
A New Efficient Optimal 2D Views Selection Method Based on Pivot Selection Techniques for 3D Indexing and Retrieval

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Literature
2.1. Methods with a Fixed Number of Views
2.2. Methods with a Dynamic Number of Views
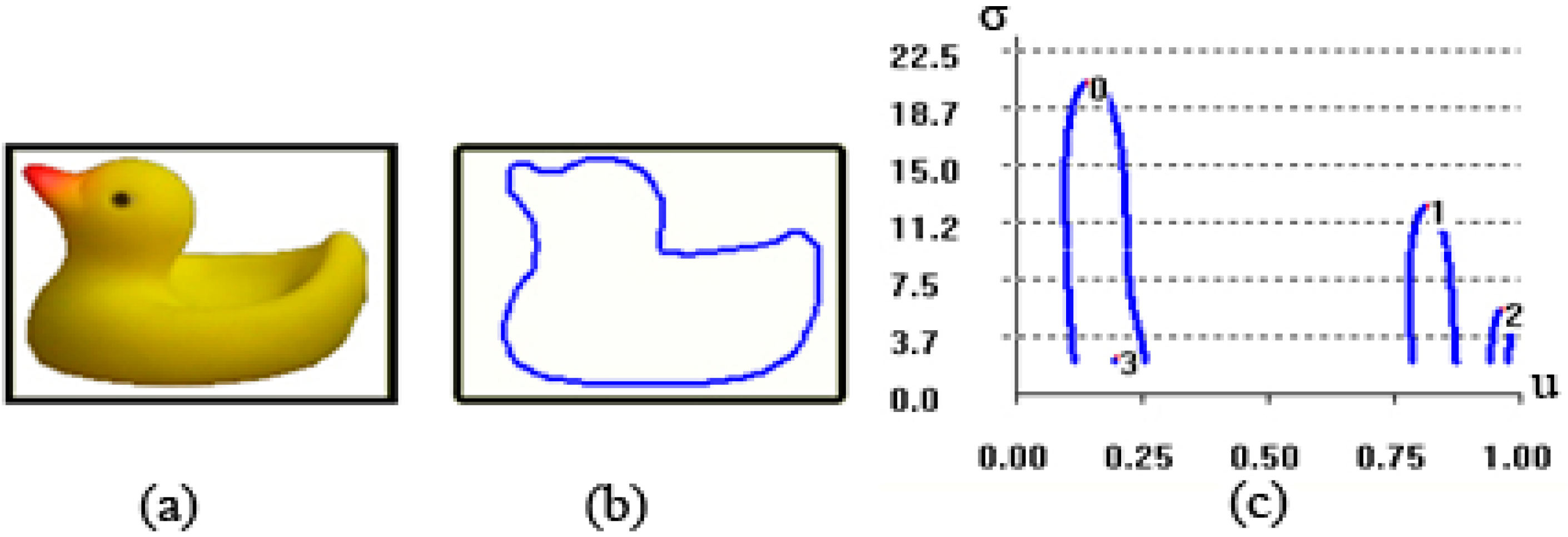
3. Proposed Method
| Algorithm 1. The proposed algorithm. |
| Input: |
| V: the set of views of 3D object |
| d: the distance metric used to compare two views |
| NP: the number of optimum views |
| Output: |
| SetPivot: set of optimum views |
| Variables: |
| setA: the set of A pairs of views used to estimates µV |
| setC: the sample N views, including the center of cluster ci // |
| Begin |
| Classify the views of V into NP clusters using a k-means clustering algorithm |
| setA = EvaluationSetA(V, d); |
| SetPivot = ∅; |
| for i: = 1 to NP do // NP present the number of clusters |
| setC = CandidatePivot(clusteri, d); // ci setC |
| bestValue = 0; |
| for (each x in setC) |
| value = getValueUv(setE, d, P ∪ x); |
| if (value is better than bestValue) |
| bestValue = value; |
| bestView = x; |
| endif |
| endfor |
| SetPivot = SetPivot ∪ bestView; |
| endfor |
| Return SetPivot; |
| End |
| Algorithm 2. The function GetValueUv. |
| Input: |
| setE: the set of A pairs of views |
| d: the distance metric used to compare two views |
| setP: the set of pivots {v1, v2, …, vk} |
| Output: |
| : the mean of the distribution |
| Begin |
|
| End |
4. Measure of Similarity
5. Experimental Results
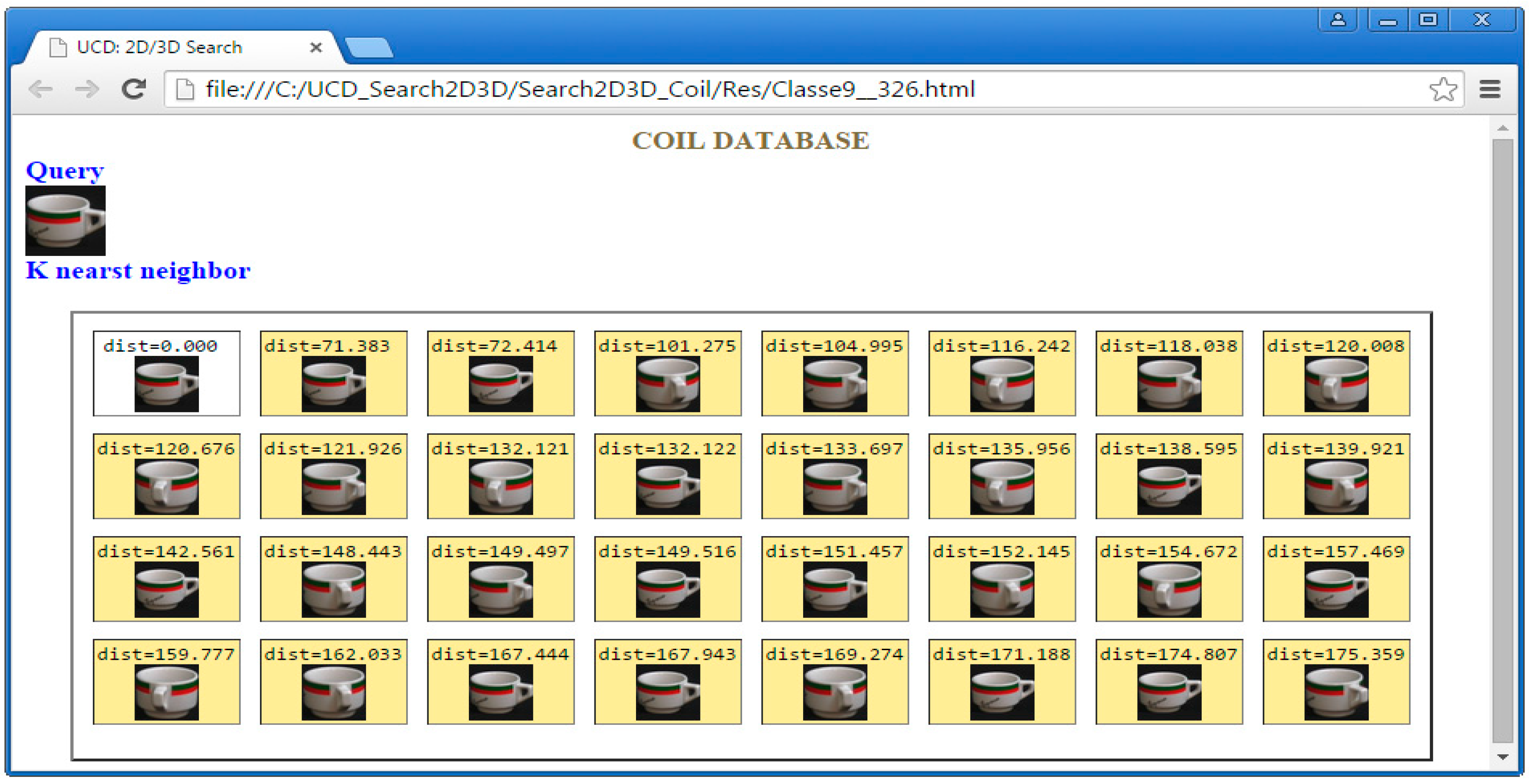
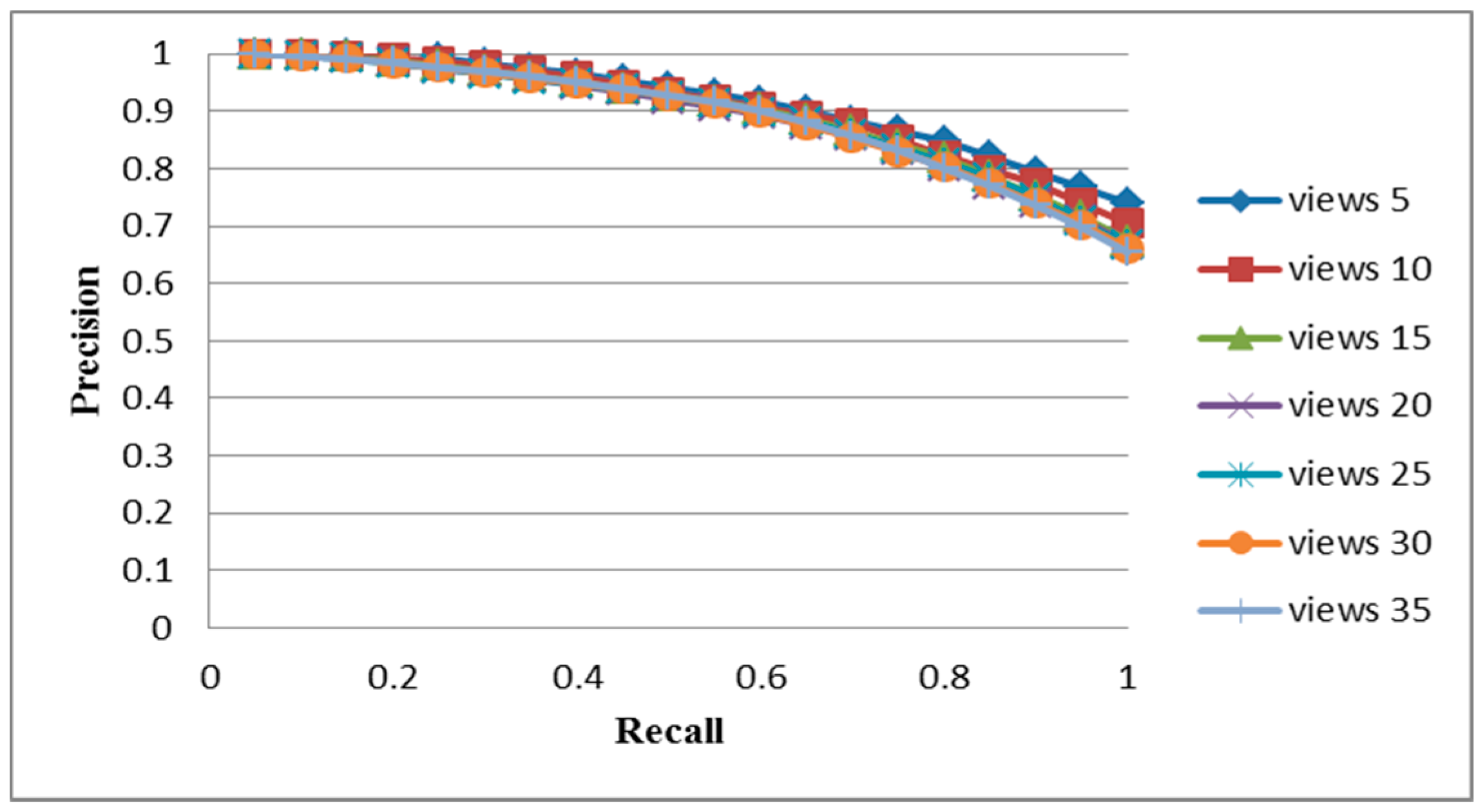
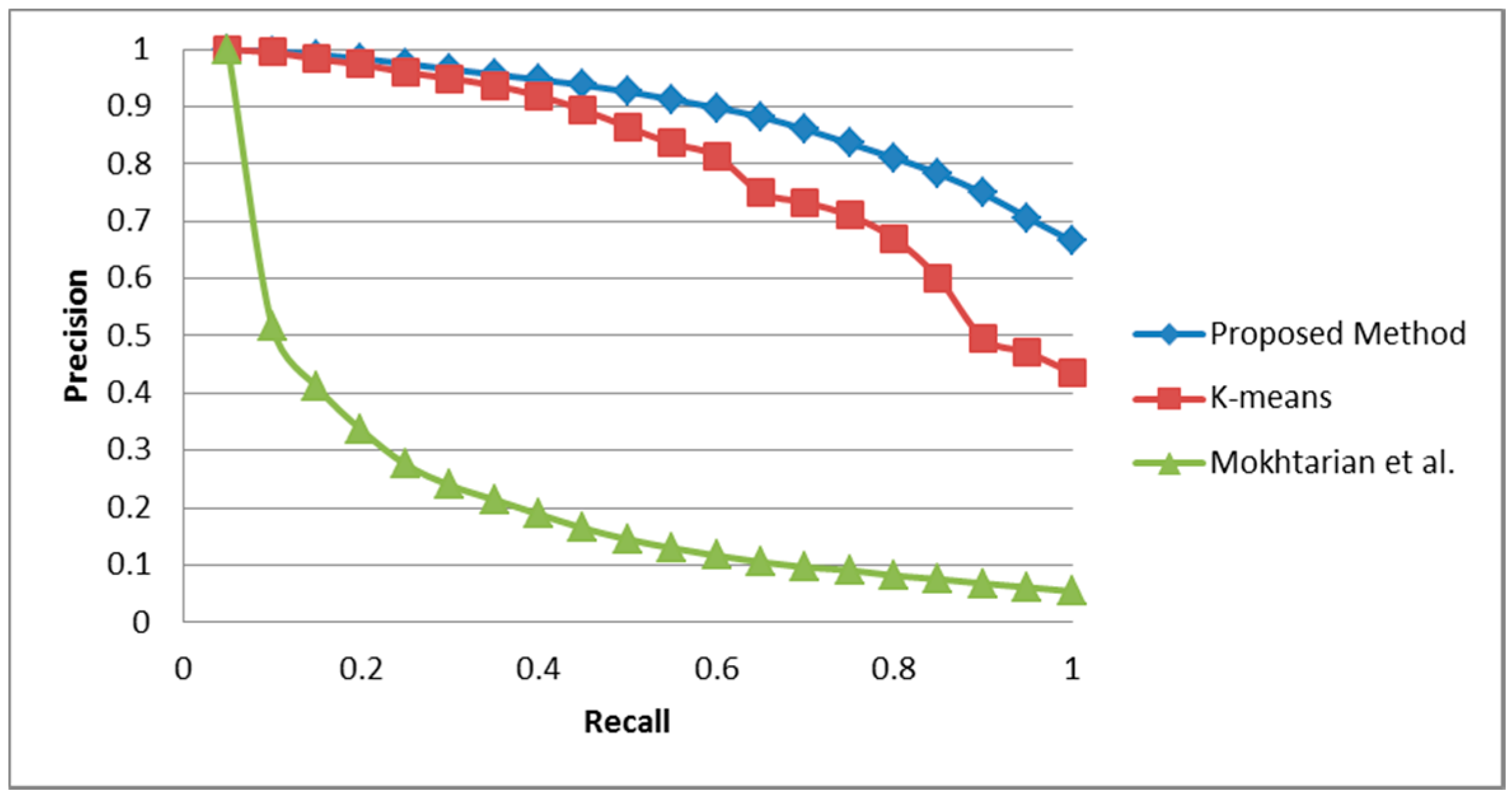
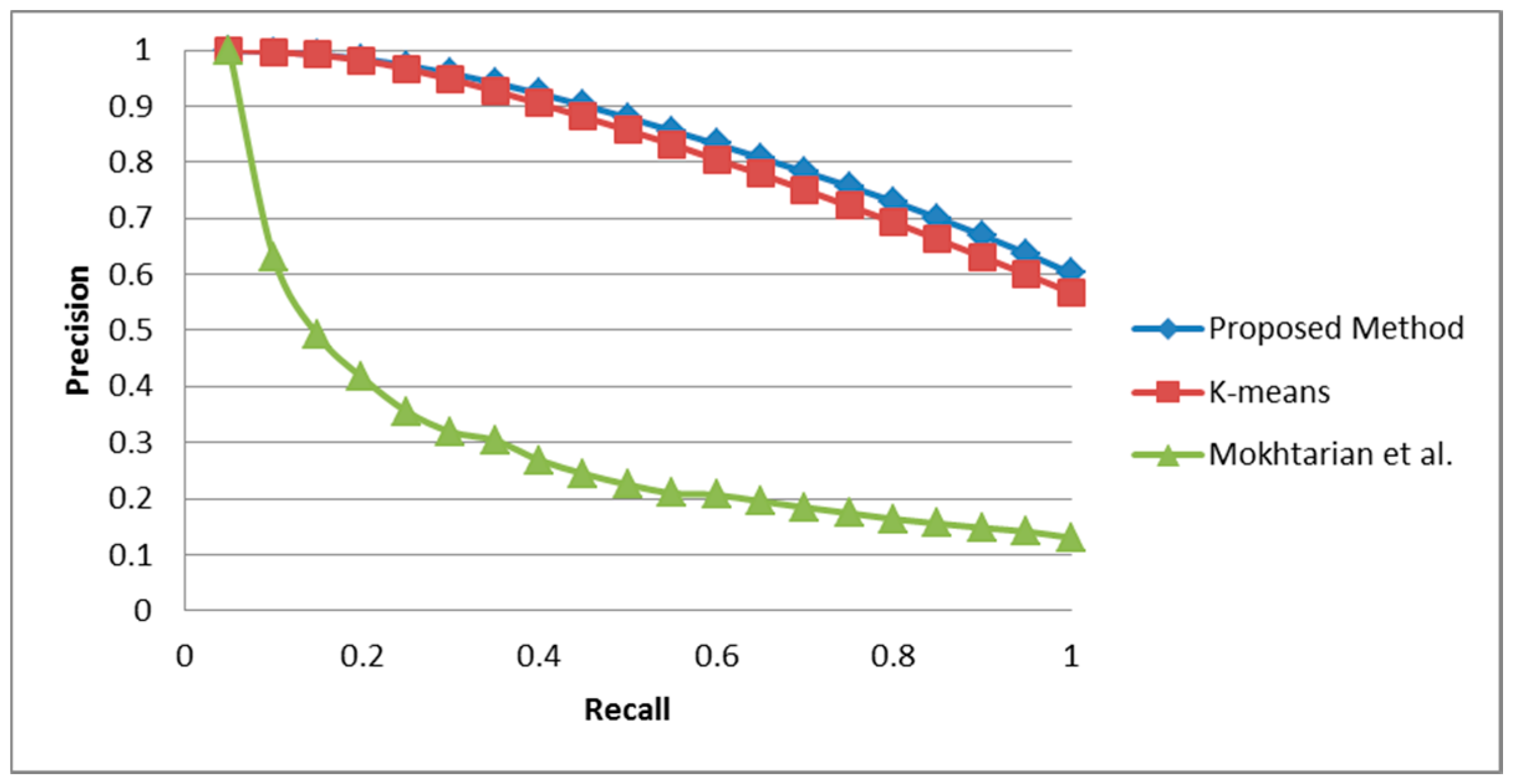
5.1. COIL-100 Database


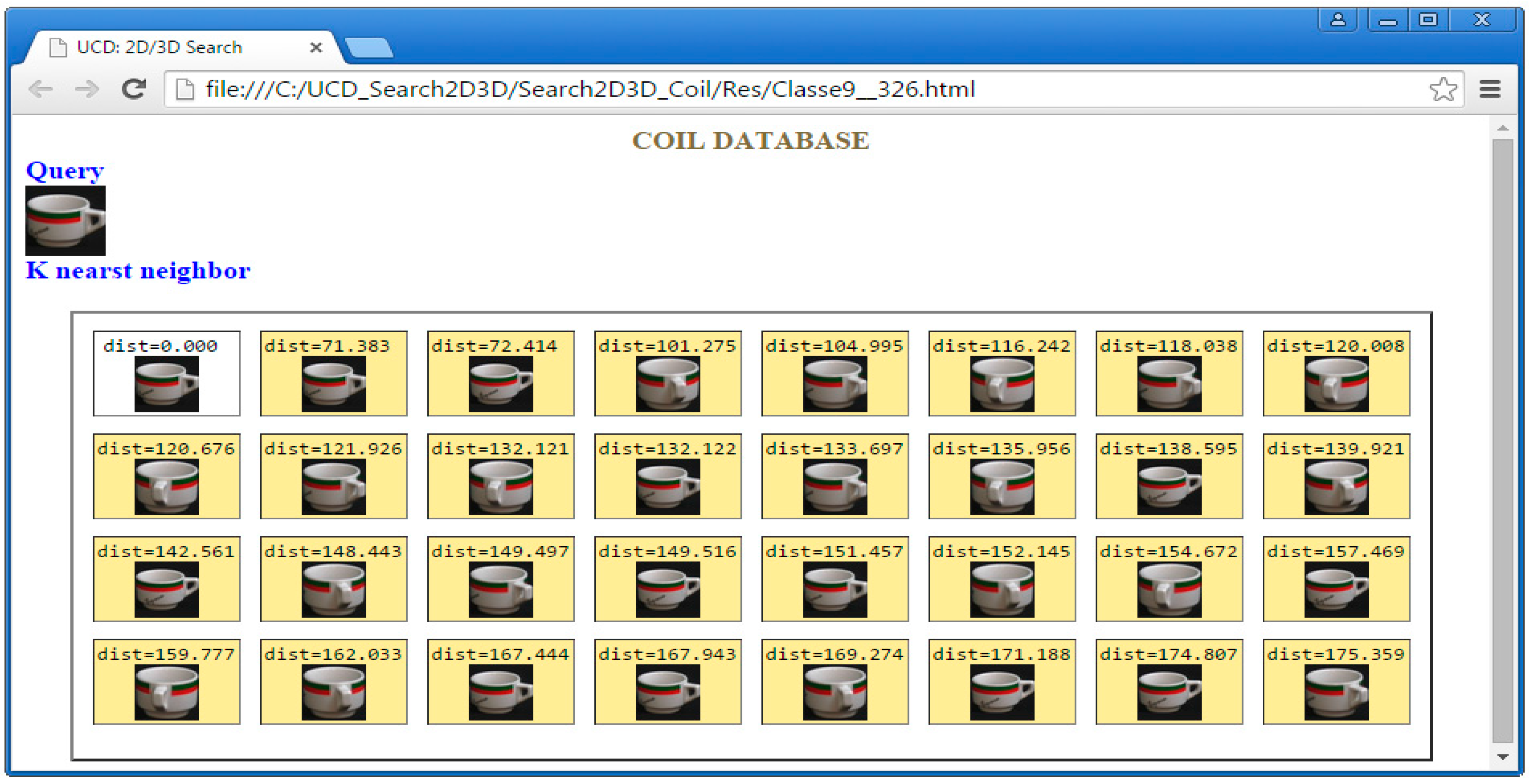
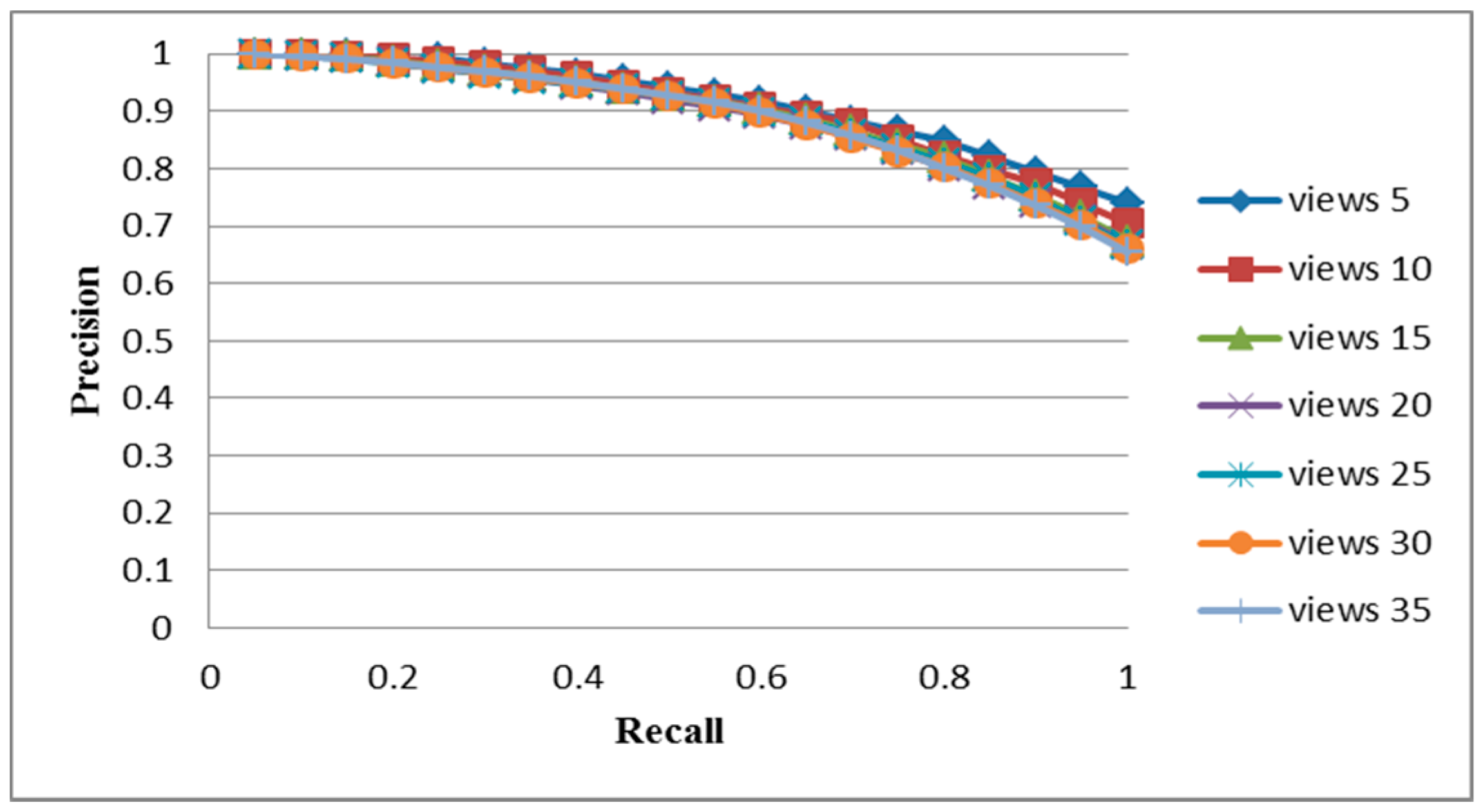
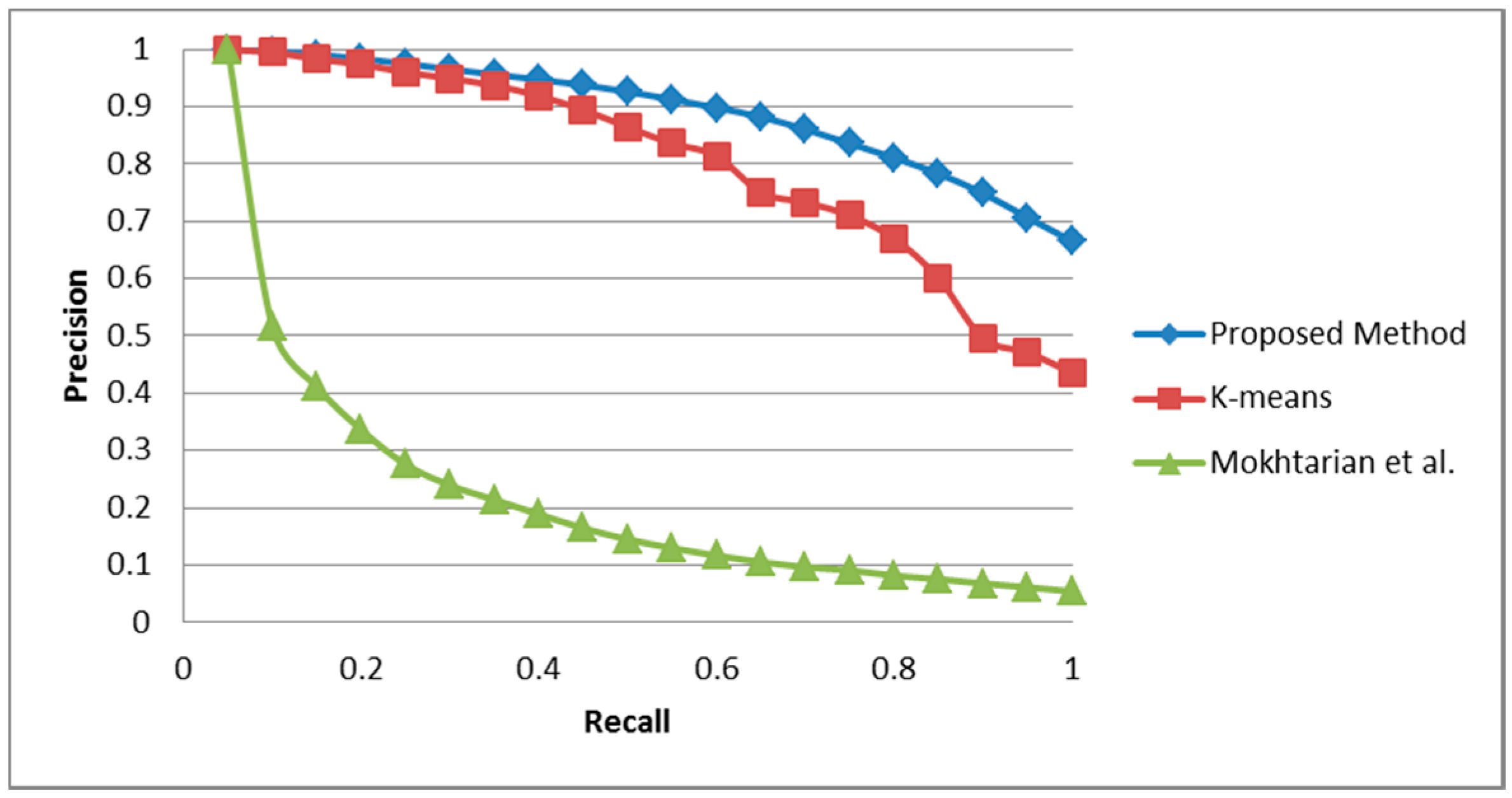
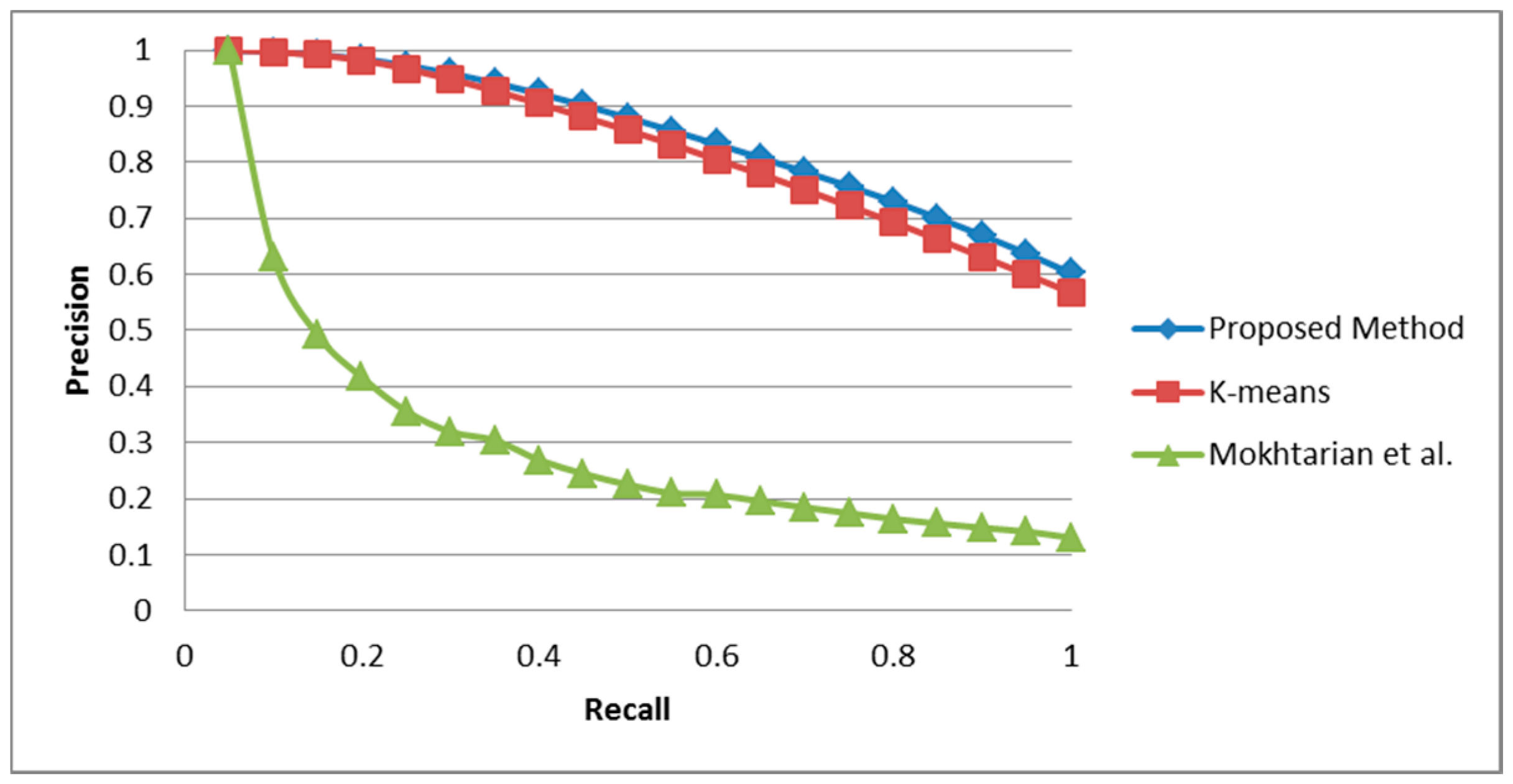
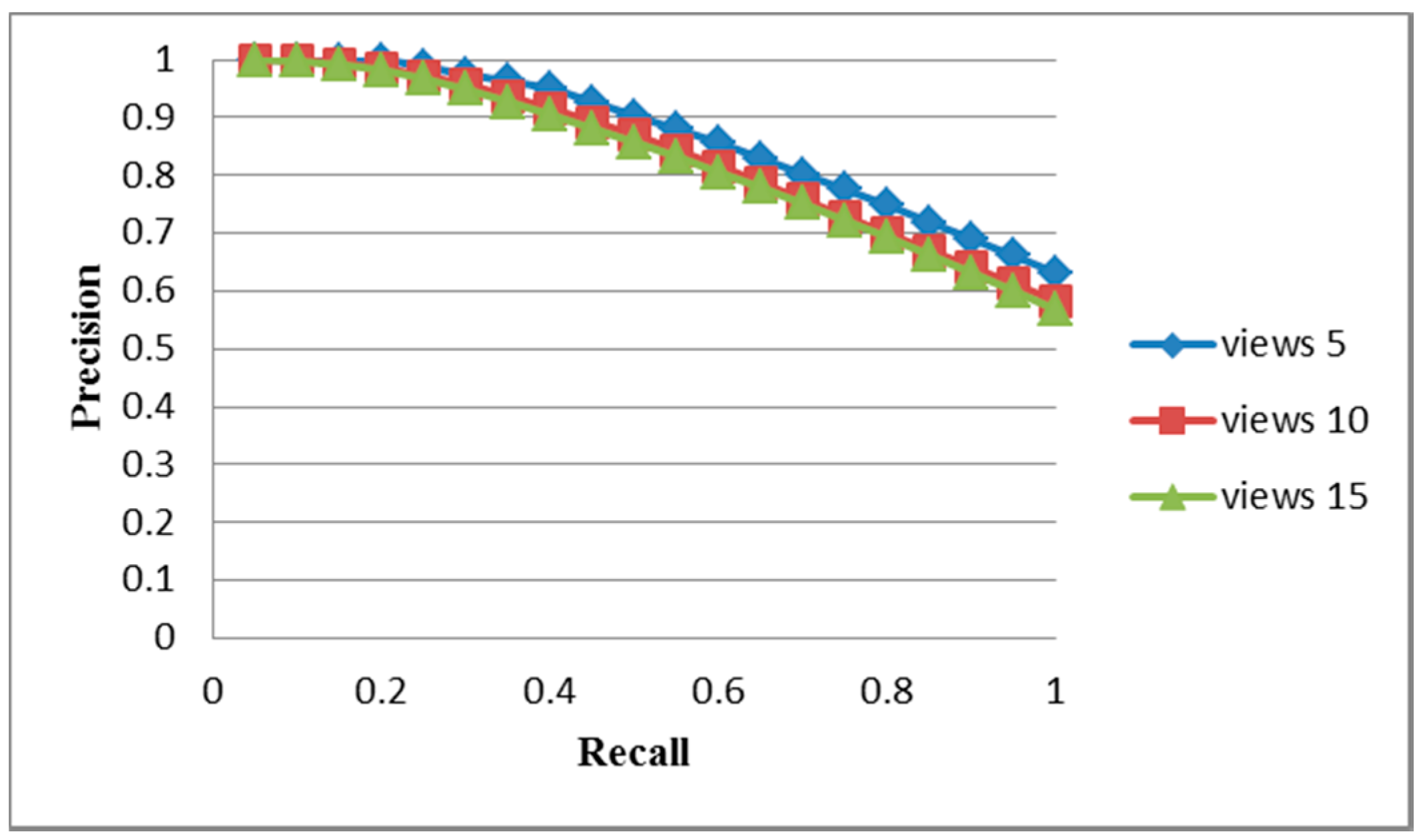
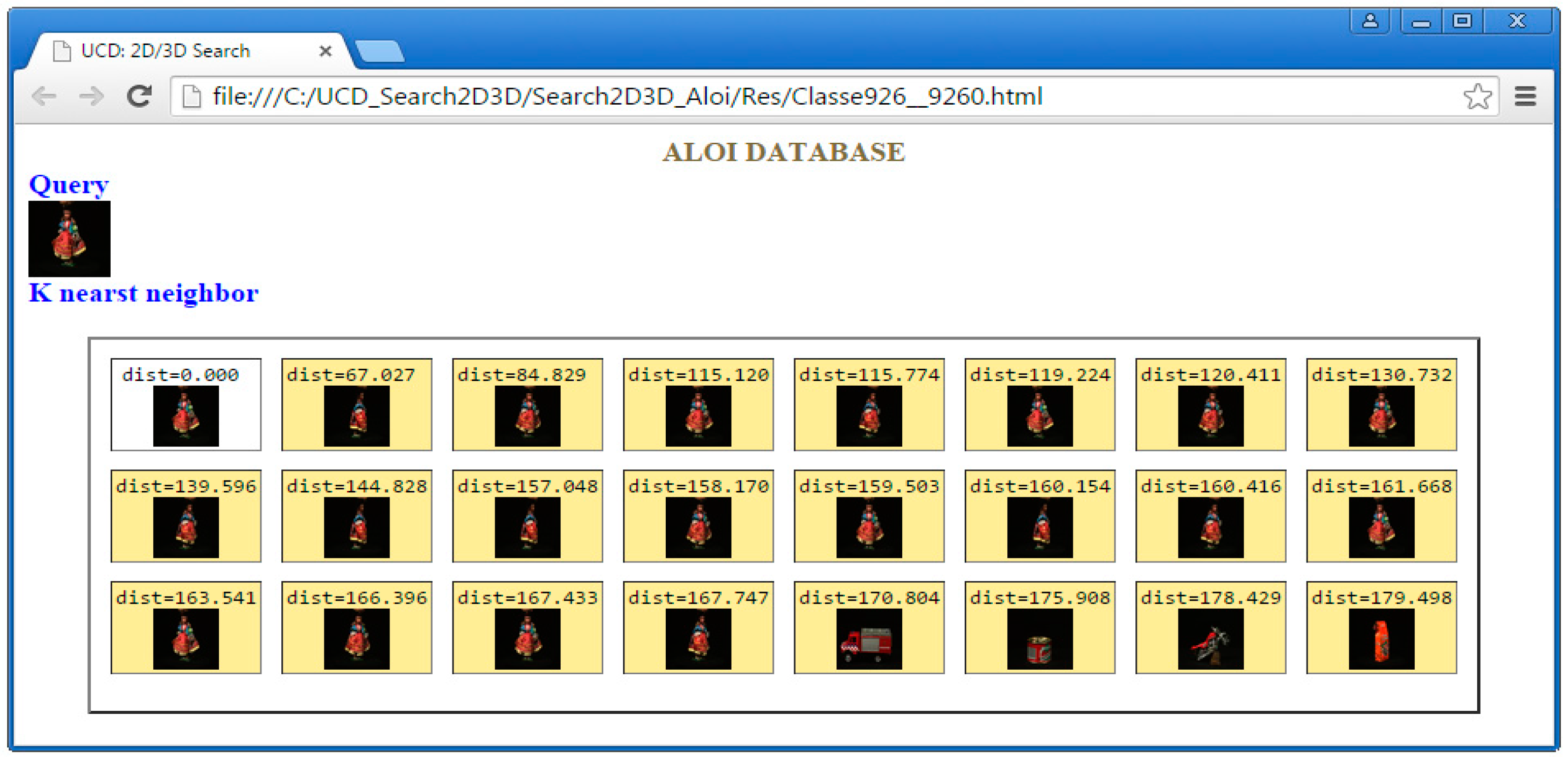
5.2. ALOI-1000 Database


6. Conclusions and Future Work
Author Contributions
Conflicts of Interest
References
- Silkan, H.; Tmiri, A.; El Alaoui Ouatik, S.; Lachkar, A. A new shape descriptor 2D for Content Based Image Retrieval. In Proceedings of the 2014 Second World Conference Complex Systems (WCCS), Agadir, Morocco, 10–12 November 2014; pp. 670–674.
- Haythem, B.; Mohamed, H.; Marwa, C.; Fatma, S.A. Fast Generalized Fourier Descriptor for object recognition of image using CUDA. In Proceedings of the 2014 World Symposium on Computer Applications & Research (WSCAR), Sousse, Tunisia, 18–20 January 2014; pp. 1–5.
- Qiuying, Y.; Ying, W. Zernike moments descriptor matching based symmetric optical flow for motion estimation and image registration. In Proceedings of the 2014 International Joint Conference on Neural Networks (IJCNN), Beijing, China, 6–11 July 2014; pp. 350–357.
- Silkan, H.; El Alaoui Ouatik, S.; Lachkar, A.; Meknassi, M. A Novel Shape Descriptor Based on Extreme Curvature Scale Space Map Approach for Efficient Shape Similarity Retrieval. In Proceedings of the 2009 Fifth International Conference on Signal-Image Technology & Internet-Based Systems (SITIS), Marrakesh, Morocco, 29 November–4 December 2009; pp. 160–163.
- Hanyf, Y.; Silkan, H.; Labani, H. Criteria and technique for choice good ρ value for D-index. In Proceedings of the International conference on Intelligent Systems and Computer Vision, Fez, Morocco, 25–26 March 2015.
- Chen, L.; Gao, Y.; Li, X.; Jensen, C.S.; Chen, G. Efficient metric indexing for similarity search. In Proceedings of the 2015 IEEE 31st International Conference on Data Engineering (ICDE), Seoul, Korea, 13–17 April 2015.
- Tosun, U. A novel indexing scheme for similarity search in metric spaces. Pattern Recognit. Lett. 2015, 54, 69–74. [Google Scholar] [CrossRef]
- Bustos, B.; Navarro, G.; Chavez, E. Pivot selection techniques for proximity searching in metric spaces. In Proceedings of the International Conference of the Chilean Computer Science Society, Punta Arenas, Chile, 7–9 November 2001; pp. 33–40.
- Mico, L.; Oncina, J.; Vidal, R. A new version of the nearest neighbor approximating and eliminating search (AESA) with linear pre-processing time and memory requirements. Pattern Recognit. Lett. 1994, 15, 9–17. [Google Scholar] [CrossRef]
- Yianilos, P. Data structures and algorithms for nearest-neighbor search in general metric spaces. In Proceedings of the 4th ACM-SIAM Symposium on Discrete Algorithms, Austin, TX, USA, 25–27 January 1993; pp. 311–321.
- Brin, S. Near neighbor search in large metric spaces. In Proceedings of the 21st Conference on Very Large Databases, Zurich, Switzerland, 11–15 September 1995; pp. 11–15.
- Karina, F.; Rodrigo, P. An Effective Permutant Selection Heuristic for Proximity Searching in Metric Spaces. In Proceedings of the 6th Mexican Conference, MCPR 2014, Cancun, Mexico, 25–28 June 2014; pp. 102–111.
- Chen, D.; Tian, X.; Shen, Y.; Ouhyoung, M. On visual similarity based 3D model retrieval. Comput. Graph. Forum 2003, 22, 223–232. [Google Scholar] [CrossRef]
- Kazhdan, M.; Funkhouser, A.S. Rusinkiewicz, Rotation invariant spherical harmonic representation of 3D shape descriptors. In Proceedings of the Eurographics Symposium on Geometry Processing, Aachen, Germany, 23–25 June 2003; pp. 156–164.
- Funkhouser, T.; Min, P.; Kazhdan, M.; Chen, J.; Halderman, A.; Dobkin, D.; Jacobs, D. A Search Engine for 3D Models. ACM Trans. Graph. 2003, 22, 83–105. [Google Scholar] [CrossRef]
- Chaouch, M.; Verroust-Blondet, A. A new descriptor for 2D depth image indexing and 3D model retrieval. In Proceedings of the IEEE International Conference on Image Processing, ICIP 2007, San Antonio, TX, USA, 16 September–19 October 2007; pp. 373–376.
- Ramezani, M.; Ebrahimnezhad, H. 3D Models’ Retrieval System Design Based on Poisson’s Histogram of 2D Selective Views. In Proceedings of the 21st Iranian Conference on Electrical Engineering (ICEE), Mashhad, Iran, 14–16 May 2013.
- Ansary, T.F.; Daoudi, M.; Vandeborre, J.P. A bayesian 3D search engine using adaptive views clustering. IEEE Trans. Multimed. 2007, 9, 78–88. [Google Scholar] [CrossRef]
- Mokhtarian, F.; Sadegh, A. Robust automatic selection of optimal views in multi-view free-form object recognition. Pattern Recognit. 2005, 38, 1021–1031. [Google Scholar] [CrossRef]
- Mokhtarian, F.; Bober, M. Curvature Scale Space Representation: Theory Application and MPEG-7 Standardization; Springer: Berlin, Germany, 2003. [Google Scholar]
- Konstantinos, S.; Theoharis, T.; Ioannis, P. ROSy+: 3D Object Pose Normalization Based on PCA and Reflective Object Symmetry with Application in 3D Object Retrieval. Int. J. Comput. Vis. 2011, 91, 262–279. [Google Scholar]
- Zezula, P.; Amato, G.; Dohnal, V.; Batko, M. Similarity Search: The Metric Space Approach (Advances in Database Systems); Springer: Berlin, Germany, 2006. [Google Scholar]
- Manjunath, B.S.; Salembier, P.; Sikora, T. (Eds.) Introduction to MPEG-7: Multimedia Content Description Interface; John Wiley & Sons, Inc.: New York, NY, USA, 2002.
- Jakub, L.; Novàk, D.; Batko, M.; Skopal, T. Visual Image Search: Feature Signatures or/and global Descriptors, similarity search and applications. In Proceedings of the 5th International Conference, SISAP 2012 Toronto, ON, Canada, 9–10 August 2012.
- Nene, S.A.; Nayar, S.K.; Murase, H. Columbia Object Image Library (COIL-100); Technical Report CUCS-006-96; Columbia University: New York, NY, USA, 1996. [Google Scholar]
- Shilane, P.; Min, P.; Kazhdan, M.; Funkhouser, T. The Princeton Shape Benchmark. In Proceedings of the International Conference on Shape Modeling and Applications (SMI'04), Genoa, Italy, 7–9 June 2004; pp. 167–178.
- MacQueen, J.B. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Berkeley, CA, USA, 21 June–18 July 1965; pp. 281–297.
- Kao, C.-C. View Based Rotation Invariant 3D Shape Retrieval. In Proceedings of the International Conference on Remote Sensing and Data (ICRSD), Hong Kong, 2–3 July 2011; pp. 150–155.
- Mathias, E.; Hildebrand, K.; Boubekeur, T.; Alexa, M. Sketch-based 3D shape retrieval. In Proceedings of the SIGGRAPH 2010 Talks, Los Angeles, CA, USA, 25–29 July 2010.
- Bober, M. MPEG-7 Visual Shape Descriptors. IEEE Trans. Circuits Syst. Video Technol. 2001, 11, 716–719. [Google Scholar] [CrossRef]
- Geusebroek, J.M.; Burghouts, G.J.; Smeulders, A.W.M. The Amsterdam library of object images. Int. J. Comput. Vis. 2005, 61, 103–112. [Google Scholar] [CrossRef]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Silkan, H.; Hanyf, Y. A New Efficient Optimal 2D Views Selection Method Based on Pivot Selection Techniques for 3D Indexing and Retrieval. Information 2015, 6, 679-692. https://doi.org/10.3390/info6040679
Silkan H, Hanyf Y. A New Efficient Optimal 2D Views Selection Method Based on Pivot Selection Techniques for 3D Indexing and Retrieval. Information. 2015; 6(4):679-692. https://doi.org/10.3390/info6040679
Chicago/Turabian StyleSilkan, Hassan, and Youssef Hanyf. 2015. "A New Efficient Optimal 2D Views Selection Method Based on Pivot Selection Techniques for 3D Indexing and Retrieval" Information 6, no. 4: 679-692. https://doi.org/10.3390/info6040679
APA StyleSilkan, H., & Hanyf, Y. (2015). A New Efficient Optimal 2D Views Selection Method Based on Pivot Selection Techniques for 3D Indexing and Retrieval. Information, 6(4), 679-692. https://doi.org/10.3390/info6040679