Smart Card Data Mining of Public Transport Destination: A Literature Review

Abstract
:1. Introduction
2. Methods
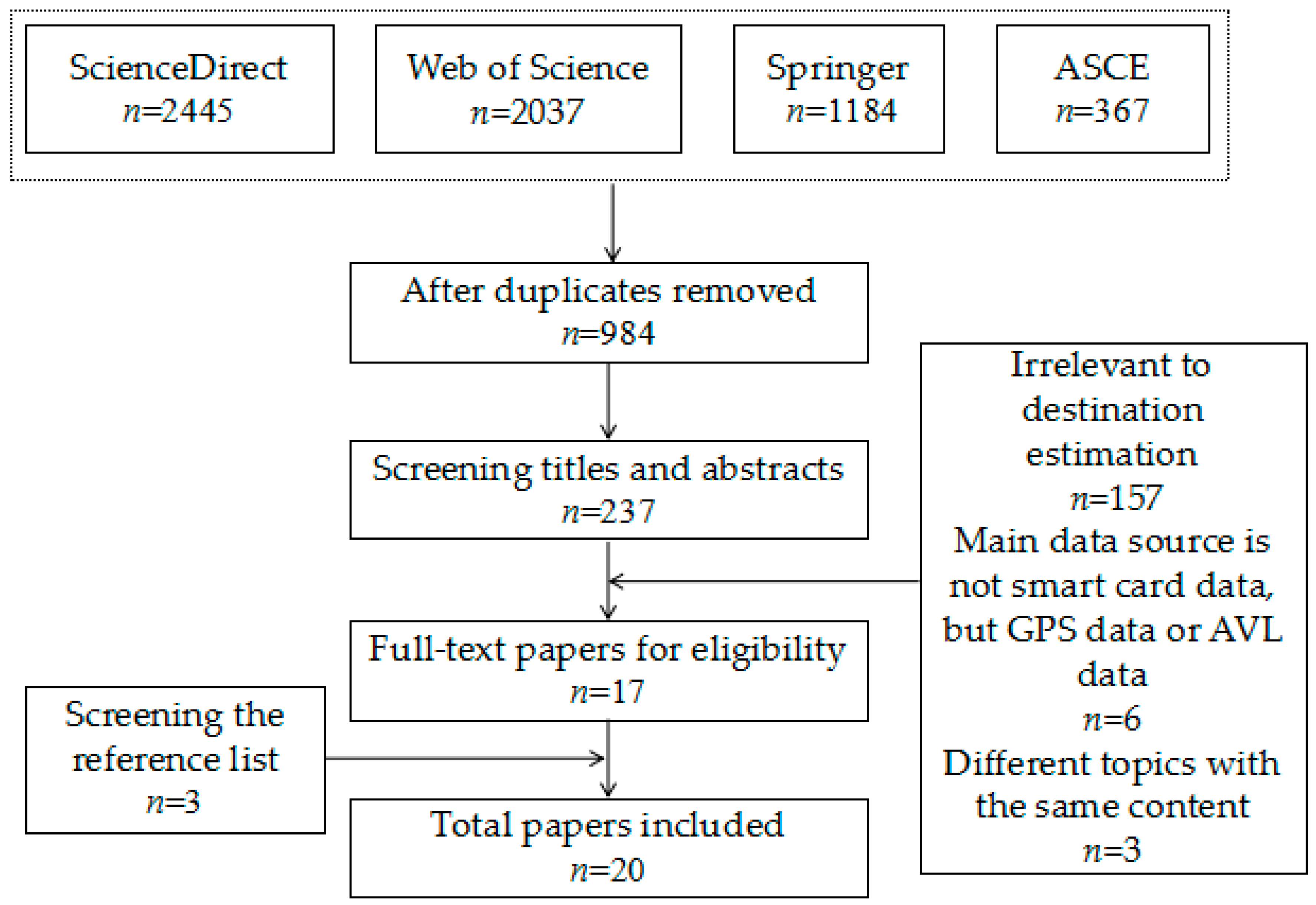
2.1. Search Strategy
2.2. Inclusion and Exclusion Criteria
2.3. Data Extraction
2.4. Quality Assessment
3. Result
3.1. Features of Reviewed Studies
3.2. Main Destination Estimation Model Description
3.2.1. Trip Chaining Model
3.2.2. Probability Model
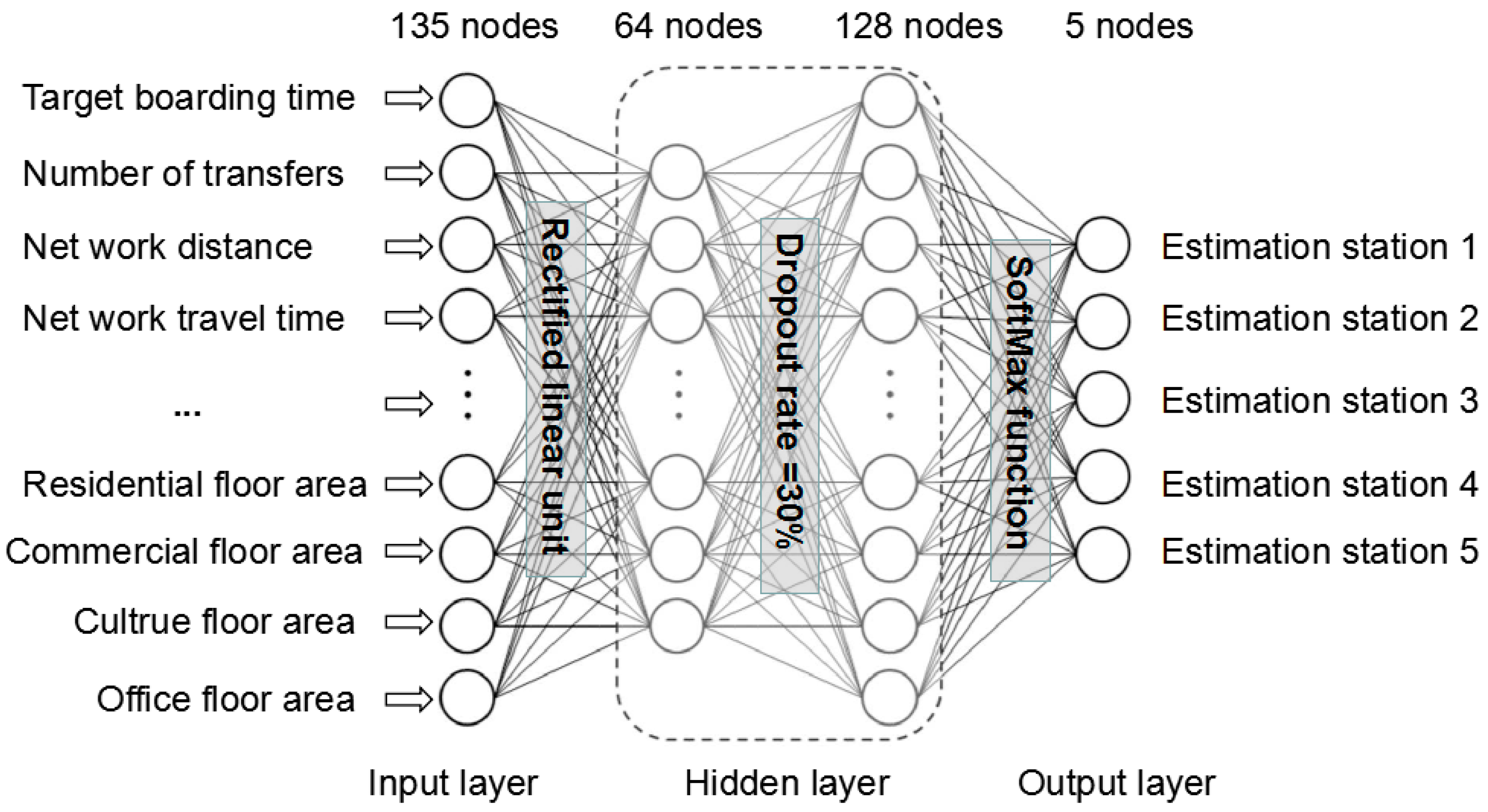
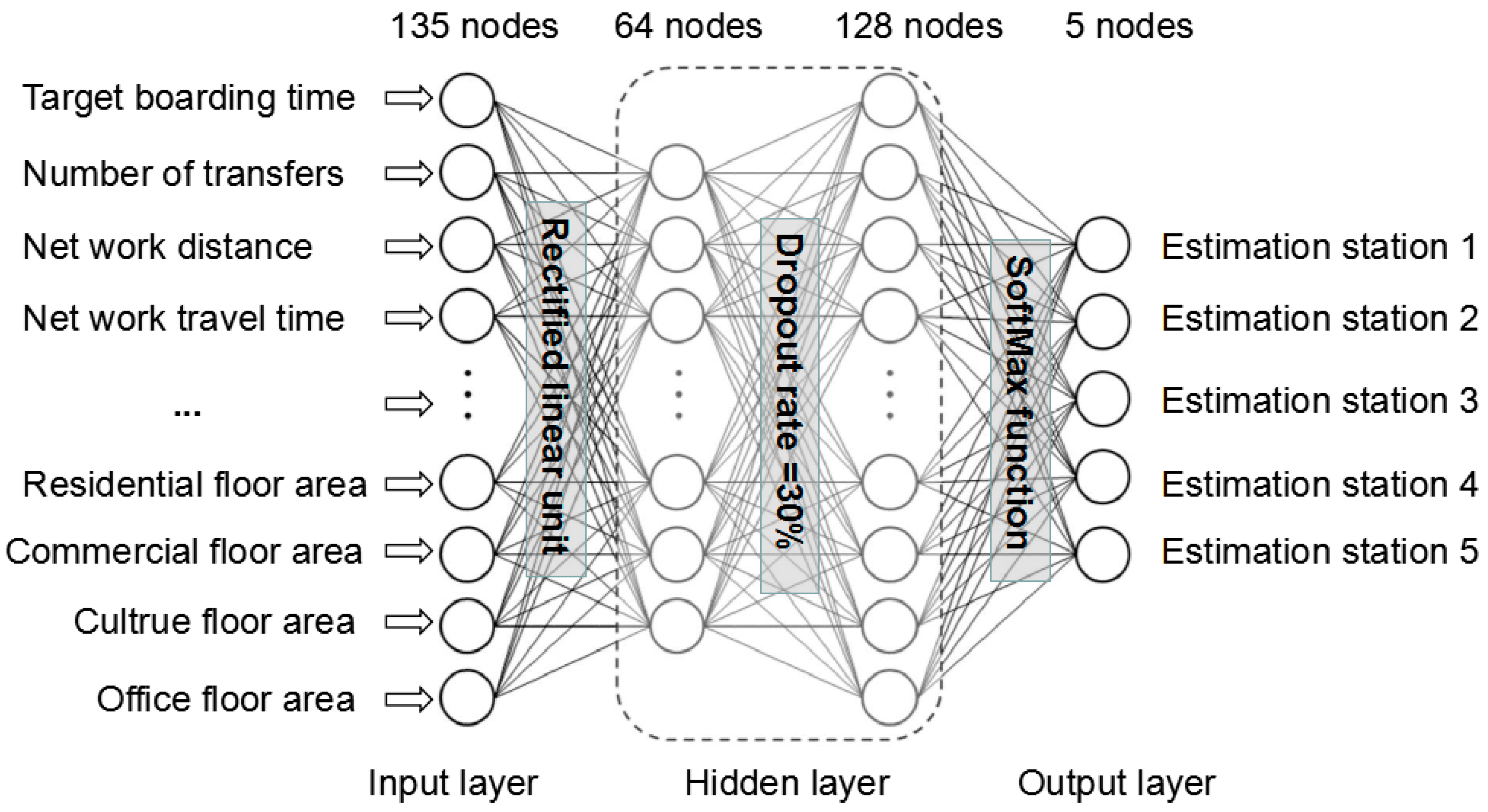
3.2.3. Deep Learning Model
3.2.4. Comparison of Three Models
3.3. Analysis of Influence Factors
3.4. Date Quality Analysis
3.4.1. Sample Size
3.4.2. Data Preparation
3.5. Sensitivity Analysis
3.6. Validation
3.7. Possible Problems in Inferring Destination
4. Quality of Reviewed Studies
5. Discussion
6. Conclusion and Future Works
- Estimation model improvement: most trip chaining model mainly considers factors of boarding time, boarding station and walking distance but the land use and public traffic network information also need to be added to the model. As to the deep learning model, different function and dropout rates need to be applied when activating the node values.
- Journey validation: Even through present studies use survey data or actual transaction data to validate their model, survey data is hard to obtain. Better validation algorithms will be developed to validate the alighting matching rate.
- Diversification of data source: with the development of technological improvement, more types of data can be used to estimate the alight station, such as GPS date or AVL (Automatic Vehicle Location) date, mobile phone MAC (Media Access Control) data, public transport video data. Therefore, new algorithms based on these multi-source data will be needed.
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Nunes, A.A.; Dias, T.G.; Cunha, J.F.E. Passenger Journey Destination Estimation from Automated Fare Collection System Data Using Spatial Validation. IEEE Trans. Intell. Transp. Syst. 2015, 17, 133–142. [Google Scholar] [CrossRef]
- Trepanier, M. Destination Estimation from Public Transport Smartcard Data. IFAC Proc. Vol. 2006, 39, 393–398. [Google Scholar] [CrossRef]
- Ma, X. Smart Card Data Mining and Inference for Transit System Optimization and Performance Improvement; University of Washington: Seattle, WA, USA, 2013. [Google Scholar]
- Kieu, L.M.; Bhaskar, A.; Chung, E. A Modified Density-based Scanning Algorithm with Noise for Spatial Travel Pattern Analysis from Smart Card AFC Data. Transp. Res. Part C Emerg. Technol. 2015, 58, 193–207. [Google Scholar] [CrossRef]
- Zhao, J.; Qu, Q.; Zhang, F.; Xu, C.; Liu, S. Spatio-temporal Analysis of Passenger Travel Patterns in Massive Smart Card Data. IEEE Trans. Intell. Transp. Syst. 2017, 18, 3135–3146. [Google Scholar] [CrossRef]
- Kusakabe, T.; Asakura, Y. Behavioural Data Mining of Transit Smart Card Data: A Data Fusion Approach. Transp. Res. Part C Emerg. Technol. 2014, 46, 179–191. [Google Scholar] [CrossRef]
- Blythe, P.; Bryan, H. Understanding Behaviour through Smartcard Data Analysis. Transport 2007, 160, 173–177. [Google Scholar]
- Ali, A.; Kim, J.; Lee, S. Travel Behavior Analysis Using Smart Card Data. KSCE J. Civ. Eng. 2016, 20, 1532–1539. [Google Scholar] [CrossRef]
- Briand, A.S.; Côme, E.; Trépanier, M.; Oukhellou, L. Analyzing Year-to-year Changes in Public Transport Passenger Behaviour Using Smart Card Data. Transp. Res. Part C Emerg. Technol. 2017, 79, 274–289. [Google Scholar] [CrossRef]
- Kim, K.S.; Cheon, S.H.; Lim, S.J. Performance Assessment of Bus Transport Reform in Seoul. Transportation 2011, 38, 719–735. [Google Scholar] [CrossRef]
- Pau, S.A. Using Smart Card Technologies to Measure Public Transport Performance: Data Capture and Analysis; Universitat Politècnica De Catalunya: Barcelona, Spain, 2014. [Google Scholar]
- Jin, K.E.; Ji, Y.S.; Moon, D.S. Analysis of Public Transit Service Performance Using Transit Smart Card Data in Seoul. KSCE J. Civ. Eng. 2015, 19, 1530–1537. [Google Scholar]
- Smart, M.; Miller, M.A.; Taylor, B.D. Transit Stops and Stations: Transit Managers’ Perspectives on Evaluating Performance. J. Public Transp. 2009, 12, 59–78. [Google Scholar] [CrossRef]
- Audouin, M.; Razaghi, M.; Finger, M. How Seoul Used the ‘t-money’ Smart Transportation Card to Re-plan the Public Transportation System of the City; Implications for Governance of Innovation in Urban Public Transportation Systems. In Proceedings of the 8th TransIST Symposium, Istanbul, Turkey, 17–18 December 2015. [Google Scholar]
- Gschwender, A.; Munizaga, M.; Simonetti, C. Using Smart Card and GPS Data for Policy and Planning: The Case of Transantiago. Res. Transp. Econ. 2016, 59, 242–249. [Google Scholar] [CrossRef]
- Yap, M.; Nijënstein, S.; Vanoort, N. Improving Predictions of the Impact of Disturbances on Public Transport Usage Based on Smart Card Data. In Proceedings of the 96th TRB Annual Meeting, Washington, DC, USA, 8–12 January 2017. [Google Scholar]
- Utsunomiya, M.; Attanucci, J.; Wilson, N.H. Potential Uses of Transit Smart Card Registration and Transaction Data to Improve Transit Planning. Transp. Res. Rec. J. Transp. Res. Board 2006, 1971, 119–126. [Google Scholar] [CrossRef]
- Bagchi, M.; White, P.R. The Potential of Public Transport Smart Card Data. Transp. Policy 2005, 12, 464–474. [Google Scholar] [CrossRef]
- Zhang, F.; Yuan, N.J.; Wang, Y.; Xie, X. Reconstructing Individual Mobility from Smart Card Transactions: A Collaborative Space Alignment Approach. Knowl. Inf. Syst. 2015, 44, 299–323. [Google Scholar] [CrossRef]
- Bagchi, M.; White, P.R. What Role for Smart-card Data from Bus Systems? Munic. Eng. 2004, 157, 39–46. [Google Scholar] [CrossRef]
- Li, D.; Lin, Y.; Zhao, X.; Song, H.; Zou, N. Estimating a Transit Passenger Trip Origin-destination Matrix Using Automatic Fare Collection System. In Proceedings of the 16th International Conference on Database Systems for Advanced Applications, Hong Kong, China, 22–25 April 2011. [Google Scholar]
- Karsten, N. Mifare—Little Security Despite Obscurity. In Proceedings of the 24th Congress of the Chaos Computer Club, Berlin, Germany, 27–30 December 2007. [Google Scholar]
- Barry, J.J.; Freimer, R.; Slavin, H.L. Use of Entry-only Automatic Fare Collection Data to Estimate Linked Transit Trips in New York City. Transp. Res. Rec. J. Transp. Res. Board 2009, 2112, 53–61. [Google Scholar] [CrossRef]
- Barry, J.J.; Newhouser, R.; Rahbee, A.; Sayeda, S. Origin and Destination Estimation in New York City with Automated Fare System Data. Transp. Res. Rec. J. Transp. Res. Board 2002, 1817, 183–187. [Google Scholar] [CrossRef]
- Munizaga, M.A.; Palma, C. Estimation of a Disaggregate Multimodal Public Transport Origin-Destination Matrix from Passive Smartcard Data from Santiago, Chile. Transp. Res. Part C Emerg. Technol. 2012, 24, 9–18. [Google Scholar] [CrossRef]
- Yu, C.; He, Z.C. Analysing the Spatial-temporal Characteristics of Bus Travel Demand Using the Heat Map. J. Transp. Geogr. 2017, 58, 247–255. [Google Scholar] [CrossRef]
- Han, G.; Sohn, K. Activity Imputation for Trip-chains Elicited From Smart-card Data Using a Continuous Hidden Markov Model. Transp. Res. Part B 2016, 83, 121–135. [Google Scholar] [CrossRef]
- Munizaga, M.; Devillaine, F.; Navarrete, C.; Silva, D. Validating Travel Behavior Estimated from Smartcard Data. Transp. Res. Part C Emerg. Technol. 2014, 44, 70–79. [Google Scholar] [CrossRef]
- Jung, J.; Sohn, K. Deep-learning Architecture to Forecast Destinations of Bus Passengers from Entry-only Smart-card Data. IET Intell. Transp. Syst. 2017, 11, 334–339. [Google Scholar] [CrossRef]
- Alsger, A.; Assemi, B.; Mesbah, M.; Ferreira, L. Validating and Improving Public Transport Origin-Destination Estimation Algorithm Using Smart Card Fare Data. Transp. Res. Part C Emerg. Technol. 2016, 68, 490–506. [Google Scholar] [CrossRef]
- Robinson, S.; Narayanan, B.; Toh, N.; Pereira, F. Methods for Pre-processing Smartcard Data to Improve Data Quality. Transp. Res. Part C Emerg. Technol. 2014, 49, 43–58. [Google Scholar] [CrossRef]
- Kuhlman, W. The Construction of Purpose-Specific OD Matrices Using Public Transport Smart Card Data. 2015. Available online: https://repository.tudelft.nl/islandora/object/uuid:7190712e-0913-4849-89ae-d1a1a88e66d2/datastream/OBJ (accessed on 13 January 2018).
- Cui, A. Bus Passenger Origin-Destination Matrix Estimation Using Automated Data Collection Systems; Massachusetts Institute of Technology: Cambridge, MA, USA, 2007. [Google Scholar]
- Nassir, N.; Khani, A.; Sang, G.L.; Hickman, M. Transit Stop-level Origin-destination Estimation through Use of Transit Schedule and Automated Data Collection System. Transp. Res. Rec. J. Transp. Res. Board 2011, 2263, 140–150. [Google Scholar] [CrossRef]
- Alsger, A.A.; Mesbah, M.; Ferreira, L.; Safi, H. Use of Smart Card Fare Data to Estimate Public Transport Origin-Destination Matrix. Transp. Res. Rec. J. Transp. Res. Board 2015, 2535, 88–96. [Google Scholar] [CrossRef]
- Wang, W.; Attanucci, J.; Wilson, N. Bus Passenger Origin-destination Estimation and Related Analyses Using Automated Data Collection Systems. J. Public Transp. 2011, 14, 131–150. [Google Scholar] [CrossRef]
- Dou, H.; Liu, H.; Yang, X. OD Matrix Estimation Method of Public Transportation Flow Based on Passenger Boarding and Alighting. Comput. Commun. 2007, 25, 79–82. [Google Scholar]
- Zhou, X.; Yang, X.; Wu, X. Origin-destination matrix estimation method of public transportaion flow based on data from bus integrated-circuit cards. J. Tongji Univ. 2012, 40, 1027–1030. [Google Scholar]
- Yang, W.; Wang, H.; Ye, X.; Xu, C.; Jiang, D. OD Matrix Inference for Urban Public Transportation Trip Based on GPS and IC Card Data. J. Chongqing Jiaotong Univ. 2015, 34, 117–121. [Google Scholar]
- Zhang, M.; Guo, Y.; Ma, Y. A Probability Model of Transit OD Distribution Based on the Allure of Bus Station. J. Transp. Inf. Saf. 2014, 32, 57–61. [Google Scholar]
- Nam, D.; Kim, H.; Cho, J.; Jayakrishnan, R. A Model Based on Deep Learning for Predicting Travel Mode Choice. In Proceedings of the Transportation Research Board 96th Annual Meeting Transportation Research Board, Washington, DC, USA, 8–12 January 2017. [Google Scholar]
- Polson, N.G.; Sokolov, V.O. Deep Learning for Short-term Traffic Flow Prediction. Transp. Res. Part C Emerg. Technol. 2017, 79, 1–17. [Google Scholar] [CrossRef]
- Jie, Y.U.; Yang, X.G. Estimation a Transit Route OD Matrix Using On/off Data: An Application of Modified BP Artificial Neural Network. Syst. Eng. 2006, 24, 89–92. [Google Scholar]
- Zhang, L.; Zhao, S.; Zhu, Y.; Zhu, Z. Study on the Method of Constructing Bus Stops OD Matrix Based on IC Card Data. In Proceedings of the International Conference on Wireless Communications, Networking and Mobile Computing, Shanghai, China, 21–25 September 2007. [Google Scholar]
- Alsger, A.; Tavassoli, A.; Mesbah, M.; Ferreira, L. Evaluation of Effects from Sample-Size Origin-Destination Estimation Using Smart Card Fare Data; American Society of Civil Engineers: Reston, VA, USA, 2017. [Google Scholar]
- Nagy, V. Theoretical Method for Building OD Matrix from AFC Data. Transp. Res. Procedia 2016, 14, 1802–1808. [Google Scholar] [CrossRef]
- Ma, X.; Wu, Y.J.; Wang, Y.; Chen, F.; Liu, J. Mining Smart Card Data for Transit Riders’ Travel Patterns. Transp. Res. Part C Emerg. Technol. 2013, 36, 1–12. [Google Scholar] [CrossRef]
- Robinson, S.; Manela, M. Automatic Identification of Vehicles with Faulty Automatic Vehicle Location and Control Units in London Buses’ IBUS System. Transp. Res. Rec. J. Transp. Res. Board 2012, 2277, 21–28. [Google Scholar] [CrossRef]
- Zhao, J.; Rahbee, A.; Wilson, N.H.M. Estimating a Rail Passenger Trip Origin-destination Matrix Using Automatic Data Collection Systems. Comput.-Aided Civ. Infrastruct. Eng. 2007, 22, 376–387. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
| Criterion | Description | Score |
|---|---|---|
| Accessing comprehensiveness of factors | 0–3 | |
| Transfer information | Include | 1 |
| Not Include | 0 | |
| Public transport network | Include | 1 |
| Not Include | 0 | |
| Land use | Include | 1 |
| Not Include | 0 | |
| Assessing smart card data collection quality | 1–5 | |
| Sample size | Small (<10,000) | 1 |
| Medium (10,000–100,000) | 2 | |
| Large (>100,000) | 3 | |
| Data cleaning | Include | 1 |
| Not Include | 0 | |
| Matching data description | Include | 1 |
| Not Include | 0 | |
| Assessing method application | 1–4 | |
| Algorithm description | Include | 1 |
| Not Include | 0 | |
| Matching rate | Low (<70%) | 1 |
| Medium (70–90%) | 2 | |
| High (>90%) | 3 | |
| Assessing model validation | 0–2 | |
| Sensitivity analysis | Include | 1 |
| Not Include | 0 | |
| Validation | Include | 1 |
| Not Include | 0 | |
| Reference | Pub. Year | Country | Journal | AFC Systems | Model | Tools | Data Source | Transit Model | Reference |
|---|---|---|---|---|---|---|---|---|---|
| Jung | 2017 | Korea | IET Intelligent Transport Systems | Entry-exit | Deep Learning Architecture | Python | Seoul metropolitan government | Bus | [21] |
| Azalden Alsger | 2016 | Australia | Transport Research Part C | Entry-only | Trip-Chaining Model | / | TransLink | Bus, Metro, Ferry | [28] |
| António A. Nunes | 2015 | Portugal | IEEE Transactions on Intelligent Transportation Systems | Entry-only | Trip-Chaining Model | / | STCP | Bus | [21] |
| Azalden Alsger | 2015 | Australia | Transportation Research Record | Entry-exit | Trip-Chaining Model | TransLink | Bus, Metro, Ferry | [21] | |
| Marcela Munizaga | 2014 | Chile | / | Entry-exit | Trip-Chaining Model | / | Transantiago | Bus-Metro Metro-Bus | [5] |
| Mengmeng Zhang | 2014 | China | Transport Information and Safety | Entry-only | Probability Model | SQL C/C++ | Bus company of Jinan | Bus | [11] |
| W. Kuhlman | 2014 | Netherlands | Delft University of Technology | Entry-exit | / | Biogeme | Bus, Tram and Metro | [32] | |
| Marcela Munizaga | 2012 | Chile | 12th WCTR | Entry-exit | Trip-Chaining Model | / | Transantiago | Bus and Metro | [10] |
| Daming Li | 2011 | China | Database Systems for Advanced Applications | Entry-only | Trip-Chaining Model | MYSQL C++ | Bus Company of Jinan | Bus | [10] |
| Wei Wang | 2011 | England | Public Transportation | Entry-only | Trip-Chaining Model | SQL | TfL (Transport For London) | Bus and Rail | [11] |
| Neema Nassir | 2011 | America | Transportation Research Record: | Entry-only | Trip-Chaining Model | SQL | Metro Transit | bus | [14] |
| A Reddy | 2009 | America | Transportation Research Record | Entry-only | Trip-Chaining Model | / | NYCT | Bus and Rail | [11] |
| JJ Barry | 2008 | America | Transportation Research Record | Entry-only | Trip-Chaining Model | / | NYCT | Subway, bus, ferry and tram | [7] |
| Jinhua Zhao | 2007 | America | Computer-Aided Civil and Infrastructure Engineering | Entry-only | Trip-Chaining Model | SQL C/C++ | CTA | Bus and Rail | [30] |
| Zhang Lianfu | 2007 | China | International Conference on Wireless Communications | Entry-only | Doubly-constrained Growth Factors Method | / | Bus Company of Changchun | Bus | [5] |
| Huili Dou | 2007 | China | Transport Information and Safety | Entry-only | Probability Model | / | Bus company of the City | Bus | [8] |
| Martin TRÉPANIER | 2006 | Canada | IFAC | Entry-only | Trip-Chaining Model | VB/SQL | STO | Bus | [15] |
| Jie YU | 2006 | China | Systems Engineering | Entry-only | BP Artificial Neural Network | / | Bus Company of Suzhou | Bus | [5] |
| Cui | 2006 | America | Massachusetts Institute of Technology | Entry-only | Trip-Chaining Mode | SQL | CTA | Bus and Rail | [26] |
| James J. Barry | 2002 | America | Transportation Research Record | Entry-only | Trip-Chaining Model | / | NYCT | Metro | / |
| Maximum Walking Distance | 402 m | 640 m | 800 m | 1000 m | 1100 m | 2000 m |
|---|---|---|---|---|---|---|
| Zhao et al. (2004) | √ | |||||
| Trépanier et al. (2006) | √ | |||||
| Cui (2006) | √ | |||||
| Wei Wang et al. (2011) | √ | |||||
| Marcela Munizaga et al. (2012, 2014) | √ | |||||
| António A. Nunes et al. (2015) | √ | |||||
| Azalden Alsger et al. (2015) | √ | |||||
| Azalden Alsger et al. (2016) | √ | √ | √ |
| Destination Estimation Model | Advantage | Disadvantage |
|---|---|---|
| Trip Chaining Model |
|
|
| Probability Model |
|
|
| Deep learning model |
|
|
| Models and Influence Factors Researchers | Jung et al. (2017) | Y Jie (2006) | M Zhang (2014) | H L Dou (2007) | A Alsger (2016, 2015); M Munizaga (2014, 2012); D Li (2011); W Wang (2011); A Reddy (2009); JJ Barry (2008); JH Zhao (2007); M Trépanier (2006); Cui (2006); James J. Barry (2002); N Nassir (2011) | AA Nunes (2015) | LF Zhang (2007) |
|---|---|---|---|---|---|---|---|
| Destination Estimation Model | Deep Learning Architecture | BP Artificial Neural Network | Probability Model | Probability Model | Trip-Chaining Model | Trip-Chaining Model | Doubly-constrained Growth Factors Method |
| Boarding locations and time | √ | √ | √ | √ | √ | ||
| Alighting locations and times | √ | ||||||
| Boarding passenger numbers | √ | √ | √ | √ | √ | ||
| Alighting passenger numbers | √ | ||||||
| Network travel times/distance | √ | √ | √ | ||||
| Number of transfers | √ | ||||||
| Walking time/distance between consecutive transactions | √ | √ | |||||
| Bus stop/line density | √ | ||||||
| Bus schedule | |||||||
| Travel zone | √ | √ | |||||
| Land use | √ | √ | |||||
| Matching rate | 60% of tight criterion 87% of relaxing criterion | 30 persons day | 90% | 89% | 65–95.4% | 62.40% | / |
| Author | Sample Size | Matching Results |
|---|---|---|
| Jung et al. (2017) | 124,513 records | 60% of tight criterion 87% of relaxing criterion |
| A Alsger et al. (2016) | 161,446 records | 76–84% |
| A A Nunes et al. (2015) | whole month of April 2010 | 62.4% |
| M Munizaga et al. (2014) | 715 records | 84.2% |
| M M Zhang et al. (2014) | NO.83 Bus of Jinan | 90% |
| M Munizaga et al. (2012) | 36,000,000 records | 80.77% |
| 38,000,000 records | 83.01% | |
| D Li et al. (2011) | Route 115 of Jinan city | 75% peak hours, 85% |
| W Wang et al. (2011) | 7386 records | 66% Northbound 65% Southbound |
| N Nassir et al. (2011) | 84,413 records | 95.4% |
| W Wang et al. (2010) | 8585 records | 62.80% |
| 12,074 records | 64.10% | |
| 24,245 records | 57.50% | |
| 10,057 records | 69.30% | |
| 17,496 records | 78.50% | |
| JM Farzin et al. (2008) | 658,000 records | 76.7% |
| JJ Barry et al. (2008, 2002) | 6,000,000 records | 90% |
| J H Zhao et al. (2007) | 2,500,000 records | 71% |
| LF Zhang et al. (2007) | Changchun morning rush hour 6:00~7:00 and evening hour 16:30~17:30 | / |
| HL Dou et al. (2007) | 396 records | 88.74% |
| M TRÉPANIER (2006) | 378,260 trips in July 2003 771,239 trips in October 2003 | 66% of all data 80% at peak hours |
| J YU et al. (2006) | Bus of NO. 41 | 30 persons-day |
| Cui (2006) | 2,736,454 records | 79% |
| Main Problems of Transaction | Processing Method | Studies |
|---|---|---|
| Missing entries/exit | Eliminated | Kusakabe T et al. (2013) N Nassir et al. (2011) A Alsger et al. (2015) A Alsger et al. (2016) |
| Missing one whole transaction in the set of a person’s travel data | Eliminated | Kusakabe T et al.(2013) N Nassir et al. (2011) A Alsger et al. (2015) |
| No next boarding information | Eliminated | Kusakabe T et al. (2013) |
| Illogical values across two attributes | Thorough analysis and subsequent pre-processing of data | A A. Nunes et al. (2015) |
| Missing the direction of travel attribute value | Checking travel direction of other transaction records with same trip, then mitigated it | A A. Nunes et al. (2015) |
| Duplicate transactions | Eliminated | A Alsger et al. (2015) |
| Parameter | Authors | Detailed Parameter | Main Conclusion |
|---|---|---|---|
| Walking distance | A A. Nunes et al. (2015) | 400 m 640 m 1000 m | If the allowable walking distance selected short, the risk of rejecting true positives is greater. If the allowable walking distance selected longer, the opportunity of accepting false positives will be bigger. |
| Walking distance | A Alsger et al. (2016) | 400 m 800 m 1000 m 1100 m | When the tolerable distance set 400 m, the matching rate is highest. While, when the distance drop to 800 m to 1100 m, the result not so good. If the walking distance beyond 800 m, the result has no significant difference. |
| Simple size | A Alsger et al. (2017) | Sample size from 1% to 100% of selected transactions | Sample size has a high impact of inferring error. Sample size affect the accuracy of OD matrix, especially the small sample size. |
| Matching criterion | Jung et al. (2017) | Tight criterion Relax criterion | Relaxing the criterion is in line with the biased behavior of bus users and applies to the high-density bus network of Seoul. |
| Literature | Validation Data | Data Source | Validated Sample Size Invalidated Sample Size (*) | Validated Accuracy Invalidated Matching Rate (*) | Transit Mode |
|---|---|---|---|---|---|
| Jung et al. (2017) | AFC data | Seoul metropolitan government | 124,513 transactions | 60% of tight criterion 87% of relaxing criterion | Bus |
| A Alsger et al. (2016) | GoCard data | TransLink | 161,446 transactions | 76–84% | Bus, Metro, Ferry |
| A A. Nunes et al. (2015) | No validation | STCP | / | 62.4% (*) | Bus |
| A Alsger et al. (2015) | AFC data | TransLink | 473,525 transactions | 88% | Bus, Metro, Ferry |
| M Munizaga et al. (2014) | OD Metro surveys data | OD Metro surveys | 715 transactions (*) | 84.20% | Bus-Metro Metro-Bus |
| M M Zhang et al. (2014) | Bus surveys data | Bus surveys | Bus NO. 83 | 90% (*) | Bus |
| M Munizaga et al. (2012) | No validation | Transantiago | 36 million March 2009 (*) 38 million June 2010 (*) | 80.77% March 2009 (*) 83.01% June 2010(*) | Bus and Metro |
| D Li et al. (2011) | No validation | Bus Company of Jinan | Bus NO. 115 of Jinan (*) | 75% (*) | Bus |
| W Wang et al. (2011) | manually-surveyed bus trips | TfL | 7386 transaction (*) | 66%Northbound (*) 65%Southbound (*) | Bus and Rail |
| N Nassir et al. (2011) | No validation | Metro Transit | 84,413 transaction (*) | 60.74% (*) | Bus |
| AFC-APC-VL data | Metro Transit | 10,886 transactions | 95.4% (*) | ||
| A Reddy (2009) | No validation | / | / | / | Metro |
| JJ Barry (2008) | Bus: ride check data Metro:purchased Metrocard and ten predetermined tours | NYCT | / | / | Metro, buses, ferry, tramway |
| Jinhua Zhao(2007) | No validation | CTA rail system | 2,500,000 transaction (*) | 71.2% (*) | Bus and Rail |
| Zhang Lianfu(2007) | No validation | Bus Company of Changchun | / | / | Bus |
| HL Dou et al. (2007) | Bus surveys data | Bus company of the derived City | 396 transaction | 88.74% | Bus |
| Martin TRÉPANIER(2006) | No validation | Smart card system of the Société de transport del’Outaouais (STO) | 378,260 trips made in July 2003 771,239 trips made in October 2003 | 66% of all data 80% at peak hours | Bus |
| J YU et al. (2006) | Bus surveys data | Bus Company of Suzhou | / | 30 person-time/day | Bus |
| Cui (2006) | No validation | CTA (Chicago Transit Authority) | 2,736,454 trips (*) | 79% | Bus and Rail |
| J J. Barry et al. (2002) | Travel diary survey | NYCT and NYMTC | Group 1–100 residents with two trips, total 200 trips Group 2–200 residents more than two trips, total 590 trips | 90% | Metro |
| Authors | Walking Distance Exceeded Maximum Distance | The Transaction Is Single | Data Error (Duplicate Transaction Records, Missing or Illogical Data) | Passenger Does Not Return the Origin Station at the Last Travel | Mixed Transportation Modes | Wrong Estimate | The Next Boarding Station May Not Nearest to the Alighting Stop of Previous Trip |
|---|---|---|---|---|---|---|---|
| M Munizaga et al. (2012) | √ | √ | √ | √ | |||
| D Li et al. (2011) | √ | √ | √ | √ | |||
| A A. Nunes et al. (2015) | √ | √ | √ | ||||
| J H Zhao et al. (2007) | √ | √ | |||||
| W Wang et al. (2011) | √ |
| Criterion | Description | Score | Number of Studies | Percentage |
|---|---|---|---|---|
| Accessing comprehensiveness of factors | 0–3 | |||
| Transfer information | Include | 1 | 20 | 100% |
| Not Include | 0 | 0 | 0% | |
| Public transport network | Include | 1 | 6 | 30% |
| Not Include | 0 | 14 | 70% | |
| Land use | Include | 1 | 3 | 15% |
| Not Include | 0 | 17 | 85% | |
| Assessing smart card data collection quality | 1–5 | |||
| Sample size | Small (<10,000) | 1 | 4 | 20% |
| Medium (10,000—100,000) | 2 | 5 | 25% | |
| Large (>100,000) | 3 | 9 | 45% | |
| Data cleaning | Include | 1 | 13 | 65% |
| Not Include | 0 | 7 | 35% | |
| Matching data description | Include | 1 | 3 | 15% |
| Not Include | 0 | 17 | 85% | |
| Assessing method application | 1–4 | |||
| Algorithm description | Include | 1 | 17 | 85% |
| Not Include | 0 | 3 | 15% | |
| Matching rate | Low (<70%) | 1 | 5 | 25% |
| Medium (70–90%) | 2 | 8 | 40% | |
| High (>90%) | 3 | 4 | 20% | |
| Assessing model validation | 0–2 | |||
| Sensitivity analysis | Include | 1 | 5 | 25% |
| Not Include | 0 | 15 | 75% | |
| Validation | Include | 1 | 9 | 45% |
| Not Include | 0 | 11 | 55% | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, T.; Sun, D.; Jing, P.; Yang, K. Smart Card Data Mining of Public Transport Destination: A Literature Review. Information 2018, 9, 18. https://doi.org/10.3390/info9010018
Li T, Sun D, Jing P, Yang K. Smart Card Data Mining of Public Transport Destination: A Literature Review. Information. 2018; 9(1):18. https://doi.org/10.3390/info9010018
Chicago/Turabian StyleLi, Tian, Dazhi Sun, Peng Jing, and Kaixi Yang. 2018. "Smart Card Data Mining of Public Transport Destination: A Literature Review" Information 9, no. 1: 18. https://doi.org/10.3390/info9010018
APA StyleLi, T., Sun, D., Jing, P., & Yang, K. (2018). Smart Card Data Mining of Public Transport Destination: A Literature Review. Information, 9(1), 18. https://doi.org/10.3390/info9010018