
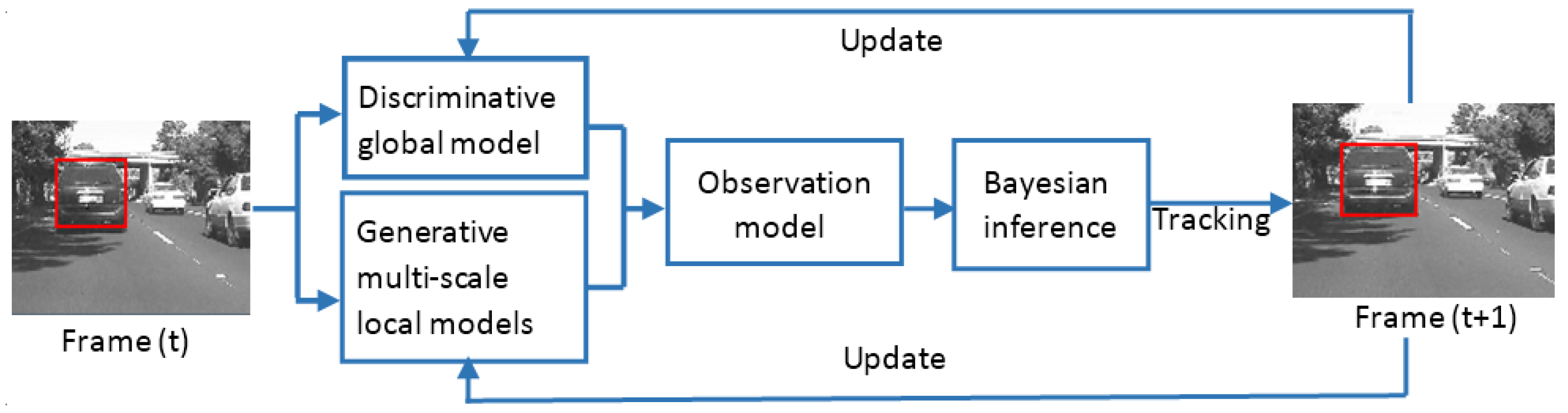
Object Tracking by a Combination of Discriminative Global and Generative Multi-Scale Local Models

Abstract
:1. Introduction
2. Discriminative Global Model
2.1. Construction of the Template Set
2.2. Sparse Discriminative Feature Selection
2.3. Confidence Measure
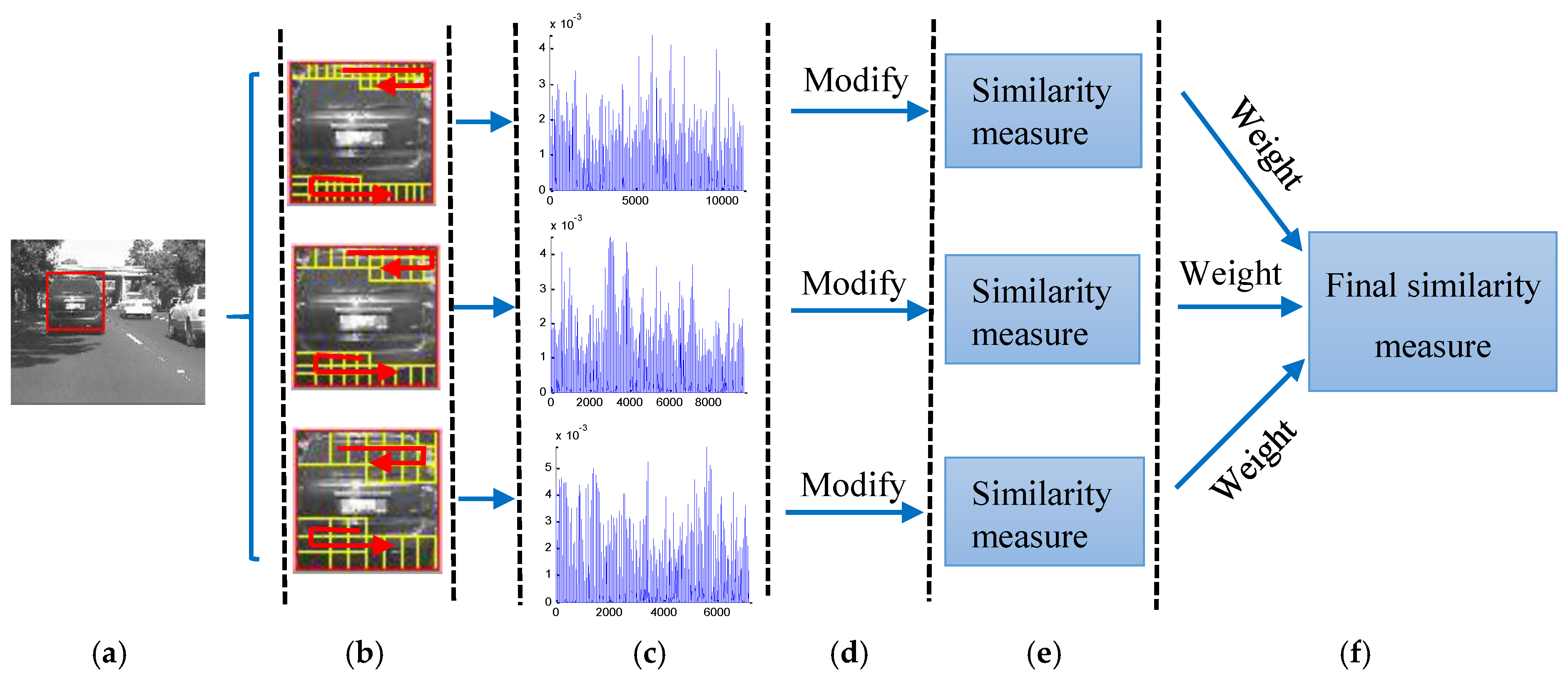
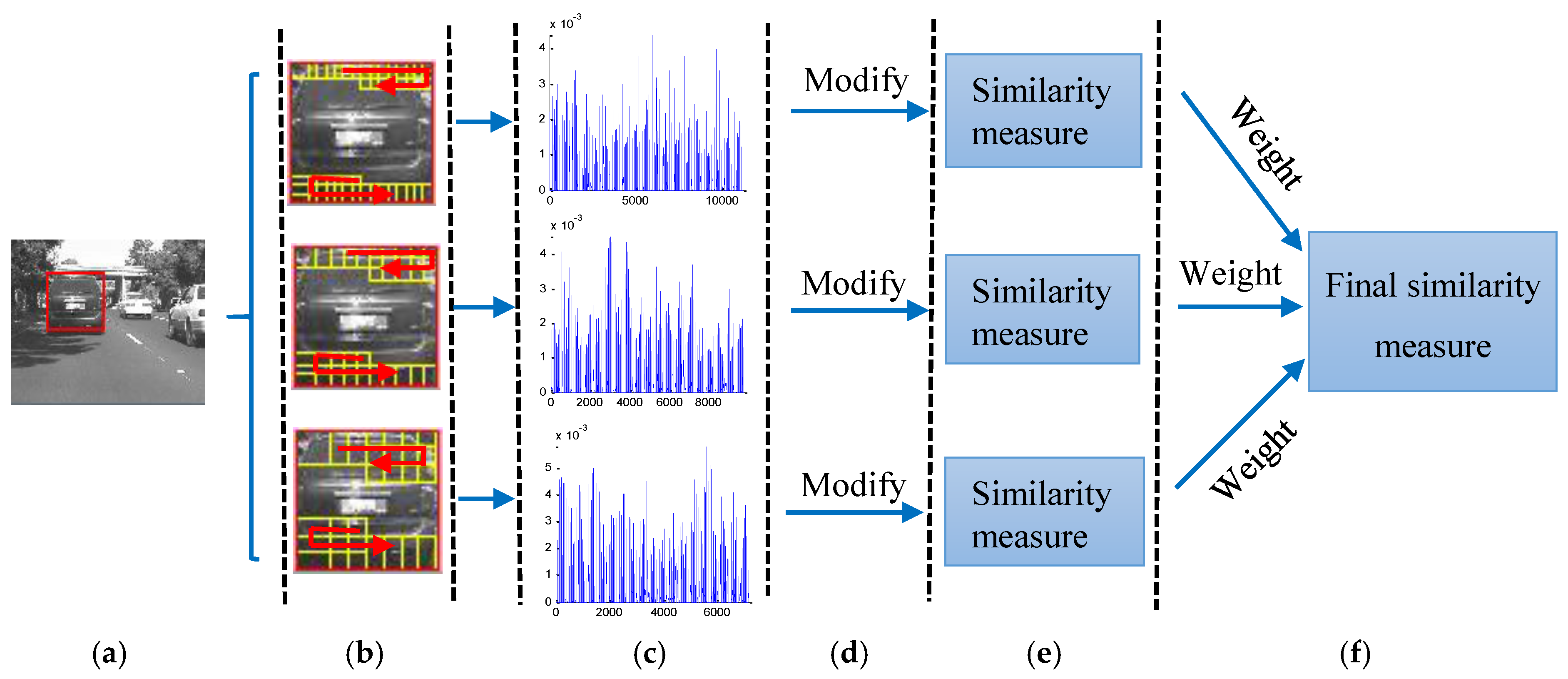
3. Generative Multi-Scale Local Model
3.1. Multi-Scale Sparse Representation Histogram
3.2. Histogram Modification
3.3. Similarity Measure
4. Tracking by Bayesian Inference
5. Online Update
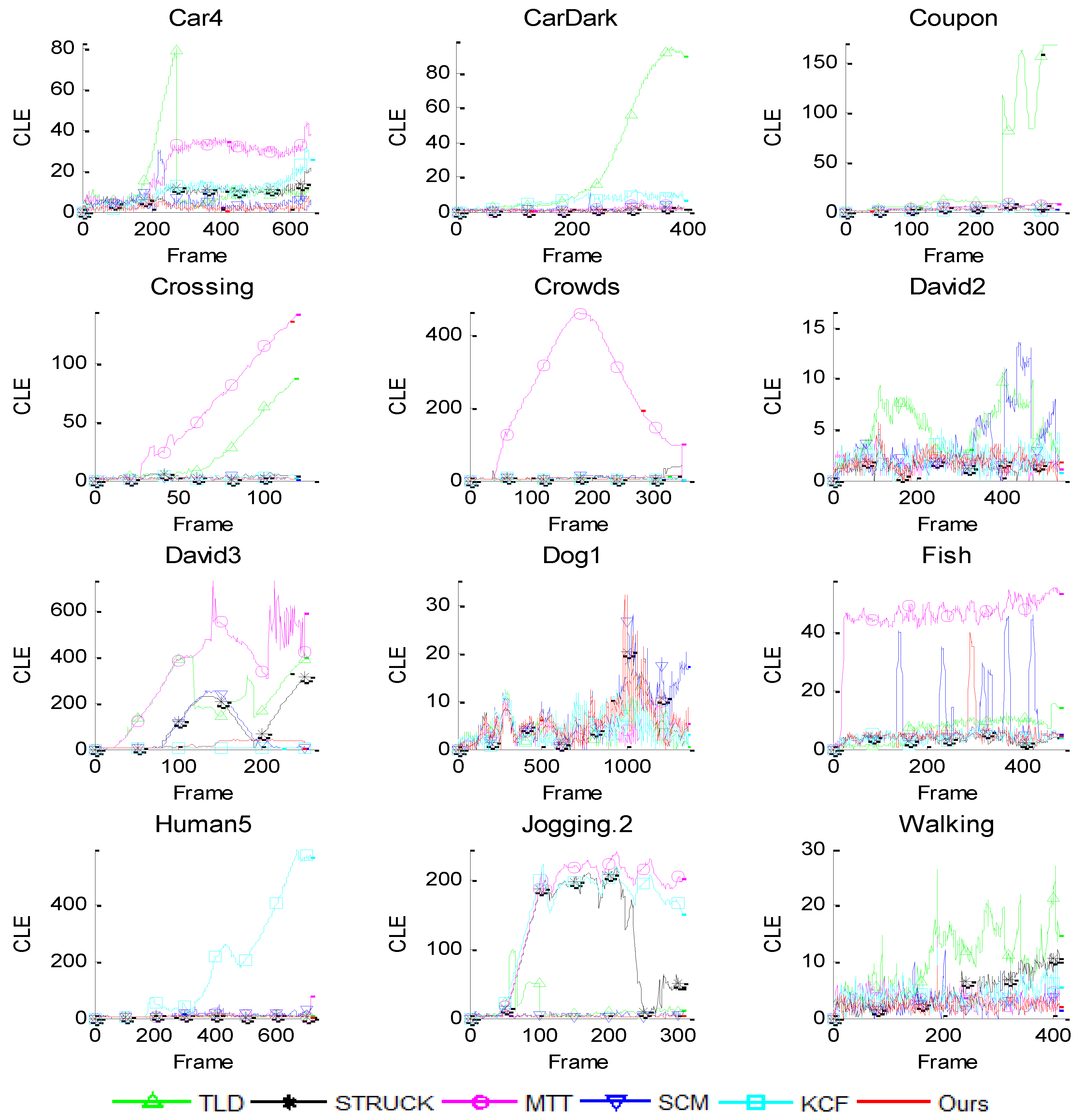
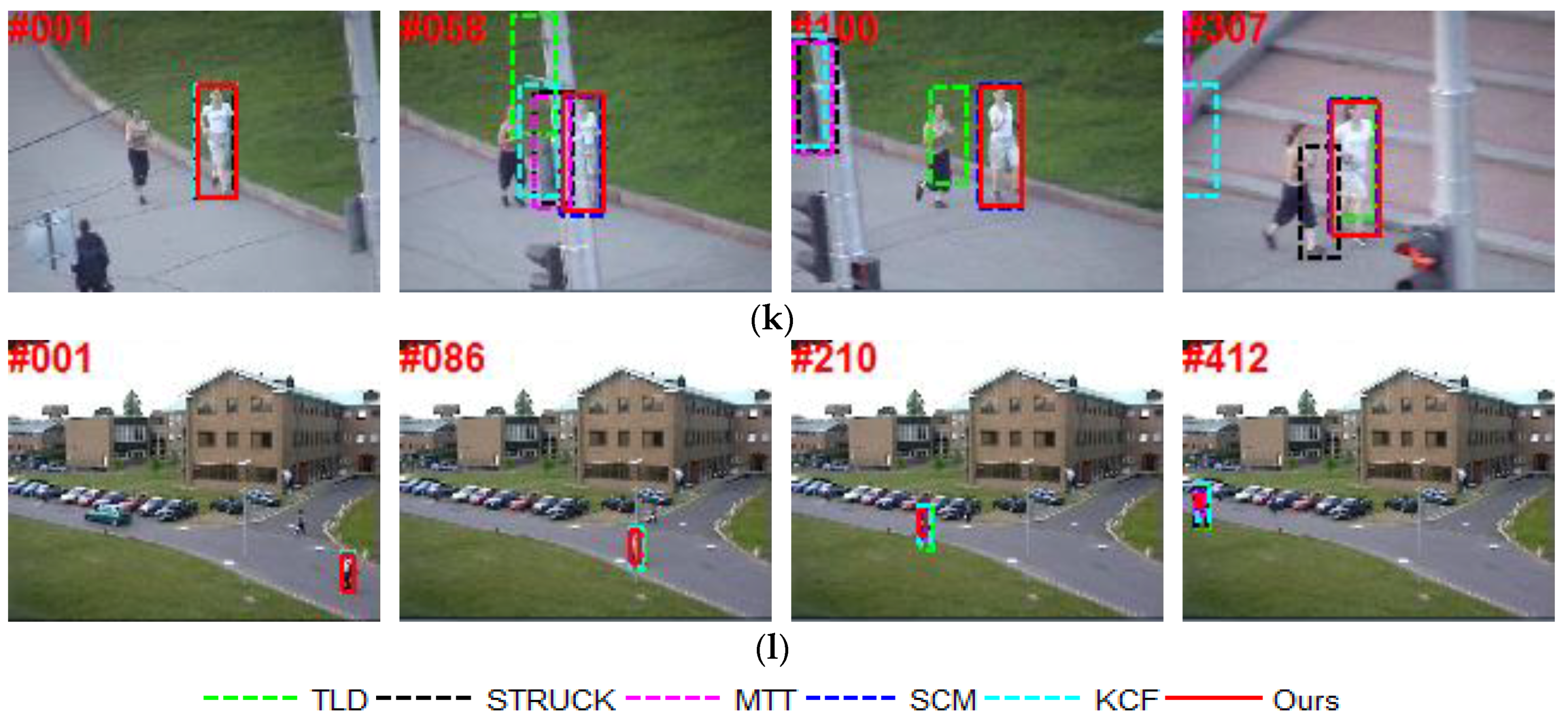
6. Experiments
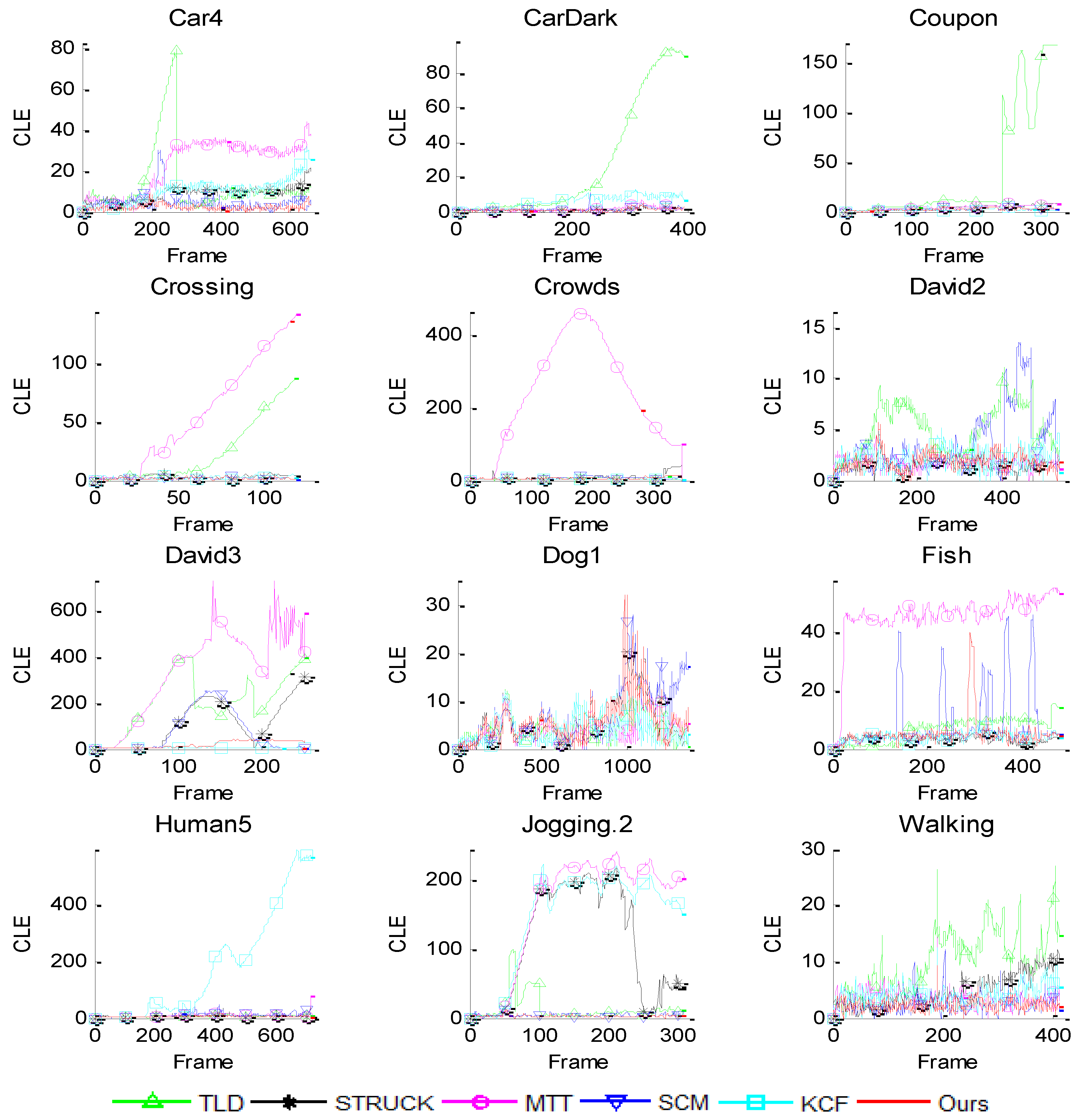
6.1. Quantitative Comparison
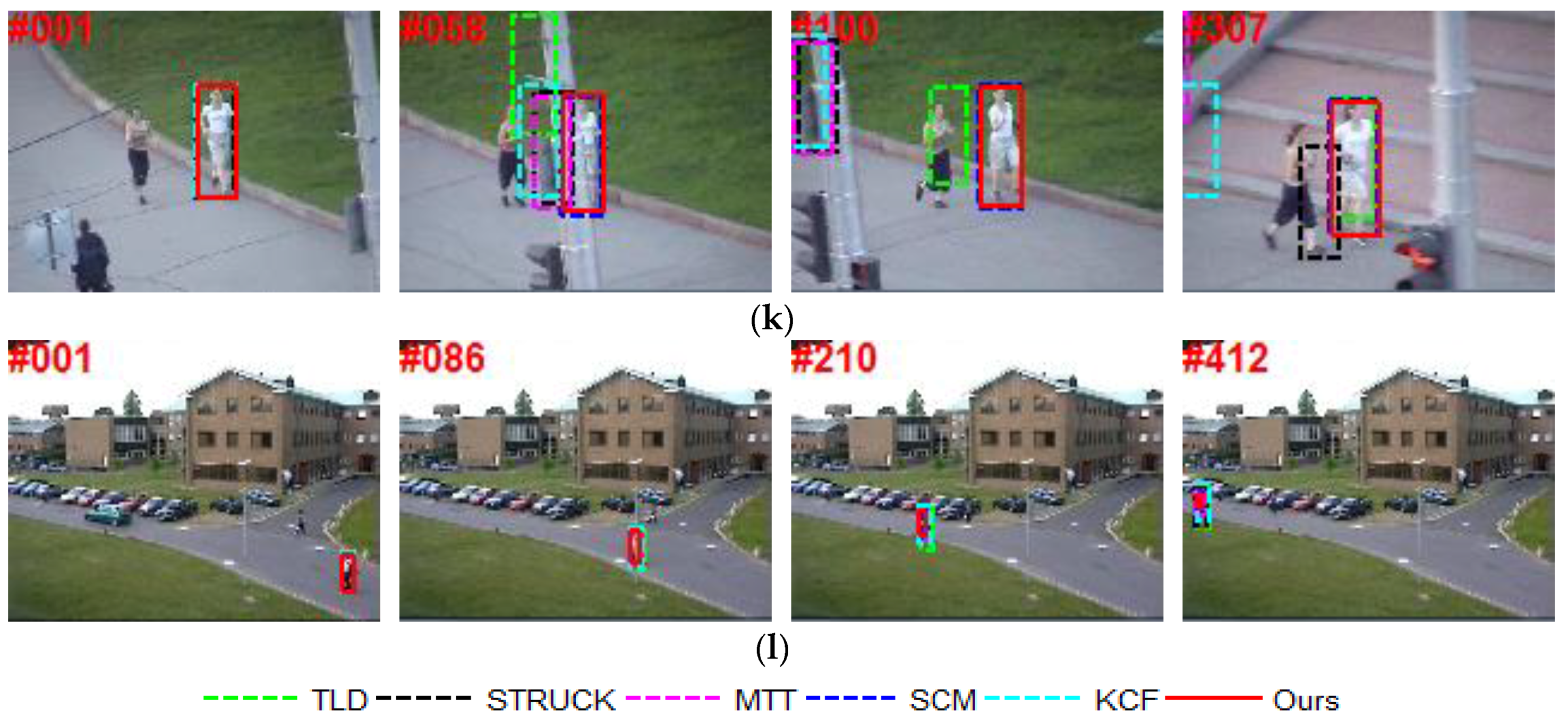
6.2. Qualitative Comparison
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Li, X.; Hu, W.M.; Shen, C.H.; Zhang, Z.F.; Dick, A.; Hengel, A.V.D. A Survey of Appearance Models in Visual Object Tracking. ACM Trans. Intell. Syst. Technol. 2013, 4, 58. [Google Scholar] [CrossRef]
- Fu, H.; Duan, R.; Kircali, D.; Kayacan, E. Onboard Robust Visual Tracking for UAVs Using a Reliable Global-Local Object Model. Sensors 2016, 16, 1406. [Google Scholar] [CrossRef] [PubMed]
- Du, D.; Zhang, L.; Lu, H.; Mei, X.; Li, X. Discriminative Hash Tracking With Group Sparsity. IEEE Trans. Cybern. 2016, 46, 1914–1925. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Zhang, J. Robust Object Tracking in Infrared Video via Adaptive Weighted Patches. Math. Comput. Appl. 2017, 22, 3. [Google Scholar] [CrossRef]
- Ruan, Y.; Wei, Z. Real-Time Visual Tracking through Fusion Features. Sensors 2016, 16, 949. [Google Scholar] [CrossRef] [PubMed]
- Krafka, K.; Khosla, A.; Kellnhofer, P.; Kannan, H. Eye Tracking for Everyone. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2176–2184. [Google Scholar]
- Monajjemi, M.; Mohaimenianpour, S.; Vaughan, R. UAV, Come To Me: End-to-End, Multi-Scale Situated HRI with an Uninstrumented Human and a Distant UAV. In Proceedings of the International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 4410–4417. [Google Scholar]
- Kwak, J.Y.; Ko, B.C.; Nam, J.Y. Pedestrian Tracking Using Online Boosted Random Ferns Learning in Far-Infrared Imagery for Safe Driving at Night. IEEE Trans. Intell. Transp. Syst. 2017, 18, 69–80. [Google Scholar] [CrossRef]
- Ross, D.A.; Lim, J.; Lin, R.S.; Yang, M.H. Incremental Learning for Robust Visual Tracking. Int. J. Comput. Vis. 2008, 77, 125–141. [Google Scholar] [CrossRef]
- Kwon, J.; Lee, K.M. Visual Tracking Decomposition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 1269–1276. [Google Scholar]
- Mei, X.; Ling, H. Robust Visual Tracking using L1 Minimization. In Proceedings of the International Conference on Computer Vision (ICCV), Kyoto, Japan, 29 September–2 October 2009; pp. 1436–1443. [Google Scholar]
- Jia, X.; Lu, H.; Yang, M.H. Visual Tracking via Adaptive Structural Local Sparse Appearance Model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 1822–1829. [Google Scholar]
- Wang, D.; Lu, H.; Bo, C. Online Visual Tracking via Two View Sparse Representation. IEEE Signal Process. Lett. 2014, 21, 1031–1034. [Google Scholar]
- Hu, W.; Li, W.; Zhang, X.; Maybank, S. Single and Multiple Object Tracking Using a Multi-Feature Joint Sparse Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 816–833. [Google Scholar] [CrossRef] [PubMed]
- Avidan, S. Support Vector Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 1064–1072. [Google Scholar] [CrossRef] [PubMed]
- Grabner, H.; Bischof, H. On-line Boosting and Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), New York, NY, USA, 17–22 June 2006; pp. 260–267. [Google Scholar]
- Babenko, B.; Yang, M.H.; Belongie, S. Visual Tracking with Online Multiple Instance Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 983–990. [Google Scholar]
- Zhang, K.; Zhang, L.; Yang, M.H. Real-time compressive tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012; pp. 864–877. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-Speed Tracking with Kernelized Correlation Filters. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 583–596. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Lu, J.; Tan, Y.P. Deep Metric Learning for Visual Tracking. IEEE Trans. Circuits Syst. Video Technol. 2016, 26, 2056–2068. [Google Scholar] [CrossRef]
- Yu, Q.; Dinh, B.T.; Medioni, G. Online Tracking and Reacquisition Using Co-trained Generative and Discriminative Trackers. In Proceedings of the European Conference on Computer Vision (ECCV), Marseille, France, 12–18 October 2008; pp. 678–691. [Google Scholar]
- Zhong, W.; Lu, H.; Yang, M.H. Robust Object Tracking via Sparse Collaborative Appearance Model. IEEE Trans. Image Process. 2014, 23, 2356–2368. [Google Scholar] [CrossRef] [PubMed]
- Zhou, T.; Lu, Y.; Di, H. Locality-Constrained Collaborative Model for Robust Visual Tracking. IEEE Trans. Circuits Syst. Video Technol. 2015, 27, 313–325. [Google Scholar] [CrossRef]
- Dou, J.; Qin, Q.; Tu, Z. Robust Visual Tracking Based on Generative and Discriminative Model Collaboration. Multimed. Tools Appl. 2016. [Google Scholar] [CrossRef]
- Wang, D.; Lu, H.; Yang, M.H. Online Object Tracking with Sparse Prototypes. IEEE Trans. Image Process. 2013, 22, 314–325. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Lim, J.; Yang, M.H. Object Tracking Benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1834–1848. [Google Scholar] [CrossRef] [PubMed]
- Kalal, Z.; Matas, J.; Mikolajczyk, K. P-N Learning: Bootstrapping Binary Classifiers by Structural Constraints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 49–56. [Google Scholar]
- Hare, S.; Saffari, A.; Torr, P. Struck: Structured Output Tracking with Kernels. In Proceedings of the International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 263–270. [Google Scholar]
- Zhang, T.; Ghanem, B.; Liu, S.; Ahuja, N. Robust visual tracking via multi-task sparse learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 2042–2049. [Google Scholar]
- Everingham, M.; Gool, L.V.; Williams, C.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequence | TLD | STRUCK | MTT | KCF | SCM | Ours |
|---|---|---|---|---|---|---|
| Car4 | 12.84 | 8.69 | 22.34 | 9.88 | 4.27 | 2.09 |
| CarDark | 27.47 | 0.95 | 1.57 | 6.05 | 1.30 | 1.04 |
| Coupon | 38.41 | 4.14 | 4.24 | 1.57 | 2.37 | 2.12 |
| Crossing | 24.34 | 2.81 | 57.15 | 2.25 | 1.57 | 1.48 |
| Crowds | 3.44 | 7.19 | 235.75 | 3.05 | 5.25 | 5.06 |
| David2 | 4.98 | 1.50 | 1.70 | 2.08 | 3.41 | 1.78 |
| David3 | 208.00 | 106.50 | 341.33 | 4.30 | 73.09 | 19.09 |
| Dog1 | 4.19 | 5.66 | 4.28 | 4.23 | 7.00 | 5.56 |
| Fish | 6.54 | 3.40 | 45.50 | 4.08 | 8.54 | 5.15 |
| Human5 | 5.31 | 6.87 | 8.28 | 175.50 | 9.33 | 4.35 |
| Jogging.2 | 13.56 | 107.69 | 157.12 | 144.47 | 4.15 | 2.46 |
| Walking | 10.23 | 4.62 | 3.47 | 3.97 | 2.49 | 2.26 |
| Average | 29.94 | 21.67 | 73.56 | 30.12 | 10.23 | 4.37 |
| Sequence | TLD | STRUCK | MTT | KCF | SCM | Ours |
|---|---|---|---|---|---|---|
| Car4 | 0.63 | 0.49 | 0.45 | 0.48 | 0.76 | 0.77 |
| CarDark | 0.45 | 0.90 | 0.83 | 0.62 | 0.84 | 0.86 |
| Coupon | 0.57 | 0.88 | 0.87 | 0.94 | 0.90 | 0.91 |
| Crossing | 0.40 | 0.68 | 0.20 | 0.71 | 0.78 | 0.80 |
| Crowds | 0.77 | 0.61 | 0.09 | 0.79 | 0.63 | 0.66 |
| David2 | 0.69 | 0.87 | 0.86 | 0.83 | 0.75 | 0.84 |
| David3 | 0.10 | 0.29 | 0.10 | 0.77 | 0.40 | 0.59 |
| Dog1 | 0.59 | 0.55 | 0.69 | 0.55 | 0.70 | 0.72 |
| Fish | 0.81 | 0.86 | 0.17 | 0.84 | 0.75 | 0.81 |
| Human5 | 0.54 | 0.35 | 0.42 | 0.18 | 0.44 | 0.72 |
| Jogging.2 | 0.66 | 0.20 | 0.13 | 0.12 | 0.73 | 0.77 |
| Walking | 0.45 | 0.57 | 0.67 | 0.53 | 0.71 | 0.71 |
| Average | 0.56 | 0.6 | 0.46 | 0.61 | 0.70 | 0.76 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, Z.; Sun, J.; Yu, J. Object Tracking by a Combination of Discriminative Global and Generative Multi-Scale Local Models. Information 2017, 8, 43. https://doi.org/10.3390/info8020043
Song Z, Sun J, Yu J. Object Tracking by a Combination of Discriminative Global and Generative Multi-Scale Local Models. Information. 2017; 8(2):43. https://doi.org/10.3390/info8020043
Chicago/Turabian StyleSong, Zhiguo, Jifeng Sun, and Jialin Yu. 2017. "Object Tracking by a Combination of Discriminative Global and Generative Multi-Scale Local Models" Information 8, no. 2: 43. https://doi.org/10.3390/info8020043
APA StyleSong, Z., Sun, J., & Yu, J. (2017). Object Tracking by a Combination of Discriminative Global and Generative Multi-Scale Local Models. Information, 8(2), 43. https://doi.org/10.3390/info8020043