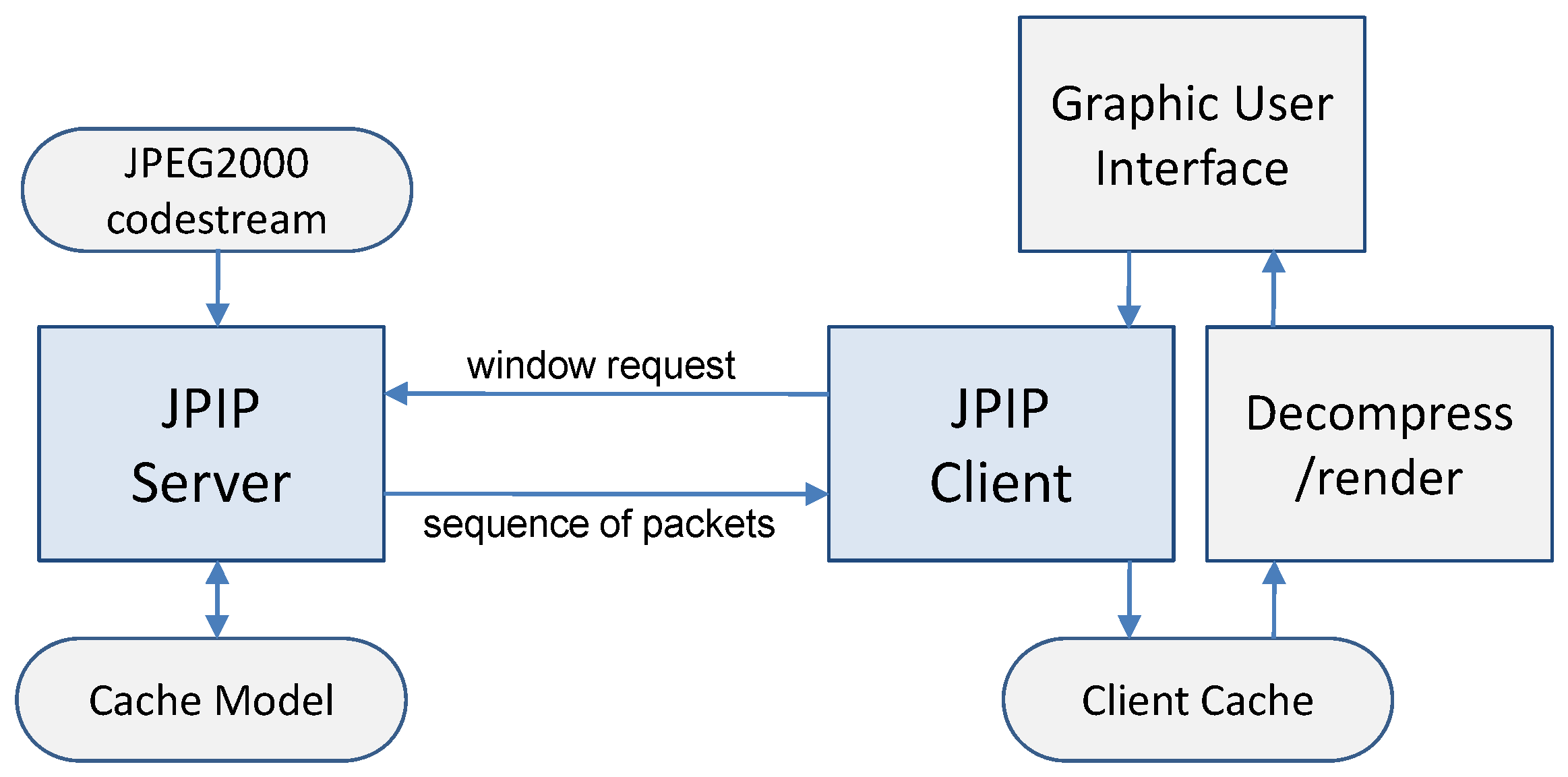
5.1. Multi-Resolution Visually Lossless Coding
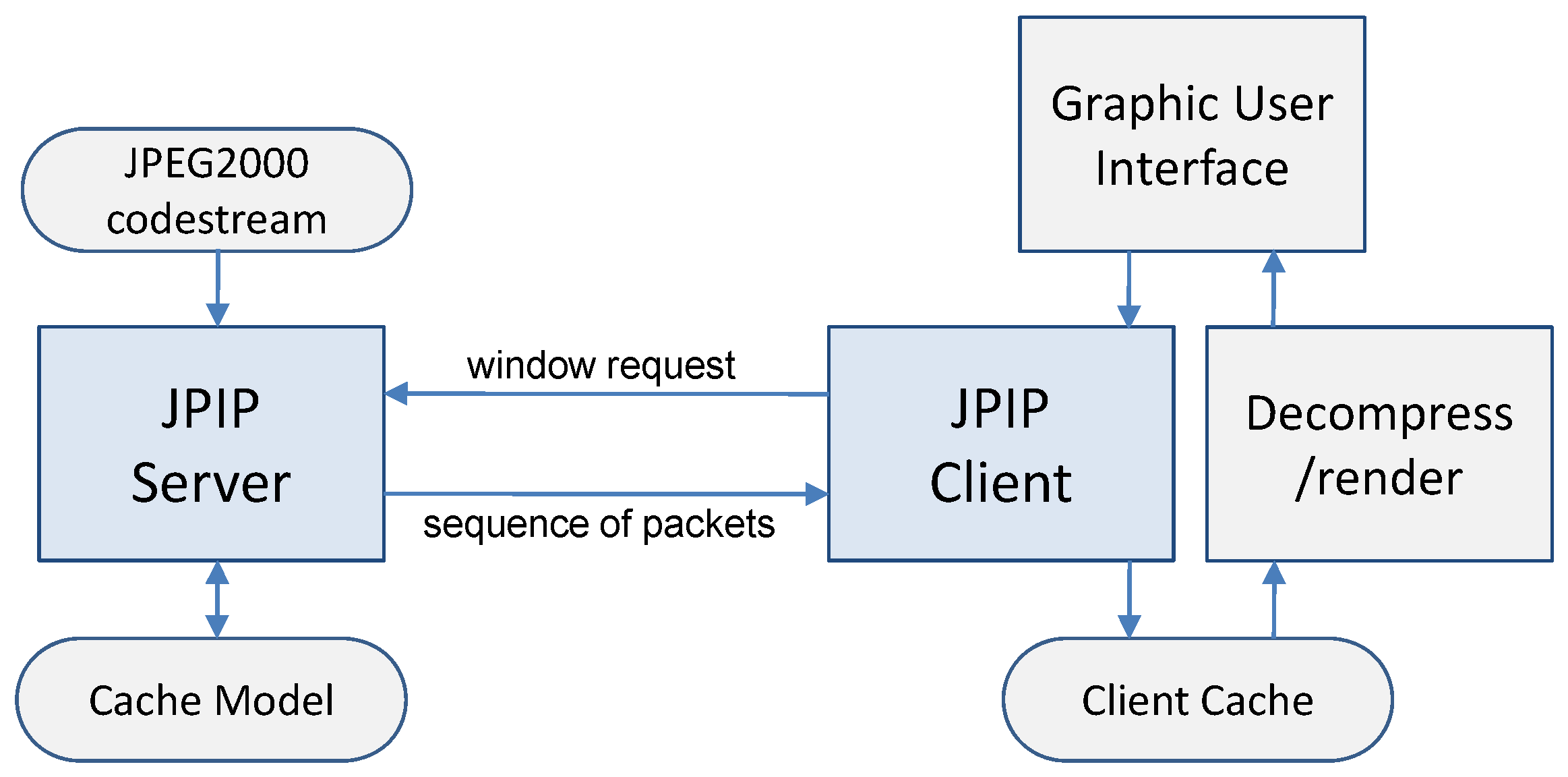
The proposed multi-resolution visually lossless coding scheme was implemented in Kakadu v6.4 (Kakadu Software, Sydney, Australia,
http://www.kakadusoftware.com). Experimental results are presented for seven digital pathology images and eight satellite images. All of the images are 24-bit color high resolution images ranging in size from 527 MB (
) to 3.23 GB (
). Each image is identified with
pathology or
satellite together with an index, e.g.,
pathology 1 or
satellite 3. Recent technological developments in digital pathology allow rapid processing of pathology slides using array microscopes [
24]. The resulting high-resolution images (referred to as virtual slides) can then be reviewed by a pathologist either locally or remotely over a telecommunications network. Due to the high resolution of the imaging process, these images can easily occupy several GBytes. Thus, remote examination by the pathologist requires efficient methods for transmission and display of images at different resolutions and spatial extents at the reviewing workstation. The satellite images employed here show various locations on Earth before and after natural disasters. The images were captured by the GeoEye-1 satellite, at 0.5 meter resolution from 680 km in space and were provided for the use of relief organizations. These images are also so large that fast rendering and significant bandwidth savings are essential for efficient remote image browsing.
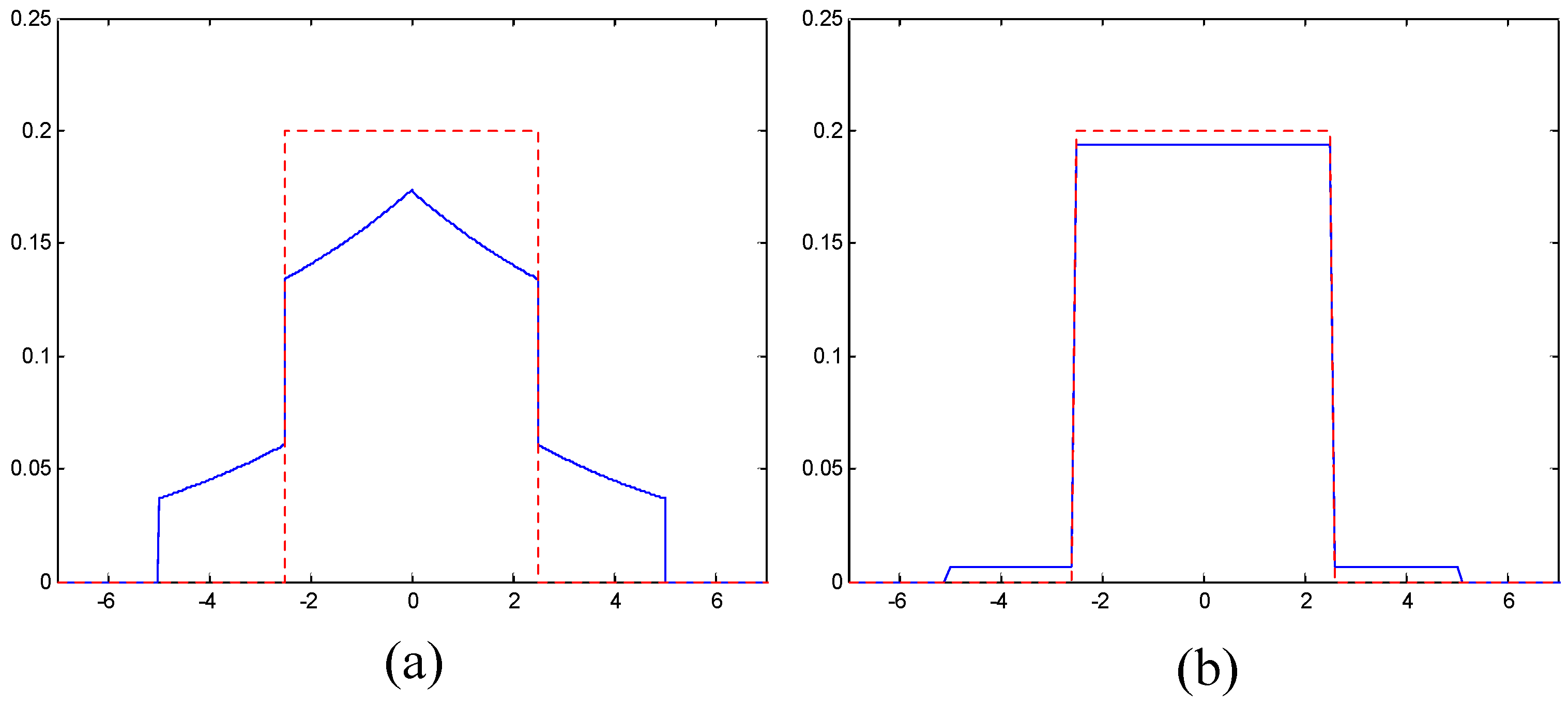
In this work, “reference images” corresponding to reduced native resolution images were created using the 9/7 DWT without quantization or coding. Reference images for intermediate resolutions were obtained by downscaling the next (higher) native resolution reference image. In what follows, the statement that a decompressed reduced resolution image is visually lossless means that it is visually indistinguishable from its corresponding reference image.
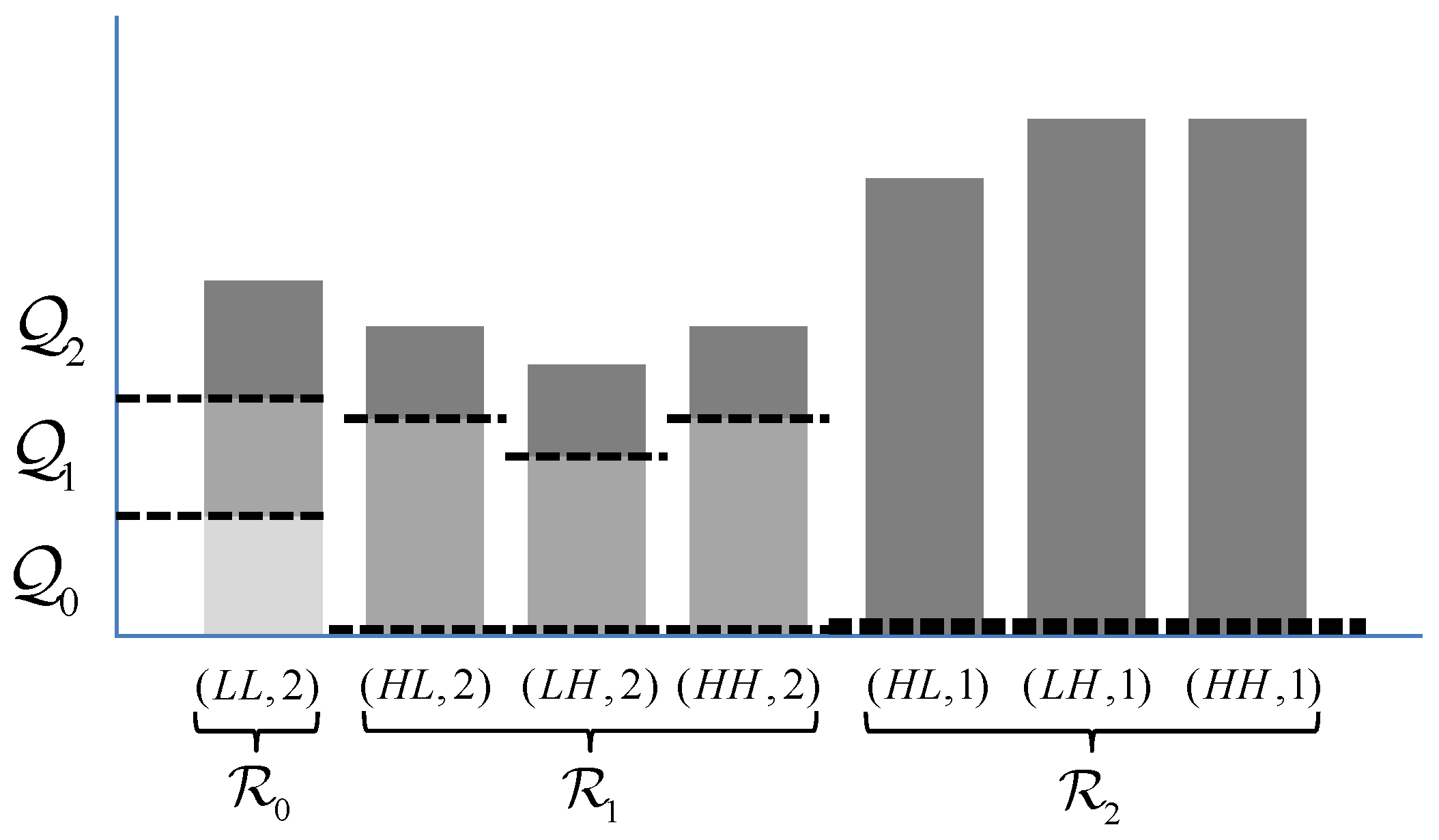
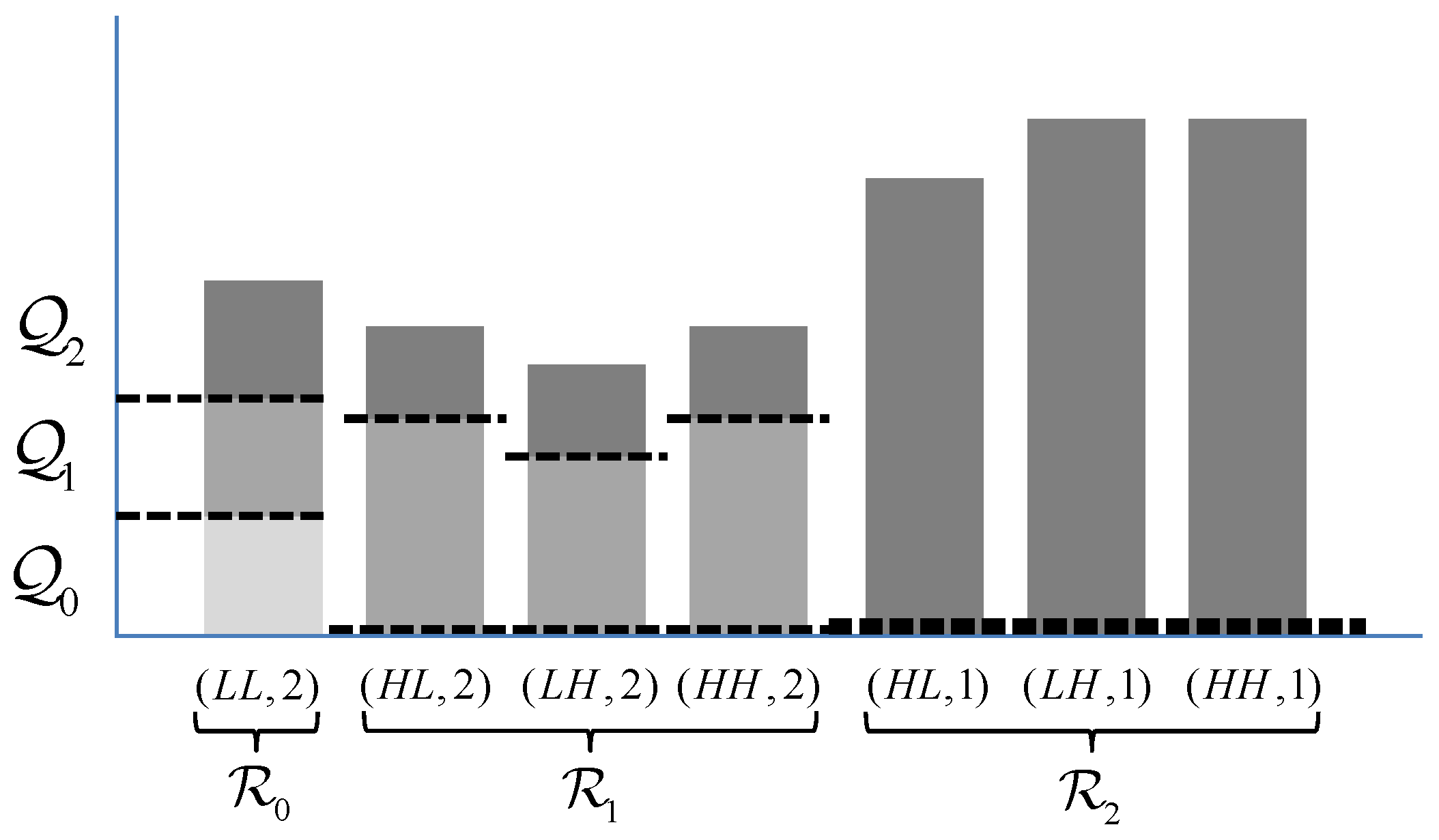
To evaluate the compression performance of the proposed method, each image was encoded using three different methods. The first method is referred to here as the six-layer method. As the name suggests, codestreams from this method employ six layers to apply the appropriate visually lossless thresholds for each of six native resolution images
. The second method, referred to as the 24-layer method, uses a total of 24 layers to provide visually lossless quality at each of the six native resolutions, plus three intermediate resolutions below each native resolution. The third method, used as a benchmark, employs the method from [
22] to yield a visually lossless image optimized for display only at full resolution. The codestream for this method contains a single layer, so this benchmark is referred to as the single-layer method. To facilitate spatial random access, all images were encoded using the CPRL (component-precinct-resolution-layer) progression order with precincts of size
at each resolution level.
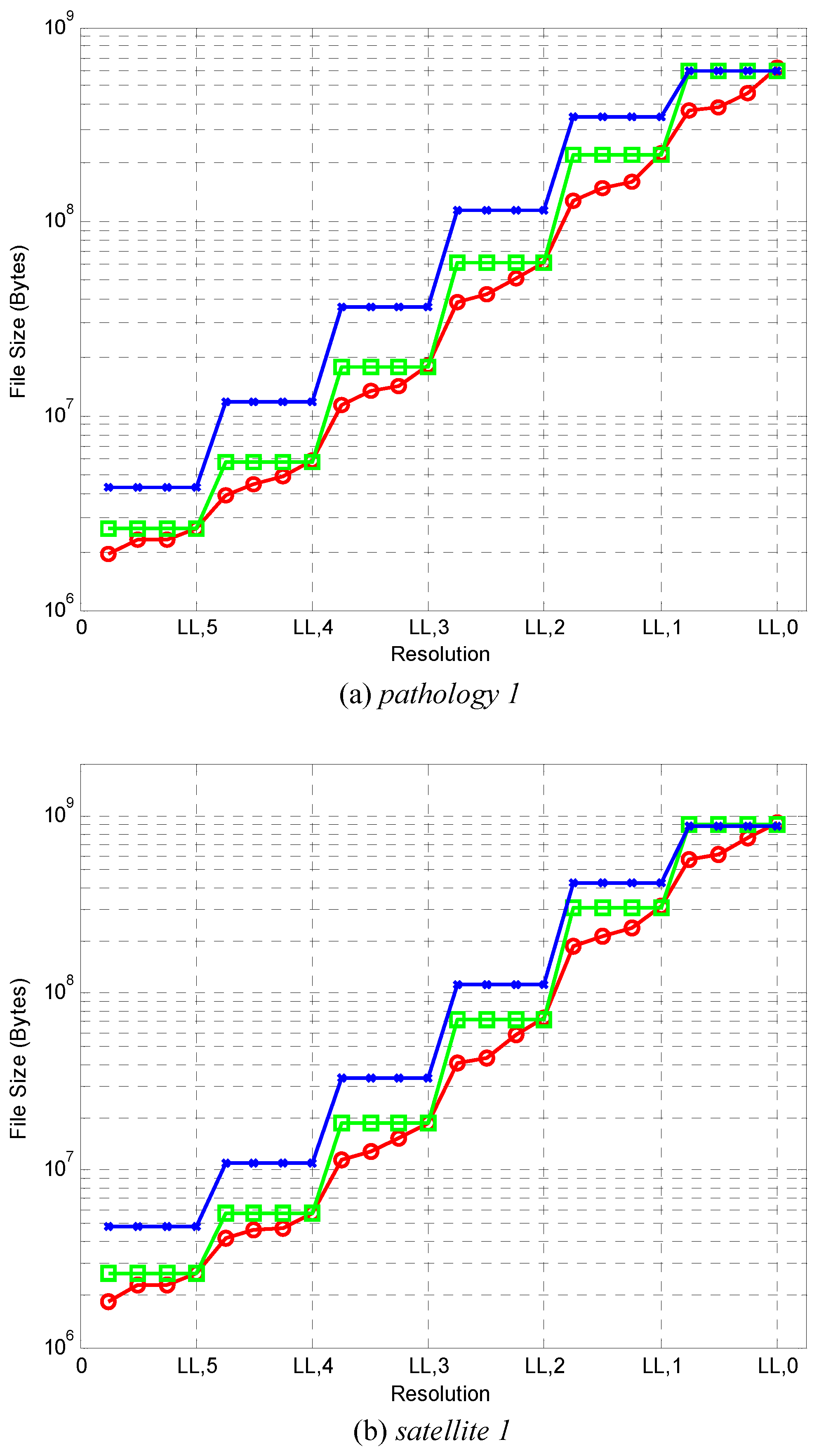
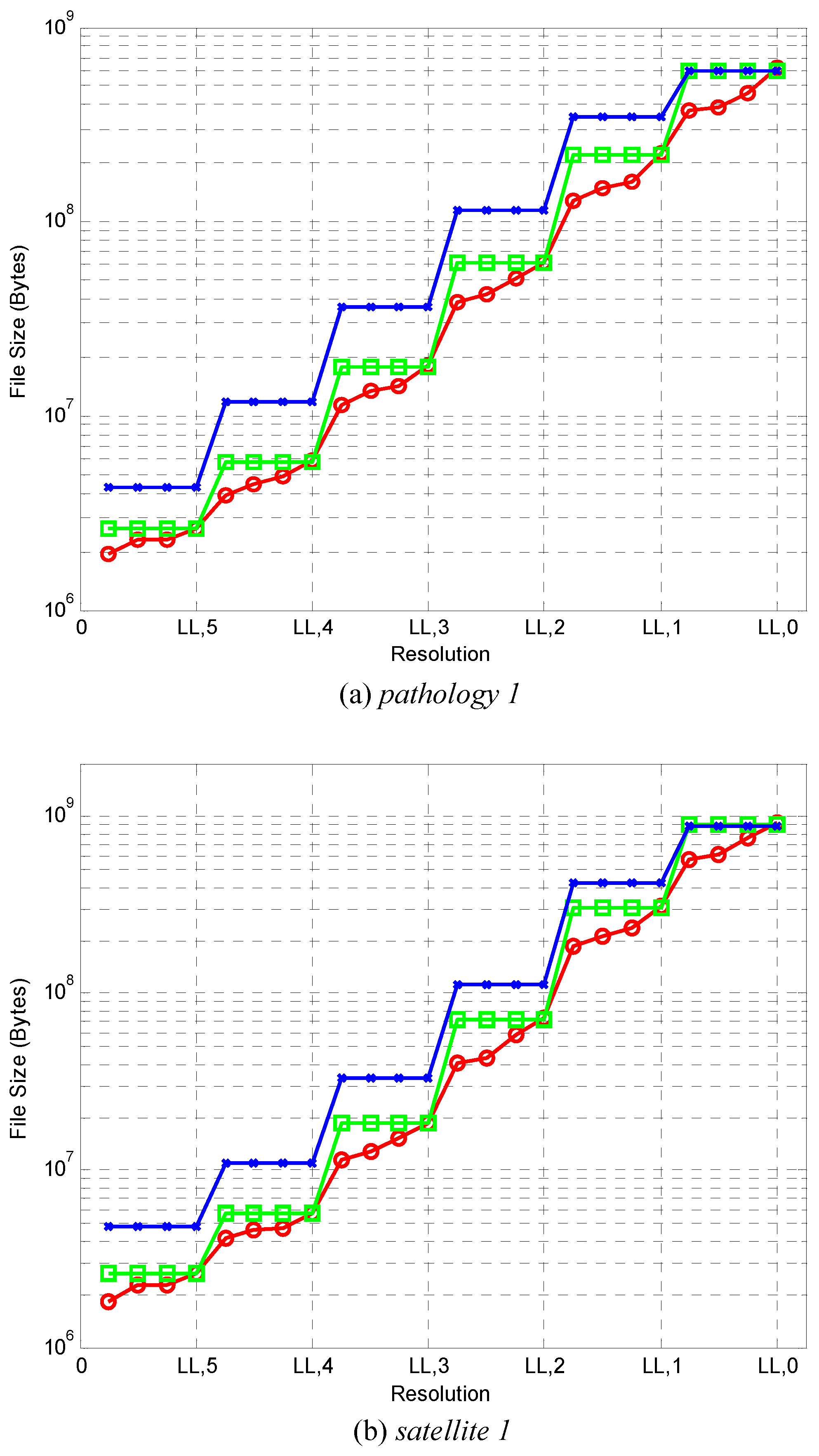
Figure 5 compares the number of bytes that must be decoded (transmitted) for each of the three coding methods to have visually lossless quality at various resolutions. Results are presented for one image of each type. Graphs for other images are similar. The number of bytes for the single-layer, six-layer, and 24-layer methods at each resolution are denoted by crosses, rectangles, and circles, respectively. As expected, the curves for the single-layer method generally lie above those of the six-layer method, which, in turn, generally lie above those of the 24-layer method. It is worth noting that the vertical axis employs a logarithmic scale, and that gains in compression ratio are significant for most resolutions.
Table 7 lists bitrates obtained (in bits-per-pixel with respect to the dimensions of the full-resolution images) averaged over all 15 test images. From this table, it can be seen that the six-layer method results in 39.3%, 50.0%, 48.1%, 42.1%, and 31.0% smaller bitrate compared to the single-layer method for reduced resolution images
and 4, respectively. In turn, for the downsampled images
and 5, the 24-layer method provides 25.0%, 30.3%, 35.5%, 39.1%, 39.1%, and 36.7% savings in bitrate, respectively compared to the six-layer method. These significant gains are achieved by discarding unneeded codestream data in the relevant subbands in a precise fashion, while maintaining visually lossless quality in all cases. Specifically, the six-layer case can discard data in increments of one layer out of six, while the 24-layer method can discard data in increments of one layer out of 24. In contrast, the single-layer method must read
all data in the relevant subbands.
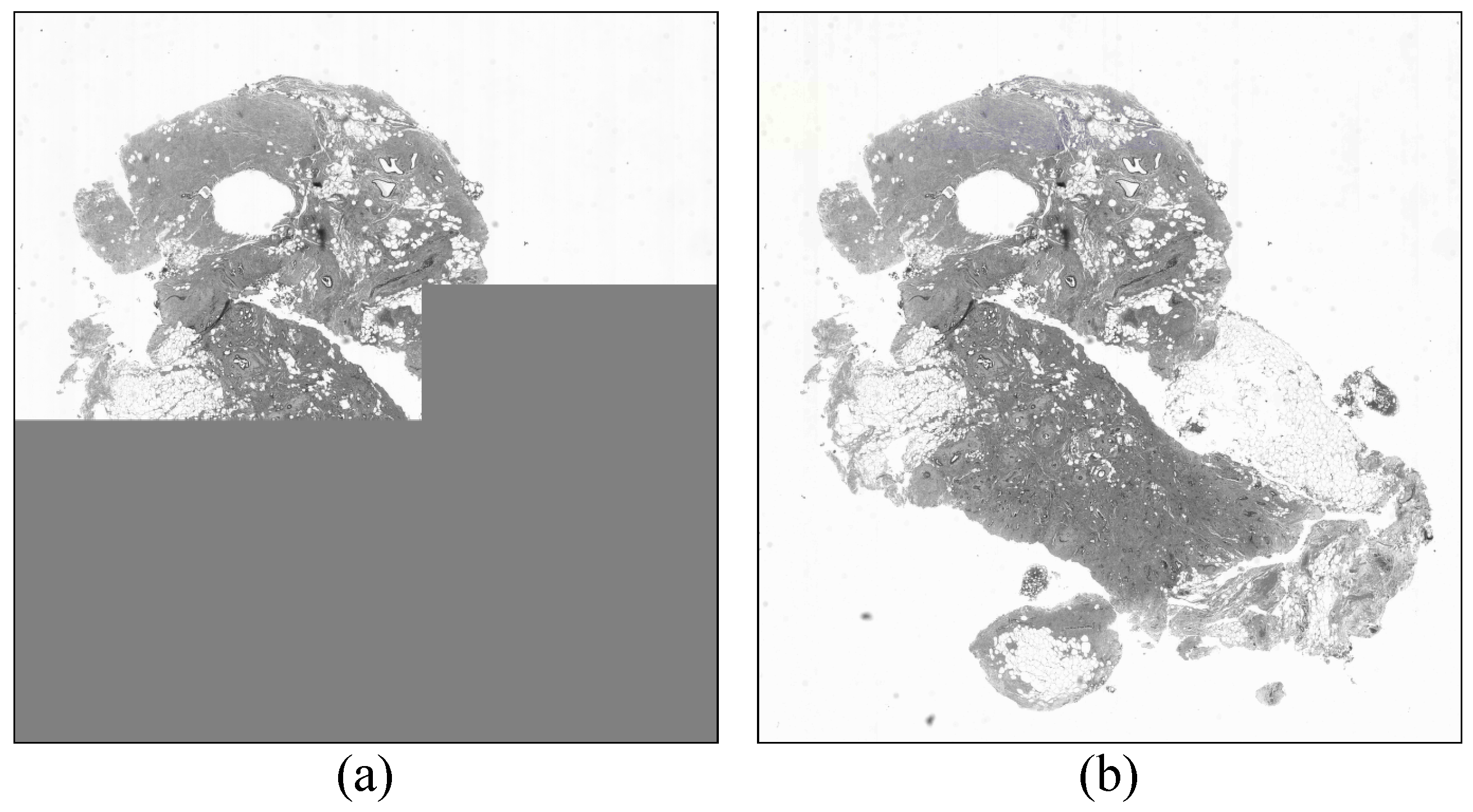
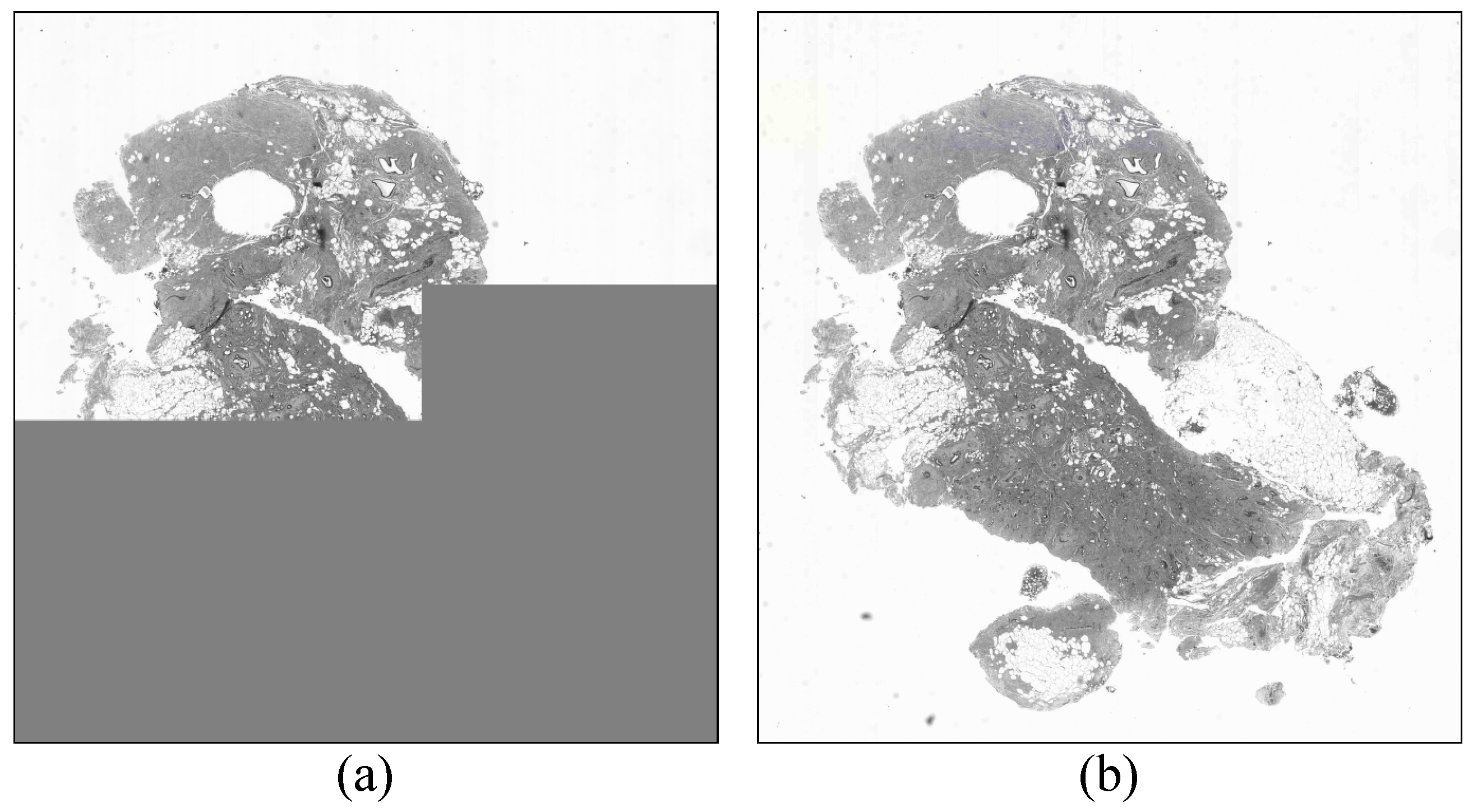
Figure 6 shows crops of the
satellite 2 image reconstructed at resolution
for the three coding methods. Each of these images is downscaled from a version of
. Specifically, for the single-layer method, the image is downscaled from all
data which amounts to 5.30 bpp, relative to the reduced resolution dimensions. For the proposed methods, the image is downscaled from three of six layers and 10 of 24 layers of
data, which amounts to 2.98 bpp and 2.09 bpp, respectively. Although the proposed methods offer significantly lower bitrates, all three resulting images have the same visual quality. That is, they are all indistinguishable from the reference image.
Although this multi-layer method provides significant gains for most resolutions, there exist a few (negligible) losses for some resolutions. Specifically, the six-layer case is slightly worse than the single-layer case for as well as for the three intermediate resolutions immediately below . The average penalty in this case is 0.72%. Similarly, the 24-layer case is slightly worse than the six-layer case at each of the six native resolutions. The average penalty for is 0.19%, 0.48%, 0.88%, 1.30%, 1.89%, and 2.23%, respectively. These minor drops in performance are due to the codestream syntax overhead associated with including more layers.
As mentioned previously, the layer functionality of JPEG 2000 enables quality scalability. As detailed in the previous paragraph, for certain isolated resolutions, the single-layer method provides slightly higher compression efficiency as compared to the six-layer and 24-layer methods. However, it provides
no quality scalability and therefore no progressive transmission capability. To circumvent this limitation, layers could be added to the so called single-layer method. To this end, codestreams from the single-layer method were partitioned into six layers. The first five layers were constructed via the arbitrary selection of five rate-distortion slope thresholds, as normally allowed by the Kakadu implementation. The six layers together yield exactly the same decompressed image as the single-layer method. In this way, the “progressivity” is roughly the same as the six-layer method, but visually lossless decoding of reduced resolution images is not guaranteed for anything short of decoding all layers for the relevant subbands.
Table 8 compares the bitrates for decoding
under the proposed six-layer visually lossless coding method vs. the one-layer method with added layers for the
pathology 3 and
satellite 6 images. As can be seen from the table, the results are nearly identical. Results for other images as well as for 24-layers are similar. Thus, the overhead associated with the proposed method is no more than that needed to facilitate quality scalability/progressivity.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}