1. Introduction
Urbanization promotes not only economic development but also people’s living style; meanwhile, it is associated with problems such as traffic jams. In recent years, a large amount of track data, such as taxi trajectory data, can be obtained with the development of mobile devices. Taxi trajectory data is used to improve taxi cruising planning [
1] and analyze the city area that people are interested in [
2]. In this paper, we use taxi trajectory data to obtain the hot traveling spots of urban residents, and try to help taxi drivers to find out the optimal path to the nearby hotspots where they can pick up a passenger. This paper adopts an improved clustering algorithm GADBSCAN to generate the hot spots subsequent to preprocessing of the taxi trajectory data. Then, we find out the potential trajectories between hotspots using start-end point based similar trajectory method and the density based epsilon distance clustering algorithm. Finally, in order to obtain the optimal route, we define a weighted tree to evaluate the potential trajectory with such factors as driving time, velocity distance and attractiveness of hot spot for loading passengers.
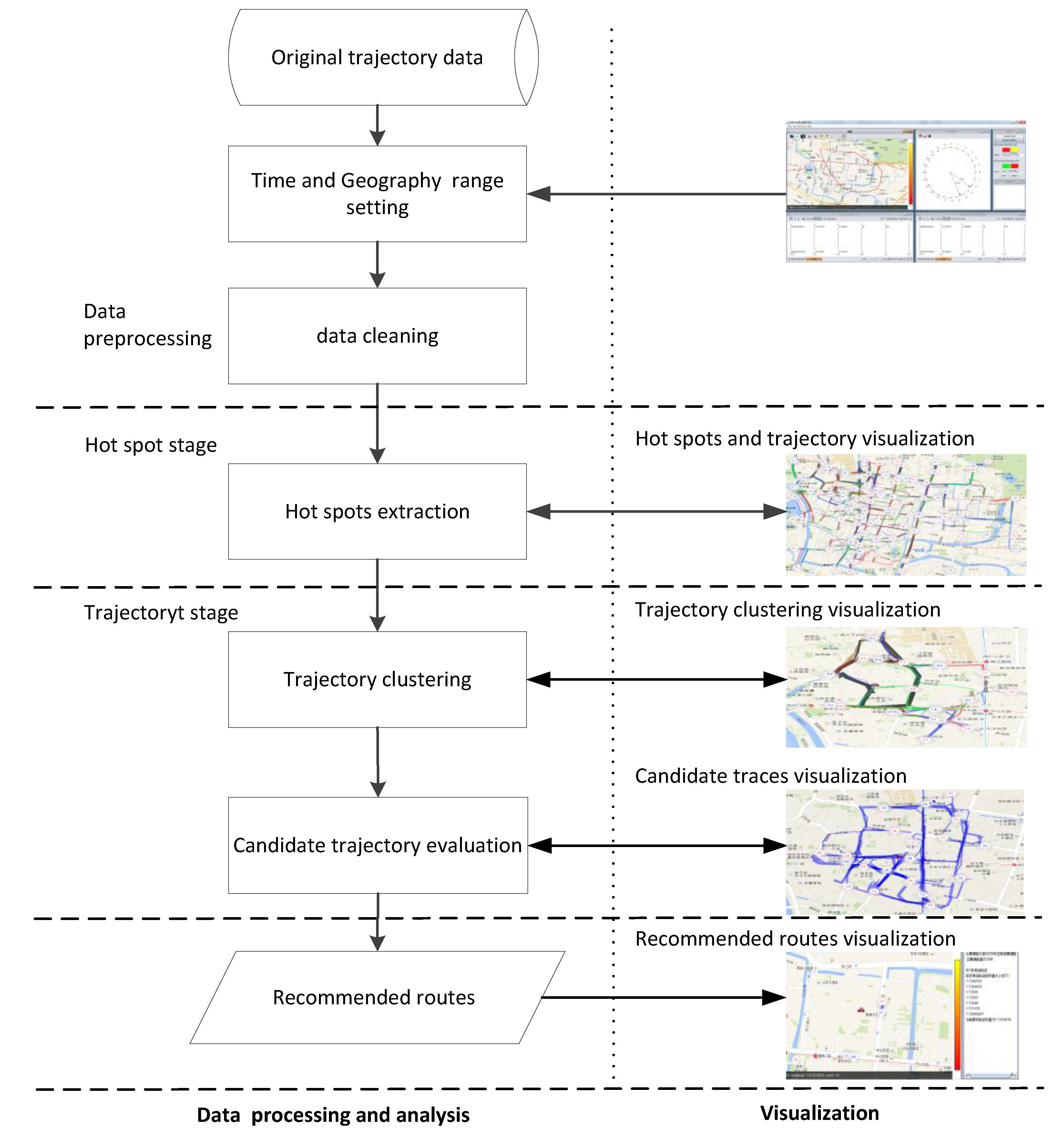
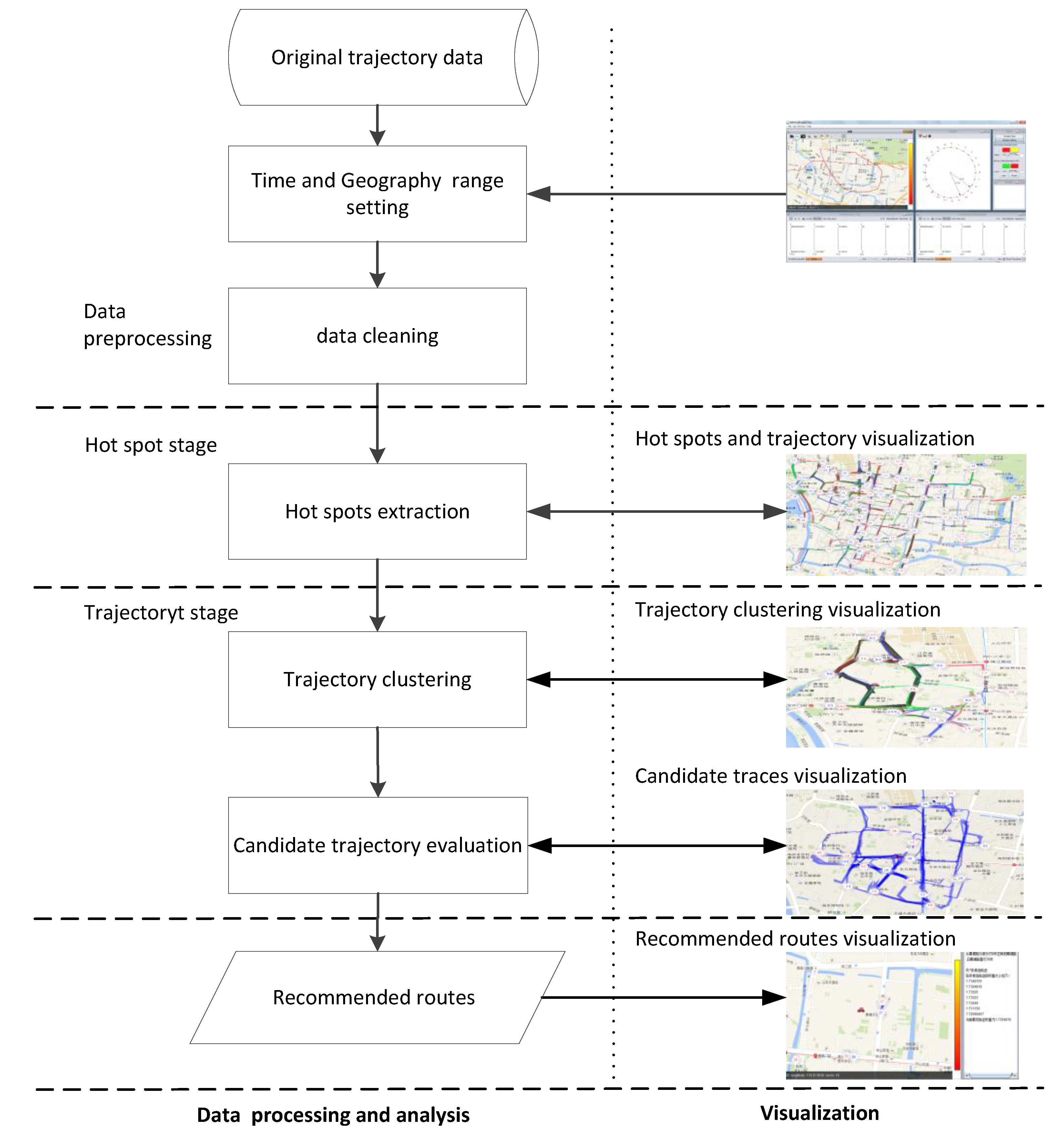
Figure 1 shows the workflow framework of this method.
Figure 1.
The workflow framework.
As regards to the rest of this paper,
Section 2 introduces the related work;
Section 3 describes the preprocessing of trajectory data;
Section 4 presents the hotspots’ extraction method;
Section 5 demonstrates the trajectory clustering algorithm, while
Section 6 shows the approach to evaluating the potential recommended routes for drivers, and presents recommended results using an example with visualization. In the end,
Section 7 presents conclusions and prospects.
4. Hot Spot Extraction
The DBSCAN algorithm [
22] can discover density-based clusters with an arbitrary shape in a noise spatial database, which takes a cluster as the max density-reachable point set. DBSCAN with proper parameters has greater advantage in dealing with outliers and noises than pure partition-based clustering or hierarchical clustering [
23]. However, it works poorly in areas with sparse vacancy or occupied events. The taxi GPS data set is typically a noisy space data with different sizes and shapes [
24], which is particularly suited for DBSCAN. Since DBSCAN is sensitive with parameters [
11], this paper improves it by the idea of grid partition [
2] and introduces average density threshold to adaptively select parameters for clusters in each grid. The algorithm to generate hotspots is called GADBSCAN.
Definition 1: A passenger-loading (unloading) point set STr is a set containing all the points meeting the vacant (occupied) event in trajectory.
Definition 2: For a loading(unloading) point Tri, its Δ-neighborhood NΔ(Tri) is defined as a point set satisfying the situation that the distance between each point in the set t and Tri is no more than Δ.
Definition 3: For a passenger loading (unloading) guest point set
STr, the average density threshold, which is denoted as
avgMinPts, is calculated by summing element number in the Δ-neighborhood of each point, and dividing with count of
STr, as Equation (3).
Definition 4: A loading (unloading) hot spot set HSTr is a non-empty subset of loading (unloading) point STr, and each point pair is density-reachable or density-connect with respect to NΔ(Tri) and avgMinPts, which is output by typical DBSCAN algorithm.
With the above definitions, a Grid Adaptive DBSCAN (GADBSCAN) algorithm is designed to make DBSCAN fit for Taxi trajectory. Its critical parameters are radius
d and density threshold
MinPts, and
d is a distance used to delimiting the neighborhood while
MinPts is a density measure that indicates the amount of points needed in a neighborhood of the point in order to assign the point and its neighbors to a cluster
. The algorithm is described as follows:
| Algorithm: GADBSCAN |
| Input: area A, STr, the minimum area radius d, density threshold MinPts |
| Output: Hot Spot Set HSTr |
| 1: Subdivides A into small grids gs as each one is 1 km × 1 km, set HSTr for each grid empty |
| 2: Subdivides STr by allocated each point in its specific grid, get {STr, gs[i][j]|each point in STr, gs[i][j] |
| located in grid gs[i][j]} |
| 3: FOR each subdivides STr, gs[i][j] of STr |
| 4: calculate averMinPtsgs |
| 5: IF (averMinPtsgs ≤ MinPts) |
| 6: HSTr, gs[i][j]. add (DBSCAN(gs, d, averMinPtsgs)) |
| 7: ELSE HSTr, gs[i][j] add (DBSCAN(gs, d, MinPts)) |
| 8: Joins density-connected clusters in adjacent grids to assemble all the subdivision to get HST |
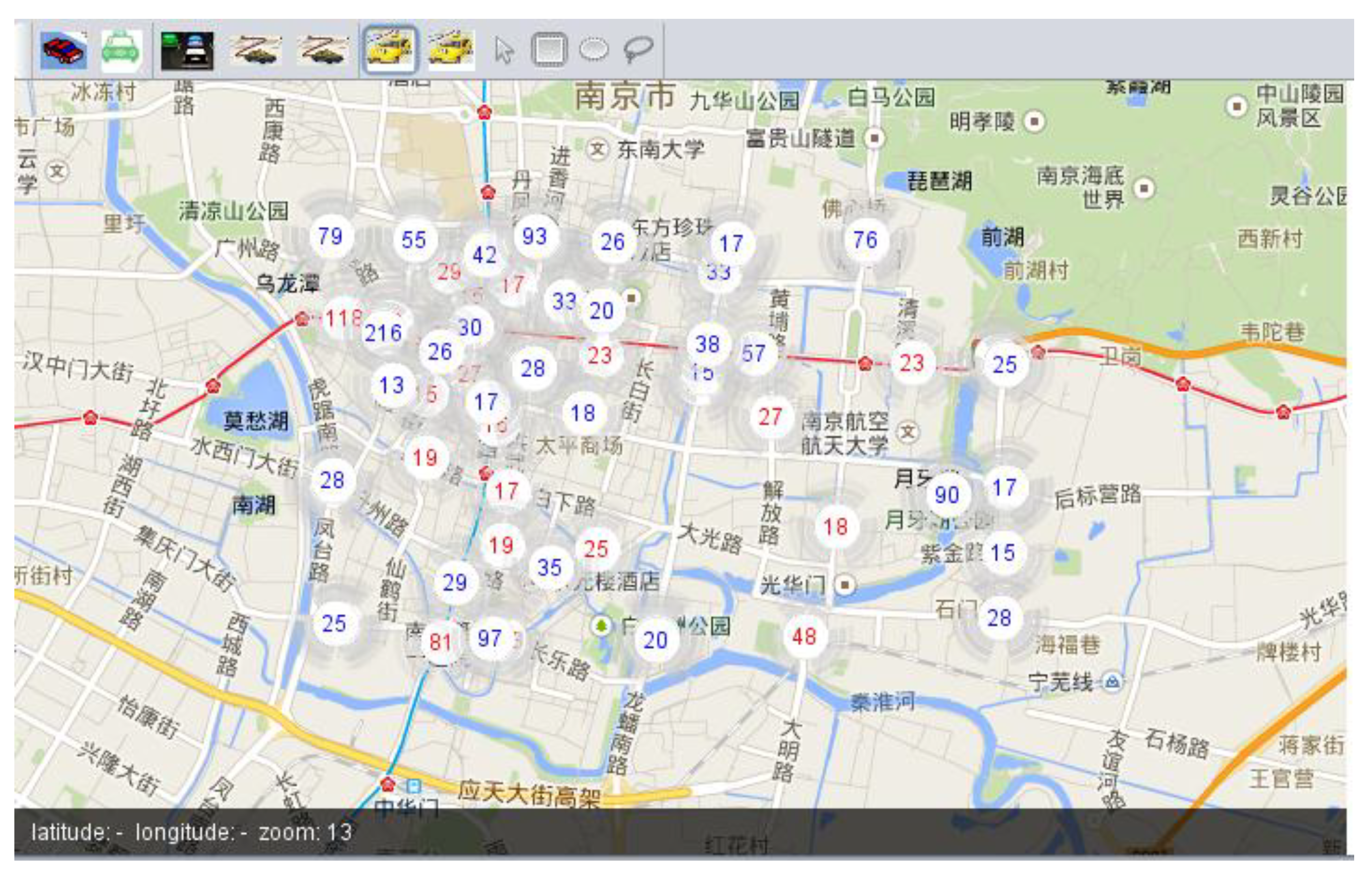
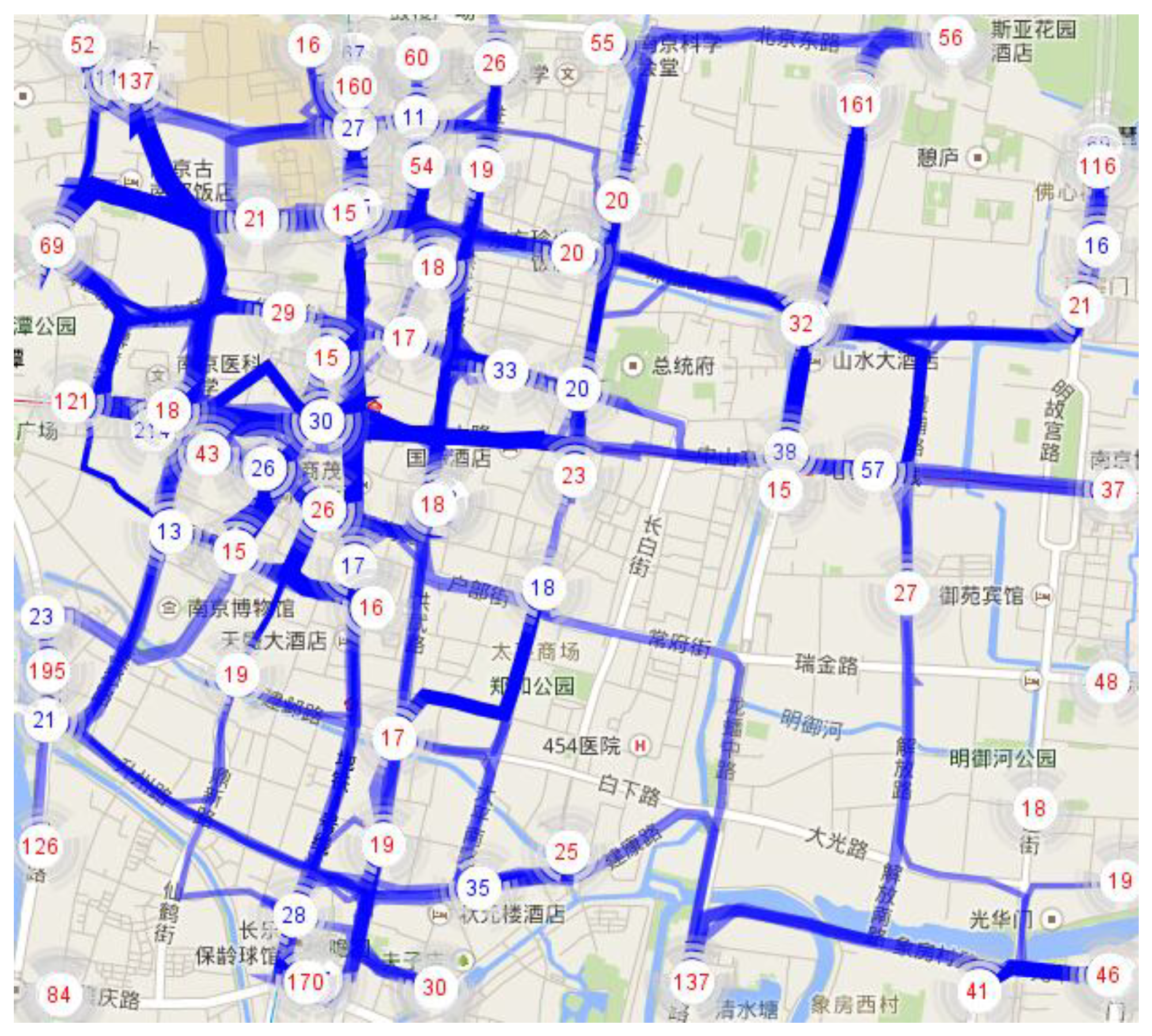
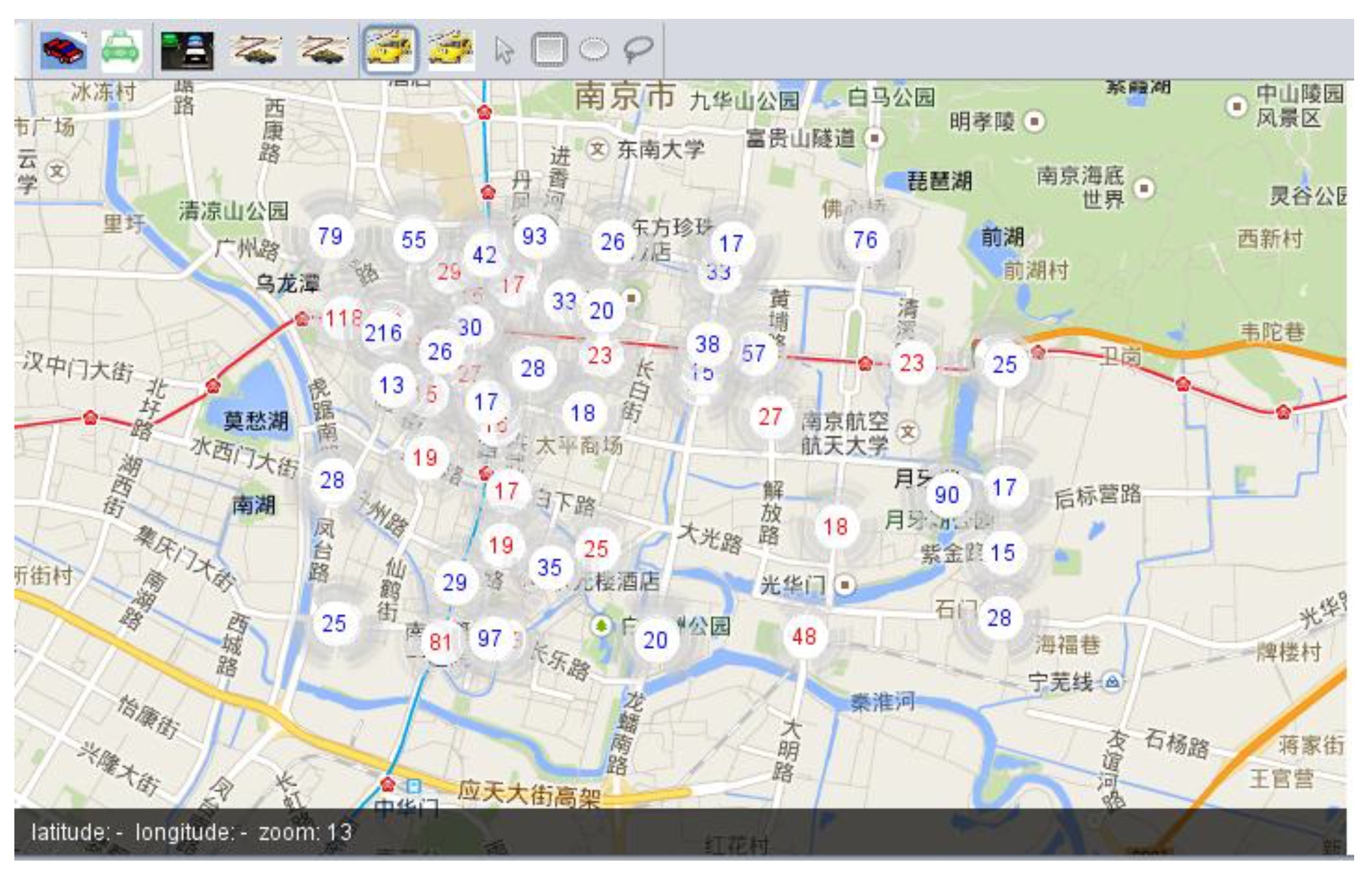
Figure 3 shows the clustering results of the above method. Circles with red numbers in them represent loading-hot spot while circles with blue numbers in them are unloading-hot spot. By the aid of visualization, hot spot distribution can be observed and explored with different parameters such as Δ and density threshold
MinPts.
At the end of this stage, loading (unloading) hot spot distribution is presented in visualization especially with map and timeline tools. The behavior patterns of people travelling in rush hours, day and night, work day and weekend will also be reflected in the hot spot distribution.
Figure 3.
Hot spot clustering results.
5. Trajectory Clustering
Taxi drivers are always eager to find the next passenger(s) instantly after their current passenger(s) is(are) unloaded. Since the loading (unloading) hot spot means there are more passengers loading (unloading) in that spot, if vacant taxi drivers go to the nearest loading hot spot at the very beginning, they intuitively have a higher chance of getting passengers.
The model for taxi in arbitrary position to loading hot spots is similar to traditional driving route recommendation models. This is usually complex in computing, and needs the support of a road network and extensive historical data. On the other side, short-day taxi data is too sparse to support the calculation from an arbitrary position to loading hot spots. When a vacant event happens, a taxi has greater possibility to stop near an unloading hot spot, so establishing a model from unloading hot spot to loading hot spot nearby may simplify the process of making a route recommendation for cruising drivers.
In this paper, we build such a hot spot-based model by extracting and clustering trajectories through loading and unloading hot spots in a specific area and period. The hot spot based clustered trajectories reflect situations on the main roads in the city. Learning from the short-dated taxi data with referenced time, velocity, distance and up spot attractiveness, we turn to evaluate potential routes from taxi position to the loading hot spot nearby. Although such a simplified model may have lower accuracy than that of the traditional route recommendation models, it works easily and effectively for short route recommendation and does not need road network information but only short-term taxi data.
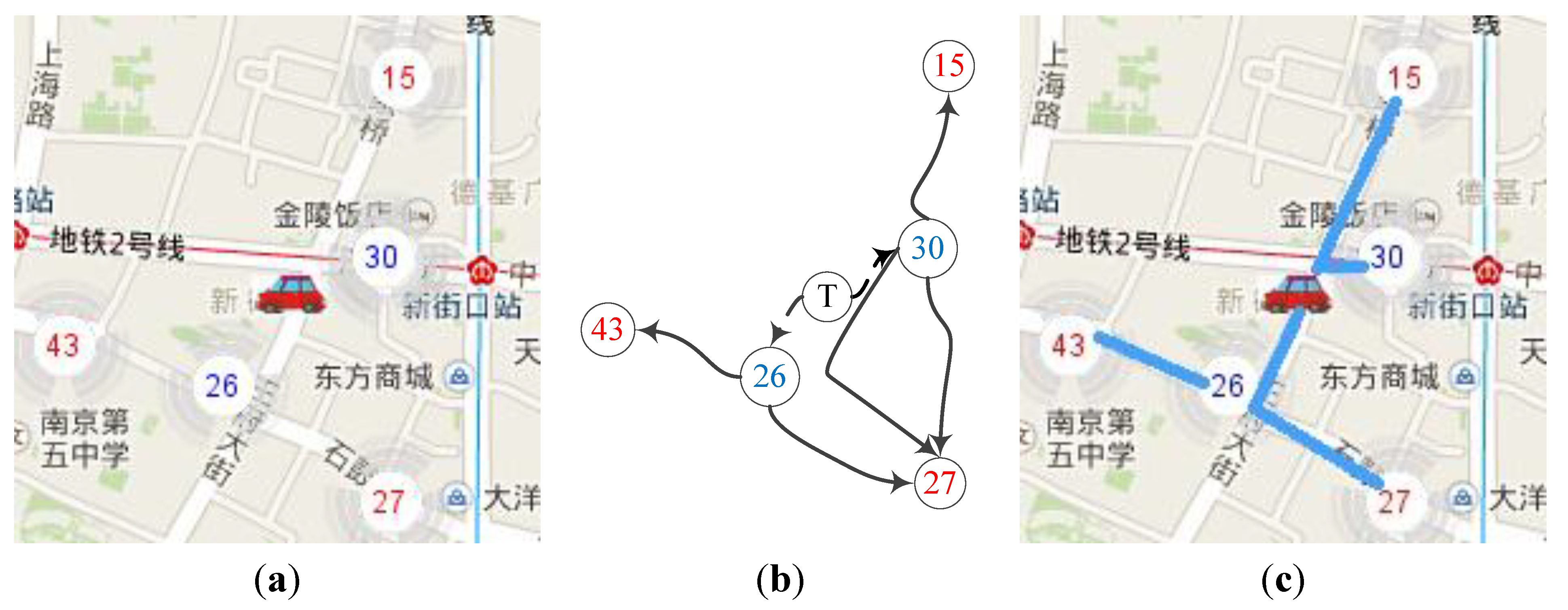
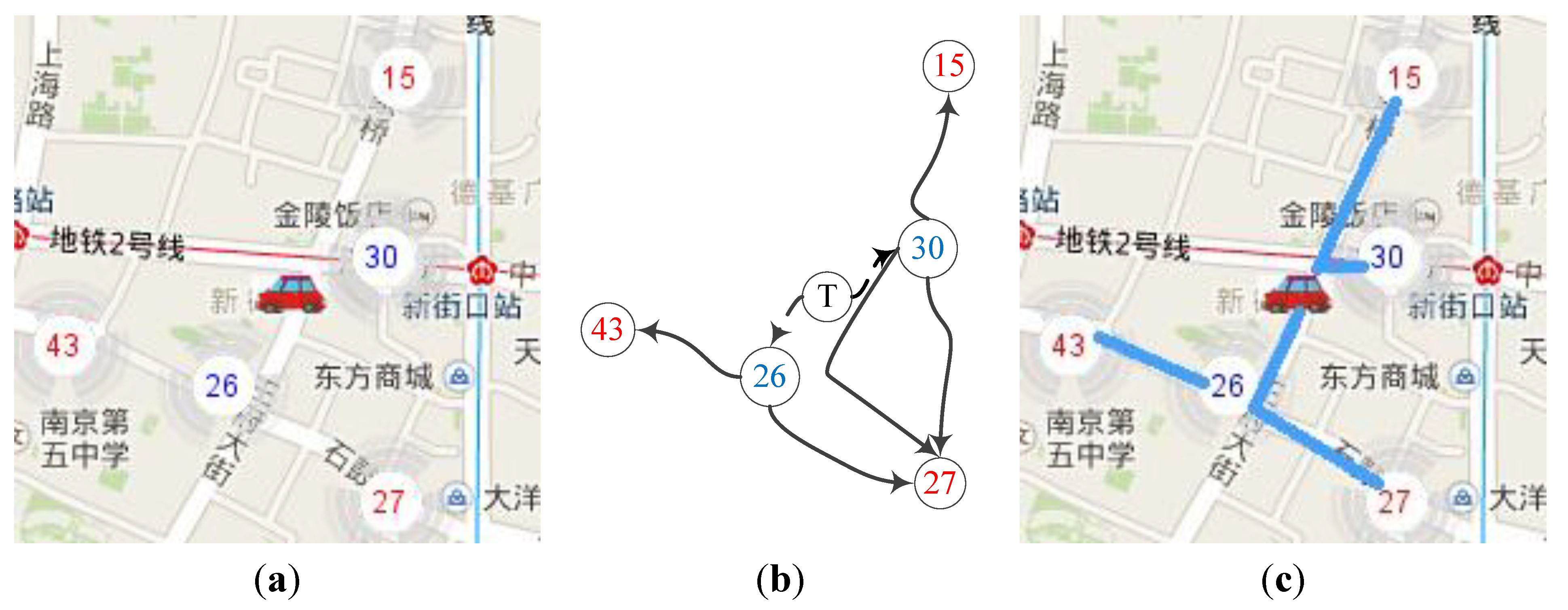
Figure 4 explains our model with an instance of a vacant taxi hunting for new passengers.
Figure 4a describes a scene that a taxi becomes vacant at the moment. There are some hot spots near the current taxi position. Then, a hot spot based model can be constructed in
Figure 4b. The map is abstracted as a unidirectional graph with unloading (blue) hot spot node to adjacent loading (red) hot spot node. The solid curves represent clustered trajectory which can be calculated; “T” represents current taxi position and the dashed curves represent the simple distance estimation in this model. Then, the problem turns to retrieving and finding the best adjacent routes. It suggests that the taxi is driven to a nearby unloading (blue) hot spot (usually no more than 1000 m), then to the next loading (red) hot spot, which gives the driver greater probability of finding new passengers. The route can be divided into two parts: the first part is the taxi to the blue point, which is marked with dotted curves such as “T” to “26”, and the second part is the trajectories from blue point to red spot marked with solid curves such as “26” to “43”. Trajectory clustering algorithm will help to find optimal routes such as the ones in
Figure 4c. For example, the taxi can go to “43” through “26”, or go to “27” through “26”. In our models, the taxi can be guided to the hotter red spots with factors such as distance, driving time, and road congestion considered simultaneously.
Figure 4.
(a) Taxi hunting for loading hot spot; (b) Hot spot based model; (c) Trajectory clustering.
The routing process can be divided into two stages. At first, sub trajectories starting from unloading hot spots to loading hot spots are extracted with the start-end point based similar trajectory clustering algorithm. Then, the clustering method of density based epsilon distance trajectory is used to find out potential routes.
5.1. Start-End Point Based Similar Trajectory Clustering
Since our simplified model only focuses on the trajectories from unloading hot spots to loading hot spots, all the trajectories will be retrieved to extract sub trajectories from unloading hot spot to its nearby loading hot spots based on the output of hot spots set in
Section 4. Then, we can focus on coarse level trajectory clustering.
Based on the idea of paper [
13], we propose a start-end point based similar trajectory method with which we can get a series of trajectory clusters that have the nearby start and end points. One pair of trajectories is compared each time with this method.
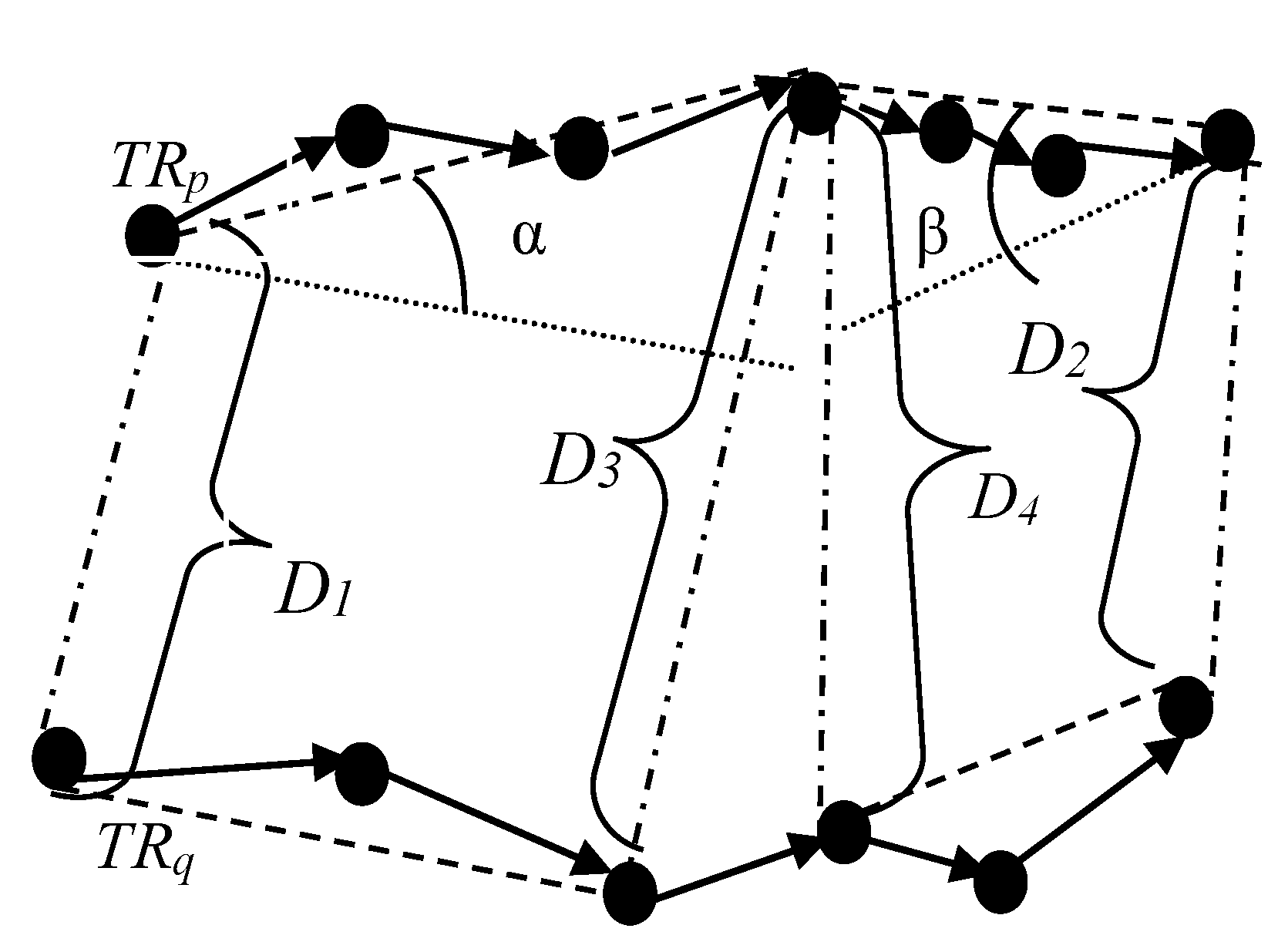
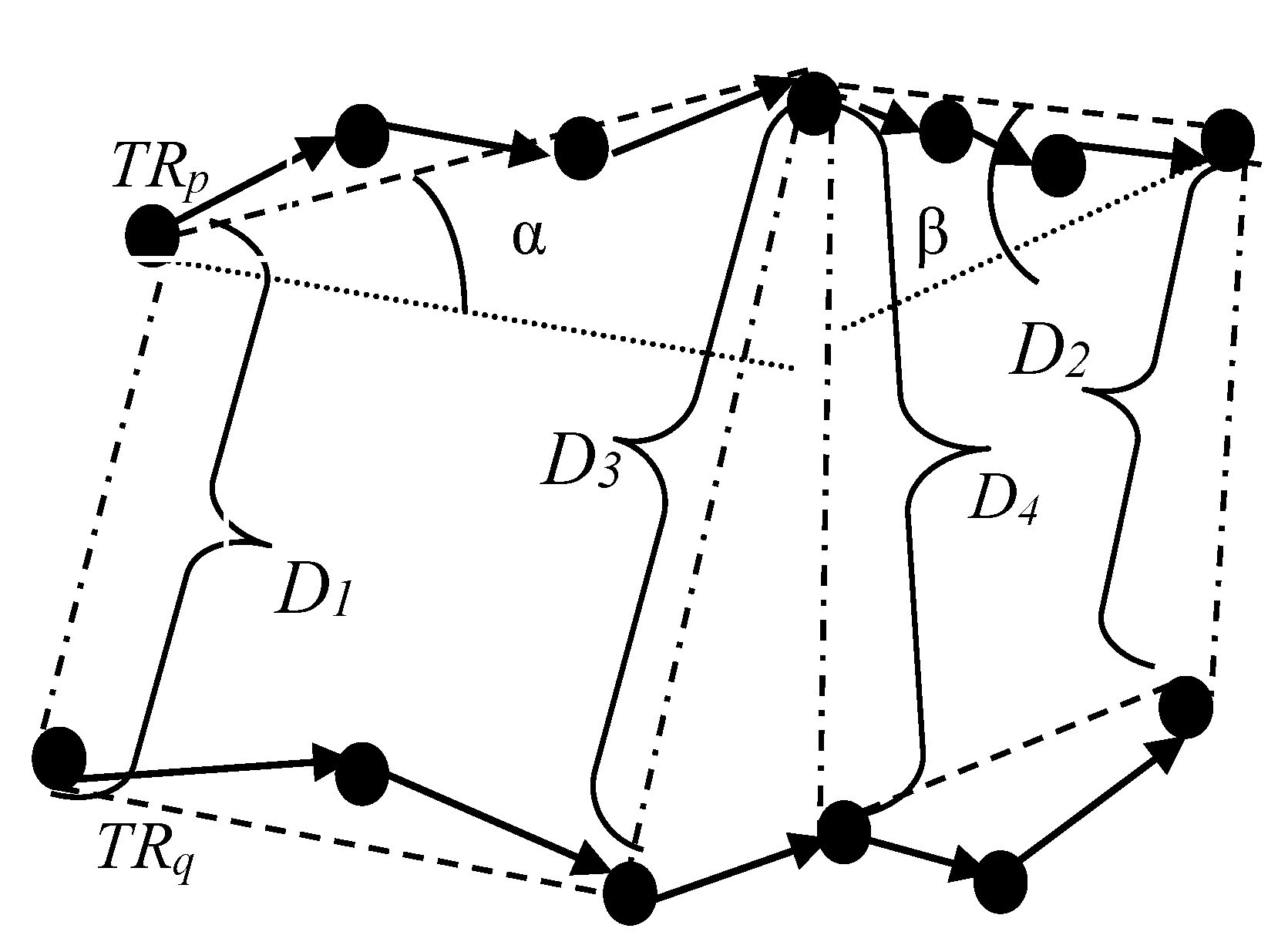
Figure 5 shows factors in the calculation of distance between two trajectories.
Figure 5.
Distance metric for two trajectories with similar start-end point.
In
Figure 5,
TRp and
TRq represent two trajectories,
D1,
D2,
D3,
D4 represent Euclidean distance and α, β represent angle.
D1 is the distance between the two start points of trajectory
TRp and TRq, and
D2 is the distance between the two end points of the trajectories, while
D3 and
D4 are the two midpoints distance of the trajectories marked as d (
TRpc,
TRqc). It should be especially stressed that if
TRp and
TRq contains an odd number of sampling points, there is only one middle distance
D3, which is d (
TRpc,
TRqc). Otherwise, there are two middle distances (
D3 and
D4)
. d (
TRpc,
TRqc) can be calculated with Equation (4).
Angle α is the angle between two start-midpoint dashed line segments of TRp and TRq, which reflects the degree of divergence between the two trajectories, while angle β is the angle between two midpoint-end dashed line segments, which reflects the degree of convergence.
We marked “GPSDirection” angle of start, middle and end sampling points on
TRp and
TRq as θ
ps, θ
pc, θ
pe, θ
qs, θ
qc, θ
qe, then α and β can be calculated with Equations (5) and (6); here, angle of middle sampling point should be handled as distance.
In our method, distance between two trajectories is defined with Equation (7).
d (TRpc, TRqc) represents the mid-point distance between
TRp, and
TRq, can be calculated as above. ω
1 and ω
2 are similar as those in paper [
16], calculated with Equations (8) and (9); ω
3 is set at 1/3.
When d (TRp, TRq) is less than the threshold t (here t is 0.8 km), the two trajectories can be merged into one category.
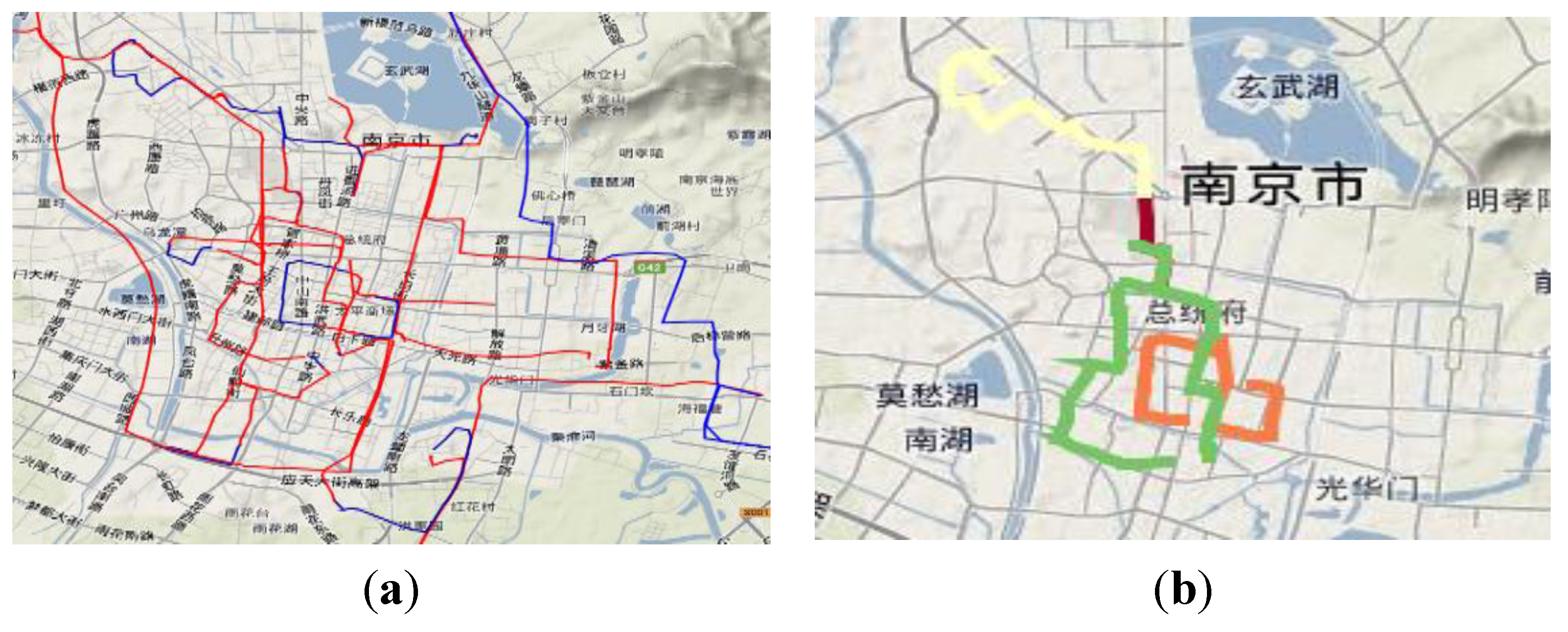
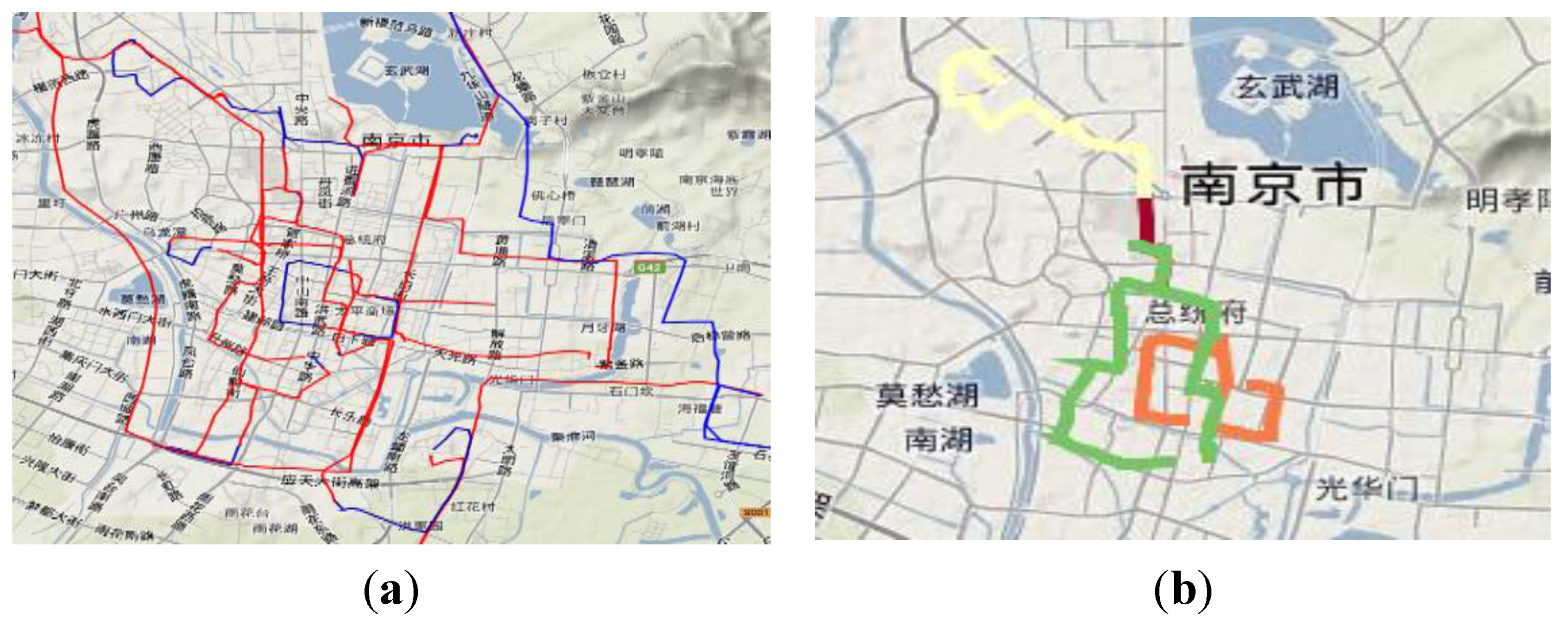
Figure 6a shows 45 trajectories of a taxi, with occupied ones shown in red and vacant ones shown in blue.
Figure 6b shows the results of the above start-end point based similar trajectory method with a distance threshold of 0.8 km, which outputs four sub trajectory sets with different colors. We can see that the green cluster has a similar endpoint but two different routes. That is the reason why we should continue to work on a finer trajectory clustering.
Figure 6.
(a) Forty-five original trajectories; (b) four sub trajectory sets after clustering (t = 0.8 km).
5.2. Epsilon Distance Trajectory Clustering
The distance calculation of two trajectories in our paper is based on the idea of [
18], which is done through repeated scanning of two trajectories to find the closest pair of positions, then by computing the mean distance of the corresponding positions and penalty distance. We introduce current driving angle to computing in order to shorten the scan range of trajectories in similar directions, and to eliminate the restriction that trajectories should have the same number of sampling points in a trajectory cluster.
Given the two trajectories TR and TR', if their angle difference is within the threshold, then we go on to traverse all the points in them. The algorithm of improved distance calculation is described below:
| Function: Distance between two trajectories |
| Input: trajectory TR, TR', distance threshold dThred, angle threshold θ |
| Output: The Dpq distance between TR and TR' |
| 1: Dpq, Codistance, Conum = 0; i = j = 1 | 15: Codistance += d; // find the nearby point |
| 2: Δα←|TR. start angle-TR'. start angle| | 16: Conum++; |
| 3: IF Δα > θ RETURN 2 × dThred | 17: IF Dpq/Conum > dThred |
| 4: ELSE | 18: RETURN Dpq + dThred |
| 5: WHILE (i < TR.length ˄ j < TR'.length) | 19: Dpq −= Codistance; Codistance /= Conum |
| 6: d←d(TRi, TR'j) | 20: i++;j++ |
| 7: WHILE (i + 1 < TR.length ˄ d(TRi+1,TR'j) < d) | 21: WHILE (i ≤ TR.length) |
| 8: Dpq += d(TRi+1,TRi) | 22: Dpq += d(TRi+1,TRi) |
| 9: i++ | 23: i++; |
| 10: d←d(TRi,TR'j) | 24: WHILE (j ≤ TR'.length) |
| 11: WHILE (j + 1 < TR'.length ˄ d(TRi,TR'j+1) < d) | 25: Dpq += d(TR'j,TR'j+1) |
| 12: Dpq += d(TR'j,TR'j+1) | 26: j++ |
| 13: j++ | 27: RETURN Dpq |
| 14: d←d(TRi,TR'j) | |
Definition 5: Given a trajectory set
STR and
dε(
TR0), the neighbor set of the epsilon distance of
TR0 is denoted as
Ndε (
TR0) which meets:
Definition 6: [core trajectory]: Given a trajectory set STR, trajectory density threshold k and the distance threshold ε, if there is TR0 ϵ STR and satisfies |Ndε(TR0)| ≥ k, then TR0 is named a core trajectory.
Distance in Definitions 5 and 6 is the distance between two trajectories calculated by the distance function above. The core trajectory and its neighbor set of the epsilon distance are in a trajectory cluster.
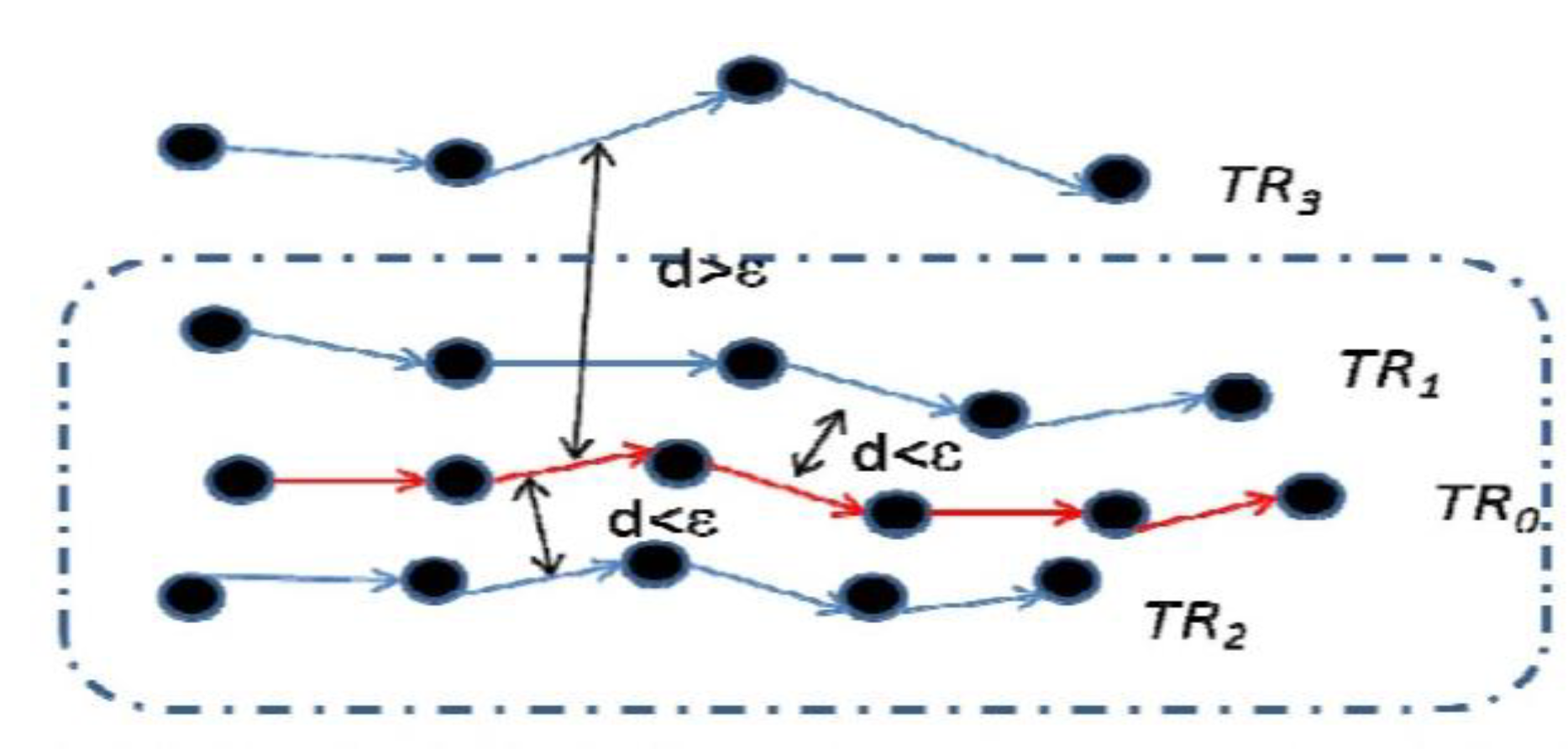
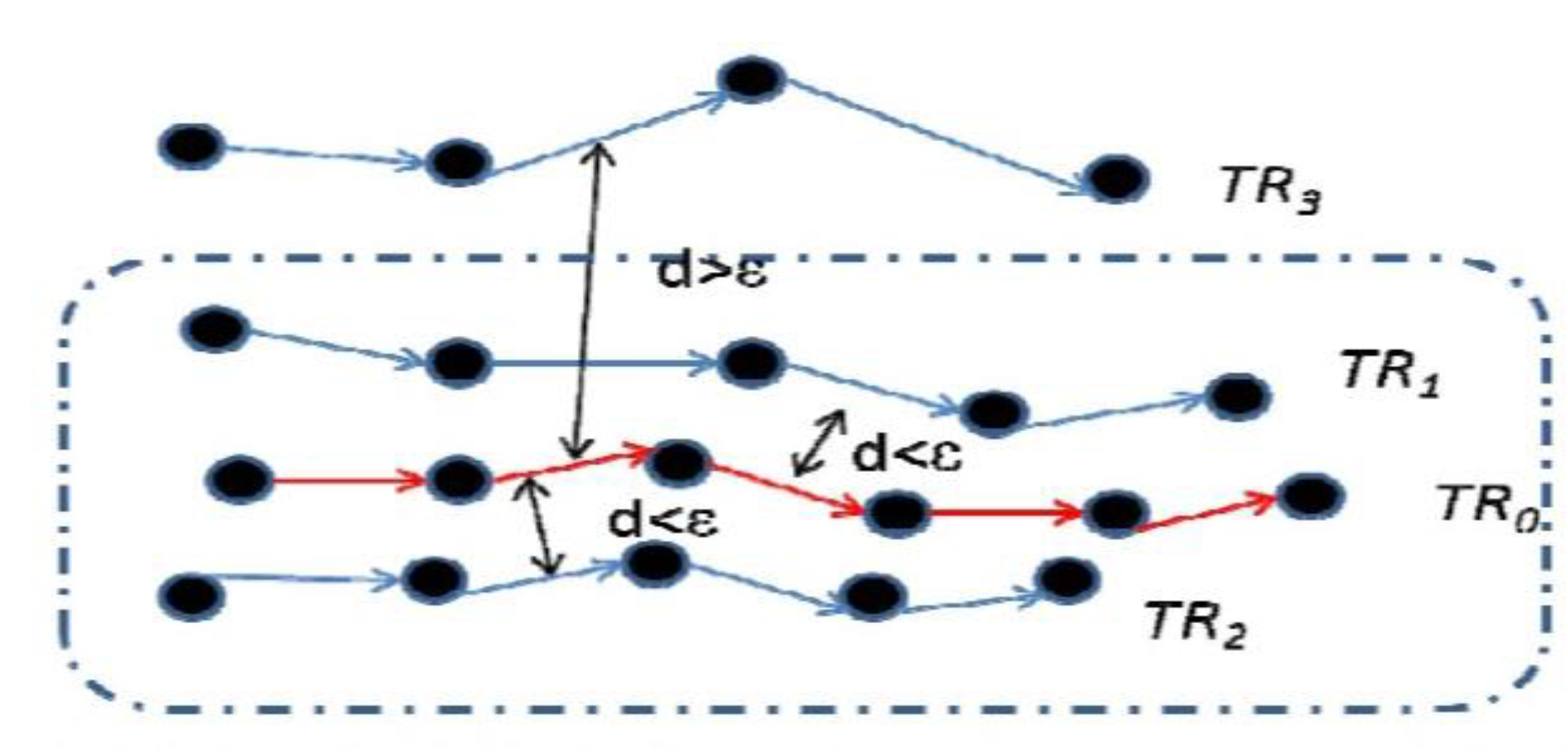
Figure 7 illustrates the two definitions above. If
k = 2, then the red trajectory
TR0 can be called a core trajectory since |
Ndε (
TR0)| ≥ 2.
Figure 7.
The illustration of trajectory cluster.
By using density based ε distance trajectory clustering algorithm, we can find trajectory cluster like {
TR0,
TR1,
TR2} in
Figure 7. The algorithm traverses each trajectory
TR0 in set
STR, constructs its ε neighborhood set
Ndε (
TR0), and determines whether
TR0 is a core trajectory. If
TR0 is a core trajectory, then delete all the trajectories of
Ndε (
TR0) from
STR, and put them in a trajectory cluster.
| Algorithm: Density based ε distance clustering |
| Input: Trajectory set STR, density threshold k, distance threshold ε |
| Output: Trajectory Clustering Set List scluster |
| 1: scluster = NULL; item = 1; |
| 2: WHILE (STR != Ф) |
| 3: FOR each TR0 ϵ STR |
| 4: Ndε(TR0).APPEND(TR0) |
| 5: FOR each TR' in STR-{TR0} |
| 6: IF distance(TR0,TR') ≤ ε |
| 7: Ndε(TR0).APPEND (TR') |
| 8: IF |Ndε(TR0)| ≥ k THEN |
| 9: STR = STR-Ndε(TR0) |
| 10: scluster[item]. APPEND (Ndε(TR0)) |
| 11: item++ |
| 12: ELSE STR = STR-{TR0} |
| 13: RETURN scluster |
The result of our density ε based distance clustering algorithm is related to the trajectory order since it uses TR0 as default cluster center. However, if we set a proper value for distance threshold ε within road width, then the cluster result is acceptable.
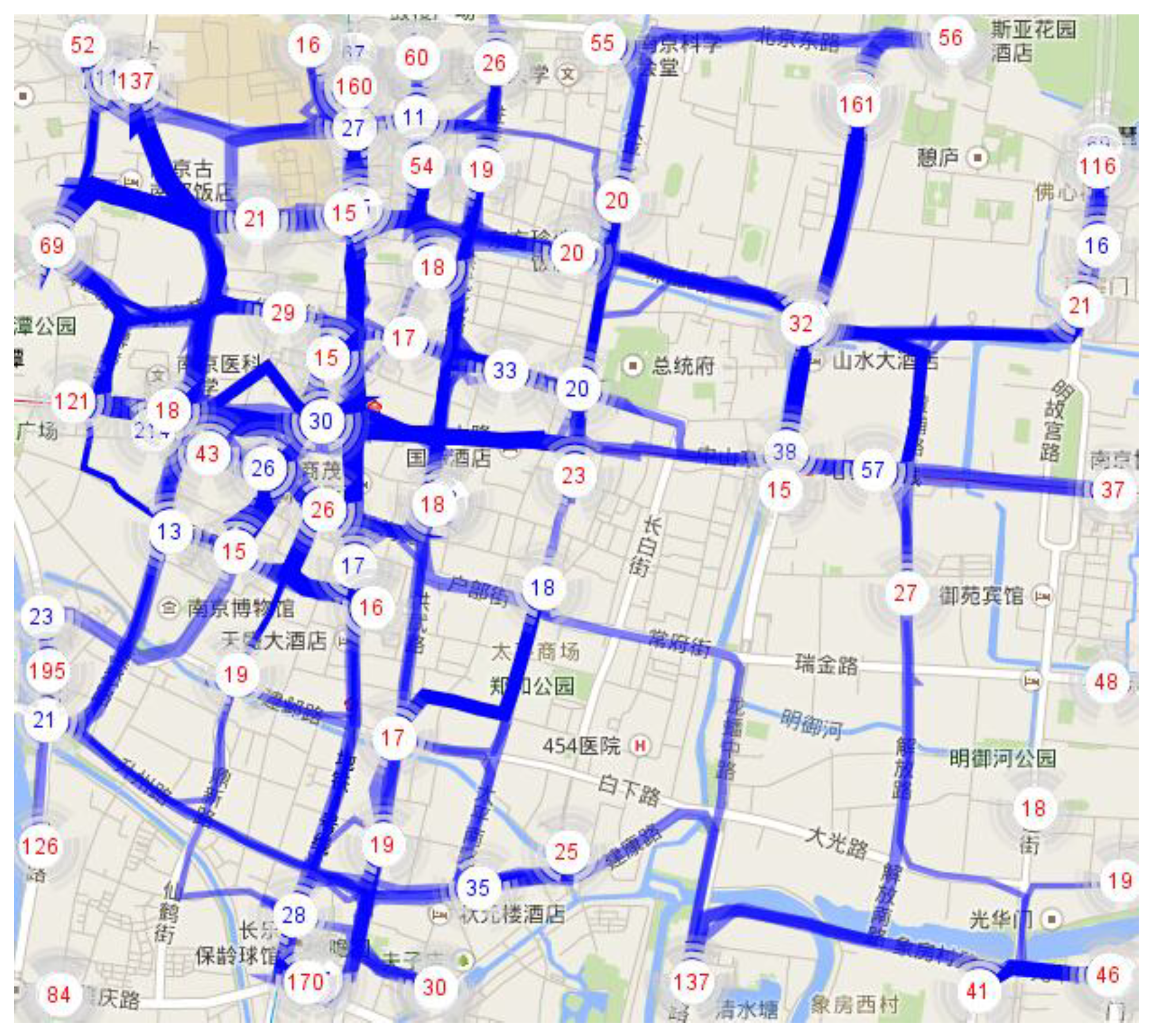
Figure 8.
Clustered trajectories based on hot spots.
After the two-stage trajectory clustering, we are ready to pick optimal routes for cruising taxi drivers. An example of clustering result is presented in
Figure 8. The figure includes 50 loading hot spots, 35 unloading hot spots and 311 potential trajectory clusters, which are extracted from 19861 original trajectories limited in an area of (118.76375,32.02073) to (118.81593,32.05973) during 8:00–9:00 in the morning of September 1, 2010. With wideness of trajectories indicating traffic flow, and darkness of colors indicating driving time cost, it is clear that the west part of the area has much heavier traffic and is busier than the east part in the rush hour.
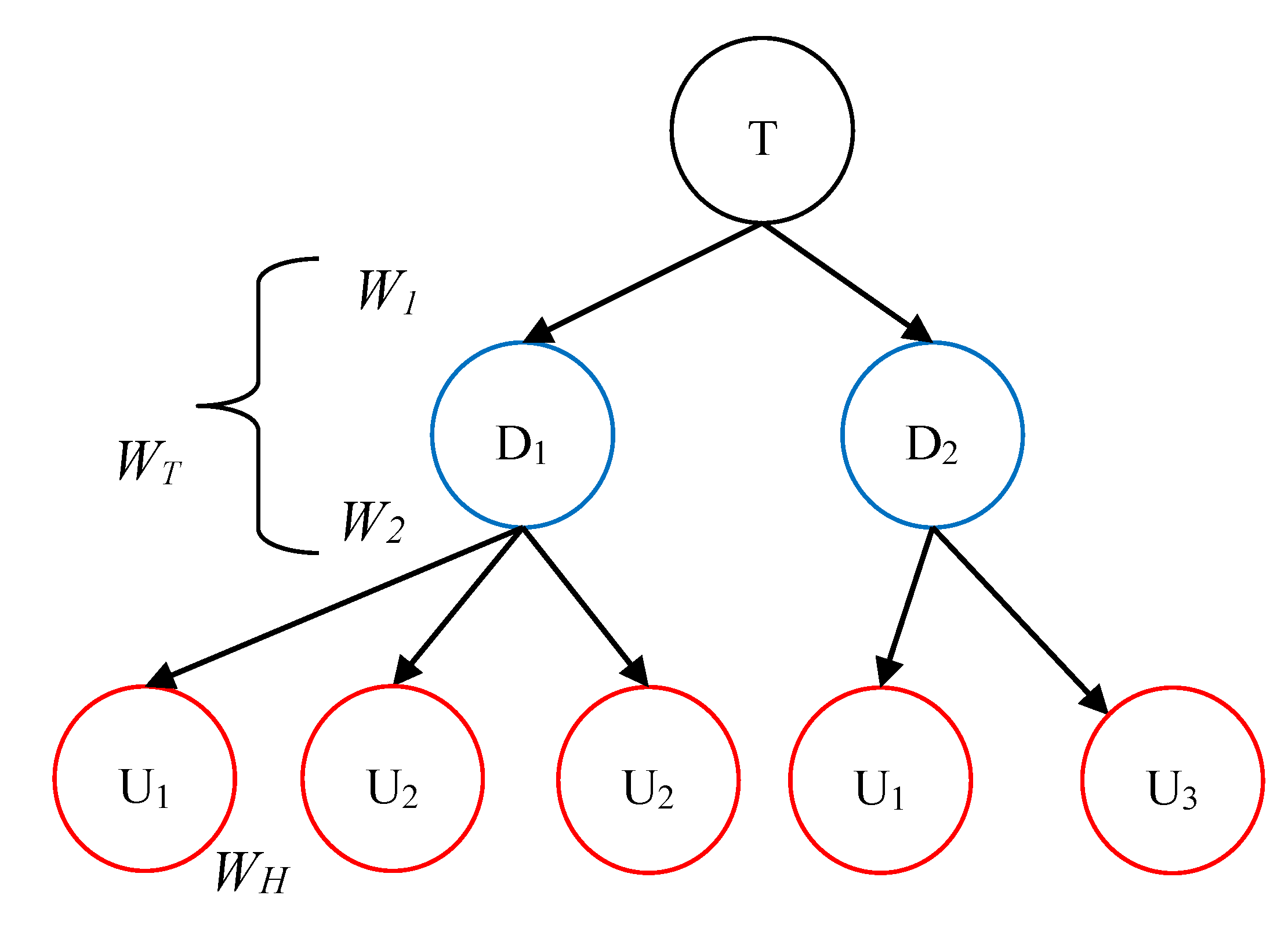
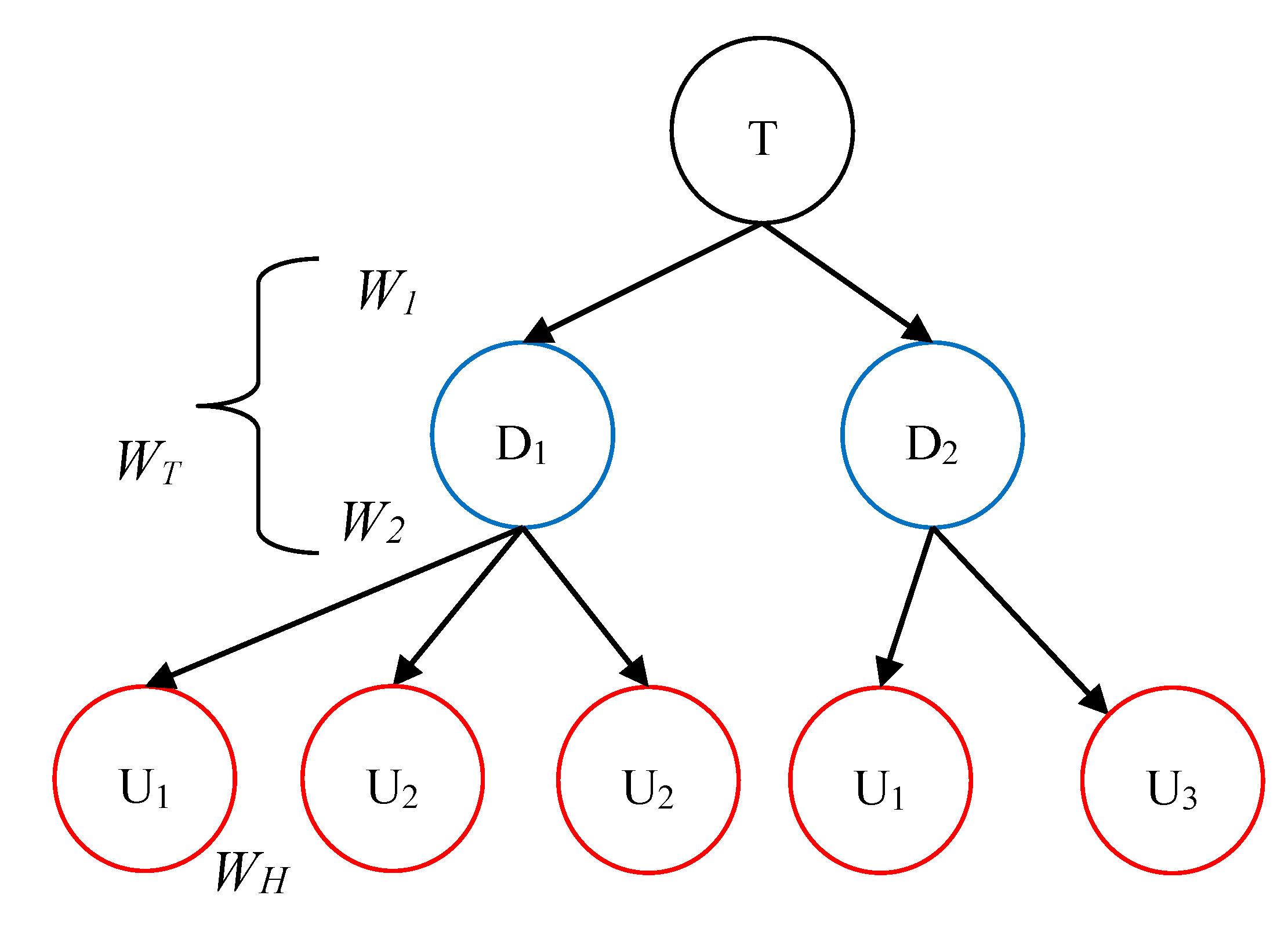
6. Route Recommendation
With the clustered trajectories based on hot spots, a three-layered weighted tree is used to evaluate potential routes (see
Figure 9); it is a sub tree with root “T” from the graph similar as
Figure 4b. Current cruising taxi position T is represented as the root in the weighted tree. All the unloading hot spots near T are represented as the nodes in the second layer. All the loading hot spots near the nodes in the second layer are represented as the nodes in the third layer, which may have duplicated copies since there may be several paths between a pair of hot spots. Since a route can be represented as a weighted path from T to leaves, we can evaluate each potential route through its corresponding factors.
Figure 9.
A weighted tree for route recommendation.
Here, score of each route is called
WF, which contains the path cost factor
WT and the hot-spot attraction factor
WH, as shown in Equation (11).
WH can be calculated with Equation (12). The parameter
k in Equation (12) with empirical range [
10,
15] is used to adjust
WH, and we set
k = 11. Here,
Hu equals the number of loading-passenger(s) event happening at a loading hot spot, which is the end point of potential route. And
Hmax and
Hmin indicate, respectively, the maximum and minimum number of loading-passenger event happening at a loading hot spot as of current area and time.
WT contains two parts:
W1, the value from the root node to the node in the second layer, representing the score of path from the current taxi position to the unloading-hot spot nearby;
W2, value from the node in the second layer to its sub nodes in the third layer, representing the score of path from the current unloading hot spot to the loading hotspot nearby.
WT can be described with Equation (13). Here, we set ɷ
1 to 1/3 and ɷ
2 to 2/3, since
W1 contains one factor, while
W2 consists of two factors.
For
W1, we focus on the distance factor between the unloading-hotspot and the position of the taxi. In Equation (14),
d0 indicates the Euclidean distance between the current position T and the unloading hotspot in this path.
dmax and
dmin indicate the Euclidean distance between T and the farthest and closest down-hot spot, respectively.
For
W2, we take into consideration the distance factor
A and the traffic condition factor
B between the current unloading hot spot and the potential loading hot spot in Equation (15).
Here,
A can also be calculated with Equation (14) in the same way
W1 is calculated; all the distances in
A are calculated by average time multiplied by average speed for each trajectory cluster; while
B is more complicated in demonstrating traffic status. As we know, the trajectory with shorter driving time and higher average speed is more attractive to a taxi driver. We set B as Equation (16). Here,
tavg0 is calculated with Equation (17), which shows the average driving time of the current trajectory’s cluster
Sc. The parameters
tavgmax and
tavgmin indicate the maximal and minimal time value of
Sc, respectively. Similarly,
vavg0 is the average speed of
Sc, calculated wit Equation (18). The parameters
vavgmax and
vavgmin indicate the maximal and minimal value of
Sc, respectively.
In Equation (18), djk represents the Euclidean distance between sampling point j and k of any trajectory in Sc, and Δtjk represents the time interval between two sampling points, while n represents the number of the trajectories at the sampling point.
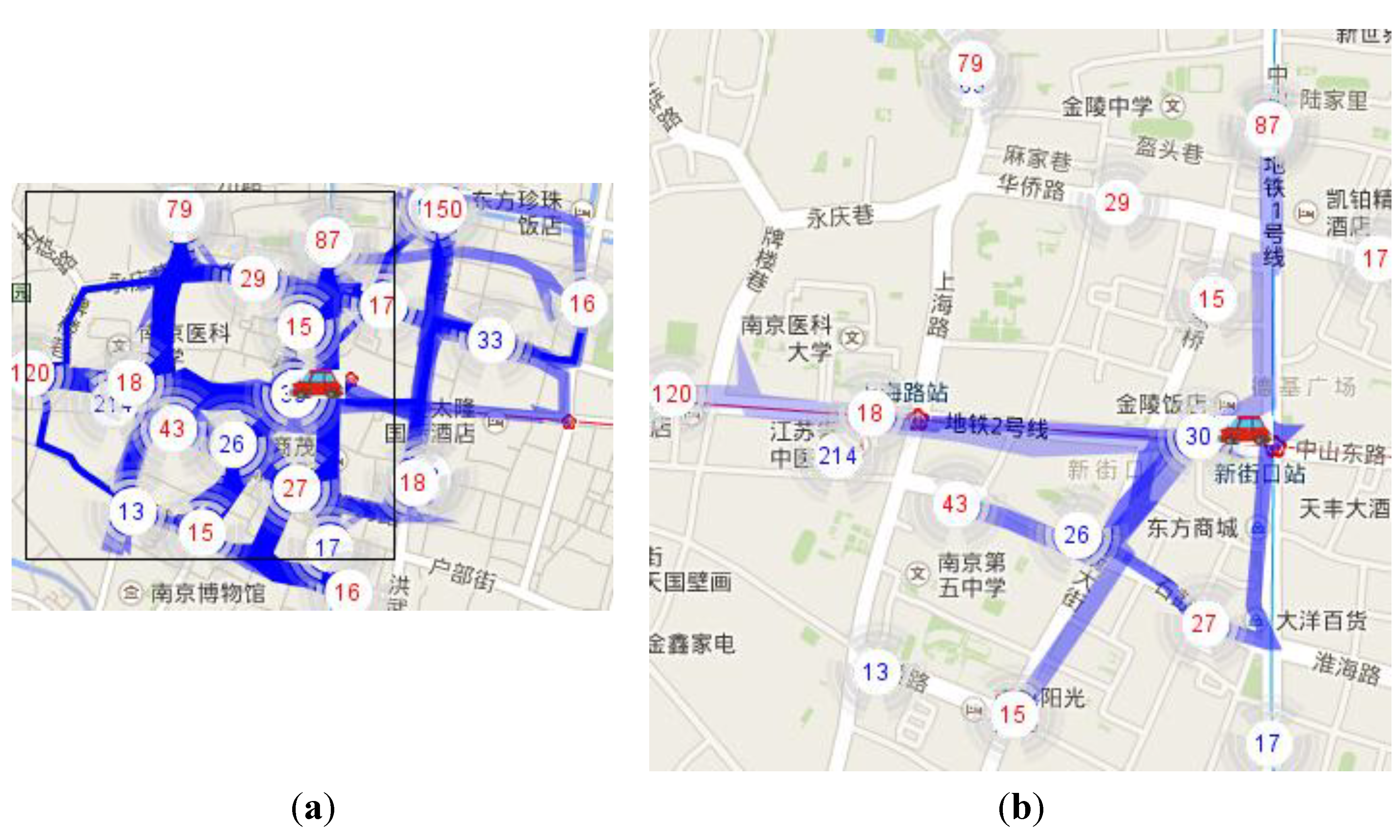
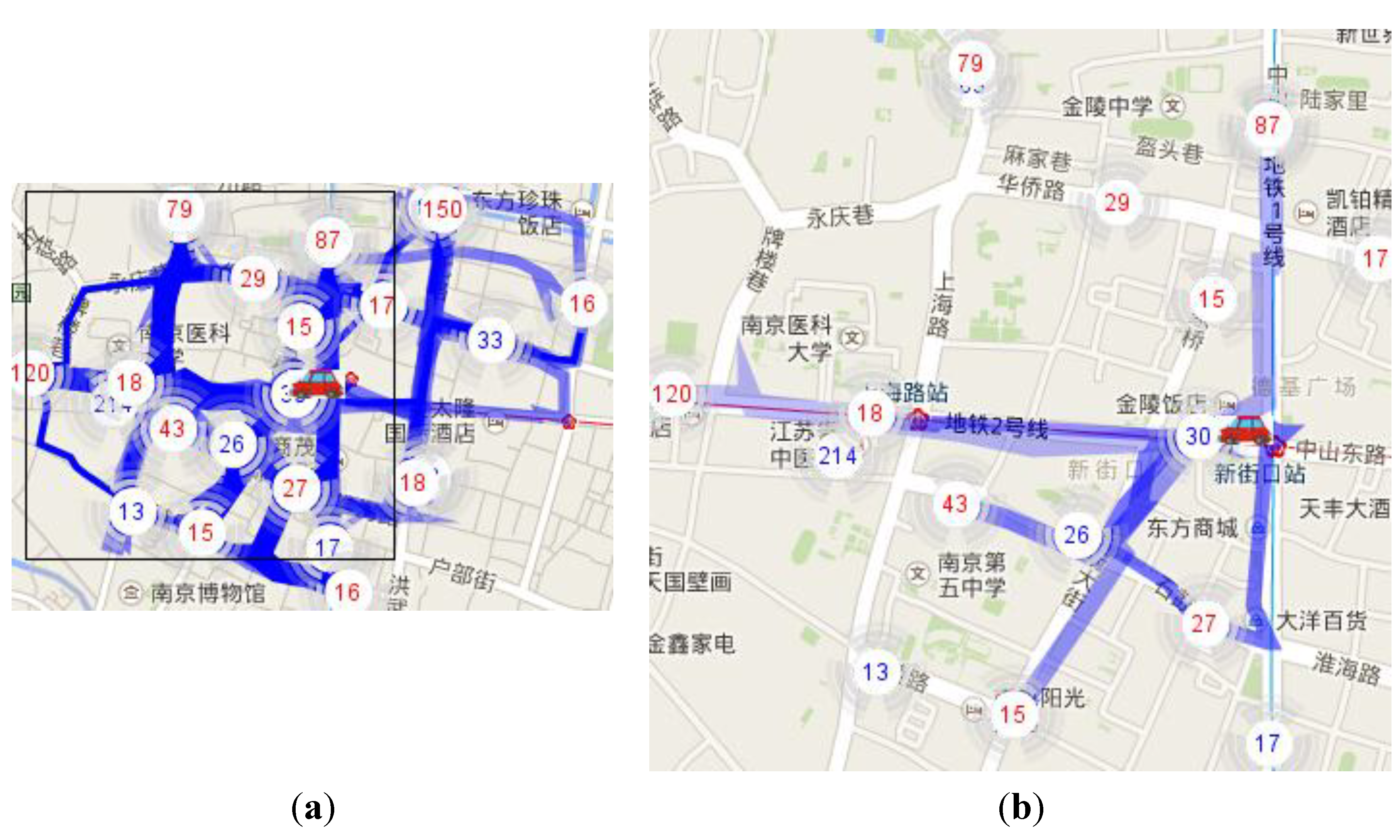
Figure 10 presents a case study of the potential route recommendation.
Figure 10a shows 116 potential routes around a cruising taxi. All the potential routes are evaluated by Equation (9). The top seven routes are drawn in
Figure 10b with their scores listed in
Table 1. The first is the recommended route of our system.
Unloading hot spot “30” is the only competitive unloading hot spot at the current position of the taxi, because all routes with the seven highest scores go through it (
Table 1).
Figure 10.
(a) 116 potential routes around a taxi; (b) the top seven routes.
Table 1.
Scores for the top seven routes.
| Routes Between Hot Spots | 43 | 27–1 | 27–2 | 87 | 120 | 18 | 15(bottom) |
|---|
| 30 | 89.66 | 88.61 | 87.06 | 87.05 | 86.65 | 86.41 | 83.44 |
From
Figure 10b, we can see that almost all the loading hot spots near “30” have been included in the top seven routes except for loading hot spot “15(loading)”. The potential route from “30” to “15(loading)” has the obvious advantage with the shortest distance, and it only got a score of 66.64. Because of the one-way rule, the real route from “30” to “15(loading) has very long distance that goes through unloading hot spot “30”, loading hot spot “18”, and loading hot spot ”29”, which means our method can mostly extract the correct routes.
Figure 11 explores details of the routes with highest scores through visualization. All the routes are ordered descendingly by score, which means
Figure 11a is the first recommended route.
In
Figure 11, trajectories in darker color are of lower average velocity, and wider lines mean more trajectories in the cluster. As we can see,
Figure 11b shows the shortest route; (a) and (c) also have advantage at a shorter distance. The score is not only related with the distance, but also with other factors like hot spot attractiveness, driving time and speed.
Figure 11a is the winner because of its overall advantages in speed, distance and attractiveness compared with the other routes. The broad width of trajectory cluster means that the route in
Figure 11a is the favorite route for taxi drivers.
Figure 11b,c represent two routes from “30” to “27”; (b) distinguishes itself as shorter distance and (c) has a little higher velocity. We evaluate (b) as being better than (c) and more taxi drivers agree with this because line (b) is wider than (c).
Figure 11d,e are typical in attractiveness.
Figure 11e is both the fastest in traffic speed and longest in distance among the top seven.
Figure 11f,g lose their scores with less attractiveness and longer distance.
Above all, our evaluation provides insightful information for taxi drivers to find suitable routes for subsequent passengers.
Figure 11.
(a) “30”–“43”; (b) “30”–“27”-1; (c) “30”–“27”-2; (d) “30”–“87”; (e) “30”–“120”; (f) “30”–“18”; (g) “30”–“15(bottom)”.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}