
The Information Content of Accounting Reports: An Information Theory Perspective

Abstract
:1. Introduction
2. Related Research
It seems reasonable to assume, however, that viewing accountancy as a communication process may provide a clearer picture of the nature and scope of the accounting function in an economic system. The opportunity exists because the underlying structure of communication theory may be used to describe the accounting process.—Norton M. Bedford and Vahe Baladouni [8] (p. 650)
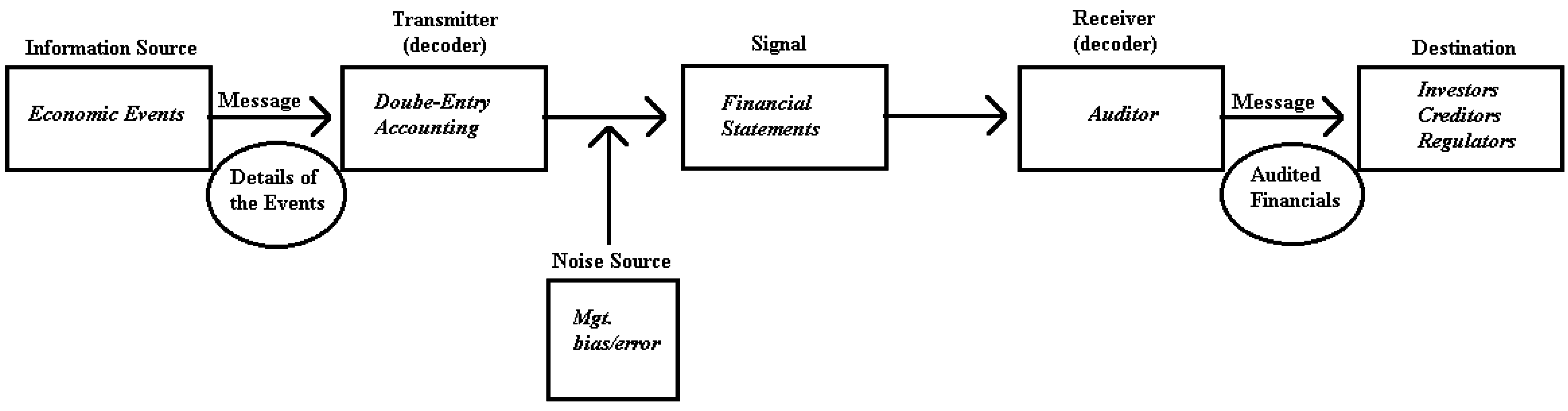
3. Accounting as a Communication System
4. Information Defined and Measured
4.1. Information and Financial Accounting
4.2. A Measure of Information Content
5. Applying the Measure to Financial Statements
5.1. Mapping the Quantitative Financial Information to States
5.2. Forming the State-Probability Distributions and
5.3. The Information Content, , of Financial Statement Variable j
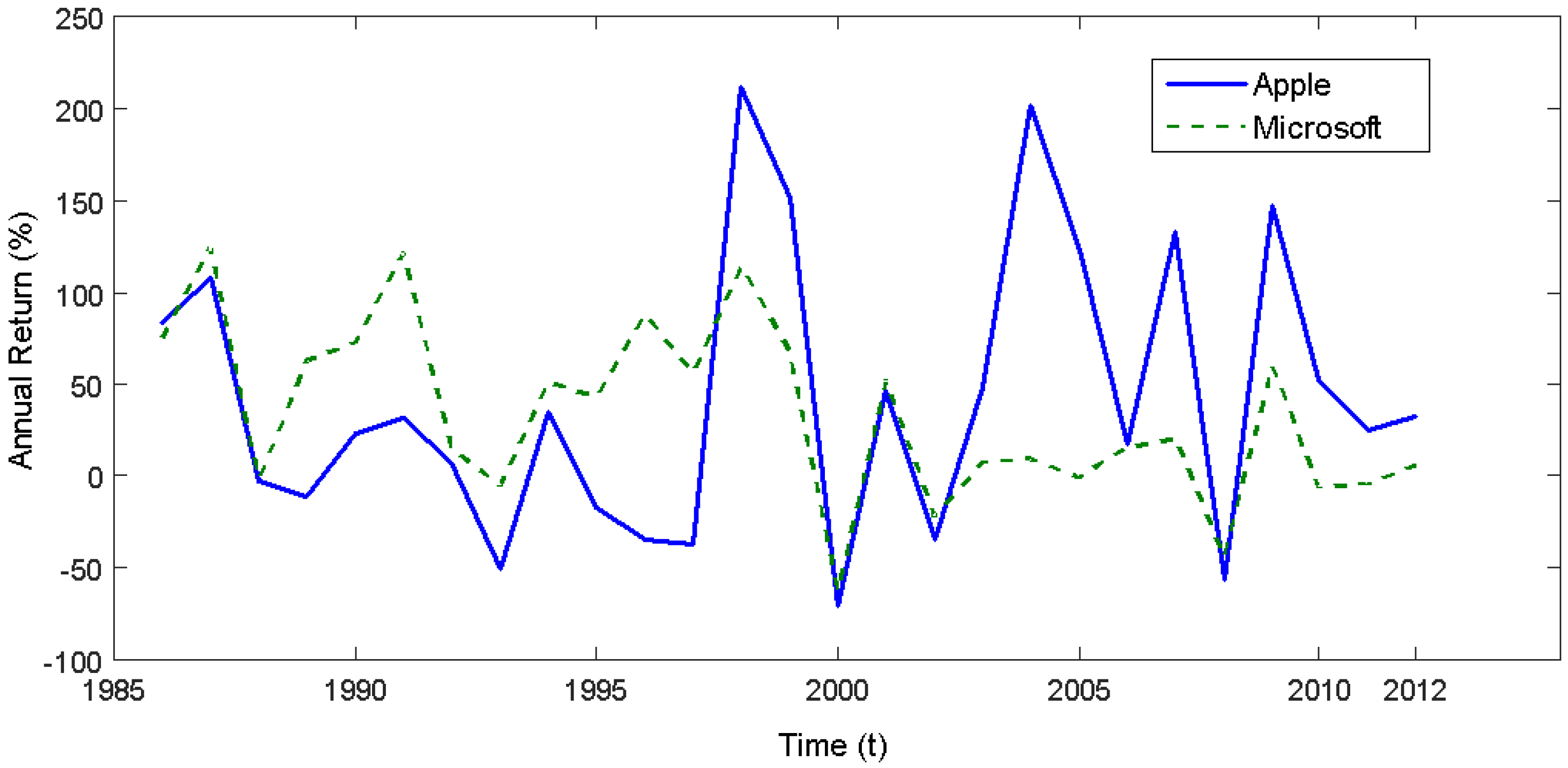
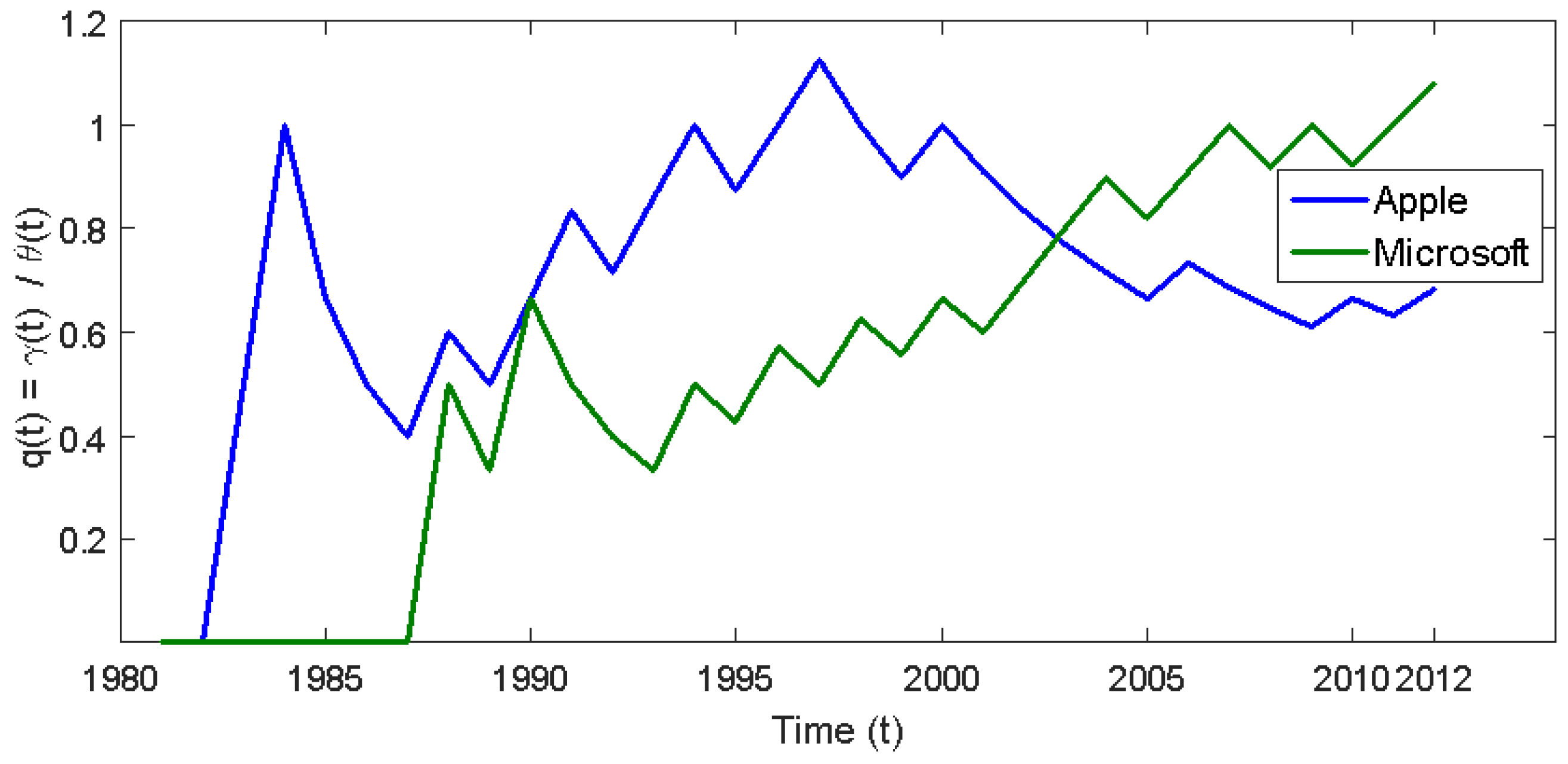
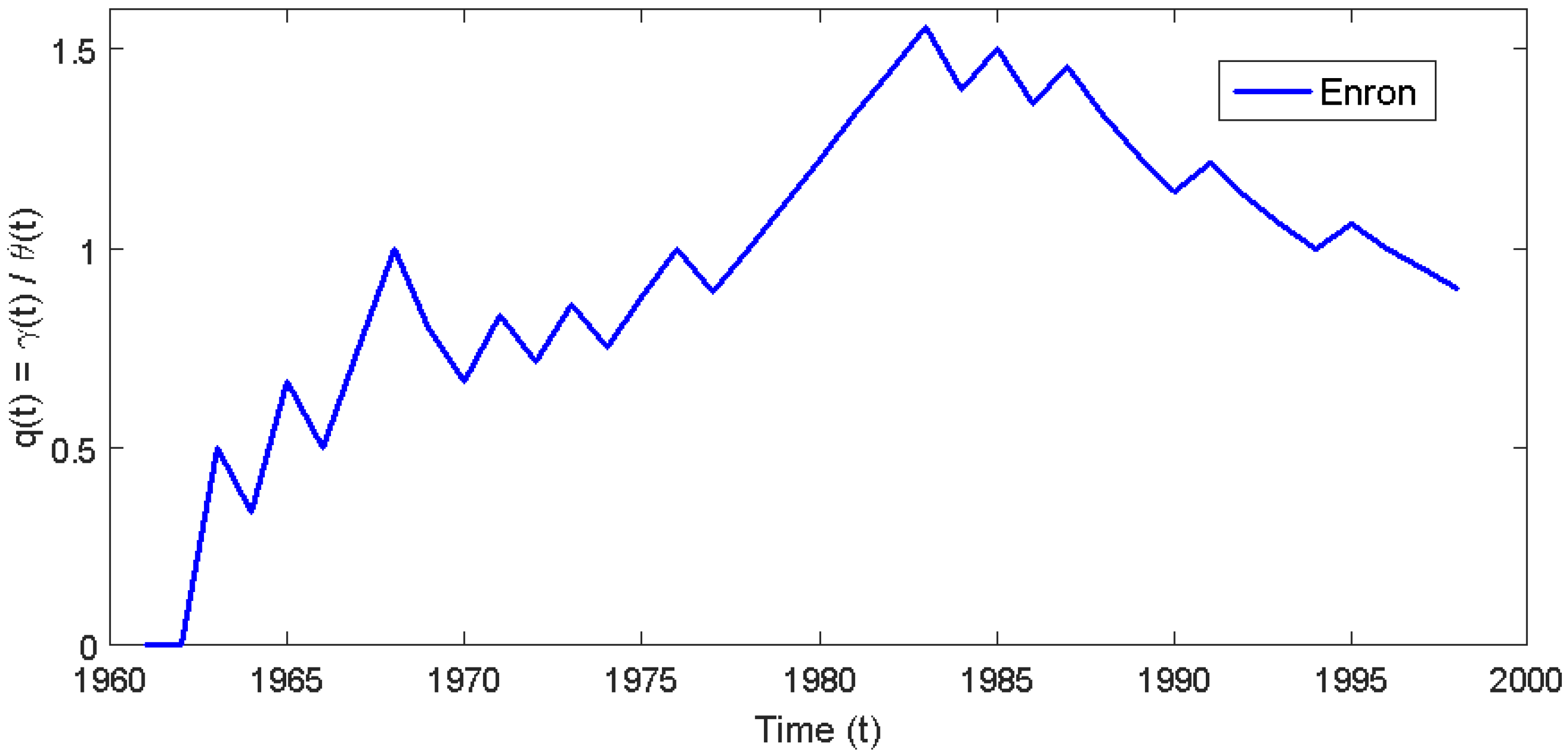
6. An Empirical Application
7. Broader Applications
8. Limitations
9. Conclusions
10. Future Research
Acknowledgments
Conflicts of Interest
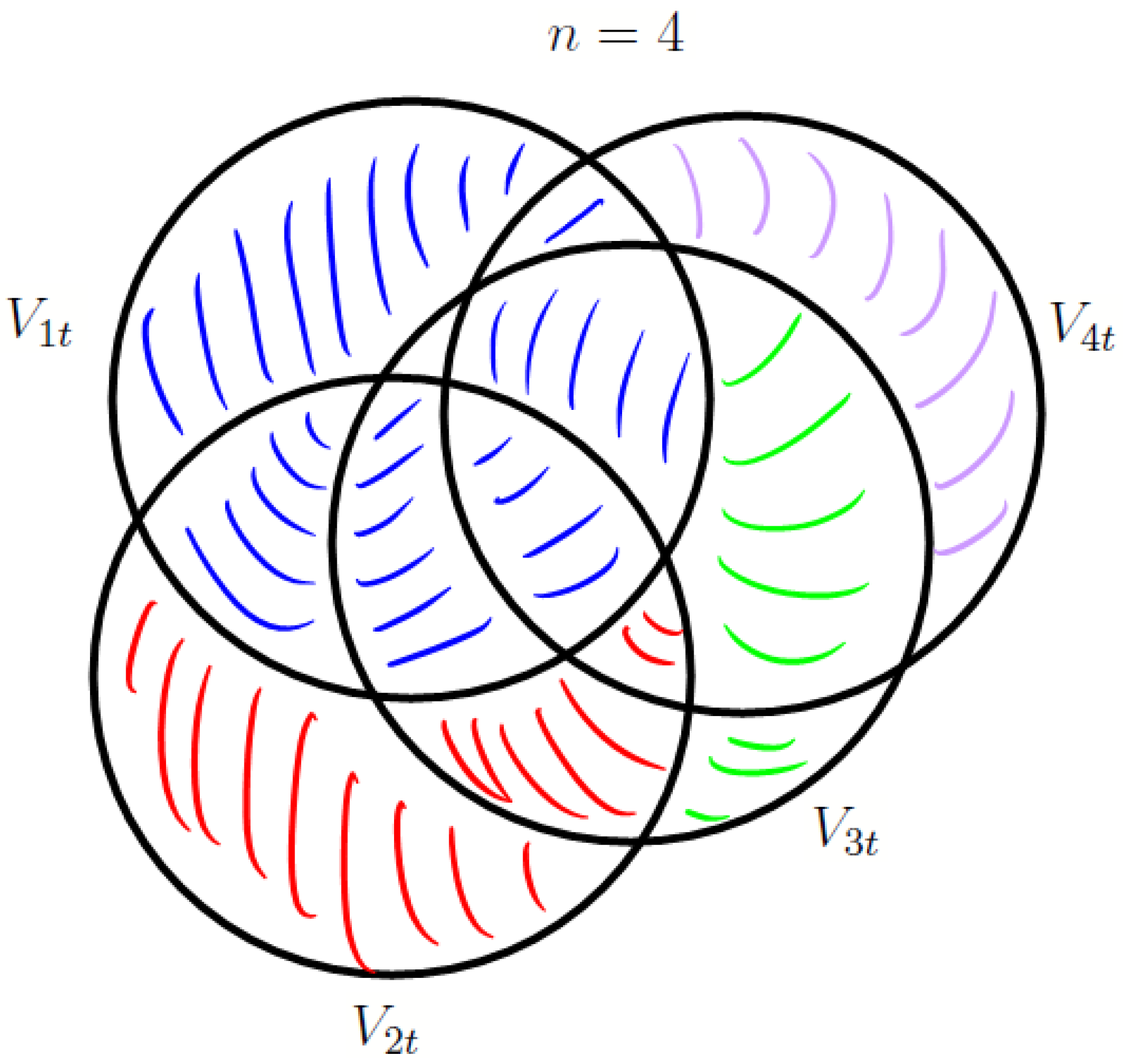
Appendix A. The Information Content, , of the Financial Statements
- = the variable with the smallest information content,
- = the starting variable index
- = the Pearson correlation between i and j through time
- ξ = the # of variables intersected

Appendix B. The Information Content of Apple’s Financial Statements

{kind=link}
{kind=link}
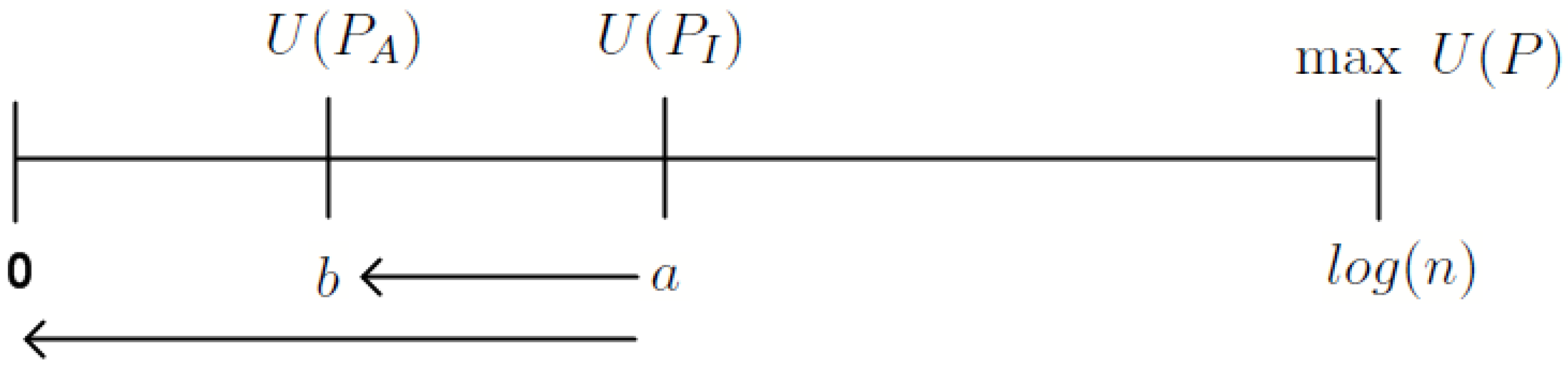{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | t | ||||||
|---|---|---|---|---|---|---|---|
| 1981 | 2 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| 1982 | 3 | 0.9944 | 0.9949 | 0.9975 | 0.9786 | 0.9845 | 0.9995 |
| 1983 | 4 | 0.9632 | 0.9834 | 0.9358 | 0.9891 | 0.9922 | 0.9822 |
| 1984 | 5 | 0.7726 | 0.8250 | 0.6654 | 0.9933 | 0.9867 | 0.9702 |
| 1985 | 6 | 0.6688 | 0.7332 | 0.5973 | 0.9942 | 0.9932 | 0.9823 |
| 1986 | 7 | 0.7222 | 0.8335 | 0.7804 | 0.9825 | 0.9827 | 0.9895 |
| 1987 | 8 | 0.8447 | 0.9024 | 0.8911 | 0.9896 | 0.9880 | 0.9931 |
| 1988 | 9 | 0.9296 | 0.9376 | 0.9612 | 0.9941 | 0.9917 | 0.9885 |
| 1989 | 10 | 0.9623 | 0.9665 | 0.9786 | 0.9970 | 0.9943 | 0.9928 |
| 1990 | 11 | 0.9737 | 0.9762 | 0.9810 | 0.9978 | 0.9935 | 0.9940 |
| Year | t | ||||
|---|---|---|---|---|---|
| 1980 | 1 | 0.0000 | 0 | 0 | 0 |
| 1981 | 2 | 0.5000 | 0.5000 | 0.5000 | 0.5000 |
| 1982 | 3 | 0.0817 | 0.0817 | 0.0817 | 0.0817 |
| 1983 | 4 | 0.0755 | 0.0755 | 0.0755 | 0.0755 |
| 1984 | 5 | 0.3709 | 0.3709 | 0.0290 | 0.3709 |
| 1985 | 6 | 0.0870 | 0.1402 | 0.0282 | 0.0870 |
| 1986 | 7 | 0.0821 | 0.3247 | 0.3787 | 0.1699 |
| 1987 | 8 | 0.0762 | 0.4142 | 0.0432 | 0.0432 |
| 1988 | 9 | 0.1737 | 0.0384 | 0.0384 | 0.0384 |
| 1989 | 10 | 0.0552 | 0.1441 | 0.0415 | 0.0297 |
| 1990 | 11 | 0.1808 | 0.1808 | 0.0196 | 0.0950 |
| Year | t | |||
|---|---|---|---|---|
| 1980 | 1 | 0 | 0 | 0 |
| 1981 | 2 | 0.5000 | 0.2500 | 0.1250 |
| 1982 | 3 | 0.0837 | 0.2563 | 0.0209 |
| 1983 | 4 | 0.0813 | 0.2692 | 0.0203 |
| 1984 | 5 | 0.5135 | 0.4497 | 0.1283 |
| 1985 | 6 | 0.1837 | 0.5367 | 0.0459 |
| 1986 | 7 | 0.4132 | 0.4324 | 0.1033 |
| 1987 | 8 | 0.4278 | 0.7416 | 0.1069 |
| 1988 | 9 | 0.1775 | 0.6144 | 0.0443 |
| 1989 | 10 | 0.1469 | 0.5425 | 0.0367 |
| 1990 | 11 | 0.1865 | 0.3916 | 0.0466 |
References
- Shannon, C. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Beaver, W.H. The information content of annual earnings announcements. J. Account. Res. 1968, 6, 67–92. [Google Scholar] [CrossRef]
- Bowen, R.M.; Burgstahler, D.; Daley, L.A. The incremental information content of accrual versus cash flows. Account. Rev. 1987, 62, 723–747. [Google Scholar]
- Freeman, R.N.; Tse, S. The multiperiod information content of accounting earnings: Confirmations and contradictions of previous earnings reports. J. Account. Res. 1989, 27, 49–79. [Google Scholar] [CrossRef]
- Landsman, W.R.; Maydew, E.L. Has the information content of quarterly earnings announcements declined in the past three decades? J. Account. Res. 2002, 40, 797–808. [Google Scholar] [CrossRef]
- Waymire, G. Additional evidence on the information content of management earnings forecasts. J. Account. Res. 1984, 22, 703–718. [Google Scholar] [CrossRef]
- Beaver, W.; Lambert, R.; Morse, D. The information content of security prices. J. Account. Econ. 1980, 2, 3–28. [Google Scholar] [CrossRef]
- Bedford, N.M.; Baladouni, V. A communication theory approach to accountancy. Account. Rev. 1962, 37, 650–659. [Google Scholar]
- Theil, H. Economics and Information Theory; North Holland Publishing Co.: Amsterdam, The Netherlands, 1967; Volume 7. [Google Scholar]
- Theil, H. On the use of information theory concepts in the analysis of financial statements. Manag. Sci. 1969, 15, 459–480. [Google Scholar] [CrossRef]
- Gibbs, J.W. On the equilibrium of heterogeneous substances. Am. J. Sci. 1878, 96, 441–458. [Google Scholar] [CrossRef]
- Lev, B. The aggregation problem in financial statements: An informational approach. J. Account. Res. 1968, 6, 247–261. [Google Scholar] [CrossRef]
- Lev, B. The informational approach to aggregation in financial statements: Extensions. J. Account. Res. 1970, 8, 78–94. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Christensen, J.A.; Demski, J. Accounting Theory; Irwin/McGraw-Hill: New York, NY, USA, 2002. [Google Scholar]
- Sun, L.; Srivastava, R.P.; Mock, T.J. An information systems security risk assessment model under the dempster-shafer theory of belief functions. J. Manag. Inf. Syst. 2006, 22, 109–142. [Google Scholar] [CrossRef]
- Jaynes, E.T. Probability Theory: The Logic of Science; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]


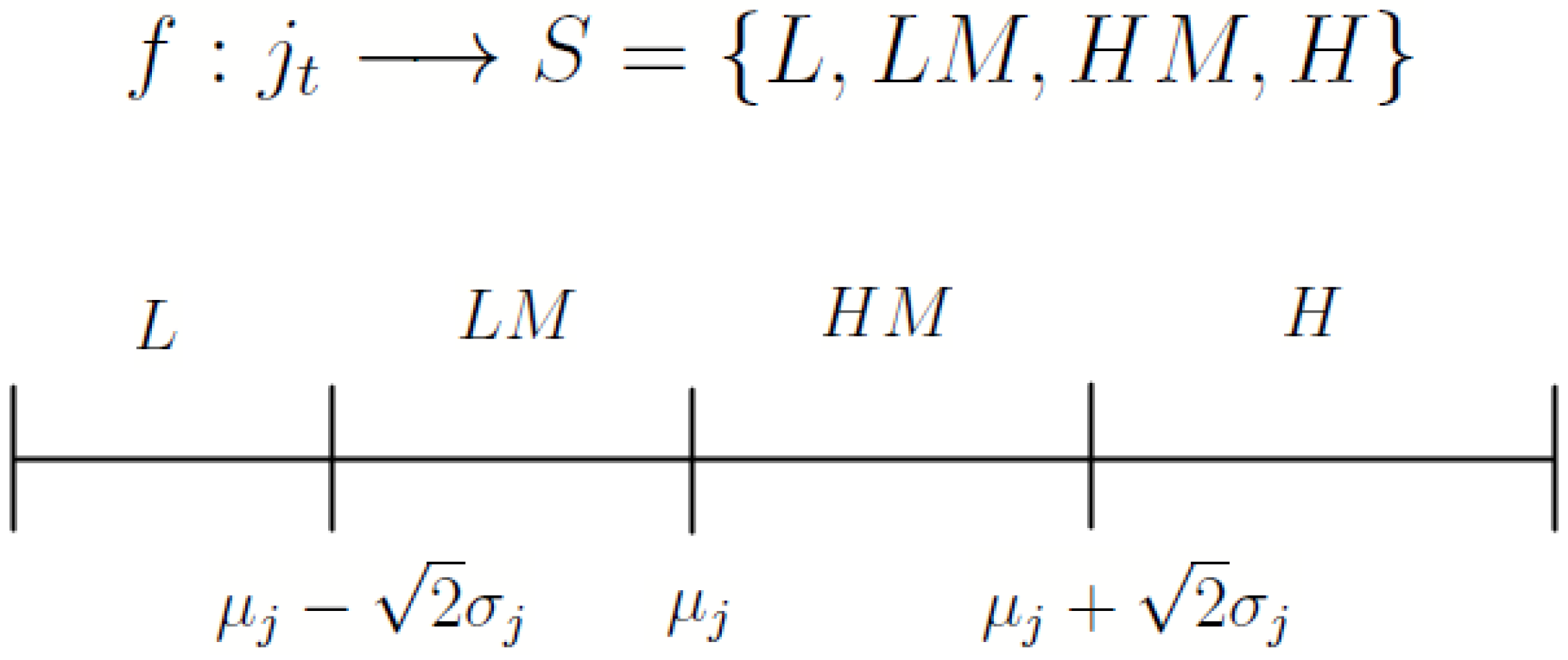

| t | ($millions) | |||
|---|---|---|---|---|
| 1980 | $11.70 | 0 | ||
| 1981 | $39.42 | |||
| 1982 | $61.306 | |||
| 1983 | $76.714 | |||
| 1984 | $64.055 | |||
| 1985 | $61.223 | |||
| 1986 | $153.963 | |||
| 1987 | $217.496 | |||
| 1988 | $400.258 | |||
| 1989 | $454.033 | |||
| 1990 | $474.895 | |||
| 1991 | $309.841 | |||
| 1992 | $530.373 | |||
| 1993 | $86.589 | |||
| 1994 | $310.178 | |||
| 1995 | $424 | |||
| 1996 | $(816) | |||
| 1997 | $(1045) | |||
| 1998 | $309 | |||
| 1999 | $601 | |||
| 2000 | $786 | |||
| 2001 | $(25) | |||
| 2002 | $65 | |||
| 2003 | $69 | |||
| 2004 | $276 | |||
| 2005 | $1335 | |||
| 2006 | $1989 | |||
| 2007 | $3496 | |||
| 2008 | $4834 | |||
| 2009 | $8235 | |||
| 2010 | $14,013 | |||
| 2011 | $25,922 | |||
| 2012 | $41,733 |
| COMPANY | # of Observations |
|---|---|
| Amazon | 15 |
| Amgen | 28 |
| Apple | 31 |
| Dell | 24 |
| Fed Ex | 33 |
| Home Depot | 31 |
| Microsoft | 26 |
| Nike | 31 |
| Starbucks | 20 |
| Walmart | 39 |
| Total Firm – Year Observations | 278 |
© 2016 by the author; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ross, J.F. The Information Content of Accounting Reports: An Information Theory Perspective. Information 2016, 7, 48. https://doi.org/10.3390/info7030048
Ross JF. The Information Content of Accounting Reports: An Information Theory Perspective. Information. 2016; 7(3):48. https://doi.org/10.3390/info7030048
Chicago/Turabian StyleRoss, Jonathan F. 2016. "The Information Content of Accounting Reports: An Information Theory Perspective" Information 7, no. 3: 48. https://doi.org/10.3390/info7030048
APA StyleRoss, J. F. (2016). The Information Content of Accounting Reports: An Information Theory Perspective. Information, 7(3), 48. https://doi.org/10.3390/info7030048