3.1. User Survey
To assess the scale of the problem under consideration, an anonymous online survey was conducted among residents of Kazakhstan regarding their password creation practices when registering on various online platforms.
The results of this survey confirmed previous statistical findings indicating that users tend to ignore recommended guidelines for creating strong passwords. In most cases, people rely on familiar and repetitive patterns when choosing their personal login and password combinations, aiming to simplify memorization and facilitate future logins and usage.
These findings highlighted the relevance of the issue and served as the starting point for this research.
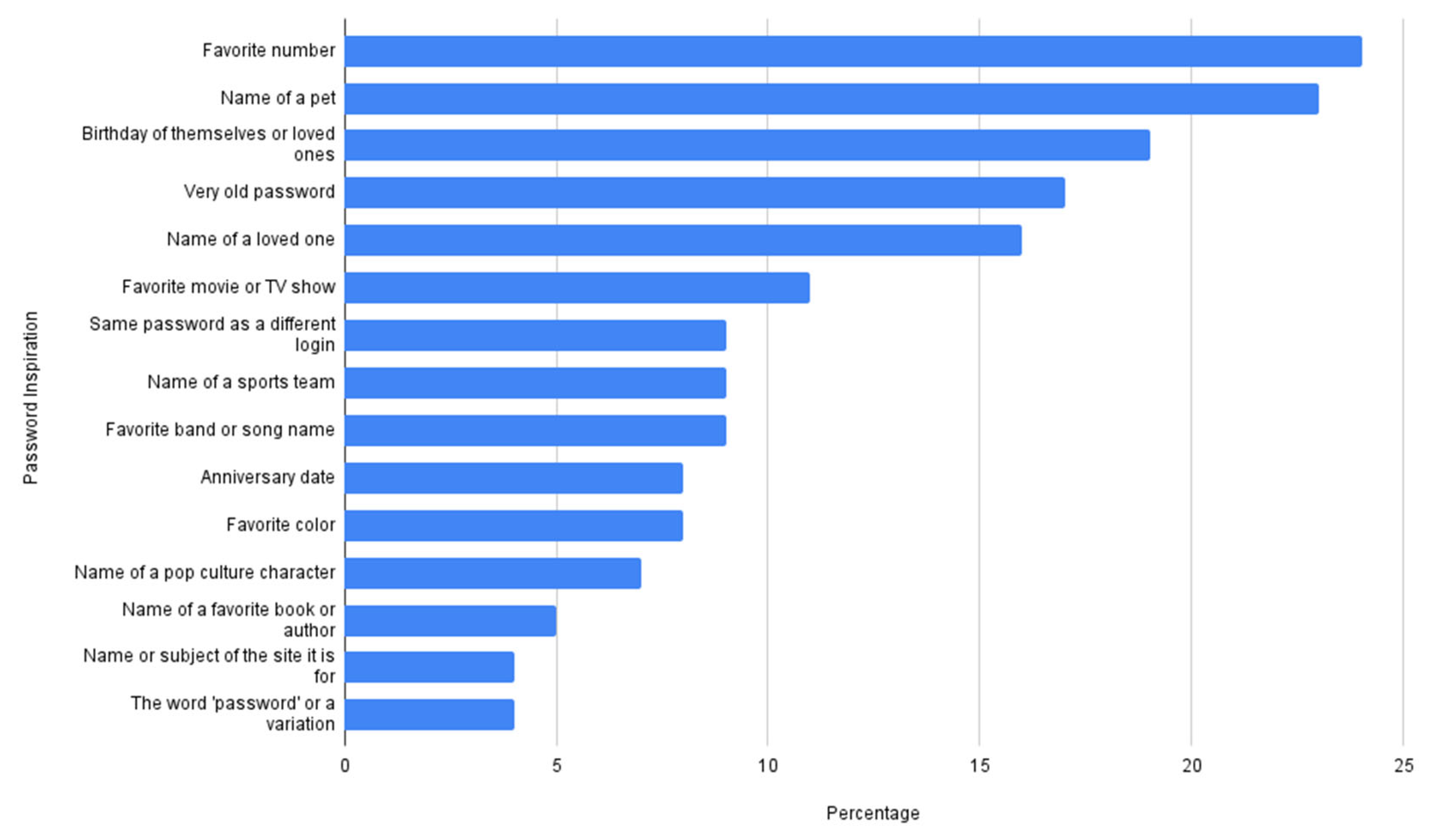
The survey included 527 respondents categorized into the following age categories. The majority of participants were 25–34 years old (174 participants), and the other groups were 46+ (121), 18–24 (116), and 35–44 (116). Participants included students, educators, IT specialists, office workers, and others, allowing for a broad perspective on password-related habits and digital hygiene awareness. The survey aimed to capture real-world practices regarding password creation, memorization, and attitudes toward password management policies. Below are the key findings and their interpretation.
All participants took part in the study voluntarily and provided informed consent via a digital form prior to participation. The study did not collect any sensitive or personally identifiable information, and no demographic data were linked to password responses.
Respondents were selected by convenience sampling—the questionnaire was distributed voluntarily to students, teachers, IT professionals and office workers.
The survey was posted via Google Forms and distributed via social media (Telegram, Instagram) and university chat rooms.
The questionnaire included both closed (multiple choice) and open-ended questions, allowing participants to give their own wording. Main topics:
Ways of creating passwords;
How often passwords are updated;
Attitudes towards security policies;
Difficulties in memorization.
The purpose of the survey was to supplement the technical analysis with behavioral data and assess real user practices. This allowed better understanding of how weak passwords are formed and to link the identified vulnerabilities to personal login/password creation rules, which is critical for personalized analysis within the neural network model. Specifically, when a user requests a new-password quality assessment, the system performs personalized fine-tuning (locally) of the base model, leveraging the user’s login and password historical data in combination with publicly available information retrieved from their social media profiles. This localized fine-tuning process ensures that the model adapts its evaluation to the user’s unique behavioral patterns as logic, which could be called their “rules of login/password creation”, and social engineering contextual background, thereby enhancing the accuracy and relevance of the password strength assessment.
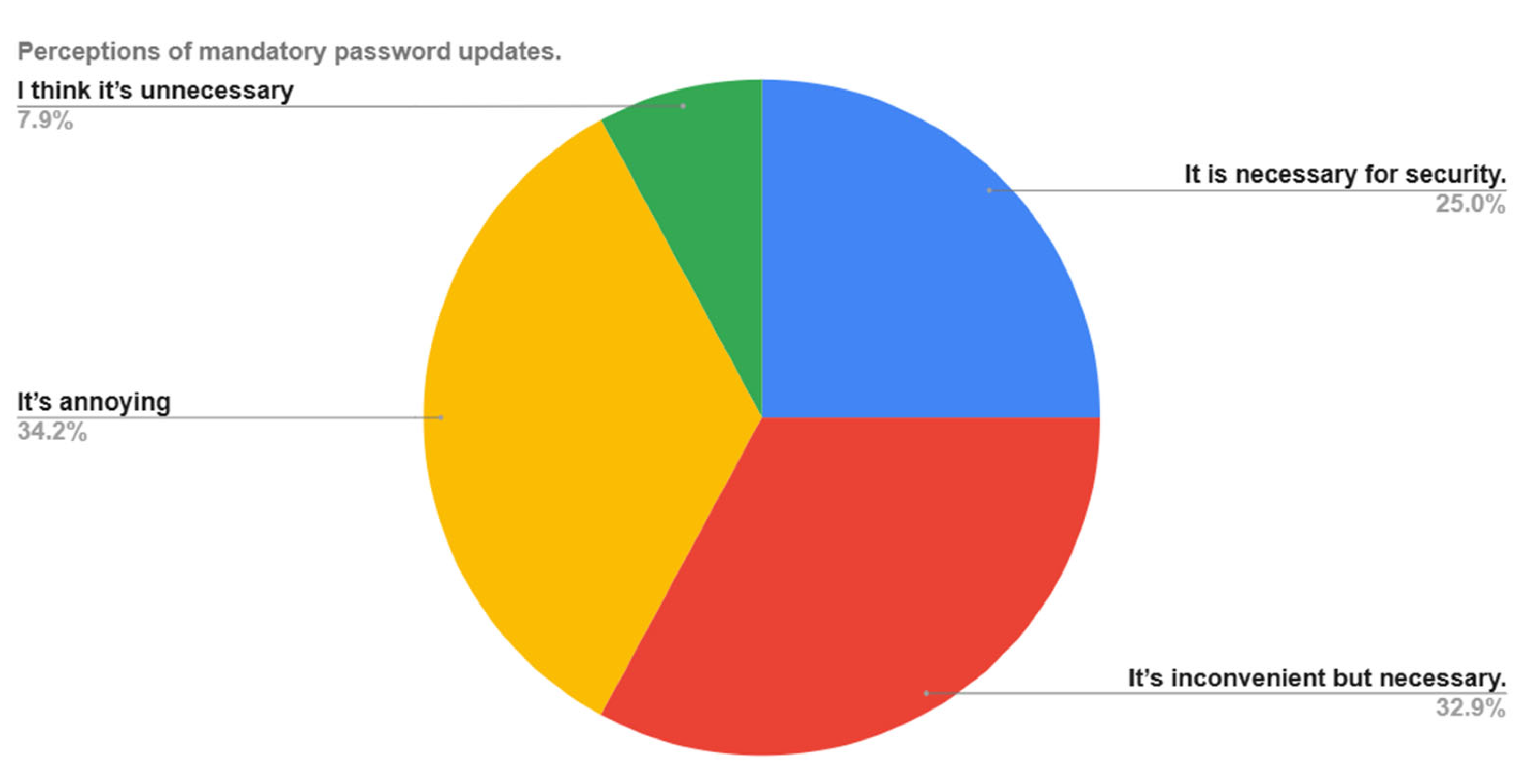
One of the key questions focused on attitudes of toward periodic password updates, a common security requirement in organizational environments. The responses were diverse and revealed a gap between formal policy expectations and real-world user sentiment, as illustrated in
Figure 1.
The survey results illustrated in
Figure 1 show that the perception of the need to regularly change passwords among users remains ambiguous. The largest share of respondents (34.2%) find this requirement annoying, while 32.9% recognize it as inconvenient but necessary. Only a quarter of respondents (25%) perceive updating passwords as an important security measure. Meanwhile, 7.9% of respondents do not think changing passwords is necessary at all. These data indicate that there is security fatigue and a need for more flexible, unobtrusive solutions in the area of credential management.
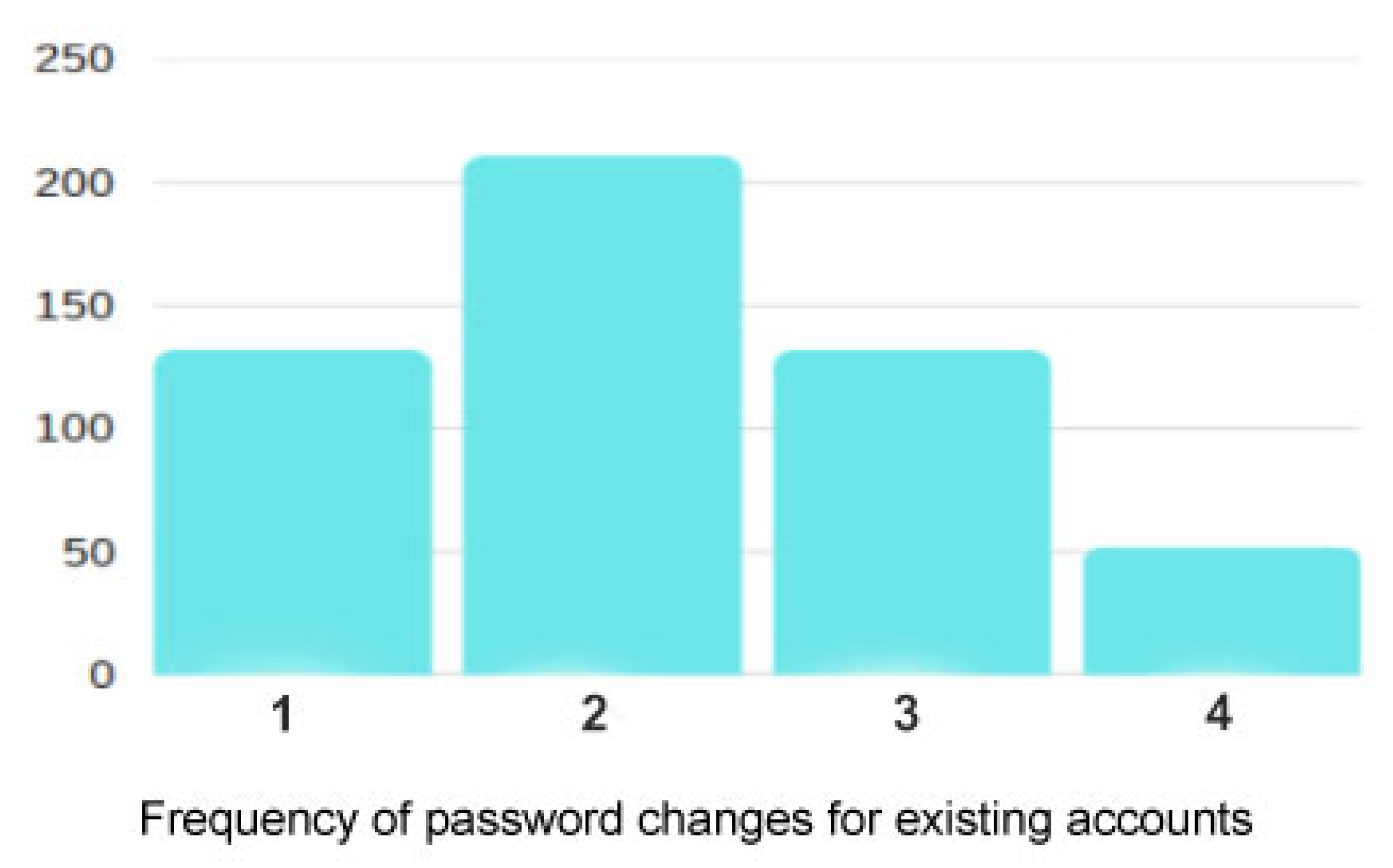
The data presented in
Figure 2 suggest that password change habits are largely reactive rather than proactive. A significant 40% of respondents reported changing passwords only when they forget them, while another 25% do so approximately once a year. Regular updates are relatively rare: just 10% change passwords every few weeks, and 25% every few months. These results point to the fact that, for most users, password maintenance is not a routine security measure but a response to inconvenience or necessity.
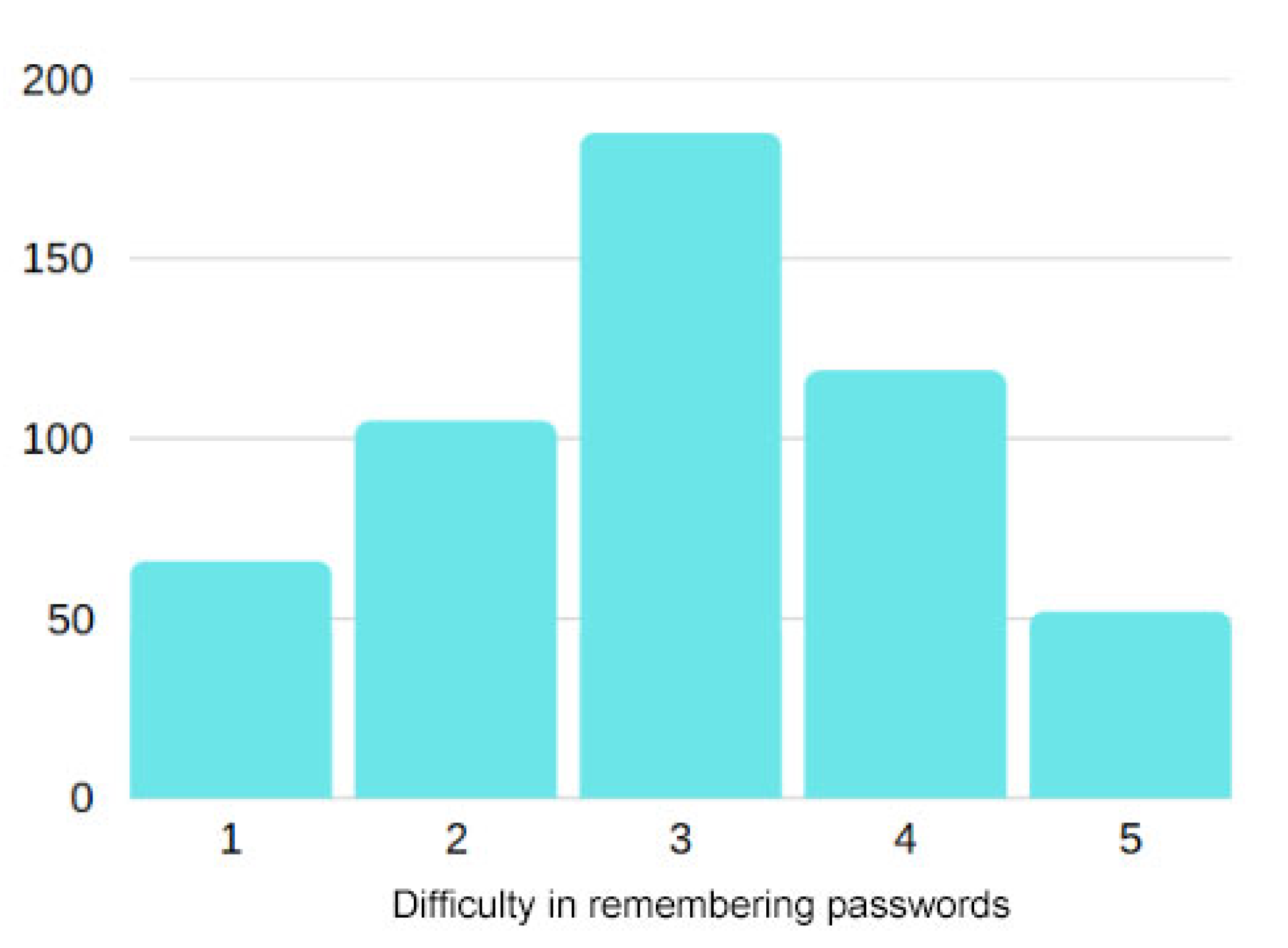
Figure 3 presents how respondents perceive the difficulty of remembering their passwords, using a scale from 1 (very easy) to 5 (very difficult). The most frequent response was level 3, selected by 185 participants, indicating a moderate level of difficulty. This suggests that while recalling passwords is not a major issue for most users, it is also not entirely effortless. The results reveal a range of user experiences: 66 respondents found it very easy (1), while 52 considered it very difficult (5). These extremes highlight the contrast between users who handle password recall with ease and those who find it challenging. Additionally, a notable number of users selected levels 2 (105) and 4 (119), which may imply that a portion of the population adopts insecure coping strategies such as reusing or writing down passwords.
Taken together, these results underscore the importance of developing security solutions that go beyond static policy enforcement and instead account for real-world user behavior. While traditional password policies emphasize complexity and regular updates, the survey data reveal that many users perceive these measures as inconvenient, unnecessary, or difficult to follow in practice. This discrepancy suggests that rigid security requirements—without adequate consideration of usability—may lead to negative outcomes such as password reuse, oversimplification, or reliance on insecure storage practices (e.g., writing passwords down).
To address this, password management systems and security interfaces should incorporate adaptive mechanisms that respond to individual behavior and cognitive patterns. For example, systems could provide personalized recommendations based on users’ password history or known habits, offering safer alternatives without overwhelming the user. Context-aware reminders triggered not by arbitrary time intervals but by risk signals or behavioral indicators—may encourage healthier password hygiene more effectively than fixed expiration policies.
3.2. New Detection Method of Recurrent Rules in Login/Password Creation
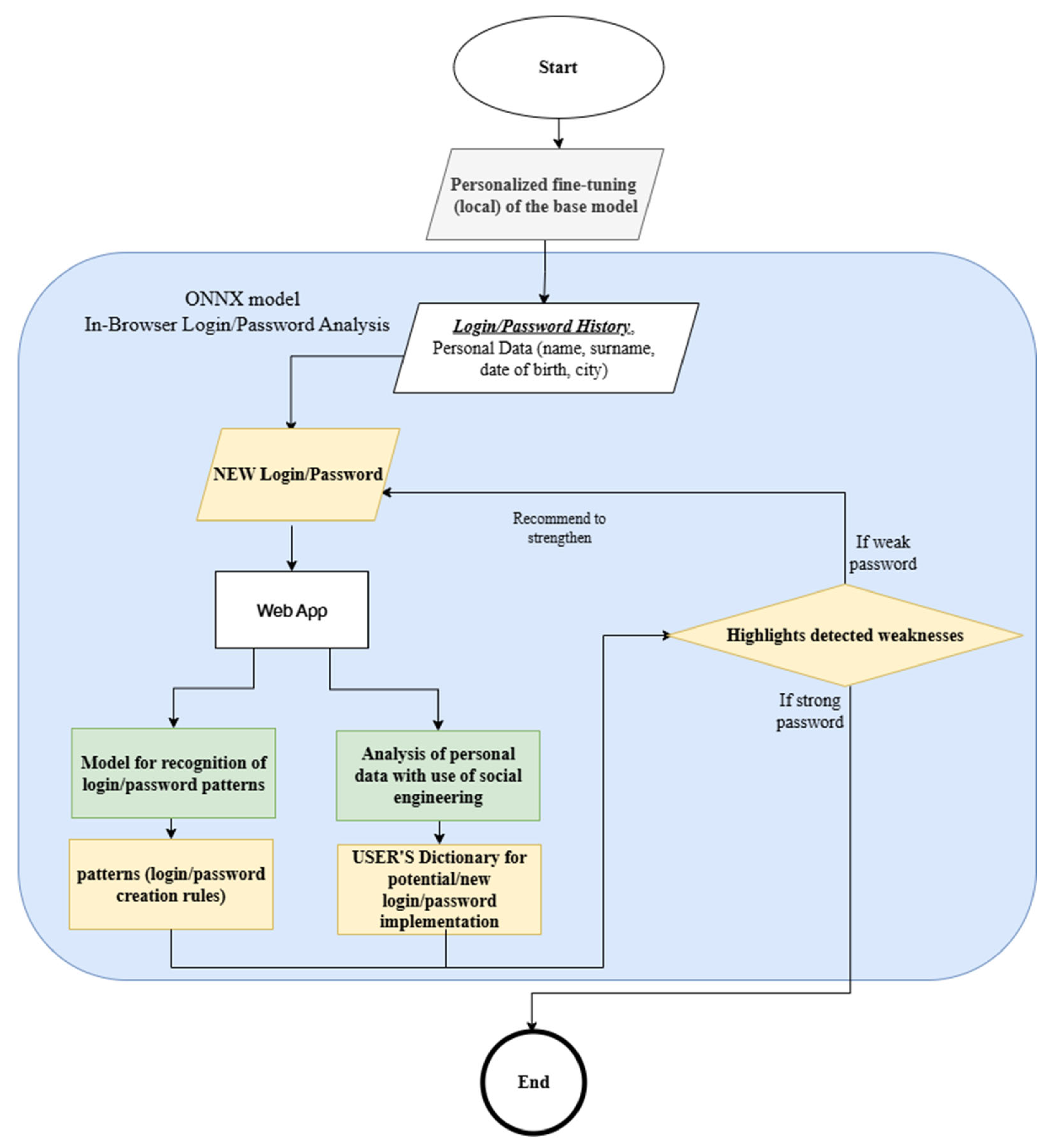
A new method, the logical explanation presented in
Figure 4, is introduced by analyzing the transparency and predictability of logins and passwords.
It is important to highlight that this method is only applicable when the user’s login and password history is available. This is precisely what makes the research both scientifically and practically novel. Existing methods do not take into account the fact that each user has their own creation rules.
The proposed method is a combination of two analytical components: first, pattern recognition in the structure of a user’s login and password history; and second, identification of the user’s personal “dictionary” by analyzing their social network activity. Based on the results of these two stages, the system evaluates the uniqueness and complexity of any newly created credential in real time and provides tailored recommendations regarding its strength.
To realise the research goal, a multi-level methodology was developed, including empirical data collection, technical processing of the data, model training and deployment of user solutions. The experimental material was based on a dataset generated from publicly available sources of compromised passwords (including RockYou 2024, LinkedIn v9.1.467, GitHub v3.17.2). After cleaning for duplicates, service characters and invalid strings, the final dataset contained more than 31,000 anonymised records suitable for sequential analysis.
Open-source datasets collected from Kaggle [
26] and GitHub [
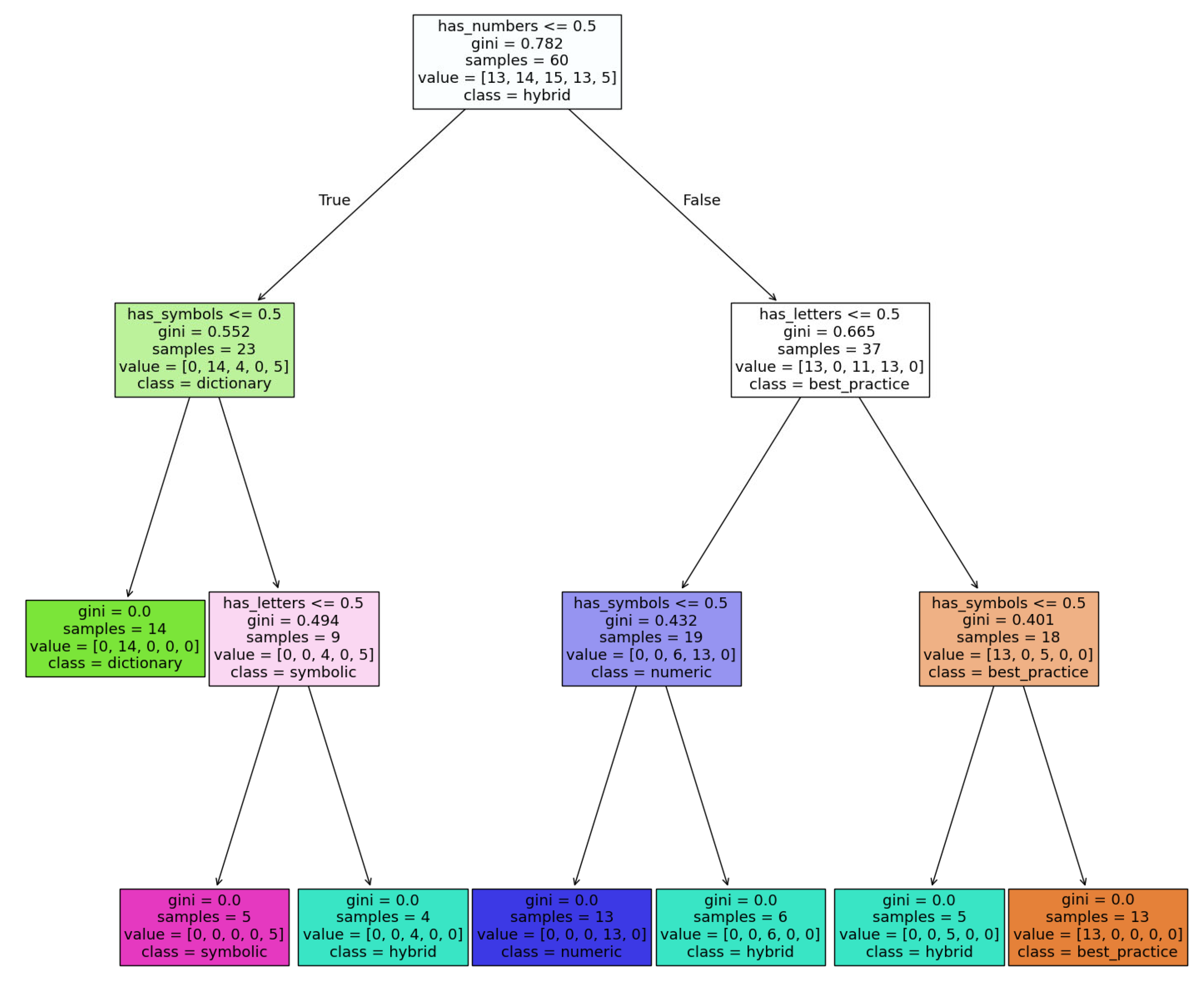
27] were used as the training set. The DecisionTreeClassifier model was trained on a portion of these data, with all tags being manually typed before training—each password was assigned a type. During training, the algorithm sequentially selects the most informative features and forms a hierarchical tree structure (
Figure 5), where each internal node corresponds to a logical condition that allows the data to be divided into more homogeneous subgroups according to the target feature.
After training was completed, the model was tested on a deferred sample, which made it possible to evaluate its ability to generalize patterns to new, previously unencountered data. To analyze the results, model predictions were obtained and then compared with actual class labels, which made it possible to quantitatively assess the accuracy of the classification. However, this solution was subsequently transformed in favour of more flexible and expressive models capable of taking into account the sequential nature of passwords and identifying complex latent dependencies in the structure of characters.
The decision tree classifier learns a mapping:
where
are binary features indicating the presence of letters (
), digits (
), and symbols (
) in a password, and K is the number of possible password classes.
At each node, the model selects a feature and threshold to split the data in a way that minimizes the Gini impurity:
where p
i is the proportion of class i within the node. The tree recursively partitions the feature space and assigns the most frequent class label at each leaf. This results in an interpretable model for password type classification based on lexical properties.
Decision trees were selected as one of the baseline models due to their widespread use in classification tasks. This algorithm was employed in a preliminary experiment to classify all passwords based on simple features such as the presence of letters, digits, symbols, and their combinations. This allowed the identification of typical structures and recurring patterns in passwords, which subsequently served as a foundation for deeper analysis and the construction of generalized masks. Thus, the decision tree model acted as an initial analytical stage from which hypotheses were formed, leading to the use of more flexible and expressive models such as LSTM.
Another investigated approach is a model based on Probabilistic Context-Free Grammar (PCFG) designed to identify stable structures in user passwords. The method involves splitting a password into logical fragments—sequences of letters (L), digits (D) and special characters (S)—and then constructing a probabilistic grammar based on the length and type of these segments.
For each password, its structure was generated, for example, L5-D4 for a password of the form Merei1611. From a formal standpoint, the PCFG model decomposes a password p into segments s1, s2, …, sn, where each segment si = (τi, vi), with τi ∈ {L, D, S} representing the type (Letter, Digit, or Symbol), and vi the corresponding substring.
The structural pattern of a password is expressed as follows:
For example, the password “Merei1611” corresponds to the structure L5–D4.
The probability of a structure is defined as follows:
where C(σ) is the frequency of structure σ in the dataset, and N is the total number of observed structures.
The conditional probability of a segment is as follows:
where C
i(v
i) is the count of substring v
i among segments of type τ
i, and ΣC
i is the total number of such segments (
Figure 6).
Assuming independence between segments, the overall probability of the password is as follows:
Password strength is then calculated as the normalized negative base-10 logarithm of this probability:
A greater score signifies a rarer and more robust password. This approach enables the model to assess the distinctiveness and predictability of passwords by analyzing their structural and lexical patterns. The model underwent training on a tailored dataset, capturing the occurrence frequencies of these structures along with the frequencies of specific substrings within the categories. During the password assessment stage, the model employs a logarithmic metric that represents the likelihood of the structure and its elements adjusted for length.
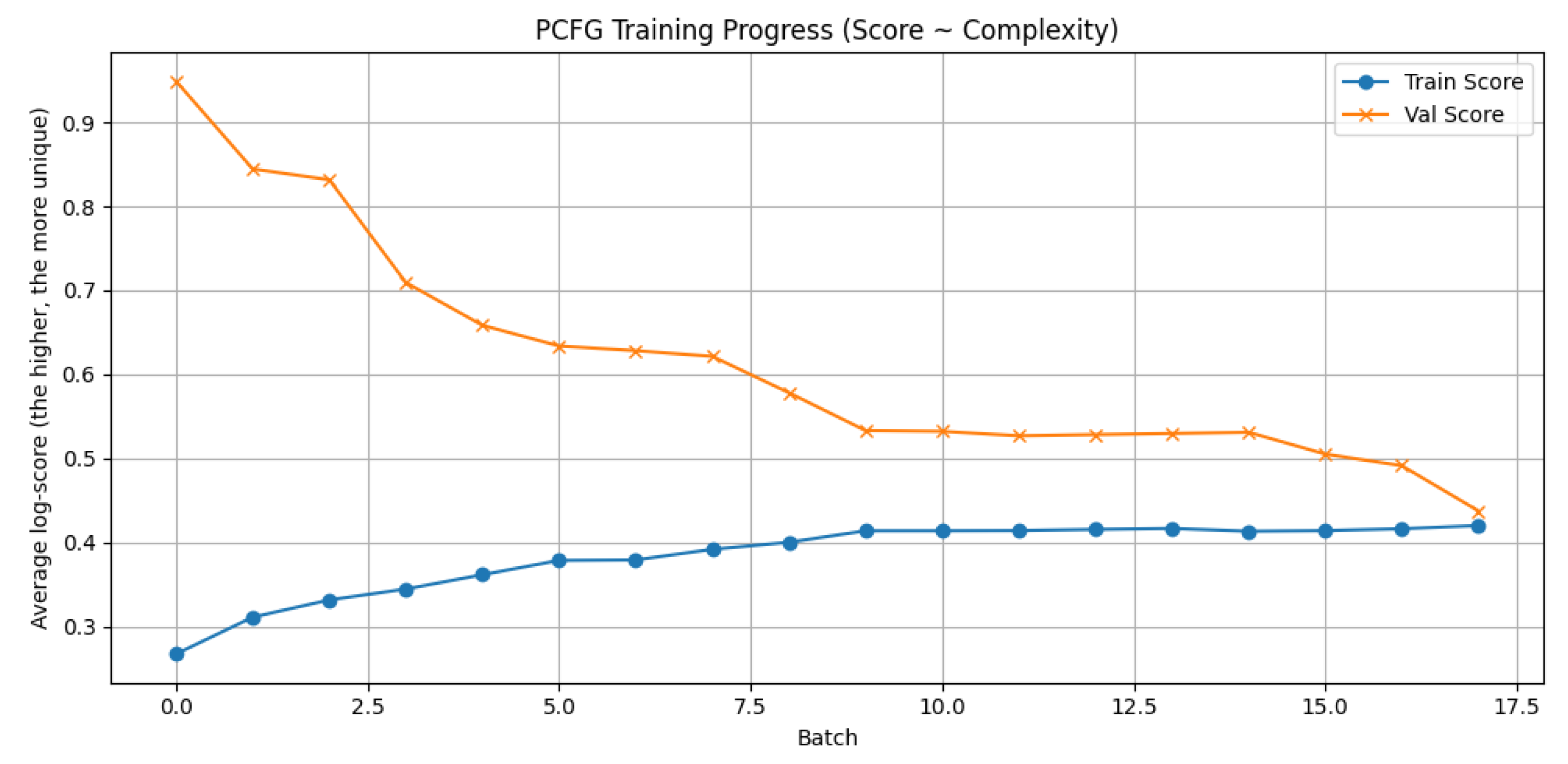
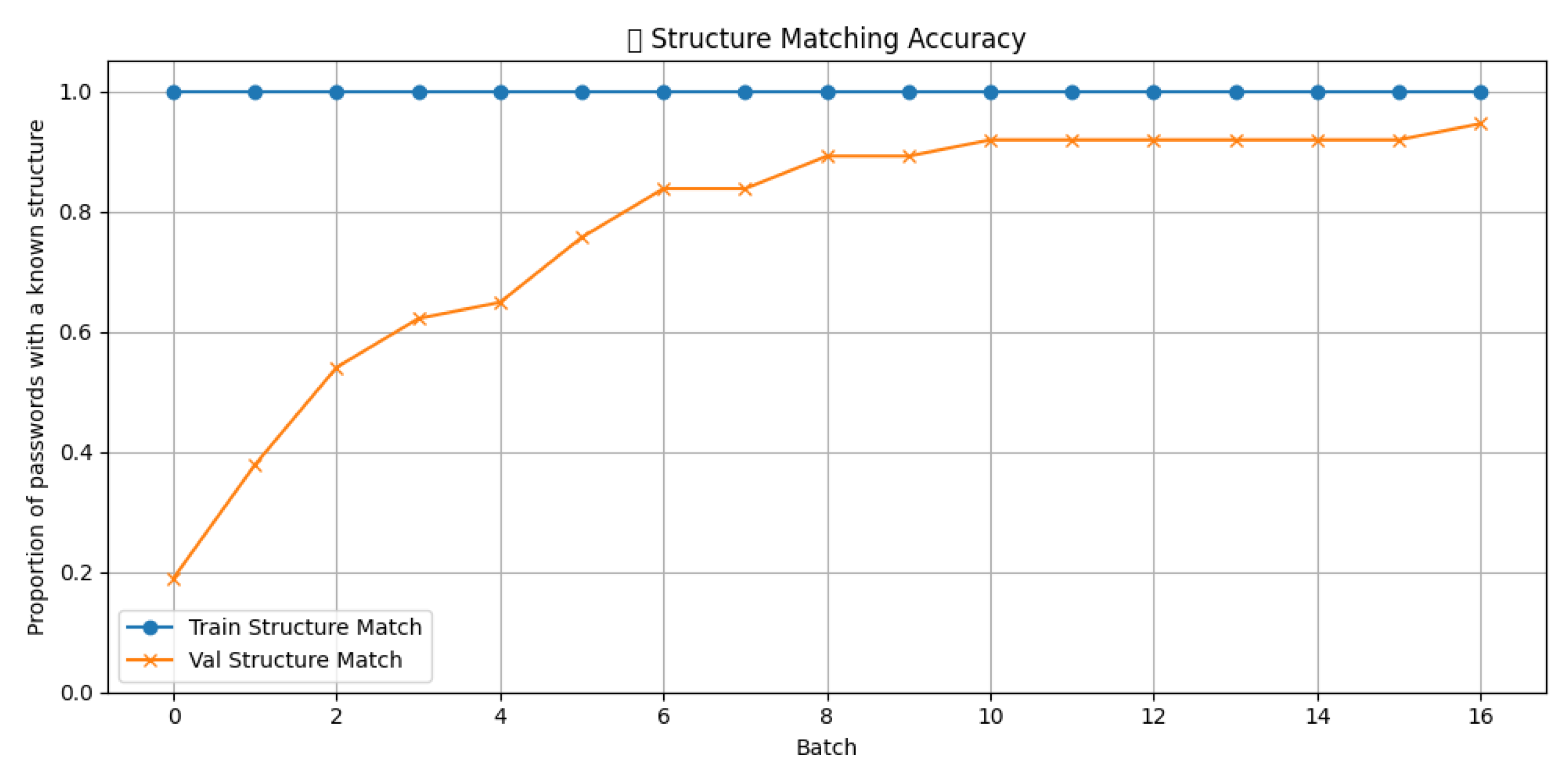
The model was trained iteratively, with progress monitoring by average score and accuracy of recognizing known structures. Two graphs were created for visualization: one shows the change in the average logarithmic score on the training and validation samples as the training batch increases (
Figure 7), and the other shows the accuracy of matching structures on both samples (
Figure 6). This allows tracking of how well the model adapts to new data and captures recurring patterns in passwords.
It turns out that PCFG and decision tree models rely on predefined rules and characteristics for password analysis. PCFG represents passwords as structured segments and uses probabilistic estimation based on their frequency, while decision trees classify data according to explicitly defined characteristics, such as length or character types.
The PCFG model was chosen as a comparative baseline due to its established role in password structure analysis. In this approach, passwords are decomposed into logical segments (e.g., letters, digits, symbols), and probabilistic rules are generated based on the frequency and arrangement of these segments in the dataset. This method was applied to explore the distribution of structural patterns and to estimate the likelihood of specific password formats. The PCFG model enabled assessment of the strength and predictability of passwords using a rule-based probabilistic framework. While effective for capturing common patterns, its limitations in handling non-standard or user-specific behaviors motivated the transition to more adaptive models such as LSTM.
However, neither approach is flexible enough. They require manual feature specification and do not take into account the human factor in password creation. Decision trees use rigid logical divisions, and PCFG does not cope well with non-standard patterns, individual habits, or emotionally charged combinations.
These limitations led to a shift towards neural network models, such as LSTM, which are capable of learning from raw data and identifying complex, personalized patterns without manual rule configuration. The basis for password analysis in this paper is a neural network model based on the LSTM architecture. This architecture was chosen due to its ability to efficiently process sequential data and capture temporal dependencies between elements of the input sequence. These properties are critical in the context of password analysis, where even minor permutations of characters can significantly alter the semantics and complexity of a password. Moreover, LSTM models have proven effective in tasks such as text generation, next-element prediction, and behavioral pattern recognition.
3.3. Technical Realization of the Proposed Method
The architecture of the developed model comprises three logical levels. The first stage involves converting input characters into dense vector representations of fixed dimensionality. This approach enables more efficient training than classical one-hot encoding, as it allows the model to capture syntactic and structural features of characters rather than merely their position in the alphabet.
At the second stage, a two-layer LSTM block is applied, which analyzes contextual relationships across the entire password string. This enables the model to recognize stable combinations of letters and digits, as well as positions of special characters characteristic of user habits. The use of two layers facilitates the processing of both short- and long-term dependencies between characters, while a dropout regularization mechanism helps prevent overfitting on limited datasets.
The final stage includes a fully connected layer that transforms the LSTM output states into a probability distribution over all possible characters in the vocabulary. This enables the model to both predict the next character and estimate the likelihood of specific structural patterns appearing in a password.
The primary distinction between the LSTM model proposed in this study and the neural network approach introduced by Melicher et al. [
13] lies in the level of abstraction and the underlying objectives of modeling password structure. Melicher et al. employ a character-level recurrent neural network aimed at estimating the probability of individual character transitions, thereby enabling fine-grained modeling of password guessability based on positional dependencies. Their architecture is optimized for client-side password strength estimation and large-scale adversarial simulation, focusing on the statistical likelihood of character sequences within passwords.
In contrast, the work presented here shifts the emphasis toward the behavioral dimension of password generation, aiming to uncover structural regularities and semantically meaningful patterns that reflect human cognitive habits and social influences. The proposed LSTM architecture is designed to detect recurrent substrings and typical combinations such as names, and birth years with the goal of constructing generalized structural masks. These masks abstract the compositional logic employed by users, allowing the model to infer common behavioral tendencies that shape password formation rules.
Thus, while Melicher et al. make a significant contribution to password guessability modeling from a probabilistic standpoint, our approach focuses on the socio-technical aspect of password creation, offering complementary insights into the human factors that contribute to predictable and vulnerable password structures.
Training was performed using the Adam optimization algorithm, which ensures fast and stable convergence in deep neural networks. Cross-entropy was used as the loss function, which is standard for multi-class classification problems. To ensure result stability and reproducibility, a fixed seed value was set across all modules involving randomness. This allows the experiments to be repeated under identical conditions, yielding consistent results. The process was conducted on a local workstation equipped with a graphics accelerator, enabling reasonable training times even when processing large volumes of string data. The training dataset consisted of thousands of passwords sourced from public leaks, which were pre-cleaned to remove duplicates and non-informative characters. Input sequences typically ranged in length from 8 to 24 characters, consistent with common user password practices.
The following formulas describe the LSTM operations for the first layer of the PasswordLSTM model, with embedding_dim = 128, hidden_dim = 256, and num_layers = 2, as per the PyTorch (2.6.0+cpu) torch.nn.LSTM documentation.
Input gate
—a fundamental component of the LSTM architecture—is responsible for regulating the inclusion of new information into the cell state. It controls the extent to which the input data at the current time step influences the memory cell update.
Forget gate
is the part of the LSTM that decides what information to delete from memory. It receives current data and the previous state as input and outputs numbers from 0 to 1, where 0 means “forget it completely” and 1 means “leave it as it is”.
Cell gate (candidate cell state) (C̃ₜ) is the part of LSTM that creates new content for memory, i.e., it suggests what can be added. It calculates possible new values using the input and previous state, but does not add them directly—this is done by the input gate.
Output gate (
) is the part of the LSTM that decides which part of the current memory state to show to the outside, i.e., what will become the new hidden state
. IT uses the current memory
, passes it through
, and filters the result using sigmoid (values from 0 to 1).
Cell state (
) is the process of updating the internal state of memory
in the LSTM. It combines the old memory
, multiplied by the forget gate, and the new proposal from the cell gate C̃ₜ, multiplied by the input gate.
Hidden state (
) is the output of the LSTM at the current step, what the LSTM “gives out”’. It is calculated based on the updated memory
(passed through
) and the output gate
, which decides what part of it to demonstrate.
In conclusion, the LSTM architecture was selected for its balanced combination of accuracy, computational efficiency, and interpretability. It not only detects repetitive structures and vulnerabilities in user passwords but also holds promise for generating secure yet memorable combinations, making it highly applicable in practical cybersecurity contexts.
Figure 8 illustrates the evolution of the loss function during the training of the PasswordLSTM model over 43 epochs. At the initial stage, both the training and validation loss curves show a sharp decrease, particularly within the first 10 epochs. This rapid drop indicates that the model quickly captures core structural dependencies in password sequences and effectively minimizes prediction error early in the learning process.
After epoch 10, the rate of loss reduction gradually slows, and by approximately epoch 15, both curves stabilize at values below 0.15. This plateau suggests that the model has reached convergence, with only marginal improvements beyond that point. The close alignment between the two curves throughout the training process reflects a strong generalization ability and an absence of overfitting, which is particularly important when working with character-level sequence data.
Overall, the training loss dynamics confirm that the model was well-tuned and trained on a clean and representative dataset. The consistent behavior of both curves across epochs demonstrates the robustness of the LSTM architecture and the adequacy of the preprocessing steps, including character tokenization, sequence normalization, and feature enrichment. These results confirm the reliability of the model in password structure recognition tasks and its readiness for practical deployment.
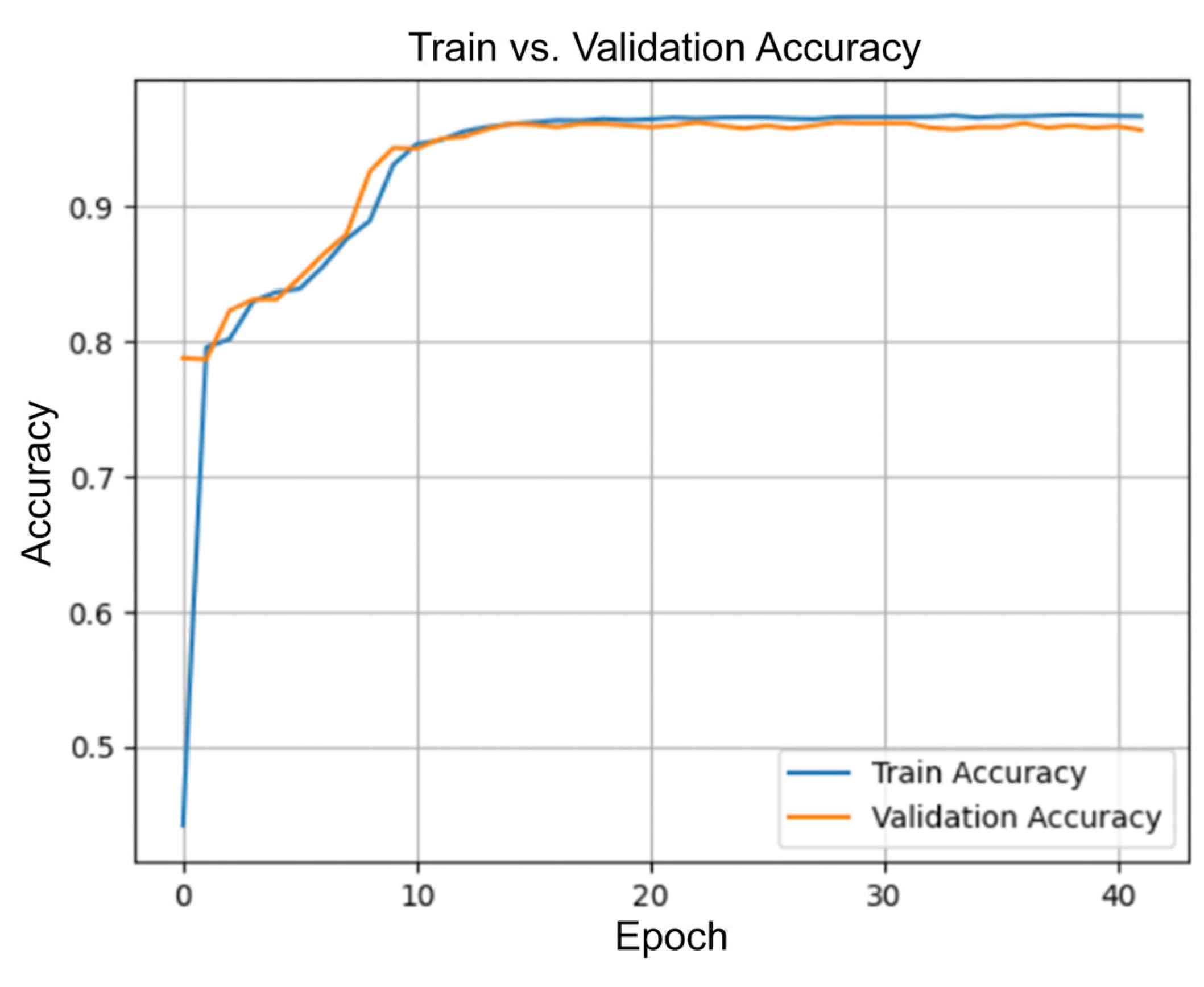
Figure 9 presents the classification accuracy of the PasswordLSTM model across 43 training epochs on both training and validation datasets. A notable increase in accuracy is observed within the first 10 epochs, where the model transitions from near-random performance to a highly accurate state. This steep growth indicates the model’s ability to rapidly extract meaningful patterns and semantic relationships within password sequences, despite the limited character set and relatively short input lengths.
Around epoch 15, both training and validation accuracy stabilize above 95%, with minimal divergence between the two curves. The close alignment of these metrics suggests that the model is not only accurate on seen data but also generalizes well to previously unseen samples. The consistent tracking of validation accuracy alongside training accuracy implies that the network did not overfit, even after prolonged exposure to the training set, which is often a challenge in character-level sequence models.
The high and stable accuracy across later epochs also validates the quality of the data preprocessing pipeline and the effectiveness of the regularization techniques applied during training. Dropout between the LSTM layers and fixed sequence normalization likely contributed to the model’s robustness. These results reinforce that the model is capable of maintaining high performance in realistic, user-facing scenarios, such as live password strength assessment or pattern analysis in browser-based security tools.
The training results presented in
Figure 5 and
Figure 6 confirm the robustness and reliability of the proposed LSTM model. The rapid convergence of the loss function and the stable accuracy above 95% on both training and validation sets demonstrate that the model effectively captures underlying patterns in password data without overfitting. The close alignment of the curves indicates strong generalization, making the model well-suited for real-world applications involving password structure analysis and prediction. Overall, the training process was successful, resulting in a stable and high-performing architecture.
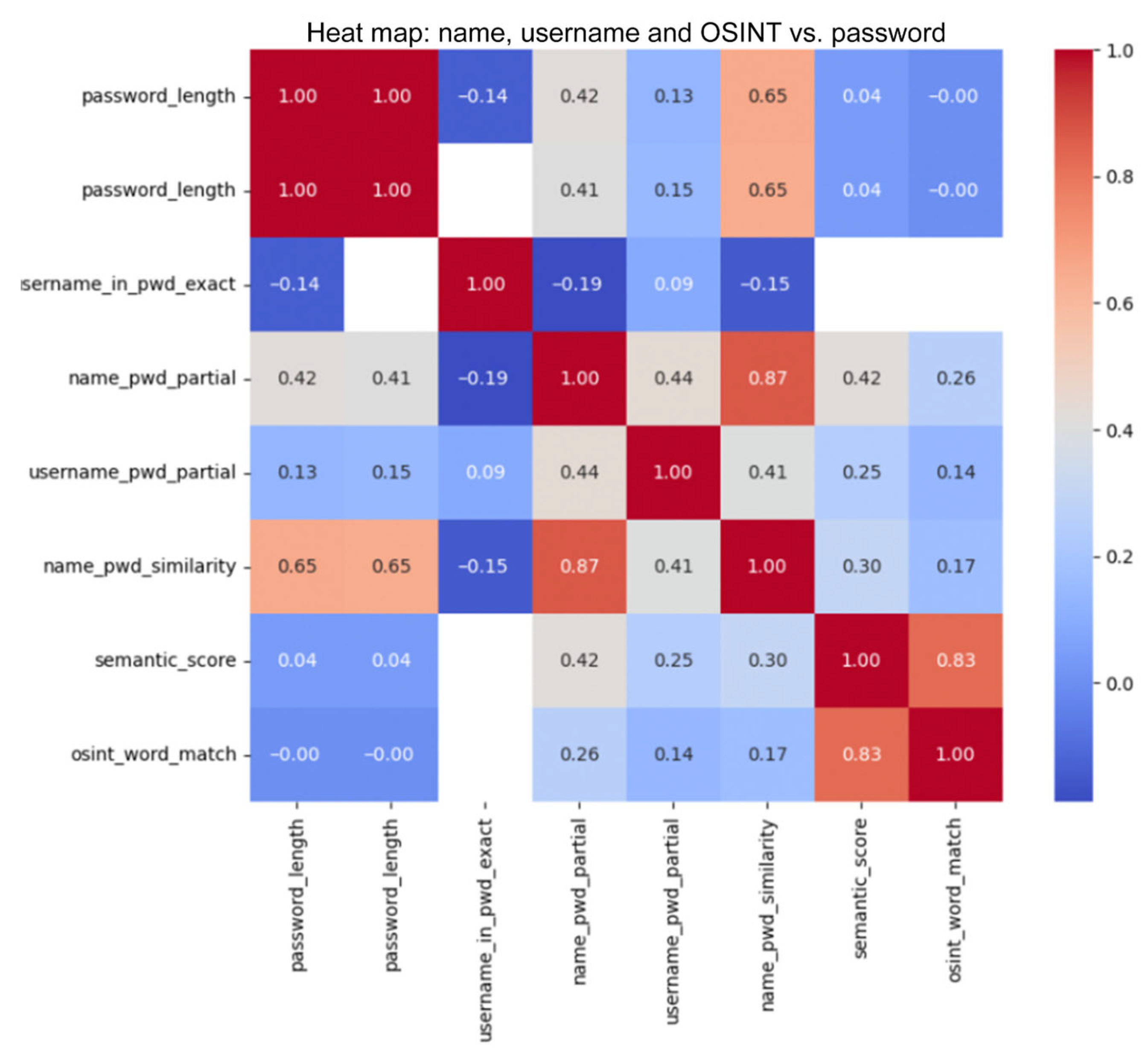
To evaluate the impact of publicly available personal data on the structure of user passwords, a two-stage analysis was performed. At the first stage, text snippets for queries containing name, city, date of birth, and address were collected using the Serper API. After text normalization, key tokens were matched to passwords from the corpus. Next, exact and partial name/login matches as well as semantic proximity to OSINT tokens were evaluated using RapidFuzz metrics. The results were combined with the main password attributes (length, presence of digits and symbols) and presented as a correlation matrix.
The analysis in
Figure 10 showed that password length is positively correlated with its similarity to the name (r ≈ 0.65), while partial matches are strongly correlated with both full similarity (r ≈ 0.87) and semantic evaluation (r ≈ 0.42). Meanwhile, adding digits or wildcards hardly reduces the predictability of a password if personal tokens remain in it.
Thus, names and related elements remain a key source of vulnerability: simply complicating the structure without removing such fragments does not provide reliable protection.
After the training phase, the model was exported in ONNX format, which allowed it to be integrated into two application tools: a web application developed in Vue 3, and a Google Chrome browser extension. This way, all of the processing is performed locally and without sending sensitive data to remote servers. By avoiding server-side storage or analysis, this design ensures maximum data confidentiality, as no user credentials are collected, stored, or processed on the server side.
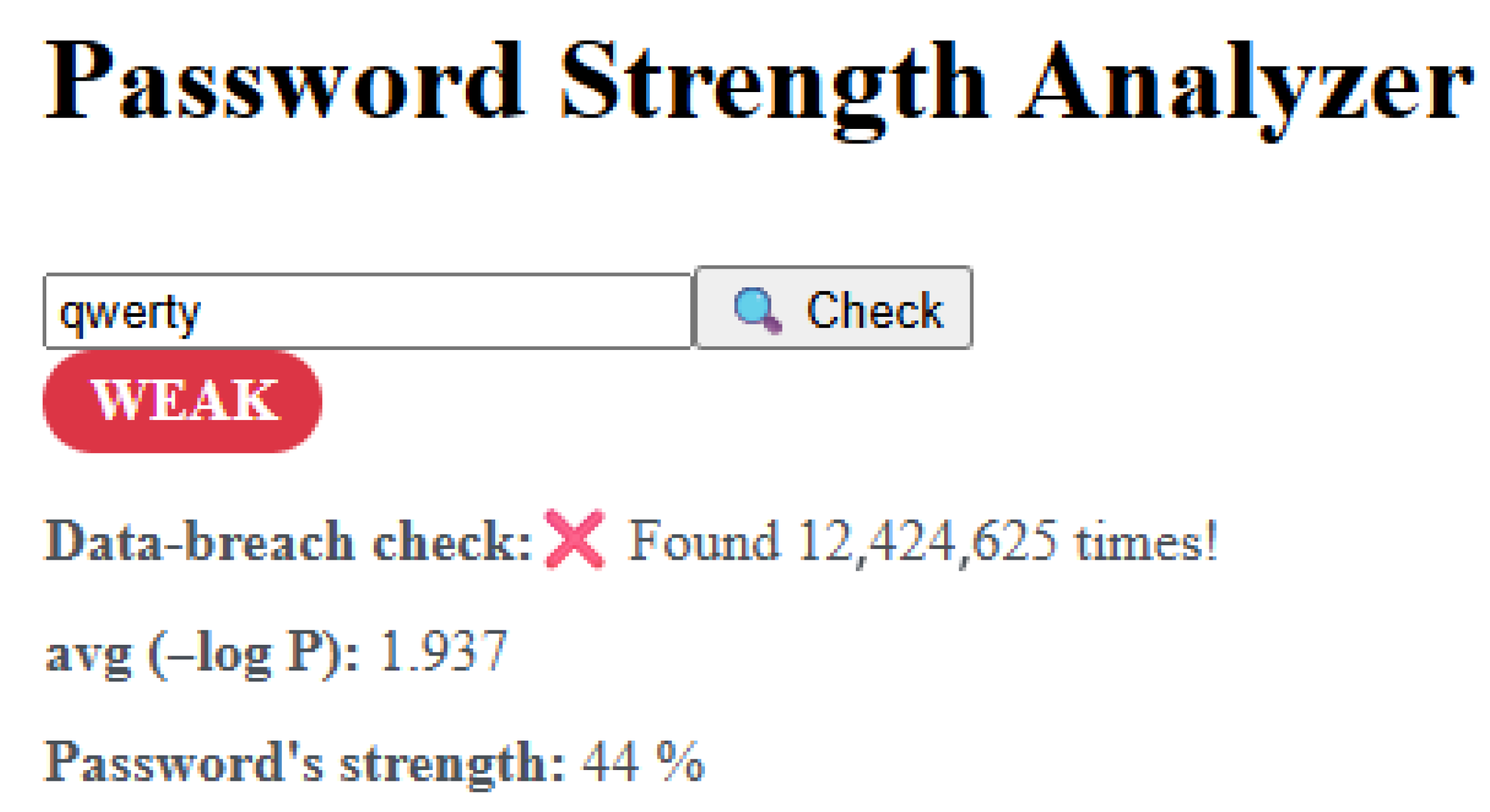
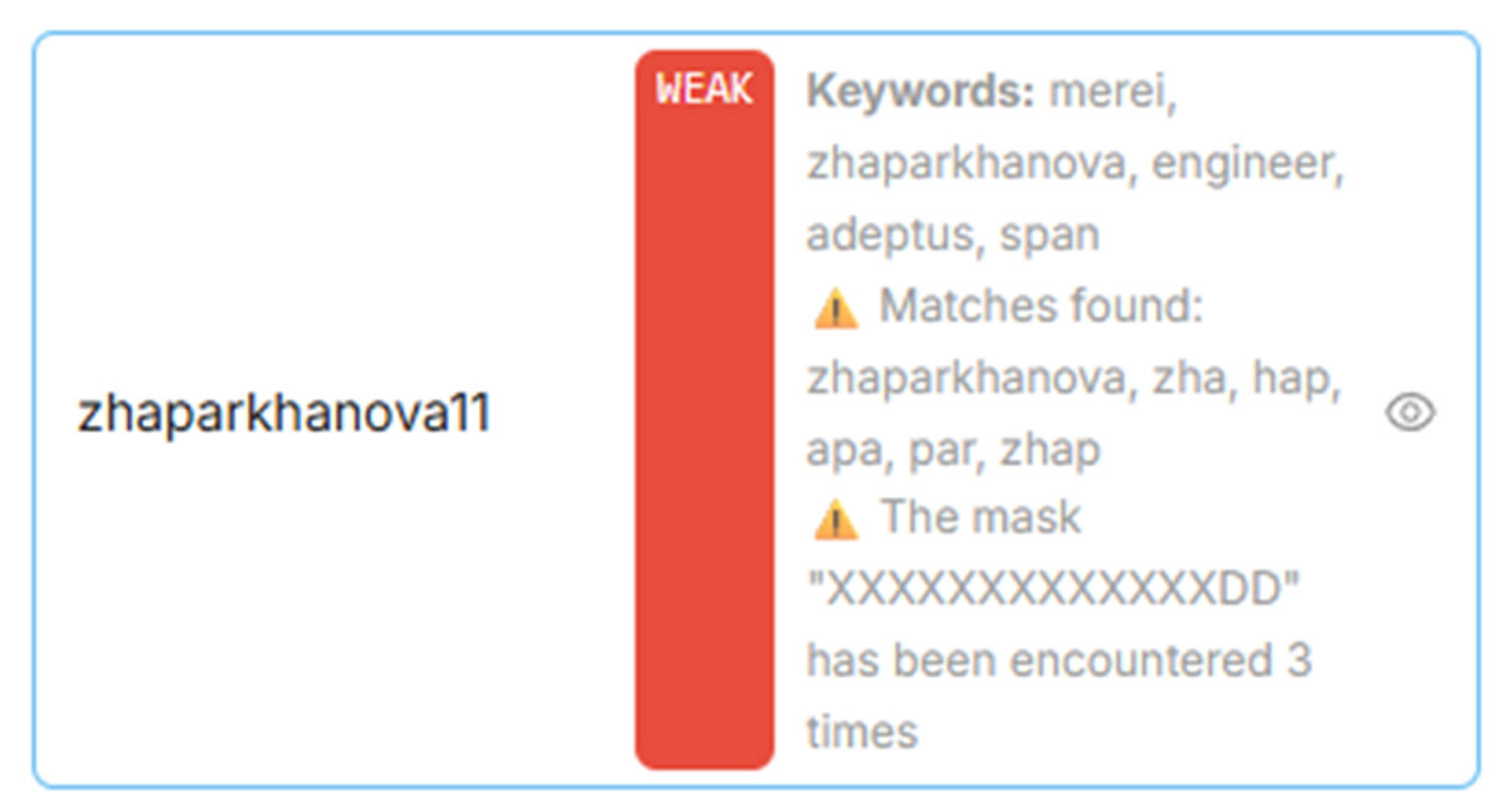
The interfaces function in real time. After entering a password, the user receives instant feedback: visualization of the string decomposition into structural elements, assignment of the security level (WEAK, MED, STRONG), and probabilistic evaluation of its guessability based on the output distribution of the model. The extension uses IndexedDB to store repetitive patterns, which allows tracking typical input patterns and tailoring recommendations to the user’s individual behavioral habits. Thus, the model implementation is not only focused on technical accuracy, but also on practical value in everyday cyber hygiene.
Building on the LSTM model’s probabilistic scoring, the system was embedded into a comprehensive password-analysis platform that delivers real-time feedback through both a browser-based web app and a Chrome extension. In the web application, the ONNX (v1.18.0) -exported model and a character-to-index dictionary are fetched on page load via onnxruntime-web (1.22.0.) (WASM), ensuring all inference runs entirely client-side. As soon as a user types a password into the bound input field and clicks “Check,” an asynchronous routine first validates that the field is not empty—resetting scores and emitting a console warning, if necessary, then calls the predictStrength function to compute two key metrics: the average negative log-probability (avg (–log P)), and a normalized strength percentage (0–100). These values update reactive Vue.js variables, instantly repainting a colored label—red for WEAK (<40%), yellow for MED (40–70%), and green for STRONG (≥70%)—alongside the raw avg metric for power users who want deeper insight (
Figure 11).
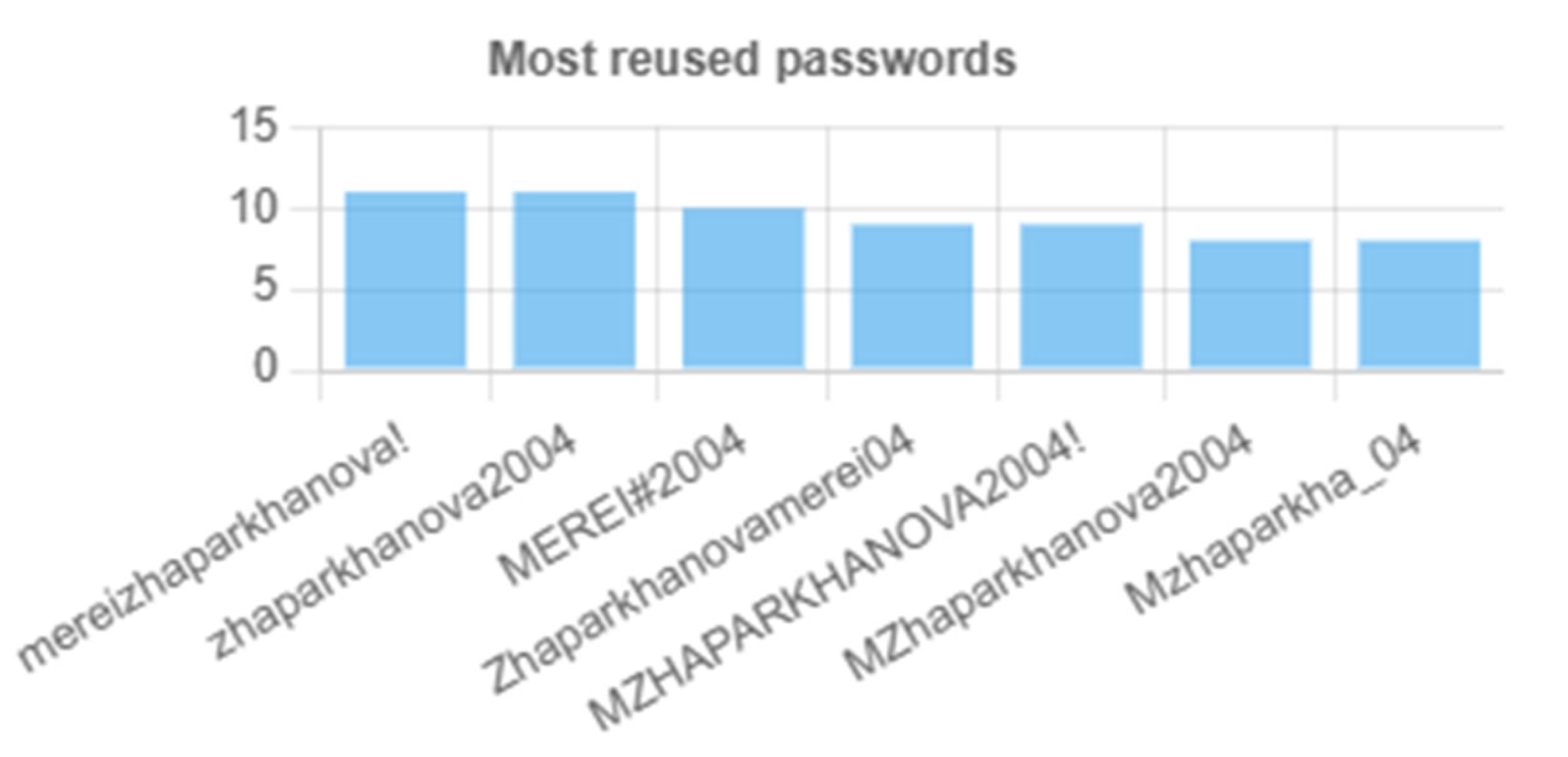
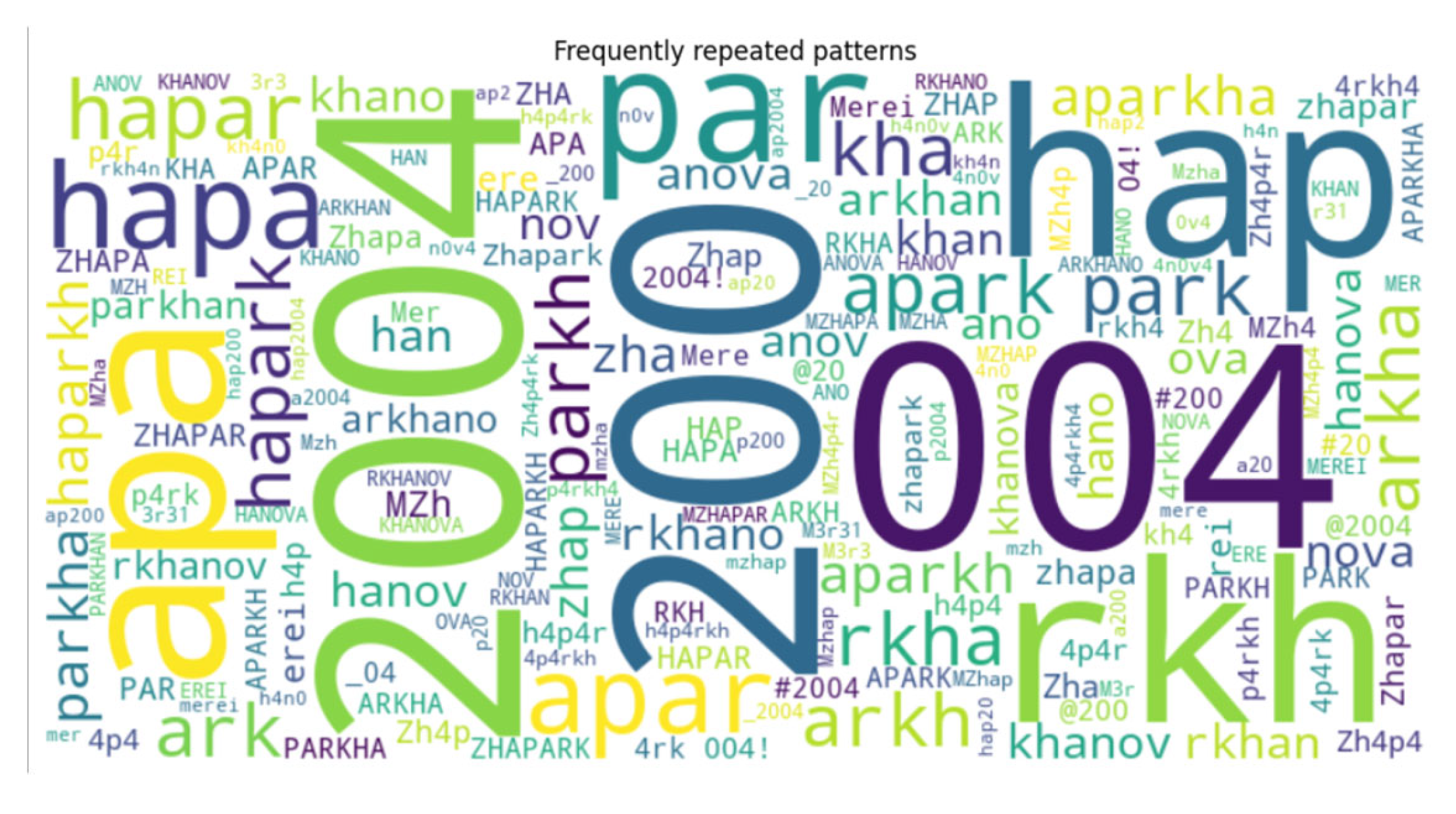
Once scored, the system cross-references the password against a precomputed list of vulnerable substrings extracted during training, flagging any matches with warning icons to highlight structural weaknesses. To guard against credential-reuse attacks, it then sends only the first five characters of the password’s SHA-1 hash to the Have I Been Pwned k-anonymity API (v3), retrieves the matching suffix list, and filters locally to display any breach count without ever exposing the full secret. Below the main panel, a dynamic password chart (
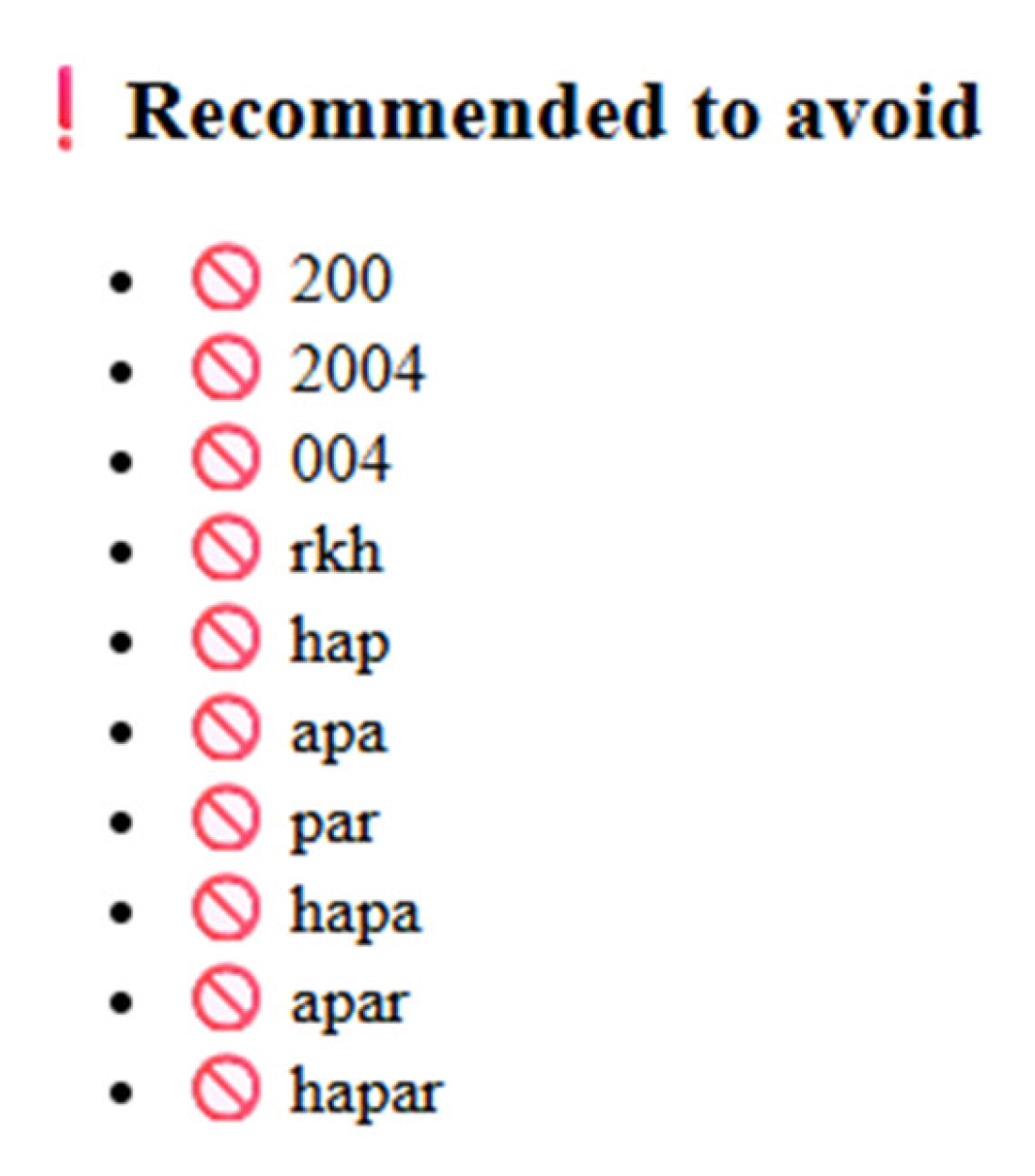
Figure 12) renders the top seven most-reused passwords, and text lists titled “Masks that make passwords easy to guess” and “Recommended to avoid” (
Figure 13) guide users away from both generic and personalized patterns.
The Chrome extension mirrors this logic on every site with ‘<input type=“password”>’ fields. Defined in manifest.json, it comprises a popup UI, background worker, and content script built with Vue 3, TypeScript 5.8, and Vite 7.0. During onboarding, users optionally enter their name and city, triggering a DuckDuckGo lookup that scrapes meaningful keywords for personalized pattern checks and stores them locally in chrome.storage and IndexedDB. The content script then injects a live badge next to each password field and listens for keystrokes; on every input it runs the same ONNX inference, pattern matching, and breach lookup via a unified rate() function, updating the badge and inline diagnostics in milliseconds. Hot-reload support via chrome.runtime messaging keeps patterns up to date without refreshing pages. All processing—model execution, keyword parsing, pattern checks—occurs on the user’s device, with only non-identifying hash prefixes or search queries leaving the browser, fully preserving privacy while delivering fast, insightful feedback (
Figure 14).




 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}