2. Related Work
The task of news generation automation has been referred to as robotic journalism, automated journalism, algorithmic journalism and computational journalism. All of these terms refer to the process of using software or algorithms to generate news stories without direct human intervention [
5]. The need to automate this process is not only to free journalists from this task but also because the speed at which information is shared in specific sectors, such as finance, is crucial for decision-making.
The surge in demand for real-time online news has driven the development of numerous automated news generation methods. These methods span from basic templates to advanced language models. In [
6], the authors describe some of the earliest efforts to automate news generation using structured data to fill templates, such as the work done by Thomson Reuters in 2006 [
7].
GAI has driven significant progress in fields like Computer Vision and Natural Language Processing. GAI models can create data that is highly similar to human-generated content. In the realm of Natural Language, they have proven capable of producing summaries and essays [
8].
Currently, Artificial Intelligence has had an impact on the automation of journalism tasks such as automated content production, data extraction, news dissemination and content optimization [
5]. In the particular case of automated content production, the resurgence of neural networks through neural generation models, the development of the transformer architecture and access to large amounts of information on the Internet allow automated content generation. For example, LLMs have been shown to generate high-quality and contextually appropriate headlines and summaries, especially when combined with human-guided prompts [
9,
10]. The integration of AI into journalism showcases its potential to address various challenges and optimize workflows across different domains. While organizations like Bloomberg utilize AI-driven tools to enhance financial journalism with customized models for precision and speed, general-purpose systems like ChatGPT demonstrate the adaptability of language models in generating high-quality content across broader contexts.
Bloomberg has implemented AI technologies for tasks such as dynamic headline generation, structured content planning, and chart and table analysis. The use of artificial intelligence has enabled partial and complete automation of financial news, improving both the speed of reaction to breaking news and the transparency of complex data analyses. The company developed BloombergGPT, a model tailored for financial applications, and integrated ethical evaluation to mitigate the risks of misinformation and inaccuracies [
11].
In addition, ChatGPT-4 has been analyzed for its role as a journalist, particularly in generating content on sensitive topics such as migration. The findings indicate that ChatGPT prioritizes factual accuracy over sensationalism and demonstrates racial awareness and objectivity compared to traditional media outlets. However, it reproduces biases inherent in its training data. This highlights the need for frameworks to critically evaluate LLMs in shaping societal narratives and their potential impact on public opinion [
12].
The use of LLMs in journalism has also highlighted significant challenges. As noted in [
13], these models are not only capable of generating accurate and high-quality news articles, but can also be exploited to produce and disseminate disinformation. The sophistication of LLMs in understanding context and crafting compelling narratives raises ethical concerns, as they can be misused to create misleading or biased content [
14]. To address these concerns, different methods are required to guide LLMs in generating ethical and accurate content. For example, combining LLMs with fine-tuned datasets has shown promise in reducing the generation of undesired outputs while maintaining the high-quality text generation capabilities of the models. Furthermore, ongoing advancements in evaluation metrics and alignment techniques aim to mitigate risks and enhance the reliability of LLM-based systems in journalism.
Automated news generation in Spanish from unstructured data has received limited attention in the literature and has mainly been explored through related tasks such as automatic summarization and headline generation. In this context, the NoticIA dataset introduces a collection of Spanish news articles paired with human-written summaries and evaluations of large language models, highlighting challenges related to factual consistency and hallucinations in automatically generated news content [
15]. These limitations are closely linked to the scarcity of resources and task-specific studies for Spanish, as discussed in recent surveys on automatic text summarization for the language [
16]. In addition, previous work has explored aspects of headline processing and generation. For instance, some studies focus on detecting misleading headlines and modeling the semantic relationship between headlines and article bodies in Spanish news data, facilitating the automatic recognition of contradictions using pre-trained language models [
17]. Overall, while existing research demonstrates progress in partial tasks related to news generation, the end-to-end generation of full news articles in Spanish from unstructured sources—particularly through systematic comparisons between open-weight and proprietary large language models remains relatively underexplored.
4. Information Gathering and Selection
Newspapers typically organize their information into sections such as sports, business, and politics. Despite the differences in the content reported in each section, the structure of that content is often similar. In [
18], the authors point out that, for a piece of information to be considered news, it must include details such as a place, a date, and an event. On this basis, the first step for the writer is to provide the model with these minimum data.
The initial data provided are used to search for additional information about the event from various news sources. The search process has two purposes: firstly, it verifies whether the data supplied by the writer can be found in news published by reputable media outlets. The fact that other media outlets report on the event allows for a certain degree of certainty that the reported event actually occurred. Secondly, it complements the initial information provided by the writer. The additional information provides the model with a better context of the event.
The selected newspapers cover a wide range of topics and offer comprehensive news coverage. La Jornada focuses on national and international news, social issues, and cultural topics. Expansión specializes in business, economics, and finance, while Reforma offers a broad spectrum of news, including politics, society, and technology. This diversity ensures that the information obtained is comprehensive and covers multiple sections. Another consideration for this selection is the political ideology of these newspaper editorial boards. We wanted to have a variety of editorial focuses to present different points of view to the writer before selecting relevant information. La Jornada is known for its left-wing ideology, while Reforma is right-wing conservative [
19,
20]. Expansión lacks a clear ideological definition, so there is no risk of political bias. Although these sources provide diversity in topics and editorial perspectives, the retrieval process is limited to Mexican news outlets. Therefore, the results of this study should be interpreted within the context of Spanish-language news from these sources, and may not generalize to other regions or media.
RSS feeds provide information such as the news title, description, publication date, and a link to the full article.
Figure 2 shows an example of an article extracted from the La Jornada RSS feed (translated from Spanish to English) in XML format. We use Feedparser 6.0.10
https://pypi.org/project/feedparser/ (accessed on 1 October 2023), a Python 3 library that parses RSS feeds, for retrieving the news articles.
For each retrieved RSS entry, the title and description are extracted. Then, they are concatenated as: news article = title + “ ” + description.
Minimal preprocessing was applied to news articles. HTML tags and non-textual elements were removed, while punctuation, casing, and stopwords were preserved to retain contextual information.
To compute semantic similarity between the initial data and news articles, we used the OpenAI text-embedding-3-small embedding model, which produces dense vector representations suitable for semantic retrieval tasks. This model supports multilingual input and can represent Spanish texts effectively. Embeddings for the initial data and news articles (the single text resulting from the concatenation described earlier) were created using this model.
The model returns a 1536-dimensional embedding vector, which represents the semantic content of the input text. The maximum input length supported by the model is 8192 tokens, which was sufficient to encode the full article content in our dataset. When articles exceeded this limit, they were truncated to the maximum allowed length. The embedding model internally produces a fixed-length vector representation for each input text, without requiring explicit pooling operations at the user level.
Cosine similarity was used to compare the embeddings of the initial data and the retrieved news articles. Cosine similarity measures the cosine of the angle between two vectors in a multidimensional space, providing a value between 0 and 1 [
21]. Cosine similarity is defined in Equation (
1):
where:
Cosine similarity values range from 1 to 0, where 1 indicates that two documents are identical, and 0 indicates that they share no features in common. Different similarity values were tested to determine which news articles would be shown to the writers, so they can select those they deem relevant and use their content to enhance the information about the event. Details of these experiments can be found in
Section 6.1.
Additionally, this module was also used to retrieve news articles that were later employed for fine-tuning the LLMs. This stage is essential for improving the accuracy and coherence of the articles generated by our model. Details of the collection of these articles are given in the following Section.
5. News Article Generation
Large language models can follow instructions, or prompts, to complete specific tasks [
8]. In the news article generation process, the primary input for the model is created through a combination of an instruction and the augmented data. This is called the prompt construction. By providing a clear and specific prompt, combined with relevant contextual data, it is possible to guide the model to produce a consistent and factually sound output.
Additionally, the behavior of the model is regulated by a set of top-level instructions, which ensure that the generated articles adhere to journalistic standards. For instance, the model is instructed to always include the essential elements of date, place, and event, while ensuring that no fabricated information is introduced, and that formal language is maintained.
The specific prompt and model behavior used to instruct the model may have the following structure:
Prompt: “Create a news article with this information: <Statement with the augmented data>.”
Model behavior: “Your task is to write news articles that always include a date, a place, and an event. You cannot hallucinate information that is not given, use formal language.”
This combination of prompt and model behavior with carefully curated augmented data ensures that the model generates high-quality, accurate, and context-rich news articles.
The expected output of the model is a news article that meets the following characteristics:
In addition, a fine-tuning process was conducted to improve the performance of LLMs in the specific task of generating news. Models were trained with a dataset of Spanish news articles, ensuring that it captured the particularities of the language and journalistic style.
A total of 15,952 news articles were collected over an 8-month period (October 2023 to May 2024) from the three RSS feeds mentioned above. These sources provide content that is freely accessible for non-commercial use. Duplicate and near-duplicate articles were removed based on URL and title matching. This collection of news articles was divided into a training set comprising 90% (14,356) and a validation set comprising 10% (1596). The GPT-2 model was fine-tuned using the full training set and evaluated on the validation set. For the other models that were fine-tuned, training was performed on a subset of 100 news articles from the training set, due to their ability to generalize from a small number of examples. The dataset of 100 news articles, was divided proportionally by the number of tokens in the length of the articles to avoid bias. The goal of fine-tuning was not to maximize model performance, but to adapt the models to journalistic structure and Spanish stylistic conventions under constrained data and computational resources. The distribution was as follows:
33 articles with more than 400 tokens provide substantial content and context, allowing the model to learn from longer and more detailed stories;
33 articles with 200 to 400 tokens help the model adapt to generating concise yet informative news articles;
34 articles with 50 to 199 tokens ensure the model can handle brief news without losing essential information.
The dataset composition allows to address a bias where the language model tended to generate articles averaging around 150 tokens. News articles with this number of tokens could be considered too short and do not provide the essential information. By diversifying the length of the training articles, we aimed to create a more balanced and versatile model.
Once the models were trained, 20 evaluation instances were defined and used based on the initial data and their corresponding augmented data from news articles not included in the full training set, and, therefore, not in the smaller training subset. This separation was enforced to prevent data leakage.
We use both publicly available and proprietary models to evaluate its performance on the proposed task. The publicly available models considered were GPT-2 and LLaMA 3, while the proprietary models included GPT-3.5, Gemini 1.0 Pro and GPT-4o-mini. Details about the parameters used, the dataset processing, and the characteristics of the fine-tuning process applied to these models are described below.
Author Contributions
Conceptualization, O.J.G. and C.V.G.M.; methodology, O.J.G. and C.V.G.M.; software, B.H.M., C.-M.Z.-M. and M.-A.B.-T.; validation, O.J.G., C.V.G.M., B.H.M. and H.C.; formal analysis, B.H.M.; investigation, O.J.G. and B.H.M.; resources, B.H.M., C.-M.Z.-M. and M.-A.B.-T.; data curation, B.H.M., C.-M.Z.-M. and M.-A.B.-T.; writing—original draft preparation, O.J.G., C.V.G.M.; writing—review and editing, O.J.G., C.V.G.M., B.H.M. and H.C.; visualization, B.H.M.; supervision, O.J.G., C.V.G.M. and H.C.; project administration, O.J.G.; funding acquisition, O.J.G. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the Mexican Government through Secretaría de Ciencia, Humanidades, Tecnología e Innovación (SECIHTI), SNII, and the Secretaría de Investigación y Posgrado of the Instituto Politécnico Nacional, Mexico, under Grant 20254348, EDI and SIBE-COFAA.
Institutional Review Board Statement
Ethical review and approval were waived for this study because it involved the annotation of publicly available news articles and did not include sensitive personal data or human subject intervention.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study. Participants were informed about the purpose of the research and participated voluntarily.
Data Availability Statement
Data and trained models used in this work can be found in the following repository:
https://tinyurl.com/bdcanw8m, accessed on 5 February 2026.
Acknowledgments
The authors would like to thank Instituto Politécnico Nacional, Escuela Superior de Cómputo, and Centro de Investigación en Computación.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Pavlik, J.V. Journalism and New Media; Columbia University Press: New York, NY, USA, 2001. [Google Scholar]
- Neil Thurman, K.D.; Kunert, J. When Reporters Get Hands-on with Robo-Writing. Digit. Journal. 2017, 5, 1240–1259. [Google Scholar] [CrossRef]
- Graefe, A. Guide to Automated Journalism; Technical Report; Columbia Journalism School: New York, NY, USA, 2016. [Google Scholar]
- Bandi, A.; Adapa, P.V.S.R.; Kuchi, Y.E.V.P.K. The power of generative ai: A review of requirements, models, input–output formats, evaluation metrics, and challenges. Future Internet 2023, 15, 260. [Google Scholar] [CrossRef]
- Kotenidis, E.; Veglis, A. Algorithmic journalism—Current applications and future perspectives. Journal. Media 2021, 2, 244–257. [Google Scholar] [CrossRef]
- Van Dalen, A. The algorithms behind the headlines: How machine-written news redefines the core skills of human journalists. Journal. Pract. 2012, 6, 648–658. [Google Scholar] [CrossRef]
- Robots Wrote This. 2006. Available online: https://www.wired.com/2006/08/robots-wrote-this/ (accessed on 9 September 2024).
- Feuerriegel, S.; Hartmann, J.; Janiesch, C.; Zschech, P. Generative AI. Bus. Inf. Syst. Eng. 2024, 66, 111–126. [Google Scholar] [CrossRef]
- Sasaki, T.; Kuge, T.; Shoji, Y.; Yamamoto, T.; Ohshima, H. Generating News Headline Containing Specific Person Name. In Proceedings of the Database Systems for Advanced Applications. DASFAA 2024 International Workshops; Morishima, A., Li, G., Ishikawa, Y., Amer-Yahia, S., Jagadish, H.V., Lu, K., Eds.; Springer: Singapore, 2025; pp. 220–227. [Google Scholar]
- Francis, M.; Rinaldi, M.; Gili, J.; De Cosmo, L.; Iannaccone, S.; Nissim, M.; Patti, V. GATTINA-GenerAtion of TiTles for Italian News Articles: A CALAMITA Challenge. In Proceedings of the 10th Italian Conference on Computational Linguistics (CLiC-It 2024); CEUR Workshop Proceedings: Pisa, Italy, 2024. [Google Scholar]
- Quinonez, C.; Meij, E. A New Era of AI-Assisted Journalism at Bloomberg. AI Mag. 2024, 45, 187–199. [Google Scholar] [CrossRef]
- Breazu, P.; Katsos, N. ChatGPT-4 as a Journalist: Whose Perspectives is it Reproducing? Discourse Soc. 2024, 35, 687–707. [Google Scholar] [CrossRef]
- Dipto Barman, Z.G.; Conlan, O. The Dark Side of Language Models: Exploring the Potential of LLMs in Multimedia Disinformation Generation and Dissemination. Mach. Learn. Appl. 2024, 16, 100545. [Google Scholar] [CrossRef]
- Fang, X.; Che, S.; Mao, M.; Zhang, H.; Zhao, M.; Zhao, X. Bias of AI-generated content: An examination of news produced by large language models. Sci. Rep. 2024, 14, 5224. [Google Scholar] [CrossRef]
- García-Ferrero, I.; Altuna, B. NoticIA: A Clickbait Article Summarization Dataset in Spanish. Proces. Leng. Nat. 2024, 73, 191–207. [Google Scholar]
- Matías-Mendoza, G.A.; Ledeneva, Y.; García-Hernández, R.A. Spanish Automatic Text Summarization: A Survey. Comput. Sist. 2024, 28, 1361–1376. [Google Scholar] [CrossRef]
- Sepúlveda-Torres, R.; Bonet-Jover, A.; Saquete, E. Detecting Misleading Headlines Through the Automatic Recognition of Contradiction in Spanish. IEEE Access 2023, 11, 72007–72026. [Google Scholar] [CrossRef]
- Jimenez, D.; Gambino, O.J.; Calvo, H. Pseudo-labeling improves news identification and categorization with few annotated data. Comput. Sist. 2022, 26, 183–193. [Google Scholar] [CrossRef]
- Sánchez, J.C.A.; Lorenzo, Y.S.; Pereyra-Zamora, P. COVID-19 vaccine strategy, news and political parallelism in Mexico. A comparative analysis of La Jornada and Reforma. Journalism 2025. [Google Scholar] [CrossRef]
- Marañón, F.; Tiscareño-García, E. Media Coverage Analysis of Migrant Caravans in Mexican Digital Newspapers. In Media, Migrants, and U.S. Border(s); Rocha de Luna, R., Bañuelos Capistrán, J., Eds.; Springer Nature: Cham, Switzerland, 2025; pp. 183–200. [Google Scholar] [CrossRef]
- Vajjala, S.; Majumder, B.; Gupta, A.; Surana, H. Practical Natural Language Processing; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2020. [Google Scholar]
- Holtzman, A.; Buys, J.; Du, L.; Forbes, M.; Choi, Y. The Curious Case of Neural Text Degeneration. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Kendall, M.G. A new measure of rank correlation. Biometrika 1938, 30, 81–93. [Google Scholar] [CrossRef]
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Landis, J.R.; Koch, G.G. The measurement of observer agreement for categorical data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef] [PubMed]
- Sai, A.B.; Mohankumar, A.K.; Khapra, M.M. A Survey of Evaluation Metrics Used for NLG Systems. ACM Comput. Surv. 2022, 55, 26. [Google Scholar] [CrossRef]
- Hashemi, H.; Eisner, J.; Rosset, C.; Van Durme, B.; Kedzie, C. LLM-Rubric: A Multidimensional, Calibrated Approach to Automated Evaluation of Natural Language Texts. In Proceedings of the Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics: Bangkok, Thailand, 2024; pp. 13806–13834. [Google Scholar]
- Berber Sardinha, T. AI-generated vs human-authored texts: A multidimensional comparison. Appl. Corpus Linguist. 2024, 4, 100083. [Google Scholar] [CrossRef]
- Zhong, M.; Tang, T.; Zhang, Z.; Liu, P.; Liu, T.; Wang, Y.; Wan, X. Towards a Unified Multi-Dimensional Evaluator for Text Generation. arXiv 2022, arXiv:2210.07197. [Google Scholar] [CrossRef]
- Rosoł, M.; Gąsior, J.S.; Łaba, J.; Korzeniewski, K.; Młyńczak, M. Evaluation of the performance of GPT-3.5 and GPT-4 on the Polish Medical Final Examination. Sci. Rep. 2023, 13, 20512. [Google Scholar] [CrossRef]
- Lin, J.C.; Younessi, D.N.; Kurapati, S.S.; Tang, O.Y.; Scott, I.U. Comparison of GPT-3.5, GPT-4, and human user performance on a practice ophthalmology written examination. Eye 2023, 37, 3694–3695. [Google Scholar] [CrossRef] [PubMed]
- Yeadon, W.; Peach, A.; Testrow, C. A comparison of human, GPT-3.5, and GPT-4 performance in a university-level coding course. Sci. Rep. 2024, 14, 23285. [Google Scholar] [CrossRef] [PubMed]
- Castillo-Campos, M.; Varona-Aramburu, D.; Becerra-Alonso, D. Artificial Intelligence Tools and Bias in Journalism-related Content Generation: Comparison Between Chat GPT-3.5, GPT-4 and Bing. Tripodos Fac. Comun. I Relac. Int. Blanquerna-URL 2024, 55, 99–115. [Google Scholar] [CrossRef]
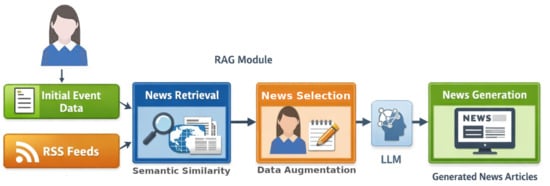
Figure 1.
Diagram of the proposed generative model.
Figure 2.
Example of a news article from La Jornada’s RSS feed.
Figure 3.
Example of the data format used to fine-tuning GPT-2.
Figure 4.
Example of the data format used to fine-tuning GPT 3.5.
Figure 5.
Example of the data format used to fine-tuning Gemini.
Figure 6.
Example of the data format used to fine-tuning LLaMA 3.
Figure 7.
Overall performance of the models in the qualitative evaluation.
Figure 8.
Qualitative evaluation of the generated news from the economy section.
Figure 9.
Qualitative evaluation of the generated news from the entertainment section.
Figure 10.
Qualitative evaluation of the generated news from the politics section.
Figure 11.
Qualitative evaluation of the generated news from the sports section.
Table 1.
Fine-Tuning Parameters for GPT-2.
| Fine-Tuning Parameters for GPT-2 |
|---|
| Base model | dquisi/storyspanishgpt2v2 |
| Epochs | 1 |
| Steps | 10,000 |
| Loss after fine-tuning | 2.96 |
| Trained tokens | 109,384 |
| Batch size | 4 |
| LR Multiplier | 0.0002 |
Table 2.
Fine-Tuning Parameters for GPT-3.5.
| Fine-Tuning Parameters for GPT-3.5 |
|---|
| Base model | gpt-3.5-turbo |
| Epochs | 4 |
| Steps | 400 |
| Loss after fine-tuning | 0.39 |
| Trained tokens | 109,384 |
| Batch size | 1 |
| LR Multiplier | 2 |
Table 3.
Fine-Tuning Parameters for Gemini.
| Fine-Tuning Parameters for Gemini |
|---|
| Base model | gemini-1.0-pro-002 |
| Epochs | 4 |
| Steps | 100 |
| Loss after fine-tuning | 1.08 |
| Trained tokens | 23,667 |
| Batch size | 1 |
| LR Multiplier | 1 |
Table 4.
Fine-Tuning Parameters for LLaMA 3.
| Fine-Tuning Parameters for LLaMA 3 |
|---|
| Base model | Meta-Llama-3.1-8B |
| Epochs | 5 |
| Steps | 60 |
| Loss after fine-tuning | 0.54 |
| Trained tokens | 81,076 |
| Batch size | 1 |
| LR Multiplier | 2 |
Table 5.
Configured parameters for text generation using GPT-4o-mini.
| Configured Parameters for GPT-4o-Mini |
|---|
| Model | gpt-4o-mini |
| Temperature | 1 |
| Max Tokens | 500 |
| Top-P | 1 |
| Frequency Penalty | 0.0 |
| Presence Penalty | 0.0 |
Table 6.
Threshold rankings assigned by the two annotators and Kendall’s agreement for each news query.
| Query | RankingAnnotator1 | RankingAnnotator2 | Kendall |
|---|
| 1 | [r3, r2, r1, r4] | [r3, r2, r1, r4] | 1.00 |
| 2 | [r3, r2, r1, r4] | [r3, r2, r1, r4] | 1.00 |
| 3 | [r3, r2, r1, r4] | [r3, r1, r2, r4] | 0.67 |
| 4 | [r3, r1, r2, r4] | [r3, r1, r2, r4] | 1.00 |
| 5 | [r3, r1, r2, r4] | [r3, r1, r2, r4] | 1.00 |
| 6 | [r3, r1, r2, r4] | [r3, r1, r2, r4] | 1.00 |
| 7 | [r3, r1, r2, r4] | [r3, r1, r2, r4] | 1.00 |
| 8 | [r3, r1, r2, r4] | [r3, r1, r2, r4] | 1.00 |
| 9 | [r3, r1, r2, r4] | [r3, r1, r2, r4] | 1.00 |
| 10 | [r3, r1, r2, r4] | [r3, r1, r2, r4] | 1.00 |
| 11 | [r3, r1, r2, r4] | [r3, r1, r2, r4] | 1.00 |
| 12 | [r3, r1, r2, r4] | [r3, r1, r2, r4] | 1.00 |
| 13 | [r3, r1, r2, r4] | [r3, r1, r2, r4] | 1.00 |
| 14 | [r3, r1, r2, r4] | [r3, r1, r2, r4] | 1.00 |
| 15 | [r2, r1, r3, r4] | [r2, r1, r3, r4] | 1.00 |
| 16 | [r3, r2, r1, r4] | [r3, r1, r2, r4] | 0.67 |
| 17 | [r3, r1, r2, r4] | [r3, r1, r2, r4] | 1.00 |
| 18 | [r3, r1, r2, r4] | [r3, r1, r2, r4] | 1.00 |
| 19 | [r3, r2, r1, r4] | [r3, r2, r1, r4] | 1.00 |
| 20 | [r3, r2, r1, r4] | [r3, r2, r1, r4] | 1.00 |
Table 7.
Examples illustrating false positives and false negatives across the evaluated thresholds.
| Evaluated Threshold | Query | Retrieved Article and Description | Classification |
|---|
| r1 | The Portuguese writer Lobo Antunes has died | A woman dies in a fire in Coyoacán. The article describes the dead of a person that is not related to the character of the query. | False positive |
| r2 | The Portuguese writer Lobo Antunes has died | Elena Poniatowska: Farewell to Pedro Friedeberg. The article discusses the farewell given to someone other than the person mentioned in the query, but who is also related to the cultural field. | False positive |
| r3 | The Portuguese writer Lobo Antunes has died | Farewell to António Lobo Antunes, the author of the oppressed. The article is related to the query and provides additional information, such as the person’s full name, and mentions one of his most renowned works. | Relevant |
| r3 | Mexico at the World Baseball Classic | Mexico makes a triumphant debut in the World Baseball Classic, defeating Great Britain 8-2. This article obtained a cosine similarity of 0.57 that is little lower than the established range r3 so was not recovered by the system, but it is relevant to the annotators. | False negative |
| r3 | USMCA Review Mexico, United States and Canada | Mexico and the U.S. will begin official USMCA talks on March 16. This article is related to the topic but it omits the keyword Canada, so the similarity value was lower that r3, but the annotators considered relevant. | False negative |
Table 8.
Retrieved news related to the query “Iran Mexico World Cup matches”.
| Newspaper | Retrieved News | Focus |
|---|
| Expansión | Iran wants to play its World Cup matches in Mexico for fear of reprisals in the US. Given that Trump has stated that he cannot guarantee the safety of the Iranian team, we will definitely not go to the US,” says the president of the Iranian Football Federation. | The Iranian national team will not play in the US for fear of reprisals. |
| Reforma | Mexico awaits FIFA decision on Iran matches.
Sheinbaum said that Mexico is awaiting FIFA’s decision on hosting Iran’s matches in the World Cup, which are currently scheduled to be played in the US. | Mexico hopes to host Iran’s matches in the World Cup |
| La Jornada | Iran is negotiating with FIFA to play the 2026 World Cup in Mexico.
Kuala Lumpur—Despite recent warnings from US President Donald Trump about the risks of war in the Middle East, Iran has not withdrawn from participating in the upcoming World Cup. Through the Iranian embassy in Mexico, the president of the Iranian Football Federation (FFIRI), Mehdi Taj, announced that negotiations are underway with FIFA to have the national team’s matches played in Mexico. | Iran is negotiating with FIFA to play the 2026 World Cup in Mexico. |
Table 9.
Analysis of generated news using scheme 1.
| Generated News | Inaccurate Information | Hallucinations |
|---|
| Anticipation for the 2026 World Cup: Mexico and Iran Prepare for a High-Voltage Encounter. Iran and Mexico Prepare for an Imminent World Cup Encounter 17 March 2026 Mexico City, Mexico— In the lead-up to the 2026 FIFA World Cup, to be held in the United States, Mexico and Iran are preparing for a crucial group stage encounter. While the exact date of the match has not yet been specified by FIFA, great interest from fans of both countries is anticipated. This match promises to be one of the highlights of the competition, given that Mexico and Iran have a rich football history and a passionate following. Expectations surrounding the event are rising, and the teams are intensifying their training to ensure peak performance. Both national teams have begun making tactical and strategic adjustments in their training sessions to arrive in top form on match day. The clash is expected to have an electrifying atmosphere, with thousands of local and visiting fans in attendance. This match reaffirms both countries’ commitment to excelling in the tournament and advancing as far as possible in the competition. The excitement surrounding this encounter is palpable, and fans of both Mexico and Iran are eagerly awaiting the final date and what promises to be a spectacular sporting event. | In the context of the 2026 FIFA World Cup, which will be held in the United States (the 2026 World Cup will be held in three venues: Mexico, Canada, and the US) | 1. Iran and Mexico are preparing for a meeting in the World Cup group stage of the tournament. (Iran will not play against Mexico in the group stage of the 2026 World Cup; Iran is in Group G and Mexico is in Group A)
2. Mexico and Iran have a rich football history (Mexico and Iran do not share a significant history with each other; there are no historic matches, finals, or relevant rivalries) |
Table 10.
Analysis of generated news using scheme 2.
| Generated News | Inaccurate Information | Hallucinations |
|---|
| Iran is negotiating to play the World Cup in Mexico despite international tensions. Kuala Lumpur, 17 March 2026—Despite recent warnings issued by US President Donald Trump regarding the risks associated with the war in the Middle East, Iran has confirmed its intention to participate in the upcoming World Cup. Mehdi Taj, president of the Football Federation of Iran (FFIRI), announced through the Iranian Embassy in Mexico that negotiations are underway with FIFA to host the national team’s matches in Mexico. This announcement comes amid heightened international tensions, with security concerns escalating due to the situation in the Middle East. However, the FFIRI’s decision reflects a strong commitment to sport and participation in one of the world’s most important sporting events. The Federation is actively working to ensure its team can compete under all necessary conditions, prioritizing the safety and well-being of players and fans. The decision to play in Mexico, a country with a strong football tradition and the experience of having hosted two World Cups, could open significant opportunities for both Iranians and football fans in the region. FIFA has not yet issued an official statement regarding this request, but Iran’s interest in participating in the tournament remains strong, demonstrating the resilience of sport in times of political turmoil. | None | None |
Table 11.
Analysis of generated news using scheme 3.
| Generated News | Inaccurate Information | Hallucinations |
|---|
| Iran seeks alternatives to play in the 2026 World Cup amid warnings from the US. Kuala Lumpur, 17 March 2026—Despite recent statements by US President Donald Trump indicating that he cannot guarantee the safety of the Iranian national team during their stay in the country, the Football Federation of Iran maintains its intention to participate in the upcoming FIFA World Cup. In response to Trump’s expressed concerns, the president of the Football Federation of Iran (FFIRI), Mehdi Taj, announced that his country will not travel to the United States for the scheduled matches in the tournament. Through the Iranian embassy in Mexico, Taj reported that negotiations are underway between the FFIRI and FIFA with the aim of hosting the Iranian national team’s matches in Mexico. Mexico City Mayor Claudia Sheinbaum stated that Mexico is awaiting a decision from FIFA on the matter. This development highlights the complex situation Iran faces in international football, in a context marked by political tensions and concerns about the safety of its athletes. The situation continues to evolve as the start of the tournament approaches, generating anticipation about the future of the Iranian team in the World Cup. | Iran seeks alternative venues for the 2026 World Cup (The president of the Football Federation of Iran (FFIRI), Mehdi Taj, is in negotiations with FIFA to have the national team’s matches played specifically in Mexico) | 1. In response to concerns expressed by Trump (Trump is not worried about the Iranian team playing in the 2026 World Cup in his country. Trump warned that he cannot guarantee the safety of the Iranian national team during their stay in the US)
2. Mexico City Mayor Claudia Sheinbaum (Claudia Sheinbaum was mayor of Mexico City from 2018 to 2023. Claudia Sheinbaum is currently the president of Mexico) |
Table 12.
Evaluation metrics of LLMs used.
| Model | Coherence | Consistency | Fluency | Relevance | Overall |
|---|
| GPT-2 Base | 0.485 | 0.485 | 0.504 | 0.484 | 0.492 |
| GPT-2 | 0.261 | 0.500 | 0.738 | 0.291 | 0.448 |
| Gemini | 0.703 | 0.789 | 0.777 | 0.716 | 0.746 |
| GPT-3.5 | 0.790 | 0.863 | 0.496 | 0.811 | 0.740 |
| LLaMA3 Base | 0.511 | 0.510 | 0.517 | 0.511 | 0.512 |
| LLaMA3 | 0.771 | 0.876 | 0.436 | 0.780 | 0.716 |
| GPT-4o-mini | 0.972 | 0.799 | 0.956 | 0.973 | 0.925 |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}