
An Overview on Evaluating and Predicting Scholarly Article Impact


Abstract
:1. Introduction
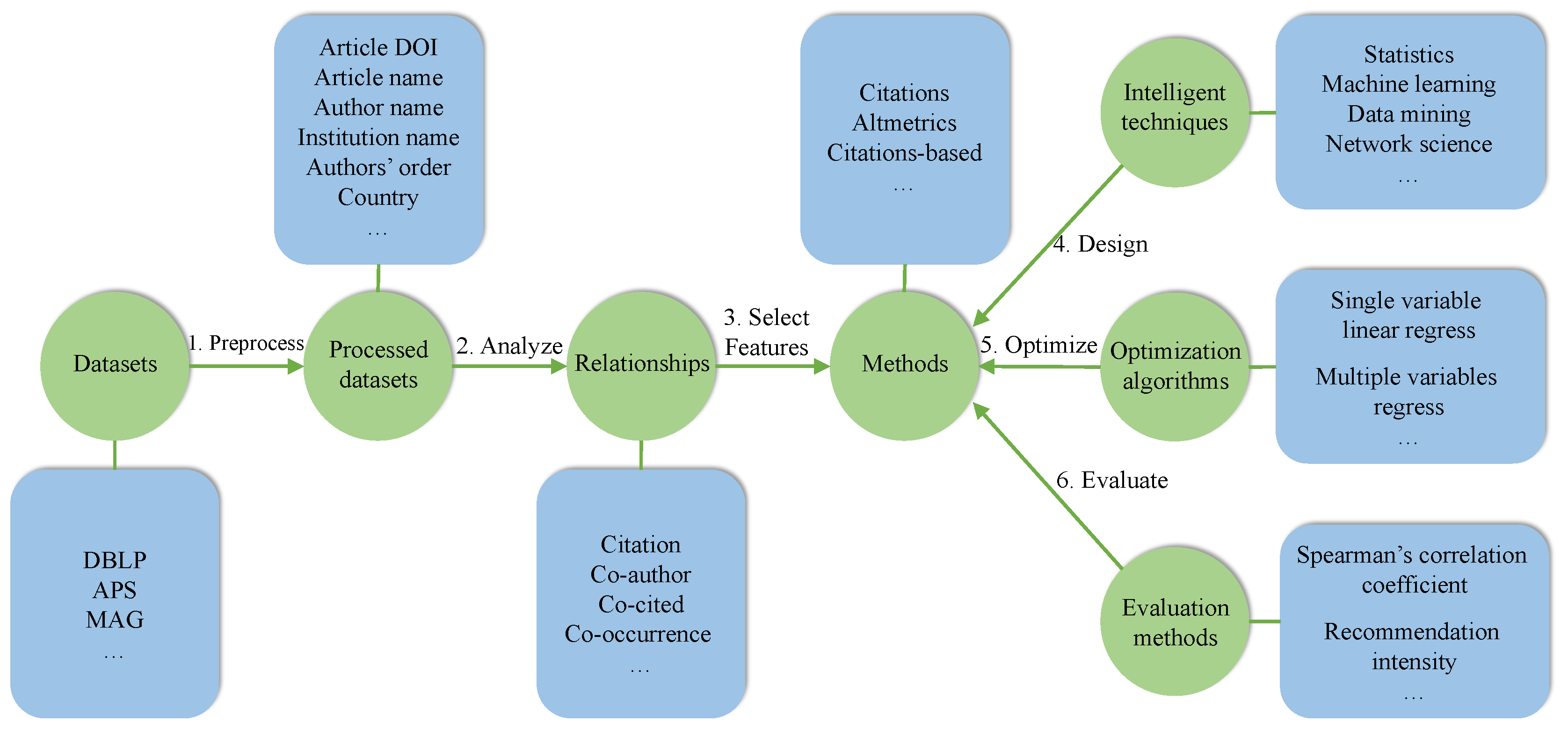
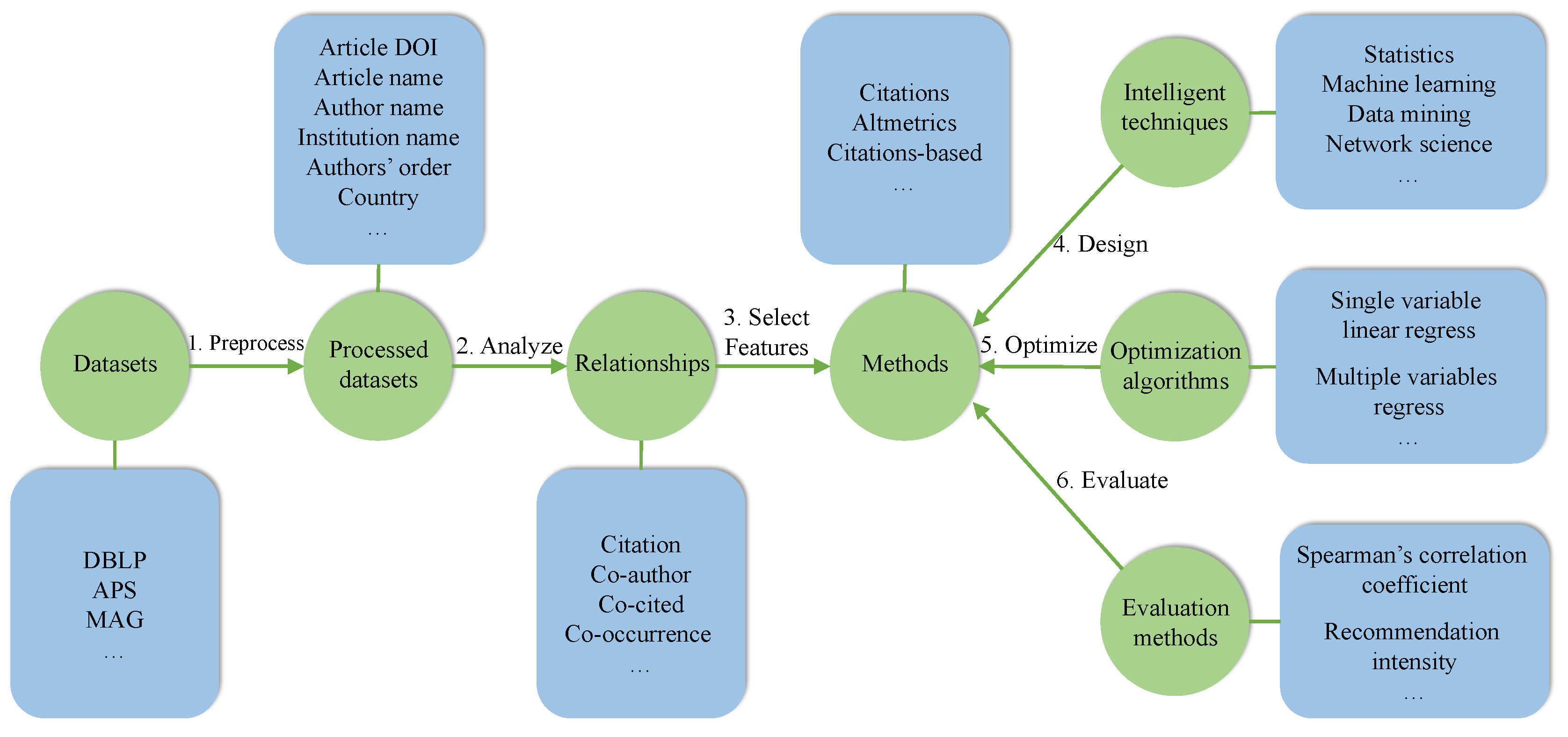
2. Key Techniques
2.1. Statistical Methods
- Pre-process data;
- Optimize parameters, for instance, multiple variables linear regression;
- Select features and improve models for scholarly evaluation and prediction. For example, use the massive existing statistics to estimate a probability density function;
- Analyse scholarly data to obtain statistical data, and then use statistical model to predict the trends of impact, top scholars, top articles, etc.
2.2. Machine Learning
- Design effective algorithms fitting to various scholarly sources of data;
- Predict future trends such as articles impact and scholars’ impact in future;
- Conduct scholarly recommendation such as recommending collaborators, the articles with top impact in various research fields.
2.3. Data Mining
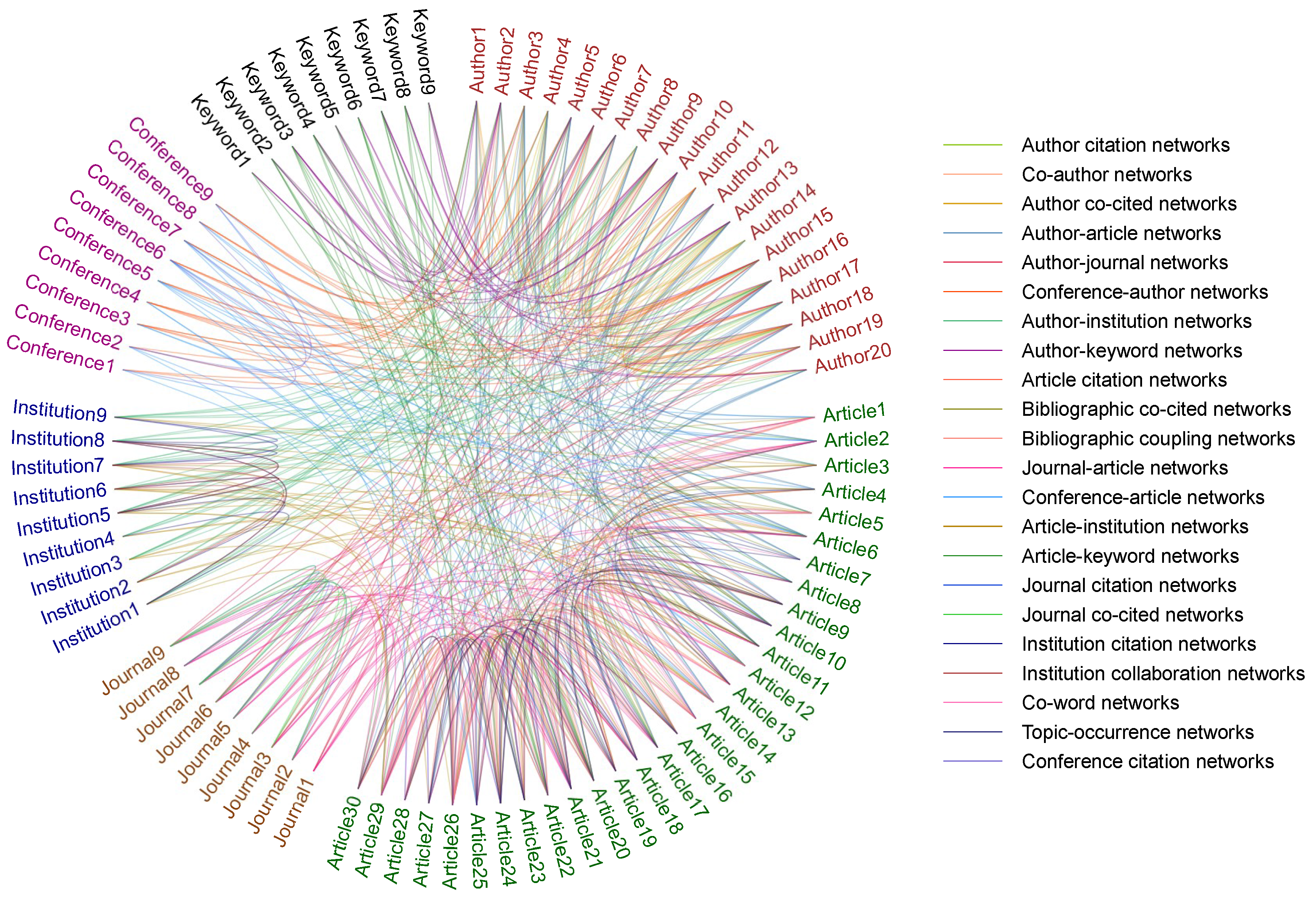
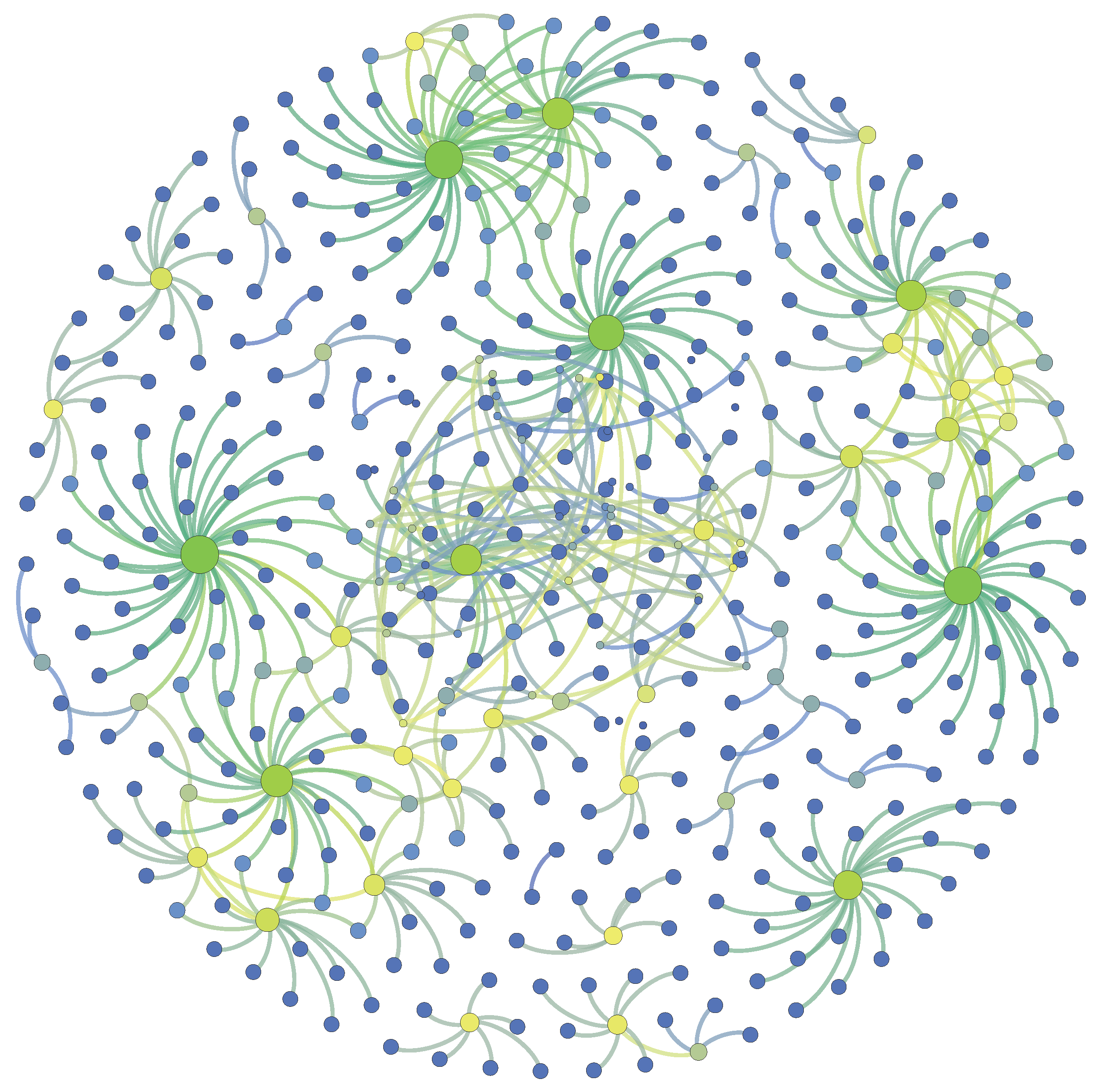
- Mining heterogeneous academic networks, such as article-author networks, author-journal networks, author-institution networks, etc.;
- Exploring the complex relationships among academic entities, including the relationships of papers, authors, journals, conferences, teams, institutions and countries;
- Seeking automatically patterns in scholarly data to predict future trends and improve predicting performance;
- Mining large data streams for effective scholarly recommendations;
- Cleaning scholarly data to gain valuable information;
- Integrating diverse kinds of scholarly data.
2.4. Network Science
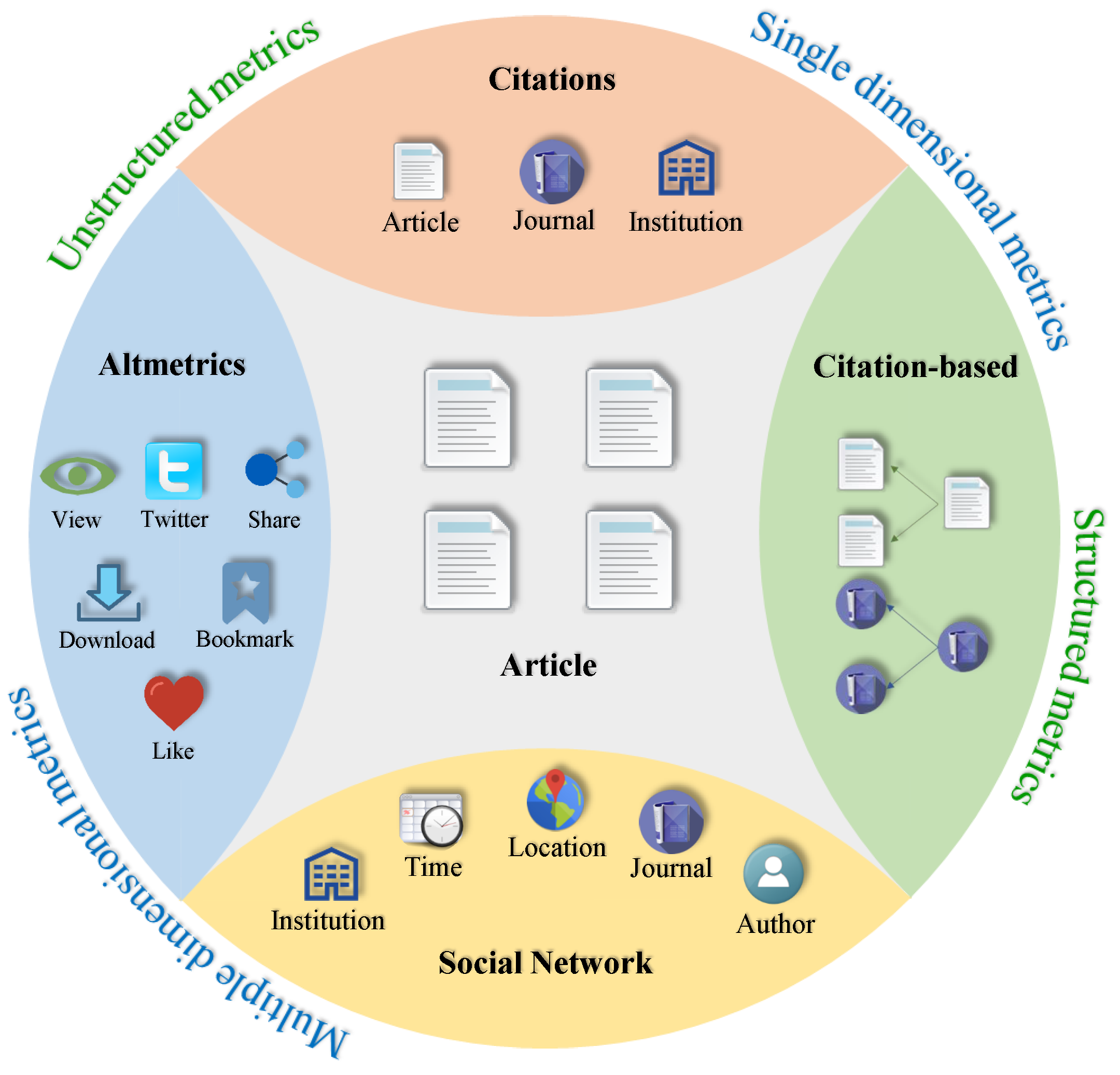
3. Article Impact Metrics
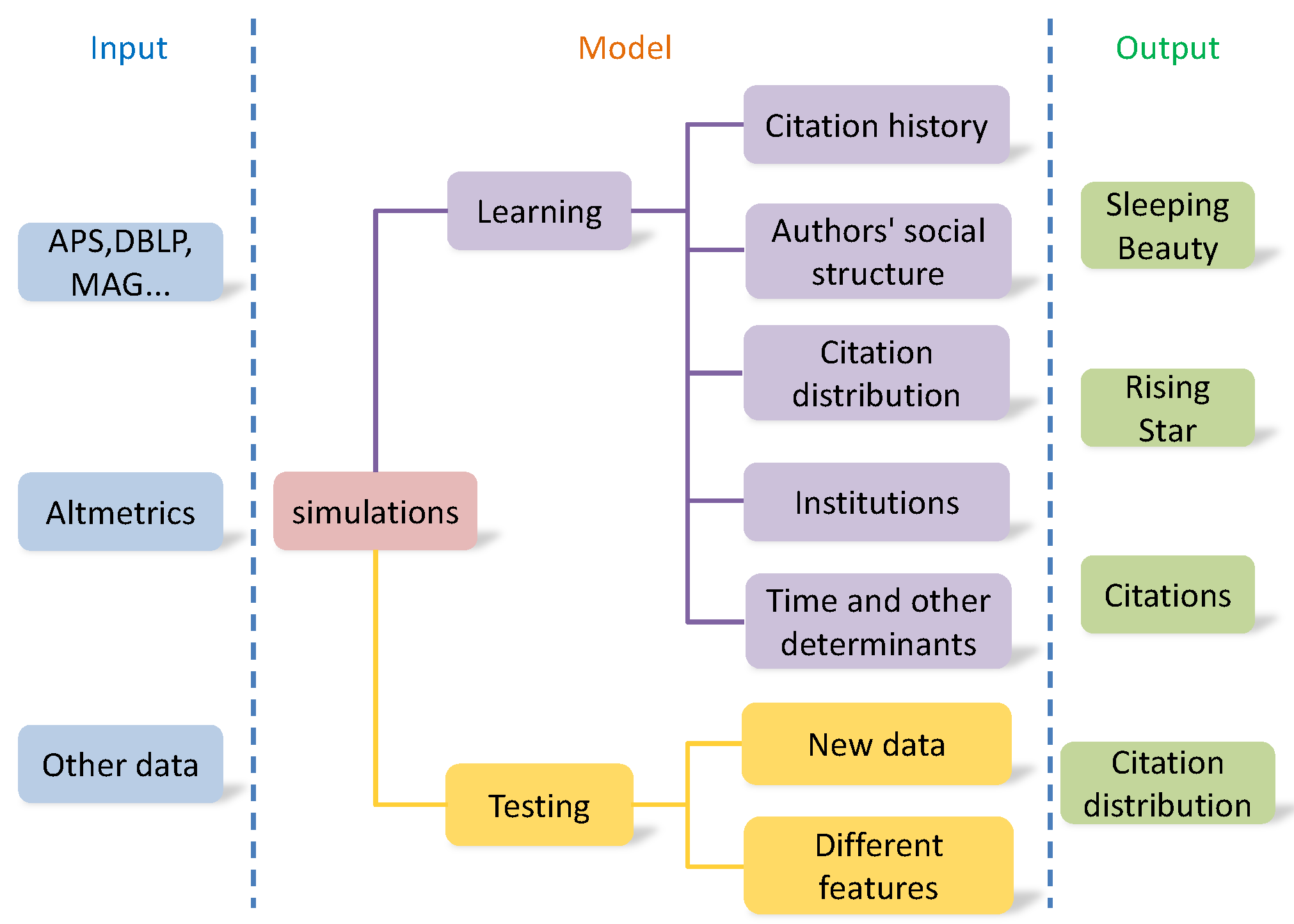
4. Article Impact Prediction
5. Open Issues and Challenges on Article Impact Metrics
5.1. Unified and Consistent Scholarly Datasets
5.2. Multidimensional Metrics
5.3. Altmetrics
5.4. Benchmarks
6. Open Issues and Challenges on Article Impact Prediction
6.1. Sleeping Beauty
6.2. Multidimensional Prediction
6.3. Rising Star
7. Conclusions
Author Contributions
Conflicts of Interest
References
- Aguinis, H.; Suárez-González, I.; Lannelongue, G.; Joo, H. Scholarly impact revisited. Acad. Manag. Perspect. 2012, 26, 105–132. [Google Scholar] [CrossRef]
- Gargouri, Y.; Hajjem, C.; Larivière, V.; Gingras, Y.; Carr, L.; Brody, T.; Harnad, S. Self-selected or mandated, open access increases citation impact for higher quality research. PLoS ONE 2010, 5, e13636. [Google Scholar] [CrossRef] [PubMed]
- Wang, D.; Song, C.; Barabási, A.L. Quantifying long-term scientific impact. Science 2013, 342, 127–132. [Google Scholar] [CrossRef] [PubMed]
- Piwowar, H. Altmetrics: Value all research products. Nature 2013, 493, 159. [Google Scholar] [PubMed]
- Chen, P.; Xie, H.; Maslov, S.; Redner, S. Finding scientific gems with Google’s PageRank algorithm. J. Informetr. 2007, 1, 8–15. [Google Scholar] [CrossRef]
- Jordan, M.; Mitchell, T. Machine learning: Trends, perspectives, and prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef] [PubMed]
- Johnson, R.A.; Wichern, D.W. Applied Multivariate Statistical Analysis; Prentice Hall: Upper Saddle River, NJ, UAS, 2002; Volume 5. [Google Scholar]
- Di Ciaccio, A.; Coli, M.; Ibanez, J.M.A. Advanced Statistical Methods for the Analysis of Large Data-Sets; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Bai, X.; Xia, F.; Lee, I.; Zhang, J.; Ning, Z. Identifying anomalous citations for objective evaluation of scholarly article impact. PLoS ONE 2016, 11, e0162364. [Google Scholar] [CrossRef] [PubMed]
- Costas, R.; Zahedi, Z.; Wouters, P. Do ‘altmetrics’ correlate with citations? Extensive comparison of altmetric indicators with citations from a multidisciplinary perspective. J. Assoc. Inf. Sci. Technol. 2015, 66, 2003–2019. [Google Scholar] [CrossRef]
- Rojas, R. Neural Networks: A Systematic Introduction; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Hearst, M.A.; Dumais, S.T.; Osman, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. Their Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Hosmer, D.W., Jr.; Lemeshow, S. Applied Logistic Regression; John Wiley & Sons: Hoboken, NJ, USA, 2004. [Google Scholar]
- Ho, T.K. Random decision forests. In Proceedings of the Third International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; Volume 1, pp. 278–282. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. Unsupervised learning. In The Elements of Statistical Learning; Springer: New York, NY, USA, 2009; pp. 485–585. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Jarrow, R.A.; Lando, D.; Turnbull, S.M. A Markov model for the term structure of credit risk spreads. Rev. Financ. Stud. 1997, 10, 481–523. [Google Scholar] [CrossRef]
- Chen, T.; He, T. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on knowledge discovery and data mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Bhise, R.; Thorat, S.; Supekar, A. Importance of data mining in higher education system. IOSR J. Hum. Soc. Sci. 2013, 6, 18–21. [Google Scholar]
- Barabási, A.L. Network science. Philos. Trans. R. Soc. Lond. A Math. Phys. Eng. Sci. 2013, 371, 20120375. [Google Scholar] [CrossRef] [PubMed]
- Yan, E.; Ding, Y. Scholarly network similarities: How bibliographic coupling networks, citation networks, cocitation networks, topical networks, coauthorship networks, and coword networks relate to each other. J. Am. Soc. Inf. Sci. Technol. 2012, 63, 1313–1326. [Google Scholar] [CrossRef]
- West, J.D.; Jensen, M.C.; Dandrea, R.J.; Gordon, G.J.; Bergstrom, C.T. Author-level Eigenfactor metrics: Evaluating the influence of authors, institutions, and countries within the social science research network community. J. Am. Soc. Inf. Sci. Technol. 2013, 64, 787–801. [Google Scholar] [CrossRef]
- Page, L.; Brin, S.; Motwani, R.; Winograd, T. The PageRank Citation Ranking: Bringing Order to the Web; Technical Report; Stanford InfoLab: Stanford, CA, USA, 1999. [Google Scholar]
- Kleinberg, J.M. Authoritative sources in a hyperlinked environment. J. ACM 1999, 46, 604–632. [Google Scholar] [CrossRef]
- Zhang, C.; Liu, C.; Yu, L.; Zhang, Z.K.; Zhou, T. Identifying the Academic Rising Stars. arXiv, 2016; arXiv:1606.05752. [Google Scholar]
- Zhang, J.; Ning, Z.; Bai, X.; Wang, W.; Yu, S.; Xia, F. Who are the Rising Stars in Academia? In Proceedings of the 16th ACM/IEEE-CS on Joint Conference on Digital Libraries, Newark, NJ, USA, 19–23 June 2016; pp. 211–212. [Google Scholar]
- Sugiyama, K.; Kan, M.Y. Serendipitous recommendation for scholarly papers considering relations among researchers. In Proceedings of the 11th Annual International ACM/IEEE Joint Conference on Digital Libraries, Ottawa, ON, Canada, 13–17 June 2011; pp. 307–310. [Google Scholar]
- Ke, Q.; Ferrara, E.; Radicchi, F.; Flammini, A. Defining and identifying Sleeping Beauties in science. Proc. Natl. Acad. Sci. USA 2015, 112, 7426–7431. [Google Scholar] [CrossRef] [PubMed]
- Bai, X.; Zhang, J.; Cui, H.; Ning, Z.; Xia, F. PNCOIRank: Evaluating the Impact of Scholarly Articles with Positive and Negative Citations. In Proceedings of the 25th International Conference Companion on World Wide Web, Montréal, QC, Canada, 11–15 April 2016; pp. 9–10. [Google Scholar]
- Zhu, X.; Turney, P.; Lemire, D.; Vellino, A. Measuring academic influence: Not all citations are equal. J. Assoc. Inf. Sci. Technol. 2015, 66, 408–427. [Google Scholar] [CrossRef]
- Sutherland, K.A. Constructions of success in academia: An early career perspective. Stud. High. Educ. 2015, 42, 743–759. [Google Scholar] [CrossRef]
- Letchford, A.; Moat, H.S.; Preis, T. The advantage of short paper titles. R. Soc. Open Sci. 2015, 2, 150266. [Google Scholar] [CrossRef] [PubMed]
- Anicich, E.M.; Swaab, R.I.; Galinsky, A.D. Hierarchical cultural values predict success and mortality in high-stakes teams. Proc. Natl. Acad. Sci. USA 2015, 112, 1338–1343. [Google Scholar] [CrossRef] [PubMed]
- Petersen, A.M. Quantifying the impact of weak, strong, and super ties in scientific careers. Adv. Short Pap. Titles 2015, 112, E4671–E4680. [Google Scholar] [CrossRef] [PubMed]
- Esfe, M.H.; Wongwises, S.; Asadi, A.; Karimipour, A.; Akbari, M. Mandatory and self-citation; types, reasons, their benefits and disadvantages. Sci. Eng. Ethics 2015, 21, 1581–1585. [Google Scholar] [CrossRef] [PubMed]
- Catalini, C.; Lacetera, N.; Oettl, A. The incidence and role of negative citations in science. Proc. Natl. Acad. Sci. USA 2015, 112, 13823–13826. [Google Scholar] [CrossRef] [PubMed]
- Priem, J. Altmetrics. In Beyond Bibliometrics: Harnessing Multidimensional Indicators of Scholarly Impact; MIT Press: Cambridge, MA, USA, 2014; pp. 263–288. [Google Scholar]
- Kwok, R. Research impact: Altmetrics make their mark. Nature 2013, 500, 491–493. [Google Scholar] [CrossRef] [PubMed]
- Cheung, M.K. Altmetrics: Too soon for use in assessment. Nature 2013, 494, 176. [Google Scholar] [CrossRef] [PubMed]
- Yan, E.; Ding, Y. Measuring scholarly impact in heterogeneous networks. Proc. Am. Soc. Inf. Sci. Technol. 2010, 47, 1–7. [Google Scholar] [CrossRef]
- Wang, Y.; Tong, Y.; Zeng, M. Ranking Scientific Articles by Exploiting Citations, Authors, Journals, and Time Information. In Proceedings of the Twenty-Seventh AAAI Conference on Artificial Intelligence, Bellevue, WA, USA, 14–18 July 2013. [Google Scholar]
- Walker, D.; Xie, H.; Yan, K.K.; Maslov, S. Ranking scientific publications using a model of network traffic. J. Stat. Mech. Theory Exp. 2007, 2007, P06010. [Google Scholar] [CrossRef]
- Sayyadi, H.; Getoor, L. FutureRank: Ranking Scientific Articles by Predicting their Future PageRank. In Proceedings of the SIAM International Conference on Data Mining (SDM 2009), Sparks, NV, USA, 30 April–2 May 2009; pp. 533–544. [Google Scholar]
- Zhou, Y.B.; Lü, L.; Li, M. Quantifying the influence of scientists and their publications: Distinguishing between prestige and popularity. New J. Phys. 2012, 14, 033033. [Google Scholar] [CrossRef]
- Wang, S.; Xie, S.; Zhang, X.; Li, Z.; Yu, P.S.; Shu, X. Future influence ranking of scientific literature. In Proceedings of the 2014 SIAM International Conference on Data Mining, Philadelphia, PA, USA, 24–26 April 2014. [Google Scholar]
- Liu, Z.; Huang, H.; Wei, X.; Mao, X. Tri-Rank: An Authority Ranking Framework in Heterogeneous Academic Networks by Mutual Reinforce. In Proceedings of the IEEE 26th International Conference on Tools with Artificial Intelligence (ICTAI), Limassol, Cyprus, 10–12 November 2014; pp. 493–500. [Google Scholar]
- Shah, N.; Song, Y. S-index: Towards better metrics for quantifying research impact. arXiv, 2015; arXiv:1507.03650. [Google Scholar]
- Small, H. Maps of science as interdisciplinary discourse: Co-citation contexts and the role of analogy. Scientometrics 2010, 83, 835–849. [Google Scholar] [CrossRef]
- Kaur, J.; Radicchi, F.; Menczer, F. Universality of scholarly impact metrics. J. Informetr. 2013, 7, 924–932. [Google Scholar] [CrossRef]
- Radicchi, F.; Fortunato, S.; Castellano, C. Universality of citation distributions: Toward an objective measure of scientific impact. Proc. Natl. Acad. Sci. USA 2008, 105, 17268–17272. [Google Scholar] [CrossRef] [PubMed]
- Schneider, M.; Kane, C.M.; Rainwater, J.; Guerrero, L.; Tong, G.; Desai, S.R.; Trochim, W. Feasibility of common bibliometrics in evaluating translational science. J. Clin. Transl. Sci. 2017, 1, 45–52. [Google Scholar] [CrossRef] [PubMed]
- Bruns, S.B.; Stern, D.I. Research assessment using early citation information. Scientometrics 2015, 108, 917–935. [Google Scholar] [CrossRef]
- Cao, X.; Chen, Y.; Liu, K.J.R. A data analytic approach to quantifying scientific impact. J. Informetr. 2016, 10, 471–484. [Google Scholar] [CrossRef]
- Klimek, P.; Jovanovic, A.S.; Egloff, R.; Schneider, R. Successful fish go with the flow: Citation impact prediction based on centrality measures for term-document networks. Scientometrics 2016, 107, 1265–1282. [Google Scholar] [CrossRef]
- Stegehuis, C.; Litvak, N.; Waltman, L. Predicting the long-term citation impact of recent publications. J. Informetr. 2015, 9, 642–657. [Google Scholar] [CrossRef]
- Yu, T.; Yu, G.; Li, P.Y.; Wang, L. Citation impact prediction for scientific papers using stepwise regression analysis. Scientometrics 2014, 101, 1233–1252. [Google Scholar] [CrossRef]
- Sarigöl, E.; Pfitzner, R.; Scholtes, I.; Garas, A.; Schweitzer, F. Predicting scientific success based on coauthorship networks. EPJ Data Sci. 2014, 3. [Google Scholar] [CrossRef]
- Eysenbach, G. Can tweets predict citations? metrics of social impact based on twitter and correlation with traditional metrics of scientific impact. J. Med. Internet Res. 2011, 13, E123. [Google Scholar] [CrossRef] [PubMed]
- Timilsina, M.; Davis, B.; Taylor, M.; Hayes, C. Towards predicting academic impact from mainstream news and weblogs: A heterogeneous graph based approach. In Proceedings of the 2016 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), San Francisco, CA, USA, 18–21 August 2016; pp. 1388–1389. [Google Scholar]
- Simkin, M.; Roychowdhury, V. Read Before You Cite! Complex Syst. 2003, 14, 269–274. [Google Scholar]
- Thelwall, M. Data Science Altmetrics. J. Data Inf. Sci. 2016, 1, 7–12. [Google Scholar] [CrossRef]
- Barbaro, A.; Gentili, D.; Rebuffi, C. Altmetrics as new indicators of scientific impact. J. Eur. Assoc. Health Inf. Libr. 2014, 10, 3–6. [Google Scholar]
- Wilsdon, J. We need a measured approach to metrics. Nature 2015, 523, 129. [Google Scholar] [CrossRef] [PubMed]
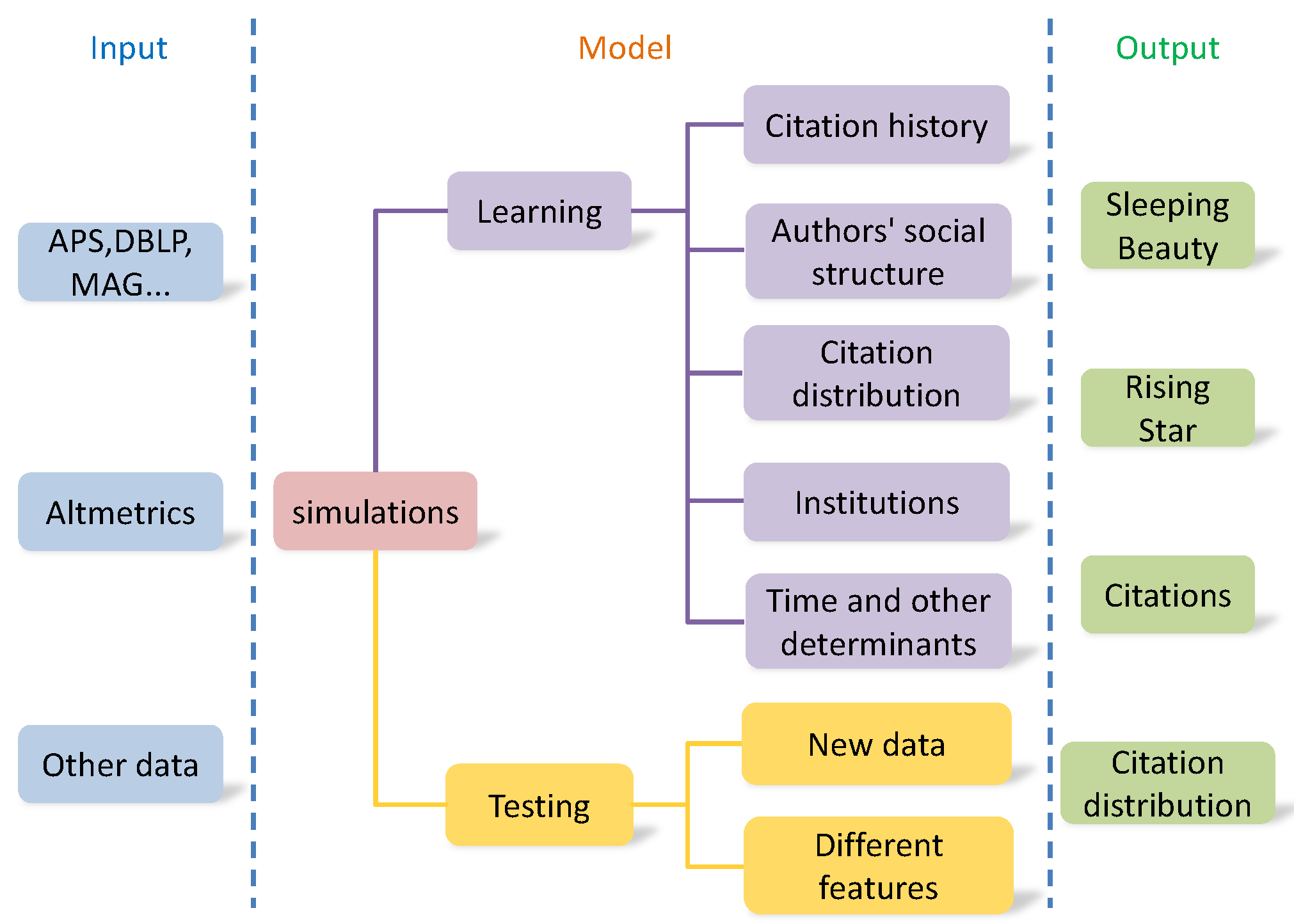

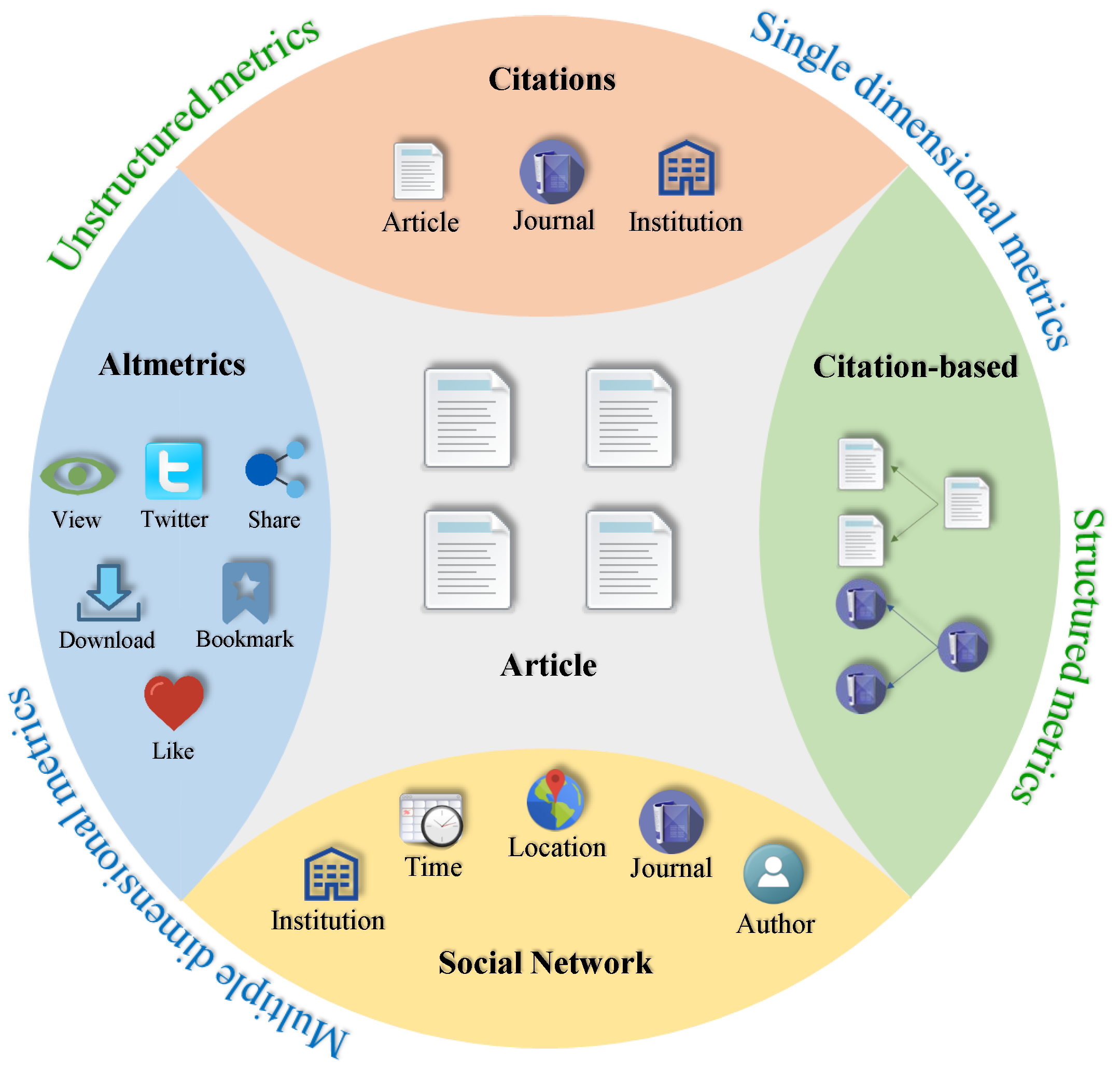{kind=link}
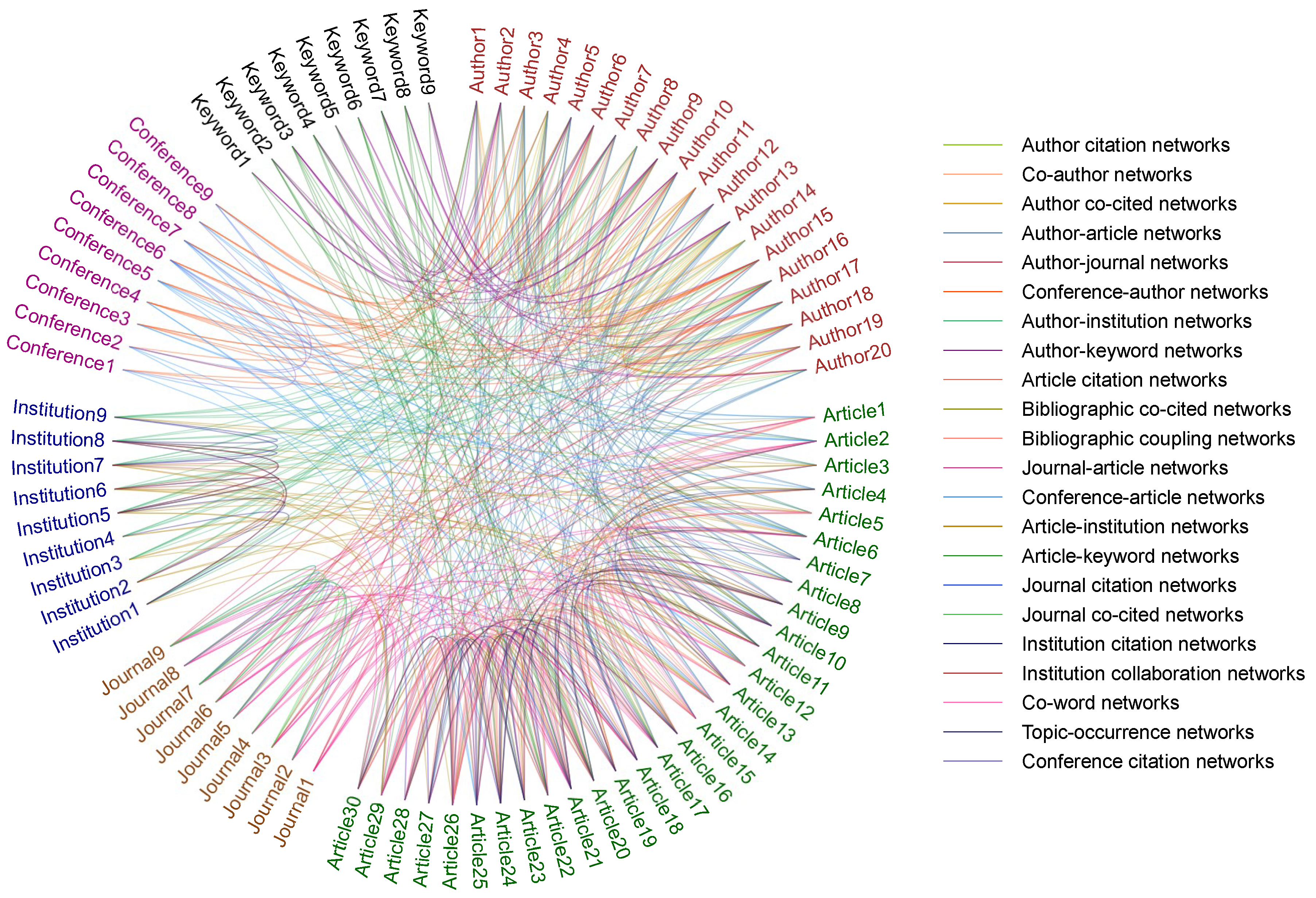{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Prediction Goal | Main Techniques |
|---|---|---|
| early citations, Journal | quantile of citations distribution | quantile regression |
| Impact Factor | ||
| authors characteristics, | citations | multivariate analysis |
| institutional factors, features | ||
| of article organization, | ||
| research approach | ||
| Social dimension: | citations | random forest classifier |
| co-authorship networks | ||
| year, page count, author count, | long-term citations | random forest |
| author name, journal, abstract | ||
| length, title length, special | ||
| issue, etc. | ||
| Altmetrics: tweeter | citations | correlation analysis, linear |
| regression analysis |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bai, X.; Liu, H.; Zhang, F.; Ning, Z.; Kong, X.; Lee, I.; Xia, F. An Overview on Evaluating and Predicting Scholarly Article Impact. Information 2017, 8, 73. https://doi.org/10.3390/info8030073
Bai X, Liu H, Zhang F, Ning Z, Kong X, Lee I, Xia F. An Overview on Evaluating and Predicting Scholarly Article Impact. Information. 2017; 8(3):73. https://doi.org/10.3390/info8030073
Chicago/Turabian StyleBai, Xiaomei, Hui Liu, Fuli Zhang, Zhaolong Ning, Xiangjie Kong, Ivan Lee, and Feng Xia. 2017. "An Overview on Evaluating and Predicting Scholarly Article Impact" Information 8, no. 3: 73. https://doi.org/10.3390/info8030073
APA StyleBai, X., Liu, H., Zhang, F., Ning, Z., Kong, X., Lee, I., & Xia, F. (2017). An Overview on Evaluating and Predicting Scholarly Article Impact. Information, 8(3), 73. https://doi.org/10.3390/info8030073