1. Introduction
Knowledge management (KM) success requires that appropriate knowledge is provided to those that need it when it is needed [
1]. This makes clear that organizations must achieve both continuous knowledge creation and knowledge retention. Given the skill shortages many organizations experience, the latter might be even more important [
2]. IT is considered a prerequisite for effective KM (e.g., [
3,
4]), and a key form of KM is IT-supported knowledge repositories [
5]. The authors of this paper consider IT-supported knowledge repositories to be one part of the organizational memory.
Knowledge processes can be categorized with respect to whether they concern knowledge creation or knowledge reuse [
6]. Focusing on the latter, it involves stages, such as capturing or documenting knowledge, packaging knowledge for reuse, distributing or disseminating knowledge and reusing knowledge [
7], and they all correspond to the processes that a knowledge repository requires. However, since knowledge repositories also aim to eventually accumulate knowledge inside people,
i.e., that people learn, we argue that knowledge repositories also are dependent on processes related to knowledge creation. Consequently, knowledge repositories form a critical part for any organization’s continuous development.
The success of an IT-supported knowledge repository, and therefore, the success of any knowledge retention activity, is dependent on whether or not the repository is actually used. For a knowledge repository to be used, the user must have sufficient time and perceive that its usage will greatly enhance performance at work [
8]. Hence, what is stored in the repository is critical for the success of organizations.
In order for knowledge to be stored in the repository, it needs to be captured. Thus, to meet KM objectives, the ability to capture is a key aspect [
9]. More precisely, the ability to capture the right knowledge [
1] is what matters. The right knowledge is knowledge that an organization needs in order to keep its “capacity for effective action or decision making in a specific organizational context” [
10] (p. 21). However, the problem is that there is a lack of awareness of the specific and complex issues related to an effective knowledge capture process and the benefits achieved through it [
11]. Yet, overlooking this process can have serious implications for organizations, as it can result in cost increases, loss of productivity, reduction in customer satisfaction, increased supply chain risks and a reduction in core competencies [
12].
Knowledge capture involves two main activities: (1) the identification of knowledge that is critical to the organizations’ business operations; and (2) the evaluation of the identified critical knowledge in order to decide whether to actually retain it for packaging and dissemination or not. Since the identification activity starts the capture process, the present paper focuses on this sub-process. Extant literature frequently discusses general KM success factors (SFs) (e.g., [
13,
14,
15]) and SFs for KM systems [
16]; however, it lacks more detailed and deep knowledge concerning SF for the specific identification activity. There is literature concerning SFs about employee contributions of knowledge to electronic knowledge repositories (EKR) (e.g., [
5,
17]), but since this is only one aspect of knowledge capture and the identification activity, our understanding of the topic is underdeveloped. This suggests that there are problematic knowledge gaps in the literature on knowledge capture and knowledge retention; gaps that this paper aims to address. Critical success factors (CSFs) are “the conditions that need to be met to assure success of the system” [
18] (p. 395). CSFs should consist of a limited number of factors [
19]. When too many success factors are selected (e.g., more than four to six), they are probably too detailed, and not all of them may be critical [
20]. Therefore, the aim of the paper is to associate critical success factors for the identification activity with knowledge retention in order to demonstrate the danger organizations are exposed to when failing to address this issue. The CSFs have been developed as an outcome of an early study conducted by two of the authors of the present paper [
21]. Having better insights into this topic will help organizations to better understand the contribution of knowledge capture trough IT-supported repositories with respect to the issue of knowledge retention.
The paper is structured as follows. The background to this paper is presented in
Section 2. This is followed by a presentation of the research process in
Section 3. The CSFs related to the identification activity, and their link to knowledge retention, are outlined in
Section 4. The paper concludes in
Section 5, which also addresses some implications and future research avenues.
2. Background
The setting of this paper is IT-supported knowledge repositories. In the KM context, IT has two generic capabilities: codifying knowledge and creating networks [
22]. IT-supported knowledge repositories include codified knowledge, which can be used by employees that have access to it. The access as such can be strategically managed, and by putting the repository in a network context supported by IT, the network itself can also increase. The authors of this study argue that knowledge repositories are promising mediums for knowledge retention. According to Martins and Meyer [
23], knowledge retention can be defined as “maintaining, not losing, knowledge that exists in the minds of people (tacit, not easily documented) and knowing (experiential action manifesting in behavior) that is vital to the organization’s overall functioning” [
23] (p. 80). In contrast to KM solutions, knowledge retention takes place during a limited period of time and addresses the challenge of transforming an “expert’s most valuable knowledge” to an organizational asset [
24] (p. 583). According to Delong [
10], knowledge retention consists of three activities, which are knowledge acquisition, storage and retrieval.
Not all knowledge is critical to organizations, and thus, not all knowledge needs to be retained. Additionally, knowledge that has been relevant in the past may become obsolete over time, or it has simply been forgotten because time elapses [
25]. Therefore, knowledge is in a constant state of change and should be updated continuously. Critical knowledge is that knowledge that is most at risk of being lost [
26]. Lost knowledge can occur at individual, group or organizational levels, have either anticipated or unanticipated effects, have tangible or intangible impacts and create immediate or delayed costs [
10]. Consequently, organizations’ activities should strive for the identification and capturing of all critical knowledge that they need in order to keep their capacity for action [
10]. Here, IT-supported knowledge repositories can step in and play an important role.
IT-supported knowledge repositories enable both individual and organizational learning and, hence, support the accumulation of knowledge inside people and the embedding of knowledge in processes, routines,
etc. [
27]. Based on Binney’s [
28] views on KM, the authors of this paper conclude that developing IT-supported knowledge repositories includes both a product and a process perspective. There must be processes associated with the management of the knowledge repository and improvements of work processes in order to support different types of knowledge conversions, as described by Nonaka and Takeuchi [
29]. The application of technology when building the repository embeds knowledge in the application and the use of it.
Different types of knowledge and their implications for KM activities are frequently discussed in the literature (e.g., [
29,
30,
31,
32,
33]). From the perspective of employees, external knowledge (non-private) is organizational knowledge that an organization will retain even if individuals leave their employment, e.g., knowledge in a knowledge repository. Tacit knowledge is difficult to identify and to express, since it is highly personal and concerns insights and intuition [
29,
30]. From an organization’s perspective, organizational knowledge stored in a repository can be regarded as explicit and organizational knowledge stored in the culture and embedded in work routines and processes as tacit.
IT-supported knowledge repositories require capturing, packaging and storing relevant knowledge. These processes take place when a knowledge repository is created for the first time in a KM implementation project, as well as every time new knowledge is generated that has potential relevance for incorporation in an existing knowledge repository. The latter is critical for having updated knowledge repositories and furthermore to maintain usefulness and trust in the repository over time. Additionally, it makes sure that organizations maintain their capacity to act.
The process of capturing critical knowledge starts when knowledge with the potential to be incorporated in the repository is identified and closes when the identified knowledge has been evaluated and passed onto the process of packaging and storing the knowledge or when a decision is made that the identified knowledge should not be retained. It is crucial to understand that relevant knowledge is not regularly generated, e.g., once or twice a week, and accordingly, knowledge access must be continuously monitored, i.e., continuously identified and, if relevant, captured.
The ability to continuously capture new, relevant and correct knowledge increases the long-term survival of a repository and, consequently, the organization using it. Furthermore, having this ability decreases the amount of knowledge that escapes identification and, in turn, increases the awareness towards knowledge loss and, thus, the importance of knowledge retention [
11].
3. Research Approach
The CSFs, which will be presented in depth in
Section 4, are based on both theoretical and empirical data. For a more detailed description concerning the CSFs development, see [
21]. The empirical data was collected by an interpretive field study of a KM implementation project called
Efficient Knowledge Management and Learning in Knowledge Intensive Organizations (EKLär), a three-year project that was completed in 2007.
The EKLär project aimed at developing an IT-supported knowledge repository for learning and sharing of the best practices with respect to treatment and prevention methods for leg ulcers. The resulting IT-supported knowledge repository can be found at [
34]. Three types of healthcare organizations were included in this project: home healthcare, primary care and hospital. The objective of these stakeholders is to provide the patients with the best possible treatment, and one essential condition for reaching this is up-to-date knowledge and the sharing of it. The project can be regarded as successful, since seven years after the project ended, the repository now contributes to the organization’s knowledge retention by providing updated, quality assured and relevant knowledge, hence enabling knowledge sharing.
To ensure the quality of the study, the research was guided by ideas that are conceptualized in the principles proposed by Klein and Myers [
35]. Data were collected by direct observations, interviews and written documents.
The qualitative data analysis, which formed the basis for the present paper’s outcomes, comprised the following steps (the first four steps were conducted in the original study; see [
21]):
- (1)
Analysis of existing literature and the data collected in the field in order to identify success factors (SFs) that influence the capture process.
- (2)
Extraction of those SF that influence the identification activity.
- (3)
Conceptual analysis, organization and grouping of SF with regard to how they influence the identification activity, as well as each other.
- (4)
Review of identified groups and paraphrasing them into four CSFs. Each included SF in the groups helped the authors to characterize the CSF. The characterization was visualized in a conceptual model.
- (5)
Association of the identified and characterized CSFs with knowledge retention and accordingly complementation of the conceptual model (
Figure 1).
The second step also analyzed whether each SF mainly influences the identification activity or the evaluation activity in the capture process. SFs that were difficult to link directly to any of these activities formed a third group of SFs. Since the largest number of SFs was related to the identification activity, this work revealed the critical importance of this activity. Together with the fact that the identification activity triggers the capture process, the need of our research is further strengthened.
Although the authors found SFs for the identification activity in both the empirical and theoretical data, their appearance was more common and clearer in the empirical data. For example, two main approaches to exploring knowledge were revealed: (1) focusing on eliciting existing external knowledge and the experience-based knowledge of the nurses and doctors; and (2) focusing on extracting knowledge from daily work processes and activities. The first approach was used when building the first version of the repository, and the main focus was on external knowledge. The second approach was utilized when preparing for maintenance of the repository, and here, the focus was on embedded knowledge.
In the literature, the identification activity is mainly mentioned in passing or implicitly when the management and capture of knowledge is discussed in general. For example, while the importance of managing tacit knowledge is frequently discussed (e.g., [
29,
36]) and designing work processes, including knowledge capture, as a SF [
16], as well as the need to learn from failure (e.g., [
37,
38]), the identification activity is not explicitly explored. Davenport and Prusak [
13] discuss the identification of knowledge that is appropriate for reaching business goals, and Chua and Lam [
38] argue that valuable knowledge remains obscured, because of a lack of effective mechanisms to distill knowledge from debriefs and discussions. The authors of this paper claim that without empirical data, the risk of missing the crucial importance of the identification activity would have been higher.
4. CSFs for the Identification Activity and Their Relation Knowledge Retention
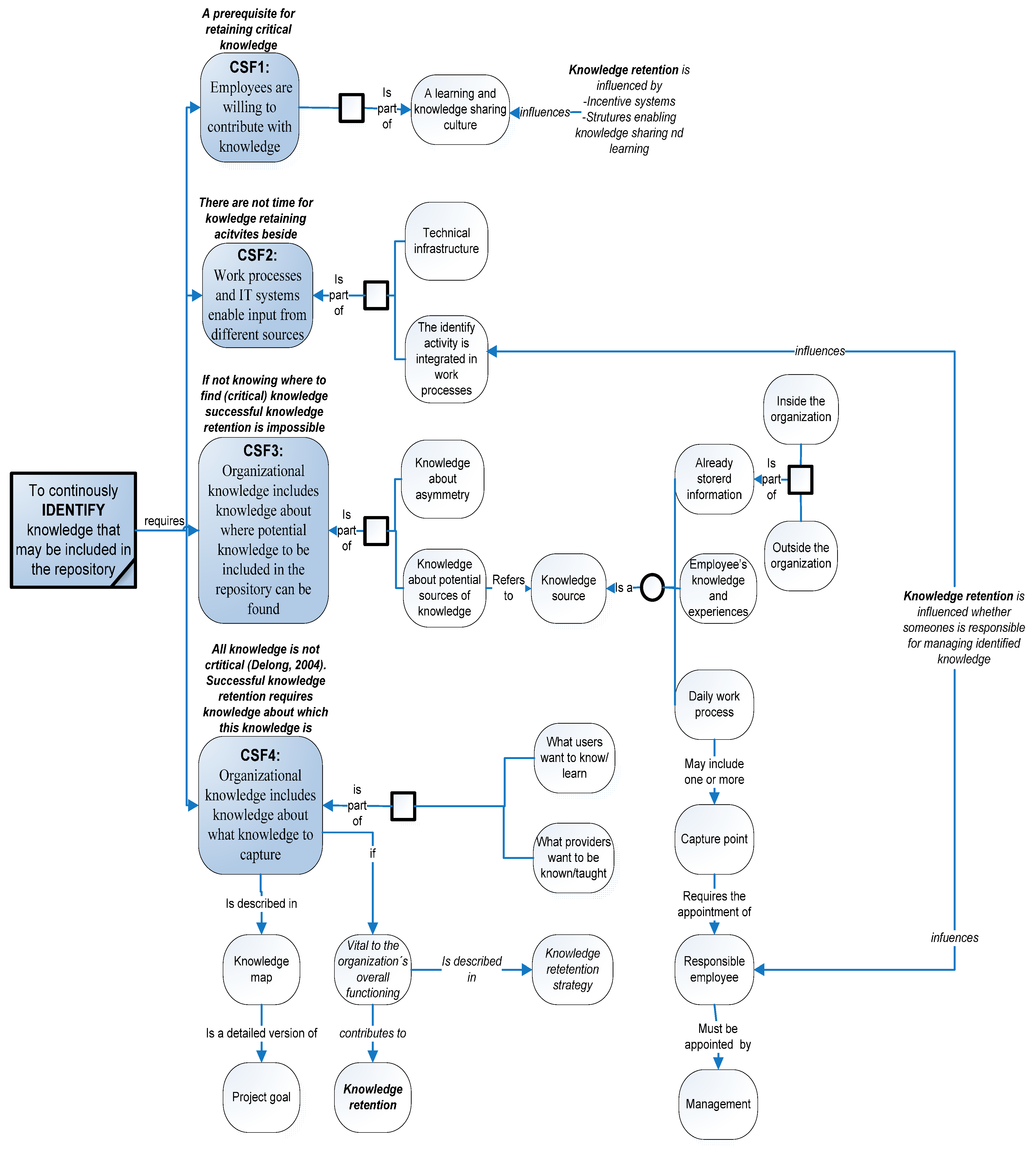
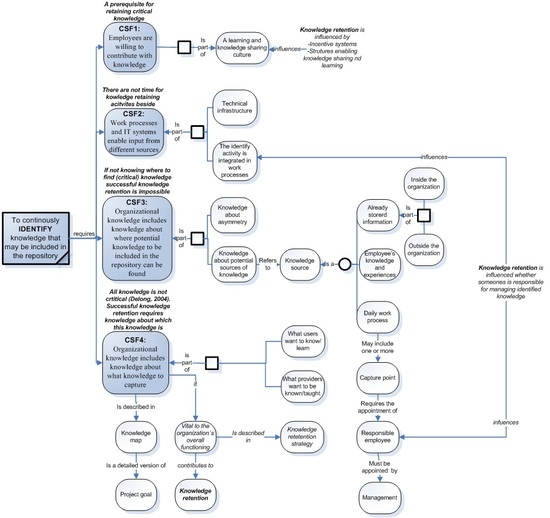
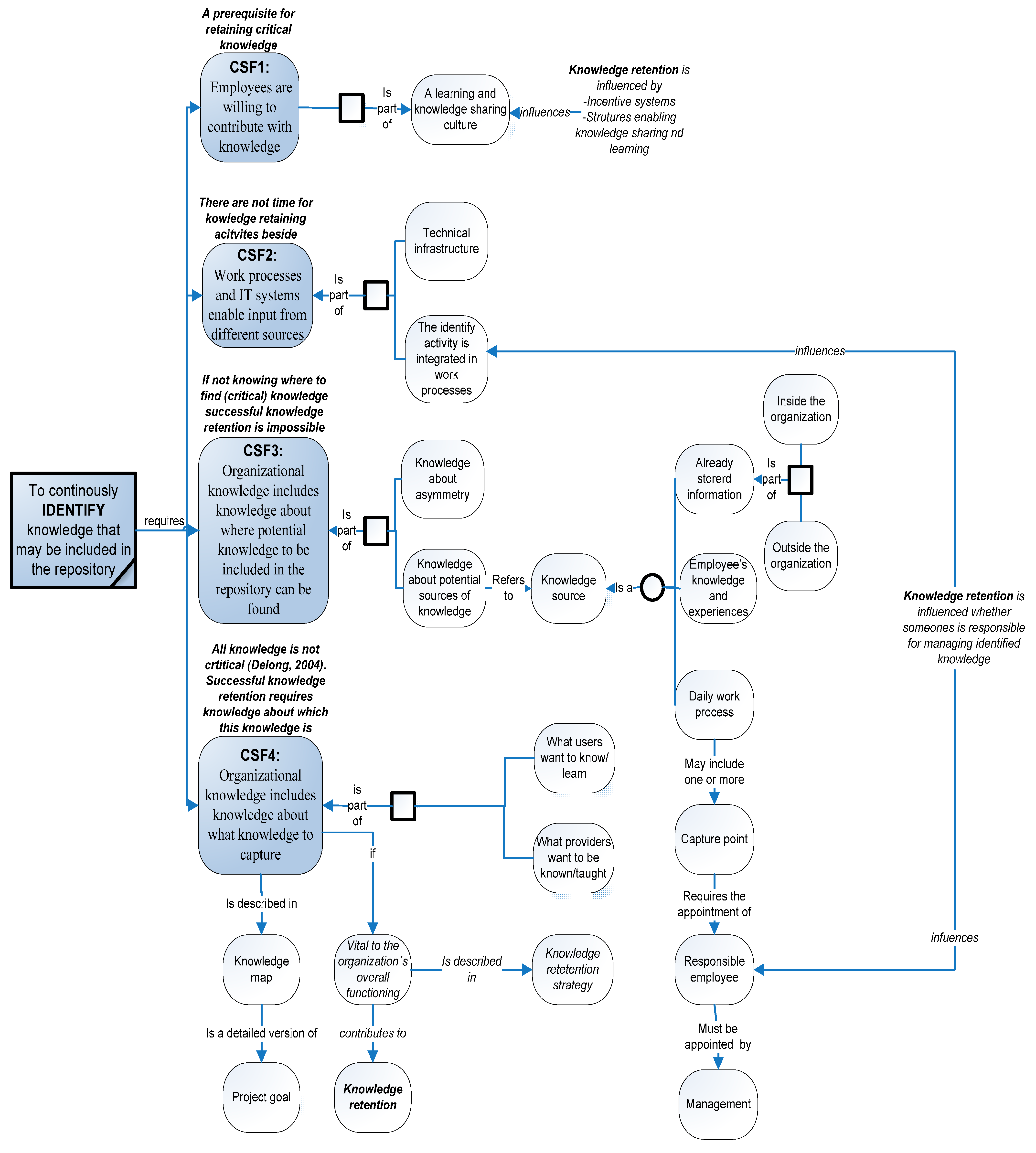
Based on the authors’ analysis, the following four CSFs for the identification activity have been identified and characterized, as well as associated with knowledge retention (
Figure 1). In order to enhance the readability, the outcome concerning knowledge retention is in italics.
Figure 1.
CSF for the identification activity and their influencing factors associated with knowledge retention.
Notes: CSF1, employees are willing to contribute with knowledge; CSF2, Work processes and IT systems enable input from different sources; CSF3, organizational knowledge includes knowledge about where potential knowledge to be included in the repository can be found; CSF4, organizational knowledge includes knowledge about what knowledge to capture.
Figure 1 shows how these CSFs influence the identification activity, as well as factors that, in turn, influence these CSFs. In addition, and mostly relevant for the present study’s focus,
Figure 1 also clarifies how these CSFs influence knowledge retention activities in organizations.
CSF1 is important for all KM work and is accordingly discussed in the literature. From a knowledge retention perspective, the importance of having incentive systems (e.g., reward systems) that encourage knowledge sharing and knowledge storage is clear. Tacit knowledge manifests in the actions and behavior of the carriers of knowledge in organizations [
23]. Hence, structures that enable and encourage organization members to meet each other, to observe each other, to give feedback,
etc., are critical.
To increase the success of knowledge retention activities in general, knowledge must be continuously monitored and, if relevant, captured. Hence, the identified work processes and IT systems must enable input from different sources (CSF2). Enabling input from different sources (CSF2) includes integrated technical infrastructure [
16] and also implies that the identification activity is integrated in work processes. One way to facilitate the latter is to use work role descriptions as “a link” between the individual and organizational levels [
39]. Furthermore, knowledge retention and knowledge sharing through IT-supported knowledge repositories involves people contributing knowledge to the repository, as well as people seeking and using knowledge from the repository for reuse [
23]. Hence, whether employees are willing to contribute with knowledge or not is really critical (CSF1). Since this willingness is a part of a learning and knowledge sharing culture, the incorporation of knowledge sharing in the organizational culture is perhaps the most important factor for successful KM system implementation [
16,
40].
Identifying knowledge that has potential for being retained and, therefore, stored in the repository requires an understanding about what knowledge to identify (CSF4) and where to find it (CSF3). The understanding about what knowledge to retain includes knowledge about what the users want and what they need to learn to meet the challenges ahead in the long run. Furthermore, it includes the knowledge that managers want to be known for in order to achieve the goals for the IT-supported knowledge repository and, hence, increase work performance (CSF4). Consequently, to have a clear goal is a SF for any knowledge management system (KMS) [
16].
What knowledge to retain and capture can be described, for example, in a knowledge map, which, in turn, can be compared with a detailed description of the goal for the repository [
41]. This underlines the importance of having a clear purpose with regard to the repository already from the beginning,
i.e., the project goal. Knowledge repositories aim at enabling knowledge sharing and, hence, counteract the asymmetry and localness of knowledge. Therefore, knowledge about potential sources of knowledge is needed (CSF3) as, e.g., already stored information both inside and outside the organization, employees’ internal knowledge and embedded knowledge in daily work processes. One potential approach when trying to capture relevant knowledge in daily work is to work with capture points, as the authors did in the EKLär project. Capture points were the working name for situations when knowledge, with the potential for storage, in daily work, was exchanged between organization members. To enable knowledge to be continuously identified and evaluated, somebody must be responsible for regularly doing it. The appointment of such a person is the task of the management,
i.e., being responsible for each discovered capture point.
The importance of a knowledge sharing culture, of which a willingness to contribute is a part (CSF1), is well known in the literature (see e.g., [
13,
36,
38,
42,
43]). The willingness to contribute was also a matter of course in the EKLär project: “We want to disseminate our knowledge. If we do this, they will learn and our telephone calls will decrease” (quotation from one of the nurses in the project group). Knowledge about where potential knowledge to be included in the repository can be found (CSF3) requires knowledge about asymmetry, which, according to Davenport and Prusak [
13], often causes KM to be inefficient. Knowledge about potential sources of knowledge is also a part of CSF3, which also includes different formats. Our two main approaches for identifying knowledge in the EKLär project revealed the importance of this. Furthermore, descriptions in the literature about different types of knowledge [
29,
30,
32] influenced the authors’ way of working in EKLär when identifying knowledge. Similar to other processes, the capture process, where the identification activity is a part, is a selected stream of activities, which are included in other activities [
44]. The identification activity must be a part of business processes. CSF2, that work processes and IT systems enable input from different sources, concerns this. Extant literature stresses that KM must be adapted to business and knowledge processes [
45] and be fitted to the operational environment [
43]. In the EKLär project, in the preparation phase, the researchers conducted observations in the dermatology and leg ulcer departments of the hospital. Data from these observations show, among other things, that some questions concern knowledge belonging to the repository. This means that other used IT systems, such as telephone advice systems, have potential for generating input to the repository. If knowledge is to be incorporated in the repository, it must be in line with the purpose of the repository,
i.e., it is critical to know what knowledge to capture (CSF4). A nurse in the project group in EKLär, when working with developing the Knowledge map, put it like this: “Which knowledge do we want to disseminate in order to reach the project goal? […] What do we want to teach the personnel?” The importance of having knowledge goals for KM success is well known in the literature (e.g., Jennex and Olfman [
16]). However, in accordance with the three levels of inquiry as described by van Gigch [
46], one must know why something is done, what to do, and how to do it. Hence, achieving the goal requires knowledge about what knowledge to capture.
CSF2 corresponds to SF1 and SF10 proposed by Jennex and Olfman [
16]. The novelty is that in the present study, these SF are related to the identification activity, and hence, their relation to each other and the identification activity is clarified. If the identification activity is not part of daily work and no one is in charge of it, the risk increases that relevant knowledge will not be included in the organizational memory. From a knowledge retention perspective, this may result in knowledge loss or attrition. Since daily work processes represent an important knowledge source, they are described in relation to CSF3.

{kind=link}
{kind=link}