International Conference on Data Mining, Sydney, Australia, 13–17 December 2010; pp. 364–373. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | UFU-CLOTHING | UFU-PAINTINGS | ||
|---|---|---|---|---|
| RMSE | Parameters | RMSE | Parameters | |
| 1. UIB | 1.114 | 1.100 | ||
| 2. UKB | 1.114 | 1.074 | ||
| 3. IKB (PCC) | 1.033 | N:30 | 1.044 | N:40 |
| 4. SVD | 1.105 | L.F.:10 | 1.111 | L.F.:10 |
| 5. SB | 1.089 | L.F.:10 | 1.109 | L.F.:10 |
| 6. IKB(SVD) | 1.037 | N:30; L.F.:30 | 1.045 | N:40; L.F.:45 |
| 7. CFAS (PCC) | 1.019 | N:30 | 1.021 | N:30 |
| 8. CFAS (SVD) | 1.031 | N:30; L.F.:30 | 1.023 | N:40; L.F.:50 |
| Methods | UFU-CLOTHING | UFU-PAINTINGS | ||
|---|---|---|---|---|
| AP@5 | AUC | AP@5 | AUC | |
| 1. UIB | 0.560 | 0.695 | 0.601 | 0.701 |
| 2. UKB | 0.568 | 0.704 | 0.613 | 0.716 |
| 3. IKB (PCC) | 0.627 | 0.743 | 0.631 | 0.736 |
| 4. SVD | 0.589 | 0.718 | 0.611 | 0.709 |
| 5. SB | 0.598 | 0.724 | 0.610 | 0.715 |
| 6. IKB (SVD) | 0.628 | 0.746 | 0.630 | 0.739 |
| 7. CFAS (PCC) | 0.644 | 0.757 | 0.651 | 0.760 |
| 8. CFAS (SVD) | 0.633 | 0.751 | 0.644 | 0.754 |
© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Melo, E.V. Improving Collaborative Filtering-Based Image Recommendation through Use of Eye Gaze Tracking. Information 2018, 9, 262. https://doi.org/10.3390/info9110262
Melo EV. Improving Collaborative Filtering-Based Image Recommendation through Use of Eye Gaze Tracking. Information. 2018; 9(11):262. https://doi.org/10.3390/info9110262
Chicago/Turabian StyleMelo, Ernani Viriato. 2018. "Improving Collaborative Filtering-Based Image Recommendation through Use of Eye Gaze Tracking" Information 9, no. 11: 262. https://doi.org/10.3390/info9110262
APA StyleMelo, E. V. (2018). Improving Collaborative Filtering-Based Image Recommendation through Use of Eye Gaze Tracking. Information, 9(11), 262. https://doi.org/10.3390/info9110262