An Effective Feature Segmentation Algorithm for a Hyper-Spectral Facial Image


Abstract
1. Introduction
2. Related Work
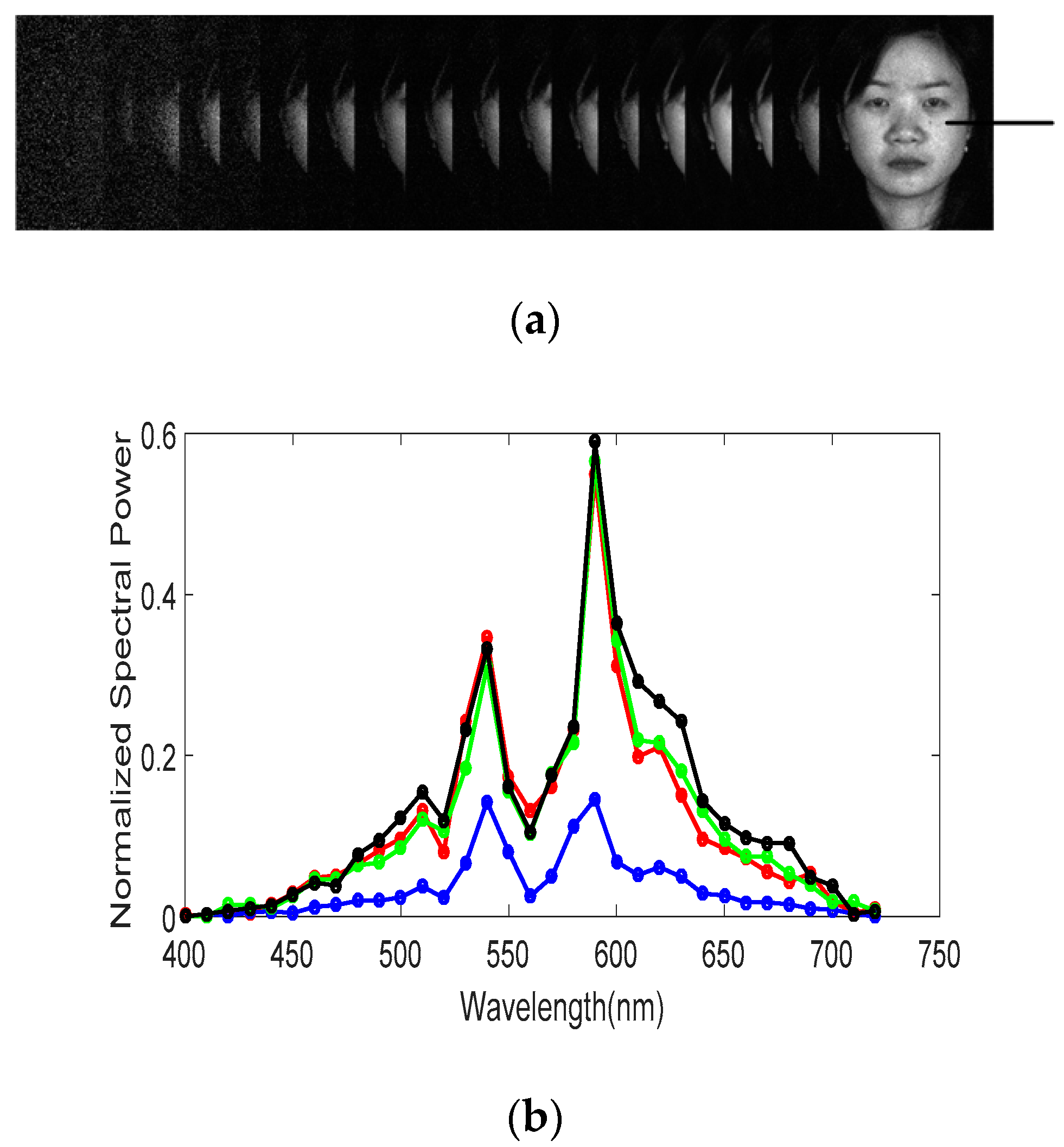
2.1. Hyper-Spectral Images
2.2. Clustering Ensemble
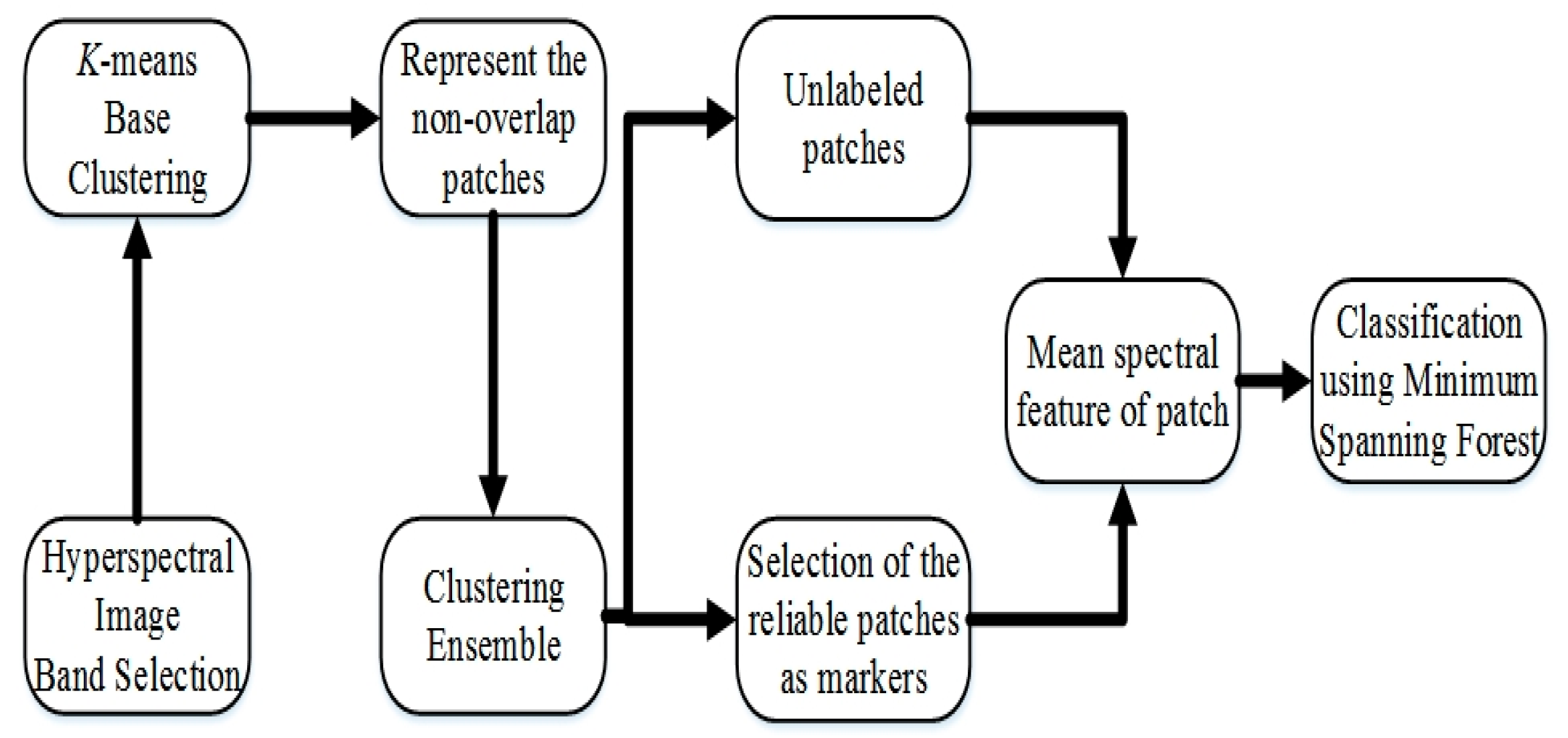
3. Skin Feature Segmentation Scheme
3.1. Band Selection and Generation of Basic Clustering
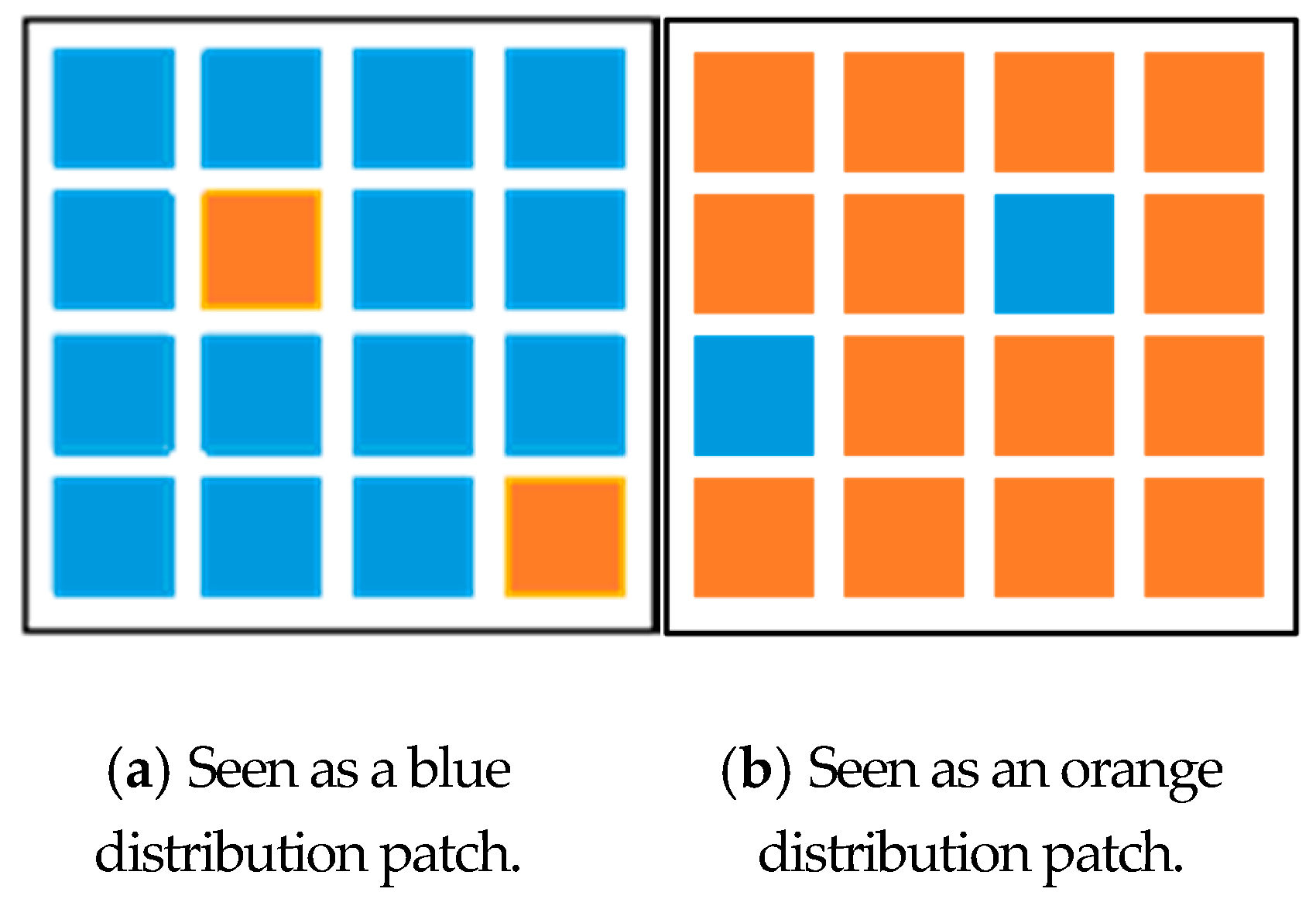
3.2. Construction and Re-Labeling of a Patch
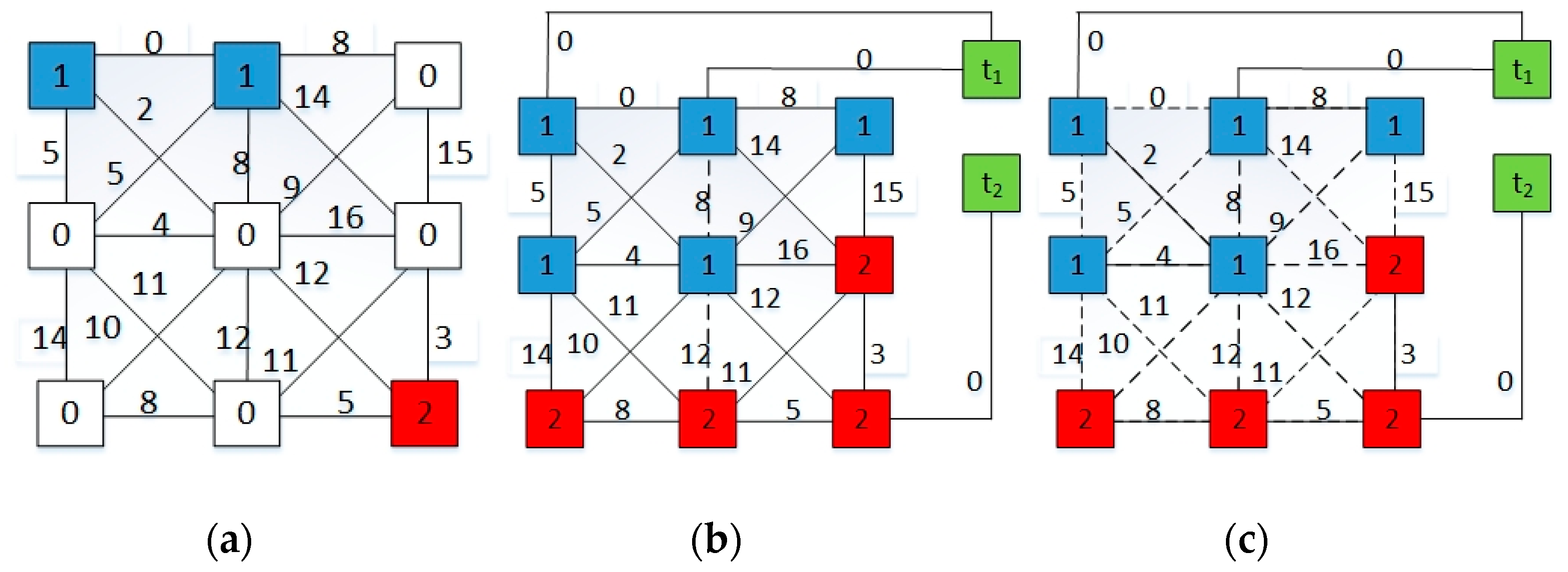
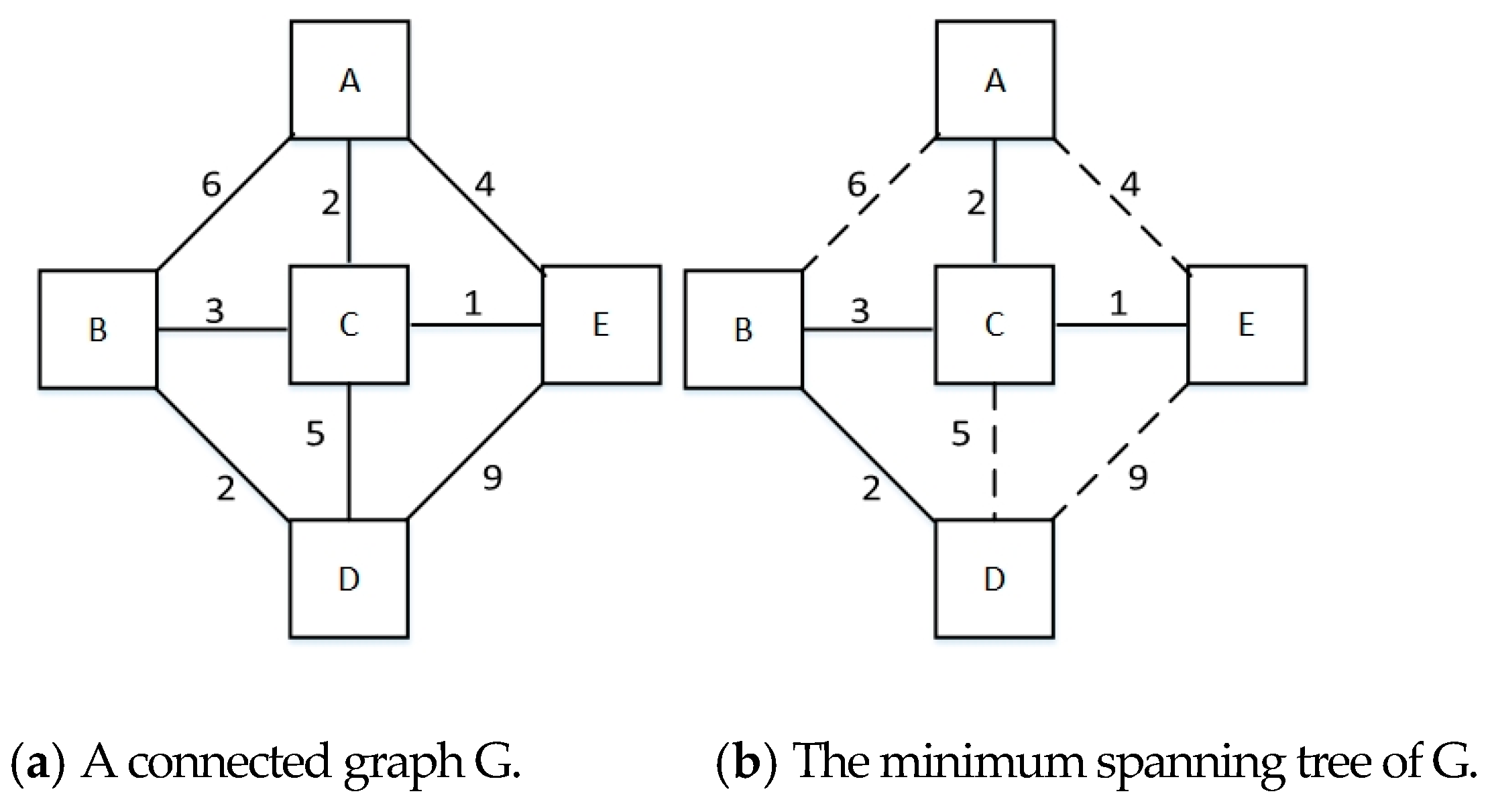
3.3. MSF for Classification
| Step 1: Choose several discriminative basic clusters (see Section 3.2) as the input of the ensemble process.Step 2: The basic clustering is represented by non-overlap neighborhood patch with 2 × 2 pixels. Depict it as a vector and re-represent it by calculating the mean spectral characteristic . |
| Step 3: Integrate selected basic clustering, to obtain the optional patches. Then, select and re-label for reliable patches as markers, from the optional patches. |
| Step 4: Group the adjacent image patches into series of Minimum Spanning Forests with 3 × 3 blocks; and then assign the unlabeled patch to markers according to the SID similarity criterion. |
3.4. Comparison Algorithm
4. Experimental Results and Discussion
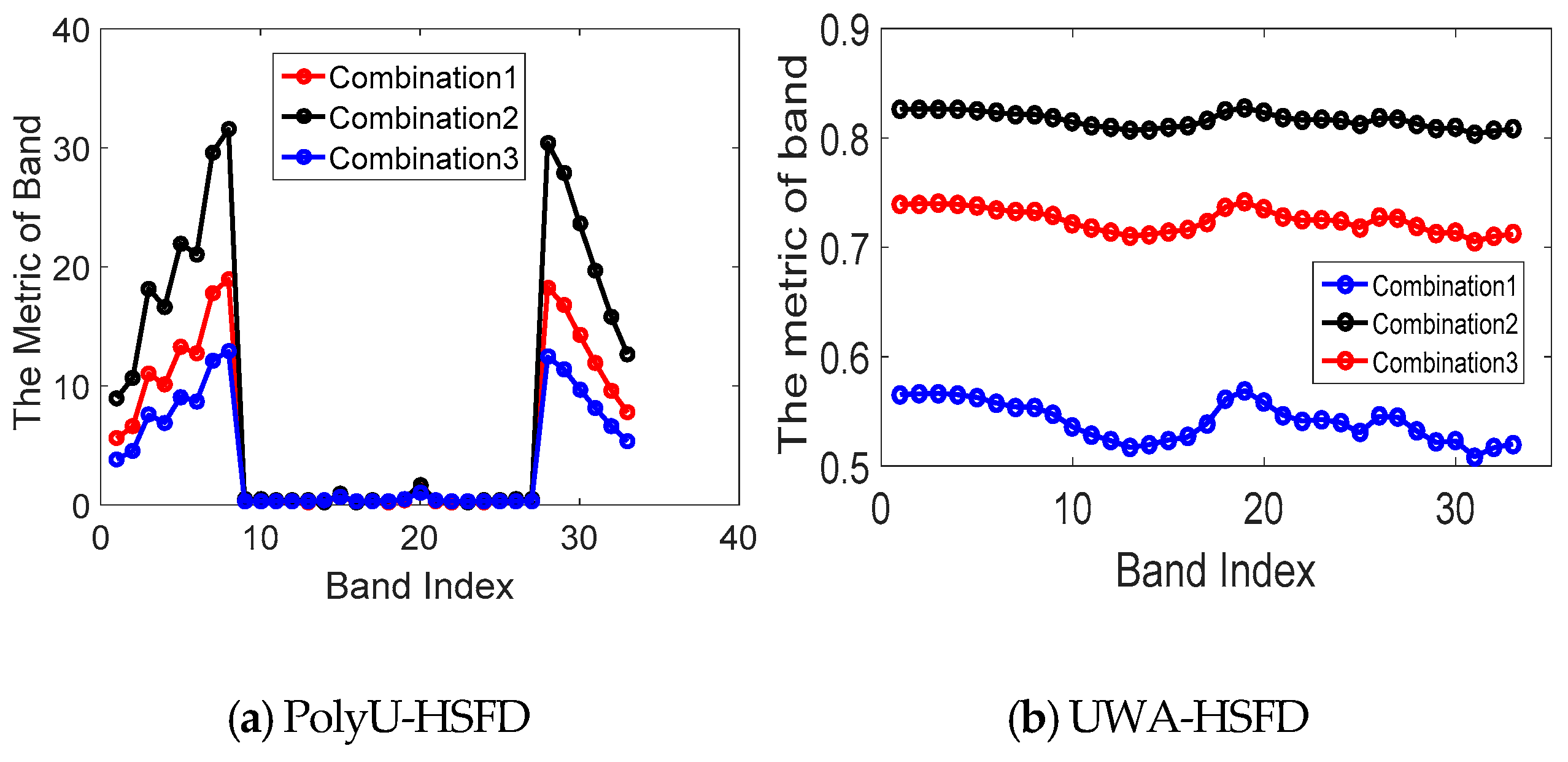
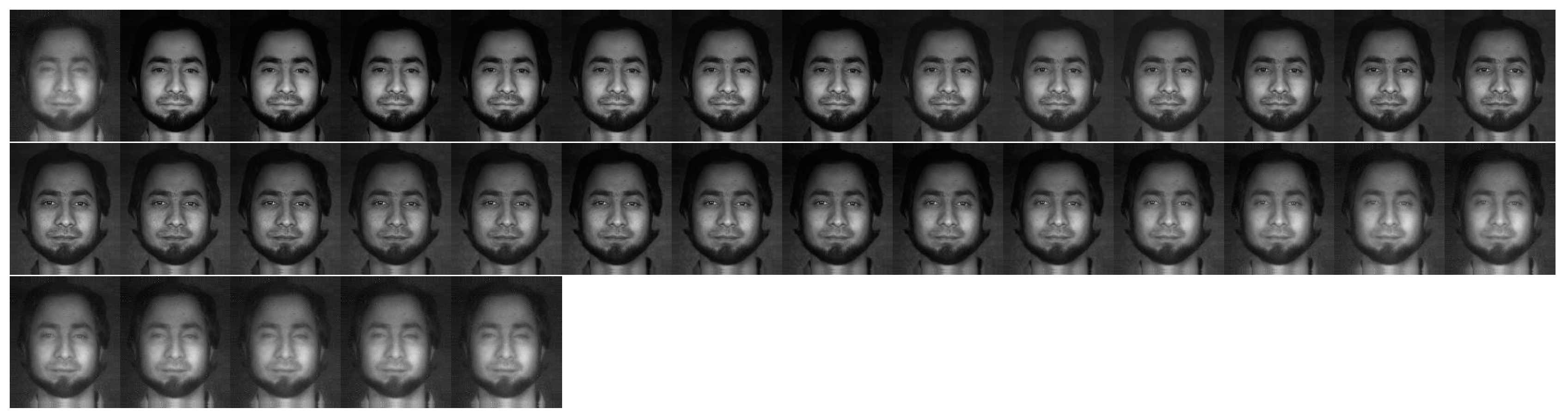
4.1. Band Selection Results
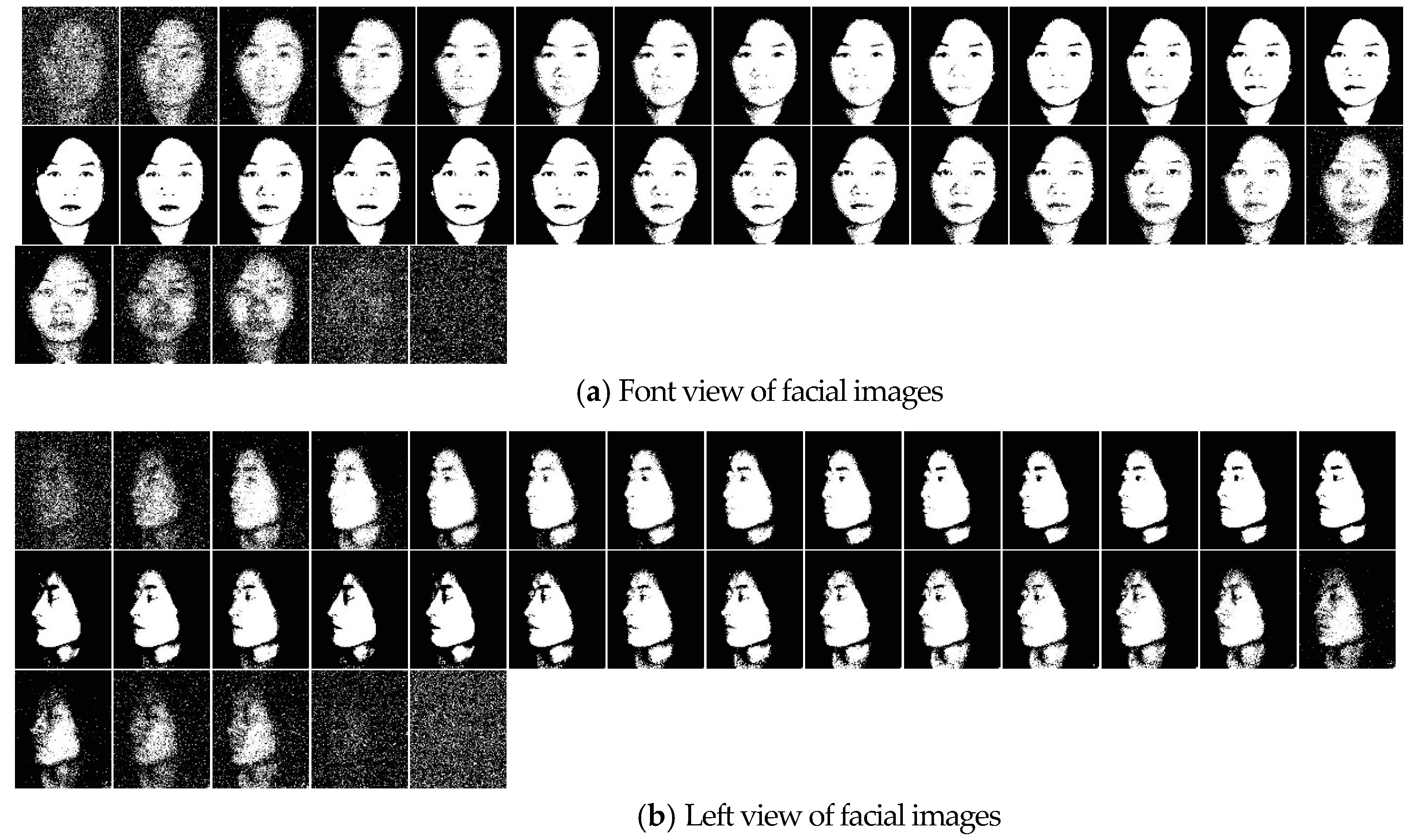
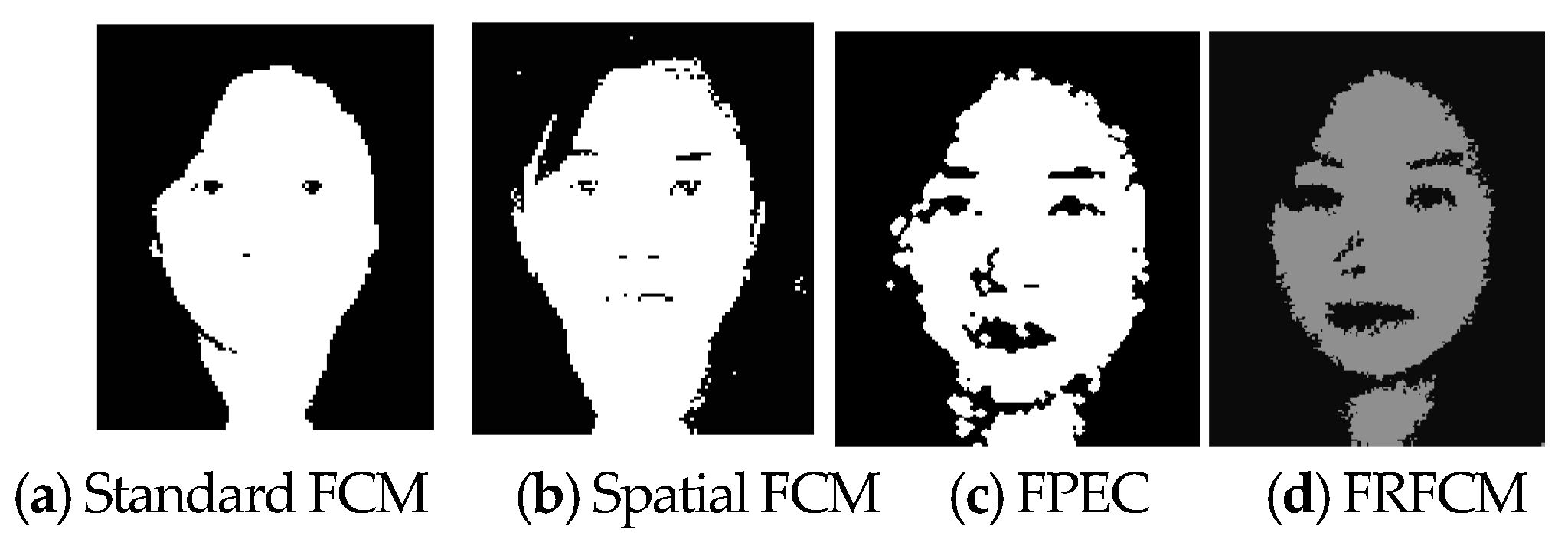
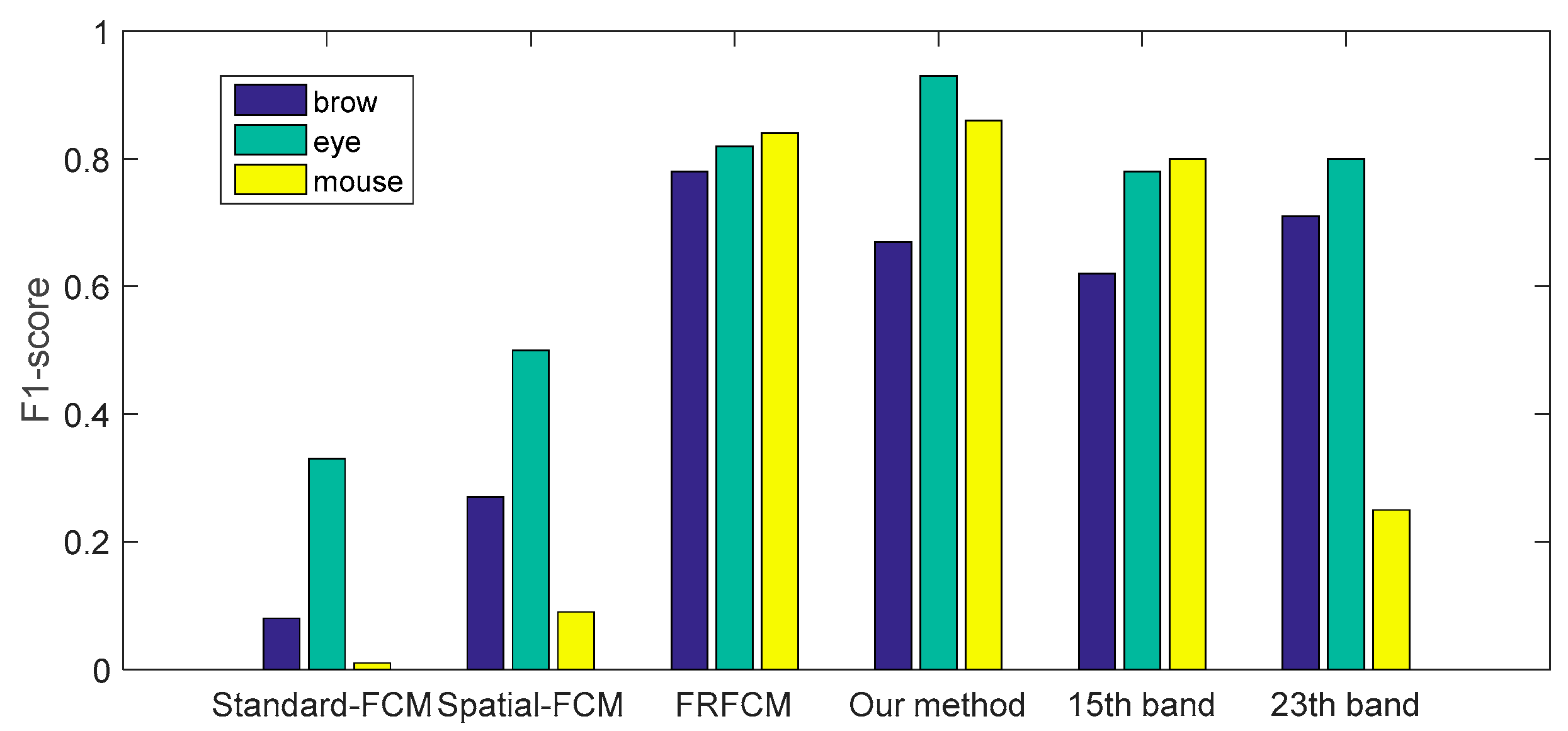
4.2. Skin Feature Segmentation of the PolyU Hyper-Spectral Face Database
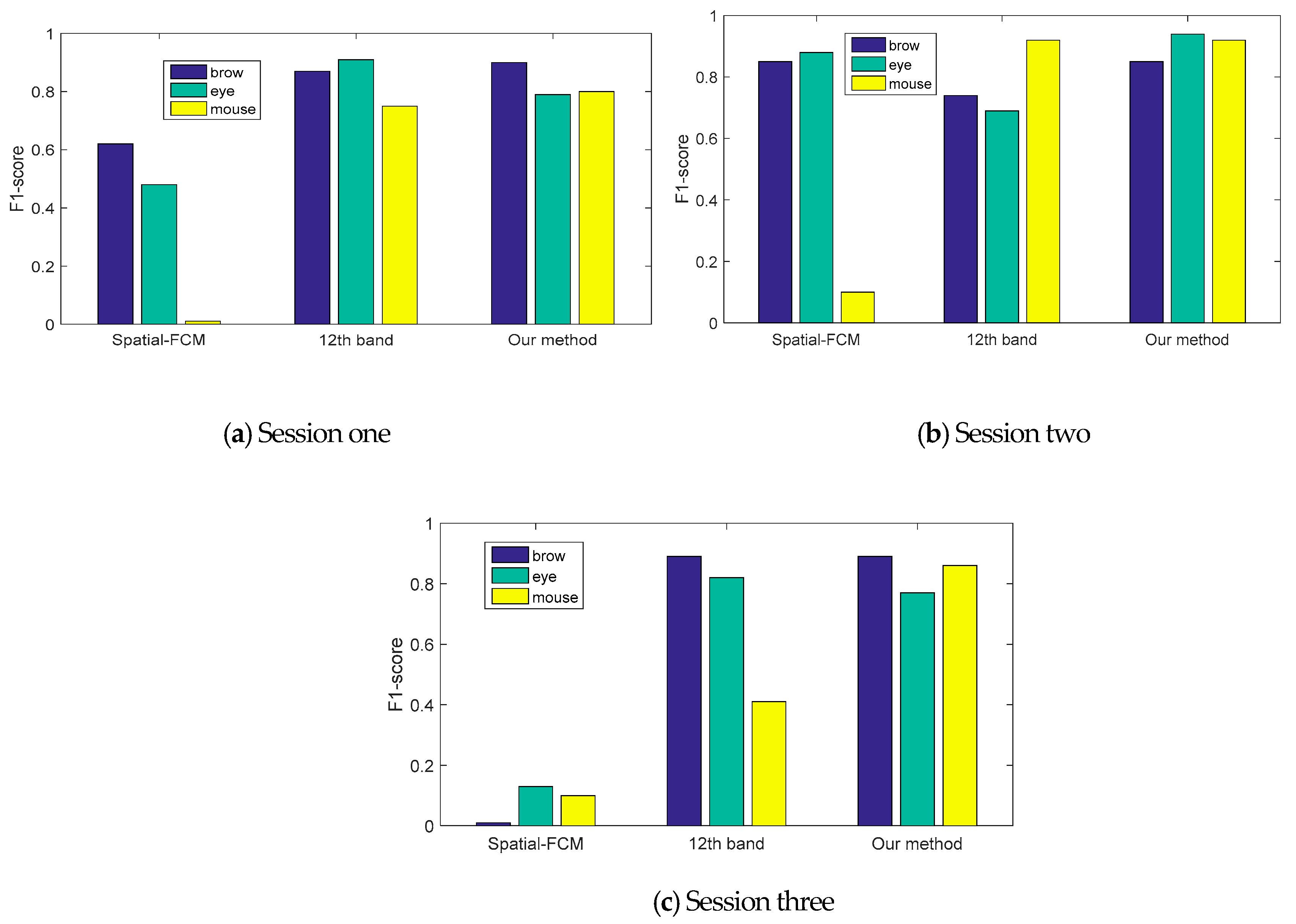
4.3. Skin Feature Segmentation of the UWA Hyper-Spectral Face Database
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ross, A.; Jain, A.K.; Qian, J.Z. Information Fusion in Biometrics. In Proceedings of the International Conference on Audio- and Video-Based Biometric Person Authentication, Halmstad, Sweden, 6–8 June 2001. [Google Scholar]
- Al-Tairi, Z.H.; Rahmat, R.W.; Saripan, M.I.; Sulaiman, P.S. Skin segmentation using YUV and RGB color spaces. J. Inf. Process. Syst. 2014, 10, 283–299. [Google Scholar] [CrossRef]
- Chelali, F.Z.; Cherabit, N.; Djeradi, A. Face recognition system using skin detection in RGB and YCbCr color space. In Proceedings of the Web Applications and Networking, Sousse, Tunisia, 21–23 March 2015. [Google Scholar]
- Kawulok, M. Fast propagation-based skin regions segmentation in color images. In Proceedings of the IEEE International Conference and Workshops on Automatic Face and Gesture Recognition, Shanghai, China, 22–26 April 2013. [Google Scholar]
- Chen, W.; Wang, K.; Jiang, H.; Li, M. Skin color modeling for face detection and segmentation: A review and a new approach. Multimed. Tools Appl. 2016, 75, 839–962. [Google Scholar] [CrossRef]
- Tan, W.R.; Chan, C.S.; Yogarajah, P.; Condell, J. A Fusion Approach for Efficient Human Skin Detection. IEEE Trans. Ind. Inform. 2012, 8, 138–147. [Google Scholar] [CrossRef]
- Xu, T.; Wang, Y.; Zhang, Z. Pixel-wise skin colour detection based on flexible neural tree. IET Image Process. 2013, 7, 751–761. [Google Scholar] [CrossRef]
- Naji, S.A.; Zainuddin, R.; Jalab, H.A. Skin segmentation based on multi pixel color clustering models. Digit. Signal Process. 2012, 22, 933–940. [Google Scholar] [CrossRef]
- Chai, D.; Ngan, K.N. Face segmentation using skin-color map in videophone applications. IEEE Trans. Circuits Syst. Video Technol. 1999, 9, 551–564. [Google Scholar] [CrossRef]
- Marzec, M.; Koprowski, R.; Wróbel, Z. Methods of face localization in thermograms. Biocybern. Biomed. Eng. 2015, 35, 138–146. [Google Scholar] [CrossRef]
- Filipe, S.; Alexandre, L.A. Thermal Infrared Face Segmentation: A New Pose Invariant Method; Springer: Berlin/Heidelberg, Germany, 2013; pp. 632–639. [Google Scholar]
- Filipe, S.; Alexandre, L.A. Algorithms for invariant long-wave infrared face segmentation: Evaluation and comparison. Pattern Anal. Appl. 2014, 17, 823–837. [Google Scholar] [CrossRef]
- Glowacz, A.; Glowacz, Z. Diagnosis of the three-phase induction motor using thermal imaging. Infrared Phys. Technol. 2016, 81, 7–16. [Google Scholar] [CrossRef]
- Zonios, G.; Bykowski, J.; Kollias, N. Skin melanin, hemoglobin, and light scattering properties can be quantitatively assessed in vivo using diffuse reflectance spectroscopy. J. Investig. Dermatol. 2001, 117, 1452–1457. [Google Scholar] [CrossRef] [PubMed]
- Di, W.; Zhang, L.; Zhang, D.; Pan, Q. Studies on Hyperspectral Face Recognition in Visible Spectrum with Feature Band Selection. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2010, 40, 1354–1361. [Google Scholar] [CrossRef]
- Li, Y.; Xie, W.; Li, H. Hyperspectral image reconstruction by deep convolutional neural network for classification. Pattern Recognit. 2016, 63, 371–383. [Google Scholar] [CrossRef]
- Huang, D.; Lai, J.; Wang, C.D. Ensemble clustering using factor graph. Pattern Recognit. 2016, 50, 131–142. [Google Scholar] [CrossRef]
- Zhao, F.; Jiao, L.; Liu, H.; Gao, X.; Gong, M. Spectral clustering with eigenvector selection based on entropy ranking. Neurocomputing 2010, 73, 1704–1717. [Google Scholar] [CrossRef]
- Bin, Z.; Chijie, Z.H.; Jun, H. Ensemble Clustering Algorithm Combined With Dimension Reduction Techniques for Power Load Profiles. Proc. CSEE 2015, 35, 3741–3749. [Google Scholar]
- He, M.; Yang, Y.; Wang, S. NMF-Based Clustering Ensemble Algorithm. Comput. Sci. 2017, 44, 58–61. (In Chinese) [Google Scholar]
- Yi, J.; Yang, T.; Jin, R.; Jain, A.K.; Mahdavi, M. Robust Ensemble Clustering by Matrix Completion. In Proceedings of the IEEE International Conference on Data Mining, Brussels, Belgium, 10–13 December 2012. [Google Scholar]
- Fern, X.Z.; Brodley, C.E. Solving cluster ensemble problems by bipartite graph partitioning. In Proceedings of the International Conference on Machine Learning, Banff, AB, Canada, 4–8 July 2004. [Google Scholar]
- Franek, L.; Jiang, X. Ensemble clustering by means of clustering embedding in vector spaces. Pattern Recognit. 2014, 47, 833–842. [Google Scholar] [CrossRef]
- Tarabalka, Y.; Chanussot, J.; Benediktsson, J.A. Segmentation and classification of hyperspectral images using minimum spanning forest grown from automatically selected markers. IEEE Trans. Syst. Man Cybern. B Cybern. 2010, 40, 1267–1279. [Google Scholar] [CrossRef] [PubMed]
- Bezdek, J.C.; Ehrlich, R.; Full, W. FCM: The fuzzy c-means clustering algorithm. Comput. Geosci. 1984, 10, 191–203. [Google Scholar] [CrossRef]
- Shokouhi, S.B.; Fooladivanda, A.; Ahmadinejad, N. Computer-aided detection of breast lesions in DCE-MRI using region growing based on fuzzy C-means clustering and vesselness filter. EURASIP J. Adv. Signal Process. 2017, 2017, 39. [Google Scholar] [CrossRef]
- Shi, A.; Gao, G.; Shen, S. Change detection of bitemporal multispectral images based on FCM and D-S theory. EURASIP J. Adv. Signal Process. 2016, 2016, 96. [Google Scholar] [CrossRef]
- Chuang, K.S.; Tzeng, H.L.; Chen, S.; Wu, J.; Chen, T.J. Fuzzy c-means clustering with spatial information for image segmentation. In Proceedings of the International Conference on Electrical Engineering, Lahore, Pakistan, 9–11 April 2009. [Google Scholar]
- Chang, C.I. An information-theoretic approach to spectral variability, similarity, and discrimination for hyperspectral image analysis. IEEE Trans. Inf. Theory 2000, 46, 1927–1932. [Google Scholar] [CrossRef]
- Lei, T.; Jia, X.; Zhang, Y.; He, L.; Meng, H.; Nandi, A.K. Significantly Fast and Robust Fuzzy C-Means Clustering Algorithm Based on Morphological Reconstruction and Membership Filtering. IEEE Trans. Fuzzy Syst. 2018, 26, 3027–3041. [Google Scholar] [CrossRef]
- Uzair, M.; Mahmood, A.; Shafait, F.; Nansen, C.; Mian, A. Is spectral reflectance of the face a reliable biometric? Opt. Express 2015, 23, 15160–15173. [Google Scholar] [CrossRef] [PubMed]
- Uzair, M.; Mahmood, A.; Mian, A. Hyperspectral Face Recognition with Spatiospectral Information Fusion and PLS Regression. IEEE Trans. Image Process. 2015, 24, 1127–1137. [Google Scholar] [CrossRef] [PubMed]
- Uzair, M.; Mahmood, A.; Mian, A. Hyperspectral Face Recognition using 3D-DCT and Partial Least Squares. BMVC 2013. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Block Size | Precision-Brow | Recall-Brow | F1-Score-Brow | Precision-Eye | Recall-Eye | F1-Score-Eye | Precision-Mouse | Recall-Mouse | F1-Mcore-Mouse |
|---|---|---|---|---|---|---|---|---|---|
| 2 × 2 | 0.75 | 0.89 | 0.82 | 0.76 | 1.00 | 0.86 | 0.89 | 0.88 | 0.88 |
| 4 × 4 | 0.13 | 0.19 | 0.15 | 0.53 | 0.83 | 0.88 | 0.55 | 0.64 | 0.59 |
| Method | Precision-Brow | Recall-Brow | Precision-Eye | Recall-Eye | Precision-Mouse | Recall-Mouse |
|---|---|---|---|---|---|---|
| Standard-FCM | 0.92 | 0.04 | 0.97 | 0.2.0 | 0 | 0 |
| spatial-FCM | 0.62 | 0.17 | 0.85 | 0.35 | 0.82 | 0.05 |
| FRFCM | 0.65 | 0.96 | 0.79 | 0.84 | 0.89 | 0.79 |
| Our method | 0.67 | 0.67 | 0.96 | 0.91 | 0.93 | 0.80 |
| 15th band | 0.59 | 0.66 | 0.80 | 0.77 | 1.00 | 0.66 |
| 23rd band | 0.67 | 0.86 | 0.82 | 0.78 | 1.00 | 0.14 |
| Method | Precision-Brow | Recall-Brow | Precision-Eye | Recall-Eye | Precision-Beard | Recall-Beard |
|---|---|---|---|---|---|---|
| spatial-FCM | 1.00 | 0.45 | 1.00 | 0.32 | 0 | 0 |
| 12th band | 0.77 | 1.00 | 0.95 | 0.87 | 0.94 | 0.62 |
| Our-method | 0.93 | 0.88 | 0.76 | 0.82 | 0.89 | 0.72 |
| Method | Precision-Brow | Recall-Brow | Precision-Eye | Recall-Eye | Precision-Beard | Recall-Beard |
|---|---|---|---|---|---|---|
| spatial-FCM | 0.85 | 0.86 | 0.93 | 0.84 | 1.00 | 0.05 |
| 12th band | 0.58 | 1 | 0. 64 | 0.75 | 1.00 | 0.84 |
| Our-method | 0.83 | 0.88 | 1.00 | 0.88 | 1.00 | 0.84 |
| Method | Precision-Brow | Recall-Brow | Precision-Eye | Recall-Eye | Precision-Beard | Recall-Beard |
|---|---|---|---|---|---|---|
| Spatial-FCM | 0 | 0 | 1.00 | 0.07 | 0 | 0 |
| 12th band | 0.83 | 0.96 | 1.00 | 0.70 | 0.83 | 0.27 |
| Our-method | 0.85 | 0.93 | 0.83 | 0.71 | 1.00 | 0.77 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Y.; Wu, M.; Zhang, L.; Wang, J.; Wei, D. An Effective Feature Segmentation Algorithm for a Hyper-Spectral Facial Image. Information 2018, 9, 261. https://doi.org/10.3390/info9100261
Zhao Y, Wu M, Zhang L, Wang J, Wei D. An Effective Feature Segmentation Algorithm for a Hyper-Spectral Facial Image. Information. 2018; 9(10):261. https://doi.org/10.3390/info9100261
Chicago/Turabian StyleZhao, Yuefeng, Mengmeng Wu, Liren Zhang, Jingjing Wang, and Dongmei Wei. 2018. "An Effective Feature Segmentation Algorithm for a Hyper-Spectral Facial Image" Information 9, no. 10: 261. https://doi.org/10.3390/info9100261
APA StyleZhao, Y., Wu, M., Zhang, L., Wang, J., & Wei, D. (2018). An Effective Feature Segmentation Algorithm for a Hyper-Spectral Facial Image. Information, 9(10), 261. https://doi.org/10.3390/info9100261