Integration of Context Information through Probabilistic Ontological Knowledge into Image Classification



Abstract
1. Introduction
2. Related Work
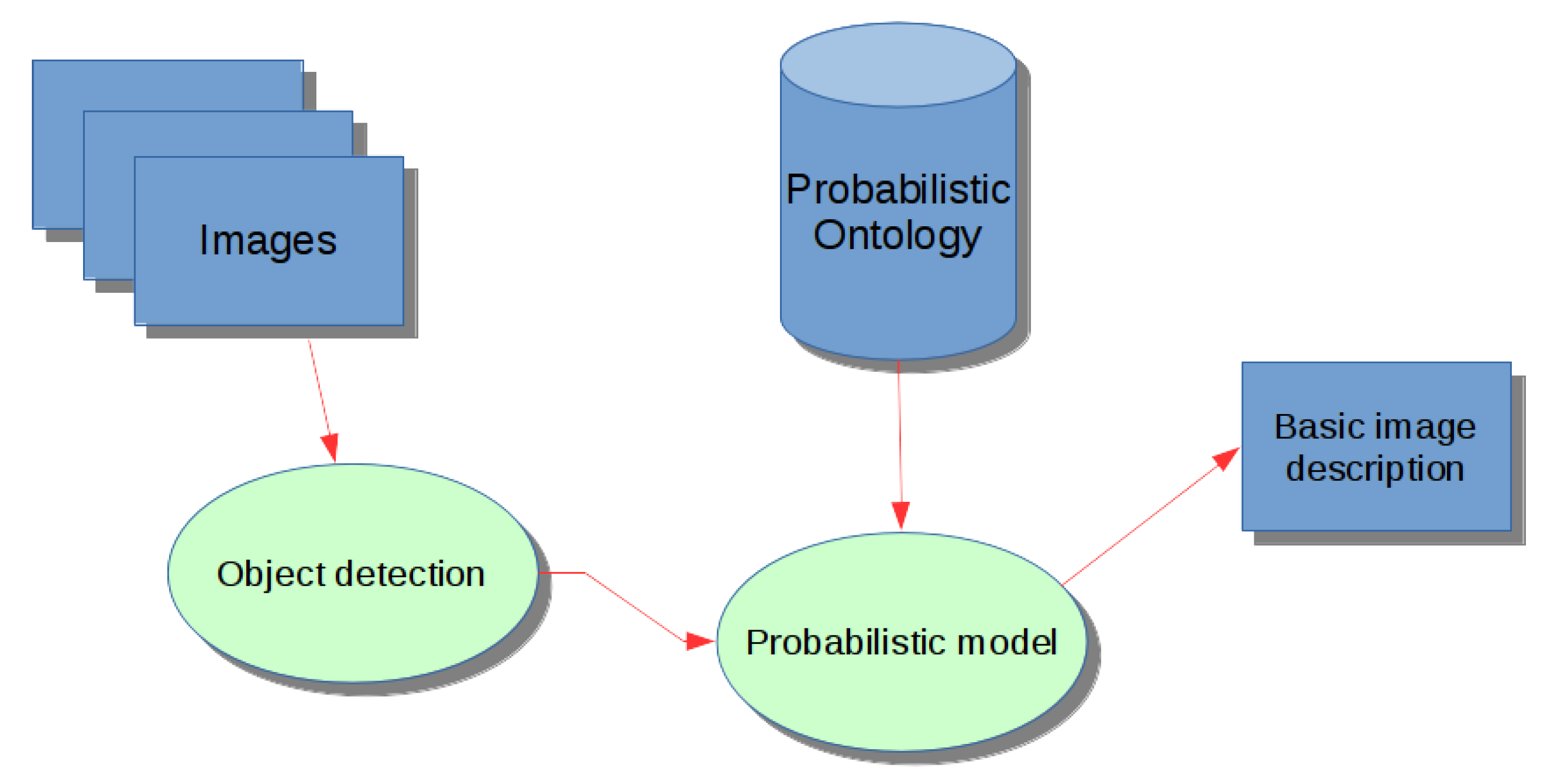
3. Materials and Methods
3.1. Probabilistic Ontology
3.2. Combination Models
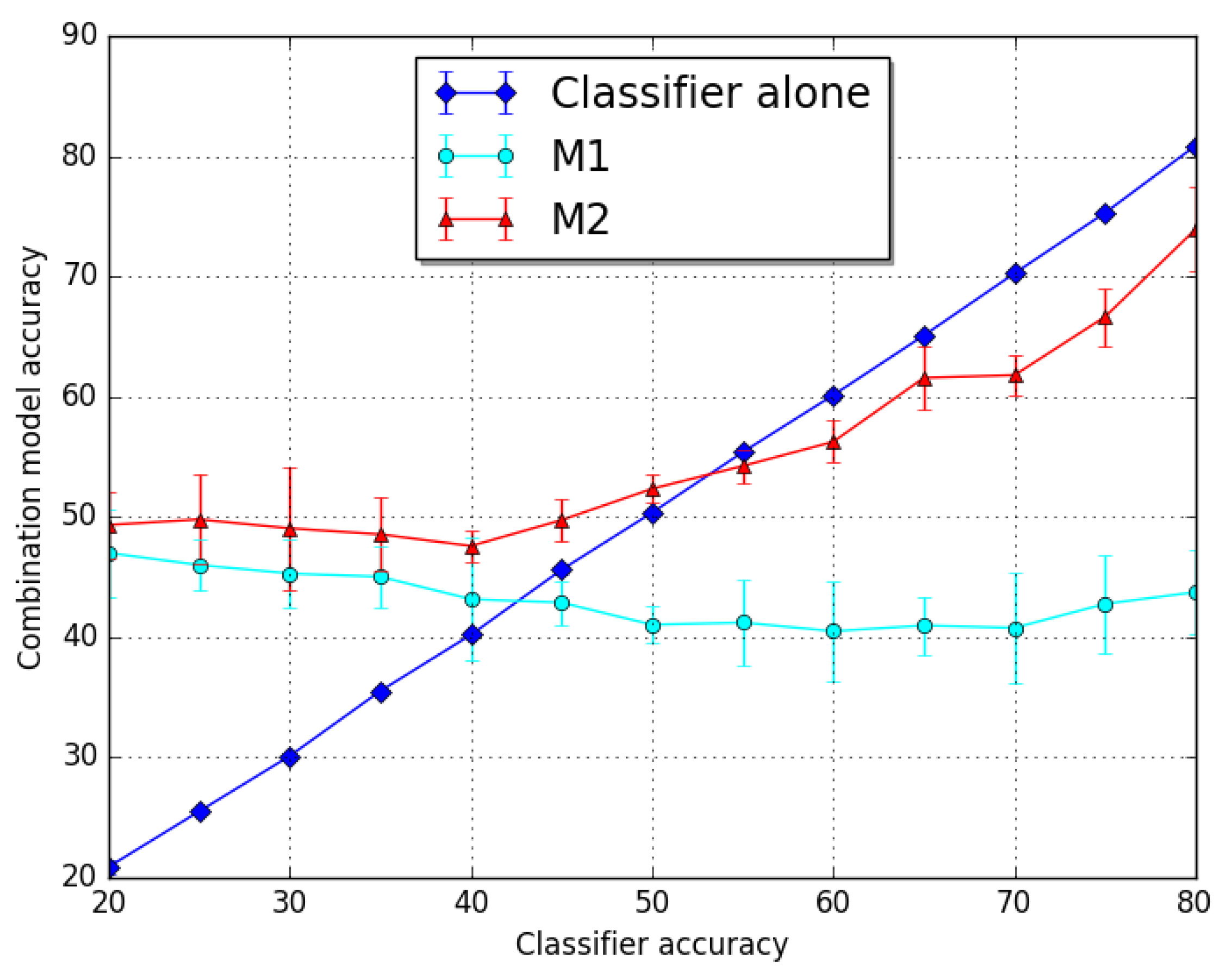
4. Results
| Algorithm 1: Pseudo-code for the simulated classifier. |
 |
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| PO | Probabilistic Ontology |
| PDE | Partial Differential Equation |
References
- Apicella, A.; Corazza, A.; Isgrò, F.; Vettigli, G. Integrating a priori probabilistic knowledge into classification for image description. In Proceedings of the 26th IEEE WETICE Conference, Poznan, Poland, 21–23 June 2017; pp. 197–199. [Google Scholar]
- Apicella, A.; Corazza, A.; Isgrò, F.; Vettigli, G. Exploiting context information for image description. In Proceedings of the International Conference on Image Analysis and Processing, Catania, Italy, 11–15 September 2017; pp. 320–331. [Google Scholar]
- Ding, Z.; Peng, Y. A Probabilistic Extension to Ontology Language OWL. In Proceedings of the 37th Annual Hawaii International Conference on System Sciences (HICSS’04)—Track 4, Big Island, HI, USA, 5–8 January 2004. [Google Scholar]
- Bach, N.; Badaskar, S. A Review of Relation Extraction; Technical Report; Language Technologies Institute, Carnegie Mellon University: Pittsburgh, PA, USA, 2007. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin, Germany, 2006. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Farhadi, A.; Hejrati, M.; Sadeghi, M.A.; Young, P.; Rashtchian, C.; Hockenmaier, J.; Forsyth, D. Every Picture Tells a Story: Generating Sentences from Images. In Proceedings of the 11th European Conference on Computer Vision: Part IV, Crete, Greece, 5–11 September 2010; pp. 15–29. [Google Scholar]
- Kulkarni, G.; Premraj, V.; Dhar, S.; Li, S.; Choi, Y.; Berg, A.C.; Berg, T.L. Baby Talk: Understanding and Generating Simple Image Descriptions. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1601–1608. [Google Scholar]
- Elliott, D.; Keller, F. Image Description using Visual Dependency Representations. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; Volume 13, pp. 1292–1302. [Google Scholar]
- Fang, H.; Gupta, S.; Iandola, F.; Srivastava, R.K.; Deng, L.; Dollar, P.; Gao, J.; He, X.; Mitchell, M.; Platt, J.C.; et al. From Captions to Visual Concepts and Back. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1473–1482. [Google Scholar]
- Chen, X.; Zitnick, C.L. Mind’s eye: A recurrent visual representation for image caption generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 2422–2431. [Google Scholar]
- Karpathy, A.; Fei-Fei, L. Deep Visual-Semantic Alignments for Generating Image Descriptions. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 664–676. [Google Scholar] [CrossRef] [PubMed]
- You, Q.; Jin, H.; Wang, Z.; Fang, C.; Luo, J. Image Captioning With Semantic Attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4651–4659. [Google Scholar]
- Wang, C.; Blei, D.M.; Fei-Fei, L. Simultaneous image classification and annotation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1903–1910. [Google Scholar]
- Tousch, A.M.; Herbin, S.; Audibert, J.Y. Semantic Hierarchies for Image Annotation: A Survey. Pattern Recognit. 2012, 45, 333–345. [Google Scholar] [CrossRef]
- Sarwar, S.; Qayyum, Z.U.; Majeed, S. Ontology based Image Retrieval Framework Using Qualitative Semantic Image Descriptions. Procedia Comput. Sci. 2013, 22, 285–294. [Google Scholar] [CrossRef]
- Hudelot, C.; Atif, J.; Bloch, I. Fuzzy spatial relation ontology for image interpretation. Fuzzy Sets Syst. 2008, 159, 1929–1951. [Google Scholar] [CrossRef]
- Mezaris, V.; Kompatsiaris, I.; Strintzis, M.G. An ontology approach to object-based image retrieval. In Proceedings of the 2003 International Conference on Image Processing, Catalonia, Spain, 14–18 September 2003. [Google Scholar]
- Hlel, E.; Jamoussi, S.; Hamadou, A.B. A Probabilistic Ontology for the Prediction of Authorìs Interests. In Proceedings of the International Conference on Computational Collective Intelligence Technologies and Applications, Madrid, Spain, 21–23 September 2015; Lectures Notes in Computer Science. Volume 9330, pp. 492–501. [Google Scholar]
- Gayathri, K.S.; Easwarakumar, K.S.; Elias, S. Probabilistic ontology based activity recognition in smart homes using Markov Logic Network. Knowl. Based Syst. 2017, 121, 173–184. [Google Scholar] [CrossRef]
- Huber, J.; Niepert, M.; Noessner, J.; Schoenfisch, J.; Meilicke, C.; Stuckenschmidt, H. An infrastructure for probabilistic reasoning with web ontologies. Semant. Web 2017, 8, 255–269. [Google Scholar] [CrossRef]
- Jules, O.; Hafid, A.; Serhani, M.A. Bayesian network, and probabilistic ontology driven trust model for SLA management of Cloud services. In Proceedings of the IEEE International Conference on Cloud Networking, Luxembourg, 8–10 October 2014; pp. 77–83. [Google Scholar]
- Lunardi, G.M.; Machado, G.M.; Machot, F.A.; Maran, V.; Machado, A.; Mayr, H.C.; Shekhovtsov, V.A.; de Oliveira, J.P.M. Probabilistic Ontology Reasoning in Ambient Assistance: Predicting Human Actions. In Proceedings of the IEEE 32nd International Conference on Advanced Information Networking and Applications, Krakow, Poland, 16–18 May 2018; pp. 593–600. [Google Scholar]
- Toussaint, G. The use of context in pattern recognition. Pattern Recognit. 1978, 10, 189–204. [Google Scholar] [CrossRef]
- Oliva, A.; Torralba, A. The role of context in object recognition. Trends Cognit. Sci. 2007, 11, 520–527. [Google Scholar] [CrossRef] [PubMed]
- Bar, M.; Ullman, S. Spatial context in recognition. Perception 1996, 25, 343–352. [Google Scholar] [CrossRef] [PubMed]
- Tanaka, J.W.; Sengco, J.A. Features and their configuration in face recognition. Mem. Cognit. 1997, 25, 583–592. [Google Scholar] [CrossRef] [PubMed]
- Bloch, I.; Colliot, O.; Camara, O.; Géraud, T. Fusion of spatial relationships for guiding recognition, example of brain structure recognition in 3D MRI. Pattern Recognit. Lett. 2005, 26, 449–457. [Google Scholar] [CrossRef]
- Choi, W.; Shahid, K.; Savarese, S. Learning context for collective activity recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 3273–3280. [Google Scholar]
- Schneiderman, H.; Kanade, T. Probabilistic Modeling of Local Appearance and Spatial Relationships for Object Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Santa Barbara, CA, USA, 23–25 June 1998; IEEE Computer Society: Washington, DC, USA, 1998; pp. 45–51. [Google Scholar]
- Schmid, C. A structured probabilistic model for recognition. In Proceedings of the 1999 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Fort Collins, CO, USA, 23–25 June 1999; Volume 2, p. 490. [Google Scholar]
- Zhang, R.; Zhang, Z.; Li, M.; Ma, W.Y.; Zhang, H.J. A probabilistic semantic model for image annotation and multimodal image retrieval. In Proceedings of the ICCV 2005 Tenth IEEE International Conference on Computer Vision, Beijing, China, 17–20 October 2005; Volume 1, pp. 846–851. [Google Scholar]
- Wang, M.; Gao, Y.; Lu, K.; Rui, Y. View-Based Discriminative Probabilistic Modeling for 3D Object Retrieval and Recognition. Trans. Image Proc. 2013, 22, 1395–1407. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Yang, Y.; Gao, Y.; Yu, Y.; Wang, C.; Li, X. A Probabilistic Associative Model for Segmenting Weakly Supervised Images. IEEE Trans. Image Process. 2014, 23, 4150–4159. [Google Scholar] [CrossRef] [PubMed]
- Eweiwi, A.; Cheema, M.S.; Bauckhage, C. Action recognition in still images by learning spatial interest regions from videos. Pattern Recognit. Lett. 2015, 51, 8–15. [Google Scholar] [CrossRef]
- Costa, P.C.G.D. Bayesian Semantics for the Semantic Web. Ph.D. Thesis, George Mason University, Fairfax, VA, USA, 12 July 2005. [Google Scholar]
- Klinov, P.; Parsia, B. Uncertainty Reasoning for the Semantic Web II: International Workshops URSW 2008–2010 Held at ISWC and UniDL 2010 Held at FLoC, Revised Selected Papers; Chapter Pronto: A Practical Probabilistic Description Logic Reasoner; Springer: Berlin/Heidelberg, Germnay, 2013; pp. 59–79. [Google Scholar]
- Abhyankar, S.; Brown, J.; Constantinescu, E.M.; Ghosh, D.; Smith, B.F.; Zhang, H. PETSc/TS: A Modern Scalable ODE/DAE Solver Library. arXiv, 2018; arXiv:1806.01437. [Google Scholar]
- Fletcher, R. Practical Methods of Optimization, 2nd ed.; Jonh Wiley & Sons: Hoboken, NJ, USA, 1987. [Google Scholar]
- Szeliski, R. Computer Vision: Algorithms and Applications, 1st ed.; Springer Inc.: New York, NY, USA, 2010. [Google Scholar]
- Zouari, H.; Heutte, L.; Lecourtier, Y. Simulating classifier ensembles of fixed diversity for studying plurality voting performance. In Proceedings of the 17th International Conference on Pattern Recognition, Cambridge, UK, 23–26 August 2004; Volume 1, pp. 232–235. [Google Scholar]
- Quattoni, A.; Torralba, A. Recognizing indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 413–420. [Google Scholar]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing; Pearson: London, UK, 2017. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | # of Items |
|---|---|
| sink | 371 |
| chair | 3604 |
| table | 558 |
| computer/monitor | 256+ 417 = 673 |
| bed | 407 |
| flower | 1822 |
| total | 7435 |
| Target Accuracy | 20% | 30% | 40% | 50% | 60% | 70% |
|---|---|---|---|---|---|---|
| Simulator Accuracy: mean | 20.76% | 30.12% | 40.20% | 50.36% | 60.63% | 70.25% |
| Simulator Accuracy: SD | 0.71% | 0.10% | 0.30% | 0.06% | 0.43% | 0.45% |
| 20% | 30% | 40% | 50% | 60% | 70% | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| # Params | M1 | M2 | M1 | M2 | M1 | M2 | M1 | M2 | M1 | M2 | M1 | M2 |
| 2 | 22.54% | 20.82% | 25.00% | 31.06% | 32.99% | 40.08% | 32.24% | 48.21% | 44.87% | 54.56% | 44.26% | 66.48% |
| 7 | 12.70% | 12.02% | 11.47% | 12.13% | 13.72% | 29.39% | 11.88% | 18.48% | 19.26% | 27.61% | 25.61% | 23.83% |
| 108 | 33.19% | 27.17% | 15.57% | 11.58% | 37.50% | 37.19% | 10.04% | 12.91% | 14.54% | 16.25% | 36.06% | 46.54% |
| 109 | 20.90% | 22.16% | 22.90% | 30.73% | 29.30% | 40.64% | 40.77% | 49.55% | 40.16% | 58.24% | 32.37% | 64.92% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Apicella, A.; Corazza, A.; Isgrò, F.; Vettigli, G. Integration of Context Information through Probabilistic Ontological Knowledge into Image Classification. Information 2018, 9, 252. https://doi.org/10.3390/info9100252
Apicella A, Corazza A, Isgrò F, Vettigli G. Integration of Context Information through Probabilistic Ontological Knowledge into Image Classification. Information. 2018; 9(10):252. https://doi.org/10.3390/info9100252
Chicago/Turabian StyleApicella, Andrea, Anna Corazza, Francesco Isgrò, and Giuseppe Vettigli. 2018. "Integration of Context Information through Probabilistic Ontological Knowledge into Image Classification" Information 9, no. 10: 252. https://doi.org/10.3390/info9100252
APA StyleApicella, A., Corazza, A., Isgrò, F., & Vettigli, G. (2018). Integration of Context Information through Probabilistic Ontological Knowledge into Image Classification. Information, 9(10), 252. https://doi.org/10.3390/info9100252