Abstract
The codewords of a low-density parity-check (LDPC) convolutional code (LDPC-CC) are characterised into structured and non-structured. The number of the structured codewords is dominated by the size of the polynomial syndrome former matrix , while the number of the non-structured ones depends on the particular monomials or polynomials in . By evaluating the relationship of the codewords between the mother code and its super codes, the low weight non-structured codewords in the super codes can be eliminated by appropriately choosing the monomials or polynomials in , resulting in improved distance spectrum of the mother code.
1. Introduction
Low-density parity-check block codes (LDPC-BCs) have been widely used in many communication standards, such as WiMax, DVB2, and 802.11n [1,2,3]. As the counterpart of LDPC-BCs, LDPC convolutional codes (LDPC-CCs), also known as specially-coupled LDPC codes, were first proposed in [4] and have been extensively investigated in [5,6,7,8,9]. For the design of practical LDPC-CCs, it is preferred to have relative large girth (the length of the shortest cycle) and large free distance (the minimum weight of the codewords), in this paper, we focus on the analysis of the low weight codewords of LDPC-CCs.
Distance spectrum can be described by a set , where , the codeword weight enumerator, is the number of codewords with Hamming weight w, and the free distance is defined as the minimum weight of the codewords. Under linear programming decoding, the low weight pseudocodewords of LPDC codes were analysed in [10,11]. The pseudocodeword performance of an LDPC-CC and the underlying quasi-cyclic (QC) code was presented in [12]. Regarding the calculation of the distance spectrum of conventional convolutional codes, some work has been done in [13,14,15], and Bocharova et al. [16] presented a more efficient bidirectional tree search algorithm called BEAST. Compared to the conventional convolutional codes, LDPC-CCs have relative larger memory order because of the sparsity of the syndrome former matrix. Instead of calculating the precise distance spectrum, Zhou et al. [17] introduced a method to estimate the distance spectrum of LDPC-CCs by evaluating the linear dependence between the low weight codewords of super codes. A super code is defined by the submatrix obtained by splitting the polynomial-domain syndrome former matrix of the mother code.
Rather than calculating or estimating the distance spectrum of LDPC-CCs. In this paper, we introduce a method to improve the distance spectrum of LDPC-CCs by eliminating the so-called non-structured low weight codewords. The codewords of polynomial-based LDPC-CCs are characterised into two categories, i.e., structured and non-structured. In the distance spectrum, the number of the structured codewords is dominated by the size of the polynomial syndrome former matrix , while the number of the non-structured ones depends on the particular monomials or polynomials in .
By evaluating the relationship of the codewords between the mother code and its super codes, we find that the structured codeword of the mother code can only be derived from the structured codewords of a super code, while the non-structured one of the mother code requires both structured and non-structured super codewords to convert. Therefore, as the main contribution of the paper, eliminating low weight non-structured codewords in the super codes by appropriately choosing the monomials in can decrease the number of low weight non-structured codewords in the mother code, resulting in improved distance spectrum.
The rest of the paper is organised as follows: Section 2 gives the definition of the polynomial-domain LDPC-CCs. The concept of structured and non-structured codewords is discussed in Section 3. Section 4 demonstrates the approach of eliminating low weight non-structured codewords, and gives the designing criteria of practical LDPC-CCs with respect to good distance spectrum. Section 5 concludes the work.
2. LDPC Convolutional Codes
An LDPC-CC of rate can be defined by the polynomial syndrome former matrix (the polynomial-domain transposed parity-check matrix)
where . The n-tuple of a codeword is given by
and we have
After multiplexing, the codeword in Equation (2) can also be expressed as
A periodically shifted codeword or (), l∈, is also a codeword, and, consequently, it satisfies the constraint imposed by the polynomial syndrome former matrix, i.e.,
Given in Equation (1), its weight matrix is defined as
where indicates the number of additive items (monomials) of the polynomial entry . Note that, if is an empty entry, then =0. The maximum power of the monomials in Equation (1) is defined as the syndrome former memory . If there are J and K monomials in each row and each column of Equation (1) respectively, then the LDPC-CC is regular and denoted by .
3. Codewords Analysis
In this section, we characterise the codewords of LDPC-CCs into two categories, i.e., structured and non-structured. The non-structured codewords can be eliminated by appropriately choosing the power of the monomials or polynomials in , while the number of the structured codewords is relevant to the size of . The main contribution of this paper is introducing an approach to reduce the number of low weight non-structured codewords so as to improve the distance spectrum for the design of practical LDPC-CCs.
3.1. Structured Codewords
In [18], Smarandache et al. introduced a method to calculate the deterministic codewords for quasi-cyclic (QC) LDPC block codes. In this section, we give the proof to show that the method can also be applied to LDPC-CCs. These deterministic codewords refer to the structured codewords in this paper.
Lemma 1. Let be the LDPC-CC defined by the polynomial syndrome former matrix in Equation (1) and let S be a subset of with elements. Arbitrarily taking rows of with the row indices in S forms the submatrix denoted by . Let be a vector defined by
where indicates excluding i from the set S, and calculates the involved permanent of the polynomial matrix. Then is a codeword in .
Proof. See the Appendix. ☐
Definition 1. A codeword calculated using Lemma 1 is defined as the base structured codeword.
Since the codeword calculated in Lemma 1 is determined by the permanent of the polynomial submatrices, modifying the powers of the monomials in only changes the form of the codewords, but not the amount of them, therefore, we call them structured. Additionally, since the sum of any (periodically shifted) codewords obtained from Lemma 1 defines another structured codeword, hence we consider them as the base ones.
Given the polynomial syndrome former matrix of size , there are base structured codewords. The minimum weight of these base structured codewords gives an upper bound on the free distance of the LDPC-CC.
To illustrate the concept of the base structured codewords, the Tanner LDPC-CC of rate is chosen as an example. This code is defined by the polynomial syndrome former matrix
which is obtained by removing the common factors of D from each column of from the code in [19] for simplicity.
According to Lemma 1, we choose the submatrix of size as follows
There are four different square submatrices of size in Equation (9), and the permanent of each square submatrix is given in Table 1. According to Equation (7), the 5-tuple sequence
or, equivalently,
is a base structured codeword of Equation (8), and it satisfies the parity-check constraint .

Table 1.
The permanent of each square submatrix of Equation (9).
| Submatrices | Permanent of the Submatrix |
|---|---|
The polynomial syndrome former matrix in Equation (8) contains five submatrices of size , and each one defines a base structured codeword. All of these five base structured codewords are presented in Table 2, and each one is of weight 24. Therefore, the free distance of the (21,3,5) Tanner LDPC-CC is upper bounded by 24 which is consistent with the estimated free distance in [17].
Table 2.
The base structured codewords of the Tanner LDPC-CC.
3.2. Non-Structured Codewords
Unlike the structured codewords, there is another category of codewords depending on the particular monomials or polynomials in . By appropriately choosing the power of each monomial, this type of codewords can be eliminated. We call them non-structured codewords in this paper. Note that, if any non-structured codewords are involved in the sum of a set of codewords, then the sum results in another non-structured codeword.
In [17], a method was introduced to estimate the distance spectrum of LDPC-CCs (mother code) by splitting the polynomial syndrome former matrix into submatrices representing “super codes” and then evaluating the linear dependence between codewords of the corresponding super codes. We apply this method to the (21,3,5) Tanner LDPC-CC.
First, the polynomial syndrome former matrix of the original code is split into two submatrices and as follows
Each one defines a super code and has free distance of 6. By computer search, there are 22 and 12 codewords of weight 6 in the set and for and , respectively. In addition, no codewords of weight smaller than six are found, therefore, the free distance of these two super codes are six. Applying Lemma 1 to and , as shown in Table 3 the codewords and are the base structured codewords, and the rest are the non-structured ones.
Table 3.
Minimum weight codewords of the super codes.
| Structured | Non-Structured | Structured |
| - | non-structured | |
| - | ||
| - | - | |
By evaluating the linear dependence between the minimum weight codewords of the super codes in Table 3, we find that the codewords of the mother code in Table 2 can be derived from each super code by summing some periodically shifted base structured codewords. For example,
Note that, the non-structured codewords of and are not involved in generating the codewords in the set .
However, the Tanner LDPC-CC has another base structured codeword of weight 24, i.e.,
which cannot be obtained using Lemma 1. Unlike the codewords , the codeword requires both structured and non-structured codewords for each super code to convert, i.e.,
Since the non-structured codewords of the super codes are always involved in the formation of the corresponding non-structured codewords of the mother code, and the non-structured codewords can be deleted by modifying the monomials in , we conjecture that eliminating the non-structured codewords in the super codes can decrease the number of non-structured codewords in the mother code.
4. Eliminating the Low Weight Non-Structured Codewords
In order to verify the conjecture in Section 3.2, in this section, we analyse the minimum weight codewords for the (57,3,5), (126,3,5), and (204,3,5) Tanner LDPC-CCs, and compare the results to that of the (21,3,5) code.
4.1. More Examples
The (57,3,5), (126,3,5), and (204,3,5) Tanner LDPC-CCs are respectively defined by the polynomial syndrome former matrices
Using the distance spectrum estimation algorithm in [17], each of them contains five codewords with the minimum weight 24. Applying Lemma 1 to each of the above three codes, we find that the five codewords calculated in [17] are all base structured ones. In other words, these LDPC-CCs do not contain any non-structured codewords of weight 24. Compared to the situation of the (21,3,5) code, the reason that the (21,3,5) code contains a non-structured codeword of weight 24 can be explained by the difference in the super codes.
Splitting the polynomial syndrome former matrix, we obtain following super codes
for the (57,3,5), (126,3,5), and (204,3,5) Tanner LDPC-CCs, respectively. By computer search, each of the above super codes contains 10 codewords of weight 6. Confirmed by Lemma 1, all of them are base structured codewords. The weight 24 structured codewords of the (57,3,5), (126,3,5), and (204,3,5) codes can be derived by summing the periodically shifted weight 6 base structured codewords of the corresponding super code.
Compared to the case of the (21,3,5) code, the (57,3,5), (126,3,5), and (204,3,5) codes do not have any non-structured codewords of weight 24. It is due to the elimination of non-structured codewords of weight 6 in the corresponding super code. Based on this observation, we conclude that when designing LDPC-CCs eliminating low weight non-structured codewords in the super codes can decrease the number of low weight non-structured codewords in the mother code.
4.2. Improved Distance Spectrum
To delete the non-structured codewords of weight 24 in the (21,3,5) code, we generate a new polynomial syndrome former matrix
where the syndrome former memory is still 21, and both the codes defined in Equations (8) and (12) have girth of 8.
In the case of Equation (12), the super code formed by the second and the third columns contains 10 structured codewords of weight 12. Compared to the super code in Equation (11), the two non-structured codewords and in Table 3 are eliminated by respectively substituting , , and for the (2,2)-th, (3,2)-th, and (4,3)-th elements in Equation (11). In addition, similar to the code in Equation (8), arbitrary two columns of Equation (12) representing a super code does not contain any non-structured codewords of weight smaller than 6. As a result, the number of the codewords of weight 24 for the code Equation (12) is reduced to five, and these five codewords are exactly the same as those obtained from Lemma 1.
Applying the distance estimation algorithm in [17] to Equation (12), the number of the codewords of weights 24, 26, 28, 30, and 32 have been reduced from 6, 5, 8, 34, and 53 for the code Equation (8) to 5,0, 0, 0, and 0, respectively. No codewords of weights 26, 28, 30, and 32 are found. The number of low weight codewords has been significantly reduced by carefully choosing the monomials in the polynomial syndrome former matrix. It shows that eliminating the low weight non-structured codewords in the super code improves the distance spectrum of the mother codes.
As shown in Figure 1, the decoding performance of the designed code in Equation (12) is compared to that of the (21, 3, 5) Tanner LDPC-CC in Equation (8). The simulation was carried out assuming binary phase-shift keyed (BPSK) modulation on an additive white Gaussian noise (AWGN) channel with 50 iterations of the on-demand variable node activation [20] sum-product pipeline [4] decoding algorithm for LDPC-CCs. As a benefit of the improved distance spectrum, the bit error ratio (BER) curve of the designed code is consistent lower than that of the Tanner code.
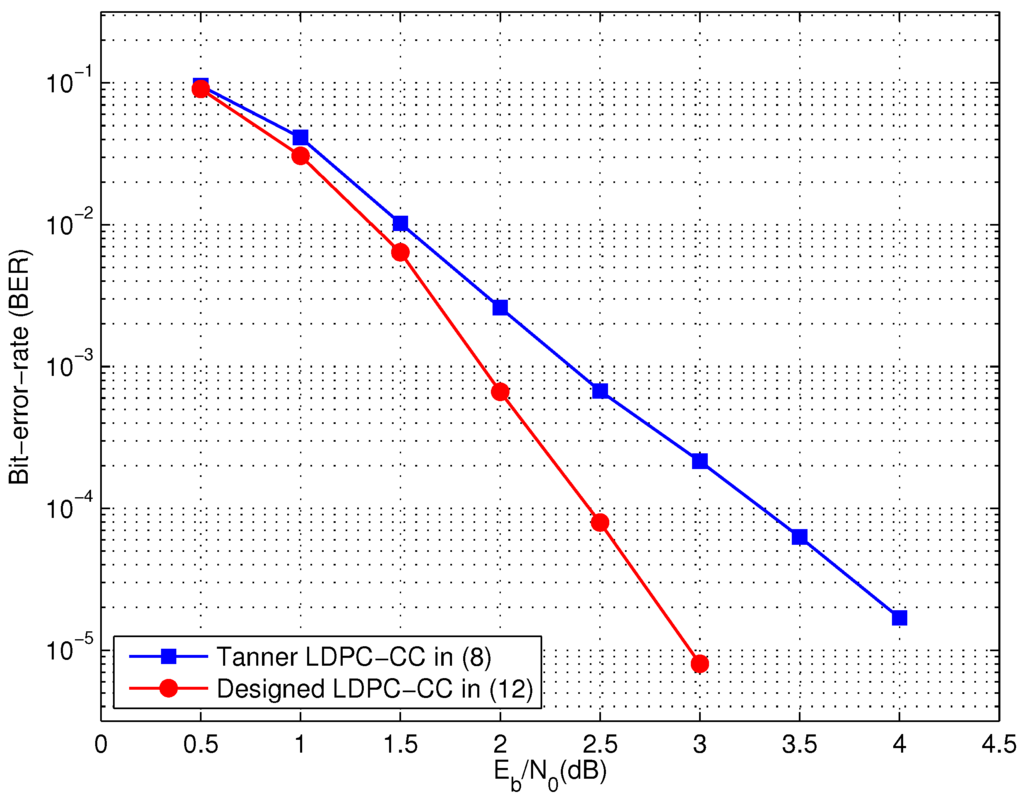
Figure 1.
Decoding performance of the codes defined in Equations (12) and (8) .
4.3. Rules for Designing Practical LDPC-CCs
Through the above analysis, to obtain good distance spectrum when designing practical LDPC-CCs based on a given weight matrix, we propose two design criteria to follow:
- ensuring that each super code does not contain any codewords with weight smaller than the minimum weight of the structured codewords calculated using Lemma 1;
- eliminating the low weight non-structured codewords of the super codes as many as possible.
In order to eliminate the non-structured codewords in the super codes, a two-step calculation is performed as follows:
- Step 1: Compute the enumerator for the structured codewords that the super code contains. In this paper, the structured codewords are calculated based on the formation of the unavoidable cycles [21]. For example, the weight matrix of the super code formed by the second and the third columns of Equation (12) is an all-one matrix of size . According to the result in [21], this weight matrix contains = 10 unavoidable cycles of length 12. If an all-one weight matrix contains only two columns or two rows, the structure of an unavoidable cycle of length n in the weight matrix forms a structured codeword of weight . Hence, we have for the super code formed by arbitrary two columns of Equation (12).
- Step 2: For each entry in the polynomial syndrome former matrix of the super code, we randomly choose a monomial with power smaller than the syndrome former memory and calculate the number of the codewords that the associated super code has. If it is larger than , this monomial is replaced by another one until a valid one is found. If all of the monomials with power smaller than have been tested, we simply increase the value of and repeat the process in Step 2.
5. Conclusions
In this paper, the codewords of polynomial-based LDPC-CCs are separated into two categories, i.e., structured codewords and non-structured codewords. In the distance spectrum, the number of the structured codewords is dominated by the size of the polynomial syndrome former matrix , while the number of the non-structured ones depends on the particular monomials or polynomials in . For the design of practical LDPC-CCs, an approach of improving the distance spectrum of the mother code is eliminating the low weight non-structured codewords in the super codes.
Acknowledgments
This work was supported by the National Natural Science Foundation of China under Grant Numbers 61401216, 61501244 and 61501245, by the Scientific Research Foundation for the Returned Overseas Chinese Scholars, State Education Ministry, by the Priority Academic Program Development of Jiangsu Higher Education Institutions, and by the Startup Foundation for Introducing Talent of Nanjing University of Information Science and Technology (NUIST).
Author Contributions
All of the authors are responsible for the concept of the paper and the results presented. Hua Zhou wrote the paper, and Jiao Feng, Peng Li and Jingming Xia reviewed and commented the paper work. The final manuscript was approved by all of the authors.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix
A. Proof of Lemma 1
Arbitrarily choose rows of forming the submatrix , for example, let us take the first rows of and obtain
where . Assuming we have -tuple of a vector
that satisfies
By expanding Equation (A3), we obtain (for simplicity, the notation “D” in Equations (A4)–(A8) is ignored)
For any square matrix A with elements from the field of characteristic 2, it holds that det(A) = perm(A). Let , according to Cramer’s rule, we have
Similarly, applying the above description to the rest of the elements in , we have
where . Taking back to Equation (A4), we obtain
and
Equation (A8) can be equivalently described as
or
where and when . Therefore, the code sequence is a codeword for the LDPC-CC defined by .
References
- IEEE 802.16e Task Group. IEEE Standard for Local and Metropolitan Area Networks Part 16: Air Interface for Fixed and Mobile Broadband Wireless Access Systems Amendment 2: Physical and Medium Access Control Layers for Combined Fixed and Mobile Operation in Licensed Bands and Corrigendum 1; IEEE Std. 802.16e; IEEE: Piscataway, NJ, USA, 2006. [Google Scholar]
- European Telecommunications Standards Institute (ETSI). DVB-T2 Implementation Guidelines for a Second Generation Digital Terrestrial Television Broadcasting System (DVB-T2); DVB Blue Book A133 or ETSI TR 102831; ETSI: Sophia Antipolis, France, 2012. [Google Scholar]
- IEEE 802.11n Task Group. IEEE Draft Standard for Information Technology: Telecommunications and information Exchange Between Systems: Local and Metropolitan Area Networks: Specific Requirements Part 11: Wireless LAN Medium Access Control (MAC) and Physical Layer (PHY) Specifications Amendment 4: Enhancements for Higher Throughput; IEEE Std. 802.11n/D2.00; IEEE: Piscataway, NJ, USA, 2007. [Google Scholar]
- Felström, A.J.; Zigangirov, K.S. Time-varying periodic convolutional codes with low-density parity-check matrices. IEEE Trans. Inf. Theory 1999, 45, 2181–2191. [Google Scholar] [CrossRef]
- Lentmaier, M.; Sridharan, A.; Costello, D.J., Jr.; Zigangirov, K.S. Iterative decoding threshold analysis for LDPC convolutional codes. IEEE Trans. Inf. Theory 2010, 56, 5274–5289. [Google Scholar] [CrossRef]
- Bazzi, L.; Ghazi, B.; Urbanke, R.L. Linear Programming Decoding of Spatially Coupled Codes. IEEE Trans. Inf. Theory 2014, 60, 4677–4698. [Google Scholar] [CrossRef]
- Schwandter, S.; Graell i Amat, A.; Matz, G. Spatially-coupled LDPC codes for decode-and-forward relaying of two correlated sources over the BEC. IEEE Trans. Commun. 2014, 62, 1324–1337. [Google Scholar] [CrossRef]
- Abu-Surra, S.; Divsalar, D.; Ryan, W.E. Enumerators for Protograph-Based Ensembles of LDPC and Generalized LDPC Codes. IEEE Trans. Inf. Theory 2011, 57, 858–886. [Google Scholar] [CrossRef]
- Kasai, K.; Declercq, D.; Poulliat, C.; Sakaniwa, K. Multiplicatively Repeated Nonbinary LDPC Codes. IEEE Trans. Inf. Theory 2011, 57, 6788–6795. [Google Scholar] [CrossRef]
- Xia, S.; Fu, F. On the minimum pseudocodewords of LDPC codes. IEEE Commun. Lett. 2006, 10, 363–365. [Google Scholar]
- Chertkov, M.; Stepanov, M. Searching for low weight pseudo-codewords. In Proceedings of the Information Theory and Application Workshop, La Jolla, CA, USA, 29 January–2 February 2007.
- Smarandache, R.; Pusane, A.E.; Vontobel, P.O.; Costello, D.J., Jr. Pseudocodeword performance analysis for LDPC convolutional codes. IEEE Trans. Inf. Theory 2009, 55, 2577–2598. [Google Scholar] [CrossRef]
- Bahl, L.R.; Cullum, C.D.; Frazer, W.D.; Jelinek, F. An efficient algorithm for computing free distance. IEEE Trans. Inf. Theory 1972, 18, 437–439. [Google Scholar] [CrossRef]
- Cedervall, M.; Johannesson, R. A fast algorithm for computing distance spectrum of convolutional codes. IEEE Trans. Inf. Theory 1989, 35, 1146–1159. [Google Scholar] [CrossRef]
- Rouanne, M.; Costello, D.J., Jr. An algorithm for computing the distance spectrum of trellis codes. IEEE J. Sel. Areas Commun. 1989, 7, 929–940. [Google Scholar] [CrossRef]
- Bocharova, I.E.; Handlery, M.; Johannesson, R. A BEAST for Prowling in Trees. IEEE Trans. Inf. Theory 2004, 50, 1295–1302. [Google Scholar] [CrossRef]
- Zhou, H.; Mitchell, D.G.M.; Goertz, N.; Costello, D.J., Jr. Distance spectrum estimation of LDPC convolutional codes. In Proceedings of the 2012 IEEE International Symposium on Information Theory Proceedings (ISIT), Cambridge, MA, USA, 1–6 July 2012.
- Smarandache, R.; Vontobel, P.O. Quasi-Cyclic LDPC Codes: Influence of proto- and Tanner-graph structure on minimum Hamming distance upper bounds. IEEE Trans. Inf. Theory 2012, 58, 585–607. [Google Scholar] [CrossRef]
- Tanner, R.M.; Sridhara, D.; Sridharan, A.; Fuja, T.E.; Costello, D.J., Jr. LDPC block and convolutional codes based on circulant matrices. IEEE Trans. Inf. Theory 2004, 50, 2966–2984. [Google Scholar] [CrossRef]
- Pusane, A.E.; Lentmaier, M.; Zigangirov, K.S.; Costello, D.J., Jr. Reduced complexity decoding strategies for LDPC convolutional codes. In Proceedings of the International Symposium on Information Theory, Chicago, IL, USA, 27 June–2 July 2004.
- Zhou, H.; Goertz, N. Unavoidable cycles in polynomial-based time-invariant LDPC convolutional codes. In Proceedings of the 11th European Wireless Conference on Sustainable Wireless Technologies, Vienna, Austria, 27–29 April 2011.
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).