Land Cover Classification from Multispectral Data Using Computational Intelligence Tools: A Comparative Study

 ,
, 

 , ,
, ,  and
and
Abstract
:1. Introduction
2. Related Work in Remote Sensing Analysis
3. Materials and Methods
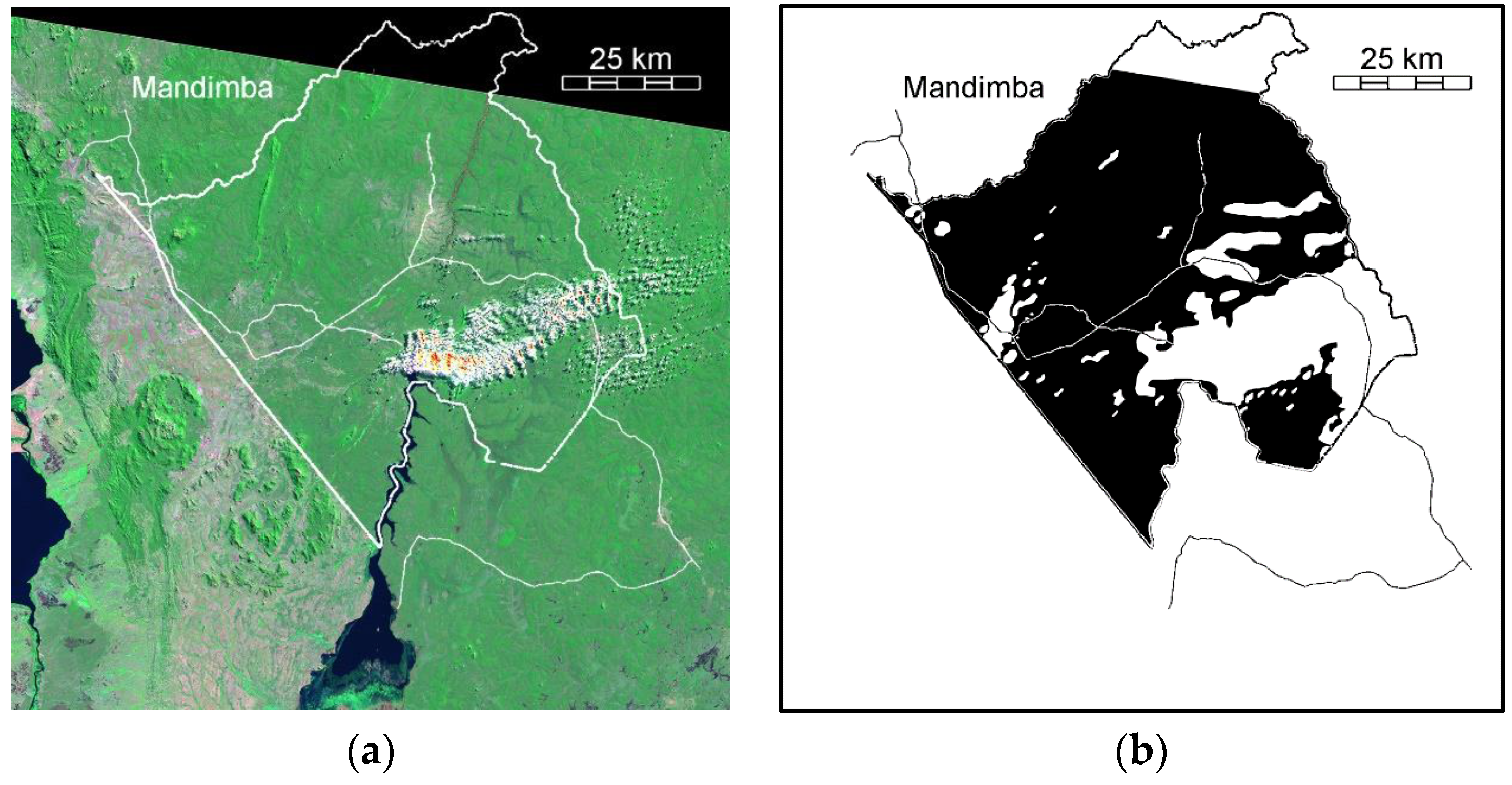
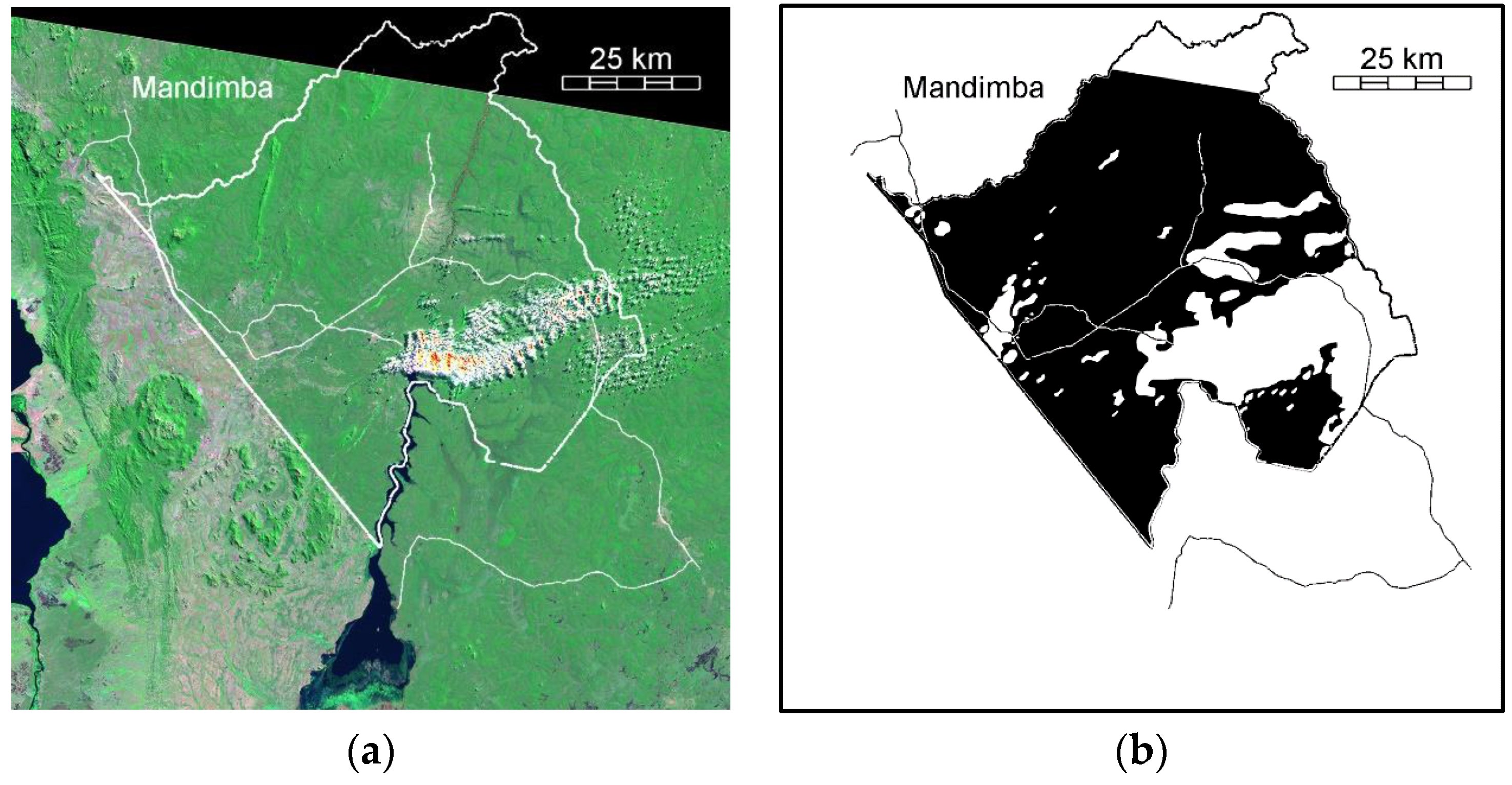
3.1. Input Data
3.2. Overview of the Fuzzy-Fusion Uninorm Method
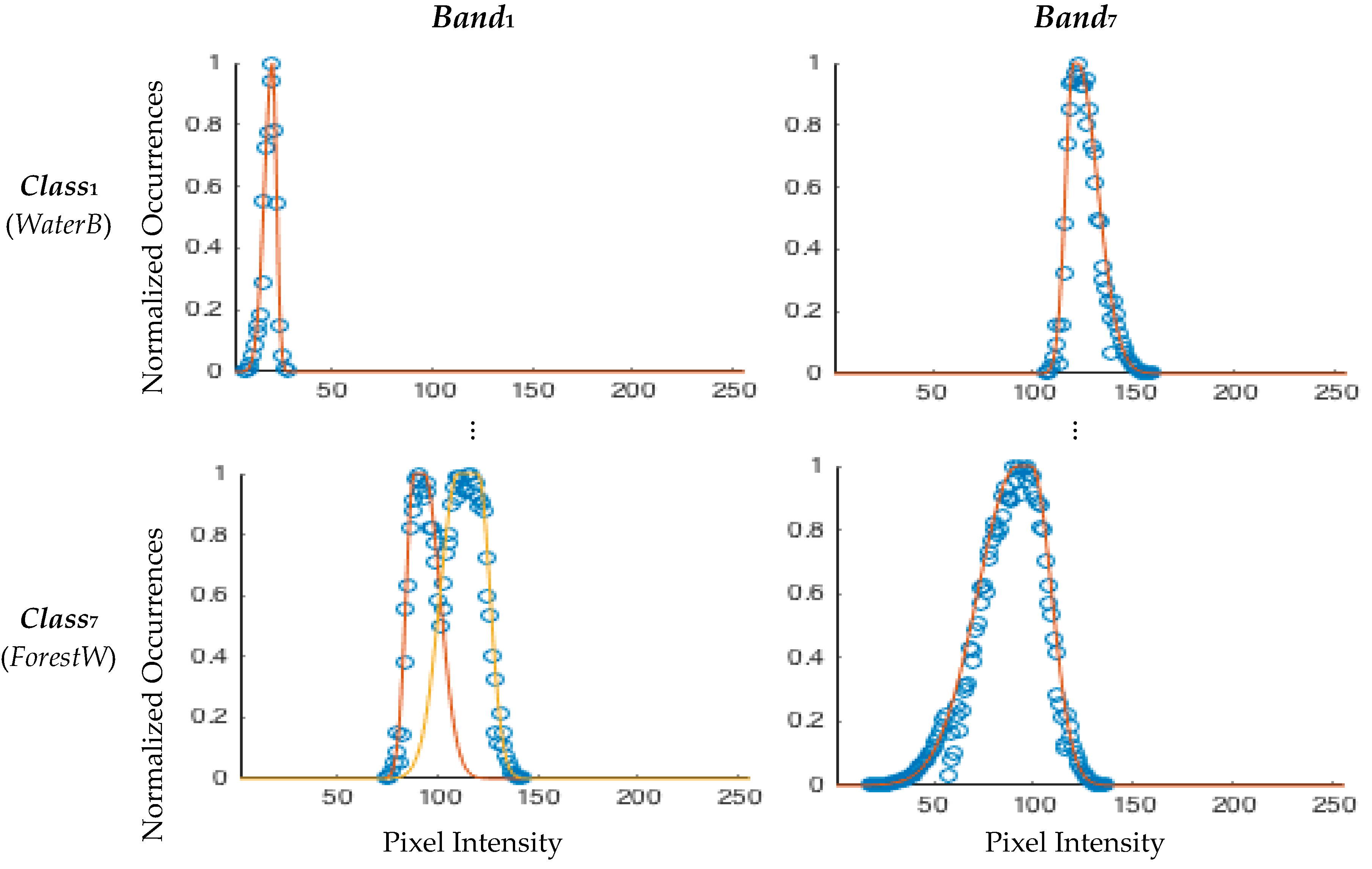
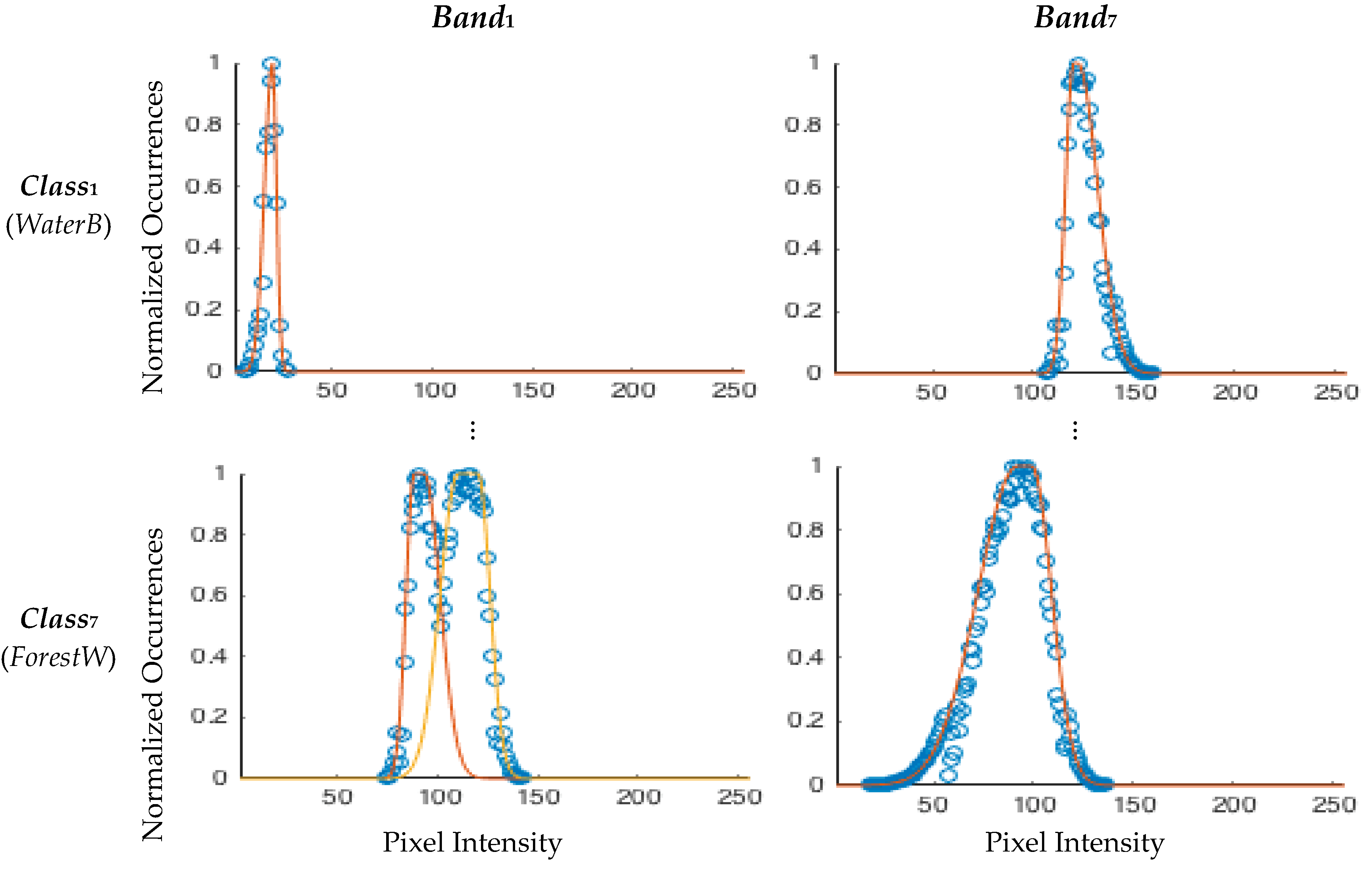
3.2.1. Training Set
- Fit the histogram with one asymmetrical Gaussian membership function;
- Apply Otsu’s thresholding method [23] to the histogram to find the two main clusters;
- Obtain for each cluster an asymmetrical Gaussian membership function, using the cluster’s mean and standard deviation values above and below the mean value;
- Fit each cluster by an asymmetrical Gaussian membership function;
- Use the root mean square error to select the membership function that best fits the cluster (choosing the resulting membership function of Step 1, 3 or 4).
3.2.2. Rule-Based System
| Rule 1: | If Band 1 is Waterbody (WaterB) and Band 2 is WaterB … and Band 7 is WaterB | Then output is WaterB; |
| Rule 2: | If Band 1 is River Bank (RiverB) and Band 2 is RiverB … and Band 7 is RiverB | Then output is RiverB; |
| Rule 3: | If Band 1 is Bare Area (BareA) and Band 2 is BareA … and Band 7 is BareA | Then output is BareA; |
| Rule 4: | If Band 1 is Cropland (CropL) and Band 2 is CropL … and Band 7 is CropL | Then output is CropL; |
| Rule 5: | If Band 1 is Grassland (GrassL) and Band 2 is GrassL … and Band 7 is GrassL | Then output is GrassL; |
| Rule 6: | If Band 1 is Shrubland (ShrubL) and Band 2 is ShrubL … and Band 7 is ShrubL | Then output is ShrubL; |
| Rule 7: | If Band 1 is Forest and Woodlands (ForestW) and Band 2 is ForestW … and Band 7 is ForestW | Then output is ForestW. |
3.2.3. Reinforcement Inference Scheme
- = aggregation operator;
- = the class number;
- = the band number;
- = class under evaluation;
- = input bands.
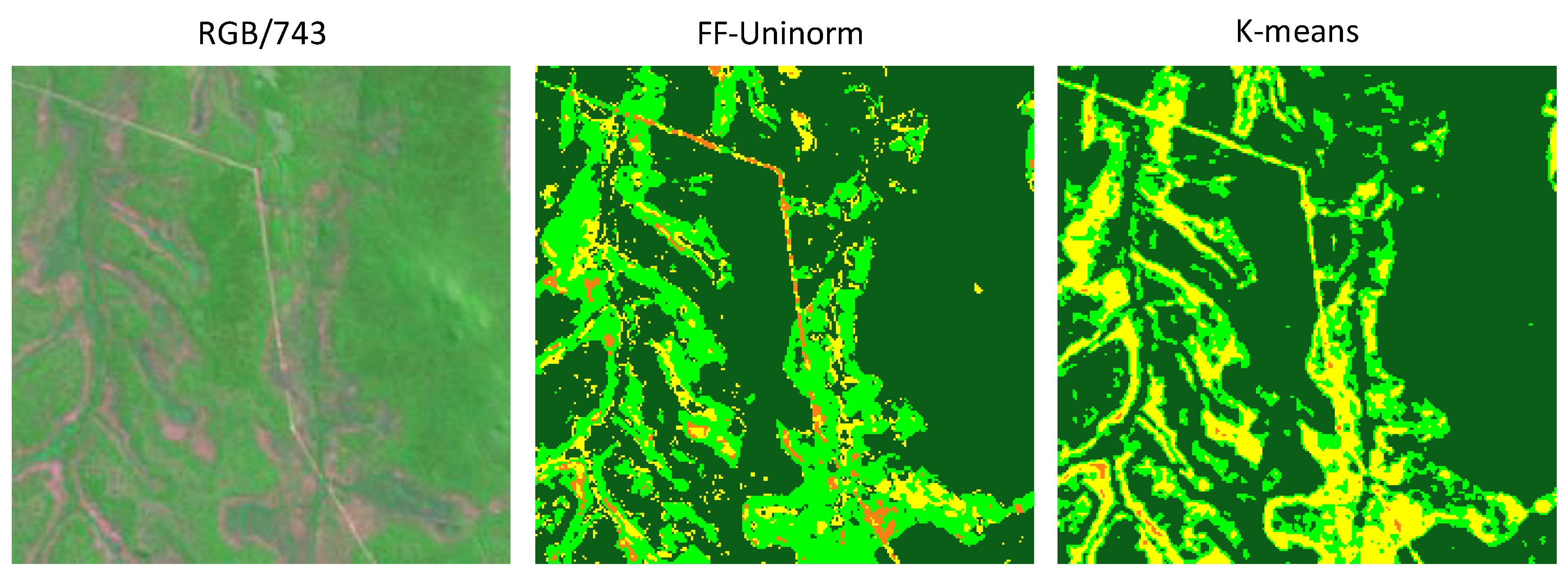
4. Assessment and Discussion
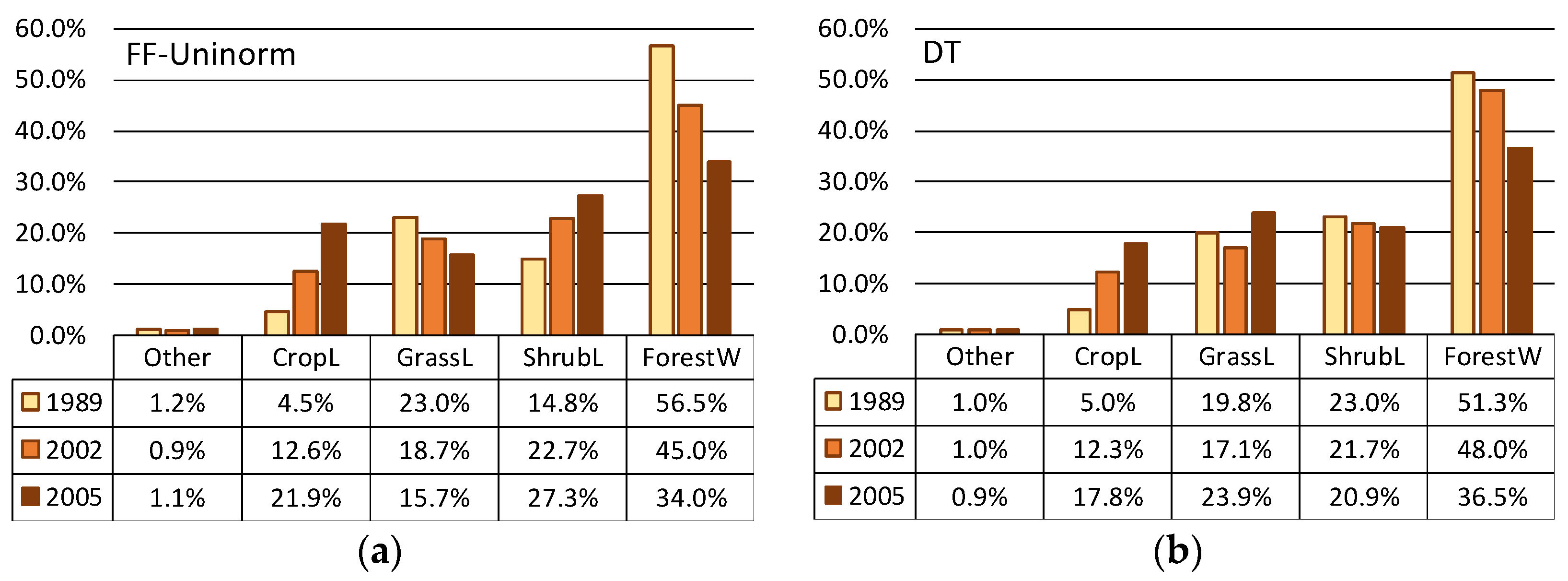
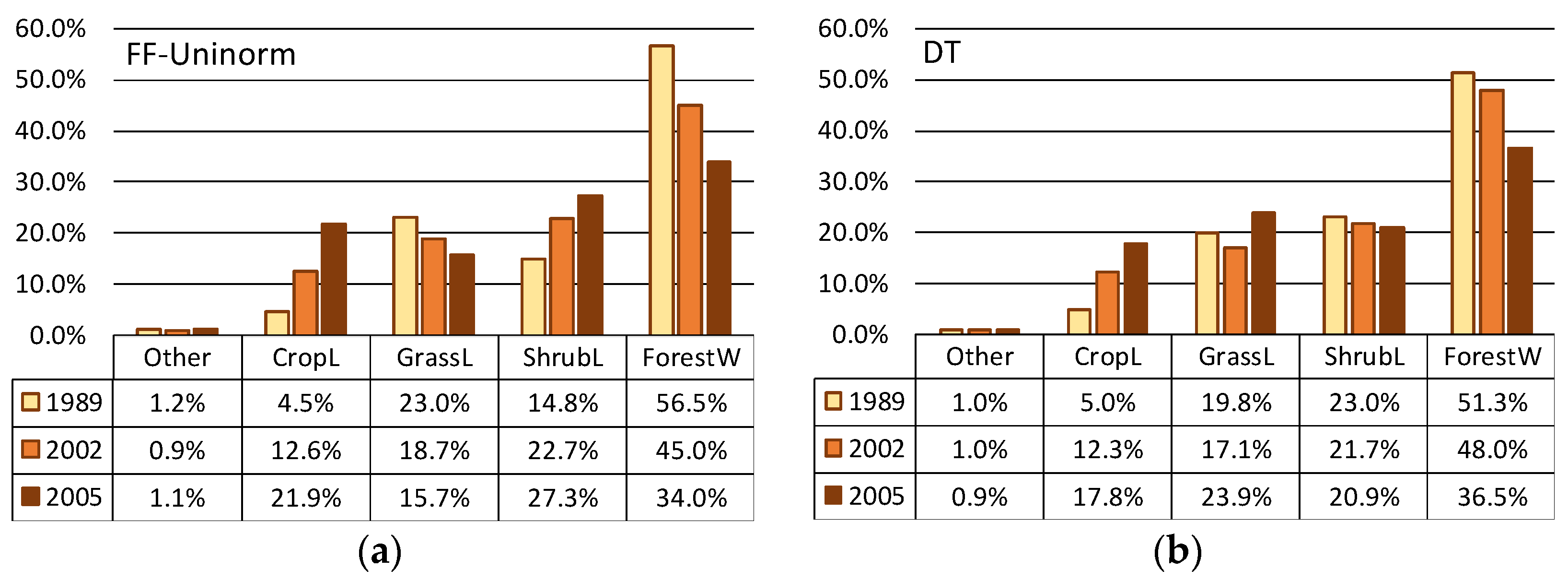
4.1. Comparison of Training Results
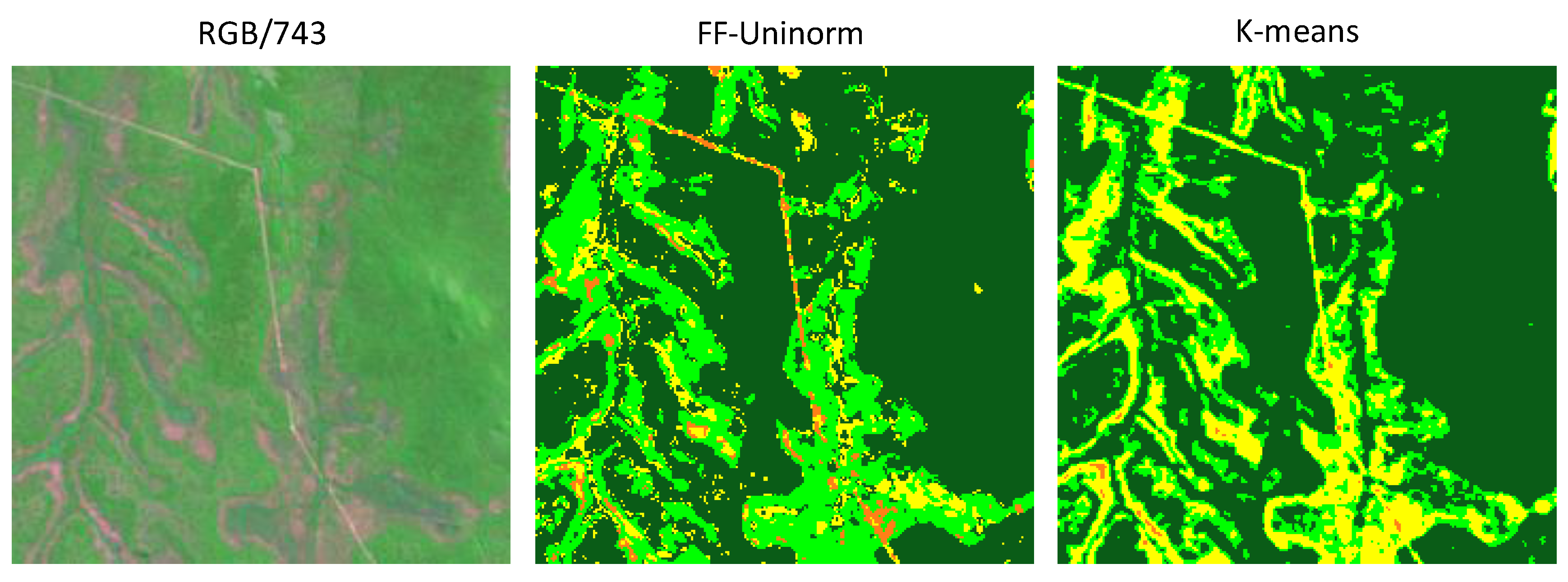
4.2. Comparison of Classification Results
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Santos, T.M.A.; Mora, A.; Ribeiro, R.A.; Silva, J.M.N. Fuzzy-fusion approach for land cover classification. In Proceedings of the 2016 IEEE 20th Jubilee International Conference on Intelligent Engineering Systems (INES), Budapest, Hungary, 30 June–2 July 2016; pp. 177–182. [Google Scholar] [CrossRef]
- Temudo, M.P.; Silva, J.M.N. Agriculture and forest cover changes in post-war Mozambique. J. Land Use Sci. 2012, 7, 425–442. [Google Scholar] [CrossRef]
- Friedl, M.A.; Brodley, C.E. Decision tree classification of land cover from remotely sensed data. Remote Sens. Environ. 1997, 61, 399–409. [Google Scholar] [CrossRef]
- Schowengerdt, R.A. Remote Sensing: Models and Methods for Image Processing; Academic Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Ishibuchi, H.; Nozaki, K.; Yamamoto, N.; Tanaka, H. Construction of fuzzy classification systems with rectangular fuzzy rules using genetic algorithms. Fuzzy Sets Syst. 1994, 65, 237–253. [Google Scholar] [CrossRef]
- Nguyen, C.H.; Pedrycz, W.; Duong, T.L.; Tran, T.S. A genetic design of linguistic terms for fuzzy rule based classifiers. Int. J. Approx. Reason. 2013, 54, 1–21. [Google Scholar] [CrossRef]
- Shackelford, A.K.; Davis, C.H. A combined fuzzy pixel-based and object-based approach for classification of high-resolution multispectral data over urban areas. IEEE Trans. Geosci. Remote Sens. 2003, 41, 2354–2363. [Google Scholar] [CrossRef]
- Barros, R.C.; Basgalupp, M.P.; de Carvalho, A.C.P.L.F.; Freitas, A.A. A Survey of Evolutionary Algorithms for Decision-Tree Induction. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2012, 42, 291–312. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Millán, V.E.G.; Sanchez-Azofeifa, G.A.; Malvárez, G.C. Mapping Tropical Dry Forest Succession With CHRIS/PROBA Hyperspectral Images Using Nonparametric Decision Trees. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 3081–3094. [Google Scholar] [CrossRef]
- Ahmed, B.; Al Noman, M.A. Land cover classification for satellite images based on normalization technique and Artificial Neural Network. In Proceedings of the 2015 1st International Conference on Computer and Information Engineering (ICCIE), Rajshahi, Bangladesh, 26–27 November 2015; pp. 138–141. [Google Scholar] [CrossRef]
- Castelluccio, M.; Poggi, G.; Sansone, C.; Verdoliva, L. Land Use Classification in Remote Sensing Images by Convolutional Neural Networks. arXiv, 2015; arXiv:1508.00092. [Google Scholar]
- Sharapov, R.; Varlamov, A. Using neural networks in remote sensing monitoring of exogenous processes. In Proceedings of the Sixth International Conference on Graphic and Image Processing (ICGIP 2014), Beijing, China, 24–26 October 2014. [Google Scholar]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed]
- Ayhan, E.; Kansu, O. Analysis of image classification methods for remote sensing. Exp. Tech. 2012, 36, 18–25. [Google Scholar] [CrossRef]
- Mather, P.; Tso, B. Classification Methods for Remotely Sensed Data, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2009. [Google Scholar]
- Fauvel, M.; Chanussot, J.; Benediktsson, J.A. Decision Fusion for the Classification of Urban Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2828–2838. [Google Scholar] [CrossRef]
- Ribeiro, R.A.; Falcão, A.; Mora, A.; Fonseca, J.M. FIF: A fuzzy information fusion algorithm based on multi-criteria decision making. Knowl.-Based Syst. 2014, 58, 23–32. [Google Scholar] [CrossRef]
- Rudas, I.J.; Pap, E.; Fodor, J. Information aggregation in intelligent systems: An application oriented approach. Knowl.-Based Syst. 2013, 38, 3–13. [Google Scholar] [CrossRef]
- Beliakov, G.; Pradera, A.; Calvo, T. Aggregation Functions: A Guide for Practitioners; Springer Publishing Company: Heidelberg, Germany, 2007; Volume 221. [Google Scholar]
- Ribeiro, R.A.; Pais, T.C.; Simões, L.F. Benefits of Full-Reinforcement Operators for Spacecraft Target Landing. In Preferences and Decisions, Models and Applications; Greco, S., Marques Pereira, R.A., Squillante, M., Yager, R.R., Kacprzyk, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 353–367. [Google Scholar]
- Torra, V.; Narukawa, Y. Modeling Decisions: Information Fusion and Aggregation Operators; Springer: Berlin/Heidelberg, Germany, 2007; Volume XIV. [Google Scholar]
- Otsu, N. A Threshold Selection Method from Gray-Level Histograms. IEEE Trans. Syst. Man. Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Marquardt, D.W. An algorithm for least-squares estimation of non-linear parameters. J. Soc. Ind. Appl. Math. 1963, 11, 431–441. [Google Scholar] [CrossRef]
- Sugeno, M. An introductory survey of fuzzy control. Inf. Sci. 1985, 36, 59–83. [Google Scholar] [CrossRef]
- Yager, R.R.; Rybalov, A. Full reinforcement operators in aggregation techniques. IEEE Trans. Syst. Man Cybern. Part B 1998, 28, 757–769. [Google Scholar] [CrossRef] [PubMed]
- Calvo, T.; Mayor, G.; Mesiar, R. Aggregation Operators: New Trends and Applications; Physica: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Rekik, A.; Zribi, M.; Benjelloun, M.; Ben Hamida, A. A k-means clustering algorithm initialization for unsupervised statistical satellite image segmentation. In Proceedings of the 2006 1ST IEEE International Conference on E-Learning in Industrial Electronics, Hammamet, Tunisia, 18–20 December 2006; pp. 11–16. [Google Scholar] [CrossRef]
- Mitra, S.; Kundu, P.P. Satellite image segmentation with Shadowed C-Means. Inf. Sci. 2011, 181, 3601–3613. [Google Scholar] [CrossRef]
- Pal, S.K.; Mitra, P. Multispectral image segmentation using the rough-set-initialized EM algorithm. IEEE Trans. Geosci. Remote Sens. 2002, 40, 2495–2501. [Google Scholar] [CrossRef]
- Bandyopadhyay, S.; Maulik, U. Genetic clustering for automatic evolution of clusters and application to image classification. Pattern Recognit. 2002, 35, 1197–1208. [Google Scholar] [CrossRef]
- Omkar, S.N.; Kumar, M.M.; Mudigere, D.; Muley, D. Urban Satellite Image Classification using Biologically Inspired Techniques. In Proceedings of the IEEE International Symposium on Industrial Electronics, Vigo, Spain, 4–7 June 2007; pp. 1767–1772. [Google Scholar] [CrossRef]
- Kanellopoulos, I.; Wilkinson, G.G. Strategies and best practice for neural network image classification. Int. J. Remote Sens. 1997, 18, 711–725. [Google Scholar] [CrossRef]
- Ross, T.J. Fuzzy Logic with Engineering Applications; John Wiley & Sons: Chichester, UK, 2009. [Google Scholar]
- Mendel, J.M. Uncertain Rule-Based Fuzzy Logic Systems: Introduction and New Directions; Prentice Hall PTR: Upper Saddle River, NJ, USA, 2001. [Google Scholar]
- Mamdani, E.H.H.; Assilian, S. An experiment in linguistic synthesis with a fuzzy logic controller. Int. J. Man Mach. Stud. 1975, 7, 1–13. [Google Scholar] [CrossRef]
- Nedeljkovic, I. Image classification based on fuzzy logic. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2004, 34, 685. [Google Scholar]
- Ruthenberg, H.; MacArthur, J.D. Farming Systems in the Tropics; Clarendon Press: Oxford, UK, 1980. [Google Scholar]
- Rouse, J.W.; Haas, R.H.; Schell, J.A.; Deering, D.W. Monitoring the Vernal Advancement and Retrogradation (Green Wave Effect) of Natural Vegetation; Technical Report for Texas A&M University; Texas A&M University: College Station, TX, USA, 1974. [Google Scholar]
- Garcia, M.L.; Caselles, V. Mapping burns and natural reforestation using Thematic Mapper data. Geocarto Int. 1991, 6, 31–37. [Google Scholar] [CrossRef]
- Rand, M. Objective Criteria for the Evaluation of Methods Clustering. J. Am. Stat. Assoc. 1971, 66, 846–850. [Google Scholar] [CrossRef]

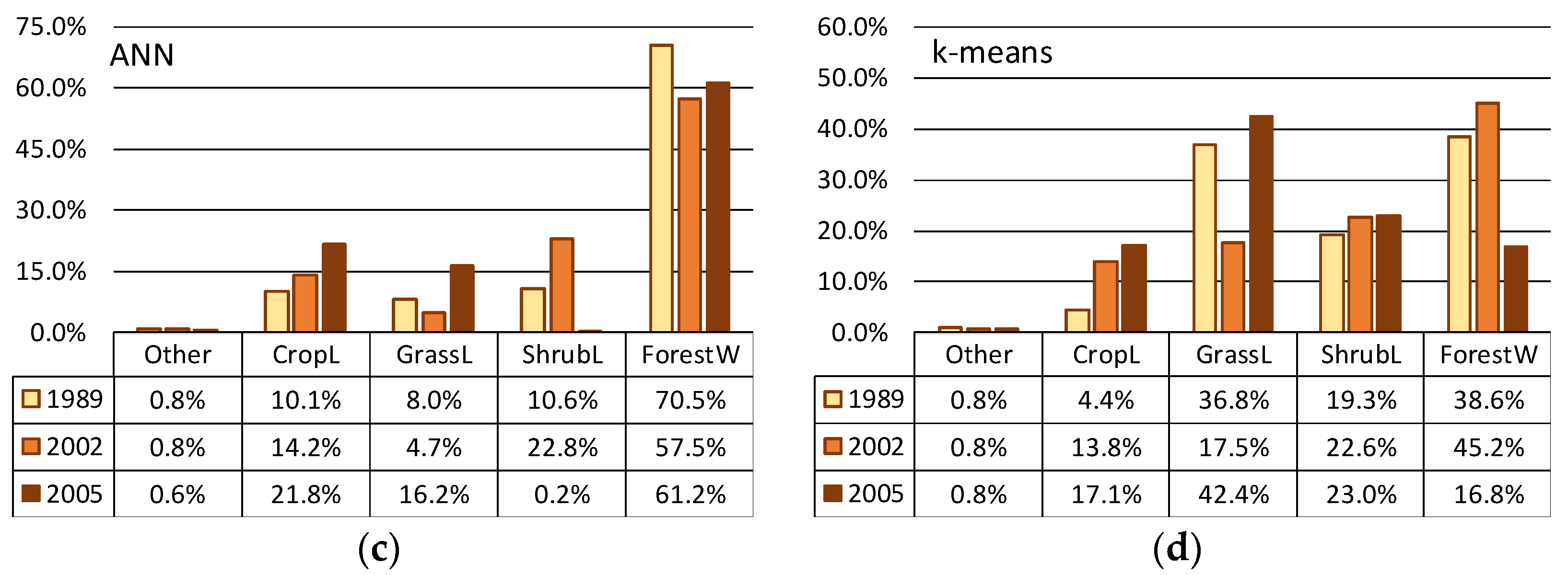


{kind=link}
{kind=link}
{kind=link}
{kind=link}
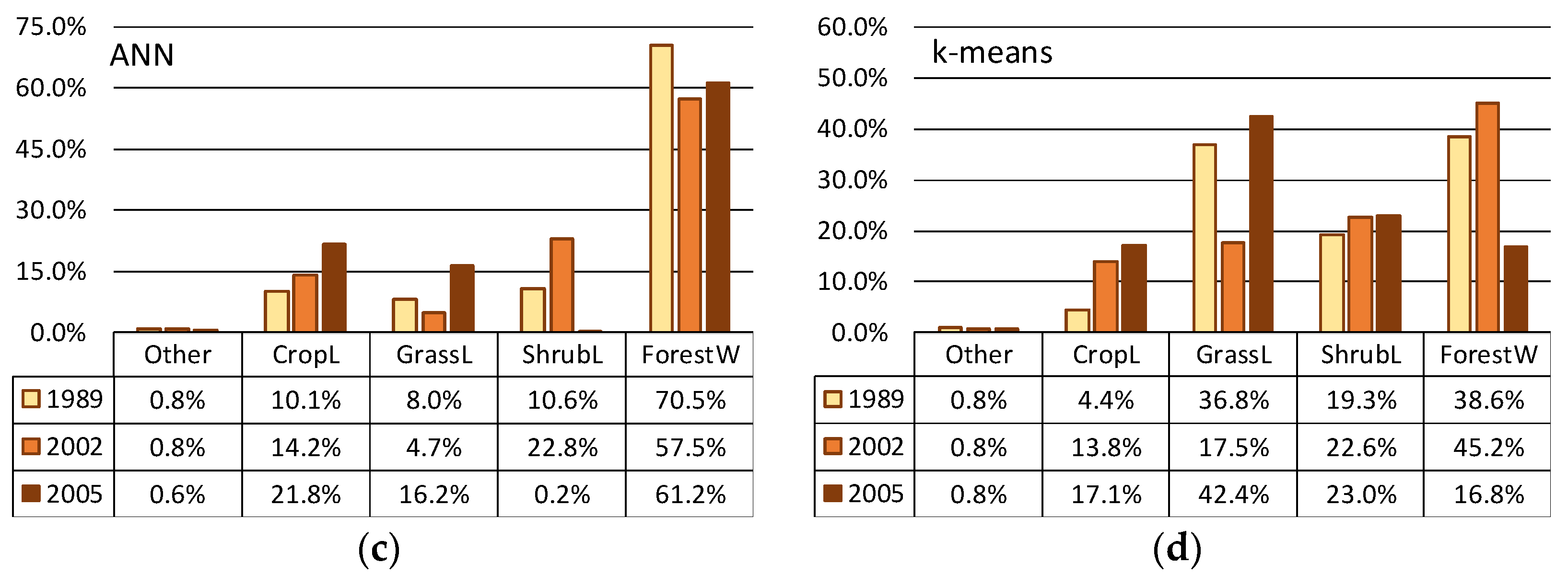{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Class Name | Abbreviation | Class Description | Merged | Samples |
|---|---|---|---|---|---|
| 1 | Waterbody | WaterB | Areas covered by water (e.g., rivers, lakes) | 1 |  |
| 2 | River Bank | RiverB | Areas nearby water bodies | 1 |  |
| 3 | Bare Area | BareA | Areas without vegetation (e.g., rock outcrops) | 2 |  |
| 4 | Croplands | CropL | Areas covered by crops | 2 |  |
| 5 | Grasslands | GrassL | Areas covered by herbaceous vegetation | 3 |  |
| 6 | Shrublands and Thickets | ShrubL | Areas covered by shrubs (closed to open) | 4 |  |
| 7 | Forest and Woodlands | ForestW | Areas with a tree canopy cover greater than 10% | 5 |  |
| Year | Method | Other | CropL | GrassL | ShrubL | ForestW | Total Avg |
|---|---|---|---|---|---|---|---|
| 1989 | FF-Uninorm | 99.9% | 83.0% | 81.5% | 69.6% | 92.5% | 88.2% |
| DT | 100.0% | 88.8% | 86.0% | 87.0% | 90.4% | 90.2% | |
| ANN | 97.7% | 99.3% | 66.8% | 70.8% | 98.4% | 95.6% | |
| k-means | 91.4% | 89.4% | 44.0% | 67.0% | 75.0% | 78.8% | |
| Training samples | 7.4% | 35.3% | 7.1% | 3.1% | 47.1% | ||
| 2002 | FF-Uninorm | 99.9% | 91.7% | 59.9% | 63.1% | 76.8% | 81.5% |
| DT | 100.0% | 87.4% | 73.4% | 69.3% | 85.5% | 85.5% | |
| ANN | 96.5% | 99.6% | 73.5% | 22.4% | 94.6% | 91.8% | |
| k-means | 92.6% | 53.0% | 33.3% | 41.9% | 74.2% | 63.0% | |
| Training samples | 7.7% | 34.5% | 10.3% | 3.4% | 44.2% | ||
| 2005 | FF-Uninorm | 99.3% | 87.3% | 63.8% | 67.3% | 72.6% | 78.1% |
| DT | 100.0% | 90.4% | 88.4% | 78.1% | 80.8% | 86.4% | |
| ANN | 99.7% | 98.8% | 84.4% | 58.5% | 94.4% | 92.1% | |
| k-means | 94.7% | 46.3% | 21.0% | 38.3% | 68.0% | 53.7% | |
| Training samples | 7.6% | 34.6% | 13.7% | 8.0% | 36.0% |
| 1989 | 2002 | 2005 | Average | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DT | ANN | k-Means | DT | ANN | k-Means | DT | ANN | k-Means | DT | ANN | k-Means | |
| FF-Uninorm | 0.77 | 0.73 | 0.75 | 0.85 | 0.79 | 0.73 | 0.80 | 0.71 | 0.84 | 0.80 | 0.74 | 0.77 |
| DT | 0.75 | 0.69 | 0.75 | 0.74 | 0.75 | 0.76 | 0.75 | 0.73 | ||||
| ANN | 0.65 | 0.62 | 0.70 | 0.65 | ||||||||
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mora, A.; Santos, T.M.A.; Łukasik, S.; Silva, J.M.N.; Falcão, A.J.; Fonseca, J.M.; Ribeiro, R.A. Land Cover Classification from Multispectral Data Using Computational Intelligence Tools: A Comparative Study. Information 2017, 8, 147. https://doi.org/10.3390/info8040147
Mora A, Santos TMA, Łukasik S, Silva JMN, Falcão AJ, Fonseca JM, Ribeiro RA. Land Cover Classification from Multispectral Data Using Computational Intelligence Tools: A Comparative Study. Information. 2017; 8(4):147. https://doi.org/10.3390/info8040147
Chicago/Turabian StyleMora, André, Tiago M. A. Santos, Szymon Łukasik, João M. N. Silva, António J. Falcão, José M. Fonseca, and Rita A. Ribeiro. 2017. "Land Cover Classification from Multispectral Data Using Computational Intelligence Tools: A Comparative Study" Information 8, no. 4: 147. https://doi.org/10.3390/info8040147
APA StyleMora, A., Santos, T. M. A., Łukasik, S., Silva, J. M. N., Falcão, A. J., Fonseca, J. M., & Ribeiro, R. A. (2017). Land Cover Classification from Multispectral Data Using Computational Intelligence Tools: A Comparative Study. Information, 8(4), 147. https://doi.org/10.3390/info8040147