Abstract
This paper presents a new biometric score fusion approach in an identification system using the upper integral with respect to Sugeno’s fuzzy measure. First, the proposed method considers each individual matcher as a fuzzy set in order to handle uncertainty and imperfection in matching scores. Then, the corresponding fuzzy entropy estimates the reliability of the information provided by each biometric matcher. Next, the fuzzy densities are generated based on rank information and training accuracy. Finally, the results are aggregated using the upper fuzzy integral. Experimental results compared with other fusion methods demonstrate the good performance of the proposed approach.
1. Introduction
Biometric systems refer to the identification of human beings by their physical or behavioral traits [1]. These traits have the advantage that they are unique and permanent, unlike conventional techniques, such as passwords and badges, which can be used fraudulently by others. Depending on the application context, biometric systems can operate in two modes, namely verification and identification [2]. In the verification mode, the system validates a query biometric by comparing only the captured biometric data with the biometric template of a specific identity stored in the database. In the identification mode, the user’s biometric input is compared to the templates of all persons enrolled in the database. Therefore, the identification task is significantly more challenging than verification [3].
Biometric systems based on a single biometric trait have several inherent problems, such as large intra-class variations, sensitivity to noise and non-universality [4]. Multibiometric systems, which combine multiple sources of biometric information, have been developed in order to overcome most of those weaknesses and to achieve better recognition performance [5]. Information from different biometric traits can be integrated at the feature extraction level (integrating the features of different biometrics), matching score level (combining the genuine and imposter scores) or decision level (combining the decisions) [5]. Compared to the feature-level and decision-level fusion, the matching score-level fusion is the most popular because it offers the best compromise in terms of the information content and the ease in fusion [6].
Several fusion methods at the matching score level have been proposed in the literature. These methods can be divided into three large groups [5,6]. The first group of methods are density based: the densities of genuine and impostor matching scores are firstly estimated, and the fusion is carried out by statistical tests (e.g., the likelihood ratio test with the Gaussian mixture model [6]). The second group of methods is transformation based: the matching scores are firstly transformed to a common domain and then combined by a simple fusion rules (e.g., sum rule-based fusion preceded by min-max normalization [4]). The third group of methods is classifier based: scores from multiple matchers are concatenated into new feature vectors, which are used to train a new classifier (e.g., SVM-based fusion [7]). However, most of these fusion methods have been implicitly designed for the verification scenario and cannot be directly applied to the identification scenario [3,8]. For instance, in [3], the authors have shown that likelihood ratio-based score fusion, which has originally designed for verification systems, is applicable to multibiometric identification systems only under certain assumptions.
Generally, combining information from multiple sources can give better classification accuracy of a multibiometric system. However, researchers have shown that fusing different matching scores does not necessarily give better performance than the best individual biometric system [9,10,11]. The performance in this case is highly dependent on the imprecise, uncertain and incomplete nature of the matching scores output by biometric sources. This is due to the noise present in the sensor during the acquisition of the biometric signal and the errors made by the feature extraction and matching processes [4]. In such cases, fusion methods have to deal with imprecise and conflicting information. Fuzzy set theory [12] provides numerous methodologies for the modeling and management of uncertainty. One of these methods, which is very useful in information fusion, is the fuzzy integral. This latter one is known to be one of the most powerful and flexible nonlinear function that can capture interactions among the various sources of information [13].
The idea of using the fuzzy integral in multibiometric systems is not new. Several researchers have attempted to use the fuzzy integral in multibiometric systems [14,15,16]. However, the Choquet fuzzy integral [17] and the Sugeno fuzzy integral [18] are often used. Recently, another fuzzy integral proposed by Wang et al. [19], namely the upper integral, has been successfully applied to classifier combination in a number of contexts [20,21,22]. To the authors’ knowledge, it has never been used for multibiometric systems. Hence, we focus in our study on using the upper integral in multibiometric identification systems.
In a previous work [23], we introduced a general framework of a multibiometric identification system based on fusion at the matching score level using fuzzy set theory. The output of each biometric matcher is modeled as a fuzzy set in order to handle uncertainty and imperfection in matching scores. Then, the fuzzy entropy estimates the reliability of the information provided by each biometric matcher. However, the results are aggregated with a simple fuzzy combination rule. In this paper, we propose using the upper integral as an aggregation operator. This novel approach provides a possibility to use all matching scores received by all users enrolled in the system, unlike most fusion approaches in multibiometric identification systems. Moreover, it can clearly express the interaction among biometric matchers and provides a measure of importance for any subset of matchers.
2. Fuzzy Measure and Upper Integral
In this section, we introduce some mathematical concepts of the fuzzy measure and the upper integral that are suitable for a multibiometric identification system.
2.1. Fuzzy Measure
Let X be an arbitrary set and denote the power set of X or the set of all subsets of X. A set function is a fuzzy measure if it satisfies the following three axioms:
- (1)
- Boundary conditions: , .
- (2)
- Monotonicity: if and .
- (3)
- Continuity: if and are monotone (an increasing sequence of measurable sets).
In general, the fuzzy measure of a union of two disjoint subsets cannot be directly computed from the fuzzy measures of the subsets. Sugeno [24] has proposed the decomposable so-called λ-fuzzy measure satisfying the following additional property:
for all with and for some .
Let be a finite set, and let . The values are called the densities of the measure. The value of the constant λ can be determined from the equation , which is equivalent to solving the following equation:
2.2. Upper Integral
Let be a nonempty set, be the power set of X, be a set function denoting the fuzzy measure and be a function. The upper integral of f with respect to a set function μ, denoted by , is described as:
where is the characteristic function of set , , and if i is expressed in binary digits as for every .
When set function μ and function f are given, the value of the upper integral is the solution of the following linear programming problem [19,25], where are unknown parameters:
where for .
Note that when μ is a λ-fuzzy measure, the values of can be computed recursively as follows:
where is the binary expression of i.
3. Proposed Method
3.1. The Fusion Model Based on the Upper Integral
Let be a set of biometric matchers in the multibiometric system and N be the number of users enrolled in the system. Each of these users has his own reference model. To simplify the notation, we assume that there is only a single reference model associated with each user for each biometric modality. A way to work at the score level is the use of a score matrix that contains the matching scores output by each biometric matchers. Let denote the generic matching score output by the k-th biometric matcher for the n-th user in the database, ; . For a given query, all outputs of biometric matchers can be organized in the score matrix S defined as:
According to [23], the output of each biometric matcher can be modeled as a fuzzy set using membership functions. Therefore, we can rewrite the score matrix S in the following way:
where is the fuzzy membership function of the k-th biometric matcher. The membership value varies from zero to one, where the case that shows absolute certainty that the identity of the user is n, from the standpoint of the k-th biometric matcher, while implies absolute certainty that the identity of the user is not n. In this study, each biometric matcher is represented by a piecewise-linear membership function defined as:
where a and d are the minimum and the maximum value of the impostor score distributions, respectively, b and e are the minimum and the maximum value of the genuine score distributions, respectively, and . The values of these parameters are learned using a training dataset for each biometric matcher.
When a biometric matcher provides a reliable result, the fuzzy set will be close to a binary set. On the contrary, when is unreliable, no opportunity should be significantly higher than the others. The fuzzy entropy of this fuzzy set is given by [26]:
where and Q is a normalizing constant. In terms of fuzzy entropy, the set constructed with a reliable biometric matcher will have a low degree contrary to a set constructed with an unreliable biometric matcher. Thus:
is interpreted as the degree in which biometric matcher identifies the identity of the user correctly. Then, each fuzzy set will be weighted by , and we can rewrite the score matrix S in the following way:
when a biometric matcher has a low uncertainty, is close to one, and it only slightly affects the corresponding fuzzy set.
Each column of the new score matrix S can be regarded as a function defined on the set X, , , , . Thus, if we know the fuzzy densities, according to Equation (3), we can compute the integral value of each column of the new matrix S, and the subscript of the maximum of all integral value is the final identity. The next task is to determine the fuzzy densities.
3.2. Determining Fuzzy Densities
Besides the fusion technique, the critical issue in the fuzzy integral is how to determine the most appropriate fuzzy densities. Various methods have been developed to determine the fuzzy densities to a given problem [27,28,29,30,31,32]. However, many of these methods are based on accuracy or on both accuracy and uncertainty. In this work, we propose a new method for determining fuzzy densities using the training accuracy and dynamic information provided by each biometric matcher.
When a multibiometric system operates in the identification mode, the matching scores of each biometric matcher are arranged in descending order to form the ranking list in order to determine potential matching identities (a lower rank indicating a better match). Let be the rank output by the k-th matcher for the n-th template in the database, ; . For a given query, we have also the rank matrix R defined as:
The fuzzy densities that we propose are based on the training accuracy and rank information as follows:
where is the training accuracy of the k-th biometric matcher. In this method, the fuzzy densities might be different for each user enrolled in the system and are also specific for the current query.
4. Experimental Results
We evaluated the performance of our method on the publicly-available benchmark database for score level fusion BSSR1 distributed by NIST (referenced as NIST-BSSR1 in the paper) [33]. This database contains three different partitions. The first partition is the NIST-Multimodal database, which contains two face scores and two fingerprint scores from 517 subjects. The second partition is the NIST-Fingerprint database, which contains two fingerprint scores from 6000 subjects. Finally, the third partition is the NIST-Face database, which contains two face scores from 3000 subjects. The face scores are generated by two commercial systems, which are labeled as Matcher C and Matcher G. One fingerprint score is obtained by comparing a pair of images of the left index finger, and another score is obtained by comparing a pair of images of the right index finger. For this database, there is no experimental protocol defined. In the experimental process, half of the imposter and the genuine scores are randomly selected to be in the training set to estimate the training accuracy and the parameters of the fuzzy membership functions. The remaining half of the scores is used to evaluate the fusion performance. The above training test partitioning is repeated 20 times, and the reported cumulative match characteristic (CMC) curves correspond to the mean identification rates over the 20 trials. In the identification system, the CMC is widely used as an accuracy performance measure. The CMC shows the ratio of correct identification versus the matching rank.
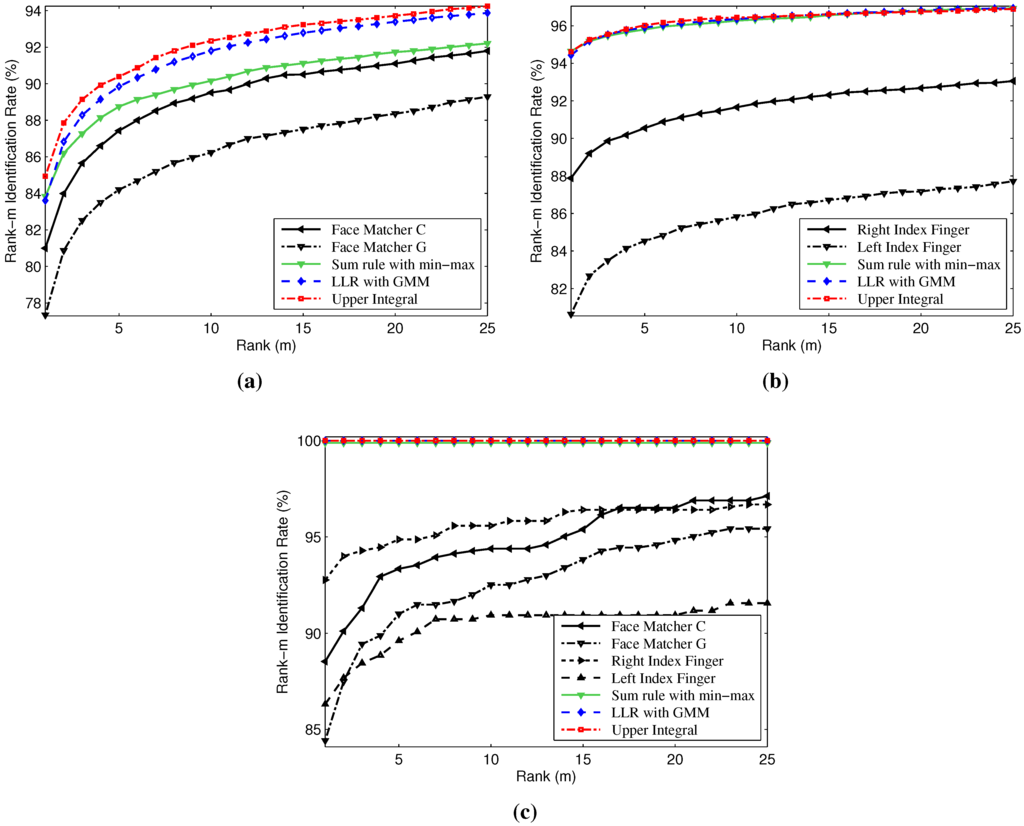
Figure 1.
Cumulative match characteristic curves of the proposed method, individual matchers and other biometric score fusion methods on the (a) NIST-Face, (b) NIST-Fingerprint and (c) NIST-Multimodal databases.
The goal of the multibiometric system is to increase precision and enhance reliability more than individual matchers. In order to demonstrate the effectiveness of our proposed method, Figure 1 shows the CMC curves of the individual matchers and the proposed method on the three partitions of the NIST-BSSR1 database. These results clearly show that our method provides a significantly better recognition rate than the individual matchers on all databases. The improvement of the rank-1 accuracy is approximately 3.88%, 6.62% and 7.24% compared to the best single matcher of the NIST-Face, NIST-Fingerprint and NIST-Multimodal databases, respectively.
In order to evaluate the efficiency of the proposed method, comparisons are made against well-established existing biometric score fusion methods, like the sum rule with min-max normalization method [4] and the likelihood ratio-based fusion with the Gaussian mixture model (LLR-GMM) [6]. Figure 1 shows also the CMC curves of these methods for the three partitions of the NIST-BSSR1 database. We can see from this figure that the recognition rates of sum rule and LLR-GMM fusion methods are comparable to our method on the NIST-Fingerprint and NIST-Multimodal databases (see Figure 1b,c), but they are inferior to our method on the NIST-Face database (see Figure 1a).
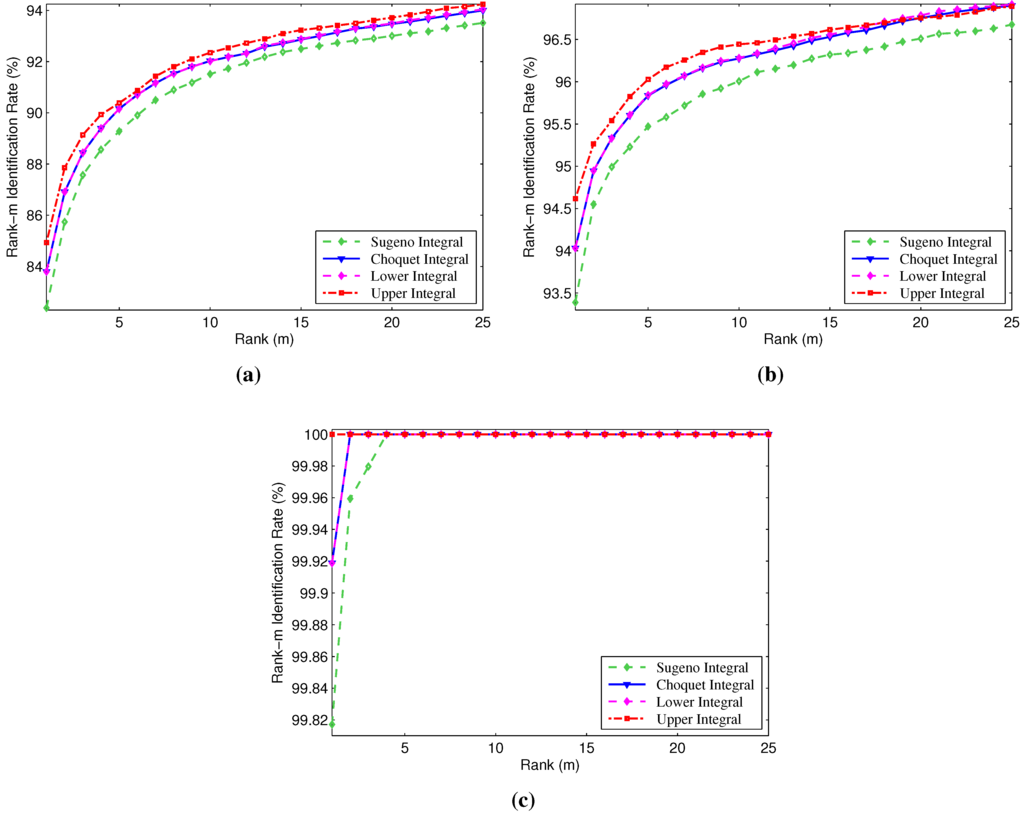
Figure 2.
Cumulative match characteristic curves of the proposed method and other fuzzy integrals on the (a) NIST-Face, (b) NIST-Fingerprint and (c) NIST-Multimodal databases.
We also compared the performance of the proposed method with other fuzzy integrals, such as the Choquet integral [17], the Sugeno integral [18] and the lower integral [19], on the three partitions of the NIST-BSSR1 database. We note that for these fuzzy integrals, we utilize the same fusion technique as used in our method. From Figure 2, we notice that the proposed method outperforms slightly all other fuzzy integral fusion methods on all databases.
5. Conclusions
In this paper, we have proposed a new biometric score fusion method based on the upper integral with respect to Sugeno’s fuzzy measure in an identification model. In order to prove the efficiency of our fusion approach, we have used a publicly-available benchmark database for the biometric score fusion problem. Experimental results exhibit that our fusion approach achieves better performance than the best single matcher and other fusion methods.
Author Contributions
All of the authors are responsible for the concept of the paper, the results presented and the writing. The final manuscript was approved by all authors.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Jain, A.K.; Flynn, P.; Ross, A. Handbook of Biometrics; Springer: Berlin, Germany, 2008. [Google Scholar]
- Jain, A.K.; Ross, A.; Prabhakar, S. An introduction to biometric recognition. IEEE Trans. Circuits Syst. Video Technol. 2004, 14, 4–20. [Google Scholar] [CrossRef]
- Nandakumar, K.; Jain, A.K.; Ross, A. Fusion in Multibiometric Identification Systems: What about the Missing Data? In Advances in Biometrics, Proceedings of the Third International Conference, ICB 2009, Alghero, Italy, 2–5 June 2009; Tistarelli, M., Nixon, M.S., Eds.; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2009; Volume 5558, pp. 743–752. [Google Scholar]
- Jain, A.K.; Nandakumar, K.; Ross, A. Score normalization in multimodal biometric systems. Pattern Recognit. 2005, 38, 2270–2285. [Google Scholar] [CrossRef]
- Ross, A.; Nandakumar, K.; Jain, A.K. Handbook of Multibiometrics; Springer: Secaucus, NJ, USA, 2006. [Google Scholar]
- Nandakumar, K.; Chen, Y.; Dass, S.C.; Jain, A.K. Likelihood Ratio Based Biometric Score Fusion. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 2, 342–347. [Google Scholar] [CrossRef] [PubMed]
- Liau, H.F.; Isa, D. Feature selection for support vector machine-based face-iris multimodal biometric system. Expert Syst. Appl. 2011, 38, 11105–11111. [Google Scholar] [CrossRef]
- Tulyakov, S.; Chaohong, W.; Govindaraju, V. Iterative Methods for Searching Optimal Classifier Combination Function. In Proceedings of the 2007 First IEEE International Conference on Biometrics: Theory, Applications, and Systems, Crystal City, VA, USA, 27–29 September 2007; pp. 1–5.
- Yishu, L.; Lihua, Y.; Suen, C.Y. The Effect of Correlation and Performances of Base-Experts on Score Fusion. IEEE Transac. Syst. Man Cybern. Syst. 2014, 44, 510–517. [Google Scholar]
- Daugman, J. Biometric Decision Landscapes; Tech. Rep. TR482; Computer Laboratory, University of Cambridge: Cambridge, MA, USA, 2000. [Google Scholar]
- Vatsa, M.; Singh, R.; Noore, A.; Houck, M. Quality-augmented fusion of level-2 and level-3 fingerprint information using DSm theory. Int. J. Approx. Reason. 2009, 50, 51–61. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 3, 338–353. [Google Scholar] [CrossRef]
- Temkoa, A.; Machob, D.; Nadeua, C. Fuzzy integral based information fusion for classification of highly confusable non-speech sounds. Pattern Recognit. 2008, 41, 1814–1823. [Google Scholar] [CrossRef]
- Pham, T.; Wagner, M. Similarity normalization for speaker verification by fuzzy fusion. Pattern Recognit. 2000, 33, 309–315. [Google Scholar] [CrossRef]
- Kwak, K.-C.; Pedrycz, W. Face recognition: A study in information fusion using fuzzy integral. Pattern Recognit. Lett. 2005, 26, 719–733. [Google Scholar] [CrossRef]
- Khalifa, A.B.; Gazzah, S.; BenAmara, N.E. Multimodal Biometric Authentication Using Choquet Integral and Genetic Algorithm. Int. J. Comput. Inf. Sci. Eng. 2013, 7, 976–986. [Google Scholar]
- Murofushi, T.; Sugeno, M.; Machida, M. Non-monotonic fuzzy measures and the Choquet integral. Fuzzy Sets Syst. 1994, 64, 73–86. [Google Scholar] [CrossRef]
- Sugeno, M. Theory of Fuzzy Integral and Its Applications. Ph.D. Thesis, Tokyo Institute of Technology, Tokyo, Japan, 1974. [Google Scholar]
- Wang, Z.; Li, W.; Leung, K.-S. Lower integrals and upper integrals with respect to nonadditive set functions. Fuzzy Sets Syst. 2008, 159, 646–660. [Google Scholar] [CrossRef]
- Chen, A.-X.; Liang, Z.-Y.; Feng, H.-M. Classification based on upper integral. In Proceedings of the 2011 International Conference on Machine Learning and Cybernetics (ICMLC), Guilin, China, 10–13 July 2011; pp. 835–840.
- Wang, X.-Z.; Wang, R.; Feng, H.-M.; Wang, H.-C. A New Approach to Classifier Fusion Based on Upper Integral. IEEE Transac. Cybern. 2014, 44, 620–635. [Google Scholar] [CrossRef] [PubMed]
- Feng, H.-M.; Wang, X.-Z. Performance improvement of classifier fusion for batch samples based on upper integral. Neural Netw. 2015, 63, 87–93. [Google Scholar] [CrossRef] [PubMed]
- Fakhar, K.; El Aroussi, M.; Saidi, M.N.; Aboutajdine, D. Score Fusion in Multibiometric Identification Based on Fuzzy Set Theory. In Image and Signal Processing; Elmoataz, A., Mammass, D., Lezoray, O., Nouboud, F., Aboutajdine, D., Eds.; Springer: Heidelberg, Germany, 2012; Volume 7340, pp. 261–268. [Google Scholar]
- Sugeno, M. Fuzzy measures and fuzzzy integrals: A survey. Fuzzy Autom. Decis. Process. 1977. [Google Scholar] [CrossRef]
- Wang, Z.; Leung, K.-S.; Wong, M.-L.; Fang, J. A new type of nonlinear integrals and the computational algorithm. Fuzzy Sets Syst. 2000, 112, 223–231. [Google Scholar] [CrossRef]
- De Luca, A.; Termini, S. A definition of a nonprobalistic entropy in the setting of fuzzy entropy. Inform. Control 1972, 20, 301–312. [Google Scholar] [CrossRef]
- Wang, Z.; Leung, K.-S.; Wang, J. A genetic algorithm for determining nonadditive set functions in information fusion. Fuzzy Sets Syst. 1999, 102, 463–469. [Google Scholar] [CrossRef]
- Pham, T.D.; Hong, Y. Information fusion by fuzzy integral. In Proceedings of the 1996 Australian and New Zealand Conference on Intelligent Information Systems, Adelaide, Australia, 18–20 November 1996; pp. 191–194.
- Liu, Y.; Li, X.; Zhuang, Z. Decision-level Information Fusion for Target Recognition Based on Choquet Fuzzy Integral. J. Electron. Inf. Technol. 2003, 25, 695–699. [Google Scholar]
- Murofushi, T.; Sugeno, M. An interpretation of fuzzy measures and the Choquet integral as an integral with respect to a fuzzy measure. Fuzzy Sets Syst. 1989, 29, 201–227. [Google Scholar] [CrossRef]
- Gader, P.D.; Mohamed, M.A.; Keller, J.M. Fusion of handwritten word classifiers. Pattern Recognit. Lett. 1996, 17, 577–584. [Google Scholar] [CrossRef]
- Wang, X.-Z.; Wang, X.-J. A new methodology for determining fuzzy densities in the fusion model based on fuzzy integral. In Proceedings of the 2004 International Conference on Machine Learning and Cybernetics, Shanghai, China, 26–29 August 2004; Volume 4, pp. 2028–2031.
- National Institute of Standards and Technology: NIST Biometric Scores Set, 2004. Available online: http://www.nist.gov/itl/iad/ig/biometricscores.cfm (accessed on 9 June 2015).
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).